
An Enhanced Deep Convolutional Neural Network for Classifying Indian Classical Dance Forms

 , and
, and
Abstract
:1. Introduction
- Bharatanatyam;
- Kathak;
- Kuchipudi;
- Odissi;
- Kathakali;
- Sattriya;
- Manipuri;
- Mohiniyattam.
2. Literature Survey
3. Proposed Methodology
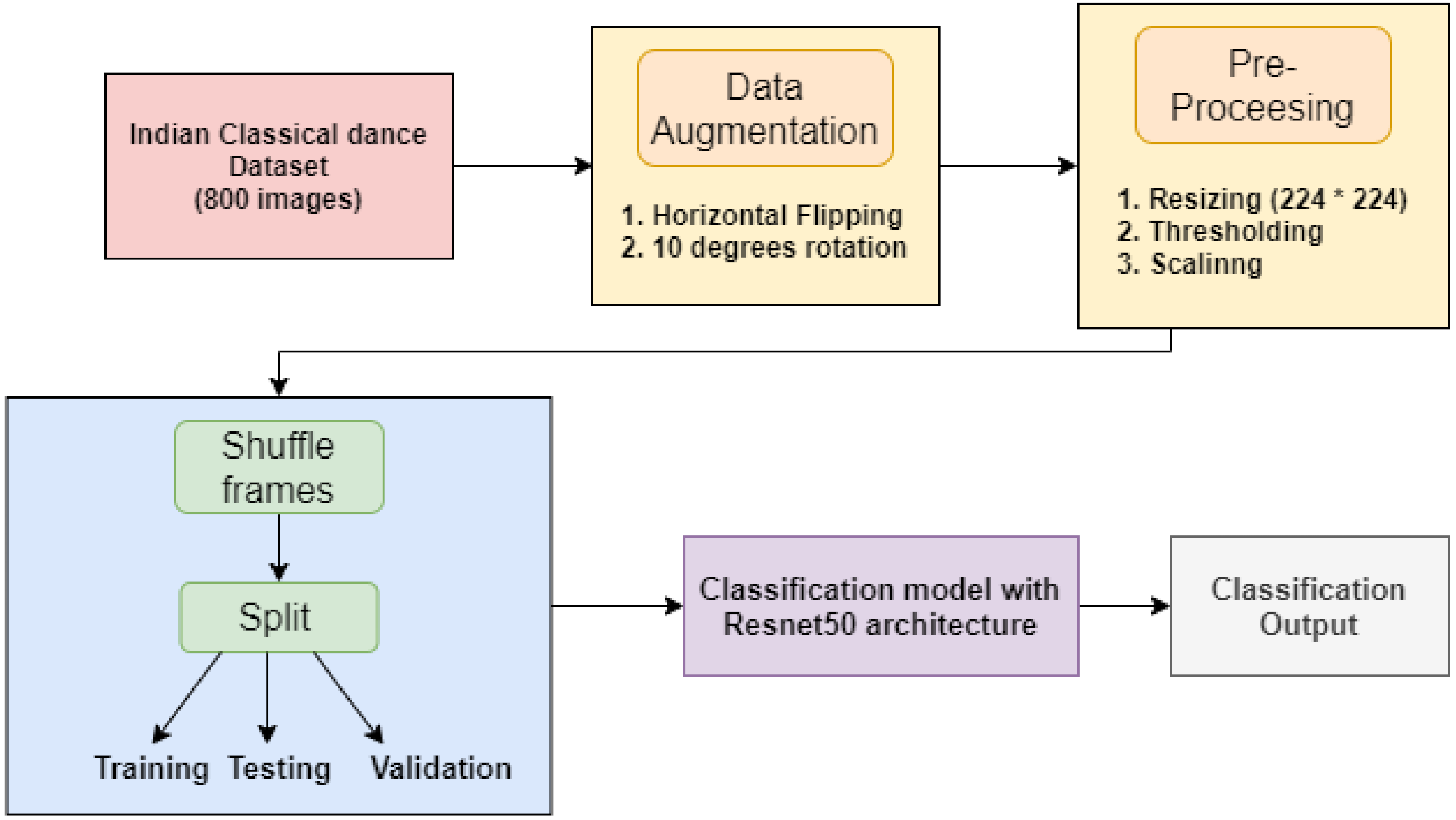
3.1. Dataset Creation
3.2. Data Augmentation
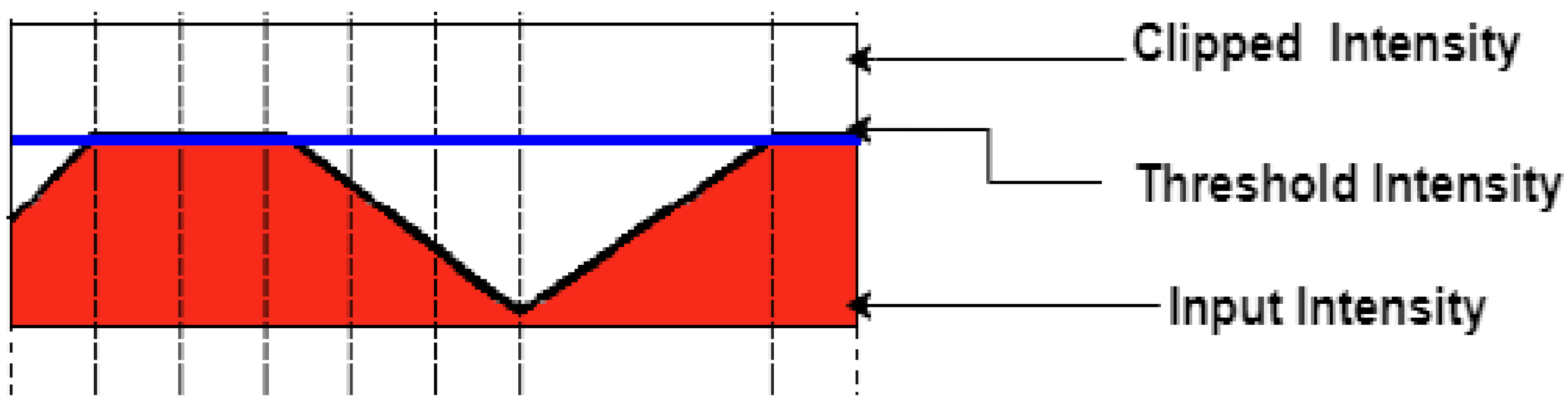
3.3. Data Pre-Processing
| Algorithm 1: Workflow of the approach. |
| The algorithm takes the images as input 1: for each image in Dataset: 2: function Preprocess (image, x_dim = 224, y_dim, threshold = 127, scale) 3: Return ProcessedImage 4: end function 5: Append(image) to array(X) 6: end for 7: read labels csv in array(Y) 8: categorical_labels = encode(Y) 9: Shuffle (X, categorical_labels) 10: X_train, Y_train, X_test, Y_test = train_test_split(X, categorical_labels) 11: function Create model 12: Initialize base_model = ResNet50 13: for layers in resnet.layer[:−14]: 14: Layers.trainable = false 15: end for 16: Add_layers (GlobalAveragePooling2D (), Dropout (0.5), Dense (256), Dropout (0.5), SoftmaxLayer) 17: Return model 18: Model.Compile (loss = Categorical_crossentropy, optimizer = Adam, metric = Accuracy) 19: function Create_Callbacks (monitor, patience, cooldown, min_lr) 20: return callbacks 21: function Train_Model (train_data, num_epochs = 15, val_frequency, callbacks) 22: return model |
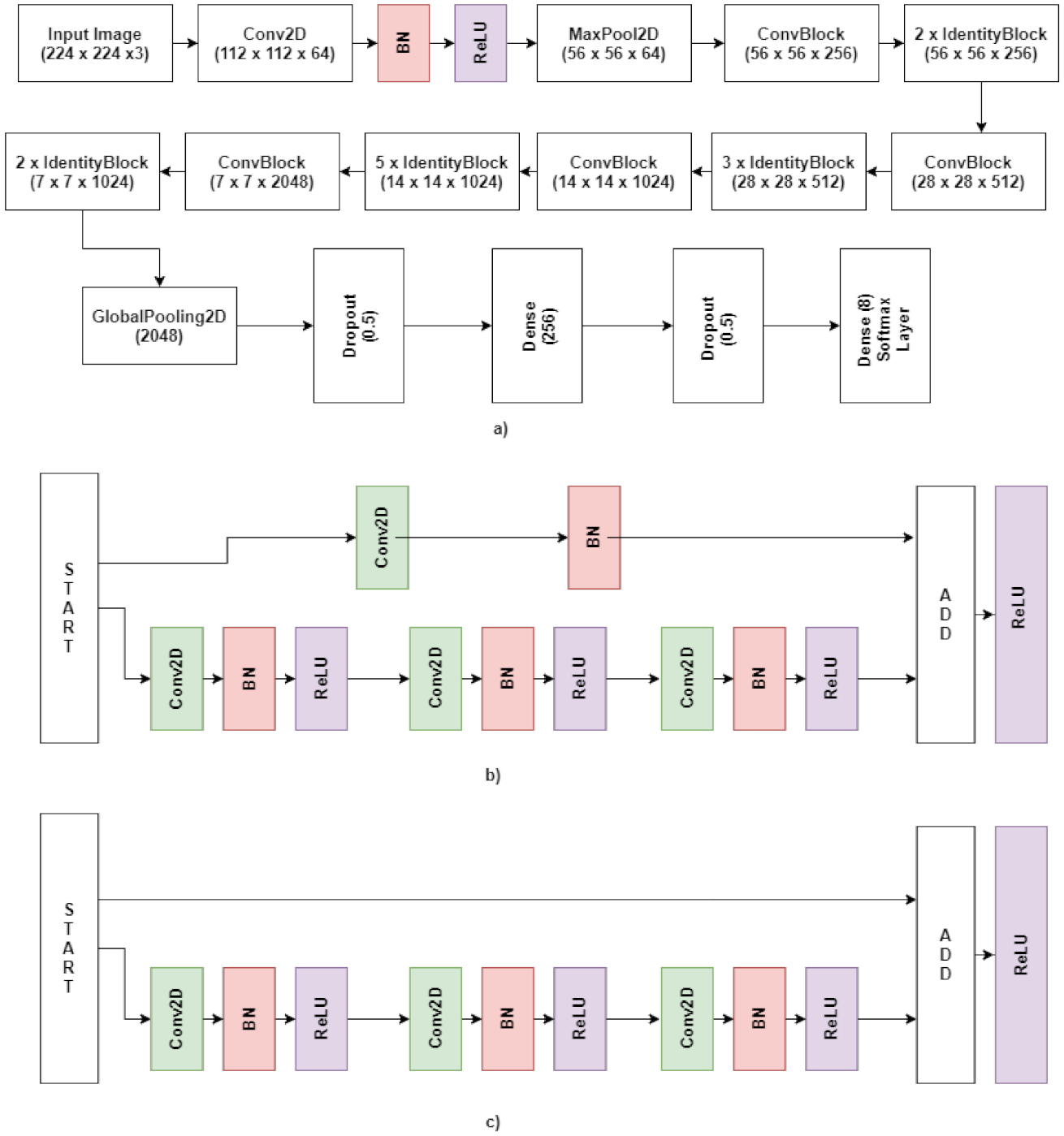
3.4. Model Architecture
3.4.1. Identity Block
3.4.2. Convolutional Block (ConvBlock)
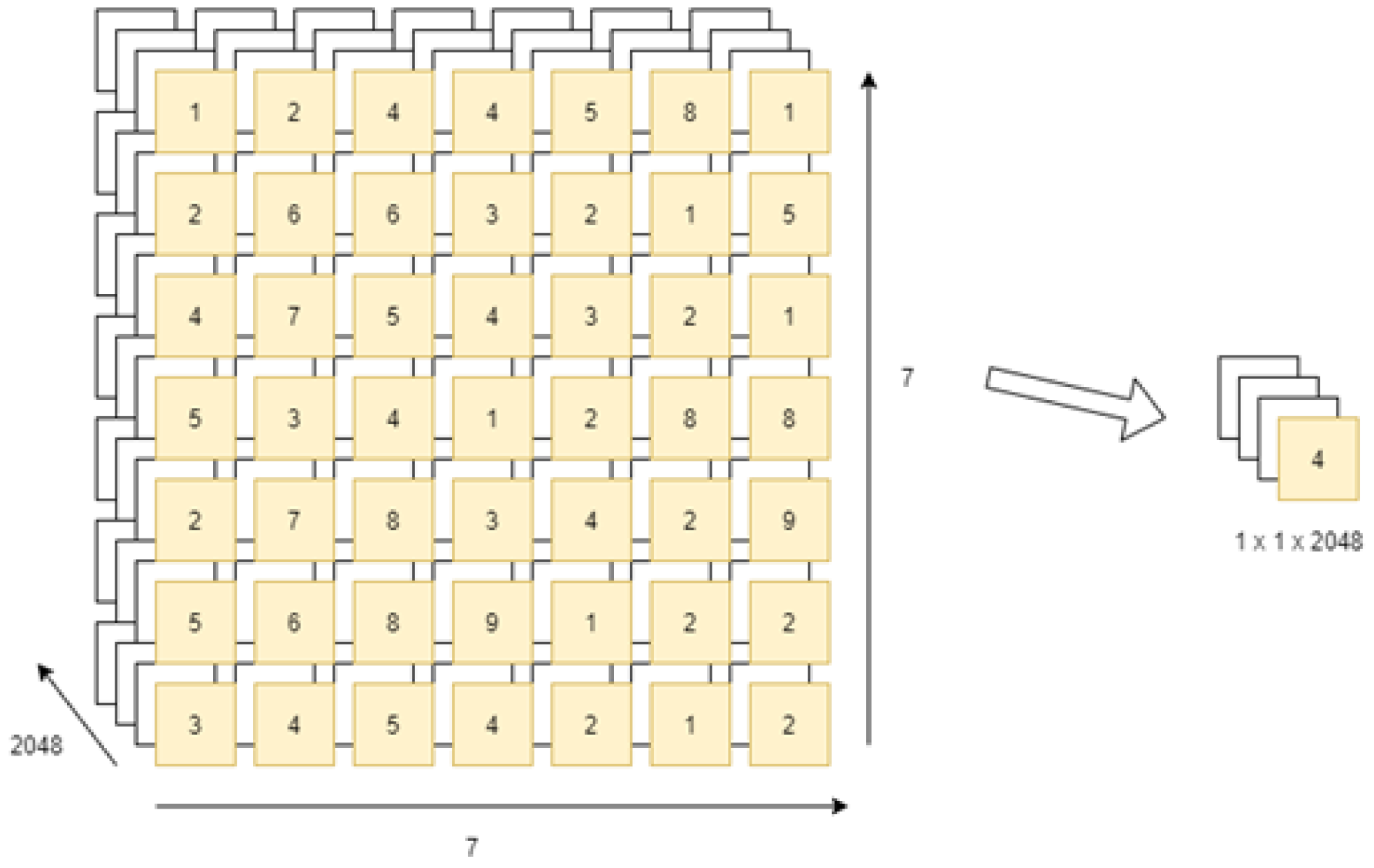
3.4.3. Global Average Pooling Layer
3.4.4. Dropout Layer
3.4.5. SoftMax Layer
3.4.6. Approach
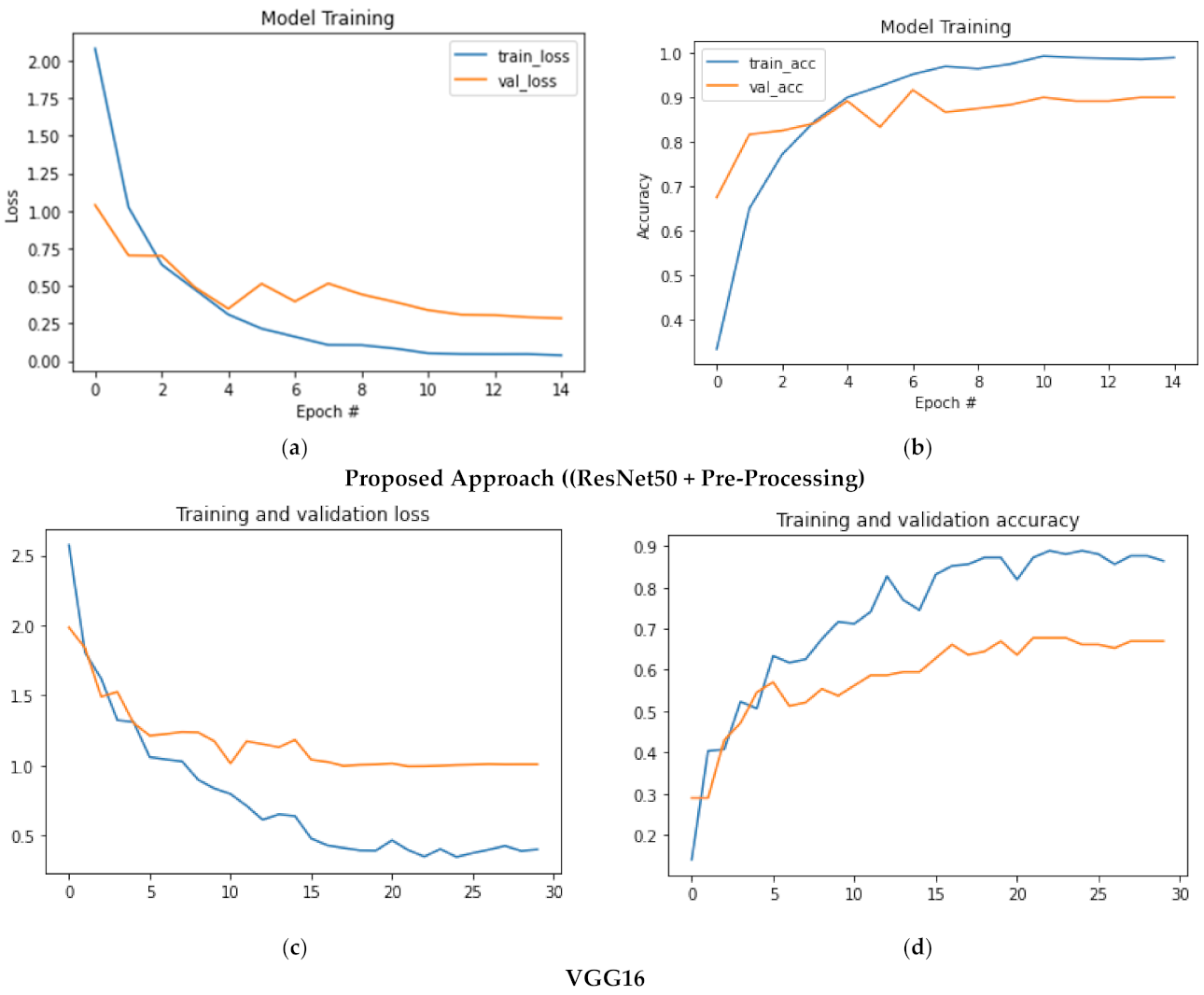
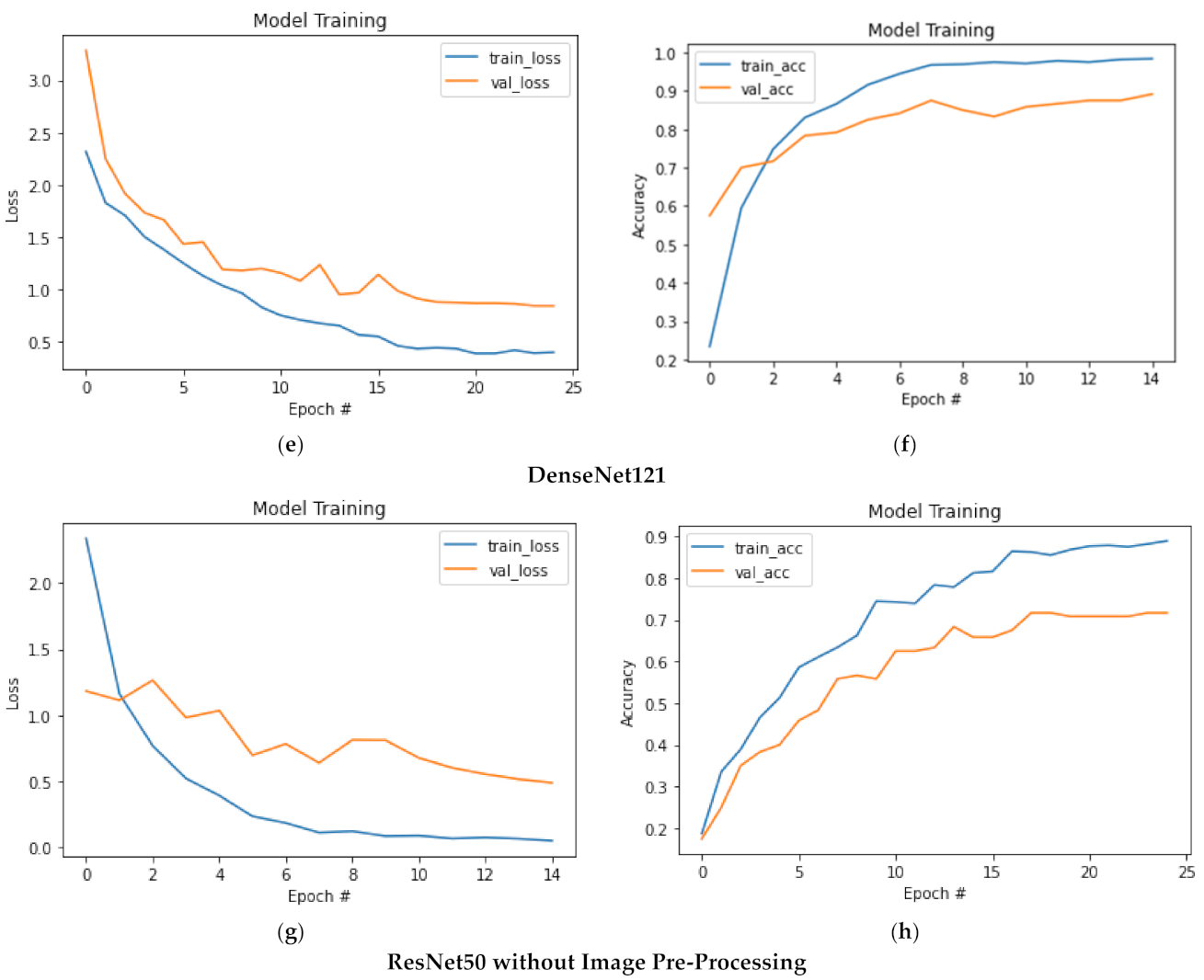
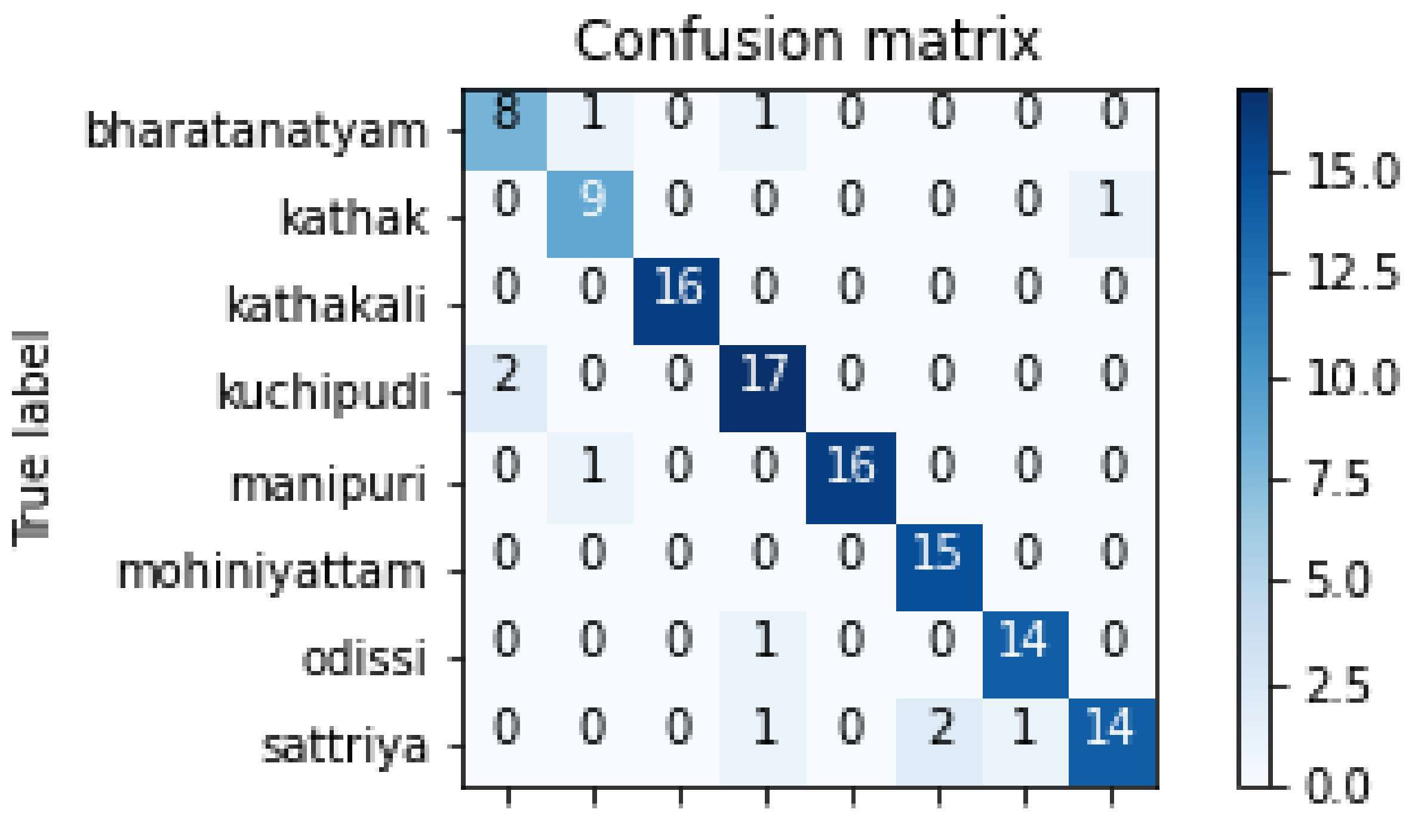
4. Results
Evaluation and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kalpana, I.M. Bharatanatyam and Mathematics: Teaching Geometry Through Dance. J. Fine Stud. Art 2015, 5, 6–17. [Google Scholar] [CrossRef] [Green Version]
- Rodriguez, G.E. Dare to Dance: Exploring Dance, Vulnerability, Anxiety and Communication. Ph.D. Thesis, University of Texas, San Antonio, TX, USA. [CrossRef] [Green Version]
- Bisht, A.; Bora, R.; Saini, G.; Shukla, P.; Raman, B. Indian Dance Form Recognition from Videos. In Proceedings of the 2017 13th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), New Delhi, India, 12–14 September 2017; Institute of Electrical and Electronics Engineers (IEEE): Jaipur, India, 2017; pp. 123–128. [Google Scholar]
- Dong, Z.; Shen, X.; Li, H.; Tian, X. Photo Quality Assessment with DCNN that Understands Image Well. In Proceedings of the International Conference on MultiMedia Modeling; Springer: Cham, Switzerland, 2015; pp. 524–535. [Google Scholar] [CrossRef]
- Evgeniou, T.; Pontil, M. Support Vector Machines: Theory and Applications. In Transactions on Petri Nets and Other Models of Concurrency XV; Springer: Berlin/Heidelberg, Germany, 2001; pp. 249–257. [Google Scholar]
- Kaushik, V.; Mukherjee, P.; Lall, B. Nrityantar. In Proceedings of the 11th Indian Conference on Computer Vision, Graphics and Image Processing, New Delhi, India, 9–11 June 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Samanta, S.; Purkait, P.; Chanda, B. Indian classical dance classification by learning dance pose bases. In Proceedings of the 2012 IEEE Workshop on the Applications of Computer Vision (WACV), Breckenridge, CO, USA, 9–11 January 2012; pp. 265–270. [Google Scholar] [CrossRef]
- Kumar, K.V.V.; Kishore, P.V.V.; Kumar, D.A. Indian Classical Dance Classification with Adaboost Multiclass Classifier on Multifeature Fusion. Math. Probl. Eng. 2017, 2017, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Wang, R. AdaBoost for Feature Selection, Classification and Its Relation with SVM, A Review. Phys. Procedia 2012, 25, 800–807. [Google Scholar] [CrossRef] [Green Version]
- Kumar, K.; Kishore, P. Indian Classical Dance Mudra Classification Using HOG Features and SVM Classifier. Int. J. Electr. Comput. Eng. (IJECE) 2017, 7, 2537–2546. [Google Scholar] [CrossRef]
- Chaves, E.; Gonçalves, C.B.; Albertini, M.; Lee, S.; Jeon, G.; Fernandes, H.C. Evaluation of transfer learning of pre-trained CNNs applied to breast cancer detection on infrared images. Appl. Opt. 2020, 59, E23–E28. [Google Scholar] [CrossRef] [PubMed]
- Brox, T.; Malik, J. Object Segmentation by Long Term Analysis of Point Trajectories. In Proceedings of the Transactions on Petri Nets and Other Models of Concurrency XV, Cachan, France, 3 December 2010; Springer Science and Business Media LLC, 2010; pp. 282–295. [Google Scholar]
- Dimitriou, N.; Delopoulos, A. Improved motion segmentation using locally sampled subspaces. In Proceedings of the 2012 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012; pp. 309–312. [Google Scholar] [CrossRef]
- Ochs, P.; Brox, T. Object segmentation in video: A hierarchical variational approach for turning point trajectories into dense regions. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1583–1590. [Google Scholar] [CrossRef]
- Dimitriou, N.; Delopoulos, A. Motion-based segmentation of objects using overlapping temporal windows. Image Vis. Comput. 2013, 31, 593–602. [Google Scholar] [CrossRef]
- Jain, N.; Gupta, V.; Shubham, S.; Madan, A.; Chaudhary, A.; Santosh, K.C. Understanding cartoon emotion using integrated deep neural network on large dataset. Neural Comput. Appl. 2021, 1–21. [Google Scholar] [CrossRef]
- Dewan, S.; Shubham, A.; Navjyoti, S. A deep learning pipeline for Indian dance style classification. Tenth International Conference on Machine Vision (ICMV 2017), Vienna, Austria, 13–15 November 2017; International Society for Optics and Photonics: Vienna, Austria, 2018; 10696. [Google Scholar] [CrossRef]
- Kishore, P.V.V.; Kumar, K.V.V.; Kumar, E.K.; Sastry, A.S.C.S.; Kiran, M.T.; Kumar, D.A.; Prasad, M.V.D. Indian Classical Dance Action Identification and Classification with Convolutional Neural Networks. Adv. Multimedia 2018, 2018, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Sahoo, P.; Soltani, S.; Wong, A. A survey of thresholding techniques. Comput. Vision, Graph. Image Process. 1988, 41, 233–260. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Jain, N.; Chauhan, A.; Tripathi, P.; Bin Moosa, S.; Aggarwal, P.; Oznacar, B. Cell image analysis for malaria detection using deep convolutional network. Intell. Decis. Technol. 2020, 14, 55–65. [Google Scholar] [CrossRef]
- Gupta, V.; Juyal, S.; Singh, G.P.; Killa, C.; Gupta, N. Emotion recognition of audio/speech data using deep learning approaches. J. Inf. Optim. Sci. 2020, 41, 1309–1317. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper Reference | Algorithm Used for Feature Extraction | Classification Technique |
|---|---|---|
| [3] | DCNN and Optical Flow for feature extraction | multi-class linear support vector machine(SVM) |
| [6] | 3-tier framework combining Inception V3 features, 3D CNN features and novel pose signatures | LSTM layer + 2 fully connectedlayers with BN + softmax layer |
| [8] | FeatureExtraction: Zernike moments, Hu moments, shape signature, LBP features, and Haar features. | AdaBoost multi feature fusion classification |
| [10] | Histogram of oriented (HOG) features of hand mudras | SVM classifier |
| [17] | Pipeline—joints identification, patches centered around regions important with respect to movement, and this forms a hierarchical dance pose descriptor. | High level RNN |
| [18] | Histogram of oriented optical flow (HOOF) features with representations | SVM with intersection kernel |
| VGG16 | DenseNet121 | ||||||||
| Precision | Recall | F1-Score | Support | Precision | Recall | F1-Score | Support | ||
| Bharatanatyam | 0.67 | 0.75 | 0.71 | 16 | Bharatanatyam | 0.57 | 0.50 | 0.53 | 16 |
| Kathak | 0.67 | 0.67 | 0.67 | 9 | Kathak | 0.80 | 0.73 | 0.76 | 11 |
| Kathakali | 0.81 | 1 | 0.9 | 13 | Kathakali | 0.82 | 1.00 | 0.90 | 18 |
| Kuchipudi | 0.78 | 0.39 | 0.52 | 18 | Kuchipudi | 0.67 | 0.71 | 0.69 | 14 |
| Manipuri | 0.67 | 0.8 | 0.73 | 15 | Manipuri | 0.93 | 0.87 | 0.90 | 15 |
| Mohiniyattam | 0.72 | 0.75 | 0.73 | 24 | Mohiniyattam | 0.65 | 0.87 | 0/90 | 15 |
| Odissi | 0.5 | 0.62 | 0.55 | 13 | Odissi | 0.86 | 0.80 | 0.83 | 15 |
| Sattriya | 0.44 | 0.33 | 0.38 | 12 | Sattriya | 0.91 | 0.62 | 0.74 | 16 |
| Accuracy | 0.67 | 120 | Accuracy | 0.77 | 120 | ||||
| Macro average | 0.66 | 0.66 | 0.65 | 120 | Macro average | 0.78 | 0.76 | 0.76 | 120 |
| Weighted average | 0.67 | 0.67 | 0.65 | 120 | Weighted average | 0.78 | 0.77 | 0.76 | 120 |
| ResNet50 (without Pre-Processing) | Proposed Approach (ResNet50 + Pre-Processing) | ||||||||
| Precision | Recall | F1-Score | Support | Precision | Recall | F1-Score | support | ||
| Bharatanatyam | 0.83 | 0.88 | 0.86 | 17 | Bharatanatyam | 0.8 | 0.8 | 0.8 | 10 |
| Kathak | 0.87 | 0.87 | 0.87 | 15 | Kathak | 0.82 | 0.9 | 0.86 | 10 |
| Kathakali | 0.9 | 1 | 0.95 | 18 | Kathakali | 1 | 1 | 1 | 16 |
| Kuchipudi | 0.83 | 0.5 | 0.62 | 10 | Kuchipudi | 0.85 | 0.89 | 0.87 | 19 |
| Manipuri | 1 | 0.87 | 0.93 | 15 | Manipuri | 1 | 0.94 | 0.97 | 17 |
| Mohiniyattam | 0.92 | 0.92 | 0.92 | 13 | Mohiniyattam | 0.88 | 1 | 0.94 | 15 |
| Odissi | 0.67 | 0.93 | 0.78 | 15 | Odissi | 0.93 | 0.93 | 0.93 | 15 |
| Sattriya | 1 | 0.82 | 0.9 | 17 | Sattriya | 0.93 | 0.78 | 0.85 | 18 |
| Accuracy | 0.87 | 120 | Accuracy | 0.91 | 120 | ||||
| Macro average | 0.88 | 0.85 | 0.85 | 120 | Macro average | 0.9 | 0.91 | 0.9 | 120 |
| Weighted average | 0.88 | 0.87 | 0.87 | 120 | Weighted average | 0.93 | 0.91 | 0.91 | 120 |
| Nrityantar [3] | CS_ISI [7] | ICD_IITR [3] | Proposed Approach | |
|---|---|---|---|---|
| Precision | 0.75 | - | 75.42 | 0.93 |
| Recall | 0.72 | - | 70.96 | 0.91 |
| F1-score | 0.71 | - | 73.12 | 0.9 |
| Accuracy | 72.35 | 86.67 | 75.83 | 91.1 |
| Number of classes | 6 | 3 | 7 | 8 |
| Learning rate | 1e-4 | - | - | 3.00E-04 |
| Optimiser | Adam | - | - | Adam |
| Loss | Categorical Entropy | - | - | Categorical Entropy |
| Decay | 0.000001 | - | - | 0.000001 |
| Batch size | 32 | - | - | 32 |
| Maximum Epoch | 100 | - | - | 15 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jain, N.; Bansal, V.; Virmani, D.; Gupta, V.; Salas-Morera, L.; Garcia-Hernandez, L. An Enhanced Deep Convolutional Neural Network for Classifying Indian Classical Dance Forms. Appl. Sci. 2021, 11, 6253. https://doi.org/10.3390/app11146253
Jain N, Bansal V, Virmani D, Gupta V, Salas-Morera L, Garcia-Hernandez L. An Enhanced Deep Convolutional Neural Network for Classifying Indian Classical Dance Forms. Applied Sciences. 2021; 11(14):6253. https://doi.org/10.3390/app11146253
Chicago/Turabian StyleJain, Nikita, Vibhuti Bansal, Deepali Virmani, Vedika Gupta, Lorenzo Salas-Morera, and Laura Garcia-Hernandez. 2021. "An Enhanced Deep Convolutional Neural Network for Classifying Indian Classical Dance Forms" Applied Sciences 11, no. 14: 6253. https://doi.org/10.3390/app11146253
APA StyleJain, N., Bansal, V., Virmani, D., Gupta, V., Salas-Morera, L., & Garcia-Hernandez, L. (2021). An Enhanced Deep Convolutional Neural Network for Classifying Indian Classical Dance Forms. Applied Sciences, 11(14), 6253. https://doi.org/10.3390/app11146253