
Sentiment Analysis and Topic Modeling on Tweets about Online Education during COVID-19


 ,
,  ,
,  , , and
, , and 
Abstract
:1. Introduction
- The analysis of the effectiveness of the e-learning system to achieve the desired learning outcome through sentiment analysis on stakeholders’ tweets.
- To analyze the thoughts and experiences of learners and teachers about the transition from face-to-face education to online education.
- To find the gap between traditional education and online education by leveraging NLP approaches for text processing, feature selection for sentiment analysis, and machine learning models for sentiment classification.
- To find the problems associated with online education in terms of technology, social setup, and interaction by employing topic modeling.
- To analyze the performance of various machine learning and deep learning models for sentiment analysis using different annotation approaches such as TextBlob, VADER (Valence Aware Dictionary for Sentiment Reasoning), and SentiWordNet, as well as the efficacy of TF-IDF (Term Frequency-Inverse Document Frequency) and BoW (Bag of Words) feature extraction approaches.
2. Related Work
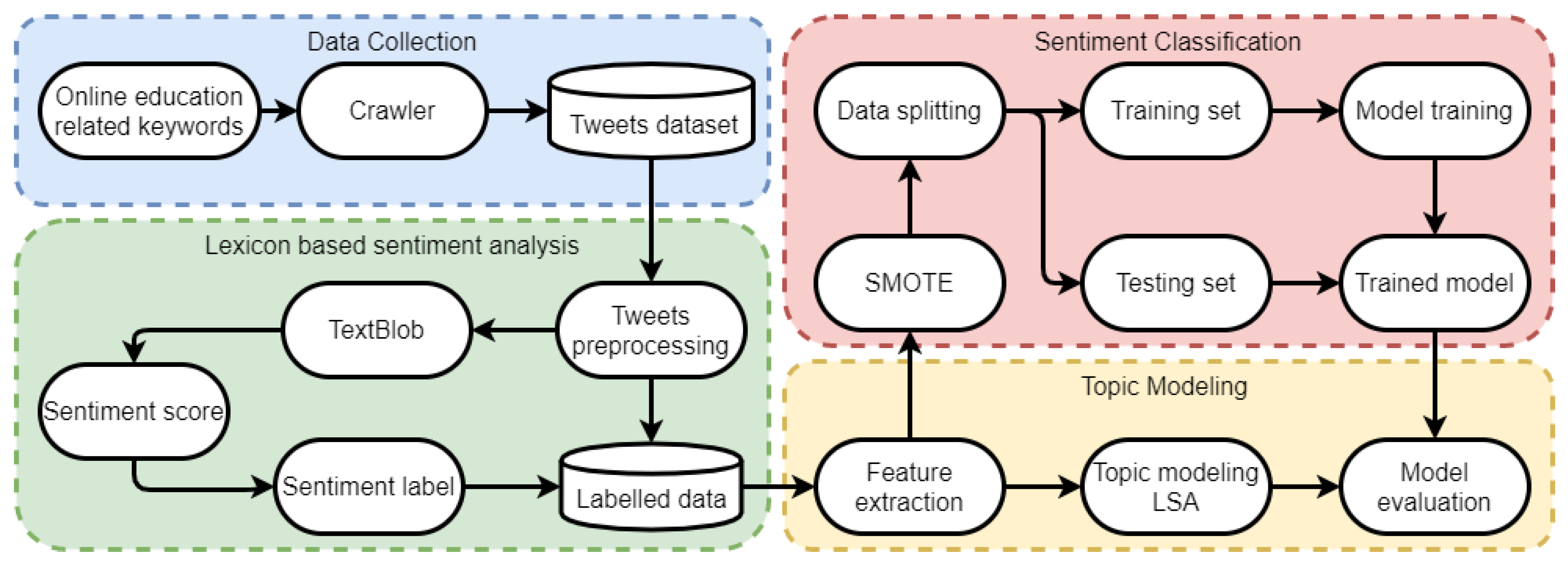
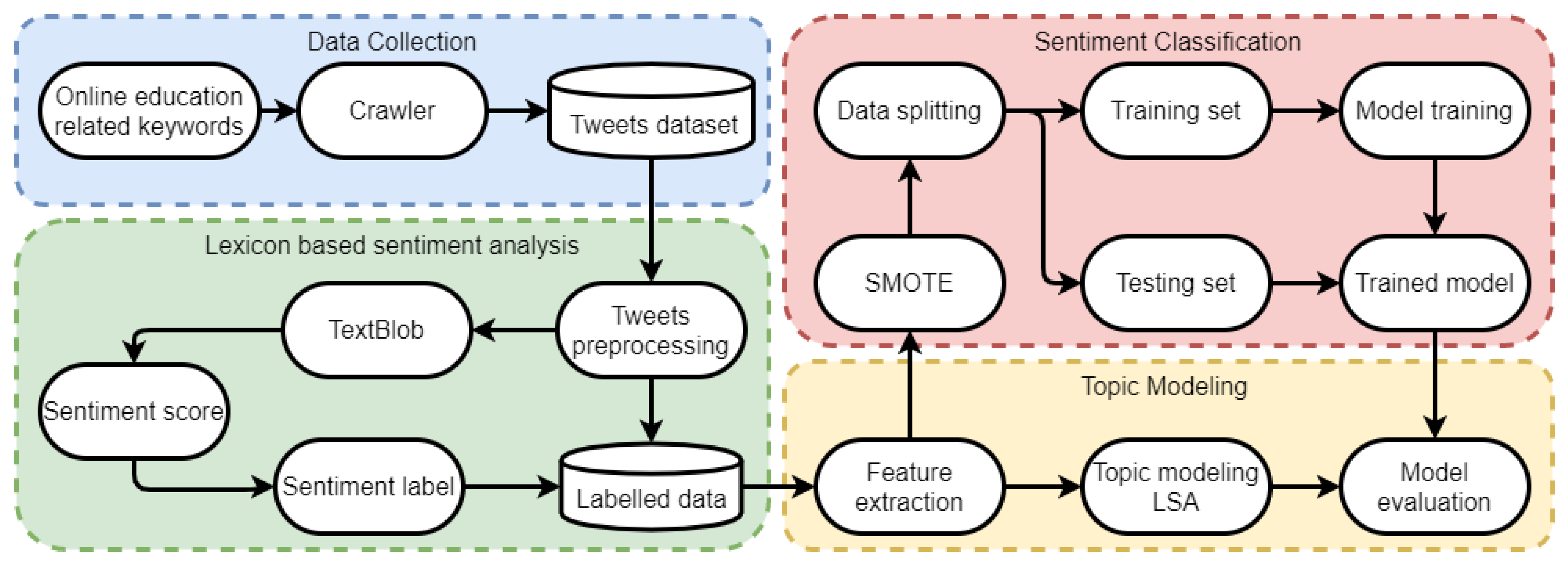
3. Materials and Methods
3.1. Dataset Description
3.2. Methodology
3.2.1. Preprocessing
- Convert to lowercase: Converting the text to lowercase reduces the complexity of the feature set as, ‘go’ and ‘Go’ are taken as different features by machine learning models, so converting to lowercase both terms will be ‘go’. Models consider upper and lower case words as different words which affect the training process and classification performance.
- URL links, tags, punctuation, and number removal: URL links, tags, punctuation, and numbers do not contribute to improving the classification performance because they provide no additional meaning for learning models and increase the complexity of feature space, so removing them helps to reduce the feature space.
- Stemming and Lemmatization: The goal of both stemming and lemmatization is to reduce inflectional forms and sometimes derivationally related forms of a word to a common base form [33]. For example, ‘walks, ‘walking’, and ‘walked’ are converted to the root word ‘walk’ in this process.
3.2.2. TextBlob
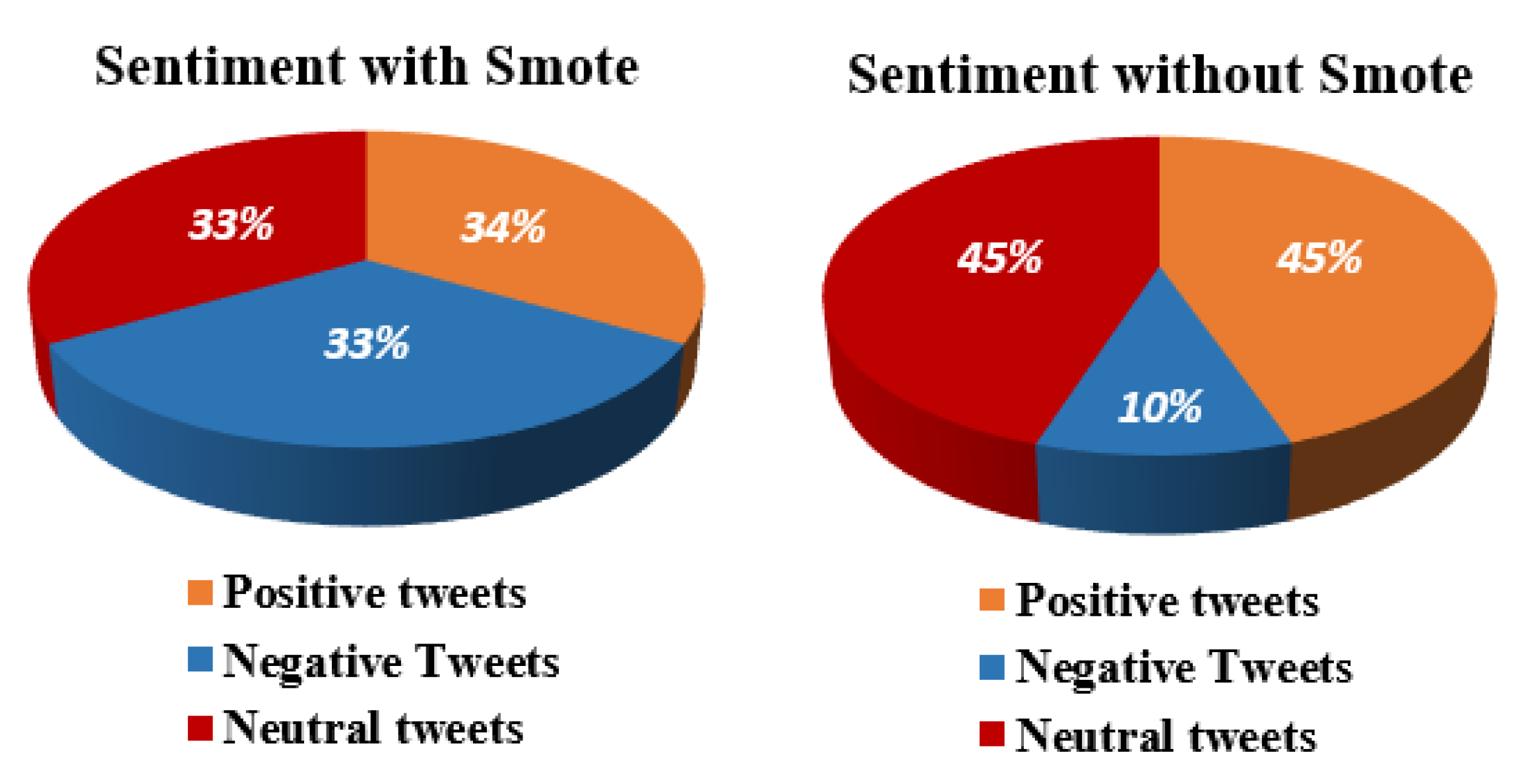
3.2.3. Synthetic Minority Oversampling Technique
3.2.4. Data Splitting
3.2.5. Feature Engineering
3.2.6. Topic Modeling
3.2.7. Supervised Machine Learning Models
3.2.8. Evaluation Measures
4. Results and Discussion
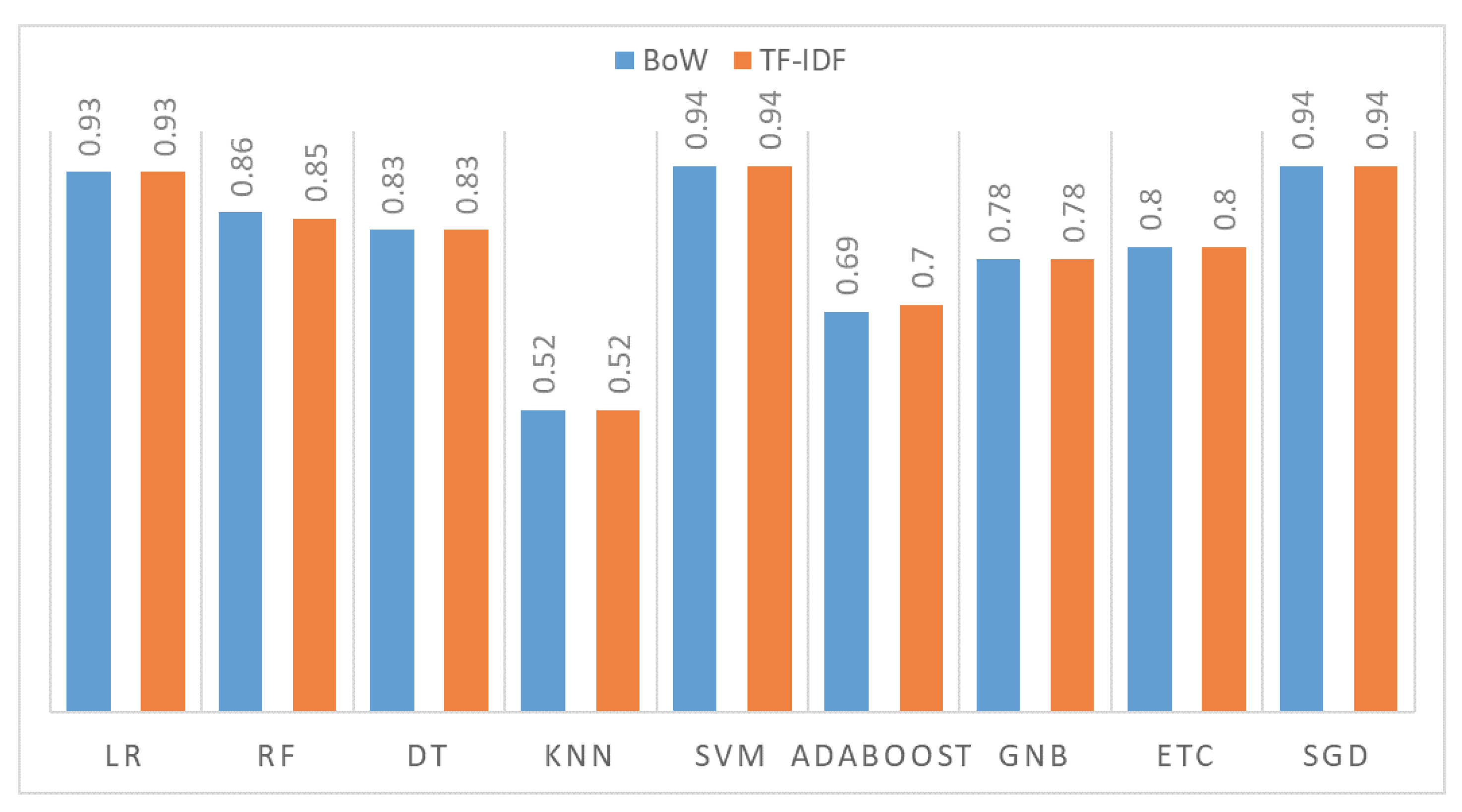
4.1. Results Using BoW and without the SMOTE Technique
4.2. Results Using BoW with the SMOTE Technique
4.3. Results Using TF-IDF Features on the Original Dataset
4.4. Results Using TF-IDF Features and the SMOTE Technique
4.5. Results Using K-Fold Cross-Validation
4.6. Comparison of TextBlob Results with VADER and SentiWordNet
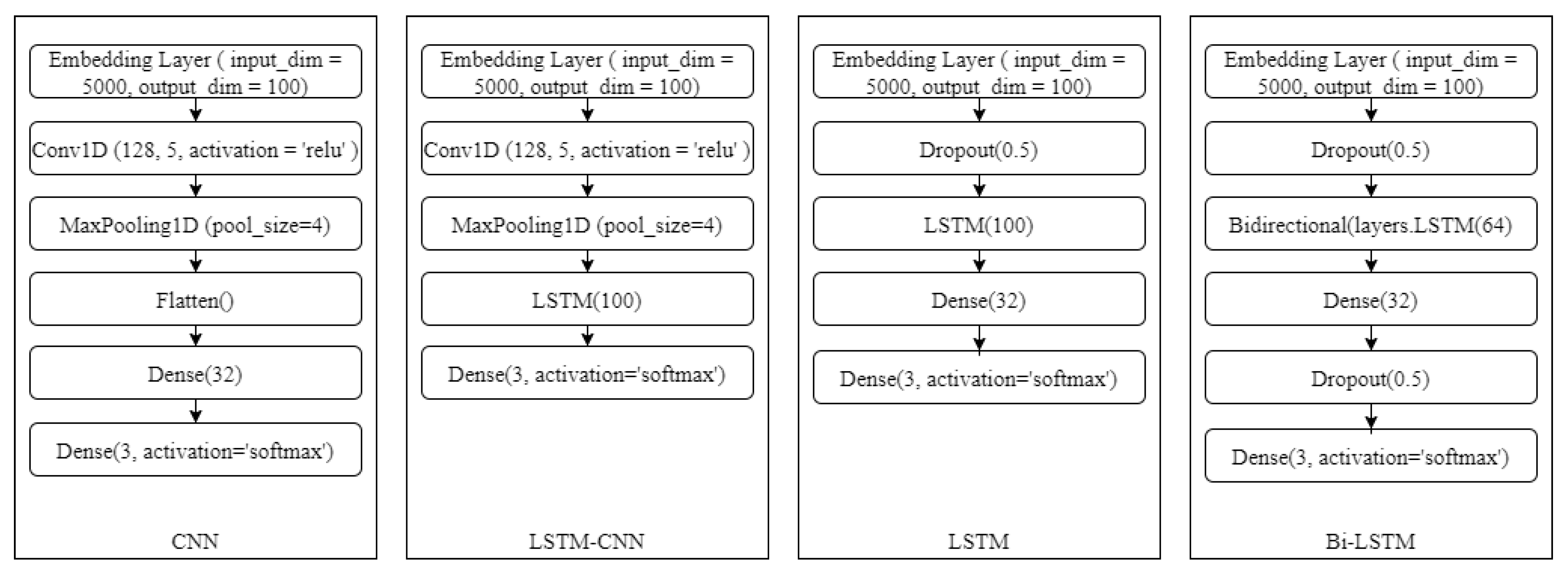
4.7. Experimental Results Using Deep Learning Models
4.8. Topic Modeling Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, X.; Liu, J. Education in and after COVID-19: Immediate responses and long-term visions. Postdigital Sci. Educ. 2020, 2, 695–699. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Long, F. The discussion of traditional teaching and multimedia teaching approach in college English teaching. In Proceedings of the International Conference on Management, Education and Social Science, Beijing, China, 16–17 January 2014; pp. 31–33. [Google Scholar]
- Nikoubakht, A.; Kiamanesh, A. The comparison of the effectiveness of computer-based education and traditional education on the numerical memory in students with mathematics disorder. J. Psychol. 2019, 18, 55–65. [Google Scholar]
- Mpungose, C.B. Emergent transition from face-to-face to online learning in a South African University in the context of the Coronavirus pandemic. Humanit. Soc. Sci. Commun. 2020, 7, 1–9. [Google Scholar] [CrossRef]
- Kanani, B. Stop Words—Machine Learning. 2020. Available online: https://cft.vanderbilt.edu/guides-sub-pages/blooms-taxonomy/ (accessed on 22 August 2021).
- Ashraf, I.; Kang, M.; Hur, S.; Park, Y. MINLOC: Magnetic field patterns-based indoor localization using convolutional neural networks. IEEE Access 2020, 8, 66213–66227. [Google Scholar] [CrossRef]
- Umer, M.; Ashraf, I.; Ullah, S.; Mehmood, A.; Choi, G.S. COVINet: A convolutional neural network approach for predicting COVID-19 from chest X-ray images. J. Ambient. Intell. Humaniz. Comput. 2021, 1–13. [Google Scholar] [CrossRef]
- Ashraf, I.; Hur, S.; Park, Y. Application of deep convolutional neural networks and smartphone sensors for indoor localization. Appl. Sci. 2019, 9, 2337. [Google Scholar] [CrossRef] [Green Version]
- Mehmood, A.; On, B.W.; Lee, I.; Ashraf, I.; Choi, G.S. Spam comments prediction using stacking with ensemble learning. J. Phys. Conf. Ser. Iop Publ. 2017, 933, 012012. [Google Scholar] [CrossRef]
- Eroğul, U. Sentiment Analysis in Turkish. Master’s Thesis, Middle East Technical University, Ankara, Turkey, 2009. [Google Scholar]
- Štrimaitis, R.; Stefanovič, P.; Ramanauskaitė, S.; Slotkienė, A. Financial Context News Sentiment Analysis for the Lithuanian Language. Appl. Sci. 2021, 11, 4443. [Google Scholar] [CrossRef]
- Rhouati, A.; Berrich, J.; Belkasmi, M.G.; Bouchentouf, T. Sentiment Analysis of French Tweets based on Subjective Lexicon Approach: Evaluation of the use of OpenNLP and CoreNLP Tools. J. Comput. Sci. 2018, 14, 829–836. [Google Scholar] [CrossRef] [Green Version]
- Cheeti, S.; Li, Y.; Hadaegh, A. Twitter based Sentiment Analysis of Impact of COVID-19 on Education Globaly. Int. J. Artif. Intell. Appl. 2021, 12, 15–24. [Google Scholar] [CrossRef]
- Relucio, F.S.; Palaoag, T.D. Sentiment analysis on educational posts from social media. In Proceedings of the 9th International Conference on E-Education, E-Business, E-Management and E-Learning, San Diego, CA, USA, 11–13 January 2018; pp. 99–102. [Google Scholar]
- Bhagat, K.K.; Mishra, S.; Dixit, A.; Chang, C.Y. Public Opinions about Online Learning during COVID-19: A Sentiment Analysis Approach. Sustainability 2021, 13, 3346. [Google Scholar] [CrossRef]
- Ashwitha, R.; Jeevitha, T.G. To Impact of COVID-19 in Education System. J. Emerg. Technol. Innov. Res. 2021, 8, 428–430. [Google Scholar]
- Anwar, K.; Adnan, M. Online learning amid the COVID-19 pandemic: Students perspectives. J. Pedagog. Res. 2020, 1, 45–51. [Google Scholar] [CrossRef]
- Althagafi, A.; Althobaiti, G.; Alhakami, H.; Alsubait, T. Arabic Tweets Sentiment Analysis about Online Learning during COVID-19 in Saudi Arabia. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 620–625. [Google Scholar]
- Hogenboom, A.; Heerschop, B.; Frasincar, F.; Kaymak, U.; de Jong, F. Multi-lingual support for lexicon-based sentiment analysis guided by semantics. Decis. Support Syst. 2014, 62, 43–53. [Google Scholar] [CrossRef] [Green Version]
- Mamtesh, M.; Mehla, S. Sentiment Analysis of Movie Reviews using Machine Learning Classifiers. Int. J. Comput. Appl. 2019, 182, 25–28. [Google Scholar] [CrossRef]
- Samuel, J.; Ali, G.; Rahman, M.; Esawi, E.; Samuel, Y. COVID-19 public sentiment insights and machine learning for tweets classification. Information 2020, 11, 314. [Google Scholar] [CrossRef]
- Jagdale, R.S.; Shirsat, V.S.; Deshmukh, S.N. Sentiment analysis on product reviews using machine learning techniques. In Cognitive Informatics and Soft Computing; Springer: Berlin/Heidelberg, Germany, 2019; pp. 639–647. [Google Scholar]
- Devika, M.; Sunitha, C.; Ganesh, A. Sentiment analysis: A comparative study on different approaches. Procedia Comput. Sci. 2016, 87, 44–49. [Google Scholar] [CrossRef] [Green Version]
- Liu, B. Sentiment analysis and opinion mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar] [CrossRef] [Green Version]
- Rustam, F.; Khalid, M.; Aslam, W.; Rupapara, V.; Mehmood, A.; Choi, G.S. A performance comparison of supervised machine learning models for COVID-19 tweets sentiment analysis. PLoS ONE 2021, 16, e0245909. [Google Scholar] [CrossRef]
- Hussain, A.; Tahir, A.; Hussain, Z.; Sheikh, Z.; Gogate, M.; Dashtipour, K.; Ali, A.; Sheikh, A. Artificial intelligence–enabled analysis of public attitudes on facebook and Twitter toward COVID-19 vaccines in the united kingdom and the united states: Observational study. J. Med. Internet Res. 2021, 23, e26627. [Google Scholar] [CrossRef]
- Alamoodi, A.; Zaidan, B.; Zaidan, A.; Albahri, O.; Mohammed, K.; Malik, R.; Almahdi, E.; Chyad, M.; Tareq, Z.; Albahri, A.; et al. Sentiment analysis and its applications in fighting COVID-19 and infectious diseases: A systematic review. Expert Syst. Appl. 2020, 167, 114155. [Google Scholar] [CrossRef] [PubMed]
- Imran, A.S.; Daudpota, S.M.; Kastrati, Z.; Batra, R. Cross-Cultural Polarity and Emotion Detection Using Sentiment Analysis and Deep Learning on COVID-19 Related Tweets. IEEE Access 2020, 8, 181074–181090. [Google Scholar] [CrossRef]
- Chintalapudi, N.; Battineni, G.; Amenta, F. Sentimental Analysis of COVID-19 Tweets Using Deep Learning Models. Infect. Dis. Rep. 2021, 13, 329–339. [Google Scholar] [CrossRef] [PubMed]
- Pace, C.; Pettit, S.K.; Barker, K.S. Best practices in middle level quaranteaching: Strategies, tips and resources amidst COVID-19. Becom. J. Ga. Assoc. Middle Level Educ. 2020, 31, 2–13. [Google Scholar] [CrossRef]
- Liguori, E.; Winkler, C. From Offline to Online: Challenges and Opportunities for Entrepreneurship Education Following the COVID-19 Pandemic. Entrep. Educ. Pedagog. 2020, 3, 346–351. [Google Scholar]
- Reddy, A.; Vasundhara, D.; Subhash, P. Sentiment Research on Twitter Data. Int. J. Recent Technol. Eng. 2019, 8, 1068–1070. [Google Scholar]
- Jivani, A. A Comparative Study of Stemming Algorithms. Int. J. Comp. Tech. Appl. 2011, 2, 1930–1938. [Google Scholar]
- Armstrong, P. Bloom’s Taxonomy. Vanderbilt University Center for Teaching. 2019. Available online: https://studymachinelearning.com/nlp-stop-words/ (accessed on 23 August 2021).
- Loria, S. textblob Documentation. Release 0.15 2018, 2, 269. [Google Scholar]
- Sohangir, S.; Petty, N.; Wang, D. Financial sentiment lexicon analysis. In Proceedings of the 2018 IEEE 12th International Conference on Semantic Computing (ICSC), Laguna Hills, CA, USA, 31 January–2 February 2018; IEEE: New York, NY, USA, 2018; pp. 286–289. [Google Scholar]
- Rupapara, V.; Rustam, F.; Shahzad, H.F.; Mehmood, A.; Ashraf, I.; Choi, G.S. Impact of SMOTE on Imbalanced Text Features for Toxic Comments Classification using RVVC Model. IEEE Access 2021, 78621–78634. [Google Scholar] [CrossRef]
- Eshan, S.C.; Hasan, M.S. An application of machine learning to detect abusive bengali text. In Proceedings of the 2017 20th International Conference of Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 22–24 December 2017; IEEE: New York, NY, USA, 2017; pp. 1–6. [Google Scholar]
- Zhang, W.; Yoshida, T.; Tang, X. A comparative study of TF* IDF, LSI and multi-words for text classification. Expert Syst. Appl. 2011, 38, 2758–2765. [Google Scholar] [CrossRef]
- Robertson, S. Understanding inverse document frequency: On theoretical arguments for IDF. J. Doc. 2004. [Google Scholar] [CrossRef] [Green Version]
- George, K.M.; Soundarabai, P.B.; Krishnamurthi, K. Impact Of Topic Modelling Methods In addition, Text Classification Techniques In Text Mining: A Survey. Int. J. Adv. Electron. Comput. Sci. 2017, 4, 72–77. [Google Scholar]
- Deerwester, S.; Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by latent semantic analysis. J. Am. Soc. Inf. Sci. 1990, 41, 391–407. [Google Scholar] [CrossRef]
- Zainuddin, N.; Selamat, A. Sentiment analysis using support vector machine. In Proceedings of the 2014 International Conference on Computer, Communications, and Control Technology (I4CT), Langkawi, Malaysia, 2–4 September 2014; IEEE: New York, NY, USA, 2014; pp. 333–337. [Google Scholar]
- AnithaElavarasi, S.; Jayanthi, J.; Basker, N. A comparative study on logistic regression and svm based machine learning approach for analyzing user reviews. Turk. J. Physiother. Rehabil. 2021, 32, 3564–3570. [Google Scholar]
- Safavian, S.R.; Landgrebe, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man, Cybern. 1991, 213, 660–674. [Google Scholar] [CrossRef] [Green Version]
- Donges, N. He Random Forest Algorithm. 2021. Available online: https://builtin.com/data-science/random-forest-algorithm (accessed on 22 August 2020).
- Rustam, F.; Ashraf, I.; Mehmood, A.; Ullah, S.; Choi, G.S. Tweets classification on the base of sentiments for US airline companies. Entropy 2019, 21, 1078. [Google Scholar] [CrossRef] [Green Version]
- Soucy, P.; Mineau, G.W. A simple KNN algorithm for text categorization. In Proceedings of the 2001 IEEE International Conference on Data Mining, San Jose, CA, USA, 29 November–2 December 2001; IEEE: New York, NY, USA, 2001; pp. 647–648. [Google Scholar]
- Brownlee, J. Machine Learning Naive Baiyes. 2021. Available online: https://machinelearningmastery.com/better-naive-bayes/ (accessed on 20 August 2020).
- Fuhua, S. Research of the Improved Adaboost Algorithm Based on Unbalanced Data. Int. J. Comput. Sci. Netw. Secur. 2014, 14, 14. [Google Scholar]
- Ohana, B.; Tierney, B. Sentiment classification of reviews using SentiWordNet. In Proceedings of the 9th IT&T Conference, Dublin, Ireland, 22–23 October 2009. [Google Scholar] [CrossRef]
- Jamil, R.; Ashraf, I.; Rustam, F.; Saad, E.; Mehmood, A.; Choi, G.S. Detecting sarcasm in multi-domain datasets using convolutional neural networks and long short term memory network model. PeerJ Comput. Sci. 2021, 7, e645. [Google Scholar] [CrossRef]
- Mohammed, S.H.; Al-augby, S. Lsa & lda topic modeling classification: Comparison study on e-books. Indones. J. Electr. Eng. Comput. Sci. 2020, 19, 353–362. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Model/Approach | Aim | Dataset | Limitations |
|---|---|---|---|---|
| [13] | Naive-based classifier (model) | Sentiment analysis of tweets on education during COVID-19 | The area of study has generated nearly 90,000 tweets. | Study did not perform topic modeling and accuracy is not significant. |
| [14] | Web analytics approach | Find sentiment on educational posts | A total of 1717 tweets collected from Twitter. | Study did not use a machine learning approach. |
| [15] | Dictionary based approach | Public Opinion on Online Learning in COVID-19 | 154 articles collected from Google. | Study did not use a machine learning approach. |
| [16] | NLP techniques and Logistic regression classifier | Sentiment Analysis on COVID-19 Epidemic’s Education | Google Forms is used to collect data. | Study did not perform topic modeling and accuracy is not significant. |
| [18] | Naïve Bayes, KNN and random forest | Sentiment analysis of online education during coronavirus | 10,445 tweets were gathered using the Twitter API. | Study did not perform topic modeling to discuss the reason behind negative sentiments |
| [20] | KNN, Naïve Bayes, and Logistic regression | Sentiment analysis of movies reviews | The data set is compiled from a variety of sources. | Study is not about online education sentiment analysis. |
| [21] | Machine learning (KNN & Naïve Bayes) | COVID-19 tweets public sentiment classification | More than 900,000 COVID-19 tweets. | Study is about general COVID-19 tweets sentiment analysis not about online education. |
| [22] | Machine learning (SVM and Naive Bayes) | Sentiment analysis on product reviews | Over 13,000 tweets obtained from six product reviews. | Study is not about online education sentiment analysis. |
| [28] | Deep learning (Multi-layer LSTM) | Sentiment analysis on COVID-19 | A total of 27,357 tweets related to COVID-19 | Accuracy is not significant and its about general COVID-19 tweets. |
| [29] | Deep learning (BERT and LSTM) | Sentiment analysis on COVID-19 | A total of 3090 tweets related to COVID-19 | Accuracy is not significant and its about general COVID-19 tweets |
| User | Location | Tweets Text |
|---|---|---|
| educationblog | USA | #EDUCATION: #Children read longer #books of greater difficulty during #lockdown periods last year, and reported tha€| https://t.co/S9UbQtKWZL (accessed on 1 September 2021) |
| Student | Gujarat, India | We havenot been given online education, so we r in severe depression |
| brenda11831 | USA | 8.4 million fewer jobs than in February 2020, just before #coronavirus shut down large swaths of the U.S. economy€| https://t.co/DevQfUWDMW (accessed on 1 September 2021) 8.4 million fewer jobs than in February 2020, just before #coronavirus shut down large swaths of the U.S. economy| https://t.co/DevQfUWDMW (accessed on 1 September 2021) |
| User | Text | Polarity Score | Sentiment |
|---|---|---|---|
| NEC_Education | functional skill key open opportunity wide range career include apprentice | −0.05 | −1 |
| Tutor_eduonix | join free live workshop COVID-19 mental health amp mindful | 0.145 | 1 |
| PrincipalTam | education around learn credible source poor | 0.0 | 0 |
| Tweets before Pre-Processing | Tweets after Pre-Processing |
|---|---|
| People have to take more precaution. time to educate everyone effectively to undo Covid19 second wave. | people precaution time educate everyone effect undo covid19 second wave |
| In the meantime, #COVID-19 cases in schools have not flared up as much as some feared amid the #pandemic restrict€| https://t.co/tcVBMglgOB (accessed on 1 September 2021) | meantime covid19 case school flare fear amid pandemic restrict |
| England: High school face mask may be lifted | england high school face mask lift |
| If education around learning what a credible source is wasn’t so poor, this wouldn’t be necessary. It’s amazingly d€| https://t.co/8sb71lALo6 (accessed on 1 September 2021) | educ around learn credible source poor necessary its amaze |
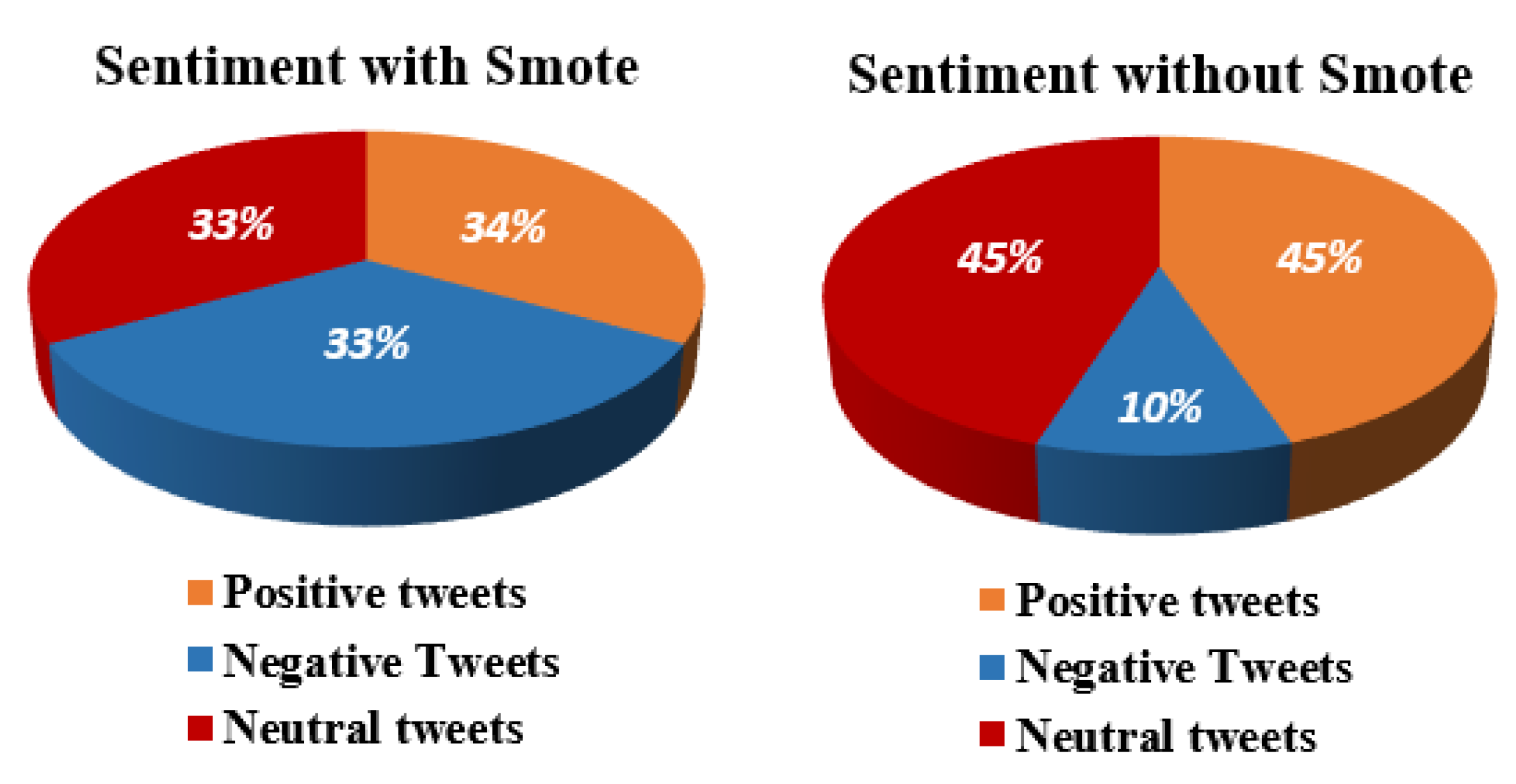
| Technique | Dataset | Positive | Negative | Neutral | Total |
|---|---|---|---|---|---|
| Total data | 7663 | 1768 | 7724 | 17,155 | |
| Original | Testing set | 436 | 1899 | 1954 | 4289 |
| Training set | 5764 | 1332 | 5770 | 12,866 | |
| Total data | 7724 | 7724 | 7724 | 23,172 | |
| SMOTE | Testing set | 1977 | 1950 | 1866 | 5793 |
| Training set | 5747 | 5774 | 5858 | 17,379 |
| S | England | High | School | Face | Mask | Lift | Wear | Right | Way | Length |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 6 |
| 2 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 4 |
| Terms | TF (doc1) | TF (doc2) | IDF | TF-IDF (doc1) | TF-IDF (doc2) |
|---|---|---|---|---|---|
| england | 1/6 | 0 | 0.3010 | 0.050 | 0 |
| high | 1/6 | 0 | 0.3010 | 0.050 | 0 |
| school | 1/6 | 0 | 0.3010 | 0.050 | 0 |
| face | 1/6 | 0 | 0.3010 | 0.050 | 0 |
| mask | 1/6 | 1/4 | 0 | 0 | 0 |
| may | 1/6 | 0 | 0.3010 | 0.050 | 0 |
| lift | 1/6 | 0 | 0.3010 | 0.050 | 0 |
| wear | 0 | 1/4 | 0.3010 | 0 | 0.07525 |
| right | 0 | 1/4 | 0.3010 | 0 | 0.07525 |
| way | 0 | 1/4 | 0.3010 | 0 | 0.07525 |
| Models | Description |
|---|---|
| SVM | SVM is one of the most widely used models for sentiment analysis [43]. It performs classification by locating the hyper-plane that is the best match for differentiating the classes. SVM is a linear model which is used with kernel sigmoid and a c = 3.0 parameter (see Table 9). |
| LR | LR is a supervised machine learning algorithm used to determine the probabilities of output variable [44]. It performs well when the nature of the output or dependent variable is binary, but it can also be good for multi-class data classification. It used the logistic function to categorize the data. |
| DT | DT collects data in the form of a tree, which may alternatively be expressed as a collection of discrete rules [45]. Decision trees can handle big data well. The DT algorithm works to split the record according to the attribute selection measures technique and select the best set of attributes. |
| RF | RF is a supervised learning algorithm. It can be used for both classification and regression. This algorithm is also the most flexible and easy to use [46]. The forest is made of trees, more trees in the forest, and the stronger they will be in prediction. RF makes random trees from randomly selected data samples, makes predictions from each tree, and votes for the best solution. |
| SGD | SGD Classifier is a linear classifier that implements regularized linear models with a stochastic gradient descent as the cost function [47]. It supplies regularized linear models with SGD learning to build an estimator. The SGD classifier works well with large-scale datasets, and it is efficient and easy to implement the method. SGD is implemented using the sci-kit library. |
| KNN | It is a supervised machine learning model used for classification of data [48]. It is a simple model which is easy to implement and interpret. KNN is also known as a lazy learner because it makes predictions based on the nearest neighbor by finding the distance. It performs well when the size of data is not too large. |
| GNB | The GNB algorithm is a special kind of Naive Bayes algorithm that is unique. It is mostly used with continuous features. It is also expected that all of the characteristics have a Gaussian distribution or a normal distribution. Naive Bayes algorithms work on the basis of the Bayes theorem. If the data contain strongly correlated characteristics, the performance of Naive Bayes might suffer [49]. |
| AdaBoost | AdaBoost is termed adaptive boosting, which is a supervised machine learning model used for the classification of data. It used a boosting mechanism to boost the classification accuracy. Adaboost used DT as a base leaner (“weak learner”) by default. The output of the learning algorithm is associated with weight, which is the end result of the density assessment [50]. |
| ETC | ETC is a tree-based ensemble model used for the classification of data by training/fitting a large number of weak learners (randomized decision trees) on distinct samples of the dataset, ETC uses the majority voting criteria to enhance prediction accuracy [25]. It is an ensemble learning model that works similarly to RF. The only difference between ETC and RF is how the forest trees are constructed. |
| Models | Hyper-Parameters |
|---|---|
| RF | n_estimators = 300, max_depth = 300 |
| LR | solver = “saga”, multi_class = “multinomial”, C = 3.0 |
| SVM | Kernel = “linear”, C = 3.0 |
| DT | max_depth = 300, random state =2 |
| KNN | n_neighbour = 5 |
| AdaBoost | n_estimator = 50, learning_rate =0.1 |
| GNB | Default setting |
| SGD | max iter = 200, tol = 1× 10 |
| ETC | n_estimators = 300, max_depth = 300 |
| Models | Accuracy | Class | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| LR | 0.93 | 0 | 0.92 | 0.92 | 0.92 |
| 1 | 0.97 | 0.93 | 0.95 | ||
| −1 | 0.90 | 0.95 | 0.92 | ||
| Macro avg | 0.93 | 0.93 | 0.93 | ||
| RF | 0.86 | 0 | 0.86 | 0.79 | 0.82 |
| 1 | 0.96 | 0.83 | 0.89 | ||
| −1 | 0.78 | 0.95 | 0.86 | ||
| Macro avg | 0.86 | 0.86 | 0.86 | ||
| DT | 0.83 | 0 | 0.84 | 0.73 | 0.78 |
| 1 | 0.92 | 0.83 | 0.87 | ||
| −1 | 0.76 | 0.95 | 0.84 | ||
| Macro avg | 0.84 | 0.83 | 0.83 | ||
| KNN | 0.52 | 0 | 0.30 | 0.87 | 0.45 |
| 1 | 0.27 | 0.97 | 0.42 | ||
| −1 | 0.99 | 0.41 | 0.58 | ||
| Macro avg | 0.52 | 0.75 | 0.48 | ||
| SVM | 0.94 | 0 | 0.94 | 0.92 | 0.93 |
| 1 | 0.98 | 0.94 | 0.99 | ||
| −1 | 0.89 | 0.95 | 0.92 | ||
| Macro avg | 0.94 | 0.94 | 0.94 | ||
| AdaBoost | 0.69 | 0 | 0.53 | 1.00 | 0.70 |
| 1 | 0.94 | 0.74 | 0.83 | ||
| −1 | 0.98 | 0.33 | 0.49 | ||
| Macro avg | 0.82 | 0.69 | 0.67 | ||
| GNB | 0.78 | 0 | 0.91 | 0.63 | 0.74 |
| 1 | 0.87 | 0.77 | 0.82 | ||
| −1 | 0.65 | 0.93 | 0.77 | ||
| Macro avg | 0.81 | 0.78 | 0.78 | ||
| ETC | 0.80 | 0 | 0.79 | 0.72 | 0.75 |
| 1 | 0.87 | 0.76 | 0.82 | ||
| −1 | 0.76 | 0.93 | 0.84 | ||
| Macro avg | 0.81 | 0.80 | 0.80 | ||
| SGD | 0.94 | 0 | 0.93 | 0.93 | 0.93 |
| 1 | 0.97 | 0.94 | 0.96 | ||
| −1 | 0.91 | 0.95 | 0.93 | ||
| Macro avg | 0.94 | 0.94 | 0.94 |
| Models | Accuracy | Class | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| LR | 0.93 | 0 | 0.91 | 0.99 | 0.95 |
| 1 | 0.98 | 0.93 | 0.95 | ||
| −1 | 0.94 | 0.72 | 0.81 | ||
| Macro avg | 0.94 | 0.88 | 0.90 | ||
| RF | 0.95 | 0 | 0.91 | 0.99 | 0.95 |
| 1 | 0.98 | 0.93 | 0.94 | ||
| −1 | 0.95 | 0.78 | 0.86 | ||
| Macro avg | 0.95 | 0.90 | 0.92 | ||
| DT | 0.95 | 0 | 0.95 | 0.95 | 0.96 |
| 1 | 0.97 | 0.95 | 0.96 | ||
| −1 | 0.86 | 0.85 | 0.84 | ||
| Macro avg | 0.93 | 0.92 | 0.92 | ||
| KNN | 0.62 | 0 | 0.99 | 0.55 | 0.71 |
| 1 | 0.30 | 0.96 | 0.45 | ||
| −1 | 0.41 | 0.92 | 0.57 | ||
| Macro avg | 0.56 | 0.81 | 0.58 | ||
| SVM | 0.95 | 0 | 0.93 | 0.99 | 0.96 |
| 1 | 0.98 | 0.95 | 0.96 | ||
| −1 | 0.89 | 0.80 | 0.84 | ||
| Macro avg | 0.94 | 0.92 | 0.92 | ||
| AdaBoost | 0.78 | 0 | 0.68 | 1.00 | 0.81 |
| 1 | 0.97 | 0.59 | 0.73 | ||
| −1 | 0.87 | 0.62 | 0.72 | ||
| Macro avg | 0.84 | 0.74 | 0.76 | ||
| GNB | 0.78 | 0 | 0.91 | 0.63 | 0.74 |
| 1 | 0.87 | 0.77 | 0.82 | ||
| −1 | 0.65 | 0.93 | 0.77 | ||
| Macro avg | 0.81 | 0.78 | 0.78 | ||
| ETC | 0.89 | 0 | 0.90 | 0.92 | 0.91 |
| 1 | 0.93 | 0.90 | 0.91 | ||
| −1 | 0.73 | 0.79 | 0.76 | ||
| Macro avg | 0.86 | 0.87 | 0.86 | ||
| SGD | 0.94 | 0 | 0.92 | 0.99 | 0.95 |
| 1 | 0.98 | 0.94 | 0.96 | ||
| −1 | 0.94 | 0.81 | 0.87 | ||
| Macro avg | 0.95 | 0.91 | 0.93 |
| Models | Accuracy | Class | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| LR | 0.93 | 0 | 0.91 | 0.92 | 0.91 |
| 1 | 0.98 | 0.92 | 0.95 | ||
| −1 | 0.90 | 0.94 | 0.92 | ||
| Macro avg | 0.93 | 0.93 | 0.93 | ||
| RF | 0.85 | 0 | 0.84 | 0.77 | 0.81 |
| 1 | 0.97 | 0.84 | 0.90 | ||
| −1 | 0.77 | 0.94 | 0.85 | ||
| Macro avg | 0.86 | 0.85 | 0.85 | ||
| DT | 0.83 | 0 | 0.83 | 0.73 | 0.78 |
| 1 | 0.92 | 0.82 | 0.87 | ||
| −1 | 0.76 | 0.94 | 0.84 | ||
| Macro avg | 0.84 | 0.83 | 0.83 | ||
| KNN | 0.52 | 0 | 0.29 | 0.88 | 0.44 |
| 1 | 0.27 | 0.97 | 0.43 | ||
| −1 | 1.00 | 0.41 | 0.58 | ||
| Macro avg | 0.52 | 0.76 | 0.48 | ||
| SVM | 0.94 | 0 | 0.92 | 0.91 | 0.91 |
| 1 | 0.98 | 0.93 | 0.96 | ||
| −1 | 0.88 | 0.94 | 0.91 | ||
| Macro avg | 0.93 | 0.93 | 0.93 | ||
| AdaBoost | 0.70 | 0 | 0.54 | 1.00 | 0.70 |
| 1 | 0.95 | 0.74 | 0.83 | ||
| −1 | 0.98 | 0.36 | 0.52 | ||
| Macro avg | 0.82 | 0.70 | 0.68 | ||
| GNB | 0.78 | 0 | 0.92 | 0.65 | 0.76 |
| 1 | 0.87 | 0.77 | 0.82 | ||
| −1 | 0.65 | 0.93 | 0.77 | ||
| Macro avg | 0.81 | 0.78 | 0.78 | ||
| ETC | 0.80 | 0 | 0.78 | 0.71 | 0.74 |
| 1 | 0.87 | 0.77 | 0.82 | ||
| −1 | 0.76 | 0.93 | 0.84 | ||
| Macro avg | 0.81 | 0.80 | 0.80 | ||
| SGD | 0.94 | 0 | 0.91 | 0.93 | 0.92 |
| 1 | 0.98 | 0.94 | 0.96 | ||
| −1 | 0.92 | 0.94 | 0.93 | ||
| Macro avg | 0.94 | 0.94 | 0.94 |
| Models | Accuracy | Class | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| LR | 0.92 | 0 | 0.88 | 0.99 | 0.93 |
| 1 | 0.96 | 0.93 | 0.94 | ||
| −1 | 0.97 | 0.60 | 0.74 | ||
| Macro avg | 0.94 | 0.84 | 0.87 | ||
| RF | 0.94 | 0 | 0.90 | 1.00 | 0.95 |
| 1 | 0.98 | 0.92 | 0.95 | ||
| −1 | 0.96 | 0.76 | 0.85 | ||
| Macro avg | 0.95 | 0.89 | 0.92 | ||
| DT | 0.93 | 0 | 0.94 | 0.94 | 0.94 |
| 1 | 0.95 | 0.95 | 0.95 | ||
| −1 | 0.82 | 0.83 | 0.82 | ||
| Macro avg | 0.90 | 0.91 | 0.90 | ||
| KNN | 0.60 | 0 | 0.98 | 0.54 | 0.70 |
| 1 | 0.26 | 0.95 | 0.70 | ||
| −1 | 0.44 | 0.70 | 0.57 | ||
| Macro avg | 0.56 | 0.75 | 0.58 | ||
| SVM | 0.95 | 0 | 0.91 | 0.99 | 0.95 |
| 1 | 0.98 | 0.93 | 0.95 | ||
| −1 | 0.94 | 0.78 | 0.85 | ||
| Macro avg | 0.94 | 0.90 | 0.92 | ||
| AdaBoost | 0.77 | 0 | 0.68 | 1.00 | 0.81 |
| 1 | 0.97 | 0.59 | 0.73 | ||
| −1 | 0.87 | 0.62 | 0.72 | ||
| Macro avg | 0.84 | 0.74 | 0.76 | ||
| GNB | 0.68 | 0 | 0.91 | 0.58 | 0.71 |
| 1 | 0.87 | 0.75 | 0.81 | ||
| −1 | 0.24 | 0.78 | 0.37 | ||
| Macro avg | 0.68 | 0.70 | 0.63 | ||
| ETC | 0.91 | 0 | 0.92 | 0.93 | 0.93 |
| 1 | 0.93 | 0.92 | 0.93 | ||
| −1 | 0.81 | 0.81 | 0.81 | ||
| Macro avg | 0.89 | 0.89 | 0.89 | ||
| SGD | 0.94 | 0 | 0.89 | 0.99 | 0.94 |
| 1 | 0.98 | 0.93 | 0.95 | ||
| −1 | 0.98 | 0.73 | 0.84 | ||
| Macro avg | 0.95 | 0.88 | 0.91 |
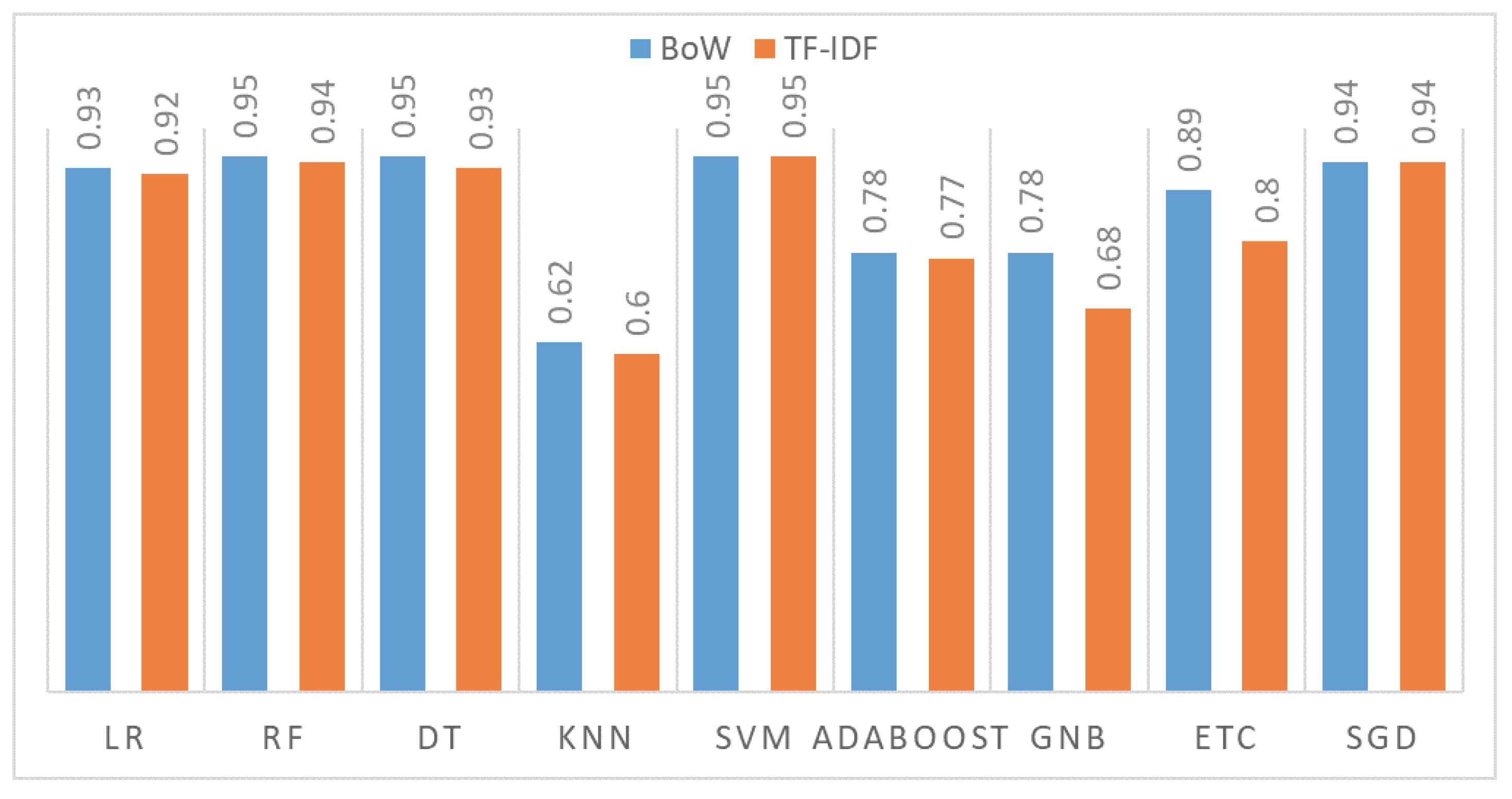
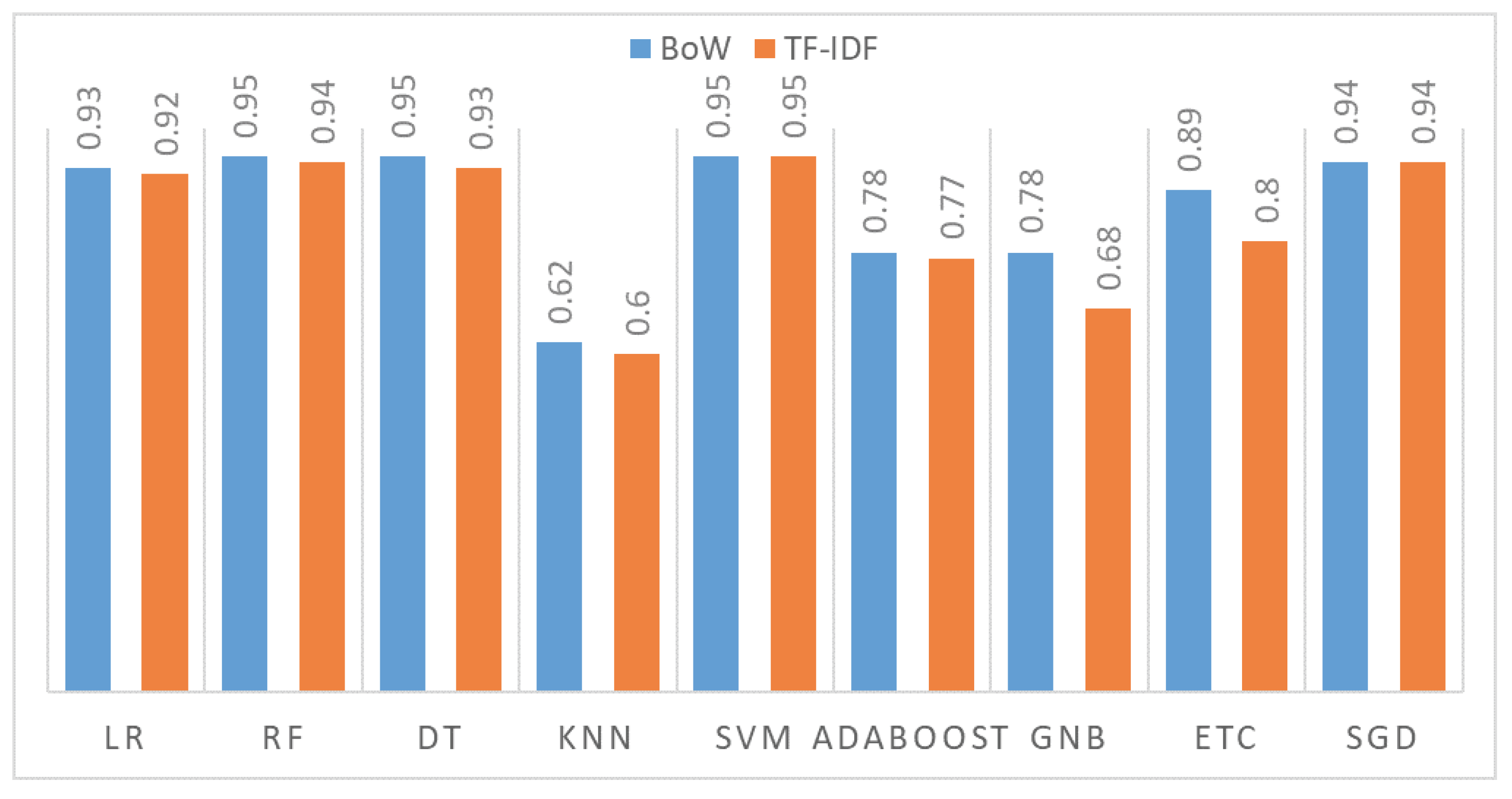
| Model | Accuracy with BoW | Accuracy with TF-IDF | ||
|---|---|---|---|---|
| With SMOTE | Original | With SMOTE | Original | |
| LR | 0.93 | 0.93 | 0.92 | 0.93 |
| RF | 0.95 | 0.86 | 0.94 | 0.85 |
| DT | 0.95 | 0.83 | 0.93 | 0.83 |
| KNN | 0.62 | 0.52 | 0.60 | 0.52 |
| SVM | 0.95 | 0.94 | 0.95 | 0.94 |
| AdaBoost | 0.78 | 0.69 | 0.77 | 0.70 |
| GNB | 0.78 | 0.78 | 0.68 | 0.78 |
| ETC | 0.89 | 0.80 | 0.91 | 0.80 |
| SGD | 0.94 | 0.94 | 0.94 | 0.94 |
| Models | Without SMOTE | Using SMOTE | ||||||
|---|---|---|---|---|---|---|---|---|
| BoW | TF-IDF | BoW | TF-IDF | |||||
| CP | WP | CP | WP | CP | WP | CP | WP | |
| LR | 4013 | 276 | 3889 | 400 | 5395 | 398 | 5471 | 322 |
| SVM | 4047 | 242 | 4032 | 257 | 5428 | 365 | 5610 | 183 |
| RF | 4042 | 247 | 4030 | 259 | 5010 | 783 | 5462 | 331 |
| DT | 4018 | 271 | 4000 | 289 | 4818 | 975 | 5506 | 287 |
| KNN | 4018 | 271 | 4000 | 289 | 4818 | 975 | 5506 | 287 |
| AdaBoost | 3354 | 935 | 3316 | 973 | 4015 | 1778 | 4407 | 1386 |
| GNB | 2910 | 1379 | 2911 | 1378 | 4501 | 1292 | 4126 | 1667 |
| ETC | 3861 | 428 | 3918 | 371 | 4705 | 1088 | 5169 | 624 |
| SGD | 4061 | 228 | 3982 | 307 | 5440 | 353 | 5536 | 257 |
| Model | SMOTE | Original | ||
|---|---|---|---|---|
| BoW | TF-IDF | BoW | TF-IDF | |
| LR | 0.93 (±0.03) | 0.90 (±0.03) | 0.91 (±0.06) | 0.91 (±0.04) |
| RF | 0.93 (±0.03) | 0.93 (±0.03) | 0.83 (±0.08) | 0.93 (±0.04) |
| DT | 0.93 (±0.04) | 0.92 (±0.04) | 0.80 (±0.08) | 0.92 (±0.05) |
| KNN | 0.58 (±0.08) | 0.56 (±0.08) | 0.48 (±0.10) | 0.47 (±0.09) |
| SVM | 0.94 (±0.03) | 0.94 (±0.02) | 0.92 (±0.06) | 0.93(±0.04) |
| Adaboost | 0.77 (±0.04) | 0.77 (±0.04) | 0.69 (±0.04) | 0.74 (±0.04) |
| GNB | 0.78 (±0.03) | 0.78 (±0.05) | 0.74 (±0.04) | 0.75 (±0.04) |
| ETC | 0.86 (±0.05) | 0.86 (±0.04) | 0.77 (±0.06) | 0.85 (±0.05) |
| SGD | 0.95 (±0.02) | 0.92(±0.02) | 0.93 (±0.04) | 0.92(±0.04) |
| Re-Sampling | Technique | Positive | Negative | Neutral |
|---|---|---|---|---|
| Without SMOTE | VADER | 8861 | 2373 | 5921 |
| SentiWordNet | 9606 | 2547 | 5002 | |
| SMOTE | VADER | 8861 | 8861 | 8861 |
| SentiWordNet | 9606 | 9606 | 9606 |
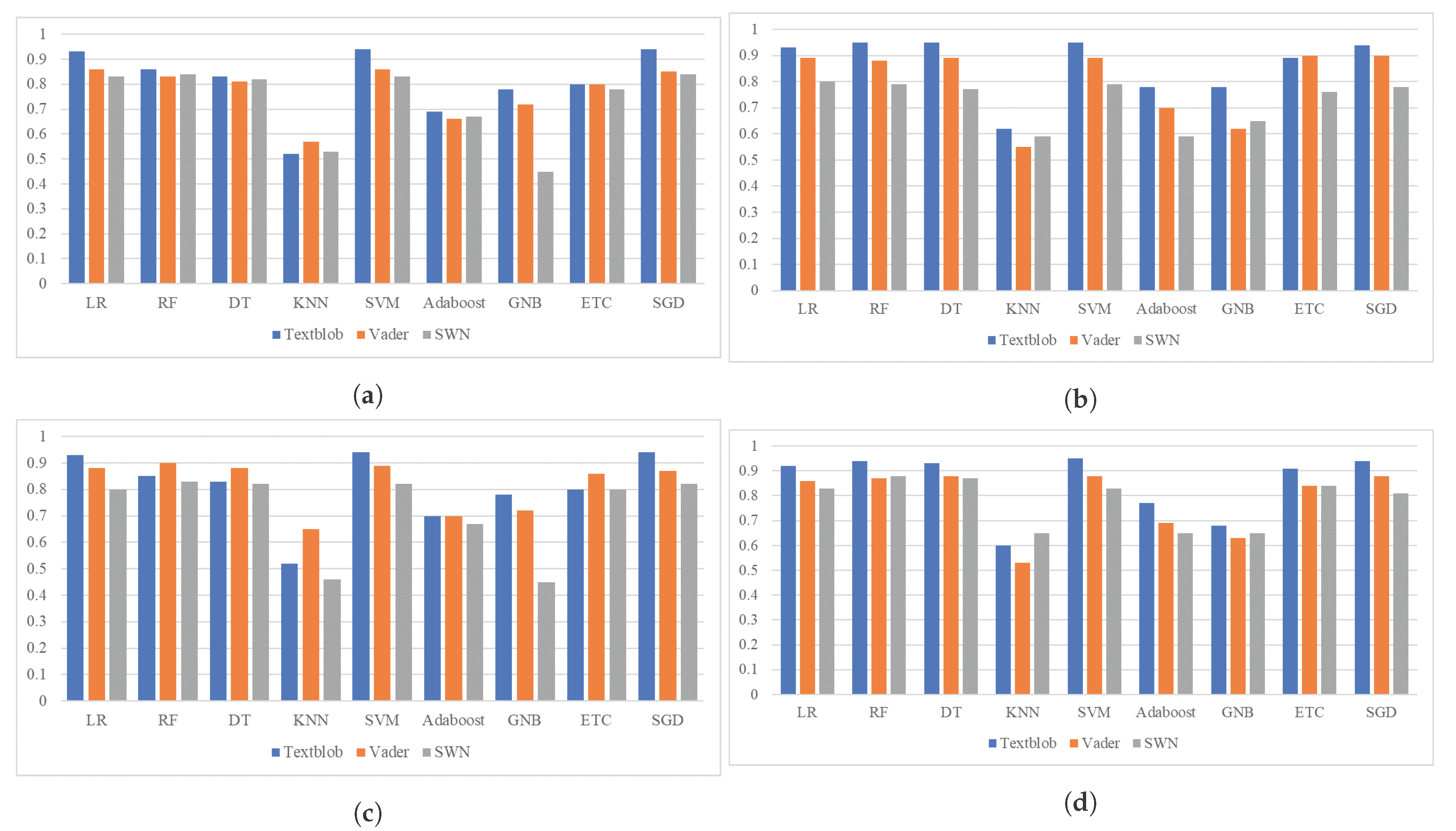
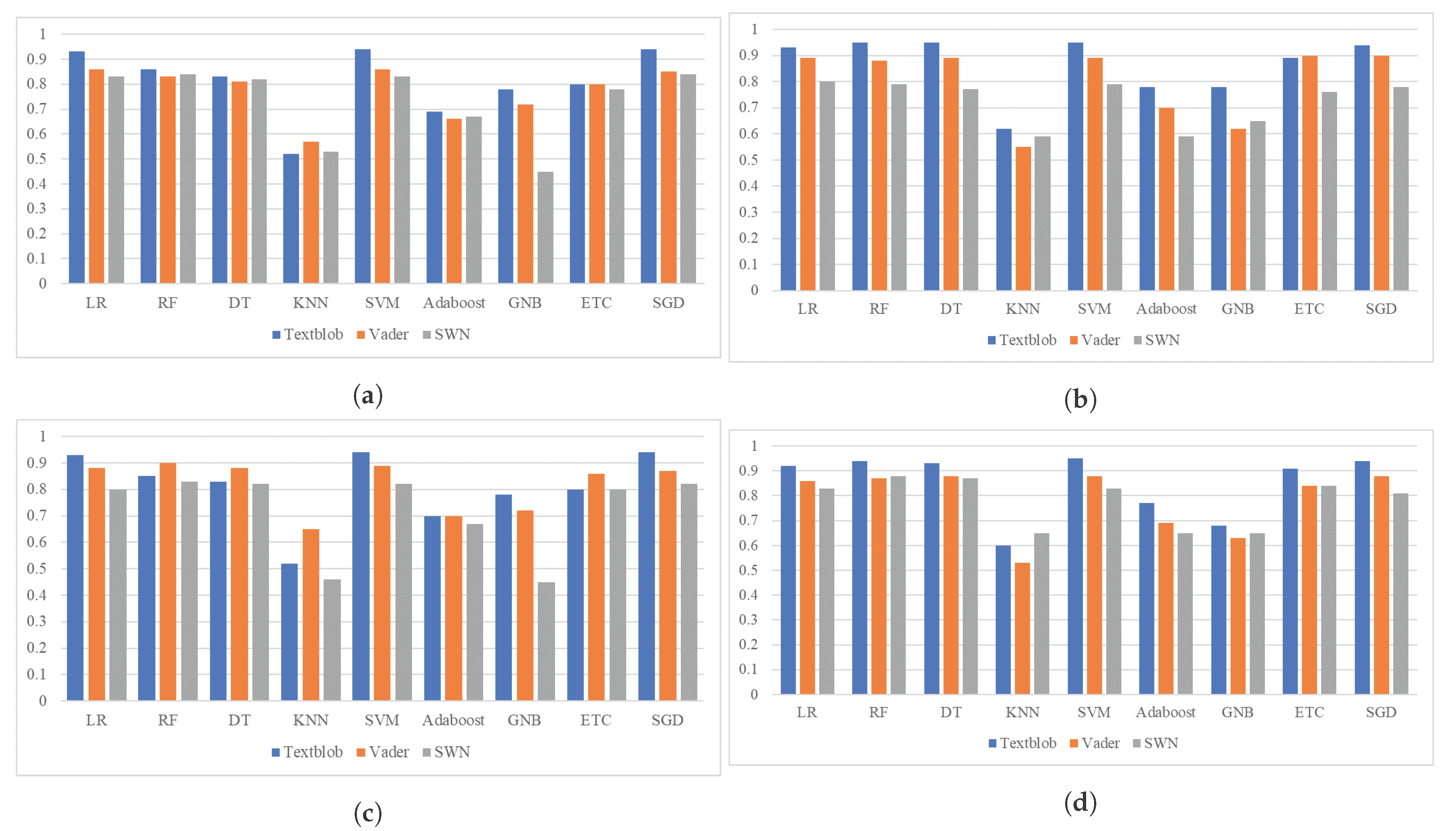
| Model | VADER | VADER + SMOTE | SentiWordNet | SentiWordNet + SMOTE | ||||
|---|---|---|---|---|---|---|---|---|
| BoW | TF-IDF | BoW | TF-IDF | BoW | TF-IDF | BoW | TF-IDF | |
| LR | 0.86 | 0.88 | 0.89 | 0.86 | 0.83 | 0.80 | 0.80 | 0.83 |
| RF | 0.83 | 0.90 | 0.88 | 0.87 | 0.84 | 0.83 | 0.79 | 0.88 |
| DT | 0.81 | 0.88 | 0.89 | 0.88 | 0.82 | 0.82 | 0.77 | 0.87 |
| KNN | 0.57 | 0.65 | 0.55 | 0.53 | 0.53 | 0.46 | 0.59 | 0.65 |
| SVM | 0.86 | 0.89 | 0.89 | 0.88 | 0.83 | 0.82 | 0.79 | 0.83 |
| Adaboost | 0.66 | 0.70 | 0.70 | 0.69 | 0.67 | 0.67 | 0.59 | 0.65 |
| GNB | 0.72 | 0.72 | 0.62 | 0.63 | 0.45 | 0.45 | 0.65 | 0.65 |
| ETC | 0.80 | 0.86 | 0.90 | 0.84 | 0.78 | 0.80 | 0.76 | 0.84 |
| SGD | 0.85 | 0.87 | 0.90 | 0.88 | 0.84 | 0.82 | 0.78 | 0.81 |
| Technique | Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| Textblob | LSTM | 0.94 | 0.92 | 0.91 | 0.91 |
| CNN | 0.91 | 0.90 | 0.87 | 0.88 | |
| CNN-LSTM | 0.92 | 0.89 | 0.88 | 0.89 | |
| Bi-LSTM | 0.94 | 0.93 | 0.94 | 0.93 | |
| VADER | LSTM | 0.91 | 0.89 | 0.89 | 0.89 |
| CNN | 0.88 | 0.87 | 0.85 | 0.86 | |
| CNN-LSTM | 0.89 | 0.87 | 0.86 | 0.86 | |
| Bi-LSTM | 0.92 | 0.91 | 0.89 | 0.90 | |
| SentiWordNet | LSTM | 0.85 | 0.82 | 0.80 | 0.81 |
| CNN | 0.82 | 0.79 | 0.77 | 0.78 | |
| CNN-LSTM | 0.82 | 0.79 | 0.77 | 0.78 | |
| Bi-LSTM | 0.85 | 0.82 | 0.80 | 0.81 |
| Topic # | Keywords |
|---|---|
| 1 | help history need paper online academic paysomeone mathematics accounts study |
| 2 | covid education blockchain business boove onlineclasses coronavirus higher assignments pandemic |
| 3 | onlinelearning students learning highereducation byjus help school assignmentdue essaywriting onlineclasses |
| 4 | highereducation due amp history coronavirus depression given also cancel severe |
| 5 | research get coronavirus may available today someonehelppaper onlinecourses also essaydue |
| 6 | courses pandemic student parents remote day see year kids college |
| 7 | one history week freeonlinecourses children check digital psychology class latest |
| 8 | webinar follow classroom complete top lms app science never hit |
| 9 | teachers student one college join university looking essaypay visit video |
| 10 | take children want future via home way top stay onlineeducation |
| Topic # | Keywords |
|---|---|
| 1 | schools closed may remain till minister education class said |
| 2 | children disabilities near challenging proved families onlineeducation impossible class puc |
| 3 | disabilities missing lagging network performing securitycameras switches families challenging proved |
| 4 | pandemic coronavirus back staying individuals furthermore resorted widespread home research |
| 5 | learning deadline miss difficult covid 19 econometrics highereducation month offers |
| 6 | deadline miss onlineclasses onlinecourses b2b reach hesitate maths lead |
| 7 | time school year hard boring highereducation make late past elearning |
| 8 | need training 2021 schools center remote green belt lean sigma |
| 9 | little onlinelearning needs minister amp mytutorhub whether teach COVID-19 |
| 10 | forced mytutorhub virtual boring needs internet teach subject educator coronavirus |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mujahid, M.; Lee, E.; Rustam, F.; Washington, P.B.; Ullah, S.; Reshi, A.A.; Ashraf, I. Sentiment Analysis and Topic Modeling on Tweets about Online Education during COVID-19. Appl. Sci. 2021, 11, 8438. https://doi.org/10.3390/app11188438
Mujahid M, Lee E, Rustam F, Washington PB, Ullah S, Reshi AA, Ashraf I. Sentiment Analysis and Topic Modeling on Tweets about Online Education during COVID-19. Applied Sciences. 2021; 11(18):8438. https://doi.org/10.3390/app11188438
Chicago/Turabian StyleMujahid, Muhammad, Ernesto Lee, Furqan Rustam, Patrick Bernard Washington, Saleem Ullah, Aijaz Ahmad Reshi, and Imran Ashraf. 2021. "Sentiment Analysis and Topic Modeling on Tweets about Online Education during COVID-19" Applied Sciences 11, no. 18: 8438. https://doi.org/10.3390/app11188438
APA StyleMujahid, M., Lee, E., Rustam, F., Washington, P. B., Ullah, S., Reshi, A. A., & Ashraf, I. (2021). Sentiment Analysis and Topic Modeling on Tweets about Online Education during COVID-19. Applied Sciences, 11(18), 8438. https://doi.org/10.3390/app11188438