
Predicting Assembly Geometric Errors Based on Transformer Neural Networks


Abstract
1. Introduction
2. Background
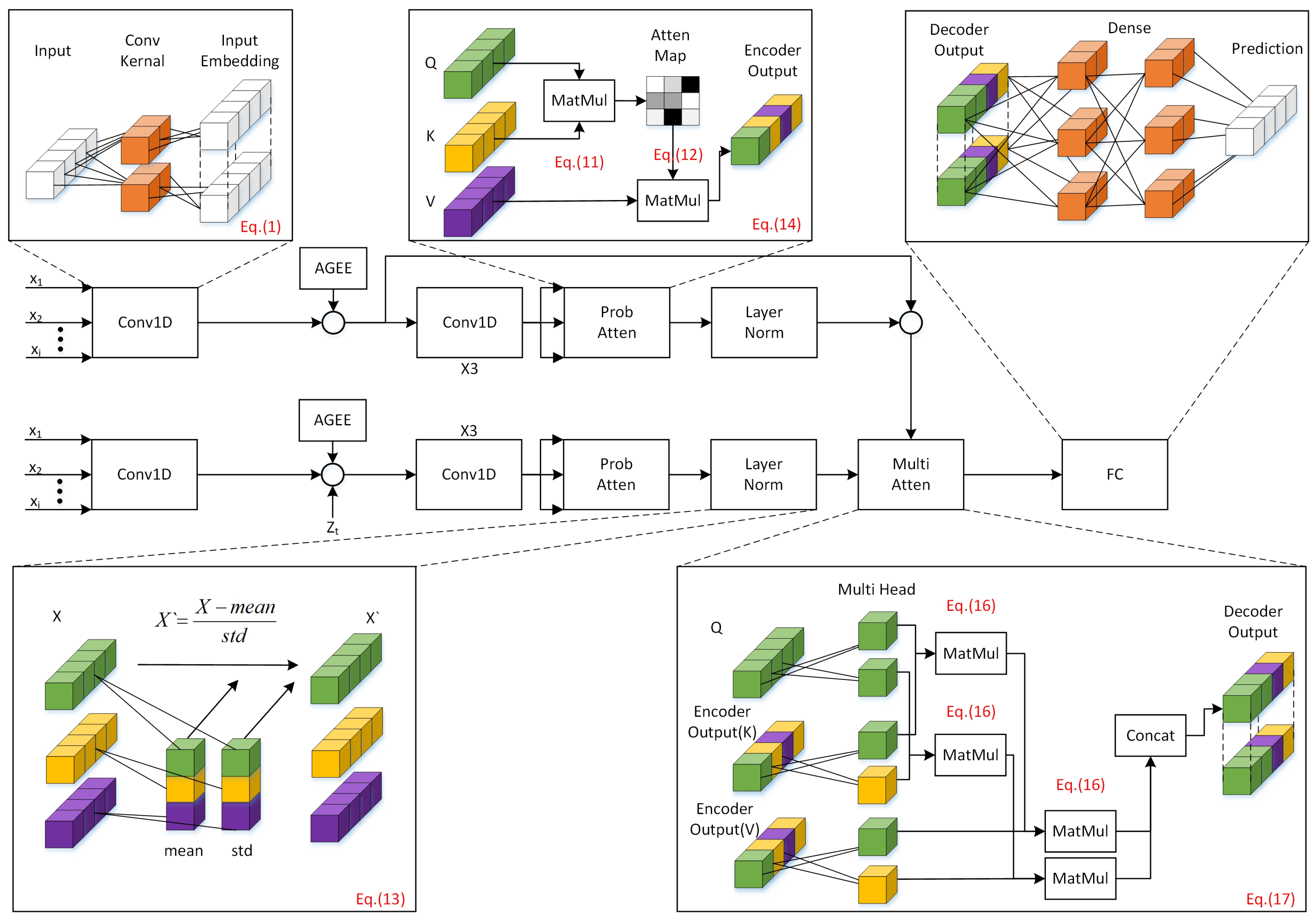
3. Model Architecture
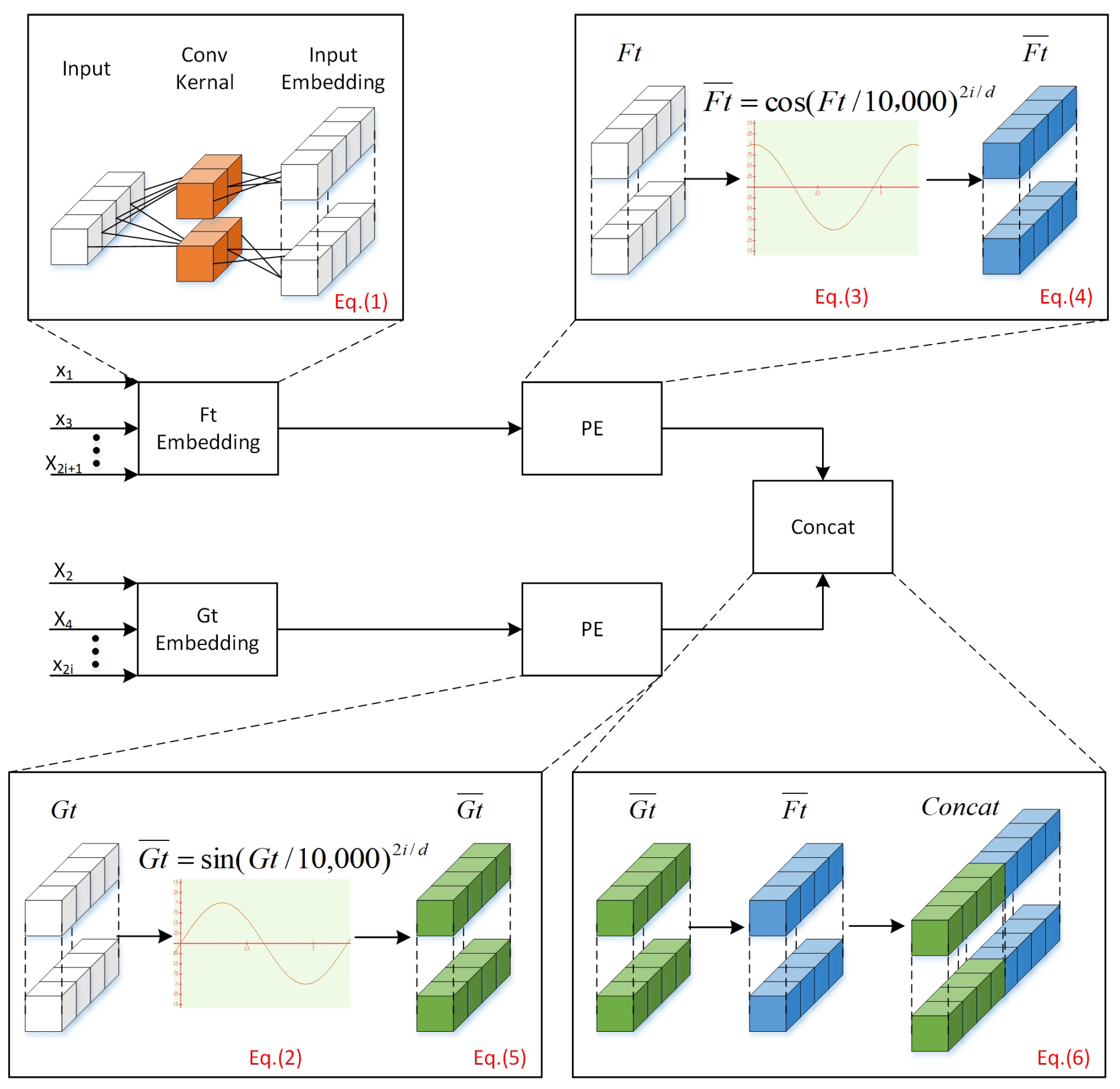
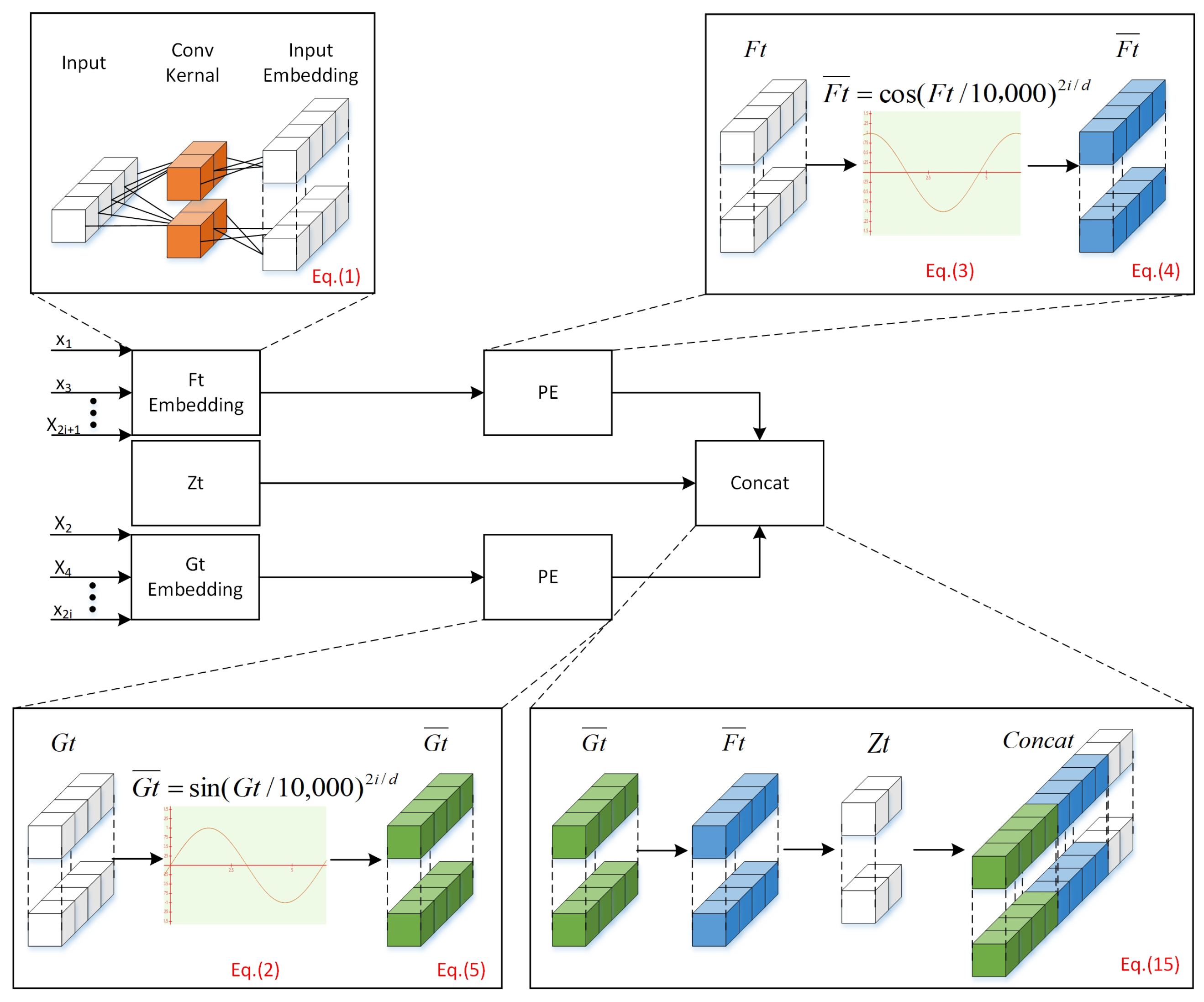
3.1. Assembly Geometric Error Embeddings
3.2. Encoder
| Algorithm 1: Prob attention |
Result: feature map S |
3.3. Decoder
4. Experimentation
4.1. Data Collection
- (1)
- ETT (Electricity Transformer Temperature): This dataset includes two categories of data collected at 1 h frequency (ETTh) and 15 min frequency (ETTm), each containing 7 items of feature data.
- (2)
- ECL (Electricity Consumption Load): This dataset contains electricity consumption data of 321 customers, with each record containing 320 items of feature data.
- (3)
- Weather: This dataset contains climate data for nearly 1600 regions in the United States, with data collected at an hourly frequency. Each record includes 12 items of feature data.
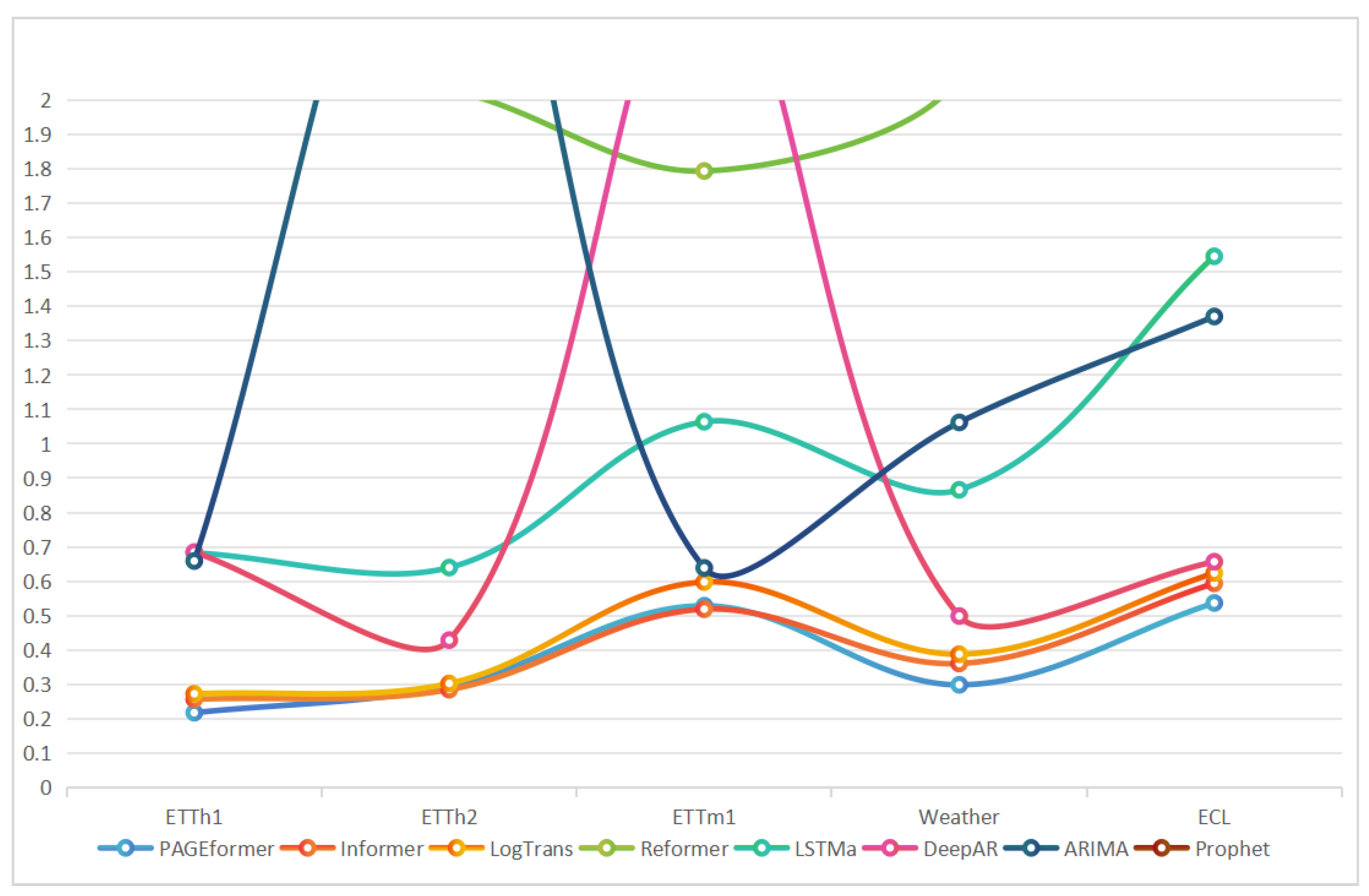
4.2. Experimental Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Gao, R.X.; Wang, L.; Helu, M.; Teti, R. Big data analytics for smart factories of the future. CIRP Ann.-Manuf. Technol. 2020, 69, 668–692. [Google Scholar] [CrossRef]
- Zhu, K.; Li, G.; Zhang, Y. Big Data Oriented Smart Tool Condition Monitoring System. IEEE Trans. Ind. Inform. 2020, 16, 4007–4016. [Google Scholar] [CrossRef]
- Wang, X.; Chen, Q.; Sun, H.; Wang, X.; Yan, H. GMAW welding procedure expert system based on machine learning. Intell. Robot. 2023, 3, 56–75. [Google Scholar] [CrossRef]
- Tao, F.; Qi, Q. Make more digital twins. Nature 2019, 573, 490–491. [Google Scholar] [CrossRef]
- Tao, F.; Zhang, H.; Liu, A.; Nee, A.Y. Digital twin in industry: State-of-the-art. IEEE Trans. Ind. Inform. 2018, 15, 2405–2415. [Google Scholar] [CrossRef]
- Wagner, R.; Schleich, B.; Haefner, B.; Kuhnle, A.; Wartzack, S.; Lanza, G. Challenges and potentials of digital twins and industry 4.0 in product design and production for high performance products. Procedia CIRP 2019, 84, 88–93. [Google Scholar] [CrossRef]
- Kongar, E.; Gupta, S.M. Disassembly sequencing using genetic algorithm. Int. J. Adv. Manuf. Technol. 2006, 30, 497–506. [Google Scholar] [CrossRef]
- Tseng, H.E.; Chang, C.C.; Lee, S.C.; Huang, Y.M. A block-based genetic algorithm for disassembly sequence planning. Expert Syst. Appl. 2018, 96, 492–505. [Google Scholar] [CrossRef]
- Yang, H.; Chen, J.; Wang, C.; Cui, J.; Wei, W. Intelligent planning of product assembly sequences based on spatio-temporal semantic knowledge. Assem. Autom. 2020, 40. [Google Scholar] [CrossRef]
- Masehian, E.; Ghandi, S. Assembly sequence and path planning for monotone and nonmonotone assemblies with rigid and flexible parts. Robot. Comput.-Integr. Manuf. 2021, 72, 102180. [Google Scholar] [CrossRef]
- Mei, B.; Zhu, W.; Zheng, P.; Ke, Y. Variation modeling and analysis with interval approach for the assembly of compliant aeronautical structures. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2019, 233, 948–959. [Google Scholar] [CrossRef]
- Chen, H.; Liu, Z.; Alippi, C.; Huang, B.; Liu, D. Explainable intelligent fault diagnosis for nonlinear dynamic systems: From unsupervised to supervised learning. IEEE Trans. Neural Netw. Learn. Syst. 2022; early access. [Google Scholar]
- Chen, H.; Huang, B. Explainable Fault Diagnosis Using Invertible Neural Networks-Part I: A Left Manifold-based Solution. Authorea Prepr. 2023. [Google Scholar] [CrossRef]
- Papadimitriou, S.; Yu, P. Optimal multi-scale patterns in time series streams. In Proceedings of the 2006 ACM SIGMOD International Conference on Management of Data, Chicago, IL, USA, 27–29 June 2006; pp. 647–658. [Google Scholar]
- Wen, B.; Chen, S.; Shao, C. Temporal action proposal for online driver action monitoring using Dilated Convolutional Temporal Prediction Network. Comput. Ind. 2020, 121, 103255. [Google Scholar] [CrossRef]
- Han, T.; Muhammad, K.; Hussain, T.; Lloret, J.; Baik, S.W. An efficient deep learning framework for intelligent energy management in IoT networks. IEEE Internet Things J. 2020, 8, 3170–3179. [Google Scholar] [CrossRef]
- Zhu, Y.; Shasha, D. Statstream: Statistical monitoring of thousands of data streams in real time. In VLDB’02, Proceedings of the 28th International Conference on Very Large Databases, Hong Kong SAR, China, 20–23 August 2002; Elsevier: Amsterdam, The Netherlands, 2002; pp. 358–369. [Google Scholar]
- Matsubara, Y.; Sakurai, Y.; Van Panhuis, W.G.; Faloutsos, C. FUNNEL: Automatic mining of spatially coevolving epidemics. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 105–114. [Google Scholar]
- Yu, D.; Guo, J.; Zhao, Q.; Hong, J. Prediction of the dynamic performance for the deployable mechanism in assembly based on optimized neural network. Procedia CIRP 2021, 97, 348–353. [Google Scholar] [CrossRef]
- Deepak, B.; Bala Murali, G.; Bahubalendruni, M.R.; Biswal, B. Assembly sequence planning using soft computing methods: A review. Proc. Inst. Mech. Eng. Part E J. Process Mech. Eng. 2019, 233, 653–683. [Google Scholar] [CrossRef]
- Oh, Y.; Ransikarbum, K.; Busogi, M.; Kwon, D.; Kim, N. Adaptive SVM-based real-time quality assessment for primer-sealer dispensing process of sunroof assembly line. Reliab. Eng. Syst. Saf. 2019, 184, 202–212. [Google Scholar] [CrossRef]
- Wang, X.; Liu, M.; Ge, M.; Ling, L.; Liu, C. Research on assembly quality adaptive control system for complex mechanical products assembly process under uncertainty. Comput. Ind. 2015, 74, 43–57. [Google Scholar] [CrossRef]
- Ab Rashid, M.F.F. A hybrid Ant-Wolf Algorithm to optimize assembly sequence planning problem. Assem. Autom. 2017, 37, 238–248. [Google Scholar] [CrossRef]
- Li, J.; Selvaraju, R.; Gotmare, A.; Joty, S.; Xiong, C.; Hoi, S.C.H. Align before fuse: Vision and language representation learning with momentum distillation. Adv. Neural Inf. Process. Syst. 2021, 34, 9694–9705. [Google Scholar]
- Bao, H.; Wang, W.; Dong, L.; Liu, Q.; Mohammed, O.K.; Aggarwal, K.; Som, S.; Piao, S.; Wei, F. Vlmo: Unified vision-language pre-training with mixture-of-modality-experts. Adv. Neural Inf. Process. Syst. 2022, 35, 32897–32912. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 11106–11115. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Left Shaft Hole | Groove Surface | Locking Block Groove | Right Shaft Hole | Left | Front | Flat | Height of the Hole Center | Lock Block Left | Lock Block Right | Right | Behind | Hole Position Height | Shaking Amount |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4.48 | 6 | 4.52 | 4.55 | 5.975 | 4.51 | 5.96 | 9.17 | 4.51 | 4.51 | 5.995 | 4.54 | 9.595 | 0.7 |
| 4.51 | 5.975 | 4.52 | 4.56 | 5.98 | 4.54 | 6.015 | 9.215 | 4.5 | 4.52 | 5.96 | 4.54 | 9.52 | 0.8 |
| 4.52 | 5.98 | 4.52 | 4.55 | 6.005 | 4.49 | 5.99 | 9.29 | 4.45 | 4.48 | 5.955 | 4.48 | 9.495 | 1.4 |
| 4.53 | 6.055 | 4.52 | 4.56 | 5.99 | 4.54 | 6.095 | 9.255 | 4.5 | 4.51 | 5.96 | 4.53 | 9.5 | 0.8 |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| Top X% to Fill | MSE | MAE |
|---|---|---|
| 10% | 0.0375 | 0.1565 |
| 20% | 0.0783 | 0.2293 |
| 30% | 0.0723 | 0.2086 |
| 40% | 0.0700 | 0.2047 |
| 50% | 0.1149 | 0.2969 |
| 60% | 0.0799 | 0.2233 |
| 70% | 0.0490 | 0.1649 |
| 80% | 0.0974 | 0.2516 |
| 100% | 0.0850 | 0.2264 |
| Method | Metric | Value |
|---|---|---|
| PAGEformer | MSE | 0.0375 |
| MAE | 0.1565 | |
| Reformer | MSE | 0.0492 |
| MAE | 0.1701 | |
| ARIMA | MSE | 0.0456 |
| MAE | 0.1833 |
| Method | PAGEformer | Informer | LogTrans | Reformer | LSTMa | DeepAR | ARIMA | Prophet | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | Input Length | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE |
| ETTh1 | 24 | 0.082 | 0.225 | 0.092 | 0.246 | 0.103 | 0.259 | 0.222 | 0.389 | 0.114 | 0.272 | 0.107 | 0.280 | 0.108 | 0.284 | 0.115 | 0.275 |
| 48 | 0.119 | 0.274 | 0.161 | 0.322 | 0.167 | 0.328 | 0.284 | 0.445 | 0.193 | 0.358 | 0.162 | 0.327 | 0.175 | 0.424 | 0.168 | 0.330 | |
| 168 | 0.186 | 0.358 | 0.187 | 0.355 | 0.207 | 0.375 | 1.522 | 1.191 | 0.236 | 0.392 | 0.239 | 0.422 | 0.396 | 0.504 | 1.224 | 0.763 | |
| 336 | 0.182 | 0.350 | 0.215 | 0.369 | 0.230 | 0.398 | 1.860 | 1.124 | 0.590 | 0.698 | 0.445 | 0.552 | 0.468 | 0.593 | 1.549 | 1.820 | |
| 720 | 0.218 | 0.325 | 0.257 | 0.421 | 0.273 | 0.463 | 2.112 | 1.436 | 0.683 | 0.768 | 0.658 | 0.707 | 0.659 | 0.766 | 2.735 | 3.253 | |
| ETTh2 | 24 | 0.090 | 0.229 | 0.099 | 0.241 | 0.102 | 0.255 | 0.263 | 0.437 | 0.155 | 0.307 | 0.098 | 0.263 | 3.554 | 0.445 | 0.199 | 0.381 |
| 48 | 0.147 | 0.301 | 0.159 | 0.317 | 0.169 | 0.348 | 0.458 | 0.545 | 0.190 | 0.348 | 0.163 | 0.341 | 3.190 | 0.474 | 0.304 | 0.462 | |
| 168 | 0.263 | 0.415 | 0.235 | 0.390 | 0.246 | 0.422 | 1.029 | 0.879 | 0.385 | 0.514 | 0.255 | 0.414 | 2.800 | 0.595 | 2.145 | 1.068 | |
| 336 | 0.293 | 0.439 | 0.258 | 0.423 | 0.267 | 0.437 | 1.668 | 1.228 | 0.558 | 0.606 | 0.604 | 0.607 | 2.753 | 0.738 | 2.096 | 2.543 | |
| 720 | 0.295 | 0.439 | 0.285 | 0.442 | 0.303 | 0.493 | 2.030 | 1.721 | 0.640 | 0.681 | 0.429 | 0.580 | 2.878 | 1.044 | 3.355 | 4.664 | |
| ETTm1 | 24 | 0.034 | 0.147 | 0.034 | 0.160 | 0.065 | 0.202 | 0.095 | 0.228 | 0.121 | 0.233 | 0.091 | 0.243 | 0.090 | 0.206 | 0.120 | 0.290 |
| 48 | 0.063 | 0.195 | 0.066 | 0.194 | 0.078 | 0.220 | 0.249 | 0.390 | 0.305 | 0.411 | 0.219 | 0.362 | 0.179 | 0.306 | 0.133 | 0.305 | |
| 96 | 0.193 | 0.365 | 0.187 | 0.384 | 0.199 | 0.386 | 0.920 | 0.767 | 0.287 | 0.420 | 0.364 | 0.496 | 0.272 | 0.399 | 0.194 | 0.396 | |
| 288 | 0.398 | 0.546 | 0.409 | 0.548 | 0.411 | 0.572 | 1.108 | 1.245 | 0.524 | 0.584 | 0.948 | 0.795 | 0.462 | 0.558 | 0.452 | 0.574 | |
| 672 | 0.529 | 0.643 | 0.519 | 0.665 | 0.598 | 0.702 | 1.793 | 1.528 | 1.064 | 0.873 | 2.437 | 1.352 | 0.639 | 0.697 | 2.747 | 1.174 | |
| weather | 24 | 0.109 | 0.236 | 0.119 | 0.256 | 0.136 | 0.279 | 0.231 | 0.401 | 0.131 | 0.254 | 0.128 | 0.274 | 0.219 | 0.355 | 0.302 | 0.433 |
| 48 | 0.181 | 0.313 | 0.185 | 0.316 | 0.206 | 0.356 | 0.328 | 0.423 | 0.190 | 0.334 | 0.203 | 0.353 | 0.273 | 0.409 | 0.445 | 0.536 | |
| 168 | 0.259 | 0.377 | 0.269 | 0.404 | 0.309 | 0.439 | 0.654 | 0.634 | 0.341 | 0.448 | 0.293 | 0.451 | 0.503 | 0.599 | 2.441 | 1.142 | |
| 336 | 0.292 | 0.397 | 0.310 | 0.422 | 0.359 | 0.484 | 1.792 | 1.093 | 0.456 | 0.554 | 0.585 | 0.644 | 0.728 | 0.730 | 1.987 | 2.468 | |
| 720 | 0.299 | 0.425 | 0.361 | 0.471 | 0.388 | 0.499 | 2.087 | 1.534 | 0.866 | 0.809 | 0.499 | 0.596 | 1.062 | 0.943 | 3.859 | 1.144 | |
| ECL | 48 | 0.261 | 0.363 | 0.238 | 0.368 | 0.280 | 0.429 | 0.971 | 0.884 | 0.493 | 0.539 | 0.204 | 0.357 | 0.879 | 0.764 | 0.524 | 0.595 |
| 168 | 0.360 | 0.426 | 0.442 | 0.514 | 0.454 | 0.529 | 1.671 | 1.587 | 0.723 | 0.655 | 0.315 | 0.436 | 1.032 | 0.833 | 2.725 | 1.273 | |
| 336 | 0.432 | 0.464 | 0.501 | 0.552 | 0.514 | 0.563 | 3.528 | 2.196 | 1.212 | 0.898 | 0.414 | 0.519 | 1.136 | 0.876 | 2.246 | 3.077 | |
| 720 | 0.423 | 0.474 | 0.543 | 0.578 | 0.558 | 0.609 | 4.891 | 4.047 | 1.511 | 0.966 | 0.563 | 0.595 | 1.251 | 0.933 | 4.243 | 1.415 | |
| 960 | 0.537 | 0.540 | 0.594 | 0.638 | 0.624 | 0.645 | 7.019 | 5.105 | 1.545 | 1.006 | 0.657 | 0.683 | 1.370 | 0.982 | 6.901 | 4.264 | |
| Method | Metric | Value |
|---|---|---|
| Prob and AGEE | MSE | 0.0375 |
| MAE | 0.1565 | |
| removes Prob | MSE | 0.0453 |
| MAE | 0.1642 | |
| removes AGEE | MSE | 0.0385 |
| MAE | 0.1599 | |
| removes Prob and AGEE | MSE | 0.1847 |
| MAE | 0.3688 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.; Li, H.; Liu, P.; Niu, B.; Sun, J.; Wen, B. Predicting Assembly Geometric Errors Based on Transformer Neural Networks. Machines 2024, 12, 161. https://doi.org/10.3390/machines12030161
Wang W, Li H, Liu P, Niu B, Sun J, Wen B. Predicting Assembly Geometric Errors Based on Transformer Neural Networks. Machines. 2024; 12(3):161. https://doi.org/10.3390/machines12030161
Chicago/Turabian StyleWang, Wu, Hua Li, Pei Liu, Botong Niu, Jing Sun, and Boge Wen. 2024. "Predicting Assembly Geometric Errors Based on Transformer Neural Networks" Machines 12, no. 3: 161. https://doi.org/10.3390/machines12030161
APA StyleWang, W., Li, H., Liu, P., Niu, B., Sun, J., & Wen, B. (2024). Predicting Assembly Geometric Errors Based on Transformer Neural Networks. Machines, 12(3), 161. https://doi.org/10.3390/machines12030161