1. Introduction
Image denoising, aimed at recovering clear images from noisy observations, remains a core challenge in computer vision, particularly in edge computing environments where computational resources are constrained. In some practical applications, denoising tasks are often complicated by the presence of mixed noise or out-of-distribution noise, making the problem more challenging. For example, in remote sensing image denoising, images are particularly susceptible to mixed noise types such as thermal noise, photon noise, and sensor artifacts, which increase the difficulty of denoising. Recent advances in deep learning have enabled the development of high-performance denoising networks, some of which specialize in handling diverse noise distributions [
1,
2,
3,
4], while others leverage innovative architectures such as deformable convolutions and invertible networks [
5,
6,
7]. Some methods prioritize computational efficiency by accelerating inference and reducing model complexity [
8,
9]. Additionally, various other approaches offer distinct advantages [
1,
10]. However, all these denoising methods rely on training with synthetic noise distributions. While these methods are effective under controlled conditions, their generalization performance often deteriorates in real-world scenarios where noise characteristics differ from training data. However, when applied to real-world scenarios, the generalization ability of these models endures enormous challenges. The noise distributions encountered in practice may be different from those observed during training, often resulting in poor performance against unseen noise. Inspired by pretrained models, this study focuses on developing a generalized denoising framework that incorporates both asymmetry and symmetry: the asymmetry arises from the distinct training tasks (pretraining on clean images vs. supervised training on noisy–clean pairs), while symmetry is achieved through an attention-based fusion mechanism, ensuring the effective integration of pretrained priors and supervised features in a structurally balanced manner.
Previous studies have primarily focused on training and evaluating models on images corrupted by Gaussian noise [
3,
4,
5,
7,
8,
9]. These approaches restrict the performance of algorithms to a single noise distribution, and their effectiveness significantly decreases when faced with other types of noise. For models trained on a single intensity of noise, retraining is often required to handle different noise intensities; otherwise, their performance declines significantly, failing to meet the expected denoising effect [
11]. Furthermore, in remote sensing, mixed noise distributions require models to handle both diverse noise types and varying intensities.
Studies have also shown that Convolutional Neural Networks (CNNs) perform well in Gaussian noise environments [
12,
13], but significantly underperform under other noise distributions such as log-normal and uniform noise [
12]. Furthermore, many denoising algorithms have made efforts to handle high-intensity noise, but they require prior knowledge of noise characteristics for effective denoising.
In practical applications, researchers often design specialized algorithms for solving specific noise types. For example, Zhao et al. [
14] proposed a Multi-Scale Geometric Analysis (MGA) CNN for handling desert noise, which has complex characteristics, i.e., nonlinear, nonstationary, and non-Gaussian. To address inconsistencies and mixed noise in Hyperspectral Images (HSI), Yuan et al. [
15] designed a Partial-DNet model combining noise intensity estimation for targeted denoising. Ge et al. [
16] constructed the Self2Self-OCT network, a self-supervised deep learning model for denoising Optical Coherence Tomography (OCT) images without clean image supervision. However, the above-mentioned algorithms represent an expensive way to circumvent the generalization problems of algorithms.
To address the generalization problem arising from discrepancies between training and actual test noise, researchers have proposed various methods. One effective way to improve the generalization ability of image denoising algorithms is to expose them to a wider variety of noise types during training. Zhang et al. [
17] proposed a Deep Convolutional Neural Network (DnCNN) based on residual learning, which is capable of handling Gaussian noise at different levels and improving generalization performance by using various noise types during training.
To address the challenge of identifying different noise intensities and denoising accordingly, Zhang et al. [
18] introduced a Fast and Flexible Denoising CNN (FFDNet), which can handle a wide range of noise levels by using adjustable noise level maps as input and effectively remove spatially varying noise. By utilizing two models to handle low and high noise levels separately, Aghajarian et al. [
19] developed a deep learning algorithm to remove Gaussian noise from grayscale and color images. Ollion et al. [
20] proposed a self-supervised blind image denoising method, using two neural networks to jointly predict the clean signal and infer the noise distribution. Additionally, Zhang et al. [
21] introduced CFPNet, which decomposes noise signals in the frequency domain and applies fine-grained denoising tailored to different frequency bands, effectively enhancing denoising performance under complex frequency bands and high-intensity noise. Du et al. [
22] introduced a dynamic dual-learning network named DualBDNet. This network adopts a dual-learning architecture combining residual and non-residual learning, enabling the model to address noise characteristics from different perspectives and effectively handle image denoising across various noise levels. These methods solve the generalization problem of different intensities of the same noise type, but fail to obtain usable results on out-of-distribution noise types, limiting their applicability in real-world scenarios.
To further enhance denoising performance and adaptability, researchers have explored hybrid deep-learning-based approaches that integrate multiple techniques, leveraging their complementary strengths. These hybrid methods aim to overcome the limitations of purely supervised or unsupervised learning by combining deep learning architectures with traditional signal processing techniques. For instance, Shukla et al. proposed a hybrid method combining wavelet transform and deep learning, where wavelet decomposition preprocesses images by separating noise from structural details before Convolutional Neural Network (CNN)-based denoising, thereby improving efficiency and preserving fine details [
23]. Similarly, Jebur introduced a hybrid approach integrating deep learning with the Self-Improved Orca Predation Algorithm (OPA), where CNNs are employed for denoising, while OPA dynamically optimizes network parameters, enhancing adaptability and robustness against various noise types [
24]. Meanwhile, Li employed a hybrid approach that fuses gradient-domain-guided filtering with the Non-Subsampled Shearlet Transform (NSST), focusing on preserving edge structures and enhancing local contrast while removing noise [
25]. These hybrid methods demonstrate significant advantages in balancing noise reduction, detail preservation, and computational efficiency, highlighting the effectiveness of combining deep learning with traditional signal processing techniques for improved image denoising performance.
Self-supervised learning does not rely on clean supervision, making it easier to use real-world noisy images for training in practical denoising scenarios. This approach allows for developing denoising models that are better suited to real-world applications. Lehtinen et al. [
26] proposed the Noise2Noise method, which trains on paired noisy images without requiring clean reference images. This approach avoids the risk of noise bias introduced by public clean-noise datasets, allowing for the use of real-world noisy datasets in practical applications. Quan et al. [
27] introduced a self-supervised learning method named Self2Self, training only with input noisy images through Bernoulli sampling instance pairs and using dropout techniques during training, addressing the issue of insufficient noise instances for training in practical application scenarios. Mansour and Heckel [
28] proposed an efficient image denoising method called Zero-Shot Noise2Noise, which does not require any training data or knowledge of noise distribution, addressing the issue of insufficient noise instances for denoising in practical applications. These methods lack extensive dataset training, theoretically limiting their performance compared to supervised learning.
The Deep Image Prior (DIP) method [
29] can achieve denoising by exploiting the differences between noise and image recovery difficulty. Ulyanov et al. [
29] proposed the DIP method. This method does not rely on extensive training with clean-noise pairs. Instead, it leverages a randomly initialized convolutional neural network. The inductive bias of the network structure naturally adapts to the low-complexity characteristics of the image. This adaptation makes it challenging to fit high-frequency noise. This method has used the network structure’s inherent characteristics to differentiate between noise and signal, avoiding noise distribution bias and enabling image denoising without extensive training data. Due to the limitation of single-image processing, these methods are resource-intensive and generally less effective in denoising.
Some studies not only attempt to train models on Gaussian noise but also perform well on other types of noise. Chen et al. [
30] proposed a training method forcing the network to focus more on image content rather than noise by masking, thus improving generalization performance. However, in practical tests, these algorithms still perform poorly under unseen high-intensity noise, making effective denoising more difficult.
In recent years, the potential of pretrained models has gained significant attention in the field of image processing [
31,
32,
33,
34,
35]. Liao et al. [
36] proposed an innovative image quality assessment method that evaluates perceptual degradation by comparing deep network feature distributions, without the need for additional training. This approach not only significantly improves evaluation efficiency but also effectively captures quality changes that are consistent with the human visual system. In this study, we similarly adopt the feature extraction capabilities of pretrained models as the foundation of our denoising process. Unlike traditional denoising methods that rely on training with specific noise types or intensities, pretrained models provide stronger generalization support, allowing the model to maintain robust denoising performance even when encountering unseen noise. This generalization capability enables the handling of complex noise, making it suitable for remote sensing images.
In the field of image denoising, enhancing the generalization capability of models is the primary challenge we aim to address. Masked Denoising (MD) [
30] is a denoising algorithm that focuses on improving the generalization performance of models, which aligns closely with the problem we are tackling. MD suggests that pixel-level masking can effectively enhance the model’s generalization ability, while we believe that block-level masking can also provide similar generalization benefits. Based on this insight, we choose MD [
30] as the main comparison for evaluating the generalization performance of denoising algorithms in the subsequent analysis.
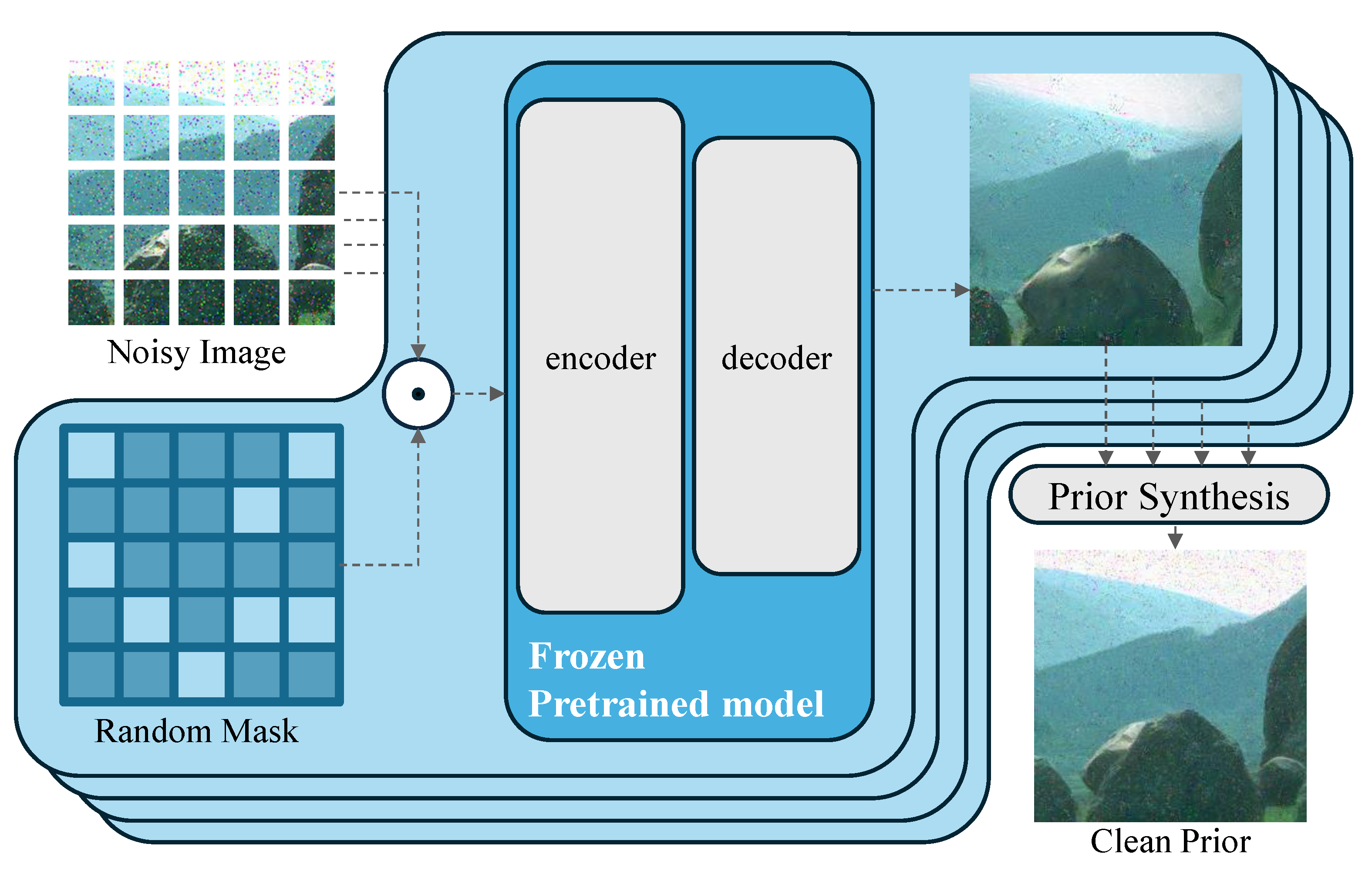
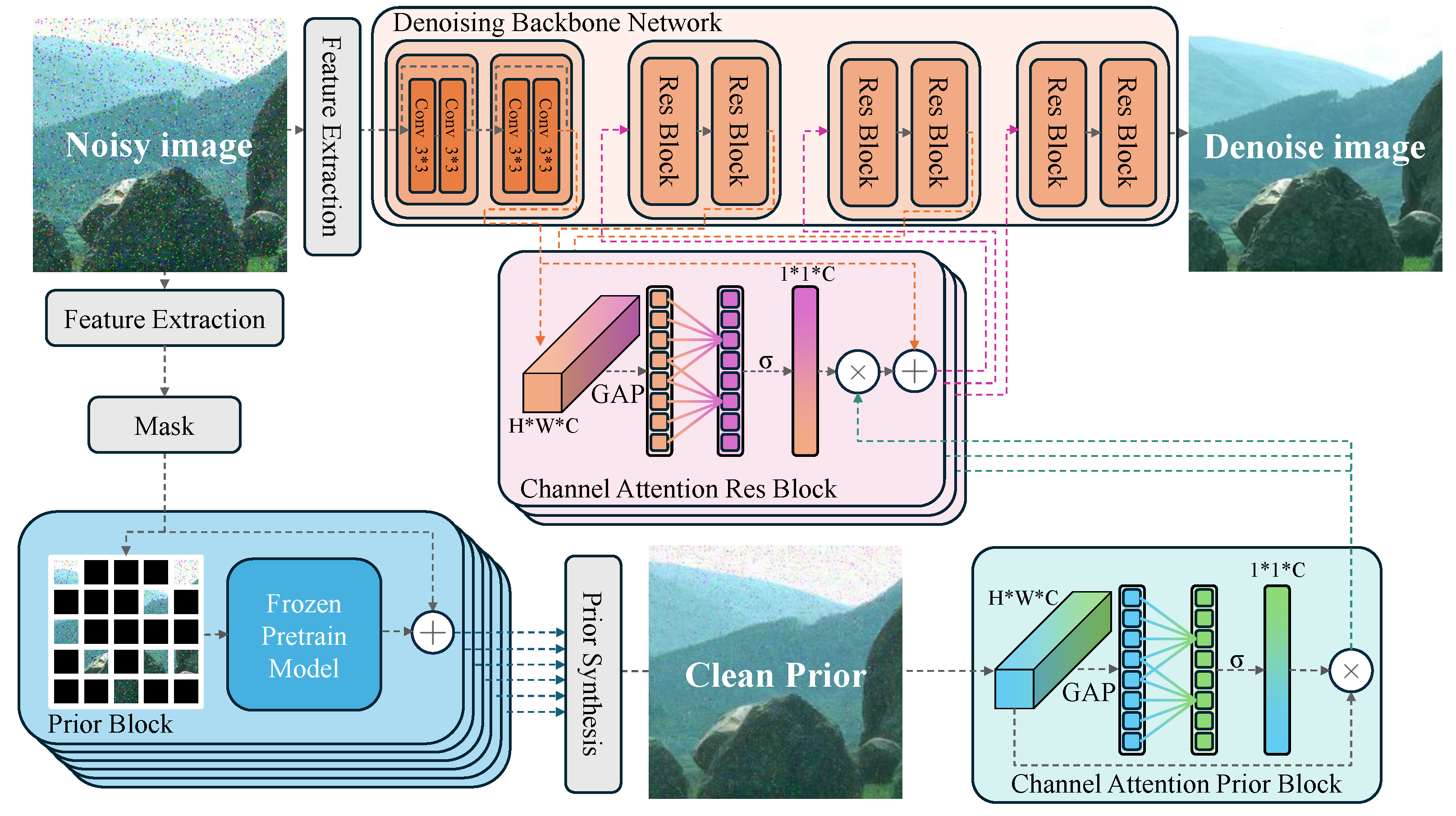
We intend to address the generalization issue in image denoising by proposing the Masked Autoencoder (MAE) pretraining method [
37], which endows the model with the ability to extract image semantics. Similar to DIP [
29], we can exploit the difference between noise and image semantic recovery to achieve preliminary denoising. The MAE-recovered image content tends to be semantically more inclined, allowing us to incorporate the strong image feature extraction capabilities of MAE self-supervised training into the existing algorithms. We use the features extracted by MAE [
37] for coarse image reconstruction, followed by a more fine-grained convolutional network to further separate noise and restore image details.
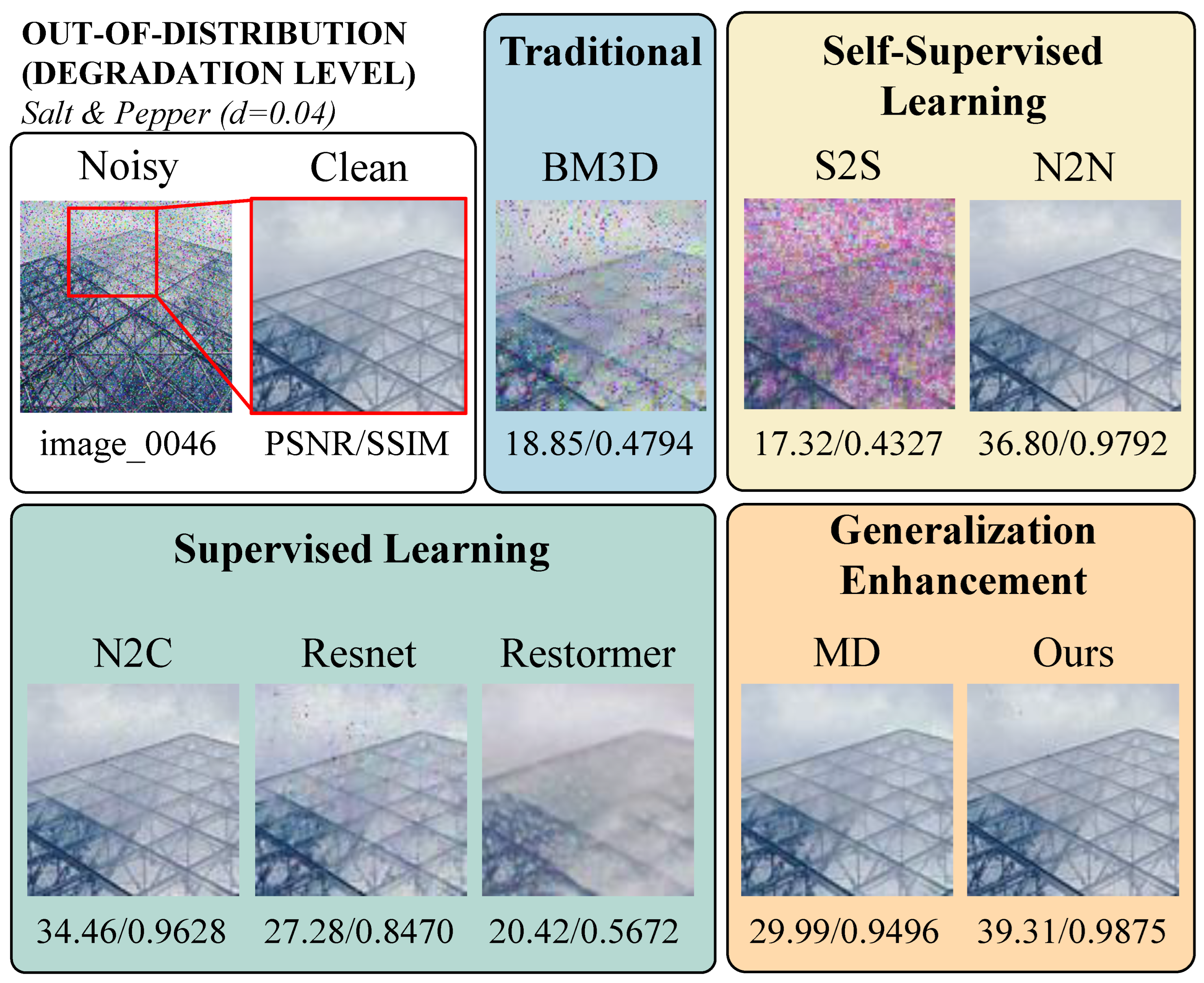
As a result, our method demonstrates superior denoising performance compared to the Masked Denoising (MD) [
30], both in in-distribution and out-of-distribution scenarios. As shown by the in-distribution denoising results in
Figure 1, our method produces cleaner texture restoration on the hat, whereas the MD algorithm [
30] introduces noticeable color artifacts. The out-of-distribution denoising results in
Figure 1 further illustrate that our method provides sharper detail recovery on the tree compared to MD [
30].
Our main contributions are as follows:
We leverage a Masked Autoencoder (MAE) pretrained on clean images to extract semantic priors without explicit denoising training. This enhances the model’s generalization across diverse noise distributions, improving robustness in both in-distribution and out-of-distribution noise scenarios.
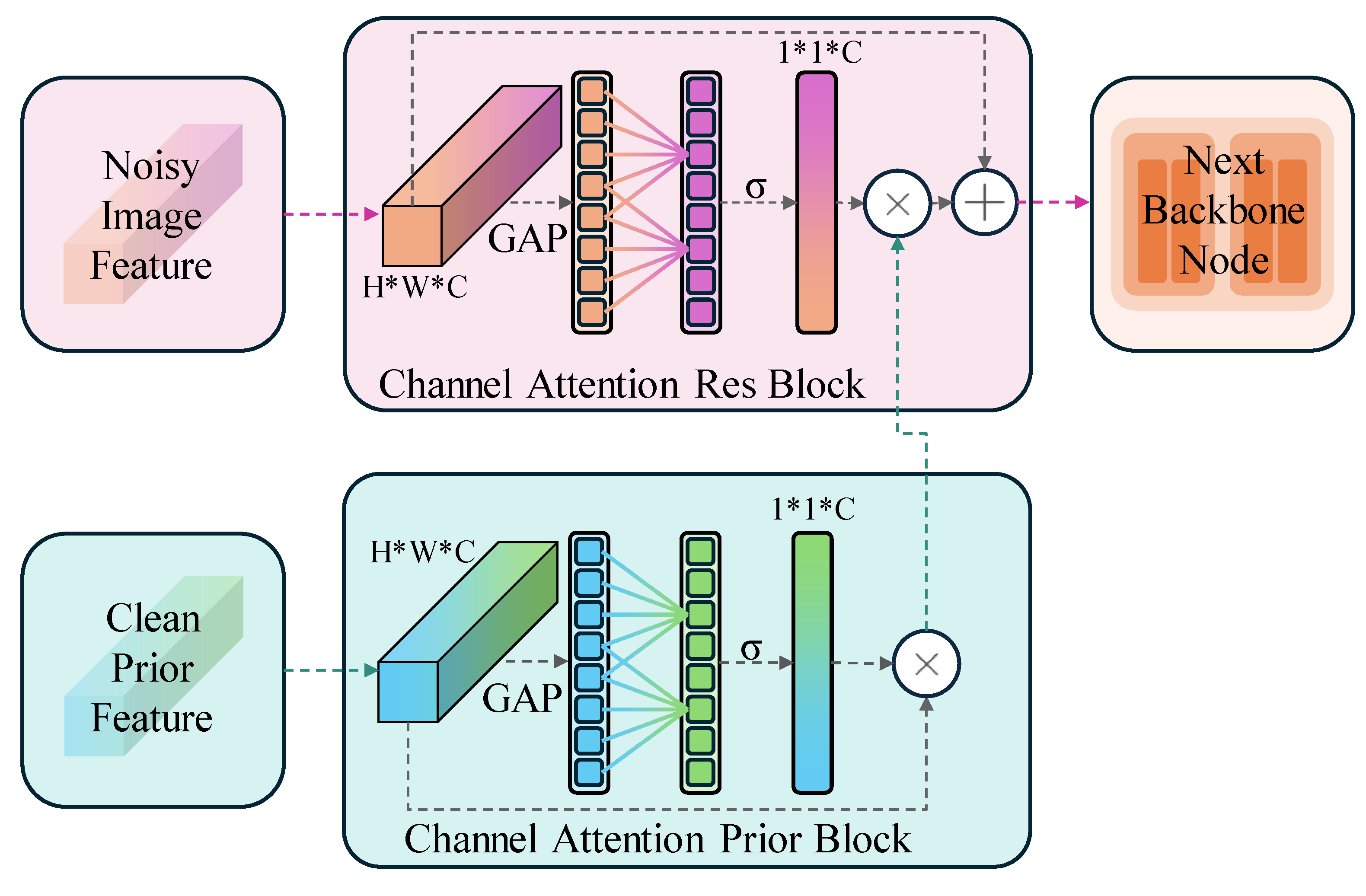
We introduce an asymmetric training framework, where one branch learns clean image priors from a pretrained model, while the other undergoes supervised noisy–clean training. To effectively merge these features, we design a symmetric channel attention mechanism, ensuring optimal fusion of pretrained priors and supervised features.
Our approach balances denoising effectiveness and computational efficiency, making it well-suited for resource-limited environments such as edge computing. Extensive experiments across multiple noise types and real-world datasets demonstrate that our method achieves state-of-the-art performance while maintaining fast inference speed.
1.1. Related Work
1.1.1. Classical Image Denoising Algorithms
Supervised learning-based image denoising algorithms typically rely on large datasets of noisy-clean image pairs to train a model that learns the denoising mapping function [
38,
39,
40]. Usually, let the input noisy image be
y, the corresponding clean image be
x, and the noise be
n. The relationship between the noisy image and the clean image is
. The goal of supervised learning methods is to learn a mapping function
such that
, where
represents the parameters of the neural network. To optimize
, these algorithms need to define a loss function
and optimize it over a large number of samples.
DnCNN is a classic image denoising model based on convolutional neural networks. This model improves denoising performance by learning the residual mapping, i.e., predicting the noise
n rather than directly predicting the clean image
x [
17].
FFDNet enhances model adaptability and flexibility by adding a noise level map as input in addition to the noisy image [
18].
HPDNet leverages a PID controller combined with an attention-based recursive network to achieve adaptive feature control, encouraging the network to extract more discriminative features and enabling faster and more robust denoising [
41].
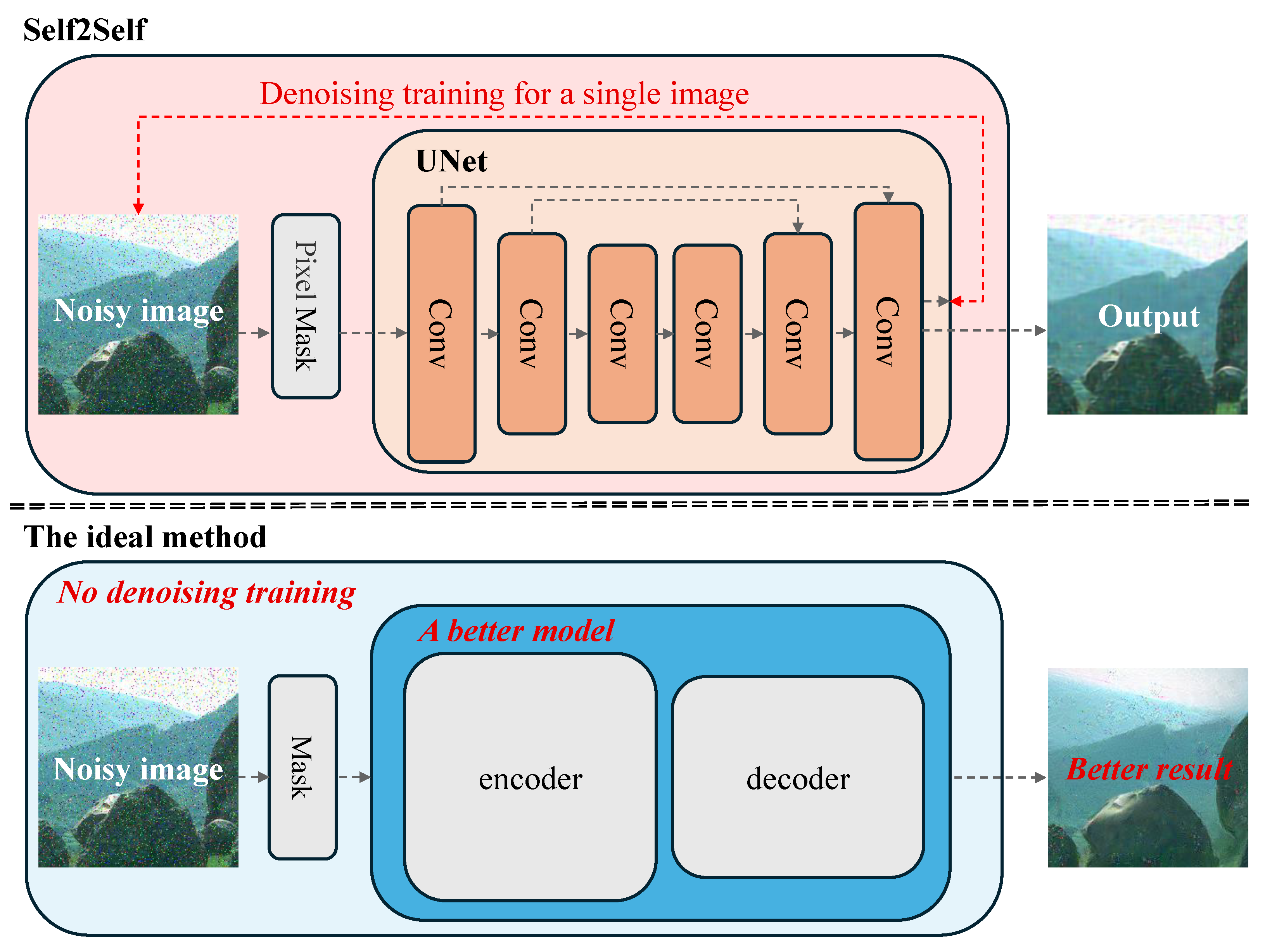
Self2Self is an unsupervised image denoising method based on self-supervised learning. It achieves unsupervised image denoising through mask training. Specifically, Self2Self uses a random mask to cover part of the input image, and trains the network to predict the covered parts based on the uncovered parts. This way indicates the network can learn some inherent structures and patterns of the image without the need for clean images [
16,
27]. The mask training approach of Self2Self significantly inspires our research.
Deep Image Prior (DIP) [
29] is a pretraining-free image denoising method, which reveals the difference in the ability of neural networks to fit low-frequency and high-frequency information. DIP [
29] directly optimizes the network parameters to make its output as close as possible to the input image, thus achieving denoising. This method demonstrates that deep neural networks can capture the structural information of images well, even without any training data. The core idea of DIP is that the network structure itself has a powerful expressive capability to recover clean images from noisy ones [
29].
1.1.2. Generalizable Image Denoising
Chen et al. [
30] proposed the MD algorithm, i.e., a supervised learning method based on mask training. This method uses Gaussian noise with a variance of 15 during training and also performs well on various other noise types, demonstrating strong generalization capabilities. The core idea of the MD algorithm [
30] is to make the model more focused on restoring the image by using mask training, thus achieving excellent denoising performance under different noise conditions. Specifically, the MD algorithm [
30] adds a mask to a certain layer of the Swin-Transformer network based on supervised learning, which can be expressed as:
where
represents the features of the input noisy image from the network,
is the corresponding random mask, ⊙ represents element-wise multiplication, and
represents a certain layer in the network. Through this training method, the MD algorithm not only performs well under training noise conditions, but also maintains good denoising performance under different noise conditions [
30].
1.1.3. Pretrained Models in Image Processing
Pretrained models have shown excellent performance in the field of image processing in recent years, especially in natural image understanding and generation.
MAE [
37] is a self-supervised learning method based on mask training, initially used for image restoration tasks. MAE trains the network to recover masked parts of the input image, thereby learning both global and local features of the image.
One significant advantage is that pretrained models like MAE [
37] can significantly reduce the cost of training on large datasets. By utilizing the pretrained MAE models [
37], we can directly apply them to downstream tasks such as image denoising without training on large datasets from scratch. This not only saves computational resources but also accelerates the research and development process.
MAE [
37] is primarily used for feature extraction in advanced vision tasks such as image classification, object detection, and image segmentation. In these tasks, MAE [
37] significantly improves model performance through its powerful feature extraction capabilities. However, its application in low-level vision tasks such as image denoising has not been widely explored.
Although MAE [
37] has achieved success in advanced vision tasks [
42,
43,
44], we believe it also has great potential in low-level vision tasks, such as image denoising.
5. Conclusions
In this paper, we have proposed a denoising framework that leverages clean image priors from pretrained models (without denoising-specific training) and demonstrated its effectiveness in enhancing the generalization ability of deep-learning-based image denoising. By utilizing the powerful feature extraction capabilities of models such as MAE [
37], our approach integrates semantic priors into the denoising process, significantly improving performance in diverse noise conditions. Experimental results confirm that our method outperforms baseline models in both in-distribution and out-of-distribution noise settings, showcasing its adaptability across different noise distributions.
A key strength of our design lies in its ability to balance asymmetry and symmetry within the denoising framework. Asymmetry arises from the dual training objectives: one component of the model learns feature representations from clean images via a pretrained network, while the other is trained through supervised learning with noisy-clean pairs. Symmetry is achieved through an efficient fusion mechanism that structurally integrates pretrained priors and supervised features, enhancing denoising quality while maintaining computational efficiency.
Beyond denoising performance, our method is particularly well-suited for real-world edge computing applications, where resource constraints necessitate an optimal trade-off between model complexity and inference speed. As detailed in the Computational Cost and Edge Deployment section, our model achieves a significant reduction in inference time and computational overhead compared to SwinIR [
53] and Restormer [
59]. The lightweight denoising network enables real-time processing on edge devices, while the use of pretrained priors ensures strong generalization without requiring multiple models for different noise types. This makes our approach particularly attractive for applications such as remote sensing, environmental monitoring, and embedded vision systems, where computational efficiency is critical.
While our method effectively integrates pretrained priors for image denoising, it has certain limitations. Since our framework leverages semantic priors extracted from clean images, it may struggle with noise patterns that exhibit strong semantic characteristics, such as structured stripe noise. In such cases, the model may have difficulty distinguishing noise from meaningful image details, potentially reducing denoising effectiveness. Future research could explore adaptive mechanisms to address this challenge, such as integrating noise modeling strategies that account for structured distortions.
Further exploration is also needed to optimize these priors for more complex imaging tasks. Future work may investigate the adaptation of our framework to specialized domains, such as night-time imaging, hyperspectral data analysis, and multimodal image restoration, where additional constraints and data characteristics play a crucial role. Additionally, the exploration of alternative self-supervised pretraining models beyond MAE could further enhance the denoising capabilities and deployment efficiency of our approach. Future work may investigate the adaptation of our framework to specialized domains, such as night-time imaging, hyperspectral data analysis, and multimodal image restoration, where additional constraints and data characteristics play a crucial role. Additionally, the exploration of alternative self-supervised pretraining models beyond MAE could further enhance the denoising capabilities and deployment efficiency of our approach.
By demonstrating both strong denoising performance and practical deployment feasibility, our study contributes a novel solution for resource-efficient and generalizable image restoration. We believe that our findings represent a step toward real-world adoption of learning-based denoising models in constrained environments and hope to inspire future research in combining semantic priors with low-cost denoising networks for robust, scalable image restoration solutions.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}