Abstract
Background: Skin cancer diagnosis faces critical challenges due to the visual similarity of lesions and dataset limitations. Methods: This study introduces HybridSkinFormer, a robust deep learning model designed to classify skin lesions from both clinical and dermatoscopic images. The model employs a two-stage architecture: a multi-layer ConvNet for local feature extraction and a residual-learnable multi-head attention module for global context fusion. A novel activation function (StarPRelu) and Enhanced Focal Loss (EFLoss) address neuron death and class imbalance, respectively. Results: Evaluated on a hybrid dataset (37,483 images across nine classes), HybridSkinFormer achieved state-of-the-art performance with an overall accuracy of 94.2%, a macro precision of 91.1%, and a macro recall of 91.0%, outperforming nine CNN and ViT baselines. Conclusions: Its ability to handle multi-modality data and mitigate imbalance highlights its clinical utility for early cancer detection in resource-constrained settings.
1. Introduction
The integumentary system as the body’s primary barrier against external insults plays a multifaceted role in maintaining homeostasis, encompassing protective, thermoregulatory, and metabolic functions [1]. As the largest organ, the skin—comprising the epidermis, dermis, and hypodermis—serves as a dynamic interface that safeguards against pathogens, mechanical stress, and ultraviolet (UV) radiation [2,3]. Despite its resilience, prolonged exposure to environmental stressors, genetic predispositions, and behavioral factors (e.g., unprotected sun exposure) elevate the risk of pathological transformations, including oncogenesis [4]. Skin cancer, characterized by uncontrolled proliferation of epidermal or melanocytic cells, ranks among the most prevalent malignancies worldwide, with melanoma alone accounting for the majority of skin cancer-related deaths [5].
Early detection of skin cancer is critical, as timely intervention can improve survival rates by up to 70%.
Advancements in deep learning (DL) have revolutionized medical image analysis, offering data-driven solutions to overcome the limitations of conventional diagnostics [6]. Convolutional neural networks (CNNs), the cornerstone of visual feature extraction, have demonstrated efficacy in skin lesion classification by automating the identification of discriminative patterns such as color heterogeneity and border irregularity. Works such as [7,8] leverage DenseNet and EfficientNet to learn deep features between lesion subtypes from datasets like HAM10000 or ISIC 2019. However, CNNs are inherently constrained by their local receptive field architecture, which limits their ability to model long-range spatial dependencies critical for capturing global lesion context [9].
Vision transformers (ViTs) [10,11], inspired by natural language processing [12], address this gap through self-attention mechanisms that enable global contextual modeling. By partitioning images into patch embeddings and encoding inter-patch relationships, ViTs such as DeiT [13] and Swin-Transformer [14] have shown promise in capturing holistic lesion characteristics, such as asymmetrical growth patterns and structural complexity. Yet, traditional ViTs suffer from high computational overhead, rendering them impractical for real-time applications or deployment on mobile IoT devices, such as portable dermatoscopes [15].
However, the current application of deep classification networks for skin disease categorization and benign–malignant lesion discrimination faces three key challenges:
- Single-Modality Dependency: Existing models are exclusively trained and tested on datasets containing only one type of image data (either dermatoscopic lesion images or clinical high-definition images). This restricts their applicability to a single imaging modality, limiting real-world usage scenarios and reducing diagnostic confidence. For instance, a model trained solely on dermatoscopic images may fail to generalize to clinical photographs with different lighting and magnification.
- Severe Class Imbalance: All datasets exhibit significant imbalance in the number of samples across lesion categories. During training, models tend to overfit to majority classes, forgetting features of minority classes. This imbalance introduces bias, causing models to favor predicting dominant categories and underperforming in rare lesion detection. For example, melanocytic nevi (with abundant samples) may overshadow vascular lesions (with scarce samples), leading to misdiagnosis of rare conditions.
- Lightweight Model Design for Resource-Constrained Systems: Developing a practical lightweight model that balances local feature extraction (e.g., texture details) and global context awareness (e.g., lesion architecture), while being deployable on medical IoT chips with limited computational resources, remains unsolved. Current models either excel in accuracy but are too heavy for edge devices or are lightweight but sacrifice multi-scale feature learning.
Major Contributions
To address the aforementioned challenges, the key contributions of this work are succinctly summarized as follows:
- Hybrid Dataset Construction: We constructed a hybrid dataset comprising high-definition local clinical lesion images and dermatoscopic images using multi-center public datasets. This dataset is designed to train a lesion disease recognition and screening model capable of handling both clinical images and dermatoscopic photography, addressing the limitation of single-modality models and expanding applicability across diverse clinical scenarios.
- HybridSkinFormer Model Architecture: To address the challenge of classifying multi-type lesion images, we propose a deep recognition model called HybridSkinFormer. This model employs a two-stage feature extraction strategy: (a) Local feature extraction via multi-layer ConvNet, capturing fine-grained details such as texture and color variations in lesions. (b) Global feature fusion using a residual-learnable multi-head attention module, enabling the model to integrate contextual information across the entire image.Additionally, we introduce a novel activation function, StarPRelu, to mitigate the “dying ReLU” problem by preserving negative gradient flow. To tackle class imbalance in the training data, we enhance the Focal Loss with an adaptive scaling mechanism, resulting in the Enhanced Focal Loss (EFLoss). EFLoss dynamically adjusts loss weights based on class sample ratios and current loss values, improving minority class representation during training.
- Adequate Experimental Validation: The trained model was evaluated on a test set disjoint from the training data and compared against state-of-the-art lightweight deep image classification models. Results demonstrate that HybridSkinFormer achieves optimal or comparable performance across all metrics, highlighting its effectiveness in multi-modality lesion classification and robustness to class imbalance.
The proposed auxiliary skin lesion discrimination model can be deployed on portable dermatoscopic devices, enabling primary hospital physicians to access auxiliary support for differential diagnosis.
2. Related Works
The rapid advancements in deep learning (DL) have profoundly influenced the domain of dermatological imaging and skin lesion detection, with numerous studies exploring innovative methodologies to enhance diagnostic accuracy and support medical training through advanced DL models. This review synthesizes key findings from recent research, focusing on convolutional neural networks (CNNs) and transfer learning (TL) frameworks for improved lesion detection and classification.
Chang et al. [16] employed the self-developed InceptionResNetV2 model to enhance image resolution and analytical capabilities on the HAM10000 dataset. Similarly, Khattar et al. [17], Shete et al. [18], Garg et al. [19], Shehzad et al. [20], and Ahmad et al. [21] devised the customized InceptionResNetV2-based ConvNet model to analyze and classify the skin lesions, focusing on optimizing the training process for dermatological education and improving lesion discrimination accuracy.
Satapathy et al. [22] utilized a Capsule Network (CapsNet) for skin lesion classification on the HAM10000 dataset. Unlike traditional convolutional neural networks (CNNs), the CapsNet architecture is specifically designed to model spatial hierarchies and preserve positional information, enabling more precise representation of lesion structures. Through this innovative approach, the model demonstrated enhanced capability in capturing complex spatial relationships within dermatoscopic images, offering a promising alternative for addressing the challenges of lesion classification caused by visual feature variability.
Xie et al. [23] conducted an exploration into the application of diverse CNN architectures on the Xiangya–Derm dataset. Nevertheless, challenges including dataset imbalance and the clinical similarity among disease categories highlighted the necessity for advanced data management strategies and optimized model training methods to reduce classification errors.
Anjum et al. [24] presented a three-stage comprehensive framework that employs models such as YOLOv2, ResNet-18, and Ant Colony Optimization (ACO) to achieve high-precision skin lesion detection and classification. While this framework demonstrates robust performance, it necessitates substantial computational resources, which may limit its applicability in resource-constrained environments. Goyal et al. [25] systematically reviewed diverse deep learning methodologies, highlighting ensemble techniques like DeeplabV3+ and Mask R-CNN. These approaches integrate semantic and instance segmentation to address noisy annotations and enhance model robustness, though they are characterized by high computational complexity and require meticulous preprocessing steps. Natasha Nigar et al. [26] emphasized the critical role of interpretability by integrating ResNet-18 with the LIME framework to generate visual explanations for predictions, thereby fostering clinical trust in AI-driven diagnostics. However, their approach is constrained by reliance on a single dataset and occasional inconsistencies in LIME-generated explanations. Collectively, these studies illustrate the dual promise and challenges of deploying deep learning models in dermatological diagnostics, particularly in balancing accuracy, interpretability, and computational efficiency.
Bian et al. [27] investigated the effectiveness of Multi-View Filtered Transfer Learning (MFTL) on ISIC 2017 and HAM10000 datasets, demonstrating notable performance improvements through selective sample distillation using Wasserstein distance. However, the study highlighted computational complexity and preprocessing hurdles as potential obstacles to broad clinical deployment.
Hosny et al. [28] proposed a novel deep inherent learning method for multi-class skin lesion classification. Combining multiple convolution filters and inherent blocks, the model overcomes image shortages and degradation. Using the HAM10000 dataset, it achieved 92.89% accuracy. Explainable AI techniques like occlusion sensitivity and feature visualization validated its ability to accurately detect lesion areas, outperforming prior methods in specificity and precision while providing transparent decision-making processes.
Naeem et al. [29] provided a comprehensive review of CNN-based melanoma detection methods, underscoring the pivotal role of diverse, large-scale datasets in enhancing model robustness. The review identified challenges in dataset diversity, computational efficiency, and model interpretability as critical areas for future research to elevate the clinical utility of AI-driven dermatological diagnostics.
Thurnhofer-Hemsi et al. [30] proposed an ensemble CNN approach with test-time shifting to address dataset imbalance, achieving superior results on the challenging HAM10000 dataset. Despite these advancements, the study acknowledged the computational burdens of ensemble learning and the need to optimize model scalability for heterogeneous clinical environments.
Liu et al. [31] introduced a multi-scale combined efficient channel attention module-empowered skin disease classification network. It improves the pyramid segmentation attention module by replacing the Squeeze-and-Excitation (SE) module module with the Efficient Channel Attention (ECA) and uses an inverted residual structure to enhance multi-scale feature extraction. Tested on ISIC2019 and HAM10000 datasets, the model achieves 77.6% and 88.2% accuracy, respectively, outperforming baseline models like ResNet and EPSANet.
Recently, Burhanettin Ozdemir and Ishak Pacal [32] devised a novel model combining ConvNeXtV2 blocks and separable self-attention, achieving 93.48% accuracy on ISIC 2019, outperforming over 20 state-of-the-art models with its efficient, hybrid architecture.
In summary, recent investigations highlight substantial progress in skin lesion classification via the integration of diverse datasets, sophisticated model architectures, and innovative methodologies like transfer learning and attention mechanisms. Notwithstanding these breakthroughs, challenges pertaining to dataset heterogeneity, computational complexity, and model interpretability remain as pivotal areas for future research. Addressing these challenges is essential to enhance the clinical applicability and trustworthiness of AI-powered diagnostic tools in dermatology, ensuring their effective deployment in real-world healthcare settings.
3. Materials and Methods
In this section, we introduce the dataset employed for training and testing, as well as the deep fitting model designed for fine-grained skin disease classification.
3.1. Datasets
This study leverages the following datasets for training and testing:
(1) ISIC Challenge 2019 Dataset: The ISIC 2019 dataset (https://challenge.isic-archive.com/data/#2019 (accessed on 8 August 2025)) is sourced from multiple international clinical centers and dermatological databases. The images are meticulously acquired using a diverse array of high-resolution dermatoscopes. In total, the dataset encompasses 33,569 skin lesion images. These images comprehensively depict a wide spectrum of skin conditions, including melanoma (MEL), basal cell carcinoma (BCC), and squamous cell carcinoma (SCC). The ISIC Challenge 2019 Dataset represents a comprehensive superset encompassing the HAM10000 [33], ISIC 2018 [8], and Bcn20000 datasets [34]. The class distribution of the skin lesions in ISIC Challenge 2019 dataset is shown in Figure 1.
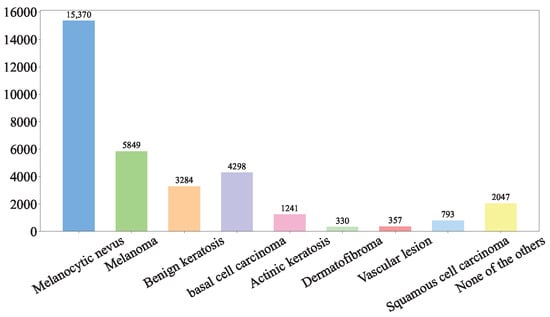
Figure 1.
ISIC Challenge 2019 Dataset.
(2) Hospital Italiano de Buenos Aires Skin Lesions Images 2019–2022 (HIBA 2019–2022): The Hospital Italiano de Buenos Aires Skin Lesions Images 2019–2022 (HIBA 2019–2022) dataset [35] is sourced from institutional records spanning 2019 to 2022. It contains information on patients with common skin lesions who visited the Dermatology Department during this period, along with their corresponding clinical and dermoscopy images. Three expert dermatologists carefully selected the cases included in the dataset. Clinical images were captured using the smartphones of the attending professionals. Dermoscopy images were obtained through a variety of professional dermatoscope devices, including the VL-7EX II video microscope (Scalar Corporation, Tokyo, Japan), Dermagraphix Mirror 7 (Canfield Scientific, Parsippany, NJ, USA), FotoFinder-compatible cameras such as the Medicam 1000s and Medicam 800Hd, and dermoscopic attachments for smartphones. The class distribution of the skin lesions in HIBA 2019–2022 dataset is shown in Figure 2.
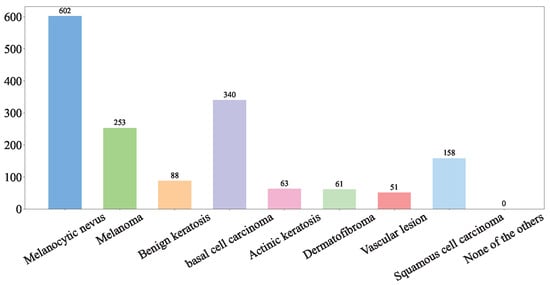
Figure 2.
HIBA 2019–2022 dataset.
(3) PAD-UFES-20: The PAD-UFES-20 dataset [36] consists of clinical images of skin lesions collected from various smartphone devices, paired with corresponding patient clinical information. Comprising 2298 samples, it covers six different types of skin lesions, including three forms of skin cancer and three common skin diseases. The distribution of the dataset can be visualized in Figure 3.
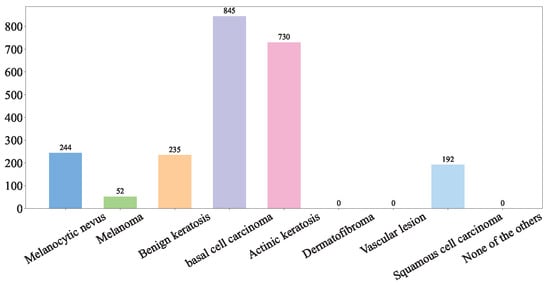
Figure 3.
PAD-UFES-20 dataset.
This study integrated the ISIC Challenge 2019 Dataset, the Hospital Italiano de Buenos Aires Skin Lesions Images (2019–2022), and the PAD-UFES-20 Dataset to form a comprehensive database of common benign and malignant skin diseases, incorporating 37,483 both clinical and dermoscopic images. This database encompasses nine distinct diagnostic categories: Melanoma (MEL), Melanocytic nevus (NV), Basal cell carcinoma (BCC), Actinic keratosis (AK), Benign keratosis (BKL, including solar lentigo/seborrheic keratosis/lichen planus-like keratosis), Dermatofibroma (DF), Vascular lesion (VASC), Squamous cell carcinoma (SCC), and Unknown (UNK). The detailed of our integrated dataset is shown in Figure 4.
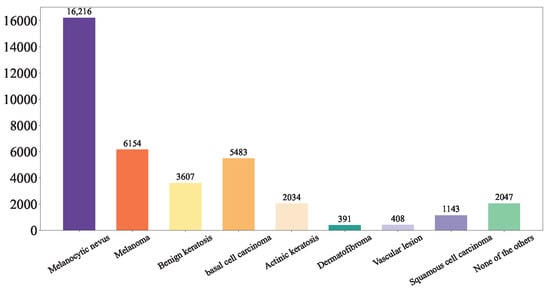
Figure 4.
Our Integrated Dataset.
First, we shuffled the data and extracted the training set Figure 5, test set Figure 6, and validation set Figure 7 using a stratified random sampling method for each category. This ensured the mutual exclusivity and randomness among the training set, test set, and validation set, while also guaranteeing that the number of samples in each category basically conforms to the distribution of the original overall dataset.
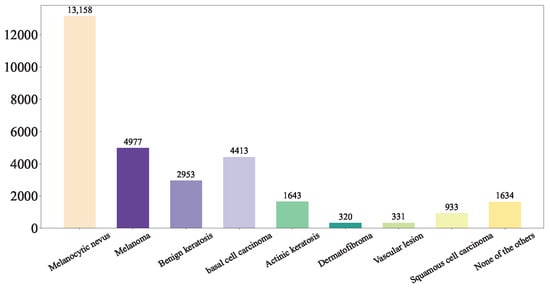
Figure 5.
Our Training Set.
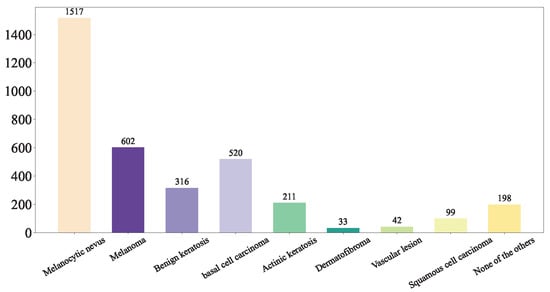
Figure 6.
Our Test Set.
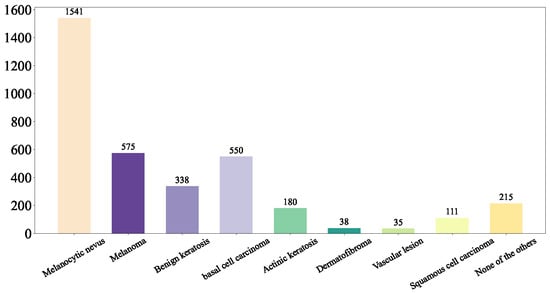
Figure 7.
Our Validation Set.
3.2. Data Preprocessing and Augmentation
To improve the generalization and accuracy of our model, we perform the following preprocessing and augmentation on images.
(1) Data Preprocessing: We meticulously crop each image in our integrated dataset (including training set, validation set and test set). We assign the skin background mucosa and noises irrelevant to lesions to . This step is essential to eliminate normal skin mucosa in the surrounding background and extraneous noise information, ensuring that the pathological skin lesions were centered within the images. To streamline the training and testing procedures, all images are standardized to a fixed resolution of (, ). This standardization is pivotal in enabling effective and consistent evaluation across different models and experiments. The preprocessing flow is depicted in Figure 8.
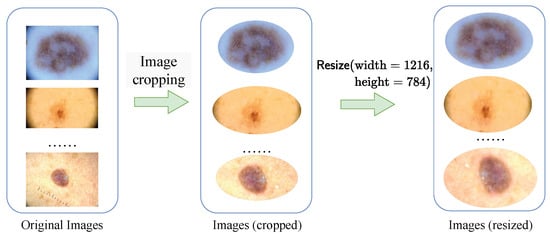
Figure 8.
The preprocessing flow.
(2) Data Augmentation: To enhance the robustness of the trained discriminative model, during the training process, the data read from the training set undergoes operations such as (a) brightness adjustment, (b) contrast enhancement, and (c) image flipping. These operations are carried out to augment the diversity of the training data, which is crucial for improving the generalization ability and stability of the discriminative model in task of lesion recognition and classification.
(a) Brightness adjustment: Through gamma correction transformation (1), lesion images with different brightness levels can be generated to simulate the variations under different exposure parameters of the dermatoscope.
where represents the pixel value of the input image at the position , and represents the pixel value of the output image at the position . is the adjustment coefficient. By setting different values of , the brightness of the image can be adjusted. When , the image becomes brighter; when , the image becomes darker.
(b) Contrast enhancement: By using the hierarchical contrast stretching algorithm (2), we can simulate the skin lesion images captured under different lighting conditions in real-world scenarios.
where denotes the pixel value of the input image at the position , and represents the pixel value of the output image at the position . , , , and are user-defined parameters. Additionally, , and , L represents the maximum range of gray-level values.
- When the pixel value is less than , the output pixel value is equal to multiplied by , which enhances the contrast of darker regions.
- When , the output pixel value is calculated as . This linear transformation adjusts the contrast of the middle-gray-level region.
- When , the output pixel value is , which adjusts the contrast of brighter regions.
In this way, the details of the image can be made clearer, enhancing the visual effect of the image and facilitating subsequent image processing tasks.
(c) Image flipping: By randomly performing horizontal or vertical flips on the input skin lesion images, we can simulate the images captured by the dermatoscope lens at different rotation angles.
3.3. HybridSkinFormer Model
3.3.1. Global Framework
The global framework of our proposed HybridSkinFormer is depicted in Figure 9.
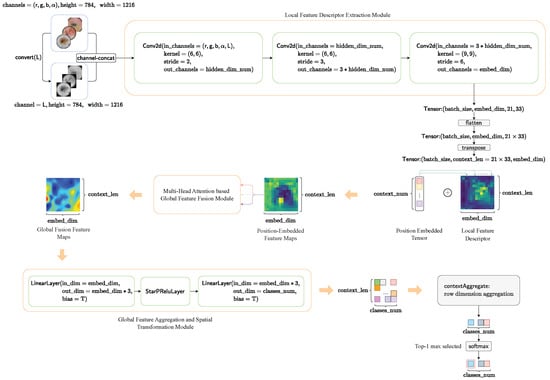
Figure 9.
The framework of our proposed HybridSkinFormer.
First, we convert the pre-processed -skin lesion image into a grayscale image using and perform channel aggregation. As a result, an aggregated five-channel original feature matrix is obtained.
Subsequently, we extract local features from the five-channel original feature matrix through three convolutional layers with gradually increasing kernel scales. This process yields a local high-dimensional feature matrix.
Then, we flatten and transpose the local feature matrix to obtain the feature context feature matrix. We use a learnable tensor to perform positional encoding on the context feature matrix. Next, we input the position-embedded context feature matrix into the global feature fusion module with a sequence of multi-layer multi- head attention feature fusion layer for. The output is a globally fused feature tensor.
After that, we input the output global feature fusion tensor into a multi-layer perceptron layer to project the features at each position into the classification weight space.
Finally, we sum the classification weights at each position to obtain an overall classification weight vector and then pass the overall classification weight vector through a softmax layer to obtain the top 1 probability of the skin lesion disease classification category.
The forward flow of our is depicted in Algorithm 1.
| Algorithm 1: Forward Framework |
 |
3.3.2. Global Feature Fusion Module
The global feature fusion module in our HybridSkinFormer is composed of a deep sequence of the multi-head attention module with -learnable residual connection and pre-normalization mechanism presented in Figure 10.
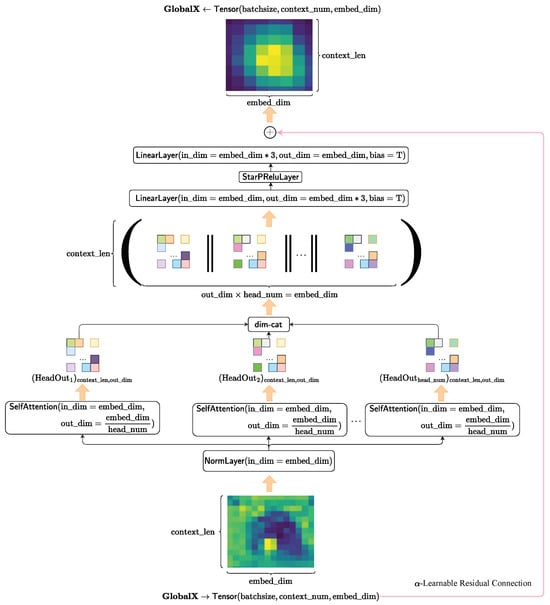
Figure 10.
The framework of the multi-head attention layer.
First, we perform pre-normalization on the input tensor along the feature dimension.
Subsequently, we feed the normalized tensor into multiple attention heads in parallel. Then, we concatenate the outputs of each attention head along the feature dimension to obtain the feature aggregation of multiple attention heads.
After that, we input the attention-aggregated feature tensor into the spatial transformation layer to map the features to a new space.
Finally, we conduct an alpha-independent learnable residual connection between the original input tensor and the transformed feature tensor to obtain the feature fusion output of this layer.
where is a independent learnable parameter.
The forward flow of the multi-head attention module with -learnable residual connection and pre-normalization mechanism in our HybridSkinFormer is depicted in Algorithm 2.
| Algorithm 2: Multi-head attention module with -learnable residual connection and pre-normalization |
 |
We adopt the QKV-softmax attention mechanism transferring from the Transformer to instantiate the . The computational flow of the QKV-softmax attention mechanism is presented in Figure 11.
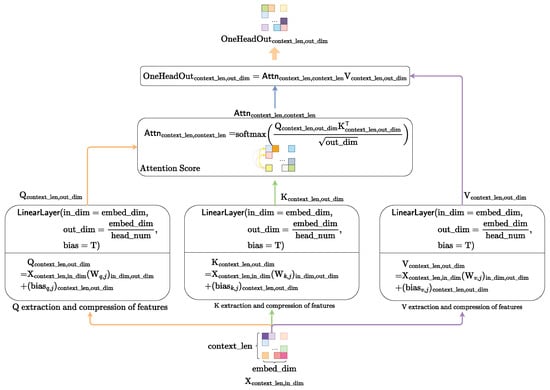
Figure 11.
The computational flow of self-attention mechanism.
First, we compute the query matrix , key matrix and value matrix from context matrix through the linear space transformation.
Subsequently, we calculate the attention score using query matrix and key matrix .
Finally, using the calculated attention score , we perform the weighted feature fusion for the value matrix to obtain the one-attention-head feature-fusion matrix .
3.4. Adaptive Activation Function
We define an adaptively learnable activation function , as shown in Equation (25), to simulate nonlinear transformations with different scales. The activation function can effectively prevent the issue of neuron death when the input signal is less than zero.
where is defined as (26).
The introduced activation function with different parameters is presented in Figure 12. From Figure 12, we know that when parameters , , , equals to .
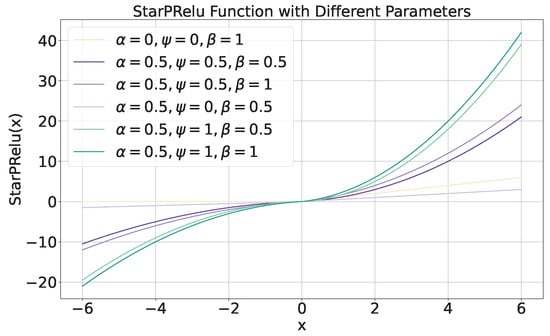
Figure 12.
The introduced activation function with different parameters.
3.5. Enhanced Focal Loss
To address the class imbalance issue in the training dataset of skin lesion images, we adopt the Category-Balanced Enhanced Focal Loss function with reward and penalty mechanisms (27). This approach assigns smaller reward coefficients to categories with larger sample sizes and larger coefficients to those with smaller sizes, effectively mitigating the model’s classification bias towards majority classes during training.
where
- is the ground truth probabilities vector of the sample i, is the groud truth probability of class j.
- is the predicted probabilities vector of the sample i, is the predicted probability of class j.
- , are the hyper-parameters. and .
- is the scalar factor for each class. The larger the proportion of samples in a class j, the smaller the . We calculate the
When it comes to a deterministic classification task, the EFLoss can be simplified as (28).
The EFLoss with different hyper-parameters is shown in Figure 13. When , and , the proposed EFLoss degenerates into traditional Cross Entropy Loss (CELoss).
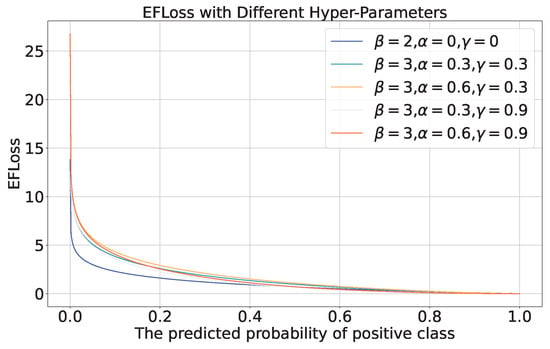
Figure 13.
EFLoss with different hyper-parameters.
4. Experiment Evaluation and Discussion
4.1. Experimental Setup and Main Results
We employ the cloud computing resources of AutoDL (https://www.autodl.com/) to train our model. The settings of the software and hardware parameters as well as the hyperparameters are shown in Table 1. The best performance of our model is achieved at .

Table 1.
Environment and Parameter Setting.
We utilize the function in util-library to calculate the parameter size and FLOPs of our HybridSkinFormer model. The parameter size of our HybridSkinFormer model is 310.599 K and the FLOPs is 817.265 M.
The training and validation loss is presented in Figure 14a. As can be seen in Figure 14a, as the number of training epochs increases, the average training and validation losses per epoch exhibit a downward trend. The training loss stabilizes around the 20th epoch, reaching a value of 0.07 at the end of the training. The validation loss stabilizes around the 30th epoch, with a value of 0.18 at the end of the training.
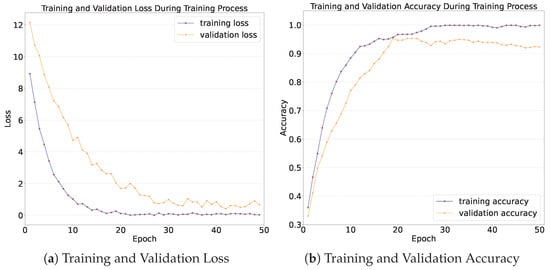
Figure 14.
Loss and accuracy during training process.
The training and validation accuracy is shown in Figure 14b. As can be seen from Figure 14b, as the number of training epochs increases, both the training accuracy and the validation accuracy exhibit an upward trend. The upward trend is most prominent during the first 10 epochs. The training accuracy increases from 36% to 90%, and the validation accuracy increases from 36% to over 80%. After 30 epochs of training, both the training accuracy and the validation accuracy of the model tend to stabilize, which indicates that the model converges after 30 epochs. Eventually, after 50 epochs of training, the training accuracy reaches 99%, and the validation accuracy reaches 93%. This implies that the model has learned the high-dimensional features of different skin lesion categories and demonstrates good generalization performance on data that are outside the training dataset.
We apply the trained model to the test set to determine whether the model simply overfits and “records” the data it saw or truly learns the hidden features in each skin lesion image. In this way, we test the availability and generalization ability of the model in the real world.
The final classification performance of the trained model on the test set is shown in the confusion matrix as Figure 15. According to the results of the confusion matrix shown in Figure 15, we calculate the precision, recall, F1-score, and Matthews Correlation Coefficient (MCC) for each category.
In addition, we calculate the overall accuracy, (macro-mean) precision, recall, F1-score, and MCC value. The calculation formulas are as follows:
where is the true positive number of class j, is the false positive number of class j, is the false negative number of class j, is the true negative number of class j.
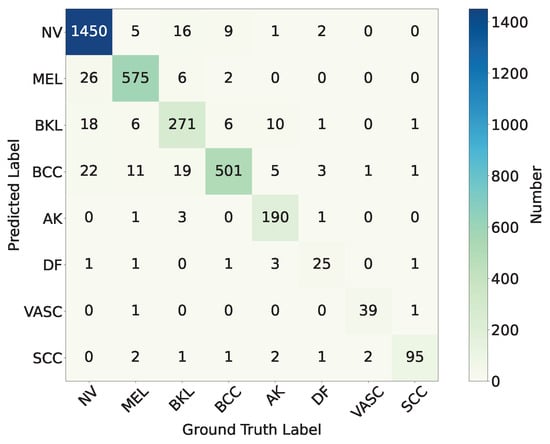
Figure 15.
The confusion matrix of trained HybridSkinFormer on test set.
Precision reflects the proportion of true positive cases among the positive cases predicted by the model, and it focuses on measuring the accuracy of the model’s predictions. Recall emphasizes the degree to which the model covers positive samples. The recall rate for malignant classified lesions is of great significance, representing the model’s ability to screen and identify malignant skin lesions.
The calculation results are shown in Table 2 and Figure 16. As can be seen from Table 2 and Figure 16, the proposed model HybridSkinFormer achieved an overall accuracy of 94.2% on the test set, along with an overall (macro mean) precision of 91.2%, an overall (macro mean) recall of 91.0%, an overall (macro mean) F1-score of 0.911, and an overall (macro mean) MCC of 0.901.
Table 2.
Evaluation Metrics of Trained HybridSkinFormer on Test Set.
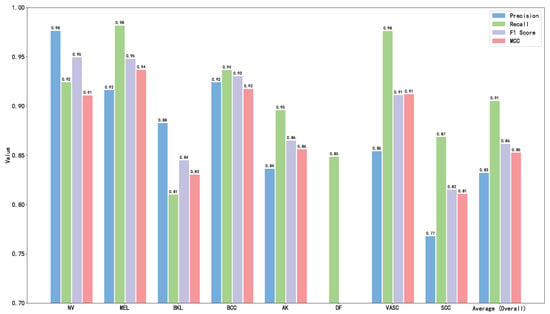
Figure 16.
Performance metrics of our HybridSkinFormer on test set.
According to the confusion matrix and Table 2: (a) Among the test samples of Melanocytic nevus (NV), 26 are misclassified as Melanoma (MEL), 18 are misclassified as Benign keratosis (BKL, including solar lentigo/seborrheic keratosis/lichen planus-like keratosis), and 22 are misclassified as Basal cell carcinoma (BCC). The precision is 97.8% and the recall is 95.6%. (b) Among the test samples of Melanoma (MEL), 11 are misclassified as Basal cell carcinoma (BCC), 6 are misclassified as Benign keratosis (BKL), and another 11 are misclassified as Basal cell carcinoma (BCC). The precision is 94.4% and the recall is 95.5%. (c) Among the test samples of Benign keratosis (BKL), 16 are misclassified as Melanocytic nevus (NV), 6 are misclassified as Melanoma (MEL), and 19 are misclassified as Basal cell carcinoma (BCC). The precision is 86.6% and the recall is 85.8%. (d) Among the test samples of Basal cell carcinoma (BCC), nine are misclassified as Melanocytic nevus (NV), six are misclassified as Benign keratosis (BKL). The precision is 89.0% and the recall is 96.3%. (e) Among Actinic keratosis (AK), 10 are misclassified as Benign keratosis (BKL), 5 are misclassified as Basal cell carcinoma (BCC). The precision is 97.4% and the recall is 90.0%. (f) Among the test samples of Dermatofibroma (DF), two are misclassified as Melanocytic nevus (NV), three are misclassified as Basal cell carcinoma (BCC). The precision is 78.1% and the recall is 75.8%. (g) Among Vascular lesion (VASC), only one is misclassified as Basal cell carcinoma (BCC). The precision is 95.1% and the recall is 92.9%. (h) Among the test samples of Squamous cell carcinoma (SCC), only four are misclassified. The precision is 91.3% and the recall is 96.0%.
In the test evaluation of this study, the model demonstrates excellent detection performance for all categories of malignant skin lesions, with the recall rate stably remaining above 95%. Specifically, the recall rate of Melanoma (MEL) reaches 95.5%, indicating that the model can successfully identify 95.5% of actual melanoma cases, effectively reducing the risk of missed diagnosis. The recall rate of Basal cell carcinoma (BCC) is 96.3%, suggesting that when detecting this common malignant skin tumor, the model can accurately capture the vast majority of cases. The recall rate of Squamous cell carcinoma (SCC) is 96.0%, also reflecting the high sensitivity of the model to this malignant lesion.
These results fully demonstrate that the model proposed in this study has excellent screening capabilities for malignant skin lesions. In clinical practice, a high recall rate can maximize the timely detection of malignant lesions, winning precious time for early intervention for patients and reducing the risk of delayed disease due to missed diagnosis. In addition, the stable performance of the model in different types of malignant lesions also provides solid data support and technical assurance for its clinical transformation and application in the field of early skin cancer diagnosis, and it is expected to become an effective auxiliary tool for dermatologists to quickly and accurately identify malignant esions.
Then, we analyze the reasons for the model’s misjudgments from the perspectives of clinical and skin lesion characteristics.
- Confusion between Melanocytic Nevus (NV) and Melanoma (MEL): In clinical or dermatoscopic images, some melanocytic nevi (NV) may exhibit characteristics indistinguishable from melanoma (MEL). In terms of color, early-stage or certain special types of MEL may show pigment distribution patterns similar to those of NV. Morphologically, atypical NV with local inflammatory cell infiltration may also present irregular shapes, consistent with the morphology of early-stage low-grade MEL.
- Confusion between Dermatofibroma (DF) and Melanocytic Nevus (NV): For dermatofibroma (DF) and melanocytic nevus (NV), pigmented DFs with tan or dark brown hues are nearly identical in color to NV, making accurate differentiation by color alone challenging. Morphologically, DF typically appears as a firm, elevated, oblate, or button-shaped nodule with a smooth surface; NV can also present as an elevated nodule with a smooth or slightly rough surface, resulting in morphological similarity.
- Confusion between Dermatofibroma (DF) and Basal Cell Carcinoma (BCC): Early-stage basal cell carcinoma (BCC) manifests as a slightly elevated, light yellow or pinkish small nodule with a firm texture on the local skin; DF may occasionally exhibit similar light yellow or pink coloration and firmness. Especially for smaller DFs, differentiation from early-stage BCC based solely on color and texture is difficult.
- Confusion between Benign Keratosis (BKL) and Melanocytic Nevus (NV): In terms of color, benign keratosis (BKL) encompasses a wide spectrum—skin-colored, light brown, dark brown, or black—overlapping considerably with NV’s color range. For example, seborrheic keratosis, a common type of BKL, often appears as brown or black flat papules or plaques, resembling pigmented NV and making color-based discrimination challenging. Morphologically, BKL typically presents as flat or slightly elevated lesions with clear borders and verrucous or papillomatous surfaces; NV can also be flat or elevated with well-defined margins. Congenital or atypical NV further blur morphological distinctions from BKL. Under dermatoscopy, both may exhibit non-specific features such as mottled or reticular pigmentation patterns, leading to diagnostic confusion in images.
- Confusion between Benign Keratosis (BKL) and Basal Cell Carcinoma (BCC): Basal cell carcinoma (BCC) often presents as a pearly or translucent papule/nodule with dilated surface capillaries. Some BKLs, such as actinic keratosis, may develop similar features during progression: mild elevation, rough texture, and vascular dilation. When occurring on the head and face—common sites for BCC—actinic keratosis closely mimics early BCC in appearance, increasing the risk of misdiagnosis. While dermatoscopic features like blue-gray globules or ulcers are typical of BCC, certain BKLs (e.g., seborrheic keratosis with comedo-like openings or milia cysts) may exhibit overlapping non-specific structures. Vascular dilation in both entities further complicates dermatoscopic differentiation.
4.2. Model Interpretability Evaluation
We utilize Grad-CAM, a widely recognized visualization tool in research, to elucidate the critical features learned by our HybridSkinFormer model, thereby offering valuable support for subsequent classification decisions. In the visualization process, Grad-CAM first employs gradient calculation methods to generate feature maps for each category. Second, these feature maps are projected onto the original image, facilitating the identification of decision-making regions within the image. Owing to its linear nature, Grad-CAM can be implemented quickly and seamlessly across various neural networks. Finally, unlike methods that utilize “bounding boxes” to indicate the position of specific objects in classification images, Grad-CAM generates a pixel map associated with the target object. This approach yields more accurate, detailed, and high-fidelity visualization results. Figure 17 shows our HybridSkinFormer Model with Grad-CAM visualization technique for the sampled malignant lesion, e.g., MEL, SCC, and BCC. Through the Grad-CAM visualization technique, it can be intuitively observed that our discriminative model is able to accurately focus its attention on the regions with prominent features of malignant lesions.
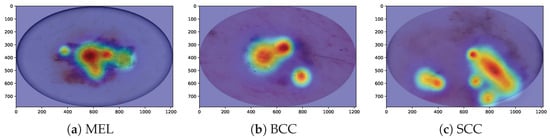
Figure 17.
Model interpretability evaluation with Grad-CAM visualization technique.
4.3. Ablation Study
To evaluate the effectiveness of the proposed StarPRelu activation function and Enhanced Focal Loss (EFLoss) function in our proposed model, we conduct the ablation study. We set three base models, Base1 (with traditional Relu activation function and CrossEntropy loss function), Base2 (with traditional Relu activation function and our EFLoss function), and Base3 (with our StarPRelu activation function and CrossEntropy loss function). Figure 18 presents the comparison of precision, overall accuracy, and recall between the base models and the HybridSkinFormer model.
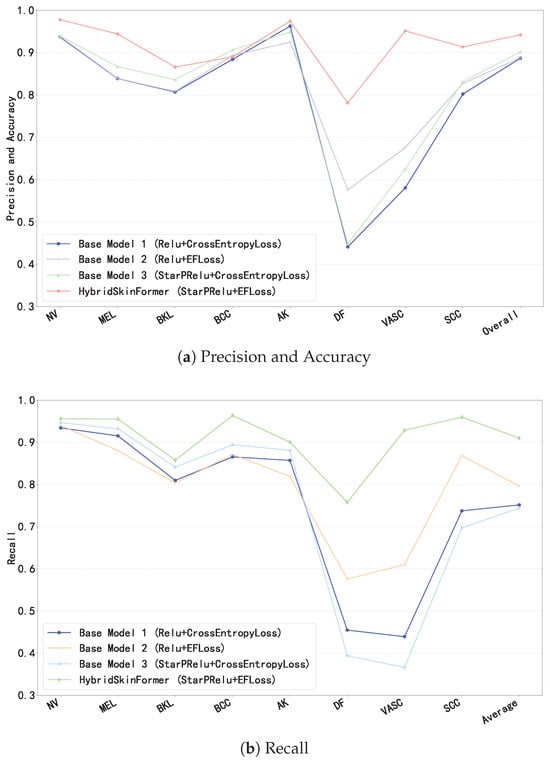
Figure 18.
Ablation study.
In Figure 18, the StarPRelu activation function and Enhanced Focal Loss (EFLoss) function comprehensively improve the model performance. Specifically, the StarPRelu activation function enhances model performance by mitigating the vanishing activation of negative inputs and preventing neuron masking. In contrast, EFLoss ensures the classification accuracy of minority classes in training datasets with imbalanced sample sizes through its loss compensation mechanism.
4.4. Comparison
We compare our proposed HybridSkinFormer with several well-known, open-source, and verifiable deep learning models for image classification. To validate the superiority of our approach, we select model variants with comparable parameter counts to ensure a fair comparison. Since all baseline models uniformly support an input format of channels = (r,g,b) and size = (256,256), we resize all input images to 256 × 256 pixels during training and testing the other compared models. Additionally, we adopt the standard Cross-Entropy Loss (CELoss) and use the identical dataset splits (training/testing) as described in this paper. The batch size is fixed at three for all experiments.
The baseline models include:
- Pure ConvNet Architectures: ResNet-20 [9], RegNetY-Small [37], ResNeXt50-32x4d [38], MobileNetV3-Small-1.0 [39], and MobileNetV3-Small-1.0 [39].
- Transformer Architecture-Based Models: DeiT-Tiny/16 [13], PVTv2-B1 [40], MobileViTv3-xxs [41], and CoaT-Tiny [42].
The confusion matrix results for each comparative model are presented in Figure 19.
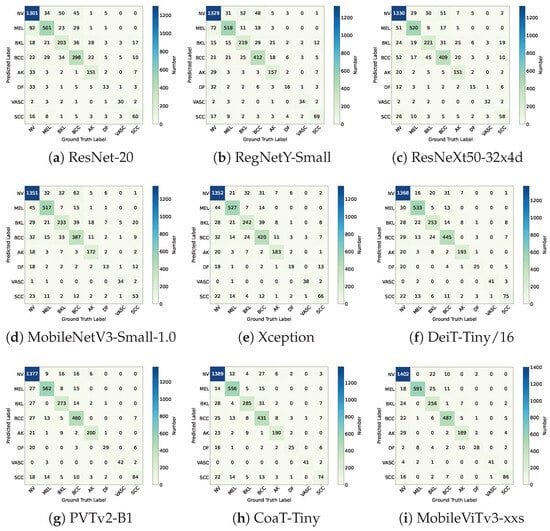
Figure 19.
The confusion matrices of the compared deep learning models.
The overall performance metrics are shown in Table 3. The bold blue values represent the best performing indicators and the blue values in regular font represent second best performing indicators. According to the overall performance metrics in Table 3, we can intuitively obtain the following:
Table 3.
Performance Comparison to the State-of-the-Art Deep Learning-based Image Classification Models.
- Overall Accuracy: HybridSkinFormer achieved the highest accuracy of 94.2% on the test dataset, outperforming the second-ranked model (MobileViTv3-xxs) by 2%. This demonstrates its superior generalization capability across multi-modality skin lesion images.
- Macro Mean Precision: The model attained a top Macro Mean Precision of 91.1%, exceeding MobileViTv3-xxs (the second-place model) by over 7%. This indicates its enhanced ability to minimize false positive predictions across all lesion classes.
- Macro Mean Recall: HybridSkinFormer achieved a Macro Mean Recall of 91.0%, comparable to MobileViTv3-xxs, highlighting its robustness in detecting positive cases without significant compromise in sensitivity relative to state-of-the-art alternatives.
- Macro Mean F1-Score: The model recorded the highest Macro Mean F1-Score of 0.911, outperforming MobileViTv3-xxs by 0.5 points. This balanced metric reflects its optimal trade-off between precision and recall across imbalanced classes.
- Macro Mean MCC (Matthews Correlation Coefficient): HybridSkinFormer achieved a leading Macro Mean MCC of 0.901, approximately 0.5 points higher than MobileViTv3-xxs. This signifies stronger overall predictive performance, particularly in distinguishing between difficult-to-classify lesion types.
Collectively, HybridSkinFormer demonstrates superior performance across all evaluated metrics, underscoring its accuracy and sensitivity in screening and classifying common skin diseases. These results highlight its clinical utility for early identification of malignant lesions, potentially enabling timely intervention and improving patient outcomes in dermatological diagnostics.
5. Conclusions
This work presents HybridSkinFormer, a hybrid deep learning framework that effectively bridges the gap between local and global feature learning for skin lesion classification. By integrating ConvNet and transformer-based attention mechanisms, the model addresses key limitations of single-modality approaches and class imbalance, achieving superior performance across multiple metrics. The introduction of StarPRelu and EFLoss enhances feature representation and training stability, respectively, ensuring robust generalization on diverse datasets. With an overall accuracy of 94.2% and strong macro-averaged scores, HybridSkinFormer demonstrates clinical viability for automated screening, particularly in distinguishing malignant lesions like melanoma (95.5% recall) and basal cell carcinoma (96.3% recall). Future work will focus on enhancing interpretability via attention visualization and validating across broader clinical datasets to further solidify its real-world impact.
Author Contributions
Conceptualization, Y.H. and X.R.; methodology, Z.Z.; software, Z.Z.; validation, Z.Z., Y.H. and K.Z.; formal analysis, Y.H.; investigation, Y.H.; resources, Y.H.; data curation, Y.H.; writing—original draft preparation, Z.Z.; writing—review and editing, Z.Z. and Y.H.; supervision, Y.R.; project administration, Y.R.; funding acquisition, Y.R. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the 135 projects for disciplines of excellence—Clinical Research Incubation Project, West China Hospital, Sichuan University (21HXFH010), the National Key Research and Development Program of China (2022YFC2504800).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets generated and/or analyzed during the current study are publicly available: (a) ISIC Challenge 2019 Dataset [https://api.isic-archive.com/collections/65/ (accessed on 8 August 2025)] and [https://api.isic-archive.com/collections/72/ (accessed on 8 August 2025)]. (b) Hospital Italiano de Buenos Aires Skin Lesions Images (2019–2022) Dataset [https://api.isic-archive.com/doi/hospital-italiano-de-buenos-aires-skin-lesions-images-2019-2022/ (accessed on 8 August 2025)]. (c) PAD-UFES-20 Dataset [https://data.mendeley.com/datasets/zr7vgbcyr2/1 (accessed on 8 August 2025)].
Acknowledgments
During the preparation of this manuscript/study, the author(s) used Draw.io (https://www.drawio.com/) for the purposes of drawing the architecture diagram. The authors have reviewed and edited the output and take full responsibility for the content of this publication.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Sanghvi, A.R. Skin Cancer: Prevention and Early Detection. In Handbook of Cancer and Immunology; Springer International Publishing: Cham, Switzerland, 2022; pp. 1–31. [Google Scholar] [CrossRef]
- de Vries, E.; Coebergh, J.W. Cutaneous malignant melanoma in Europe. Eur. J. Cancer 2004, 40, 2355–2366. [Google Scholar] [CrossRef]
- Garbe, C.; Leiter, U. Melanoma epidemiology and trends. Clin. Dermatol. 2009, 27, 3–9. [Google Scholar] [CrossRef] [PubMed]
- Van der Leest, R.J.; De Vries, E.; Bulliard, J.L.; Paoli, J.; Peris, K.; Stratigos, A.J.; Trakatelli, M.; Maselis, T.; Šitum, M.; Pallouras, A.; et al. The Euromelanoma skin cancer prevention campaign in Europe: Characteristics and results of 2009 and 2010. J. Eur. Acad. Dermatol. Venereol. 2011, 25, 1455–1465. [Google Scholar] [CrossRef]
- Siegel, R.L.; Giaquinto, A.N.; Jemal, A. Cancer statistics, 2024. CA A Cancer J. Clin. 2024, 74, 12–49. [Google Scholar] [CrossRef]
- Melarkode, N.; Srinivasan, K.; Qaisar, S.M.; Plawiak, P. AI-powered diagnosis of skin cancer: A contemporary review, open challenges and future research directions. Cancers 2023, 15, 1183. [Google Scholar] [CrossRef]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef] [PubMed]
- Codella, N.C.; Gutman, D.; Celebi, M.E.; Helba, B.; Marchetti, M.A.; Dusza, S.W.; Kalloo, A.; Liopyris, K.; Mishra, N.; Kittler, H.; et al. Skin lesion analysis toward melanoma detection: A challenge. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 168–172. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Khan, S.; Ali, H.; Shah, Z. Identifying the role of vision transformer for skin cancer—A scoping review. Front. Artif. Intell. 2023, 6, 1202990. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2023, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. arXiv 2021, arXiv:2012.12877. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar] [CrossRef]
- Ring, C.; Cox, N.; Lee, J.B. Dermatoscopy. Clin. Dermatol. 2021, 39, 635–642. [Google Scholar] [CrossRef]
- Chang, C.H.; En Wang, W.; Hsu, F.Y.; Jhen Chen, R.; Chang, H.C. AI HAM 10000 Database to Assist Residents in Learning Differential Diagnosis of Skin Cancer. In Proceedings of the 2022 IEEE 5th Eurasian Conference on Educational Innovation (ECEI), Taipei, Taiwan, 10–12 February 2022; pp. 1–3. [Google Scholar] [CrossRef]
- Khattar, S.; Kaur, R.; Gupta, G. A Review on Preprocessing, Segmentation and Classification Techniques for Detection of Skin Cancer. In Proceedings of the 2023 2nd Edition of IEEE Delhi Section Flagship Conference (DELCON), Rajpura, India, 24–26 February 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Shete, A.S.; Rane, A.S.; Gaikwad, P.S.; Patil, M.H. Detection of skin cancer using cnn algorithm. Int. J. 2021, 6. [Google Scholar]
- Garg, R.; Maheshwari, S.; Shukla, A. Decision support system for detection and classification of skin cancer using CNN. In Proceedings of the Innovations in Computational Intelligence and Computer Vision (ICICV 2020), Rajasthan, India, 17–19 January 2020; Springer: Singapore, 2021; pp. 578–586. [Google Scholar]
- Thwin, S.M.; Park, H.S. Skin Lesion Classification Using a Deep Ensemble Model. Appl. Sci. 2024, 14, 5599. [Google Scholar] [CrossRef]
- Ahmad, B.; Usama, M.; Huang, C.M.; Hwang, K.; Hossain, M.S.; Muhammad, G. Discriminative Feature Learning for Skin Disease Classification Using Deep Convolutional Neural Network. IEEE Access 2020, 8, 39025–39033. [Google Scholar] [CrossRef]
- Satapathy, S.C.; Cruz, M.; Namburu, A.; Chakkaravarthy, S.; Pittendreigh, M.; Satapathy, S.C. Skin cancer classification using convolutional capsule network (CapsNet). J. Sci. Ind. Res. 2020, 79, 994–1001. [Google Scholar]
- Xie, B.; He, X.; Zhao, S.; Li, Y.; Su, J.; Zhao, X.; Kuang, Y.; Wang, Y.; Chen, X. XiangyaDerm: A Clinical Image Dataset of Asian Race for Skin Disease Aided Diagnosis. In Proceedings of the Large-Scale Annotation of Biomedical Data and Expert Label Synthesis and Hardware Aware Learning for Medical Imaging and Computer Assisted Intervention, Shenzhen, China, 13 and 17 October 2019; Zhou, L., Heller, N., Shi, Y., Xiao, Y., Sznitman, R., Cheplygina, V., Mateus, D., Trucco, E., Hu, X.S., Chen, D., et al., Eds.; Springer: Cham, Switzerland, 2019; pp. 22–31. [Google Scholar]
- Anjum, M.A.; Amin, J.; Sharif, M.; Khan, H.U.; Malik, M.S.A.; Kadry, S. Deep Semantic Segmentation and Multi-Class Skin Lesion Classification Based on Convolutional Neural Network. IEEE Access 2020, 8, 129668–129678. [Google Scholar] [CrossRef]
- Goyal, M.; Oakley, A.; Bansal, P.; Dancey, D.; Yap, M.H. Skin Lesion Segmentation in Dermoscopic Images with Ensemble Deep Learning Methods. IEEE Access 2020, 8, 4171–4181. [Google Scholar] [CrossRef]
- Nigar, N.; Umar, M.; Shahzad, M.K.; Islam, S.; Abalo, D. A Deep Learning Approach Based on Explainable Artificial Intelligence for Skin Lesion Classification. IEEE Access 2022, 10, 113715–113725. [Google Scholar] [CrossRef]
- Bian, J.; Zhang, S.; Wang, S.; Zhang, J.; Guo, J. Skin Lesion Classification by Multi-View Filtered Transfer Learning. IEEE Access 2021, 9, 66052–66061. [Google Scholar] [CrossRef]
- Hosny, K.M.; Said, W.; Elmezain, M.; Kassem, M.A. Explainable deep inherent learning for multi-classes skin lesion classification. Appl. Soft Comput. 2024, 159, 111624. [Google Scholar] [CrossRef]
- Naeem, A.; Farooq, M.S.; Khelifi, A.; Abid, A. Malignant Melanoma Classification Using Deep Learning: Datasets, Performance Measurements, Challenges and Opportunities. IEEE Access 2020, 8, 110575–110597. [Google Scholar] [CrossRef]
- Thurnhofer-Hemsi, K.; López-Rubio, E.; Domínguez, E.; Elizondo, D.A. Skin Lesion Classification by Ensembles of Deep Convolutional Networks and Regularly Spaced Shifting. IEEE Access 2021, 9, 112193–112205. [Google Scholar] [CrossRef]
- Liu, H.; Dou, Y.; Wang, K.; Zou, Y.; Sen, G.; Liu, X.; Li, H. A skin disease classification model based on multi scale combined efficient channel attention module. Sci. Rep. 2025, 15, 6116. [Google Scholar] [CrossRef]
- Ozdemir, B.; Pacal, I. A robust deep learning framework for multiclass skin cancer classification. Sci. Rep. 2025, 15, 4938. [Google Scholar] [CrossRef]
- Tschandl, P.; Rosendahl, C.; Kittler, H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci. Data 2018, 5, 180161. [Google Scholar] [CrossRef]
- Hernández-Pérez, C.; Combalia, M.; Podlipnik, S.; Codella, N.C.F.; Rotemberg, V.; Halpern, A.C.; Reiter, O.; Carrera, C.; Barreiro, A.; Helba, B.; et al. BCN20000: Dermoscopic lesions in the wild. Sci. Data 2024, 11, 641. [Google Scholar] [CrossRef]
- Ricci Lara, M.A.; Rodríguez Kowalczuk, M.V.; Lisa Eliceche, M.; Ferraresso, M.G.; Luna, D.R.; Benitez, S.E.; Mazzuoccolo, L.D. A dataset of skin lesion images collected in Argentina for the evaluation of AI tools in this population. Sci. Data 2023, 10, 712. [Google Scholar] [CrossRef] [PubMed]
- Pacheco, A.G.; Lima, G.R.; Salomão, A.S.; Krohling, B.; Biral, I.P.; De Angelo, G.G.; Alves, F.C., Jr.; Esgario, J.G.; Simora, A.C.; Castro, P.B.; et al. PAD-UFES-20: A skin lesion dataset composed of patient data and clinical images collected from smartphones. Data Brief 2020, 32, 106221. [Google Scholar] [CrossRef]
- Radosavovic, I.; Kosaraju, R.P.; Girshick, R.; He, K.; Dollár, P. Designing Network Design Spaces. arXiv 2020, arXiv:2003.13678. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. arXiv 2019, arXiv:1905.02244. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. PVT v2: Improved baselines with pyramid vision transformer. Comput. Vis. Media 2022, 8, 415–424. [Google Scholar] [CrossRef]
- Wadekar, S.N.; Chaurasia, A. MobileViTv3: Mobile-Friendly Vision Transformer with Simple and Effective Fusion of Local, Global and Input Features. arXiv 2022, arXiv:2209.15159. [Google Scholar] [CrossRef]
- Xu, W.; Xu, Y.; Chang, T.; Tu, Z. Co-Scale Conv-Attentional Image Transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9961–9970. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef]



















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).