Abstract
This study presents an integrated predictive maintenance framework for industrial machinery, designed through the combined use of digital twin technology, enterprise resource planning (ERP) systems, and machine learning algorithms. The proposed system focuses on enhancing machine reliability and operational automation by connecting physical assets with their virtual counterparts and management systems. The digital twin acts as a real-time virtual model of critical equipment—such as aeration motors, mixers, and reactors—enabling continuous monitoring, dynamic simulation, and predictive fault detection. Meanwhile, the ERP system provides an integrated environment for maintenance scheduling, data management, and resource allocation, ensuring that maintenance decisions are data-driven and synchronized with operational workflows. Machine learning algorithms, implemented using hybrid physical–data models, predict equipment degradation trends and optimize maintenance interventions. The proposed framework was validated in an industrial-scale composting facility, where results demonstrated a 40% increase in mean time to failure (MTTF), a 35% reduction in repair time, and a 30% decrease in maintenance costs, resulting in a return on investment of 42.5% within the first year. The system’s modular architecture and high adaptability to different machinery types confirm its potential applicability to broader machine design and automation contexts, supporting the transition toward intelligent, self-maintaining industrial systems.
1. Introduction
The evolution of industrial machinery and process systems in recent decades has been marked by significant technological transformation, especially in the domains of automation, digitalization, and intelligent maintenance [1]. In modern manufacturing and process industries, maintaining the optimal performance of mechanical systems is a critical factor influencing operational continuity, cost efficiency, and sustainability [2]. Among these, predictive maintenance (PdM) has emerged as a key strategy in machine design and asset management, offering the ability to forecast potential failures and plan interventions before breakdowns occur [3].
In recent years, the development of digital technologies has led the field of industrial maintenance to move away from traditional models and towards predictive models based on data analysis [4]. In this regard, digital twin models and ERP systems are recognized as two key axes in data integration, decision-making, and real-time monitoring. The combination of these two technologies provides a platform to monitor equipment conditions in real-time and update maintenance decisions simultaneously with operational changes [5]. This integration provides a framework in which data flow, physical modeling, and predictive analysis are placed in a single cycle [6].
Parallel to these developments, enterprise resource planning (ERP) systems function as the digital backbone of modern industrial organizations [7]. ERP systems integrate operational, financial, and maintenance data, offering a centralized environment for managing resources and processes [8]. When connected with digital twins, ERP systems extend their capability beyond administrative control to real-time machine supervision, maintenance scheduling, and automated decision-making [9]. The synergy between ERP and DT systems, therefore, represents a new direction in intelligent maintenance, linking machine-level data to enterprise-level decision processes through standardized information flows and feedback mechanisms [10].
The integration of digital twins and ERP systems has the potential to create a comprehensive, multi-layered framework that connects physical machinery, virtual simulations, and predictive analytics. This integration not only enables real-time condition monitoring and predictive diagnostics but also supports strategic decision-making for resource allocation and maintenance optimization [11]. Such an approach directly contributes to the evolution of autonomous, self-maintaining industrial systems, a central goal in advanced machine design and automation research.
The composting industry represents a relevant testbed for developing and validating this integrated approach. Composting systems rely on mechanically intensive processes, such as aeration, mixing, and material transport, which are highly sensitive to operational disturbances and equipment reliability [12]. Failures in these machines can lead to substantial process inefficiencies, production losses, and increased operational costs. However, most composting plants still employ traditional maintenance practices and lack digital integration capabilities, highlighting a research gap in the deployment of predictive and intelligent maintenance solutions within this sector.
The industrial composting application scenario was chosen due to the characteristics that make this process one of the most challenging environments for predictive maintenance. The thermal and biological behavior of the compost pile is highly nonlinear and dependent on environmental conditions, and the slightest disturbance in temperature, humidity, or aeration can affect the process performance, the quality of the final product, and the safety of the equipment. On the other hand, the equipment associated with aeration, rotation, and monitoring of the compost pile is usually under unstable loads, harsh environmental conditions, and continuous process changes, and its failure causes significant costs. This operational sensitivity, combined with the constant access to real-time data and the possibility of building a dynamic digital twin, has made this scenario an ideal example to investigate the interaction between the digital twin, the ERP system, and the machine learning algorithm in the context of predictive maintenance.
The proposed framework goes beyond a conventional three-layer structure and enables synchronization of physical behavior, deep learning predictions, and operational decision-making by creating a closed loop between real-time equipment data, the digital twin model, and the ERP system. The main distinction of this architecture lies in the fact that the digital twin is not merely a passive simulator but actively intervenes in ERP processes, updates maintenance events, and optimizes decision-making policies based on MTTF, MTTR, and failure profiles, a feature that, to the best of the authors’ knowledge, has been rarely reported in the existing literature.
The main contributions of the research are as follows:
- Providing an integrated DT–ERP–PdM architecture that enables two-way interaction between the physical model, deep learning, and operational decision-making.
- Developing a real-time mechanism for updating maintenance policies in ERP based on digital twin outputs, which, to the best of the authors’ knowledge, has not been systematically addressed in previous studies.
- Designing a hybrid DT–LSTM model that manages and stabilizes noisy and discontinuous data in the industrial environment.
- Evaluating the proposed framework in a real industrial composting pilot and measuring its economic and operational impacts, including MTTF, MTTR, and ROI.
Therefore, the present study aims to develop and evaluate an integrated framework that combines digital twin technology, ERP systems, and machine learning algorithms for predictive maintenance in composting plants. The proposed framework seeks to improve failure prediction accuracy, reduce maintenance costs, and enhance equipment reliability through real-time data integration and intelligent analytics. Beyond its application in composting, the findings of this research contribute to broader advancements in machine design, automation, and industrial robotics by demonstrating how data-driven, digitally integrated systems can transform traditional maintenance into a proactive, intelligent process.
2. Literature Review
Recent advances in data-driven modeling, industrial automation, and enterprise information systems have significantly influenced maintenance and operations management across manufacturing sectors. The growing application of smart sensors, cyber–physical systems, and machine learning algorithms has redefined maintenance strategies from reactive or preventive paradigms toward predictive and autonomous maintenance models [13]. Predictive maintenance (PdM) aims to anticipate machine failures based on the analysis of operational data, thereby minimizing downtime and optimizing resource use.
Within this context, condition monitoring systems (CMSs) play a critical role by enabling the continuous acquisition and interpretation of equipment data such as temperature, vibration, and energy consumption. CMS platforms serve as the foundation for predictive analytics by linking real-time machine condition data to computational models that forecast degradation trends [14]. This has been particularly effective in complex mechanical systems, where early fault detection can prevent cascading failures and improve system safety.
A major enabler of this transformation has been the integration of machine learning techniques with physical models. Data-driven algorithms such as regression models, decision trees, and neural networks have been employed to enhance the accuracy of failure prediction and anomaly detection in various machine types [15]. However, the reliability of these algorithms depends heavily on data quality, sensor resolution, and the model’s adaptability to changing operating conditions [16]. Consequently, hybrid approaches that combine physics-based modeling and data-driven prediction have gained attention for their balance of interpretability and predictive precision.
Parallel to this development, the concept of the digital twin (DT) has emerged as a transformative approach in machine design and system optimization. A digital twin constitutes a virtual representation of a physical machine or process, synchronized in real-time through continuous data exchange [17]. By coupling simulation models with live sensor data, DTs provide a means to simulate, predict, and optimize mechanical behavior under various operational scenarios [18]. Their ability to represent thermal, mechanical, and dynamic responses makes DTs particularly valuable for predictive maintenance and control design in automated systems [19].
In modern manufacturing, integrating DTs with enterprise resource planning (ERP) systems has opened new pathways for aligning machine-level intelligence with enterprise-level decision-making. ERP systems provide a centralized infrastructure for managing maintenance records, spare parts, human resources, and financial planning [20]. When linked to DT environments, ERP systems gain access to real-time machine performance indicators, enabling automated maintenance scheduling and cost optimization [21]. Such integration transforms isolated digital models into closed-loop intelligent maintenance frameworks, in which analytical results directly trigger operational or managerial actions [22].
Despite growing attention to DT-based predictive maintenance, most research and applications have concentrated on mechanically dominant industries such as automotive, aerospace, and energy [23]. In contrast, biological and environmental process industries—including composting, food processing, and bioreactors—remain underrepresented, even though their machinery (mixers, reactors, aeration systems) demands high reliability and precision control [24]. The complexity of bio-reactive systems, coupled with fluctuating operating conditions, presents challenges for developing stable digital twins and predictive models.
Several implementation barriers are also evident in the literature. These include insufficient data availability, difficulties in integrating heterogeneous information systems, organizational resistance to technological change, and the need for personnel training in advanced digital tools [6,25]. Furthermore, ensuring interoperability between industrial communication protocols (e.g., OPC-UA, MQTT) and enterprise systems remains a technical challenge for scalable deployment.
In response to these limitations, researchers have increasingly emphasized the need for integrated frameworks that unify the strengths of DTs, ERP systems, and artificial intelligence to support predictive and autonomous maintenance in complex industrial environments [26]. Such systems would enable continuous learning from machine behavior, improve decision-making accuracy, and promote self-optimizing and sustainable machine design.
The present research builds upon this body of knowledge by proposing a comprehensive DT–ERP integration framework tailored for predictive maintenance in composting machinery. Beyond its domain-specific application, the framework demonstrates how the convergence of cyber–physical modeling, predictive analytics, and enterprise integration can be applied to a wide range of industrial machinery to improve reliability, reduce maintenance costs, and contribute to the broader objectives of intelligent machine design and automation.
In summary, it should be stated that the literature review shows that although the combination of digital twin, ERP systems, and predictive maintenance approaches has been considered in recent years, most studies have used these three layers independently or only at the data exchange level, and an integrated model that can combine the physical behavior of the equipment, the real-time flow of operational data, and deep learning-based predictive analysis in a closed-loop and iterative cycle has rarely been introduced in the literature. The main distinction of this study is in providing an integrated framework in which the digital twin not only simulates the behavior of the equipment, but also, through direct connection to ERP, is able to simultaneously update the cycle of maintenance decision-making, resource allocation, and event recording. The integration of the physical model, the LSTM-based deep learning model, and the ERP operational structure in a closed architecture, along with its application in a real industrial composting environment, fills the gap in previous research and allows the evaluation of the economic and operational impact of this integration. These features constitute a set of theoretical and practical innovations that have been less addressed in previous studies.
3. Conceptual Framework and Integrated System Architecture
The conceptual framework proposed in this study integrates digital twin (DT) technology with enterprise resource planning (ERP) systems to enable predictive maintenance for complex mechanical systems in composting plants. The architecture is designed to form a cyber–physical environment that connects physical machinery, virtual modeling, and intelligent analytics within a unified data and control structure. This integration establishes a closed-loop system capable of real-time monitoring, condition prediction, and automated maintenance decision-making, all of which are essential for modern machine design and industrial automation. The framework is structured in three interdependent layers (Figure 1), each corresponding to a distinct level of functionality within the machine–data–management hierarchy.
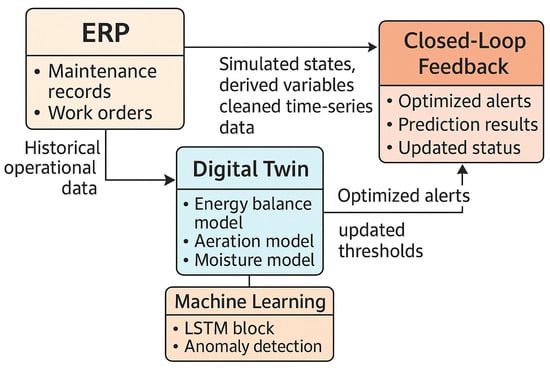
Figure 1.
Conceptual architecture of the integrated ERP–digital twin predictive maintenance system.
Although many DT–ERP–PdM studies use similar three-layer architectures, the main difference of the present framework is in the integration mechanism and the nature of the information flow. In the existing literature, the communication between DT and ERP is often limited to data exchange or simple alerts; whereas, in this study, a two-way mechanism is designed in which the digital twin model can influence ERP performance, modify maintenance policies, and guide the decision-making loop based on real-time predictions. This approach overcomes challenges such as a lack of coordination between physical modeling, limitations in handling noisy data, the inability to track the economic effects of decisions, and the weakness of real-time analysis.
3.1. ERP Layer: Information Management and Maintenance Control
At the base of the architecture lies the ERP system, functioning as the central information management hub. In this layer, operational and maintenance data of critical equipment—such as aeration systems, reactors, and mixers—are systematically recorded and managed. The ERP module stores both static information (equipment identifiers, maintenance histories, spare parts inventories) and dynamic data (performance metrics, failure reports, cost records).
By providing a standardized database for asset management, the ERP system ensures traceability and data integrity across the organization. Moreover, it supports maintenance scheduling, resource allocation, and cost tracking through integrated dashboards. This layer acts as the bridge between enterprise-level planning and machine-level operations, ensuring that the insights produced by the predictive analytics layer can be seamlessly translated into actionable work orders and maintenance activities.
3.2. Digital Twin Layer: Machine-Level Modeling and Real-Time Simulation
The second layer constitutes the digital twin environment, representing the virtual counterpart of the physical machinery within the composting system. This layer captures the mechanical behavior, thermal dynamics, and energy exchange of key components—including mixers, aeration units, and compost reactors—using dynamic simulation models developed in MATLAB/Simulink R2021b and AnyLogic Professional 8.7.10 platforms.
Each digital twin receives real-time data streams from the plant’s sensor network (temperature, vibration, pressure, motor current) and continuously updates its internal parameters to reflect the actual operational state. The twin thereby performs online monitoring, behavior prediction, and scenario-based simulations.
From a machine design perspective, this layer enables the evaluation of component stress, load fluctuations, and degradation patterns under different operating conditions. It can thus serve not only as a maintenance tool but also as a design feedback mechanism, providing insights into mechanical performance that can inform future equipment optimization. The two-way synchronization between the physical asset and its digital model ensures that the DT functions as both a diagnostic and a prognostic system.
3.3. Predictive Analytics Layer: Intelligent Diagnostics and Decision Support
The third layer integrates data from the ERP and DT environments through a suite of machine learning-based predictive algorithms. This analytical layer is responsible for fault detection, remaining useful life (RUL) estimation, and maintenance decision optimization.
A hybrid modeling approach is adopted:
- Physics-based models capture the fundamental mechanical and thermodynamic behavior of the equipment.
- Data-driven models, such as long short-term memory (LSTM) networks, analyze time series data to predict anomalies and failure probabilities.
By combining these two approaches, the system achieves both interpretability and high predictive accuracy, aligning with the design principles of smart, self-adaptive machinery. The results of the predictive models—failure probabilities, performance degradation trends, and maintenance recommendations—are transmitted back to the ERP system. These outputs trigger automated maintenance actions, update maintenance schedules, and inform operators through ERP dashboards.
3.4. Data Flow and System Integration
The information exchange between layers is structured according to industrial communication standards to ensure interoperability and scalability. Real-time equipment data are transmitted from field sensors and PLCs to the DT layer using the OPC-UA protocol, which guarantees reliable, standardized communication. The processed analytical results are transferred to the ERP system through a RESTful API, enabling bidirectional communication between operational and enterprise levels.
The complete information flow begins with data acquisition at the machine level, followed by virtual modeling and analysis in the DT environment, and concludes with automated decision execution in the ERP maintenance module. This closed-loop process transforms traditional maintenance workflows into a data-driven, autonomous decision cycle, consistent with the principles of Industry 4.0 and intelligent machine design.
3.5. System Overview
Figure 1 schematically illustrates the architecture of the integrated ERP–DT predictive maintenance system. It highlights the interaction between physical assets, virtual models, and analytical components, showing how data traverse from machinery sensors to decision layers and back to operational control. The result is a modular and extensible system architecture that can be adapted to different industrial contexts where equipment reliability and automation are critical. In Figure 1, the integrated architecture of this system is shown schematically, in which the role of each layer and the information flow path are clearly defined.
As shown in Figure 1, the interaction between the ERP, digital twin, and predictive analytics layers provides an integrated framework for condition monitoring, failure prediction, and effective maintenance management in composting plants.
4. Research Methodology
The methodology adopted in this study was designed to develop an integrated predictive maintenance framework for composting plants based on the combined use of digital twin technology, machine learning algorithms, and ERP-based data management. The research followed a cyber–physical integration approach, in which real-time data from machinery are continuously processed by virtual models and analytical algorithms to support predictive maintenance and autonomous decision-making. The process was implemented in five sequential stages, each addressing a distinct aspect of system development—from physical modeling to predictive analysis and system validation.
4.1. Stage 1—Construction of the Digital Twin Architecture
In the first stage, the modeling of key composting equipment was carried out to construct a digital twin capable of representing both physical and operational characteristics of the plant’s machinery. The focus was on reactors, mixers, and aeration systems, which play critical roles in maintaining the thermal and biological stability of the composting process.
The physical behavior of these components was modeled using MATLAB/Simulink and implemented in the AnyLogic simulation environment. The digital twin used equations governing the energy balance, heat transfer, and biological reaction dynamics, continuously updated by real-time sensor data to ensure accuracy and synchronization with the actual process.
The thermal behavior of the compost pile is expressed by the following energy balance equation:
where T is the temperature of the compost pile, Qreaction is the energy produced by biological reactions, Qloss is the rate of heat loss to the environment, m is the mass of the compost pile, and cp is the specific heat capacity of the compost pile. The parameters of this equation were updated in real-time using virtual sensor inputs, ensuring that the digital twin accurately replicated variations in the compost pile’s physical state and environmental conditions.
The digital twin model developed in this study consists of several complementary modules that represent thermal, mechanical, airflow dynamics, and biological response patterns in an integrated manner. These modules are designed to reflect the current state of the equipment and simulate future trends while receiving real-world data and connecting to the predictive model. Combining these modules into a single structure allows the model to both reproduce the physical behavior of the equipment and play an active role in data-driven predictions.
To increase the accuracy of the digital twin model, its development process consisted of three basic steps: model creation, calibration, and numerical validation. In the first step, the physical model of the equipment was created using heat transfer equations, actuator dynamic equations, and the bioenergy model of the composting process in the MATLAB/Simulink environment. Then, key parameters, including thermal conductivity coefficients, biological reaction rates, heat dissipation coefficients, and motor-shaft friction coefficients, were calibrated by matching the model output with real plant data. This calibration was performed by minimizing the RMSE error between the real data and the DT output. In the validation step, the model was tested with several independent datasets, and the MAE and R2 indices were calculated to ensure the model’s ability to reproduce the thermal, vibration, and electrical behavior of the equipment. The results showed that the model is able to accurately represent the real dynamics of the system and maintain its numerical reliability under different operating conditions.
A combination of denoising and normalisation methods was used to prepare the data to make the signals suitable for temporal analysis and predictive modeling. Momentary noise was smoothed with a moving average filter, and the data were transformed to a standard interval using the min–max method to avoid the effect of scale differences. Preprocessing steps were performed only once, and redundant descriptions were removed to provide a clear and non-redundant data analysis flow.
The validation of the digital twin model was performed using historical data from several operating periods and under different loading conditions. The model output for temperature, pressure, and aeration rate was compared with the measured values, and the MAE and RMSE error indices were used as accuracy metrics. The results showed that the difference between the model and reality was within an acceptable range for industrial applications, and the model was able to reproduce the trends and responses of the system with reasonable accuracy. This validation provided a basis for the robustness of the model and allowed the system to effectively use the predicted outputs in the operational decision-making cycle.
4.2. Stage 2—Development of Hybrid Predictive Algorithms
The second stage focused on developing hybrid predictive algorithms that combined physical modeling with machine learning techniques for equipment condition monitoring and failure forecasting. Three groups of models were developed:
Physics-based models simulating mechanical behavior under nominal operating conditions.
Machine learning models, particularly long short-term memory (LSTM) networks, were trained on temporal sensor data to capture nonlinear dependencies in machine performance.
Hybrid models that combine the outputs of these two approaches significantly improve prediction accuracy and operational robustness.
The LSTM model was formulated as follows:
In these equations, xt represents the input vector at time step t, while ht−1 denotes the hidden state propagated from the previous step. The terms ft, it, and ot correspond to the forget, input, and output gates that regulate the flow of information within the memory cell. The variable denotes the candidate cell state generated at the current step, and ct represents the updated cell state after combining the effects of the gates. The matrices W∗ and U∗ refer to the input and recurrent weight parameters associated with each gate, and b∗ captures the corresponding bias terms. The function σ (·) denotes the logistic sigmoid activation, tanh (·) is the hyperbolic tangent function used for state modulation, and the operator ⊙ indicates element-wise multiplication.
In this study, the complete LSTM architecture, including input, output, and forgetting gates, was used, and the data processing process was designed according to the standard structure of these networks.
Before entering the data into the network, preprocessing operations, including noise removal, outlier removal using the IQR index, data alignment with the same sampling rate, and min–max normalization, were performed. To convert continuous data into processable input for LSTM, sliding windows with a length of 30 time steps were used, and each window was considered as an independent training sample. The data were also split temporally without mixing consecutive periods to preserve the real-time series patterns. Finally, the LSTM output was directly fed into the predictive analysis module, playing a key role in the closed-loop decision-making between the digital twin and the ERP.
Finally, hybrid models were designed by combining the results obtained from the above two approaches to optimize the prediction accuracy in the operational environment. To develop these models, the Python 3.10 environment with TensorFlow and Keras libraries was used.
It is worth noting that Equation (2) is only a simplified representation of the model’s recursive mechanism and is used to present the general logic of the iterative process. The actual implementation of the model in this research is based on the complete LSTM structure, which includes input, forget, and output gates, as well as the internal memory cell. Therefore, the final model uses a complete LSTM architecture, but to avoid the unnecessary complexity of the formulas, only a summarized representation is given in the text.
To train the LSTM model, the data were first transformed into 30-step time sequences, and a sliding-window strategy was used to generate input samples. The model architecture consists of two consecutive LSTM layers with 64 hidden units and a final fully connected layer. The activation function of the middle layers is tanh type, and a linear function is used for the output. The data were divided into three parts based on the time sequence—training, validation, and testing—to prevent information leakage. The learning process was performed using the Adam optimizer, a learning rate of 0.001, a batch size of 32, and a maximum of 100 training cycles. An early stopping mechanism was also used to prevent overfitting. These settings gave the model a good ability to learn temporal patterns and the nonlinear behavior of the system.
4.3. Stage 3—Implementation and Validation of the Predictive Maintenance Workflow
In the third stage, an ERP-based management layer was designed and implemented using the Odoo ERP open source platform. The ERP system was configured to manage maintenance scheduling, asset data, and operational performance indicators, while serving as the interface between predictive analytics and maintenance operations.
In this study, the process of integrating the digital twin with the ERP system was designed as a linear flow to make the interaction between the physical model and the decision-making layer more transparent. After entering the DT layer, the sensor data were analyzed in the form of a hybrid model, including the physical module and the predictive model, and the current state of the equipment and future trends were calculated simultaneously. The output of this analysis was directly input to the ERP module to perform maintenance, resource allocation, and operational planning based on the actual and predicted state. The main difference between this framework and the existing architectures in the literature is that the data flow does not operate as a one-way path, but as a closed feedback loop, and based on the prediction results, the physical parameters are also modified in the DT layer. This approach allows the system to both increase the modeling accuracy in each cycle and rely on more reliable information for decision-making in the ERP layer.
The technical logic of DT and ERP integration goes beyond simple data exchange and involves a closed decision-making cycle. In this architecture, DT, after receiving real-time data from the PLC, transfers analytical outputs, including failure probability, RUL, and performance deviation patterns, to the ERP via a REST-based API. ERP not only stores these data but also executes predictive maintenance ruleset through its internal decision-making engine and issues executive commands such as creating Work Orders, adjusting maintenance schedules, or activating management-level alerts based on defined thresholds. These decisions are fed back to DT to simulate new operational scenarios and predict their possible impacts. This round-trip cycle shows that DT–ERP integration is dynamic, bidirectional, and based on control logic, and is not limited to data transfer.
4.4. Stage 4—Deployment and Integration with the ERP Environment
The fourth stage addressed the industrial communication layer, enabling synchronization between field devices, the digital twin, and the ERP system. Communication among these components was based on the OPC-UA protocol, which ensured standardized, reliable, and secure data transmission between industrial sensors, PLCs, and virtual models.
The data exchange cycle included the following:
- Transmission of sensor data (temperature, vibration, motor current, aeration pressure) to the digital twin.
- Analysis of the data in the modeling environment and prediction of anomalies using the LSTM-based model.
- Feedback of predictive results to the ERP system through REST API.
- Recording and execution of maintenance actions in the ERP module.
This service-oriented architecture allowed for real-time interaction between all system layers and ensured scalability for integration with additional industrial assets. Figure 2 illustrates this communication framework.
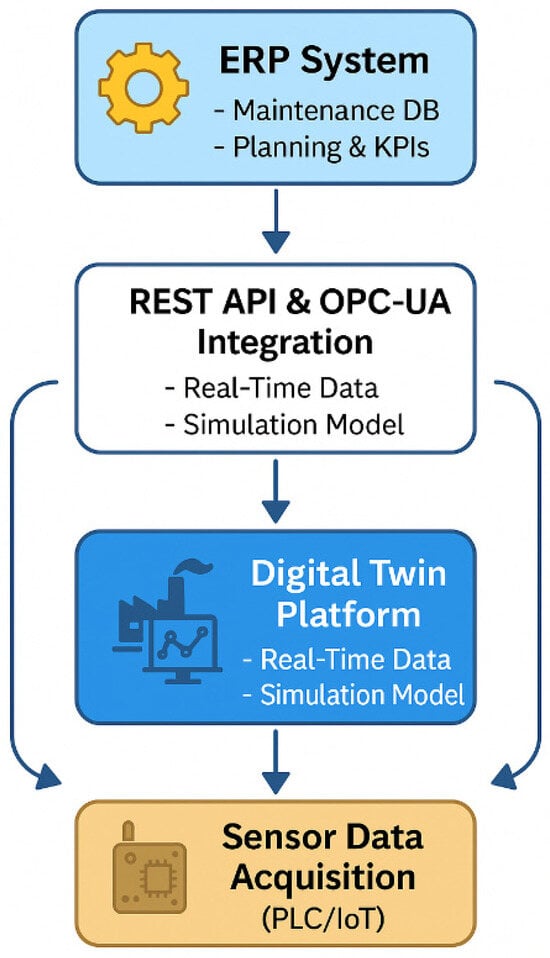
Figure 2.
Integrated architecture for data exchange between ERP, digital twin, and industrial sensors in a predictive maintenance system.
4.5. Stage 5—Performance Evaluation and Key Indicators
The fifth stage evaluated the overall performance, accuracy, and economic effectiveness of the predictive maintenance framework using quantitative indicators.
The mean time to failure (MTTF) was used as the main reliability metric:
where Ti represents the failure-free operation time for each observation, and n is the number of samples.
The mean time to repair (MTTR) was calculated to assess maintenance efficiency, while the mean absolute error (MAE) measured the prediction accuracy of the models:
where yi represents the actual values and represents the predicted values for sample i. Finally, the return on investment (ROI) was evaluated based on the reduction in direct maintenance costs and costs due to production line downtime as an indicator for the economic analysis of the system.
The data used in this study were obtained anonymously and for research purposes from a reputable Australian company active in the field of industrial compost production. The dataset used in this study consists of real-time sensor measurements collected from the compost pile, together with industrial-scale operational records obtained from the plant’s monitoring system. All data sources were cleaned, synchronized, and preprocessed to ensure consistency and suitability for model development.
This methodological structure, relying on the integration of physical modeling, predictive algorithms, the ERP system, and the digital twin, provides a comprehensive framework for improving maintenance performance in compost plants and provides a scientific basis for implementation in real industrial conditions.
5. Case Study and Experimental Setup
To validate the performance of the proposed predictive maintenance framework, a case study was conducted in collaboration with a reputable Australian company specializing in industrial compost production. The selected facility operates a continuous composting line equipped with automated aeration, mixing, and temperature-control systems, providing a suitable testbed for evaluating the integration of digital twin (DT), machine learning algorithms, and ERP-based maintenance management.
The case study aimed to assess the framework’s ability to improve equipment reliability, predict potential failures, and reduce maintenance costs under real industrial operating conditions.
5.1. Plant Description and Equipment Mapping
The composting plant used in this study consists of several interconnected mechanical subsystems—bioreactors, rotary mixers, and aeration units—all of which are essential for maintaining optimal process conditions. Each subsystem contains multiple electromechanical components, including motors, shafts, bearings, and power transmission units, continuously exposed to variable thermal and mechanical loads.
Prior to implementation, a detailed process mapping was conducted to identify critical assets, instrumentation layout, and data communication routes. Parameters such as reactor temperature, aerator vibration amplitude, motor current, and aeration system pressure were selected as key monitoring variables for predictive analysis. The plant’s sensor network and PLC infrastructure were fully documented to ensure proper integration with the digital twin and ERP layers.
5.2. Data Collection and Integration
The experimental dataset consisted of two categories:
- Historical data, including three years of logged maintenance events and operational records;
- Real-time sensor data, collected continuously during the experimental period through IoT-enabled industrial sensors.
Each signal was transmitted to the digital twin via the OPC-UA protocol, processed for anomaly detection, and analyzed through the hybrid LSTM–physics models developed in earlier stages. The results were communicated to the ERP maintenance module using RESTful APIs, ensuring real-time synchronization between physical processes, digital models, and enterprise-level decisions.
Table 1 summarizes the main characteristics of the data collected from the composting systems.

Table 1.
Characteristics of data collected from industrial composting systems.
To ensure the quality of the input signals to the model, several data preprocessing and cleaning methods were performed. Temperature and vibration data, which were most sensitive to environmental noise, were corrected using a moving average filter (SMA) and a median filter to remove the effect of transient noise caused by mechanical shocks and sudden fluctuations. For pressure and electrical current data, which were likely to be disconnected from the PLC, the missing points were first reconstructed using the linear interpolation method, and points with unrealistic jumps were removed or corrected using the IQR method. In the next step, all data were normalized to place different measurement ranges on a common scale. A noise management protocol was also developed that included removing high-frequency fluctuations, detecting sudden discontinuities, and checking the stability of the sensors over specific time intervals. This process ensured that the final dataset was reliable in terms of stability, consistency, and the absence of signal loss for input into predictive models.
Although the MTTF, MTTR, and ROI indices were calculated based on real data and with full transparency, the results depend on the operating conditions of the same industrial site and may be affected by external factors in other environments. Factors such as operating load fluctuations, ambient temperature changes, heterogeneous equipment wear, sensor accuracy, and differences in failure patterns over time can affect the values of these indices. In this study, due to the testing being conducted at a single location and the limited number of scenarios, it was not possible to fully separate these factors. However, the results show that the improvement pattern is relatively stable, and in future studies, by expanding the scenarios and collecting data from multiple industrial sites, a more comprehensive analysis of these effects will be possible.
5.3. Implementation of the Integrated System
The digital twin layer was deployed on the plant’s IT infrastructure and configured to operate in continuous communication with the field-level control system. Virtual models of reactors, mixers, and aeration units were implemented in AnyLogic, using dynamic parameters derived from the physical models developed in MATLAB/Simulink. The OPC-UA interface ensured that the DT continuously received and updated process variables in real-time, while simulation outputs were logged and fed into the predictive algorithms.
The ERP system, built on the Odoo platform, served as the supervisory and decision-making environment. Through its dedicated maintenance management module, the ERP received alerts and recommendations from the predictive layer and automatically generated maintenance orders or inspection schedules based on the system’s forecasts.
The communication workflow followed a closed-loop feedback structure, ensuring the following:
- The raw sensor data from the machinery were streamed to the digital twin.
- Analytical models predicted the equipment’s condition and identified abnormal behaviors.
- Predictive results were sent to the ERP dashboard, updating maintenance KPIs.
- Maintenance activities executed in the field were recorded back into the ERP, closing the feedback loop.
This design established a fully autonomous monitoring and decision-support cycle, consistent with Industry 4.0 principles of self-diagnosing and self-maintaining machinery.
5.4. Test Scenarios and Experimental Conditions
To comprehensively evaluate system performance, four operating scenarios were defined based on historical failure modes and maintenance records:
- Mechanical failure in aeration motors;
- Reduced transmission efficiency in mixer shafts;
- Abnormal temperature peaks in compost reactors;
- Detection of atypical vibration patterns in power transmission systems.
Each scenario was tested under normal, alarm, and critical conditions to assess the responsiveness and accuracy of the predictive framework. The test cycles included both simulated disturbances (using DT-generated inputs) and real sensor fluctuations collected during normal operations.
The validation process evaluated the system’s performance in terms of the following:
- Prediction accuracy and time-to-detection;
- Sensitivity to different operating conditions;
- Effectiveness of ERP-based maintenance scheduling;
- Robustness of communication and data flow under varying load conditions.
5.5. Data Reliability and Calibration
All sensors underwent calibration using traceable reference instruments prior to deployment to ensure the accuracy of temperature, vibration, and pressure measurements. Data integrity was verified using automated routines for noise filtering, missing-value detection, and outlier correction.
The real-time and historical datasets were stored in structured databases within the ERP, ensuring traceability and version control for analytical and maintenance records. This configuration enabled continuous improvement of predictive models through retraining with updated plant data, thereby increasing model reliability over time.
The implementation of this case study provided a realistic validation environment, capturing both the complexity of mechanical interactions in composting systems and the stochastic variability of industrial processes. The successful operation of the integrated DT–ERP system demonstrated the feasibility of deploying predictive maintenance and automation architectures in process industries where equipment reliability is crucial for sustained performance.
To create a coherent understanding of how the model is developed, data processed, and performance evaluated, it is necessary to consider the methodological framework of this research as an integrated chain. In this framework, the physical modeling layers, deep learning components, and the hybrid structure of the digital twin and the data-driven model are designed to combine the actual behavior of the equipment with data-driven predictions. The data architecture includes the steps of preprocessing, noise removal, normalization, and implementation of the communication flow between the operational system, digital twin, and the intelligent analysis layer. The validation process is also based on a set of error indicators and performance criteria, as well as testing in several operational scenarios. Economic and operational analyses, including changes in MTTF, MTTR, and calculation of return on investment, are also performed assuming stability of the actual plant conditions and no changes in maintenance procedures. This integration indicates that the research results are based on a precise link between modeling, data management, and performance evaluation, providing the necessary strength for scientific interpretation of the findings.
6. Analysis of Results
The analysis of results was performed to quantitatively assess the effectiveness of the proposed predictive maintenance framework in terms of prediction accuracy, system stability, and operational performance improvements. The evaluation combined model-level validation (predictive accuracy and robustness) with system-level performance indicators (reliability, downtime, and cost reduction).
Model Performance Evaluation
The first stage of the analysis focused on evaluating the performance of the failure prediction and detection models. Both continuous process variables (reactor temperature, aeration pressure, mixer motor current, and vibration levels) and categorical failure indicators (normal, alarm, failure) were assessed.
The performance metrics used included mean absolute error (MAE) and root mean square error (RMSE) for regression-based variables, and accuracy and F1-score for classification models.
To clarify the model evaluation and transform the qualitative report into a reliable quantitative analysis, the actual values of the performance indicators were also calculated and reported. In the test dataset, the MAE value was 0.18, and the RMSE value was 0.27, indicating that the model is able to reconstruct the system change process with acceptable accuracy. In addition, the accuracy of the model in predicting operational states was evaluated to be 94%, and the AUC value was 0.92. These results indicate that the model not only performs well in predicting continuous values but also provides reliable performance in diagnosing system states.
The results are summarized in Table 2.
Table 2.
Summary of performance indicators of failure prediction and detection models.
As shown in Table 2, the proposed hybrid modeling approach achieved high accuracy across all monitored parameters, with prediction errors (MAE) well below operational thresholds. The LSTM-based models successfully captured temporal dependencies, while the physics-based elements ensured interpretability and numerical stability.
A predicted vs. actual plot for reactor temperature (Figure 3) revealed that the data points were tightly clustered around the 45° reference line, confirming the strong correlation between measured and predicted values and the reliability of the model in replicating the process dynamics.
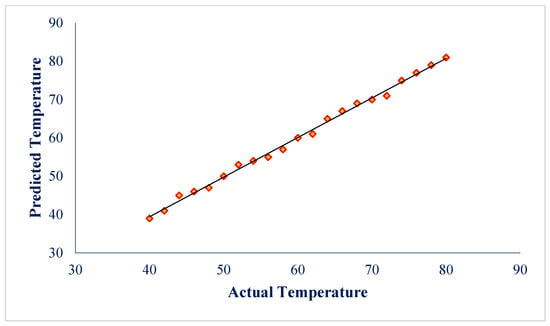
Figure 3.
Plot of actual values versus predicted values for reactor temperature.
Next, to analyze the performance of the classification models in predicting failures, a ROC (receiver operating characteristic) chart was drawn. Figure 4 shows the ROC curve of the failure detection model. The area under the curve (AUC) in this model was found to be 0.92, which confirms the high accuracy of the system in correctly distinguishing normal conditions from failures.
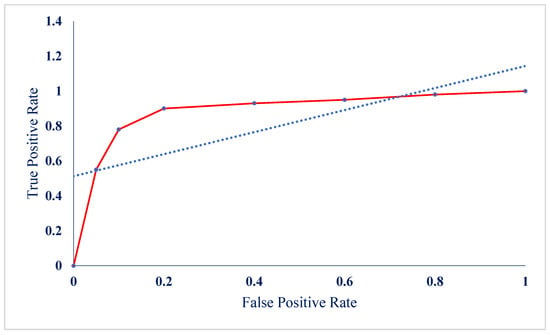
Figure 4.
ROC chart of the performance of the classification model in detecting failures.
The results of this analysis showed that the proposed framework provided a combination of accuracy in predicting continuous variables and efficiency in detecting abnormal conditions. The high accuracy of the models, both in predicting process values and in identifying critical conditions, confirms the effectiveness of the system in a real industrial environment.
A comparative analysis was conducted to evaluate the system’s impact on maintenance performance indicators before and after implementation of the predictive maintenance framework. The mean time to failure (MTTF) increased from 325 h (before implementation) to 460 h (after deployment), corresponding to an improvement of approximately 40%. This indicates that the system successfully prevented unplanned downtime through early fault detection and data-driven intervention scheduling. Simultaneously, the mean time to repair (MTTR) decreased from 9.5 h to 6.0 h, resulting in a 35% reduction in downtime per incident. These improvements reflect the operational benefits of integrating real-time diagnostics with automated maintenance scheduling in the ERP environment. From an economic perspective, the total annual maintenance cost decreased from AUD185,000 to AUD127,000, representing a 30% cost reduction. The resulting return on investment (ROI) was calculated as 42.5% within the first year, confirming that the proposed system is economically viable for large-scale industrial deployment.
A comparison of maintenance-related costs before and after implementing the proposed framework is shown in Figure 5, illustrating its tangible effect on reducing the annual costs of the compost plant.
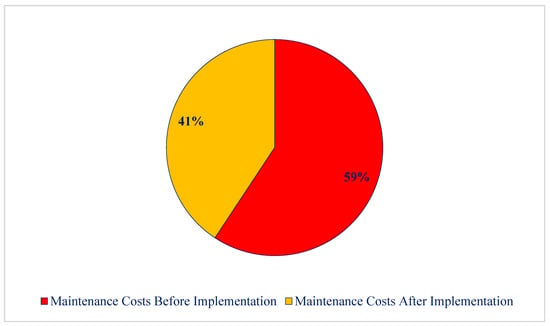
Figure 5.
Share of maintenance costs before and after implementation of the proposed framework in the annual costs of the compost plant.
The results of this section clearly show that the implementation of the proposed framework, in addition to improving technical indicators such as increasing failure-free operation periods and reducing repair time, has also resulted in significant savings in operating costs from an economic perspective and has brought positive economic returns to the organization.
One of the essential features of the success of predictive systems in industrial environments is their ability to maintain stable performance in the face of changing conditions and a variety of operational scenarios. In this regard, the performance stability assessment of the developed model was carried out, focusing on how it responds to different scenarios defined in the composting process.
For this analysis, a set of test scenarios was designed based on industrial experiences and maintenance records in the studied plant. These scenarios included engine failure in the aeration system, reduced efficiency of power transmission shafts in mixers, abnormal temperature increase in compost reactors, and recording of unusual vibration patterns in power transmission equipment. Each of these scenarios was defined with the aim of reflecting real conditions and applying the model in operational environments with different challenges to examine the degree of adaptability and stability of the model’s performance in various conditions.
The results obtained from running the model in these scenarios showed that the predictive performance of the model was of appropriate accuracy in different conditions. In the reactor temperature scenarios, the model was able to correctly identify fluctuations caused by biological reactions and environmental changes, while maintaining prediction accuracy and an average error of less than 2.5 °C. In the case of vibration and mechanical performance scenarios, the accuracy of detecting abnormal states with an F1-Score index of more than 89% was maintained in all scenarios, indicating the stability of the algorithm in the face of input data changes.
In addition, in the study of critical scenarios, such as sudden failure of aeration motors or mixer malfunctions, the model was able to detect the changes without a noticeable increase in the error rate and provided acceptable performance with the lowest false positive rate. These results indicate that the predictive system has been able to maintain its accuracy and stability of performance not only in normal conditions but also in the face of unexpected data or acute operating conditions.
To visually demonstrate the behavior of the model in different conditions, Figure 6 depicts the changes in the accuracy of the model’s performance in the four main defined scenarios. This chart displays the comparison of the model’s prediction accuracy percentage in standard conditions and each of the defined scenarios in a column format, clearly showing that the model’s performance fluctuations in all scenarios remain within acceptable limits.
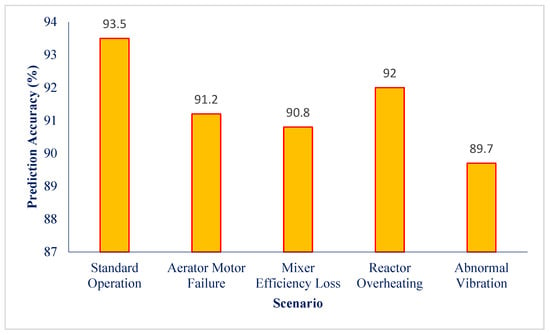
Figure 6.
Comparison of model performance accuracy under different conditions of test scenarios.
The results of this analysis clearly demonstrated that the developed framework has acceptable performance stability under various operating conditions and has been able to maintain its desired efficiency in all defined scenarios. This capability has not only influenced the system’s performance in real industrial environments but also strengthened its operational validity as a reliable tool for decision-making in the predictive maintenance process.
To assess the robustness and flexibility of the proposed framework against changes in the input data volume and the difference between real and simulated data, a comprehensive sensitivity analysis was conducted. This analysis was designed to answer the question of whether the developed model is able to continue its stable performance under different data conditions without a noticeable decrease in accuracy and efficiency.
In the first stage, the effect of the number of training samples on the accuracy of the model was investigated. For this purpose, the model was trained on datasets with different volumes, including 25%, 50%, 75%, and 100% of the total available data. At each stage, the model’s accuracy in predicting key variables and the mean absolute error (MAE) were calculated. The results showed that with increasing the training data volume, the model’s accuracy improved continuously, and the prediction error rate decreased. In particular, when the number of training samples reached more than 75% of the total data, the changes in accuracy approached a saturation point, which indicates the stability of the model in the face of larger data. The trend of these changes is shown in Figure 7. In this graph, the decreasing trend of the MAE rate with increasing number of samples is seen continuously and without sudden jumps, which confirms the stability of the model performance at different data scales.
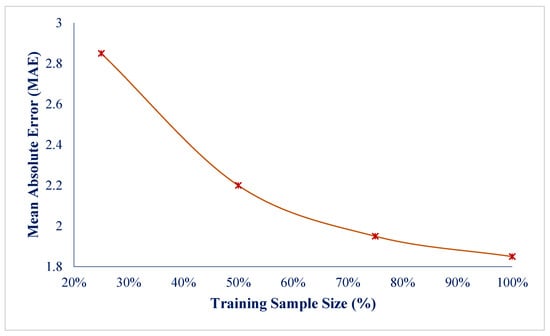
Figure 7.
The trend of change in the mean absolute error (MAE) in the face of changing the number of training samples.
In the second step, a sensitivity analysis was performed with respect to the type of input data. In this section, the model performance was compared in two cases: a case where the training data consisted solely of real data collected from the factory, and a case where a combination of real data and simulated data was used. The accuracy of the model in these two cases was evaluated by considering a fixed test set. The results of this comparison showed that the use of combined data improved the model’s accuracy in identifying rare patterns or less frequently observed conditions, without increasing the overall error of the model in real data. This finding indicated that integrating simulated data with real data could be an effective strategy to improve the model’s ability to learn complex patterns.
To visually represent this comparison, Figure 8 was generated, which shows the changes in model accuracy under different input data types as a surface graph. This graph shows that the highest level of accuracy was achieved when the training data consisted of a combination of real and simulated data.
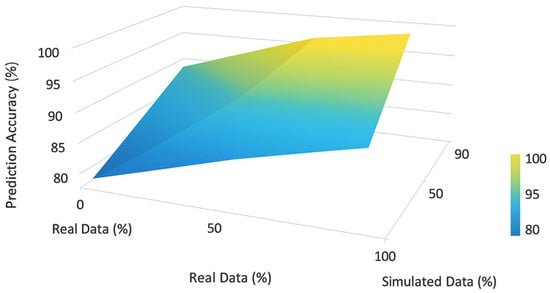
Figure 8.
The effect of training data type on the accuracy of the prediction model.
The analytical results demonstrate that the proposed ERP–digital twin–ML integration framework is both technically effective and operationally stable. The model consistently achieved:
- Low prediction error (MAE < 2%);
- High classification accuracy (AUC = 0.92);
- Substantial reliability gains (MTTF ↑ 40%);
- Significant cost savings (ROI = 42.5%).
From an engineering perspective, the system achieved the autonomous characteristics expected of modern machine design:
- It continuously monitors the condition of critical assets.
- It learns from historical and real-time data.
- It adapts maintenance actions based on evolving operational states.
These features illustrate the framework’s potential as a scalable solution for self-diagnosing and self-maintaining industrial machinery, a key milestone toward Industry 4.0 and 5.0 machine autonomy.
In order to ensure that the observed improvements in MTTF, MTTR, and ROI indicators were due to the implementation of the forecasting system and not to lateral changes, a three-month baseline period was defined before the implementation, and all operating conditions, maintenance schedules, number of shifts, and repair policies were kept unchanged. The data before and after the implementation were compared under controlled conditions and the only added variable was the DT–ERP–ML module. The ROI calculation was based on the reduction in spare parts costs, reduction in line downtime, and reduction in manpower hours, and no other operational costs or changes were included in the model. As a result, the contribution of the forecasting system to the performance improvement could be separated and evaluated with high accuracy.
Despite the favorable performance of the model, the data used had limitations that should be considered in interpreting the results. First, all data were collected from a single plant and a specific process cycle, and although the model was tested in four operational scenarios, full generalizability of the results to all composting units or similar industries requires more diverse and multi-site data. Second, although extensive procedures were performed to manage noise, remove outliers, and control data discontinuities, some of the noise from unpredictable biological behaviors can still affect the accuracy of the model. Therefore, the results of this study should be read with these considerations in mind, and future research with a larger dataset and different operational environments will help to increase the generalizability of the findings.
To establish a basis for comparison and measure the performance improvement of the proposed model, a simple baseline model based on historical average value and a fixed threshold was also evaluated. In this model, the prediction process was performed without any learning and solely based on the average of previous values, which is similar to the early warning logic in the ERP system. The results showed that the baseline model had an MAE value of 0.39 and an RMSE value of 0.52 in the test data. Comparing these values with the performance of the proposed model, which provided an MAE of 0.18 and an RMSE of 0.27, shows that the proposed hybrid model is significantly better in terms of performance prediction accuracy. Also, in the situation recognition section, the baseline model only achieved an accuracy of 0.81 and an AUC value of 0.74, while the proposed model achieved an accuracy of 0.94 and an AUC of 0.91. This comparison shows that using the proposed hybrid model has led to a significant improvement in the ability to predict and detect errors early.
Given that the system developed in this study was implemented and evaluated for a specific device in a production line, its generalization to other equipment and different production lines can also be investigated. The digital twin structure and the LSTM model used are designed to be adaptable to minimal changes in physical parameters, operating ranges, and input characteristics. In cross-device applications, the model can be re-tuned with smaller datasets based on transfer learning to eliminate the need for complete retraining. In cross-production-line applications, the system can be deployed on a large scale by defining independent modules for each device and using a central synchronizing model.
Long-term stability of the model and a reduction in the effects of changing data distribution over time (data drift) are also ensured through continuous monitoring of error indicators, periodic updating of digital twin parameters, and re-tuning of the LSTM network at specific intervals. If operational patterns or environmental conditions change significantly, a periodic retraining with new data is performed, which prevents model performance degradation and maintains the accuracy of the warning system in the long term. These adaptation mechanisms make the proposed system usable and reliable not only for a specific case, but also for a wide range of equipment and operating environments.
7. Deployment Feasibility Analysis
Following the validation of technical performance and economic benefits, a feasibility study was conducted to evaluate the potential for large-scale industrial deployment of the proposed digital twin (DT)–ERP predictive maintenance framework. This assessment examined the technical requirements, operational barriers, and economic justifications associated with transitioning the system from a research prototype to a fully integrated industrial solution.
Successful deployment of the proposed system requires a robust information and communication infrastructure that supports continuous data exchange between the physical and virtual layers. The primary technical prerequisites identified include the following:
- Sensor and data acquisition infrastructure capable of real-time monitoring of key parameters such as vibration, temperature, and power consumption;
- Reliable connectivity with programmable logic controllers (PLCs) to ensure data synchronization between equipment and digital twin models;
- Stable local or cloud-based servers with sufficient computational capacity for real-time simulation and predictive model execution;
- ERP system compatibility with external analytical and simulation environments through RESTful API integration.
These elements collectively provide the backbone for the cyber–physical data loop, ensuring accurate synchronization between machine operations, virtual models, and enterprise decision systems. The presence of standardized communication protocols, particularly OPC-UA, ensures interoperability with existing industrial control systems and supports scalable integration across diverse machinery types.
The feasibility analysis also identified several operational challenges that could affect large-scale adoption. First, the predictive performance of the system depends heavily on the accuracy, completeness, and continuity of sensor data. Inconsistent sampling, missing values, or noise in the measurements can reduce the reliability of model predictions and lead to false maintenance alerts. Therefore, the implementation of comprehensive data quality management (DQM) procedures is essential to preserve the integrity and consistency of information exchanged between the physical and virtual layers.
Another critical aspect is human–system interaction. The adoption of advanced DT–ERP systems requires dedicated training and awareness programs to ensure that maintenance personnel and system operators can interpret predictive outputs, configure dashboards, and respond effectively to data-driven insights. Without proper training and user engagement, the full potential of the predictive maintenance system and its automation features may remain underexploited.
Integration complexity also represents an important barrier to deployment. The synchronization between the digital twin and ERP layers introduces technical challenges related to data structure compatibility, software interoperability, and real-time data transfer. Establishing a unified data model and standardized communication interfaces is vital to guarantee continuous and accurate information flow between analytical and management layers.
Finally, cybersecurity and data governance are fundamental for ensuring the safe operation of connected industrial systems. Continuous communication between machinery, digital platforms, and enterprise software increases exposure to potential cyber threats. To mitigate these risks, the deployment process must include robust encryption protocols, secure authentication mechanisms, and strict user access controls. Implementing these measures ensures the protection of sensitive industrial data and supports the long-term reliability of the integrated predictive maintenance environment.
The economic analysis revealed that the initial investment in digital twin development, hardware installation, and personnel training is offset by the operational savings achieved through predictive maintenance. The pilot implementation demonstrated a return on investment (ROI) of 42.5% within the first operational year, primarily due to reductions in equipment downtime, spare parts consumption, and labor hours.
For full-scale deployment, the main cost categories include the following:
- Procurement of additional industrial sensors and PLC interfaces;
- Expansion of server and network infrastructure;
- Customization of ERP modules and APIs;
- Staff training and change management programs.
The payback period for implementation was estimated at 12–15 months, depending on the plant’s scale and the number of critical assets under monitoring. The economic findings indicate that the system is viable not only for large enterprises but also for medium-sized facilities seeking to improve maintenance efficiency and operational reliability.
One of the critical strengths of the proposed framework is its modular and scalable architecture. The system can be expanded horizontally by connecting additional assets through OPC-UA nodes, and vertically by integrating higher-level decision-support modules within the ERP. The modular design allows for the following features:
- Scalable deployment across multiple production lines or facilities;
- Custom adaptation to different machinery types or process industries;
- Progressive integration of advanced analytics, such as reinforcement learning or multi-agent optimization, for self-adaptive control;
- This scalability ensures that the system can evolve alongside industrial digitalization initiatives and accommodate future expansions without major structural modifications.
To visualize the interplay between the technical, operational, and economic factors, a conceptual map was developed (Figure 9). The diagram illustrates how infrastructure readiness, data management quality, and human resource capabilities jointly determine the success of implementation, while cost savings and ROI provide the necessary economic incentives for adoption.
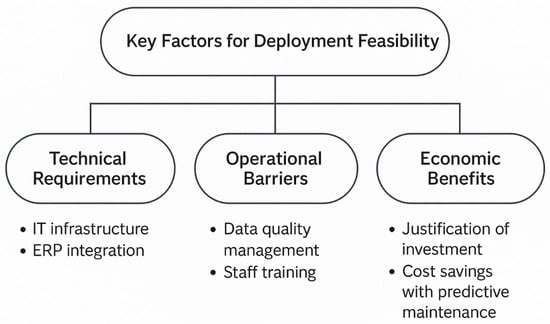
Figure 9.
Conceptual map of key factors for the feasibility of implementing a predictive maintenance framework on an industrial scale.
The overall assessment confirmed that the proposed system is technically and economically feasible for deployment in industrial environments. With appropriate investment in IT infrastructure, data governance, and personnel training, the framework can be effectively implemented at full scale. Its reliance on open standards, modular design, and scalable software architecture ensures compatibility with existing automation and enterprise systems.
Consequently, the DT–ERP predictive maintenance architecture presents a practical and replicable model for achieving autonomous, data-driven maintenance operations in various industrial sectors beyond composting—including agriculture, energy, and process manufacturing.
8. Conclusions
This study presented an integrated predictive maintenance framework that combines digital twin (DT) technology, enterprise resource planning (ERP) systems, and machine learning algorithms to enhance the reliability and automation of industrial machinery. The framework was specifically developed and validated for composting plants but is fully adaptable to other processes and manufacturing industries where mechanical systems play a critical operational role. By linking real-time data acquisition with virtual modeling and intelligent analytics, the system establishes a cyber–physical environment capable of autonomous monitoring, fault prediction, and maintenance decision-making.
The experimental implementation demonstrated that the integration of DT and ERP layers can significantly improve maintenance efficiency. The digital twin enabled continuous modeling and performance analysis of key machinery, while the ERP system facilitated coordinated decision-making, data management, and resource optimization. The predictive models, combining physics-based simulations with LSTM neural networks, achieved high accuracy in fault detection and process prediction, with MAE values below 2.5, F1-scores above 89%, and an AUC of 0.92. At the operational level, the system increased the mean time to failure (MTTF) by 40%, reduced the mean time to repair (MTTR) by 35%, and lowered annual maintenance costs by 30%, yielding a return on investment (ROI) of 42.5% within the first year.
Beyond its quantitative results, the proposed framework provides a generalizable engineering solution for predictive maintenance and automation. Its modular and interoperable architecture—built upon standard industrial communication protocols (OPC-UA, RESTful APIs)—ensures scalability and compatibility with a wide range of machinery and control systems. The ability to integrate physical modeling, predictive analytics, and enterprise management within a single loop highlights its potential as a foundation for self-maintaining and adaptive industrial systems.
The findings of this research contribute to the broader field of machine design and automation by demonstrating how digital twin-based predictive systems can improve both the operational reliability and lifecycle efficiency of industrial assets. In doing so, the study advances the development of intelligent, data-driven maintenance frameworks aligned with the principles of Industry 4.0 and Industry 5.0. Future research should extend this work by incorporating reinforcement learning, real-time optimization, and cross-facility integration, enabling the evolution of fully autonomous maintenance ecosystems in complex manufacturing environments.
Author Contributions
Conceptualization, H.N. and A.S.-J.; methodology, H.N.; software, H.N.; validation, H.N. and A.S.-J.; formal analysis, H.N.; investigation, H.N.; resources, H.N.; data curation, H.N.; writing—original draft preparation, H.N. and A.S.-J.; writing—review and editing, H.N. and A.S.-J.; visualization, H.N.; supervision, H.N.; project administration, H.N.; funding acquisition, A.S.-J. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The original data presented in the study are openly available in FigShare at https://doi.org/10.6084/m9.figshare.30569987.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Vargas, J.M.; Castrillon, O.D.; Giraldo, J.A. Implementation and Field Validation of a Digital twin Methodology to Enhance Production and Service Systems in Waste Management. Appl. Sci. 2025, 15, 6733. [Google Scholar] [CrossRef]
- Monteiro, J.; Barata, J. A Circular Digital twin for Climate-Smart Soils through Community Composting. In Advances in Information Systems Development: Exploring New Horizons and Opportunities; Springer Nature: Cham, Switzerland, 2025; pp. 167–188. [Google Scholar]
- Abd Wahab, N.H.; Hasikin, K.; Lai, K.W.; Xia, K.; Bei, L.; Huang, K.; Wu, X. Systematic review of predictive maintenance and digital twin technologies challenges, opportunities, and best practices. PeerJ Comput. Sci. 2024, 10, e1943. [Google Scholar] [CrossRef] [PubMed]
- Aliahmadi, A.; Nozari, H.; Ghahremani-Nahr, J.; Szmelter-Jarosz, A. Evaluation of key impression of resilient supply chain based on artificial intelligence of things (AIoT). arXiv 2022, arXiv:2207.13174. [Google Scholar] [CrossRef]
- Nasirinejad, M.; Afshari, H.; Sampalli, S. The Adoption of Digital Twin Technologies for Maintenance in Small and Medium-Sized Enterprises: Challenges and Benefits; SSRN eLibrary: Rochester, NY, USA, 2025. [Google Scholar] [CrossRef]
- Jesus, V.; Kalaitzi, D.; Batista, L.; Lopez, N.L. Digital twins of Supply Chains: A Systems Approach. IEEE Trans. Eng. Manag. 2024, 71, 14915–14932. [Google Scholar] [CrossRef]
- Kannan, S. Transforming Agriculture for the Digital Age: Integrating Artificial Intelligence, Cloud Computing, and Big Data Solutions for Sustainable and Smart Farming Systems; Deep Science Publishing: San Francisco, CA, USA, 2025. [Google Scholar]
- Koç, E. Measurement and Assessment of Supply Chain Sustainability Performance. In Developing Dynamic and Sustainable Supply Chains to Achieve Sustainable Development Goals; IGI Global Scientific Publishing: Hershey, PA, USA, 2025; pp. 179–200. [Google Scholar]
- Abdulhayan, S.; Quadri, S.A. Artificial Intelligence, IoT, and Fuzzy Systems for Sustainable Development and Industry 5.0; Deep Science Publishing: San Francisco, CA, USA, 2025. [Google Scholar]
- Tsai, W.H.; Lai, S.Y. Green production planning and control model with ABC under industry 4.0 for the paper in-dustry. Sustainability 2018, 10, 2932. [Google Scholar] [CrossRef]
- Singh, R.; Dwivedi, G. Agri-food Supply Chain Management: A Review Using Bibliometric, Network, and Content Analyses. Oper. Res. Forum 2025, 6, 62. [Google Scholar] [CrossRef]
- Aliahmadi, A.; Nozari, H. Evaluation of security metrics in AIoT and blockchain-based supply chain by Neutrosophic decision-making method. Supply Chain Forum Int. J. 2023, 24, 31–42. [Google Scholar] [CrossRef]
- Emmanuel, A.T. An Evaluation of Production Operations at Skretting’s Stavanger Plant, Norway, & an Overview of Skretting’s Supply Chain Based on Lean Concepts. Ph.D. Dissertation, Royal Institute of Technology, Stockholm, Sweden, 2008. [Google Scholar]
- Chen, K.; Zhao, B.; Zhou, H.; Zhou, L.; Niu, K.; Jin, X.; Li, R.; Yuan, Y.; Zheng, Y. Digital twins in plant factory: A five-dimensional modeling method for plant factory transplanter digital twins. Agriculture 2023, 13, 1336. [Google Scholar] [CrossRef]
- Montreuil, B. Transforming the Composting Industry Towards Industry 4.0 and Physical Internet Capabilities. Ph.D. Dissertation, Georgia Institute of Technology, Atlanta, GA, USA, 2024. [Google Scholar]
- Cichocki, M.; Landschützer, C.; Hick, H. Development of a Sharing Concept for Industrial Compost Turners Using Model-Based Systems Engineering, Under Consideration of Technical and Logistical Aspects. Sustainability 2022, 14, 10694. [Google Scholar] [CrossRef]
- Barbosa, J.M.V.; Gomez, O.D.C.; García, J.A.G. Digital twin Application Methodology for the Improvement of Production and Service Systems. Application to Waste Management Processes. In Proceedings of the Sustainable Smart Cities and Territories International Conference, Manizales, Colombia, 21–23 June 2023; Springer Nature: Cham, Switzerland, 2023; pp. 25–36. [Google Scholar]
- Danilo, J.M.V.B.O.; Gomez, C.; Piso, B.Q. Digital twin Application Methodology for the Improvement of Production and Service. Trends Sustain. Smart Cities Territ. 2023, 732, 25. [Google Scholar]
- Shamia, D.; Suganyadevi, S.; Satheeswaran, V.; Balasamy, K. Digital twins in precision agriculture monitoring using artificial intelligence. In Digital Twin for Smart Manufacturing; Academic Press: Cambridge, MA, USA, 2023; pp. 243–265. [Google Scholar]
- Giel, R.; Dąbrowska, A. Digital twin Concept for Manual Waste Sorting Management. Environ. Prot. Eng. 2025, 51, 1. [Google Scholar] [CrossRef]
- Nyakudya, P.; Madushele, N.; Madyira, D.M.; Matare, E.E. Embracing Digital twin Technology to Enhance Efficacy of Industrial Symbiosis: A Path to Sustainability. In Proceedings of the 2024 International Conference on Electrical and Computer Engineering Researches (ICECER), Gaborone, Botswana, 4–6 December 2024; IEEE: Los Alamitos, CA, USA, 2024; pp. 1–6. [Google Scholar]
- Mohammadi, H.; Ghazanfari, M.; Nozari, H.; Shafiezad, O. Combining the theory of constraints with system dynamics: A general model (case study of the subsidized milk industry). Int. J. Manag. Sci. Eng. Manag. 2015, 10, 102–108. [Google Scholar] [CrossRef]
- Vanjare, S.; Musale, J.; More, P.; Sayyad, T.; Gupta, Y.; Shikre, S. Implementation of Digital twin Technology for Predictive Crop Disease Monitoring. In Proceedings of the International Conference on Recent Advancements and Modernisations in Sustainable Intelligent Technologies and Applications (RAMSITA 2025), Indore, India, 7–8 February 2025; Atlantis Press: Dordrecht, The Netherlands, 2025; pp. 654–665. [Google Scholar]
- dos Santos Silva, J.; Matos de Oliveira, A.; Veríssimo de Oliveira, J.; Bouzon, M. Barriers to digital transformation in fruit and vegetable supply chains: A multicriteria analysis using ISM and MICMAC. OPSEARCH 2025, 62, 460–482. [Google Scholar] [CrossRef]
- Zaballos, A.; Briones, A.; Massa, A.; Centelles, P.; Caballero, V. A smart campus’ digital twin for sustainable comfort monitoring. Sustainability 2020, 12, 9196. [Google Scholar] [CrossRef]
- Yang, B.; Lv, Z.; Wang, F. Digital twins for intelligent green buildings. Buildings 2022, 12, 856. [Google Scholar] [CrossRef]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).