
A CNN Regression Approach to Mobile Robot Localization Using Omnidirectional Images






Abstract
1. Introduction
2. Convolutional Neural Networks
2.1. Feature Extraction Using CNNs
2.2. CNNs for Localization
3. Solving Hierarchical Localization by Means of a Classification CNN and Regression CNNs
3.1. Visual Localization of a Mobile Robot
- The robot captures an image from an unknown position (test image);
- An estimation of the area where the robot is located is performed. To carry out this, we use a CNN trained to solve a classification problem, whose architecture will be detailed in Section 3.2;
- Restricted to the area extracted in the previous step, the coordinates of the point from which the image was captured are estimated. To this end, a CNN trained to solve a regression problem is used, as described in Section 3.3.
3.2. Coarse Localization Stage Using a Classification CNN
- Epochs: these define the number of times that the learning algorithm will run through the entire training dataset;
- Initial Learn Rate: this controls how much the model has to change in response to the estimated error each time the weights are updated;
- Optimization algorithm: this changes the attributes of the CNN in order to reduce the losses;
- Loss function: this is an error function that can be used to determine the loss of the model and, as a consequence, update the weights to reduce the loss in the sucesive iterations;
- Batch size: this determines the number of samples that will be passed through to the network at one time.
3.3. Fine Localization Stage Using a Regression CNN
4. Data Base
5. Experiments
5.1. Results of the Coarse Localization Stage
5.1.1. Training Process of the Classification CNN
- 30 epochs;
- Initial Learn Rate: 0.001;
- Optimization algorithm: Adam;
- Loss function: Categorical cross entropy loss;
- Batch size: 50.
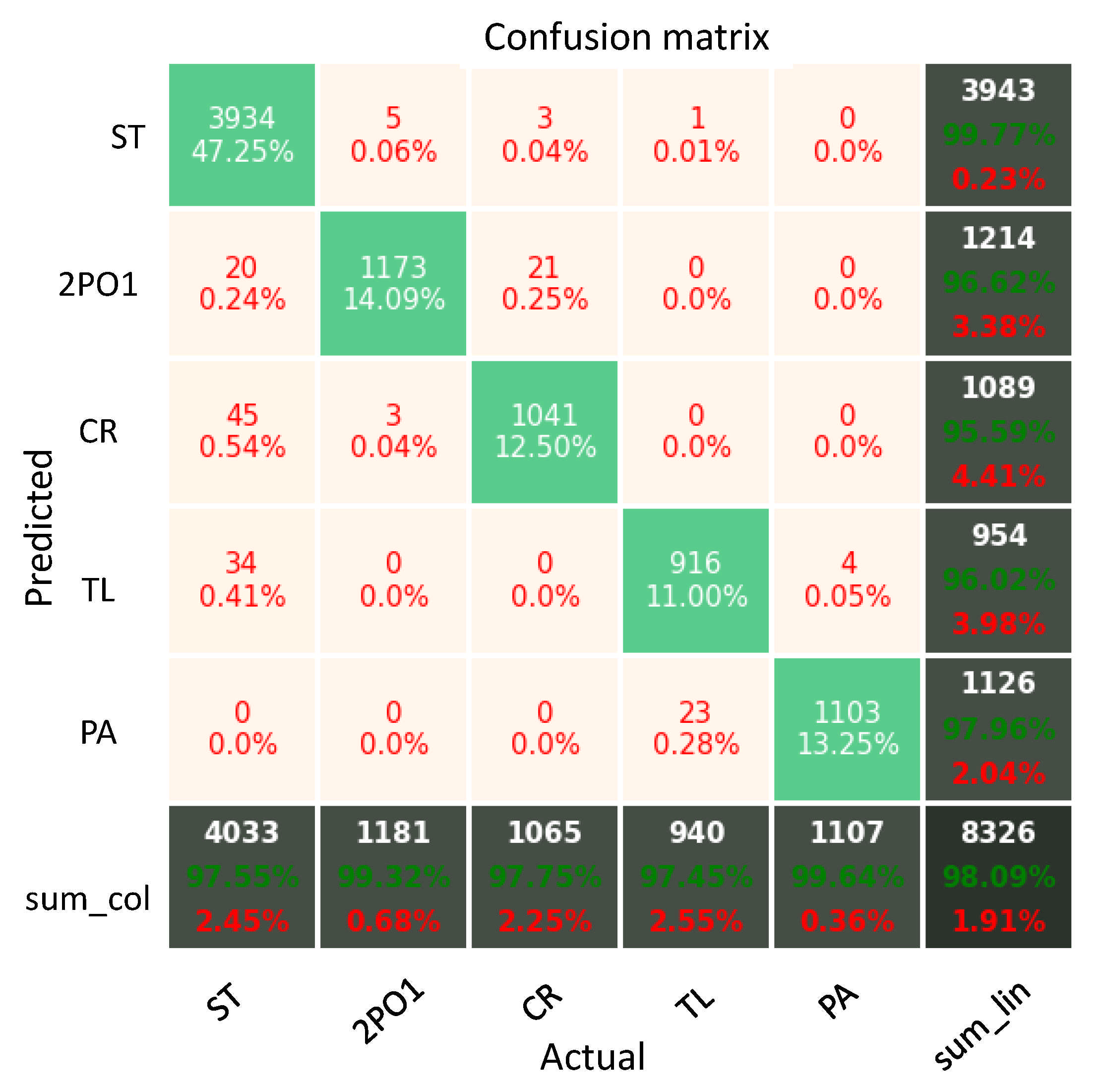
5.1.2. Results of the Classification CNN
5.2. Results of the Fine Localization Stage
5.2.1. Training Process of the Regression CNNs
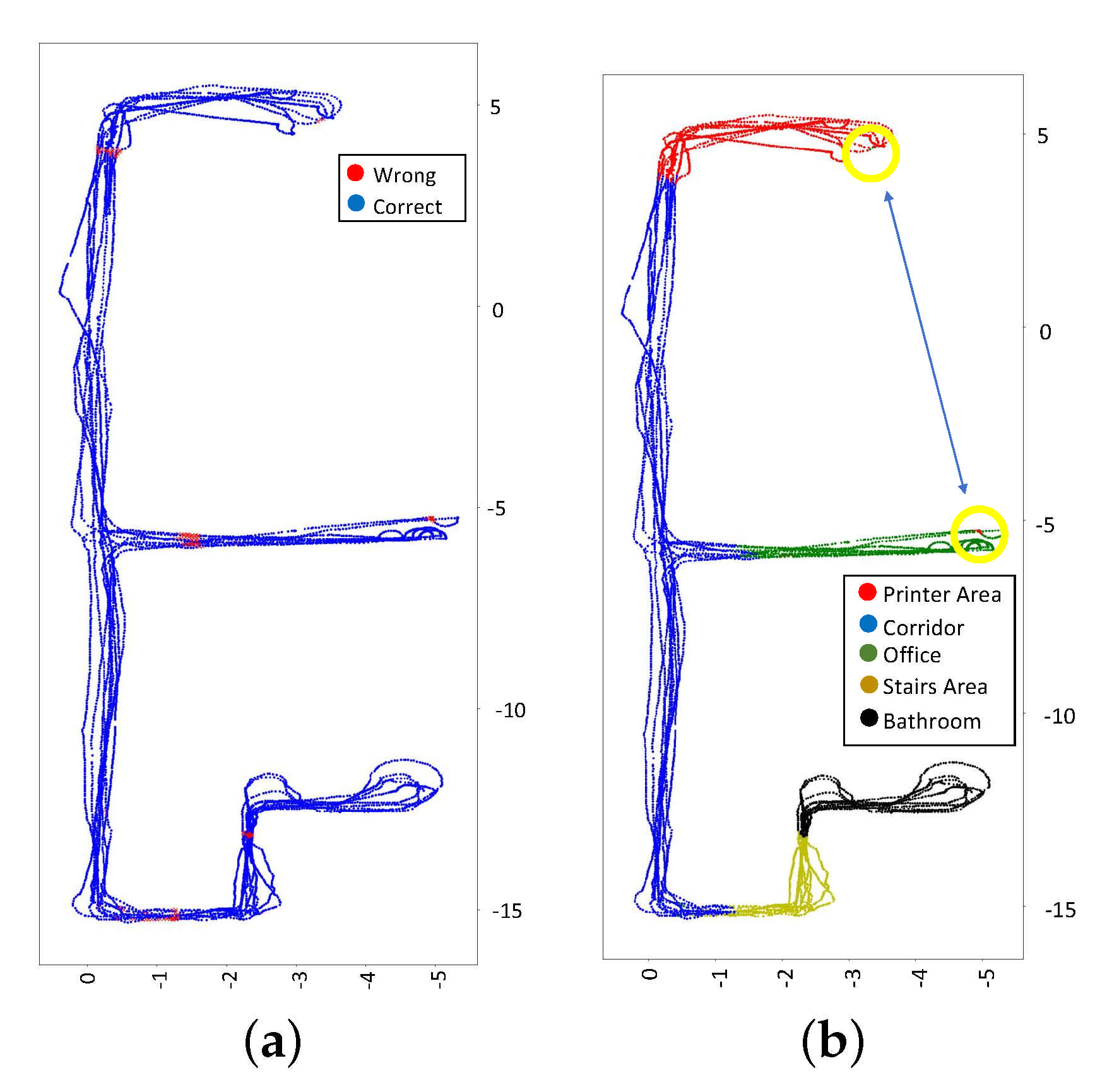
5.2.2. Results of the Regression CNNs
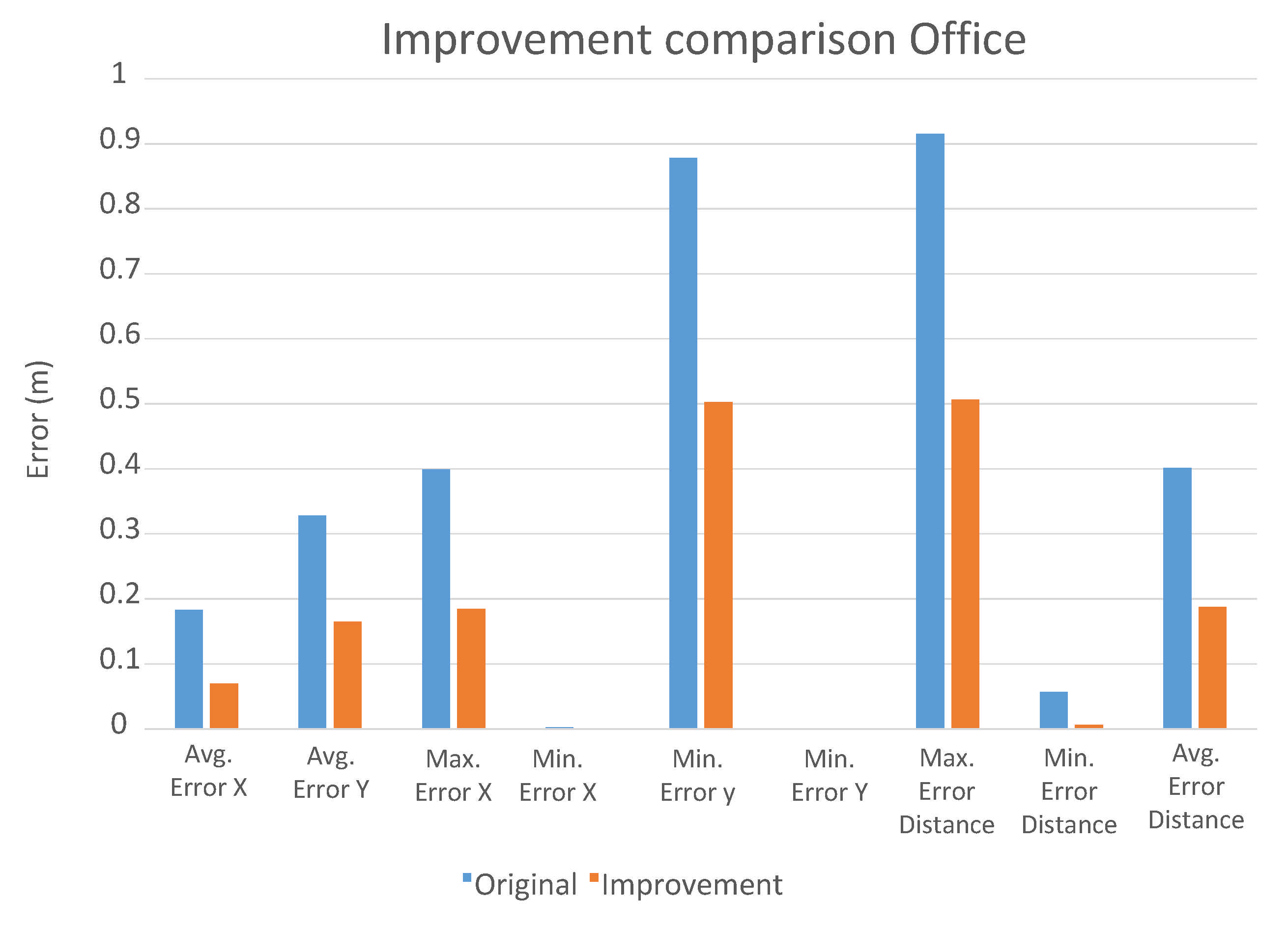
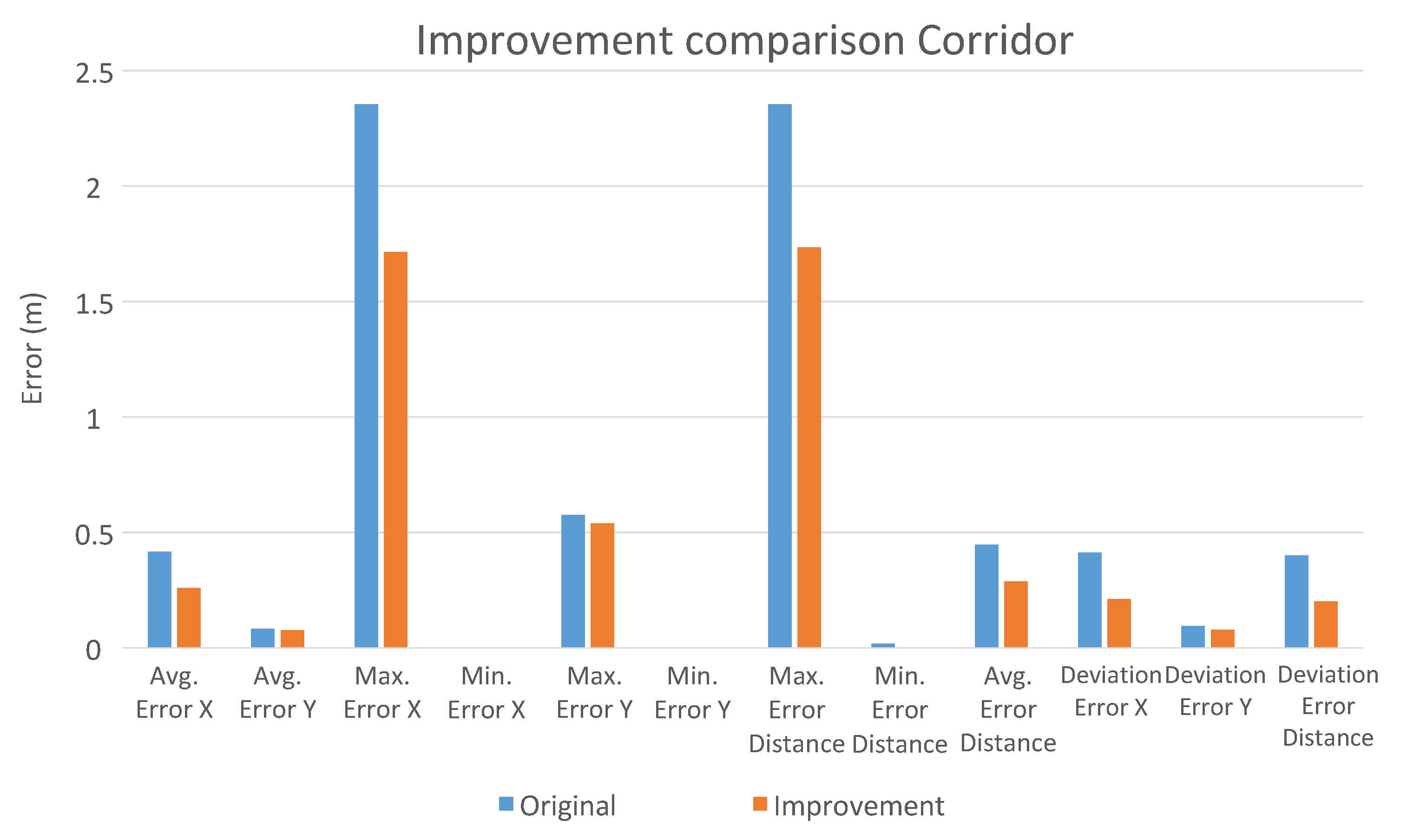
5.2.3. Improvement of the Regression CNNs
6. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hamid, M.; Adom, A.; Rahim, N.; Rahiman, M. Navigation of mobile robot using Global Positioning System (GPS) and obstacle avoidance system with commanded loop daisy chaining application method. In Proceedings of the 2009 5th International Colloquium on Signal Processing Its Applications, Kuala Lumpur, Malaysia, 6–8 March 2009; pp. 176–181. [Google Scholar] [CrossRef]
- Markom, M.A.; Adom, A.H.; Tan, E.S.M.M.; Shukor, S.A.A.; Rahim, N.A.; Shakaff, A.Y.M. A mapping mobile robot using RP Lidar scanner. In Proceedings of the 2015 IEEE International Symposium on Robotics and Intelligent Sensors (IRIS), Langkawi, Malaysia, 18–20 October 2015; pp. 87–92. [Google Scholar] [CrossRef]
- Almansa-Valverde, S.; Castillo, J.C.; Fernández-Caballero, A. Mobile robot map building from time-of-flight camera. Expert Syst. Appl. 2012, 39, 8835–8843. [Google Scholar] [CrossRef]
- Jiang, G.; Yin, L.; Jin, S.; Tian, C.; Ma, X.; Ou, Y. A Simultaneous Localization and Mapping (SLAM) Framework for 2.5D Map Building Based on Low-Cost LiDAR and Vision Fusion. Appl. Sci. 2019, 9, 2105. [Google Scholar] [CrossRef]
- Ballesta, M.; Gil, A.; Reinoso, O.; Payá, L. Building Visual Maps with a Team of Mobile Robots; INTECHOpen: London, UK, 2011; Chapter 6. [Google Scholar] [CrossRef]
- Se, S.; Lowe, D.; Little, J. Vision-based mobile robot localization and mapping using scale-invariant features. In Proceedings of the 2001 ICRA. IEEE International Conference on Robotics and Automation, Seoul, Korea, 21–26 May 2001; Volume 2, pp. 2051–2058. [Google Scholar] [CrossRef]
- Gil, A.; Reinoso, O.; Ballesta, M.; Juliá, M.; Payá, L. Estimation of Visual Maps with a Robot Network Equipped with Vision Sensors. Sensors 2010, 10, 5209–5232. [Google Scholar] [CrossRef] [PubMed]
- Ali, S.; Al Mamun, S.; Fukuda, H.; Lam, A.; Kobayashi, Y.; Kuno, Y. Smart Robotic Wheelchair for Bus Boarding Using CNN Combined with Hough Transforms; In International Conference on Intelligent Computing; Springer: Cham, Switzerland, 2018; pp. 163–172. [Google Scholar] [CrossRef]
- Khan, A.; Sohail, A.; Zahoora, U.; Saeed, A. A Survey of the Recent Architectures of Deep Convolutional Neural Networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef]
- Andreasson, H. Local Visual Feature Based Localisation and Mapping by Mobile Robots. Ph.D. Thesis, Örebro University, Örebro, Sweden, 2008. ISSN 1650-8580 ISBN 978-91-7668-614-0. [Google Scholar]
- Ravankar, A.A.; Ravankar, A.; Emaru, T.; Kobayashi, Y. Multi-Robot Mapping and Navigation Using Topological Features. Proceedings 2020, 42, 6580. [Google Scholar] [CrossRef]
- Lowe, D. Object Recognition from Local Scale-Invariant Features. Proc. IEEE Int. Conf. Comput. Vis. 2001, 2, 1150–1157. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Amorós, F.; Payá, L.; Mayol-Cuevas, W.; Jiménez, L.; Reinoso, O. Holistic Descriptors of Omnidirectional Color Images and Their Performance in Estimation of Position and Orientation. IEEE Access 2020, 8, 81822–81848. [Google Scholar] [CrossRef]
- Abdi, H.; Williams, L. Principal Component Analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Weinberger, K. Densely Connected Convolutional Networks. arXiv 2016, arXiv:1608.06993. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2017, 25, 1097–1105. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Taoufiq, S.; Nagy, B.; Benedek, C. HierarchyNet: Hierarchical CNN-Based Urban Building Classification. Remote Sens. 2020, 12, 3794. [Google Scholar] [CrossRef]
- Tanaka, M.; Umetani, T.; Hirono, H.; Wada, M.; Ito, M. Localization of Moving Robots By Using Omnidirectional Camera in State Space Framework. Proc. ISCIE Int. Symp. Stoch. Syst. Theory Its Appl. 2011, 2011, 19–26. [Google Scholar] [CrossRef][Green Version]
- Huei-Yung, L.; Chien-Hsing, H. Mobile Robot Self-Localization Using Omnidirectional Vision with Feature Matching from Real and Virtual Spaces. Appl. Sci. 2021, 11, 3360. [Google Scholar] [CrossRef]
- Ishii, M.; Sasaki, Y. Mobile Robot Localization through Unsupervised Learning using Omnidirectional Images. J. Jpn. Soc. Fuzzy Theory Intell. Inform. 2015, 27, 757–770. [Google Scholar] [CrossRef][Green Version]
- Cebollada, S.; Payá, L.; Juliá, M.; Holloway, M.; Reinoso, Ó. Mapping and localization module in a mobile robot for insulating building crawl spaces. Autom. Constr. 2018, 87, 248–262. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. [Google Scholar]
- Da Silva, S.P.P.; da Nòbrega, R.V.M.; Medeiros, A.G.; Marinho, L.B.; Almeida, J.S.; Filho, P.P.R. Localization of Mobile Robots with Topological Maps and Classification with Reject Option using Convolutional Neural Networks in Omnidirectional Images. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Kim, K.W.; Hong, H.G.; Nam, G.P.; Park, K.R. A Study of Deep CNN-Based Classification of Open and Closed Eyes Using a Visible Light Camera Sensor. Sensors 2017, 17, 1534. [Google Scholar] [CrossRef] [PubMed]
- Cebollada, S.; Payá, L.; Román, V.; Reinoso, O. Hierarchical Localization in Topological Models Under Varying Illumination Using Holistic Visual Descriptors. IEEE Access 2019, 7, 49580–49595. [Google Scholar] [CrossRef]
- Kanezaki, A.; Matsushita, Y.; Nishida, Y. Rotationnet: Joint object categorization and pose estimation using multiviews from unsupervised viewpoints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5010–5019. [Google Scholar]
- Sünderhauf, N.; Shirazi, S.; Dayoub, F.; Upcroft, B.; Milford, M. On the performance of ConvNet features for place recognition. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 4297–4304. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Kunii, Y.; Kovacs, G.; Hoshi, N. Mobile robot navigation in natural environments using robust object tracking. In Proceedings of the IEEE 26th International Symposium on Industrial Electronics (ISIE), Edinburgh, UK, 19–21 June 2017; pp. 1747–1752. [Google Scholar]
- Payá, L.; Reinoso, O.; Berenguer, Y.; Úbeda, D. Using omnidirectional vision to create a model of the environment: A comparative evaluation of global-appearance descriptors. J. Sens. 2016, 2016, 1209507. [Google Scholar] [CrossRef] [PubMed]
- Sinha, H.; Patrikar, J.; Dhekane, E.G.; Pandey, G.; Kothari, M. Convolutional Neural Network Based Sensors for Mobile Robot Relocalization. In Proceedings of the 23rd International Conference on Methods Models in Automation Robotics (MMAR), Miedzyzdroje, Poland, 27–30 August 2018; pp. 774–779. [Google Scholar] [CrossRef]
- Payá, L.; Peidró, A.; Amorós, F.; Valiente, D.; Reinoso, O. Modeling Environments Hierarchically with Omnidirectional Imaging and Global-Appearance Descriptors. Remote Sens. 2018, 10, 522. [Google Scholar] [CrossRef]
- Xu, S.; Chou, W.; Dong, H. A robust indoor localization system integrating visual localization aided by CNN-based image retrieval with Monte Carlo localization. Sensors 2019, 19, 249. [Google Scholar] [CrossRef]
- Chaves, D.; Ruiz-Sarmiento, J.; Petkov, N.; Gonzalez-Jimenez, J. Integration of CNN into a Robotic Architecture to Build Semantic Maps of Indoor Environments. In Proceedings of the Advances in Computational Intelligence, Gran Canaria, Spain, 12–14 June 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 313–324. [Google Scholar]
- Pronobis, A.; Caputo, B. COLD: COsy Localization Database. Int. J. Robot. Res. 2009, 28, 588–594. [Google Scholar] [CrossRef]
- COsy Localization Database. Available online: https://www.cas.kth.se/COLD/cold-freiburg.html (accessed on 21 July 2021).
- Cebollada, S.; Payá, L.; Mayol, W.; Reinoso, O. Evaluation of Clustering Methods in Compression of Topological Models and Visual Place Recognition Using Global Appearance Descriptors. Appl. Sci. 2019, 9, 377. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
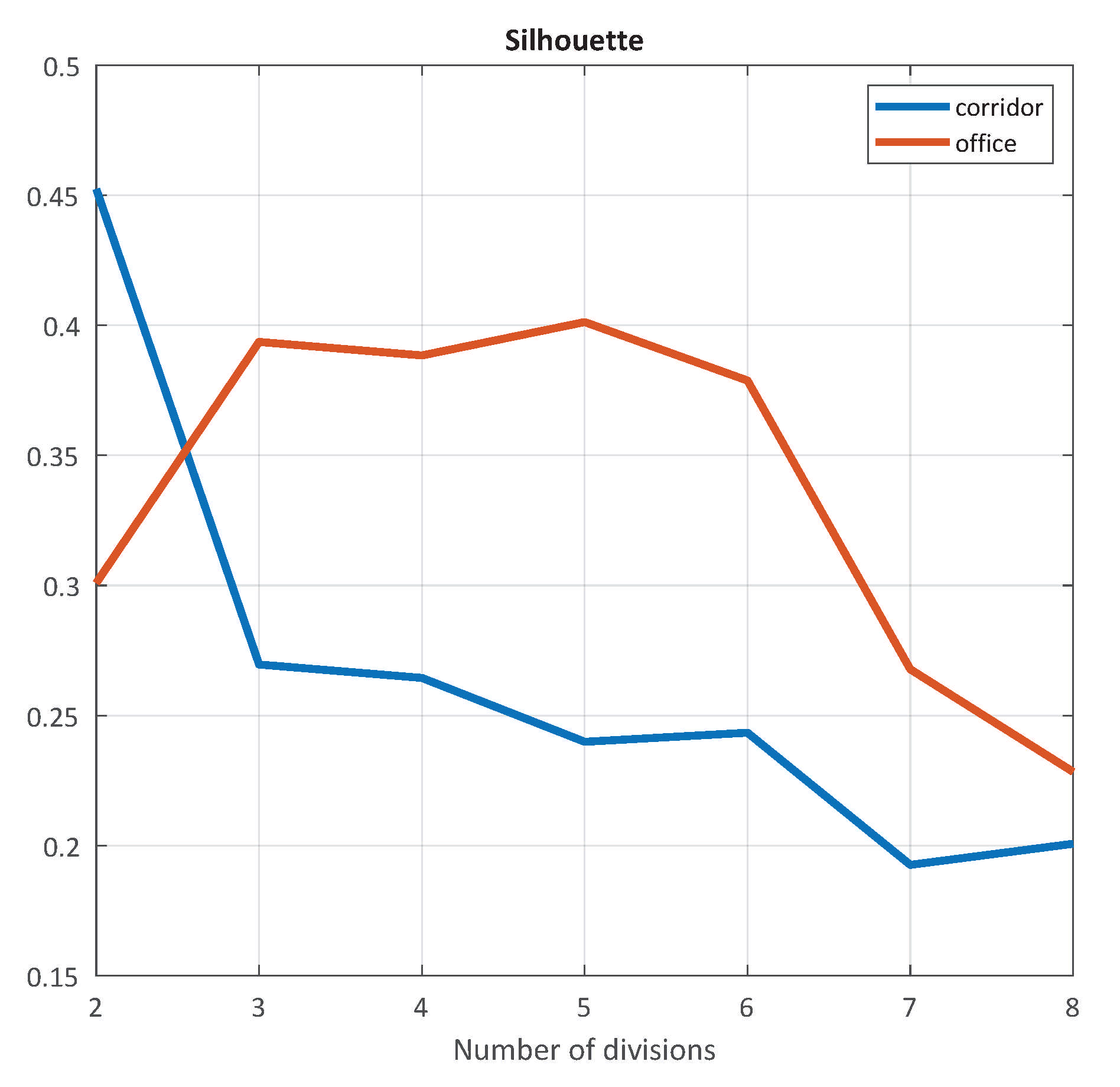{kind=link}
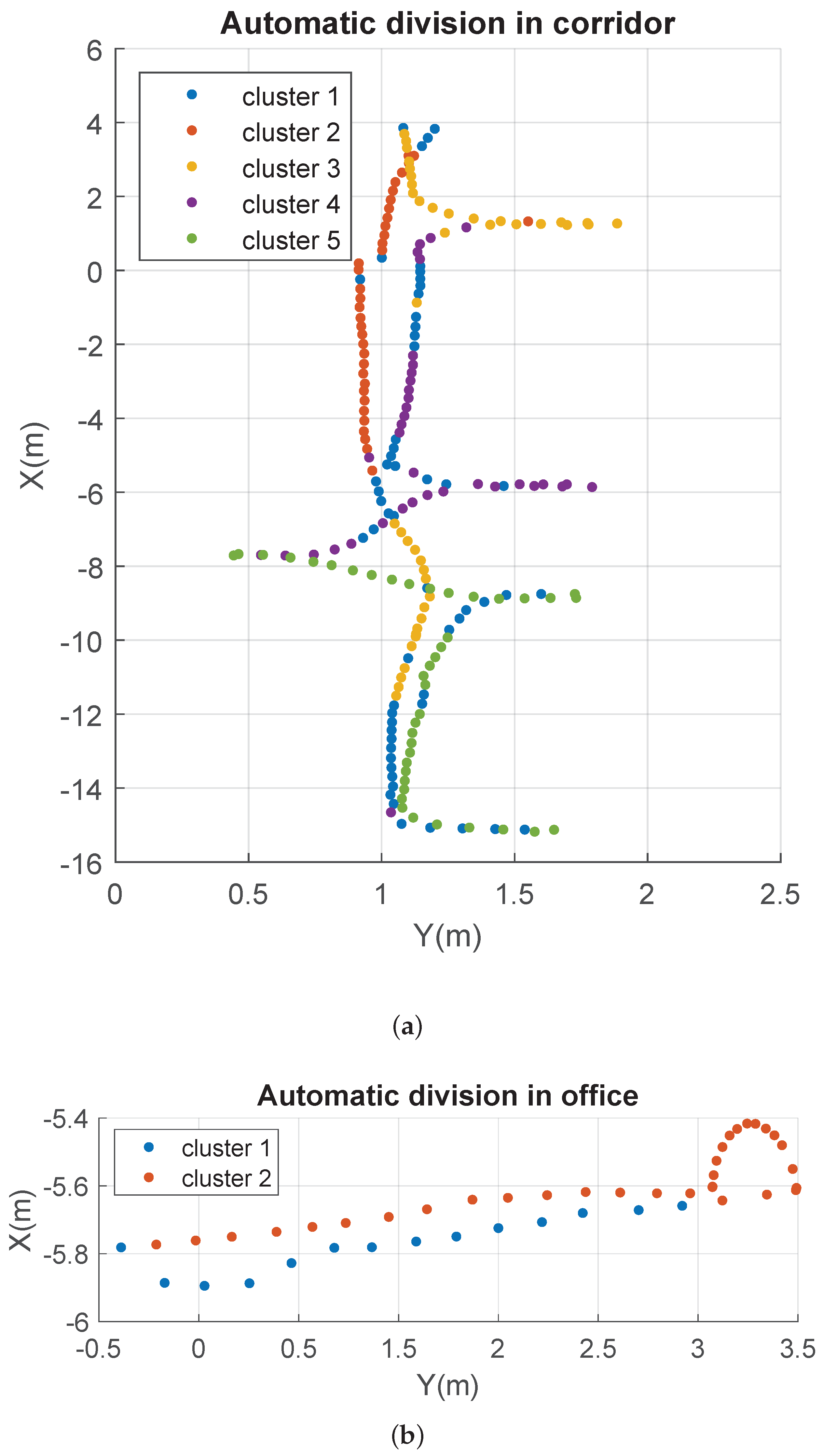{kind=link}
| Code | Room Name | Number of Images | ||
|---|---|---|---|---|
| Cloudy | Sunny | Night | ||
| 1-PA | Printer area | 692 | 985 | 716 |
| 2-CR | Corridor | 2472 | 3132 | 2537 |
| 8-TL | Toilet | 683 | 854 | 645 |
| 9-ST | Stairs area | 433 | 652 | 649 |
| 5-2PO1 | Office | 609 | 745 | 649 |
| - | Total | 4889 | 6368 | 5196 |
| Code | One-Hot Vector |
|---|---|
| CR | [1, 0, 0, 0, 0] |
| PA | [0, 1, 0, 0, 0] |
| 2PO1 | [0, 0, 1, 0, 0] |
| ST | [0, 0, 0, 1, 0] |
| TL | [0, 0, 0, 0, 1] |
| Room | ||||||
|---|---|---|---|---|---|---|
| Stairs | Toilet | Corridor | Printer Area | Office | Average | |
| Average error X (m) | 0.0738 | 0.0823 | 0.8753 | 0.1466 | 0.1828 | 0.4523 |
| Average error Y (m) | 0.1033 | 0.0814 | 0.0902 | 0.2245 | 0.328 | 0.1452 |
| Maximum error X (m) | 0.4254 | 0.4999 | 7.1901 | 0.4312 | 0.3991 | 7.1901 |
| Minimum error X (m) | 0.0014 | 0.0005 | 0.00014 | 0.0012 | 0.0026 | 0.0001 |
| Maximum error Y (m) | 0.755 | 0.4061 | 0.5747 | 0.652 | 0.8784 | 0.8784 |
| Minimum error Y (m) | 0.0003 | 0.0001 | 0.0008 | |||
| Maximum error Euclidean distance (m) | 0.7557 | 0.5207 | 7.1907 | 0.6606 | 0.9152 | 7.1907 |
| Minimum error Euclidean distance (m) | 0.00768 | 0.006 | 0.0169 | 0.0342 | 0.0569 | 0.006 |
| Average error Euclidean distance (m) | 0.1398 | 1.313 | 8.9920 | 2.9280 | 0.4011 | 0.5315 |
| Error deviation in X (m) | 0.0678 | 0.0852 | 1.2302 | 0.1081 | 0.1034 | 0.8979 |
| Error deviation in Y (m) | 0.1339 | 0.0813 | 0.0944 | 0.1514 | 0.2181 | 0.1586 |
| Error deviation Euclidean distance (m) | 0.1382 | 0.1005 | 1.2199 | 0.144 | 0.1961 | 0.8801 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ballesta, M.; Payá, L.; Cebollada, S.; Reinoso, O.; Murcia, F. A CNN Regression Approach to Mobile Robot Localization Using Omnidirectional Images. Appl. Sci. 2021, 11, 7521. https://doi.org/10.3390/app11167521
Ballesta M, Payá L, Cebollada S, Reinoso O, Murcia F. A CNN Regression Approach to Mobile Robot Localization Using Omnidirectional Images. Applied Sciences. 2021; 11(16):7521. https://doi.org/10.3390/app11167521
Chicago/Turabian StyleBallesta, Mónica, Luis Payá, Sergio Cebollada, Oscar Reinoso, and Francisco Murcia. 2021. "A CNN Regression Approach to Mobile Robot Localization Using Omnidirectional Images" Applied Sciences 11, no. 16: 7521. https://doi.org/10.3390/app11167521
APA StyleBallesta, M., Payá, L., Cebollada, S., Reinoso, O., & Murcia, F. (2021). A CNN Regression Approach to Mobile Robot Localization Using Omnidirectional Images. Applied Sciences, 11(16), 7521. https://doi.org/10.3390/app11167521