1. Introduction
The representation of any data fed to a machine learning model impacts the usefulness of that data [
1]. The model cannot learn what it cannot see and a data representation will present its perspective of the data to the model [
2].
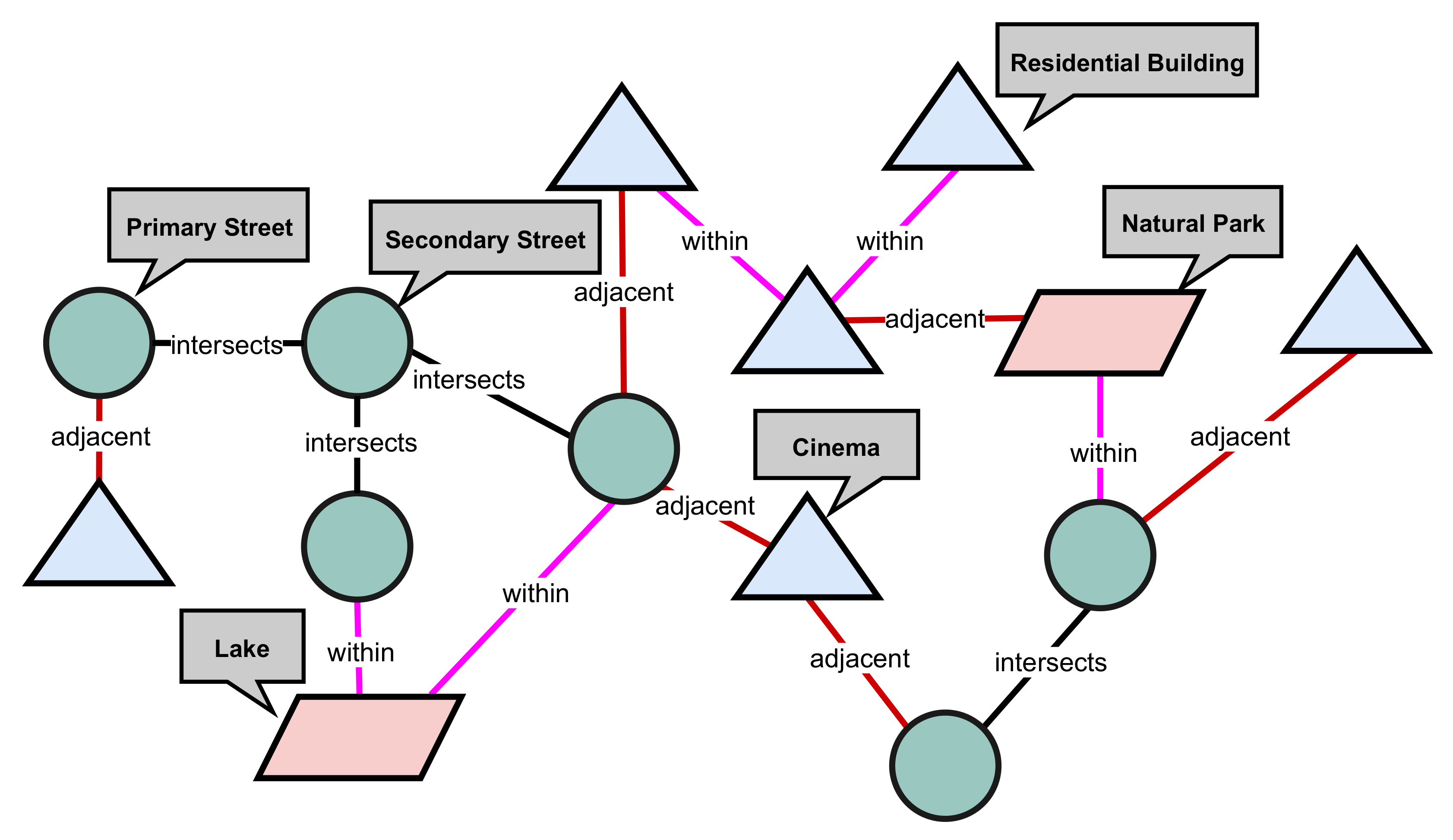
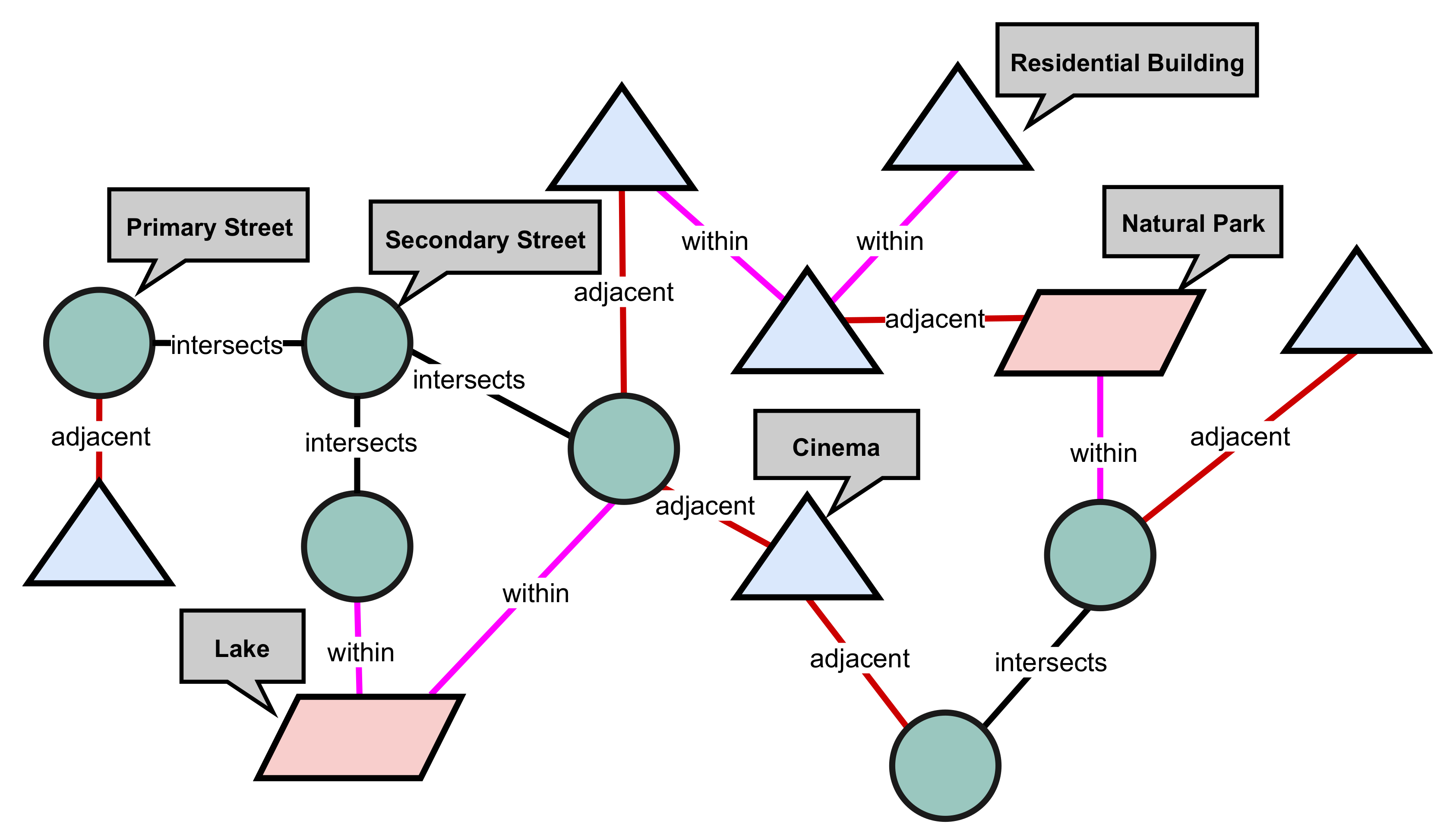
A spatial network is defined as a network where the nodes and edges are spatial entities with a metric imposed on them [
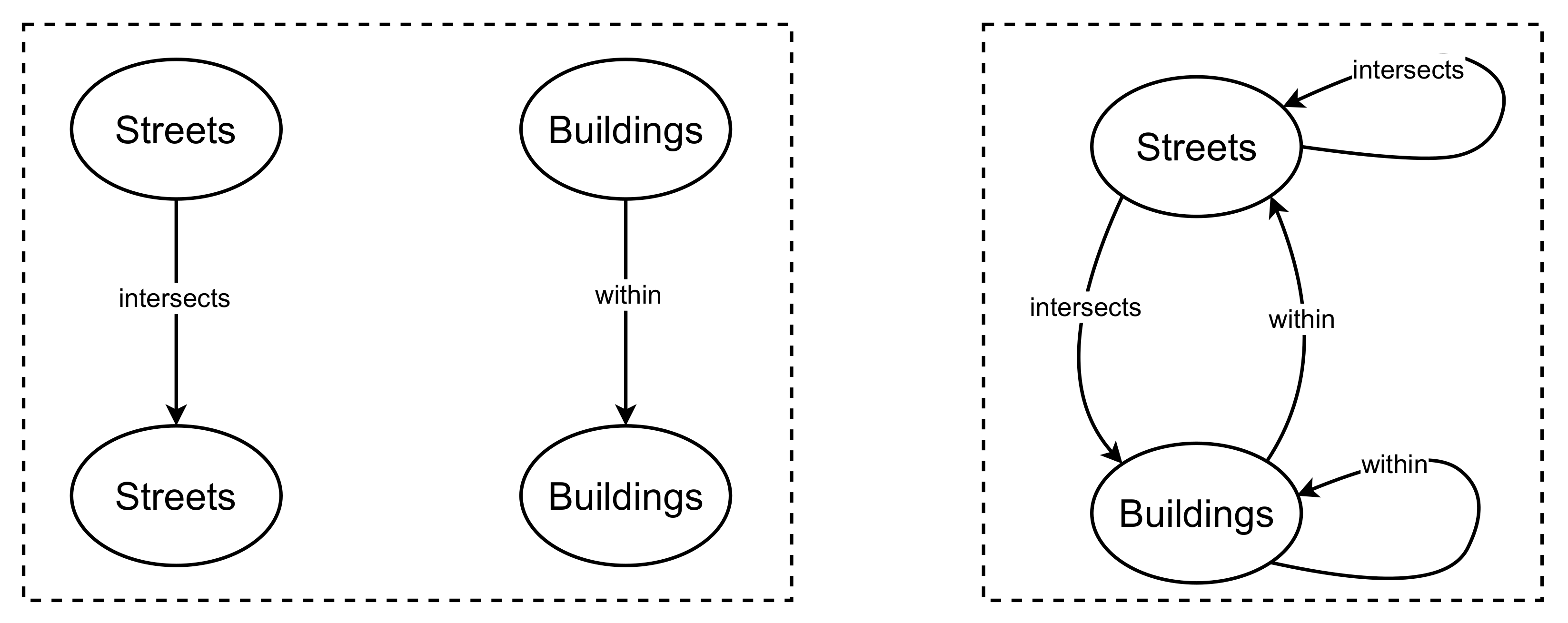
3]. Examples of spatial networks include street networks, rail networks, social networks. Spatial networks can be described through representations for a machine learning task. A type of representation is the homogeneous graph representation (we use the terms data representation and graph representation interchangeably). A homogeneous graph representation is defined as one where there is only one node and edge type in the graph [
4]. For example, we can describe a street network using a homogeneous graph representation. Here, the graph nodes will denote street segments and the graph edges will denote adjacency or intersection. Nonetheless, homogeneous graph representations fail to capture the multi-type nature of spatial networks. Typically, spatial networks exist as a combination of objects with mixed types and relations. For example, the street network will exist alongside other spatial entities such as buildings or water bodies. We can address this limitation by describing spatial networks using heterogeneous graph representations. A heterogeneous graph representation is defined as one where there is at least two types of nodes or edges in the graph [
4]. Thus, a heterogeneous graph representation offers a rich perspective of the data by describing the multi-type nature of spatial networks [
4].
Machine learning models perform better when the choice of representation captures the explanatory factors of variation behind the data [
2]. This is particularly important for spatial networks where entities exhibit inter-dependence. Let us take for example, a heterogeneous graph representation of a spatial network describing streets and buildings, where the nodes are street segments or buildings and the edges are spatial relations. There is a higher likelihood of a node being a
residential building if it is sufficiently connected to one or more
residential streets [
5,
6]. Intuitively, residential streets are likely to be constructed near or around residential buildings. From the machine learning models’ perspective, this is a better representation and could improve model performance. It follows then that the heterogeneous graph representation could improve model performance for machine learning tasks on spatial networks. See
Figure 1 for an illustration of the heterogeneous graph representation of a spatial network.
Graph Neural Networks (GNNs) are a type of artificial neural network that is designed to learn directly on graphs. In contrast to traditional machine learning methods which are designed to work on structured data, GNNs are capable of embedding both the relational and contextual information about spatial elements during the learning process [
7,
8]. However, many applications of GNNs to spatial problems have been on homogeneous graph representations [
8]. This may be due to the fact that deriving the homogeneous data representation typically only involves retrieving the physical representation [
8]. Compared to deriving the heterogeneous graph representation which could easily be non-trivial, e.g., due to an arbitrary number of possible relations. We are of the opinion that learning on heterogeneous graph representations of spatial networks is an important direction, especially within the context of GNNs. Describing spatial entities closer to their true state using heterogeneous graph representations could present insights into the model that would otherwise be ignored. We posit that heterogeneous graph representations could improve model performance for spatial networks. Consequently, we adopt the GNN paradigm of learning for our experiments.
While advances in machine learning techniques and a proliferation of spatial data have benefited Geo-AI efforts in solving many inference tasks, there have been concerns about the robustness of general models versus specialised models for Geo-AI. Studies have shown that specialised models for spatial tasks usually perform better than general models for spatial data [
8,
9]. For example, Aodha et al. [
10] demonstrate that encoding the geographical location as a probability prior improves the model performance of off-the-shelf fine-grained image classifiers. Similarly, Chu et al. [
11] who show that leveraging geographical information could significantly improve model performance for image classifiers in resource-constrained environments. Yan et al. [
12] develop mathematical embeddings for places using spatial context which outperforms mainstream embeddings. This begs the question:
What defines a specialised model for spatial data? We adopt the definition by Goodchild [
13] which outlines the following criteria to identify a specialised model for spatial data.
- 1.
Invariance test—the model results should vary across space.
- 2.
Representation test—the model should contain spatial representations.
- 3.
Formulation test—the model formulation should use spatial concepts.
- 4.
Outcome test—the model inputs and outputs should differ.
A model is said to be specialised for spatial data if it meets at least one of the four criteria. It is important to mention that equal importance is assumed for all the criteria. In this article, we focus on criteria 2—the representation test.
In this article, we study the link between data representations and the performance of machine learning models on spatial problems. Fundamentally, we seek to understand the impact of data representations on model performance. We focus on Graph Neural Network models for the problem of semantic inference on spatial networks. Spatial semantics can be defined as the descriptions or meanings of spatial objects, such as the type of a street, the use of a building. The process of predicting these semantics is referred to as
semantic inference. We formulate two semantic inference tasks to guide our study: inference of street types and inference of building types (
Section 3). These tasks are formulated specially to address the semantic inference problem on OpenStreetMap [
5]. We propose an approach to derive heterogeneous graph representations from spatial entities of different types (
Section 4). We develop this approach into a reusable code package called
HetSpatial. Then, we develop a neural network framework for transductive learning on heterogeneous graph representations to address the inference tasks (
Section 5). Similarly, we train models for the homogeneous graph representations using state of the art GNN methods. We compare the performance for models trained using the heterogeneous graph representation and homogeneous graphs representations. Our evaluations show model improvements of up to 40% average F-score using heterogeneous graph representations and 20% average F-score using homogeneous graph representations. To the best of our knowledge, this is the first attempt to empirically measure the impact of representations on model performance for spatial tasks. We release the code and data used for our experiments. The deepening integration of artificial intelligence and geographical information science vis-à-vis Geo-AI demands investigation into the efficient development of prediction models. We believe that our contributions in this paper will benefit Geo-AI by offering insights on the impact of representations on model performance for geo-spatial data [
9,
13]. Efficiently integrating multiple data sources for inference have been identified as one of the challenges of Geo-AI [
14]. Towards this, heterogeneous representations could be a promising solution, e.g., for multi-modal learning, hybrid forms of spatial networks (socio-spatial networks) described using heterogeneous representations [
15,
16].
2. Background
Our study seeks to address the semantic inference problem in spatial networks. We discuss machine learning approaches to this problem. Corcoran et al. [
6] attempt to predict the semantics of streets on OpenStreetMap using the street geometries. They focus on inferring street types, using geometric properties such as length and linearity. The street segments are modelled as graphs and a Markov random field model is used to perform inference. They use data from Boston, achieving 68% precision and 65% recall on the classification tasks. Iddianoze and McArdle [
5] develop machine learning models using contextual information to predict the semantics of streets on OpenStreetMap. They define contextual information as the type of objects that lie within the neighbourhood of a street. Similarly, they focus on street types as the semantics of the streets. They train tree-based models to perform inference. Bonafilia et al. [
17] developed both weakly-supervised and semi-supervised machine learning models for building maps. They focus on building detection and road segmentation. Their models achieve improved performance by using data collected from OpenStreetMap. Iddianozie and McArdle [
7] proposed the use of transfer learning to develop transferable models to mitigate the data availability problem for enriching spatial semantics. Using a statistical multi-measure, they are able to determine apriori the suitability of a model for a domain.
Our work in this article focuses on Graph Neural Networks (GNNs) which are a type of Artificial Neural Networks designed to work on graphs. GNNs can be broadly classified into spectral and spatial approaches. Spectral GNNs derive object representations through operations on the graph Laplacian matrix, which could be very expensive to compute, thereby affecting scalability [
18,
19,
20,
21]. Spatial GNNs derive representations directly from the graph, operating on spatially close neighbours of a graph object [
22,
23]. Graph Neural Networks (GNNs) are capable of encoding the relational inductive bias in structures, hereby addressing a limitation of standard machine learning methods [
7,
9,
24,
25]. This capability has been leveraged to improve model performance. He et al. [
26] proposed a hybrid neural architecture that is comprised of a Convolutional Neural Network (CNNs) and a Graph Neural Network (GNN). Their architecture is targeted at inferring the attributes of street networks. Their evaluations show that incorporating the GNN allows their architecture to mitigate the receptive field limitation of CNNs. Iddianozie and McArdle [
8] develop effective Graph Neural Network models to infer spatial semantics using a node importance sampling technique. Their technique enables the GNN to outperform vanilla GNNs on the street semantics inference task. However, they focus on homogeneous graph representations, whereas, heterogeneous graph representations could offer a richer representation of data and improve model performance [
4]. Our work in this article extends the applications of GNNs to the semantic inference of spatial networks using heterogeneous graph representations. We can also classify Graph Neural Networks based on the type of graph representations they are designed to work on as:
Homogeneous Graph Neural Networks and
Heterogeneous Graph Neural Networks. Similar to our earlier definitions of homogeneous and heterogeneous graph representations, a graph neural network is said to be homogeneous if it is designed to work on homogeneous graph representations and heterogeneous if it is designed to work on heterogeneous graph representations. GCN [
19], GAT [
23], GraphSAGE [
22] are some examples of Homogeneous GNNs while HetGCN [
27] and HAN [
28] are some examples of Heterogeneous GNNs. We study both homogeneous and heterogeneous GNNs in this paper, in order to understand the relationship between model performance and data representations.
3. Preamble
We define important concepts in this section.
Table 1 outlines notations and their definitions.
Definition 1. Spatial Entity: A spatial entity is defined as an object that is embedded in space, where is a set of geo-coordinates that defines its bounds or location in space and is a set of real-valued features that describes .
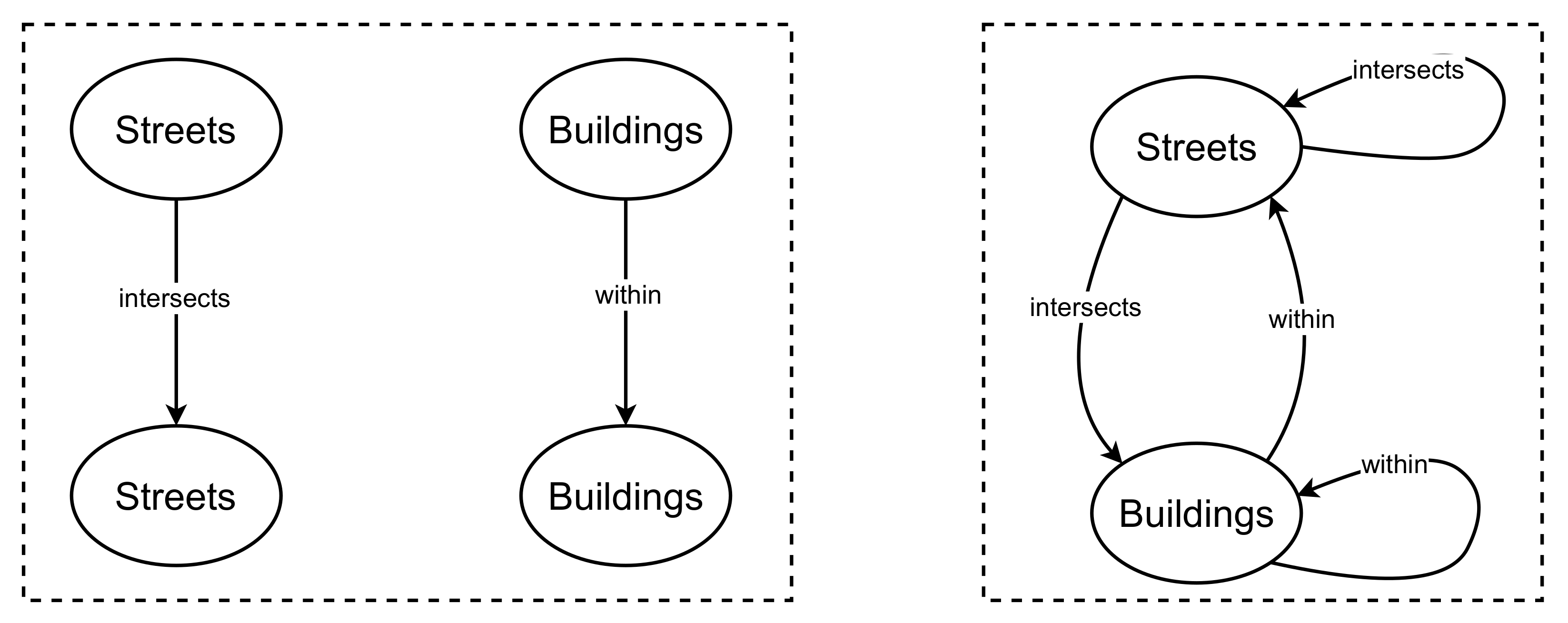
Definition 2. Graph Representation: We define a graph representation as , where and denote the object set and relation set, respectively. The objects are mapped to types based on a function , the relations are mapped to types based on a function . Thehomogeneousgraph representation is one where and and theheterogeneousgraph representation is one where where .
Definition 3. Semantic Path: A semantic path is a path on an instance of a graph representation , denoted in the form , that defines a composite relation between graph objects where ∘ denotes the composition operator on relations.
Definition 4. Network Schema: A network schema defines the object and relational constraints for a graph representation which is a directed graph representation where the objects are mapped to types as and the relations are mapped to types as . A graph representation defined by a network schema is called an instance of that network schema.
3.1. Graph Neural Networks
Graph neural networks are designed to learn a representation
for the nodes of a graph using the node and edge connectivity.
is computed for a node
by an incremental update using the aggregations of the neighbours of
v. The neighbours are defined as the nodes within the
k-hop neighbourhood of
v. The representation of a node
v at the
k-th layer of the GNN can be defined as:
where
is the representation of a node
v at the
k-th layer,
is the attribute vector and
is the set of nodes within the
k-hop neighbourhood of
v.
Problem Definition
Our problem definition is two-fold. Firstly, given a set of spatial elements presented in any generic format. We seek to derive graph representations for these elements. In this article, we derive both homogeneous and heterogeneous graph representation as stated in Definition 2. Secondly, we seek to infer the object types in . Recall that the object type mapping is defined by the function . The labels of is given by , where c is the number of class labels that we consider for that particular instance of . In this article, we focus on inferring object types. The objective of the second problem is to develop a function which given a graph representation , supervisedly learns the mapping between and .
6. Conclusions
In this article, we have studied the problem of data representations for the semantic inference of spatial networks using Graph Neural Networks. Based on the fact that data representations impact the performance of a machine learning model [
2], we seek to explore the link between data representation and model performance. We argue that the expressive nature of heterogeneous graph representations of spatial networks offers richer structural and semantic information which may improve model performance for certain tasks than their homogeneous counterparts. We focus on street type and building type inference problems in spatial networks. Our empirical evaluations show that heterogeneous graph representations may indeed be better suited for the street type inference problem than the homogeneous graph representation.
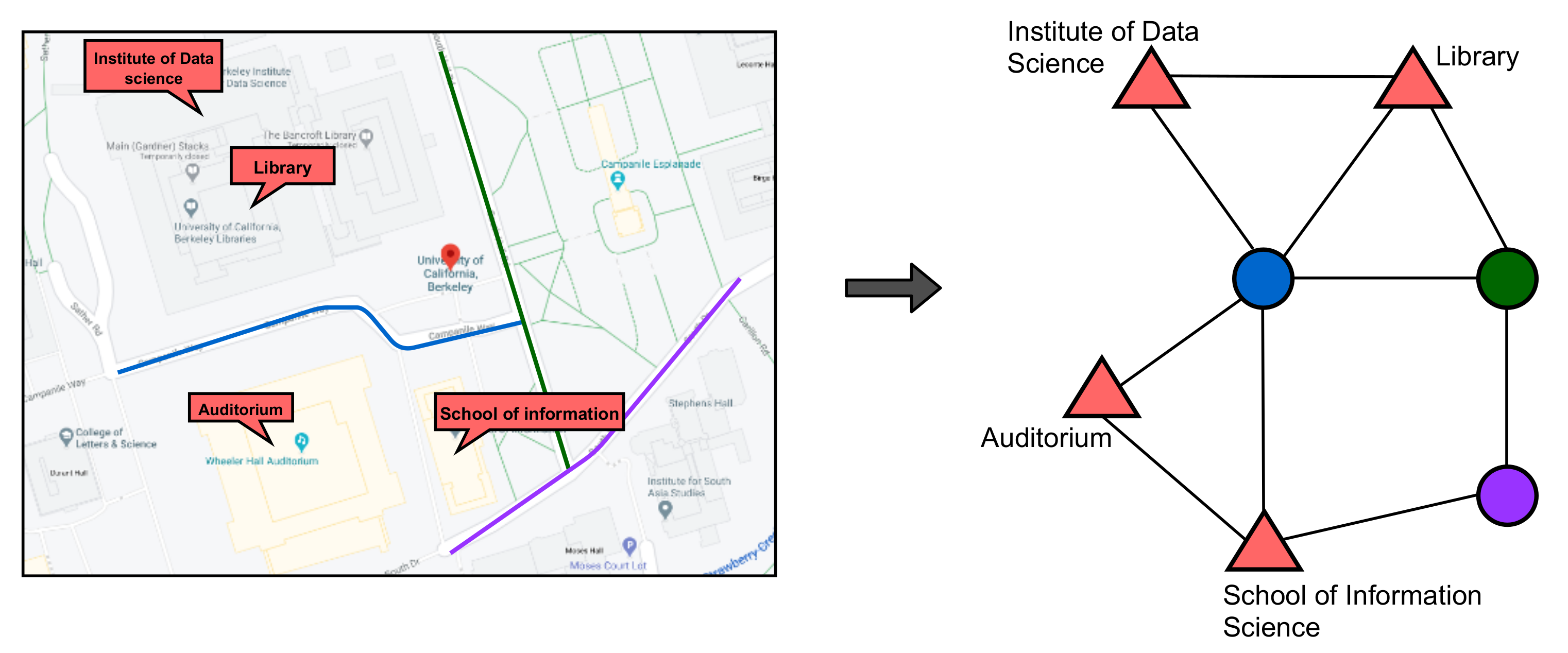
As part of our contributions, we propose an approach to generate heterogeneous representations of spatial networks from generic representations, which we developed into a python package called
HetSpatial and release for public use available on
https://github.com/chiddianozie/hetspatial (accessed on 14 June 2021). Furthermore, we implement a neural architecture for learning on heterogeneous graph representations for inferring the semantics of different spatial objects. Then, we evaluate this neural architecture against homogeneous learning approaches. We release the code and datasets for our experiments. For future work, we will improve the
HetSpatial package to cover more spatial entities and relations, as shown in
Figure 2.
Advancements in Geo-AI will benefit from a deeper understanding of specialised models for spatial data. Our work in this article contributes to this understanding by offering insight into the relationship between data
representations and model performance on geo-spatial data. A promising frontier for Geo-AI is the efficient integration of multiple data sources for data-driven tasks. One example is a combination of image and textual data for inference, also known as multi-modal learning [
16]. Another example is hybridizing spatial networks by interfacing them with social networks, into a type of socio-spatial network [
15]. In this regard, we hope our work will inspire conviction that the expressive nature of heterogeneous representations makes them worth exploring.







{kind=link}
{kind=link}
{kind=link}