1. Introduction
The exponentiated exponential (EE) distribution was introduced by Gupta and Kundu [
1]. It has become a prominent generalization of the classical exponential distribution. Its flexibility and asymmetrical structure enable more precise modeling of various real-world phenomena characterized by non-monotonic hazard functions, making it a valuable tool in many areas, such as reliability analysis, survival analysis, and actuarial science. The primary advantage of the EE distribution is its ability to model more complex lifetime behaviors compared to the standard exponential distribution, which assumes a constant hazard rate. In contrast, the EE distribution offers more shape flexibility, accommodating increasing and decreasing hazard rates. This makes it particularly useful for systems where the risk of failure or event occurrence varies over time, such as in biomedical research, engineering reliability, and ecological studies. Another significant benefit is that the EE distribution provides closed-form expressions for important characteristics like the cumulative distribution function (CDF), moments, moment-generating function (MGF), and reliability measures. This mathematical simplicity enhances its computational efficiency, making it suitable for both theoretical analysis and practical applications. Many authors have studied the EE distribution, among them: Gupta and Kundu [
2,
3], Zheng [
4], Sarhan [
5], Abdel-Hamid and Al-Hussaini [
6], Chen and Lio [
7], Ismail [
8], Han and Kundu [
9], Ateya and Mohammed [
10], Pandey et al. [
11], and Kabdwal et al. [
12].
A random variable
X is defined to follow the EE distribution if its probability density function (PDF) and CDF are expressed as:
and
This paper addresses unexplored aspects of the exponentiated exponential distribution, specifically, the distributions of the random sum, the linear combination of independent exponentiated exponential random variables, and the reliability index , particularly in cases with unequal scale parameters. It introduces and applies the saddlepoint approximation method to calculate these distributions and the reliability index. This is novel, as previous works have not focused on these aspects of the exponentiated exponential distribution. The saddlepoint approximation is highlighted as a computationally efficient alternative to exact simulation methods, offering the advantage of maintaining high accuracy while significantly reducing computation time. The key contributions of this study include bridging theoretical gaps in the exponentiated exponential (EE) distribution by deriving saddlepoint approximations for previously unexplored properties. The work demonstrates an effective balance between computational efficiency and precision, making it particularly valuable for applications that require rapid and accurate reliability assessments. Additionally, it provides a foundation for extending saddlepoint methods to more complex scenarios, such as bivariate distributions, paving the way for future research.
A random sum, or stopped sum, refers to the total obtained by summing a random number of random variables. This concept is widely applicable in many fields such as actuarial science, queuing theory, reliability engineering, and finance, where sums of random variables often come with a stopping rule defined by an independent random variable. Mathematically, let
N be a discrete random variable indicating the stopping point, and let
be independent and identically distributed random variables; then, the random sum is given by
. It can effectively model a variety of real-world phenomena [
13]. In actuarial science, random sums are used to model the total claim amount for insurance portfolios, where the number of claims is distributed (often as Poisson or Negative Binomial), and each claim amount represents a random variable. In queuing systems, random sums help evaluate total waiting times and service durations, offering insights for resource allocation and customer service optimization. In reliability engineering, random sums model the lifetime of a system that fails once a certain number of component failures occur, facilitating maintenance planning and replacement scheduling. In finance, random sums can represent cumulative returns on assets in a portfolio with investments made at random intervals, supporting risk management and strategic investment planning. For more applications of the random sum, see Rao et al. [
14] and Malinovskii [
15].
The distribution of a linear combination of
n random variables is fundamental in statistics and probability theory. The linear combination is expressed as
, where
represents random variables, and
are constants. This concept finds extensive applications across various fields, including finance, where portfolio returns are modeled as a linear combination of returns from individual assets [
16]. In hydrology, the net flow from a reservoir basin is determined by subtracting the amount of water used for purposes such as domestic consumption and agriculture from the total rainfall in the area [
17]. For more applications of the distribution of the linear combination of random variables, see Arellano and Gento [
18], Nadarajah [
17], Marques et al. [
19], and Krishnamoorthy [
20].
In the context of reliability, the stress–strength model illustrates the lifespan of a component characterized by a random strength
and subjected to random stress
. The component fails when the applied stress exceeds its strength while it continues to operate effectively whenever
. Consequently, the reliability index
indicates the likelihood of the component operating without failure. This model finds extensive applications in various engineering domains, including structural integrity assessments, the deterioration of rocket motors, static fatigue in ceramic materials, fatigue failures in aircraft structures, and the aging of concrete pressure vessels. For more details, see Weerahandi and Johnson [
21], Kohansal [
22], Kayal et al. [
23], and Pakdaman et al. [
24].
The saddlepoint approximation was first introduced to statistics by Daniels [
25]. This approximation method provides an approach to approximate a density or mass function using its moment-generating or cumulant-generating function. Lugannani and Rice [
26] later proposed a saddlepoint approximation to the CDF of continuous distributions. Daniels [
27] introduced two continuity modifications for discrete distributions. Barndorff-Nielsen and Cox [
28] developed a saddlepoint density approximation for conditional distributions, and Skovgaard [
29] extended this with a double saddlepoint approximation for the CDF. The saddlepoint approximation is widely recognized for its exceptional accuracy in statistical computations, especially in approximating distributions that are challenging to derive precisely. This method achieves a high level of precision in approximating probabilities and reliability indices, often producing results that closely align with those obtained through exact methods. The saddlepoint approximation method stands out among asymptotic approximation methods due to its superior accuracy and robustness. While many asymptotic methods rely on large-sample assumptions that can lead to significant errors in small or moderate samples, the saddlepoint approximation delivers precise results even in these scenarios. It effectively captures the behavior of the distribution’s tail and central regions, where other asymptotic methods may struggle. For a comprehensive review and applications of saddlepoint approximations, refer to Butler [
30]. For recent studies and advancements in saddlepoint approximation, see Alhejaili and Abd-Elfattah [
31], Gatto [
32], Abd El-Raheem and Abd-Elfattah [
33,
34], Meng et al. [
35], Goodman [
36], Abd El-Raheem et al. [
37,
38], Arevalillo [
39], and Abd El-Raheem et al. [
40,
41].
This article discusses the saddlepoint approximations for the EE distribution in various contexts.
Section 2 introduces the saddlepoint approximation to the Poisson-EE random sum distribution, accompanied by a simulation study (
Section 2.1) and a numerical example (
Section 2.2) to validate the results.
Section 3 extends the analysis to a linear combination of EE random variables, presenting both a simulation study (
Section 3.1) and a corresponding illustrative example (
Section 3.2).
Section 4 focuses on the saddlepoint approximation to the reliability index,
, with a simulation study in
Section 4.1 to evaluate its accuracy. Finally,
Section 5 concludes the article by summarizing the findings and emphasizing the computational efficiency and accuracy of the proposed approximations.
2. Saddlepoint Approximation to the Poisson-EE Random Sum Distribution
In this section, the saddlepoint approximation to the Poisson-EE random sum distribution is derived. The Poisson-EE random sum is the sum of a random sample from the EE distribution with sample size, N, independent Poisson random variables.
The saddlepoint approximation of the PDF,
, is given by [
25]:
where
is the cumulant generating function (CGF) of
X,
is the unique solution to the saddlepoint equation
The saddlepoint approximation of the CDF,
, is given by [
26]:
where
and
represent the CDF and PDF of the standard normal distribution, respectively, and
is the mean of the distribution. Here,
and
.
Let
and
be the MGFs of
N and
X, respectively. It is easy to show that the MGF of
is given by:
and its CGF is given by:
where
and
are the CGFs of
N and
X, respectively.
By replacing
with
in (
3), the saddlepoint approximation to the PDF of
is given by:
The saddlepoint approximation to the CDF of
is given by:
where
and
with
being the solution to the equation
, and
representing the sign of
.
For the Poisson-EE random sum distribution, the CGF of
is given by:
Thus, the saddlepoint equation is
where
is the digamma function. The saddlepoint
can be obtained by solving Equation (
8) numerically using the Newton–Raphson method.
The saddlepoint approximations to PDF and CDF of the Poisson-EE random sum distribution are given by (
5) and (
6), respectively.
2.1. Simulation Study
In this section, a simulation study is performed to evaluate the accuracy of the saddlepoint method for approximating the distribution of the Poisson-EE random sum. To verify the accuracy of the saddlepoint method, its results must be compared with the exact value, but the exact value cannot be calculated analytically, so we approximate the exact value using the simulation method in which we generate
values of
, where each simulation involves generating a value
N from a Poisson
distribution and then generating
N values from the EE
distribution. Thus, the simulated (exact) value of
can be obtained from the following formula:
where
is the indicator function.
During the article, we use the term “exact value” to refer to the value approximated using the simulation method.
The simulation study is carried out according to the following three scenarios of the parameters of the EE distribution:
Scenario I: and .
Scenario II: and .
Scenario III: and .
The proposed scenarios allow for studying different shapes of the hazard rate function of the distribution under study. This diversity ensures that the accuracy of the saddlepoint approximation is tested across a diverse set of conditions.
The procedures for approximating the CDF of the Poisson-EE random sum distribution using the simulation and saddlepoint methods are carried out according to Algorithm 1.
Table 1 presents both the exact values and the saddlepoint approximations of
with the MSE of the saddlepoint approximation method for the different simulation scenarios. Moreover, the computing time in minutes for the simulation method (Time (exact)) and saddlepoint approximation method (Time (sadd)) are recorded and displayed in
Table 1.
| Algorithm 1: Approximating the CDF of the Poisson-EE random sum distribution. |
Specify the values of the parameters , and . For the given value of the parameter , generate a random number N from the Poisson distribution. For the given values of the parameters and , generate N random variables , from the EE distribution as follows:
where is a random variable from the uniform (0, 1) distribution. Evaluate the value of the random sum . Use the saddlepoint approximation in ( 6) to approximate . Simulate values of under the same setup. Evaluate the simulated (exact) value of using the simulated samples in step 6 and the formula in ( 9). Repeat steps 2 through 7 a thousand times. Evaluate the average of the values and , , where and are the approximated values of the CDF using the saddlepoint and simulation methods, respectively. Evaluate the mean square error (MSE) of the saddlepoint method compared to the exact value as
|
From the results in
Table 1, we note the following key points:
The saddlepoint approximation () closely matches the exact CDF () with minimal MSEs across all scenarios and parameter settings.
The differences between the two methods are negligible, typically on the order of to , indicating high precision of the saddlepoint method.
The simulation (exact) method requires significantly more computational time, ranging from approximately 99 to 182 min depending on the scenario and parameters. In contrast, the saddlepoint approximation is highly efficient, completing calculations in a fraction of a minute (approximately 0.013 to 0.018 min). This demonstrates the computational superiority of the saddlepoint method.
In general, the saddlepoint approximation method provides an excellent balance between accuracy and computational efficiency, making it a convenient alternative to the simulation method for approximating the CDF of the Poisson-EE random sum distribution.
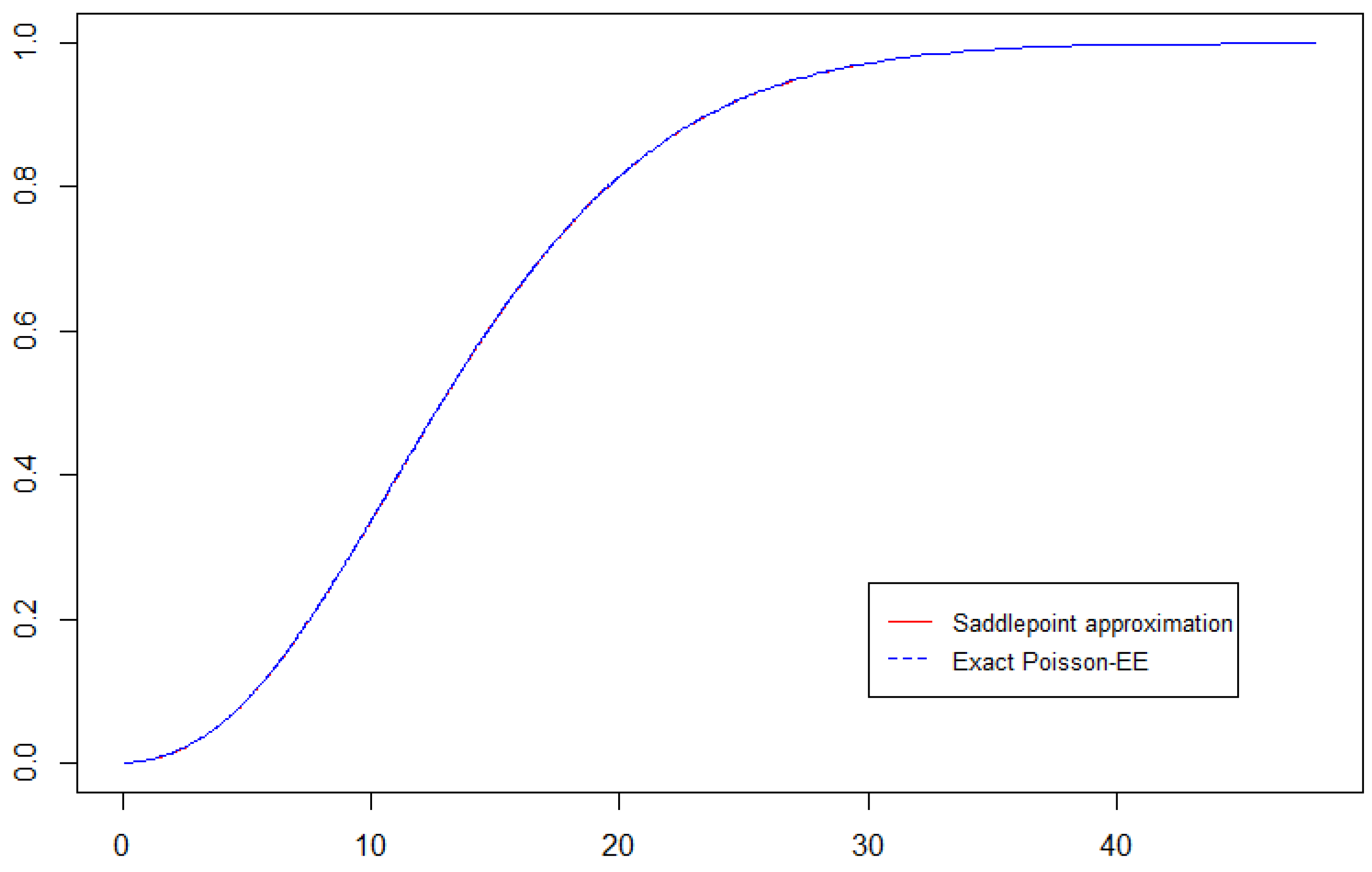
To demonstrate the accuracy of the saddlepoint approximation across a broad range of
s values, a comparative plot of the exact CDF for the Poisson(8)-EE(0.8, 0.5) distribution alongside the saddlepoint approximation is presented in
Figure 1.
Figure 1 demonstrates the accuracy of the saddlepoint approximation in approximating the CDF of the Poisson-EE random sum over a broad range of values. The tight overlap between the two curves indicates that the saddlepoint method provides an excellent approximation.
2.2. Numerical Example
To demonstrate the proposed procedures in this section, we use a synthetic dataset representing the total healthcare costs for patients in a hospital. The total cost of care for a patient’s stay in a hospital may depend on a random number of procedures or treatments, each with a randomly distributed cost. The total cost is thus a random sum. Assume that the number of procedures or treatments, N, that the patient undergoes is a random variable following a Poisson distribution and the cost of each treatment or medical procedure that the patient needs is a random variable, , following the EE distribution. Thus, we need to approximate the distribution of . The following data, 44.81, 67.03, 45.91, 8.01, 24.52, 47.67, 38.42, represent the cost of a random number of medical services that a patient receives in a hospital, where the number of medical services is generated from the Poisson distribution and the cost of each service is generated from the EE distribution.
The saddlepoint approximation is used to approximate
at different values of
s. The results of the saddlepoint approximation
are presented in
Table 2. The comparison between the second column (
, the exact values) and the third column (
, the saddlepoint approximations) of
Table 2 reveals that the two methods produce results that are extremely close to each other across all values of
s. The discrepancies between the exact values and the approximations are generally negligible, often differing only in the third or fourth decimal place.
3. Saddlepoint Approximation to the Linear Combination of EE Random Variables
The linear combination of the EE random variables is given by:
where
are independent EE random variables, with shape parameter
and scale parameter
, and the
’s are real constants.
The MGFs of
and
are respectively defined as:
and
Thus, the CGF of
is given by:
Let
be the PDF of
, then the saddlepoint approximation
is defined as:
where
is the saddlepoint that satisfies th equation:
The saddlepoint
can be obtained by solving Equation (
15) numerically using the Newton–Raphson method.
Let
be the CDF of
, then the saddlepoint approximation
is defined as
where
and
.
The saddlepoint approximations to the PDF and CDF of the sum of n independent EE random variables, , can be obtained as a special case of the saddlepoint approximations to the PDF and CDF of the linear combination, , when .
3.1. Simulation Study
In this section, we conduct a simulation study to assess the accuracy of the saddlepoint method for approximating the distribution of the linear combination of n independent EE random variables, .
The simulation study is conducted according to the following scenarios of the parameters of the EE distribution and the constants , .
Scenario A: , , and , .
Scenario B: , , and , .
Scenario C: , , and , .
Scenario D: , , and , .
Scenario E: , , and , .
Scenario F: , , and , .
Scenarios A, B, C, and D deal with the case of the linear combination, , while Scenarios E and F deal with the case of the sum, . The parameter values and are chosen to represent a diverse set of conditions, including both identically and non-identically random variable cases. Furthermore, the different values of and allow for considering the various shapes of the hazard rate function (increasing and decreasing) of the considered distribution. Moreover, the positive and negative values of the constant are assumed to study a diverse set of conditions. This diversity ensures that the accuracy of the saddlepoint approximation is tested across a range of realistic settings.
The processes for approximating the CDF of the linear combination of
n independent EE random variables,
, using the simulation and saddlepoint methods are performed following Algorithm 2 outlined below:
| Algorithm 2. Approximating the CDF of the linear combination of n independent EE random variables. |
- 1.
Specify the values of the constants and the values of the parameters and , . - 2.
For the given values of the parameters and , generate a random sample of size n from the EE distribution as follows:
where , is a random sample from the standard uniform distribution. - 3.
Use the values of and the random sample , generated in step 2 to evaluate the value of the linear combination . - 4.
Use the saddlepoint approximation in ( 16) to approximate . - 5.
Generate values of under the same setup. - 6.
Calculate the simulated (exact) value of using the simulated samples in step 5 and the formula in ( 17).
where represents the indicator function. - 7.
Repeat steps 2 to 6 a total of 1000 times. - 8.
Calculate the average of the values and , , where and are the approximated values of the CDF using the saddlepoint and simulation methods, respectively. - 9.
Calculate the MSE of the saddlepoint method compared to the exact value as
|
Table 3 displays both the exact values and the saddlepoint approximation of
. The exact CDF values for
are determined by simulating
values of
and using the formula in (
17). The MSE for the saddlepoint approximation method, along with the computation times in minutes for both the simulation and saddlepoint approximation methods, are also included in
Table 3.
From the results in
Table 3, we note the following main points:
The saddlepoint approximation method closely approximates the exact CDF values () with very low MSEs, typically ranging between and . In most cases, the differences between the values of and are negligible. This indicates that the saddlepoint approximation method is a reliable substitute for the simulation method.
The exact method is significantly more time-consuming, requiring approximately 68 to 189 min depending on the scenario and the value of n. The saddlepoint approximation is vastly more efficient, completing calculations in less than a minute, typically within 0.02 to 0.06 min.
Figure 2 compares the exact CDF for the linear combination
of independent EE random variables with its saddlepoint approximation. The graph shows that the saddlepoint approximation closely follows the exact CDF curve, which indicates that the saddlepoint approximation method provides a high degree of accuracy in approximating the distribution of the linear combination.
3.2. Illustrative Example
To illustrate the suggested procedures in this section, we assume an artificial dataset of daily rainfall accumulation where each day’s rainfall follows the EE distribution. When we accumulate these daily values over several days, we obtain a distribution of total rainfalls over this period. The following data, 3.08, 9.29, 9.10, 9.31, 14.77, 9.58, 1.05, 4.51, 10.01, 7.77, represent the daily rainfall depth in millimeters (mm) over the ten days generated from the EE distribution.
It may be necessary for meteorologists to calculate the probability that the total rainfall depth during a given period will not exceed a certain value, i.e., calculate
, where
is the daily rainfall that follows the EE distribution. The saddlepoint approximation in (
16) is used to approximate
at different values of
s. The exact value of
, along with the corresponding saddlepoint approximation for different values of
s, are presented in
Table 4.
The comparison between the second column (
, the exact values) and the third column (
, the saddlepoint approximations) in
Table 4 demonstrates that the values of
and
are highly similar for all tested values of
s. The differences between the exact and approximate values are minimal, typically observed in the third or fourth decimal place. The saddlepoint approximation maintains accuracy across a wide range of
s values, from 50 to 140. This consistency suggests the robustness of the saddlepoint method.







{kind=link}
{kind=link}