An Appraisal Model Based on a Synthetic Feature Selection Approach for Students’ Academic Achievement


Abstract
:1. Introduction
- The large amount of long-established data must reveal intrinsic patterns for the analysis to be highly valuable. Therefore, use data collected from elementary school to establish a feasible supervised learning model.
- Utilise a data mining technique and proposed feature selection approach to determine the key factors of students’ academic achievement from the vast amount of data.
- Find the differences between and properties of different algorithms, and provide the research results to educational and tutorship personnel for reference.
2. Literature Review
2.1. Related Factors in Academic Achievement
- After the action, individuals or groups successfully achieve the goal that they set;
- In certain fields (disciplines), the attainment of various honours (such as awards and academic degrees);
- The scores that are obtained from the test of academic achievement or vocational achievement; and
- The scores in various subjects that students obtain in school.
- The four factors that affect academic achievement are attitude to education, living environment, value concept, and language type [10];
- Factors of academic achievement should be divided into internal and external factors. Internal factors involve intelligence, motivation, personality, and so on. External factors relate to teaching methods, type of learning groups individuals participate in, influence of teachers [11], and so on;
- According to [12], the main factors of academic achievement are individual psychological factors, physiological factors, and related environmental factors (family, school, society); and
- Parents affect students’ academic achievement through various factors, such as parenting style, educational values, educational beliefs, and family atmosphere [13].
2.2. Feature Selection
- to reduce the dimension of the data and shorten the training times of algorithms;
- to enhance the operation effectively;
- to improve the accuracy of classification;
- to improve the generalisation ability and prevent overfitting; and
- for simplification of models, to make them easier to interpret by researchers and users.
2.2.1. Multilayer Perceptron (MLP)
2.2.2. Radial Basis Function (RBF) Network
2.2.3. Discriminant Analysis (DA)
2.2.4. Cascade Correlation Network (CCN)
2.2.5. Decision Tree Forest (DTF)
2.3. Support Vector Machine (SVM)
2.4. Decision Table/Naïve Bayes (DTNB)
2.5. Bayes Net (BN)
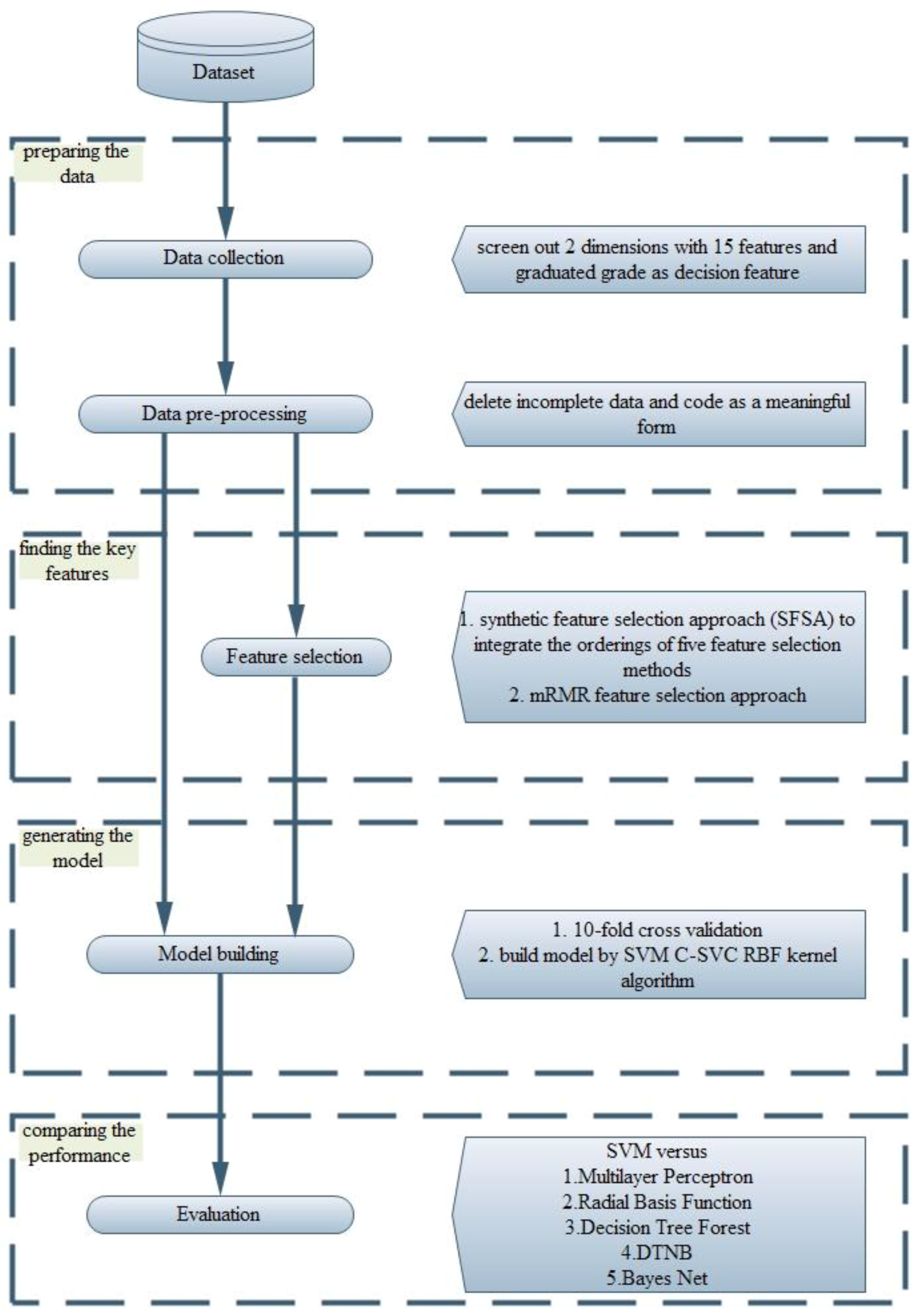
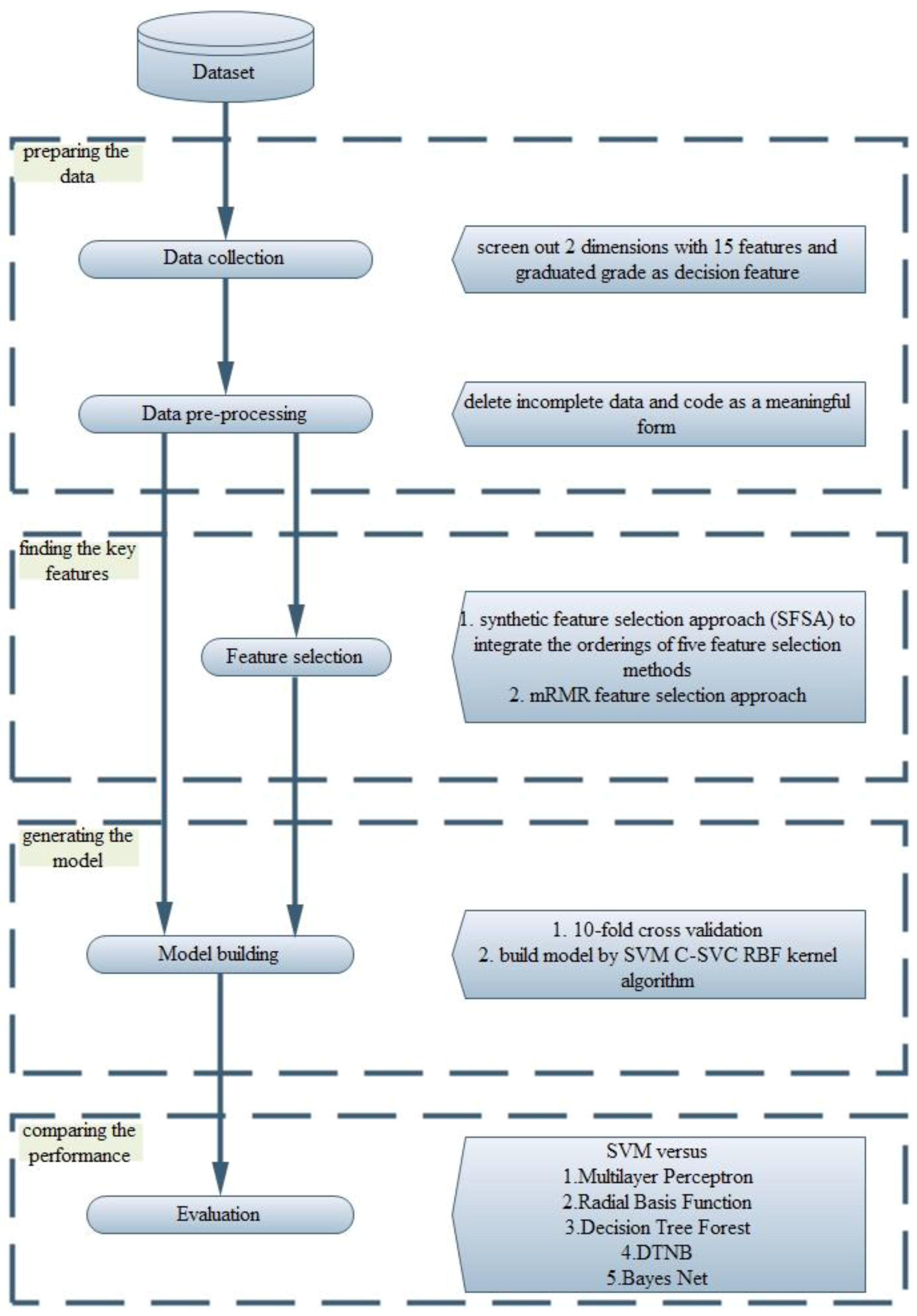
3. Proposed Method
3.1. The Purposes of the Proposed Feature Selection Approach
3.2. Procedure of the Proposed Method
- (1)
- Apply the five feature selection methods to select features and rank the methods in terms of the importance of their selected features, where the first rank corresponds to a score of 1, the second corresponds to a score of 2, etc. If a feature is not selected by any feature selection method, then assign it a score of 16;
- (2)
- Sum the scores of the five feature selection methods for each feature; and
- (3)
- Rank the summed scores in ascending order: a larger score denotes a less important feature.
4. Data Analysis and Results
4.1. Students’ Academic Achievement Dataset
4.1.1. Dimension of Study Efficiency
4.1.2. Dimension of Environment and Background
- Education levels of parents (EB_1): The level of education has an ordering; hence, this feature is coded in Table 3.
- Occupations of parents (EB_2): For this feature, the symbols of job classification can be obtained by using the information query system from the Council of Labour Affairs Vocational Training Council, Taiwan; this study lists the symbols in Table 4.
- Ages of parents (EB_3): The feature is a numeric value, so there is no need to process it.
- Number of children (EB_4): This refers to the number of children in the student’s family. This feature is a numeric value, so there is no need to process it.
- Self-ranking (EB_5): This feature refers to the ranking of the student among his or her brothers and sisters. The feature is a numeric value, so there is no need to process it.
- Student identity background (EB_6): This refers to the student’s family situation, which is recorded as text in the school database. This study codes systematically each label of the feature in Table 5. Furthermore, if a student has a variety of identities, the recorded markings will be joined. For instance, if the students’ identities are foreign student, low-income household student, and single-parent student, their record will contain “FLS”.
- Teacher (EB_7) refers to the tutor or teacher who has taught the student. Different teachers were coded from T1 to T15 based on the class taught.
4.1.3. Decision Class
4.2. Verification and Comparison
- (A)
- In feature selection: First, this study utilises MLP, RBF, DA, CCN, and DTF to rank the 15 features. Then, this study employs the proposed SFSA to synthesise the rankings of the five feature selection methods, as described in Step 3 in Section 3. The results of the SFSA are listed in Table 7. Second, the features selected using mRMR are ranked in the following order: SE_1, SE_2, SE_3, SE_4, SE_5, SE_6, SE_7, SE_8, EB_1, EB_2, EB_3, EB_4, EB_5, EB_6, and EB_7. The first three key features are language average score, math average score, and science average score for student’s academic achievement.
- (B)
- In building the model: The main objective is to build an optimal model with fewer features. First, this study uses all features to establish a prediction model. Second, the results of the proposed SFSA are utilised to sequentially remove the less important features for building the prediction model. Lastly, when removing features no longer improves the accuracy, the key features and optimal model have been obtained. The results of all features and selected features are shown in Table 8.
- (C)
- In the results: From Sequence 6 in Table 8, after six less influential features have been deleted, the accuracy is better than those of the full-feature model and other sequentially deleted feature models. Deleting the six least important features improved the accuracy by 8.66%. Therefore, the nine key features are from the categories “study efficiency” (SE_1, SE_2, SE_3, SE_4, SE_5, SE_6, and SE_8) and “environment and background” (EB_6 and EB_7), with the ordering: SE_1 > SE_3 > SE_2 > SE_5 > SE_8 > EB_7 > SE_4 > SE_6 > EB_6. Finally, this study uses the classifier with the six least important features deleted for comparison with other classifiers; the result is shown in Table 9. The proposed feature selection approach with SVM outperforms other classifiers in terms of accuracy, and the standard deviation is smaller than those of other classifiers. This paper also builds the appraisal model by using mRMR-selected features with an SVM; the results show that the proposed feature selection with an SVM outperforms mRMR-selected features with an SVM in terms of accuracy, as shown in Table 9.
4.3. Findings
- (1)
- (2)
- Key features: Based on Table 8, the nine key features that are related to students’ academic achievement are language, science, math, social science, behaviour, teacher, arts, physical education, and student identity background. The important results are described as follows:
- (a)
- (b)
- (c)
- (d)
- (e)
- (f)
- (3)
- By repeatedly performing the experiment using different combinations of features, we found that SVM, which is used for classification in this study, can accurately identify the two least influential features: age of parents (SE_3) and self-rank (EB_5). The evidence shows that age of parents (SE_3) and self-rank (EB_5) are not important features for students’ academic achievement.
- (4)
- Two different kinds of feature selection approaches are used to select nine key features. The proposed method selects seven numeric and two symbolic features, while mRMR selects eight numeric and one symbolic feature. Then, the appraisal model is built by an SVM. The classification accuracy of the proposed feature selection approach is better than that of mRMR.
5. Conclusions
- Collect more samples for solving the class imbalance problem;
- Through stratified sampling, the class samples may be made more balanced; and
- Employ additional algorithms with different feature selection approaches.
Author Contributions
Conflicts of Interest
References
- Fayyad, U.M.; Piatetsky-Shapiro, G.; Smyth, P.; Uthurusamy, R. Advances in Knowledge Discovery and Data Mining; AAAI Press: Palo Alto, CA, USA, 1996. [Google Scholar]
- Maimon, O.; Last, M. Knowledge Discovery and Data Mining: The Info-Fuzzy Network (ifn) Methodology; Springer Science & Business Media: Berlin, Germany, 2013; Volume 1. [Google Scholar]
- Smyth, P.; Pregibon, D.; Faloutsos, C. Data-driven evolution of data mining algorithms. Commun. ACM 2002, 45, 33–37. [Google Scholar] [CrossRef]
- Smyth, P. Breaking out of the Black-Box: Research Challenges in Data Mining. In Proceedings of the Sixth Workshop on Research Issues in Data Mining and Knowledge Discovery (DMKD2001), Santra Barbara, CA, USA, 20 May 2001. [Google Scholar]
- Gronlund, N.E. Assessment of Student Achievement; Allyn & Bacon Publishing: Needham Heights, MA, USA, 1998. [Google Scholar]
- Tionn, C.H. Zhang Dictionary of Psychology; Tung Hua Book Co., Ltd.: Taipei City, Taiwan, 2006. [Google Scholar]
- Blau, P.M.; Duncan, O.D. The American Occupational Structure; Free Press: New York, NY, USA, 1967. [Google Scholar]
- Coleman, J.S. Social capital in the creation of human capital. Am. J. Sociol. 1988, 94, S95–S120. [Google Scholar] [CrossRef]
- Meighan, R.; Bondi, H. Theory and Practice of Regressive Education; Educational Heretics Press: Shrewsbury, UK, 1993. [Google Scholar]
- Chen, K.X. Sociology of Education; National Taiwan Normal University Bookstore: Taipei City, Taiwan, 1993. [Google Scholar]
- Wang, W.K. Cognitive Development and Education: The Application of Piaget Theories; Wu-Nan Book Inc.: Taipei City, Taiwan, 1991. [Google Scholar]
- Chen, Y.H. The Research of Relationship Between Home Environment, Reading Motivation and Language Subject That Affects Elementary School Students Academic Achievement. Master’s Thesis, National Kaohsiung Normal University, Kaohsiung, Taiwan, 2001. [Google Scholar]
- Liao, R.Y. Analysis of High Academic Achievement Aboriginal Children and Family Factors-A Case Study of Community Balanao. Master’s Thesis, National Hualien Teachers College, Hualien, Taiwan, 2001. [Google Scholar]
- Hall, M.A. Correlation-Based Feature Selection for Machine Learning. Ph.D. Thesis, The University of Waikato, Hamilton, New Zealand, 1999. [Google Scholar]
- Bermingham, M.L.; Pong-Wong, R.; Spiliopoulou, A.; Hayward, C.; Rudan, I.; Campbell, H.; Wright, A.F.; Wilson, J.F.; Agakov, F.; Navarro, P.; et al. Application of high-dimensional feature selection: Evaluation for genomic prediction in man. Sci. Rep. 2015, 5. [Google Scholar] [CrossRef] [PubMed]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef] [PubMed]
- Posner, M.I. Foundations of Cognitive Science; MIT Press: Cambridge, MA, USA, 1989. [Google Scholar]
- Rosenblatt, F. Perceptions and the Theory of Brain Mechanisms; Spartan Books: Washington, DC, USA, 1962. [Google Scholar]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Pal, S.K.; Mitra, S. Multilayer perceptron, fuzzy sets, and classification. IEEE Trans. Neural Netw. 1992, 3, 683–697. [Google Scholar] [CrossRef] [PubMed]
- Ruck, D.W.; Rogers, S.K.; Kabrisky, M.; Maybeck, P.S.; Oxley, M.E. Comparative analysis of backpropagation and the extended Kalman filter for training multilayer perceptrons. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 686–691. [Google Scholar] [CrossRef]
- Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Control Signals Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Benvenuto, N.; Piazza, F. On the complex backpropagation algorithm. IEEE Trans. Signal Process. 1992, 40, 967–969. [Google Scholar] [CrossRef]
- Karlik, B.; Olgac, A.V. Performance analysis of various activation functions in generalized mlp architectures of neural networks. Int. J. Artif. Intell. Expert Syst. 2011, 1, 111–122. [Google Scholar]
- Broomhead, D.S.; Lowe, D. Multivariable functional interpolation and adaptive networks. Complex Syst. 1988, 2, 321–355. [Google Scholar]
- Billings, S.A.; Zheng, G.L. Radial basis function network configuration using genetic algorithms. Neural Netw. 1995, 8, 877–890. [Google Scholar] [CrossRef]
- Chen, S.; Cowan, C.F.N.; Grant, P.M. Orthogonal least squares learning algorithm for radial basis function networks. IEEE Trans. Neural Netw. 1991, 2, 302–309. [Google Scholar] [CrossRef] [PubMed]
- Rosenblum, M.; Yacoob, Y.; Davis, L.S. Human expression recognition from motion using a radial basis function network architecture. IEEE Trans. Neural Netw. 1996, 7, 1121–1138. [Google Scholar] [CrossRef] [PubMed]
- Friedman, J.H. Regularized Discriminant Analysis. J. Am. Stat. Assoc. 1989, 84, 165–175. [Google Scholar] [CrossRef]
- Klecka, W.R. Discriminant Analysis; Sage: Newcastle upon Tyne, UK, 1980. [Google Scholar]
- Loog, M.; Duin, R.P.W.; Haeb-Umbach, R. Multiclass linear dimension reduction by weighted pairwise fisher criteria. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 762–766. [Google Scholar] [CrossRef]
- McLachlan, G. Discriminant Analysis and Statistical Pattern Recognition; John Wiley & Sons: Chichester, UK, 2004; Volume 544. [Google Scholar]
- Bickel, P.J.; Levina, E. Some theory for Fisher’s linear discriminant function, ‘naive Bayes’, and some alternatives when there are many more variables than observations. Bernoulli 2004, 10, 989–1010. [Google Scholar] [CrossRef]
- Morrison, D.G. On the interpretation of discriminant analysis. J. Market. Res. 1969, 6, 156–163. [Google Scholar] [CrossRef]
- Fahlman, S.E.; Lebiere, C. The cascade-correlation learning architecture. In Advances in Neural Information Processing Systems 2 (NIPS 1989); Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1990. [Google Scholar]
- Fahlman, S.E. The Recurrent Cascade-Correlation Architecture; Carnegie-Mellon University, Department of Computer Science: Pittsburgh, PA, USA, 1991. [Google Scholar]
- Hwang, J.-N.; You, S.-S.; Lay, S.-R.; Jou, I.-C. The cascade-correlation learning: A projection pursuit learning perspective. IEEE Trans. Neural Netw. 1996, 7, 278–289. [Google Scholar] [CrossRef] [PubMed]
- Kovalishyn, V.V.; Tetko, I.V.; Luik, A.I.; Kholodovych, V.V.; Villa, A.E.P.; Livingstone, D.J. Neural Network Studies. 3. Variable Selection in the Cascade-Correlation Learning Architecture. J. Chem. Inf. Comput. Sci. 1998, 38, 651–659. [Google Scholar] [CrossRef]
- Hall, L.O.; Bensaid, A.M.; Clarke, L.P.; Velthuizen, R.P.; Silbiger, M.S.; Bezdek, J.C. A comparison of neural network and fuzzy clustering techniques in segmenting magnetic resonance images of the brain. IEEE Trans. Neural Netw. 1992, 3, 672–682. [Google Scholar] [CrossRef] [PubMed]
- Han, J.; Moraga, C. The Influence of the Sigmoid Function Parameters on the Speed of Backpropagation Learning. In IWANN ‘96, Proceedings of the International Workshop on Artificial Neural Networks: From Natural to Artificial Neural Computation; Springer: London, UK, 1995; pp. 195–201. [Google Scholar]
- Hoehfeld, M.; Fahlman, S.E. Learning with limited numerical precision using the cascade-correlation algorithm. IEEE Trans. Neural Netw. 1992, 3, 602–611. [Google Scholar] [CrossRef] [PubMed]
- Díaz-Uriarte, R.; de Andrés, S.A. Gene selection and classification of microarray data using random forest. BMC Bioinform. 2006, 7. [Google Scholar] [CrossRef] [PubMed]
- Cutler, L.B.a.A. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar]
- Ho, T.K. Random decision forests. In ICDAR ‘95, Proceedings of the Third International Conference on Document Analysis and Recognition, 14–15 August 1995; IEEE: Washington, DC, USA, 1995; pp. 278–282. [Google Scholar]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin, Germany, 2013. [Google Scholar]
- Vapnik, V.N.; Vapnik, V. Statistical Learning Theory; Wiley: New York, NY, USA, 1998; Volume 1. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Humby, E. Programs from Decision Tables; American Elsevier: New York, NY, USA, 1973. [Google Scholar]
- Kohavi, R. The power of decision tables. In Machine Learning: Ecml-95; Springer: Berlin, Germany, 1995; pp. 174–189. [Google Scholar]
- Hand, D.J.; Yu, K. Idiot’s bayes—Not so stupid after all? Int. Stat. Rev. 2001, 69, 385–398. [Google Scholar]
- Rish, I. An Empirical Study of the Naive Bayes Classifier. In Proceedings of the IJCAI 2001 Workshop on Empirical Methods in Artificial Intelligence, Seattle, WA, USA, 4 August 2001; IBM: New York, NY, USA, 2001; pp. 41–46. [Google Scholar]
- Ben-Gal, I. Bayesian networks. In Encyclopedia of Statistics in Quality and Reliability; John Wiley & Sons Ltd.: Chichester, UK, 2007. [Google Scholar]
- Jensen, F.V. An Introduction to Bayesian Networks; UCL Press: London, UK, 1996; Volume 210. [Google Scholar]
- Nielsen, T.D.; Jensen, F.V. Bayesian Networks and Decision Graphs; Springer Science & Business Media: Berlin, Germany, 2009. [Google Scholar]
- Hongeng, S.; Brémond, F.; Nevatia, R. Bayesian framework for video surveillance application. In Proceedings of the 2000 15th International Conference on Pattern Recognition, Barcelona, Spain, 3–7 September 2000; IEEE: New York, NY, USA, 2000; pp. 164–170. [Google Scholar]
- Lan, P.; Ji, Q.; Looney, C.G. Information fusion with bayesian networks for monitoring human fatigue. In Proceedings of the 2002 Fifth International Conference on Information Fusion, Annapolis, MD, USA, 8–11 July 2002; IEEE: New York, NY, USA, 2002; pp. 535–542. [Google Scholar]
- Sahin, F.; Bay, J. Learning from experience using a decision-theoretic intelligent agent in multi-agent systems. In Proceedings of the 2001 IEEE Mountain Workshop on Soft Computing in Industrial Applications, SMCia/01., Blacksburg, VA, USA, 27 June 2001; IEEE: New York, NY, USA, 2001; pp. 109–114. [Google Scholar]
- Fayyad, U.; Piatetsky-Shapiro, G.; Smyth, P. The kdd process for extracting useful knowledge from volumes of data. Commun. ACM 1996, 39, 27–34. [Google Scholar] [CrossRef]
- Barrow, L.H.; Kristo, J.V.; Andrew, B. Building bridges between science and reading. Read. Teach. 1984, 38, 188–192. [Google Scholar]
- Chall, J.S. Stages of Reading Development; McGraw-Hill: New York, NY, USA, 2011. [Google Scholar]
- Yore, L.D. A preliminary exploration of grade five students’ science achievement and ability to read science textbooks as a function of gender, reading vocabulary, and reading comprehension. In Proceedings of the 60th Annual Meeting of the National Association for Research in Science Teaching, Washington, DC, 23–25 April 1987. [Google Scholar]
- Friedman, I.A.; Kass, E. Teacher self-efficacy: A classroom-organization conceptualization. Teach. Teach. Educ. 2002, 18, 675–686. [Google Scholar] [CrossRef]
- Goddard, R.D. The impact of schools on teacher beliefs, influence, and student achievement. Teach. Beliefs Classr. Perform. Impact Teach. Educ. 2003, 6, 183–202. [Google Scholar]
- Goddard, R.D.; Hoy, W.K.; Hoy, A.W. Collective teacher efficacy: Its meaning, measure, and impact on student achievement. Am. Educ. Res. J. 2000, 37, 479–507. [Google Scholar] [CrossRef]
- Tschannen-Moran, M.; Barr, M. Fostering student learning: The relationship of collective teacher efficacy and student achievement. Leadersh. Policy Sch. 2004, 3, 189–209. [Google Scholar] [CrossRef]
- Bull, S.; Feldman, P.; Solity, J. Classroom Management: Principles to Practice; Routledge: Abingdon, UK, 2013. [Google Scholar]
- Burden, P.R. Classroom Management and Discipline: Methods to Facilitate Cooperation and Instruction; Longman Publishers USA: White Plains, NY, USA, 1995. [Google Scholar]
- Cangelosi, J.S. Classroom Management Strategies: Gaining and Maintaining Students’ Cooperation; John Wiley & Sons Incorporated: Chichester, UK, 2007. [Google Scholar]
- Barron, F.; Harrington, D.M. Creativity, intelligence, and personality. Ann. Rev. Psychol. 1981, 32, 439–476. [Google Scholar] [CrossRef]
- Smith, R.A.; Simpson, A. Aesthetics and Arts Education; University of Illinois Press: Champaign, IL, USA, 1991. [Google Scholar]
- Chomitz, V.R.; Slining, M.M.; McGowan, R.J.; Mitchell, S.E.; Dawson, G.F.; Hacker, K.A. Is there a relationship between physical fitness and academic achievement? Positive results from public school children in the northeastern united states. J. Sch. Health 2009, 79, 30–37. [Google Scholar] [CrossRef] [PubMed]
- Coe, D.P.; Pivarnik, J.M.; Womack, C.J.; Reeves, M.J.; Malina, R.M. Effect of physical education and activity levels on academic achievement in children. Med. Sci. Sports Exerc. 2006, 38, 1515–1519. [Google Scholar] [CrossRef] [PubMed]
- Astone, N.M.; McLanahan, S.S. Family structure, parental practices and high school completion. Am. Sociol. Rev. 1991, 56, 309–320. [Google Scholar] [CrossRef]
- Nisbet, J. Family environment and intelligence. Eugen. Rev. 1953, 45, 31–40. [Google Scholar] [PubMed]

{kind=link}
| Scope | Coverage | Factor |
|---|---|---|
| student | personal aspects | Language average score |
| Math average score | ||
| Science average score | ||
| Arts average score | ||
| Social average score | ||
| Physical average score | ||
| Integrated activities average score | ||
| Behaviour average score | ||
| environment | family aspects | Education levels of parents |
| Occupations of parents | ||
| Ages of parents | ||
| Number of children | ||
| Self-ranking | ||
| school aspects | Teacher | |
| social aspects | Student Identity Background |
| Dimension | Feature Name | Code | Value |
|---|---|---|---|
| Study Efficiency | Language average score | SE_1 | Numeric, [0, 100] |
| Math average score | SE_2 | Numeric, [0, 100] | |
| Science average score | SE_3 | Numeric, [0, 100] | |
| Arts average score | SE_4 | Numeric, [0, 100] | |
| Social average score | SE_5 | Numeric, [0, 100] | |
| Physical average score | SE_6 | Numeric, [0, 100] | |
| Integrated activities average score | SE_7 | Numeric, [0, 100] | |
| Behaviour average score | SE_8 | Numeric, [0, 100] | |
| Environment and Background | Education levels of parents | EB_1 | Symbolic, [S, A, B, C, D] |
| Occupations of parents | EB_2 | Symbolic, [J0, J1, J2, J3, …, J9] | |
| Ages of parents | EB_3 | Numeric, [30, …, 64] | |
| Number of children | EB_4 | Symbolic, [C1, C2, …, C5] | |
| Self-ranking | EB_5 | Symbolic, [S1, S2, S3, S4] | |
| Student Identity Background | EB_6 | Symbolic, [G, ST, LST, S, T, F, FS, LS, L, AS, A, FT, FST] | |
| Teacher | EB_7 | Symbolic, [T1, T2, …, T15] | |
| Decision feature | The graduated grade of students | Class | Symbolic, [S, A, B] |
| Education Levels | Symbol |
|---|---|
| Master’s degree or higher | S |
| University or college | A |
| Senior high school | B |
| Junior high school | C |
| Elementary school | D |
| Occupations Classification | Symbol |
|---|---|
| Soldier (currently serving ) | J0 |
| Administrative and Managers | J1 |
| Professionals | J2 |
| Technicians and associate professionals | J3 |
| Transactional staff | J4 |
| Service staff and sales staff | J5 |
| Agriculture, forestry, animal husbandry and fisheries staff | J6 |
| Skilled workers and technology-related personnel | J7 |
| Machinery and equipment operating workers and assembly workers | J8 |
| Unskilled workers and labour-type workers | J9 |
| Student Identity | Symbol |
|---|---|
| Generally Student | G |
| Aboriginal student | A |
| Foreign child student | F |
| Low-income household student | L |
| Single-parent student | S |
| Inter-generational education student | T |
| SE_1 | SE_2 | SE_3 | SE_4 | SE_5 | SE_6 | SE_7 | SE_8 | EB_1 | EB_2 | EB_3 | EB_4 | EB_5 | EB_6 | EB_7 | Class |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 83.78 | 80.55 | 79.50 | 87.25 | 77.23 | 81.63 | 89.25 | 83.45 | B | J9 | 38.00 | C3 | S2 | G | T1 | A |
| 88.80 | 75.50 | 78.98 | 87.50 | 80.25 | 87.60 | 88.50 | 84.88 | B | J3 | 39.00 | C3 | S1 | G | T1 | A |
| 78.10 | 79.83 | 75.23 | 84.88 | 70.85 | 82.78 | 88.50 | 87.70 | B | J3 | 46.00 | C4 | S4 | G | T1 | A |
| … | |||||||||||||||
| 73.83 | 61.83 | 73.80 | 79.50 | 74.40 | 79.78 | 86.00 | 85.25 | B | J4 | 45.00 | C1 | S1 | G | T15 | B |
| 93.25 | 80.43 | 88.70 | 91.00 | 88.58 | 89.13 | 92.38 | 91.50 | C | J8 | 38.00 | C3 | S2 | G | T15 | S |
| 89.00 | 78.68 | 80.65 | 89.88 | 83.25 | 86.98 | 91.88 | 92.25 | A | J9 | 41.00 | C2 | S2 | G | T15 | A |
| Feature | Ranking Score of Five Methods | Proposed Order | |||||
|---|---|---|---|---|---|---|---|
| MLP | RBF | DA | CCN | DTF | Summation | ||
| SE_1 | 3 | 1 | 1 | 2 | 1 | 8 | 1 |
| SE_2 | 2 | 2 | 3 | 3 | 4 | 14 | 3 |
| SE_3 | 1 | 3 | 2 | 1 | 2 | 9 | 2 |
| SE_4 | 6 | 7 | 8 | 10 | 6 | 37 | 7 |
| SE_5 | 4 | 8 | 7 | 8 | 3 | 30 | 4 |
| SE_6 | 11 | 5 | 6 | 13 | 5 | 40 | 8 |
| SE_7 | 10 | 4 | 16 | 16 | 8 | 54 | 11 |
| SE_8 | 5 | 6 | 4 | 9 | 7 | 31 | 5 |
| EB_1 | 8 | 15 | 12 | 11 | 13 | 59 | 12 |
| EB_2 | 9 | 13 | 11 | 6 | 12 | 51 | 10 |
| EB_3 | 14 | 9 | 16 | 14 | 10 | 63 | 15 |
| EB_4 | 13 | 11 | 10 | 12 | 14 | 60 | 13 |
| EB_5 | 16 | 14 | 9 | 7 | 15 | 61 | 14 |
| EB_6 | 12 | 12 | 7 | 5 | 11 | 47 | 9 |
| EB_7 | 7 | 10 | 5 | 4 | 9 | 35 | 6 |
| Sequence | Excluded Feature | Remaining Features | Accuracy | Improvement |
|---|---|---|---|---|
| 0 | none | SE_1, SE_2, SE_3, SE_4, SE_5, SE_6, SE_7, SE_8, EB_1, EB_2, EB_3, EB_4, EB_5, EB_6, EB_7 | 83.57% | _ |
| 1 | EB-3 | SE_1, SE_2, SE_3, SE_4, SE_5, SE_6, SE_7, SE_8, EB_1, EB_2, EB_4, EB_5, EB_6, EB_7 | 81.15% | −2.42% |
| 2 | EB_5 | SE_1, SE_2, SE_3, SE_4, SE_5, SE_6, SE_7, SE_8, EB_1, EB_2, EB_4, EB_6, EB_7 | 82.21% | −1.36% |
| 3 | EB_4 | SE_1, SE_2, SE_3, SE_4, SE_5, SE_6, SE_7, SE_8, EB_1, EB_2, EB_6, EB_7 | 85.39% | 1.82% |
| 4 | EB_1 | SE_1, SE_2, SE_3, SE_4, SE_5, SE_6, SE_7, SE_8, EB_2, EB_6, EB_7 | 89.22% | 5.65% |
| 5 | SE_7 | SE_1, SE_2, SE_3, SE_4, SE_5, SE_6, SE_8, EB_2, EB_6, EB_7 | 85.83% | 2.26% |
| 6 | EB_2 | SE_1, SE_2, SE_3, SE_4, SE_5, SE_6, SE_8, EB_6, EB_7 | 92.23% | 8.66% |
| 7 | EB_6 | SE_1, SE_2, SE_3, SE_4, SE_5, SE_6, SE_8, EB_7 | 91.50% | 7.93% |
| 8 | SE_6 | SE_1, SE_2, SE_3, SE_4, SE_5, SE_8, EB_7 | 90.62% | 7.05% |
| Algorithm | Proposed Feature Selection (FS) | mRMF FS | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy (SD) | Precision | Recall | F1 | Accuracy (SD) | Precision | Recall | F1 | |
| MLP | 86.94% (4.36) | 0.89 | 0.89 | 0.89 | 84.82% (5.54) | 0.84 | 0.91 | 0.87 |
| RBF | 87.18% (4.08) | 0.86 | 0.92 | 0.89 | 83.63% (6.75) | 0.82 | 0.92 | 0.87 |
| DTF | 89.64% (3.53) | 0.90 | 0.92 | 0.91 | 88.70% (3.56) | 0.89 | 0.91 | 0.90 |
| DTNB | 87.94% (3.65) | 0.92 | 0.86 | 0.89 | 88.31% (3.46) | 0.92 | 0.87 | 0.89 |
| BN | 87.57% (4.04) | 0.92 | 0.86 | 0.89 | 88.84% (3.76) | 0.93 | 0.87 | 0.90 |
| SVM | 92.23% (1.68) | 0.94 | 0.92 | 0.93 | 90.05% (2.13) | 0.91 | 0.91 | 0.91 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, C.-H.; Liu, W.-X. An Appraisal Model Based on a Synthetic Feature Selection Approach for Students’ Academic Achievement. Symmetry 2017, 9, 282. https://doi.org/10.3390/sym9110282
Cheng C-H, Liu W-X. An Appraisal Model Based on a Synthetic Feature Selection Approach for Students’ Academic Achievement. Symmetry. 2017; 9(11):282. https://doi.org/10.3390/sym9110282
Chicago/Turabian StyleCheng, Ching-Hsue, and Wei-Xiang Liu. 2017. "An Appraisal Model Based on a Synthetic Feature Selection Approach for Students’ Academic Achievement" Symmetry 9, no. 11: 282. https://doi.org/10.3390/sym9110282
APA StyleCheng, C.-H., & Liu, W.-X. (2017). An Appraisal Model Based on a Synthetic Feature Selection Approach for Students’ Academic Achievement. Symmetry, 9(11), 282. https://doi.org/10.3390/sym9110282