Prediction of Soluble Solids Content in Green Plum by Using a Sparse Autoencoder

Abstract
1. Introduction
2. Experiments
2.1. Green Plum Samples
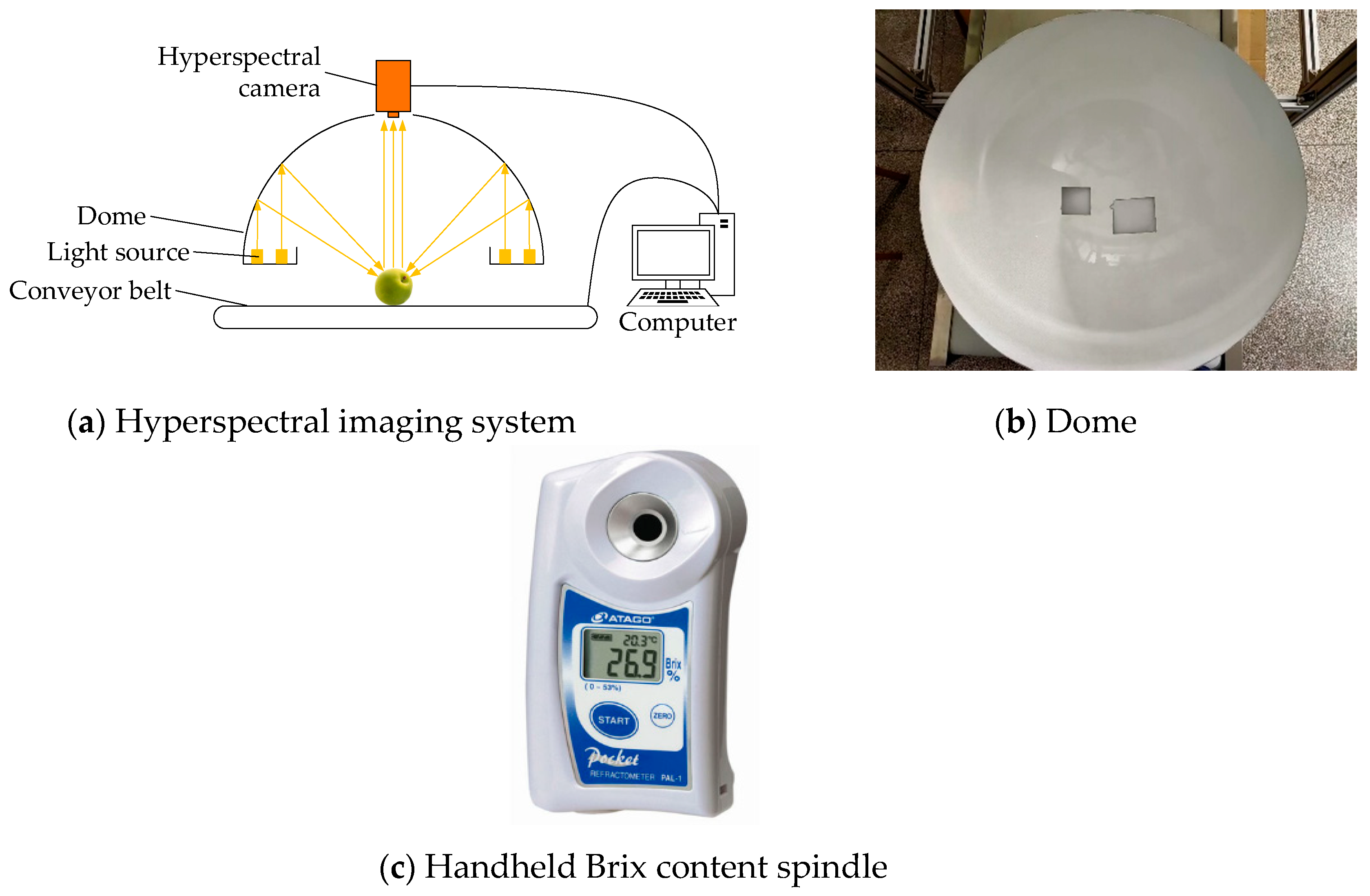
2.2. Equipment
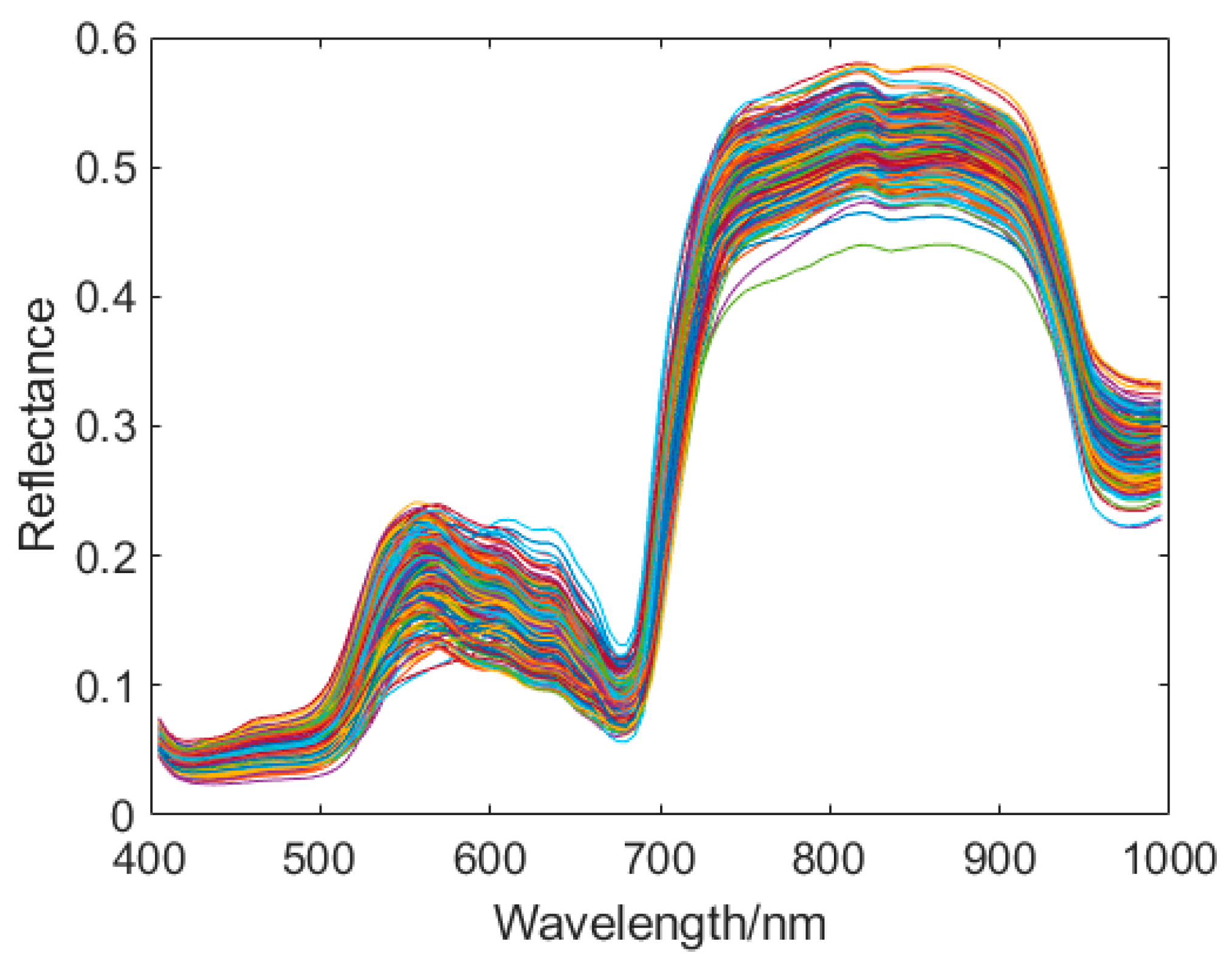
2.3. Hyperspectral Data Acquisition
2.4. Green Plum SSC Testing
2.5. Image Processing
3. Model Establishment
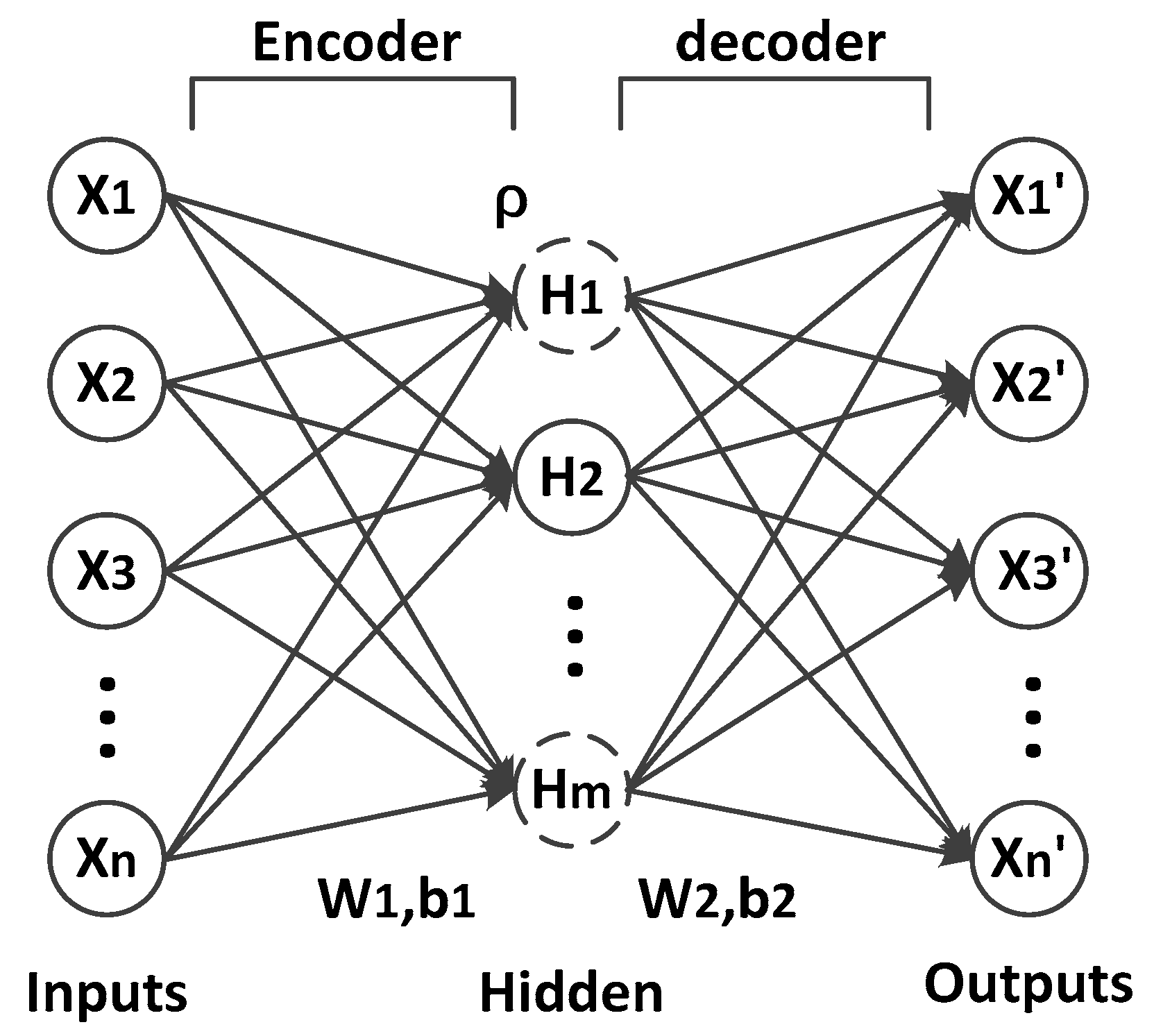
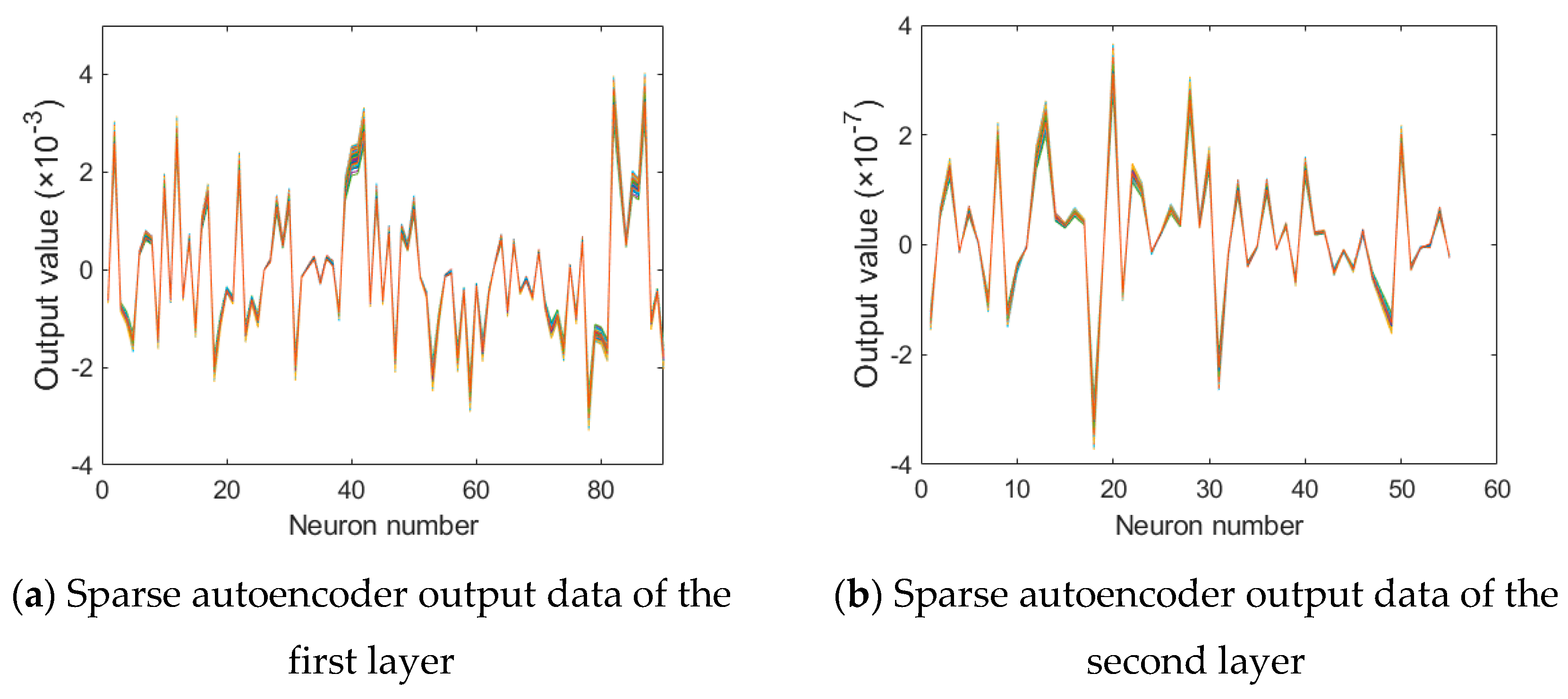
3.1. SAE
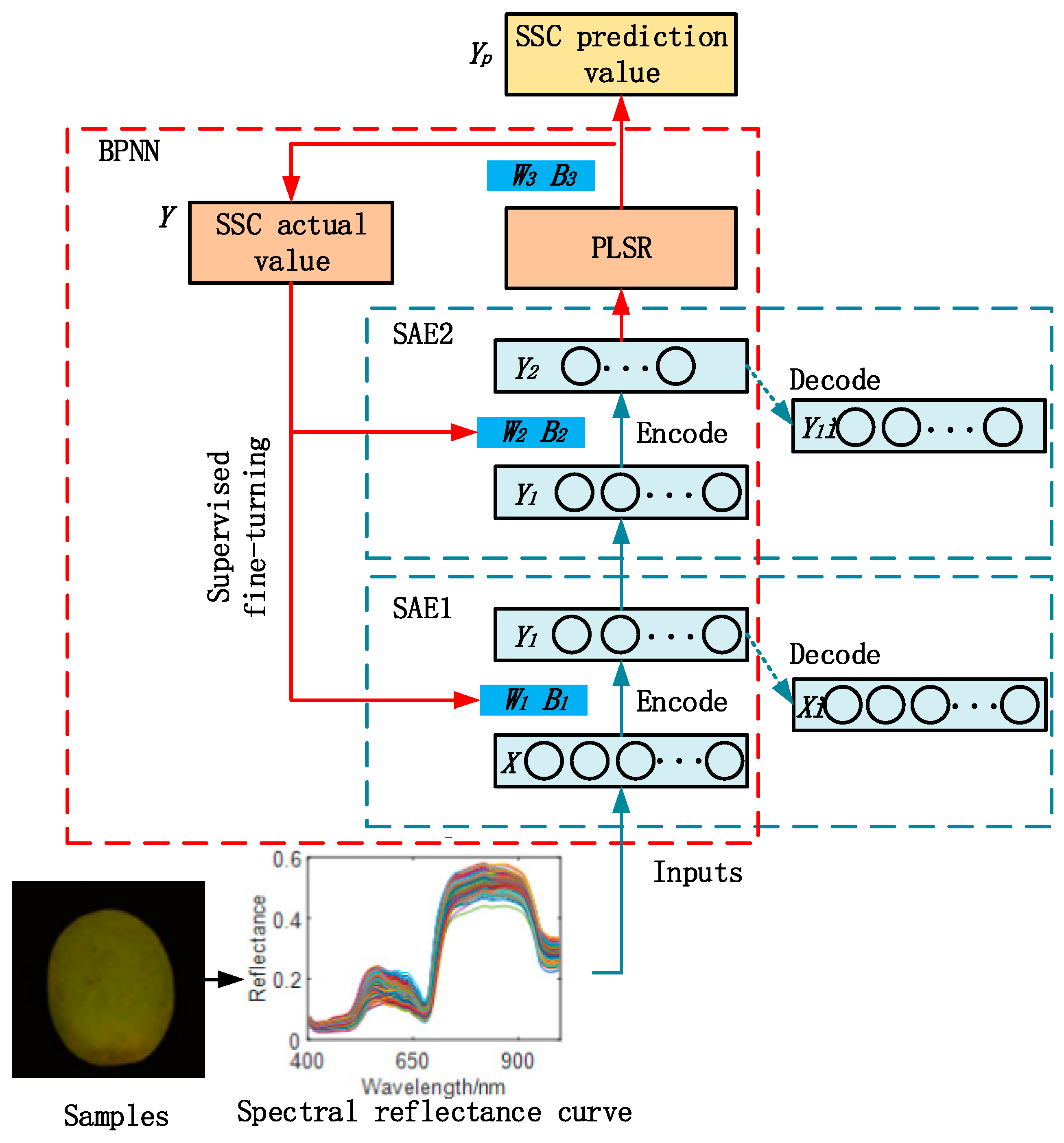
3.2. SAE–PLSR
4. Results and Discussion
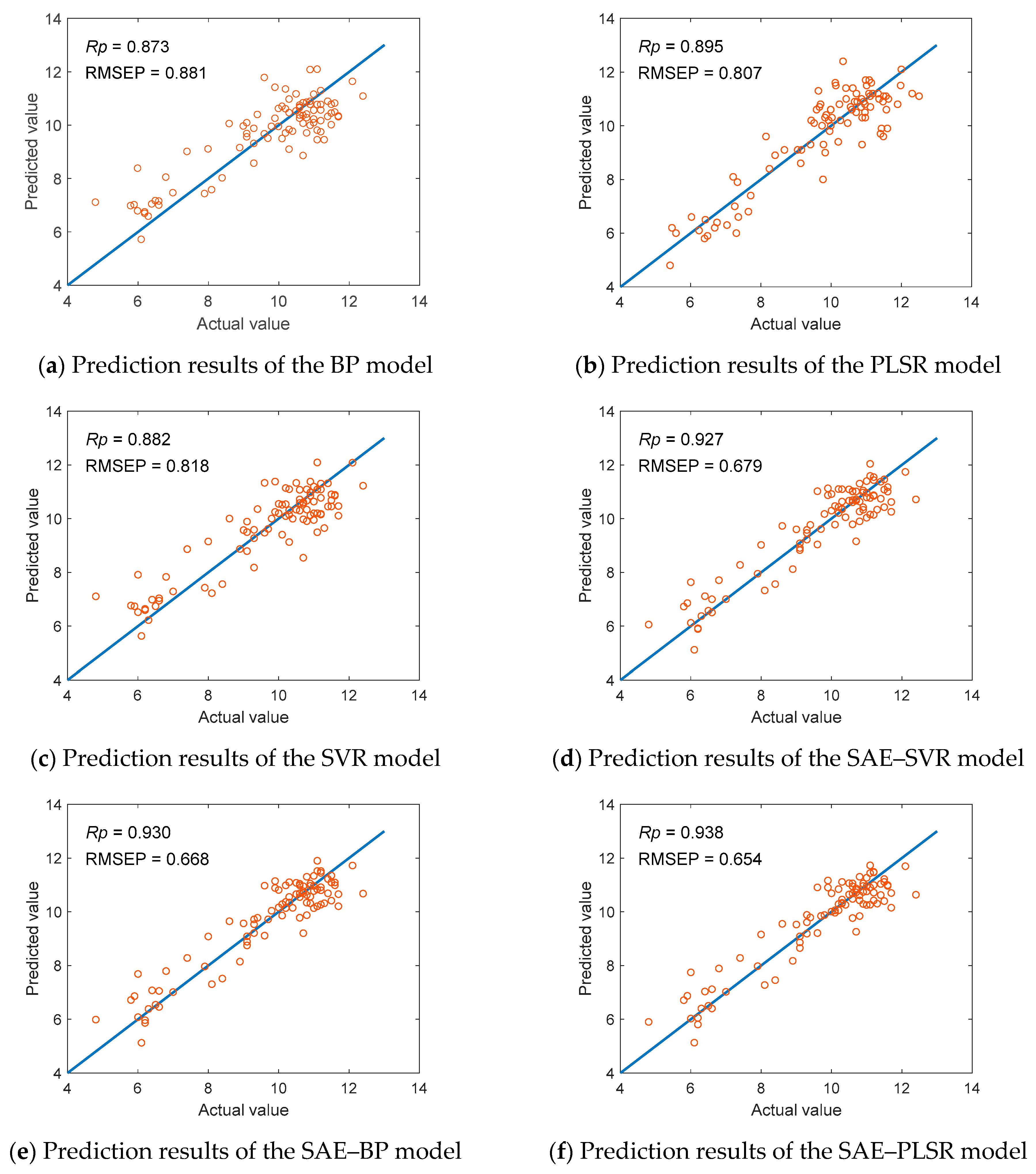
4.1. Performance Analysis of SAE–PLSR Model
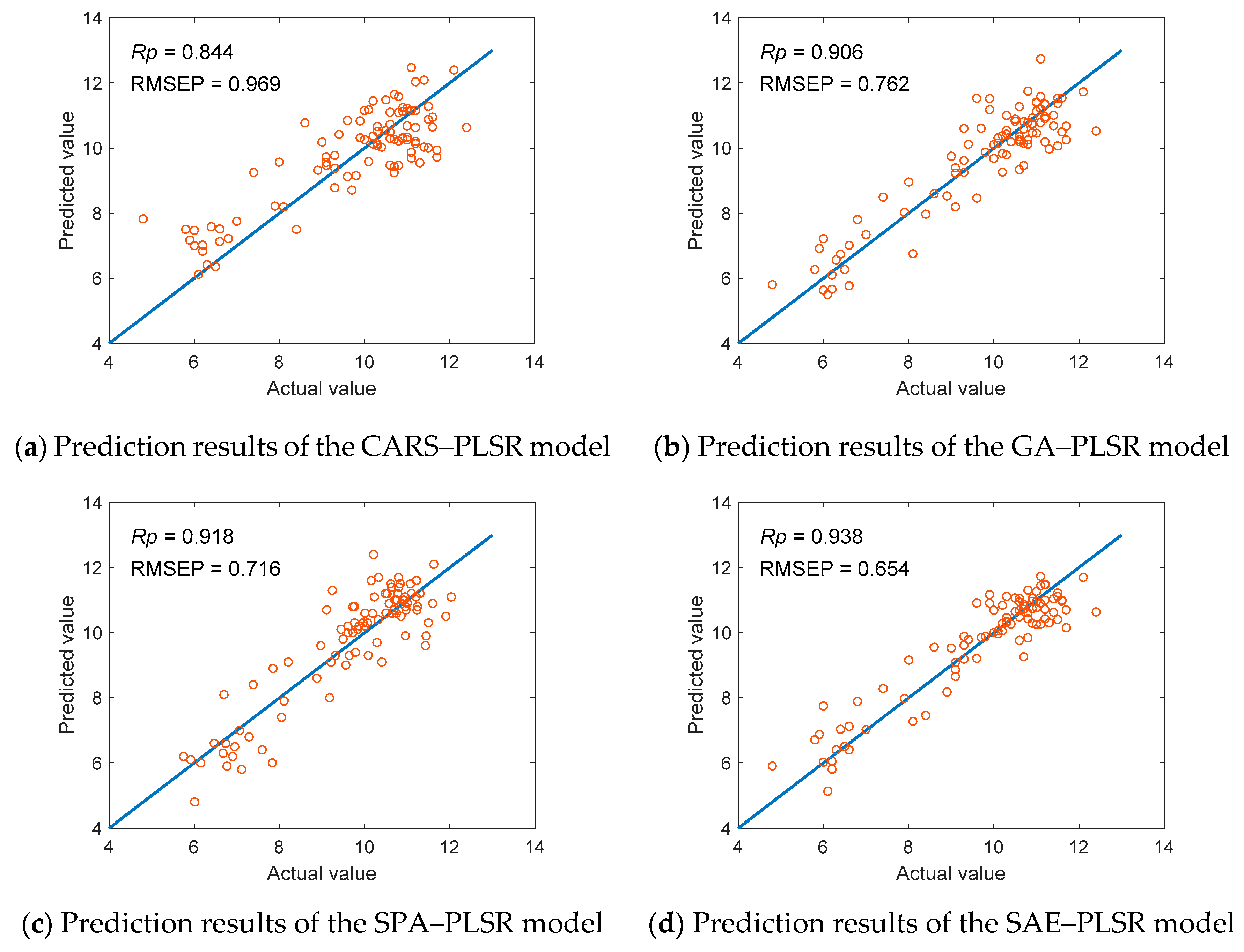
4.2. Performance Analysis of Feature Extraction Methods
4.3. Influence of Sparsity Parameter ρ on Prediction Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wang, X.; Matetić, M.; Zhou, H.; Zhang, X.; Jemrić, T. Postharvest Quality Monitoring and Variance Analysis of Peach and Nectarine Cold Chain with Multi-Sensors Technology. Appl. Sci. 2017, 7, 133. [Google Scholar] [CrossRef]
- Xiao, H.; Feng, L.; Song, D.; Tu, K.; Peng, J.; Pan, L. Grading and Sorting of Grape Berries Using Visible-Near Infrared Spectroscopy on the Basis of Multiple Inner Quality Parameters. Sensors 2019, 19, 2600. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Liu, Y.; Yang, Y.; Zhang, Z.; Chen, K. Assessment of Tomato Color by Spatially Resolved and Conventional Vis/NIR Spectroscopies. Spectrosc. Spectr. Anal. 2019, 39, 3585–3591. [Google Scholar]
- Huang, Y.; Lu, R.; Chen, K. Assessment of Tomato Soluble Solids Content and pH by Spatially-Resolved and Conventional Vis/NIR Spectroscopy. J. Food Eng. 2018, 236, 19–28. [Google Scholar] [CrossRef]
- Huang, Y.; Lu, R.; Chen, K. Detection of Internal Defect of Apples by a Multichannel Vis/NIR spectroscopic system. Postharvest Biol. Technol. 2020, 116, 111065. [Google Scholar] [CrossRef]
- Ni, C.; Wang, D.; Tao, Y. Variable Weighted Convolutional Neural Network for the Nitrogen Content Quantization of Masson Pine Seedling Leaves with Near-Infrared Spectroscopy. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2019, 209, 32–39. [Google Scholar] [CrossRef]
- Cheng, W.; Sun, D.W.; Pu, H. Heterospectral Two-Dimensional Correlation Analysis with Near-Infrared Hyperspectral Imaging for Monitoring Oxidative Damage of Pork Myofibrils During Frozen Storage. Food Chem. 2018, 248, 119–127. [Google Scholar] [CrossRef]
- Wang, X.; An, S.; Xu, Y.; Hou, H.; Chen, F.; Yang, Y.; Zhang, S.; Liu, R. A Back Propagation Neural Network Model Optimized by Mind Evolutionary Algorithm for Estimating Cd, Cr, and Pb Concentrations in Soils Using Vis-NIR Diffuse Reflectance Spectroscopy. Appl. Sci. 2020, 10, 51. [Google Scholar] [CrossRef]
- Zheng, X.; Peng, Y.; Wang, W. A Nondestructive Real-Time Detection Method of Total Viable Count in Pork by Hyperspectral Imaging Technique. Appl. Sci. 2017, 7, 213. [Google Scholar] [CrossRef]
- Caporaso, N.; Whitworth, M.B.; Fisk, I.D. Protein Content Prediction in Single Wheat Kernels Using Hyperspectral Imaging. Food Chem. 2018, 240, 32–42. [Google Scholar] [CrossRef]
- Lu, X.; Sun, J.; Mao, H.; Wu, X.; Gao, H. Quantitative Determination of Rice Starch Based on Hyperspectral Imaging Technology. Int. J. Food Prop. 2017, 20 (Suppl. S1), S1037–S1044. [Google Scholar] [CrossRef]
- Zhou, F.; Peng, J.; Zhao, Y.; Huang, W.; Jiang, Y.; Li, M.; Wu, X.; Lu, B. Varietal Classification and Antioxidant Activity Prediction of Osmanthus Fragrans Lour. Flowers Using UPLC–PDA/QTOF–MS and Multivariable Analysis. Food Chem. 2017, 217, 490–497. [Google Scholar] [CrossRef] [PubMed]
- Krepper, G.; Romeo, F.; Fernandes, D.; Diniz, P.; de Araujo, M.; Di Nezio, M.; Pistonesi, M.; Centurion, M. Determination of Fat Content in Chicken Hamburgers Using NIR Spectroscopy and the Successive Projections Algorithm for Interval Selection in PLS Regression (iSPA-PLS). Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2018, 189, 300–306. [Google Scholar] [CrossRef] [PubMed]
- Zhu, T.; Xie, L.; Wei, H.; Wang, H.; Zhao, X.; Zhang, K. Clear-sky Direct Normal Irradiance Estimation Based on Adjustable Inputs and Error Correction. J. Renew. Sustain. Energy 2019, 11, 056101. [Google Scholar] [CrossRef]
- Weng, S.; Guo, B.; Tang, P.; Yin, X.; Pan, F.; Zhao, J.; Huang, L.; Zhang, D. Rapid Detection of Adulteration of Minced Beef Using Vis/NIR Reflectance Spectroscopy with Multivariate Methods. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2020, 230, 118005. [Google Scholar] [CrossRef]
- Deng, F.; Pu, S.; Chen, X.; Shi, Y.; Yuan, T.; Pu, S. Hyperspectral Image Classification with Capsule Network Using Limited Training Samples. Sensors 2018, 18, 3153. [Google Scholar] [CrossRef]
- Liu, L.; Ji, M.; Buchroithner, M. Transfer Learning for Soil Spectroscopy Based on Convolutional Neural Networks and Its Application in Soil Clay Content Mapping Using Hyperspectral Imagery. Sensors 2018, 18, 3169. [Google Scholar] [CrossRef]
- Li, K.; Wang, M.; Liu, Y.; Yu, N.; Lan, W. A Novel Method of Hyperspectral Data Classification Based on Transfer Learning and Deep Belief Network. Appl. Sci. 2019, 9, 1379. [Google Scholar] [CrossRef]
- Sun, W.; Shao, S.; Zhao, R.; Yan, R.; Zhang, X.; Chen, X. A Sparse Auto-encoder-Based Deep Neural Network Approach for Induction Motor Faults Classification. Measurement 2016, 89, 171–178. [Google Scholar] [CrossRef]
- Li, S.; Yu, B.; Wu, W.; Su, S.; Ji, R. Feature Learning Based on SAE–PCA Network for Human Gesture Recognition in RGBD Images. Neurocomputing 2015, 151, 565–573. [Google Scholar] [CrossRef]
- Han, X.; Zhong, Y.; Zhang, L. Spatial-spectral Unsupervised Convolutional Sparse Auto-encoder Classifier for Hyperspectral Imagery. Photogramm. Eng. Remote Sens. 2017, 83, 195–206. [Google Scholar] [CrossRef]
- Fan, Y.; Zhang, C.; Liu, Z.; Qiu, Z.; He, Y. Cost-sensitive Stacked Sparse Auto-encoder Models to Detect Striped Stem Borer Infestation on Rice Based on Hyperspectral Imaging. Knowl.-Based Syst. 2019, 168, 49–58. [Google Scholar] [CrossRef]
- Peng, X.; Feng, J.; Xiao, S.; Yan, W.; Zhou, J.; Yang, S. Structured AutoEncoders for Subspace Clustering. IEEE Trans. Image Process. 2018, 27, 5076–5086. [Google Scholar] [CrossRef] [PubMed]
- Blaschke, T.; Olivecrona, M.; Engkvist, O.; Bajorath, J.; Chen, H. Application of Generative Autoencoder in de Novo Molecular Design. Mol. Inform. 2017, 37, 1700123. [Google Scholar] [CrossRef] [PubMed]
- Wen, L.; Gao, L.; Li, X. A New Deep Transfer Learning Based on Sparse Auto-Encoder for Fault Diagnosis. IEEE Trans. Syst. Man Cybern. Syst. 2017, 49, 136–144. [Google Scholar] [CrossRef]
- Luo, X.; Xu, Y.; Wang, W.; Yuan, M.; Ban, X.; Zhu, Y.; Zhao, W. Towards Enhancing Stacked Extreme Learning Machine with Sparse Autoencoder by Correntropy. J. Frankl. Inst. 2017, 355, 1945–1966. [Google Scholar] [CrossRef]
- Wang, X.; Zhao, M.; Ju, R.; Song, Q.; Hua, D.; Wang, C.; Chen, T. Visualizing quantitatively the freshness of intact fresh pork using acousto-optical tunable filter-based visible/near-infrared spectral imagery. Comput. Electron. Agric. 2013, 99, 41–53. [Google Scholar] [CrossRef]
- Xu, S.; Zhao, Y.; Wang, M.; Shi, X. Comparison of Multivariate Methods for Estimating Selected Soil Properties from Intact Soil Cores of Paddy Fields by Vis–NIR Spectroscopy. Geoderma 2018, 310, 29–43. [Google Scholar] [CrossRef]
- Ni, C.; Zhang, Y.; Wang, D. Moisture Content Quantization of Masson Pine Seedling Leaf Based on Stacked Autoencoder with Near-Infrared Spectroscopy. J. Electr. Comput. Eng. 2018, 1–8. [Google Scholar] [CrossRef]
- Ni, C.; Li, Z.; Zhang, X.; Sun, X.; Huang, Y.; Zhao, L.; Zhu, T.; Wang, D. Online Sorting of the Film on Cotton Based on Deep Learning and Hyperspectral Imaging. IEEE Access 2020. [Google Scholar] [CrossRef]
- Wang, X.; Wang, X.; Zhang, F.; Ding, J.; Kung, H.; Latif, A.; Johnson, V. Estimation of Soil Salt Content (SSC) in The Ebinur Lake Wetland National Nature Reserve (ELWNNR), Northwest China, Based on a Bootstrap-BP Neural Network Model and Optimal Spectral Indices. Sci. Total Environ. 2018, 615, 918–930. [Google Scholar] [CrossRef] [PubMed]
- Zhang, N.; Liu, X.; Jin, X.; Li, C.; Wu, X.; Yang, S.; Ning, J.; Yanne, P. Determination of Total Iron-reactive Phenolics, Anthocyanins and Tannins in Wine Grapes of Skins and Seeds Based on Near-infrared Hyperspectral Imaging. Food Chem. 2017, 237, 811–817. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Riccioli, C.; Sun, D. Comparison of Hyperspectral Imaging and Computer Vision for Automatic Differentiation of Organically and Conventionally Farmed Salmon. J. Food Eng. 2017, 196, 170–182. [Google Scholar] [CrossRef]
- Li, B.; Cobo-Medina, M.; Lecourt, J.; Harrison, N.; Harrison, R.; Cross, J. Application of Hyperspectral Imaging for Nondestructive Measurement of Plum Quality Attributes. Postharvest Biol. Technol. 2018, 141, 8–15. [Google Scholar] [CrossRef]
- Tang, G.; Huang, Y.; Tian, K.; Song, X.; Yan, H.; Hu, J.; Xiong, Y.; Min, S. A New Spectral Variable Selection Pattern Using Competitive Adaptive Reweighted Sampling Combined with Successive Projections Algorithm. Analyst 2014, 139, 4894. [Google Scholar] [CrossRef]
- Tang, J.; Deng, C.; Huang, G. Extreme Learning Machine for Multilayer Perceptron. IEEE Trans. Neural Netw. Learn. Syst. 2015, 27, 809–821. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
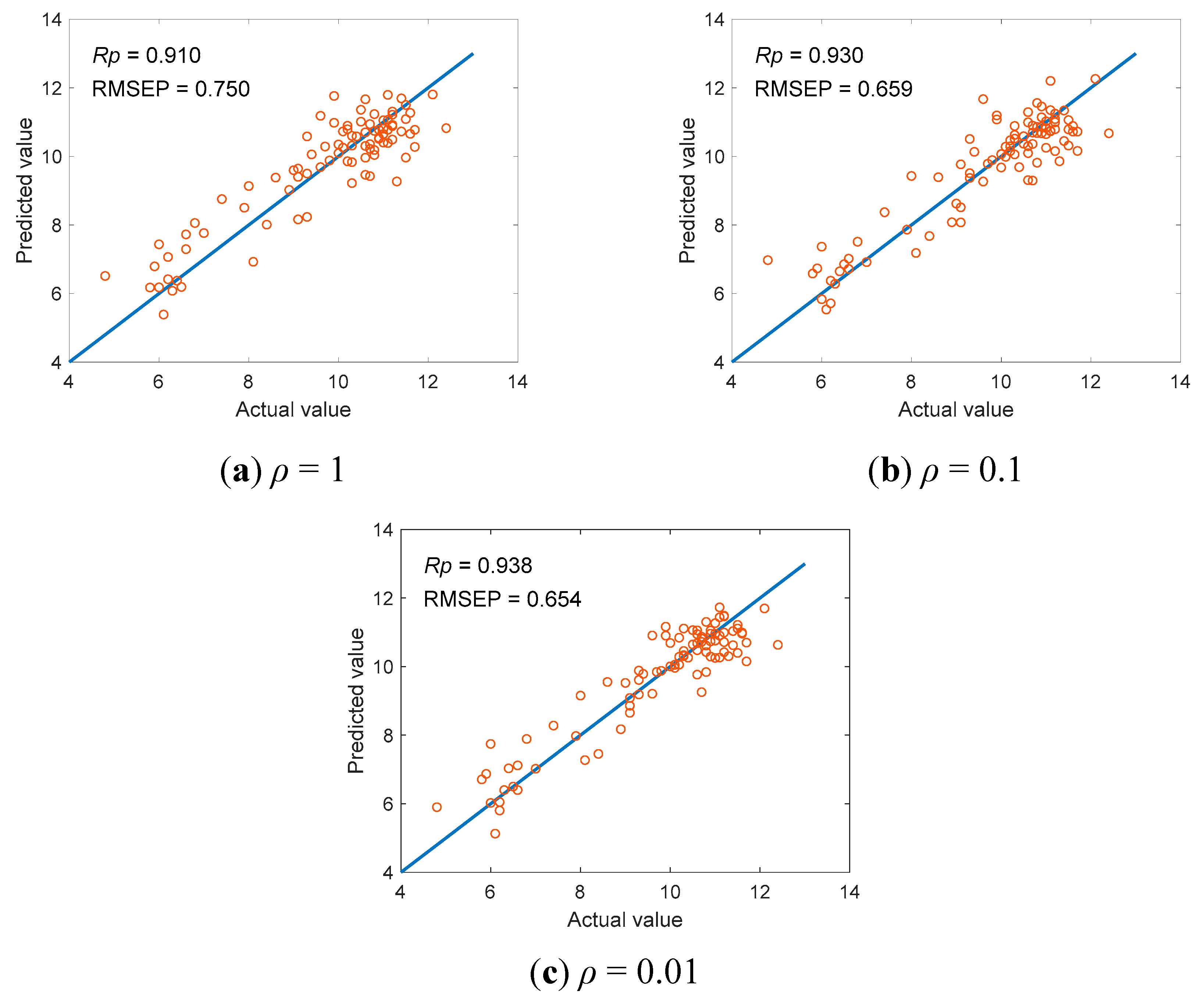{kind=link}
| Sample Set | n | Max | Min | Mean | SD |
|---|---|---|---|---|---|
| Calibration set | 274 | 13.1 | 5.8 | 9.7 | 1.768 |
| Prediction set | 92 | 12.4 | 5.8 | 9.7 | 1.819 |
| Model | RC | RMSEC | RP | RMSEP |
|---|---|---|---|---|
| BP | 0.886 | 0.820 | 0.873 | 0.881 |
| SVR | 0.894 | 0.628 | 0.882 | 0.818 |
| PLSR | 0.968 | 0.442 | 0.895 | 0.807 |
| SAE–BP | 0.942 | 0.582 | 0.930 | 0.668 |
| SAE–SVR | 0.939 | 0.602 | 0.927 | 0.679 |
| SAE–PLSR | 0.957 | 0.542 | 0.938 | 0.654 |
| Model | RC | RMSEC | RP | RMSEP |
|---|---|---|---|---|
| SPA–PLSR | 0.925 | 0.675 | 0.918 | 0.716 |
| CARS–PLSR | 0.869 | 0.870 | 0.844 | 0.969 |
| GA–PLSR | 0.955 | 0.526 | 0.906 | 0.762 |
| SAE–PLSR | 0.957 | 0.542 | 0.938 | 0.654 |
| ρ | RC | RMSEC | RP | RMSEP |
|---|---|---|---|---|
| 1 | 0.929 | 0.633 | 0.910 | 0.750 |
| 0.1 | 0.949 | 0.574 | 0.930 | 0.659 |
| 0.01 | 0.957 | 0.542 | 0.938 | 0.654 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, L.; Wang, H.; Liu, Y.; Liu, Y.; Zhang, X.; Fei, Y. Prediction of Soluble Solids Content in Green Plum by Using a Sparse Autoencoder. Appl. Sci. 2020, 10, 3769. https://doi.org/10.3390/app10113769
Shen L, Wang H, Liu Y, Liu Y, Zhang X, Fei Y. Prediction of Soluble Solids Content in Green Plum by Using a Sparse Autoencoder. Applied Sciences. 2020; 10(11):3769. https://doi.org/10.3390/app10113769
Chicago/Turabian StyleShen, Luxiang, Honghong Wang, Ying Liu, Yang Liu, Xiao Zhang, and Yeqi Fei. 2020. "Prediction of Soluble Solids Content in Green Plum by Using a Sparse Autoencoder" Applied Sciences 10, no. 11: 3769. https://doi.org/10.3390/app10113769
APA StyleShen, L., Wang, H., Liu, Y., Liu, Y., Zhang, X., & Fei, Y. (2020). Prediction of Soluble Solids Content in Green Plum by Using a Sparse Autoencoder. Applied Sciences, 10(11), 3769. https://doi.org/10.3390/app10113769