Abstract
Uncertain regression analysis is a powerful tool for analyzing and interpreting the complex relationships between explanatory and response variables under uncertain environments, and a crucial step in analyzing datasets containing complex uncertainties is statistical inference based on uncertain parameter estimation methods. However, the existing parameter estimation studies of uncertain regression models all fail to effectively avoid the negative impact of outliers on the estimation results. To solve the above problem and further enrich the parameter estimation research, this paper constructs a symmetric statistical invariant for the uncertain regression model based on observed data and uncertain disturbance terms. Based on this statistical invariant, the least absolute deviation criterion is applied to propose a least absolute deviation estimation for the uncertain regression model. Finally, two numerical examples are provided to illustrate the advantages of the proposed method compared to existing methods, and the comparative results show that in certain scenarios, the least absolute deviation estimation method exhibits superior performance compared to other existing methods in terms of mean squared error, mean absolute error, and mean absolute percentage error. Furthermore, as a byproduct of this paper, the proposed method is applied to sports statistics, and two empirical cases are also provided to demonstrate the effectiveness of this application.
1. Introduction
As a core method in statistics for exploring relationships between variables, the evolution of regression analysis reflects the continuous theoretical innovation and paradigm expansion within the discipline in order to address the ever-emerging challenges of real-world data. This evolution can be traced back to the revelation of Galton [1] for the “regression to the mean” law in genetic phenomena at the end of the 19th century, which laid the empirical foundation for the concept of regression. Subsequently, the classical linear regression analysis was established through the theoretical refinement of the least squares method, becoming the cornerstone of relationship modeling, and the classical discussions on this topic can be found in Draper and Smith [2].
As application scenarios have become increasingly complex, a series of key model variants have emerged. In order to handle categorical response variables, Berkson [3] systematically proposed a logistic regression model based on the Logit function. For the sake of overcoming estimation instability caused by multicollinearity of independent variables, Hoerl and Kennard [4] introduced ridge regression with L2 penalty. In the era of high-dimensional data analysis, to simultaneously perform variable selection and parameter estimation, Tibshirani [5] proposed lasso regression with L1 penalty. For the purpose of combining the advantages of ridge regression and lasso regression and handle highly correlated variable groups, Zou and Hastie [6] further developed elastic network regression.
Overall, regression analysis has evolved from a tool describing linear relationships into a vast methodological system encompassing parametric, nonparametric, and regularized methods, its development driven by a deep understanding and modeling need for complex data structures. For those wishing to gain a deep understanding of regression analysis methods and keep abreast of its latest developments, the following works are widely considered to be of significant reference value. The work of Freund et al. [7] systematically explained the principles of regression model construction, statistical inference, and diagnostic techniques, covering a variety of application scenarios from basic to advanced. The work of Sen and Srivastava [8] focused on the combination of theoretical framework and computational methods, providing readers with rigorous mathematical derivations and practical implementation guidance, and the work of Chatterjee and Simonoff [9] focused on the theoretical expansion and practical application of linear and generalized linear models, and explored contemporary hot topics such as high-dimensional data modeling. These documents not only comprehensively review the core concepts and application paradigms of regression analysis but also deeply analyze important recent advances in the field, such as regularization methods and nonparametric techniques, providing researchers with a crucial perspective on the evolution and cutting-edge trends of the discipline.
The aforementioned classic research methods are all based on probability theory, constructing nondeterministic phenomena arising from randomness in the real world into stochastic models with repeatability and statistical regularity, and characterizing them using mathematical tools such as probability distributions and random variables. However, in practical observation, besides the aforementioned stochastic environments, another fundamentally different type of uncertainty widely exists. Its core characteristic is that the related phenomena do not have a stable frequency of occurrence, or it is difficult to obtain reliable statistical regularities through a large number of repeated experiments. This type of uncertainty often stems from incomplete information, cognitive ambiguity, system complexity, or lack of knowledge, and its essence is closer to cognitive uncertainty than objective randomness. If we forcibly use probability theory tools to model a system with cognitive uncertainty, we will inevitably get a result of frequency instability, which will violate the original theoretical assumption (frequency stability assumption). Relevant references can be found in Jiang and Ye [10] and Liu [11]. Therefore, traditional probabilistic frameworks often face limitations in theoretical foundation or empirical evidence when dealing with such cognitive uncertainty or knowledge uncertainty problems. To rigorously characterize this cognitive uncertainty that cannot be fully described by the classical probability framework, Liu [12] and Liu [13] established and systematized a completely new axiomatic system of mathematics, named as uncertainty theory, which aims to provide a self-consistent quantitative and analytical tool for non-random phenomena that lack sufficient historical data, rely on expert beliefs, or have unique one-off occurrences. The regression analysis paradigm developed on this theoretical basis naturally gave rise to uncertain regression analysis, which was investigated by Yao and Liu [14]. This emerging branch replaces the random error term or parameters in traditional regression models with uncertain variables that follow the axiomatic system of uncertainty theory, thus constructing a new type of uncertain regression model.
Building upon the work of Yao and Liu [14], the uncertain regression model system has been systematically expanded and deepened. For example, addressing the modeling needs of multiple response variables, Ye and Liu [15] proposed a multiple uncertain regression model, achieving simultaneous analysis of the correlation structure between multidimensional variables. In addition, many scholars have also studied other types of uncertain regression models, such as uncertain regression models with autoregressive time series errors (Chen [16]) and moving average time series errors (Chen [17]), uncertain panel regression model (Jiang and Ye [10]), and uncertain nonparametric regression model (Ding and Zhang [18]). In addition to this, the statistical inference of unknown parameters and uncertain disturbance terms for uncertain regression models has always been a hot topic of academic attention. Among them, the research on statistical inference of unknown parameters has yielded rich results, with representative works including least squares estimation (Yao and Liu [14]), least absolute deviations estimation (Liu and Yang [19]), uncertain maximum likelihood estimation (Lio and Liu [20], and Liu and Qin [21]), Tukey’s biweight estimation (Chen [22]), and moment estimation (Liu [11]), while the exploration of statistical inference of uncertain disturbance terms has also accumulated a series of key research conclusions, and the relevant results includes moment estimation (Lio and Liu [23]), uncertain maximum likelihood estimation (Lio and Liu [20], and Liu and Liu [24]), and least squares estimation (Liu and Liu [25]).
However, the aforementioned parameter estimation studies of uncertain regression models all fail to effectively avoid the negative impact of outliers on the estimation results. In particular, the least squares estimation method based on the uncertainty distribution function suffers from this problem. Since the objective function is constructed based on the deviation between the empirical distribution function and the population distribution function, squaring actually increases the relative weight of the deviation caused by outliers in the objective function. To address this issue, this paper will apply the least absolute deviation criterion to construct the least absolute deviation estimation for uncertain regression model. The main contributions of this paper are as follows:
- A symmetric statistical invariant based on uncertain regression model was constructed, and the least absolute deviation estimation of the uncertain regression model was proposed by applying the least absolute deviation criterion to this statistical invariant.
- The least absolute deviation estimation of the uncertain regression model was applied to the uncertain linear regression model, uncertain exponential growth model, and uncertain logistic decay model, respectively, and the advantages of the proposed method were illustrated with two numerical examples.
- The method proposed in this paper was applied to two typical scenarios in sports statistics, and the corresponding uncertain statistical models were studied based on real data.
2. Estimating Unknown Parameters of Uncertainty Distribution via the Least Absolute Deviation Criterion
Determining the unknown parameters of the uncertainty distribution function is a fundamental step in constructing an uncertain statistical model. This process provides methodological support for subsequent statistical inference and decision-making, making it possible to achieve robust optimization and precise risk management of the system in an uncertain environment. Specifically, given a family of uncertainty distribution functions with unknown parameters, where is the vector of unknown parameters to be determined and is the parameters space. For an uncertain variable that follows this family of uncertainty distribution functions , we assume that a set of observed values data can be obtained through observations. Then the parameter estimation problem in uncertain statistics is determining the vector of unknown parameters in the family of uncertainty distribution functions based on this set of observed values data and the operational rules of uncertainty theory.
One of the widely adopted fundamental ideas in the field of uncertain statistics is that by constructing a certain mathematical proximity measure, search for the optimal population distribution within the preset family of uncertainty distribution functions such that the distance between this distribution function and the empirical distribution function derived from the observed values data is minimized, thereby determining the vector of unknown parameters . Note that the empirical distribution function of the set of observed values data is
Based on this, Ning and Liu [26] constructed an objective function that estimates the vector of unknown parameters by minimizing the sum of the absolute values of the differences between the empirical distribution function of the set of observed values data and the assumed population distribution function . Specifically, the least absolute deviation estimation based on uncertainty distribution can be transformed into solving the following optimization problem,
To facilitate the subsequent construction of theoretical models and mathematical derivations, the parameter estimation based on the least squares criterion under the assumption of a normal uncertainty distribution will be presented below.
Assume that there is a set of independent and identically distributed observed values data follows a normal uncertainty distribution , where is the expected value parameter and is the standard deviation parameter. Note that the distribution function of the normal uncertainty distribution is
Then the least squares estimations of the unknown parameters and are the solutions to the following optimization problem,
3. Symmetric Statistical Invariant of Uncertain Regression Model
In the standard setting of uncertain regression analysis, we usually assume the existence of p-dimensional explanatory variables and corresponding response variables y. To explore in depth the synergistic effect mechanism of these explanatory variables on the response variable under uncertain conditions, Yao and Liu [14] pioneered the construction of an uncertain regression model structure as follows,
The core innovation of this model lies in modeling the non-deterministic factors in the variable relationship that are difficult to quantify precisely as uncertain variables. Here, the function f represents the deterministic relationship structure between the explanatory variables and the response variable y, is the parameter vector to be estimated, and is defined as an uncertain disturbance term with zero expected value and standard deviation , denoted as .
Suppose that there is a set of observation sequences
with regarding the explanatory variables and the response variable y. If both the unknown parameter vector in the uncertain regression model (3) and the standard deviation of the uncertain disturbance term take their theoretical true values, then based on the model structure, we can derive that
After standardization transformation, the above formula becomes
Substituting actual observed data , into this expression, we can define a set of real-valued functions for the parameters and as
The above n functions constructed in this way can be regarded as a set of concrete implementations of the standardized uncertain variables. According to the fundamental principles of uncertainty theory, this set of function values should follow a standard uncertain normal distribution , that is, we can reasonably infer that
when the unknown parameters and take their theoretical true values. Thus, the problem of estimating the unknown parameters and in the uncertain regression model (3) is transformed into finding the optimal parameter values such that can be regarded as a set of observed values from the population distribution as much as possible. Here, the population distribution is the statistical invariant constructed in uncertain regression analysis, and then the corresponding parameter estimation problem in uncertain regression analysis is transformed into a parameter estimation problem based on this statistical invariant. Because the uncertainty distribution of the statistical invariant is symmetric about the zero point, it is also called the symmetric statistical invariant.
The following examples will present the symmetric statistical invariants of the specific uncertain regression models corresponding to observation sequences.
Example 1.
Uncertain linear regression model is a classic and widely used statistical analysis method, whose core objective is to characterize the relationship between the response variable and one or more explanatory variables under uncertain environments through a linear function. Specifically, assuming we have a response variable y and p explanatory variables , the uncertain linear regression model can be expressed as
where is the intercept term, and are the regression coefficients corresponding to each independent variable, reflecting the marginal effect of each explanatory variable on the response variable, and the variable ε is the uncertain error term, which is usually assumed to follow a normal uncertainty distribution with zero mean and constant variance , in order to capture uncertain variations that the model cannot explain.
Example 2.
Uncertain exponential growth model is a mathematical framework used to characterize the phenomenon where the growth rate is proportional to the current value under uncertain environments, characterized by slow initial growth followed by rapid acceleration. This dynamic process is commonly seen in biological population growth, financial investment appreciation, and diffusion processes. Specifically, assuming we have a response variable y and a explanatory variable x, the uncertain exponential growth model can be expressed as
where denotes the initial reference level or lower limit, represents the initial size or scaling factor when , while is the growth rate parameter, which determines the speed of process expansion, and the variable ε is the uncertain error term, which is usually assumed to follow a normal uncertainty distribution with zero mean and constant variance , in order to capture uncertain variations that the model cannot explain.
Example 3.
Uncertain logistic decay model is a mathematical model used to describe the dynamic characteristics of the decay process under uncertain environments, which typically unfolds in three stages: initial decay with slow acceleration, a significant increase in the decay rate in the middle stage, and a gradual leveling off in the later stage. This S-shaped decay curve is commonly seen in natural and social phenomena such as biodegradation processes, chemical decomposition, and increasing market saturation. Specifically, assuming we have a response variable y and a explanatory variable x, the uncertain logistic decay model can be expressed as
where denotes the initial reference level, represents the initial value or maximum possible value of the decay process, controls the horizontal position of the curve, while determines the decay rate, and the variable ε is the uncertain error term, which is usually assumed to follow a normal uncertainty distribution with zero mean and constant variance , in order to capture uncertain variations that the model cannot explain.
4. Least Absolute Deviation Estimation of Uncertain Regression Model
This section will systematically study the parameter estimation problem in uncertain regression analysis based on the least absolute deviation criterion, focusing on how to determine the least absolute deviation estimation of the unknown parameter vector and disturbance term in the model within the framework of uncertainty theory, and thus establish a new parameter estimation method in uncertain regression analysis.
Based on the above analysis, the least absolute deviation problem of the unknown parameters and the uncertain disturbance term in the uncertain regression model (3) is transformed into the least absolute deviation estimation problem of the uncertainty distribution function with as the observed values data and as the population distribution.
It should be noted that the empirical distribution function constructed from the function values can be expressed as
Moreover, the theoretical distribution function of the standard normal uncertainty distribution has the following analytical form,
Then based on the basic criterion of least absolute deviation estimation and optimization problem (1), the estimated values of parameters and can be obtained by solving the following optimization problem,
Here the solutions and to the optimization problem (12) is also referred to as the least absolute deviation estimation of the uncertain regression model (3).
The following examples will present the least absolute deviation estimations of the specific uncertain regression models.
Example 4.
According to optimization problem (12), the least absolute deviation estimations of and σ in Example 1 solve the following optimization problem
Example 5.
According to optimization problem (12), the least absolute deviation estimations of and σ in Example 2 solve the following optimization problem
Example 6.
According to optimization problem (12), the least absolute deviation estimations of and σ in Example 3 solve the following optimization problem
5. Numerical Examples
In this section, we will provide two numerical examples to illustrate the method of least absolute deviation estimation of the specific uncertain regression model, and compare it with existing methods to demonstrate the effectiveness of the method proposed in this paper.
Example 7.

Consider an uncertain exponential growth model, mathematically expressed as
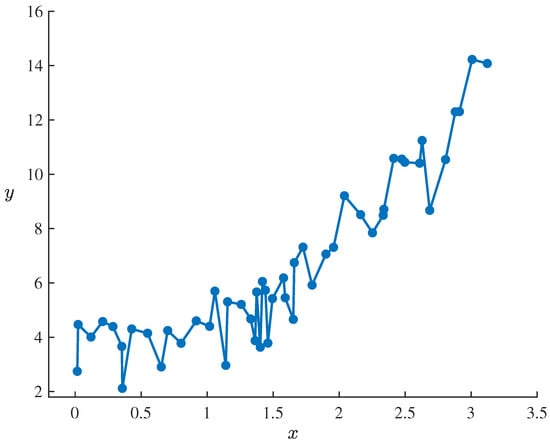
In this model, , , and are parameters to be estimated, and ε is an uncertain disturbance term, assumed to follow a normal uncertainty distribution with an expected value of 0 and a standard deviation of σ. For empirical analysis, we consider a dataset containing 50 sets of observations, presented in Table 1 and Figure 1, reflecting the observed relationship between the independent variable x and the response variable y.
Table 1.
Dataset containing 50 sets of observations of uncertain exponential growth model (16) in Example 7.
Figure 1.
Dataset containing 50 sets of observations of uncertain exponential growth model (16) in Example 7.
Denote the dataset by with . Then it follows from Example 2 that the statistical invariants of uncertain exponential growth model (16) corresponding to dataset , are
By using the conclusion of Example 5, we can infer that the least absolute deviation estimations of and σ are the optimal solutions of the following optimization problem,
which can be obtained as
Based on this, a fitted uncertain exponential growth model can be obtained as
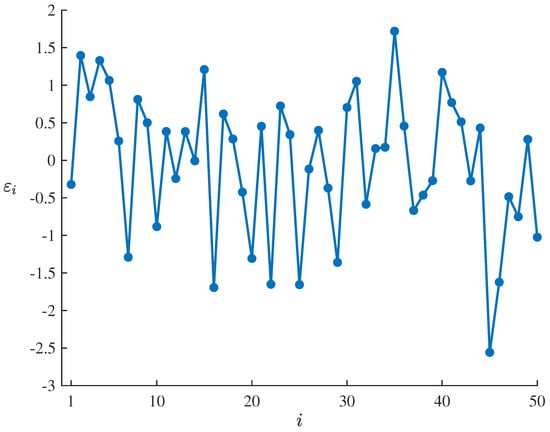
To test the suitability of the fitted uncertain exponential growth model (17) for the dataset , , the residuals of the estimated model corresponding to the dataset can be calculated by means of
which are showed in Table 2 and Figure 2. Set the significance level as , it follows from the uncertain hypothesis testing proposed by Ye and Liu [27] that the corresponding standardized critical value is
and the test is
As shown in Table 2 and Figure 2, only is outside the interval , which does not meet the condition that the number of outliers with is at least 3. Thus
therefore failing to reject the compatibility assumption of the estimated model at significance level of . This result indicates that the fitted uncertain exponential growth model (17) can well adapt to and fit the dataset , .
Table 2.
Residuals of the fitted uncertain exponential growth model (17) corresponding to the dataset , .
Figure 2.
Residuals of the fitted uncertain exponential growth model (17) corresponding to the dataset , .
Finally, based on the dataset , in Table 1 and Figure 1, we will combine the existing parameter estimation methods for uncertain regression models, such as the least squares estimation method studied by Wang et al. [28] and the uncertain maximum likelihood estimation method explored by Liu and Qin [21], to perform statistical inference on the uncertain exponential growth model (16), and obtain
estimated based on the least squares estimation method and
estimated based on the uncertain maximum likelihood estimation method, respectively. To further compare the performance of the models, the mean squared error (MSE), mean absolute error (MAE), and mean absolute percentage error (MAPE) of models (17)–(19) on the same dataset , are calculated, and the corresponding calculation formulas are as follows,
and
respectively. Table 3 lists the comparison results of the error indices for these three estimated models. The result in the Table 3 shows that the MSE, MAE and MAPE obtained based on model (17) are all lower than those corresponding to models (18) and (19). This difference indicates that the least absolute deviation estimation method proposed in this paper exhibits superior fitting and prediction performance in parameter estimation of uncertain regression models.
Example 8.
Consider an uncertain logistic decay model, mathematically expressed as
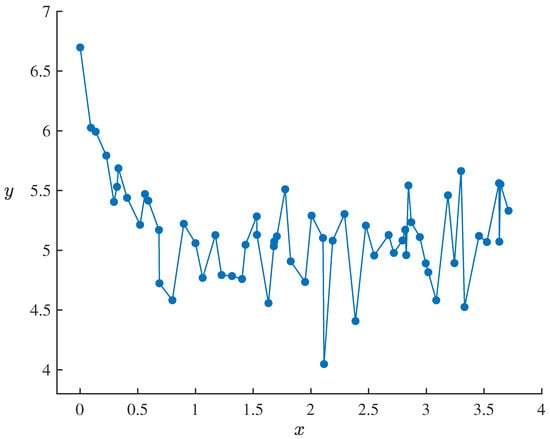
In this model, , , , and are parameters to be estimated, and ε is an uncertain disturbance term, assumed to follow a normal uncertainty distribution with an expected value of 0 and a standard deviation of σ. For empirical analysis, we consider a dataset containing 60 sets of observations, presented in Table 4 and Figure 3, reflecting the observed relationship between the independent variable x and the response variable y.
Table 4.
Dataset containing 60 sets of observations of uncertain logistic decay model (20) in Example 8.
Figure 3.
Dataset containing 60 sets of observations of uncertain logistic decay model (20) in Example 8.
Denote the dataset by with . Then it follows from Example 3 that the statistical invariants of uncertain logistic decay model (20) corresponding to dataset , are
By using the conclusion of Example 6, we can infer that the least absolute deviation estimations of and σ are the optimal solutions of the following optimization problem,
which can be obtained as
Based on this, a fitted uncertain logistic decay model can be obtained as
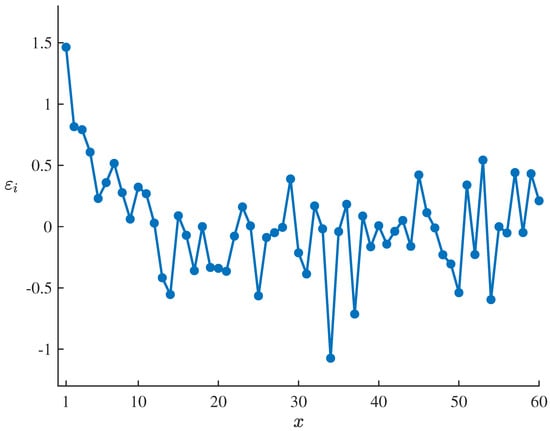
To test the suitability of the fitted uncertain logistic decay model (21) for the dataset , , the residuals of the estimated model corresponding to the dataset can be calculated by means of
which are showed in Table 5 and Figure 4. Set the significance level as , it follows from the uncertain hypothesis testing proposed by Ye and Liu [27] that the corresponding standardized critical value is
and the test is
As shown in Table 5 and Figure 4, only are outside the interval , which does not meet the condition that the number of outliers with is at least 7. Thus
therefore failing to reject the compatibility assumption of the estimated model at significance level of . This result indicates that the fitted uncertain logistic decay model (21) can well adapt to and fit the dataset , .
Table 5.
Residuals of the fitted uncertain logistic decay model (21) corresponding to the dataset , .
Figure 4.
Residuals of the fitted uncertain logistic decay model (21) corresponding to the dataset , .
Finally, based on the dataset , in Table 4 and Figure 3, we will combine the existing parameter estimation methods for uncertain regression models, such as the least squares estimation method studied by Wang et al. [28] and the uncertain maximum likelihood estimation method explored by Liu and Qin [21], to perform statistical inference on the uncertain exponential growth model (16), and obtain
estimated based on the least squares estimation method and
estimated based on the uncertain maximum likelihood estimation method, respectively. To further compare the performance of the models, the mean squared error (MSE), mean absolute error (MAE), and mean absolute percentage error (MAPE) of models (21)–(23) on the same dataset , are calculated, and the corresponding calculation formulas are as follows,
and
respectively. Table 6 lists the comparison results of the error indices for these three estimated models. The result in the Table 6 shows that the MSE, MAE and MAPE obtained based on model (21) are all lower than those corresponding to models (22) and (23). This difference indicates that the least absolute deviation estimation method proposed in this paper exhibits superior fitting and prediction performance in parameter estimation of uncertain regression models.
6. Application in Sport Statistics
In sports statistics, scientifically quantifying the complex relationship between athletes’ physiological indicators, athletic performance, and economic value is crucial for training optimization, talent selection, and market evaluation. However, sports data is often affected by measurement errors, individual differences, and outliers. Traditional regression methods are sensitive to outliers, potentially weakening the model’s robustness and explanatory power. Therefore, this section introduces uncertain regression model and least absolute deviation criterion method to improve the stability and reliability of statistical inference under non-ideal data environments in sports statistics.
Specifically, this section focuses on two typical sports statistics scenarios: First, modeling the correlation between athletes’ physiological indicators and athletic performance. We select the weight, speed and agility performance, and flexibility and strength performance of adolescent athletes as explanatory variables to explore their relationship with lung capacity. In this scenario, individual physiological compensation and fluctuations in test conditions can easily lead to observational anomalies. Uncertain regression models and least absolute deviation criterion can effectively suppress the interference of outliers on model parameters, revealing the intrinsic correlations more robustly. Second, predicting the market value of FIFA football players. Player market value is influenced by multiple uncertain variables, including age, overall rating, international reputation, weak foot, skill moves, and often includes a few high-leverage observed values (such as superstar players). Traditional regression methods are easily affected by extreme values, leading to systematic biases in prediction. This section constructs an uncertain regression model based on the least absolute deviation criterion to enhance the inclusiveness of unconventional observed values and improve the robustness and practical reference value of market value prediction. Through empirical analysis of the two scenarios described above, this section systematically verifies the advantages of least absolute deviation estimation in sports statistics, providing a more robust and stable analytical method for modeling complex sports data, and promoting the cross-integration of statistical methods and sports science.
6.1. Uncertain Lung Capacity Model
To investigate the relationship between weight, speed and agility performance, flexibility and strength performance and lung capacity of young athletes, Li [29] collected relevant data from 18 young athletes, as shown in Table 7.
Table 7.
Dataset of the weight, speed and agility performance, flexibility and strength performance and lung capacity of 18 young athletes.
Let the lung capacity of the adolescent athletes be the response variable y, and let the weight (), speed and agility performance (), and flexibility and strength performance () of the adolescent athletes be the explanatory variables. And represent the dataset in Table 7 as
Then we use the following uncertain linear regression model,
to fit the dataset , . In this model, , , , and are parameters to be estimated, and is an uncertain disturbance term, assumed to follow a normal uncertainty distribution with an expected value of 0 and a standard deviation of .
It follows from Example 1 that the statistical invariants of uncertain linear regression model (24) corresponding to dataset , are
By using the conclusion of Example 4, we can infer that the least absolute deviation estimations of and are the optimal solutions of the following optimization problem,
which can be obtained as
Based on this, a fitted uncertain lung capacity model can be obtained as
To test the suitability of the fitted uncertain lung capacity model (25) for the dataset , , the residuals of the estimated model corresponding to the dataset can be calculated by means of
which are showed in Table 8 and Figure 5. Set the significance level as , it follows from the uncertain hypothesis testing proposed by Ye and Liu [27] that the corresponding standardized critical value is
and the test is
As shown in Table 8 and Figure 5, only is outside the interval , which does not meet the condition that the number of outliers with is at least 2. Thus
therefore failing to reject the compatibility assumption of the estimated model at significance level of . This result indicates that the fitted uncertain lung capacity model (25) can well adapt to and fit the dataset , .
Table 8.
Residuals of the fitted uncertain lung capacity model (25) corresponding to the dataset , .
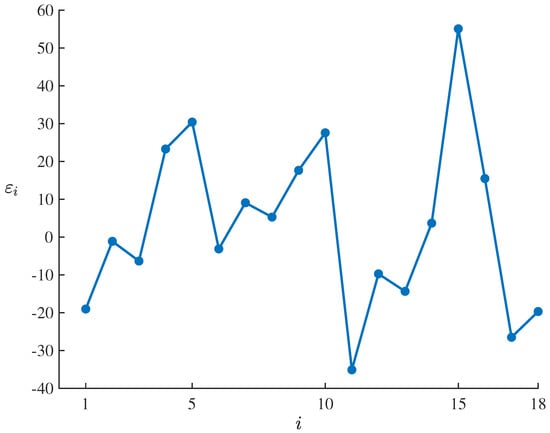
Figure 5.
Residuals of the fitted uncertain lung capacity model (25) corresponding to the dataset , .
6.2. Uncertain FIFA Football Player Valuation Model
To investigate the relationship between age, overall rating, international reputation, weak foot, skill moves and the player market value, we collected relevant data from 28 football players retrieved from Website [30], as shown in Table 9.
Table 9.
Dataset of the age, overall rating, international reputation, weak foot, skill moves and the player market value of 28 football players.
Let the player market value of the football players be the response variable y, and let the age (), overall rating (), international reputation (), weak foot (), and skill moves () of the football playerss be the explanatory variables. And represent the dataset in Table 9 as
Then we use the following uncertain linear regression model,
to fit the dataset , . In this model, , , , , , and are parameters to be estimated, and is an uncertain disturbance term, assumed to follow a normal uncertainty distribution with an expected value of 0 and a standard deviation of .
It follows from Example 1 that the statistical invariants of uncertain linear regression model (26) corresponding to dataset , are
with . By using the conclusion of Example 4, we can infer that the least absolute deviation estimations of and are the optimal solutions of the following optimization problem,
which can be obtained as
and
Based on this, a fitted uncertain FIFA football player valuation model can be obtained as
To test the suitability of the fitted uncertain FIFA football player valuation model (27) for the dataset , , the residuals of the estimated model corresponding to the dataset can be calculated by means of
which are showed in Table 10 and Figure 6. Set the significance level as , it follows from the uncertain hypothesis testing proposed by Ye and Liu [27] that the corresponding standardized critical value is
and the test is
As shown in Table 10 and Figure 6, only is outside the interval , which does not meet the condition that the number of outliers with is at least 2. Thus
therefore failing to reject the compatibility assumption of the estimated model at significance level of . This result indicates that the fitted uncertain FIFA football player valuation model (27) can well adapt to and fit the dataset , .
Table 10.
Residuals of the fitted uncertain FIFA football player valuation model (27) corresponding to the dataset , .
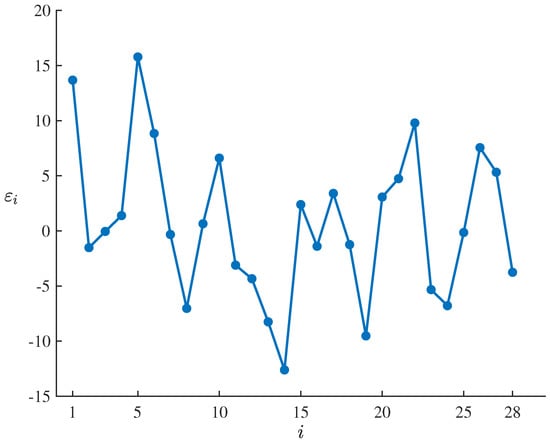
Figure 6.
Residuals of the fitted uncertain FIFA football player valuation model (27) corresponding to the dataset , .
7. Conclusions
For the purpose of enriching the statistical inference study in uncertain regression analysis, a symmetric statistical invariant for the uncertain regression model based on observed data and uncertain disturbance terms was constructed in this paper. Based on the constructed statistical invariant, the least absolute deviation criterion was also applied to propose the least absolute deviation estimation for the uncertain regression model. Following that, the least absolute deviation estimation of the uncertain regression model was applied to the uncertain linear regression model, uncertain exponential growth model, and uncertain logistic decay model, respectively, and the advantages of the proposed method were also illustrated with two numerical examples by comparing with existing methods. Finally, the proposed method was also applied to two typical scenarios in sports statistics, and the corresponding uncertain statistical models were studied based on real data to illustrate the application effect.
In addition, future research directions could focus on the numerical solution algorithms for the corresponding least absolute deviation estimations, error analysis, and application research in typical cognitive uncertainty scenarios such as social statistics and psychostatistics.
Funding
This work was supported by the National Team Science and Technology Support Youth Project of the General Administration of Sport of China (No. 24QN022).
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The author declares no conflicts of interest that relate to the research described in this paper. Neither the entire paper nor any part of its content has been published or has been accepted elsewhere. It is also not being submitted to any other journal.
References
- Galton, F. Family likeness in stature. Proc. R. Soc. Lond. 1886, 40, 42–73. [Google Scholar] [CrossRef]
- Draper, N.R.; Smith, H. Applied Regression Analysis, 2nd ed.; John Wiley and Sons: New York, NY, USA, 1981. [Google Scholar]
- Berkson, J. Application of the logistic function to bio-assay. J. Am. Stat. Assoc. 1944, 39, 357–365. [Google Scholar] [PubMed]
- Hoerl, A.; Kennard, R. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. Stat. Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B Stat. Methodol. 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Freund, R.; Wilson, W.; Sa, P. Regression Analysis; Elsevier: Amsterdam, The Netherlands, 2006. [Google Scholar]
- Sen, A.; Srivastava, M. Regression Analysis: Theory, Methods and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Chatterjee, S.; Simonoff, J. Handbook of Regression Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Jiang, B.; Ye, T. Uncertain panel regression analysis with application to the impact of urbanization on electricity intensity. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 13017–13029. [Google Scholar] [CrossRef]
- Liu, Y. Moment estimation for uncertain regression model with application to factors analysis of grain yield. Commun. Stat. Simul. Comput. 2024, 53, 4936–4946. [Google Scholar] [CrossRef]
- Liu, B. Uncertainty Theory, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Liu, B. Some research problems in uncertainty theory. J. Uncertain Syst. 2009, 3, 3–10. [Google Scholar]
- Yao, K.; Liu, B. Uncertain regression analysis: An approach for imprecise observations. Soft Comput. 2018, 22, 5579–5582. [Google Scholar] [CrossRef]
- Ye, T.; Liu, Y.H. Multivariate uncertain regression model with imprecise observations. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 4941–4950. [Google Scholar] [CrossRef]
- Chen, D. Uncertain regression model with autoregressive time series errors. Soft Comput. 2021, 25, 14549–14559. [Google Scholar] [CrossRef]
- Chen, D. Uncertain regression model with moving average time series errors. Commun. Stat. Theory Methods 2023, 52, 7632–7646. [Google Scholar] [CrossRef]
- Ding, J.; Zhang, Z. Statistical inference on uncertain nonparametric regression model. Fuzzy Optim. Decis. Mak. 2021, 20, 451–469. [Google Scholar] [CrossRef]
- Liu, Z.; Yang, Y. Least absolute deviations estimation for uncertain regression with imprecise observations. Fuzzy Optim. Decis. Mak. 2020, 19, 33–52. [Google Scholar] [CrossRef]
- Lio, W.; Liu, B. Uncertain maximum likelihood estimation with application to uncertain regression analysis. Soft Comput. 2020, 24, 9351–9360. [Google Scholar] [CrossRef]
- Liu, Y.; Qin, Z. Modified maximum likelihood approach in uncertain regression analysis and application to factors analysis of urban air quality. Math. Comput. Simul. 2025, 234, 219–234. [Google Scholar] [CrossRef]
- Chen, D. Tukey’s biweight estimation for uncertain regression model with imprecise observations. Soft Comput. 2020, 24, 16803–16809. [Google Scholar] [CrossRef]
- Lio, W.; Liu, B. Residual and confidence interval for uncertain regression model with imprecise observations. J. Intell. Fuzzy Syst. 2018, 35, 2573–2583. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, B. A modified uncertain maximum likelihood estimation with applications in uncertain statistics. Commun. Stat. Theory Methods 2024, 53, 6649–6670. [Google Scholar]
- Liu, Y.; Liu, B. Estimation of uncertainty distribution function by the principle of least squares. Commun. Stat. Theory Methods 2024, 53, 7624–7641. [Google Scholar] [CrossRef]
- Ning, S.; Liu, Y. Estimation of unknown parameters in uncertainty distribution via the least absolute deviation principle and its application in uncertain statistics. Commun. Stat. Simul. Comput. 2025. accepted. [Google Scholar]
- Ye, T.; Liu, B. Uncertain hypothesis test with application to uncertain regression analysis. Fuzzy Optim. Decis. Mak. 2022, 21, 157–174. [Google Scholar] [CrossRef]
- Wang, H.; Liu, Y.; Shi, H. Estimating unknown parameters and disturbance term in uncertain regression models by the principle of least squares. Symmetry 2024, 16, 1182. [Google Scholar] [CrossRef]
- Li, C. The application of Excel multivariate linear regression in sports statistics. China Manag. Inform. 2011, 14, 65–66. [Google Scholar]
- FIFA23 Official Dataset. 2025. Available online: https://www.kaggle.com/datasets/bryanb/fifa-player-stats-database (accessed on 11 September 2025).






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.