1. Introduction
Consider a discrete-time jump control system [
1,
2,
3], modeled by:
where
,
, and
, with
. To obtain the optimal control of the above system, one has to minimize the quadratic cost function
where
and
are symmetric positive semi-definite (SPSD) and symmetric positive definite (SPD) matrices, respectively, representing the state and control weighting terms in the cost function. The corresponding optimal control feedback gain is given by:
where
is defined as a convex combination of
via the stochastic weights
. To achieve the optimal control
, one has to solve the coupled discrete-time algebraic Riccati equation (CDARE):
for
.
Among the various approaches developed for solving the CDARE (
1), iterative methods remain prominent. Commonly used iterations typically reformulate the problem as either optimization-based methods [
4] or fixed-point iterations [
5,
6], drawing on classical linear–quadratic regulator theory. Enhanced variants based on linear matrix inequality (LMI) formulations have also been proposed [
7,
8]. However, such methods often exhibit slow convergence of the objective function and limited numerical precision, particularly in large-scale or tightly coupled scenarios. Fixed-point schemes address the CDARE directly by recasting it as a fixed-point problem. Notably, Ivanov [
9] introduced two distinct fixed-point iterations, which were later accelerated by incorporating extrapolation techniques that leverage information from the current iteration to replace the previous one, thereby obviously improving the convergence rate.
To circumvent the computational cost associated with explicit matrix inversion, inverse-free fixed-point methods have been introduced. These schemes are inspired by the Schulz iteration [
10], which recasts matrix inversion as a Newton-type process, replacing inversions with matrix multiplications [
11,
12,
13]. While inverse-free methods demonstrate notable computational efficiency in practice, their theoretical convergences are generally linear.
To further accelerate convergence, Newton-type methods have garnered attention. For continuous-time coupled Riccati equations, Feng and Chu [
14] proposed a Newton-based approach that extends the block-diagonal structure originally developed in [
15] and generalizes the pseudo-Newton strategies given in [
13]. For the discrete-time case in (
1), Newton-type iteration was explored in [
16], though the convergence analysis therein is restricted to settings where each weighting matrix
is symmetric positive definite. In practical large-scale systems, however, the output matrix
often has low rank, rendering the associated
only positive semi-definite. In such a case, the above Newton variants, including the inverse-free version [
17], become inapplicable. For other methods applicable to similar types of equations, readers may also refer to [
18,
19].
The key to applying Newton’s method to large-scale CDARE (
1) lies in efficiently computing the solution of large-scale coupled Stein equations (CSEs). Recently, a novel operator Smith algorithm (OSA) was introduced for solving CSEs with SPSD constant matrices [
20]. This method interprets the coupling unknowns as operator-valued expressions and employs a doubling strategy to accelerate the iteration, demonstrating well-behaved numerical performance on large-scale problems. Another approach to handling large-scale CSEs with low-rank structure is to represent the low-rank matrix in the HODLR structured form [
21,
22]. However, after performing matrix operations with sparse matrices, the HODLR-structured matrix requires restructuring; otherwise, the dense matrix will not be adapted to large-scale computations.
Inspired by the development of OSA in [
20], we propose an operator Newton method (ONM) tailored to solving large-scale CDAREs (
1). The main contributions are summarized as follows:
We develop an operator Newton iteration scheme grounded in the structure of the OSA for solving the CDARE (
1) and rigorously establish the convergence as well as the convergence rate. Crucially, unlike existing inverse-free schemes [
11,
12,
13] that require invertible
to initiate the iteration, our method allows for SPSD initial
.
A low-rank variant of the operator Newton method is constructed to address the large-scale system. When the matrix admits low-rank representation, the proposed method ensures that the rank of the initial residual remains fixed across iterations, effectively mitigating rank inflation.
We employ a doubling-based operator formulation for Newton’s subproblem, i.e., the coupled Stein equations, and embed the truncation–compression (TC) technique to control the growth of the column of low-rank factors. This enables efficient low-rank approximation to the solution without compromising numerical stability.
We propose a scalable residual evaluation strategy for large-scale CDARE and validate the proposed method on practical problems from engineering applications. Numerical experiments demonstrate that, for a comparable level of residual accuracy, the presented operator Newton method significantly reduces CPU time relative to the standard Newton’s method with the incorporation of the HODLR structure [
21,
22].
The paper is structured as follows.
Section 2 reviews the operator Smith algorithm, and presents several lemmas required for constructing the operator Newton method.
Section 3 introduces the iterative scheme of the operator Newton method for solving the CDAREs and establishes corresponding theorems on the convergence and convergence rate.
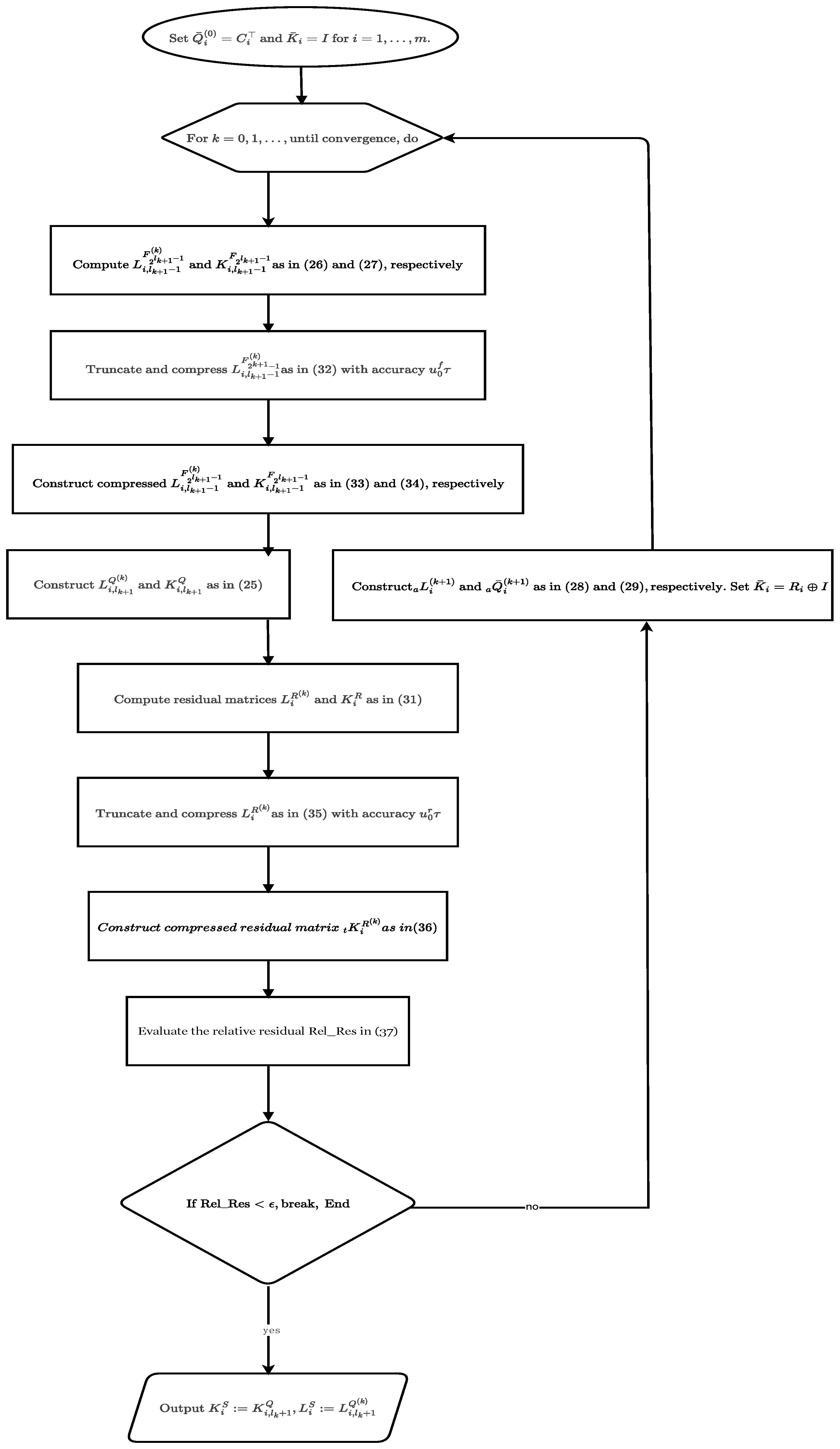
Section 4 develops a low-rank variant of the operator Newton method tailored for large-scale problems with low-rank structures. By incorporating the truncation and compression technique, the scheme effectively controls the growth of the iterative matrix sequence. A detailed analysis of the computational complexity per iteration is also provided.
Section 5 demonstrates the effectiveness of the proposed operator Newton method in solving large-scale practical CDAREs.
5. Numerical Examples
In this section, we demonstrate the effectiveness of the proposed ONM_lr algorithm for computing the solution of large-scale CDARE (
1), through examples drawn from [
27,
28,
29,
30]. The implementation of ONM_lr was coded by MATLAB R2019a on a 64-bit Windows 10 desktop, equipped with a 3.0 GHz Intel Core i5 processor (6 cores/6 threads) and 32 GB of RAM. The machine precision was set to
eps =
. Especially, the HODLR structure [
21,
22] used in the standard Newton’s method was also coded by MATLAB and can be viewed at
https://github.com/numpi/hm-toolbox (accessed on 30 July 2025.).
The maximum number of columns in the low-rank factors was restricted to
, and the truncation–compression (TC) tolerance was chosen as
. The residuals were evaluated as in (
36), and the stopping criterion was set to a tolerance of
. We did not compare the proposed method with the recently developed inverse-free fixed-point methods [
12,
13], as those approaches require the initial matrices
to be nonsingular—an assumption that is clearly not satisfied in large-scale engineering problems with low-rank structure.
Example 1. This example is adapted from a slightly modified all-pass single-input single-output (SISO) system originally studied in [29], generating an all-pass SISO system. In this setting, the controllability and observability Gramians satisfy a quasi-inverse relation, i.e., for some . Consequently, the system exhibits a single Hankel singular value with multiplicity equal to the system order. The derived system matrices are as follows:
where
and
are both tri-diagonal matrices
but with
and
, respectively. We consider
and select the probability matrix
.
We first compare the performance of the ONM_lr algorithm with the standard Newton’s method incorporating the HODLR structure (SN_HODLR) for CDARE of dimensions
and
. The results are reported in
Table 2, where columns It., CPU, and Rel_Res report the iteration number, elapsed CPU time, and the relative residuals of the CDARE, respectively, when the algorithm terminates. For
, ONM_lr achieves the prescribed residual level in approximately 6.2 s, while the SN_HODLR requires about 1320 s to reach termination, roughly 212 times longer than ONM_lr. For
, ONM_lr reaches the prescribed residual in about 6.7 s, whereas the SN_HODLR is out of memory during iterations and fails to complete the computation.
We then assess the performance of the ONM_lr algorithm on larger CDARE with dimensions
,
,
, and
, and summarize the numerical results in
Table 3. The quantities
and
denote the CPU time of the
k-th iteration and the cumulative runtime up to iteration
k, respectively. The column Rel_Res reports the relative residuals of the CDARE at each iteration, while the NC column indicates the maximum number of columns in
. As shown in
Table 3, ONM_lr consistently achieves a residual on the order of
after 4 iterations. Moreover, the column Rel_Res clearly demonstrates the algorithm’s quadratic convergence rate.
To further illustrate the convergence characteristics of the OSA used to solve each subproblem, we depict its convergence trajectories under various dimensions in
Figure 2. In each subplot, the outer iterations 1 through 4 are represented by red, yellow, green, and orange, respectively. Within each color, a gradient from light to dark corresponds to increasing values drawn from the interval
. The concentric rings indicate logarithmic scales from
to
. The convergence behavior of the OSA is marked by black circles, blue pentagrams, purple stars, and brown diamonds across the four outer iterations. From the number of concentric levels traversed by each marker, it is evident that the OSA achieves near-quadratic convergence across all subproblems. This reinforces the effectiveness of the proposed operator Newton framework in delivering rapid and robust convergence from inner iterations to the overall CDARE solution.
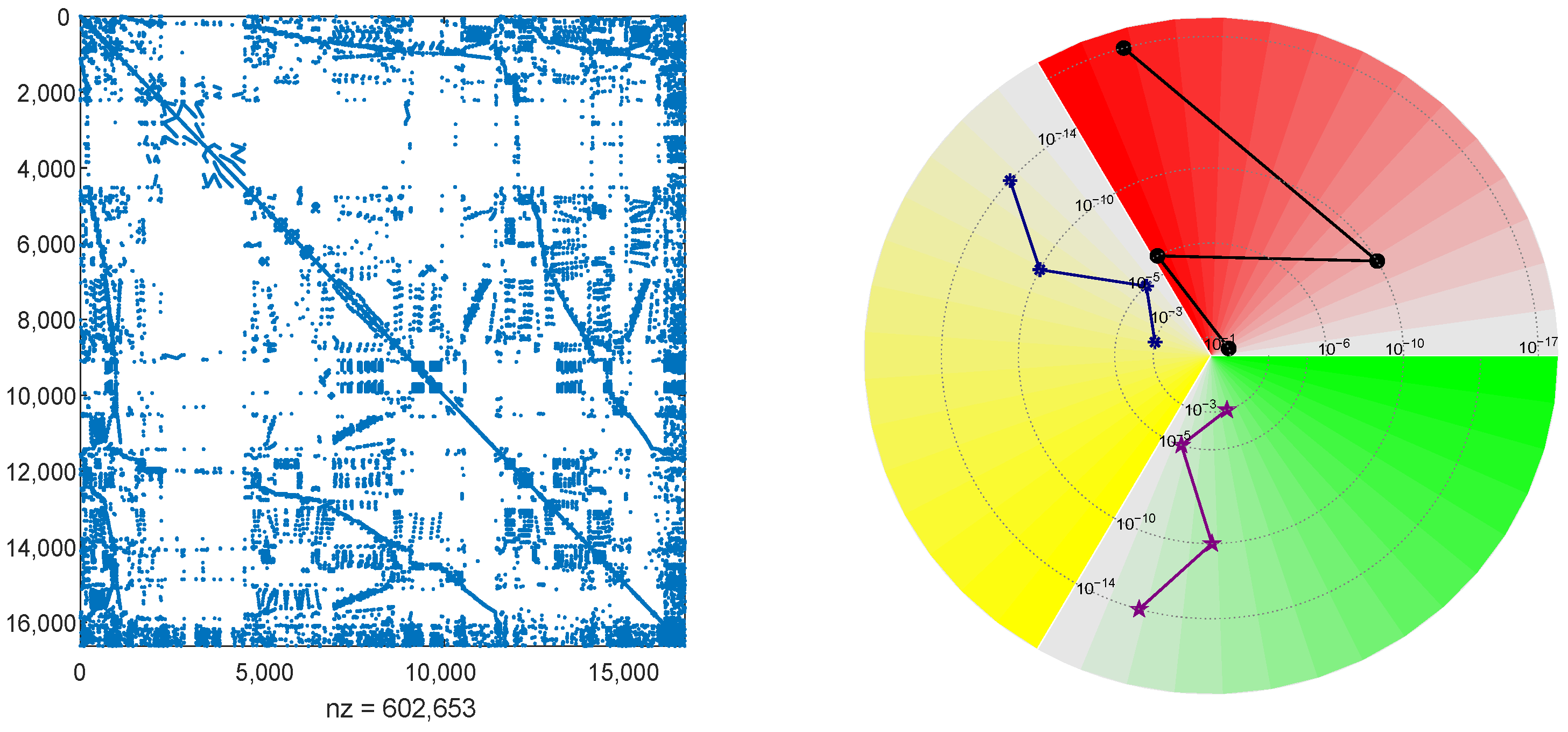
Example 2. Consider a structural model of a vertically mounted stand, representative of machinery control systems. This model corresponds to a segment of a machine tool frame, where a series of guide rails is fixed along one surface to facilitate the motion of a tool slide during operation [28,31]. The geometry has been modeled and meshed using ANSYS, and the spatial discretization employs linear Lagrange elements within the finite element framework implemented in FEniCS. The resulting system matrices are
where random scalars
are used for certain parameterizations, and the vector
B has 392 nonzero elements, with a maximum entry of at most
. Due to the structural similarity between
and
, only the sparsity pattern of
is depicted on the left panel of
Figure 3. Vectors
and
are mostly zero, with five nonzero entries located at rows (3341, 6743, 8932, 11,324, 16,563) for
and (1046, 2436, 6467, 8423, 12,574) for
, respectively. Full matrix data are available from [
27] and at the MOR Wiki repository (
https://morwiki.mpi-magdeburg.mpg.de/morwiki/index.php/Vertical_Stand) (accessed on 30 July 2025). For this example, we set
and define the mode transition probability matrix as
.
We apply the ONM_lr algorithm to solve the resulting coupled CDARE. We omit the comparison with the standard Newton’s method incorporating the HODLR structure, as it is out of memory capacity during iterations at this problem dimension.
Table 4 summarizes the numerical results of ONM_lr. The residuals decrease to
after only three outer iterations. The columns
and
report the cumulative and per-iteration CPU time, respectively. The NC column shows that the column dimension of
increases by more than twice in the first iteration but grows more slowly in subsequent iterations. The Rel_Res column confirms that ONM_lr retains a quadratic convergence.
To further investigate the convergence of the OSA for the subproblems, we present their convergence histories in the right panel of
Figure 3. The red, yellow, and green colors correspond to the first, second, and third subproblem solving, respectively, with increasing intensities representing values in
. Concentric circles indicate residual magnitudes from
to
. The convergence trajectories are plotted using black circles, blue pentagrams, and purple stars. The number of magnitude levels traversed by these markers provides clear evidence of nearly quadratic convergence for the OSA. This validates the robustness and efficiency of the ONM_lr algorithm in conjunction with the OSA strategy.
Example 3. Consider a semi-discretized heat transfer model arising from the optimal cooling of steel profiles in automated control systems, as studied in [27]. The dimension of the resulting dynamical system depends on the level of refinement applied to the computational mesh. Spatial discretization is performed using linear Lagrange elements via the ALBERTA-1.2 finite element toolbox [30]. We slightly modify the model matrices as follows:
where
and
is estimated by
‘normest’ in Matlab. We take
and
for
and
and
for
.
. In this experiment, we take
and
with
and
being random numbers in (0,1). Matrices
,
, and
can be found at [
27], or the MOR Wiki repository (
https://morwiki.mpi-magdeburg.mpg.de/morwiki/index.php/Steel_Profile) (accessed on 30 July 2025). The probability matrix is defined as
.
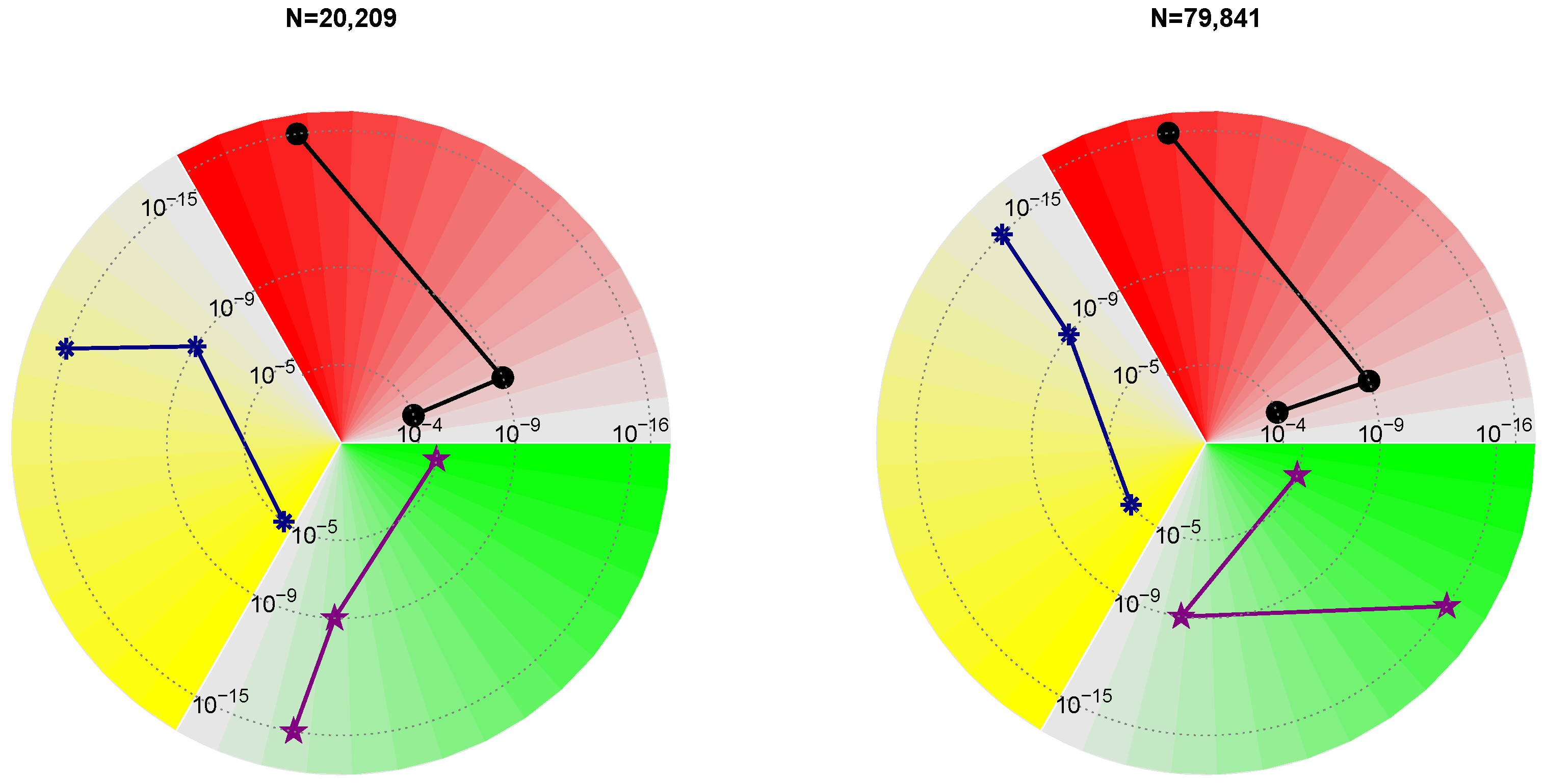
To assess the performance of the proposed ONM_lr algorithm, we solve Equation (
1) for two system sizes:
and
. Again, we omit the comparison with the standard Newton’s method incorporating the HODLR structure, as it is out of memory capacity during iterations at this problem dimension. The numerical results of ONM_lr are reported in
Table 5. In both cases, ONM_lr attains a residual norm on the order of
within just three outer iterations. The cumulative CPU times are approximately 10.5 s and 19.5 s. The It. column records the number of outer iterations, while the NC column reflects the maximum number of columns in
at each step. The modest growth in NC, remaining below two times across iterations, highlights the efficiency of the truncation–compression (TC) strategy employed within both the outer ONM_lr iterations and the inner OSA iterations. Furthermore, the Rel_Res column confirms the quadratic convergence of ONM_lr.
To further visualize the convergence characteristics of the subproblem solvers, we depict the residual histories for both problem sizes in the right panel of
Figure 4. Each subplot uses red, yellow, and green markers to represent the first through third subproblem solving. Within each color, darker shades correspond to higher iteration indices. Concentric rings denote residual levels ranging from
to
. The convergence paths of the operator Smith iteration are illustrated using black circles, blue pentagrams, and purple stars. The number of magnitude rings traversed by these markers clearly indicates that each subproblem is solved with nearly quadratic convergence. This further confirms the rapid and robust performance of the ONM_lr algorithm when combined with the OSA subproblem strategy.





{kind=link}
{kind=link}
{kind=link}
{kind=link}