
Explainable Internet Traffic Classification




Abstract
1. Introduction
2. Related Work
3. Materials and Methods
3.1. Data Sets
3.1.1. UniBS Data Set
3.1.2. UPC Data-Set
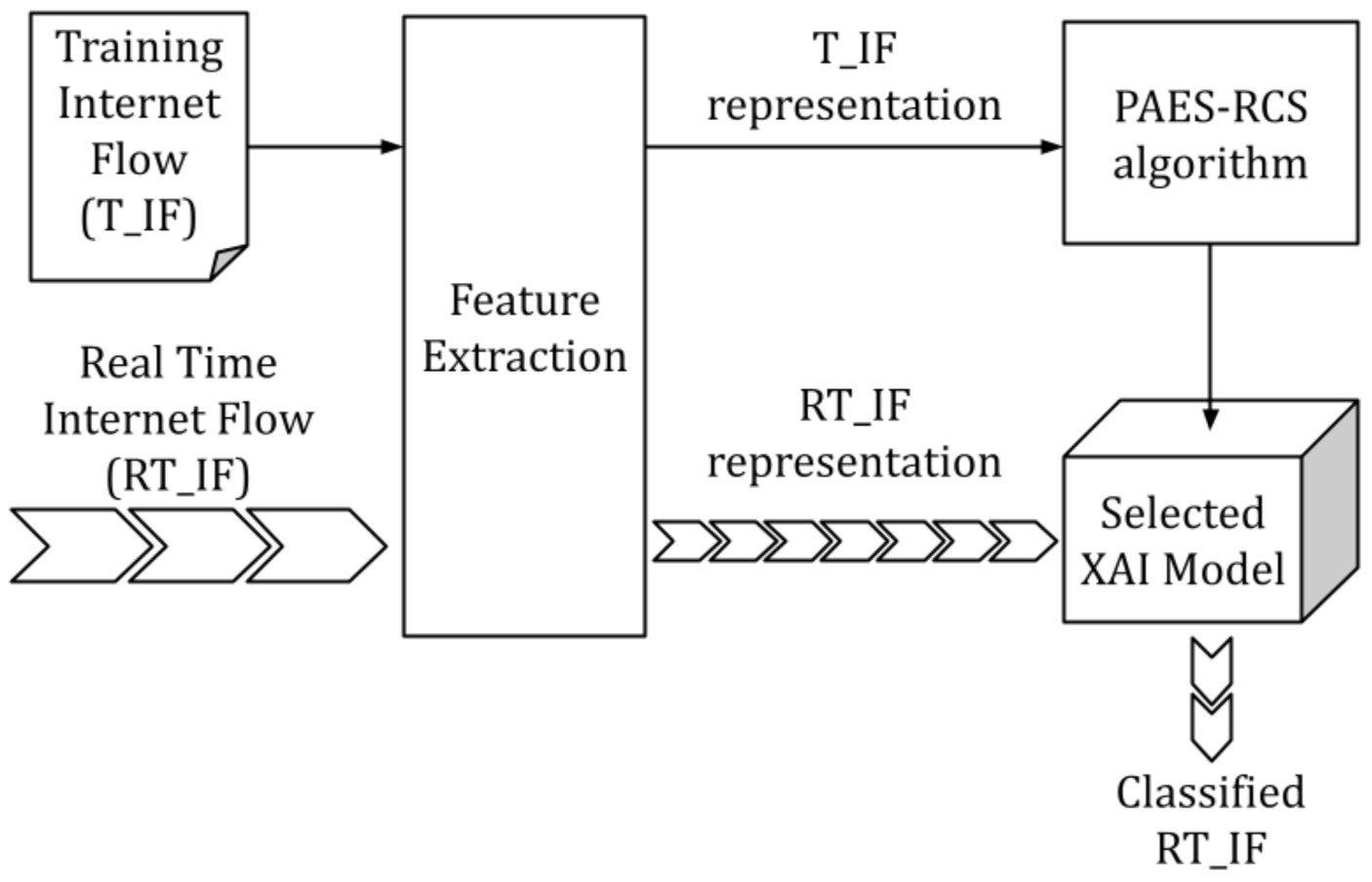
3.2. The Proposed Traffic Classification System
3.2.1. PAES-RCS Method
3.2.2. Feature Extraction
- Statistical features: the flow is described by a set of statistical values (namely 21), reported in Table 3.It is important to highlight that in this work, such features have only been computed for flows made of five or more packets.
- Composite features: the flow is described by an array , where H is the number of analyzed flow packets, of higher granularity (i.e., packet level) features [34]:where
- -
- with is the direction of the packet
- -
- with is the dimension in Byte of the packet, normalized with respect to
- -
- with is the time in seconds between packet i and packet
Clearly, such features depend on the parameter H and can only be computed for those flows made of at least H packets. In the experimental results, we will consider .
4. Experimental Results
- True Positive Rate
- False Positive Rate
- Accuracy
4.1. SVM Classifier
4.2. C4.5 Decision Tree
4.3. PAES-RCS
4.4. Comparison among the Different Classification Models
- R1: IF f_Sµ is VL THEN Y is Skype
- R2: IF f_N is L THEN Y is Amule
- R3: IF r_SM is H AND r_TM is M THEN Y is Mail
- R4: IF f_N is H AND f_V is VH AND r_V is H AND r_Sm is L AND f_SM is F ML AND r_SM is H AND r_Sµ is H AND f_Sσ is VH AND r_Sσ is VH AND f_TM is H THEN Y is Mail
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Moore, D.; Keys, K.; Koga, R.; Lagache, E.; Claffy, K. CoralReef software suite as a tool for system and network administrators. In Usenix LISA; Usenix: San Diego, CA, USA, 2001; pp. 4–7. [Google Scholar]
- Roughan, M.; Sen, S.; Spatscheck, O.; Duffield, N. Class-of-service Mapping for QoS: A Statistical Signature-based Approach to IP Traffic Classification. In Proceedings of the 4th ACM SIGCOMM Conference on Internet Measurement, IMC ’04, Taormina Sicily, Italy, 25–27 October 2004; pp. 135–148. [Google Scholar]
- Salman, O.; Elhajj, I.H.; Kayssi, A.; Chehab, A. A review on machine learning—Based approaches for internet traffic classification. Ann. Telecommun. 2020, 75, 673–710. [Google Scholar] [CrossRef]
- Cao, J.; Wang, D.; Qu, Z.; Sun, H.; Li, B.; Chen, C.L. An improved network traffic classification model based on a support vector machine. Symmetry 2020, 12, 301. [Google Scholar] [CrossRef]
- Rezaei, S.; Liu, X. Deep Learning for Encrypted Traffic Classification: An Overview. IEEE Commun. Mag. 2019, 57, 76–81. [Google Scholar] [CrossRef]
- Muhammad Ashfaq Khan, Y.K. Deep Learning-Based Hybrid Intelligent Intrusion Detection System. Comput. Mater. Contin. 2021, 68, 671–687. [Google Scholar] [CrossRef]
- Alqahtani, H.; Sarker, I.H.; Kalim, A.; Hossain, S.M.M.; Ikhlaq, S.; Hossain, S. Cyber Intrusion Detection Using Machine Learning Classification Techniques. In International Conference on Computing Science, Communication and Security; Springer: Berlin/Heidelberg, Germany, 2020; pp. 121–131. [Google Scholar]
- Salloum, S.A.; Alshurideh, M.; Elnagar, A.; Shaalan, K. Machine learning and deep learning techniques for cybersecurity: A review. In Joint European-US Workshop on Applications of Invariance in Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 50–57. [Google Scholar]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Fernandez, A.; Herrera, F.; Cordon, O.; Jose del Jesus, M.; Marcelloni, F. Evolutionary Fuzzy Systems for Explainable Artificial Intelligence: Why, When, What for, and Where to? IEEE Comput. Intell. Mag. 2019, 14, 69–81. [Google Scholar] [CrossRef]
- Ducange, P.; Mannara, G.; Marcelloni, F.; Pecori, R.; Vecchio, M. A novel approach for internet traffic classification based on multi-objective evolutionary fuzzy classifiers. In Proceedings of the 2017 IEEE International Conference on Fuzzy Systems, FUZZ-IEEE 2017, Naples, Italy, 9–12 July 2017; pp. 1–6. [Google Scholar]
- Fazzolari, M.; Alcalá, R.; Nojima, Y.; Ishibuchi, H.; Herrera, F. A review of the application of multiobjective evolutionary fuzzy systems: Current status and further directions. IEEE Trans. Fuzzy Syst. 2013, 21, 45–65. [Google Scholar] [CrossRef]
- Antonelli, M.; Ducange, P.; Marcelloni, F. Multi-Objective Evolutionary Design of Fuzzy Rule-Based Systems. In Handbook on Computational Intelligence: Volume 2: Evolutionary Computation, Hybrid Systems, and Applications; World Scientific: Singapore, 2016; pp. 635–670. [Google Scholar]
- Coello, C.A.C.; Brambila, S.G.; Gamboa, J.F.; Tapia, M.G.C.; Gómez, R.H. Evolutionary multiobjective optimization: Open research areas and some challenges lying ahead. Complex Intell. Syst. 2020, 6, 221–236. [Google Scholar] [CrossRef]
- Barsacchi, M.; Bechini, A.; Ducange, P.; Marcelloni, F. Optimizing partition granularity, membership function parameters, and rule bases of fuzzy classifiers for big data by a multi-objective evolutionary approach. Cogn. Comput. 2019, 11, 367–387. [Google Scholar] [CrossRef]
- Gallo, G.; Bernardi, M.L.; Cimitile, M.; Ducange, P. An Explainable Approach for Car Driver Identification. In Proceedings of the 2021 IEEE International Conference on Fuzzy Systems, FUZZ-IEEE 2021, Luxemburg, 11–14 July 2021; in press. [Google Scholar]
- Frank, J.; Mda-c, N.U. Artificial Intelligence and Intrusion Detection: Current and Future Directions. In Proceedings of the 17th National Computer Security Conference, Baltimore, Maryland, 11–14 October 1994. [Google Scholar]
- Pacheco, F.; Exposito, E.; Gineste, M.; Baudoin, C.; Aguilar, J. Towards the deployment of machine learning solutions in network traffic classification: A systematic survey. IEEE Commun. Surv. Tutor. 2018, 21, 1988–2014. [Google Scholar] [CrossRef]
- Este, A.; Gringoli, F.; Salgarelli, L. Support Vector Machines for TCP traffic classification. Comput. Netw. 2009, 53, 2476–2490. [Google Scholar] [CrossRef]
- Sun, G.; Chen, T.; Su, Y.; Li, C. Internet traffic classification based on incremental support vector machines. Mob. Netw. Appl. 2018, 23, 789–796. [Google Scholar] [CrossRef]
- Qu, H.; Jiang, J.; Zhao, J.; Zhang, Y.; Yang, J. A novel method for network traffic classification based on robust support vector machine. Trans. Emerg. Telecommun. Technol. 2020, 31, e4092. [Google Scholar] [CrossRef]
- Dong, S. Multi class SVM algorithm with active learning for network traffic classification. Expert Syst. Appl. 2021, 176, 114885. [Google Scholar] [CrossRef]
- Zhongsheng, W.; Jianguo, W.; Sen, Y.; Jiaqiong, G. Traffic identification and traffic analysis based on support vector machine. Concurr. Comput. Pract. Exp. 2020, 32, e5292. [Google Scholar] [CrossRef]
- Mousavi, S.M.; Abdullah, S.; Niaki, S.T.A.; Banihashemi, S. An intelligent hybrid classification algorithm integrating fuzzy rule-based extraction and harmony search optimization: Medical diagnosis applications. Knowl. Based Syst. 2021, 220, 106943. [Google Scholar] [CrossRef]
- Joshuva, A.; Vishnuvardhan, R.; Deenadayalan, G.; Sathishkumar, R.; Sivakumar, S. Implementation of rule based classifiers for wind turbine blade fault diagnosis using vibration signals. Int. J. Recent Technol. Eng. 2019, 8, 320–331. [Google Scholar]
- Li, G.; Wu, H.; Jiang, G.; Xu, S.; Liu, H. Dynamic gesture recognition in the internet of things. IEEE Access 2018, 7, 23713–23724. [Google Scholar] [CrossRef]
- Alonso, J.M.; Castiello, C.; Magdalena, L.; Mencar, C. Explainable Fuzzy Systems: Paving the way from Interpretable Fuzzy Systems to Explainable AI Systems. In Studies in Computational Intelligence; Springer Nature: Cham, Switzerland, 2021. [Google Scholar]
- Dwivedi, P.K.; Tripathi, S.P. A Review of Multi-Objective Evolutionary Based Fuzzy Classifiers. Recent Adv. Comput. Sci. Commun. 2020, 13, 77–85. [Google Scholar] [CrossRef]
- Trawiński, K.; Cordón, O.; Quirin, A. A Study on the Use of Multiobjective Genetic Algorithms for Classifier Selection in FURIA-based Fuzzy Multiclassifiers. Int. J. Comput. Intell. Syst. 2017, 5, 231–253. [Google Scholar] [CrossRef]
- Alcalá, R.; Nojima, Y.; Herrera, F.; Ishibuchi, H. Multiobjective genetic fuzzy rule selection of single granularity-based fuzzy classification rules and its interaction with the lateral tuning of membership functions. Soft Comput. 2011, 15, 2303–2318. [Google Scholar] [CrossRef]
- Elhag, S.; Fernández, A.; Altalhi, A.; Alshomrani, S.; Herrera, F. A multi-objective evolutionary fuzzy system to obtain a broad and accurate set of solutions in intrusion detection systems. Soft Comput. 2019, 23, 1321–1336. [Google Scholar] [CrossRef]
- Zheng, J.; Wang, L.; Wang, J.J. A cooperative coevolution algorithm for multi-objective fuzzy distributed hybrid flow shop. Knowl. Based Syst. 2020, 194, 105536. [Google Scholar] [CrossRef]
- Ducange, P.; Fazzolari, M.; Marcelloni, F. An overview of recent distributed algorithms for learning fuzzy models in Big Data classification. J. Big Data 2020, 7, 1–29. [Google Scholar] [CrossRef]
- Rizzi, A.; Iacovazzi, A.; Baiocchi, A.; Colabrese, S. A low complexity real-time Internet traffic flows neuro-fuzzy classifier. Comput. Netw. 2015, 91, 752–771. [Google Scholar] [CrossRef]
- Al-Obeidat, F.; El-Alfy, E.S. Hybrid multicriteria fuzzy classification of network traffic patterns, anomalies, and protocols. Pers. Ubiquitous Comput. 2019, 23, 777–791. [Google Scholar] [CrossRef]
- Dusi, M.; Gringoli, F.; Salgarelli, L. Quantifying the accuracy of the ground truth associated with Internet traffic traces. Comput. Netw. 2011, 55, 1158–1167. [Google Scholar] [CrossRef]
- Mohammady, M.; Wang, L.; Hong, Y.; Louafi, H.; Pourzandi, M.; Debbabi, M. Preserving Both Privacy and Utility in Network Trace Anonymization. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, CCS ’18, Toronto, ON, Canada, 15–19 October 2018; pp. 459–474. [Google Scholar]
- Elnawawy, M.; Sagahyroon, A.; Shanableh, T. FPGA-Based Network Traffic Classification Using Machine Learning. IEEE Access 2020, 8, 175637–175650. [Google Scholar] [CrossRef]
- Saber, M.A.S.; Ghorbani, M.; Bayati, A.; Nguyen, K.K.; Cheriet, M. Online data center traffic classification based on inter-flow correlations. IEEE Access 2020, 8, 60401–60416. [Google Scholar] [CrossRef]
- Bujlow, T.; Carela-Español, V.; Barlet-Ros, P. Independent Comparison of Popular DPI Tools for Traffic Classification. Comput. Netw. 2015, 76, 75–89. [Google Scholar] [CrossRef]
- Carela-Español, V.; Bujlow, T.; Barlet-Ros, P. Is Our Ground-Truth for Traffic Classification Reliable? In Proceedings of the 15th International Conference on Passive and Active Measurement, Los Angeles, CA, USA, 10–11 March 2014; Volume 8362, pp. 98–108. [Google Scholar]
- Gómez, S.E.; Hernández-Callejo, L.; Martínez, B.C.; Sánchez-Esguevillas, A.J. Exploratory study on class imbalance and solutions for network traffic classification. Neurocomputing 2019, 343, 100–119. [Google Scholar] [CrossRef]
- Nascimento, Z.; Sadok, D. MODC: A pareto-optimal optimization approach for network traffic classification based on the divide and conquer strategy. Information 2018, 9, 233. [Google Scholar] [CrossRef]
- Antonelli, M.; Ducange, P.; Marcelloni, F. A fast and efficient multi-objective evolutionary learning scheme for fuzzy rule-based classifiers. Inf. Sci. 2014, 283, 36–54. [Google Scholar] [CrossRef]
- Segatori, A.; Marcelloni, F.; Pedrycz, W. On Distributed Fuzzy Decision Trees for Big Data. IEEE Trans. Fuzzy Syst. 2017, 26, 174–192. [Google Scholar] [CrossRef]
- Platt, J. Fast Training of Support Vector Machines Using Sequential Minimal Optimization. In Advances in Kernel Methods: Support Vector Learning; MIT Press: Cambridge, MA, USA, 1999; pp. 185–208. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Class | >3 pkts | >5 pkts | >10 pkts |
|---|---|---|---|
| 4628 | 4627 | 4621 | |
| Skype | 2516 | 2484 | 2412 |
| Firefox | 906 | 906 | 901 |
| Safari | 13,204 | 13,300 | 13,178 |
| BitTorrent | 2414 | 2411 | 1761 |
| Amule | 5311 | 5296 | 5202 |
| Class | >3 pkts | >5 pkts | >10 pkts |
|---|---|---|---|
| SSHD | 7863 | 7769 | 7739 |
| XRDP | 3196 | 3031 | 2926 |
| DNSMasq | 2993 | 1731 | 631 |
| Chrome | 4549 | 4540 | 3635 |
| Firefox | 1926 | 1924 | 1147 |
| Amule | 4594 | 2362 | 1282 |
| Description of the Feature | U/M | Features | |
|---|---|---|---|
| Forward | Reverse | ||
| Flow duration | Δ | ||
| Number of transferred packets | - | f_N | r_N |
| Transferred volume | B | f_V | r_V |
| Minimum packet size | B | f_Sm | r_Sm |
| Maximum packet size | B | f_SM | r_SM |
| Average packet size | B | f_Sµ | r_Sµ |
| Standard deviation of packet size | B | f_Sσ | r_Sσ |
| Minimum inter-packet time | f_Tm | r_Tm | |
| Maximum inter-packet time | f_TM | r_TM | |
| Average inter-packet time | f_Tµ | r_Tµ | |
| Standard deviation of inter-packet time | f_Tσ | r_Tσ | |
| Data-Set | Features | Accuracy |
|---|---|---|
| UniBS | Statistical | 0.759 |
| Composite () | 0.662 | |
| Composite () | 0.717 | |
| Composite () | 0.874 | |
| UPC | Statistical | 0.71 |
| Composite () | 0.538 | |
| Composite () | 0.776 | |
| Composite () | 0.896 |
| Feature | Class | TPR | FPR |
|---|---|---|---|
| Statistical | 0.75 | 0.06 | |
| Skype | 0.55 | 0.006 | |
| Firefox | 0.38 | 0.001 | |
| Safari | 0.81 | 0.12 | |
| BitTorrent | 0.95 | 0.003 | |
| Amule | 0.71 | 0.13 | |
| Composite () | 0 | 0 | |
| Skype | 0.59 | 0.01 | |
| Firefox | 0 | 0.001 | |
| Safari | 0.86 | 0.31 | |
| BitTorrent | 0.89 | 0.001 | |
| Amule | 0.77 | 0.18 | |
| Composite () | 0.19 | 0.002 | |
| Skype | 0.57 | 0.007 | |
| Firefox | 0.9 | 0.01 | |
| Safari | 0.86 | 0.3 | |
| BitTorrent | 0.96 | 0.002 | |
| Amule | 0.726 | 0.12 | |
| Composite () | 0.9 | 0.004 | |
| Skype | 0.56 | 0.005 | |
| Firefox | 0.96 | 0.001 | |
| Safari | 0.89 | 0.005 | |
| BitTorrent | 0.95 | 0.002 | |
| Amule | 0.95 | 0.06 |
| Feature | Class | TPR | FPR |
|---|---|---|---|
| Statistical | SSHD | 0.93 | 0.297 |
| XRDP | 0.64 | 0.66 | |
| DNSMasq | 0.95 | 0 | |
| Chrome | 0.54 | 0.05 | |
| Firefox | 0 | 0 | |
| Amule | 0.79 | 0.004 | |
| Composite () | SSHD | 1 | 0.63 |
| XRDP | 0 | 0 | |
| DNSMasq | 0.78 | 0.004 | |
| Chrome | 0 | 0 | |
| Firefox | 0 | 0 | |
| Amule | 0.72 | 0.028 | |
| Composite () | SSHD | 0.99 | 0.11 |
| XRDP | 0.95 | 0.1 | |
| DNSMasq | 0.89 | 0 | |
| Chrome | 0.74 | 0.007 | |
| Firefox | 0 | 0 | |
| Amule | 0.46 | 0.001 | |
| Composite () | SSHD | 0.97 | 0.01 |
| XRDP | 0.97 | 0.01 | |
| DNSMasq | 0.99 | 0 | |
| Chrome | 0.98 | 0.008 | |
| Firefox | 0.001 | 0 | |
| Amule | 0.76 | 0.01 |
| Skype | Firefox | Safari | BitTorrent | Amule | ||
|---|---|---|---|---|---|---|
| 4174 | 0 | 0 | 411 | 0 | 36 | |
| Skype | 31 | 1351 | 0 | 110 | 40 | 880 |
| Firefox | 0 | 6 | 865 | 5 | 0 | 25 |
| Safari | 964 | 0 | 0 | 11,778 | 1 | 435 |
| BitTorrent | 0 | 68 | 2 | 0 | 1685 | 6 |
| Amule | 82 | 55 | 34 | 314 | 7 | 4710 |
| Data-Set | Features | Accuracy |
|---|---|---|
| UniBS | Statistical | 0.969 |
| Composite () | 0.82 | |
| Composite () | 0.86 | |
| Composite () | 0.961 | |
| UPC | Statistical | 0.981 |
| Composite () | 0.867 | |
| Composite () | 0.964 | |
| Composite () | 0.966 |
| Feature | Class | TPR | FPR |
|---|---|---|---|
| Statistical | 0.96 | 0.005 | |
| Skype | 0.92 | 0.008 | |
| Firefox | 0.98 | 0.001 | |
| Safari | 0.97 | 0.02 | |
| BitTorrent | 0.97 | 0.001 | |
| Amule | 0.96 | 0.006 | |
| Composite () | 0.78 | 0.07 | |
| Skype | 0.59 | 0.008 | |
| Firefox | 0.98 | 0.002 | |
| Safari | 0.83 | 0.11 | |
| BitTorrent | 0.96 | 0.001 | |
| Amule | 0.83 | 0.058 | |
| Composite () | 0.85 | 0.05 | |
| Skype | 0.7 | 0.01 | |
| Firefox | 0.98 | 0.01 | |
| Safari | 0.86 | 0.07 | |
| BitTorrent | 0.97 | 0.001 | |
| Amule | 0.84 | 0.04 | |
| Composite () | 0.95 | 0.005 | |
| Skype | 0.9 | 0.01 | |
| Firefox | 0.98 | 0 | |
| Safari | 0.97 | 0.02 | |
| BitTorrent | 0.953 | 0 | |
| Amule | 0.95 | 0.01 |
| Feature | Class | TPR | FPR |
|---|---|---|---|
| Statistical | SSHD | 0.99 | 0.001 |
| XRDP | 0.99 | 0.001 | |
| DNSMasq | 0.99 | 0.001 | |
| Chrome | 0.97 | 0.001 | |
| Firefox | 0.9 | 0.007 | |
| Amule | 0.98 | 0.001 | |
| Composite () | SSHD | 0.95 | 0.002 |
| XRDP | 0.74 | 0.002 | |
| DNSMasq | 0.99 | 0.001 | |
| Chrome | 0.86 | 0.007 | |
| Firefox | 0.349 | 0.002 | |
| Amule | 0.94 | 0.003 | |
| Composite () | SSHD | 0.99 | 0.002 |
| XRDP | 0.99 | 0.02 | |
| DNSMasq | 0.99 | 0.01 | |
| Chrome | 0.94 | 0.02 | |
| Firefox | 0.79 | 0.01 | |
| Amule | 0.98 | 0.001 | |
| Composite () | SSHD | 0.99 | 0.001 |
| XRDP | 0.99 | 0.001 | |
| DNSMasq | 0.98 | 0.001 | |
| Chrome | 0.94 | 0.02 | |
| Firefox | 0.72 | 0.01 | |
| Amule | 0.97 | 0.002 |
| SSHD | XRDP | DNSMasq | Chrome | Firefox | Amule | |
|---|---|---|---|---|---|---|
| SSHD | 7756 | 5 | 1 | 2 | 1 | 4 |
| XRDP | 6 | 3017 | 0 | 4 | 2 | 2 |
| DNSMasq | 2 | 1 | 1726 | 0 | 0 | 2 |
| Chrome | 1 | 0 | 5 | 4404 | 129 | 1 |
| Firefox | 0 | 0 | 2 | 183 | 1735 | 4 |
| Amule | 10 | 10 | 6 | 14 | 3 | 2319 |
| Parameter | Description | Value |
|---|---|---|
| PAES archive dimension | 64 | |
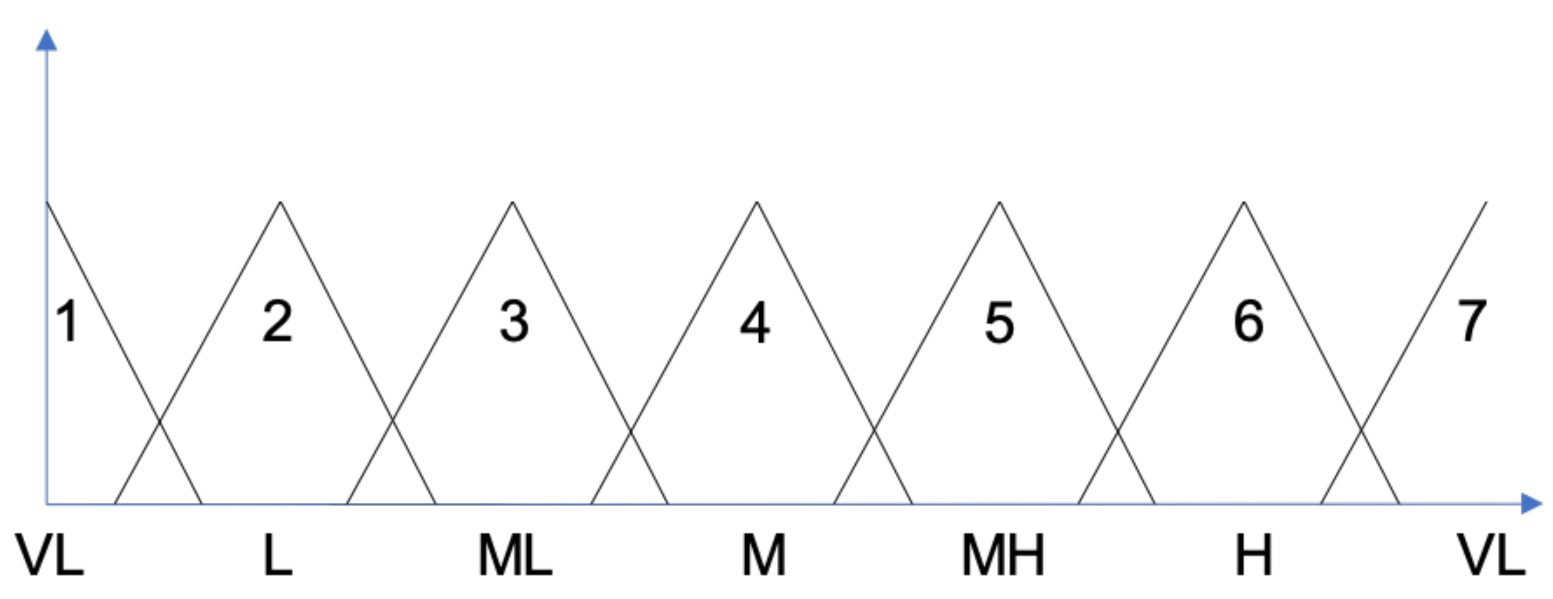
| Number of fuzzy sets per variable | 7 | |
| Minimum number of rules in | 5 | |
| Maximum number of rules in | 100 | |
| Total number of fitness evaluations | 50,000 | |
| Probability of applying crossover operator to | 0.1 | |
| Probability of applying crossover operator to | 0.5 | |
| Probability of applying first mutation operator to | 0.1 | |
| Probability of applying second mutation operator to | 0.7 | |
| Probability of applying mutation operator to | 0.2 |
| Feature | Solution | Acc | Rules | TRL |
|---|---|---|---|---|
| Statistical | First | 0.875 | 17.86 | 95.8 |
| Median | 0.86 | 10.83 | 32.9 | |
| Last | 0.595 | 7.6 | 8.47 | |
| Composite () | First | 0.704 | 35.3 | 98.13 |
| Median | 0.691 | 26.63 | 79.23 | |
| Last | 0.64 | 25.0 | 76.93 | |
| omposite () | First | 0.72 | 21.4 | 41.86 |
| Median | 0.704 | 10.8 | 13.8 | |
| Last | 0.652 | 8.4 | 8.4 | |
| Composite () | First | 0.802 | 15.6 | 40.53 |
| Median | 0.734 | 10.03 | 18.67 | |
| Last | 0.629 | 8.07 | 8.2 |
| Feature | Solution | |||
|---|---|---|---|---|
| Statistical | First | 0.861 | 15.93 | 59.06 |
| Median | 0.843 | 11.17 | 24.9 | |
| Last | 0.61 | 8.73 | 9.06 | |
| Composite () | First | 0.662 | 14.86 | 22.2 |
| Median | 0.647 | 10.9 | 13.57 | |
| Last | 0.612 | 7.07 | 7.07 | |
| Composite () | First | 0.816 | 17.53 | 36.46 |
| Median | 0.79 | 12.37 | 18.63 | |
| Last | 0.6 | 8.67 | 8.67 | |
| Composite () | First | 0.886 | 16.73 | 50.87 |
| Median | 0.877 | 11.27 | 20.4 | |
| Last | 0.645 | 8.87 | 9.0 |
| First | Median | Last | |||||
|---|---|---|---|---|---|---|---|
| Feature | Class | TPR | FPR | TPR | FPR | TPR | FPR |
| Statistical | 0.814 | 0.006 | 0.801 | 0.006 | 0.152 | 0.027 | |
| Skype | 0.636 | 0.006 | 0.619 | 0.007 | 0.503 | 0.009 | |
| Firefox | 0.696 | 0.002 | 0.653 | 0.002 | 0.375 | 0.004 | |
| Safari | 0.955 | 0.005 | 0.941 | 0.006 | 0.810 | 0.018 | |
| BitTorrent | 0.955 | 0.001 | 0.949 | 0.001 | 0.653 | 0.006 | |
| Amule | 0.836 | 0.006 | 0.819 | 0.007 | 0.499 | 0.019 | |
| Composite () | 0.000 | 0.032 | 0.000 | 0.032 | 0.000 | 0.032 | |
| Skype | 0.588 | 0.007 | 0.592 | 0.007 | 0.592 | 0.007 | |
| Firefox | 0.892 | 0.001 | 0.736 | 0.002 | 0.637 | 0.002 | |
| Safari | 0.876 | 0.013 | 0.865 | 0.014 | 0.944 | 0.006 | |
| BitTorrent | 0.968 | 0.001 | 0.968 | 0.001 | 0.807 | 0.003 | |
| Amule | 0.791 | 0.008 | 0.771 | 0.009 | 0.312 | 0.025 | |
| Composite () | 0.088 | 0.029 | 0.029 | 0.031 | 0.000 | 0.032 | |
| Skype | 0.583 | 0.007 | 0.583 | 0.007 | 0.583 | 0.007 | |
| Firefox | 0.902 | 0.001 | 0.822 | 0.001 | 0.492 | 0.003 | |
| Safari | 0.896 | 0.011 | 0.877 | 0.013 | 0.901 | 0.010 | |
| BitTorrent | 0.969 | 0.001 | 0.969 | 0.001 | 0.839 | 0.003 | |
| Amule | 0.758 | 0.009 | 0.776 | 0.009 | 0.564 | 0.016 | |
| Composite () | 0.547 | 0.015 | 0.502 | 0.017 | 0.048 | 0.031 | |
| Skype | 0.572 | 0.007 | 0.572 | 0.007 | 0.572 | 0.007 | |
| Firefox | 0.892 | 0.001 | 0.768 | 0.001 | 0.398 | 0.004 | |
| Safari | 0.917 | 0.009 | 0.892 | 0.011 | 0.891 | 0.012 | |
| BitTorrent | 0.957 | 0.001 | 0.956 | 0.001 | 0.750 | 0.003 | |
| Amule | 0.788 | 0.008 | 0.779 | 0.009 | 0.506 | 0.019 | |
| First | Median | Last | |||||
|---|---|---|---|---|---|---|---|
| Feature | Class | TPR | FPR | TPR | FPR | TPR | FPR |
| Statistical | SSHD | 0.948 | 0.004 | 0.941 | 0.005 | 0.813 | 0.014 |
| XRDP | 0.883 | 0.003 | 0.885 | 0.003 | 0.531 | 0.014 | |
| DNSMasq | 0.969 | 0.001 | 0.961 | 0.001 | 0.694 | 0.005 | |
| Chrome | 0.933 | 0.003 | 0.894 | 0.005 | 0.510 | 0.021 | |
| Firefox | 0.201 | 0.015 | 0.203 | 0.014 | 0.156 | 0.015 | |
| Amule | 0.871 | 0.003 | 0.835 | 0.004 | 0.567 | 0.010 | |
| Composite () | SSHD | 0.950 | 0.004 | 0.952 | 0.003 | 0.945 | 0.004 |
| XRDP | 0.592 | 0.011 | 0.582 | 0.011 | 0.524 | 0.012 | |
| DNSMasq | 0.853 | 0.004 | 0.845 | 0.004 | 0.752 | 0.006 | |
| Chrome | 0.101 | 0.033 | 0.089 | 0.033 | 0.015 | 0.036 | |
| Firefox | 0.000 | 0.015 | 0.000 | 0.015 | 0.002 | 0.015 | |
| Amule | 0.917 | 0.003 | 0.903 | 0.004 | 0.854 | 0.006 | |
| Composite () | SSHD | 0.972 | 0.002 | 0.973 | 0.002 | 0.896 | 0.008 |
| XRDP | 0.636 | 0.011 | 0.646 | 0.010 | 0.432 | 0.016 | |
| DNSMasq | 0.930 | 0.001 | 0.906 | 0.002 | 0.371 | 0.010 | |
| Chrome | 0.943 | 0.003 | 0.877 | 0.005 | 0.534 | 0.020 | |
| Firefox | 0.033 | 0.017 | 0.000 | 0.018 | 0.022 | 0.018 | |
| Amule | 0.848 | 0.003 | 0.835 | 0.004 | 0.600 | 0.009 | |
| Composite () | SSHD | 0.972 | 0.003 | 0.972 | 0.003 | 0.871 | 0.012 |
| XRDP | 0.887 | 0.004 | 0.881 | 0.004 | 0.495 | 0.017 | |
| DNSMasq | 0.970 | 0.000 | 0.949 | 0.000 | 0.556 | 0.003 | |
| Chrome | 0.954 | 0.002 | 0.947 | 0.002 | 0.562 | 0.019 | |
| Firefox | 0.113 | 0.012 | 0.091 | 0.012 | 0.086 | 0.012 | |
| Amule | 0.809 | 0.003 | 0.773 | 0.003 | 0.389 | 0.009 | |
| Skype | Firefox | Safari | BitTorrent | Amule | ||
|---|---|---|---|---|---|---|
| 823 | 0 | 0 | 99 | 0 | 9 | |
| Skype | 0 | 326 | 0 | 111 | 4 | 73 |
| Firefox | 0 | 0 | 173 | 2 | 2 | 2 |
| Safari | 26 | 4 | 0 | 2538 | 0 | 64 |
| BitTorrent | 0 | 15 | 2 | 2 | 451 | 12 |
| Amule | 6 | 34 | 19 | 112 | 0 | 896 |
| SSHD | XRDP | DNSMasq | Chrome | Firefox | Amule | |
|---|---|---|---|---|---|---|
| SSHD | 1449 | 91 | 0 | 8 | 0 | 0 |
| XRDP | 3 | 581 | 0 | 40 | 0 | 1 |
| DNSMasq | 0 | 0 | 342 | 1 | 0 | 8 |
| Chrome | 24 | 2 | 0 | 887 | 3 | 0 |
| Firefox | 11 | 0 | 01 | 256 | 106 | 0 |
| Amule | 15 | 8 | 1 | 39 | 0 | 395 |
| Training | Test | ||||||
|---|---|---|---|---|---|---|---|
| Data-Set | Feature | SVM | C4.5 | PAES-RCS | SVM | C4.5 | PAES-RCS |
| UniBS | Statistical | 0.864 | 0.972 | 0.893 | 0.759 | 0.969 | 0.875 |
| Composite () | 0.741 | 0.842 | 0.752 | 0.662 | 0.828 | 0.704 | |
| Composite () | 0.85 | 0.871 | 0.804 | 0.717 | 0.86 | 0.72 | |
| Composite () | 0.964 | 0.974 | 0.839 | 0.874 | 0.961 | 0.802 | |
| UPC | Statistical | 0.854 | 0.99 | 0.883 | 0.71 | 0.981 | 0.861 |
| Composite () | 0.635 | 0.887 | 0.721 | 0.538 | 0.867 | 0.662 | |
| Composite () | 0.884 | 0.983 | 0.892 | 0.776 | 0.964 | 0.816 | |
| Composite () | 0.977 | 0.973 | 0.904 | 0.896 | 0.966 | 0.886 | |
| C4.5 | PAES-RCS | ||||
|---|---|---|---|---|---|
| Data-Set | Feature | Tree Dimension | Leaves | TRL | Rules |
| UniBS | Statistical | 449 | 228 | 95.8 | 17.86 |
| Composite () | 194 | 118 | 98.13 | 35.3 | |
| Composite () | 889 | 435 | 41.86 | 21.4 | |
| Composite () | 712 | 383 | 40.53 | 15.6 | |
| UPC | Statistical | 3321 | 147 | 59.06 | 15.93 |
| Composite () | 247 | 134 | 22.2 | 14.86 | |
| Composite () | 364 | 176 | 36.46 | 17.53 | |
| Composite () | 447 | 223 | 50.87 | 16.73 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Callegari, C.; Ducange, P.; Fazzolari, M.; Vecchio, M. Explainable Internet Traffic Classification. Appl. Sci. 2021, 11, 4697. https://doi.org/10.3390/app11104697
Callegari C, Ducange P, Fazzolari M, Vecchio M. Explainable Internet Traffic Classification. Applied Sciences. 2021; 11(10):4697. https://doi.org/10.3390/app11104697
Chicago/Turabian StyleCallegari, Christian, Pietro Ducange, Michela Fazzolari, and Massimo Vecchio. 2021. "Explainable Internet Traffic Classification" Applied Sciences 11, no. 10: 4697. https://doi.org/10.3390/app11104697
APA StyleCallegari, C., Ducange, P., Fazzolari, M., & Vecchio, M. (2021). Explainable Internet Traffic Classification. Applied Sciences, 11(10), 4697. https://doi.org/10.3390/app11104697