1. Introduction
Decanter centrifuges are continuously working apparatuses for solid-liquid separation [
1]. Within the centrifuge, settling, sediment consolidation, and sediment transport take place simultaneously. The machine is flexible in its application through a variety of adjustable machine and process variables. These parameters, however, influence each other, so that the same separation result can be obtained with different combinations of parameters [
2]. This increases the difficulty of dimensioning and modelling the decanter centrifuge. There are three general modelling options: purely parametric modelling, purely non-parametric modelling, or a combination of both.
The use of artificial neural networks (ANN) as non-parametric models to solve engineering tasks has increased in the recent years [
3,
4,
5,
6]. These networks serve as universal function approximators, i.e., they are able to reflect arbitrarily defined model functions. The advantage of an ANN-based model is that it can be created and used without an a-priori knowledge of the physical correlations in the actual process. But, the setup of an ANN requires knowledge and experience about how to create such a model. However, the quality and quantity of the data available for training and testing are crucial. If the data is noisy or sparse, the reliability of the ANN decreases. On the other hand, relevant parameters are often available and mathematical-physical basic equations, empirical correlations, or numerical models already exist as parametric models investigating technical processes. However, such approaches are often connected with specific assumptions, which, in some cases, can deviate significantly from reality. Grey box modelling represents a modelling approach that consists of a parametric and a non-parametric model. Combining the two principal methods has several advantages compared to the individual view, which is described more detailed later in this article.
Gonzalez-Fernandez et al. [
7] provide a review of publications about the use of artificial intelligence in olive oil production, where centrifuges are commonly used.
Funes et al. [
8] introduce an ANN predicting quality parameters of olive oil during its processing in a disc stack separator. Process variables, like the feed temperature and the feed flow of oil must and water and the temperature and the flow of oil at the outlet, serve as input parameters for the ANN. Near-infrared sensors at the outlet measure specific quality parameters, which are used as output parameters. The feed-forward, backpropagation ANN is designed to correlate the quality parameters as a function of the process variables to predict the machine and product behaviour for process regulation and optimisation.
Jiménez et al. [
9,
10] use a neural network designed for the optimisation of an olive oil elaboration process in a decanter centrifuge. Qualitative parameters of the fruit, like fat content and moisture, and process variables of the feed, like temperature, flow rate, and dilution ratio serve as input. The aim is to predict the fat content of olive pomace and oil moisture by means of applying an ANN. The authors have shown that this approach allows reasonable predictions for this specific application. However, the authors also clarify that the influence of other essential process variables of the machine, such as pool depth, rotational speed, and differential speed, cannot be predicted with the neural network based on the applied training data set. This requires either an extension of the training data regarding the effects to be modelled or mathematical models that describe the correlations.
In general, purely ANN modelling approaches are often highly specialised for their purpose. Thus, transfer to other applications or extension of variables, if it is necessary, require redesign and further training of the system. The generalisation of such approaches is often a major challenge.
Thompson and Kramer [
11] present a method to develop a grey box model in chemical processes. They use a simple process model, boundary conditions and equations known beforehand to enhance a neural network. This supports the network to compensate for the lack and low quality of the data, and thus extends the range of application. As an exemplary case study, the authors describe the synthesis of a grey box model for a fed-batch penicillin fermentation.
Menesklou et al. [
12] introduce a dynamic process model for decanter centrifuges. The model enhances the work by Gleiss et al. [
13] integrating the conical part of the decanter centrifuge. Furthermore, improved material functions are derived to consider shear thickening effects during sediment consolidation. This mechanistic approach considers settling behaviour, sediment consolidation and sediment transport. Additionally, the authors have validated the model with experiments using different calcium carbonate water slurries and decanter centrifuges from lab- to industrial-scale [
14]. In some applications, for example at relatively deep pool depths, local turbulence and flows in some areas of the centrifuge can influence the separation result. The assumption of a plug flow in these areas is no longer applicable. One possibility to characterise this behaviour is a complex flow simulation using Computational Fluid Dynamics (CFD) [
15]. An alternative possibility is the use of a grey box model. The articles described previously have shown that it is indeed possible to model technical processes and especially centrifuges using ANN. However, these cases are often very specific and typically limited to their specific applications. Combining a numerical process model, for example as described in Menesklou et al. [
12], with a neural network is intended to extend and generalise the overall range of applications.
This article presents the development of a grey box model based on a dynamic process model and a neural network. For this purpose, the parametric model by Menesklou et al. [
12] is combined with a neural network and trained with experimental data to consider such specific flow effects on the separation behaviour at rather deep pool depths. In general, this extends the application range of the numerical process model without losing the advantages of a process model. As a result, the simulation tool can
learn to consider further effects and thus to increase its accuracy and scope.
3. Methodology
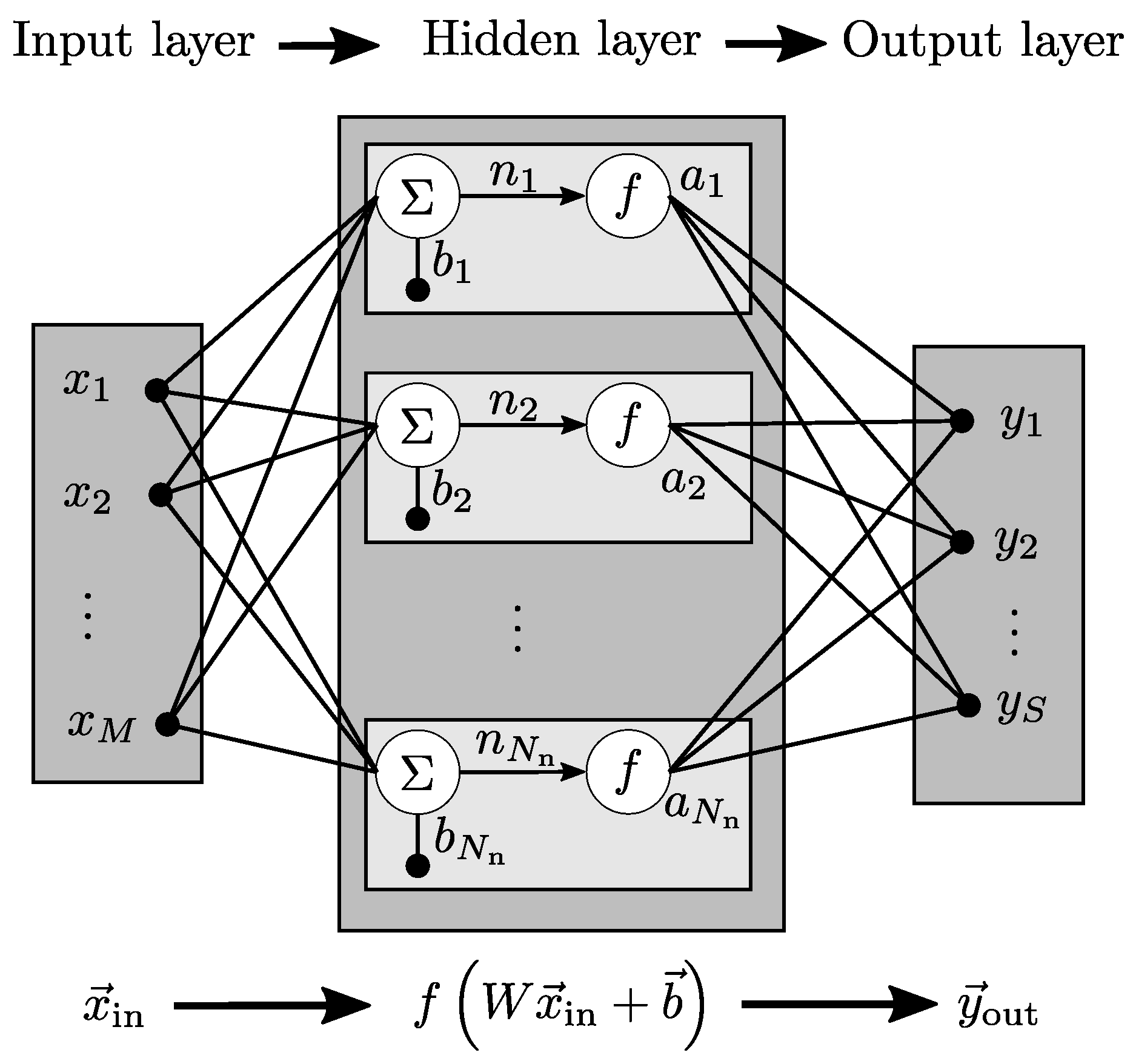
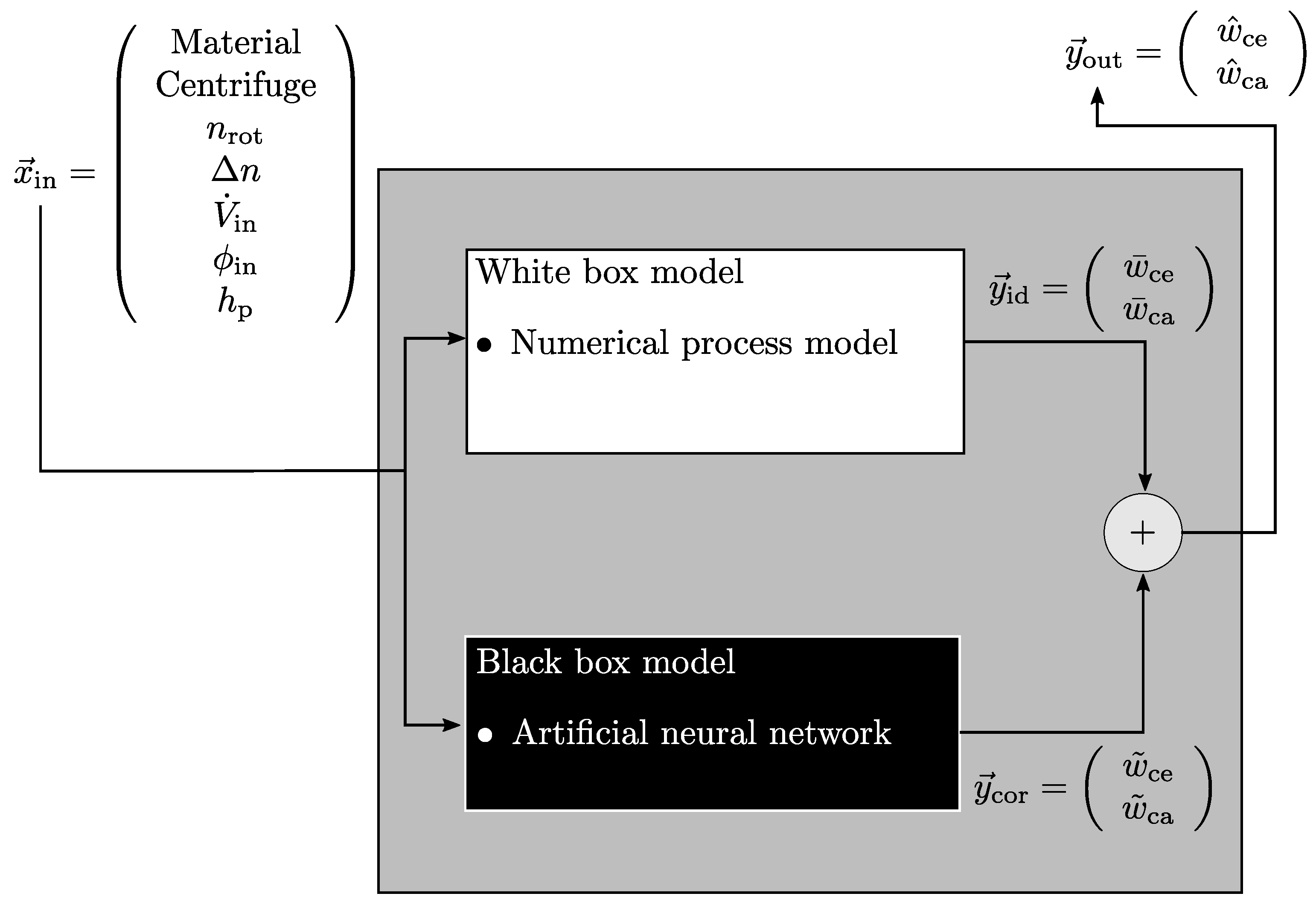
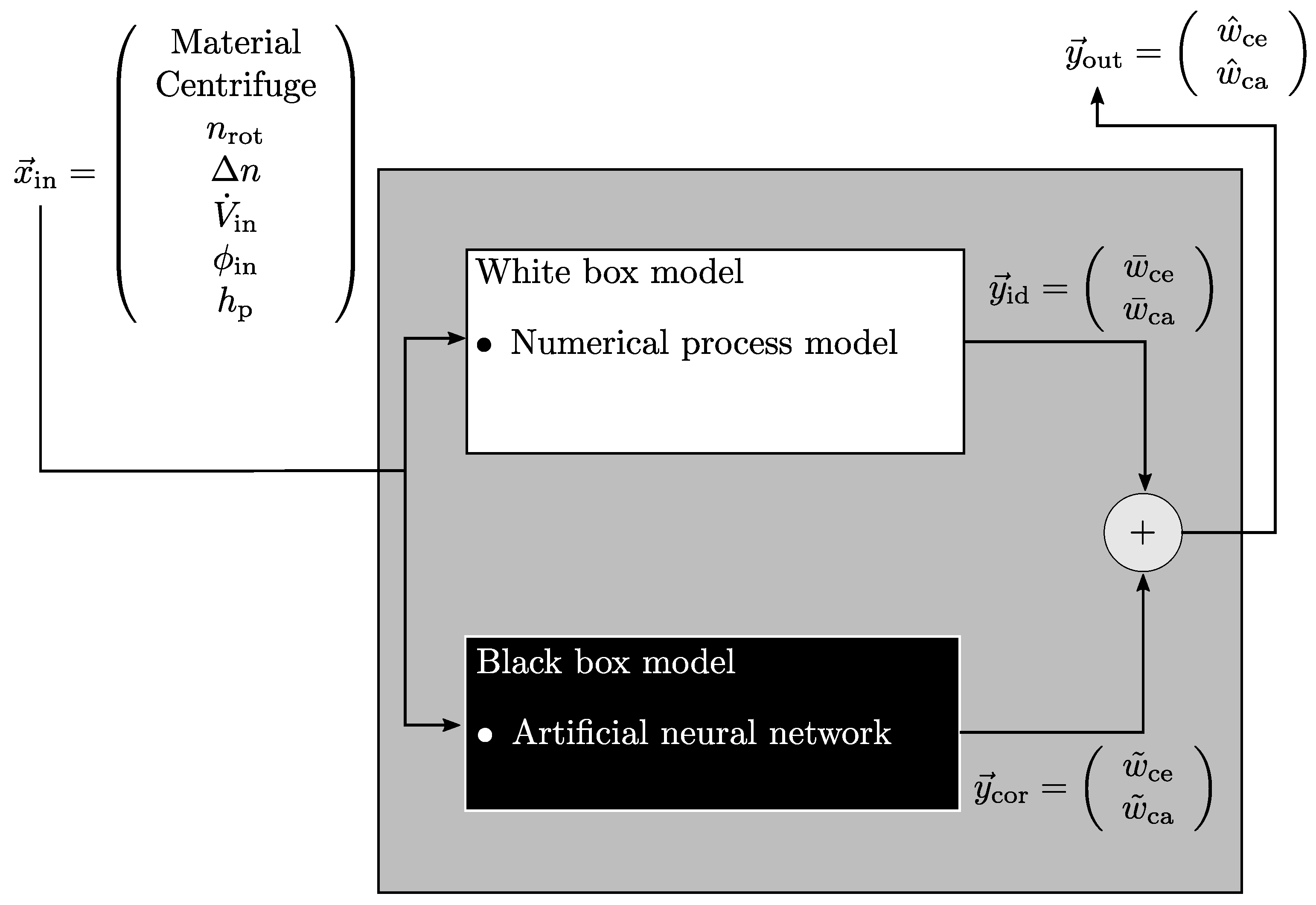
The grey box model used in this article is a stationary one and its structure is parallel, which is shown schematically in
Figure 3.
The rotational speed
, differential speed
, volumetric flow rate
, solids volume fraction at the inlet
, and the pool depth
are used as input variables
. These represent typical process variables which are essential for the application of decanter centrifuges in the actual production process. The input variables are passed to the white box and black box. A numerical process model, as described in the previous section, is implemented for the white box model. Thus, this part represents the physical basis and serves as an ideal estimator for the simulated process. The simulated output
consists of the solids mass fraction of the centrate
and cake
. Furthermore, the black box is a neural network that corrects the simulation data according to the input variables and adjustment, if it is necessary. Adding the ideal, physical simulation result
to the correction value
from the neural network,
leads to the overall output
. In this case, the black box model is designed to potentially correct the white box model in the trained area. Therefore, summation is selected to combine both output components. Beyond the trained area, the grey box model only uses the white box model results. At this point it should be noted that in principle the grey box model may also be used in areas where the white box model would fail entirely, but, the focus of the study lies on the interpolative use, which is why it will not be discussed further. However, correction does not mean that the simulation results are unreliable and have to be corrected in all cases. In previous works [
12,
13,
14] it was demonstrated that the method is indeed valid. Here, an enhancement must be created to consider effects that have not been modelled or to cover cases where no physical equations are known. The used neural network is a multilayer perceptron (a subcategory of feedforward networks) with an input and output layer and one hidden layer, which uses a sigmoid function as activation function. The number of neurons is optimised (
) via a bayesian optimisation and later varied from 3 to 50 to be discussed in the following section. The trained model can under- or overfit the data, since no physical equation is given as a basis, which determines the principal characteristics and trends of the data. Thus, underfitting means that the model does not adequately describe the trend of the data and overfitting means that the model captures almost every dependency including, for example, measurement inaccuracies, which is not a reasonable interpretation of the data. Therefore, a bayesian regularisation backpropagation algorithm is chosen to train the neural network. This technique includes a bayesian regularisation within the framework of the Levenberg-Marquardt algorithm [
23]. It is specifically developed to have good generalisation capabilities [
24,
25] and to be practicable for limited training data access. Typically, the mean of the sum of squared network errors MSE is used during training of feedforward neural networks to evaluate the performance of the network. The MSE is defined as follows:
Here,
is the number of training data,
is the network error. For a given number of neurons, the network adjusts the weights so that the MSE becomes minimal. With more neurons, the network tends to better reproduce the training data, which can lead to overfitting. This is reflected by the fact that the individual weights become relatively large. The evaluation function for the bayesian regularisation training algorithm is enhanced by the mean of the sum of squared network weights MSW,
where
is the number of neurons and
are the weights of the neurons. This leads to the evalutation function for the bayesian regularisation training algorithm:
which combines the previously mentioned criterias MSE and MSW. The performance ratio
balances both components and is automatically adjusted during training [
24,
25]. Thus, overfitting is additionally considered and penalised, which leads to the fact that this training algorithm has good generalisation capabilities.
Because of tolerances of the analytics, measurement devices, and sampling, the experimental data contain a specific measurement error. Similarly, the simulations include a trust interval influenced by assumptions made in the modelling. Therefore, a trust interval for the deviation between simulation and experiment is determined. If the deviation is within this tolerance, the remaining deviation is not modelled by the neural network. This should reduce the sensitivity for under- and overfitting additionally. The trust interval is absolute for the deviation from the cake solids content and absolute for the centrate. These values were determined due to the possibility of representative sampling. A variation of the trust intervals is discussed later in the results section.
Table 1 lists the range and order of magnitude of the input variables with units.
For training, i.e., weighting of the individual nodes, it is more convenient that all data are of the same order of magnitude. Therefore, the dimensional data is normalised to the corresponding maximum value. As a result, the input values are always between zero and one. The correction parameter has the unit and can thus principally vary between 0 and 100 . The variable called relative correction parameter in the following section is the correction parameter related to 100 .
In this case, the data set consists of 62 individual data points. Each data point represents a parameter constellation between process variables and the output variables. Additionally, the individual data points are representative and informative. This means that they were determined to cover the required range of application and to be significant. In this case, the number of data points are few for the typical usage of neural networks. The measurement of the data points is associated with a significant experimental and time effort. Therefore, measurement data for parameter variations, as in this case, are only available to a limited amount from industrial practice. However, the flexibility of neural networks is a great advantage, which is why this methodology is used in this study. The neural network is intended to support a physically based white box model as a black box model in the concept of grey box modelling. The data set can also be easily extended with additional data points and the neural network can be retrained. This makes it possible to flexibly expand the range of applications. Typically, the data for neural networks is divided into training, testing, and validation data to determine the correct number of neurons and to avoid under- or overfitting. In this case, 50 data points (80%) were used for trainig, 6 data points (10%) for testing, and 6 data points (10%) for validation. The purpose is that the neural network is able to reproduce the data used. However, under- or overfitting can occur relatively easily and is therefore discussed in the results section. In this paper, the concept and methodology of grey box modelling is tested on the decanter centrifuge, where data is limited.
4. Results and Discussion
In this section, the settings of the neural network and validation of the training data are discussed.
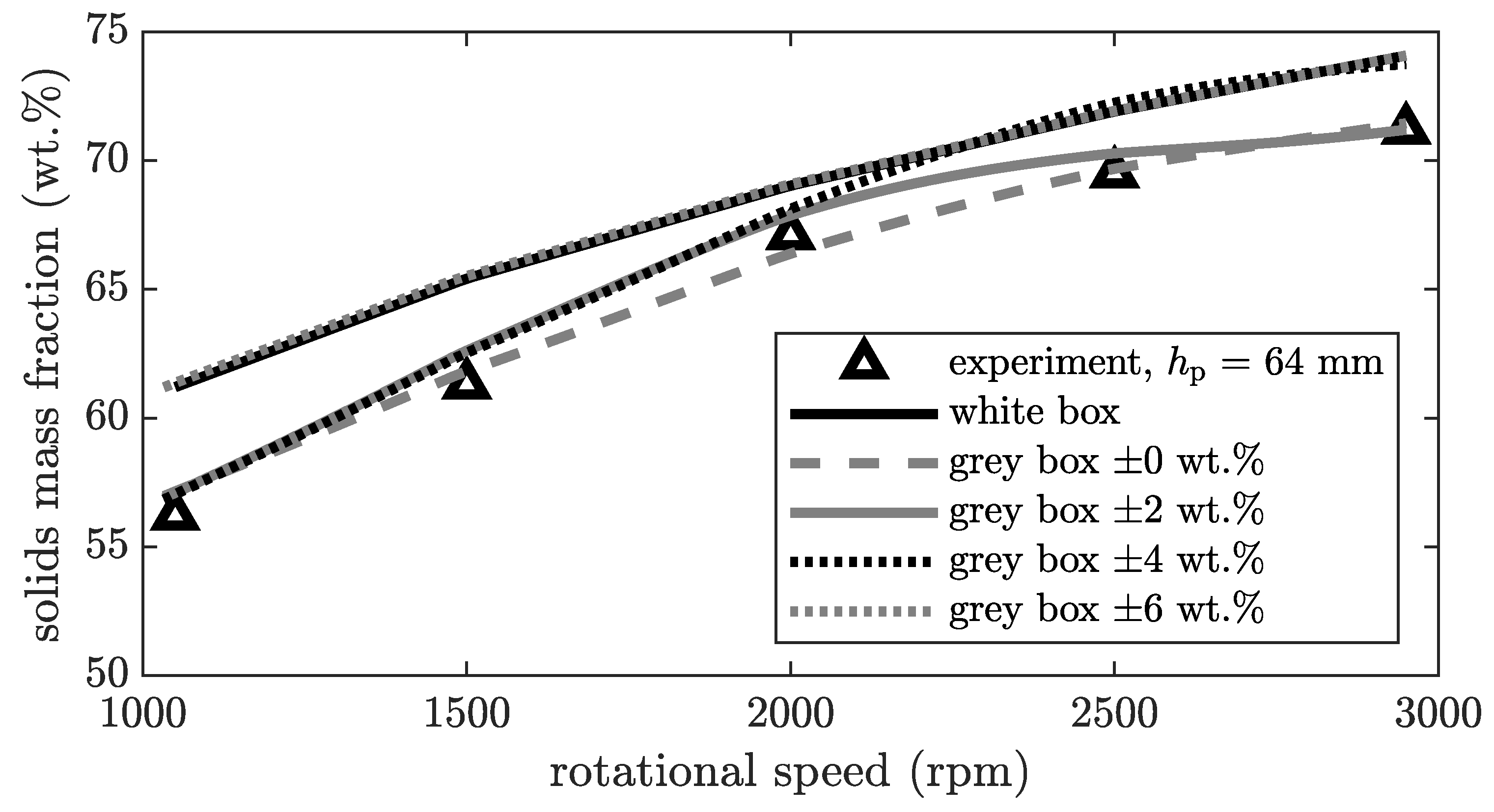
Figure 4 and
Figure 5 are based on a neural network with 42 neurons. The influence of the number of neurons is discussed later (see
Figure 6). In
Figure 4, the solids mass fraction of the cake is plotted against the rotational speed for a constant pool depth
, volumetric flow rate at the inlet
, and solids mass fraction at the inlet
.
The trust interval varies between and . As described previously, if the deviation between simulation and experiment is smaller than the trust interval, this deviation is not considered in the neural network. The output at the cake discharge represents a mean value over the whole sediment height. Based on preliminary tests, a trust interval of is determined. This means that the experimental part the training data for the neural network can be determined with this precision. A trust interval of means that the data can be measured perfectly and without error, which is not realistic and therefore not appropriate, although in this case the grey box model with a trust interval of describes the results best. For the neural network, all measurement inaccuracies are modelled and thus lead to overfitting of the system. The opposite is a trust interval of or even higher, meaning that the deviations between simulation and experiment are excluded and thus not modelled.
Figure 5 shows the solids mass fraction of the centrate as a function of the volumetric flow rate at the inlet for a constant rotational speed of
. The trust interval varies between
and
.
Sampling for a representative sample is easier with centrate than with cake, as the centrate is typically more liquid and homogeneous. Therefore, the trust interval for the centrate is smaller and is determined to be . As mentioned above, a trust interval of is not appropriate, because the experimental training data cannot be determined with this precision. All inaccuracies are modelled. However, there is no general rule or methodology to calculate the trust interval. It is a combination of the experimental error, which is calculable, and the quality of the simulations, which is difficult to quantify in detail. The quality of the simulation is about how much the simplifications and assumptions made during modelling affect the accuracy of the simulation result.
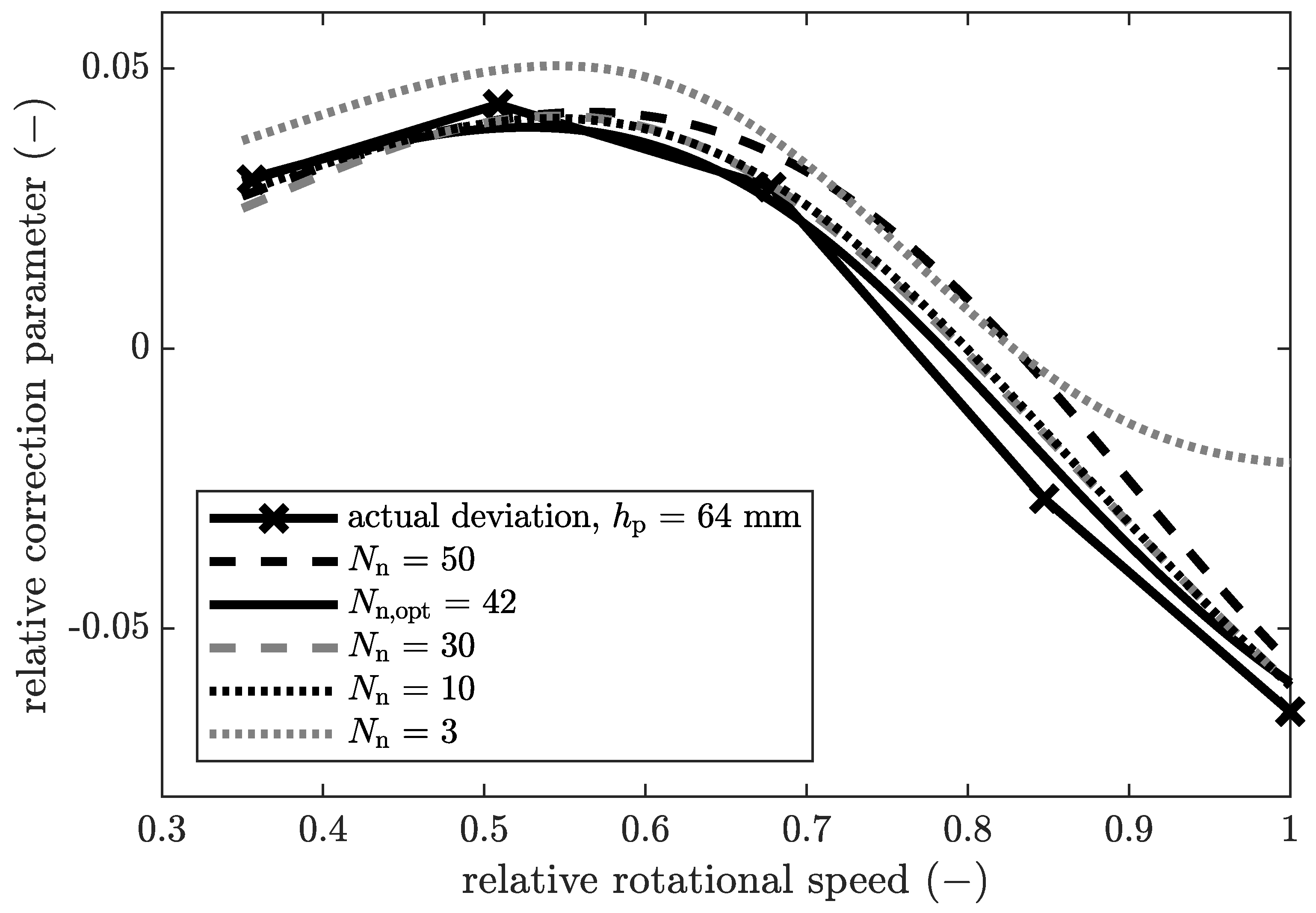
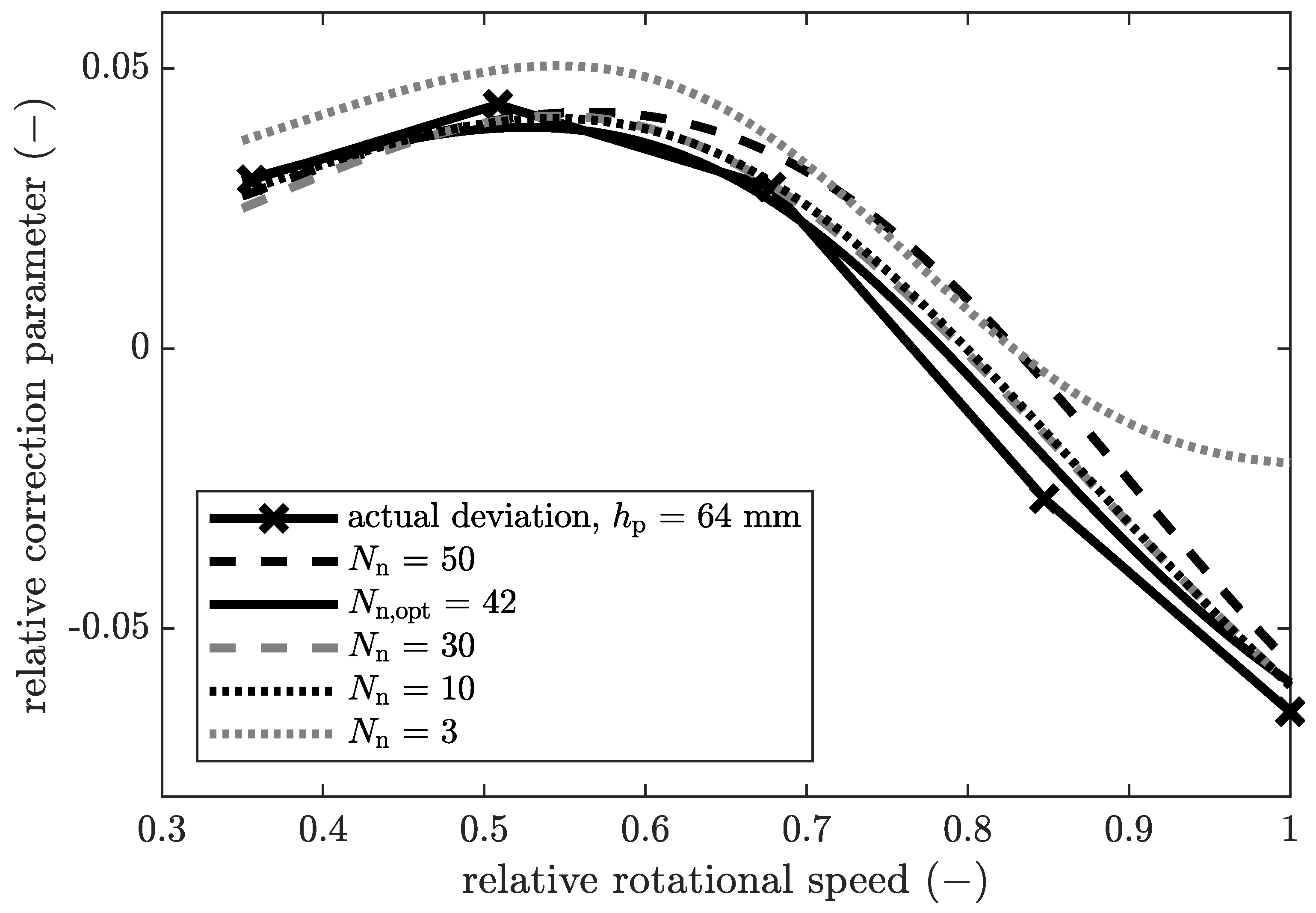
The analysis of a variation of the number of neurons in the hidden layer of the neural network is depicted in
Figure 6. The relative correction parameter for the solids mass fraction of the centrate is shown over the relative rotational speed.
Here, the experimentally determined correction parameter is compared to the trained neural network. This selection represents only a part of the total amount of data. Nevertheless, it is exemplary for the in principle behaviour of this neural network. For all neural networks with ten or more neurons, the actual deviation can be modelled tendentially. However, differences in accuracy can be seen in certain sections. Between relative rotational speeds of
and
, the graph for
deviates significantly from the experimentally determined data, which represent the actual deviation. For this network, the trend is not reproduced in this section. This indicates underfitting of this network. Typically,
is an extremely low value for the number of neurons. All other neural networks shown here map the training data very well. Furthermore, the curves do not show any overfitting. This is due to the bayesian regularisation backpropagation training algorithm that was developed specifically for this purpose.The number of neurons has only a minor influence on the quality and overfitting of the neural network in a wide range. Consequently, the model is more flexible in use, for example, when new data is included and the neural network needs to be retrained. This is a major advantage in engineering applications. By using Bayesian optimisation with neural networks [
26], the optimal number of neurons could be obtained automatically. This optimisation algorithm compares the RMSE of all networks and selects the one with the minimal RMSE. Based on these results, the following validation is carried out with
and a trust interval of
for the centrate and
for the cake of. In the following, the relative output of the black box model is shown in the upper graphs (a). The absolute output of the black box model is the difference between the white and grey box models and can therefore be derived in the graphs below (b).
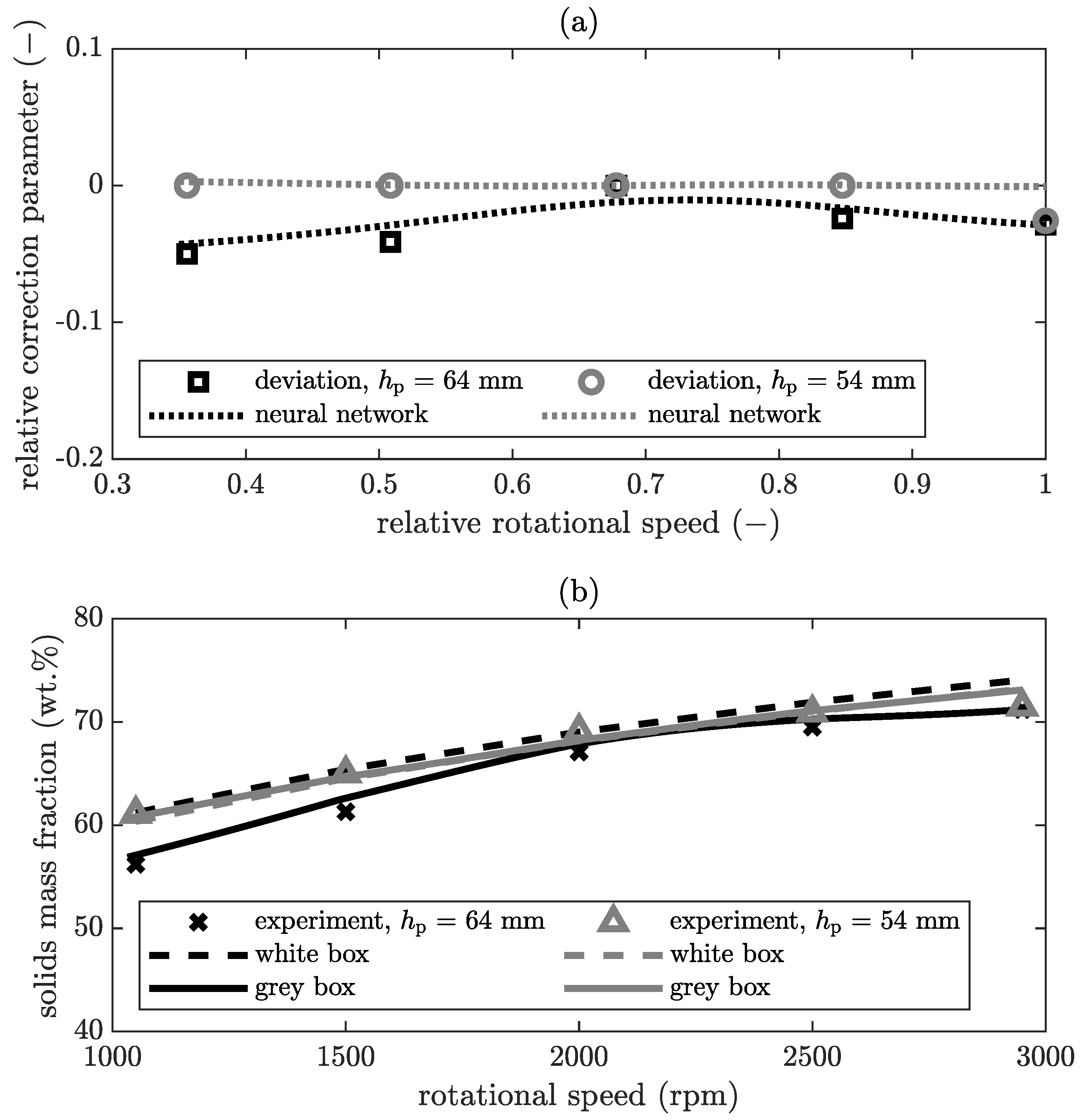
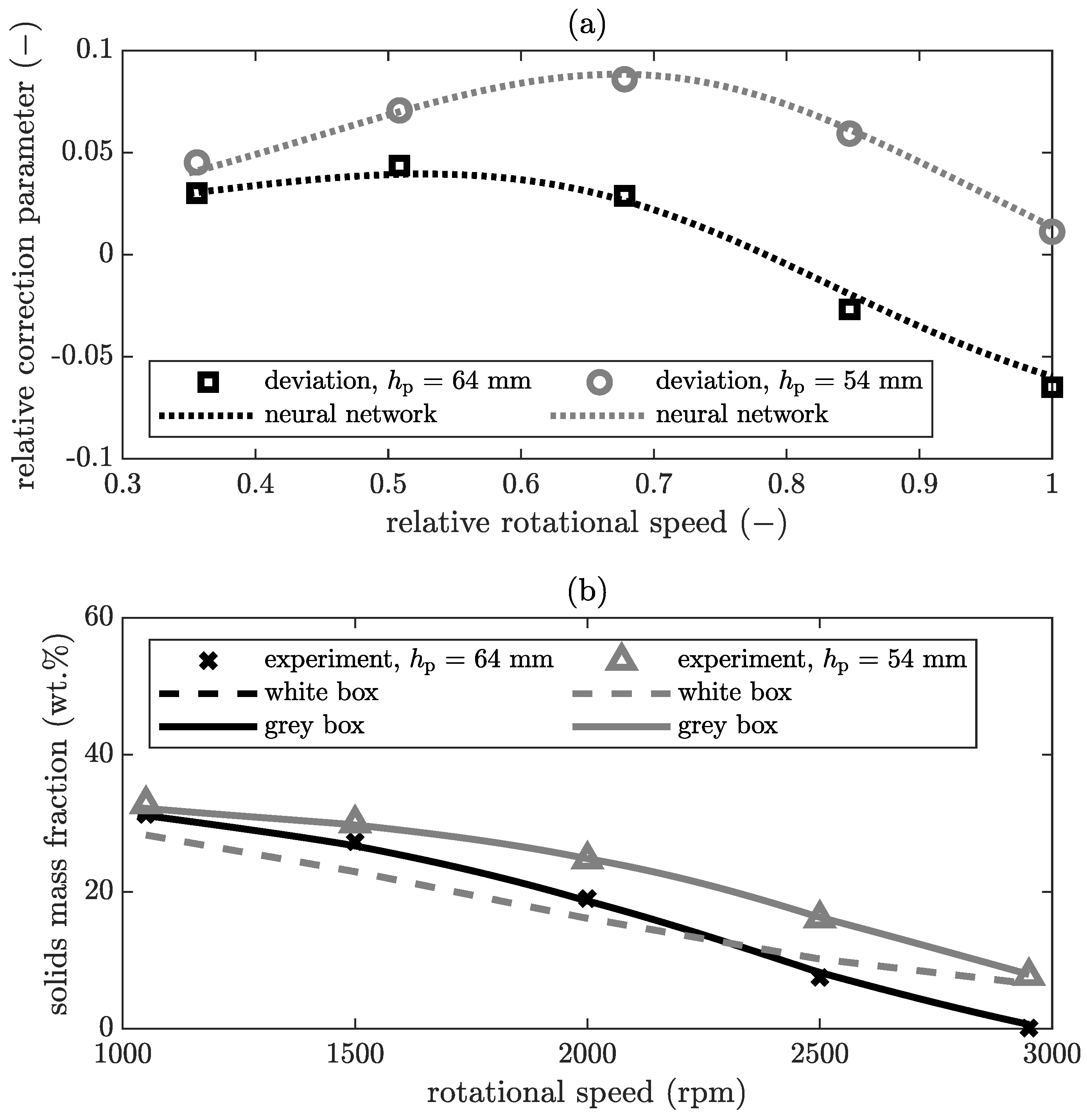
In
Figure 7a, the relative correction parameter is plotted over the relative rotational speed for the solids mass fraction of the cake. On this basis, the simulation of the white box model is adjusted and results in the grey box model. In
Figure 7b the corresponding result is compared between the experimental value, the result of the pure white box model and the grey box model.
The deviation function demonstrates that the neural network can model the actual deviation for this combination of parameters. For a pool depth of
, the deviations are within the range of the trust interval and are therefore not modelled. Thus, the results of the white and grey box model for a pool depth of
in
Figure 7b are similar. In the case of a pool depth of
, small deviations between white box model and experimental data exists which exceed the predefined trust interval. With the deviation function, the neural network describes these discrepancies to correct the white box model. As a result, the grey box model and white box model outputs differ in
Figure 7b. Now, the grey box model represents the experimental data better than the white box model. However, the trust interval is defined by the user and depends on the preferences of the user. The measurement error of the experiments can be determined relatively easily in this case, but it is difficult to evaluate the accuracy of the simulation. For the same parameters as in
Figure 7, the solids mass fraction in the centrate is displayed in
Figure 8.
Here again, the upper diagram in
Figure 8a demonstrates that the neural network describes the deviation. For both pool depths, the white box model follows the general trend that the solids mass fraction decreases with increasing rotational speed and the two white box models are basically equivalent, as the white box model is not sensitive enough to this difference in the pool depth. A more detailed discussion has been provided in previous publications with validation tests [
12,
14]. The experimental results reveal that for the same rotational speed, the solids mass fraction is higher at the smaller pool depth. Thus, the separation is better with increasing pool depth. However, the simulation shows no significant difference in the variation of the pool depth. There are several reasons for this. On the one hand, this is due to flow effects, such as the type of the developed flow, the effective pool depth, and the flow path due to the centrifuge geometry. This has an intensified influence if the pool is relatively deep and the centrifuge has a low degree of filling, which means that the volume flowing freely is tendentially larger. Leung et al. [
27] assume that a so-called stagnant layer is formed on the surface under which the pool stands. This means that a particle is considered to be separated when it migrates out of the stagnating layer. However, there are contrary opinions in the literature about the conditions under which this stagnant layer is formed. Such flow phenomena affect the residence time behaviour of the particles. For this reason, the assumption of a developed plug flow along the entire pool depth up to the sediment surface for the calculation of the separation efficiency is not valid anymore. In this case, the root mean square error (RMSE) for a pool depth of 54
is reduced from 6
(white box model) to
(grey box model). For the pool depth of 64
, the reduction is from
to
, which is in both cases a significant improvement.
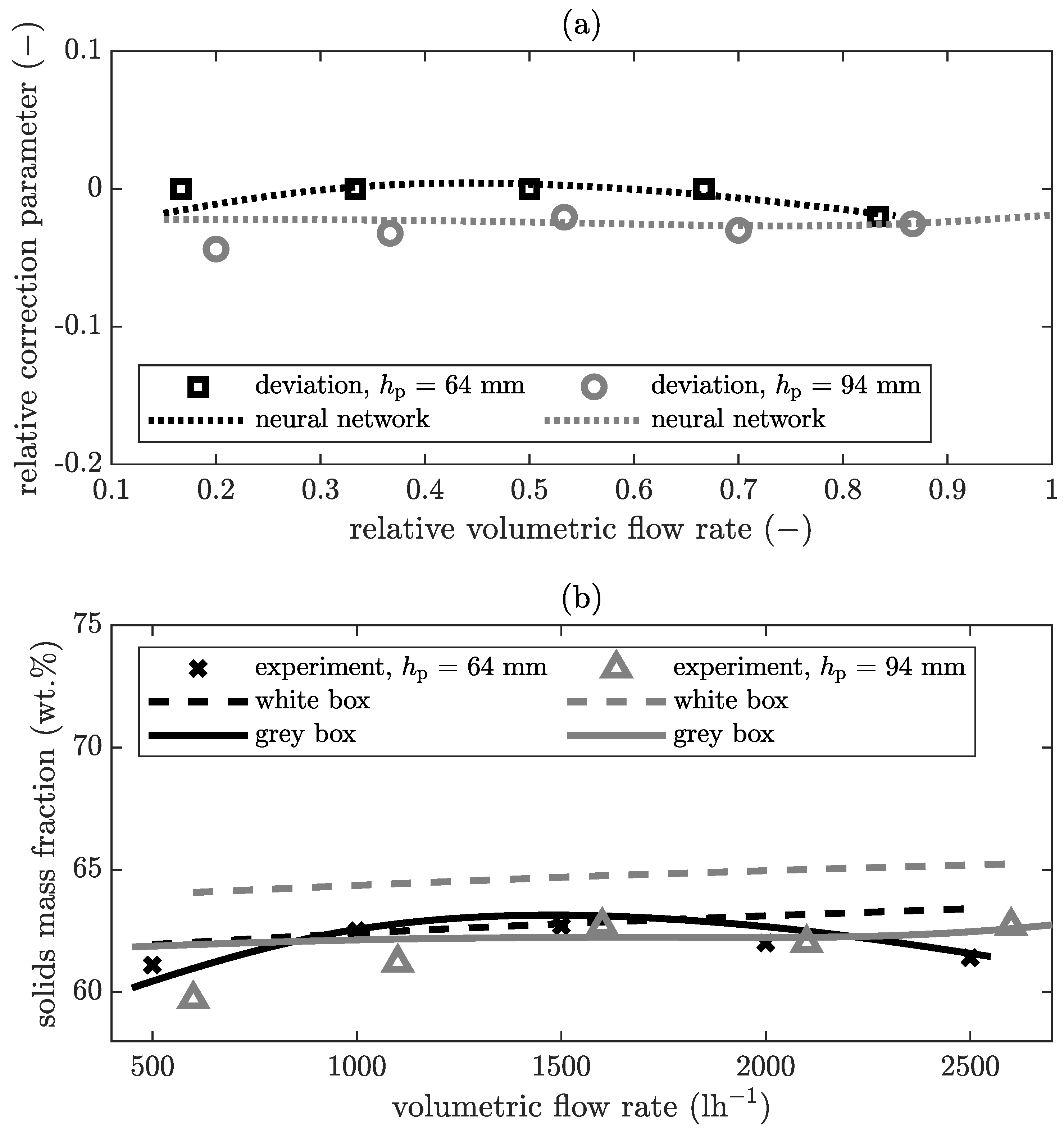
In
Figure 9a, the relative correction parameter is plotted over the relative volumetric flow rate for a rotational speed of
. In
Figure 9b the corresponding result is compared to the experimental value, the result of the pure white box model and the grey box model.
The deviation function demonstrates that the neural network can model the actual deviation for this combination of parameters. The influence of the volumetric flow rate on the solids mass fraction of the cake at a rotational speed of
is minimal. Also, the influence of the pool depth is negligible. The white box model reflects this behaviour. Here, the neural network models only small deviations between experiment and white box model, since these are larger than the previously defined trust interval. The solids mass fraction for a volumetric flow rate between
and
is approximately constant for a pool depth of
. Therefore, the black box model corrects the white box model for this range with a factor that is approximately constant. The solids mass fraction at
is
, which is slightly lower than the other values for a pool depth of
. Due to the regularisation, the black box model is a compromise between the perfect reproduction of all training data and overfitting. As a result, the trend of this point is not clearly reproduced, as the other data are approximately constant at volumetric flow rates greater than
. For example, if the trend of decreasing solids mass fraction at smaller volumetric flow rates (
) continues, this might be modelled by the neural network if included in the training data set. For the same parameter as in
Figure 9, the results for the centrate are plotted in
Figure 10.
The experimental results indicate that the volume flow in this range between and has no influence on the solids mass fraction in the centrate. In each case, the centrate is almost clear, which is equivalent to a solids mass fraction smaller than . This means that the centrifuge is not filled to the maximum capacity and there is still enough volume available for clarification. In general, if the volumetric flow rate increases further, the decanter centrifuge will reach its maximum capacity at a certain level, and separation will start to fail. The simulation results of the white box model already show a decrease in separation efficiency, which means an increase in the solids mass fraction in the centrate, starting at volumetric flow rate of . Therefore, the neural network has to correct the white box model. In this case, the RMSE for the pool depth of 64 is reduced from (white box model) to (grey box model). For the pool depth of 94 , the reduction is from to , which is in both cases an improvement. Particularly in this case, the improvement is of practical relevance, as it is obvious from this that the capacity of the centrifuge has not yet been reached as predicted by the white box model and that the volumetric flow rate can be increased further. This study did not investigate experimentally at which volumetric flow rate this maximum capacity level is reached. The grey box model is used in this work purely interpolatively. Outside the trained area, the white box model is considered correct. The intention is to improve exactly those domains in which the white box model is inaccurate. Nevertheless, the combination of white and black box model in extrapolation outside the trained domain is interesting and will be the subject of future investigations. As already described above, the white box model is based on the assumption that the flow regime is a plug-flow and flows directly towards the weir. The local separation efficiency is calculated by comparing the residence time with the settling time. At relatively deep pool depths, local eddies in the flow are possible in reality. This influences the residence time and would typically increase it, because the particles may circulate in the pool. With the same sedimentation time, the separation efficiency increases with increasing residence time. The white box model is unable to reflect this behaviour. However, the results of the grey box model show that by training the neural network, it can describe these deviations and thus represent this effect.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}