We propose a variety of shrinkage estimators for simultaneously estimating individual means, and discuss their properties. In particular, we theoretically prove that the proposed estimators have better precision than the individual studies’ estimates in terms of a mean squared error criterion under some conditions.
Indeed, there are infinitely many estimators
that improve upon
, including very complex and unrealistic ones [
25]. In addition, it is quite easy to find an estimator that locally improves upon
, such as
. While the problem of deriving/assessing estimators has been intensively discussed in the statistical decision theory, it has rarely been appreciated in meta-analytical settings. The goal of this article is to facilitate the applications of shrinkage estimators in the context of meta-analyses.
In the subsequent sections, we will introduce three estimators that help reduce the WMSE and TMSE by shrinking
toward a restricted space of
.
Section 3.1 will discuss the shrinkage towards the zero vector
, the most traditional shrinkage scheme.
Section 3.2 will consider the shrinkage toward
under constraints
.
Section 3.3 will explore the shrinkage towards the
sparse space
.
3.1. Shrinkage Estimation for Means
To estimate
, we propose the James–Stein (JS) estimator of the form
This estimator is a modification of the original JS estimator [
29] that was derived under the unit variances (
for
). See
Appendix A.1 for the details. The JS estimator reduces variance by shrinking the vector
toward
while it produces bias. The degree of shrinkage is determined by the factor
that usually ranges from 0 (0% shrinkage) to 1 (100% shrinkage), and occasionally becomes greater than 1 (overshrinkage).
It can be shown in
Appendix A.1 that
has the following WMSE
where
is a random variable having a noncentral
-distribution with the noncentral parameter
and the degrees of freedom
. Thus,
has a smaller WMSE than
when
. Indeed, the WMSE is minimized at
at which the WMSE is
by the inverse moment of the central
-distribution with
. Thus, the JS estimator gains the greatest advantage if all the individual means are zero. This gain is appealing for meta-analyses for small individual effects (true means close to zero). Even if
, the JS estimator has a smaller WMSE than
. The reduction of the WMSE diminishes as
departs from zero.
One might ask where the special formula of the JS estimator comes from. The JS estimator
can be derived as an empirical Bayes estimator under the prior
:
where the shrinkage factor
is the estimator of
. See
Appendix A.2 for the detailed derivations. Thus, if
, the JS estimator minimizes the Bayes risk, and hence, is the optimal estimator under the prior.
A minor modification to the JS estimator can reduce the WMSE further. The modification is made in order to avoid the effect of an overshrinkage,
, by which all the signs of
are reverted. The overshrinkage phenomenon occurs with a small probability, and therefore, the modification is minor in the majority of cases. A modified estimator is the
positive-part JS estimator
where
. Consequently,
has a smaller WMSE than
(p. 356, Theorem 5.4 of [
25].
In summary, this subsection proposes two estimators ( and ) that improve upon the standard unbiased estimator .
3.2. Estimation under Ordered Means
Our next proposal is a shrinkage estimator under ordered means. We consider the case where the ordering constraints are known by the study design. Thus, the parameter is known to be restricted on the space . For instance, suppose that represents the time index ( for the oldest study, and for the newest study) at which a treatment effect is estimated. Then, one may assume a trend due to the improvements of treatments over time.
For instance, the true means may be . This trend could be modeled by a meta-regression with , where values and are unknown. In practice, one does not know any structure of the means (e.g., linear regression) except for . If some knowledge, such as a linear model on covariates, is true, one could use meta-regression. However, we do not adopt any model, permitting various non-linear settings such as and .
The use of the standard unbiased estimator
is not desirable under the ordering constraints. Due to random variations, the estimator
can be outside the parameter space, namely,
. Under this setting, an estimator accounting for the parameter restriction improves upon the unrestricted estimator
, even though the former is a biased estimator [
30].
The restricted maximum likelihood (RML) estimator satisfying
is calculated by the pool-adjacent-violators algorithm (PAVA)
This gives the RML estimator
, which has a smaller WMSE than
. For an example of
, one has the data of
, and the PAVA results in
Hence,
is equal to
itself or an average including
. Of course,
if
. For theories and applications of the PAVA, we refer to [
31,
32,
33]. The max min formula written above can be found in Chapter 8 of [
30] or [
34].
It is clear that
is different from order statistics
that are a permutation of
and also improve the WMSE in some cases [
34]. However, the permuted estimator loses the information of individual studies’ identifications, and therefore, is not considered in this article.
Below, we further improve
with the aid of the JS estimator. Let
be the indicator function;
or
if
is true or false, respectively. We adjust the estimator of Chang [
35] who proposed the JS-type estimator under the order restriction as follows:
where “RJS” stands for “Restricted JS”. Note that
has a smaller WMSE than
, and hence, the former improves upon the latter [
35].
We further improve the RJS estimator by the positive-part RJS estimator given by
Consequently,
has a smaller WMSE than
(Theorem 5.4 of Lehmann and Casella [
25]). Note that, if
is not satisfied, then
.
In summary, this subsection proposes three estimators (, , and ) that improve upon the standard unbiased estimator under .
3.3. Estimation under Sparse Means
Our third proposal is a shrinkage estimator under
sparse normal means where most of the
s are zero [
27,
28]. The vector
is called
sparse if the number
is much smaller than
, e.g.,
. In practice, one does not know which components are zeros, and how many components are zero. Nonetheless, one could assume that many of
are zero. However, the elements of
are almost always nonzero, which disagree with the true values
.
Under the sparse means, it is quite reasonable to estimate
as exactly zero if
is close to zero. Accordingly, one can use a thresholding estimator
for a critical value
. The idea was proposed by Bancroft [
36] who formulated
pretest estimators that incorporate a preliminary hypothesis test into estimation. Judge and Bock [
37] extensively studied pretest estimators with applications to econometrics; see also more recent works [
38,
39,
40,
41,
42,
43]. Among all, we particularly note that Shih et al. [
41] proposed the
general pretest (GPT) estimator that includes empirical Bayes and Types I-II shrinkage pretest estimators for the univariate normal mean.
We modify the GPT estimator to be adopted to meta-analyses as follows:
for
,
, and
is the upper
p-th quantile of
for
. To implement the GPT estimator, the values of
and
, and the probability function
must be chosen. They cannot be chosen to minimize the WMSE and TMSE criteria since pretest estimators do not permit tractable forms of MSEs [
38,
41]. Fortunately, for any value of
and
, and a function
, one can show that
has smaller WMSE and TMSE values than
provided
; see
Appendix A.3 for the proof.
For the above reasons, we apply statistically interpretable choices of
,
, and
. The special case of
leads to the usual pretest estimator
for which
is arbitrary. Thus, we retain
if
is rejected in favor of
at the 5% level. Otherwise, we discard
, and conclude
.
For the GPT estimator, we set
(50% shrinkage) as suggested by Shih et al. [
41]. To facilitate the interpretability of pretests, we chose
(5% level) and
(10% level). Thus, we propose the estimator
Thus, if is rejected at the 5% level, we set . If is accepted at the 5% level, but rejected at the 10% level, we set . If is accepted at the 10% level, we set . Thus, gives a weaker shrinkage than does. Obviously, we obtain a relationship .
The GPT estimator introduced above is not an empirical Bayesian estimator. If
,
, and
were chosen, the resultant GPT estimator would be an empirical Bayes estimator [
41]. However, we do not consider this estimator in our analysis.
In summary, this subsection proposes two estimators ( and ) that improve upon the standard unbiased estimator provided .





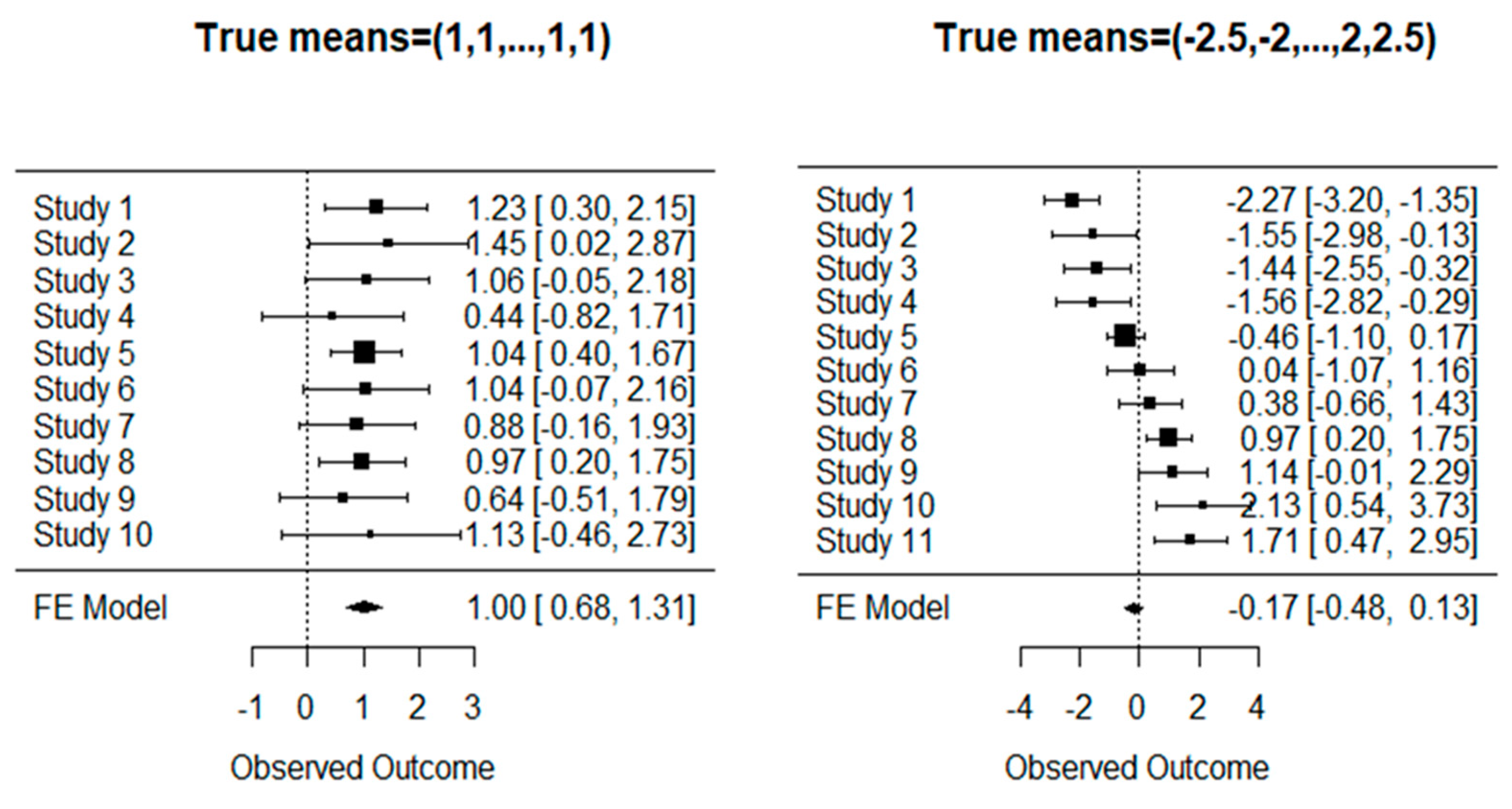{kind=link}