Abstract
Using optimal assembly relationships, companies can enhance product quality without significantly increasing production costs. However, predicting Assembly Geometric Errors presents a challenging real-world problem in the manufacturing domain. To address this challenge, this paper introduces a highly efficient Transformer-based neural network model known as Predicting Assembly Geometric Errors based on Transformer (PAGEformer). This model accurately captures long-range assembly relationships and predicts final assembly errors. The proposed model incorporates two unique features: firstly, an enhanced self-attention mechanism to more effectively handle long-range dependencies, and secondly, the generation of positional information regarding gaps and fillings to better capture assembly relationships. This paper collected actual assembly data for folding rudder blades for unmanned aerial vehicles and established a Mechanical Assembly Relationship Dataset (MARD) for a comparative study. To further illustrate PAGEformer performance, we conducted extensive testing on a large-scale dataset and performed ablation experiments. The experimental results demonstrated a 15.3% improvement in PAGEformer accuracy compared to ARIMA on the MARD. On the ETH, Weather, and ECL open datasets, PAGEformer accuracy increased by 15.17%, 17.17%, and 9.5%, respectively, compared to the mainstream neural network models.
1. Introduction
Primary manufacturing processes encompass component assembly, product design, and component machining. This stage is also the most challenging to standardize and automate. The integration of intelligence with industrialization has become a focal point of recent advancements with the development of information technology. A vast amount of data has accumulated in the industrial sector with the adoption of intelligent devices. Predicting the quality of assembly processes has become possible through the analysis of historical industrial big data [,,,]. For example, the assembly process for folding rudder blades for unmanned aerial vehicles entails selecting components from a pool of qualified parts and assembling them to minimize the deviation of the rudder oscillation. All components within a permissible tolerance range are considered normal and qualified products.
However, this assembly method exhibits drawbacks, including significant variations in assembly accuracy and inconsistent inspection indicators. In practical scenarios, these issues may arise from excessive adjustments in the assembly process, resulting in non-compliance with inspection indicators. Consequently, this reduces assembly efficiency and increases the time cost due to incorrect assembly. To mitigate these effects, data-driven approaches can analyze and discover patterns within the vast amount of data generated during production and manufacturing processes. This enables the improvement of product quality by precisely controlling assembly accuracy. Currently, this method is the most feasible.
In order to improve assembly geometric errors, the majority of manufacturing plants undergo digital transformation [,,]. Utilizing traditional data-driven methods involves processing and predicting collected data, thereby establishing a mapping between the physical world and the digital world, known as a digital twin. Although these traditional data-driven methods exhibit strong operability (such as utilizing genetic algorithms to analyze assembly or disassembly sequences, among others) and can effectively improve overall assembly geometric errors, their accuracy and robustness are compromised when predicting errors in the assembly process of increasingly complex products [,,,]. To overcome the limitations of traditional data-driven methods, machine learning techniques have emerged as the mainstay in this field. However, existing research employing machine learning methods often develops algorithms only for specific combinations of components, resulting in poor generality of datasets for other models. Moreover, these methods are sensitive to environmental factors, rendering many Assembly Geometric Error accuracy predicting algorithms ineffective if environmental changes occur during data collection [,,].
Previous studies have shown that using Transformers as a basis has yielded good results in prediction tasks such as sensor network monitoring [], human behavior prediction [], energy and smart grid management [], economics and finance [], and disease propagation analysis []. However, these methods are developed for time series forecasting, emphasizing the impact of continuous changes in datasets. In contrast, predicting assembly geometric errors requires capturing implicit information between assembly components. Therefore, using neural networks based on time series data directly for predicting assembly geometric errors may not yield satisfactory results.
To address the issue of predicting assembly geometric errors not related to time series using Transformers, this paper analyzed the data generated during the production manufacturing process and input paired data with assembly relationships into the neural network structure, facilitating a more robust establishment of correlations between the data. Consequently, the paper enhanced the long time series network structure and introduced a self-attention network structure based on assembly data pairs to achieve more accurate predictions of overall assembly geometric errors. To better evaluate the testing results, we acquired actual assembly data for folding rudders in unmanned aerial vehicles to establish a dataset of measurement data and errors for training and testing purposes.
In summary, this paper proposes a novel pair feature distance method to enhance data correlation for predicting assembly geometric errors. Furthermore, based on this data pair, a self-attention structure is introduced, focusing on global features and extracting local features.
The subsequent sections of this article are organized as follows: Section 2 reviews current research related to assembly data errors. Section 3 introduces the overall structure of neural networks, detailing the processing of pair feature distances in assembly data and the internal composition of encoders and decoders. Section 4 presents and analyzes the experimentally obtained predicted results. Finally, Section 5 provides a comprehensive summary of the entire article.
2. Background
The accuracy control prediction system in the assembly field is predominantly propelled by artificial-intelligence-based neural networks. Earlier research primarily concentrated on artificial neural network systems, grey prediction systems, fuzzy control theory, and various other aspects. Examples encompass numerical algorithms analyzing the final unfolding angles of adjusted joints in a linkage, neural networks predicting final errors for achieving higher accuracy, and adaptive support vector machines (ASVMs) based on the SVM framework predicting the assembly quality of automotive sunroofs. Alternative approaches include using artificial intelligence techniques to narrow down the search space for assembly sequence planning, considering an analysis of the limitations of existing methods [,,]. Leveraging the potent fitting capability of machine learning, these methods can yield superior results compared to traditional algorithms. Another category of methods addresses scenarios in which traditional algorithms are insufficient for analyzing complex mechanical products. In such scenarios, artificial intelligence can be trained and fitted based on data to predict the performance of assembling complex products, for example, the Assembly Quality Adaptive Control System (A_QACS). This system is proposed for assembly recognition of complex mechanical products under uncertainty. Additionally, a proposed multi-objective discrete particle swarm optimization algorithm is designed to enhance the efficiency of assembly planning [,].
In recent years, artificial-intelligence-based neural networks have rapidly advanced, particularly with the introduction of the Transformer architecture based on the self-attention mechanism. Consequently, methods developed based on the Transformer approach have gradually replaced sequential or time-related data analysis and prediction techniques [,,]. Therefore, this paper aims to propose a new approach for predicting assembly errors based on a neural network architecture using the Transformer framework.
3. Model Architecture
This article analyzes the data characteristics of Assembly Geometric Errors to establish a structure named Assembly Geometric Error Embeddings (AGEE), which associates assembly relationships as input. To better handle structures with assembly relationships and the final errors caused by errors in other parts, this article introduces an efficient neural network architecture named PAGEformer. PAGEformer perceptively considers both long sequence relations and global consideration of local information. This architecture comprises an Encoder structure and a Decoder structure. The Encoder transforms the input sequence into hidden representations or feature vectors []. It consists of multiple identical layers, each containing prob attention, conv1d, and layer norm. The prob attention structure filters weights representing global information and local assembly relationship information through KL divergence computation, enabling more accurate error prediction. The purpose of the Decoder is to generate the target sequence, including prob attention, conv1d, layer norm, and a regular multihead attention structure. The Decoder incorporates the position of the data to be predicted into the AGEE structure, yielding the final prediction results. An overview is presented in Figure 1.
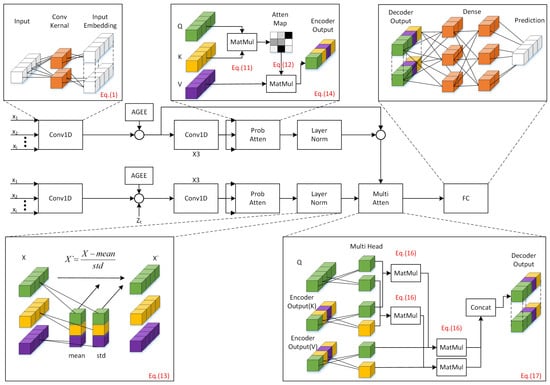
Figure 1.
Illustration of the structure of PAGEformer, elucidating how input data are overlaid with assembly relationship information through AGEE. The Encoder comprises prob attention, conv1d, and layer norm. The Decoder, in addition to receiving the output from the Encoder through multihead attention, shares a similar structure with the Encoder. Finally, the fully connected layer is utilized to generate the ultimate prediction result. Here, conv1d is used to increase the dimensionality of the data and is combined with prob attention. Prob attention aims to better capture the correlations between Assembly Geometric Errors. Conventional self-attention is primarily used to establish features between long time-series data. Therefore, we processes the data pairs in AGEE to facilitate prob attention in extracting the relationships between assembly data. Additionally, prob attention filters out Q values that better reflect assembly relationships through KL divergence. For detailed calculation methods, please refer to Section 3.2. Layer norm is a common standardization method that helps the model converge better during training. Multi Atten is a common self-attention mechanism used to enhance the correlations between data. FC is used to project high-dimensional information onto the prediction dimension.
3.1. Assembly Geometric Error Embeddings
In typical scenarios, input data undergo differentiation, incorporating weighted positional information to capture temporal sequences. Nevertheless, this method might not comprehensively depict the assembly relationships among diverse components. In response to this limitation, our paper introduces the Assembly Geometric Error Embeddings method. This method establishes local assembly relationships among components and long-term sequential connections in the data before entering the Encoder and Decoder. This methodology aids the Encoder and Decoder in effectively capturing feature information, thereby augmenting the accuracy of prediction errors.Consider the input data as X = {⋯,. Classify the data into two categories, namely “gap” and “fill”, based on the assembly relationship. Next, vectorize the data and perform calculations using the provided formula in Equation (1).
where represents the -th element of the input sequence, denotes the i-th weight of the convolutional kernel, b is the bias term, and N represents the input length. By varying the number of convolutional kernels, we can derive distinct output dimensions denoted as , , and . Specifically, represents the dimension formed by stacking the outcomes of Q Conv1D convolutions, is the dimension formed by stacking the outcomes of Conv1D convolutions, and is the dimension formed by stacking the outcomes of V Conv1D convolutions.
In this paper, the fitting relationships for shaft and slider are classified as “gap”, while those for holes and slots are categorized as “fill”. The positions corresponding to “gap” and “fill” are determined using Equations (2) and (3).
where denotes the model’s dimension, and {⋯}. The embedding position is represented by , with dimensions identical to those of the data for filling and gaps, pos signifies the position of filling or gaps, d represents the dimension of , represents even dimensions, and signifies odd dimensions.
Let us assume the filling data input for a set of t components is represented by ={⋯, and the gap data input is denoted as ={⋯. By evaluating Equation (1), , and as follows: and gap data . Combining Equation (2) and Equation (3), the new vector containing “fill” and “gap” information can be computed according to Equations (4) and (5).
where . The two input vectors are concatenated, which can be expressed by Equation (6).
where and . The obtained final vectors serve as the input vectors for the neural network. AGEE as depicted in Figure 2.
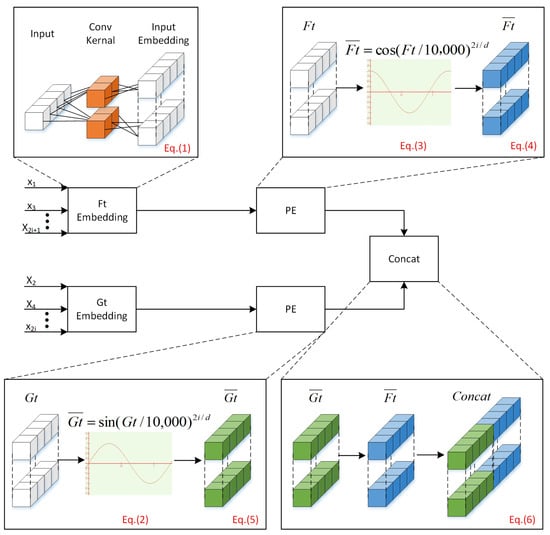
Figure 2.
Segregation of the input into “gap” and “fill” components. Each component is subsequently subjected to conv1D transformation, resulting in the Lx×dmodel dimension. Following this, each component is individually combined with PE, and ultimately, the outcomes of both are concatenated to form INPUTE.
3.2. Encoder
The Encoder consists of prob attention, conv1d, and layer normalization components. In the attention mechanism, there might be partially activated Queries, permitting specific Query key dot product calculations with minimal contribution to the prediction to overpower the probability distribution after the softmax function. This suggests that certain Queries result in inefficient utilization of computational resources. To mitigate this limitation and improve prediction accuracy, it is imperative to filter out fully activated Queries. Non-activated Queries display characteristics akin to a uniform distribution; therefore, representative Queries can be identified by computing the Kullback–Leibler (KL) divergence between the distribution of distinct Queries and a uniform distribution. Attention can be expressed by Equation (7).
where and . Q, K, and V represent three distinct results derived from applying to various conv1D operations, “i” represents the i-th row in Q, K, V, and j represents the j-th column in Q, K, V. Let , , stand for the i-th row in Q, K, and V, respectively. represents the attention score of the i-th q in the sequence, p is the probability score of the i-th q and j-th k calculated from . The prob_attention is expressed by Equations (8) and (9).
The probability of the uniform distribution is as . So, the Kullback–Leibler (KL) divergence for measuring the probability distribution between can be expressed as Equation (10).
Removing the constant term [], we define the i-th query’s sparsity measurement as expressed by Equation (11).
The dimension of is consistent with Q. We sort the values computed based on M and select the top 10% to fill in . The remaining values are filled with the overall mean 10%, which was obtained through testing, and the specific results are shown in Section 4.2. So, the prob_attention can be expressed as Equation (12).
Conv1d is a one-dimensional convolutional module with a kernel size of 3 and a stride of 2. Its main role is to reduce the size of the feature map and lower the computational complexity. Finally, the data is normalized through layer norm as in Equation (13).
where , , and are learnable scaling and bias parameters. So output can be expressed as Equation (14).
where is the input after undergoing Encoder embedding, and is the output of the Encoder.
Self-attention computation requires memory of O() and comes at the cost of quadratic dot product calculations. In this paper, because M values are used for calculation, the overhead of M is O(), and the computational cost of attention calculation after M screening is O(/10). Therefore, the overall cost is higher with O(/10) compared to regular self-attention.
We have implemented the prob attention in Python 3.6 with Pytorch 1.8.0. The pseudo-code is given in Algorithm 1.
| Algorithm 1: Prob attention |
Result: feature map S |
3.3. Decoder
The Decoder block is similar to the Encoder block, but with an additional Multi-head Attention layer. The Decoder input vector contains additional placeholders for prediction, where k is the number of errors to be predicted. The values at these positions are filled with zeros and can be expressed as in Equation (15).
where , . The Decoder input vectors serve as the input vectors for the neural network. AGEE as depicted in Figure 3.
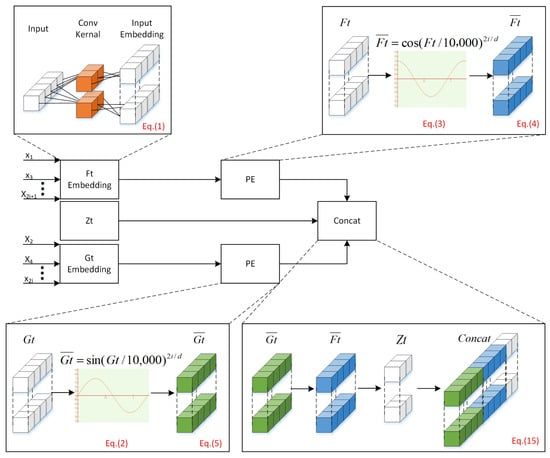
Figure 3.
The input to the Decoder, after undergoing the AGEE, includes an additional placeholder, , at the output position, filled with zeros.
A standalone attention module is incapable of providing a comprehensive global representation of temporal relationships in sequence data. Hence, by partitioning into multiple segments and independently computing them using attention modules, the outcomes are concatenated along the relevant dimension. This methodology is termed as Multi-head Attention. The computation for the i-th attention module can be articulated through Equation (16).
Therefore, Multi-head Attention can be represented as Equation (17).
where attention represents the calculation of the attention mechanism, Concat denotes the concatenation of outputs from multiple attention heads along the last imension, and is the weight matrix for the linear transformation of the concatenated output.
4. Experimentation
4.1. Data Collection
To validate the effectiveness of PAGEformer, we collaborated with North Navigation Control Technology Co., Ltd. and collected measurement data during the manufacturing process of folding rudder blades for unmanned aerial vehicles produced by the company. The Mechanical Assembly Relationship Dataset (MARD) comprises 2262 sets of data, with each set consisting of 13 measurement data items and 1 assembly error data item (Table 1).

Table 1.
Mechanical assembly relationship dataset (partial).
To further evaluate the performance of PAGEformer, additional tests were conducted using the following three publicly available datasets:
- (1)
- ETT (Electricity Transformer Temperature): This dataset includes two categories of data collected at 1 h frequency (ETTh) and 15 min frequency (ETTm), each containing 7 items of feature data.
- (2)
- ECL (Electricity Consumption Load): This dataset contains electricity consumption data of 321 customers, with each record containing 320 items of feature data.
- (3)
- Weather: This dataset contains climate data for nearly 1600 regions in the United States, with data collected at an hourly frequency. Each record includes 12 items of feature data.
We employed single 4090 GPU for training, and the training of MARD took approximately 10 h. PAGEformer can adapt input data based on the required measurement data for components, such as data for 20 measurements and two predicted errors. Thus, it can predict various fitting errors of components in industrial production. However, due to the large amount of measurement data for components, it is necessary to select relevant data that play a decisive role in dimensional fitting, which typically requires collaboration with mechanical engineers. Regarding the scalability to other domains, this paper demonstrates PAGEformer’s predictive performance on long time-series data, as shown in Section 4.2, which proves its effectiveness in predicting data with long time-series correlations for the majority of cases.
To facilitate the introduction of hyperparameters, the following parameters are based on the data in MARD. The training data has a batch size of 32. The Encoder sequence length is 13, which is the dimensionality parameter used in MARD for predicting the final error. The Decoder sequence length is 14, comprising 13 dimensionality datums and 1 placeholder datum filled with 0. Conv1D has a kernel size of 3, a stride of 1, padding of 1, and outputs a dimensionality of 512 for embedding purposes. In prob attention, the threshold for filtering is set to 0.1. LayerNorm is used to prevent division by zero, thus adding 0.00001 to the denominator. The Elu activation function is chosen with an alpha value of 1. Dropout is set to 0.5. In the Decoder, the number of heads in multihead attention is eight. The Adam optimizer is chosen with a learning rate of 0.0005. MSE is selected as the loss function. The FC output dimensionality is 14, with the first 13 representing the input data and the last one representing the predicted data output by the model.
4.2. Experimental Results and Discussion
The performance of the PAGEformer method can be assessed through MARD. The evaluation used two metrics: Mean Absolute Error (MAE) and Mean Squared Error (MSE). The test results of different values of in MARD are displayed in Table 2 and the line graph is shown in Figure 4.
Table 2.
The test results of MARD with different values.
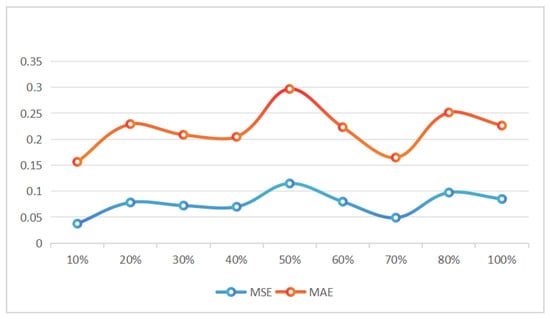
Figure 4.
A line graph of the MSE for different values of .
Table 3 provides a comparison of the MSE and MAE metric values for PAGEformer, Reformer, and ARIMA on the MARD. The data demonstrates that the accuracy of PAGEformer on MARD has increased by 15.3% compared to the best-performing ARIMA.
Table 3.
Comparative test results of various methods for MARD.
In order to further evaluate the performance of PAGEformer, we conducted comparative tests with seven different methods using three publicly available datasets. The seven existing methods employed in the comparison are as follows:
(1) Informer, (2) LogTrans, (3) Reformer, (4) LSTMa, (5) DeepAR, (6) ARIMA, (7) Prophet.
In this case as well, the individual methods were evaluated using the MSE and MAE metrics. All models were trained and tested on a single Nvidia 4090 GPU. The experimental results obtained are presented in Table 4. In order to show the comparison results more intuitively, Figure 5 is drawn according to the data in Table 4.
Table 4.
A comparison of PAGEformer with mainstream methods.
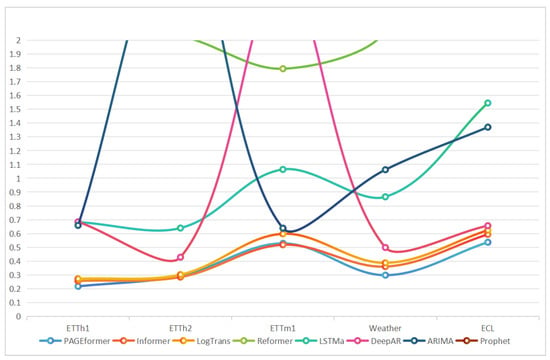
Figure 5.
Comparison of PAGEformer with other methods on mainstream datasets.
Table 4 illustrates that PAGEformer significantly enhances the inference ability across all datasets. Compared to the best model, PAGEformer accuracy has improved by 15.17%, 17.17%, and 9.5% on the publicly available ETH, Weather, and ECL datasets, respectively. The aforementioned data substantiate that the proposed method can effectively measure hidden correlations in data, thus predicting the overall errors of the assembly process. Additionally, in Table 4, PAGEformer demonstrated accuracy in predicting sequence data, indicating its capability to learn the correlation of different errors and perform well in predicting time series. This suggests that the prediction ability of PAGEformer has good scalability. To further validate the improvements in PAGEformer, we conducted ablation experiments with two modifications: gap and filling encoding and prob attention. The experimental results are presented in Table 5.
Table 5.
A comparison of ablation experiments for PAGEformer with MARD.
5. Conclusions
This study explores the prediction of Assembly Geometric Errors and introduces PAGEformer, a neural network capable of determining the feature distance of assembly relationships using collected component data. By integrating an enhanced and efficient long temporal attention structure, it improves the prediction of errors post-assembly. To validate these improvements, the study collects a substantial amount of component data and post-assembly errors from an actual manufacturing environment, creating the Mechanical Assembly Relationship Dataset (MARD). Experimental results show that PAGEformer achieves an accuracy on MARD 15.3% higher than that of ARIMA. To further evaluate PAGEformer performance on extended temporal data, the study conducts tests on public datasets and performs ablation experiments to scrutinize the effectiveness of the enhancements. The outcomes on public datasets showcase PAGEformer’s commendable performance in standard long temporal tests, and the ablation experiments affirm the effectiveness of the two proposed enhancements.
Author Contributions
Software, P.L. and J.S.; Writing—original draft, W.W.; Writing—review and editing, B.W.; Project administration, H.L. and B.N. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (62303070) and the Key Research Project of Science and Technology Department of Jilin Province (20210201113GX).
Data Availability Statement
The data presented in this study are available on request from the corresponding author (Due to the sensitive nature of the MARD data involving military confidentiality, permission needs to be obtained. The remaining data are from public datasets).
Conflicts of Interest
Wu Wang, Botong Niu and Jing Sun were employeed by North Navigation Control Technology Co., Ltd., and they declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results. The authors declare no conflict of interest.
References
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Gao, R.X.; Wang, L.; Helu, M.; Teti, R. Big data analytics for smart factories of the future. CIRP Ann.-Manuf. Technol. 2020, 69, 668–692. [Google Scholar] [CrossRef]
- Zhu, K.; Li, G.; Zhang, Y. Big Data Oriented Smart Tool Condition Monitoring System. IEEE Trans. Ind. Inform. 2020, 16, 4007–4016. [Google Scholar] [CrossRef]
- Wang, X.; Chen, Q.; Sun, H.; Wang, X.; Yan, H. GMAW welding procedure expert system based on machine learning. Intell. Robot. 2023, 3, 56–75. [Google Scholar] [CrossRef]
- Tao, F.; Qi, Q. Make more digital twins. Nature 2019, 573, 490–491. [Google Scholar] [CrossRef]
- Tao, F.; Zhang, H.; Liu, A.; Nee, A.Y. Digital twin in industry: State-of-the-art. IEEE Trans. Ind. Inform. 2018, 15, 2405–2415. [Google Scholar] [CrossRef]
- Wagner, R.; Schleich, B.; Haefner, B.; Kuhnle, A.; Wartzack, S.; Lanza, G. Challenges and potentials of digital twins and industry 4.0 in product design and production for high performance products. Procedia CIRP 2019, 84, 88–93. [Google Scholar] [CrossRef]
- Kongar, E.; Gupta, S.M. Disassembly sequencing using genetic algorithm. Int. J. Adv. Manuf. Technol. 2006, 30, 497–506. [Google Scholar] [CrossRef]
- Tseng, H.E.; Chang, C.C.; Lee, S.C.; Huang, Y.M. A block-based genetic algorithm for disassembly sequence planning. Expert Syst. Appl. 2018, 96, 492–505. [Google Scholar] [CrossRef]
- Yang, H.; Chen, J.; Wang, C.; Cui, J.; Wei, W. Intelligent planning of product assembly sequences based on spatio-temporal semantic knowledge. Assem. Autom. 2020, 40. [Google Scholar] [CrossRef]
- Masehian, E.; Ghandi, S. Assembly sequence and path planning for monotone and nonmonotone assemblies with rigid and flexible parts. Robot. Comput.-Integr. Manuf. 2021, 72, 102180. [Google Scholar] [CrossRef]
- Mei, B.; Zhu, W.; Zheng, P.; Ke, Y. Variation modeling and analysis with interval approach for the assembly of compliant aeronautical structures. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2019, 233, 948–959. [Google Scholar] [CrossRef]
- Chen, H.; Liu, Z.; Alippi, C.; Huang, B.; Liu, D. Explainable intelligent fault diagnosis for nonlinear dynamic systems: From unsupervised to supervised learning. IEEE Trans. Neural Netw. Learn. Syst. 2022; early access. [Google Scholar]
- Chen, H.; Huang, B. Explainable Fault Diagnosis Using Invertible Neural Networks-Part I: A Left Manifold-based Solution. Authorea Prepr. 2023. [Google Scholar] [CrossRef]
- Papadimitriou, S.; Yu, P. Optimal multi-scale patterns in time series streams. In Proceedings of the 2006 ACM SIGMOD International Conference on Management of Data, Chicago, IL, USA, 27–29 June 2006; pp. 647–658. [Google Scholar]
- Wen, B.; Chen, S.; Shao, C. Temporal action proposal for online driver action monitoring using Dilated Convolutional Temporal Prediction Network. Comput. Ind. 2020, 121, 103255. [Google Scholar] [CrossRef]
- Han, T.; Muhammad, K.; Hussain, T.; Lloret, J.; Baik, S.W. An efficient deep learning framework for intelligent energy management in IoT networks. IEEE Internet Things J. 2020, 8, 3170–3179. [Google Scholar] [CrossRef]
- Zhu, Y.; Shasha, D. Statstream: Statistical monitoring of thousands of data streams in real time. In VLDB’02, Proceedings of the 28th International Conference on Very Large Databases, Hong Kong SAR, China, 20–23 August 2002; Elsevier: Amsterdam, The Netherlands, 2002; pp. 358–369. [Google Scholar]
- Matsubara, Y.; Sakurai, Y.; Van Panhuis, W.G.; Faloutsos, C. FUNNEL: Automatic mining of spatially coevolving epidemics. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 105–114. [Google Scholar]
- Yu, D.; Guo, J.; Zhao, Q.; Hong, J. Prediction of the dynamic performance for the deployable mechanism in assembly based on optimized neural network. Procedia CIRP 2021, 97, 348–353. [Google Scholar] [CrossRef]
- Deepak, B.; Bala Murali, G.; Bahubalendruni, M.R.; Biswal, B. Assembly sequence planning using soft computing methods: A review. Proc. Inst. Mech. Eng. Part E J. Process Mech. Eng. 2019, 233, 653–683. [Google Scholar] [CrossRef]
- Oh, Y.; Ransikarbum, K.; Busogi, M.; Kwon, D.; Kim, N. Adaptive SVM-based real-time quality assessment for primer-sealer dispensing process of sunroof assembly line. Reliab. Eng. Syst. Saf. 2019, 184, 202–212. [Google Scholar] [CrossRef]
- Wang, X.; Liu, M.; Ge, M.; Ling, L.; Liu, C. Research on assembly quality adaptive control system for complex mechanical products assembly process under uncertainty. Comput. Ind. 2015, 74, 43–57. [Google Scholar] [CrossRef]
- Ab Rashid, M.F.F. A hybrid Ant-Wolf Algorithm to optimize assembly sequence planning problem. Assem. Autom. 2017, 37, 238–248. [Google Scholar] [CrossRef]
- Li, J.; Selvaraju, R.; Gotmare, A.; Joty, S.; Xiong, C.; Hoi, S.C.H. Align before fuse: Vision and language representation learning with momentum distillation. Adv. Neural Inf. Process. Syst. 2021, 34, 9694–9705. [Google Scholar]
- Bao, H.; Wang, W.; Dong, L.; Liu, Q.; Mohammed, O.K.; Aggarwal, K.; Som, S.; Piao, S.; Wei, F. Vlmo: Unified vision-language pre-training with mixture-of-modality-experts. Adv. Neural Inf. Process. Syst. 2022, 35, 32897–32912. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 11106–11115. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).