
Consistency Analysis and Accuracy Assessment of Eight Global Forest Datasets over Myanmar



Abstract
:1. Introduction
2. Materials and Methods
2.1. Global Land Cover Datasets
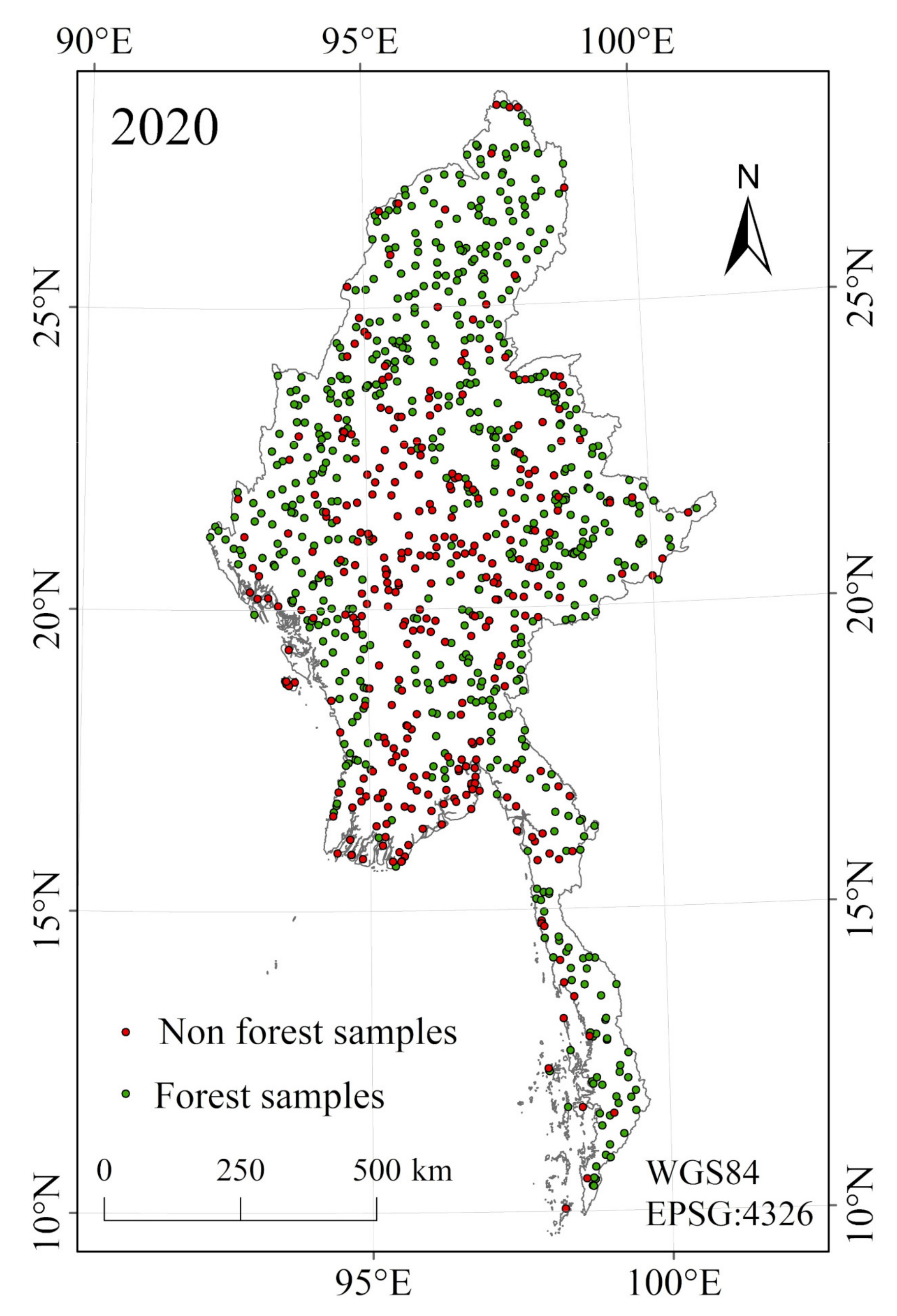
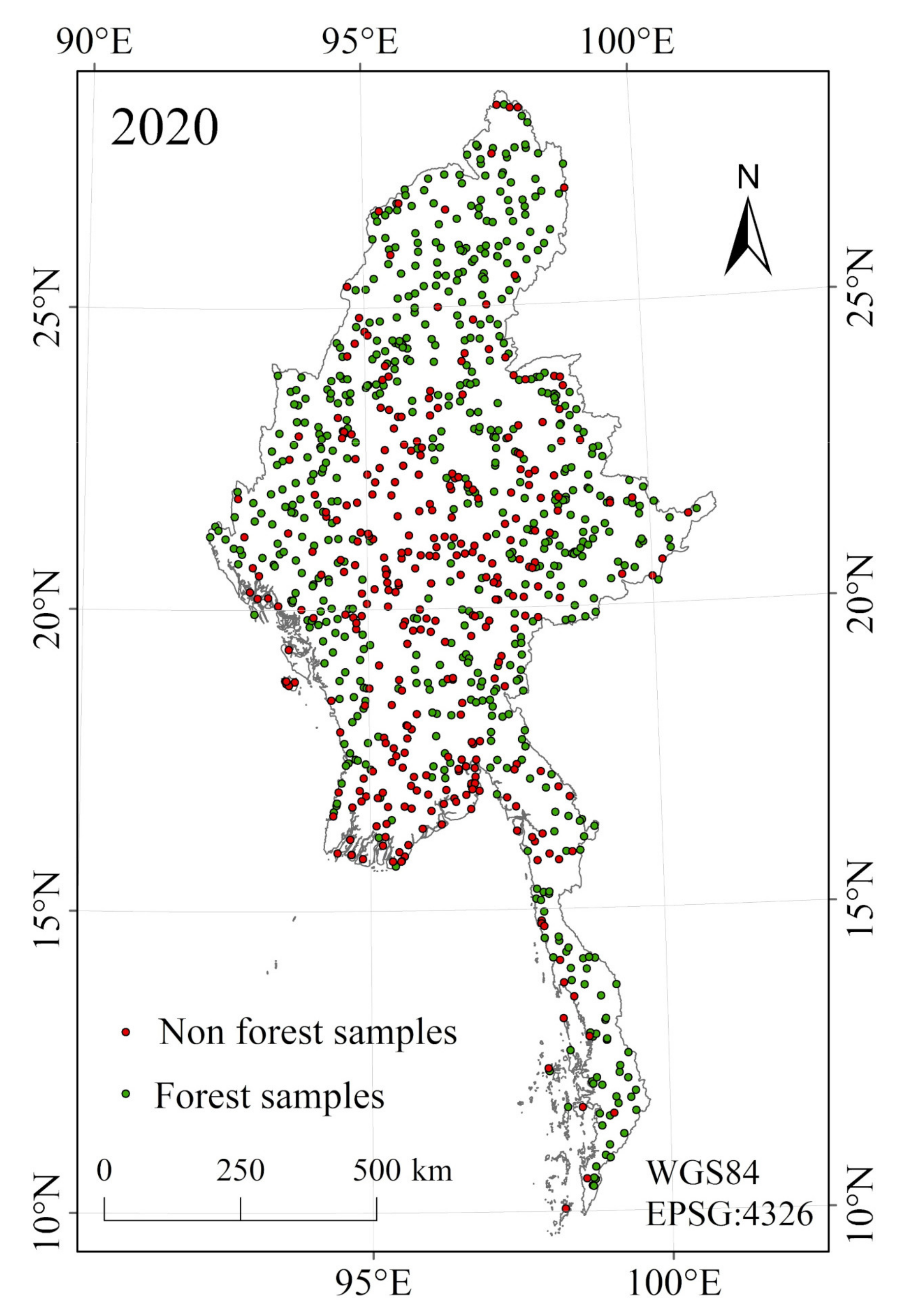
2.2. Auxiliary Data
2.3. Forest Data Harmonization for Comparison and Analysis
3. Results
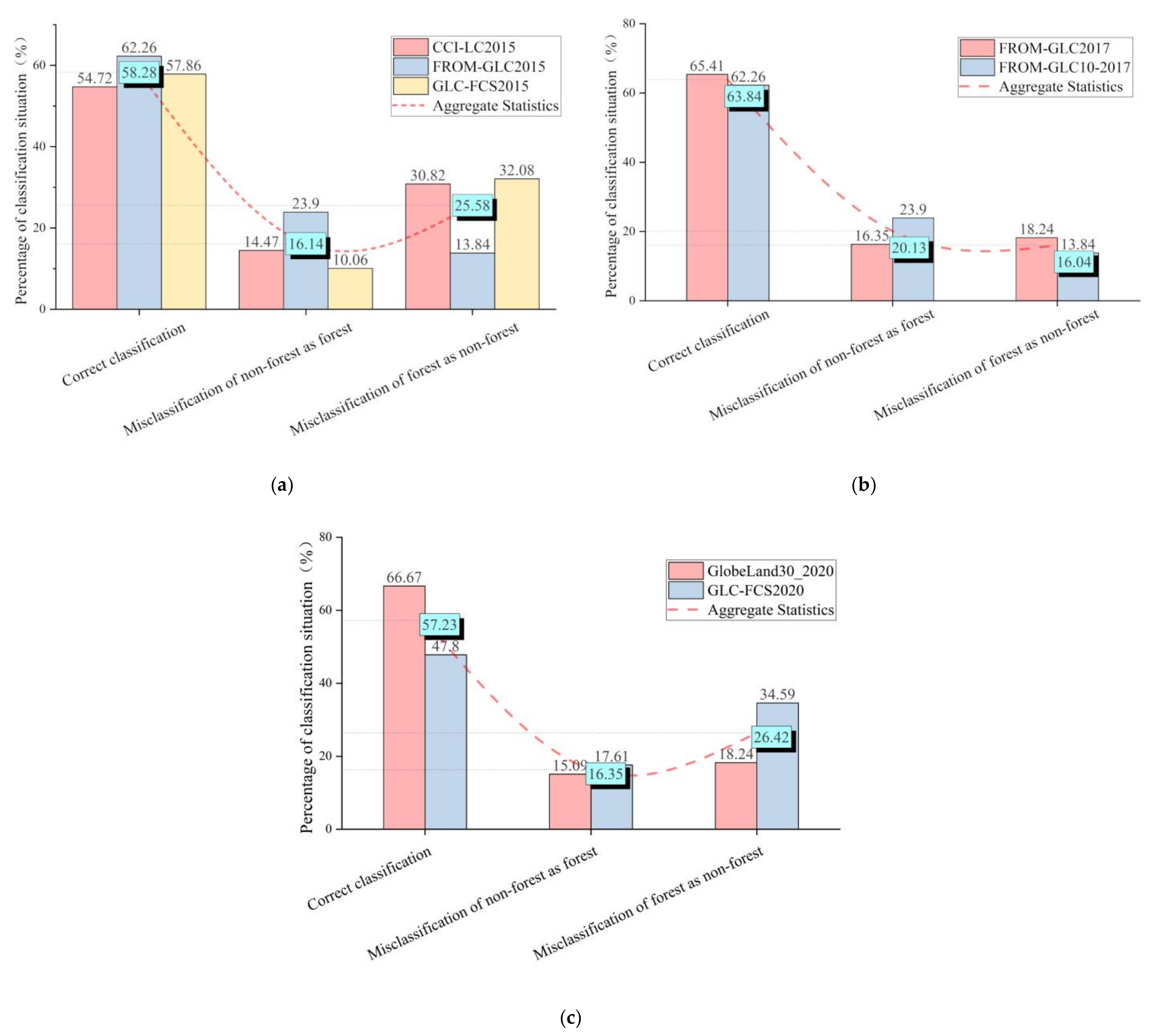
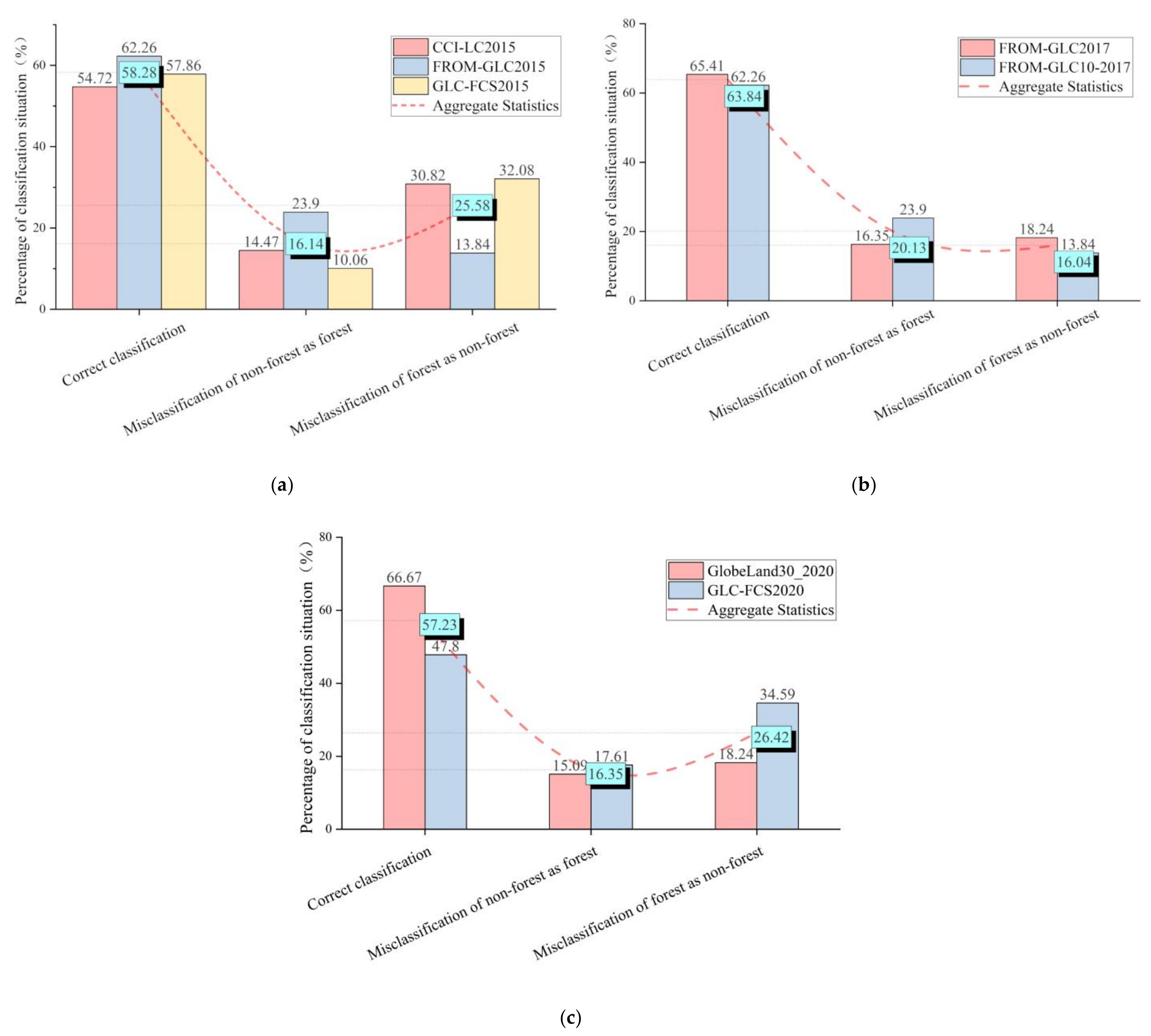
3.1. Accuracy Assessments
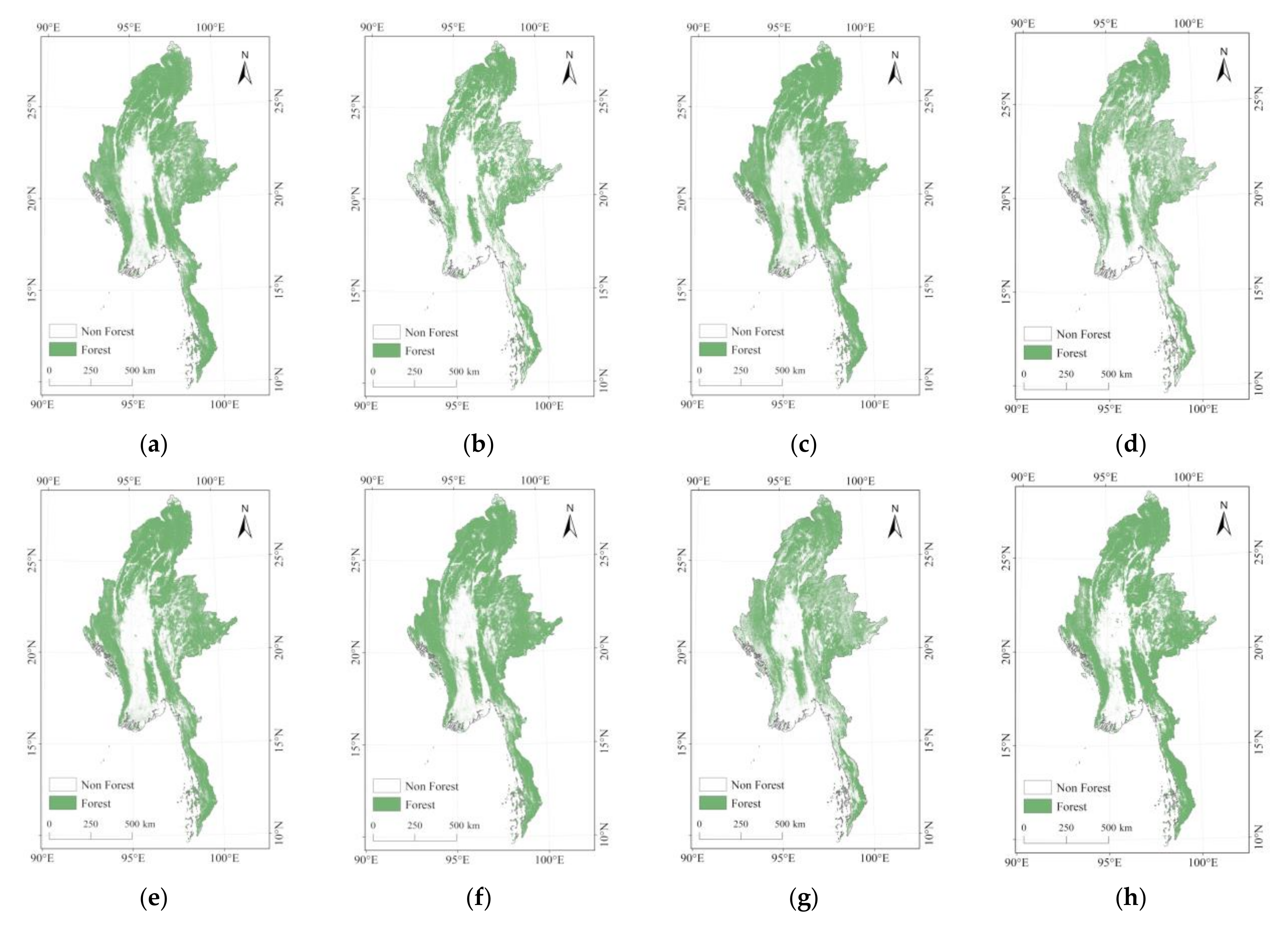
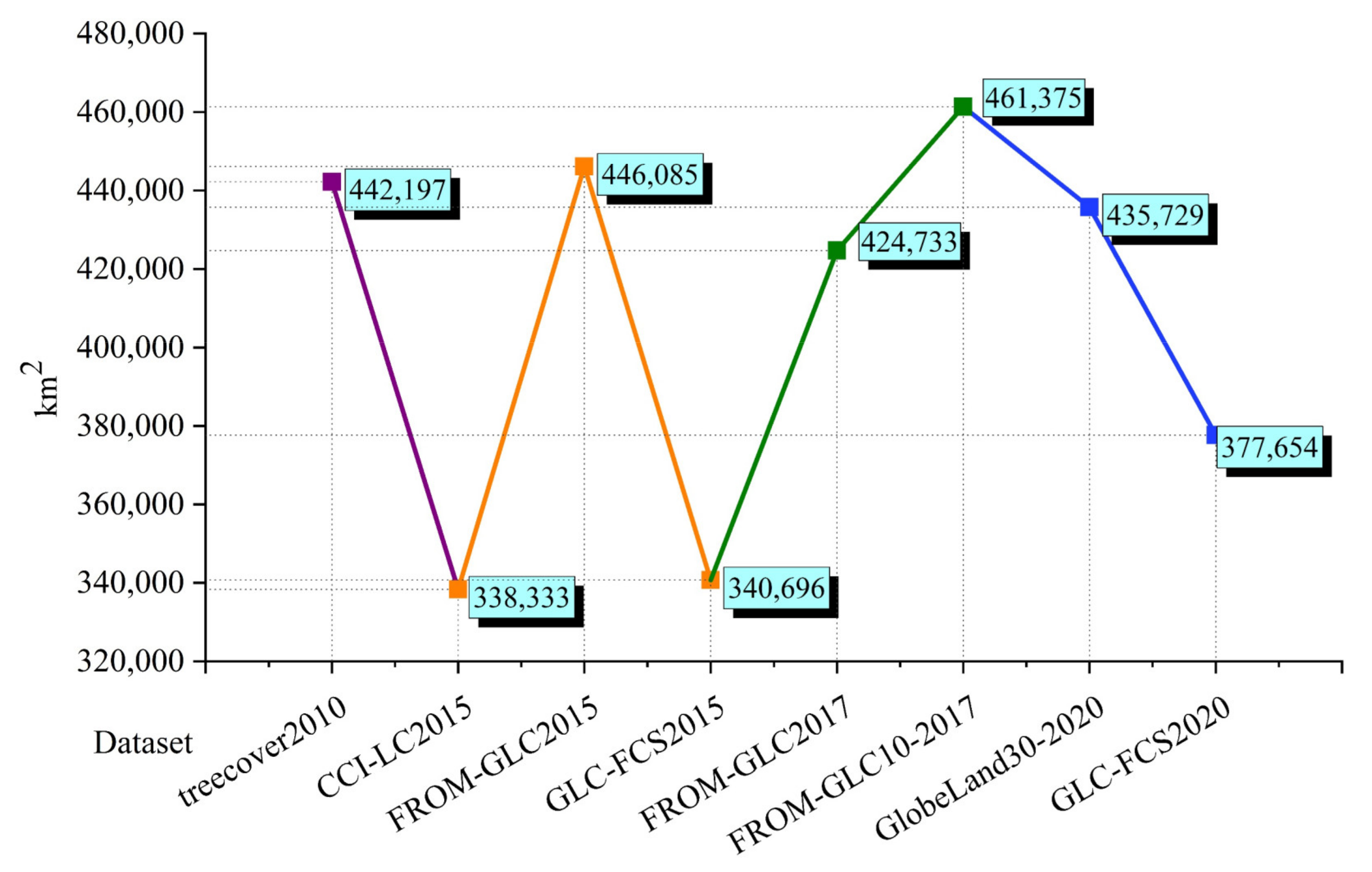
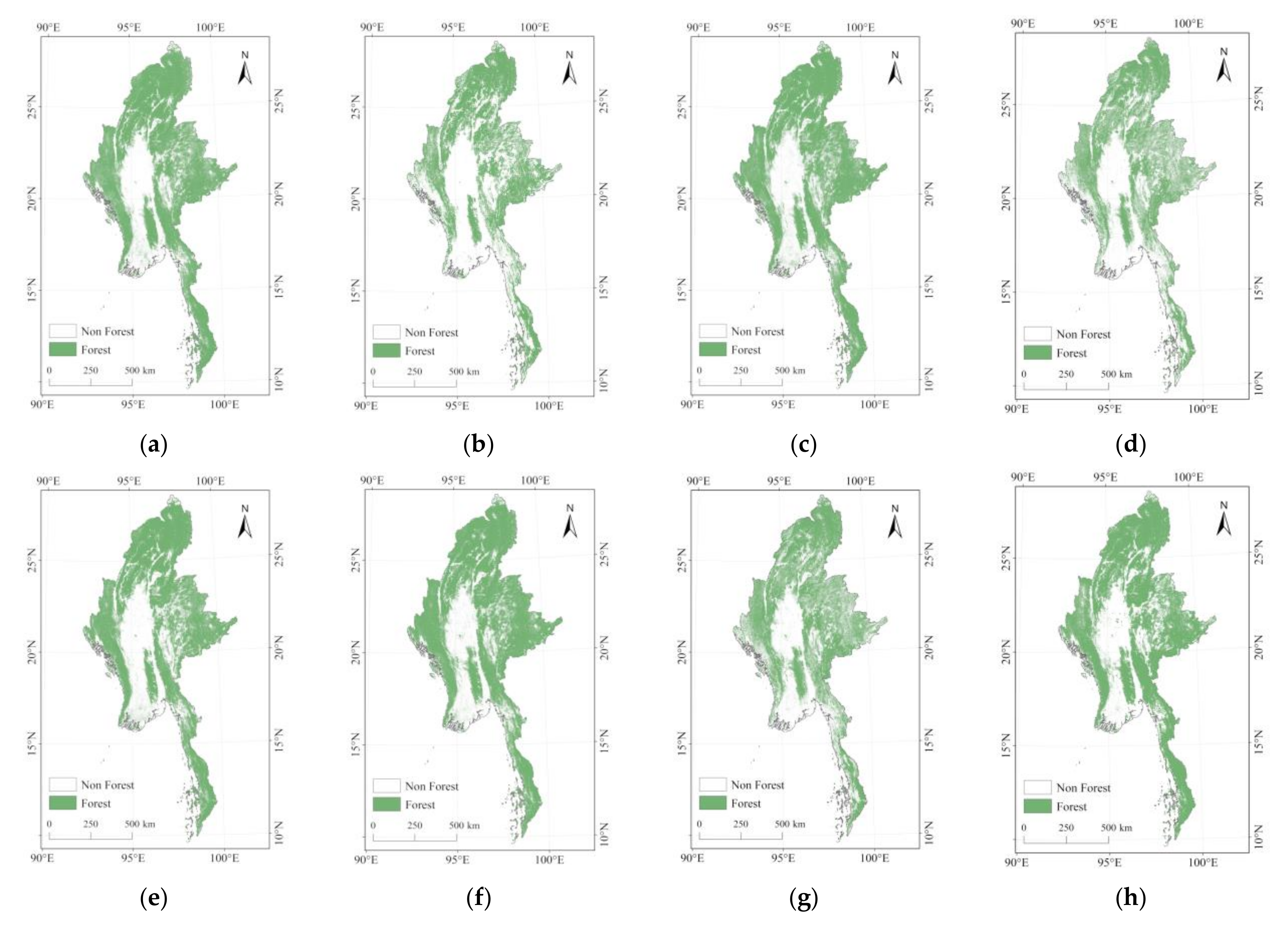
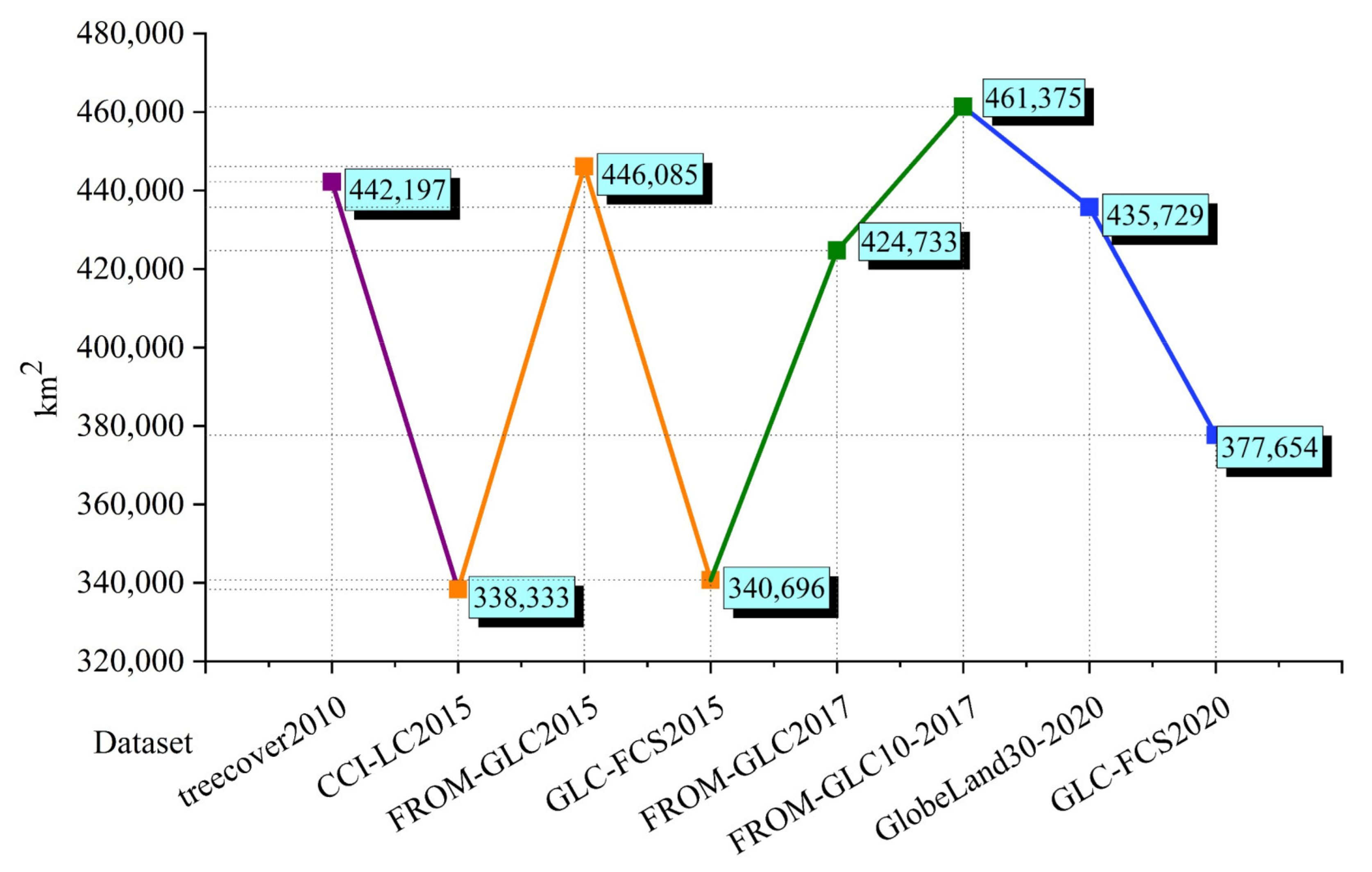
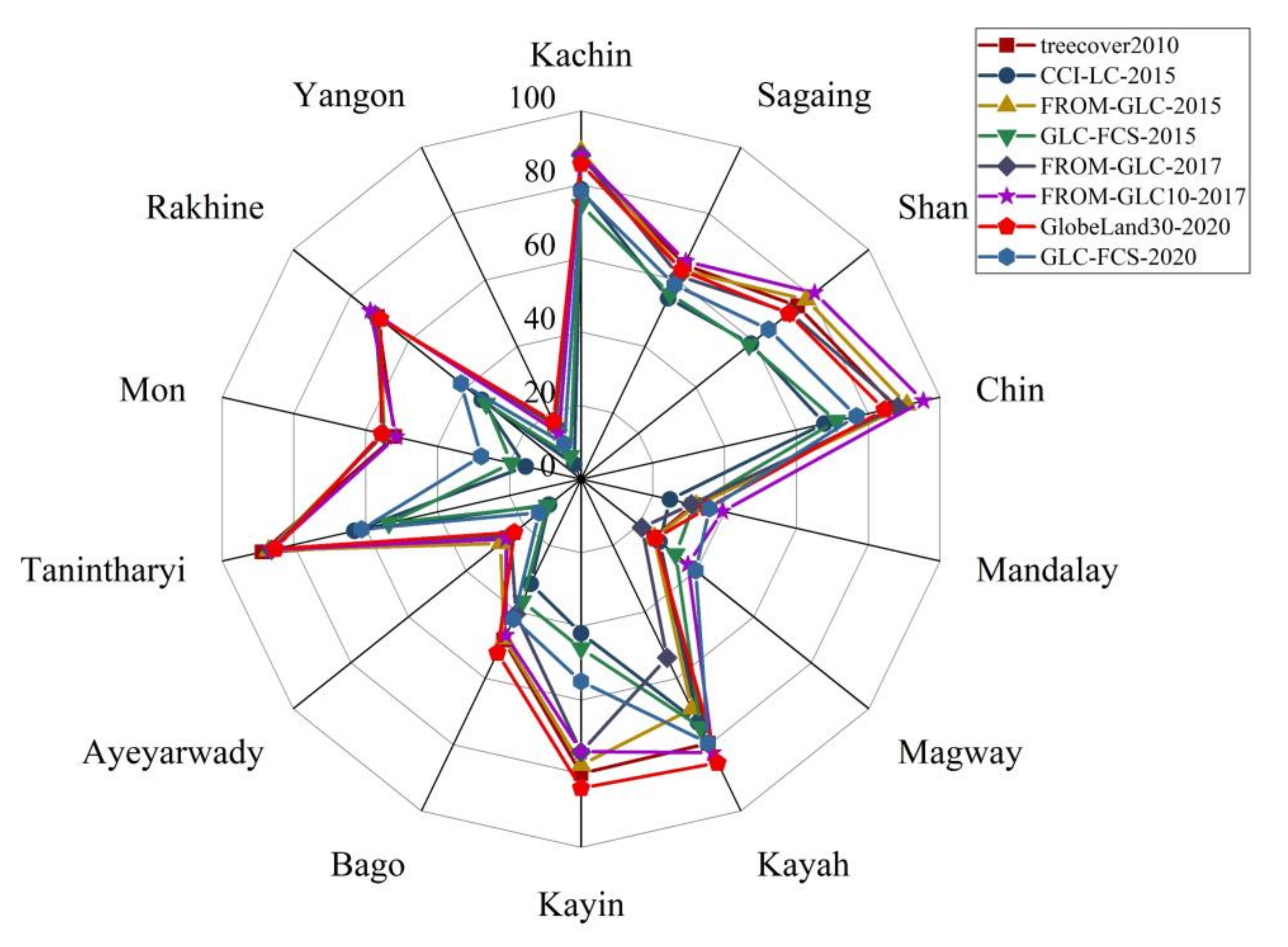
3.2. Comparison of Forest Area
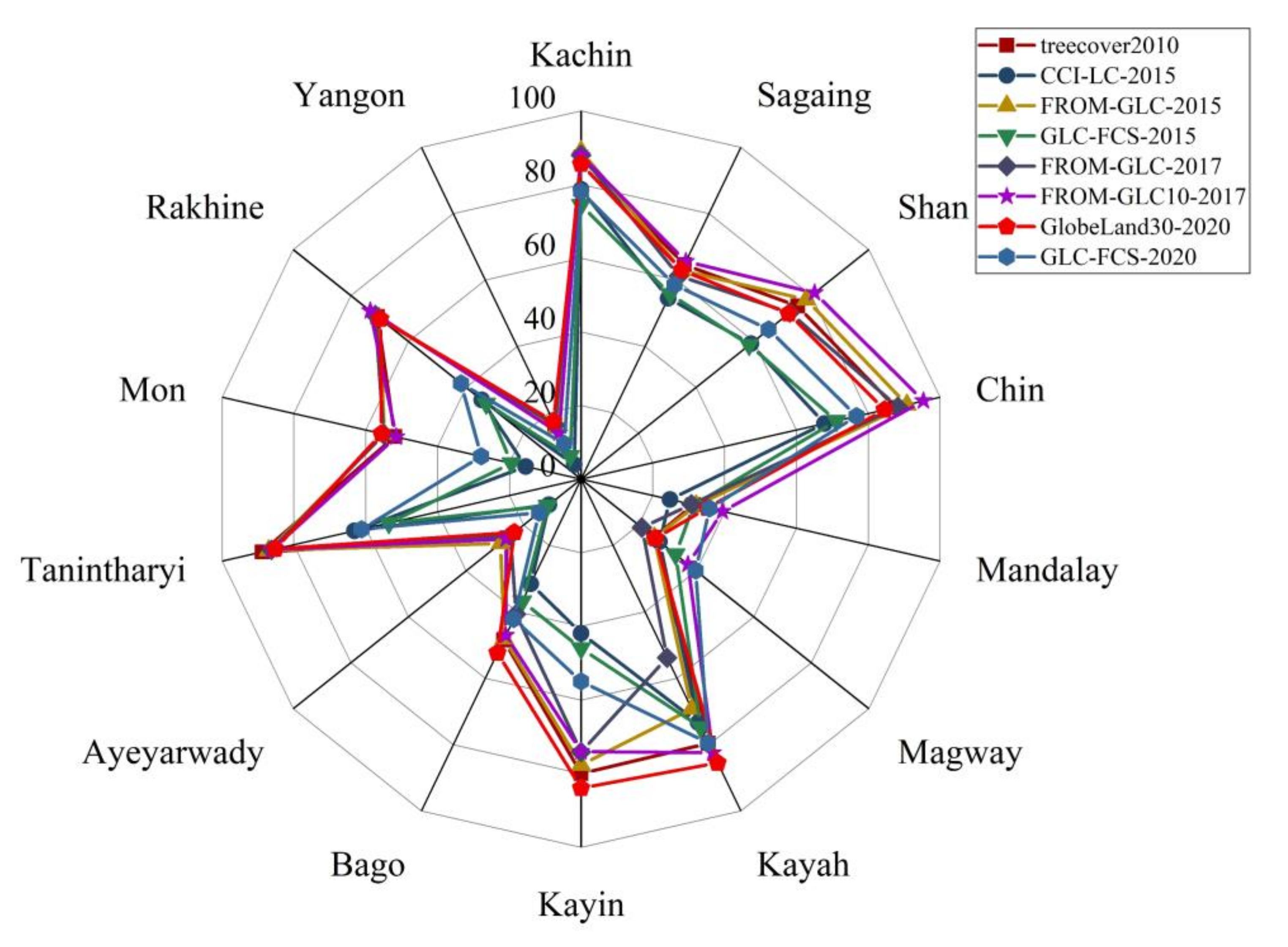
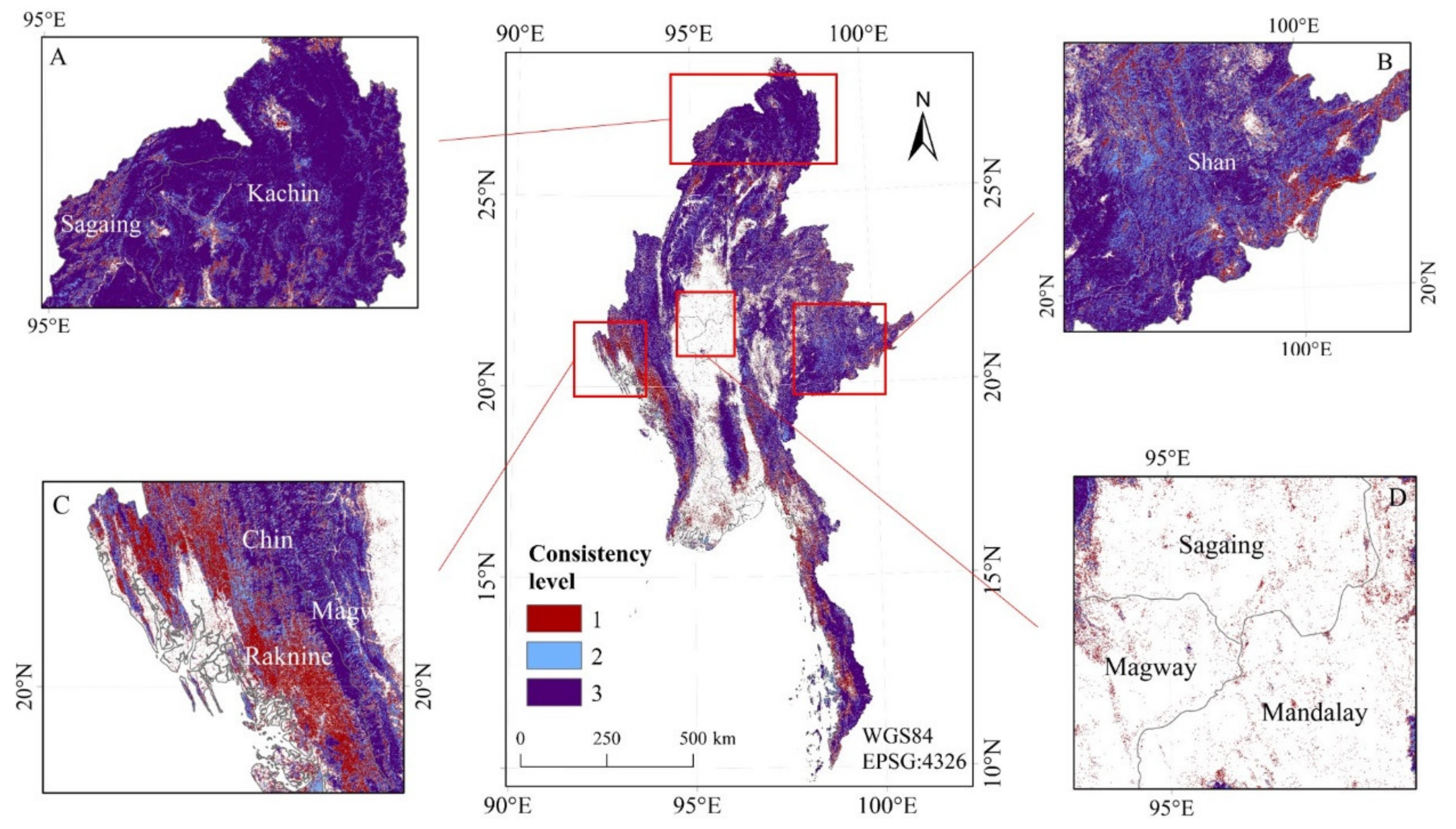
3.3. Spatial Consistency Comparison
3.3.1. Spatial Consistency of Eight Datasets over Different Years
3.3.2. Spatial Consistency of Three Datasets in 2015
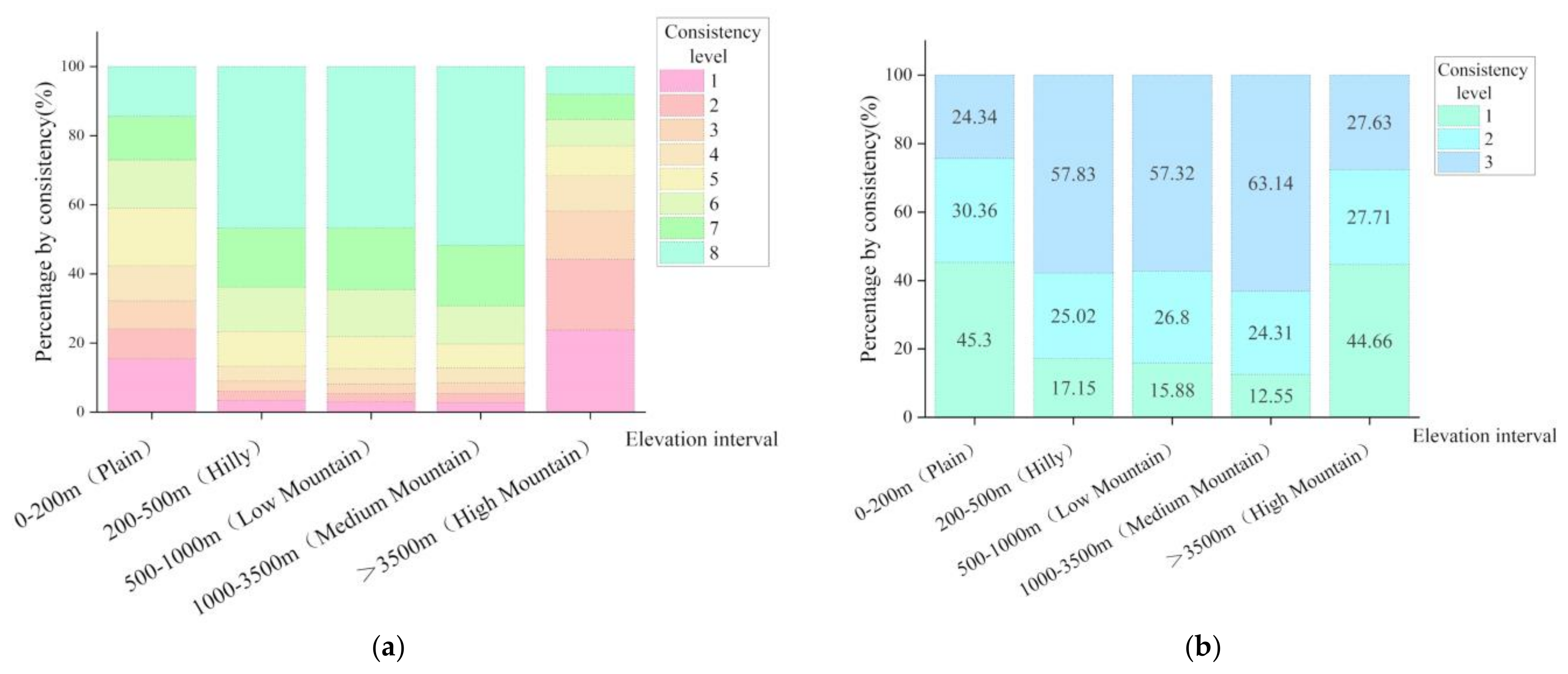
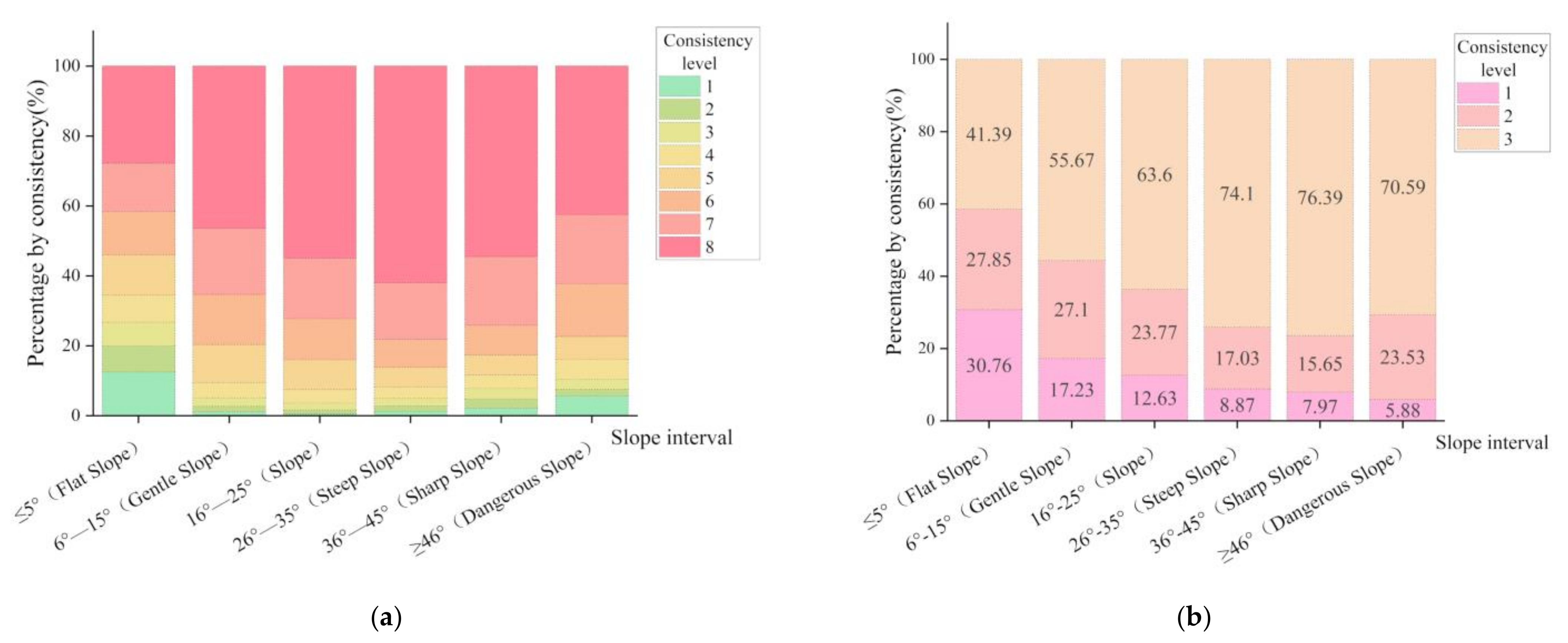
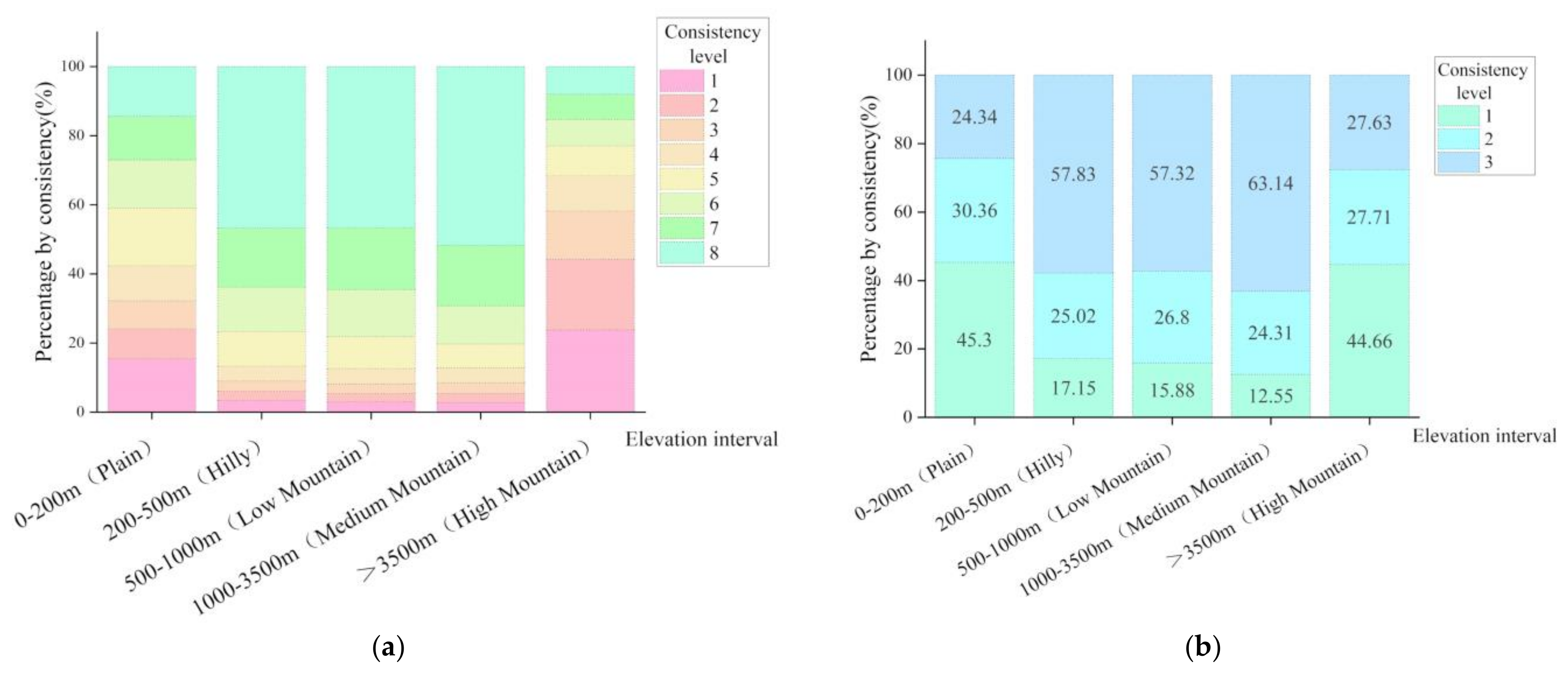
3.4. Factors Influencing on the Spatial Consistency
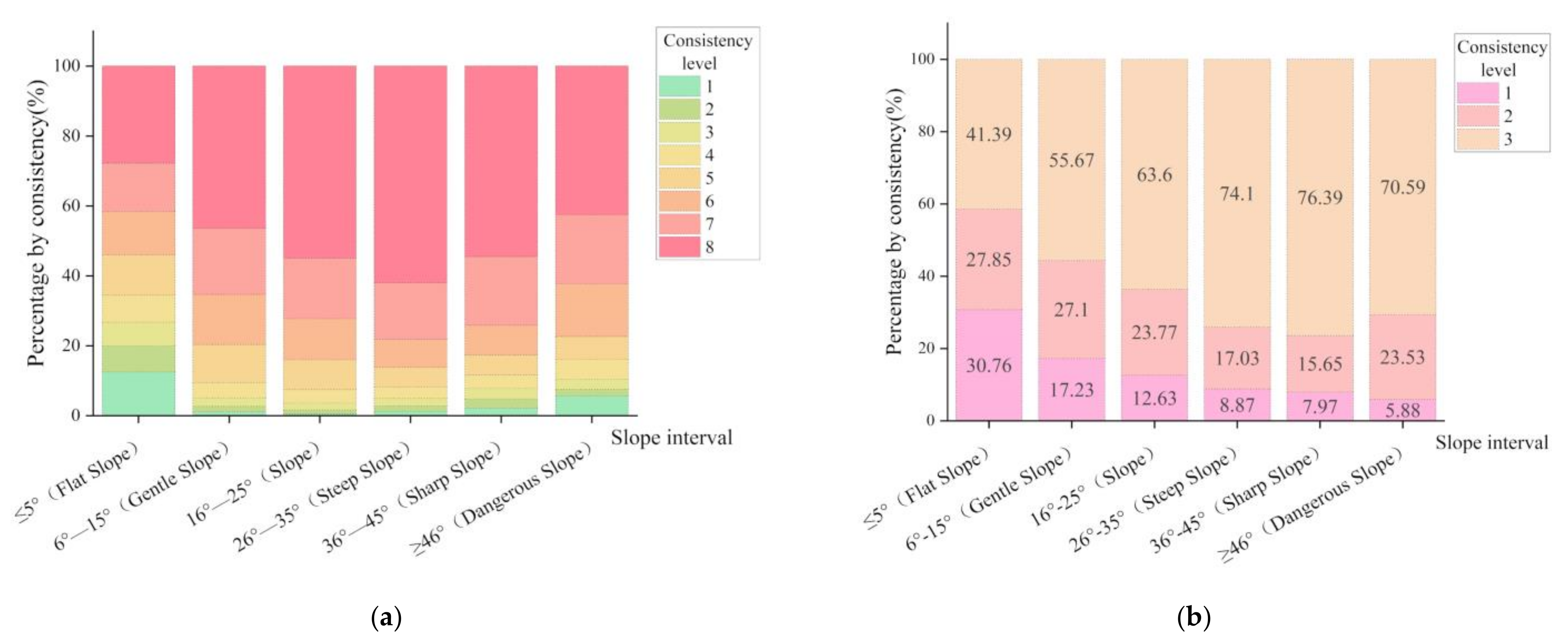
3.4.1. Influence of Terrain on the Consistency
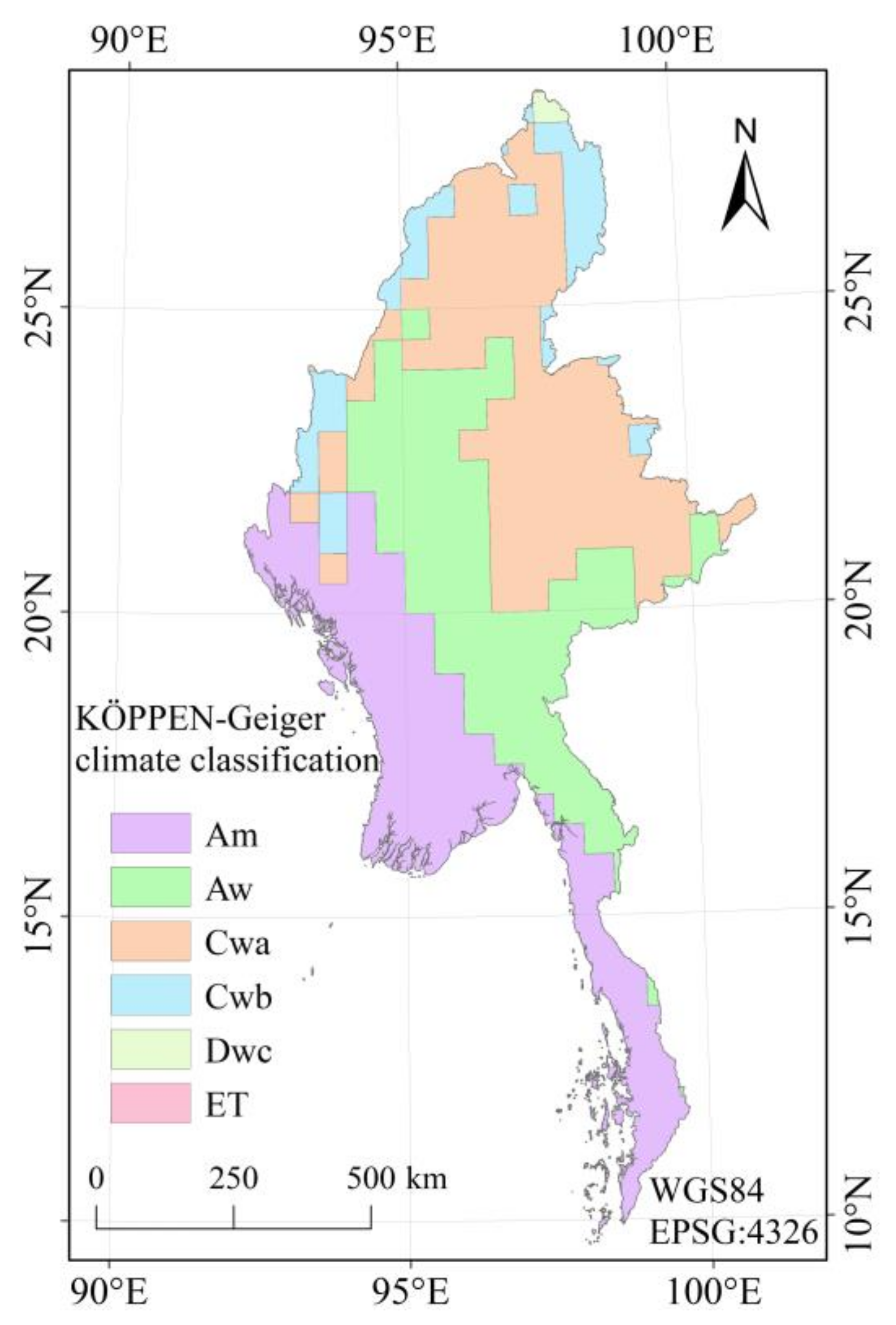
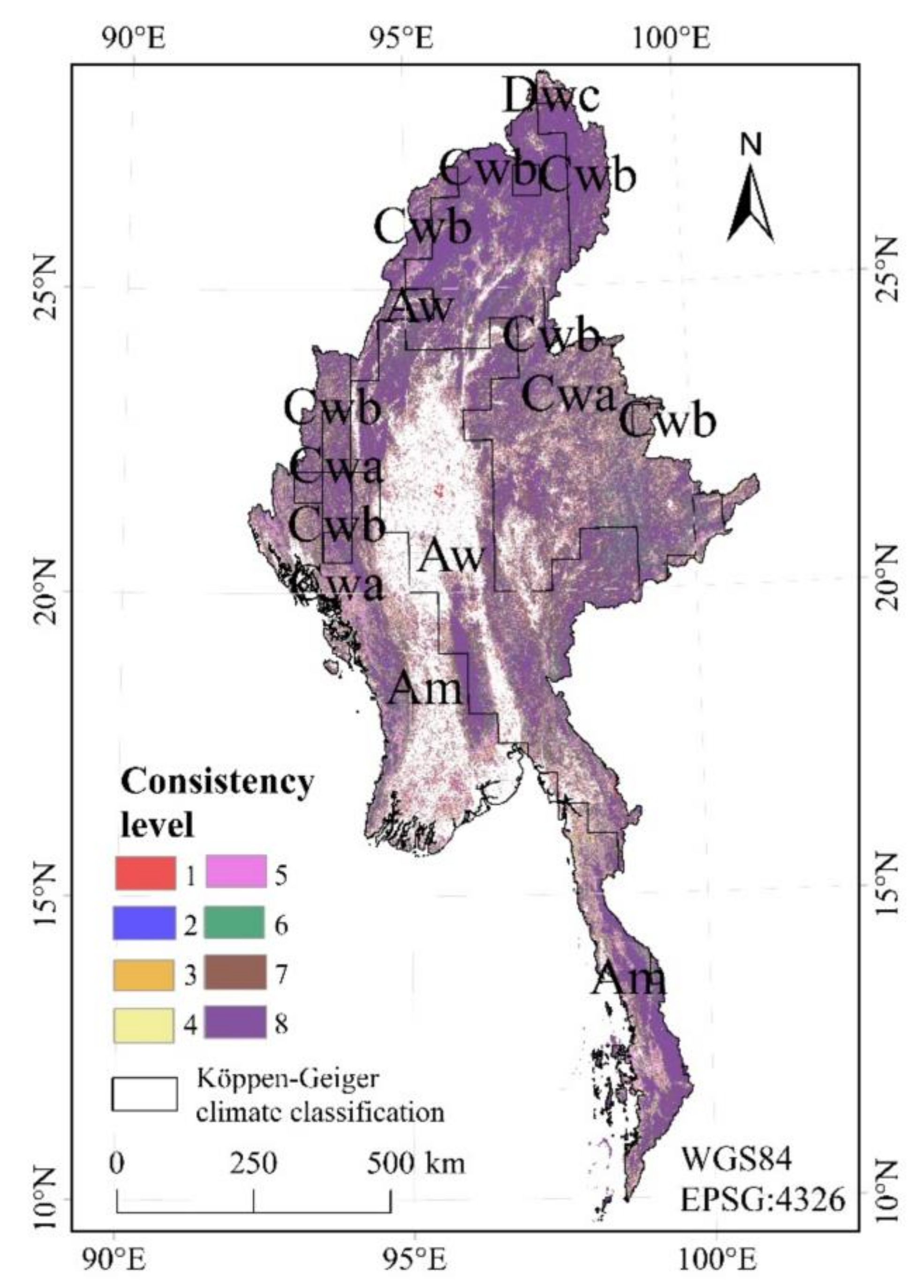
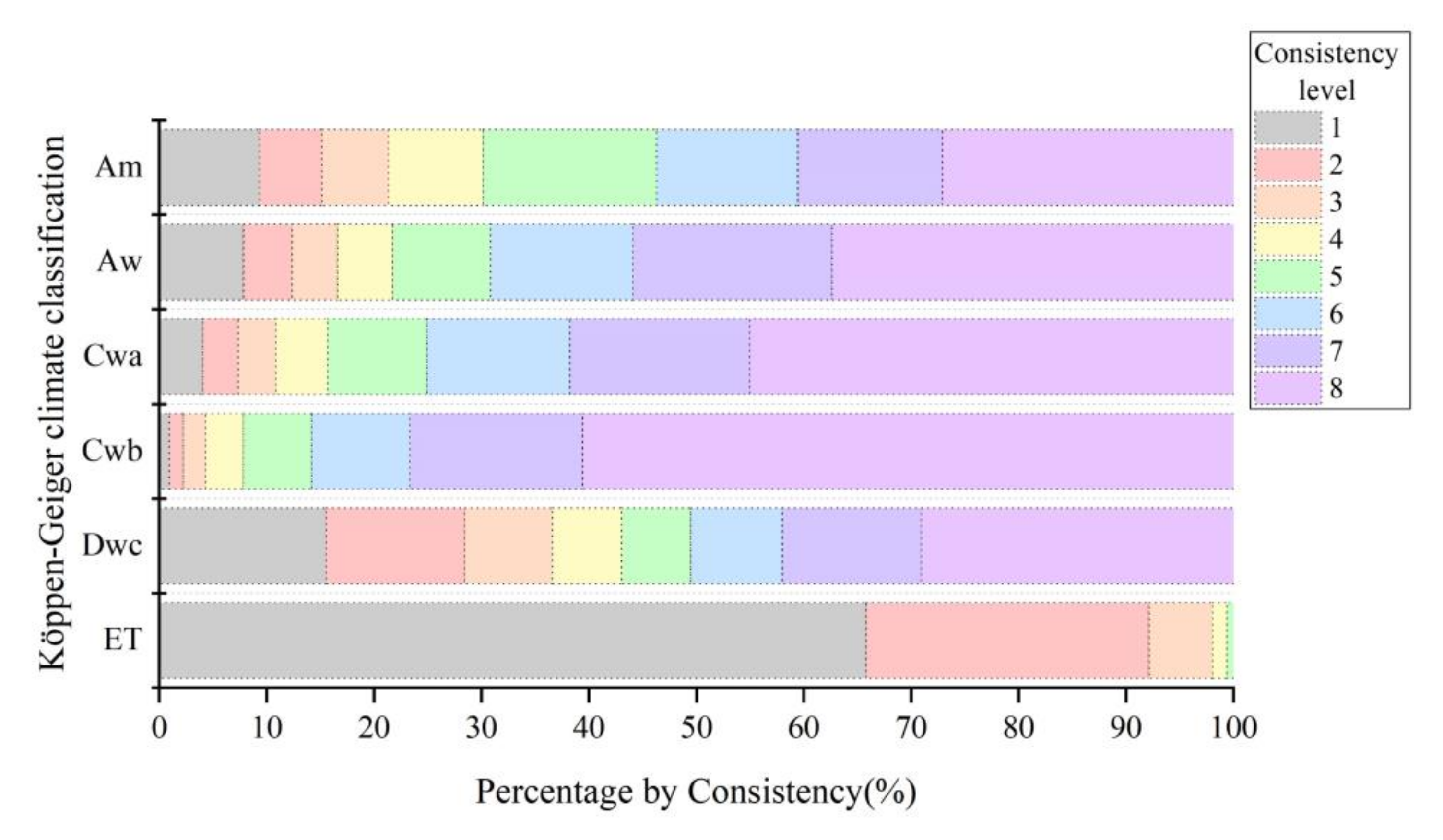
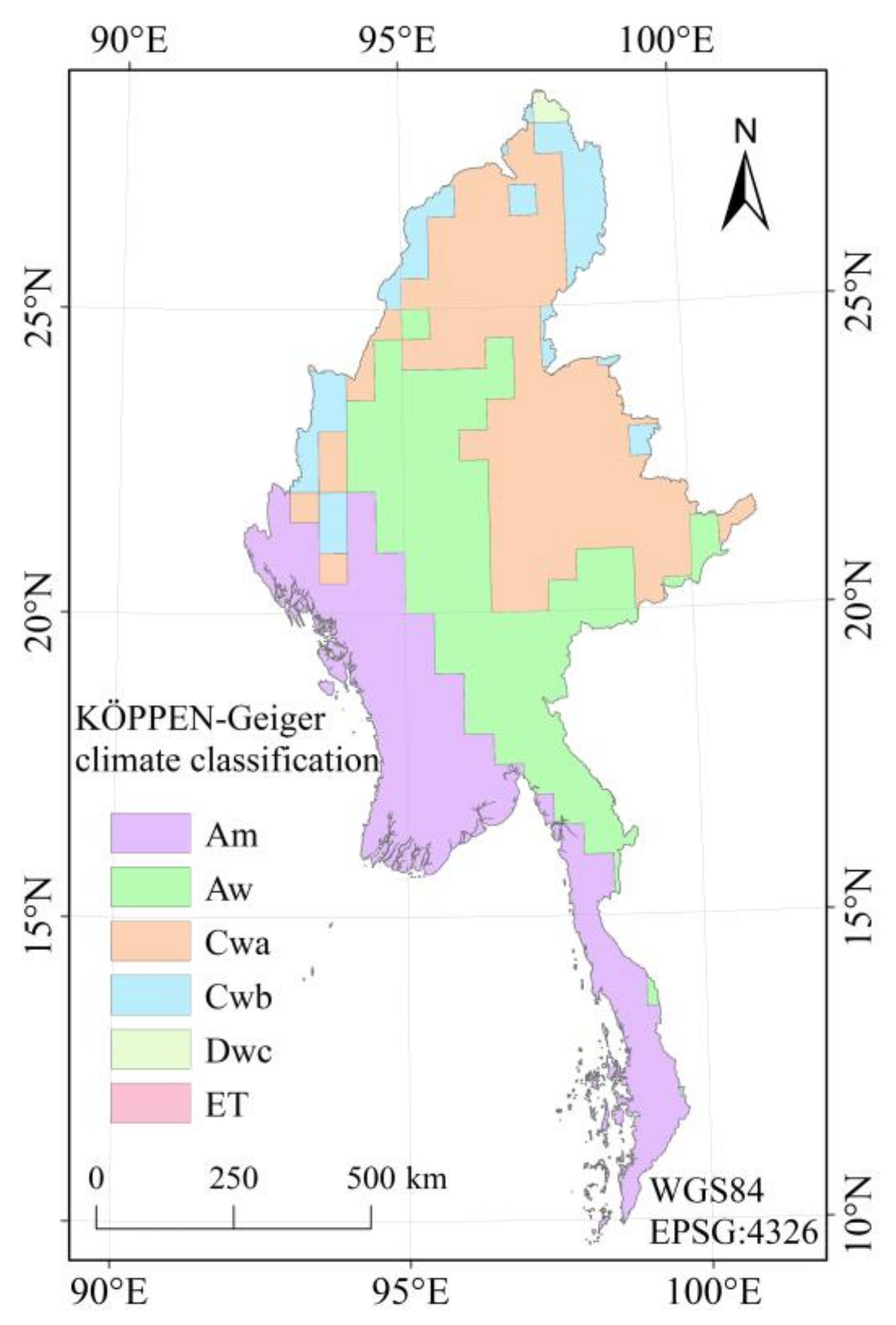
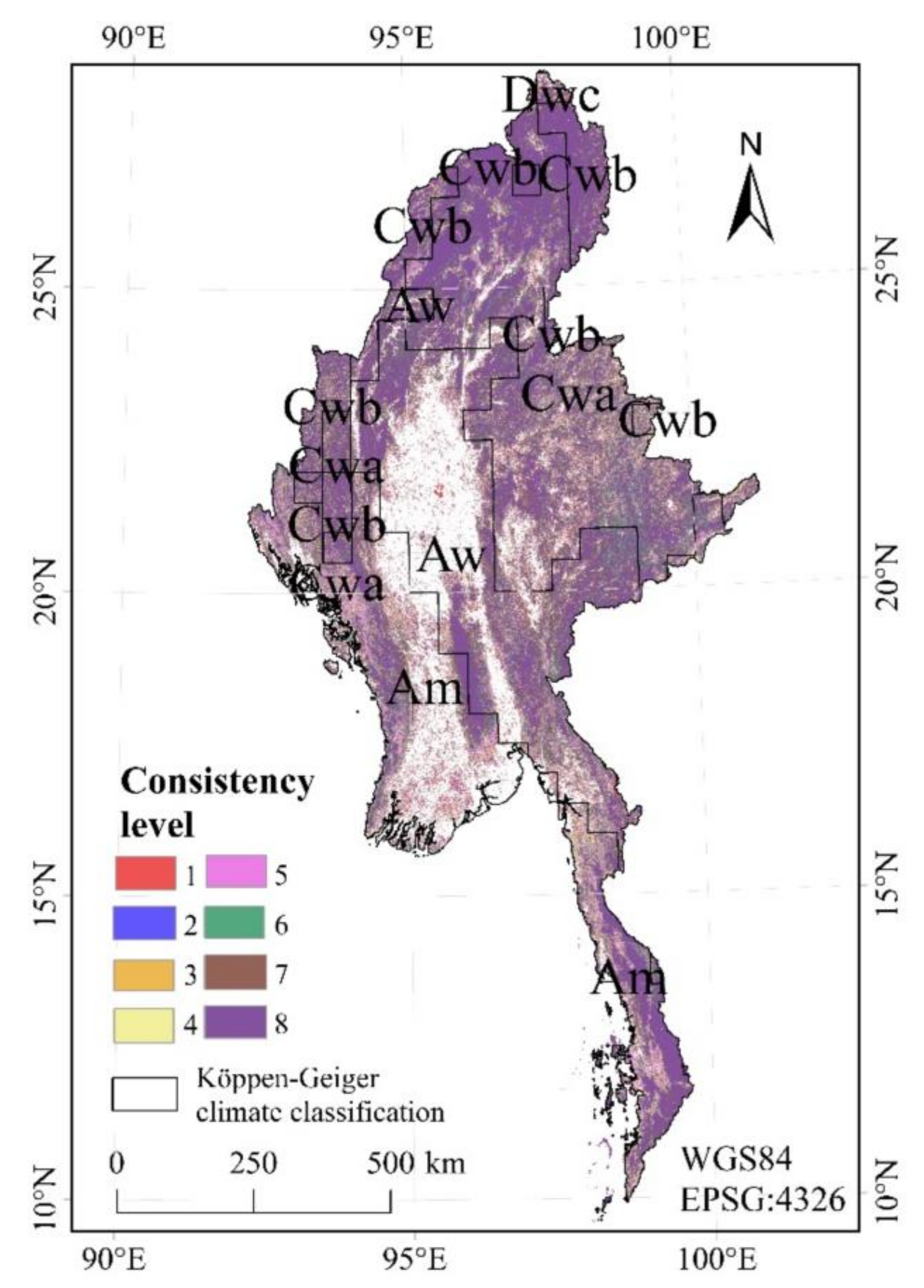
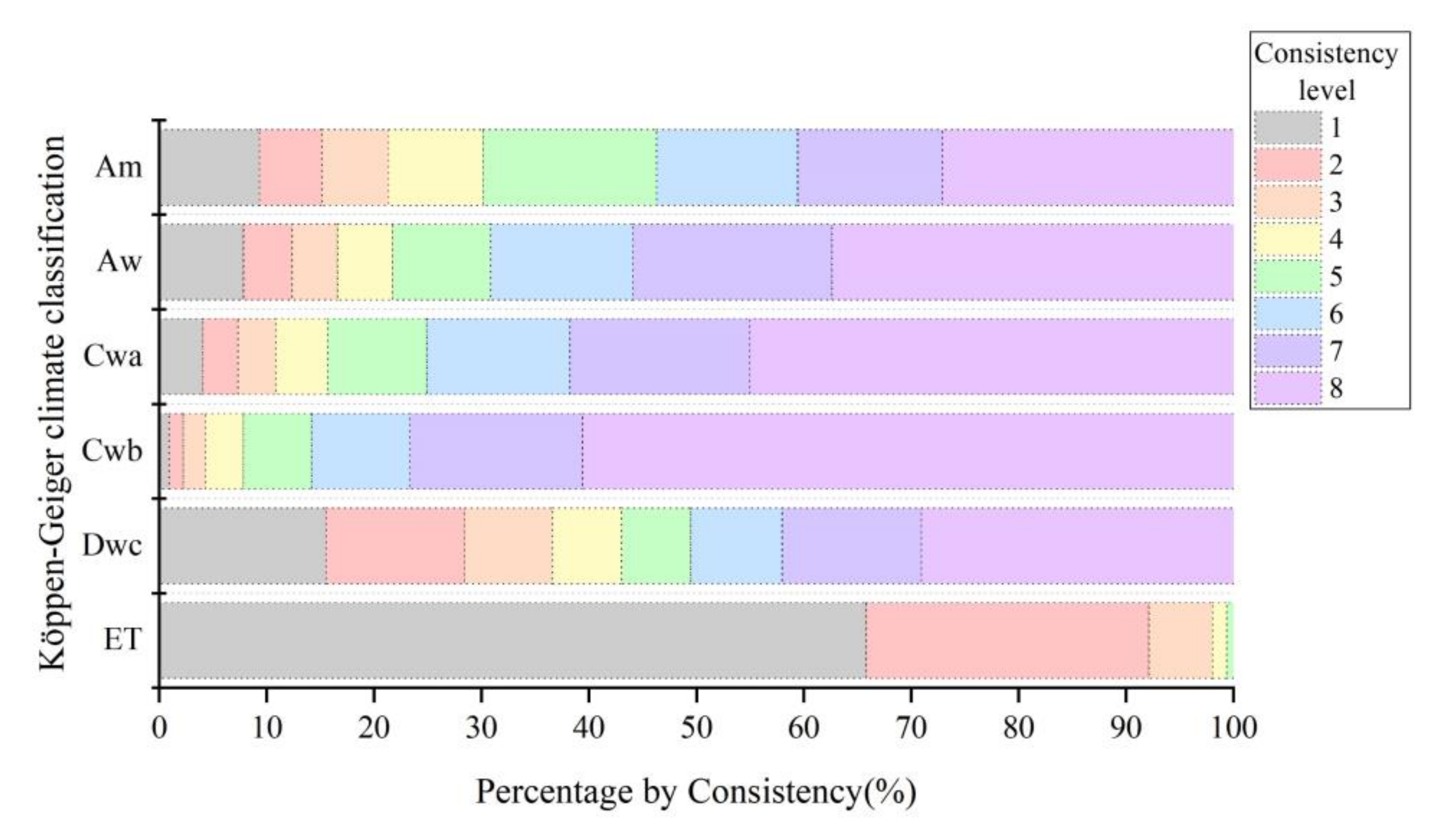
3.4.2. Influence of Climate on the Consistency
4. Discussion
4.1. Discrepancies among Datasets
4.2. Challenges and Prospect of Forest Mapping at Large Scale
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sullivan, B.W.; Nifong, R.L.; Nasto, M.K.; Alvarez-Clare, S.; Dencker, C.M.; Soper, F.M.; Shoemaker, K.T.; Ishida, F.Y.; Zaragoza-Castells, J.; Davidson, E.A. Biogeochemical recuperation of lowland tropical forest during succession. Ecology 2019, 100, e02641. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hill, S.L.L.; Arnell, A.; Maney, C.; Butchart, S.H.M.; Hilton-Taylor, C.; Ciciarelli, C.; Davis, C.; Dinerstein, E.; Purvis, A.; Burgess, N.D. Measuring Forest Biodiversity Status and Changes Globally. Front. For. Glob. Chang. 2019, 2, 70. [Google Scholar] [CrossRef]
- Laurin, G.V.; Vittucci, C.; Tramontana, G.; Ferrazzoli, P.; Guerriero, L.; Papale, D. Monitoring tropical forests under a functional perspective with satellite-based vegetation optical depth. Glob. Chang. Biol. 2020, 26, 3402–3416. [Google Scholar] [CrossRef] [PubMed]
- Lwin, K.K.; Ota, T.; Shimizu, K.; Mizoue, N. A country-scale analysis revealed effective land-use zoning affecting forest cover changes in Myanmar. J. For. Res. 2020, 25, 389–396. [Google Scholar] [CrossRef]
- Lee, D.K. Challenging forestry issues in Asia and their strategies. RAP Publ. 2009, 3, 65–76. [Google Scholar]
- Aye, W.N.; Wen, Y.; Marin, K.; Thapa, S.; Tun, A.W. Contribution of Mangrove Forest to the Livelihood of Local Communities in Ayeyarwaddy Region, Myanmar. Forests 2019, 10, 414. [Google Scholar] [CrossRef] [Green Version]
- Htun, N.Z.; Mizoue, N.; Kajisa, T.; Yoshida, S. Deforestation and forest degradation as measures of Popa Mountain Park (Myanmar) effectiveness. Environ. Conserv. 2009, 36, 218–224. [Google Scholar] [CrossRef]
- Lechner, A.M.; Foody, G.M.; Boyd, D.S. Applications in Remote Sensing to Forest Ecology and Management. One Earth 2020, 2, 405–412. [Google Scholar] [CrossRef]
- Gao, Y.; Skutsch, M.; Paneque-Gálvez, J.; Ghilardi, A. Remote sensing of forest degradation: A review. Environ. Res. Lett. 2020, 15, 103001. [Google Scholar] [CrossRef]
- Pettorelli, N.; Bühne, H.S.T.; Tulloch, A.; Dubois, G.; Macinnis-Ng, C.; Queirós, A.M.; Keith, D.A.; Wegmann, M.; Schrodt, F.; Stellmes, M.; et al. Satellite remote sensing of ecosystem functions: Opportunities, challenges and way forward. Remote Sens. Ecol. Conserv. 2017, 4, 71–93. [Google Scholar] [CrossRef]
- Hansen, M.C.; Reed, B.W. A comparison of the IGBP DISCover and University of Maryland 1 km global land cover products. Int. J. Remote Sens. 2000, 21, 1365–1373. [Google Scholar] [CrossRef]
- Loveland, T.R.; Belward, A.S. The IGBP-DIS global 1km land cover data set, DISCover: First results. Int. J. Remote Sens. 1997, 18, 3289–3295. [Google Scholar] [CrossRef]
- Loveland, T.R.; Reed, B.C.; Brown, J.; Ohlen, D.; Zhu, Z.; Yang, L.; Merchant, J.W. Development of a global land cover characteristics database and IGBP DISCover from 1 km AVHRR data. Int. J. Remote Sens. 2000, 21, 1303–1330. [Google Scholar] [CrossRef]
- Bartholomé, E.; Belward, A.S. GLC2000: A new approach to global land cover mapping from Earth observation data. Int. J. Remote Sens. 2005, 26, 1959–1977. [Google Scholar] [CrossRef]
- Friedl, M.A.; McIver, D.K.; Baccini, A.; Gao, F.; Schaaf, C.; Hodges, J.C.F.; Zhang, X.Y.; Muchoney, D.; Strahler, A.H.; Woodcock, C.E.; et al. Global land cover mapping from MODIS: Algorithms and early results. Remote Sens Environ. 2002, 83, 287–302. [Google Scholar] [CrossRef]
- Friedl, M.A.; Sulla-Menashe, D.; Tan, B.; Schneider, A.; Ramankutty, N.; Sibley, A.; Huang, X. MODIS Collection 5 global land cover: Algorithm refinements and characterization of new datasets. Remote Sens. Environ. 2010, 114, 168–182. [Google Scholar] [CrossRef]
- Arino, O.; Bicheron, P.; Achard, F.; Latham, J.; Witt, R.; Weber, J.-L. The most detailed portrait of Earth. Eur. Sp. Agency 2008, 136, 25–31. [Google Scholar]
- Bontemps, S.; Defourny, P.; van Bogaert, E.; Kalogirou, V.; Perez, J.R. GLOBCOVER 2009 Products Description and Validation Report. ESA Bull. 2011, 136, 53. [Google Scholar]
- Defourny, P.; Kirches, G.; Brockmann, C.; Boettcher, M.; Peters, M.; Bontemps, S.; Lamarche, C.; Schlerf, M.; Santoro, M. Product User Guide Version; ESA Climate Office: Harwell, UK, 2012; Volume 2, p. 325. [Google Scholar]
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.; Zhao, Y.; Liang, L.; Niu, Z.; Huang, X.; Fu, H.; Liu, S.; et al. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data. Int. J. Remote Sens. 2012, 34, 2607–2654. [Google Scholar] [CrossRef] [Green Version]
- Yu, L.; Wang, J.; Gong, P. Improving 30 m global land-cover map FROM-GLC with time series MODIS and auxiliary data sets: A segmentation-based approach. Int. J. Remote Sens. 2013, 34, 5851–5867. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; et al. Global land cover mapping at 30 m resolution: A POK-based operational approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef] [Green Version]
- Gong, P.; Liu, H.; Zhang, M.; Li, C.; Wang, J.; Huang, H.; Clinton, N.; Ji, L.; Li, W.; Bai, Y.; et al. Stable classification with limited sample: Transferring a 30-m resolution sample set collected in 2015 to mapping 10-m resolution global land cover in 2017. Sci. Bull. 2019, 64, 370–373. [Google Scholar] [CrossRef] [Green Version]
- Gao, Y.; Liu, L.; Zhang, X.; Chen, X.; Mi, J.; Xie, S. Consistency Analysis and Accuracy Assessment of Three Global 30-m Land-Cover Products over the European Union using the LUCAS Dataset. Remote Sens. 2020, 12, 3479. [Google Scholar] [CrossRef]
- Wei, Y.; Lu, M.; Wu, W.; Ru, Y. Multiple factors influence the consistency of cropland datasets in Africa. Int. J. Appl. Earth Obs. Geoinf. 2020, 89, 102087. [Google Scholar] [CrossRef]
- Pérez-Hoyos, A.; Rembold, F.; Kerdiles, H.; Gallego, J. Comparison of Global Land Cover Datasets for Cropland Monitoring. Remote Sens. 2017, 9, 1118. [Google Scholar] [CrossRef] [Green Version]
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R. High-resolution global maps of 21st-century forest cover change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef] [Green Version]
- Hui, Z.; Fu, X.; Jinwei, D. Research ON Forest Resource Changes Monitoring Based ON Multi-Source Remote Sensing Images—Taking the Loess Plateau as an Example; Beijing Forestry University: Beijing, China, 2020. [Google Scholar]
- Zhang, X.; Liu, L.; Chen, X.; Xie, S.; Gao, Y. Fine Land-Cover Mapping in China Using Landsat Datacube and an Operational SPECLib-Based Approach. Remote Sens. 2019, 11, 1056. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Liu, L.; Chen, X.; Gao, Y.; Xie, S.; Mi, J. GLC_FCS30: Global land-cover product with fine classification system at 30 m using time-series Landsat imagery. Earth Syst. Sci. Data 2021, 13, 2753–2776. [Google Scholar] [CrossRef]
- Zhao, Y.; Gong, P.; Yu, L.; Hu, L.; Li, X.; Li, C.; Zhang, H.; Zheng, Y.; Wang, J.; Zhao, Y.; et al. Towards a common validation sample set for global land-cover mapping. Int. J. Remote Sens. 2014, 35, 4795–4814. [Google Scholar] [CrossRef]
- Farr, T.; Kobrick, M. Shuttle radar topography mission produces a wealth of data. Eos Trans. Am. Geophys. Union 2000, 81, 583–585. [Google Scholar] [CrossRef]
- Rabus, B.; Eineder, M.; Roth, A.; Bamler, R. The shuttle radar topography mission—A new class of digital elevation models acquired by spaceborne radar. ISPRS J. Photogramm. Remote Sens. 2003, 57, 241–262. [Google Scholar] [CrossRef]
- Rubel, F.; Kottek, M. Observed and projected climate shifts 1901-2100 depicted by world maps of the Köppen-Geiger climate classification. Meteorol. Z. 2010, 19, 135–141. [Google Scholar] [CrossRef] [Green Version]
- Chen, D.; Lu, M.; Zhou, Q.; Xiao, J.; Ru, Y.; Wei, Y.; Wu, W. Comparison of Two Synergy Approaches for Hybrid Cropland Mapping. Remote Sens. 2019, 11, 213. [Google Scholar] [CrossRef] [Green Version]
- Kang, J.; Wang, Z.; Sui, L.; Yang, X.; Ma, Y.; Wang, J. Consistency Analysis of Remote Sensing Land Cover Products in the Tropical Rainforest Climate Region: A Case Study of Indonesia. Remote Sens. 2020, 12, 1410. [Google Scholar] [CrossRef]
- Xu, Y.; Yu, L.; Feng, D.; Peng, D.; Li, C.; Huang, X.; Lu, H.; Gong, P. Comparisons of three recent moderate resolution African land cover datasets: CGLS-LC100, ESA-S2-LC20, and FROM-GLC-Africa30. Int. J. Remote Sens. 2019, 40, 6185–6202. [Google Scholar] [CrossRef]
- Yang, R.; Luo, Y.; Yang, K.; Hong, L.; Zhou, X. Analysis of Forest Deforestation and its Driving Factors in Myanmar from 1988 to 2017. Sustainability 2019, 11, 3047. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Myint, S.W. Environmental Concerns of Deforestation in Myanmar 2001–2010. Remote Sens. 2016, 8, 728. [Google Scholar] [CrossRef] [Green Version]
- Nabil, M.; Zhang, M.; Bofana, J.; Wu, B.; Stein, A.; Dong, T.; Zeng, H.; Shang, J. Assessing factors impacting the spatial discrepancy of remote sensing based cropland products: A case study in Africa. Int. J. Appl. Earth Obs. Geoinf. 2020, 85, 102010. [Google Scholar] [CrossRef]
- Arjasakusuma, S.; Pribadi, U.A.; Seta, G.A. Accuracy and Spatial Pattern Assessment of Forest Cover Change Datasets in Central Kalimantan. Indones. J. Geogr. 2018, 50, 222–227. [Google Scholar] [CrossRef]
- Manakos, I.; Tomaszewska, M.; Gkinis, I.; Brovkina, O.; Filchev, L.; Genc, L.; Gitas, I.Z.; Halabuk, A.; Inalpulat, M.; Irimescu, A.; et al. Comparison of Global and Continental Land Cover Products for Selected Study Areas in South Central and Eastern European Region. Remote Sens. 2018, 10, 1967. [Google Scholar] [CrossRef] [Green Version]
- Feng, D.; Yu, L.; Zhao, Y.; Cheng, Y.; Xu, Y.; Li, C.; Gong, P. A multiple dataset approach for 30-m resolution land cover mapping: A case study of continental Africa. Int. J. Remote Sens. 2018, 39, 3926–3938. [Google Scholar] [CrossRef]
- Lesiv, M.; Fritz, S.; McCallum, I.; Tsendbazar, N.; Herold, M.; Pekel, J.-F. Evaluation of ESA CCI prototype land cover map at 20 m. Int. Inst. Appl. Syst. Anal. IIASA 2017. [Google Scholar] [CrossRef]
- Cui, L.; Du, H.; Zhou, G.; Li, X.; Mao, F.; Xu, X.; Fan, W.; Li, Y.; Zhu, D.; Liu, T.; et al. Combination of decision tree and mixed pixel decomposition for extracting bamboo forest information in China. Remote Sens. 2019, 23, 166–176. [Google Scholar]
- Arekhi, M.; Goksel, C.; Sanli, F.B.; Senel, G. Comparative Evaluation of the Spectral and Spatial Consistency of Sentinel-2 and Landsat-8 OLI Data for Igneada Longos Forest. ISPRS Int. J. Geo-Inf. 2019, 8, 56. [Google Scholar] [CrossRef] [Green Version]
- Reiche, J.; Hamunyela, E.; Verbesselt, J.; Hoekman, D.; Herold, M. Improving near-real time deforestation monitoring in tropical dry forests by combining dense Sentinel-1 time series with Landsat and ALOS-2 PALSAR-2. Remote Sens. Environ. 2018, 204, 147–161. [Google Scholar] [CrossRef]
- Sui, L.; Kang, J.; Yang, X.; Wang, Z.; Wang, J. Inconsistency distribution patterns of different remote sensing land-cover data from the perspective of ecological zoning. Open Geosci. 2020, 12, 324–341. [Google Scholar] [CrossRef]
- Fang, X.; Zhao, W.; Zhang, C.; Zhang, D.; Wei, X.; Qiu, W.; Ye, Y. Methodology for credibility assessment of historical global LUCC datasets. Sci. China Earth Sci. 2020, 63, 1013–1025. [Google Scholar] [CrossRef]
- Lossou, E.; Owusu-Prempeh, N.; Agyemang, G. Monitoring Land Cover changes in the tropical high forests using multi-temporal remote sensing and spatial analysis techniques. Remote Sens. Appl. Soc. Environ. 2019, 16, 100264. [Google Scholar] [CrossRef]
- Huang, J.; Li, Z.; Chen, E.; Zhao, L.; Bingping, M.O. Classification of plantation types based on WFV multispectral imagery of the GF-6 satellite. Remote Sens. 2021, 25, 539–548. [Google Scholar]
- Liu, H.; Gong, P.; Wang, J.; Wang, X.; Ning, G.; Xu, B. Production of global daily seamless data cubes and quantification of global land cover change from 1985 to 2020 iMap World 1.0. Remote Sens. Environ. 2021, 258, 112364. [Google Scholar] [CrossRef]
- Zurqani, H.A.; Post, C.J.; Mikhailova, E.A.; Schlautman, M.; Sharp, J.L. Geospatial analysis of land use change in the Savannah River Basin using Google Earth Engine. Int. J. Appl. Earth Obs. Geoinf. 2018, 69, 175–185. [Google Scholar] [CrossRef]
- Reddy, C.S.; Pasha, S.V.; Satish, K.; Unnikrishnan, A.; Chavan, S.B.; Jha, C.S.; Diwakar, P.G.; Dadhwal, V.K. Quantifying and predicting multi-decadal forest cover changes in Myanmar: A biodiversity hotspot under threat. Biodivers. Conserv. 2019, 28, 1129–1149. [Google Scholar] [CrossRef]
- Leimgruber, P.; Kelly, D.S.; Steininger, M.K.; Brunner, J.; Müller, T.; Songer, M. Forest cover change patterns in Myanmar (Burma) 1990–2000. Environ. Conserv. 2005, 32, 356–364. [Google Scholar] [CrossRef] [Green Version]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Time | Satellite | Spatial Resolution | Classification Scheme |
|---|---|---|---|---|
| Hansen | 2010 | Landsat 7 ETM+ | 30 m | |
| CCI-LC | 2015 | ENVISAT/MERIS/ SPOT-VGT/PROBA-V | 300 m | LCCS |
| FROM-GLC | 2015 | Landsat TM/ETM+/OLI | 30 m | Two level classification system of level 1 and level 2 |
| 2017 | 30 m | 10 classes | ||
| FROM-GLC10 (2017) | LandsatTM/ETM/OLI/ Sentinel-2 | 10 m | 10 classes | |
| GLC-FCS | 2015 | Landsat TM/ETM+/OLI | 30 m | Global surface fine classification |
| 2020 | Landsat/Sentinel-1SAR | 30 m | Global surface fine classification | |
| GlobeLand30 | 2020 | Landsat TM5/ETM+/OLI/ HJ-1/GF-1 | 30 m | 10 classes |
| Dataset | Time | Forest Related Types and Codes |
|---|---|---|
| Hansen (treecover) | 2010 | Forest |
| CCI-LC | 2015 | 50: Tree cover, broadleaved, evergreen, closed to open (>15%) 60, 61, 62: Tree cover, broadleaved, deciduous, closed to open (>15%) 70, 71, 72: Tree cover, needleleaved, evergreen, closed to open (>15%) 80, 81, 82: Tree cover, needleleaved, deciduous, closed to open (>15%) 90: Tree cover, mixed leaf type (broadleaved and needleleaved) 100: Mosaic tree and shrub (>50%)/herbaceous cover (<50%) 160: Tree cover, flooded, fresh or brakish water 170: Tree cover, flooded, saline water |
| FROM-GLC | 2015 | 21: Broadleaf, leaf-on 22: Broadleaf, leaf-off 23: Needleleaf, leaf-on 24: Needleleaf, leaf-off 25: Mixed leaf, leaf-on 26: Mixed leaf, leaf-off |
| 2017 | 2: Forest | |
| FROM-GLC10 (2017) | 20: Forest | |
| GLC-FCS | 2015 | 50: Evergreen broadleaved forest 60: Deciduous broadleaved forest 61: Open deciduous broadleaved forest (0.15 < fc < 0.4) 62: Closed deciduous broadleaved forest (fc> 0.4) 70: Evergreen needle-leaved forest 71: Open evergreen needle-leaved forest (0.15 < fc < 0.4) 72: Closed evergreen needle-leaved forest (fc > 0.4) 80: Deciduous needle-leaved forest 81: Open deciduous needle-leaved forest (0.15 < fc < 0.4) 82: Closed deciduous needle-leaved forest (fc > 0.4) 90: Mixed leaf forest (broadleaved and needle-leaved) |
| 2020 | 51: Open evergreen broadleaved forest 52: Closed evergreen broadleaved forest 61: Open deciduous broadleaved forest (0.15 < fc < 0.4) 62: Closed deciduous broadleaved forest (fc > 0.4) 71: Open evergreen needle-leaved forest (0.15 < fc < 0.4) 72: Closed evergreen needle-leaved forest (fc > 0.4) 81: Open deciduous needle-leaved forest (0.15 < fc < 0.4) 82: Closed deciduous needle-leaved forest (fc > 0.4) 91: Open mixed leaf forest (broadleaved and needle-leaved) 92: Closed mixed leaf forest (broadleaved and needle-leaved) | |
| GlobeLand30 | 2020 | 20: Forest (The land covered by trees with crown coverage of more than 30%, including deciduous broad-leaved forest, evergreen broad-leaved forest, deciduous coniferous forest, evergreen coniferous forest, mixed forest, and sparse forest land with crown coverage of 10–30%) |
| Year | Dataset | Land Type | UA (%) | PA (%) | Commission (%) | Omission (%) | OA (%) | Kappa |
|---|---|---|---|---|---|---|---|---|
| 2010 | treecover | forest | 81.65 | 91.33 | 18.35 | 8.67 | 82.23 | 0.62 |
| non forest | 84.28 | 68.29 | 15.72 | 31.71 | ||||
| 2015 | CCI-LC | forest | 84.76 | 73.29 | 15.24 | 26.71 | 75.59 | 0.51 |
| non forest | 65.68 | 79.18 | 34.32 | 20.82 | ||||
| FROM-GLC2015 | forest | 80.72 | 90.51 | 19.28 | 9.49 | 80.94 | 0.59 | |
| non forest | 81.97 | 66.03 | 18.03 | 33.87 | ||||
| GLC-FCS2015 | forest | 82.03 | 68.19 | 17.97 | 31.81 | 71.41 | 0.43 | |
| non forest | 60.92 | 76.44 | 39.08 | 23.56 | ||||
| 2017 | FROM-GLC2017 | forest | 87.44 | 87.00 | 12.56 | 13.00 | 83.51 | 0.64 |
| non forest | 77.01 | 77.25 | 22.99 | 22.75 | ||||
| FROM-GLC10 | forest | 84.55 | 93.00 | 15.45 | 7.00 | 84.48 | 0.65 | |
| non forest | 84.93 | 69.16 | 15.07 | 30.84 | ||||
| 2020 | GlobeLand30 | forest | 87.52 | 87.38 | 12.48 | 12.62 | 83.51 | 0.64 |
| non forest | 76.47 | 76.23 | 23.53 | 23.77 | ||||
| GLC-FCS2020 | forest | 84.83 | 74.26 | 15.17 | 25.74 | 74.41 | 0.47 | |
| non forest | 60.96 | 74.69 | 39.04 | 25.31 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xing, H.; Niu, J.; Liu, C.; Chen, B.; Yang, S.; Hou, D.; Zhu, L.; Hao, W.; Li, C. Consistency Analysis and Accuracy Assessment of Eight Global Forest Datasets over Myanmar. Appl. Sci. 2021, 11, 11348. https://doi.org/10.3390/app112311348
Xing H, Niu J, Liu C, Chen B, Yang S, Hou D, Zhu L, Hao W, Li C. Consistency Analysis and Accuracy Assessment of Eight Global Forest Datasets over Myanmar. Applied Sciences. 2021; 11(23):11348. https://doi.org/10.3390/app112311348
Chicago/Turabian StyleXing, Huaqiao, Jingge Niu, Chang Liu, Bingyao Chen, Shiyong Yang, Dongyang Hou, Linye Zhu, Wenjun Hao, and Cansong Li. 2021. "Consistency Analysis and Accuracy Assessment of Eight Global Forest Datasets over Myanmar" Applied Sciences 11, no. 23: 11348. https://doi.org/10.3390/app112311348
APA StyleXing, H., Niu, J., Liu, C., Chen, B., Yang, S., Hou, D., Zhu, L., Hao, W., & Li, C. (2021). Consistency Analysis and Accuracy Assessment of Eight Global Forest Datasets over Myanmar. Applied Sciences, 11(23), 11348. https://doi.org/10.3390/app112311348