
Hyper-Heuristic Approach for Tuning Parameter Adaptation in Differential Evolution



Abstract
1. Introduction
- Setting the lower and upper border for the Taylor series when tuning the curve parameters for success rate-based scaling factor sampling improves flexibility and allows for finding a simpler dependence;
- The number of degrees of freedom, found by the proposed approach, places the Student’s distribution between the usually applied normal and Cauchy distributions;
- The DE algorithm applied instead of the EGO algorithm on the upper level is capable of finding efficient solutions, despite the problem complexity and dimension;
- The Friedman ranking procedure, used instead of the total standard score for heuristics comparison during a search, is a good alternative with comparable performance and does not require any baseline results;
- The designed heuristic for scaling factor adaptation is simple and can be efficiently applied to many other DE variants.
2. Background
2.1. Differential Evolution
2.2. Parameter Adaptation in Differential Evolution
2.3. L-NTADE Algorithm
2.4. Hyper-Heuristic Approach
3. Related Work
4. Proposed Approach
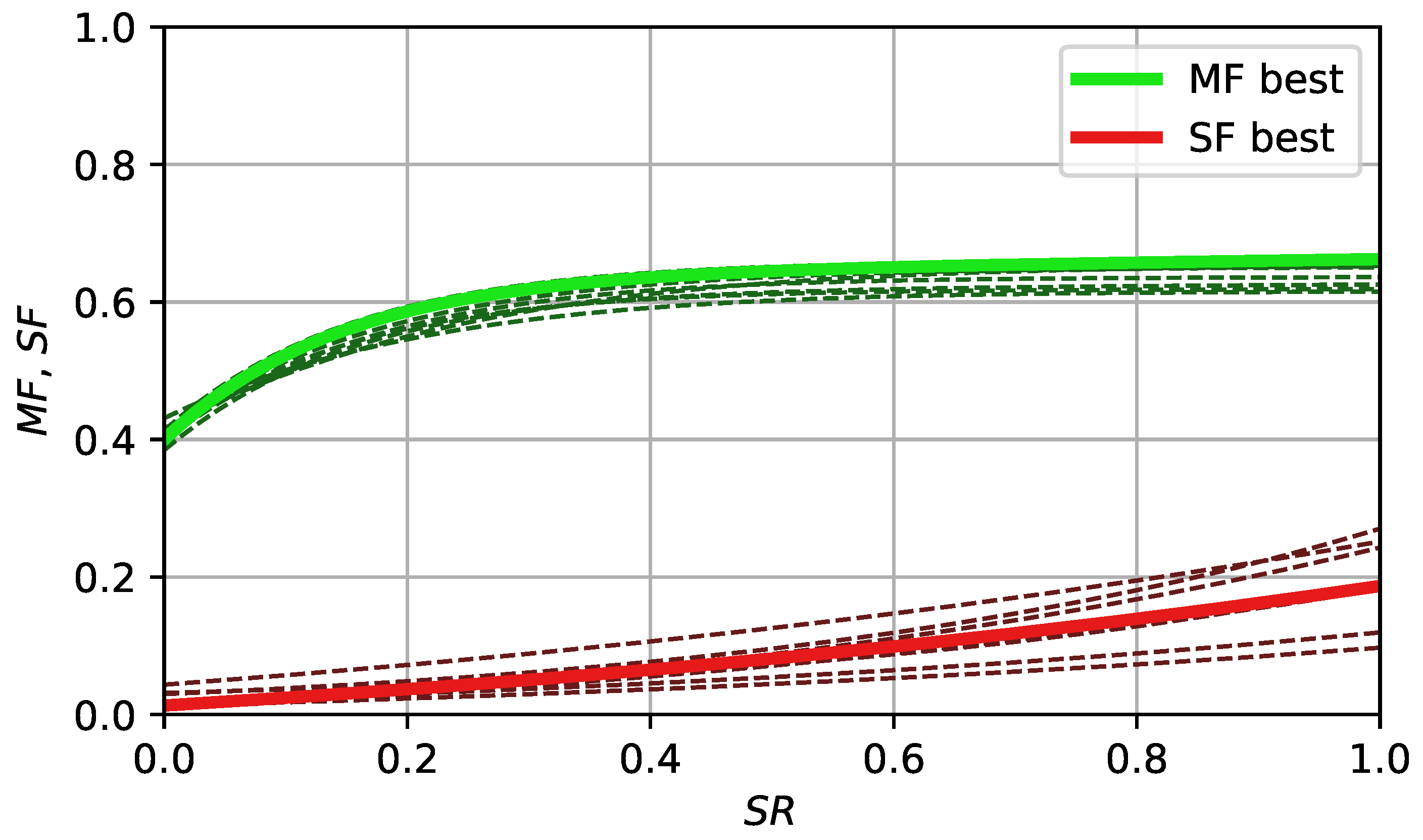
4.1. Scaling Factor Sampling
4.2. Evaluating Designed Heuristics
- Initialize the population of 29-dimensional vectors randomly, with N individuals.
- Pass the parameters c to the L-NTADE algorithm and run it for every set of coefficients.
- Collect a set of results, i.e., a tensor with dimensions .
- Rank the solutions using Friedman ranking; for this, perform independent ranking for every function and sum the ranks.
- Begin the main loop of DE and use ranks as fitness values; store N new solutions in the trial population .
- Evaluate new individuals in by running the L-NTADE algorithms with the corresponding tuning parameters.
- Join together the results of the current population and and apply Friedman ranking again to the tensor of size .
- If the rank of the trial individual with index i is better than the rank of the target individual, then perform the replacement.
5. Experimental Setup and Results
5.1. Benchmark Functions and Parameters
5.2. Numerical Results
6. Discussion
- Proposing more flexible methods to control the random distribution of F values and tuning them;
- Reducing the found heuristic to a set of simple rules and equations without many parameters of Taylor series;
- Applying the new heuristic to other DE-based algorithms and replacing the success history adaptation;
- Determining the dependence of the parameter on some of the values present in the DE algorithm.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| GA | Genetic Algorithms |
| GP | Genetic Programming |
| EC | Evolutionary Computation |
| DE | Differential Evolution |
| EGO | Efficient Global Optimization |
| CEC | Congress on Evolutionary Computation |
| SHADE | Success History Adaptive Differential Evolution |
| LPSR | Linear Population Size Reduction |
| LBC | Linear Bias Change |
| RSP | Rank-based Selective Pressure |
| HHF | Hyper-Heuristic Generation of Scaling Factor F |
| L-NTADE | Linear Population Size Reduction–Newest and Top Adaptive Differential Evolution |
References
- Eshelman, L.J.; Schaffer, J.D. Real-Coded Genetic Algorithms and Interval-Schemata. In Foundations of Genetic Algorithms; Elsevier: Amsterdam, The Netherlands, 1992. [Google Scholar]
- Deb, K.; Agrawal, R.B. Simulated Binary Crossover for Continuous Search Space. Complex Syst. 1995, 9, 115–148. [Google Scholar]
- Poli, R.; Kennedy, J.; Blackwell, T.M. Particle swarm optimization. Swarm Intell. 1995, 1, 33–57. [Google Scholar]
- Storn, R.; Price, K. Differential evolution – a simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Feoktistov, V. Differential Evolution in Search of Solutions; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Das, S.; Suganthan, P. Differential evolution: A survey of the state-of-the-art. IEEE Trans. Evol. Comput. 2011, 15, 4–31. [Google Scholar] [CrossRef]
- Das, S.; Mullick, S.; Suganthan, P. Recent advances in differential evolution—An updated survey. Swarm Evol. Comput. 2016, 27, 1–30. [Google Scholar] [CrossRef]
- Al-Dabbagh, R.D.; Neri, F.; Idris, N.; Baba, M.S.B. Algorithmic design issues in adaptive differential evolution schemes: Review and taxonomy. Swarm Evol. Comput. 2018, 43, 284–311. [Google Scholar]
- Tanabe, R.; Fukunaga, A. Success-history based parameter adaptation for differential evolution. In Proceedings of the IEEE Congress on Evolutionary Computation, Cancun, Mexico, 20–23 June 2013; IEEE Press: Piscataway, NJ, USA, 2013; pp. 71–78. [Google Scholar] [CrossRef]
- Piotrowski, A.P.; Napiorkowski, J.J. Step-by-step improvement of JADE and SHADE-based algorithms: Success or failure? Swarm Evol. Comput. 2018, 43, 88–108. [Google Scholar] [CrossRef]
- Stanovov, V.; Semenkin, E. Surrogate-Assisted Automatic Parameter Adaptation Design for Differential Evolution. Mathematics 2023, 11, 2937. [Google Scholar] [CrossRef]
- Jones, D.R.; Schonlau, M.; Welch, W.J. Efficient Global Optimization of Expensive Black-Box Functions. J. Glob. Optim. 1998, 13, 455–492. [Google Scholar] [CrossRef]
- Stanovov, V.; Akhmedova, S.; Semenkin, E. Dual-Population Adaptive Differential Evolution Algorithm L-NTADE. Mathematics 2022, 10, 4666. [Google Scholar] [CrossRef]
- Awad, N.; Ali, M.; Liang, J.; Qu, B.; Suganthan, P. Problem Definitions and Evaluation Criteria for the CEC 2017 Special Session and Competition on Single Objective Bound Constrained Real-Parameter Numerical Optimization; Technical Report; Nanyang Technological University: Singapore, 2016. [Google Scholar]
- Kumar, A.; Price, K.; Mohamed, A.K.; Suganthan, P.N. Problem Definitions and Evaluation Criteria for the CEC 2022 Special Session and Competition on Single Objective Bound Constrained Numerical Optimization; Technical Report; Nanyang Technological University: Singapore, 2021. [Google Scholar]
- Brest, J.; Greiner, S.; Boškovic, B.; Mernik, M.; Žumer, V. Self-adapting control parameters in differential evolution: A comparative study on numerical benchmark problems. IEEE Trans. Evol. Comput. 2006, 10, 646–657. [Google Scholar] [CrossRef]
- Brest, J.; Maucec, M.; Bovsković, B. The 100-Digit Challenge: Algorithm jDE100. In Proceedings of the 2019 IEEE Congress on Evolutionary Computation (CEC), Wellington, New Zealand, 10–13 June 2019; pp. 19–26. [Google Scholar]
- Brest, J.; Maucec, M.; Bosković, B. Differential Evolution Algorithm for Single Objective Bound-Constrained Optimization: Algorithm j2020. In Proceedings of the 2020 IEEE Congress on Evolutionary Computation (CEC), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Zhang, J.; Sanderson, A.C. JADE: Adaptive Differential Evolution with Optional External Archive. IEEE Trans. Evol. Comput. 2009, 13, 945–958. [Google Scholar] [CrossRef]
- Tanabe, R.; Fukunaga, A. Improving the search performance of SHADE using linear population size reduction. In Proceedings of the IEEE Congress on Evolutionary Computation, CEC, Beijing, China, 6–11 July 2014; pp. 1658–1665. [Google Scholar] [CrossRef]
- Price, K.V.; Awad, N.H.; Ali, M.Z.; Suganthan, P.N. The 2019 100-Digit Challenge on Real-Parameter, Single Objective Optimization: Analysis of Results; Technical Report; Nanyang Technological University: Singapore, 2019. [Google Scholar]
- Stanovov, V.; Akhmedova, S.; Semenkin, E. Selective Pressure Strategy in differential evolution: Exploitation improvement in solving global optimization problems. Swarm Evol. Comput. 2019, 50, 100463. [Google Scholar]
- Brest, J.; Maučec, M.; Boškovic, B. Single objective real-parameter optimization algorithm jSO. In Proceedings of the IEEE Congress on Evolutionary Computation, Donostia, Spain, 5–8 June 2017; IEEE Press: Hoboken, NJ, USA, 2017; pp. 1311–1318. [Google Scholar] [CrossRef]
- Stanovov, V.; Akhmedova, S.; Semenkin, E. LSHADE Algorithm with Rank-Based Selective Pressure Strategy for Solving CEC 2017 Benchmark Problems. In Proceedings of the 2018 IEEE Congress on Evolutionary Computation (CEC), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Viktorin, A.; Senkerik, R.; Pluhacek, M.; Kadavy, T.; Zamuda, A. Distance based parameter adaptation for Success-History based Differential Evolution. Swarm Evol. Comput. 2019, 50, 100462. [Google Scholar] [CrossRef]
- Stanovov, V.; Akhmedova, S.; Semenkin, E. The automatic design of parameter adaptation techniques for differential evolution with genetic programming. Knowl. Based Syst. 2022, 239, 108070. [Google Scholar] [CrossRef]
- Chen, X.; Shen, A. Self-adaptive differential evolution with Gaussian–Cauchy mutation for large-scale CHP economic dispatch problem. Neural Comput. Appl. 2022, 34, 11769–11787. [Google Scholar] [CrossRef]
- Santucci, V.; Baioletti, M.; Bari, G.D. An improved memetic algebraic differential evolution for solving the multidimensional two-way number partitioning problem. Expert Syst. Appl. 2021, 178, 114938. [Google Scholar]
- Yang, M.; Cai, Z.; Li, C.; Guan, J. An improved adaptive differential evolution algorithm with population adaptation. In Proceedings of the Annual Conference on Genetic and Evolutionary Computation, Amsterdam, The Netherlands, 6–10 July 2013. [Google Scholar]
- Yi, W.; Chen, Y.; Pei, Z.; Lu, J. Adaptive differential evolution with ensembling operators for continuous optimization problems. Swarm Evol. Comput. 2021, 69, 100994. [Google Scholar] [CrossRef]
- Burke, E.; Hyde, M.; Kendall, G.; Ochoa, G.; Özcan, E.; Woodward, J. A Classification of Hyper-Heuristic Approaches: Revisited. In Handbook of Metaheuristics; Springer International Publishing: Cham, Switzerland, 2019; pp. 453–477. [Google Scholar] [CrossRef]
- Haraldsson, S.O.; Woodward, J. Automated design of algorithms and genetic improvement: Contrast and commonalities. In Proceedings of the Companion Publication of the 2014 Annual Conference on Genetic and Evolutionary Computation, Vancouver, BC, Canada, 12–16 July 2014. [Google Scholar]
- Mohamed, A.; Hadi, A.A.; Fattouh, A.; Jambi, K. LSHADE with semi-parameter adaptation hybrid with CMA-ES for solving CEC 2017 benchmark problems. In Proceedings of the 2017 IEEE Congress on Evolutionary Computation (CEC), Donostia, Spain, 5–8 June 2017; pp. 145–152. [Google Scholar]
- Stanovov, V.; Semenkin, E. Genetic Programming for Automatic Design of Parameter Adaptation in Dual-Population Differential Evolution. In Proceedings of the Companion Conference on Genetic and Evolutionary Computation, Lisbon, Portugal, 15–19 July 2023. [Google Scholar]
- Price, K.V.; Kumar, A.; Suganthan, P.N. Trial-based dominance for comparing both the speed and accuracy of stochastic optimizers with standard non-parametric tests. Swarm Evol. Comput. 2023, 78, 101287. [Google Scholar] [CrossRef]
- Price, K.; Storn, R.; Lampinen, J. Differential Evolution: A Practical Approach to Global Optimization; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Gamperle, R.; Muller, S.; Koumoutsakos, A. A Parameter Study for Differential Evolution. Adv. Intell. Syst. Fuzzy Syst. Evol. Comput. 2002, 10, 293–298. [Google Scholar]
- Zaharie, D. Critical values for the control parameters of differential evolution algorithms. Crit. Values Control Parameters Differ. Evol. Algorithmss 2002, 2, 62–67. [Google Scholar]
- Ali, M.; Törn, A. Optimization of Carbon and Silicon Cluster Geometry for Tersoff Potential using Differential Evolution. In Optimization in Computational Chemistry and Molecular Biology: Local and Global Approaches; Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar] [CrossRef]
- Kumar, A.; Misra, R.K.; Singh, D. Improving the local search capability of Effective Butterfly Optimizer using Covariance Matrix Adapted Retreat Phase. In Proceedings of the 2017 IEEE Congress on Evolutionary Computation (CEC), Donostia, Spain, 5–8 June 2017; pp. 1835–1842. [Google Scholar]
- Stanovov, V.; Akhmedova, S.; Semenkin, E. NL-SHADE-RSP Algorithm with Adaptive Archive and Selective Pressure for CEC 2021 Numerical Optimization. In Proceedings of the 2021 IEEE Congress on Evolutionary Computation (CEC), Kraków, Poland, 28 June–1 July 2021; pp. 809–816. [Google Scholar] [CrossRef]
- Stanovov, V.; Akhmedova, S.; Semenkin, E. NL-SHADE-LBC algorithm with linear parameter adaptation bias change for CEC 2022 Numerical Optimization. In Proceedings of the 2022 IEEE Congress on Evolutionary Computation (CEC), Padua, Italy, 18–23 July 2022. [Google Scholar]
- Mohamed, A.W.; Hadi, A.A.; Agrawal, P.; Sallam, K.M.; Mohamed, A.K. Gaining-Sharing Knowledge Based Algorithm with Adaptive Parameters Hybrid with IMODE Algorithm for Solving CEC 2021 Benchmark Problems. In Proceedings of the 2021 IEEE Congress on Evolutionary Computation (CEC), Kraków, Poland, 28 June–1 July 2021; pp. 841–848. [Google Scholar]
- Cuong, L.V.; Bao, N.N.; Binh, H.T.T. Technical Report: A Multi-Start Local Search Algorithm with L-SHADE for Single Objective Bound Constrained Optimization; Technical Report; SoICT, Hanoi University of Science and Technology: Hanoi, Vietnam, 2021. [Google Scholar]
- Biswas, S.; Saha, D.; De, S.; Cobb, A.D.; Das, S.; Jalaian, B. Improving Differential Evolution through Bayesian Hyperparameter Optimization. In Proceedings of the 2021 IEEE Congress on Evolutionary Computation (CEC), Kraków, Poland, 28 June–1 July 2021; pp. 832–840. [Google Scholar]
- Bujok, P.; Kolenovsky, P. Eigen Crossover in Cooperative Model of Evolutionary Algorithms Applied to CEC 2022 Single Objective Numerical Optimisation. In Proceedings of the 2022 IEEE Congress on Evolutionary Computation (CEC), Padua, Italy, 18–23 July 2022. [Google Scholar]
- Biedrzycki, R.; Arabas, J.; Warchulski, E. A Version of NL-SHADE-RSP Algorithm with Midpoint for CEC 2022 Single Objective Bound Constrained Problems. In Proceedings of the 2022 IEEE Congress on Evolutionary Computation (CEC), Padua, Italy, 18–23 July 2022. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rank | ||||||
|---|---|---|---|---|---|---|
| 1 | 637 | 3.635 | 0.400 | 0.662 | 0.013 | 0.187 |
| 2 | 625 | 3.369 | 0.402 | 0.619 | 0.008 | 0.182 |
| 3 | 640 | 3.453 | 0.398 | 0.636 | 0.018 | 0.119 |
| 4 | 613 | 3.353 | 0.416 | 0.652 | 0.030 | 0.270 |
| 5 | 652 | 3.543 | 0.385 | 0.625 | 0.013 | 0.097 |
| 6 | 432 | 2.981 | 0.414 | 0.650 | 0.043 | 0.252 |
| 7 | 463 | 3.472 | 0.413 | 0.662 | 0.013 | 0.243 |
| 8 | 582 | 3.197 | 0.431 | 0.615 | 0.031 | 0.189 |
| Algorithm | ||||
|---|---|---|---|---|
| L-NTADE-HHF vs. | 11/15/4 | 17/8/5 | 15/7/8 | 17/4/9 |
| LSHADE-SPACMA [33] | (31.38) | (93.37) | (60.70) | (64.55) |
| L-NTADE-HHF vs. | 9/14/7 | 20/9/1 | 23/7/0 | 26/0/4 |
| jSO [23] | (14.94) | (147.01) | (192.86) | (184.63) |
| L-NTADE-HHF vs. | 4/16/10 | 16/11/3 | 23/6/1 | 24/3/3 |
| EBOwithCMAR [40] | (−39.75) | (102.60) | (162.33) | (174.57) |
| L-NTADE-HHF vs. | 8/18/4 | 20/9/1 | 23/7/0 | 25/2/3 |
| L-SHADE-RSP [24] | (11.62) | (138.18) | (183.07) | (172.99) |
| L-NTADE-HHF vs. | 12/7/11 | 23/4/3 | 30/0/0 | 29/0/1 |
| NL-SHADE-RSP [41] | (11.54) | (176.22) | (259.17) | (246.89) |
| L-NTADE-HHF vs. | 7/19/4 | 23/7/0 | 28/2/0 | 27/2/1 |
| NL-SHADE-LBC [42] | (12.74) | (183.84) | (239.78) | (225.46) |
| L-NTADE-HHF vs. | 11/12/7 | 17/12/1 | 23/7/0 | 26/2/2 |
| L-NTADE [13] | (27.52) | (105.74) | (157.15) | (182.49) |
| L-NTADE-HHF vs. | 4/26/0 | 13/16/1 | 22/8/0 | 28/1/1 |
| L-NTADEMF [11] | (20.20) | (64.65) | (135.34) | (191.34) |
| L-NTADE-HHF vs. | 0/30/0 | 1/29/0 | 3/27/0 | 1/29/0 |
| L-NTADE-AHF | (2.29) | (9.79) | (3.03) | (3.11) |
| Algorithm | Total | ||||
|---|---|---|---|---|---|
| LSHADE-SPACMA [33] | 171.12 | 167.56 | 137.75 | 121.96 | 598.39 |
| jSO [23] | 166.36 | 177.38 | 183.68 | 190.26 | 717.69 |
| EBOwithCMAR [40] | 141.15 | 164.69 | 172.70 | 180.51 | 659.04 |
| L-SHADE-RSP [24] | 163.95 | 171.30 | 171.71 | 172.28 | 679.25 |
| NL-SHADE-RSP [41] | 177.54 | 246.55 | 285.47 | 284.82 | 994.38 |
| NL-SHADE-LBC [42] | 165.00 | 228.15 | 250.02 | 247.88 | 891.05 |
| L-NTADE [13] | 175.91 | 151.82 | 147.98 | 152.27 | 627.99 |
| L-NTADEMF [11] | 168.70 | 126.46 | 126.62 | 135.35 | 557.13 |
| L-NTADE-HHF | 160.41 | 106.62 | 86.60 | 81.94 | 435.57 |
| L-NTADE-AHF | 159.86 | 109.47 | 87.48 | 82.71 | 439.52 |
| Algorithm | ||
|---|---|---|
| L-NTADE-HHF vs. APGSK-IMODE [43] | 8/2/2 (40.45) | 7/1/4 (26.02) |
| L-NTADE-HHF vs. MLS-LSHADE [44] | 8/1/3 (30.45) | 5/1/6 (−0.06) |
| L-NTADE-HHF vs. MadDE [45] | 8/2/2 (39.81) | 7/1/4 (22.51) |
| L-NTADE-HHF vs. EA4eigN100 [46] | 6/2/4 (4.32) | 6/1/5 (4.93) |
| L-NTADE-HHF vs. NL-SHADE-RSP-MID [47] | 5/4/3 (9.61) | 5/2/5 (10.61) |
| L-NTADE-HHF vs. L-SHADE-RSP [24] | 7/3/2 (29.80) | 5/3/4 (9.54) |
| L-NTADE-HHF vs. NL-SHADE-RSP [41] | 7/2/3 (25.57) | 5/3/4 (9.80) |
| L-NTADE-HHF vs. NL-SHADE-LBC [42] | 8/3/1 (36.95) | 4/5/3 (13.44) |
| L-NTADE-HHF vs. L-NTADE [13] | 6/5/1 (28.68) | 3/5/4 (2.61) |
| L-NTADE-HHF vs. L-NTADEMF [11] | 3/7/2 (3.79) | 4/5/3 (6.67) |
| L-NTADE-HHF vs. L-NTADE-AHF | 1/11/0 (7.74) | 2/6/4 (−7.54) |
| Algorithm | Total | ||
|---|---|---|---|
| APGSK-IMODE [43] | 99.73 | 104.65 | 204.38 |
| MLS-LSHADE [44] | 83.25 | 63.17 | 146.42 |
| MadDE [45] | 104.92 | 102.62 | 207.53 |
| EA4eigN100 [46] | 52.73 | 65.55 | 118.28 |
| NL-SHADE-RSP-MID [47] | 73.28 | 84.95 | 158.23 |
| L-SHADE-RSP [24] | 83.58 | 73.85 | 157.43 |
| NL-SHADE-RSP [41] | 104.52 | 98.07 | 202.58 |
| NL-SHADE-LBC [42] | 72.00 | 71.40 | 143.40 |
| L-NTADE [13] | 81.12 | 71.20 | 152.32 |
| L-NTADEMF [11] | 62.03 | 68.05 | 130.08 |
| L-NTADE-HHF | 58.40 | 69.92 | 128.32 |
| L-NTADE-AHF | 60.43 | 62.58 | 123.02 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stanovov, V.; Kazakovtsev, L.; Semenkin, E. Hyper-Heuristic Approach for Tuning Parameter Adaptation in Differential Evolution. Axioms 2024, 13, 59. https://doi.org/10.3390/axioms13010059
Stanovov V, Kazakovtsev L, Semenkin E. Hyper-Heuristic Approach for Tuning Parameter Adaptation in Differential Evolution. Axioms. 2024; 13(1):59. https://doi.org/10.3390/axioms13010059
Chicago/Turabian StyleStanovov, Vladimir, Lev Kazakovtsev, and Eugene Semenkin. 2024. "Hyper-Heuristic Approach for Tuning Parameter Adaptation in Differential Evolution" Axioms 13, no. 1: 59. https://doi.org/10.3390/axioms13010059
APA StyleStanovov, V., Kazakovtsev, L., & Semenkin, E. (2024). Hyper-Heuristic Approach for Tuning Parameter Adaptation in Differential Evolution. Axioms, 13(1), 59. https://doi.org/10.3390/axioms13010059