Abstract
The estimation of unknown quantities from multiple independent yet non-homogeneous samples has garnered increasing attention in various fields over the past decade. This interest is evidenced by the wide range of applications discussed in recent literature. In this study, we propose a preliminary test estimator for the common mean with unknown and unequal variances. When there exists prior information regarding the population mean with consideration that might be equal to the reference value for the population mean, a hypothesis test can be conducted: versus . The initial sample is used to test , and if is not rejected, we become more confident in using our prior information (after the test) to estimate . However, if is rejected, the prior information is discarded. Our simulations indicate that the proposed preliminary test estimator significantly decreases the mean squared error (MSE) values compared to unbiased estimators such as the Garybill-Deal (GD) estimator, particularly when closely aligns with the hypothesized mean (). Furthermore, our analysis indicates that the proposed test estimator outperforms the existing method, particularly in cases with minimal sample sizes. We advocate for its adoption to improve the accuracy of common mean estimation. Our findings suggest that through careful application to real meta-analyses, the proposed test estimator shows promising potential.
MSC:
62H15; 62E15; 62F03; 62H10
1. Introduction
As medical knowledge continues to expand rapidly, healthcare providers face significant challenges in thoroughly evaluating and analyzing the necessary data to make well-informed decisions [1,2,3]. The complexity of these challenges is further heightened by the variety of findings, presented in different studies, which are sometimes conflicting. Meta-analysis, along with research synthesis or integration, has become an effective tool for addressing these issues. This method achieves its objective by applying rigorous statistical techniques to aggregate the results from multiple individual studies, thereby combining their findings [2,4]. Additionally, meta-analysis has gained widespread attention across numerous scientific fields, such as education, social sciences, and medicine. For example, in education has been used to consolidate research on the effectiveness of coaching in improving Scholastic Aptitude Test (SAT) scores in both verbal and mathematical sections [5]. In social sciences, it has been used to synthesize studies on gender differences in quantitative, verbal, and visual-spatial abilities [6]. In healthcare, meta-analysis has been particularly valuable during the COVID-19 pandemic, enhancing our understanding of the virus and informing public health strategies [7,8].
The challenge of combining two or more unbiased estimators is a common issue in applied statistics, with significant implications across various fields. A notable example of this problem occurred when Meier [9] was tasked with making inferences about the mean albumin level in plasma protein in human subjects using data from four separate experiments. Similarly, Eberhardt et al. [10] faced a scenario where they needed to draw conclusions about the mean selenium content in non-fat milk powder by integrating results from four different methods across four experiments.
Most of the early research on drawing inferences about the common mean focuses on point estimation and theoretical decision rules regarding . Graybill and Deal were the first among a few researchers to research about estimating [11]. Since then, numerous works have been building upon and expanding upon their initial work [12,13,14,15,16,17,18], along with the related references. Conversely, Meier [9] developed a method for estimating the confidence interval for . In addition, refs. [19,20] have devised approximate confidence intervals. The properties of such estimators have accumulated substantial attention in the literature. Sinha et al. [2] derived an unbiased estimator of the variance for the Graybill-Deal estimator, and Krishnamoorthy and Moore [21] considered this in the prediction problem of linear regression.
In some cases, researchers find situations where prior information on the mean population is available, whether through pre-test information or historical data. Pretest or preliminary tests or shrinkage estimators involve the concept of leveraging preliminary information to improve parameter estimation accuracy. These estimators work with the idea of borrowing strength from both sample data and pre-test information, resulting in higher efficiency and reliability than traditional estimators. Bancroft [22] and Stein [23] introduced and extensively examined the preliminary test shrinkage estimator. Their method has influenced numerous advancements and applications in statistics and has established a basis for the use of shrinkage estimators in contemporary statistical practice [24,25,26]. Thompson [27] proposed a shrinkage technique given as
where (accept ), (reject ) and as prior guess. This was aimed at improving the current estimator of a parameter to estimate the mean, thereby reducing the mean square error (MSE) of the uniform minimum-variance unbiased estimator (UMVUE) for the population mean. It has been observed that the shrinkage estimator performs better than the conventional estimator when the assumed value of q aligns closely with the prior guess. Consequently, instead of treating q as a constant value in the shrinkage estimator, it is advisable to regard it as a weight ranging between 0 and 1 [27]. In this context, q can be viewed as a continuous function dependent on certain pertinent statistics, anticipating that its value will decrease consistently as the deviation from a reference value increases.
This preliminary test has been widely used in statistics [24,25,26]. Khan et al. [24] deployed a preliminary test for estimating the mean of a univariate normal population with an unknown variance. Shih et al. [25] proposed a class of general pretest estimators for the univariate normal mean which included numerous existing estimators, such as pretest, shrinkage, Bayes, and empirical Bayes estimators. In the context of meta-analysis, Taketomi et al. [26] proposed simultaneous estimation of individual means using the James–Stein shrinkage estimators, which improved upon individual studies’ estimators. Literature has observed that when prior information is available, shrinkage estimators for parameters of various distributions tend to outperform standard estimators in terms of MSE, especially when the estimated value is close to the true value [22,27,28].
The use of prior information in estimating the common mean has several significant advantages. For example, it allows researchers to leverage significant past knowledge, which could be from historical data, expert opinion, or preliminary investigations, improving the accuracy of the estimation process. Secondly, they tend to strike a compromise between bias and variance, resulting in estimates that are both unbiased and more efficient than traditional estimators, particularly in circumstances with small sample sizes. However, there are limited research studies on point estimation of proposing preliminary test-based estimators. It is therefore, in this study we propose a preliminary test estimator for the common mean with unknown and unequal variances. In order to find the ideal estimator, the properties of the proposed preliminary test estimator will be examined, which includes its theoretical basis and performance-based criteria such as bias and MSE.
2. Background
To define the current problem, we assume there are k independent normal populations with a common mean , but with unknown and potentially unequal variances . We assume we have independent and identically distributed () observations from , and we define and as
where , . Note that these statistics are all mutually independent. Again, it can be noted that are minimal sufficient statistics for but not complete [29]. As a result, one cannot get the uniformly minimum variance unbiased estimator (UMVUE) if it exists using the standard Rao-Blackwell theorem on an unbiased estimator for estimating . For the case of k when the population variances are fully known, can be readily estimated as
This estimator, , is the UMVUE, the best linear unbiased estimator (BLUE), and the maximum likelihood estimator (MLE). In the context of our current problem, where the population variances are unknown and possibly unequal, the most appealing unbiased estimator for is the Graybill-Deal (GD) estimator [11], which is
In the case of two samples, GD [11] first demonstrated that an unbiased estimator in Equation (6) has a lower variance compared to either sample mean, provided that both sample sizes exceed 10.
Khatri and Shah [30] proposed an exact variance formula for which is complex and not easily applied. To tackle this inference issue, Meier [9] derived a first-order approximation of the variance of , given by
where .
A few years later, Sinha [31] developed an unbiased estimator for the variance of that takes the form of a convergent series. A first-order approximation of this estimator is
The above estimator is comparable to Meier’s [9] approximate estimator, defined as
The “classical” meta-analysis variance estimator, is given as
Approximate variance estimator proposed by Hartung [32], is given as
3. Proposed Preliminary Test Estimator
It is reasonable to test a null hypothesis when uncertain non-sample prior information is available. A preliminary test estimator is a two-step process that estimates a key parameter using the results of a preliminary test. To estimate , we consider the hypothesis
Our proposed preliminary test estimate for is as follows:
where is unbiased estimator of . Shih et al. [25] defined be a test function with , , and . For , then randomized test is defined as
The rejection or failure to reject will be based on the t statistic. A standard notation for a t statistic based on a sample of size n is . We can refer to this t computed from a specific set of data as the observed value of our test statistic, and reject when , where is degrees of freedom and is Type-I error level. A test for based on a p-value on the other hand is based on , and we reject at level if . We let as usual. Then stands for the central t variable with degrees of freedom, and stands for the upper percentile of . The general preliminary test estimator [33] can be defined as
The estimator can also be written as
In this study, we focus only on the case where . We can define our proposed preliminary test estimator with unknown variance as
where is the indicator function defined as if A is true and if A is false. A random p-value which has a distribution under is defined as , where . Most suggested tests for are based on and values. To simplify the notation, we will denote by small p and by large P. In our context, we have independent t statistics, , and also independent p-values, . In the following, we suggest various test procedures for testing based on suitable combinations of and [34]. Depending on the test procedure we use, the rejection set A will be defined and used to compute the Bias and MSE of the preliminary test estimator of the common mean .
3.1. P-Value Based Exact Tests
Suppose are independent p-values obtained from k continuous distributions of test statistics, then when individual hypothesis is true, is uniformly distributed over the interval . Testing the joint null hypothesis versus . Five p-value-based exact tests based on and p-value from k independent studies as available in the literature are listed below.
3.1.1. Tippett’s Test
Suppose are independent and ordered p-values. Then is rejected if . If the overall significance level is then . Interestingly, this test is equivalent to the test based on suggested by Cohen and Sackrowitz [35]. This test was proposed by Tippet et al. [36] also called the union-intersection.
3.1.2. Wilkinson’s Test
Wilkinson [37] provided a generalization of Tippett’s test, where are ordered p-values with the smallest p-value, as a test statistic. The common mean null hypothesis will be rejected if , where follows a beta distribution with parameters r and under the null hypothesis and satisfies . This generates a series of tests for various values of .
3.1.3. Inverse Normal Test
Stouffer et al. [38], reported that the Inverse Normal test procedure involves transforming the p-values to the corresponding standard normal distributions. The test statistic is defined as , where is the standard normal cumulative distribution function (CDF). The common mean null hypothesis will be rejected if , where denotes the upper level cut-off point of the standard normal distribution.
3.1.4. Fisher’s Inverse -Test
Fisher [39] noted that the test statistic has a distribution with degrees of freedom when is true. This procedure uses the to combine the k independent p-values. The common mean null hypothesis will be rejected if , where denotes the upper critical value of -distribution with degrees of freedom.
3.1.5. The Logit Test
This exact test procedure which involves transforming each p-value into a logit was proposed by Mudholker and George [40]. The test statistic is defined as , where G follows student’s t-distribution with degrees of freedom. The common mean null hypothesis is rejected if .
3.2. Exact Tests
3.2.1. Modified t
Fairweather [41] suggested using a weighted linear combination of the namely, , where , with . The null hypothesis is rejected if , where with computed by simulation.
3.2.2. Modified F
Jordan and Krishnamoorthy [42] suggested using linear combinations of the ’s namely, , where , with for . The null hypothesis will be rejected if , where with computed by simulation.
3.3. Properties of the Proposed Preliminary Test Estimator
3.3.1. Bias
Bias of the proposed preliminary test estimator is equal to , where
Given that the rejection of and are dependent upon sample mean and sample variance and , respectively, it may be concluded that and are not mutually independent.
3.3.2. Mean Square Error
The MSE of can be expressed as
4. Simulation Study
Bias and Mean Squared Error
We will now assess the effectiveness of the proposed preliminary test estimator performs in terms of bias and MSE. To achieve a high level of accuracy, each simulated bias and MSE value was calculated using replications, resulting in an exceptionally large simulation. It should be noted that MSE and relative efficiency (RE) of the proposed preliminary test estimator are functions of and . Among these parameters, n represents the sample size, and is the estimated value of the parameter used in the proposed preliminary test estimator. These extensive computations were carried out using statistical software R [43]. The procedure for our proposed preliminary test estimator of common mean is defined as:
- Select two positive integers and .
- Generate independent random observations and .
- Test versus at significance level using p-value and exact based tests in Section 3 for versus .
- If we fail to reject , we take the estimator of . However, if is rejected we take the estimator of as .
- The effectiveness of this proposed estimator is assessed using the simulated bias as and simulated MSE as .
The expression provided in Equation (12) for bias, can be computed for various values of . Without loss of generality, in our computed simulated bias and MSE, we set , and .
Remark 1.

Table 1, Table 2 and Table 3 provide some illustrative values. Generally, it is observed that as δ increases, the bias increases in magnitude for unequal sample sizes. Ultimately, for a value of δ close to 1, the bias approaches zero. Furthermore, the comparison of tables reveals that as the sample size increases, the magnitude of bias decreases. Furthermore, as μ deviates further from , the bias becomes larger and is dependent on . In particular, when and , the bias of our proposed test estimator appears to approach zero. Furthermore, as μ deviates further from , the MSE becomes larger and independent on when .
Table 1.
Simulated bias (MSE) of the proposed estimator for different choices of ().
Table 2.
Simulated bias (MSE) of the proposed estimator for different choices of ().
Table 3.
Simulated bias (MSE) of the proposed estimator for different choices of ().
Remark 2.
Table 1, Table 2 and Table 3 illustrate the changes in MSE with respect to both δ and sample size. Specifically, an increase in δ leads to a corresponding increase in MSE. Furthermore, the comparison across the tables shows that as the sample size grows, the MSE decreases accordingly. The minimum MSE is consistently observed when the estimated value is close to the true value , regardless of the test performed. It is also noteworthy that the MSE values are nearly identical across all p-value-based tests, except for the Inverse Normal test. On the other hand, the modified exact tests tend to produce higher MSE values compared to their P-value-based counterparts.
Remark 3.
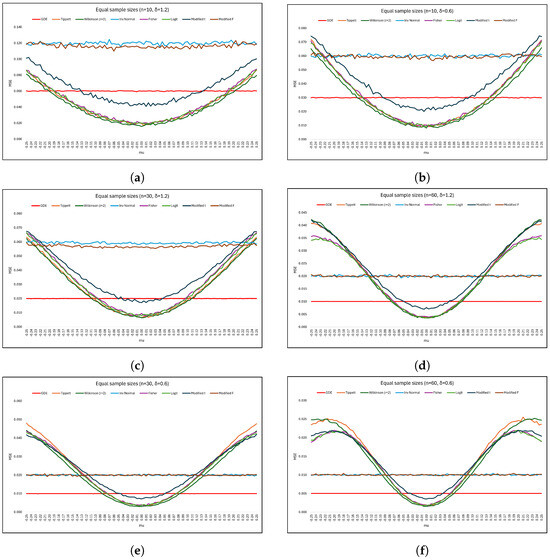
To evaluate the performance of the proposed preliminary test estimator () in comparison to the conventional single-stage estimator () using equal sample sizes () and a fixed significance level (), it is observed that as the sample size (n) increases, the MSE generally decreases. Notably, when μ is closer to the hypothesized mean (), the preliminary test estimator outperforms the unbiased estimator across various values of δ. This range of values where the preliminary test estimator excels can be referred to as its effective interval. After reaching a minimum at , a slight rise in MSE is observed as μ deviates further from . This trend is evident in the results depicted in Figure 1a,b, indicating that for and , the proposed estimator performs better than the unbiased estimator when . Conversely, for and , the proposed estimator outperforms the unbiased estimator when and , respectively (as shown in Figure 1c,e for ). Again, for and , the proposed estimator outperforms the unbiased estimator when and , respectively (as shown in Figure 1d,f for ). The preliminary test estimator, employing Tippett, Wilkinson (r = 2), Fisher’s inverse , logit, and modified t tests, demonstrates satisfactory performance within its effective interval, as indicated by MSE values. These findings are consistent with the conclusions drawn by Kifle et al. (2021) regarding the efficacy of Fisher’s inverse and modified t tests across various sample sizes and significance levels [33].
Figure 1.
Efficiency of estimator based on p-value and modified exact tests with respect to .
5. Application in Biological Research
To demonstrate the practical applicability of the proposed preliminary test estimator, we analyzed data from four experiments used to estimate the percentage of albumin in plasma protein of normal human subjects. This dataset is reported in Meier [9] and appears in Table 4. For this dataset, previous studies focusing on the test problem [44,45], have compared the various test procedures for testing versus .
Table 4.
Albumin in plasma protein.
In our scenario, we could consider 59.50 as our non-sample prior information and apply our proposed preliminary test estimator to address this issue. According to the findings presented in Table 5, the estimated mean () derived from p-value based tests (including Tippett’s, Wilkinson ( and ), Inverse normal, and Fisher’s tests) notably integrates the non-sample prior information.
Table 5.
The proposed test estimator for albumin in plasma protein with .
In our second application of the proposed preliminary test estimator, we analyzed the data from four experiments about non-fat milk powder. This data set is reported by Eberhardt et al. [10] and appears in Table 6. We can compute values of for different values of with fixed sampling values, based on P-value and modified exact tests. The resulting values are shown in Table 7.
Table 6.
Selenium in non-fat milk powder.
Table 7.
The proposed test estimator for selenium in non-fat milk powder for various values of .
The findings presented in Table 7 suggest that when is below 110.00, . However, when falls within the range of 110.00 to 110.50, tests including Tippett’s, Wilkinson’s (, , and ), Fisher’s, and the logit tests do not reject the null hypothesis (), indicating an estimated common mean of equal to 110.00, whereas other tests reject , estimating the common mean equal to 109.60. For , tests based on Wilkinson’s ( and ) and the modified F tests also fail to reject , with an estimated equal to 110.00. Both the Inverse normal test and the Modified t test accepted the null hypothesis for various values of . This may be because the Inverse normal test transforms p-values into z-scores and combines them, whereas the Modified t test adjusts the traditional t test procedure to address specific issues such as heteroscedasticity or small sample sizes.
From the above results, we do not intend to make any broad conclusions here, but our simulation results suggest that our proposed preliminary test estimator based on Tippett’s, Wilkinson’s (, , and ), Fisher’s, and the logit tests are feasible and could be applied to this specific case if prior information about the population mean is available.
6. Conclusions
The past decade has witnessed increased interest in estimating unknown quantities using data from multiple independent yet non-homogeneous samples. This approach finds application across various domains, as evidenced by the diverse range of applications discussed in the most recent book by Sinah et al. [2]. In this study, we introduce a preliminary test estimator that integrates non-sample prior information. Our simulations indicate that this proposed estimator exhibits distinct advantages in certain scenarios, particularly when dealing with very small sample sizes and situations where exceeds . Notably, the proposed estimator significantly reduces MSE values compared to traditional unbiased estimators, especially when is in proximity to . Moreover, the performance of the proposed estimator, when based on Tippett’s, Wilkinson’s (, , and ), Fisher’s, and logit tests, surpasses that of , particularly in cases involving very small sample sizes. For substantial sample sizes, the effectiveness of the suggested estimator, deploying Inverse normal and modified F tests, appeared to demonstrate consistent and dependable performance, MSE discrepancy of less than compared to the MSE of the unbiased estimator. Consequently, we advocate for the adoption of the proposed estimator to enhance the accuracy of estimation. Nevertheless, no universally optimal estimator performs best across all scenarios. Consequently, it becomes crucial to select an appropriate estimator tailored to each specific scenario. The decision on which estimator to employ relies on the objectives of the research, making it challenging to devise a purely statistical strategy for selection. Our findings in this article suggest that through careful application to real meta-analyses, the proposed estimator exhibits promising potential.
This article primarily considered the scenario under the general preliminary test estimator whereby . Extensions of this work could explore cases where and through the introduction of a randomized test, where the probability function is treated as a shrinkage parameter. Consequently, the proposed estimator would transition to a non-randomized form [25]. Additionally, it’s pertinent to highlight that this study focuses on the univariate common mean of multiple normal populations. Future extensions could broaden the scope to encompass multiple responses, such as bivariate common mean.
Author Contributions
Conceptualization, P.M.M. and Y.G.K.; methodology, P.M.M. and Y.G.K.; software, P.M.M.; validation, P.M.M. and Y.G.K.; formal analysis, P.M.M.; investigation, P.M.M. and Y.G.K.; resources, P.M.M.; data curation, P.M.M.; writing—original draft preparation, P.M.M.; writing—review and editing, P.M.M., Y.G.K. and C.S.M.; visualization, P.M.M.; supervision, Y.G.K. and C.S.M.; project administration, Y.G.K. and C.S.M.; funding acquisition, Y.G.K. and C.S.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the University Staff Doctoral Programme (USDP) hosted by the University of Limpopo in collaboration with the University of Maryland Baltimore County. Again, the first author acknowledges the financial support from the Research and Innovation Department of the University of Fort Hare.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding author.
Acknowledgments
The authors extend their gratitude to Bimal Sinha of the University of Maryland in Baltimore County, USA, for his insightful guidance and support. Our heartfelt thanks go to three reviewers for their excellent comments, which helped us clarify several key points and enhance the quality of this paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wang, X.M.; Zhang, X.R.; Li, Z.H.; Zhong, W.F.; Yang, P.; Mao, C. A brief introduction of meta-analyses in clinical practice and research. J. Gene Med. 2021, 23, e3312. [Google Scholar] [CrossRef] [PubMed]
- Sinha, B.K.; Hartung, J.; Knapp, G. Statistical Meta-Analysis with Applications; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Haidich, A.B. Meta-analysis in medical research. Hippokratia 2010, 14, 29. [Google Scholar] [PubMed]
- Glass, G.V. Primary, secondary, and meta-analysis of research. Educ. Res. 1976, 5, 3–8. [Google Scholar] [CrossRef]
- DerSimonian, R.; Laird, N. Evaluating the effect of coaching on SAT scores: A meta-analysis. Harv. Educ. Rev. 1983, 53, 1–15. [Google Scholar] [CrossRef]
- Hedges, L.V. Advances in statistical methods for meta-analysis. New Dir. Program Eval. 1984, 24, 25–42. [Google Scholar] [CrossRef]
- Liu, Q.; Qin, C.; Liu, M.; Liu, J. Effectiveness and safety of SARS-CoV-2 vaccine in real-world studies: A systematic review and meta-analysis. Infect. Dis. Poverty 2021, 10, 132. [Google Scholar] [CrossRef]
- Watanabe, A.; Kani, R.; Iwagami, M.; Takagi, H.; Yasuhara, J.; Kuno, T. Assessment of efficacy and safety of mRNA COVID-19 vaccines in children aged 5 to 11 years: A systematic review and meta-analysis. JAMA Pediatr. 2023, 177, 384–394. [Google Scholar] [CrossRef]
- Meier, P. Variance of a weighted mean. Biometrics 1953, 9, 59–73. [Google Scholar] [CrossRef]
- Eberhardt, K.R.; Reeve, C.P.; Spiegelman, C.H. A minimax approach to combining means, with practical examples. Chemom. Intell. Lab. Syst. 1989, 5, 129–148. [Google Scholar] [CrossRef]
- Graybill, F.A.; Deal, R. Combining unbiased estimators. Biometrics 1959, 15, 543–550. [Google Scholar] [CrossRef]
- Kubokawa, T. Admissible minimax estimation of a common mean of two normal populations. Ann. Stat. 1987, 1245–1256. [Google Scholar] [CrossRef]
- Brown, L.D.; Cohen, A. Point and confidence estimation of a common mean and recovery of interblock information. Ann. Stat. 1974, 2, 963–976. [Google Scholar] [CrossRef]
- Cohen, A.; Sackrowitz, H.B. On estimating the common mean of two normal distributions. Ann. Stat. 1974, 1274–1282. [Google Scholar] [CrossRef]
- Moore, B.; Krishnamoorthy, K. Combining independent normal sample means by weighting with their standard errors. J. Stat. Comput. Simul. 1997, 58, 145–153. [Google Scholar] [CrossRef]
- Huang, H. Combining estimators in interlaboratory studies and meta-analyses. Res. Synth. Methods 2023, 14, 526–543. [Google Scholar] [CrossRef] [PubMed]
- Dong, Y.F.; Chen, W.X.; Xie, M.Y. Best linear unbiased estimators of location and scale ranked set parameters under moving extremes sampling design. Acta Math. Appl. Sin. Engl. Ser. 2023, 39, 222–231. [Google Scholar] [CrossRef]
- Khatun, H.; Tripathy, M.R.; Pal, N. Hypothesis testing and interval estimation for quantiles of two normal populations with a common mean. Commun. Stat.-Theory Methods 2022, 51, 5692–5713. [Google Scholar] [CrossRef]
- Marić, N.; Graybill, F.A. Evaluation of a method for setting confidence intervals on the common mean of two normal populations. Commun. Stat.-Simul. Comput. 1979, 8, 53–60. [Google Scholar] [CrossRef]
- Pagurova, V.I.; Gurskii, V. A confidence interval for the common mean of several normal distributions. Theory Probab. Appl. 1980, 24, 882–888. [Google Scholar] [CrossRef]
- Krishnamoorthy, K.; Moore, B.C. Combining information for prediction in linear regression. Metrika 2002, 56, 73–81. [Google Scholar] [CrossRef]
- Bancroft, T.A. On biases in estimation due to the use of preliminary tests of significance. Ann. Math. Stat. 1944, 15, 190–204. [Google Scholar] [CrossRef]
- Stein, C. Inadmissibility of the usual estimator for the mean of a multivariate normal distribution. In Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistic, 26–31 December 1954; University of California Press: Berkeley, CA, USA, 1956; Volume 3, pp. 197–207. [Google Scholar]
- Khan, S.; Saleh, A.M.E. On the comparison of the pre-test and shrinkage estimators for the univariate normal mean. Stat. Pap. 2001, 42, 451–473. [Google Scholar] [CrossRef]
- Shih, J.H.; Konno, Y.; Chang, Y.T.; Emura, T. A class of general pretest estimators for the univariate normal mean. Commun. Stat.-Theory Methods 2023, 52, 2538–2561. [Google Scholar] [CrossRef]
- Taketomi, N.; Konno, Y.; Chang, Y.T.; Emura, T. A meta-analysis for simultaneously estimating individual means with shrinkage, isotonic regression and pretests. Axioms 2021, 10, 267. [Google Scholar] [CrossRef]
- Thompson, J.R. Some shrinkage techniques for estimating the mean. J. Am. Stat. Assoc. 1968, 63, 113–122. [Google Scholar] [CrossRef]
- Mphekgwana, P.M.; Kifle, Y.G.; Marange, C.S. Shrinkage Testimator for the Common Mean of Several Univariate Normal Populations. Mathematics 2024, 12, 1095. [Google Scholar] [CrossRef]
- Pal, N.; Lin, J.J.; Chang, C.H.; Kumar, S. A revisit to the common mean problem: Comparing the maximum likelihood estimator with the Graybill–Deal estimator. Comput. Stat. Data Anal. 2007, 51, 5673–5681. [Google Scholar] [CrossRef]
- Khatri, C.; Shah, K. Estimation of location parameters from two linear models under normality. Commun. Stat.-Theory Methods 1974, 3, 647–663. [Google Scholar]
- Sinha, B.K. Unbiased estimation of the variance of the Graybill-Deal estimator of the common mean of several normal populations. Can. J. Stat. 1985, 13, 243–247. [Google Scholar] [CrossRef]
- Hartung, J. An alternative method for meta-analysis. Biom. J. J. Math. Methods Biosci. 1999, 41, 901–916. [Google Scholar] [CrossRef]
- Kifle, Y.G.; Moluh, A.M.; Sinha, B.K. Comparison of local powers of some exact tests for a common normal mean with unequal variances. In Methodology and Applications of Statistics; Springer: Berlin/Heidelberg, Germany, 2021; pp. 77–101. [Google Scholar]
- Kifle, Y.G.; Moluh, A.M.; Sinha, B.K. Inference about a Common Mean Vector from Several Independent Multinormal Populations with Unequal and Unknown Dispersion Matrices. Mathematics 2024, 12, 2723. [Google Scholar] [CrossRef]
- Cohen, A.; Sackrowitz, H. Exact tests that recover interblock information in balanced incomplete blocks designs. J. Am. Stat. Assoc. 1989, 84, 556–559. [Google Scholar] [CrossRef]
- Tippett, L.H.C. The Methods of Statistics: An Introduction Mainly for Workers in the Biological Sciences; Williams & Norgate: London, UK, 1931. [Google Scholar]
- Wilkinson, B. A statistical consideration in psychological research. Psychol. Bull. 1951, 48, 156. [Google Scholar] [CrossRef] [PubMed]
- Stouffer, S.A.; Suchman, E.A.; DeVinney, L.C.; Star, S.A.; Williams, R.M., Jr. The American Soldier: Adjustment during Army Life. (Studies in Social Psychology in World War ii); Princeton University Press: Princeton, NJ, USA, 1949; Volume 1. [Google Scholar]
- Fisher, R. Statistical Methods for Research Workers, 4th ed.; Oliver and Boyd: Edinburgh, Scotland; London, UK, 1932. [Google Scholar]
- George, E.O.; Mudholkar, G.S. The Logit Method for Combining Tests; Technical Report; Department of Statistics, Rochester University: Rochester, NY, USA, 1979. [Google Scholar]
- Fairweather, W.R. A method of obtaining an exact confidence interval for the common mean of several normal populations. J. R. Stat. Soc. Ser. (Appl. Stat.) 1972, 21, 229–233. [Google Scholar] [CrossRef]
- Jordan, S.M.; Krishnamoorthy, K. Exact confidence intervals for the common mean of several normal populations. Biometrics 1996, 52, 77–86. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Chang, C.H.; Pal, N. Testing on the common mean of several normal distributions. Comput. Stat. Data Anal. 2008, 53, 321–333. [Google Scholar] [CrossRef]
- Li, X.; Williamson, P.P. Testing on the common mean of normal distributions using Bayesian methods. J. Stat. Comput. Simul. 2014, 84, 1363–1380. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).