Abstract
Modern construction and infrastructure projects produce large volumes of heterogeneous data, including building information models, JSON sensor streams, and maintenance logs. Ensuring interoperability and data integrity across diverse software platforms requires standardized data exchange methods. However, traditional neutral object models, often constrained by rigid and incompatible schemas, are ill-suited to accommodate the heterogeneity and long-term nature of such data. Addressing this challenge, the study proposes a schema-less data exchange approach that improves flexibility in representing and interpreting infrastructure information. The method uses dynamic JSON-based objects, with infrastructure model definitions serving as semantic guidelines rather than rigid templates. Rule-based reasoning and dictionary-guided term mapping are employed to infer entity types from semi-structured data without enforcing prior schema conformance. Experimental evaluation across four datasets demonstrated exact entity-type match rates ranging from 61.4% to 76.5%, with overall success rates—including supertypes and ties—reaching up to 95.0% when weighted accuracy metrics were applied. Compared to a previous baseline, the method showed a notable improvement in exact matches while maintaining overall performance. These results confirm the feasibility of schema-less inference using domain dictionaries and indicate that incorporating schema-derived constraints could further improve accuracy and applicability in real-world infrastructure data environments.
1. Introduction
1.1. Research Background and Motivation
The construction industry is undergoing a rapid digital transformation driven by advancements in technologies such as building information modeling (BIM), internet of things (IoT), and cloud computing. This transformation has necessitated a shift toward data-driven decision-making, where insights derived by analyzing project data are used in critical decision-making throughout the lifecycle of a built asset. The ability to effectively leverage data is becoming increasingly essential for improving the efficiency, reducing costs, and enhancing the overall project outcomes.
Modern construction projects involve experts from diverse disciplines such as architecture; structural engineering; mechanical, electrical, and plumbing (MEP) engineering; and project management. These disciplines generate and utilize data from different perspectives, requiring data exchange methodologies that can effectively coordinate them [1]. Furthermore, the data evolve throughout the project lifecycle, necessitating mechanisms to manage data versioning and ensure backward compatibility [2,3]. Finally, the data exchange method must incorporate conflict-detection mechanisms to identify and resolve the inconsistencies or contradictions in data originating from different data sources [3].
The existing data exchange methods [1] are characterized by rigidity, complexity, and difficulty in accommodating diverse data sources and evolving requirements. Although several data exchange standards exist within the construction domain, such as industry foundation classes (IFCs), these methods often exhibit significant limitations. Their rigid schema structures struggle to accommodate the diverse and evolving data formats generated by modern construction projects. The inherent complexity of these standards can hinder seamless data exchange, leading to interoperability challenges and impeding the efficient flow of information across project stakeholders.
Schema-less data such as JSON [4] can provide flexibility, as their structure is implicit and not strictly enforced. However, without any agreed-upon data exchange conventions backed by proper management, schema-less data may complicate exchange efforts due to ambiguity of the meanings they carry. Therefore, to take advantage of schema-less data for sharing construction design and engineering information, a measure for sharing the structure and meaning of the data is needed.
1.2. Research Objectives and Scope
This study aimed to develop and present a flexible schema-agnostic data exchange methodology, facilitating data integration of heterogeneous JSON-encoded construction engineering information such as BIM data and construction-phase data such as job progress throughout the lifecycle of a construction project. To identify each data object, various data matching techniques were employed to infer the structure and validate the content without strict schema definitions. This study focuses on information flows across various disciplines such as architecture, structural and MEP engineering, project management, construction management, etc.
1.3. Contributions of This Study
This study introduces a methodology that leverages dynamic data, embraces a schema-agnostic design, and implements a data dictionary-based approach to handle engineering data from a construction project, thus creating a unique and adaptable solution for facilitating data-driven decision-making in construction. It focuses on the interoperability of diverse non-geometric data (cost, schedule, and materials) using standard classifications (dictionaries) and offers a pragmatic approach when full standard compliance is difficult.
Unlike black-box machine learning (ML)/large language model (LLM)-based approaches, this methodology ensures transparency and explainability of the inference, which are critical in construction, where trust and verification are paramount. Also, it demonstrates that semantic interpretation and validation are possible with a relatively lightweight approach without requiring large-scale training data or high-performance computing, as in the case of ML/LLM.
This methodology enables enhanced assessment of the data quality by quantifying the degree of match with the dictionary definitions rather than a binary ‘good-or-bad’ metric. Its data dictionary incorporates additional contexts such as synonyms and importance levels.
2. Theoretical Background and Related Work
2.1. Construction Information Modeling and Data Exchange
The increasing digitization of documents and information in civil infrastructure projects demands seamless data sharing among the project participants. This requires interoperability and compatibility among the diverse data types and formats used in design, engineering, and management software.
Data exchange between various engineering software and hardware systems used for road design and structural analysis was initially addressed in the 1980s and 1990s with the development of neutral data formats for digitizing information in various fields, such as CAD/CAE. In the construction sector, IFC, which defines the various elements comprising the facilities and the relationships between them, is being developed as the standard for data exchange formats based on neutral data models.
Most neutral data models are considered static because the structure and terminology of the models cannot be altered by their user. Table 1 summarizes advantages and disadvantages of static data model-based exchange.

Table 1.
Advantages and disadvantages of static data exchange approaches.
2.2. Integration of Unstructured Project Information with Structured Object Representations
The majority of the information required during the implementation of a construction project is digitized into semi-structured formats, such as text or tables (e.g., Excel). To effectively utilize this semi-structured and unstructured information in construction projects, it must be effectively linked to well-structured object models. The Construction Operations Building Information Exchange (COBie) [5] maintains the building maintenance information in a spreadsheet table format (XML) and assigns IDs to the IFC objects of the target facility to link them with the object model. In contrast, in W3C Linked Building Data (see References), the ontology for the spatial structure of a building is defined using semantic web technologies, enabling the linking of component information based on this ontology in a Linked Data format.
However, the exchange of diverse unstructured and semi-structured information in conjunction with BIM models cannot be adequately addressed by simply expanding neutral models. Sobkhiz and El-Diraby [6] proposed a method for deriving unique models tailored to project-specific situations by combining the semantic networks extracted through natural language analysis of project documents with an analysis of the communication network of a user. However, finding an effective method to ensure that the situational data model derived from the analysis of specific cases can be understood and shared by all project participants remains a challenge for future research.
2.3. Schema Inference and Ontology Matching for Dynamic Data Objects
Dynamic objects are self-describing data structures, often represented in formats such as JSON, XML, or YAML, which enable the modeling of real-world phenomena or abstract concepts through hierarchically structured item-name/content pairs. Unlike traditional schema-bound approaches, dynamic objects are not derived from a fixed data model, which facilitates flexible data representation and adaptation to evolving information requirements.
To ensure the accurate interpretation of the data exchange with dynamic objects, several methodologies have been developed to convey the semantic meaning without relying on rigid, predefined schemas.
2.3.1. Schema Inference
Schema inference techniques aim to derive a data structure or schema from dynamic objects, enabling interpretations based on patterns and relationships within the data.
Inferring the schemas from dynamic data, such as JSON data, involves discovering their implicit structure through frequency analysis of the data element occurrences and tree structure matching, effectively approximating a schema by identifying recurring patterns in the data organization.
By inferring a schema, different systems can understand and process the data, even if they do not have prior knowledge of their structure.
Cánovas Izquierdo and Cabot [7] proposed an iterative schema-merging technique that extracts schemas from individual JSON documents and progressively merges them, thus addressing the need to discover and visualize implicit schemas in schema-free JSON data.
Klettke et al. [8] utilized a structure identification graph to discern hierarchical relationships between JSON nodes. Their approach employed a reverse engineering technique that extracted an explicit schema after data storage and detected structural outliers. This strategy aligns with the scalable implementation of lazy-schema evolution in NoSQL data stores.
Baazizi et al. [9] developed a two-phase inference algorithm that analyzes field occurrence frequencies to identify mandatory/optional fields and union types, allowing users to adjust the precision–conciseness balance of the algorithm by modifying the equivalence relation (E) parameters. The approach addressed the challenges in schema inference from massive, schema-less JSON datasets, where the absence of schema information can negatively affect the query correctness and optimization.
2.3.2. Ontology Matching
Ontology matching addresses the challenge of semantic interoperability by identifying the correspondence between different ontologies or knowledge representations.
When dynamic object reference concepts are defined in different ontologies, ontology matching helps to resolve these differences and ensures that all systems interpret the data consistently.
Ontology matching approaches leverage the existing ontologies and semantic relationships to align dynamic objects with established knowledge domains, thereby facilitating meaning transfer through shared vocabulary and concepts.
Miller et al. [10] proposed an instance-based matching approach that infers schema mappings by analyzing not only the schema structure but also the characteristics of actual data instances (values), such as data types, value distributions, and patterns. For example, they determined that two attributes are likely to correspond if they consistently contain values of a similar format (e.g., date formats), aligning with the schema mapping problem of discovering queries to transform source data into a different but fixed target schema.
Madhavan et al. [11] modeled two schemas internally as schema graphs (representing shared types, referential integrity, and views as nodes and edges) and then automatically generated mappings by calculating the linguistic (name, type) and structural (context, sub-leaf) similarities. Although this approach is intended for translation between two schemas, its similarity-based discovery of the data structure can also be applied to schema-less ontology discovery and matching.
Suchanek et al. [12] identified the correspondence between schemas or ontologies by integrating diverse techniques, including lexical analysis of names, structural analysis using graph-based representations, semantic reasoning leveraging WordNet and background knowledge, and instance-based matching. This multifaceted approach enabled the construction of an extensible ontology by automatically extracting and unifying facts from Wikipedia, thereby achieving a high degree of accuracy in the resulting knowledge base.
2.3.3. Data Mapping
Data-mapping techniques define explicit transformations and correspondences between elements in dynamic objects and those in target systems. They establish clear links to ensure consistent and accurate translation of information between the source and target data models.
For construction data mapping, particularly ontology-based approaches, semantic technologies can be used to refine the matching logic, leveraging rule-based reasoning or semantic descriptions during the dictionary matching phase. Beach et al. [13] proposed a method to flexibly interpret and validate data by transforming the BIM data, such as IFC, into a resource description framework (RDF) and applying semantic web technologies such as SPARQL (SPARQL Protocol and RDF Query Language) and Semantic Web Rule Language (SWRL), thus facilitating automated regulatory compliance within the construction sector.
2.4. Verifying Correctness of Dynamic Data Objects
Because there are no fixed schemas that would normally enforce data integrity, dynamic, schema-less data require verification to ensure their correctness. This verification requires a multifaceted approach, encompassing both the verification of its structural integrity and validation of its semantic meaning against the expected domain knowledge.
2.4.1. Structural Correctness
Verifying the structural correctness of dynamic data involves assessing whether the data adhere to expected patterns, hierarchies, and relationships, ensuring that they are well-formed and consistent in terms of their organization. In the context of the structural correctness of dynamic data, schema inference is often employed, wherein the inferred schema is compared with the dynamic data.
Klettke et al. [14] proposed the “structural outlier” metric, a composite indicator combining attribute (key) omission/addition rates, type mismatch rates, and nested structure inconsistency rates, as a measure of the structural conformity between automatically inferred JSON schemas (using their approach from [8]) and actual documents; this method aimed to capture the degree of heterogeneity of the JSON data and reveal structural outliers.
Afsari et al. [15] verified the correctness of BIM data by first examining the formal validity (structure, data types, etc.) of the JSON documents and then performing schema validation against a defined ifcJSON4 schema, which mirrors the EXPRESS schema matching used with the IFC data (in the SPF format).
2.4.2. Semantic Correctness
Beyond structural integrity, semantic correctness ensures that data accurately represent the intended meaning and comply with domain-specific constraints, requiring methods that validate both content and its correspondence to real-world concepts. Domain rule-based approaches establish semantic correctness by defining explicit rules and constraints that reflect inherent properties and relationships within a specific domain, allowing for validation against these predefined expectations. On the other hand, ontology-based approaches leverage formal ontologies and semantic reasoning to verify the semantic correctness and map the data to well-defined concepts and relationships within an ontology to ensure consistency and adherence to domain knowledge.
Solihin et al. [16] highlighted that neutral data models defined with EXPRESS schemas, such as IFC, include definitions of the object relationships and constraints that cannot be expressed with a simple JSON schema alone, necessitating a semantic validation step to ensure the logical consistency of the data; their study aimed to define the requirements for a good-quality IFC model and propose automatable rules for measuring its completeness and correctness.
Lee et al. [17] validated the consistency of the exchanged data by verifying their conformance to the model view definitions (MVDs), which are subsets of the IFC schema, using rule sets that verify whether the information required by the receiver is lost or inconsistent during the data exchange. The study focused on identifying requirements/rules and developing rule-based data validation processes to enhance BIM data interoperability.
The following research cases utilized ifcOWL, which transforms the IFC into an RDF/OWL ontology, to represent the BIM objects as classes and relationships, thus enabling the constraint compliance to be evaluated through logical inference engines:
Venugopal et al. [18] and Terkaj et al. [19] used the ontology to clarify the data elements required for unambiguous information exchange between different project stakeholders [18] or to translate the integrity constraints of the original IFC schema into an OWL class expression [19].
Pauwels et al. [20] checked the compliance of the model data against rulesets defined in the SWRL. A subsequent study [21] proposed enhancing the ifcOWL with optimized geometric semantics to identify incorrect spatial relationships between the building elements. Han et al. [22] defined the physical dependencies among structural components, such as support and containment relationships (e.g., a beam cannot be installed until a column is erected) and developed a construction sequencing ontology based on these relationships. Ontology reasoning was employed to identify incorrect construction sequences by integrating the ontology with the BIM models and construction schedules.
Table 2 summarizes the related research works discussed above, grouped by methodology.
Table 2.
Comparison of the research works related to this research.
3. Proposed Methodology: Schema-Agnostic Information Exchange Based on Dynamic Data Objects
3.1. Overview of Methodology
The proposed methodology is founded on dynamic data objects and schema agnosticism, whereby JSON-based dynamic objects are used for data exchange instead of a fixed, neutral model. It is based on schema agnosticism, which allows a data recipient to interpret and utilize the incoming data without knowing the exact schema employed by the data producer. In the context of schema agnosticism, the data dictionary defines classes and members but serves primarily as a reference guide to help recipients understand the semantics of the received data rather than to enforce a rigid structure.
3.1.1. Data Dictionary
Inferring the types and attributes of the data objects from the schema-less JSON data is a significant challenge because of the absence of explicit structural definitions. A data dictionary serves as a reference for semantic interpretation. It offers a primary, yet effective, means of inference by resolving ambiguities in interpretation and assuring data integrity.
This approach involves semantically aligning the keys (fields) found within the schema-less JSON data against formally defined terms and concepts residing in authoritative domain dictionaries or industry classification systems, such as OmniClass, UniClass, buildingSMART Data Dictionary (bSDD), or relevant national standards. These curated resources provide controlled vocabularies and standardized definitions for various types of facilities, components, and their associated attributes or properties within the architecture, engineering, and construction (AEC) domain. By matching the JSON keys to these standard definitions, the intended meaning and type of the data object can be reliably inferred. Because this logic is fixed and explicitly defined, the inference process remains consistent, transparent, and explainable when compared with less interpretable ML approaches.
3.1.2. Object Class Inference Mechanism
The inference techniques discussed above (key name pattern matching, value heuristics, and semantic dictionary matching) are used to align a given data object to a class. The data object properties are defined in the data dictionary derived from a domain-specific classification system such as OmniClass.
These mechanisms operate on a predefined set of criteria that maps the observed features within the JSON data (such as specific key names, value patterns, or successful matches to dictionary/ontology terms) to a specific object category or semantic interpretation.
A key advantage of this approach is its inherent transparency and explainability; the reasoning of the system for classifying an object is directly traceable through the applied explicit logic.
The practical implementation of this inference logic frequently involves the utilization of rule engines or custom-developed scripts designed to evaluate these conditions against the incoming JSON objects. For example, developers can encode deterministic checks that reflect the domain knowledge, such as: “IF the object contains a key named ‘pier_count’ OR a key named ‘deck_type’ THEN classify the object as ‘Bridge’.”
Rule-based classifiers have demonstrated high accuracy in specific controlled scenarios within the AEC domain, such as classifying BIM elements based on geometric and topological clues using IF–THEN rules [23] or mapping textual requirements to BIM elements via predefined correspondence rules [24].
Although a potentially large number of patterns and rules must be enumerated in advance to effectively handle diverse data sources and variations in terminology, the explicit rule-based logic derived from domain knowledge and dictionary definitions remains a viable and transparent method for interpreting the intended meaning of schema-less JSON data in dynamic exchange scenarios.
3.2. Core Components
There are two fundamental components underpinning the proposed schema-agnostic exchange methodology: the data dictionary/ontology establishing the semantic context and the dynamic data object acting as a flexible information carrier.
3.2.1. Data Dictionary/Ontology
In this study, the data dictionary serves as a lightweight domain ontology and is the semantic cornerstone of the proposed schema-agnostic methodology. Derived from an established classification (similar to OmniClass; for further details on the classification system, see [25]), it provides the ground-truth definitions for classes (representing concepts) and their attributes (properties).
It provides a structured knowledge base necessary for interpreting dynamic data objects reliably in a distributed and heterogeneous environment rather than enforcing structural conformance, as in the case of a rigid schema. It acts as a shared, unambiguous reference point, enabling consistent interpretation of the meaning embedded within incoming, potentially schema-less, dynamic data objects.
To fulfill this role effectively, the data dictionary performs several critical functions:
- Semantic Definition: It disambiguates the meaning of keys or attribute names used in the dynamic data; for instance, it clarifies whether a “length” attribute refers to a physical dimension (e.g., of a beam) or a time duration (e.g., of a task).
- Concept Identification: It formally identifies and describes the core entities pertinent to the construction project domain, such as physical elements, spaces, activities, and resources.
- Relationship Indication: It explicitly defines the key relationships between concepts, including inheritance (is-a), composition/decomposition (part-of), and association (refers-to). This helps the receiving systems to understand the intended structure and context (e.g., “Column” is-a “StructuralMember”; “ReinforcementBar” part-of “Beam”).
- Data Type and Unit Guidance: It specifies the expected data types (e.g., string, number, Boolean, object reference, and list) and the associated units of measure (e.g., m, mm, kg, and MPa) for the attributes. Although not strictly enforced at the schema level, this guidance is crucial for ensuring consistency during data generation and subsequent validation.
3.2.2. Dynamic Data Object
A dynamic data object, typically represented using a lightweight hierarchical format such as JSON, serves as a flexible container for exchanging information fragments related to specific physical or conceptual entities within a project. Unlike the data conforming to rigid schemas, these dynamic objects primarily consist of attribute–value pairs, where the structure and included attributes can vary based on the data source and the specific information being conveyed at that time.
A critical characteristic of each dynamic data object intended to represent a persistent project entity (e.g., a specific column, beam, activity, or requirement) is the inclusion of a unique, immutable identifier such as a global unique identifier (GUID) or a project-specific URN. The identifier ensures that disparate data objects, potentially generated by different systems or at different times, can be reliably associated with the same real-world or conceptual entity that they describe (e.g., urn:uuid:f81d4fae-7dec-11d0-a765-00a0c91e6bf6). Persistent identification is fundamental for integrating information from various sources and tracking the evolution of entities throughout the lifecycle of a project.
Beyond the identifier, the object contains various key–value pairs representing the properties of the entities, where the keys usually correspond semantically to the member names defined in the data dictionary, and the values are specific data (e.g., “elementLength”: 12.5, “concreteGrade”: “C24”). Optionally, objects might also contain metadata fields (e.g., @type, _classId) that explicitly link them to their corresponding class definitions in the data dictionary, although this is not strictly required in a truly schema-agnostic approach where the type is inferred.
3.3. Mitigating Uncertainty in Class Inference Using a Data Dictionary
The core methodology proposed in this study focuses on implicitly inferring the object types based on their content and structure against a data dictionary. Alternatively, explicit methods can also achieve this association; they provide direct linkage information, simplifying the type identification process but potentially sacrificing some of the flexibility inherent in a purely schema-agnostic approach. Table 3 summarizes several explicit identification methods with advantages and disadvantages of each method.
Table 3.
Advantages and disadvantages of object type identification methodologies.
Building upon the previously discussed implicit identification techniques, this section introduces enhancements designed to mitigate uncertainties and improve the accuracy and reliability of inferring the class types from schema-less data by refining both the underlying knowledge base and the matching logic. The approaches proposed here focus on improving the inference accuracy without resorting to ML, instead relying on enriching the explicit, human-curated data dictionary and refining rule-based inference mechanisms.
Refining the logic used to infer the object types and matching them with the dictionary definitions is crucial for improving the accuracy. This involves moving beyond simple comparisons and incorporating sophisticated evaluation techniques.
To provide an objective measure of how well a given JSON object aligns with a specific dictionary class definition, the match between them is quantified using several metrics and combined into a final score, typically ranging from 0 to 1 (or 0% to 100%). The definitions of the mathematical notations used to express the scoring procedure are as follows:
- -
- J is the input JSON object.
- -
- C is a candidate class definition from the data dictionary.
- -
- Keys(J) is the set of keys present in the JSON object J.
- -
- Members(C) is the set of all the members (attributes) defined for class C in the dictionary.
- -
- MatchedMembers(J, C) is the subset of Members(C) for which a corresponding key exists in Keys(J) (considering synonym mapping).MatchedMembers(J, C) = {m ∈ Members(C)|∃ k ∈ Keys(J) such that k maps to m}.
- -
- ConformingMembers(J, C) is the subset of MatchedMembers(J, C), where the value associated with the corresponding key in J conforms to the constraints (type, format, range, unit, etc.) specified for the member m in the dictionary definition C.
- -
- NoiseKeys(J, C) is the subset of Keys(J) that does not map to any member in Members(C).NoiseKeys(J, C) = {k ∈ Keys(J)|¬∃ m ∈ Members(C) such that k maps to m}.
- -
- |S| denotes the cardinality (number of elements) of a set S.
- -
- Coverage (ScoreCov): Calculate the percentage of members defined in the dictionary (especially mandatory members) that are present in the JSON object.
Weights can be applied based on member importance.
- -
- Accuracy/Conformance (ScoreAcc): Measure how well the values of the members present in the JSON object conform to the specifications (type, format, unit, range, enum, etc.) in the dictionary.
Penalties can be adjusted for mismatches.
- -
- Redundancy/Noise (ScoreNoise): Quantify the proportion of members present in the JSON object that are not defined in the dictionary class definition. A higher noise score generally indicates a poorer match.
This score typically acts as a penalty in the final calculation.
- -
- (Optional) Semantic Fit: Incorporate a score reflecting the semantic similarity between key names, even if they do not exactly match. Inferred meanings that align well can contribute positively to the score.
The final match score (ScoreFinal) is calculated by combining the individual metric scores using weights that reflect their relative importance.
where wCov, wAcc, and wNoise are non-negative weighting factors (≥0) assigned to the Coverage, Accuracy, and Noise scores, respectively.
These weights represent the emphasis placed on each aspect of the match. They are configured based on the specific priorities of the application. For example:
- -
- If the primary objective is to ensure that all the expected data fields are present (completeness), then wCov is assigned a relatively high value.
- -
- If the correctness of the values for the present fields (precision) is more critical, wAcc has a higher weight.
- -
- wNoise determines the penalty applied for extraneous keys present in the JSON object but not defined in the dictionary class.
The calculated final score provides an objective measure of how well a JSON object satisfies the requirements of a specific dictionary definition, even in the absence of explicit type information.
During score calculation, weights can be added to differentiate more critical members (e.g., higher weights for mandatory members or key indicators). Weights can also be used to indicate missing non-mandatory members or the presence of significant “noise” (undefined members). Additionally, a “confidence score” can be derived along with the inferred type to quantify the certainty of the inference.
3.4. Validation Framework for Dynamic Data
Effective validation of dynamic data, particularly in a schema-agnostic context, necessitates the definition of specific metrics to quantitatively assess their structural integrity, completeness, and accuracy against the expectations set by the data dictionary and domain knowledge. Section 3.3 explained the calculation of match scores based on various comparison factors. The present section outlines a framework for evaluating the quality and conformity of dynamic data objects during the validation process described later in Section 3.4.3.
The methodology presented in the previous sections is described in the following sequential steps. Broadly speaking, the process involves establishing and managing a data dictionary, which serves as an authoritative semantic reference. Subsequently, dynamic data objects are generated by the source systems, wherein the metadata are potentially embedded or packaged according to agreed-upon conventions and then shared or aggregated. Upon reception, the core validation and inference engine utilizes the prepared dictionary to interpret the intended meaning of an object, assess its quality against the defined metrics, and determine its suitability for downstream use. Figure 1 illustrates the data exchange process.
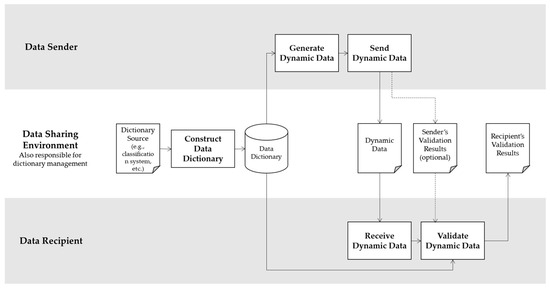
Figure 1.
Overall process flow of the dynamic data exchange framework.
3.4.1. Preparation Phase: Data Dictionary Construction and Management
The first step involves the construction and management of a data dictionary. Based on a selected standard classification system (such as OmniClass, UniClass, KCCS, or a project-specific adaptation), precise definitions must be established for each relevant class (representing concepts or object types) and its associated members (attributes or properties). Table 4 describes the information fields required for each entry in the dictionary.
Table 4.
Structure of the data dictionary.
The data dictionary must provide version information to allow for the tracking of changes and ensure that the consuming systems can reference the correct version. Furthermore, mechanisms must be established to ensure the accessibility of the dictionary to all participating systems involved in data sharing and validation. This typically involves providing access via API endpoints, shared libraries, or dedicated registry services.
3.4.2. Data Generation and Sharing Phase
Following the preparation of the Data Dictionary, the next phase involves the generation and subsequent sharing of dynamic data objects. Schema-less JSON data objects are generated that typically reflect the specific viewpoints or requirements of different project domains or disciplines. This process often involves exporting information from the existing specialized software systems or capturing data from sensors and other sources.
To facilitate interpretation by the recipient, the data originator can choose to perform its own preliminary type inference and calculate the match scores for the generated data against the relevant dictionary definitions before transmission. The results of this pre-validation, such as the inferred type and its confidence level, can be captured as metadata accompanying the data.
The generated JSON data objects, along with any accompanying metadata, are then prepared for transmission. Although various transmission methods can be employed, the core JSON data can be packaged with the associated metadata that provide the essential context. These metadata may include the following:
- Dictionary Context Information: Details specifying the classification system(s) and version(s) of the Data Dictionary that were used as the basis for generating the data or are intended to be used for its interpretation (e.g., {“dictionaryRefs”: [“KCCS_v2.1”, “UniClass2015_v1.8”]}). This ensures that the recipient uses the correct semantic reference framework.
- Inference Results of the Sender (Optional): The outcome of any preliminary type inference performed by the sender, potentially including the most likely class type and an associated confidence score (e.g., {“senderInferredType”: {“type”: “KCCS:11-22-33”, “confidence”: 0.92}}). If provided, this information can serve as a suggestion or starting point for the independent inference process of the receiver but does not replace it.
- Match Score of the Sender (Optional): The match score calculated by the sender, quantifying the conformance of the data to the dictionary definition from the perspective of the originator (e.g., {“senderMatchScore”: 0.88}). When available, this score offers the receiver an initial indication of the data quality as assessed by the sender, although the receiver must perform its own comprehensive validation to make a definitive quality judgment.
3.4.3. Data Validation Phase—Reception and Evaluation
Upon receiving the data package, validation and interpretation commence, leveraging the previously established Data Dictionary to assess the incoming information. This evaluation process is central to ensuring the reliability and utility of schema-agnostic data exchange.
- Data Reception and Context Verification:The receiving system first ingests the data package, which includes dynamic JSON objects and the accompanying metadata. A critical initial action involves parsing the metadata to identify the specified data dictionary version(s) referenced by the sender. The system must ensure that it has the correct version of the dictionary, as this provides the essential semantic framework for all subsequent interpretation and validation tasks.
- Execution of Type Inference:For each received JSON object, the core-type inference algorithm, detailed in Section 3.3, is executed. By utilizing the loaded data dictionary, the algorithm analyzes the structure keys and potentially the values of the object to identify the most probable class definition(s) that it represents. Although the sender-provided indications may be available in the metadata, the receiving system performs this inference independently to arrive at an objective classification. This process typically yields one or more candidate class types, each associated with a calculated confidence or similarity score that reflects the strength of the match based on the inference logic.
- Initial Screening via Inference Results:The outcome of the type inference is subjected to a preliminary assessment. If the highest calculated confidence score for an object fails to meet a predefined minimum threshold (e.g., 0.7), or if the scores for the top two candidate classes are too close to distinguish reliably, the object may be flagged as “Type Ambiguous” or “Unclassifiable.” Such objects may be excluded from further automated processing or routed for manual inspection, thereby preventing erroneous interpretations downstream. The objects that pass this initial screening proceed with a provisionally assigned inferred type.
- Quantification of Match Degree:Following a successful type inference, the system performs a detailed quantification of the match degree between the actual JSON object and the specific definition of its inferred class within the data dictionary. This involves applying the comprehensive scoring mechanism described in Section 3.3, which calculates metrics, such as Coverage, Accuracy/Conformance, and Noise/Redundancy (as defined conceptually in Section 3.4.1). The system meticulously compares the object keys, conformance of its values (type, format, range, and unit), and structural characteristics against the dictionary requirements for the inferred class. This calculation yields individual scores for each metric and culminates in a single, comprehensive final match score (e.g., a value between 0 and 1 or 0–100%), objectively representing the overall conformance of the object to its inferred semantic definition.
- Final Validation Verdict:The calculated final match score is then compared against a predefined acceptance threshold (e.g., 0.8 or 80%) to determine the final validation outcome.
- -
- Validation Passed: If the score meets or exceeds the threshold, the object is considered successfully validated. It is typically marked as “Verified” or “Passed,” confirming its inferred type and deeming it sufficiently reliable for integration into downstream applications, analyses, or data stores.
- -
- Validation Failed/Review Required: If the score falls below the threshold, the object is flagged as “Validation Failed” or “Requires Review.” Critically, the individual metric scores (Coverage, Accuracy, Noise) calculated during the quantification of the degree of match provide valuable diagnostic information. By examining these sub-scores, users or automated systems can identify the specific reasons for the low overall score, such as missing mandatory attributes (low coverage), incorrect data value formats (low accuracy), and the presence of many unexpected fields (high noise). This allows for targeted troubleshooting or data cleansing.
- Utilization of Results:All results from the validation process, including the inferred class type, confidence score, final match score, individual metric scores, and final validation status (Passed/Failed/Review), are recorded for each data object. This information serves multiple purposes: generating data quality reports, enabling filtering or querying of data based on the validation status or quality scores, prioritizing data remediation tasks, and potentially providing insights to improve the upstream data generation processes.
3.5. Expected Benefits
The adoption of the proposed schema-agnostic methodology, grounded in dynamic data objects and semantic interpretation using a data dictionary, is expected to yield significant benefits for the exchange of construction information.
By moving beyond the constraints of rigid, predefined schemas, this approach enhances the semantic understanding of diverse data fragments originating from various sources, thus enabling a more flexible and adaptive integration environment.
Furthermore, the ability to quantitatively assess the data quality through objective match scoring promotes increased reliability and trust in shared information, facilitating early detection and remediation of errors or inconsistencies.
Ultimately, these improvements in data interoperability, semantic clarity, and verifiable quality are expected to contribute to a higher standard of data-driven decision-making throughout the project lifecycle.
4. Experimentation and Evaluation
4.1. Experiment Design
The experiment aims to validate the core components of the proposed methodology, specifically (1) the ability to accurately infer the class type of schema-less JSON objects representing construction components using dictionary-based member matching and (2) the effectiveness of the calculated degree of match (Coverage, Accuracy, Noise, Final Score) in reflecting the conformance of the object to its inferred dictionary definition.
For the experimental algorithms, software scripts were developed in C# to implement the core methodology:
- Loading and parsing the Data Dictionary.
- Ingesting and iterating through the objects in both JSON datasets.
- Executing the type inference algorithm (detailed in Section 3.3) based on member matching against the dictionary.
- Calculating the degree of match metrics (Coverage, Accuracy) and the final match score for each object against its inferred class definition (as per Section 3.3 and Section 3.4.3).
4.1.1. Datasets Used
The datasets used for the experiment were derived from the IFC sample datasets representing various facility types (buildings, bridges, and road sections). These are available online from the official GitHub websites of buildingSMART International [26,27].
Four JSON datasets were prepared from these sample datasets encoded in the STEP Physical File format (ISO-10303-21 [28]). They were converted to the JSON format, which generally conforms to ifcJSON, while maintaining the local object identifiers and references rather than embedding them explicitly. Although the datasets included explicit entity-type identifiers, they were not used in the type inference process. Table 5 provides a brief description of each dataset and Figure 2 shows screenshots of the rendered IFC model.
Table 5.
Descriptions of the datasets.
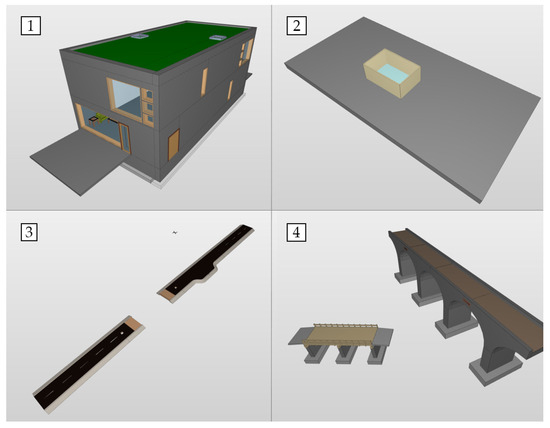
Figure 2.
Rendered images of four sample IFC models from which JSON datasets were derived. Numbers shown in each subfigure correspond to the description items listed in Table 5.
4.1.2. Data Dictionary Construction
A data dictionary was constructed based on the principles outlined in Section 3.2.1. The dictionary was constructed by parsing the IFC schema and generating a subset of the items listed in Table 4. Through this process, the dictionary was populated with information on each entity type, supertype, and names and data types of its constituent members. Additionally, by exploiting the semantic information provided by the IFC schema, we extracted and converted it into the dictionary entry details of the required status of individual members, correctness of enumeration values, relationships and cardinalities among the entities, and accuracy of both the references and inverse references between the related entities.
Items not defined within the IFC schema, such as semantic synonyms and format constraints, were omitted from the dictionary. Furthermore, although the IFC schema explicitly specifies constraints for certain entity member values, these constraints were not applied in our experiments.
4.1.3. Experimental Procedure
The experiments were conducted on each sample dataset according to the following procedure:
- Convert the IFC file to JSON (ifcJSON-style type annotations included for result validation only).
- Run a software script to transform the EXPRESS schema (matching the IFC version of the dataset) into a dictionary.
- For each object of the dataset:
- Compare the attribute names of the dynamic object against the data dictionary to extract the candidate entity types.
- Eliminate any entity whose required properties are not present in the object from the candidate set.
- Sort the remaining candidates in descending order by the number of attributes they share with the object (i.e., entities with a higher ScoreAcc are ranked first). The inverse references are also counted as attributes.
- Apply a higher weight (WAcc) to attributes defined in the higher-level supertypes. The datasets used in these experiments contain no noise, and the weighted scores are not adjusted.
- Report both the entity with the highest raw ScoreAcc and that with the highest WAcc-adjusted score as the inferred types and compare them against the true IFC entity type of the objects.
4.1.4. Evaluation Metrics
The performance of the methodology was assessed using the following metrics (Table 6):
Table 6.
List of evaluation metrics used in the experiment.
4.2. Experimental Results
The outcomes of inferring the entity types for the individual objects in the sample JSON dataset using the data dictionary can be categorized as follows:
- The top-scoring candidate entity type exactly matches the actual entity type of the object (exact match).
- The top-scoring candidate corresponds to a supertype of the actual entity (e.g., the inferred candidate is IfcWall, where the true type is IfcWallStandardCase).
- There are multiple top-scoring (tied) candidates, one of which matches the actual entity type of the object (i.e., match among ties).
- Among multiple top-scoring ties, one candidate corresponds to a supertype of the actual entity (match with the supertype among the ties).
- None of the candidates match the actual entity type of the object (no match).
Table 7 and Figure 3 summarize the inference results for the JSON sample dataset. The dataset indices follow those presented in Table 4 and Figure 1. Each outcome simultaneously presents the inference results based solely on the unweighted ScoreAcc (i.e., without any adjustment by WAcc) and inference results based on the scores adjusted by WAcc (i.e., weighted).
Table 7.
IFC entity inference results for the sample JSON datasets.
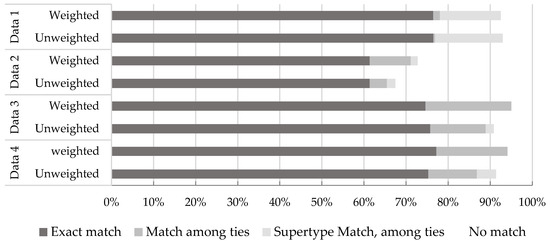
Figure 3.
Graphical representation of the entity inference results.
4.3. Analysis and Discussion of the Results
The experimental evaluation yielded exact match success rates ranging from 61.4% (Dataset 2) to 76.5% (Dataset 1) across the four sample datasets. When considering the presence of the inferred entity type among multiple top-scoring candidates and allowing for matches to any supertype of that entity, the success rates increased to between 67.5% (Dataset 2, unweighted) and 95.0% (Dataset 3, weighted). In comparison with the methodology in a prior study by the authors [29], this represents an overall improvement: although the total matching rate (including supertypes) on Dataset 2 decreased slightly from 75.2% to 72.8%, the exact match rate improved substantially from 46.5% to 61.4%.
This performance gain appears to be attributable to the incorporation of accuracy measures semantically derived from the data model in addition to the leveraging of object-property coverage, as in the previous approach. When accuracy weights were applied to the hierarchical levels of the entity attributes, the exact match differences remained within 0.04–1.9%. However, under a more relaxed criterion that the correct type appears among the highest-scoring candidates, accuracy weighting yielded discriminative improvements of approximately 1.2–6.0% depending on the dataset.
We also observed that multiple top-scoring entity-type candidates occurred in many cases (from 0.4% in the unweighted analysis of Dataset 1 to 20.4% in the weighted analysis of Dataset 3). This tendency increased when hierarchical accuracy weights were applied, reflecting the highly structured nature of the IFC data model, where many entities share the same level in the hierarchy. However, this may likewise arise in any classification-based definition of dynamic objects. Notably, our experimental methodology does not apply the additional constraints defined in the IFC schema for entity selection. Incorporating such constraints into the matching process can further improve the inference accuracy by increasing the match probabilities and reducing the number of tied candidates.
In scenarios where dynamic objects are generated from classification schemes and their formats are inferred, additional constraints, such as those on the data scope presented in this paper, and reasoning based on the data labels (e.g., attribute names) may further enhance the discriminative power.
Overall, these results substantiate the core hypothesis of this study that for dynamic data adhering to the standard classification schemes, explicit schema information is not strictly necessary to infer the content by matching against a data dictionary. Nevertheless, applying this approach to practical environments requires supplementary constraints and refinement to ensure a robust performance.
5. Conclusions
This study presented a schema-agnostic methodology for exchanging digital construction engineering information, thereby addressing the limitations of traditional schema-bound approaches for handling the diversity and dynamism of data in modern projects. The following sections summarize the key findings and contributions of the study.
The practical value of this methodology stems from its potential to enhance the reliability of data sharing and integration in complex multidisciplinary construction projects. Collaboration among stakeholders is facilitated using diverse software tools and data formats by enabling the interpretation and validation of data without rigid schema enforcement. The objective quality assessment allows recipients to make informed decisions about data trustworthiness and to identify potential issues early. The expected advantages include improved semantic understanding of the shared data, increased confidence in data quality through quantitative metrics, and easier integration of data from various sources, potentially leading to improved project efficiency and outcomes. The systematic use of a dictionary also promotes explicit domain knowledge formalization and reuse.
Achieving and maintaining stakeholder consensus on the shared Data Dictionary and implementing robust governance for its versioning and evolution throughout a project represent significant practical and organizational hurdles. In addition, the reliance of the methodology on predefined dictionary rules limits its ability to accurately interpret or validate data patterns that are entirely novel or deviate significantly from established definitions, potentially requiring manual interventions or dictionary updates.
Future research should explore enhancing the inference accuracy by incorporating Natural Language Processing or word embedding models to better handle ambiguous terminology and subtle data variations. Interdisciplinary data sharing services such as Common Data Environment (CDE) is another area this study fits in; future research will provide mechanisms to ensure integrity of the data in such environments. Rigorous validations through large-scale case studies using diverse real-world construction project datasets with standardized data dictionaries are essential to assess the scalability of the methodology, its robustness against practical data imperfections, and its overall effectiveness in industry settings.
Author Contributions
Conceptualization, methodology, data curation, writing—original draft preparation, S.Y.; visualization, writing—review and editing, H.W.J.; investigation, resources, H.K.; validation, T.C.; supervision, project administration, M.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the “National R&D Project for Smart Construction Technology (No. RS-2020-KA156050)” funded by the Korea Agency for Infrastructure Technology Advancement under the Ministry of Land, Infrastructure, and Transport, and managed by the Korea Expressway Corporation.
Data Availability Statement
Data are available in a publicly accessible repository.
Acknowledgments
During the preparation of this manuscript, the authors used ChatGPT-4o for the literature search and English translation. The authors reviewed and edited the manuscript and take full responsibility for its content.
Conflicts of Interest
Authors Seokjoon You and Hyon Wook Ji are employed by the Saman Corporation. Authors Hyunseok Kwak and Taewon Chung are employed by the Hanmac Engineering. Author Moongyo Bae is employed by the Precast & Pile Tech Corporation.
Abbreviations
The following abbreviations are used in this manuscript:
| CAD | Computer-Aided Design |
| CAE | Computer-Aided Engineering |
| IFC | Industry Foundation Classes |
| IoT | Internet of Things |
| ISO | International Organization for Standardization |
| JSON | JavaScript Object Notation |
| LLM | Large Language Model |
| MEP | Mechanical, Engineering and Plumbing |
| ML | Machine Learning |
| OWL | Web Ontology Language |
| STEP | Standard for the Exchange of Product Model Data |
| URN | Uniform Resource Name |
| W3C | World-Wide Web Consortium |
| XML | Extensive Markup Language |
| YAML | YAML Ain’t Markup Language |
References
- Eastman, C.; Teicholz, P.; Sacks, R.; Liston, K. BIM Handbook: A Guide to Building Information Modeling for Owners, Managers, Designers, Engineers, and Contractors; John Wiley & Sons: Hoboken, NJ, USA, 2008; pp. 66–91. [Google Scholar]
- Solihin, W.; Eastman, C.; Lee, Y.C. A framework for fully integrated building information models in a federated environment. Adv. Eng. Inform. 2016, 30, 168–189. [Google Scholar] [CrossRef]
- Sachs, R.; Wang, Z.; Ouyang, B.; Utkucu, D.; Chen, S. Toward artificially intelligent cloud-based building information modelling for collaborative multidisciplinary design. Adv. Eng. Inform. 2022, 53, 101711. [Google Scholar] [CrossRef]
- Introducting JSON. Available online: https://www.json.org/json-en.html (accessed on 21 August 2025).
- East, E.W. Construction Operations Building Information Exchange (COBIE) Requirements Definition and Pilot Implementation Standard (EDRC/CERL TR-07-30); Engineer Research and Development Center, US Army Corps of Engineers: Champaign, IL, USA, 2007. [Google Scholar]
- Sobkhiz, S.; El-Diraby, T. Dynamic integration of unstructured data with BIM using a no-model approach based on machine learning and concept networks. Autom. Constr. 2023, 150, 104859. [Google Scholar] [CrossRef]
- Cánovas Izquierdo, J.L.; Cabot, J. Discovering implicit schemas in JSON data. In Proceedings of the International Conference on Web Engineering, Aalborg, Denmark, 8–12 July 2013. [Google Scholar] [CrossRef]
- Klettke, M.; Störl, U.; Shenavai, M.; Scherzinger, S. NoSQL schema evolution and big data migration at scale. In Proceedings of the 2016 IEEE International Conference on Big Data, Washington, DC, USA, 5–8 December 2016. [Google Scholar] [CrossRef]
- Baazizi, M.-A.; Colazzo, D.; Ghelli, G.; Sartiani, C. Parametric schema inference for massive JSON datasets. VLDB J. 2019, 28, 497–521. [Google Scholar] [CrossRef]
- Miller, R.J.; Haas, L.M.; Hernández, M.A. Schema mapping as query discovery. In Proceedings of the International Conference on Very Large Data Bases, Cairo, Egypt, 10–14 September 2000. [Google Scholar]
- Madhavan, J.; Bernstein, P.A.; Rahm, E. Generic schema matching with cupid. VLDB 2001, 1, 49–58. [Google Scholar]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A core of semantic knowledge. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007. [Google Scholar]
- Beach, T.H.; Rezgui, Y.; Li, H.; Kasim, T. A rule-based semantic approach for automated regulatory compliance in the construction sector. Expert. Syst. Appl. 2015, 42, 5219–5231. [Google Scholar] [CrossRef]
- Klettke, M.; Störl, U.; Scherzinger, S. Schema extraction and structural outlier detection for JSON-based NoSQL data stores. In Proceedings of the Database System for Business, Technology and Web, Hamburg, Germany, 6 March 2015. [Google Scholar]
- Afsari, K.; Eastman, C.M.; Castro-Lacouture, D. JavaScript Object Notation (JSON) data serialization for IFC schema in web-based BIM data exchange. Autom. Constr. 2017, 77, 24–51. [Google Scholar] [CrossRef]
- Solihin, W.; Eastman, C.; Lee, Y.C. Toward robust and quantifiable automated IFC quality validation. Adv. Eng. Inform. 2015, 29, 739–756. [Google Scholar] [CrossRef]
- Lee, Y.-C.; Eastman, C.M.; Solihin, W. Rules and validation processes for interoperable BIM data exchange. J. Comput. Des. Eng. 2021, 8, 97–114. [Google Scholar] [CrossRef]
- Venugopal, M.; Eastman, C.M.; Teizer, J. An ontology-based analysis of the industry foundation class schema for building information model exchanges. Adv. Eng. Inform. 2015, 29, 940–957. [Google Scholar] [CrossRef]
- Terkaj, W.; Šojić, A. Ontology-based representation of IFC EXPRESS rules: An enhancement of the ifcOWL ontology. Autom. Constr. 2015, 57, 188–201. [Google Scholar] [CrossRef]
- Pauwels, P.; Van Deursen, D.; Verstraeten, R.; De Roo, J.; De Meyer, R.; Van de Walle, R.; Van Campenhout, J. A semantic rule checking environment for building performance checking. Autom. Constr. 2011, 20, 506–518. [Google Scholar] [CrossRef]
- Pauwels, P.; Krijnen, T.; Terkaj, W.; Beetz, J. Enhancing the ifcOWL ontology with an alternative representation for geometric data. Autom. Constr. 2017, 80, 77–94. [Google Scholar] [CrossRef]
- Han, K.K.; Cline, D.; Golparvar-Fard, M. Formalized knowledge of construction sequencing for visual monitoring of work-in-progress via incomplete point clouds and low-LoD 4D BIMs. Adv. Eng. Inform. 2015, 29, 889–901. [Google Scholar] [CrossRef]
- Sacks, R.; Ma, L.; Yosef, R.; Borrmann, A.; Daum, S.; Kattel, U. Semantic enrichment for building information modeling: Procedure for compiling inference rules and operators for complex geometry. J. Comput. Civ. Eng. 2017, 31, 1–12. [Google Scholar] [CrossRef]
- Zhou, P.; El-Gohary, N. Automated matching of design information in BIM to regulatory information in energy codes. In Proceedings of the Construction Research Congress 2018, New Orleans, Louisiana, 2–4 April 2018. [Google Scholar]
- Chung, T.; Bok, J.H.; Ji, H.W. A multi-story expandable systematic hierarchical construction information classification system for implementing information processing in highway construction. Appl. Sci. 2023, 13, 10191. [Google Scholar] [CrossRef]
- Sample & Test Files. Available online: https://github.com/buildingSMART/Sample-Test-Files (accessed on 16 June 2025).
- Sample & Test Files. Available online: https://github.com/buildingsmart-community/Community-Sample-Test-Files (accessed on 16 June 2025).
- ISO 10303-21:2002; Industrial Automation Systems and Integration—Product Data Representation and Exchange—Part 21: Implementation Methods: Clear Text Encoding of the Exchange Structure. ISO: Geneva, Switzerland, 2002.
- You, S.J.; Kim, S.W. Schema-agnostic dynamic object data exchange methodology applicable to digitized construction engineering information. J. Korea Acad.-Ind. Coop. Soc. 2023, 10, 848–855. (In Korean) [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).