
Enhanced Malignancy Prediction of Small Lung Nodules in Different Populations Using Transfer Learning on Low-Dose Computed Tomography

 ,
,
Abstract
1. Introduction
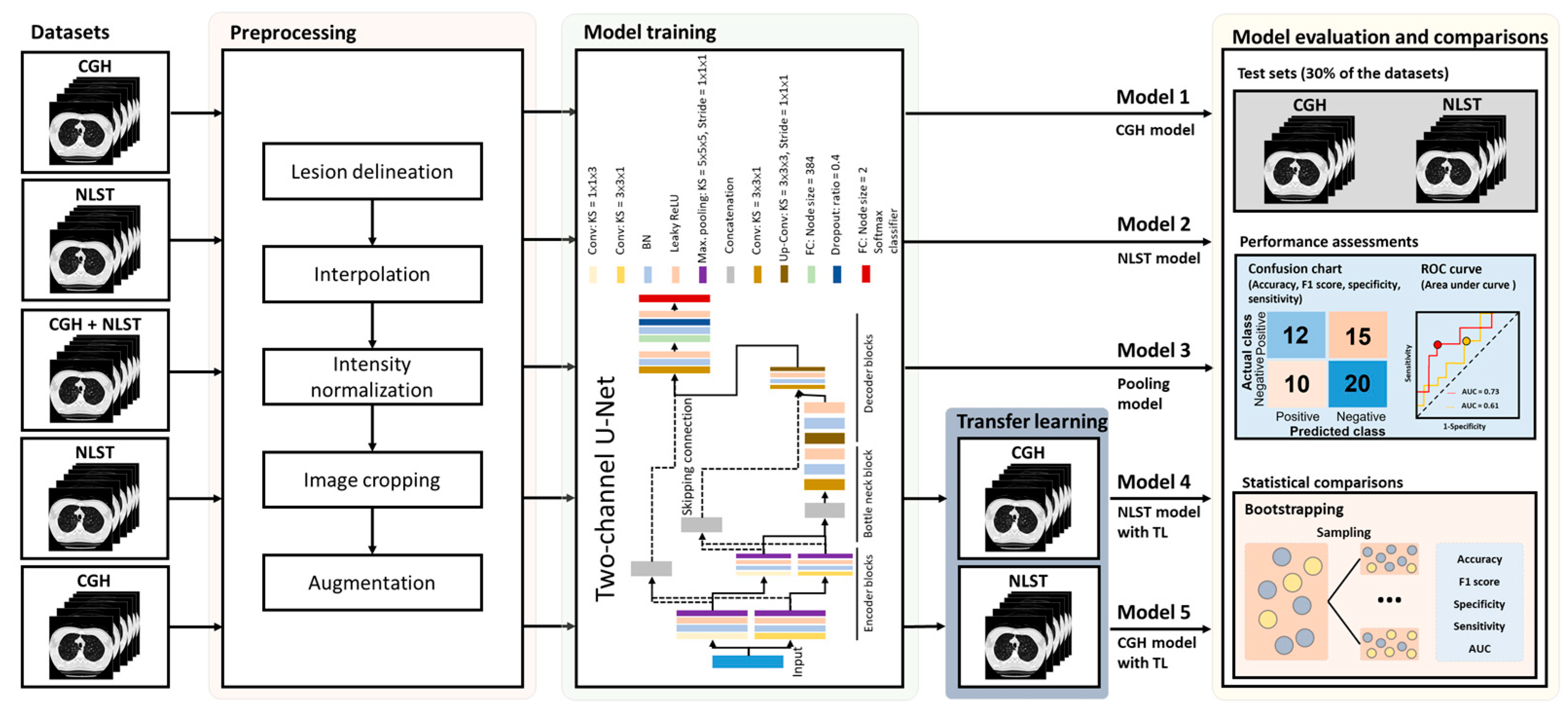
2. Materials and Methods
2.1. Study Cohort
2.2. Imaging Parameters of Low-Dose Computed Tomography
2.3. Segmentation of Small Lung Nodules
2.4. Data Augmentation of the Training Sets
2.5. Network Architecture and Model Building
2.6. Assessment of Model Performance and Statistical Analysis
3. Results
3.1. Demography of Study Cohorts
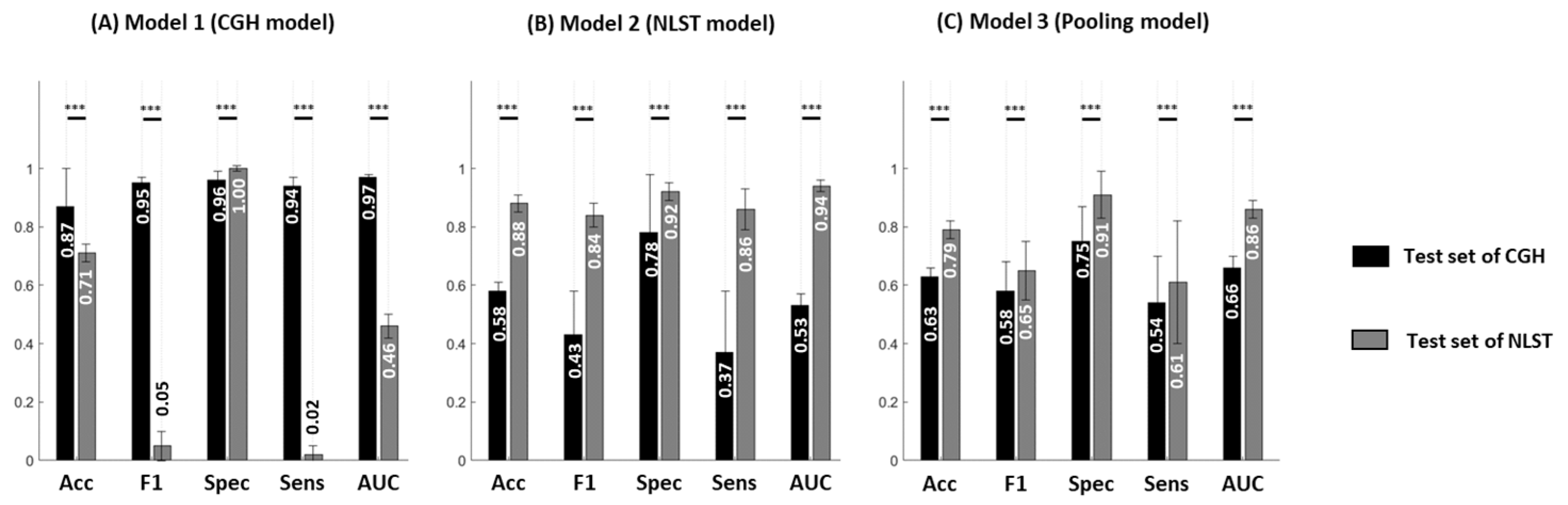
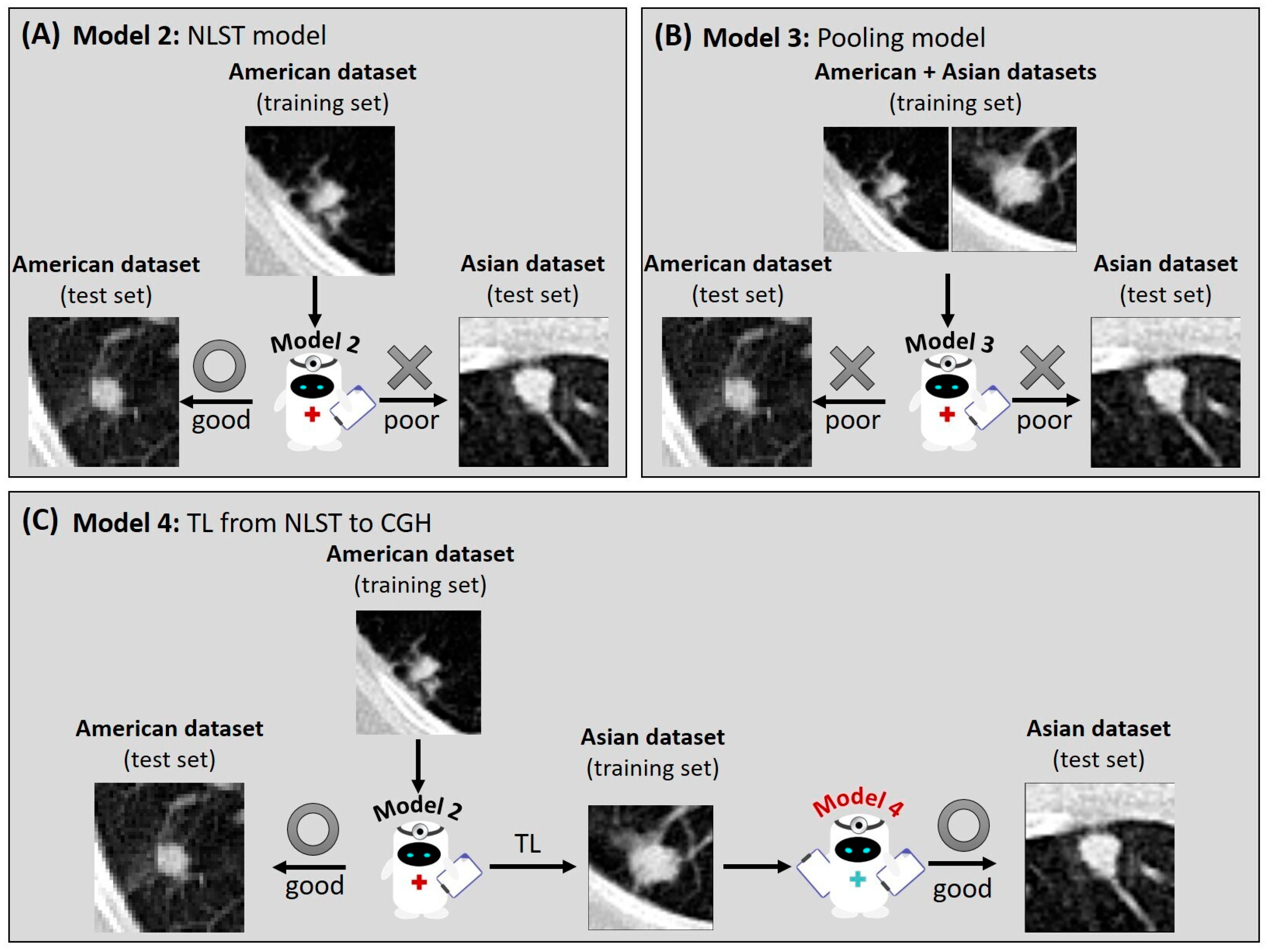
3.2. Reduced Model Performance in Different Datasets
3.3. Impact of Population Variation on Model Performance
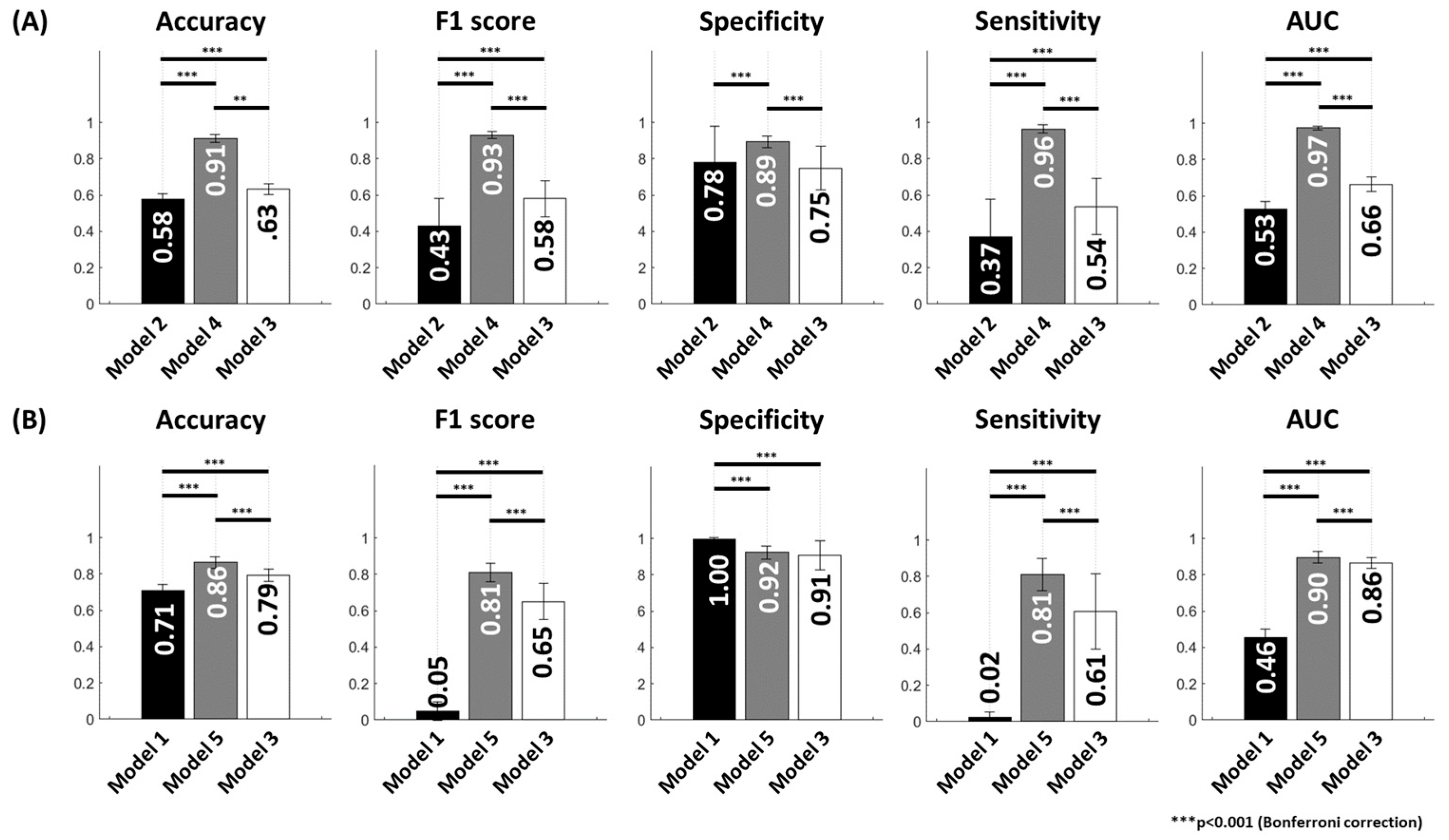
3.4. Improvement of Model Performance Through TL
3.5. Training Time for the Proposed Models
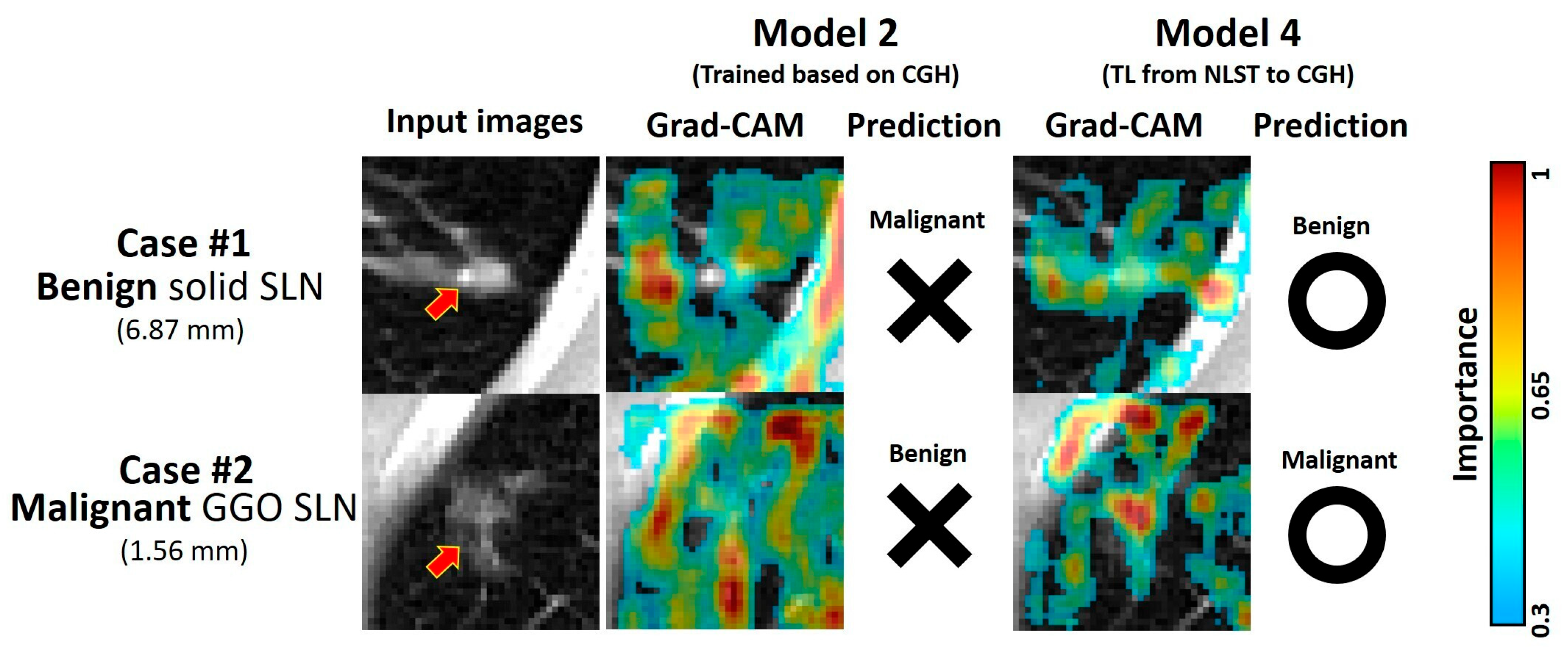
3.6. Demonstrative Cases of Malignancy Prediction
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SLN | Small lung nodule |
| DL | Deep-learning |
| LDCT | Low-dose computed tomography |
| TL | Transfer learning |
| CGH | Cathay General Hospital |
| NLST | National Lung Screening Trial |
| IRB | Institutional review board |
| HU | Hounsfield unit |
| ReLU | Rectified linear unit |
| AUC | Area under the receiver operating characteristic curve |
| Grad-CAM | Gradient-weighted class activation map |
References
- Yang, C.Y.; Lin, Y.T.; Lin, L.J.; Chang, Y.H.; Chen, H.Y.; Wang, Y.P.; Shih, J.Y.; Yu, C.J.; Yang, P.C. Stage Shift Improves Lung Cancer Survival: Real-World Evidence. J. Thorac. Oncol. 2023, 18, 47–56. [Google Scholar] [CrossRef] [PubMed]
- He, S.; Li, H.; Cao, M.; Sun, D.; Yang, F.; Yan, X.; Zhang, S.; He, Y.; Du, L.; Sun, X.; et al. Survival of 7,311 lung cancer patients by pathological stage and histological classification: A multicenter hospital-based study in China. Transl. Lung Cancer Res. 2022, 11, 1591–1605. [Google Scholar] [CrossRef] [PubMed]
- Huang, M.-D.; Weng, H.-H.; Hsu, S.-L.; Hsu, L.-S.; Lin, W.-M.; Chen, C.-W.; Tsai, Y.-H. Accuracy and complications of CT-guided pulmonary core biopsy in small nodules: A single-center experience. Cancer Imaging 2019, 19, 51. [Google Scholar] [CrossRef]
- Uzun, Ç.; Akkaya, Z.; Düşünceli Atman, E.; Üstüner, E.; Peker, E.; Gülpınar, B.; Elhan, A.H.; Ceyhan, K.; Atasoy, K. Diagnostic accuracy and safety of CT-guided fine needle aspiration biopsy of pulmonary lesions with non-coaxial technique: A single center experience with 442 biopsies. Diagn. Interv. Radiol. 2017, 23, 137–143. [Google Scholar] [CrossRef]
- Cai, J.; Vonder, M.; Du, Y.; Pelgrim, G.J.; Rook, M.; Kramer, G.; Groen, H.J.M.; Vliegenthart, R.; de Bock, G.H. Who is at risk of lung nodules on low-dose CT in a Western country? A population-based approach. Eur. Respir. J. 2024, 63, 2301736. [Google Scholar] [CrossRef]
- McWilliams, A.; Tammemagi, M.C.; Mayo, J.R.; Roberts, H.; Liu, G.; Soghrati, K.; Yasufuku, K.; Martel, S.; Laberge, F.; Gingras, M.; et al. Probability of cancer in pulmonary nodules detected on first screening CT. N. Engl. J. Med. 2013, 369, 910–919. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Wei, Y.; Wang, D.; Chen, B.; Sun, H.; Lei, Y.; Zhou, Q.; Luo, Z.; Jiang, L.; Qiu, R.; et al. Deep learning for malignancy risk estimation of incidental sub-centimeter pulmonary nodules on CT images. Eur. Radiol. 2024, 34, 4218–4229. [Google Scholar] [CrossRef]
- Cui, S.L.; Qi, L.L.; Liu, J.N.; Li, F.L.; Chen, J.Q.; Cheng, S.N.; Xu, Q.; Wang, J.W. A prediction model based on computed tomography characteristics for identifying malignant from benign sub-centimeter solid pulmonary nodules. J. Thorac. Dis. 2024, 16, 4238–4249. [Google Scholar] [CrossRef]
- Yu, A.C.; Mohajer, B.; Eng, J. External Validation of Deep Learning Algorithms for Radiologic Diagnosis: A Systematic Review. Radiol. Artif. Intell. 2022, 4, e210064. [Google Scholar] [CrossRef]
- Papalampidou, A.; Papoutsi, E.; Katsaounou, P.A. Pulmonary nodule malignancy probability: A diagnostic accuracy meta-analysis of the Mayo model. Clin. Radiol. 2022, 77, 443–450. [Google Scholar] [CrossRef]
- Lam, D.C.; Liam, C.K.; Andarini, S.; Park, S.; Tan, D.S.W.; Singh, N.; Jang, S.H.; Vardhanabhuti, V.; Ramos, A.B.; Nakayama, T.; et al. Lung Cancer Screening in Asia: An Expert Consensus Report. J. Thorac. Oncol. 2023, 18, 1303–1322. [Google Scholar] [CrossRef] [PubMed]
- Balzer, B.W.R.; Loo, C.; Lewis, C.R.; Trahair, T.N.; Anazodo, A.C. Adenocarcinoma of the Lung in Childhood and Adolescence: A Systematic Review. J. Thorac. Oncol. 2018, 13, 1832–1841. [Google Scholar] [CrossRef] [PubMed]
- Jung, K.J.; Jeon, C.; Jee, S.H. The effect of smoking on lung cancer: Ethnic differences and the smoking paradox. Epidemiol. Health 2016, 38, e2016060. [Google Scholar] [CrossRef]
- Brenner, D.R.; Hung, R.J.; Tsao, M.S.; Shepherd, F.A.; Johnston, M.R.; Narod, S.; Rubenstein, W.; McLaughlin, J.R. Lung cancer risk in never-smokers: A population-based case-control study of epidemiologic risk factors. BMC Cancer 2010, 10, 285. [Google Scholar] [CrossRef] [PubMed]
- Lui, N.S.; Benson, J.; He, H.; Imielski, B.R.; Kunder, C.A.; Liou, D.Z.; Backhus, L.M.; Berry, M.F.; Shrager, J.B. Sub-solid lung adenocarcinoma in Asian versus Caucasian patients: Different biology but similar outcomes. J. Thorac. Dis. 2020, 12, 2161–2171. [Google Scholar] [CrossRef]
- Qin, Y.; Xu, Y.; Ma, D.; Tian, Z.; Huang, C.; Zhou, X.; He, J.; Liu, L.; Guo, C.; Wang, G.; et al. Clinical characteristics of resected solitary ground-glass opacities: Comparison between benign and malignant nodules. Thorac. Cancer 2020, 11, 2767–2774. [Google Scholar] [CrossRef]
- Kim, H.Y.; Lampertico, P.; Nam, J.Y.; Lee, H.C.; Kim, S.U.; Sinn, D.H.; Seo, Y.S.; Lee, H.A.; Park, S.Y.; Lim, Y.S.; et al. An artificial intelligence model to predict hepatocellular carcinoma risk in Korean and Caucasian patients with chronic hepatitis B. J. Hepatol. 2022, 76, 311–318. [Google Scholar] [CrossRef]
- Gernaat, S.A.M.; van Velzen, S.G.M.; Koh, V.; Emaus, M.J.; Isgum, I.; Lessmann, N.; Moes, S.; Jacobson, A.; Tan, P.W.; Grobbee, D.E.; et al. Automatic quantification of calcifications in the coronary arteries and thoracic aorta on radiotherapy planning CT scans of Western and Asian breast cancer patients. Radiother. Oncol. 2018, 127, 487–492. [Google Scholar] [CrossRef]
- Yamaguchi, T.; Inoue, K.; Tsunoda, H.; Uematsu, T.; Shinohara, N.; Mukai, H. A deep learning-based automated diagnostic system for classifying mammographic lesions. Medicine 2020, 99, e20977. [Google Scholar] [CrossRef]
- Yan, K.; Cai, J.; Zheng, Y.; Harrison, A.; Jin, D.; Tang, Y.-B.; Tang, Y.-X.; Huang, L.; Xiao, J.; Lu, L. Learning From Multiple Datasets With Heterogeneous and Partial Labels for Universal Lesion Detection in CT. IEEE Trans. Med. Imaging 2020, 40, 2759–2770. [Google Scholar] [CrossRef]
- Baltagi, B.H.; Griffin, J.M.; Xiong, W. To Pool or Not to Pool: Homogeneous Versus Heterogeneous Estimators Applied to Cigarette Demand. Rev. Econ. Stat. 2000, 82, 117–126. [Google Scholar] [CrossRef]
- Seoni, S.; Shahini, A.; Meiburger, K.M.; Marzola, F.; Rotunno, G.; Acharya, U.R.; Molinari, F.; Salvi, M. All you need is data preparation: A systematic review of image harmonization techniques in Multi-center/device studies for medical support systems. Comput. Methods Programs Biomed. 2024, 250, 108200. [Google Scholar] [CrossRef]
- Iman, M.; Arabnia, H.R.; Rasheed, K. A Review of Deep Transfer Learning and Recent Advancements. Technologies 2023, 11, 40. [Google Scholar] [CrossRef]
- Clark, K.; Vendt, B.; Smith, K.; Freymann, J.; Kirby, J.; Koppel, P.; Moore, S.; Phillips, S.; Maffitt, D.; Pringle, M.; et al. The Cancer Imaging Archive (TCIA): Maintaining and Operating a Public Information Repository. J. Digit. Imaging 2013, 26, 1045–1057. [Google Scholar] [CrossRef] [PubMed]
- National Lung Screening Trial Research, T.; Aberle, D.R.; Berg, C.D.; Black, W.C.; Church, T.R.; Fagerstrom, R.M.; Galen, B.; Gareen, I.F.; Gatsonis, C.; Goldin, J.; et al. The National Lung Screening Trial: Overview and study design. Radiology 2011, 258, 243–253. [Google Scholar] [CrossRef]
- Lee, W.K.; Wu, C.C.; Lee, C.C.; Lu, C.F.; Yang, H.C.; Huang, T.H.; Lin, C.Y.; Chung, W.Y.; Wang, P.S.; Wu, H.M.; et al. Combining analysis of multi-parametric MR images into a convolutional neural network: Precise target delineation for vestibular schwannoma treatment planning. Artif. Intell. Med. 2020, 107, 101911. [Google Scholar] [CrossRef]
- Quach, L.D.; Quoc, K.N.; Quynh, A.N.; Thai-Nghe, N.; Nguyen, T.G. Explainable Deep Learning Models With Gradient-Weighted Class Activation Mapping for Smart Agriculture. IEEE Access 2023, 11, 83752–83762. [Google Scholar] [CrossRef]
- Zhang, X.; Rao, L.; Liu, Q.; Yang, Q. Meta-analysis of associations between cooking oil fumes exposure and lung cancer risk. Indoor Built Environ. 2021, 31, 820–837. [Google Scholar] [CrossRef]
- Xue, Y.; Jiang, Y.; Jin, S.; Li, Y. Association between cooking oil fume exposure and lung cancer among Chinese nonsmoking women: A meta-analysis. Oncol. Targets Ther. 2016, 9, 2987–2992. [Google Scholar] [CrossRef]
- Manos, D.; Seely, J.M.; Taylor, J.; Borgaonkar, J.; Roberts, H.C.; Mayo, J.R. The Lung Reporting and Data System (LU-RADS): A Proposal for Computed Tomography Screening. Can. Assoc. Radiol. J. 2014, 65, 121–134. [Google Scholar] [CrossRef]
- Abu Qubo, A.; Numan, J.; Snijder, J.; Padilla, M.; Austin, J.H.M.; Capaccione, K.M.; Pernia, M.; Bustamante, J.; O’Connor, T.; Salvatore, M.M. Idiopathic pulmonary fibrosis and lung cancer: Future directions and challenges. Breathe 2022, 18, 220147. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Leader, J.K.; Wang, R.; Wilson, D.; Herman, J.; Yuan, J.M.; Pu, J. Vasculature surrounding a nodule: A novel lung cancer biomarker. Lung Cancer 2017, 114, 38–43. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.C.; Xu, Q.S.; Shi, Y.B.; Ma, X.J. Clinical-radiological predictive model in differential diagnosis of small (≤ 20 mm) solitary pulmonary nodules. BMC Pulm. Med. 2021, 21, 281. [Google Scholar] [CrossRef] [PubMed]
- Ang, L.; Ghosh, P.; Seow, W.J. Association between previous lung diseases and lung cancer risk: A systematic review and meta-analysis. Carcinogenesis 2021, 42, 1461–1474. [Google Scholar] [CrossRef]
- Ebrahimi, A.; Luo, S.; Chiong, R. Introducing Transfer Learning to 3D ResNet-18 for Alzheimer’s Disease Detection on MRI Images. In Proceedings of the 2020 35th International Conference on Image and Vision Computing New Zealand (IVCNZ), Wellington, New Zealand, 25–27 November 2020; pp. 1–6. [Google Scholar]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2016, Athens, Greece, 17–21 October 2016; pp. 424–432. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | CGH Dataset | NLST Dataset | p Value |
|---|---|---|---|
| Patient number | 628 | 600 | |
| Age at diagnosis | 59.45 ± 13.07 | 61.48 ± 4.71 | <0.001 * |
| Gender (M/F) | 259 (41.24%)/369 (58.76%) | 365 (60.83%)/235 (39.17%) | <0.001 * |
| SLN number | 669 | 600 | |
| Pathology | <0.001 * | ||
| Benignness | 354 (52.91%) | 427 (71.17%) | |
| Malignancy | 315 (47.09%) | 173 (28.83%) | |
| Eq. Diameter (mm) | 3.48 ± 1.86 | 4.37 ± 1.58 | 0.792 |
| Volume (mm3) | 557.96 ± 764.60 | 503.25 ± 619.38 | 0.453 |
| SLN types | <0.001 * | ||
| Solid | 272 (40.66%) | 427 (71.17%) | |
| Partial solid | 206 (30.79%) | 60 (10.00%) | |
| GGO | 191 (28.55%) | 113 (18.83%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.-R.; Hou, K.-Y.; Wang, Y.-C.; Lin, S.-P.; Mo, Y.-H.; Peng, S.-C.; Lu, C.-F. Enhanced Malignancy Prediction of Small Lung Nodules in Different Populations Using Transfer Learning on Low-Dose Computed Tomography. Diagnostics 2025, 15, 1460. https://doi.org/10.3390/diagnostics15121460
Chen J-R, Hou K-Y, Wang Y-C, Lin S-P, Mo Y-H, Peng S-C, Lu C-F. Enhanced Malignancy Prediction of Small Lung Nodules in Different Populations Using Transfer Learning on Low-Dose Computed Tomography. Diagnostics. 2025; 15(12):1460. https://doi.org/10.3390/diagnostics15121460
Chicago/Turabian StyleChen, Jyun-Ru, Kuei-Yuan Hou, Yung-Chen Wang, Sen-Ping Lin, Yuan-Heng Mo, Shih-Chieh Peng, and Chia-Feng Lu. 2025. "Enhanced Malignancy Prediction of Small Lung Nodules in Different Populations Using Transfer Learning on Low-Dose Computed Tomography" Diagnostics 15, no. 12: 1460. https://doi.org/10.3390/diagnostics15121460
APA StyleChen, J.-R., Hou, K.-Y., Wang, Y.-C., Lin, S.-P., Mo, Y.-H., Peng, S.-C., & Lu, C.-F. (2025). Enhanced Malignancy Prediction of Small Lung Nodules in Different Populations Using Transfer Learning on Low-Dose Computed Tomography. Diagnostics, 15(12), 1460. https://doi.org/10.3390/diagnostics15121460