Figure 1.
Examples of typical display defect types and their manifestations. The yellow boxes indicate the defect locations. The images are shown under different background colors to better illustrate defect visibility.
Figure 1.
Examples of typical display defect types and their manifestations. The yellow boxes indicate the defect locations. The images are shown under different background colors to better illustrate defect visibility.
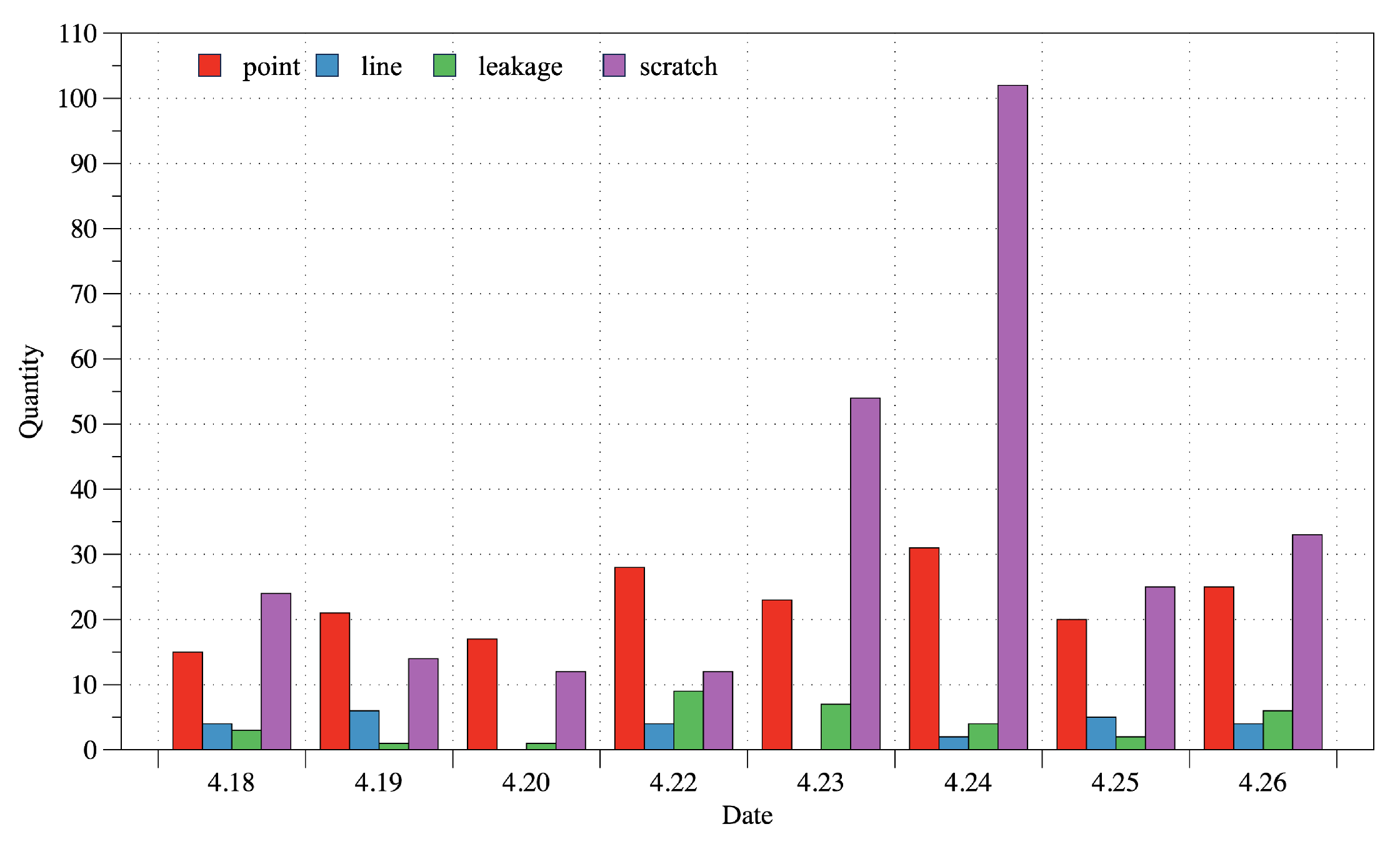
Figure 2.
Distribution of various defect data generated by a certain LCD display manufacturing plant from 18 April to 26 April 2024.
Figure 2.
Distribution of various defect data generated by a certain LCD display manufacturing plant from 18 April to 26 April 2024.
Figure 3.
Basic structure of GAN.
Figure 3.
Basic structure of GAN.
Figure 4.
The framework of the proposed SWG-VGG model. The left side shows the training phase with SE-enhanced generator and VGG-based perceptual loss; the right side shows the image generation phase.
Figure 4.
The framework of the proposed SWG-VGG model. The left side shows the training phase with SE-enhanced generator and VGG-based perceptual loss; the right side shows the image generation phase.
Figure 5.
SWG-VGG generator structure.The generator consists of five parts, marked as 1–5 in the figure: (1) input noise mapping layer; (2) upsampling layers with transposed convolutions; (3) channel attention mechanism(SE module); (4) high-resolution feature reconstruction; and (5) output layer producing RGB images via Tanh activation.
Figure 5.
SWG-VGG generator structure.The generator consists of five parts, marked as 1–5 in the figure: (1) input noise mapping layer; (2) upsampling layers with transposed convolutions; (3) channel attention mechanism(SE module); (4) high-resolution feature reconstruction; and (5) output layer producing RGB images via Tanh activation.
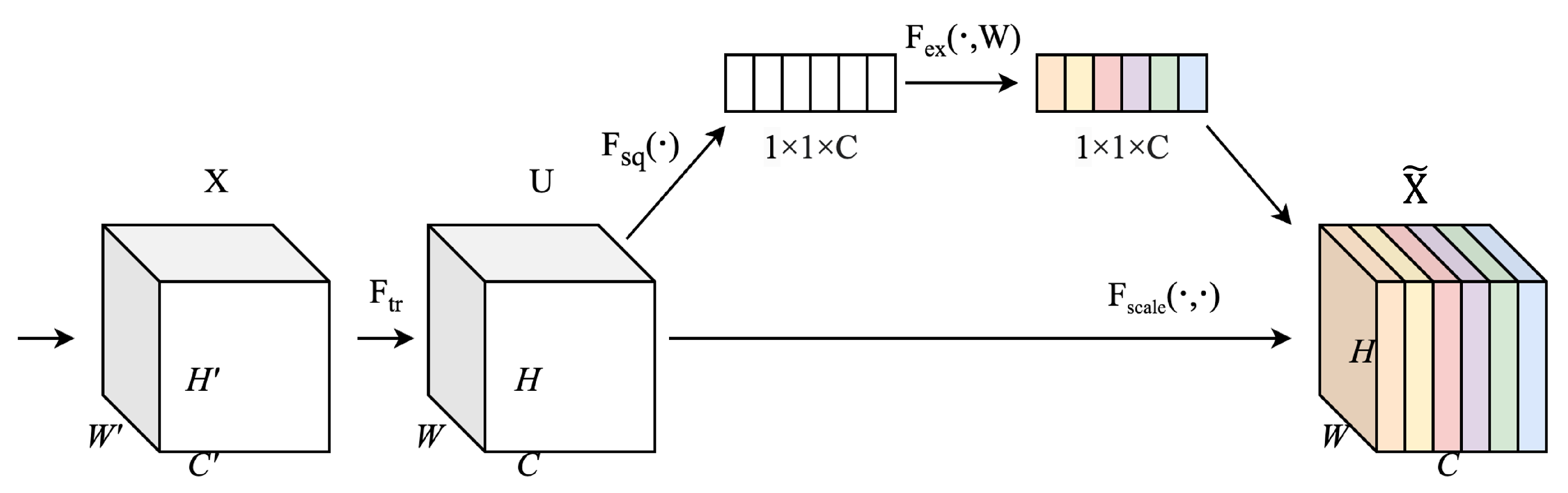
Figure 6.
Structure of the SE module. The feature maps after excitation are shown in different colors to indicate channel-wise weighting by the SE module.
Figure 6.
Structure of the SE module. The feature maps after excitation are shown in different colors to indicate channel-wise weighting by the SE module.
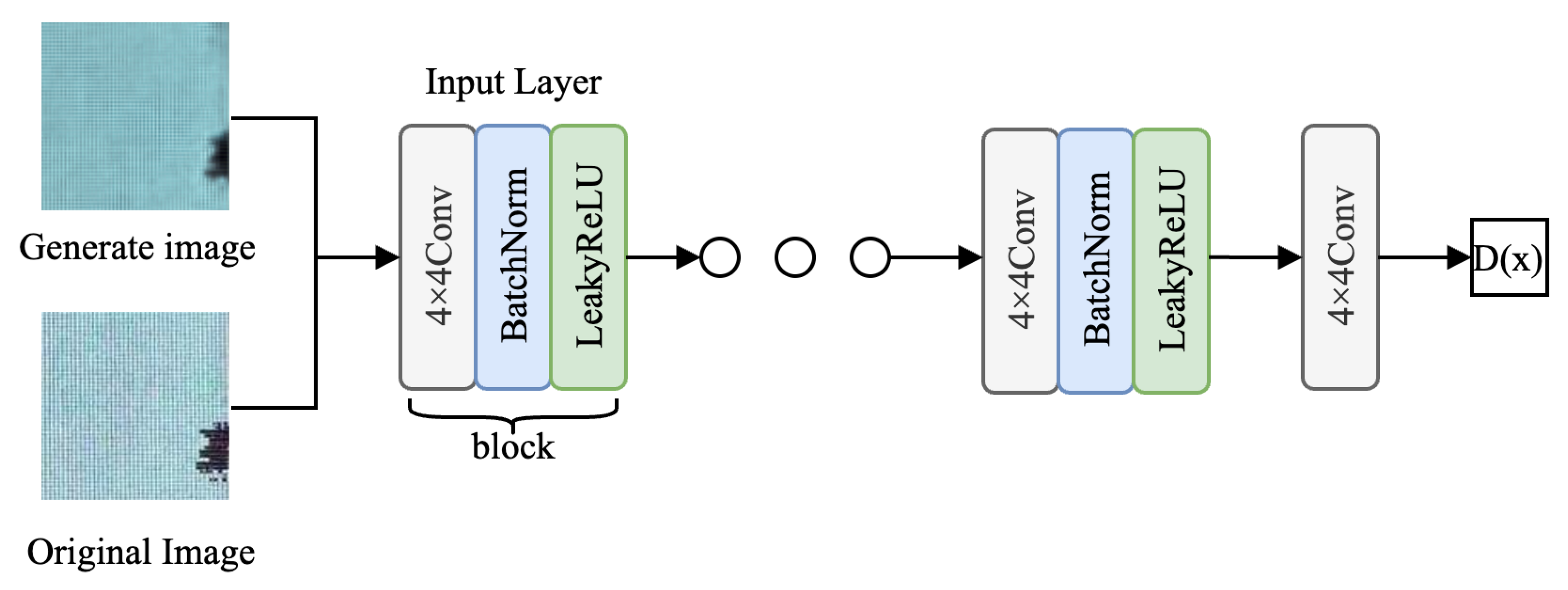
Figure 7.
SWG-VGG discriminator structure.
Figure 7.
SWG-VGG discriminator structure.
Figure 8.
Illustration of perceptual loss calculation using the VGG network. Different colors represent feature maps extracted from different layers of the VGG model.
Figure 8.
Illustration of perceptual loss calculation using the VGG network. Different colors represent feature maps extracted from different layers of the VGG model.
Figure 9.
Comparison graph of generator loss of four models.
Figure 9.
Comparison graph of generator loss of four models.
Figure 10.
Comparison of leakage defect images generated by four models at different training stages.
Figure 10.
Comparison of leakage defect images generated by four models at different training stages.
Figure 11.
Comparison of line defect images generated by four models at different training stages. In the figure, #1, #2, #3, and #4 are Model 1, 2, 3, and 4 respectively, and 100, 300, 500, … 2000 are training rounds respectively.
Figure 11.
Comparison of line defect images generated by four models at different training stages. In the figure, #1, #2, #3, and #4 are Model 1, 2, 3, and 4 respectively, and 100, 300, 500, … 2000 are training rounds respectively.
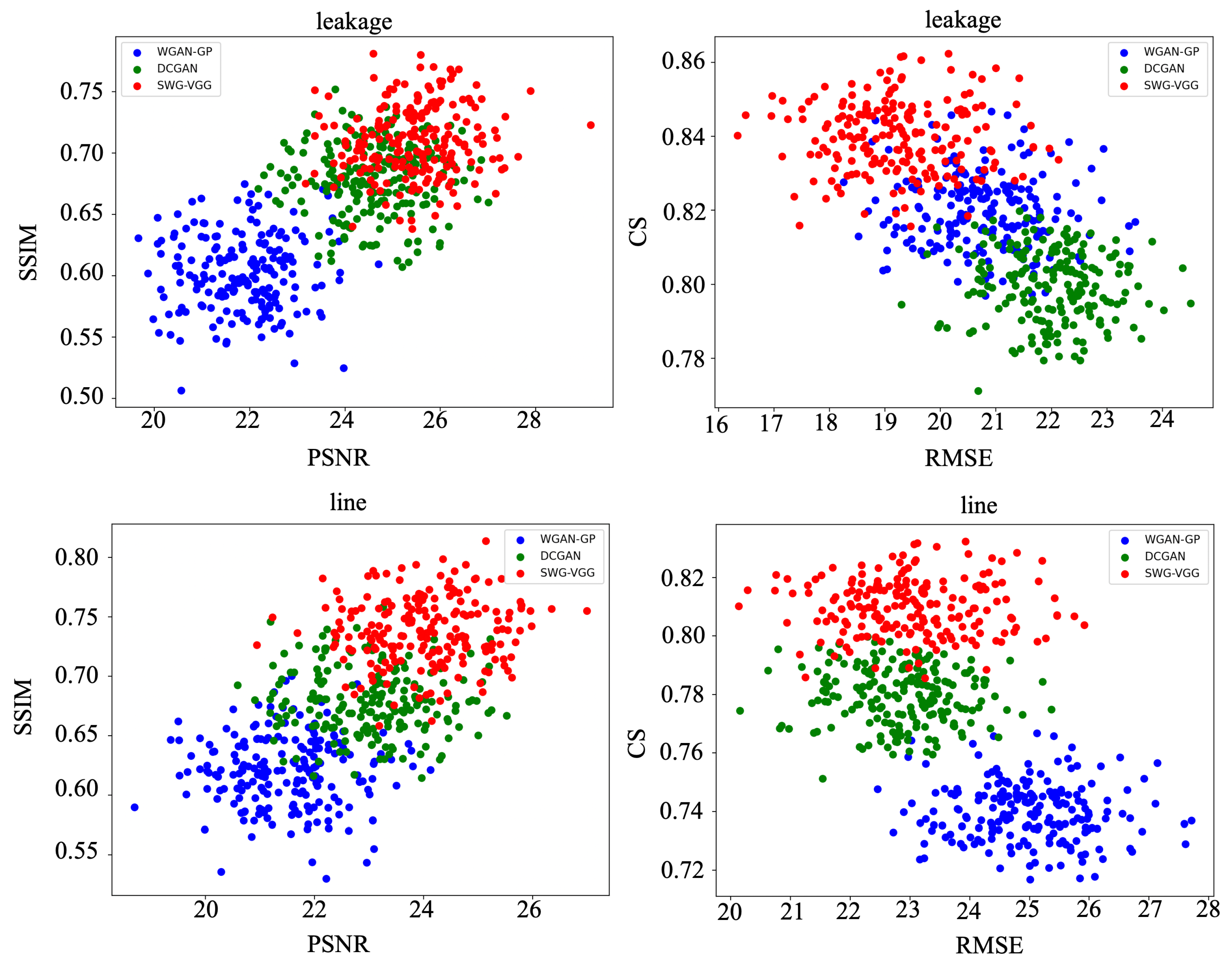
Figure 12.
The three models randomly generate 200 images of leakage defects and line defects, and the scores of the four indicators are scatter plots.
Figure 12.
The three models randomly generate 200 images of leakage defects and line defects, and the scores of the four indicators are scatter plots.
Figure 13.
The three models randomly generate 200 images of line defects and line defects, and the scores of the four indicators are scatter plots.
Figure 13.
The three models randomly generate 200 images of line defects and line defects, and the scores of the four indicators are scatter plots.
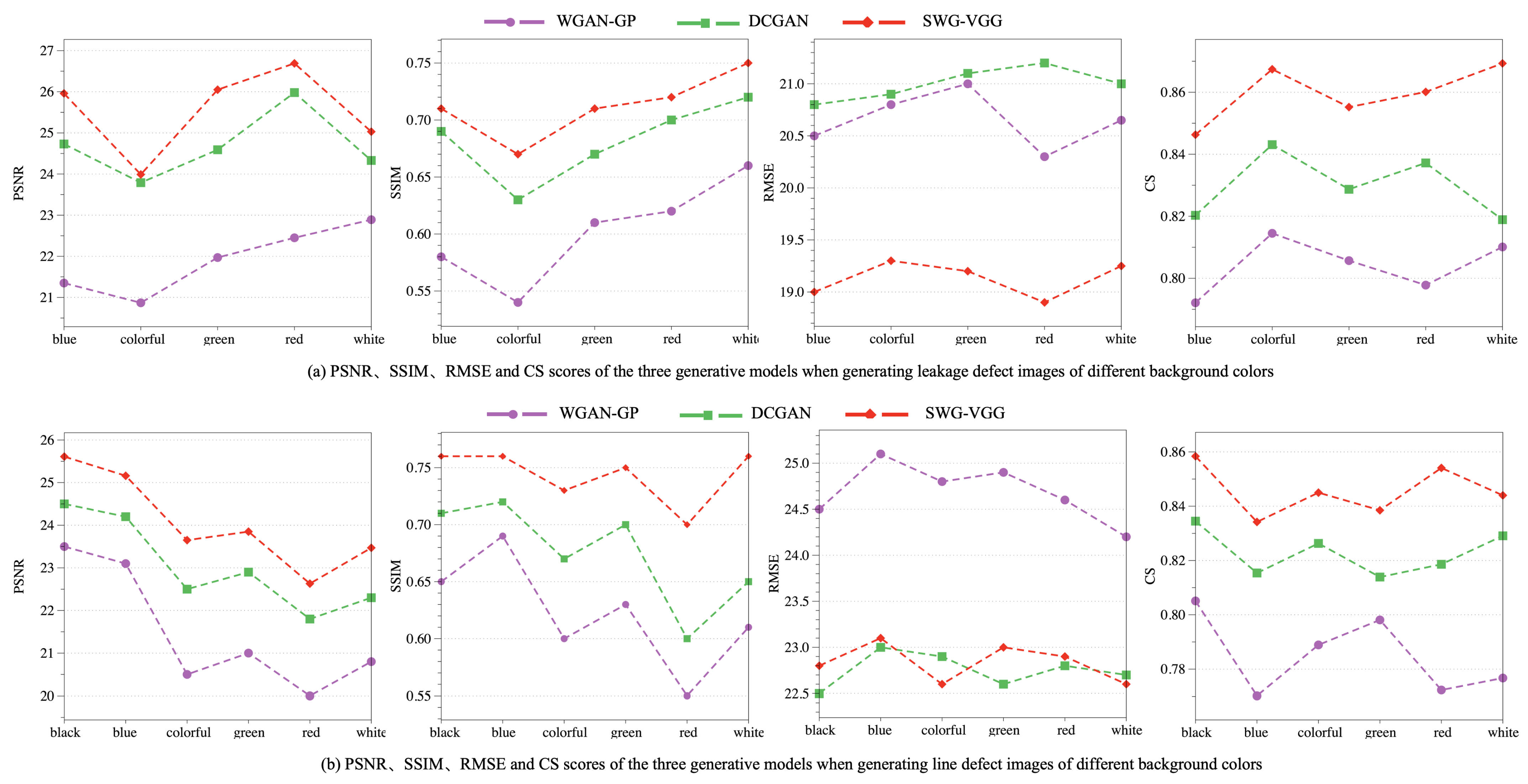
Figure 14.
The line defect images with different background colors generated by WGAN-GP, DCGAN, and SWG-VGG models compared with the original defect images.
Figure 14.
The line defect images with different background colors generated by WGAN-GP, DCGAN, and SWG-VGG models compared with the original defect images.
Figure 15.
The leakage defect images with different background colors generated by WGAN-GP, DCGAN, and SWG-VGG models are compared with the original defect images.
Figure 15.
The leakage defect images with different background colors generated by WGAN-GP, DCGAN, and SWG-VGG models are compared with the original defect images.
Figure 16.
Other line defects and leakage defect images generated by SWG-VGG.
Figure 16.
Other line defects and leakage defect images generated by SWG-VGG.
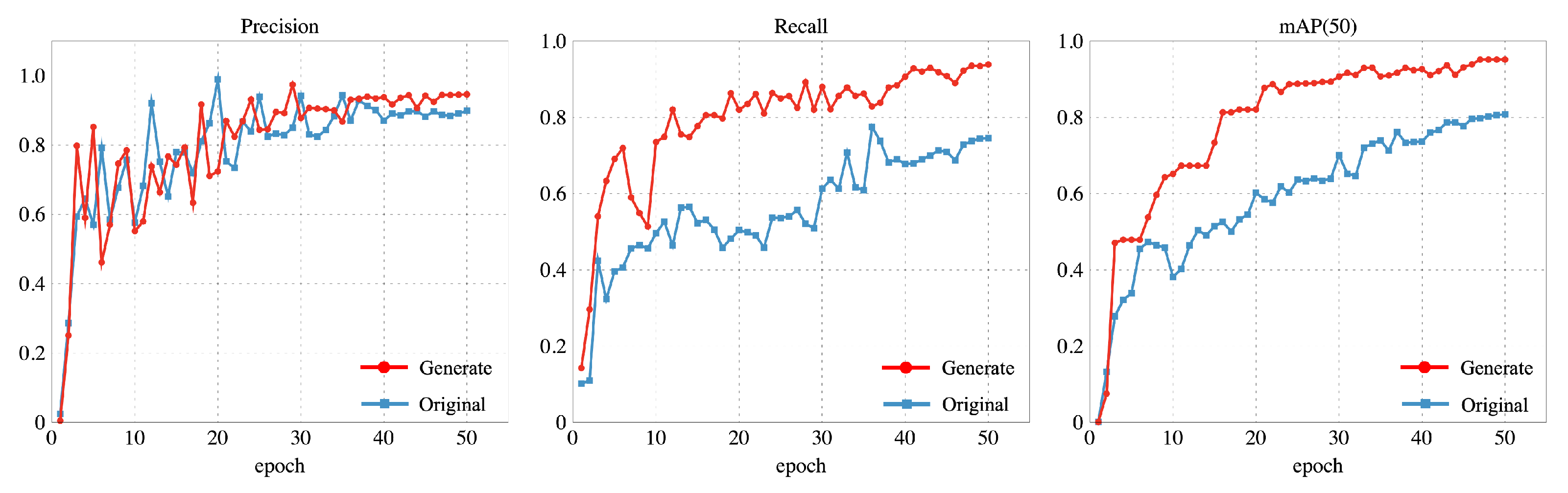
Figure 17.
The original dataset and the enhanced dataset were used to calculate the precision, recall, and mAP@50 values.
Figure 17.
The original dataset and the enhanced dataset were used to calculate the precision, recall, and mAP@50 values.
Table 1.
Distribution of line defect and leakage defect sample data.
Table 1.
Distribution of line defect and leakage defect sample data.
| Color | Line | Leakage |
|---|
| black | 30 | - |
| blue | 30 | 30 |
| colorful | 30 | 30 |
| green | 30 | 30 |
| red | 30 | 30 |
| white | 30 | 30 |
Table 2.
Comparison of PSNR, SSIM, RMSE, and CS scores of four models.
Table 2.
Comparison of PSNR, SSIM, RMSE, and CS scores of four models.
| Model | Basic | SE | Lp | PSNR | SSIM | RMSE | CS |
|---|
| #1 | ✓ | | | 21.96 | 0.7593 | 22.7464 | 0.7807 |
| #2 | ✓ | ✓ | | 22.53 | 0.7697 | 21.6463 | 0.7947 |
| #3 | ✓ | | ✓ | 22.35 | 0.7805 | 22.0119 | 0.7904 |
| #4 | ✓ | ✓ | ✓ | 23.56 | 0.8010 | 21.0226 | 0.8249 |
Table 3.
The scores of leakage defect images generated by four models at different training stages.
Table 3.
The scores of leakage defect images generated by four models at different training stages.
| Index | Epoch | #1 | #2 | #3 | #4 |
|---|
| PSNR | 100 | 12.00 | 12.21 | 14.33 | 14.30 |
| 300 | 12.61 | 12.29 | 14.96 | 15.11 |
| 500 | 13.28 | 10.52 | 13.84 | 15.15 |
| 1000 | 16.80 | 16.34 | 14.94 | 15.65 |
| 1500 | 16.52 | 18.05 | 16.42 | 19.44 |
| 1800 | 20.30 | 18.22 | 19.49 | 22.35 |
| 1900 | 20.62 | 20.90 | 21.19 | 23.42 |
| 2000 | 21.80 | 22.84 | 22.08 | 23.70 |
| SSIM | 100 | 0.1798 | 0.1793 | 0.1725 | 0.1740 |
| 300 | 0.1827 | 0.1848 | 0.1707 | 0.1894 |
| 500 | 0.1816 | 0.1679 | 0.1608 | 0.1754 |
| 1000 | 0.1829 | 0.1885 | 0.1833 | 0.1965 |
| 1500 | 0.6217 | 0.5819 | 0.6322 | 0.7215 |
| 1800 | 0.6972 | 0.6987 | 0.7106 | 0.7926 |
| 1900 | 0.7759 | 0.7810 | 0.8046 | 0.8193 |
| 2000 | 0.7843 | 0.7835 | 0.8102 | 0.8267 |
| RMSE | 100 | 59.3700 | 55.5023 | 33.1832 | 34.3475 |
| 300 | 54.5426 | 59.9566 | 37.1613 | 40.6640 |
| 500 | 58.2816 | 50.9405 | 44.7288 | 41.8722 |
| 1000 | 33.5461 | 34.5441 | 41.4788 | 25.0741 |
| 1500 | 27.5829 | 24.3175 | 24.5222 | 27.4031 |
| 1800 | 23.1108 | 25.9828 | 25.5988 | 20.6448 |
| 1900 | 22.4806 | 21.8311 | 21.0781 | 19.9285 |
| 2000 | 20.6460 | 20.2264 | 20.9203 | 19.1279 |
| CS | 100 | 0.1613 | 0.2361 | 0.5423 | 0.5570 |
| 300 | 0.5488 | 0.5703 | 0.5428 | 0.5336 |
| 500 | 0.5364 | 0.5912 | 0.2860 | 0.3082 |
| 1000 | 0.5377 | 0.5306 | 0.4802 | 0.5647 |
| 1500 | 0.6936 | 0.6232 | 0.6806 | 0.7637 |
| 1800 | 0.7636 | 0.7887 | 0.7647 | 0.8181 |
| 1900 | 0.7944 | 0.7974 | 0.8115 | 0.8361 |
| 2000 | 0.8183 | 0.8251 | 0.8204 | 0.8447 |
Table 4.
The scores of line defect images generated by four models at different training stages.
Table 4.
The scores of line defect images generated by four models at different training stages.
| Index | Epoch | #1 | #2 | #3 | #4 |
|---|
| PSNR | 100 | 10.37 | 10.32 | 15.29 | 12.94 |
| 300 | 17.13 | 17.07 | 18.39 | 18.46 |
| 500 | 19.23 | 18.69 | 19.09 | 17.60 |
| 1000 | 18.21 | 19.47 | 19.00 | 19.56 |
| 1500 | 19.90 | 19.64 | 20.83 | 20.11 |
| 1800 | 20.63 | 19.74 | 20.69 | 21.00 |
| 1900 | 21.18 | 21.34 | 21.22 | 22.52 |
| 2000 | 22.15 | 22.21 | 22.59 | 23.41 |
| SSIM | 100 | 0.1186 | 0.1167 | 0.1110 | 0.1834 |
| 300 | 0.1071 | 0.1657 | 0.1763 | 0.1505 |
| 500 | 0.2221 | 0.3036 | 0.3950 | 0.3577 |
| 1000 | 0.4424 | 0.4960 | 0.5472 | 0.5043 |
| 1500 | 0.5605 | 0.5819 | 0.5426 | 0.6551 |
| 1800 | 0.6594 | 0.6504 | 0.6652 | 0.7412 |
| 1900 | 0.6901 | 0.7151 | 0.7167 | 0.7743 |
| 2000 | 0.7343 | 0.7559 | 0.7508 | 0.7753 |
| RMSE | 100 | 48.4817 | 53.9752 | 47.7323 | 46.4447 |
| 300 | 45.2747 | 45.2692 | 43.2359 | 44.8728 |
| 500 | 41.0415 | 37.3073 | 30.8688 | 27.3125 |
| 1000 | 29.0428 | 29.1529 | 25.9287 | 26.7886 |
| 1500 | 27.3991 | 25.9757 | 25.4813 | 24.2669 |
| 1800 | 26.5216 | 25.3317 | 24.1104 | 23.5695 |
| 1900 | 24.9189 | 23.5068 | 23.4058 | 22.8818 |
| 2000 | 24.8468 | 23.0662 | 23.1034 | 22.9172 |
| CS | 100 | 0.1689 | 0.1656 | 0.1247 | 0.1397 |
| 300 | 0.1476 | 0.2834 | 0.2720 | 0.1312 |
| 500 | 0.3450 | 0.4024 | 0.5200 | 0.5511 |
| 1000 | 0.4890 | 0.4710 | 0.4493 | 0.4979 |
| 1500 | 0.6812 | 0.6490 | 0.6675 | 0.6512 |
| 1800 | 0.7021 | 0.7146 | 0.7193 | 0.7580 |
| 1900 | 0.7367 | 0.7517 | 0.7591 | 0.7954 |
| 2000 | 0.7430 | 0.7643 | 0.7603 | 0.8051 |
Table 5.
Table of scores of defect images generated by WGAN-GP, DCGAN, and SWG-VGG models in various indicators.
Table 5.
Table of scores of defect images generated by WGAN-GP, DCGAN, and SWG-VGG models in various indicators.
| | WGAN-GP | DCGAN | SWG-VGG |
|---|
| | PSNR | SSIM | RMSE | CS | PSNR | SSIM | RMSE | CS | PSNR | SSIM | RMSE | CS |
| Leakage | 21.80 | 0.78 | 20.65 | 0.82 | 22.90 | 0.76 | 20.90 | 0.80 | 23.70 | 0.83 | 19.13 | 0.84 |
| Line | 22.12 | 0.73 | 24.85 | 0.74 | 21.96 | 0.78 | 22.76 | 0.78 | 23.41 | 0.78 | 22.92 | 0.81 |
| AV | 21.96 | 0.76 | 22.75 | 0.78 | 22.43 | 0.77 | 21.83 | 0.79 | 23.56 | 0.80 | 21.02 | 0.83 |
Table 6.
Ttable of scores of various indicators of WGAN-GP, DCGAN and SWG-VGG models in different training stages.
Table 6.
Ttable of scores of various indicators of WGAN-GP, DCGAN and SWG-VGG models in different training stages.
| Index | Epoch | WGAN-GP | DCGAN | SWG-VGG |
|---|
| PSNR | 100 | 11.18 | 13.03 | 13.62 |
| 300 | 14.87 | 15.67 | 16.78 |
| 500 | 16.25 | 15.53 | 16.37 |
| 1000 | 17.50 | 17.43 | 17.60 |
| 1500 | 18.21 | 18.73 | 19.77 |
| 1800 | 20.46 | 19.53 | 21.67 |
| 1900 | 20.90 | 21.16 | 22.97 |
| 2000 | 21.97 | 22.43 | 23.55 |
| SSIM | 100 | 0.1492 | 0.1448 | 0.1787 |
| 300 | 0.1449 | 0.4243 | 0.1699 |
| 500 | 0.2018 | 0.2568 | 0.2665 |
| 1000 | 0.3126 | 0.3537 | 0.3504 |
| 1500 | 0.5911 | 0.5846 | 0.6883 |
| 1800 | 0.6783 | 0.6812 | 0.7669 |
| 1900 | 0.7330 | 0.7543 | 0.7968 |
| 2000 | 0.7593 | 0.7751 | 0.8010 |
| RMSE | 100 | 53.9258 | 47.5982 | 40.3961 |
| 300 | 49.9086 | 46.4057 | 42.7684 |
| 500 | 49.6615 | 40.9613 | 34.5923 |
| 1000 | 31.2944 | 32.7761 | 25.9313 |
| 1500 | 27.4910 | 25.0741 | 25.8350 |
| 1800 | 24.8162 | 25.2559 | 22.1071 |
| 1900 | 23.6997 | 22.4554 | 21.4051 |
| 2000 | 22.7464 | 21.8290 | 21.0225 |
| CS | 100 | 0.1651 | 0.2671 | 0.3483 |
| 300 | 0.3482 | 0.4171 | 0.3324 |
| 500 | 0.4407 | 0.4499 | 0.4296 |
| 1000 | 0.5133 | 0.4827 | 0.5313 |
| 1500 | 0.6874 | 0.6550 | 0.7074 |
| 1800 | 0.7328 | 0.7468 | 0.7880 |
| 1900 | 0.7655 | 0.7799 | 0.8157 |
| 2000 | 0.7806 | 0.7925 | 0.8249 |
Table 7.
MAP@50 values of various defects in the original dataset and the dataset after adding generated images.
Table 7.
MAP@50 values of various defects in the original dataset and the dataset after adding generated images.
| | Original Dataset | Generate Dataset |
|---|
| | Leakage | Line | Point | Scratch | Leakage | Line | Point | Scratch |
| mAP@50 | 0.941 | 0.609 | 962 | 972 | 0.995 | 0.990 | 0.923 | 0.995 |
| AV | 0.871 | 0.976 |
Table 8.
Distribution of various defects in different number of datasets.
Table 8.
Distribution of various defects in different number of datasets.
| | | Detect |
|---|
| Datasets | Leakage | Line | Point | Scratch |
| #1 | train | 500 | 500 | 500 | 500 |
| val | 25 | 25 | 25 | 25 |
| #2 | train | 500 | 500 | 500 | 500 |
| val | 25 | 25 | 25 | 25 |
| #3 | train | 500 | 500 | 500 | 500 |
| val | 25 | 25 | 25 | 25 |
| #4 | train | 500 | 500 | 500 | 500 |
| val | 25 | 25 | 25 | 25 |
Table 9.
Statistics of each defect accuracy and average accuracy of different data sets.
Table 9.
Statistics of each defect accuracy and average accuracy of different data sets.
| Datasets | Leakage | Line | Point | Scratch | AV |
|---|
| #1 | 0.995 | 0.990 | 0.923 | 0.995 | 0.976 |
| #2 | 0.994 | 0.982 | 0.939 | 0.995 | 0.978 |
| #3 | 0.995 | 0.980 | 0.931 | 0.993 | 0.975 |
| #4 | 0.996 | 0.987 | 0.954 | 0.994 | 0.983 |














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}