Abstract
We propose a novel approach for clustering problem, which refers to as Graph Regularized Orthogonal Subspace Non Negative Matrix Factorization (GNMFOS). This type of model introduces both graph regularization and orthogonality as penalty terms into the objective function. It not only obtains the uniqueness of matrix decomposition but also improves the sparsity of decomposition and reduces computational complexity. Most importantly, using the idea of iteration under weak orthogonality, we construct an auxiliary function for the algorithm and obtain convergence proof to compensate for the lack of convergence proof in similar models. The experimental results show that compared with classical models such as GNMF and NMFOS, our algorithm significantly improves clustering performance and the quality of reconstructed images.
1. Introduction
Clustering is a fundamental technique in data analysis, extensively applied in image processing, document classification, and other fields. As an unsupervised learning method, it aims to partition a dataset into distinct groups such that data points within the same group are more similar to each other than to those in different groups. Common clustering algorithms determine the relationship between data points by measuring their similarity, and assign data points with similar features to the same cluster. Due to the non-negativity requirement in many real-world applications, Non-negative Matrix Factorization (NMF) has attracted considerable attention as a dimensionality reduction and clustering technique. NMF effectively reduces storage cost and computation complexity by producing interpretable parts-based representations. NMF has been successfully applied and extended to various domains including clustering and classification [1,2,3], image analysis [4,5,6], spectral analysis [7,8], and blind source separation [9,10]. More recently, NMF-related methods have also found applications in micro-video classification [11], RNA-seq data deconvolution [12], attributed network anomaly detection [13], and signal processing tasks such as dynamic spectrum cartography and tensor completion [14], which further demonstrate the method’s adaptability and growing relevance.
Various extensions of NMF have been proposed to capture the latent structures within data. For example, Cai et al. [15] proposed Graph Regularized NMF (GNMF) by incorporating a graph Laplacian term into the objective function, enabling the preservation of intrinsic geometric structure. Hu et al. [16] further introduced GCNMF by integrating GNMF with Convex NMF. Meng et al. [17] extended the regularization to both the sample and feature spaces, resulting in the Dual-graph Sparse NMF (DSNMF) method. Other notable variants include GDNMF [18], DNMF [19], RHDNMF [20], AWMDNMF [21], TGLMC [22], and PGCNMF [23], each offering improvements for non-linear or structured data modeling.
In the context of image clustering, Li et al. [24] observed that local representations are often associated with orthogonality. Ding et al. [25] introduced Orthogonal NMF (ONMF), demonstrating that orthogonality enhances sparsity, reduces redundancy, and improves the interpretability and uniqueness of clustering results. However, enforcing strict orthogonality often leads to high computational cost, especially for large document datasets.
To overcome such problems, researchers have proposed a series of methods with orthogonal constraints [26,27,28]. Unfortunately, among the existing results (to the best of our ability to search for all existing results), there is a lack of NMF methods that simultaneously consider the orthogonality of coefficient matrices in orthogonal subspaces and the intrinsic geometric structures hidden in data and feature manifolds. Or, even if a similar model is proposed, the convergence proof of the update algorithm is missing or incorrect.
In this paper, we propose a novel approach that combines graph Laplacian and nonnegative matrix factorization in orthogonal subspaces. The generation of orthogonal factor matrices is incorporated as a penalty term into the objective function, along with the addition of a graph regularization term. On one hand, by introducing orthogonal penalties and graph Laplacian terms, the orthogonality of the factor matrices is achieved through the factorization process, reducing the computational burden imposed by enforcing orthogonality constraints. On the other hand, it enhances sparsity in the coefficient matrix to some extent and utilizes the geometric structure properties of the data, thereby improving the ability to recover underlying nonlinear relationships. We have uniformly named this series of models as Graph Regularized Nonnegative Matrix Factorization on Orthogonal Subspace (GNMFOS), and of course, some special cases will be annotated with lowercase letters and numbers, such as GNMFOSv2. We develop two efficient algorithms to solve the proposed models and demonstrate their convergence. Moreover, we construct the objective function of GNMFOS using Euclidean distance and optimize it using the MUR. Finally, we conduct experiments to evaluate the proposed algorithms. The experimental results show that GNMFOS and GNMFOSv2 combine the advantages of previous algorithms, resulting in improved effectiveness and robustness.
In this study, the orthogonal constraints in matrix factorization inherently exhibit mathematical symmetry, ensuring balanced and reciprocal relationships between data representations. This symmetry not only simplifies the computational model but also enhances the interpretability of clustering results.
The remaining contents of this paper are as follows. Section 2 presents a review of related work, including NMF, NMFOS, and GNMF. Section 3 provides a detailed description of our proposed method, including the derivation of update rules and corresponding algorithms. Section 3 also presents the convergence analysis of the algorithms. Section 4 will show experimental results and the relevant analysis. Section 5 is a summary of the paper and also discusses future research directions.
2. Preliminaries
In this section, we will introduce some symbols in Table 1, then introduce some models and related works to serve as the foundation for our paper.

Table 1.
Important symbols annotated in this paper.
2.1. NMF
The classical NMF [29] is a nonnegative matrix factorization algorithm that focuses on analyzing data matrices consisting of nonnegative elements. Given a nonnegative data matrix X, the aim of NMF is to find two nonnegative matrices W and H, such that the product of W and H can closely approximate the original matrix X, i.e.,
The optimization model for NMF can be formulated as follows:
2.2. NMFOS
Although NMF has many advantages, it is not easy to obtain the desired solution. Chris Ding et al. [25] extended the traditional NMF by adding an orthogonal constraint on the basis or coefficient matrix into the objective function’s constraints. Li et al. [30] optimized the above model; they proposed a novel approach called Nonnegative Matrix Factorization with Orthogonal Subspace (NMFOS), which is based on the idea of putting the orthogonality as a penalty term into the objective function, and obtained the following new model.
Here, the orthogonality of H is shown (and G’s is ) with parameter controlling the orthogonality of the vectors in H.
2.3. GNMF
Graph regularization is a data processing method based on manifolds. The core concept is that manifolds can enhance the smoothness of data in linear and nonlinear spaces by minimizing (1) beolw. As demonstrated by existing studies, incorporating the geometric structure information from data points can enhance the clustering performance of NMF [31,32]. So, the p-nearest neighbor graph is constructed based on the input data matrix X to effectively capture the geometric structure. Meanwhile, in order to characterize the similarity between adjacent points, a weight matrix is defined. In this paper, the weight matrix below is commonly used.
Here, represents the set of p-nearest neighbors for data point . There are many options for defining containing heat kernal weight matrix and dot-product weight matrix With the help of the weight matrix S, the Laplacian matrix L is defined to characterize the degree of similarity between points in geometric structure and , where D is the degree matrix with . Inspired by manifold learning, Cai et al. [15] proposed the GNMF algorithm. The core idea is the graph regularization
Then, the optimization model of GNMF is given by
In fact, the minimization of (1) shows that if two data points are close in original data’ distribution, they will also be close under the new basis vectors and . The regularization parameter controls the smoothness of the model.
3. A New Model
In this section, we will combine NMFOS and GNMF to introduce a new method called Graph Regularized Non-negative Matrix Factorization on Orthogonal Subspaces (GNMFOS). More importantly, we also provide a convergence proof for this new model to compensate for the lack or inadequacy of algorithm convergence proof. Note that in order to enhance the clustering performance, our model GNMFOS integrates the advantages of existing methods.
3.1. GNMFOS
By putting both the orthogonality and the Graph Laplacian into the objective function, GNMFOS is formulated as follows.
where , , . Considering the Lagrange function in (2), we obtain the following update rules.
The update rule (3) and its convergence proof are the same as in [15]. But (4) is new and it is hard to prove its convergence directly, as the orthogonality of H requires handling the fourth power term of H, which makes it difficult to implement the commonly used approach of using second-order Taylor formula to construct auxiliary functions and further obtain convergence proofs for updating rules. To clarify this difficult task, the first and second derivatives of the objective function with respect to are given below.
According to tradition, the auxiliary function of H should be defined as follows:
So, we can ensure that leads to the same update rule in (4). Returning to the Taylor series expansion of , it is easy to obtain
In this way, a difficulty of convergence proof between and arises, i.e., when proving that the function is an auxiliary function, we cannot prove that
So, we improve (2) by proposing a new variant model where H is weakly orthogonal. This new model is called weakly orthogonal because it is obtained by orthogonalizing the t-th iteration of H with the (t − 1)-th iteration, where the t-th iteration is treated as an unknown variable and the (t − 1)-th iteration is treated as a constant (). Then, the following new model is now arrived at.
Here, and represent the orthogonal penalty parameter and regularization parameter, respectively. The parameter is used to adjust the degree of orthogonality in H, while the parameter balances the reconstruction error in the first term and the graph regularization in the third term of the objective function. It is worth mentioning that if the update rule for H converges, we have reason to suspect that approximates , and .
Due to the non-convexity of the objective function in both variables W and H in (5), we adopt an iterative optimization algorithm and utilize multiplicative update rules to obtain local optima (original idea comes from [33,34,35]). The variables W and H are updated alternately while keeping the other variable fixed.
We can rewrite the objective function of in trace form as follows.
where and represent the Lagrange multipliers for and in (5), respectively. Let , then, the Lagrangian function follows:
The function L solves for stable points of W and H, respectively, and obtains the following equations.
With the help of KKT conditions and , multiplying both sides of (6) by and (7) by , we will receive the iterative update rule for (5):
In summary, we can now develop the efficient algorithm below to solve (5). For a detailed proof of the convergence of Algorithm 1, please refer to Appendix A.
| Algorithm 1 GNMFOS |
|
3.2. GNMFOSv2
In Algorithm 1, if or occurs in a certain iteration, the update rule will automatically stop, regardless of whether it reaches a stable point. This phenomenon is called “zero locking”. In [36], Andri Mirzal found that almost all NMF algorithms based on MUR exhibit zero locking phenomenon. So, Andri Mirzal proposed adding a small positive number to the denominator of the update rule to avoid this phenomenon. Using this approach, we will change the update rules (8) and (9) to the following format and rename it as GNMFOSv2.
3.3. Complexity of Algorithms
In this subsection, the computational complexity of Algorithms 1 and 2 is analyzed. In computer science, the computational complexity is the amount of resources required to run the algorithm, especially the time (CPU usage time) and space (memory usage space) requirements. Here, we mainly measure the space requirements, which refers to the basic arithmetic operations of floating-point numbers used to measure the cost of computing steps. The symbol means the value is of the same order as n.
Recall that M denotes the number of features, N denotes the number of samples, K denotes the number of clusters, and p denotes the number of nearest neighbors. In Algorithms 1 and 2, each iteration of the computational complexity of , , , and are all . Similarly, the complexities of and are both , while ’s is . In addition, we also need to provide an additional complexity of to construct the p-nearest neighbor graph.
In conclusion, the computational complexity of each iteration in Algorithms 1 and 2 is .
| Algorithm 2 GNMFOSv2 |
|
4. Experimental Results and Analysis
In this section, we will assess the performance of Algorithms 1 and 2 through experimental evaluation. Firstly, we compare our algorithms with other classical algorithms in the clustering performance based on image datasets. Secondly, the clustering results for document datasets are compared. Thirdly, parameter sensitivity and weighting scheme selection for S are also analyzed, and this helps us to identify suitable parameters and construction schemes for the algorithm proposed in this paper.
4.1. Evaluation Indicators and Data Sets
In order to compare the clustering performance, we use four evaluation indicators, including Purity, Mutual information (MI), Normalized Mutual Information (NMI) and Accuracy (ACC), and the higher value indicates better clustering quality [36]. These indicators can reflect the advantages of our algorithm from different perspectives.
Specifically, the Purity measures the extent to which clusters contain a single class, defined as
The notation represents the count of occurrences where the j-th input class is assigned to the i-th cluster, with N denoting the total number of samples.
The ACC reflects the percentage of correctly clustered samples after optimal label mapping, defined as
N represents the total number of samples. is a mapping function that denotes the mapping of the computed clustering label to the true clustering label .
MI and NMI quantify the shared information between the cluster assignments and true labels, measuring the quality of clustering from an information-theoretic perspective.
Here, C and represent a set of true labels and a set of clustering labels, respectively, and denotes the entropy function. and denote the i-th class and the j-th cluster. represents the joint probability distribution function of clustering and class labels. and correspond to the marginal probability distribution functions of classes and clusters, respectively.
To assess the algorithm’s performance, we conduct tests using three publicly available image datasets (including AR, ORL, and Yale datasets) and two public document datasets (including TDT2 and TDT2 all).
4.2. Comparison Algorithms
This section will list several classic algorithms for comparison and provide a brief introduction to each of them.
- K -means [37]: This algorithm directly performs clustering operations on the original matrices without extracting or analyzing them.
- NMF [29]: This algorithm only directly obtains the factorization of two non-negative matrices without adding any other conditions or constraints.
- ONMF [25]: Building upon NMF, an orthogonal constraint is introduced to the basis matrix or coefficient matrix.
- NMFSC [38]: The algorithm adds sparse representation on NMF, representing the data as a linear combination of a small number of basis vectors.
- GNMF [15]: By integrating graph theory and manifold assumptions with the original NMF, the algorithm extracts the intrinsic geometric structure of the data.
- NMFOS [30]: Building on ONMF, this algorithm incorporates an orthogonal constraint on the coefficient matrix as a penalty term in the objective function.
- NMFOSv2 [36]: This algorithm, based on NMFOS, introduces a small term into the denominator of the update rule formula.
Meanwhile, our new models proposed in this paper are listed below.
- GNMFOS: Building upon NMFOS, this algorithm incorporates the graph Laplacian term into the objective function.
- GNMFOSv2: Building upon GNMFOS, this algorithm introduces a small term into the denominator of the update rule formula.
For consistency, we consider using Frobenius norm for all calculations. In the experiments, the termination criteria and the selection of relevant parameters are computed according to the numerical values chosen by the corresponding original papers’ authors. Additionally, aspects such as the input raw dataset and related settings are kept consistent across all methods in this paper. Each algorithm is run 10 times, and the average values of Purity, NMI, MI, and ACC from these 10 runs are calculated for evaluation.
4.3. Parameter Settings
In Algorithms 1 and 2, there are four parameters: regularization parameter , orthogonality parameter , nearest neighbor point p, and in the denominator of Algorithm 2. Different parameter values will lead to different clustering results. To control variables and investigate the clustering effects of different algorithms, the experiments in Section 4.4.1 initially choose the same set of parameters: the maximum number of iterations , , , , and . In the parameter sensitivity subsection, different parameters will be further explored to identify the optimal parameters suitable for the algorithm.
4.4. Clustering Results for Image Datasets
In this subsection, we will compare the clustering performance based on the AR, ORL, and Yale datasets.
4.4.1. Comparison Display on Image Datasets
We will compare the various indicators’ values under different K (number of clusters) on each dataset. Therefore, the first column in Table 2, Table 3 and Table 4 contains all the values of K used. Each table consists of four sub-tables, which display the overall values of all comparison algorithms in one dataset and one evaluation indicator, respectively. The maximum value is represented in bold. To ensure accuracy, the experiments are conducted with 10 runs at different cluster numbers, and the results are averaged. Of course, in order to see the differences between the four evaluation metrics in each dataset more clearly, we will draw line graphs in different colors to show the corresponding effects, for detailed information, please refer to Figure 1, Figure 2 and Figure 3.
Table 2.
The clustering performance on AR.
Table 3.
The clustering performance on ORL.
Table 4.
The clustering performance on Yale.
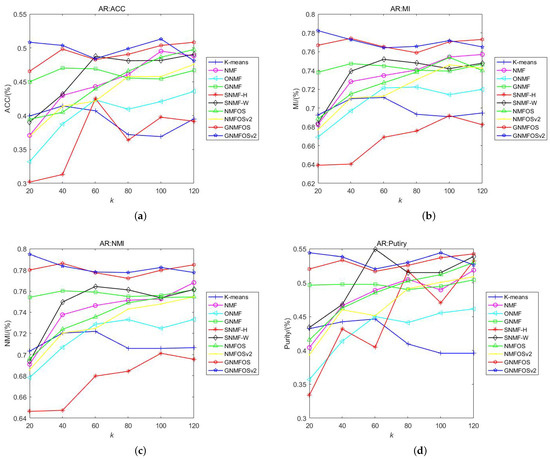
Figure 1.
The clustering performance on AR. (a) ACC; (b) MI; (c) NMI; (d) Purity.
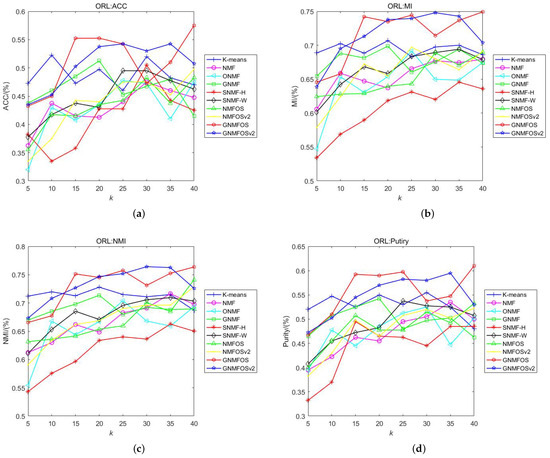
Figure 2.
The clustering performance on ORL. (a) ACC; (b) MI; (c) NMI; (d) Purity.
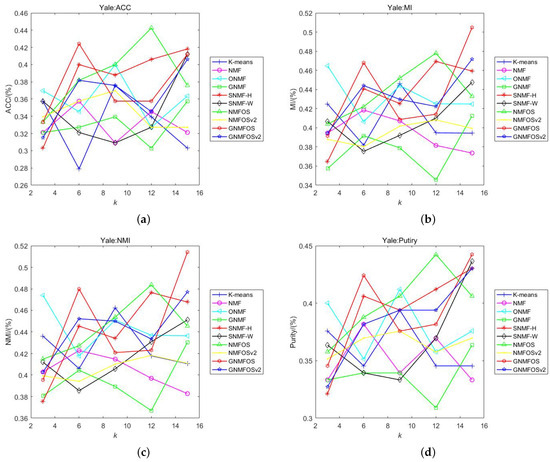
Figure 3.
The clustering performance on Yale. (a) ACC; (b) MI; (c) NMI; (d) Purity.
Discussion of Results on AR Dataset:
- For indicators of ACC, MI, NMI, and Purity, GNMFOS achieves the highest values at the same clusters’ number in AR dataset, while GNMFOSv2 outperforms GONMF at other cluster numbers. Overall, GNMFOSv2 has the highest clustering indicator values.
- The differences in ACC, MI, NMI, and Purity, as well as their average values, for GNMFOS and GNMFOSv2 are not significant across different cluster numbers K. In contrast, most of other algorithms show larger fluctuations in clustering indicator values at different K. This shows that GNMFOS and GNMFOSv2 exhibit better stability across different cluster numbers, making them more suitable for applications.
- Among the orthogonal-based algorithms, ONMF, NMFOS, NMFOSv2, GNMFOS, and GNMFOSv2, the clustering performance of the proposed GNMFOS and GNMFOSv2 algorithms is the best. This indicates that our algorithms enhance the clustering performance and improve the sparse representation capability based on NMF methods.
- Among the graph Laplacian-based algorithms, GNMFOSv2 and GNMFOS consistently rank among the top two (followed by GNMF). This indicates that our models effectively utilize the hidden geometric structure information in data space.
Discussion of Results on ORL Dataset:
- When K is small (≤10), K-means achieves the highest values in ACC, MI, NMI, and Purity. When K is larger, the GNMFOS and GNMFOSv2 algorithms consistently rank among the top two in terms of the four clustering indicators. This shows that our algorithms are more suitable for larger numbers of clusters in the ORL dataset.
- Overall, GNMFOS has higher average values in ACC, MI, and Purity compared to GNMFOSv2 (NMI is slightly lower than GNMFOSv2), but the differences between GNMFOS and GNMFOSv2 are not significant. This indicates that, for the ORL dataset, GNMFOS is slightly more applicable.
- In terms of ACC, MI, NMI, and Purity, GNMFOS achieves the overall highest values at the same number of clusters . This indirectly indicates that the GNMFOS algorithm is suitable for clustering the dataset into the original classes.
- Among the orthogonal-based algorithms (including ONMF, NMFOS, and NMFOSv2), GNMFOS and GNMFOSv2 exhibit the best clustering performance. This also indicates that our algorithms enhance the clustering performance and improve the sparse representation capability of NMF-based methods.
- Among the graph Laplacian-based algorithms including GNMF, GNMFOS and GNMFOSv2 exhibit the best clustering performance. This also indicates that our models effectively utilize the hidden geometric structure information in data space.
Discussion of Results on Yale Dataset:
- On the Yale dataset, no algorithm consistently leads in all four clustering indicators, so they need to be discussed separately. For ACC, NMFOS has the highest value (e.g., 0.4424 when ). However, it is worth noting that GNMFOS and GNMFOSv2 do not significantly lag behind NMFOS. Specifically, at , GNMFOS achieves the second-highest rank. For MI, NMFOS also achieves the highest value, but GNMFOS lags behind it by only 0.04%, and GNMFOS attains the overall highest value at , indicating strong competitiveness in MI. For NMI, GNMFOS has the highest value and achieves the overall highest value at . For Purity, NMFOS has the highest value, but GNMFOS attains the overall highest values at and , indicating that GNMFOS is also highly competitive.
- Although in some indicators, the values of NMFOS are slightly higher than those of GNMFOS and GNMFOSv2, these differences are moderate. The results indicate that both the GNMFOS and NMFOS algorithms are viable choices for the Yale dataset.
- For all four clustering indicators at , ONMF has the highest values, indicating that the ONMF algorithm maybe more suitable for smaller K.
- When K increases, the values of ACC, MI, NMI, and Purity for NMFOS do not consistently increase or decrease monotonically. But for GNMFOS, the values of MI and NMI significantly increase. This indicates that our algorithms are more suitable for clustering experiments with larger numbers of clusters on the Yale dataset.
- The orthogonal-based algorithms (ONMF, NMFOS, NMFOSv2, GNMFOS, and GNMFOSv2) exhibit the overall best performance, indicating that algorithms with orthogonality are more suitable for the Yale dataset.
Overall, the algorithms proposed in this paper outperform algorithms that solely possess orthogonal, manifold, or sparse constraints. The results indicate that our algorithms successfully integrate the advantages of orthogonal constraints and geometric structures, further optimizing over the compared algorithms for a better learning of parts-based representation in the dataset. So, the above results demonstrate that our GNMFOS and GNMFOSv2 algorithms have strong competitiveness in clustering.
However, it is worth noting that no single algorithm consistently outperforms others across all four clustering indicators on the Yale dataset. This reflects the inherent trade-offs among different clustering evaluation metrics and highlights the limitations of current algorithms in achieving uniformly best performance. Such a phenomenon is common in clustering tasks where different metrics emphasize distinct aspects of clustering quality. Future work could focus on developing methods that balance multiple criteria more effectively.
4.4.2. Summary of Analysis on Image Datasets
In this part, we will summarize the above analysis on image datasets.
- In orthogonal-based algorithms, such as ONMF, NMFOS, NMFOSv2, GNMFOS, and GNMFOSv2, they outperform NMF, GNMF, SNMF-H, and SNMF-W algorithms on the Yale dataset. Moreover, on the AR and ORL datasets, GNMFOS and GNMFOSv2 exhibit the best clustering performance among them. In graph Laplacian-based algorithms, such as GNMF, GNMFOS, and GNMFOSv2, their clustering performance is almost superior to other algorithms. This is because graph-based algorithms consider local geometric structures, preserving locality in low-dimensional data space. The GNMFOS and GNMFOSv2 algorithms combine the advantages of orthogonality and graph, enhancing clustering performance and improving the sparse representation capability of NMF based models.
- Due to the various backgrounds in each dataset (e.g., lighting conditions, poses, etc.), the performances of GNMFOS and GNFOSv2 are different. For different feature dimensions, the values of ACC, MI, NMI, and Purity also show slight variations, but the overall performance of GNMFOS and GNFOSv2 remains stable.
- For the Yale dataset, GNMFOS and GNMFOSv2 do not significantly outperform, indicating that orthogonal penalty constraints and graph Laplacian constraints may not necessarily enhance clustering performance in certain situations. Therefore, further research is needed to develop more effective algorithms in the future.
- Considering the results for different clustering numbers K across the three image datasets, the clustering indicators (ACC, MI, NMI, and Purity) of the GNMFOS and GNMFOSv2 algorithms exhibit some fluctuations. However, overall, they outperform algorithms that only have orthogonal or manifold structure constraints, sparse constraints, or no constraints.
In conclusion, our algorithms demonstrate the best overall clustering performance for image datasets, and the above results have clearly shown that incorporating the orthogonality and graph regularity into the NMF model can enhance the clustering performance of the corresponding algorithms.
4.5. Clustering Results for Document Datasets
This subsection conducts clustering experiments on document datasets TDT2all and TDT2. In addition to the newly proposed GNMFOS and GNMFOSv2 models, the NMF, GNMF, NMFOS, and NMFOSv2 algorithms, which have shown excellent performance on image datasets, are selected for comparison. Similarly, detailed information on cluster numbers K is provided in the first column of Table 5 and Table 6. The tables consist of four sub-tables corresponding to four evaluation indicators, with the maximum values highlighted in bold. Adopting the same approach, we run tests separately for different cluster numbers and average the results over 10 runs. Details will be listed in Table 5 and Table 6. Figure 4 and Figure 5 display the corresponding line color images.
Table 5.
The clustering performance on TDT2all.
Table 6.
The clustering performance on TDT2.
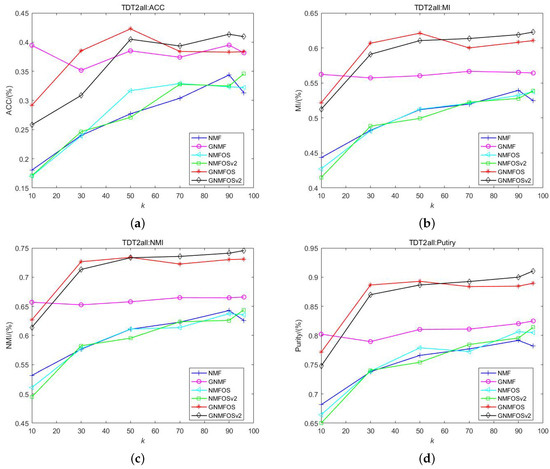
Figure 4.
The clustering performance on TDT2all. (a) ACC; (b) MI; (c) NMI; (d) Purity.
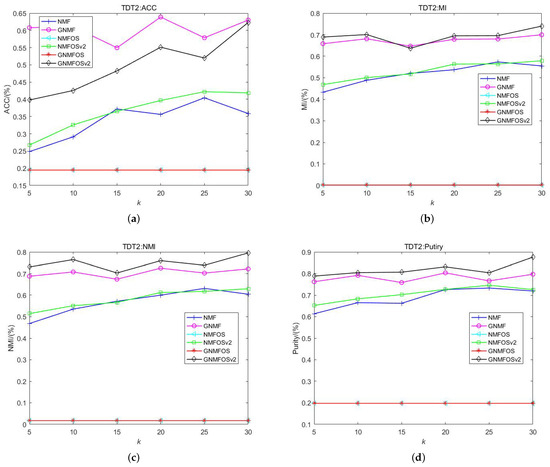
Figure 5.
The clustering performance on TDT2. (a) ACC; (b) MI; (c) NMI; (d) Purity.
- For the TDT2all dataset, when , GNMFOSv2 achieves the maximum values in ACC, NMI, MI, and Purity; when , GNMFOS achieves the maximum values in ACC, NMI, MI, and Purity; when , GNMF achieves the maximum values in ACC, NMI, MI, and Purity. Although GNMF has the best average performance in the ACC metric, GNMFOS, proposed in this paper, achieves the highest ACC value at , reaching 42.27%. This suggests that GNMFOSv2 is more suitable when the number of clusters is close to the size of the document dataset itself; GNMFOS is more suitable when the number of clusters is moderate; and GNMF is more suitable when the number of clusters is very small. Additionally, GNMFOS ranks first in the average Purity indicator, while GNMFOSv2 ranks first in the average NMI and MI indicators.
- From Figure 4, it can be observed that, for the TDT2all dataset, the clustering performance is relatively optimal when the number of clusters K is set to 50. This suggests that the optimal number of clusters for the TDT2all dataset is 50. Additionally, the GNMF, GNMFOS, and GNMFOSv2 algorithms outperform the NMF, NMGOS, and NMFOSv2 algorithms significantly across all four indicators. This indicates that graph Laplacian-based algorithms can enhance clustering performance for the TDT2all document dataset.
- For the TDT2 dataset, the GNMFOSv2 algorithm achieves the best performance in terms of MI, NMI, and Purity across different numbers of clusters K and their average values. The GNMF algorithm performs better in terms of ACC; however, the ACC values of GNMFOSv2 increase as the number of clusters K increases. Particularly at , the ACC value of GNMFOSv2 is only 0.7% lower than that of the GNMF algorithm. This indicates that when the number of clusters is close to the class structure of the document dataset itself, the GNMFOSv2 algorithm has significant potential in terms of ACC. Combining MI, NMI, and Purity, it can be concluded that the GNMFOSv2 algorithm is more suitable for the TDT2 document dataset when the number of clusters is relatively large.
- Additionally, it is worth nothing that the NMFOS and GNMGOS algorithms exhibit extremely low values in terms of ACC, NMI, MI, and Purity for the TDT2 dataset, and these values do not change with varying numbers of clusters K. This could be due to the zero-locking phenomenon mentioned earlier. In contrast, the NMFOSv2 and GNMFOSv2 algorithms incorporate into their iteration processes, preventing the zero-locking phenomenon. This suggests that the proposed GNMFOSv2 algorithm is practically significant, addressing issues observed in other algorithms.
- However, it is worth noting that no single algorithm consistently outperforms others across all four clustering indicators on the Yale dataset. This reflects the inherent trade-offs among different clustering evaluation metrics and highlights the limitations of current algorithms in achieving uniformly best performance. Such a phenomenon is common in clustering tasks where different metrics emphasize distinct aspects of clustering quality. Future work could focus on developing methods that balance multiple criteria more effectively.
- Considering the results of the two document datasets at different clustering numbers K, it can be concluded that the clustering indicators ACC, MI, NMI, and Purity of the GNMFOS and GNMFOSv2 algorithms exhibit some fluctuations, but overall, these algorithms outperform the other. Therefore, the proposed GNMFOS and GNMFOSv2 algorithms can effectively learn the parts-based representation of the dataset, making them effective for document clustering.
4.6. Parameter Sensitivity
We are now investigating how different choices of algorithm parameters will affect their numerical performance. Clearly, if an algorithm is not sensitive to different parameter choices, it can be considered more robust and easier to apply in practice. There are four parameters that affect the experimental results: the regularization parameter , the orthogonality parameter , the nearest neighbor point p, and the in Algorithm 2. So, in this subsection, we will compare the parameter choices of the GNMFOS and GNMFOSv2 algorithms.
Considering the comprehensiveness of the experiments, we first fix the nearest neighbor point p and , and let and vary in . Specifically, in the experiments, we set the parameters , as a group for testing, and the experimental results are shown in Figure 6 and Figure 7.
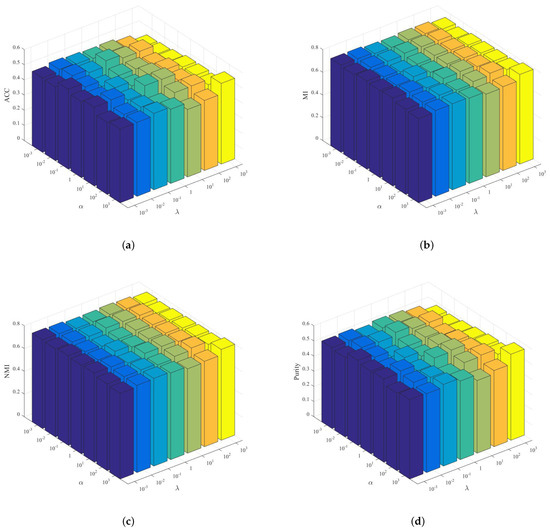
Figure 6.
Performance variations in ACC, MI, NMI, and Purity with respect to different combinations of and values on AR dataset in GNMFOS. (a) ACC; (b) MI; (c) NMI; (d) Purity.
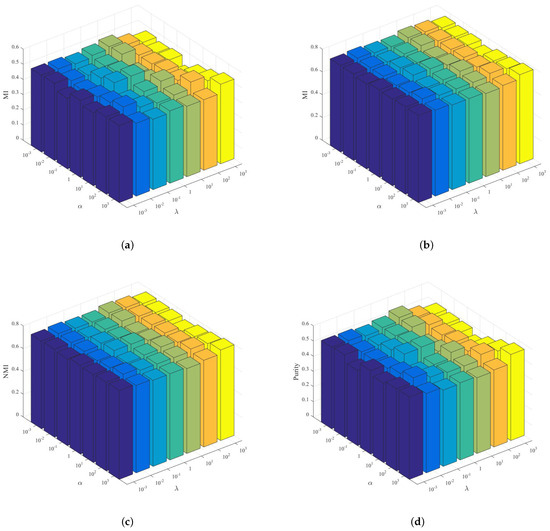
Figure 7.
Performance variations in ACC, MI, NMI, and Purity with respect to different combinations of and values on AR dataset in GNMFOSv2. (a) ACC; (b) MI; (c) NMI; (d) Purity.
For the AR dataset, taking the number of classes in the dataset itself as the clustering number , when the parameters , are set to , the clustering performance of the GNMFOS algorithm is relatively optimal. When the parameters , are set to , the clustering performance of the GNMFOSv2 algorithm is relatively optimal. At the same time, it can be observed that the clustering metrics of GNMFOS and GNMFOSv2 algorithms do not fluctuate much when the parameters and change. This indicates that these two algorithms are not sensitive to different parameter choices, making them more suitable for practical applications.
Then, based on Figure 6 and Figure 7, fixing the optimal parameters {, } = {1000, 1000} and {, } = {1,1} for GNMFOS and GNMFOSv2, respectively, we let the nearest neighbor point p vary in the range . The experimental results are shown in Figure 8. It can be observed that for the AR dataset, the clustering performance of the GNMFOS algorithm is relatively optimal when the nearest neighbor point . As we can see, the performance of GNMFOS is stable with respect to the parameters and .
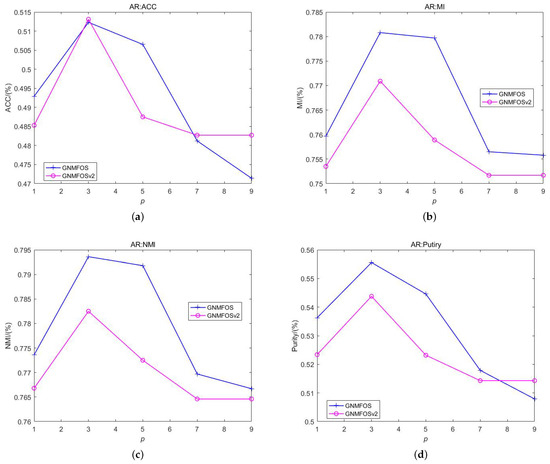
Figure 8.
The performance of GNMFOS and GNMFOSv2 as p increases on AR dataset. (a) ACC; (b) MI; (c) NMI; (d) Purity.
However, it is important to note that GNMFOS and GNMFOSv2 rely on the assumption that two neighboring data points share the same label. Clearly, as p increases, this assumption may fail. This is also why the performance of GNMFOS and GNMFOSv2 decreases with increasing p. It demonstrates the existence of an optimal neighborhood size p for effectively learning the underlying manifold structures of the data.
Due to the fact that the parameter on the denominator of Algorithm 2’s MUR cannot be too large, as it might affect the convergence of finer rules, we uniformly set it to .
Considering the overall results, the performance of the GNMFOS and GNMFOSv2 algorithms is highly robust to different values of parameters , , and p. The algorithm exhibits stability even across a wide range of parameter values, demonstrating its ability to capture both global and local geometric structures effectively and showcasing good generalization ability. The following bar charts demonstrate the robustness of our new algorithms well, and the subsequent line graphs in Figure 8 also illustrate the conclusion that the parameter p is also robust.
4.7. Weighting Scheme Selection
There are several choices for defining the weight matrix S on the p-nearest neighbors. Three popular schemes are 0-1 weighting, heat kernel weighting, and dot product weighting. In our previous experiments, for simplicity, we used 0-1 weighting, where, for a given point x, the p-nearest neighbors are treated as equally important. However, in many cases, it is necessary to distinguish these p nearest neighbors, especially when p is large. In such cases, heat kernel weighting or dot product weighting can be used [15].
For image data, Figure 9 and Figure 10 illustrate the relationship between the clustering performance of the GNMFOS algorithm and that of the GNMFOSv2 algorithm on the AR dataset as the number of nearest neighbors p varies. The cluster number is set to 120, matching the number of classes in the dataset. It can be observed that for the GNMFOSv2 algorithm, different values of p correspond to different optimal schemes. This variation might be attributed to the impact of the parameter in the update rule of the algorithm. The optimal weighting scheme can be chosen based on practical considerations.
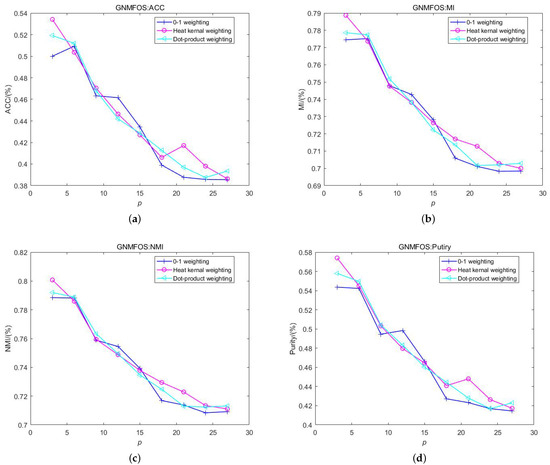
Figure 9.
The performance of GNMFOS and with different weighting schemes on AR dataset. (a) ACC; (b) MI; (c) NMI; (d) Purity.
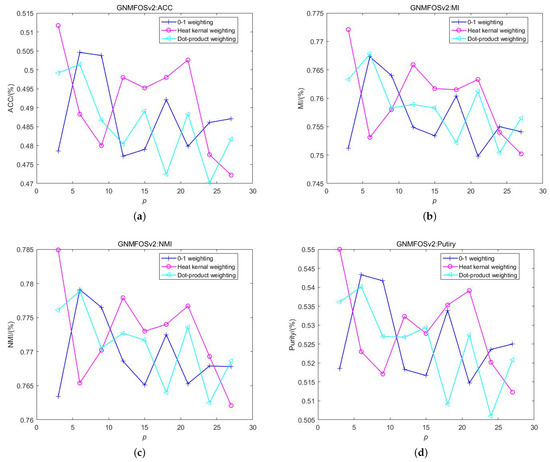
Figure 10.
The performance of GNMFOSv2 and with different weighting schemes on AR dataset. (a) ACC; (b) MI; (c) NMI; (d) Purity.
For the GNMFOS algorithm, the heat kernel scheme is superior to the 0-1 weighting scheme and the dot product weighting scheme when . When , the 0-1 weighting scheme is optimal, and when , the heat kernel scheme is optimal. However, the heat kernel scheme involves a parameter , which is crucial for this scheme. Automatically selecting the parameter is a challenging problem that has garnered significant interest among researchers.
For document data, document vectors are often normalized to unit vectors. In this case, the dot product of two document vectors becomes their cosine similarity, a widely used document similarity metric in the information retrieval community. Therefore, using dot product weighting is common for document data. Unlike the 0-1 weighting, the dot product weighting does not involve any parameters.
Figure 11 and Figure 12 illustrate the relationship between the clustering performance of the GNMFOSv2 algorithm with 0-1 weighting and dot product weighting schemes on the TDT2all document dataset as the number of nearest neighbors p varies. The cluster number is set to 96, matching the number of classes in the dataset. It can be observed that for the GNMFOS algorithm, the dot product weighting scheme performs better, especially when p is large. For the GNMFOSv2 algorithm, the 0-1 weighting scheme exhibits significant fluctuations. Specifically, at and , the values of the four clustering metrics are low, while at , the values are high. However, at , the clustering performance is optimal. Overall, the 0-1 weighting scheme is more suitable for the GNMFOSv2 algorithm.
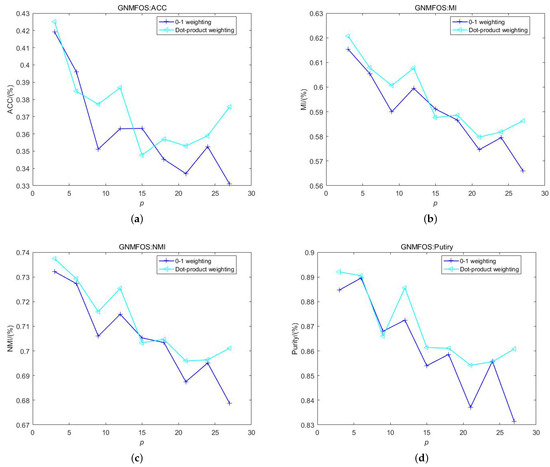
Figure 11.
The performance of GNMFOS and with different weighting schemes on TDT2all dataset. (a) ACC; (b) MI; (c) NMI; (d) Purity.
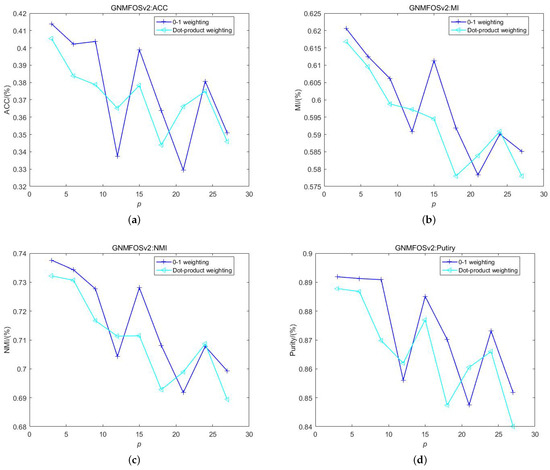
Figure 12.
The performance of GNMFOSv2 and with different weighting schemes on TDT2all dataset. (a) ACC; (b) MI; (c) NMI; (d) Purity.
5. Conclusions
Two effective algorithms are developed to solve the proposed model, and more importantly, their convergence has been theoretically proven.
The main contributions of this work are summarized as follows:
- GNMFOS integrates the strengths of both NMFOS and GNMF by incorporating orthogonality constraints and a graph Laplacian term into the objective function. This enhances the model’s capability in sparse representation, reduces computational complexity, and improves clustering accuracy by leveraging the underlying geometric structure of both data and feature spaces.
- The model supports flexible control over orthogonality and regularization through parameters and , respectively. This makes GNMFOS adaptable to various real-world scenarios.
- Extensive experiments on three image datasets and two document datasets demonstrate the superior clustering performance of GNMFOS and its variant GNMFOSv2. The image experiments show better parts-based feature learning and higher discriminative power, while the document experiments suggest improved semantic structure representation.
In future work, we aim to apply GNMFOS to data from diverse fields such as medicine, engineering, and management to further validate its effectiveness. In addition, considering the inherent complexity of NMF-based optimization models, developing more efficient algorithms for large-scale and constrained scenarios remains an important research direction.
Author Contributions
W.L., J.Z., and Y.C. wrote the main manuscript text. All authors reviewed the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
The second and third authors are partially supported by the China Tobacco Hebei industrial co., Ltd. Technology Project, China (Grant No. HBZY2023A034), Natural Science Foundation of Tianjin City, China (Grant Nos. 24JCYBJC00430 and 18JCYBJC16300), the Natural Science Foundation of China (Grant No. 11401433), and the Ordinary Universities Undergraduate Education Quality Reform Research Project of Tianjin, China (Grant No. A231005802).
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Acknowledgments
We would like to acknowledge the anonymous reviewers for their meticulous and effective review of this article.
Conflicts of Interest
Authors Wen Li, Jujian Zhao, Yasong Chen were employed by the School of Mathematical Sciences, Tiangong University, China. The authors declare that this study received funding which were listed in the ’Founding’ section.The funder was not involved in the study design, collection, analysis, interpretation of data, the writing of this article, or the decision to submit it for publication.
Appendix A. Convergence Proof of the Algorithm 1
In this section, we will prove the convergence of Algorithm 1. Since the objective function of (5) has a non-negative lower bound, we only need to prove that the objective function value of (5) does not increase with respect to the update rules (8) and (9). Before introducing the convergence theorem and its proof, we first import a definition from [39]; then, a lemma follows.
Definition A1.
Let be continuously differentiable with , and also be continuously differentiable. Then, G is called an auxiliary function of F if it satisfies the following conditions:
for any [39].
Lemma A1.
Let G be an auxiliary function of F. Then, F is nonincreasing under the sequence of matrices generated by the following update rule:
Proof.
By Definition (A1), the formula
holds naturally. □
Next, we will prove two important lemmas. Firstly, rewrite the symbols involved in the objective function . Let and be the parts of (5) related to and , respectively. Then, the first-order derivative and the second-order derivative of with respect to are as follows:
Similarly, taking the first- and second-order derivatives of over , then
Secondly, according to the Lemma A1, it is sufficient to prove that and do not increase under the sequence and sequence via (8) and (9), respectively. We now construct the following auxiliary functions.
Thus, the two key lemmas and their proofs are presented below.
Lemma A2.
Let be defined as in (A2). Then, is an auxiliary function of .
Proof.
The following equation is obtained from ’s Taylor expansion:
To prove that , it is sufficient to show that
holds, and in fact, this is true because of the following inequality:
So, by (A4), one has that
Therefore,
follows. Meanwhile, it is easy to see that . By Definition A1, we obtain that is an auxiliary function of . □
Lemma A3.
Let be defined as in (A3). Then, is an auxiliary function of .
Proof.
Compared to Lemma A2, the proof method is similar, but due to the complexity of auxiliary function, the steps are a bit cumbersome. Therefore, we provide them in detail. By a Taylor series expansion of , we have
Similar to (A4), the following three inequalities are obtained:
With the help of these three inequalities, one can prove that
Therefore,
is obtained. Additionally, is true. Then, is an auxiliary function of . □
Based on the above preparations, we can now provide the convergence theorem and its proof for the main conclusion of this paper.
Theorem A1.
For a given matrix , the objective function in (5) is non-increasing under the matrix sequences generated by the update rules (8) and (9). In other words, (8) and (9) are two convergent iterative formats.
References
- Devarajan, K. Nonnegative matrix factorization: An analytical and interpretive tool in computational biology. PLoS Comput. Biol. 2008, 4, e1000029. [Google Scholar] [CrossRef] [PubMed]
- Gao, Z.; Wang, Y.T.; Wu, Q.W.; Ni, J.C.; Zheng, C.H. Graph regularized l2, 1-nonnegative matrix factorization for mirna-disease association prediction. BMC Bioinform. 2020, 21, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Liu, Z.; Pu, J.; Song, B. Adaptive graph regularized nonnegative matrix factorization for data representation. Appl. Intell. 2020, 50, 438–447. [Google Scholar] [CrossRef]
- Gillis, N.; Glineur, F. A multilevel approach for nonnegative matrix factorization. J. Comput. Appl. Math. 2012, 236, 1708–1723. [Google Scholar] [CrossRef]
- Hoyer, P.O. Non-negative matrix factorization with sparseness constraints. J. Mach. Learn. Res. 2002, 5, 457–469. [Google Scholar]
- Wang, D.; Lu, H. On-line learning parts-based representation via incremental orthogonal projective non-negative matrix factorization. Signal Process. 2013, 93, 1608–1623. [Google Scholar] [CrossRef]
- Berry, M.W.; Browne, M.; Langville, A.N.; Pauca, V.P.; Plemmons, R.J. Algorithms and applications for approximate nonnegative matrix factorization. Comput. Stat. Data Anal. 2007, 52, 155–173. [Google Scholar] [CrossRef]
- Pauca, V.P.; Piper, J.; Plemmons, R.J. Nonnegative matrix factorization for spectral data analysis. Linear Algebra Its Appl. 2006, 416, 29–47. [Google Scholar] [CrossRef]
- Bertin, N.; Badeau, R.; Vincent, E. Enforcing harmonicity and smoothness in bayesian non-negative matrix factorization applied to polyphonic music transcription. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 538–549. [Google Scholar] [CrossRef]
- Zhou, G.; Yang, Z.; Xie, S.; Yang, J.M. Online blind source separation using incremental nonnegative matrix factorization with volume constraint. IEEE Trans. Neural Netw. 2023, 22, 550–560. [Google Scholar] [CrossRef] [PubMed]
- Fan, F.; Jing, P.; Nie, L.; Gu, H.; Su, Y. SADCMF: Self-Attentive Deep Consistent Matrix Factorization for Micro-Video Multi-Label Classification. IEEE Trans. Multimed. 2024, 26, 10331–10341. [Google Scholar] [CrossRef]
- Chen, D.; Li, S.X. An augmented GSNMF model for complete deconvolution of bulk RNA-seq data. Math. Biosci. Eng. 2025, 22, 988. [Google Scholar] [CrossRef] [PubMed]
- Xi, L.; Li, R.; Li, M.; Miao, D.; Wang, R.; Haas, Z. NMFAD: Neighbor-aware mask-filling attributed network anomaly detection. IEEE Trans. Inf. Forensics Secur. 2024, 20, 364–374. [Google Scholar] [CrossRef]
- Chen, X.; Wang, J.; Huang, Q. Dynamic Spectrum Cartography: Reconstructing Spatial-Spectral-Temporal Radio Frequency Map via Tensor Completion. IEEE Trans. Signal Process. 2025, 73, 1184–1199. [Google Scholar] [CrossRef]
- Cai, D.; He, X.; Han, J.; Huang, T.S. Graph regularized nonnegative matrix factorization for data representation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 1548–1560. [Google Scholar] [CrossRef] [PubMed]
- Hu, W.; Choi, K.S.; Wang, P.; Jiang, Y.; Wang, S. Convex nonnegative matrix factorization with manifold regularization. Neural Netw. 2015, 63, 94–103. [Google Scholar] [CrossRef] [PubMed]
- Meng, Y.; Shang, R.; Jiao, L.; Zhang, W.; Yuan, Y.; Yang, S. Feature selection based dual-graph sparse non-negative matrix factorization for local discriminative clustering. Neurocomputing 2018, 290, 87–99. [Google Scholar] [CrossRef]
- Long, X.; Lu, H.; Peng, Y.; Li, W. Graph regularized discriminative non-negative matrix factorization for face recognition. Multimed. Tools Appl. 2014, 72, 2679–2699. [Google Scholar] [CrossRef]
- Shang, F.; Jiao, L.; Wang, F. Graph dual regularization non-negative matrix factorization for co-clustering. Pattern Recognit. 2012, 45, 2237–2250. [Google Scholar] [CrossRef]
- Che, H.; Li, C.; Leung, M.; Ouyang, D.; Dai, X.; Wen, S. Robust hypergraph regularized deep non-negative matrix factorization for multi-view clustering. IEEE Trans. Emerg. Top. Comput. Intell. 2025, 9, 1817–1829. [Google Scholar] [CrossRef]
- Yang, X.; Che, H.; Leung, M.; Liu, C.; Wen, S. Auto-weighted multi-view deep non-negative matrix factorization with multi-kernel learning. IEEE Trans. Signal Inf. Pract. 2025, 11, 23–34. [Google Scholar] [CrossRef]
- Liu, C.; Li, R.; Che, H.; Leung, M.F.; Wu, S.; Yu, Z.; Wong, H.S. Beyond euclidean structures: Collaborative topological graph learning for multiview clustering. IEEE Trans. Neural Netw. Learn. Syst. 2025, 36, 10606–10618. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Zhang, X.; Zheng, S.; Li, D. Semi-supervised convex nonnegative matrix factorizations with graph regularized for image representation. Neurocomputing 2017, 237, 1–11. [Google Scholar] [CrossRef]
- Li, S.Z.; Hou, X.W.; Zhang, H.J.; Cheng, Q.S. Learning spatially localized, parts-based representation. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Ding, C.; Li, T.; Peng, W.; Park, H. Orthogonal nonnegative matrix t-factorizations for clustering. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 126–135. [Google Scholar]
- Li, S.; Li, W.; Hu, J.; Li, Y. Semi-supervised bi-orthogonal constraints dual-graph regularized nmf for subspace clustering. Appl. Intell. 2022, 52, 227–3248. [Google Scholar] [CrossRef]
- Liang, N.; Yang, Z.; Li, Z.; Han, W. Incomplete multi-view clustering with incomplete graph-regularized orthogonal non-negative matrix factorization. Appl. Intell. 2022, 52, 14607–14623. [Google Scholar] [CrossRef]
- Zhang, X.; Xiu, X.; Zhang, C. Structured joint sparse orthogonal nonnegative matrix factorization for fault detection. IEEE Trans. Instrum. Meas. 2023, 72, 1–15. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Wu, X.; Peng, H. Nonnegative matrix factorization on orthogonal subspace. Pattern Recognit. Lett. 2010, 31, 905–911. [Google Scholar] [CrossRef]
- Peng, S.; Ser, W.; Chen, B.; Sun, L.; Lin, Z. Robust nonnegative matrix factorization with local coordinate constraint for image clustering. Eng. Appl. Artif. Intell. 2020, 88, 103354. [Google Scholar] [CrossRef]
- Tosyali, A.; Kim, J.; Choi, J.; Jeong, M.K. Regularized asymmetric nonnegative matrix factorization for clustering in directed networks. Pattern Recognit. Lett. 2019, 125, 750–757. [Google Scholar] [CrossRef]
- Guo, J.; Wan, Z. A modified spectral prp conjugate gradient projection method for solving large-scale monotone equations and its application in compressed sensing. Math. Probl. Eng. 2019, 2019, 5261830. [Google Scholar] [CrossRef]
- Li, T.; Wan, Z. New adaptive barzilai–borwein step size and its application in solving large-scale optimization problems. ANZIAM J. 2019, 61, 76–98. [Google Scholar]
- Lv, J.; Deng, S.; Wan, Z. An efficient single-parameter scaling memoryless broyden-fletcher-goldfarb-shanno algorithm for solving large scale unconstrained optimization problems. IEEE Access 2020, 8, 85664–85674. [Google Scholar] [CrossRef]
- Mirzal, A. A convergent algorithm for orthogonal nonnegative matrix factorization. J. Comput. Appl. Math. 2014, 260, 149–166. [Google Scholar] [CrossRef]
- Wang, J.; Wang, J.; Ke, Q.; Zeng, G.; Li, S. Fast approximate k-means via cluster closures. In Multimedia Data Mining and Analytics: Disruptive Innovation; Springer: Berlin/Heidelberg, Germany, 2015; pp. 373–395. [Google Scholar]
- Hoyer, P.O. Non-negative sparse coding. In Proceedings of the 12th IEEE Workshop on Neural Networks for Signal Processing, Martigny, Switzerland, 6 September 2002; pp. 557–565. [Google Scholar]
- Lee, D.D.; Seung, H.S. Algorithms for non-negative matrix factorization. Adv. Neural Inf. Process. Syst. 2000, 13, 535–541. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).