Abstract
In this paper, we present the unit-power half-normal distribution, derived from the power half-normal distribution, for data analysis in the open unit interval. The statistical properties of the unit-power half-normal model are described in detail. Simulation studies are carried out to evaluate the performance of the parameter estimators. Additionally, we implement the quantile regression for this model, which is applied to two real healthcare data sets. Our findings suggest that the unit power half-normal distribution provides a robust and flexible alternative for existing models for proportion data.
Keywords:
power half-normal distribution; proportion data; maximum likelihood estimation; regression model MSC:
60E05; 62E15; 62F10
1. Introduction
To study and interpret real events, new statistical models must continuously be built. In recent times, models limited to the interval have generated a lot of interest. This type of models is mainly used to study proportion data, such as survival rate data and product failure, among others. Different areas, such as health, actuarial and financial sciences, require this type of distributions. So, recently, several distributions with positive support have been transformed to distributions with unit support, such as the cases of Jones [1] in the Kumaraswamy distribution, Gómez-Déniz et al. [2] in the log-Lindley distribution, Mazucheli et al. [3], in the Lindley distribution, Abd El-Monsef et al. [4], who proposed a new two-parameter omega unitary distribution, Altun et al. [5], who studied a distribution called enhanced second-order Lindley distribution modeling data on the interval (0,1), and, recently, Ahmad et al. [6], who studied the exponential pareto distribution.
One of the distributions that is mainly used for this type of data is the Beta distribution. Interest in this type of model has been increasing, and many researchers have transformed known distributions with positive support into distributions with unitary support, an example of which can be found in articles such as Grassia [7], based on the Gamma distribution, Ghitany et al. [8], based on the Inverse Gamma distribution, Mazucheli et al. [9], based on the Birnbaum-Saunders distribution, Modi et al. [10], based on Burr distribution III, Korkmaz and Chesneau [11], based on Burr distribution XII, Haq et al. [12], based on the modified Burr III distribution, and, more recently, Bakouch et al. [13], based on half-normal distribution.
The aim of this paper is to introduce a new distribution with a bounded domain on (0,1). This distribution is originated by modifying the representation of the power half-normal (PHN) distribution proposed by Gómez et al. [14]. One of the motivations of this work is to generate alternatives to well-known distributions used in the statistical analysis of certain type of data. This work is based on the PHN distribution whose probability density function f (pdf), cumulative distribution function F (cdf), and quantile function Q are:
where the parameters are and . and denote the pdf and cdf of the standard normal distribution, respectively.
At present, this model continues to be studied. For example, Barrios et al. [15] performed an extension of the distribution using the slash process, resulting in a model with higher kurtosis, i.e., with heavier tails. In addition, Pallini [16] introduced a discretized model based on the PHN distribution. The interest in further investigating models with support on the interval (0,1) is of great importance, since in many areas, such as finance, actuarial sciences, engineering, and health, databases that belong to this type of interval are handled. To consider a new model with unit support based on the PHN model is a promising alternative for more accurate inferential studies.
The rest of the paper is organized as follows. In Section 2, we introduce our proposal, the unit-power half-normal (UPHN) distribution. Several important properties of this new model are presented. In Section 3, inference is performed, and maximum likelihood (ML) estimators are obtained. In Section 4, the reparametrized model in terms of a quantile is presented. In Section 5, a simulation study is carried out to analyse the performance of ML estimators in finite samples for the proposed model without and with covariates. In Section 6, two real data applications are presented, and we are again dealing with cases without and with covariates. Finally, in Section 7, some concluding comments are presented.
2. Unit Power Half-Normal Distribution
In this section, we will discuss the stochastic representation of the UPHN model, including its pdf, cdf, and some properties of the model.
2.1. Stochastic Representation
Definition 1.
A random variable X follows a distribution with parameters and if its stochastic representation is given by:
where . The notation will be used.
2.2. Pdf, Cdf, Survival, and Hazard Functions
Proposition 1.
Let . Then, the pdf of X is given by:
Proof.
By considering the stochastic representation given in (4), , we have that
Taking into account that , (5) follows. □
Proposition 2.
Let . Then, its cdf is given by:
Proof.
- If , then . Therefore, .
- It follows from the fact that for ,Making , we obtain the result.
- If , then:
□
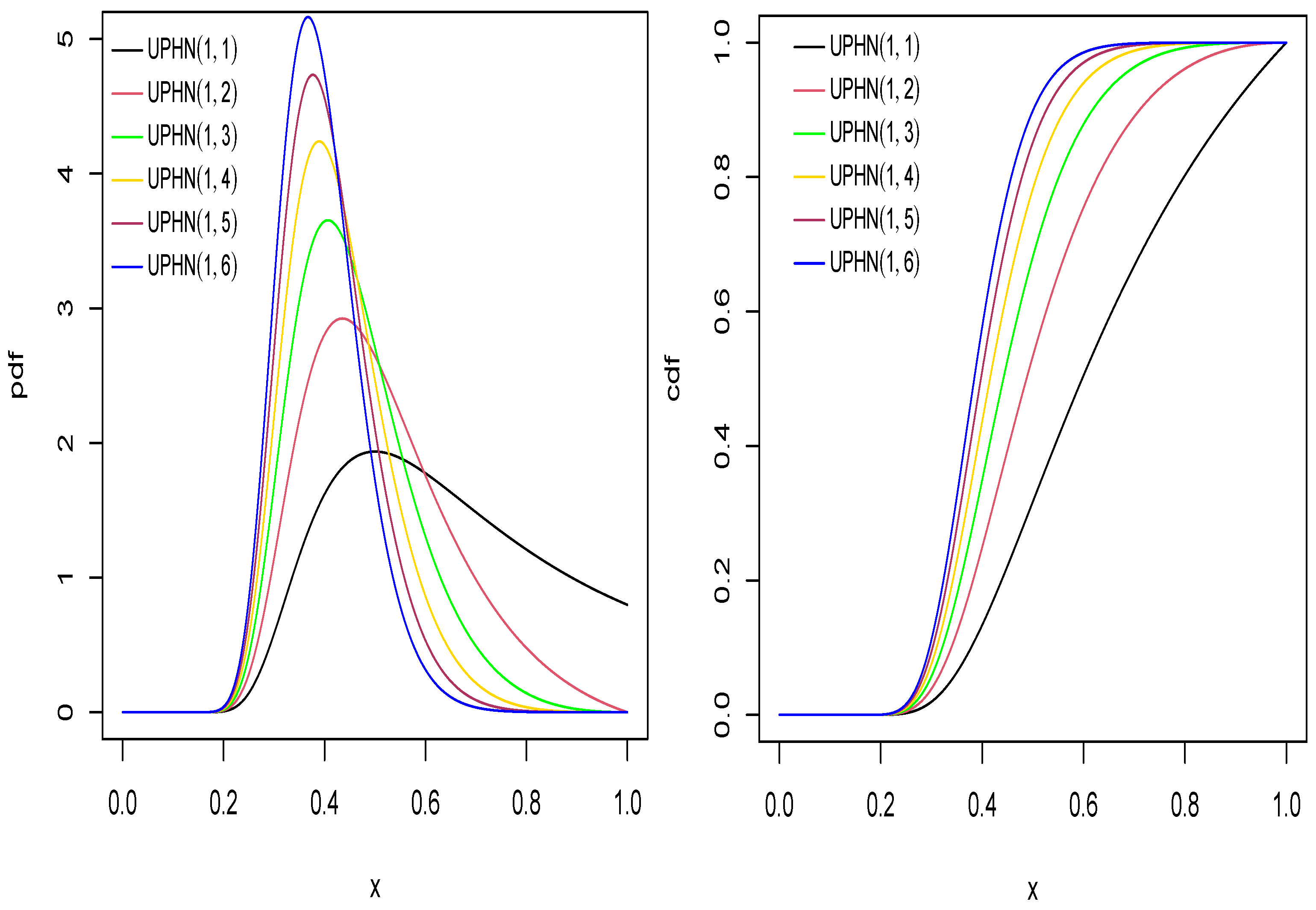
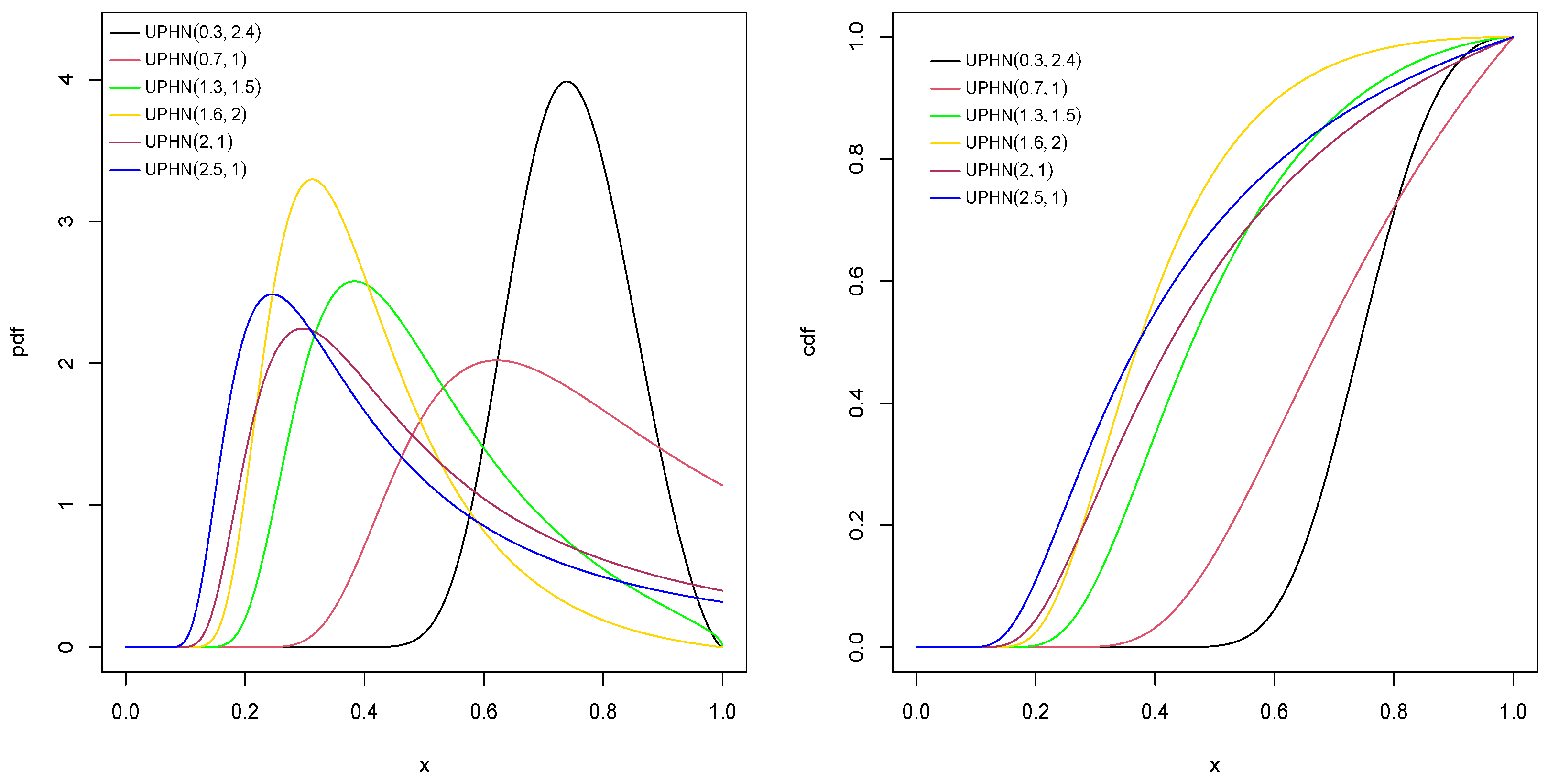
Figure 1 shows the pdf and cdf of the UPHN model of with different values for . Figure 2 shows the pdf and cdf of the UPHN model, for different values of .
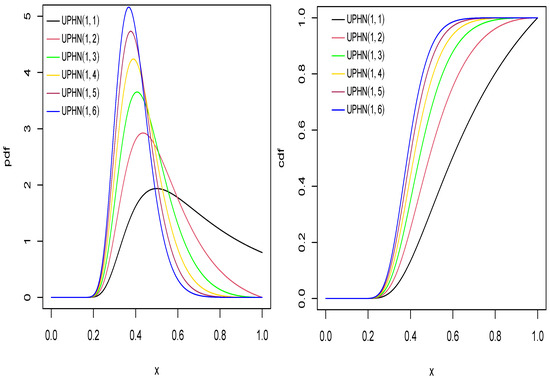
Figure 1.
Pdf and cdf for UPHN model with different values of .
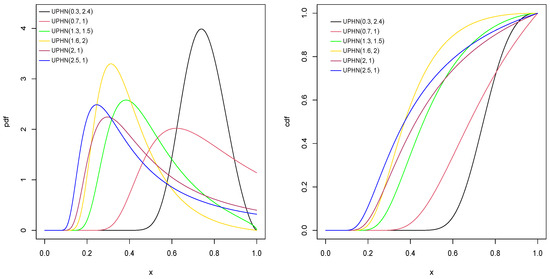
Figure 2.
Pdf and cdf for UPHN model for some values of parameters and .
Proposition 3.
Let . Then, the survival and hazard function of X are given by:
for .
Proof.
Both functions are immediately obtained from their definitions, since and . □
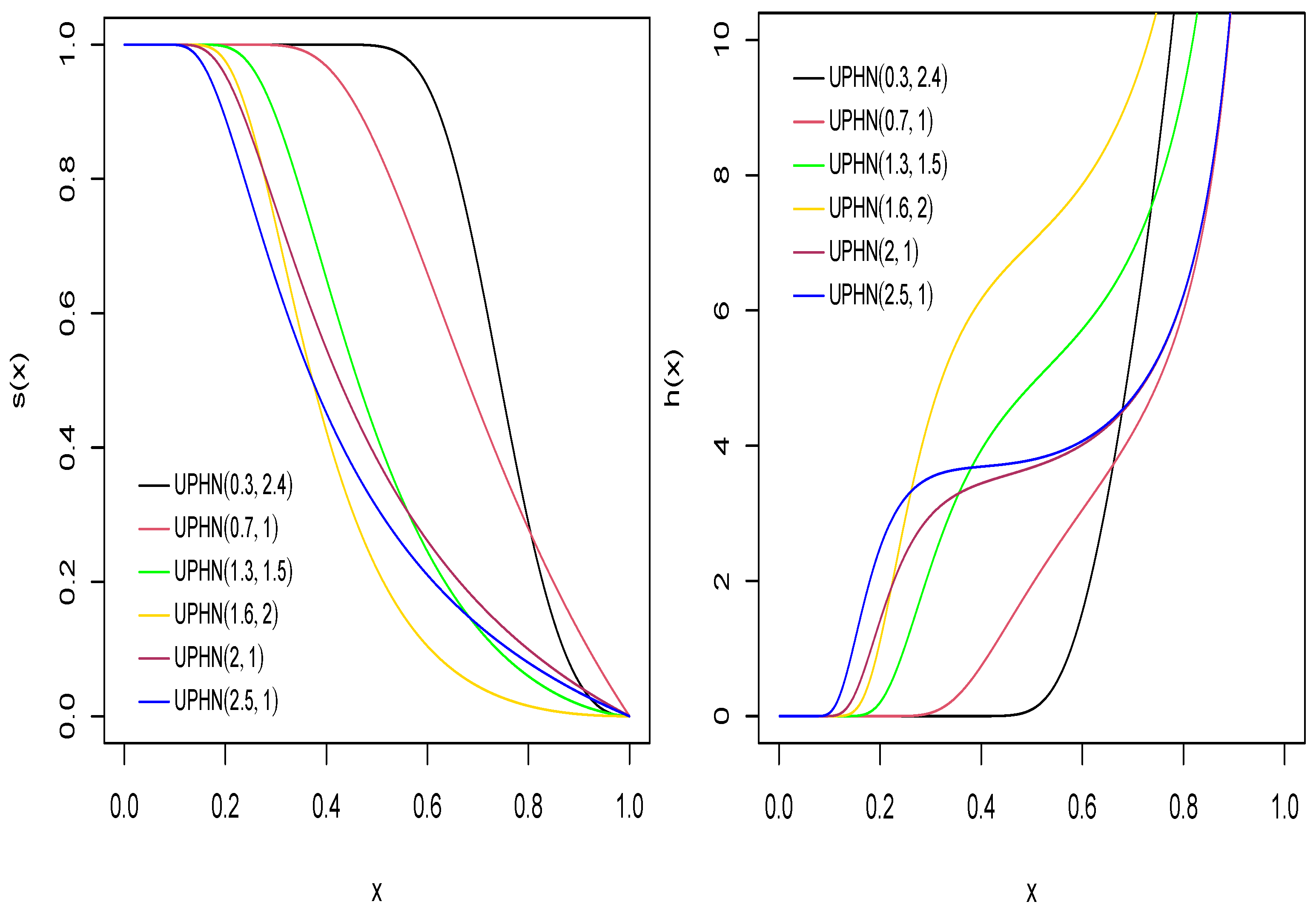
Figure 3 shows the survival and the hazard function for the UPHN model, considering several values of and . We highlight that the hazard function is increasing.
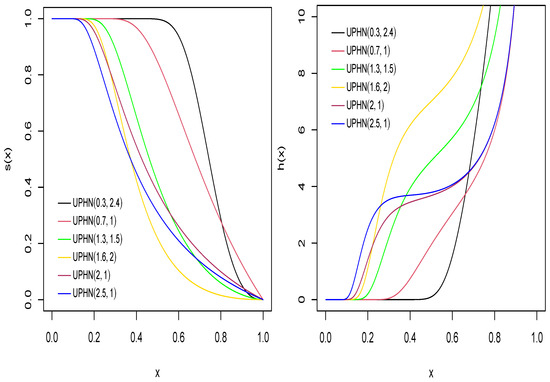
Figure 3.
Survival and hazard functions for model for some values of parameters and .
2.3. Moments
Proposition 4.
Let . Then, the n-th moment of X, where n is a positive integer, is given by:
where , are computed numerically.
Proof.
The moments are immediately obtained from their definition.
Making the change of variable , we have that:
and defining as the integral, the result is obtained. □
Corollary 1.
Let . Then, the skewness and kurtosis coefficients are
where .
Proof.
It is immediately obtained from the definition of these coefficients. □
Table 1 and Table 2 provide us and for several values of parameters and . We can observe that for low values of and , the skewness coefficient is negative and for high values, positive skewness is obtained. As for the kurtosis coefficient, the observed effect is more dispersed.

Table 1.
Skewness coefficient of model for different values of and .
Table 2.
Kurtosis coefficient of model for different values of and .
2.4. Incomplete Moments
The k-th incomplete moments of the UPHN distribution are given by:
This integral cannot be solved analytically. In particular, for , we have:
where and . , are computed numerically.
2.5. The Lorenz Curve and the Gini Index
The standard definition of the Lorenz curve [17] is provided in terms of the first incomplete moment and the expected value of X. Specifically, for the UPHN model, the following closed form expression is obtained
The Gini index, also known as the Gini coefficient (see [18,19]), is a statistical dispersion metric associated with the Lorenz curve, intended to represent income inequality, wealth inequality, or consumption inequality within a nation or social group. The Gini index is defined as:
Proposition 5.
Let . Then, the Gini index is given by:
Proof.
By definition, the proof is direct. □
Proposition 6.
Let ; the Renyi entropy of order δ for X is given by:
where and .
Proof.
The Renyi entropy is defined as . Therefore, we have:
Making the change of variable , the result is obtained. □
2.6. Shannon Entropy
The entropy of a random variable X is a measure of its uncertainty. The Shannon entropy measure is defined by:
If follows, after extensive algebraic manipulations, that the Shannon entropy for the UPHN model is:
where , , and with and as given above.
2.7. Quantiles
Proposition 7.
Let . Then, the quantile function is given by:
Proof.
It follows from a direct computation, by applying the definition of quantile function. □
Corollary 2.
The quartiles for the distribution are:
- 1.
- (First quartile) .
- 2.
- (Median) .
- 3.
- (Third quartile) .
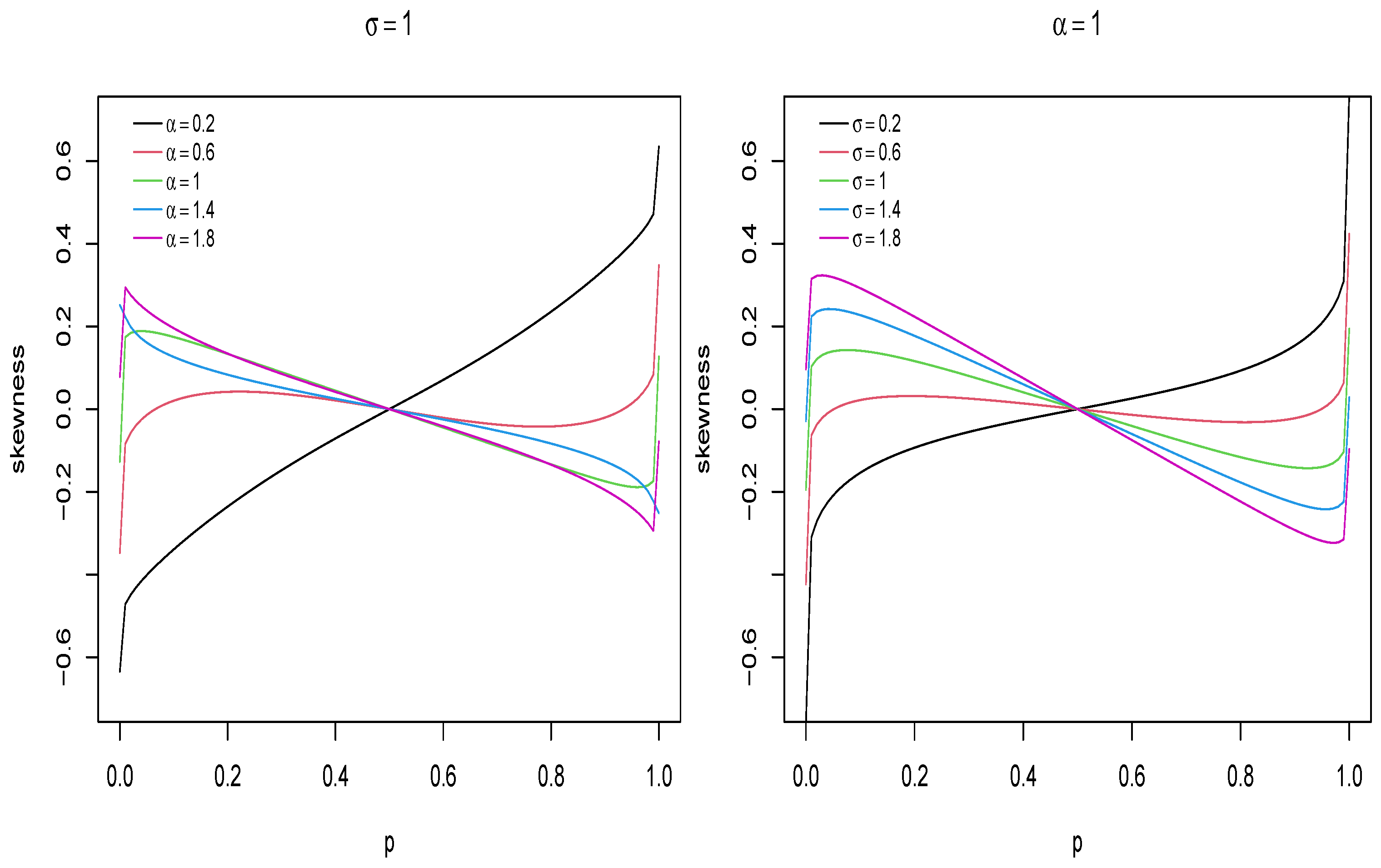
The quantile function can also be used to study the kurtosis and skewness in the UPHN model. A classical measurement for skewness was introduced by MacGillivray [20], which is given by:
In particular, the MacGuillevray skewness measurement can efficiently describe the effect of the parameters on asymmetry. In Figure 4, the behavior of the asymmetry coefficient is plotted with respect to the values of the parameters.
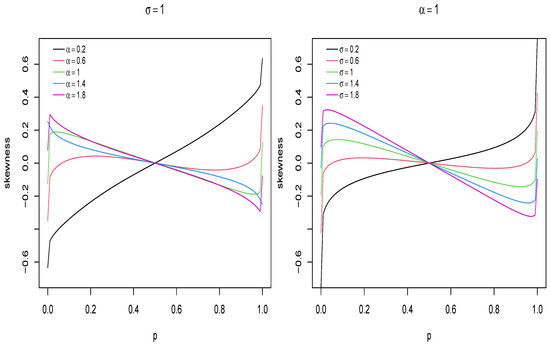
Figure 4.
Plots of the MacGillivray skewness coefficient in UPHN model.
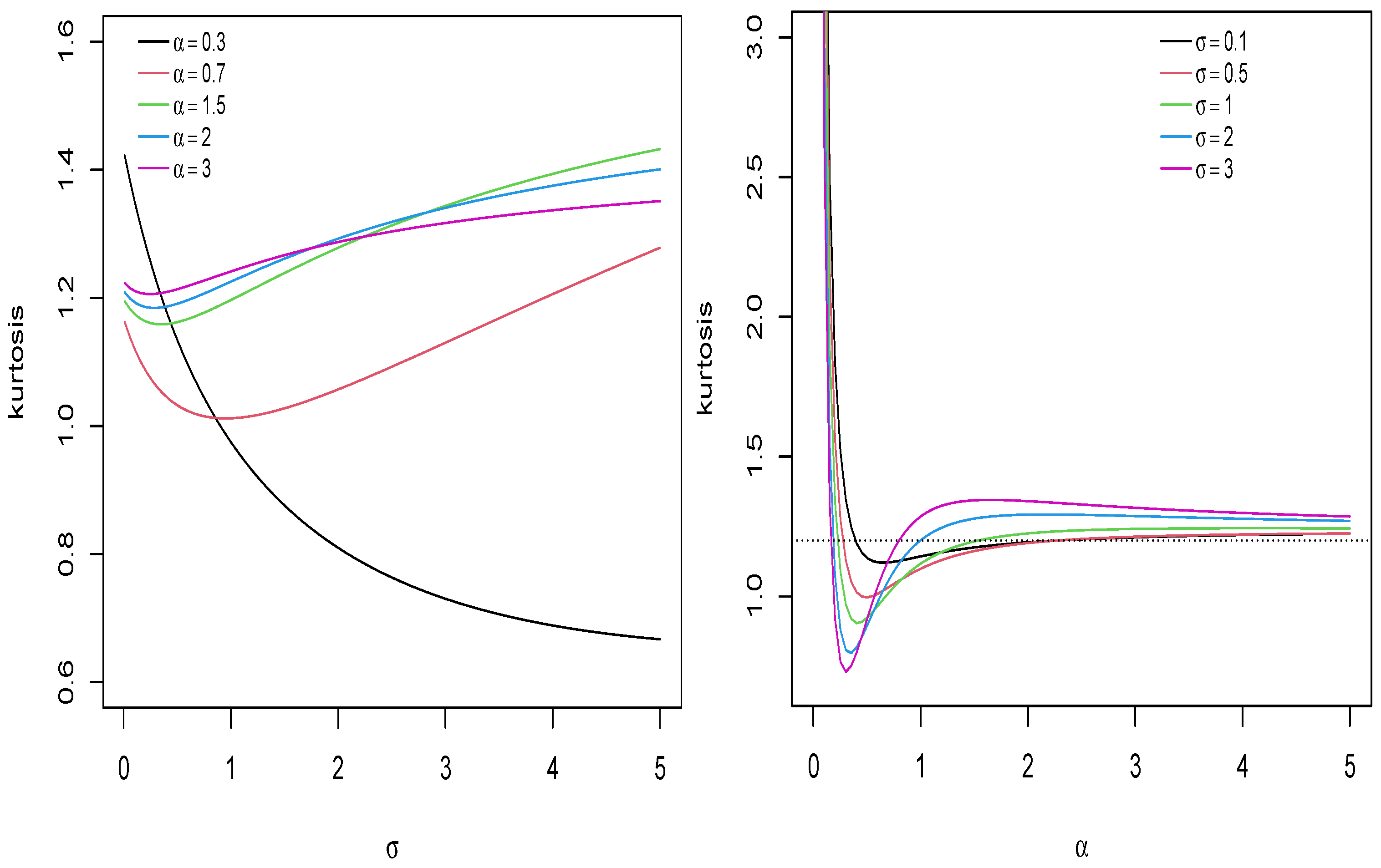
The kurtosis of the UPHN distribution can also be studied using the Moors kurtosis coefficient [21], usually given by:
It can be seen in [21] that for large values of (11), the distribution has heavy tails and for small values, the model has lighter tails. Figure 5 shows the behavior of the Moors kurtosis coefficient for the UPHN distribution.
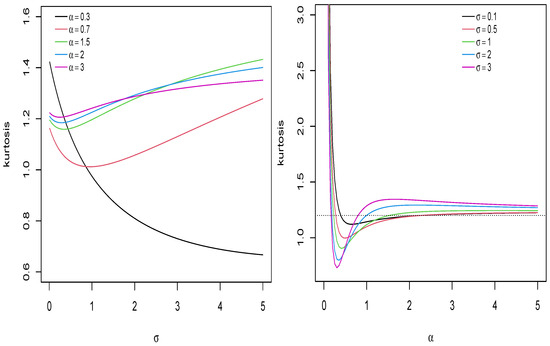
Figure 5.
Plots of the Moors kurtosis coefficient for the model.
2.8. Order Statistics
Order statistics have a wide range of applications in physical and life sciences (see, for instance, Balakrishnan and Cohen [22]). From a statistical perspective, they allow the computation of useful functions such as the sample range and the sample median. The following result states the pdf of k-th order statistic from a UPHN random sample of size n, which is arranged in a non-decreasing order.
Proposition 8.
Let be independent and identically distributed random variables. Then, the pdf of the k-th order statistic, , is given by:
Corollary 3.
Let be a random sample from a distribution. Then,
- 1.
- The pdf of the minimum, , is
- 2.
- The pdf of the maximum, , is
2.9. Bonferroni Curve
In various disciplines, such as socioeconomics and public health sciences, there is a need to compare and analyze inequality in distributions. Bonferroni curves are tools useful to reach this aim. It is worth mentioning that these curves have applications not only in economics to study income and poverty, but also in medicine or reliability. A detailed discussion can be seen in Bonferroni [23] or Arcagni and Porro [24]. The expressions of these curves for the UPHN model are presented below.
Proposition 9.
Let . Then, for the Bonferroni curve, say , is given by:
where .
Proof.
The expression above is obtained by using the definition of the Bonferroni curve, that is,
where is the expected value of the corresponding non-negative random variable and . □
3. Inference
In this section, the inference about the parameters in the UPHN distribution is carried out from a classical point of view. Let us consider a random sample of X∼. The maximum likelihood (ML) estimation method is discussed below. Given a random sample of size n from , the log-likelihood function is given by:
where . Therefore, the score assumes the form where:
The ML estimators (MLEs) can be obtained by solving the likelihood Equations (13) and (14). Numerical methods, such as the Newton–Raphson procedure, must be used. Alternative maximization techniques could also be applied, for instance, those proposed in MacDonald [25].
The asymptotic variance of the MLEs, say , can be estimated by the Fisher information matrix defined as , where is the log-likelihood function of the UPHN model given in (12). Recall that, under the regularity conditions,
where stands for convergence in distribution and denotes the standard bivariate normal distribution. The elements of the matrix are given by , and . Explicitly, we have:
In practice, it is not possible to obtain in a closed form the expected value of previous expressions. However, the covariance matrix of the MLEs, , can be estimated consistently by , where denotes the observed information matrix, which is obtained as
The asymptotic variances of and are estimated by the diagonal elements of , and their standard errors by the square root of asymptotic variances.
4. Quantile Regression
We now introduce a regression study, in which a quantile regression model is proposed to describe the conditional quantile of the response variable. Given the quantile function of the distribution, the pdf of the UPHN distribution can be reparameterized in terms of its quantile, denoted as .
Let . Then, the reparameterized pdf for the UPHN model is:
where , , , , and .
The cdf of the reparameterized UPHN distribution is:
4.1. Model Formulation
Let us suppose that is fixed and we have a random sample ∼, . Here, the parameters and are unknown. As a result, the suggested quantile regression model can be defined as:
where and act as the regression coefficient vector and the ith vector of covariate values, respectively. It is important to note that g is the link function that associates the covariates with the response variable. We can obtain a median quantile regression for a unit response variable when . Taking into account that the UPHN distribution is a probability model with support on , we use and define the logit-link function as:
4.2. ML Method for the Regression Coefficients
Now, our objective is to estimate the unknown parameters of the UPHN quantile regression model using the ML technique. For this purpose, the logit link function is considered:
From the above formula, the inverse link function is:
Let us now have a random sample with , and observed values . Then, using the pdf introduced in (15), the associated log-likelihood function is:
where denotes the unknown vector of parameters. The ML estimators of , denoted as is achieved by maximizing with respect to . The optim function of the R software, 4.3.1 version, [26] can be used to maximize .
4.3. Model Checking
Once we have fitted the model, it is crucial to assess whether the regression model is appropriate for the data. In this sense, the analysis of residuals is key to check or validate the fitted model. We focus on the Cox–Snell residuals (Cox and Snell 1968) [27], which are calculated for the observation as:
Here, stands for the estimated cdf of the UPHN distribution reparameterized in terms of quantiles. If the fitted model provides a good fit for the data, the residual will be an observation of a random variable from an exponential distribution with a scale parameter of one.
5. Simulation
In this section, a simulation study is carried out to evaluate the performance of the ML estimators. We used R software 4.3.1 version, for our calculations, developing customized code that integrates the optim function from R package stats [28].
5.1. Simulation 1
Next, an algorithm to generate samples from the is provided. Algorithm 1 is based on the inverse transformation method, where the inverse of the cdf is used.
| Algorithm 1 Simulating values from the distribution. |
|
As parameter values in our simulation, we consider and . For the sample size, we consider . For each sample size and every combination of , , we perform 1000 repetitions and the corresponding ML estimates are calculated. The results are given in Table 3. As summaries, we provide the estimated bias (bias) for the ML estimators of and , standard errors (SE), the root of the estimated mean square error (RMSE), and the empirical coverage probability (CP) for the asymptotic intervals based on MLEs to 95%. For the ML estimators of and , it should be noted that, as the sample size increases, the bias, SE, and RMSE decrease. It should also be noted that as the sample size increases, the SE and RMSE are closer, which suggests that the standard errors of the ML estimators are well estimated. As for the CPs, we highlight that they are close to the nominal level 0.95.
Table 3.
Estimated bias, SE, and RMSE for ML estimators in finite samples from the model.
5.2. Simulation 2
In this section, data are generated from the quantile regression model with sample sizes and quantile levels under two different scenarios. In the first scenario, three covariates are considered, that is,
where , , and , whereas in the second scenario, five covariates are proposed
where , , , , , , , and .
For fixed values of n and p, the response variable is generated as
where is an observation generated from a continuous uniform distribution on , that is, and is calculated as
For both scenarios, and fixed , Monte Carlo replicates were performed. Then, the empirical bias, RMSE, and CP are calculated by
respectively, where , , is the indicator function defined by
and is the estimated standard error of .
These summaries are provided in Table 4 and Table 5. In both settings, the good performance of our estimators is observed.
Table 4.
Empirical bias, RMSE, and for the true values , , , and with simulated data.
Table 5.
Empirical bias, RMSE, and for the true values , , , , , , and with simulated data.
6. Applications
In this section, the unit-power half-normal quantile regression model is applied to two real-world health data sets. The first one involves patient health outcomes and the second one examines survival rates under a specific treatment. We compare the results with those obtained from the Kumaraswamy (kum), the unit-Birnbaum–Saunders (ubs) [9], the unit-generalized half-normal-X (ughnx) [13], the unit-Gompertz (ugompertz) [29], and the unit-Weibull (uweibull) [30] quantile regression models.
We performed our calculations by using the R software. To fit the unit-power half-normal quantile regression model, we implemented our own code, combining existing functions available in R packages. For the Kumaraswamy, the unit-Birnbaum–Saunders, the unit-generalized half-normal-X, the unit-Gompertz, and the unit-Weibull quantile regression models, we used the R package unitquantreg [31]. The codes are available in a public GitHub repository (https://github.com/DarlinSoto/UPHN (accessed on 12 August 2024)).
6.1. Application 1: Body Fat Data Set
This data set was reported and studied in [32] and consists of 298 observations about the body fat percentage of individuals treated at a public hospital in Curitiba, Paraná, Brazil. The data set includes the variables: fat percentage of arms, legs, body, android, gynecoid, the body mass index (), age (years), gender (female or male), and level of physical activity (sedentary, insufficiently active, or active). The goal is to explore the functional relationship between the covariates gender, age, body mass index, and the level of physical activity, with the response variable body fat in arms. The assumed regression model for is
where
To explore the relationship between gender, age, body mass index, and the level of physical activity with the body fat in arms, the unit-power half-normal, the Kumaraswamy, the unit-generalized half-normal-X, the unit-Gompertz, and the unit-Weibull quantile regression models were fitted to the data and the fits were compared by using goodness-of-fit measurements. Table 6 presents the maximum likelihood estimates and their standard errors, Table 7 shows their p-values, and Table 8 shows the negative value of the log-likelihood, Akaike information criterion, Bayesian information criterion, and Hannan and Quinn information criterion given by
where n is the sample size, k is the number of parameters, and L is the likelihood function evaluated in the estimated parameters.
Table 6.
Maximum likelihood estimates and their standard errors for different distributions (uphn, kum, ughnx, ugompertz, and uweibull) in body fat data.
Table 7.
p-values of Wald test for , coefficients for different distributions (uphn, kum, ughnx, ugompertz, and uweibull) in body fat data.
Table 8.
Model selection criteria for different distributions (uphn, kum, ughnx, ugompertz, and uweibull) for body fat data.
According to the results presented in Table 6 and Table 7, and for all quantile levels p, the unit-power half-normal, the unit-generalized half-normal-X, the unit-Gompertz, and the unit-Weibull quantile regression models show that all covariates are statistically significant at the 0.05 level. On the other hand, the Kumaraswamy quantile regression model shows that all variables are significant except for the IPAQ_suffactive variable. Upon analyzing the signs of , we observe that an increase in covariates such as Age and BodyMassIndex corresponds to an increase in arm fat percentage. Moreover, males exhibit lower arm fat percentages than females, and individuals with a sedentary lifestyle demonstrate an increase in arm fat percentages compared to those with insufficiently active or active lifestyles.
Based on the results given in Table 8, the unit-power half-normal quantile regression model consistently shows higher log-likelihood values across all quantile levels p compared to the Kumaraswamy, the unit-generalized half-normal-X, the unit-Gompertz, and the unit-Weibull quantile regression models. Consequently, all goodness-of-fit measurements indicate that the unit-power half-normal quantile regression model provides the best fit to these data, while the unit-Gompertz model provides the worst one.
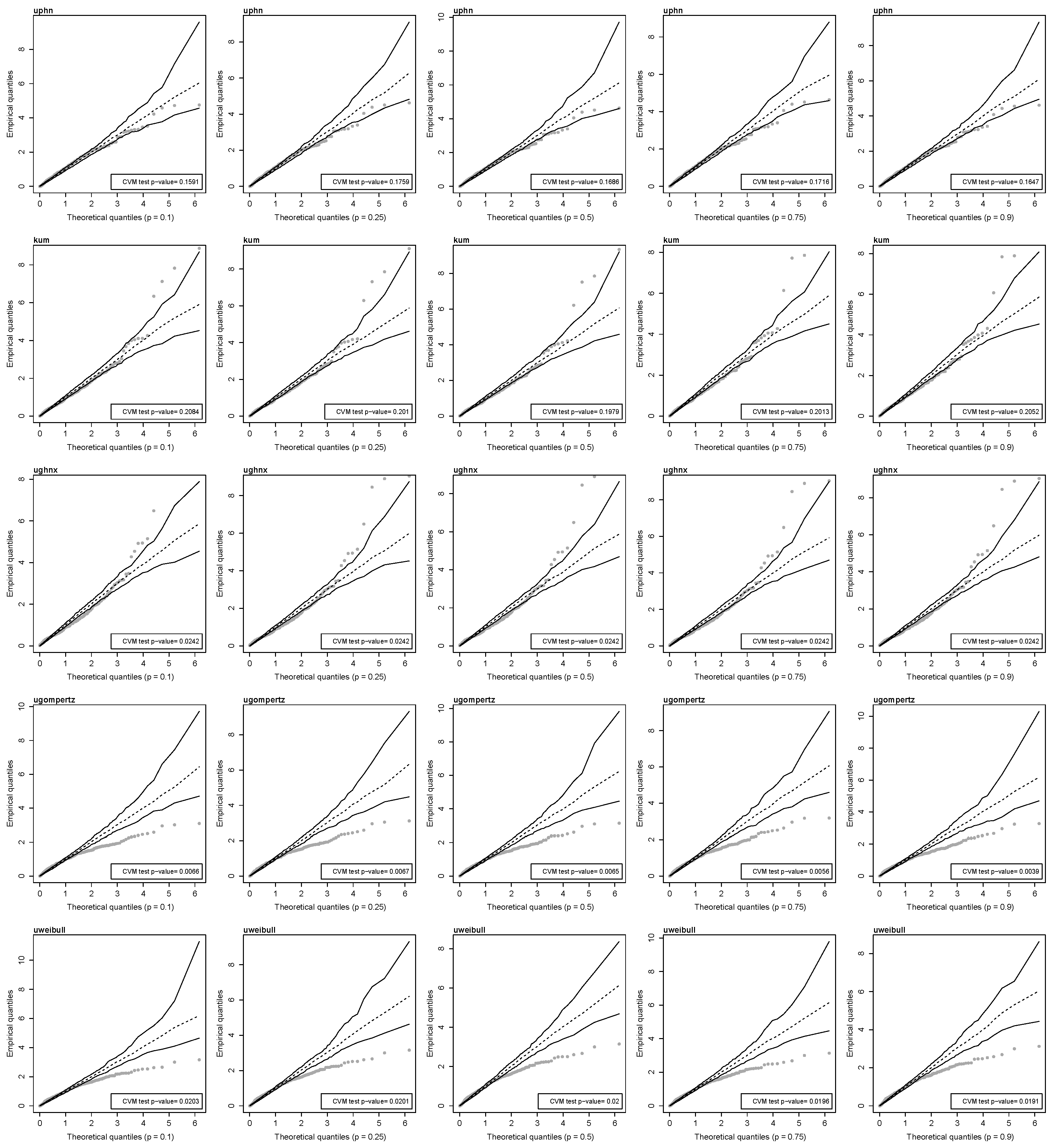
To validate these inferences, we conducted a diagnostic analysis for the fitted models. The Cox–Snell quantile residuals are considered, QQ plots are carried out by using their simulated envelopes. The Cramér–von Mises test is applied, where the null hypothesis is that the residuals come from an exponential distribution with a scale parameter of one. These plots are given in Figure 6. This figure suggests that the unit-power half-normal and Kumaraswamy quantile regression models provide a more substantial agreement with the data set compared to the unit-generalized half-normal-X, unit-Gompertz, and unit-Weibull quantile regression models, mainly because most of the residuals envelopes fail to cover the grey points, and the null hypothesis that the residuals come from an exponential distribution is rejected at the 5% significance level.
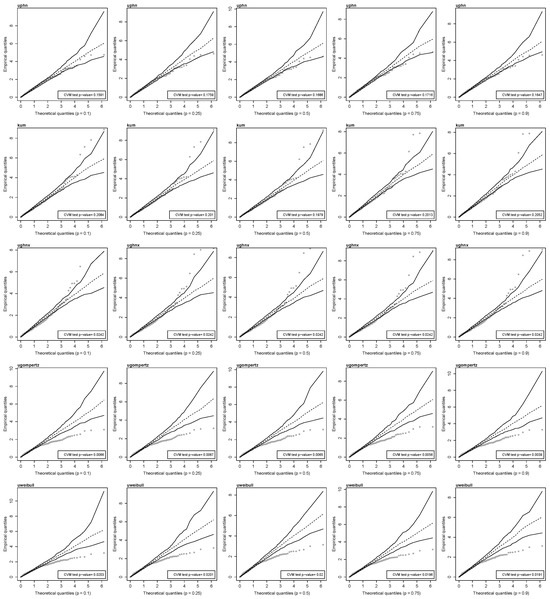
Figure 6.
QQ plots with envelopes of Cox–Snell residuals for the indicated 100 p-th quantile level and Cramér-von Mises test p-value for residuals obtained from different distributions (uphn, kum, ughnx, ugompertz, and uweibull) with body fat data.
Therefore, the unit-power half-normal quantile regression model provides the best fit for the data, as it consistently shows the minimum goodness-of-fit measures, with all coefficients being statistically significant. The model’s assumptions are validated through diagnostic analyses, which confirm its reliability to describe the relationships between the covariates and arm fat percentage.
6.2. Application 2: Autologous Stem Cell Transplants Data Set
We consider another application linked to autologous peripheral blood stem cell (PBSC) transplants, which have been extensively utilized to accelerate hematologic recovery after myeloablative therapy for diverse malignant hematological disorders. The data set comprises a study involving 239 patients who agreed to undergo autologous PBSC transplant following myeloablative chemotherapy doses between 2003 and 2008 at the Edmonton Hematopoietic Stem Cell Lab within the Cross Cancer Institute of Alberta Health Services. This data set has been studied in [33] and contains information about the patients’ age, gender, and clinical characteristics. We aim to explain the response variable recovery rates for viable CD34+ cells (rcd) in terms of age, gender, and chemotherapy. The regression model assumed for is given by
where
We examined the relationship between gender, age, chemotherapy, and the recovery rate for viable CD34+ cells by fitting the unit-power half-normal, the Kumaraswamy, the unit-generalized half-normal-X, the unit-Gompertz, and the unit-Birnbaum–Saunders quantile regression models, and evaluated the fits using goodness-of-fit measures.
Table 9 and Table 10 present the maximum likelihood estimates, their standard errors, and their p-values. For the unit-power half-normal and the unit-Gompertz quantile regression models, all quantile levels show statistically significant regression coefficients for the variables age and chemo at the 5% level. On the other hand, for the unit-generalized half-normal-X and the unit-Birnbaum–Saunders quantile regression models, the variable chemo is the only one statistically significant at the 5% level, while for the Kumaraswamy quantile regression, none of the three variables is statistically significant at the 5% level. Thus, based on the unit-power half-normal and the unit-Gompertz quantile regressions, we may conclude that the covariates Age and Chemo significantly affect the response variable recovery rate for viable CD34+ cells. Specifically, as Age increases, the recovery rate for viable CD34+ cells also increases. Additionally, patients receiving chemotherapy on a three-day protocol exhibit a higher recovery rate for viable CD34+ cells than those on a one-day protocol.
Table 9.
Maximum likelihood estimates with their standard errors across different distributions (uphn, kum, ughnx, ugompertz, and ubs) with PBSC data.
Table 10.
p-values of Wald test for coefficients , across different distributions (uphn, kum, ughnx, ugompertz, and ubs) for PBSC data.
Table 11 displays the model selection criteria for the unit-power half-normal, the Kumaraswamy, the unit-generalized half-normal-X, the unit-Gompertz, and the unit-Birnbaum–Saunders quantile regressions. From this table, it can be said that the log-likelihood values of the unit-power half-normal quantile regression surpass those of the Kumaraswamy, the unit-generalized half-normal-X, the unit-Gompertz, and the unit-Birnbaum–Saunders quantile regressions. Therefore, based on these criteria, we may conclude that the unit-power half-normal model has a superior performance.
Table 11.
Model selection criteria for different distributions (uphn, kum, ughnx, ugompertz, and ubs) for PBSC data.
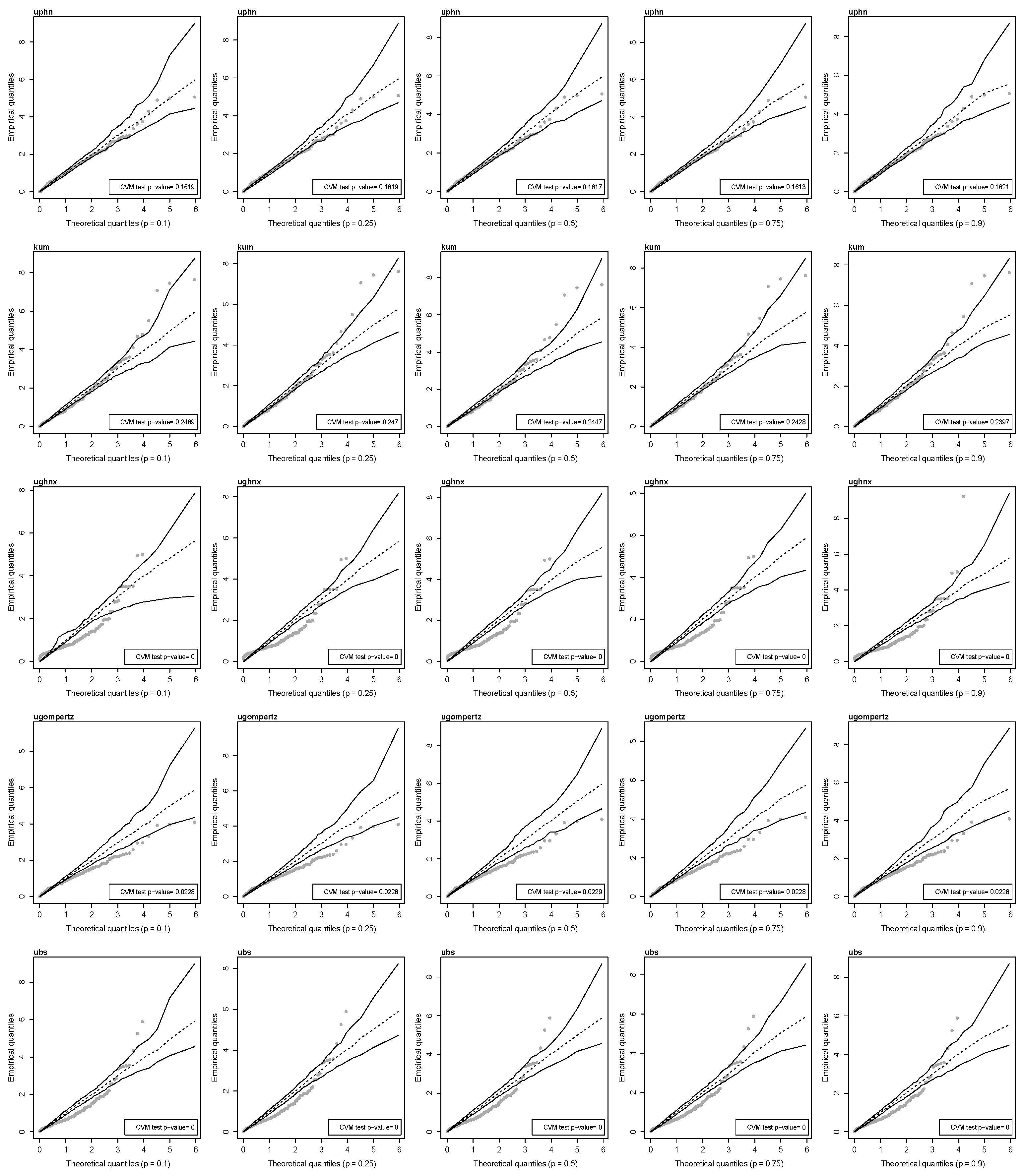
Finally, Figure 7 displays the QQ plots of the Cox–Snell quantile residuals and the p-value of the Cramér–von Mises test for the null hypothesis that the residuals come from an exponential distribution with a scale parameter of one. This figure indicates that most of the Cox–Snell quantile residuals obtained from the unit-power half-normal and the Kumaraswamy quantile regressions are inside the simulated envelopes. However, this is not the case for the Cox–Snell quantile residuals obtained from the unit-generalized half-normal-X, the unit-Gompertz, and the unit-Birnbaum–Saunders quantile regressions. These facts suggest that the assumption about Cox–Snell quantile residuals may not be right in those cases. This is validated by the p-value of the Cramér–von Mises test, where for the unit-generalized half-normal, the unit-Gompertz, and the unit-Birnbaum–Saunders quantile regressions, the p-value is less than 0.05, rejecting the null hypothesis that residuals come from an exponential distribution.
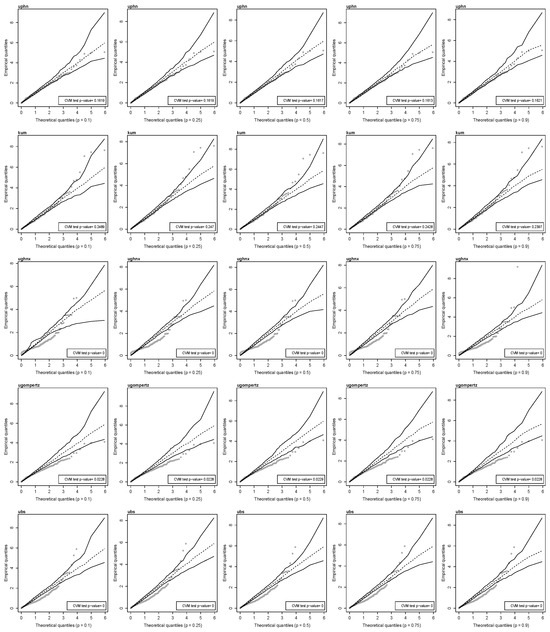
Figure 7.
QQ plots with envelopes of Cox–Snell residuals for the proposed 100 p-th quantile level and Cramér–von Mises test p-value for residuals obtained from different distributions (uphn, kum, ughnx, ugompertz, and uweibull) with PBSC data.
Therefore, the unit-power half-normal quantile regression model is the best fit for the autologous stem cell transplants data. It consistently shows higher log-likelihood values and better model selection criteria compared to the other models. The significant coefficients for age and chemotherapy at the 5% level highlight their strong association with recovery rates for viable CD34+ cells. Furthermore, diagnostic analyses, including QQ plots and the Cramér–von Mises test, validate the model’s assumptions, confirming its superior performance.
7. Conclusions
In this paper, we have put forth a new quantile regression model. The predictor covariates were linked to the quantile of the dependent variable through the logit link function. We examined various aspects such as estimation, inference relying on the maximum likelihood method, and diagnoses via the quantile residual. We evaluated two real data sets drawn from medical data using our proposed quantile regression model and the previously introduced Kumaraswamy quantile regression models. The outcomes showed that our proposed quantile regression fitted well to the two real-world data sets. In the first one, the covariates age, body mass index, gender, and level of physical activity are statistically significant to evaluate the level of physical activity with the body fat in arms. For the second data set, the covariates age and chemo are statistically significant to explain the response variable recovery rates for viable CD34+ cells (rcd), using our proposed quantile regression model as an alternative to other rival models outlined in the related literature. We carried out a comparison based on different information criteria and the model’s goodness of fit, showing its suitability.
Author Contributions
Conceptualization, K.I.S. and Y.M.G.; software, D.S.; formal analysis, K.I.S., Y.M.G. and I.B.-C.; investigation, K.I.S., Y.M.G. and I.B.-C.; writing—original draft preparation, K.I.S., Y.M.G., D.S. and I.B.-C.; writing—review and editing, K.I.S., Y.M.G., D.S., I.B.-C. and D.S.; supervision, Y.M.G. and I.B.-C.; funding acquisition, Y.M.G. and I.B.-C. All authors have read and agreed to the published version of the manuscript.
Funding
The research of I. Barranco-Chamorro was supported by the IOAP of the University of Seville, Spain.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data sets are available in the references given in Section 6.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Jones, M.C. Kumaraswamy’s Distribution: A Beta-Type Distribution with Some Tractability Advantages. Stat. Methodol. 2009, 6, 70–81. [Google Scholar] [CrossRef]
- Gómez-Déniz, E.; Sordo, M.A.; Calderín-Ojeda, E. The Log-Lindley distribution as an alternative to the beta regression model with applications in insurance. Insur. Math. Econ. 2014, 54, 49–57. [Google Scholar] [CrossRef]
- Mazucheli, J.; Bapat, S.R.; Menezes, A.F.B. A new one-parameter unit Lindley distribution. Chil. J. Stat. 2019, 1, 53–67. [Google Scholar]
- Abd El-Monsef, M.M.E.; El-Awady, M.M.; Seyam, M.M. A new quantile regression model for modelling child mortality. Int. J. Biomath. 2022, 10, 142–149. [Google Scholar]
- Altun, E.; Cordeiro, G.M. The unit-improved second-degree Lindley distribution: Inference and regression modelling. Comput. Stat. 2020, 35, 259–279. [Google Scholar] [CrossRef]
- Ahmad, H.H.; Almetwally, E.M.; Elgarhy, M.; Ramadan, D.A. On Unit Exponential Pareto Distribution for Modeling the Recovery Rate of COVID-19. Processes 2023, 11, 232. [Google Scholar] [CrossRef]
- Grassia, A. On a Family of Distributions with Argument between 0 and 1 Obtained by Transformation of the Gamma Distribution and Derived Compound Distributions. J. Stat. 1977, 19, 108–114. [Google Scholar] [CrossRef]
- Ghitany, M.; Mazucheli, J.; Menezes, A.; Alqallaf, F. The unit-inverse Gaussian distribution: A new alternative to two-parameter distributions on the unit interval. Commun. Stat. Theory Methods 2018, 48, 3423–3438. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.B.; Dey, S. The unit-Birnbaum-Saunders distribution with applications. Chil. J. Stat. 1977, 1, 47–57. [Google Scholar]
- Modi, K.; Gill, V. Unit Burr III distribution with application. J. Stat. Manag. Syst. 2019, 23, 579–592. [Google Scholar] [CrossRef]
- Korkmaz, M.; Chesneau, C. On the unit Burr-XII distribution with the quantile regression modeling and applications. Comput. Appl. Math. 2021, 40, 29. [Google Scholar] [CrossRef]
- Haq, M.; Hashmi, S.; Aidi, K.; Ramos, P.F.L. Unit Modified Burr-III Distribution: Estimation, Characterizations and Validation Test. Ann. Data Sci. 2023, 10, 415–449. [Google Scholar] [CrossRef]
- Bakouch, H.S.; Nikb, A.S.; Asgharzadehb, A.; Salinas, H.S. A flexible probability model for proportion data: Unit-half-normal distribution. Commun. Stat. Case Stud. Data Anal. 2021, 7, 271–288. [Google Scholar] [CrossRef]
- Gómez, Y.M.; Bolfarine, H. Likelihood-based inference for the power half-normal distribution. J. Stat. Theory Appl. 2015, 14, 383–398. [Google Scholar] [CrossRef]
- Barrios, L.; Gómez, Y.M.; Venegas, O.; Barranco-Chamorro, I.; Gómez, H.W. The Slashed Power Half-Normal Distribution with Applications. Mathematics 2022, 10, 1528. [Google Scholar] [CrossRef]
- Pallini, A. The discrete Powe Half-Normal Distribution. Statistica 2022, 82, 229–242. [Google Scholar]
- Lorenz, M.O. Methods of measuring the concentration of wealth. J. Am. Stat. Assoc. 1905, 9, 209–219. [Google Scholar] [CrossRef]
- Gini, C. On the measurement of concentration and variability of characters. Metron 2005, 1, 1–38. [Google Scholar]
- Gini, C. Measurement of inequality of incomes. Econ. J. 1921, 31, 124–126. [Google Scholar] [CrossRef]
- MacGillivray, H.L. Skewness and Asymmetry: Measures and Orderings. Ann. Stat. 1986, 14, 994–1011. [Google Scholar] [CrossRef]
- Moors, J.J. A quantile alternative for kurtosis. J. R. Stat. Soc. Ser. D 1988, 37, 25–32. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Cohen, C.A. Order Statistics and Inference: Estimation Methods; Statistical Modeling and Decision Science; Elsevier Science: Amsterdam, The Netherlands, 1991. [Google Scholar]
- Bonferroni, C.E. Elementi di Statistica Generale; Libreria Seber: Firenze, Italy, 1930. [Google Scholar]
- Arcagni, A.; Porro, F. The Graphical Representation of Inequality. Rev. Colomb. Estad. 2014, 37, 419–436. [Google Scholar] [CrossRef]
- MacDonald, I.L. Does Newton-Raphson really fail? Stat. Methods Med Res. 2014, 23, 308–311. [Google Scholar] [CrossRef] [PubMed]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2024; Available online: https://www.R-project.org/ (accessed on 31 July 2024).
- Cox, D.R.; Snell, E.J. A general definition of residuals. J. Royal Stat. Soc. Ser. B 1968, 30, 248–265. [Google Scholar] [CrossRef]
- Bolar, K. STAT: Interactive Document for Working with Basic Statistical Analysis. 2019. Available online: https://cran.r-project.org/web/packages/STAT/index.html (accessed on 1 April 2024).
- Mazucheli, J.; Menezes, A.F.; Dey, S. Unit-Gompertz Distribution with Applications. Statistica 2019, 79, 25–43. [Google Scholar]
- Mazucheli, J.; Menezes, A.F.B.; Alqallaf, F.; Ghitany, M.E. Bias-Corrected Maximum Likelihood Estimators of the Parameters of the Unit-Weibull Distribution. Austrian J. Stat. 2021, 50, 41–53. [Google Scholar]
- Menezes, A.F.B. unitquantreg: Parametric Quantile Regression Models for Bounded Data. 2023. Available online: https://cran.r-project.org/web/packages/unitquantreg/index.html (accessed on 15 April 2024).
- Petterle, R.; Bonat, W.; Scarpin, C.; Jonasson, T.; Borba, V. Multivariate quasi-beta regression models for continuous bounded data. Int. J. Biostat. 2021, 17, 39–53. [Google Scholar] [CrossRef]
- Yang, H.; Acker, J.P.; Cabuhat, M.; Letcher, B.; Larratt, L.; McGann, L.E. Association of post-thaw viable CD34+ cells and CFU-GM with time to hematopoietic engraftment. Bone Marrow Transplant. 2005, 35, 881–887. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).