1. Introduction
In multi-label learning, each object is represented by a single instance and is associated with multiple class label [
1,
2,
3]. The main task of learning is to build an effective classifier based on the training data and predict the most relevant set of labels for each unseen instance. Nowadays, multi-label learning has been applied in various fields [
1,
4], such as music emotion classification [
5], video classification [
6], Internet [
7], text classification [
8,
9], and information retrieval [
10].
In recent years, multi-label learning has attracted extensive attentions from researchers. Existing research has demonstrated that exploiting label correlation can provide important information for the prediction of new instances and significantly boost classification performance. For example, if a piece of news is related to the theme of “Olympics”, it is more likely to belong to the theme of “sports” and “culture”, vice versa, “war” is unlikely. When an image was annotated with “reef”, the probability of being annotated with “waves” will be very high, and the probability of being annotated with “desert” will be very low.
Through the investigation and research of previous work on multi-label learning, a lot of methods [
11,
12,
13,
14,
15] have been proposed by exploiting label correlations. For example, in CLR [
14], an extra calibration label is introduced and utilized to separate the relevant and irrelevant labels for each instance. JFSC [
15] learns the label-specific and shared features based on pairwise label correlation. In DLCL [
12], a novel multi-label learning method is proposed, which can find the latent class labels in the training data. DLCL exploits the correlation between known and latent class labels to enhance the performance of the classifier. The Maximal Correlation Embedding Network (MCEN) uses the label similarity by embedding the maximum correlations in the label space to solve the problem of missing labels [
16]. MLC-EBMD [
17] introduces a multi-label classification framework based on Boolean matrix decomposition to improve the ability to predict labels in high-dimensional label space, and it also performs dimension reduction in the feature space.
The aforementioned methods definitely enhance the prediction accuracy of the multi-label algorithm by resolving and using the correlation of label. These methods on modeling label correlation mainly use either popular regular constraints, which means that any two labels with a strong relationship are assigned to similar model coefficients, or label ranking. It is noted that these methods mainly model label correlations in an indirect way, i.e., adding extra constraints on the coefficients or outputs of a multi-label classification model based on a pre-learned label correlation graph. However, in such an indirect way on modeling label correlation, the inherent correlations between different labels will not be well kept. It would be better if a direct way could be proposed. Moreover, in the environment of big data, it is convenient to collect a massive amount of data. However, the curse of dimension has brought great obstacles to multi-label learning.Therefore, it is wise to construct learning models in the low-dimensional feature and label space [
18,
19,
20].
To solve the above mentioned issues, in this paper, we propose a new approach for Multi-Label Learning by Correlation Embedding, namely MLLCE, where the feature space dimension reduction and the multi-label classification are integrated into a unified framework. First, we project the original high-dimensional feature space to a low-dimensional latent space by a mapping matrix. To model label correlation, we learn an embedding matrix from the pre-defined label correlation graph by graph embedding. Then, we use the embedding matrix as the model coefficients to construct a multi-label classifier from the low-dimensional latent feature space to the label space. In this way, the inherent correlations between different labels will be directly kept in the model coefficients. Finally, we extend the proposed method MLLCE to the nonlinear version, i.e., NL-MLLCE. The comparison experiment with the state-of-the-art approaches shows that the proposed method MLLCE has a competitive performance in multi-label learning.
The rest of this paper is organized as follows.
Section 2 reviews the previous methods of using label correlation for multi-label learning.
Section 3 introduces the proposed method MLLCE in detail. Comparative experiment results and analyses are presented in
Section 4. Finally, we conclude this paper in
Section 5.
2. Related Works
In multi-label learning, mining the correlation among labels can provide important information, make the prediction results more accurate, and boost the performance of the model. According to the ways on modeling label correlations, existing multi-label learning algorithm can be divided into three categories, i.e., first-order, second-order, and high-order algorithms. The first-order methods [
21,
22] deal with multi-label classification problems without modeling the label correlations. BR [
21] is a typical first-order algorithm whose basic idea is to transform a multi-label learning problem into multiple independent binary classification problems. The second-order methods exploit the pairwise relationship between labels [
23,
24,
25]. For the high-order methods, the relationship between all class labels or a subset is modeled, such as [
26,
27,
28]. For example, the classifier chain (CC) [
29] is a chain algorithm that uses a vector of class labels as additional instance attributes to model high-order label correlation. The Probabilistic Classifier Chain (PCC) [
30] is a probabilistic version of CC. LELC [
31] combines label embedding and label correlation to solve multi-label text classification problems. HIDDEN [
32] learns the hierarchical multi-label classification based on the joint learning of document classifier and label embedding. ELM-LMF [
33] generates the latent label matrix and
k-label dependency matrix based on the label matrix decomposition. CLP-RNN [
34] is a multi-label classification method that allows the selection of dynamic and context-dependent label ordering based on label embedding. The MLL-FLSDR [
20] algorithm is a multi-label learning method for solving the problem with many labels and features based on the label embedding, which reduces the dimension in both feature space and label space.
The second-order methods deal with the multi-label learning problem by exploring the pairwise relationship between the labels that can be divided into two types. First, the second-order methods incorporate the classification criteria ranking loss into the objective function of multi-label learning, such as Rank-SVM [
23], MIMLfast [
24], and LSEP [
25]. Second, the second-order methods constrain the label correlations to the model coefficients or outputs, such as [
11,
35,
36,
37,
38]. LLSF [
35] used the correlation between the labels to learn specific label features for multi-label learning. LSF-CI [
36] is a multi-label feature multi-label learning method which considered the relevant information of the label space and the feature space simultaneously. There are also some algorithms that tend to investigate global and local label correlations. ML-LOC [
11] exploits local pairwise label correlation for multi-label learning. LF-LPLC [
37] learns specific label features and exploits local pairwise label correlation for multi-label learning. GRRO [
38] is a multi-label feature selection method that exploits the global pairwise label correlation to facilitate the selection of features. These algorithms only utilize positive label correlation between labels, while some of the label are negatively correlated or mutually exclusive with each other. To solve this problem, several algorithms have been proposed to model the negative correlation between labels. For example, the LPLC [
39] is a simple and effective Bayesian model to investigate the positive correlation and negative correlation between the labels, and it finds the positive and negative relevance class labels for each label. Nan et al. [
40] exploited the local positive and negative correlation between labels through
kNN method. Most of these multi-label learning algorithms model label correlation with external conditions, and may not be able to maintain the correlation structure of labels well.
Dimension reduction is a fundamental pre-processing procedure for high-dimensional data, and many methods have been proposed for multi-label learning, such as MLDA [
41], SSMLDA [
42], and MLLS [
43]. Through the overview of dimension reduction [
44], dimension reduction can basically be divided into three categories, i.e, dimension reduction of the feature space, dimension reduction of the label space, and dimension reduction of the label and feature spaces simultaneously. PCA [
45] is a method of dimension reduction in feature space based on label-independence. DCR [
46] is a new multi-label feature selection method by combining feature relevance and label relevance. In [
47], the authors propose a dimension reduction method DSE to learn the sparse weight matrix by projecting the original sample into a low-dimensional subspace. MDDM [
48] is a multi-label dimension reduction approach based on maximizing the dependency between feature descriptions and relevant class labels. CLEMS [
49] performs the dimension reduction of the label space through embedded instances. In addition, some methods are proposed to reduce dimension of the label space, such as [
50,
51]. GIMC [
52] learns a nonlinear mapping of the features by reducing the instance features and labels.
In the environment of big data, the feature space of data sets becomes larger and larger, adopting dimension reduction, which can help to get rid of redundant features and obtain a more compact feature space, and further improve the performance of a model. To solve the above mentioned issues, in this paper, we propose a new approach for Multi-Label Learning by Correlation Embedding, namely MLLCE, where the feature space dimension reduction and the multi-label classification are integrated into a unified framework. We learn an embedding matrix from the pre-defined label correlation graph by graph embedding and utilize the embedding matrix as the model coefficients.
3. The Proposed Method
In multi-label learning, is the feature matrix and is the label matrix, where n is the number of instances, d is the dimension and q is the number of class labels. The i-th example is denoted by a vector with d attribute values , and is a set of possible labels for , where indicates the i-th instance belonging to the j-th label, otherwise, .
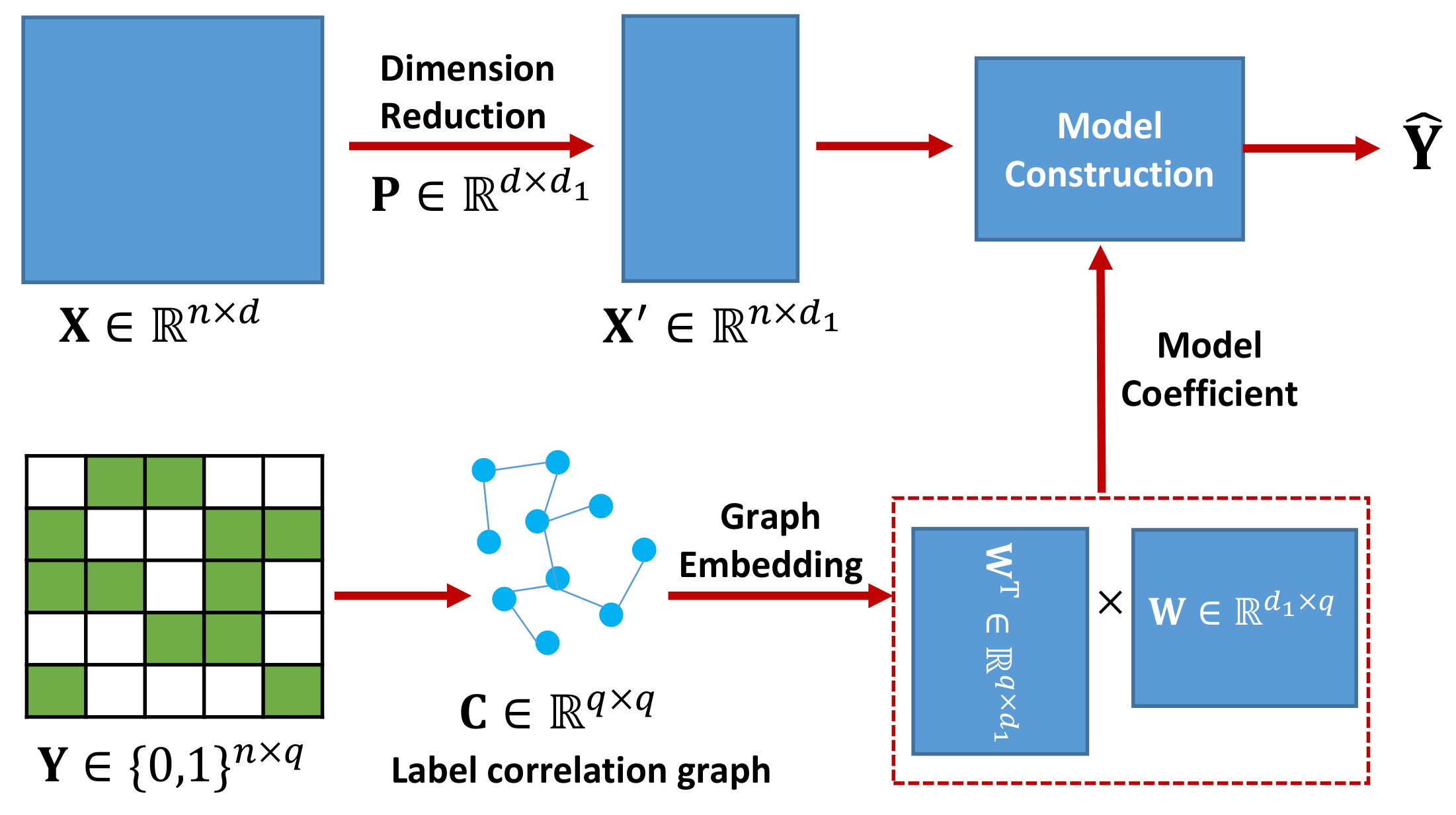
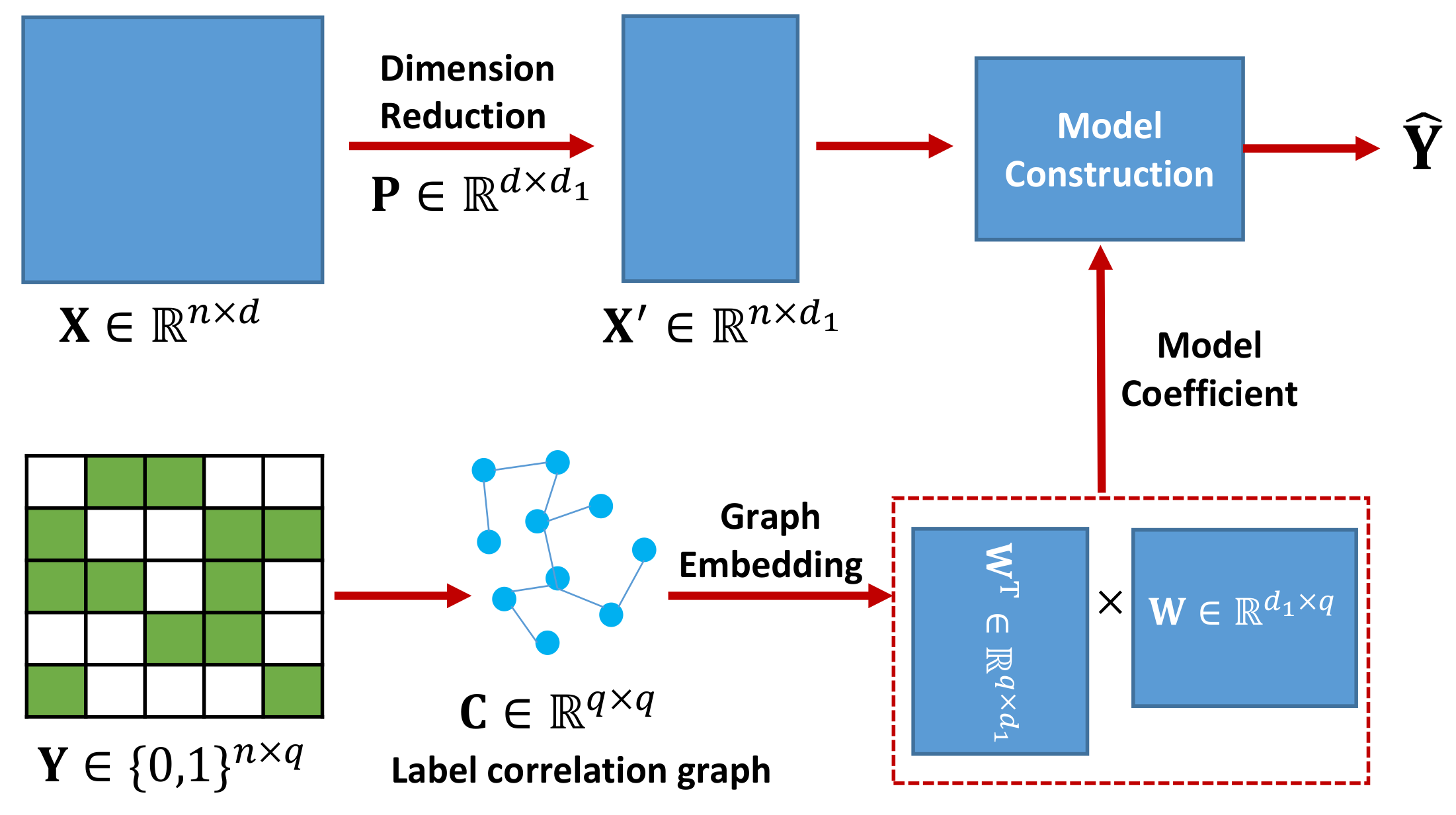
In this paper, we integrate the feature space dimension reduction and the multi-label classification into a unified framework. The learning framework of our proposed method MLLCE is shown in
Figure 1. First, we project the original high-dimensional feature space to a low-dimensional latent space by a mapping matrix. To model label correlation, we learn an embedding matrix from the pre-defined label correlation graph by graph embedding. Then, we use the embedding matrix as the model coefficients to construct a multi-label classifier from the low-dimensional latent feature space to the label space. In this way, the inherent correlations between different labels will be directly kept in the model coefficients. Finally, we extend the proposed method MLLCE to the nonlinear version, i.e., NL-MLLCE.
3.1. Label Correlation Embedding
Exploiting the label correlation can improve the generalization ability of a model and significantly improve the accuracy of model prediction in multi-label learning [
53,
54]. In this paper, we model the label correlation under the second-order strategy.
First, we calculate the label correlation matrix
by cosine similarity based on the label matrix
, where
n represents the number of samples, and
q indicates the number of labels. Each element
indicates the correlation between the
i-th and
j-th labels, and it is obtained by Equation (
1).
where
represents the value of the element in the
h-th row and
i-th column of
, and
represents the value of the element in the
h-th row and
j-th column of
.
Second, we decompose the label correlation matrix
into a low-dimensional space by graph embedding as follows
For
, we can utilize it as the model coefficient to construct a multi-label classifier. In this paper, we first construct a linear model for multi-label classification as follows
where
,
and
are non-negative weight parameters. The
-norm regularization term is imposed on
to ensure the sparsity, which can select discriminative features. In addition,
norm has been confirmed to be robust to outliers and noise [
55].
Previous studies mainly constrain the correlation between labels on the model coefficient matrix or the output by manifold regularization [
35,
36]. Different from previous studies, we directly model the pairwise label correlations by graph embedding, and the structure of label correlation will be well kept in
.
3.2. Dimension Reduction
During the past decades, multi-label classifiers are generally constructed from the feature space to the label space [
56,
57] directly. However, the high dimension of multi-label data in the feature space puts great pressure on time and memory costs. To address this issue, we explicitly introduce a feature dimension reduction stage that the data is projected from the original feature space to the low-dimensional feature space by mapping matrix.
We adopt the multiple linear regression model to build a linear classification model
from the low-dimensional feature space to the label space, where
is the feature mapping matrix, and
is the model coefficient matrix. Consequently, the objective function can be rewritten as follows
For any matrix
,
, The
of
is defined as
. Consequently, we can rewrite the third term
by 2
, where
is a diagonal matrix with its diagonal element
and
is a small positive constant. As a result, the objective function becomes
3.3. Optimization
For problem (
5), it is convex, and there are two parameters, i.e.,
and
. We adopt the effective alternate optimization strategy. Specifically, in each iteration, we update one parameter and fix the other one. We use
to represent the objective function in problem (
5), where
indicates the set of the two parameters.
3.3.1. Update
By fixing
, the problem (
5) is simplified as
Then, we can obtain the gradient w.r.t
as
According the gradient descend algorithm,
can be updated by
where
is step size of
in the gradient descent update rules. Choosing an appropriate step size is crucial to improve the convergence rate and reduce the total running time of MLLCE. According to the literature [
58], we adopt the Armijo rule to automatically determine the step size
in each iteration.
3.3.2. Update
With
fixed, the Equation (
5) becomes:
Therefore, we can obtain the gradient w.r.t
as
Consequently,
can be updated by
Similarly, the step size
is also determined by the Armijo rule [
58]. According to the above optimization process, we give the pseudo code of the proposed method MLLCE in Algorithm 1.
| Algorithm 1: Improving Multi-Label Learning by Correlation Embedding |
![Applsci 11 12145 i001]() |
3.4. Non-Linear Extension of MLLCE
In addition, by considering nuclear techniques [
59], a non-linear version of the MLLCE method can be derived by introducing the kernel trick. Specifically, we adopt a nonlinear feature mapping
, which maps the original feature space to the higher-dimensional Reproducing Kernel Hilbert Space (RKHS). Accordingly, the feature mapping matrix is set to be
, where
,
. The kernel matrix is usually given as
,
.
Consequently, for the nonlinear version of MLLCE, the objective function of problem (
5) can be rewritten as
Then, similar to the optimization of the linear version of MLLCE method,
and
are updated through an effective alternate optimization manner. The specific optimization process is based on Equations (
7)–(
11).
3.5. Complexity Analysis
For the proposed approach, data matrix , projection matrix , , label matrix , , label correlation matrix , which n and q are the number of instance and label respectively, d and are the dimension of the original and the low-dimensional feature space.
In Algorithm 1, steps 5–7 are the most time-consuming parts. For steps 5 and 6, the update needs to be calculated by steps 2 and 3, in which the calculation mainly consists of some matrix multiplications. Therefore, the total time complexity is , where t is the number of iterations. After the optimization, we only need to save and , it can lead to a memory cost of .
4. Experiment
4.1. Comparing Algorithms
In order to verify the performance of our proposed method, the paper selects five existing state-of-the-art multi-label classification approaches to compare with MLLCE, i.e., BR, JFSC, ML-LSS, MLL-FLSDR, and Glocal. The detailed information regarding the method of comparison and the linear and non-linear proposed in this paper are as follows:
- (1)
BR [
21]: The basic idea of BR is to decompose a multi-label learning problem into a set of independent binary classification sub-problems. In this paper, linear regression is adopted as the base learner for each binary classification sub-problem, where the regularization parameter is searched in
.
- (2)
JFSC [
15]: JFSC is a feature selection and multi-label classification algorithm by exploiting label correlation. The search scope for parameters
and
are
. Parameter
is searched in
.
- (3)
ML-LSS [
60]: ML-LSS is proposed for multi-label learning by modeling local similarity. Parameter
are tuned in
.
- (4)
MLL-FLSDR [
20]: A multi-label learning method based on label embedding that is used to solve the problem of many labels and features, where the parameter
is searched in
,
, and
and
are searched in
.
- (5)
Glocal [
61]: A multi-label learning approach that utilized the global and local label correlation. The parameter
and the parameters
to
are tuned in
,
k is searched in
, where
l is the number of labels in each data set.
g is searched in
.
- (6)
MLLCE and NL-MLLCE:The two versions of our proposed method in this paper. Parameter and are tuned in . is the feature dimension in the low feature space, where d is the dimension of the original feature space.
4.2. Data Sets
In this paper, a total of 15 multi-label benchmark data sets are used to verify the effectiveness of our method. Detailed information about these data sets are summarized in
Table 1. For each data set S,
denotes the number of instances,
denotes the number of features, and
denotes the number of labels. In addition,
is cardinality, which indicates the average number of labels belonging to instances, and
denotes the ratio of unconditionally dependent label pairs.
4.3. Evaluation Metrics
A great many evaluation metrics have been proposed to evaluate the performance of multi-label learning algorithms. In the paper, we choose six common evaluation metrics. Define a test data , where the ground truth labels set of the instance is represented as , , is the set of predicted class labels for the i-th instance, is the the confidence score that belongs to label y.
Hamming Loss evaluates the error between the predicted label of each instance obtained by the model and the true label of each instance.
where
indicates the symmetric difference between two sets.
One Error evaluates the proportion of instances whose top-ranked label is not in the ground truth label set.
where
represents the indication function.
Ranking Loss indicates how many irrelevant labels are ranked higher than related labels.
Average Precision evaluates the proportion of the label that is ranked before the relevant label of the instance is still the related label.
Micro F1-Measure evaluates the prediction performance of the learned classifier on the label set.
Example-based F1 is the integrated version of precision and recall for each instance.
where
and
are the precision and recall for the
i-th instance.
Macro AUC evaluates the probability that a positive instance is ranked before a negative instance, averaged over all labels.
where
indicates that it does not belong to a set of test instances labeled
.
For the AUC and AP evaluation metrics, the larger the value, the better the classification result. Hamming loss, One Error, Ranking Loss, and Coverage value are smaller, indicating better classification performance.
4.4. Experimental Results
For each data set, 80% is used for training and 20% is used for test set. The average value as well as standard deviation of each comparison algorithm in terms of each the evaluation metric are recorded in
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8 for 13 data sets. The best results in each row of the table will be emphasized in bold.
To further understand whether MLLCE makes a significant performance difference, we adopt the Wilcoxon signed-rank test [
62]. For any pair of two comparing classifiers, the test can return three probabilities between them: the probability that the first classifier has a higher score than the second (left), the probability that differences are within the region of practical equivalence (rope), or that the second classifier has a higher score (right). The sum of the probabilities of left, right, and rope is 1. The larger the value of left or right, the better the performance of the first or second classifier is. A large value of rope indicates that there is no significant difference in the performance between the two classifiers. The results of Wilcoxon signed-rank test in terms of seven metrics are reported in
Table 9,
Table 10,
Table 11 and
Table 12.
Based on the experimental results, we can observe the following conclusions.
The linear and the nonlinear versions of the method MLLCE have comparable performance. In addition, the nonlinear MLLCE is better than the MLLCE method in terms of average precision, ranking loss, one error, and AUC, which indicates that the proposed nonlinear method can improve classification performance to some extent.
Compared to the the five comparison methods, MLLCE achieves competitive performance in terms of ranking loss, Micro F1, AUC, one error, average precision, Example-based F1 on the 15 data sets, and these results clearly show the effectiveness of MLLCE in multi-label learning.
In Hamming loss, the performance of all the comparing algorithms are not significantly different. However, according to
Table 2, it is noted that MLLCE still achieves a relatively good performance.
MLLCE outperforms ML-LSS and Glocal on all evaluation metrics except hamming loss, Micro F1 and Example-based F1 Since ML-LSS adds sample similarity to the model, ML-LSS has better performance in Micro F1 and Example-based F1 metrics. These results verify the feasibility of our proposed method MLLCE through graph embedding to model label correlation.
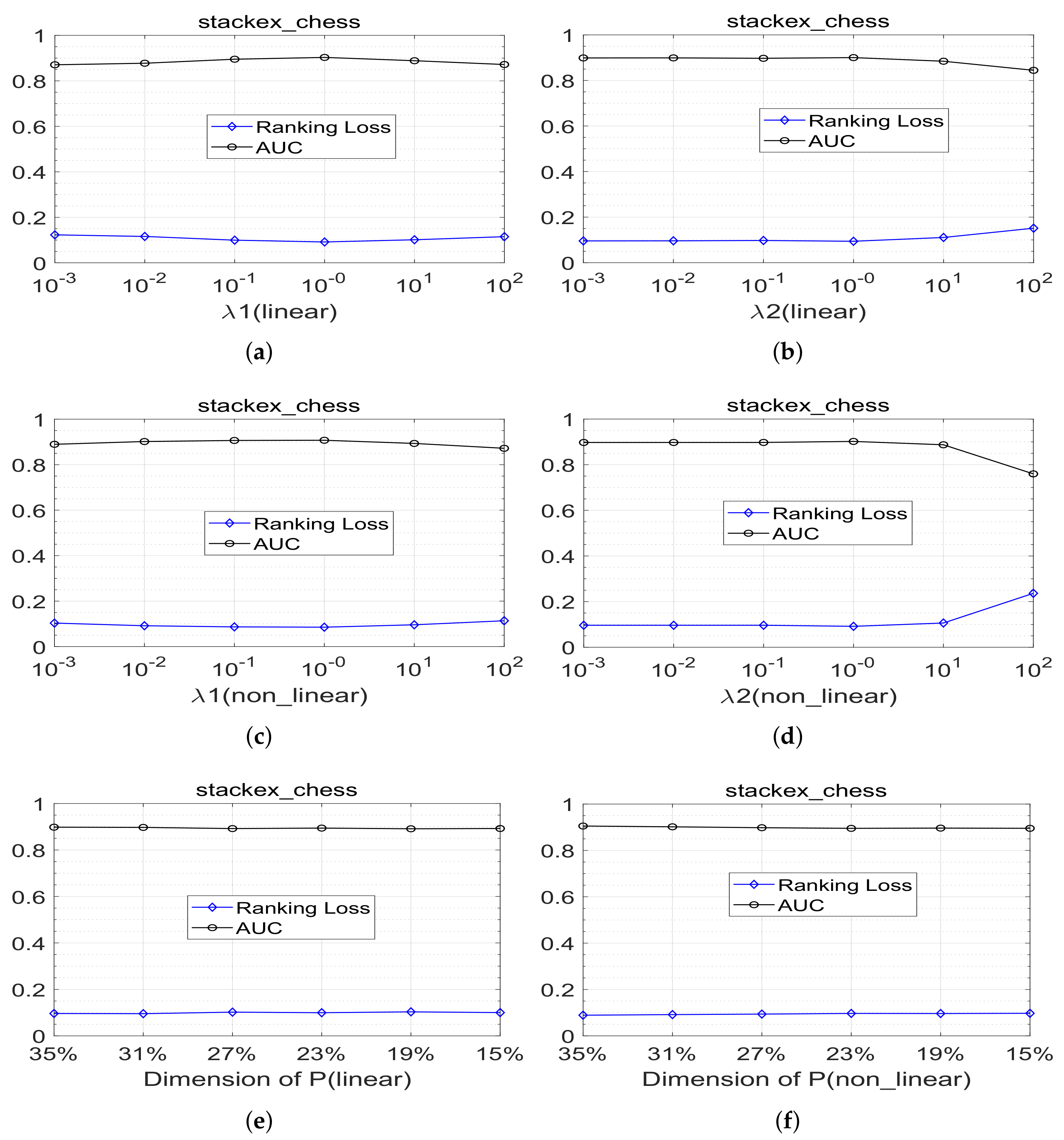
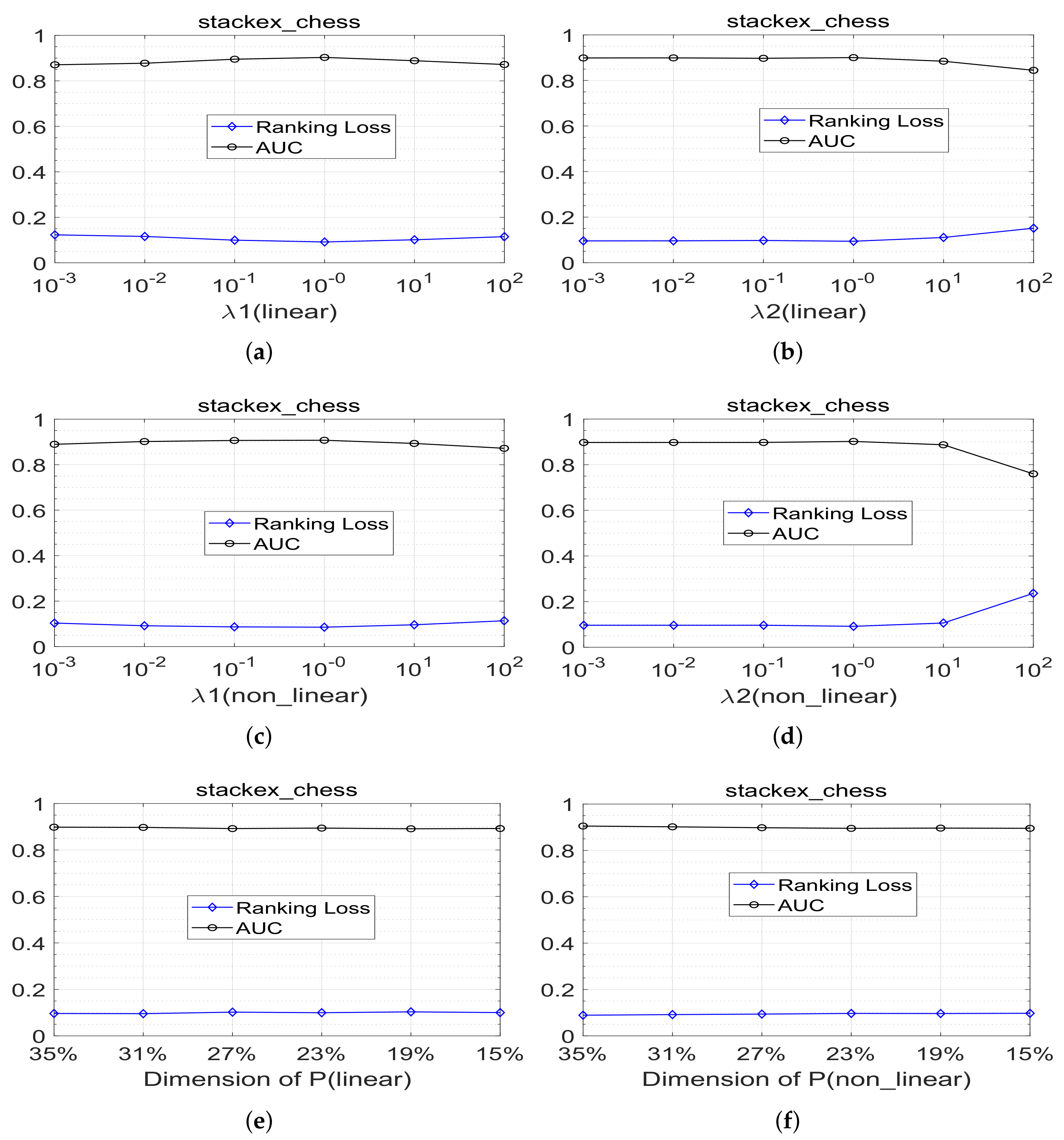
4.5. Sensitivity Analysis
There are three parameters , and in our paper, where parameter controls the loss of matrix embedding of label correlation . The parameter controls the sparsity of the model coefficient matrix . Parameter indicates the reduced feature space dimension.
The search range of parameter
and
regarding the linear and nonlinear MLLCE methods proposed in the paper are both
. The variation range value of low-dimensional feature dimension
is
,
d is the dimension of the original feature space on each data set. We perform the experiment on stackex-chess data set by dividing the 80% training and 20% test part of data set five times randomly.
Figure 2a–d shows the average experimental results of parameters
and
with different values in terms of the evaluation metric ranking loss and AUC.
Figure 2e,f shows the average experimental results of MLLCE with different values of
in terms of the evaluation metric ranking loss and AUC. We can note that the performance of MLLCE is not so sensitive to the value of
.
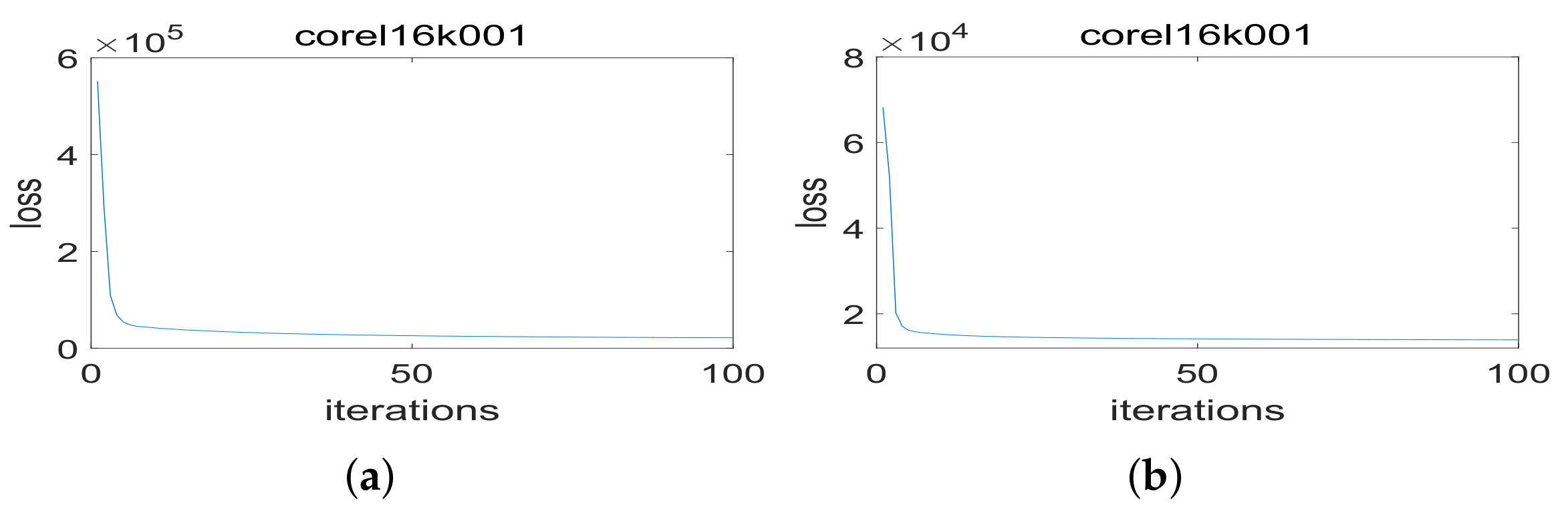
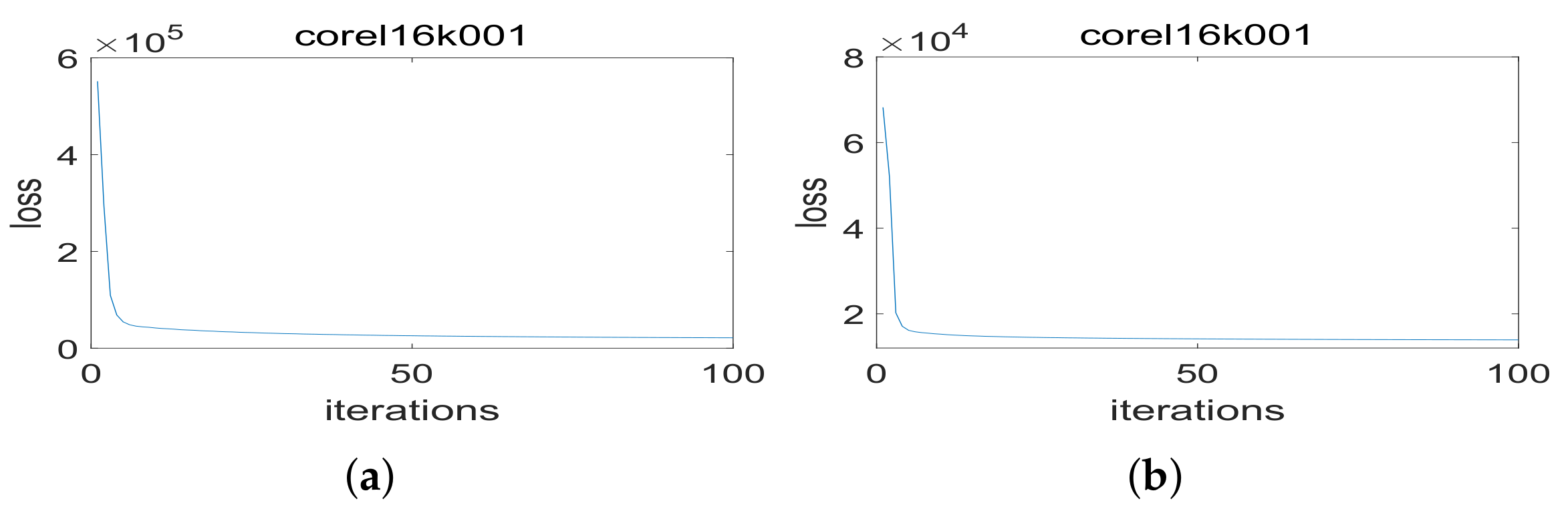
4.6. Convergence
To illustrate the convergence of the proposed method,
Figure 3 shows the change curve of the total loss of the objective function of the linear and nonlinear MLLCE as the number of iteration increases on data set corel16k001. In the experiment, we set that if the total loss of the objective function decreases less than
after an alternate iteration, the iterative optimization process will be terminated. As shown in
Figure 3, the total loss value is rapidly reduced in the initial iteration and gradually converges with the iterative optimization process.



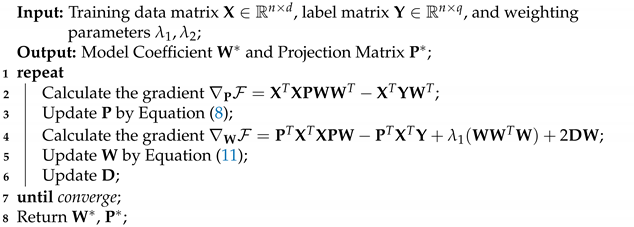

{kind=link}
{kind=link}
{kind=link}