Abstract
The nonconvex and nonsmooth optimization problem has been attracting increasing attention in recent years in image processing and machine learning research. The algorithm-based reweighted step has been widely used in many applications. In this paper, we propose a new, extended version of the iterative convex majorization–minimization method (ICMM) for solving a nonconvex and nonsmooth minimization problem, which involves famous iterative reweighted methods. To prove the convergence of the proposed algorithm, we adopt the general unified framework based on the Kurdyka–Łojasiewicz inequality. Numerical experiments validate the effectiveness of the proposed algorithm compared to the existing methods.
Keywords:
iterative reweighted algorithm; linearization; nonconvex optimization; nonsmooth objective function; Kurdyka–Łojasiewicz property MSC:
65K10; 65K05; 68U10
1. Introduction
In this paper, we consider the following nonconvex and nonsmooth optimization problem of a specific structure in a n-dimensional real vector space:
where is a proper, lower semicontinuous (l.s.c.), convex and continuously differentiable function which has the Lipschitz gradient with Lipschitz constant , is a proper, l.s.c. and convex function, is a proper and l.s.c. function, and is continuously differentiable. Furthermore, we assume that the coordinate functions of g are convex, and the function h has a strictly continuous gradient and is coordinate-wise nondecreasing, i.e., , where and with i-th standard basis vector for . We also suppose that F is coercive, closed and definable in an o-minimal structure. Several nonconvex optimization problems in image processing or signal processing have an objective function of the form (1). For example, a nonconvex and nonsmooth minimization problem for image denoising
has the form of the problem (1) whose objective function satisfies all assumptions. Here, is an observed noisy image, u is a restored image, and are positive parameters. The following nonconvex minimization for compressive sensing problem is also an example of the proposed problem (1):
where are positive parameters, A is a matrix with , and b is an observed signal. As we will see in the numerical experiments, we will apply the proposed method to this application.
Minimizing the sum of a finite number of given functions is an important issue of mathematical optimization research. For the minimizing of convex functions, many efficient algorithms were proposed with convergence analysis, such as gradient based method [1,2], the iterative shrinkage thresholding algorithm [3], proximal point method [4] and alternating minimization algorithm. On the other hand, it is difficult to prove the global convergence of an algorithm to solve the nonconvex minimization problem. Nevertheless, several algorithms for solving nonconvex minimization problems have been developed. Extensions in the nonconvex setting of many first-order algorithms have been proposed, such as the gradient method, proximal point method [5] and iterative shrinkage thresholding algorithm [6] for nonconvex optimization. Recently, Attouch et al. [7] extended the alternating minimization algorithm by adding a proximal term to minimize the nonconvex function. The iteratively reweighted algorithm [8] was proposed for solving a nonconvex minimization problem in compressive sensing. The iteratively reweighed least square method [9] was also developed for the nonconvex norm-based model applied to the compressive sensing problem. Very recently, Ochs et al. [10] extended these algorithms in a framework of the iterative convex majorization–minimization method (ICMM) to solve nonsmooth and nonconvex optimization problems and gave the global convergence analysis.
The Kurdyka–Łojasiewicz (KL) inequality is key when proving the global convergence of algorithms for nonsmooth and nonconvex optimization problems. A function which satisfies the KL inequality is called a KL function. Smooth KL functions and nonsmooth KL functions were introduced in [11,12,13,14]. Almost objective functions of the minimization problem in image processing satisfy the KL inequality, and it is a very useful when we deal with nonconvex objective functions. Many methods [7,15,16] whose global convergence was given based on the KL inequality have been proposed. Recently, Ochs et al. [17] proposed an inertial proximal algorithm by combining forward–backward splitting with an inertial force. Attouch et al. [18] proposed a general framework for the global convergence of descent methods for minimizing the KL function. In this paper, we utilize this general framework for the convergence of the proposed method.
In general, a nonlinear optimization problem does not have a closed-form solution. Hence, iterative algorithms frequently are used to solve a nonlinear minimization problem. Several algorithms minimize alternatively a linear approximation of nonlinear differentiable objective function. This technique is called “linearization”. The linearization technique of continuously differentiable objective function was applied in many algorithms [3,19,20] to solve constrained or unconstrained optimization problems.
The ICMM [10] is a popular algorithm for solving the problem (1). In this article, we propose an extension of the ICMM to solve the nonconvex and nonsmooth minimization problem (1). The linearization of the convex differentiable function f is considered unlike the ICMM. This enables the proposed method to deal with more applications. Further details of applications are given in Section 3. Based on the general framework introduced in [18], we prove the global convergence of the proposed model. From numerical experiments, we demonstrate the superiority of the proposed method over the existing methods, which are presented in Section 4.
The rest of this paper is organized as follows. In Section 2, we present the mathematical preliminary for nonconvex optimization and introduce the ICMM. In Section 3, we propose an extended version of the ICMM, and the iterative reweighted algorithms, which are special examples of the ICMM, are also suggested. The global convergence of the proposed algorithm is proved. In Section 4, numerical experiments are provided for our method, with comparisons to state-of-the-art methods. Finally, Section 5 summarizes our work.
2. Background
In this section, we present the mathematical preliminary for our work, and the iterative convex majorization–minimization method [10] is introduced.
2.1. Mathematical Preliminary
In Section 2.1, we introduce basic mathematical concepts and properties. More details are given in [21,22].
The concept of the Lipschitz continuity of a function is important in mathematical optimization theory. In the problem (1), we consider a continuously differentiable function which is included in a class of functions, namely the function with the Lipschitz gradient. This class is denoted by . A continuously differentiable function has a Lipschitz gradient with constant L if there exists with
There is a property for a function with the Lipschitz gradient: If is a continuously differentiable function whose gradient is Lipschitz continuous with Lipschitz constant , i.e., , then, for any , the following inequality holds:
Now we introduce the generalized subdifferentials for a nonsmooth and nonconvex function.
Definition 1.
For a function and a point ,
- ω is a regular subgradient of f at , denoted by , if
- v is a (limiting) subgradient of f at , denoted by , if there are sequences , with .
A trivial property of the subdifferential is that . Moreover, there are many important properties of the subdifferential. These properties will be used to prove the convergence of the proposed method.
Proposition 1 (subgradient properties).
Let be a function.
- 1.
- If f is convex, the regular and limiting subdifferentials are same sets, which is the subdifferential in the convex analysis:
- 2.
- If f is continuously differentiable on a neighborhood of , then .
- 3.
- If g is a l.s.c. function and f is continuously differentiable on a neighborhood of , then we can obtain the subdifferential of as follows:
- 4.
- If a proper and l.s.c. function has a local minimum at , then . Furthermore, if f is convex, then this condition is also sufficient for a global minimum.
For obtain the global convergence of the proposed algorithm, the objective function in the problem (1) must be a Kurdyka–Łojasiewicz function.
Definition 2.
A function satisfies the Kurdyka–Łojasiewicz (KL) property at a point if there exist , neighborhood U of , and a continuous and convex function which satisfy
- (i)
- ;
- (ii)
- ϕ is differentiable in ;
- (iii)
- for all ;
- (iv)
- For any ,
A function is called Kurdyka–Łojasiewicz (KL) function if F satisfies the KL property at every point in .
Although the KL property is a strong condition, many functions are KL functions. The semialgebraic functions [23] are typical examples of KL functions. The set of semialgebraic functions involves polynomials, indicator functions of semialgebraic sets [23], and the norm. The compositions, finite sums, and finite products of semialgebraic functions are also semialgebraic. However, log and exponential functions are not semialgebraic functions. Recently, a class of definable functions in the log-exp o-minimal structure [24,25] was proposed, which involves log and exponential functions, and all semialgebraic functions. Moreover, it is proved that the functions in this class are KL functions. More details of the log-exp o-minimal structure are given in [24,25].
Lastly, we recall the general framework for an iterative algorithm when the objective function in an unconstrained minimization problem is a KL function. We consider a nonconvex unconstrained minimization problem:
where F is a l.s.c. and proper function. Attouch et al. [18] suggested a framework for the convergence of an iterative method to solve the nonconvex minimization problem (3). They proved that a given algorithm converges when the following three conditions hold: Let be a sequence generated by a given iterative algorithm.
Hypothesis 1 (sufficient decrease condition).
There exists a positive value such that for each ,
Hypothesis 2 (relative error condition).
For each , there exists a sequence such that
where b is a fixed positive constant.
Hypothesis 3 (continuity condition).
There exists a subsequence and such that
The following theorem is the convergence result, and the proof is given in ([18], Theorem 2.9).
Theorem 1.
Let be a proper l.s.c. function. We consider a sequence that satisfies Hypotheses 1–3. If F has the KL property at the cluster point specified in Hypothesis 3, then the sequence converges to as k goes to infinity, and is a critical point of F. Moreover, the sequence has a finite length, i.e.,
2.2. Iterative Convex Majorization–Minimization Method
This section recalls the iterative convex majorization–minimization method (ICMM) [10] for solving the following nonconvex minimization problem:
where is proper, l.s.c., and bounded below. The further assumptions are required; is proper, l.s.c., and convex. is coordinatewise convex. is coordinatewise nondecreasing.
The ICMM to solve this nonconvex problem (4) is a famous iterative algorithm. This algorithm is an adopted majorization–minimization technique that chooses a suitable family of convex surrogate functions called majorizers, and it minimizes a convex majorizer function instead of the objective function G at each iteration. The specific algorithm is summarized in Algorithm 1.
| Algorithm 1 Iterative Convex Majorization–Minimization Method (ICMM). |
Initialization Choose a starting point with and define a suitable family of convex surrogate functions such that for all , holds, where
repeat until The algorithm satisfies a stopping condition |
The convergence of Algorithm 1 was studied in [10]. Additional conditions are required for the global convergence of the ICMM. First, h should have a locally Lipschitz continuous gradient on a compact set B containing all , and majorizers should have globally Lipschitz continuous gradients on B for all , with a uniform Lipschitz constant. Another condition is that should be strongly convex, which is a stronger condition. To show the global convergence of the ICMM, it was proved that the objective function G satisfies the three Hypotheses 1–3 for any KL function G, which were introduced in the previous section. Then, Theorem 1 is applied. As examples of the ICMM, several iteratively reweighted convex algorithms were introduced in [10], such as the iterative reweighted algorithm, iteratively reweighted tight convex algorithm, iteratively reweighted Huber algorithm and iteratively reweighted least squares algorithm.
3. Proposed Algorithm
3.1. Proximal Linearized Iteratively Convex Majorization–Minimization Method
In this section, we propose a novel algorithm for solving the nonconvex and nonsmooth minimization problem (1). The ICMM in Algorithm 1, introduced in the previous section, can be applied to the problem (1), since is also a proper, l.s.c, convex function. This yields the following iteration:
In many cases, this problem does not have a closed form solution and we cannot compute the exact solution of (5). Since the convergence of the ICMM is only guaranteed under the assumption that the subproblem (5) is solved exactly, it is not applicable to many problems. To overcome this fatal drawback, an inexact stopping criterion of the subproblem (5) was also proposed in [26]. Specifically, solving the subproblem (5) requires an inner algorithm such as the iterative shrinkage thresholding algorithm [27], and fast iterative shrinkage thresholding algorithm [3]. However, it is often time consuming for solving a large-scale problem. Therefore, we extend the ICMM by adopting a linearization technique of f. Here, we consider the linear approximation of f at the k-th iterate with an additional proximal term instead of :
Utilizing this technique, we propose the following minimization of a convex surrogate function:
where is a proximal parameter. The proposed algorithm is summarized in Algorithm 2 and it is called as proximal linearized ICMM (PL-ICMM).
| Algorithm 2 Proximal Linearized Iteratively Convex Majorization–Minimization Method (PL-ICMM). |
Conditions
Initialization Choose a starting point with and define a suitable family of convex surrogate functions such that for all , holds, where
repeat Solve
until The algorithm satisfies a stopping condition. |
The proposed method can be regarded as a generalized version of the ICMM and is more applicable than the ICMM. For examples, the PL-ICMM can be directly applied to the following minimizations for a regression problem, while the ICMM cannot be applied:
and
where , , , and .
Many iteratively reweighted algorithms [28,29,30] are examples of the ICMM, which use a weighted function appropriately to serve a convex majorizer in the ICMM. A convex majorizer has the form for some given . The weight must be selected such that the function satisfies the conditions of the class of convex majorizers. Similar to the ICMM, the PL-ICMM is a general algorithm which includes lots of iteratively reweighted algorithms. We also introduce proximal linearized versions of iteratively reweighted algorithms.
| Algorithm 3 Proximal linearized iteratively reweighted algorithm (PL-IRL1). |
Conditions
Initialization Choose a starting point with . repeat . Solve
until The algorithm satisfies a stopping condition |
First, we propose proximal linearized iteratively reweighted algorithm (PL-IRL1). We further assume that the function h is concave on . For a concave function h, we can define the limiting supergradient of h as an element of . The set of all limiting supergradients of h is denoted by . Since is convex and differentiable, on has only one element from the property 2 in Proposition 1. The PI-IRL1 considers the majorizer and minimizes iteratively the following convex problem:
In ([10], Proposition 2), it was proved that the majorizer is the optimal majorizer of at . The PL-IRL1 is summarized in Algorithm 3.
Remark 1.
We assume that p is also continuously differentiable and has a Lipschitz continuous gradient with Lipschitz constant , and h is additively separable, i.e.,
Then, the proximal iteratively reweighted algorithm [31] can be applied to the problem (1), which is the following iterative algorithm:
where , and is a parameter. Hence, our PL-IRL1 can be also regraded as an extension of the proximal iteratively reweighted algorithm.
Due to the optimality of the iterative reweighted algorithm, it has been used frequently to solve many applications. However, it cannot be applied to solve the problem (1) when h is not concave on , such as . For nonconcave function h, the iterative reweighted least square algorithm (IRLS) is well known. For a proximal linearized version of IRLS, we need more assumptions that h is additively separable on and each separable function is convex in and concave in for some . The IRLS makes use of a convex majorizer
where the weights are given as and the the square in means the coordinatewise square operation. This yields the following iterative algorithm:
The specific algorithm is given in Algorithm 4.
| Algorithm 4 Proximal Linearized Iterative Reweighted Least Square Algorithm (PL-IRLS). |
Conditions
Initialization Choose a starting point with . repeat . , . Solve
until The algorithm satisfies a stopping condition |
The majorization property of PL-IRLS can be also obtained from ([10], Proposition 23), when has the form for any .
3.2. Convergence Analysis of the PL-ICMM
First, we prove the partial convergence of the PL-ICMM. From the following proposition, the sequence generated by Algorithm 2 induces the convergence of the sequence of objective function value at .
Proposition 2.
Let be generated by Algorithm 2, and let for all . If , then the sequence monotonically decreases and hence converges.
Proof.
Let F be bounded below by L. We can obtain
where the second inequality is obtained from the property (2) and the majorization property of , the third inequality is obtained from the optimality of the subproblem in Algorithm 2 and the last inequality is obtained from the majorization property of . The sequence decreases and is bounded from below. Hence, it converges. ☐
We can also obtain the local convergence of the PL-ICMM, given in the following proposition.
Proposition 3.
Let F be coercive. Then the sequence is bounded and has at least one accumulation point.
Proof.
By Proposition 2, the sequence is monotonically decreasing, and therefore the sequence is contained in the level set
From the coercivity of F, we conclude the boundedness of the set . By the Bolzano–Weierstrass theorem, has at least one accumulation point. ☐
Now, we prove the global convergence of the proposed algorithm. We utilize the general framework for the convergence of an iterative method, introduced in [18]. Specifically, we prove the three Hypothesis 1–3 with in the problem (1) and the sequence generated by the PL-ICMM. As a result, we obtain the global convergence of the PL-ICMM by using Theorem 1. We further assume the following:
- h has a locally Lipschitz gradient on a compact set containing the sequence , and majorizers have a Lipschitz gradient on a compact set containing the sequence with a common Lipschitz constant.
To prove the global convergence of the PL-ICMM, we need the following lemma which shows the subdifferential calculus about the composition and summation of two functions. The proof of this lemma is provided in ([10], Lemma 1).
Lemma 1.
Under the given conditions for PL-ICMM, the following holds for all :
- 1.
- For all ,
- 2.
- For all ,
First we prove the sufficient decreasing condition for the proposed method in the following proposition.
Proposition 4 (Sufficient decreasing conditions).
Let . There exists such that for all
Proof.
From the property (2) of functions, we have
By the definition of the subdifferential of a convex function, we can obtain
where and are subderivatives of p and at , respectively. Since is the minimizer of the problem
there exist the subderivatives and by Lemma 1 such that
From the facts that and , we obtain that for all ,
where the third inequality is obtained from Equations (8)–(10) and the last equality is obtained from the property (11). Let . Since , . Therefore, we can obtain the following result:
☐
The relative error condition (Hypothesis 2) for the PL-ICMM is proved in Proposition 5.
Proposition 5 (relative error condition).
For all , there exists a positive constant (independent of k) and such that
Proof.
By the optimality of the subproblem of PL-ICMM and Lemma 1, there exist and , satisfying
Let . Then, by Lemma 1 and the property of the subdifferential,
We can decompose
for some . Similarly, for any subderivative , can also be decomposed as
where . Hence, it can be obtained from Lemma 1 that is a subderivative of F at , i.e., , where .
From Proposition 4 and the coercivity of F, the sequence is bounded. Hence, we can find a compact set containing this sequence in . The convexity of g implies the Lipschitz continuity on a compact, convex subset of involving for all k. From the further assumption, and are Lipschitz continuous on a compact, convex subset B of containing for all k. Let and be the Lipschitz constants of g and , respectively. The common Lipschitz constant of on B is set to be . By the property of the local Lipschitz continuity of g, we can obtain
Since , the following identities hold:
Proposition 6 (continuity condition).
There exists a convergent subsequence of and its limit satisfying
Proof.
The boundedness of implies the existence of a convergent subsequence. Let be a convergent subsequence of such that as . We define sequences and such that
Let . Clearly, is a convex function. Due to the strict continuity of , is bounded. Clearly, is bounded from the continuity of . Therefore, is bounded and . Using the facts of the lower semicontinuity of F, the continuity of f and the convexity of p, we obtain
Thus, as . ☐
In Propositions 4–6, we show that PL-ICMM satisfies the three alternative Hypotheses 1–3. Finally, we can obtain the global convergence of the proposed algorithm.
Theorem 2.
Let be a proper l.s.c. function. Let the sequence be generated by PL-ICMM. If F has the property at the cluster point , then the sequence converges to as and is a critical point of Moreover, the sequence has a finite length, i.e.,
Proof.
Propositions 4–6 yield all of the requirements for Theorem 1. According to Theorem 1, we can obtain the final results. ☐
4. Numerical Experiments and Discussion
In this section, we present the numerical results of the proposed methods, and applications of the proposed algorithms are provided. We consider compressive sensing in signal processing. All numerical experiments are implemented with MATLAB R2020b on a 64-bit Windows 10 desktop with an Intel Xeon(R) 2.40 GHz CPU, with 64 GB RAM.
4.1. Numerical Results for PL-IRL1
First, we show the performance of PL-IRL1. The main concept of compressive sensing is that a sparse signal can be recovered from incomplete information, i.e., underdetermined system where . We say that x is k-sparse if x has only k-nonzero elements. The compressive sensing problem is generally an ill-posed problem, and there exist many solutions mathematically. To obtain the sparse solution, the basic model for compressive sensing is called lasso, which has the following form:
where with , , is a positive regularization parameter. This problem is a convex relaxation of the following nonconvex minimization problem:
where is defined as the number of nonzero elements of input x. Recently, sparse signal recovery from an observed signal corrupted impulsive noise was interested in lots of works [32,33,34,35]. For the sparse recovery with impulsive noise, the following -fidelity based convex problem can be often applied:
We also consider nonconvex varations of this model for a compressive sensing problem with impulsive noise as follows:
and
where is a positive parameter. Unfortunately the PL-IRL1 can be directly applied to these nonconvex problems. Hence, we add the auxiliary variable and adopt the penalty technique, leading us to obtain the following nonconvex and nonsmooth minimization problems:
and
where is a positive penalty constant. We set
In this setting, the minimization problems (14) and (15) have the form of problem (1). Since the objective function of the problem (14) is definable in the log-exp o-minimal structure, it is a KL function. The objective function of the minimization problem (15) is a semialgebraic function and it is also a KL function. Moreover, these are closed and coercive. The function f is a convex, proper and continuously differentiable function, p is a convex, proper and l.s.c function, and g is a proper and l.s.c function. The function is coordinatewise nondecreasing, continuously differentiable and concave. Since the objective function involves nondifferentiable term , the proximal iterative reweighted algorithm proposed in [31] cannot be applied. Hence, we can apply IRL1 [10] or PL-IRL1 to solve the given problem (14). The IRL1 or PL-IRL1 applied to the problem (14) is given as follows:
and
respectively. For solving the convex subproblem of IRL1, the optimality conditions are given as follows:
This system (18) of equations does not have a closed form solution. Hence, the IRL1 cannot be employed to solve the problem (14). On the other hand, the optimality conditions of the convex subproblem of our method are given as
These equations in (19) are separable, and each problem has a closed form solution:
where shrink function is defined as
To show the convergence of the PL-IRL1 to solve problems (14) and (15), we perform the numerical experiments in the following setting. The size of A is and . We use an orthonormal Gaussian measurement matrix A whose entries are randomly chosen by standard Gaussian distribution, and then each column of A is divided by its norm. The number l of nonzero elements of the original sparse signal is fixed at 50, the locations of nonzero elements are selected randomly, and the values of nonzero elements are chosen by Gaussian distribution . The observed data b can be calculated by
where n is the Gaussian mixture noise that consists of two Gaussian components, which is one of impulsive noise in signal processing [36]. The measured equation of n is given by
where and are Gaussian noise with mean 0 and standard deviation and . The denotes the background noise, and represents the influence of outliers. The parameter controls the proportion of the large outliers and controls the strength of the outliers. Here, we fixed these parameters at .
Since , the Lipschitz constant of is . So, is set to be . The regularization parameter is fixed at for (14) or for (15); the penalty parameter is set to be 2 for (14) or 28 for (15); and the controlling parameter of nonconvexity is set to be . For the stopping condition of our algorithm, we use relative errors over energy function values, whose specific formulation is given as
For this setting, 100 different numerical tests are conducted.
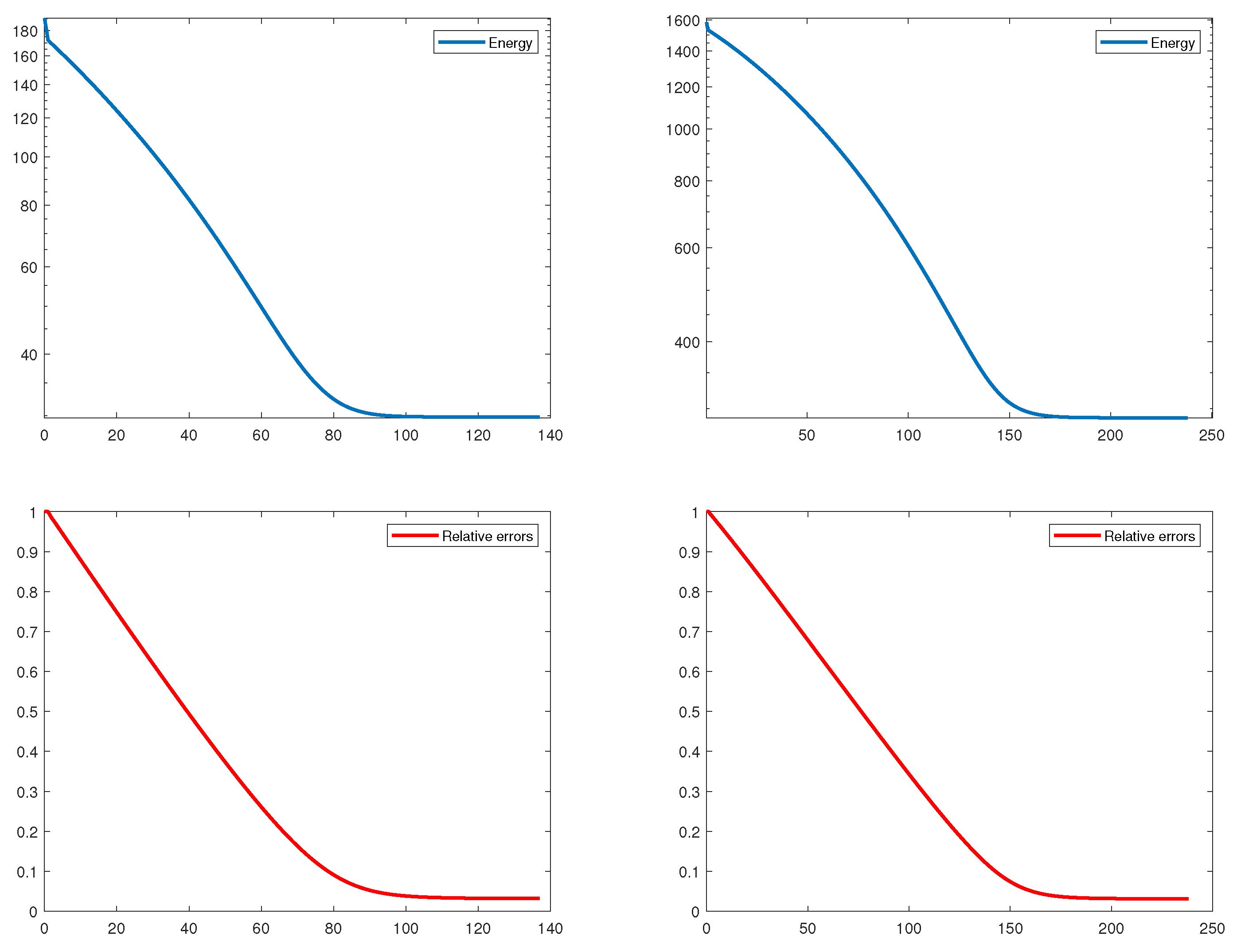
In Table 1, we present the computing time, number of iterations, final energy value, and relative error. From the relative errors, we can observe that the proposed algorithm finds an approximated sparse solution with small error for all cases. In Figure 1, we illustrate the relative errors and energy values over k iterations. Since the penalty parameter for (14) is smaller than that for (15), the computing time of our method for solving (14) is faster than that for solving (15). We can also see similar results in terms of the number of iterations. Ultimately, we can show in Figure 1 and Table 1 the fast convergence of the PL-IRL1, and the final energy value has enough small value.

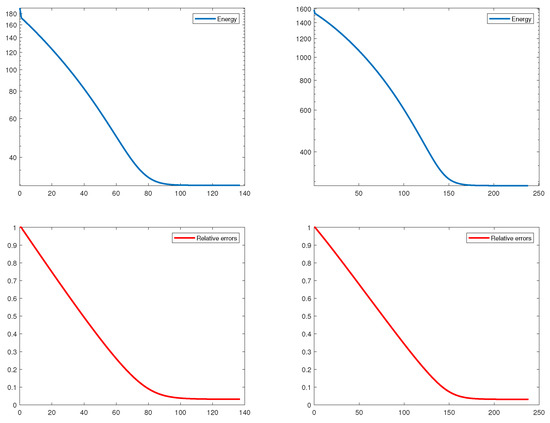
4.2. Numerical Results for PL-IRLS
Second, we present numerical results of PL-IRLS compared with the iPiano [17] method for the compressive sensing problem in signal processing. Specifically, the restoration of the sparse signal corrupted by additive Gaussian noise is considered. We apply the algorithms PL-IRLS and iPiano to the following unconstrained problems:
and
where are positive parameters, c is a positive constant, and is the parameter that controls the nonconvexity of regularizing term. These problems are a nonconvex variations of lasso, which is a well-known model for compressive sensing. The objective functions of problems (20) and (21) are definable in the log-exp o-minimal structure, and they are also close, coercive KL functions. With setting
all assumptions in Algorithm 4 are satisfied. Since the norm of the Hessian matrix of h is bounded on , it has also a strictly continuous gradient. The PL-IRLS applied to the problems (20) and (21) can be obtained by
The subproblem in (22) is a quadratic problem, and its normal equation is given as follows:
It can be rewritten as the following linear equation,
where is a diagonal matrix whose diagonal entries consist of . Since is a diagonal matrix, this linear equation can be solved exactly and easily. The majorization property of PL-IRLS is obtained from ([10], Proposition 23) for any and .
In this experiment, we use partial discrete cosine transform (DCT) matrices A whose i-th rows are selected from the DCT matrix. We note that the partial DCT matrices are implicitly stored, i.e., matrix-vector multiplications in or are computed by the DCT or inverse of DCT. Hence, we can use partial DCT matrices of very large sizes. Here, the size is fixed at = (100,000, 30,000). Then, the original IRLS can be actually applied to the nonsmooth and nonconvex problem (20), which is given by
Since the size of our measurement matrix is very large, finding the exact solution of this linear equation is time consuming and it seem to be impossible in many cases.
The number l of nonzero elements of the sparse signal is fixed at 2000, and the locations of nonzero elements are randomly chosen. The values of nonzero elements are selected from standard Gaussian distribution. The observed data b is measured by the formula
where n is the Gaussian white noise with mean 0 and standard deviation 0.02. The regularization parameters are fixed at for (20) or for (21) in all tests. The values of are also fixed at . The proximity parameter in our method is set to be because the norm of a partial DCT matrix is less than or equal to 1.
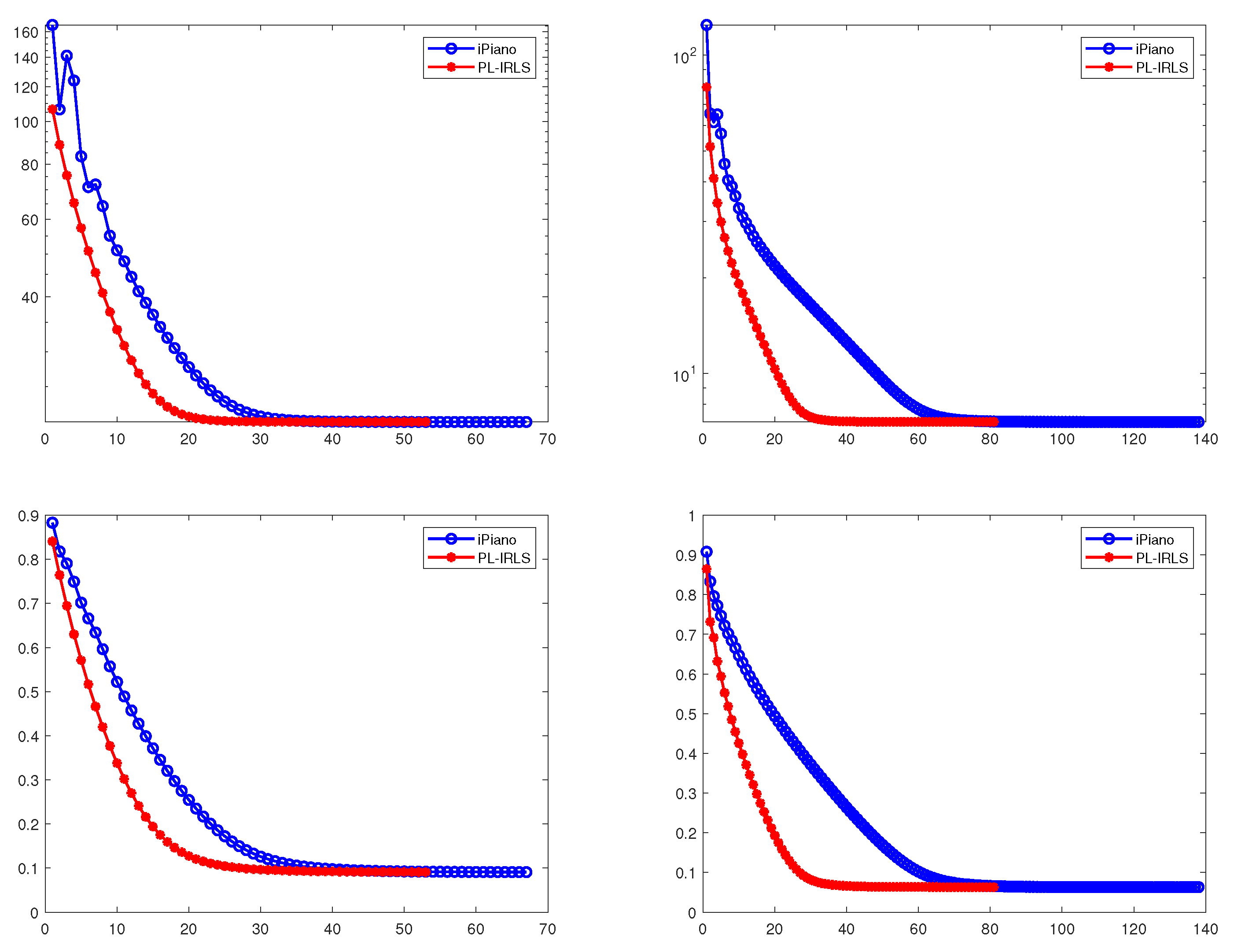
We present the mean values and standard deviations over 100 trials of computing time, number of iterations, energy value and relative error in Table 2. In Figure 2, we plot the relative errors and energy values of PL-IRLS and iPiano over iterations. Figure 2 shows the convergence of PL-IRLS and iPiano. For the tests, average values of the energy value and relative error for PL-IRLS are almost same with those for the iPiano. This shows that PL-IRLS and iPiano recover almost the same sparse solutions. Hence, it demonstrates the similar performance between PL-IRLS and iPiano in terms of the accuracy and optimization of energy functional. On the other hand, it can be observed in Table 2 and Figure 2 that PL-IRLS is faster than iPiano. Therefore, PL-IRLS is superior to iPiano for solving the nonconvex and nonsmooth problems (20) and (21). In conclusion, PL-IRLS gives better performance over iPiano.
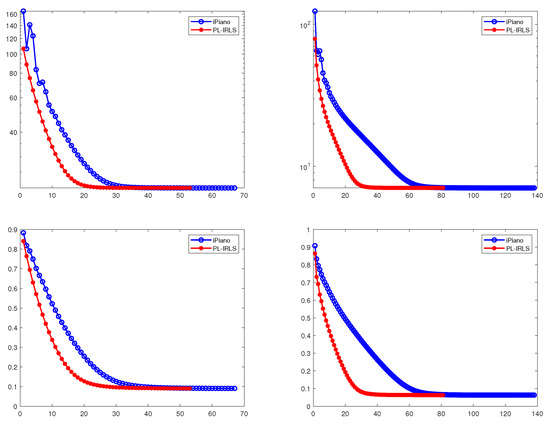
5. Conclusions
In this paper, we proposed proximal linearized reweighted algorithms to solve nonconvex and nonsmooth unconstrained minimization problem (1). Based on the general unified framework, we suggested an extension of the iterative convex majorization–minimization method for solving (1). Moreover, extended versions of the iteratively reweighted algorithm and iterative least square algorithm were also introduced. The global convergence of the proposed algorithm was also proved under uncertain assumptions. Lastly, the numerical results related to compressive sensing demonstrated that the proposed methods provides the outstanding performance compared with state-of-the-art methods. Recently, several algorithms were extended by imposing an additional inertial term, resulting in a faster convergence rate. In future, we will study a proximal linearized reweighted algorithm with an inertial force.
Author Contributions
Conceptualization, M.K.; Formal analysis, J.Y. and M.K.; Funding acquisition, M.K.; Methodology, J.Y. and M.K.; Software, M.K.; Validation, J.Y. and M.K.; Writing original draft, J.Y. and M.K.; Writing review and editing, J.Y. and M.K. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by research fund of Chungnam National University.
Acknowledgments
The authors would like to thank the referees for their helpful comments. The authors would like to thank Chungnam National University for funding support.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| l.s.c. | Lower semicontinuous |
| ICMM | Iterative convex majorization–minimization method |
| KL | Kurdyka–Łojasiewicz |
| PL-ICMM | Proximal linearized iterative convex majorization–minimization method |
| PL-IRL1 | Proximal linearized iteratively reweighted algorithm |
| PL-IRLS | Proximal linearized iteratively reweighted least square algorithm |
| IRL1 | Iteratively reweighted algorithm |
| DCT | discrete cosine transform |
References
- Curry, H.B. The method of steepest descent for non-linear minimization problems. Q. Appl. Math. 1944, 2, 258–261. [Google Scholar] [CrossRef] [Green Version]
- Nesterov, Y.E. A method for solving the convex programming problem with convergence rate O . Dokl. Akad. Nauk Sssr 1983, 269, 543–547. [Google Scholar]
- Beck, A.; Teboulle, M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef] [Green Version]
- Rockafellar, R.T. Monotone operators and the proximal point algorithm. SIAM J. Control Optim. 1976, 14, 877–898. [Google Scholar] [CrossRef] [Green Version]
- Kaplan, A.; Tichatschke, R. Proximal point methods and nonconvex optimization. J. Glob. Optim. 1998, 13, 389–406. [Google Scholar] [CrossRef]
- Gong, P.; Zhang, C.; Lu, Z.; Huang, J.; Ye, J. A general iterative shrinkage and thresholding algorithm for non-convex regularized optimization problems. In Proceedings of the 30th International Conference on Machine Learning. PMLR 2013, 28, 37–45. [Google Scholar]
- Attouch, H.; Bolte, J.; Redont, P.; Soubeyran, A. Proximal alternating minimization and projection methods for nonconvex problems: An approach based on the Kurdyka-Łojasiewicz inequality. Math. Oper. Res. 2010, 35, 438–457. [Google Scholar] [CrossRef] [Green Version]
- Candes, E.J.; Wakin, M.B.; Boyd, S.P. Enhancing sparsity by reweighted ℓ1 minimization. J. Fourier Anal. Appl. 2008, 14, 877–905. [Google Scholar] [CrossRef]
- Lai, M.J.; Xu, Y.; Yin, W. Improved iteratively reweighted least squares for unconstrained smoothed ℓq minimization. SIAM J. Numer. Anal. 2013, 51, 927–957. [Google Scholar] [CrossRef]
- Ochs, P.; Dosovitskiy, A.; Brox, T.; Pock, T. On iteratively reweighted algorithms for nonsmooth nonconvex optimization in computer vision. SIAM J. Imaging Sci. 2015, 8, 331–372. [Google Scholar] [CrossRef]
- Łojasiewicz, S. Sur la géométrie semi-et sous-analytique. Ann. l’Institut Fourier 1993, 43, 1575–1595. [Google Scholar] [CrossRef]
- Łojasiewicz, S. Une propriété topologique des sous-ensembles analytiques réels. Les Équations aux Dérivées Partielles 1963, 117, 87–89. [Google Scholar]
- Bolte, J.; Daniilidis, A.; Lewis, A.; Shiota, M. Clarke subgradients of stratifiable functions. SIAM J. Optim. 2007, 18, 556–572. [Google Scholar] [CrossRef] [Green Version]
- Bolte, J.; Daniilidis, A.; Lewis, A. The Lojasiewicz inequality for nonsmooth subanalytic functions with applications to subgradient dynamical systems. SIAM J. Optim. 2007, 17, 1205–1223. [Google Scholar] [CrossRef]
- Bolte, J.; Combettes, P.L.; Pesquet, J.C. Alternating proximal algorithm for blind image recovery. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 1673–1676. [Google Scholar] [CrossRef] [Green Version]
- Attouch, H.; Bolte, J. On the convergence of the proximal algorithm for nonsmooth functions involving analytic features. Math. Program. 2009, 116, 5–16. [Google Scholar] [CrossRef]
- Ochs, P.; Chen, Y.; Brox, T.; Pock, T. iPiano: Inertial proximal algorithm for nonconvex optimization. SIAM J. Imaging Sci. 2014, 7, 1388–1419. [Google Scholar] [CrossRef]
- Attouch, H.; Bolte, J.; Svaiter, B.F. Convergence of descent methods for semi-algebraic and tame problems: Proximal algorithms, forward–backward splitting, and regularized Gauss–Seidel methods. Math. Program. 2013, 137, 91–129. [Google Scholar] [CrossRef]
- Osher, S.; Mao, Y.; Dong, B.; Yin, W. Fast linearized Bregman iteration for compressive sensing and sparse denoising. Commun. Math. Sci. 2010, 8, 93–111. [Google Scholar]
- Bolte, J.; Sabach, S.; Teboulle, M. Proximal alternating linearized minimization for nonconvex and nonsmooth problems. Math. Program. 2014, 146, 459–494. [Google Scholar] [CrossRef]
- Rockafellar, R.T.; Wets, R.J.B. Variational Analysis; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009; Volume 317. [Google Scholar]
- Mordukhovich, B.S.; Nam, N.M.; Yen, N. Fréchet subdifferential calculus and optimality conditions in nondifferentiable programming. Optimization 2006, 55, 685–708. [Google Scholar] [CrossRef] [Green Version]
- Bochnak, J.; Coste, M.; Roy, M.F. Real Algebraic Geometry; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013; Volume 36. [Google Scholar]
- Wilkie, A.J. Model completeness results for expansions of the ordered field of real numbers by restricted Pfaffian functions and the exponential function. J. Am. Math. Soc. 1996, 9, 1051–1094. [Google Scholar] [CrossRef]
- Dries, L.P.D.v.d. Tame Topology and O-Minimal Structures; Cambridge University Press: Cambridge, UK, 1998; Volume 248. [Google Scholar]
- Kang, M. Approximate versions of proximal iteratively reweighted algorithms including an extended IP-ICMM for signal and image processing problems. J. Comput. Appl. Math. 2020, 376, 112837. [Google Scholar] [CrossRef]
- Combettes, P.L.; Wajs, V.R. Signal recovery by proximal forward-backward splitting. Multiscale Model. Simul. 2005, 4, 1168–1200. [Google Scholar] [CrossRef] [Green Version]
- Chartrand, R.; Yin, W. Iteratively reweighted algorithms for compressive sensing. In Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NV, USA, 31 March–4 April 2008; pp. 3869–3872. [Google Scholar]
- Daubechies, I.; DeVore, R.; Fornasier, M.; Güntürk, C.S. Iteratively reweighted least squares minimization for sparse recovery. Commun. Pure Appl. Math. 2010, 63, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Needell, D. Noisy signal recovery via iterative reweighted L1-minimization. In Proceedings of the 2009 Conference Record of the Forty-Third Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 1–4 November 2009; pp. 113–117. [Google Scholar]
- Sun, T.; Jiang, H.; Cheng, L. Global convergence of proximal iteratively reweighted algorithm. J. Glob. Optim. 2017, 68, 815–826. [Google Scholar] [CrossRef]
- Ji, Y.; Yang, Z.; Li, W. Bayesian sparse reconstruction method of compressed sensing in the presence of impulsive noise. Circuits Syst. Signal Process. 2013, 32, 2971–2998. [Google Scholar] [CrossRef]
- Javaheri, A.; Zayyani, H.; Figueiredo, M.A.; Marvasti, F. Robust sparse recovery in impulsive noise via continuous mixed norm. IEEE Signal Process. Lett. 2018, 25, 1146–1150. [Google Scholar] [CrossRef]
- Wen, F.; Liu, P.; Liu, Y.; Qiu, R.C.; Yu, W. Robust Sparse Recovery in Impulsive Noise via ℓp-ℓ1 Optimization. IEEE Trans. Signal Process. 2016, 65, 105–118. [Google Scholar] [CrossRef]
- Wen, J.; Weng, J.; Tong, C.; Ren, C.; Zhou, Z. Sparse signal recovery with minimization of 1-norm minus 2-norm. IEEE Trans. Veh. Technol. 2019, 68, 6847–6854. [Google Scholar] [CrossRef]
- Wen, F.; Pei, L.; Yang, Y.; Yu, W.; Liu, P. Efficient and robust recovery of sparse signal and image using generalized nonconvex regularization. IEEE Trans. Comput. Imaging 2017, 3, 566–579. [Google Scholar] [CrossRef] [Green Version]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).