
A Short-Term Prediction Model of PM2.5 Concentration Based on Deep Learning and Mode Decomposition Methods


Abstract
:1. Introduction
2. Data and Methods
2.1. The Source of Data
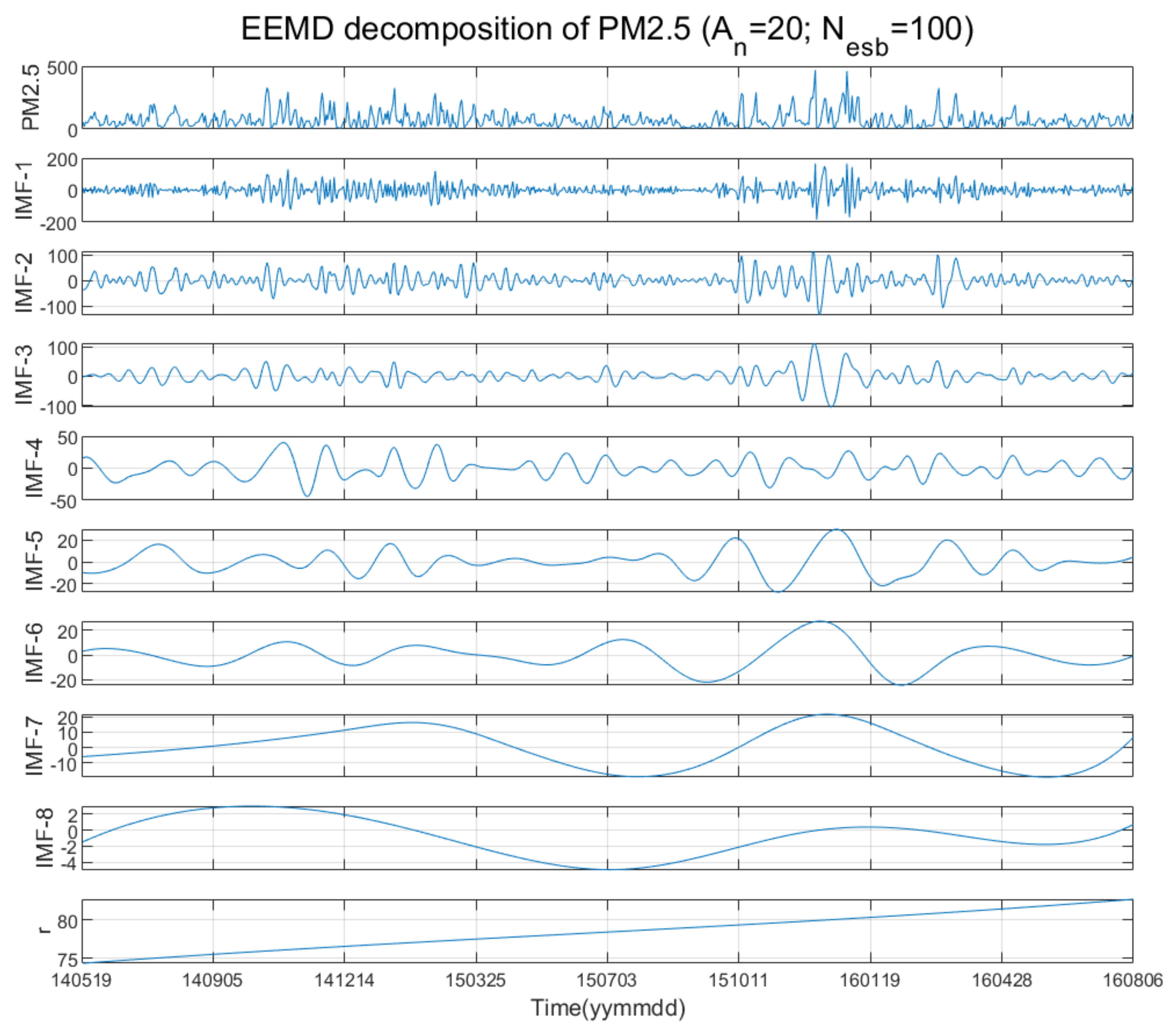
2.2. Ensemble Empirical Mode Decomposition (EEMD)
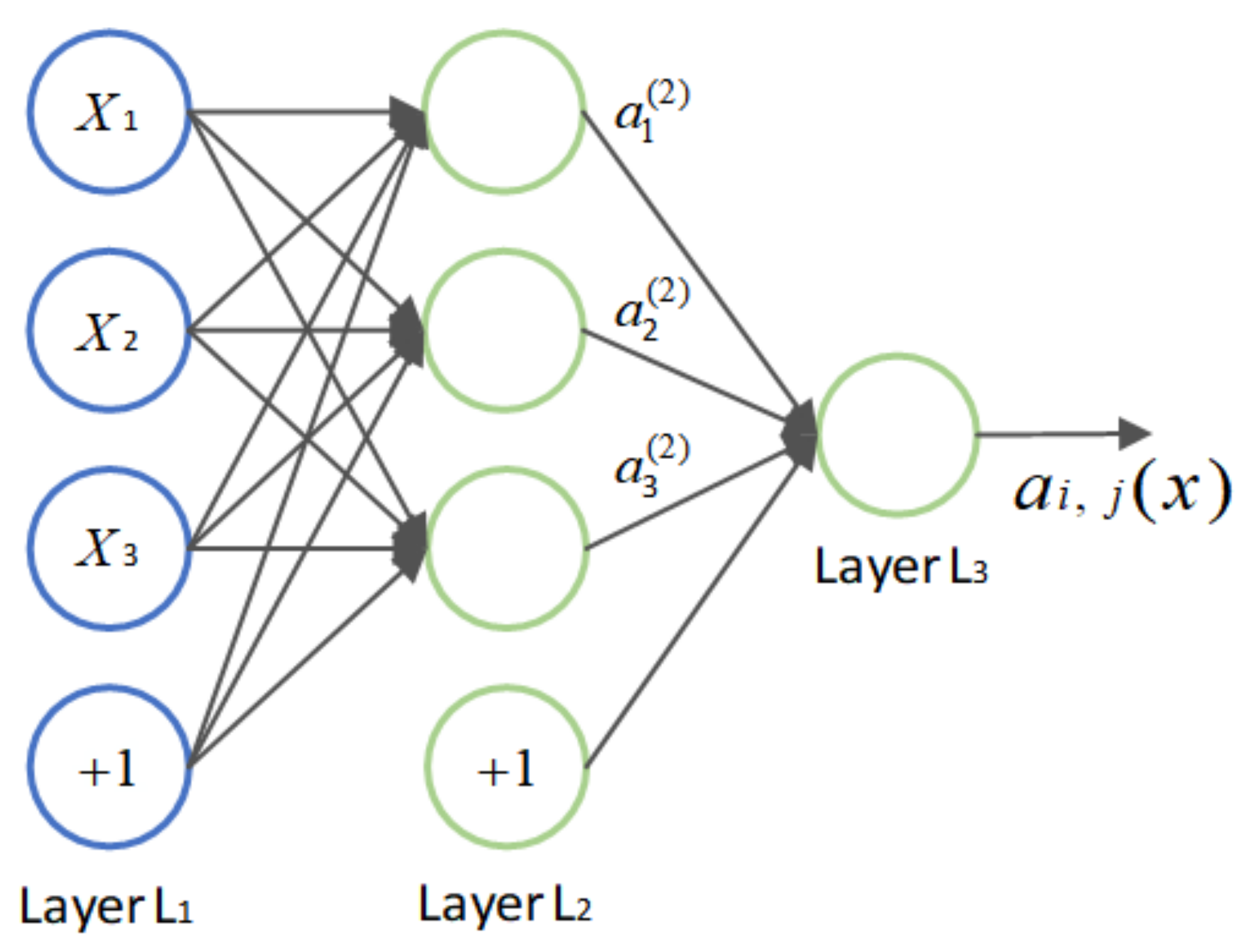
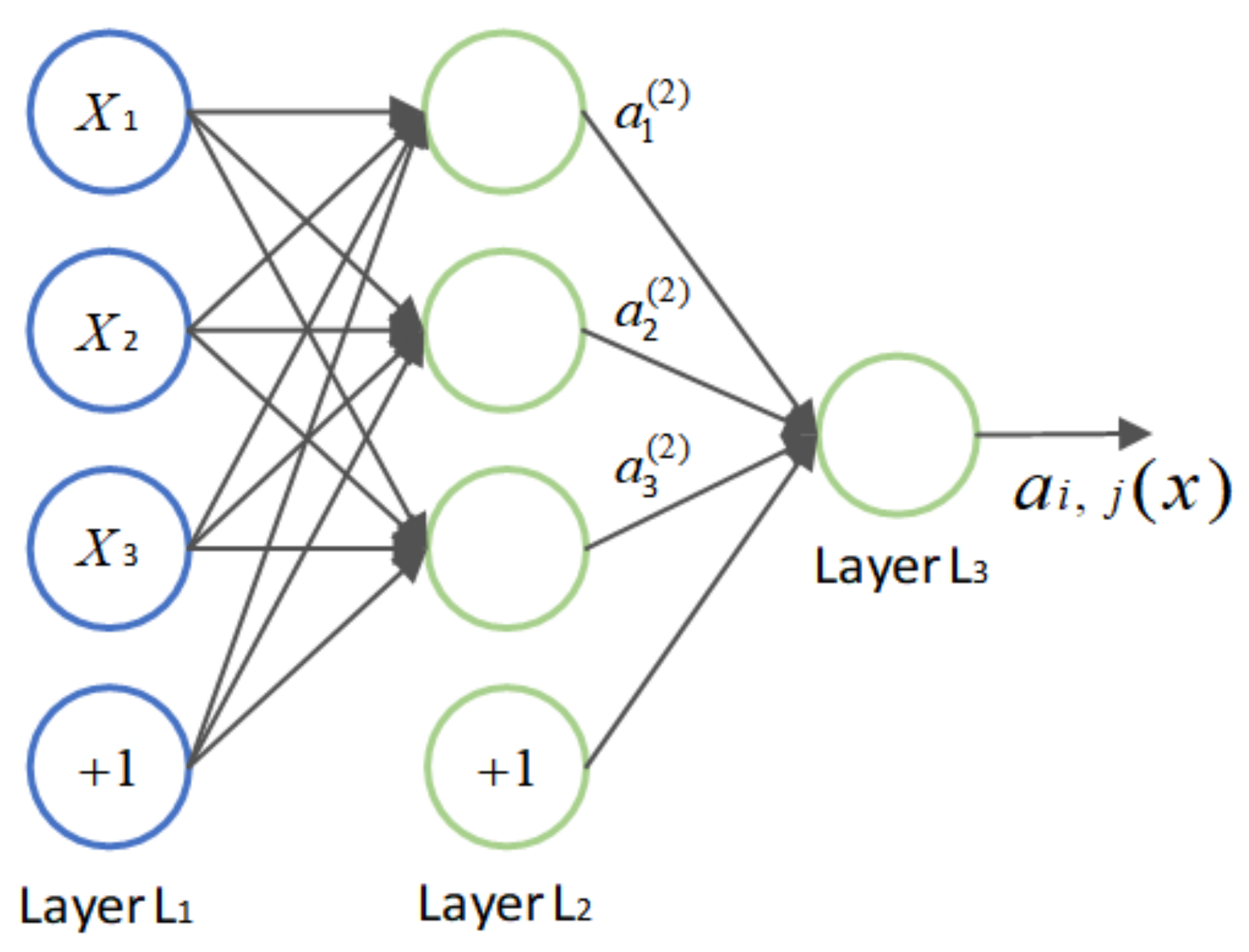
2.3. BP Neural Network
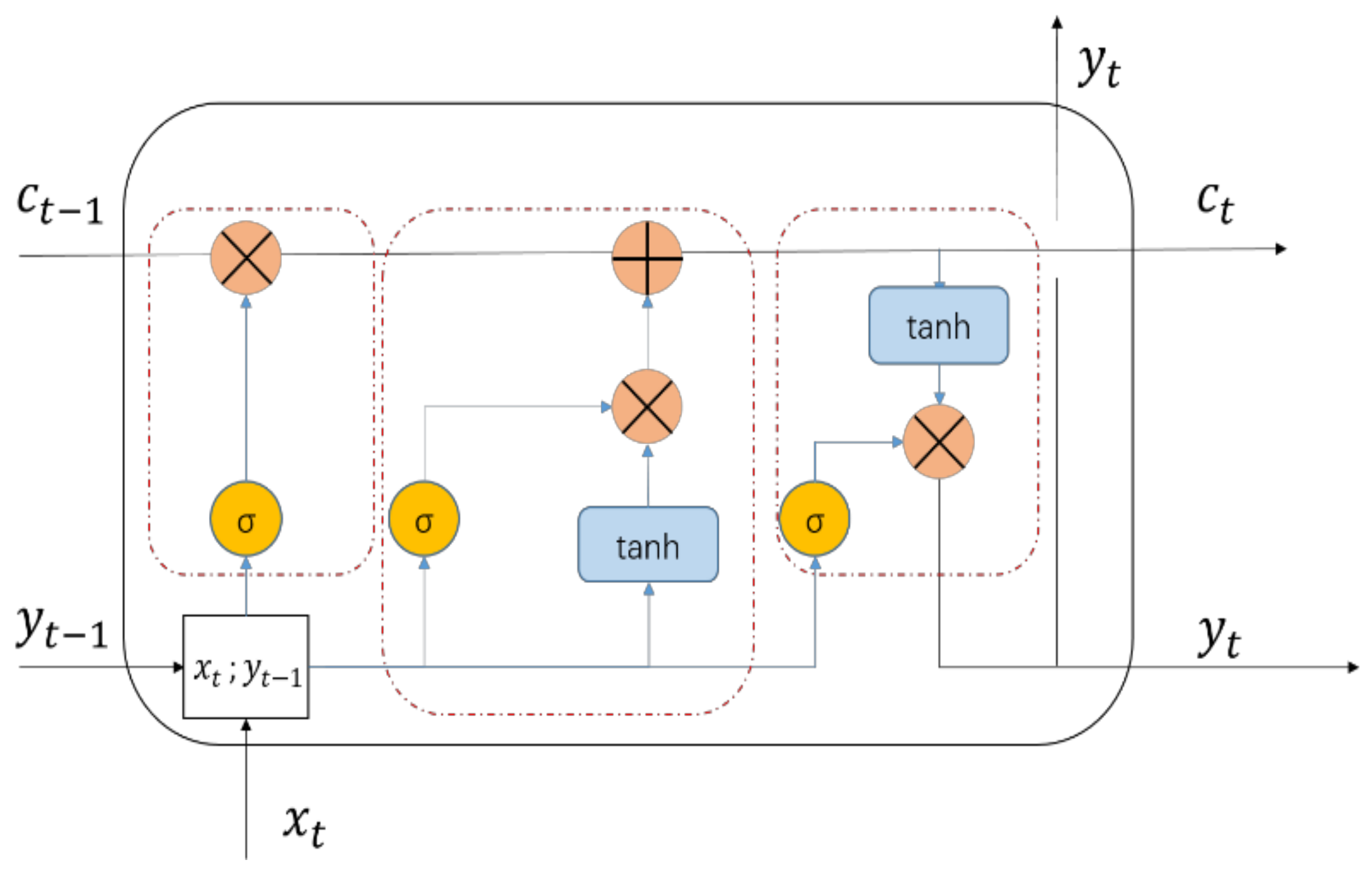
2.4. CNN-LSTM Neural Network
2.5. Experimental Design
3. Results
3.1. PM2.5 Time-Decomposition by EEMD
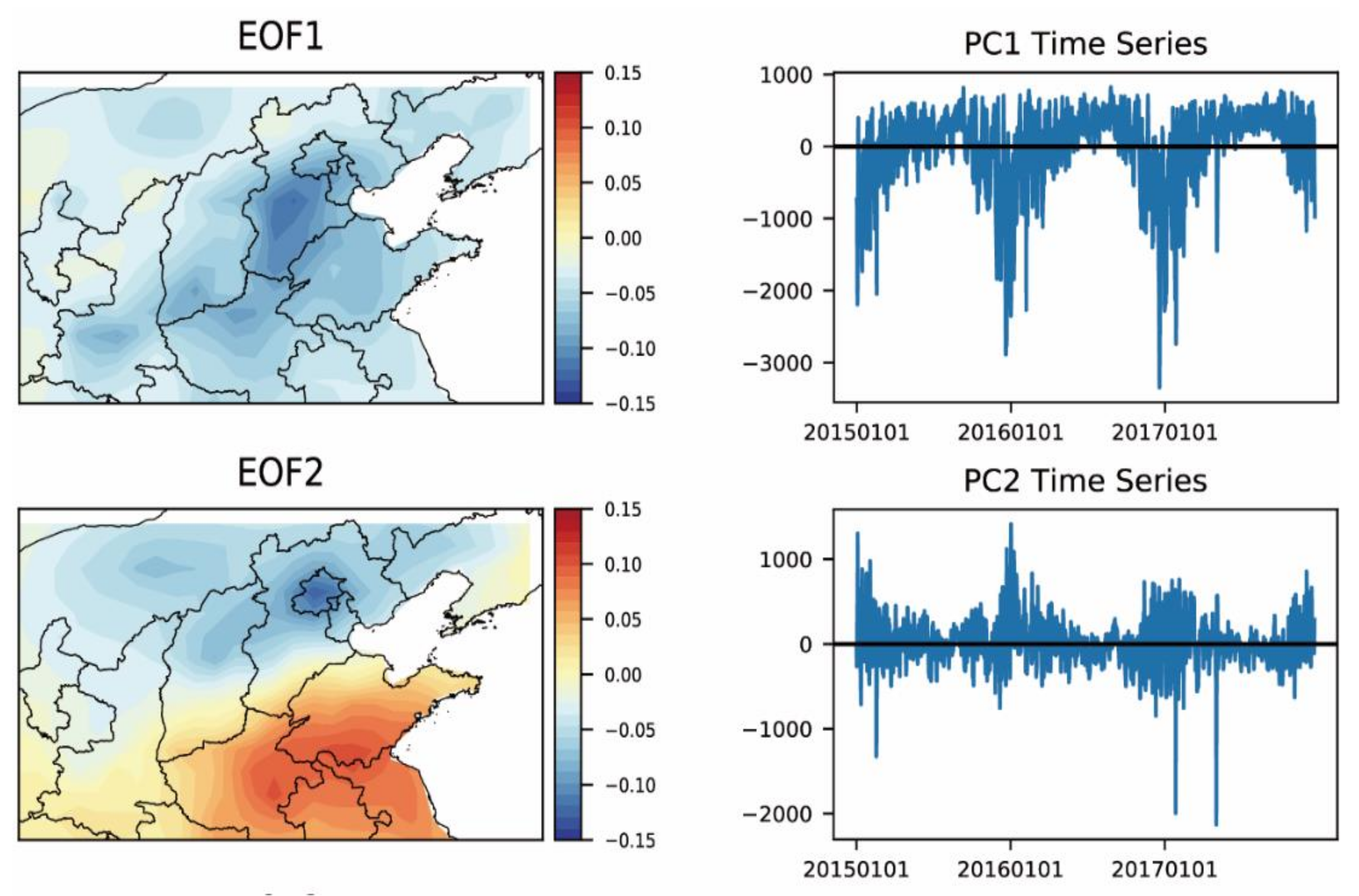
3.2. PM2.5 Spatial Analysis by EOF
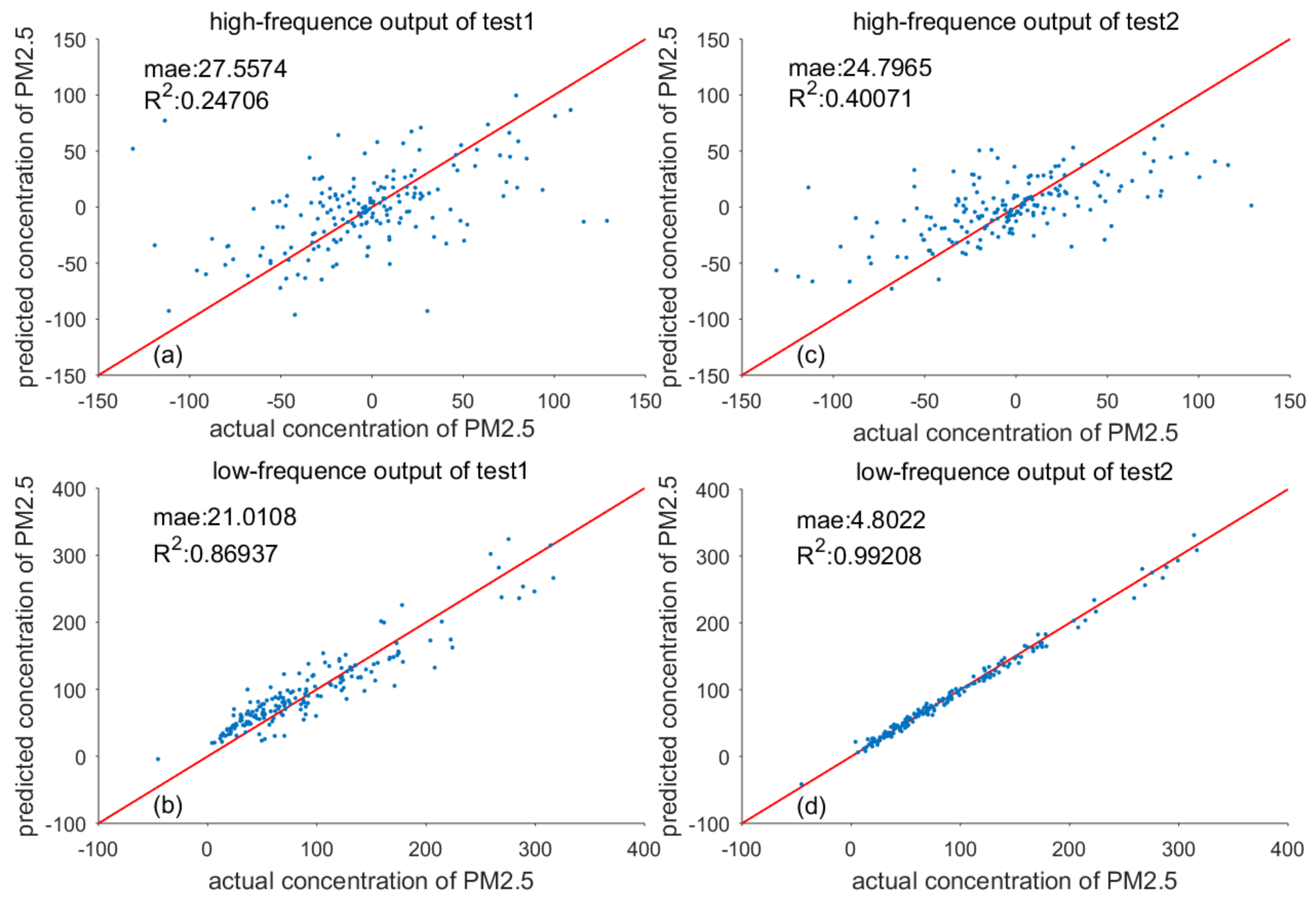
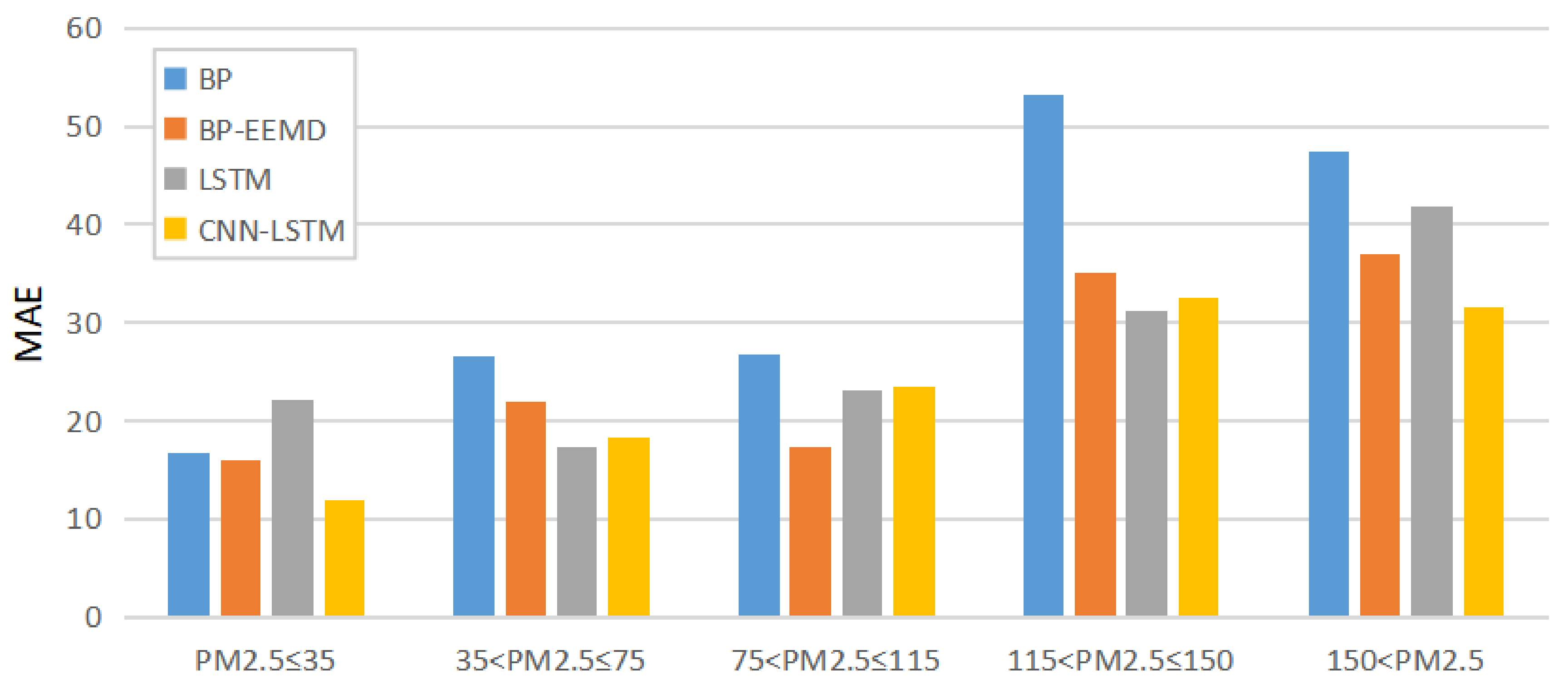
3.3. Experimental Analyses
4. Summary and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Ensemble Empirical Mode Decomposition (EEMD)
- Add a group of white noise to the original signal to get a new signal sequence :
- Decompose to obtain a set of imfj(t) components:where represents the IMF component (the same below), represents the trend term.
- Repeat step (1) (2) (m) times, add different white noise each time, and get a new set of IMF component:
- Take the mean value of each IMF components as the final result:
Appendix B. Back Propagation Neural Network (BP)
- In the incentive transmission, the input layer transmits the received normalized input variables to the hidden layer. Then, the hidden layer neurons process the received data by weighted summation, and then substitute them into the activation function to transmit the activated value to the output layer. The output layer obtains the final result after weighted summation and activation again. We define that the input layer, the hidden layer and the output layer as follows, respectively:where w is the connection weight, b is the offset, f is the activation function, the common activation functions are sigmoid, tanh, Relu, etc., and g is the linear transfer function.
- During the weight updating phase, in order to minimize the value of error function, the gradient descent algorithm is used to gradually modify the connection weight and offset value of output layer and hidden layer:where d and h represent the gradient term of corresponding layer neurons, and and represent the learning rate. Offsets updating is similar to weights updating.
- Specific parameters of the BP neural network:
Appendix C. CNN-LSTM Neural Network
- Convolution layer: the convolution kernel size is 3 × 3, the number of convolution kernels in the first layer of 3D Convolution (Conv3D) is 100, the number of convolution kernels in the second layer of Conv3D is 50, and the number of convolution kernels in the third layer of Conv3D is 5.
- Pool layer: the pool area size of the first layer Max pooling is 3 × 3 × 3, and the pool area size of the second layer is 2 × 3 × 3.
- LSTM layer: the number of neurons in the first layer of LSTM is 100, and that in the second layer is 50.
- FC layer: the number of neurons is 50.
- Activation function: sigmoid function.
- RMSPROP is selected as the optimizer, the initial learning rate is 0.001, the number of iterations is 64, and the batch size is 32.

References
- Aznarte, J.L.; Siebert, N. Dynamic Line Rating Using Numerical Weather Predictions and Machine Learning: A Case Study. IEEE Trans. Power Deliv. 2017, 32, 335–343. [Google Scholar] [CrossRef]
- Baker, K.R.; Foley, K.M. A nonlinear regression model estimating single source concentrations of primary and secondarily formed PM2.5. Atmos. Environ. 2011, 45, 3758–3767. [Google Scholar] [CrossRef]
- Chen, Y.; Schleicher, N.; Fricker, M.; Cen, K.; Liu, X.; Kaminski, U.; Yu, Y.; Wu, X.; Norra, S. Long-term variation of black carbon and PM2.5 in Beijing, China with respect to meteorological conditions and governmental measures. Environ. Pollut. 2016, 212, 269–278. [Google Scholar] [CrossRef]
- Chen, Y. Spatial and Temporal Variation Characteristics of PM2.5 Pollution in Autumn and Winter in Eastern Coastal Areas. J. Agric. Catastrophol. 2019, 9, 53–56. [Google Scholar]
- Feng, X.; Li, Q.; Zhu, Y.; Hou, J.; Jin, L.; Wang, J. Artificial neural networks forecasting of PM2.5, pollution using air mass trajectory based geographic model and wavelet transformation. Atmos. Environ. 2015, 107, 118–128. [Google Scholar] [CrossRef]
- Cracknell, A.P.; Varotsos, C.A. New aspects of global climate-dynamics research and remote sensing. Int. J. Remote Sens. 2011, 32, 579–600. [Google Scholar] [CrossRef]
- Ferm, M.; Watt, J.; O’Hanlon, S.; De Santis, F.; Varotsos, C. Deposition measurement of particulate matter in connection with corrosion studies. Anal. Bioanal. Chem. 2006, 384, 1320–1330. [Google Scholar] [CrossRef]
- Hrust, L.; Klaić, Z.B.; Križan, J.; Antonić, O.; Hercog, P. Neural network forecasting of air pollutants hourly concentrations using optimised temporal averages of meteorological variables and pollutant concentrations. Atmos. Environ. 2009, 43, 5588–5596. [Google Scholar] [CrossRef]
- Huang, C.J.; Kuo, P.H. A Deep CNN-LSTM Model for Particulate Matter (PM2.5) Forecasting in Smart Cities. Sensors 2018, 18, 2220. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, F.; Li, X.; Wang, C.; Xu, Q.; Wang, W.; Luo, Y.; Tao, L.; Gao, Q.; Guo, J.; Chen, S.; et al. PM2.5 spatiotemporal variations and the relationship with meteorological factors during 2013–2014 in Beijing, China. PLoS ONE 2015, 10, e0141642. [Google Scholar]
- Varotsos, C.; Ondov, J.; Tzanis, C.; Öztürk, F.; Nelson, M.; Ke, H.; Christodoulakis, J. An observational study of the atmospheric ultra-fine particle dynamics. Atmos. Environ. 2012, 59, 312–319. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.; Tung, C.C.; Liu, H.H. The Empirical Mode Decomposition and the Hilbert Spectrum for Nonlinear and Non-Stationary Time Series Analysis. Proc. Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Huang, Y.; Song, F.; Liu, Q.; Li, W.; Zhang, W.; Chen, K. A bird’s eye view of the air pollution-cancer link in China. Chin. J. Cancer 2014, 33, 176–188. [Google Scholar] [CrossRef] [PubMed]
- Jin, X.; Yang, N.; Wang, X.; Bai, Y.; Su, T.; Kong, J. Deep Hybrid Model Based on EMD with Classification by Frequency Characteristics for Long-Term Air Quality Prediction. Mathematics 2020, 8, 214. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Xie, G.; Ren, J.; Guo, L.; Yang, Y.; Xu, X. Urban PM2.5 Concentration Prediction via Attention-Based CNN–LSTM. Appl. Sci. 2020, 10, 1953. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Zhang, Q.; Zhang, Y.; Zheng, B.; Wang, K.; Chen, Y.; Wallington, T.J.; Han, W.; Shen, W.; Zhang, X.; et al. Source contributions of urban PM2.5 in the Beijing–Tianjin–Hebei region: Changes between 2006 and 2013 and relative impacts of emissions and meteorology. Atmos. Environ. 2015, 123, 229–239. [Google Scholar] [CrossRef] [Green Version]
- Lv, Y.; Fu, Y.; Xin, S.G.; Wang, Y. The Harm of PM2.5 to Human Body. Liaoning Chem. Ind. 2017, 46, 618–620. [Google Scholar]
- Nunnari, G.; Dorling, S.; Schlink, U. Modelling SO2 concentration at a point with statistical approaches. Environ. Model. Softw. 2004, 19, 887–905. [Google Scholar] [CrossRef]
- Stern, R.; Builtjes, P.; Schaap, M.; Timmermans, R.; Vautard, R.; Hodzic, A.; Memmesheimer, M.; Feldmann, H.; Renner, E.; Wolke, R.; et al. A model inter-comparison study focussing on episodes with elevated PM10 concentrations. Atmos. Environ. 2008, 42, 4567–4588. [Google Scholar] [CrossRef]
- Qu, Y.; Qian, X.; Song, H.; He, J.; Li, J.; Xiu, H. Machine-learning-based model and simulation analysis of PM2.5 concentration prediction in Beijing. Chin. J. Eng. 2019, 41, 401–407. [Google Scholar]
- Shi, M. PM2.5 Concentration Prediction Based on Space-Time Mixed Model; Yanshan University: Hebei, China, 2018. [Google Scholar]
- Siwek, K.; Osowski, S. Improving the accuracy of prediction of PM10 pollution by the wavelet transformation and an ensemble of neural predictors. Eng. Appl. Artif. Intell. 2012, 25, 1246–1258. [Google Scholar] [CrossRef]
- Zhang, C.N.; Wang, M.H.; Hu, Z.D.; Yuan, Y.; Liu, H.; Qiu, F. Temporal and spatial distribution of PM2.5 concentration and the correlation of PM2.5 and meteorological factors in Kunming City. J. Yunnan Univ. (Nat. Sci. Ed.) 2016, 38, 90–98. [Google Scholar]
- Zhang, L.; Wang, T.; Liu, S.; Fang, K. Prediction Model of PM2.5 Concentration Based on CPSO-BP Neural Network. J. Gansu Sci. 2020, 32, 47–62. [Google Scholar]
- Zhang, Y.W.; Hu, J.Y.; Wang, R. PM2.5 forecasting model based on neural network. J. Jiangsu Norm. Univ. (Nat. Sci. Ed.) 2015, 33, 63–65. [Google Scholar]
- Zhao, C.X.; Wang, Y.Q.; Wang, Y.J.; Zhang, H.L.; Zhao, B.Q. Temporal and Spatial Distribution of PM2.5 and PM10 Pollution Status and the Correlation of Particulate Matters and Meteorological Factors During Winter and Spring in Beijing. Environ. Sci. 2014, 35, 418–427. [Google Scholar]
- Zhao, W.F.; Lin, R.S.; Tang, W.; Zhou, Y. Forecasting Model of Short-Term PM2.5 Concentration Based on Deep Learning. J. Nanjing Norm. Univ. (Nat. Sci. Ed.) 2019, 42, 32–41. [Google Scholar]
- Zhou, Q.; Jiang, H.; Wang, J.; Zhou, J. A hybrid model for PM2.5, forecasting based on ensemble empirical mode decomposition and a general regression neural network. Sci. Total Environ. 2014, 496, 264–274. [Google Scholar] [CrossRef] [PubMed]
- Yao, X.F.; Ge, B.Z.; Zheng, H.T.; Ma, Y.; Gao, C.; Wang, Z. Spatiotemporal Distribution Characteristics of PM2.5 Concentration and Its Main Control Factors in China Based on Multivariate Data Analysis. Clim. Environ. Res. 2018, 23, 596–606. [Google Scholar]
- Sun, W.; Zhang, H.; Palazoglu, A.; Singh, A.; Zhang, W.; Liu, S. Prediction of 24-hour-average PM2.5 concentrations using a hidden Markov model with different emission distributions in Northern California. Sci. Total Environ. 2013, 443, 93–103. [Google Scholar] [CrossRef] [PubMed]
- Xu, H.; Zhang, L. The Forecast of PM2.5 Concentration Based on GM-ARMA Model——Taking Yangzhou as an Example. J. Nantong Vocat. Univ. 2018, 32, 67–71. [Google Scholar]
- Wu, Z.; Huang, N.E. Ensemble empirical mode decomposition: A noise assisted data analysis method. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Varotsos, C.; Ondov, J.; Efstathiou, M. Scaling properties of air pollution in athens, greece and baltimore, maryland. Atmos. Environ. 2005, 39, 4041–4047. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment | Model | Input | Output |
|---|---|---|---|
| 1 | BP | M + d_PM2.5 | d_PM2.5 |
| 2 | EEMD+BP | M + d_PM2.5 | d_PM2.5 |
| 3 | LSTM | 6 h_PM2.5 | d_PM2.5 |
| 4 | CNN+LSTM | 6 h_PM2.5 | d_PM2.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, J.; Yang, F.; Ren, X.-C.; Zou, S. A Short-Term Prediction Model of PM2.5 Concentration Based on Deep Learning and Mode Decomposition Methods. Appl. Sci. 2021, 11, 6915. https://doi.org/10.3390/app11156915
Wei J, Yang F, Ren X-C, Zou S. A Short-Term Prediction Model of PM2.5 Concentration Based on Deep Learning and Mode Decomposition Methods. Applied Sciences. 2021; 11(15):6915. https://doi.org/10.3390/app11156915
Chicago/Turabian StyleWei, Jun, Fan Yang, Xiao-Chen Ren, and Silin Zou. 2021. "A Short-Term Prediction Model of PM2.5 Concentration Based on Deep Learning and Mode Decomposition Methods" Applied Sciences 11, no. 15: 6915. https://doi.org/10.3390/app11156915
APA StyleWei, J., Yang, F., Ren, X.-C., & Zou, S. (2021). A Short-Term Prediction Model of PM2.5 Concentration Based on Deep Learning and Mode Decomposition Methods. Applied Sciences, 11(15), 6915. https://doi.org/10.3390/app11156915