Abstract
Ensemble clustering has become a widely used technique for improving robustness and accuracy by combining multiple clustering results. However, traditional ensemble clustering methods often fail to provide fair treatment between groups defined by sensitive attributes. Central to many ensemble methods is the symmetric co-association matrix, which captures pairwise similarity between data points based on their co-occurrence across base clusterings. This paper introduces a fair ensemble clustering method based on the symmetric co-association matrix. The proposed method integrates fairness constraints into the objective function of the ensemble process, using the results from base clusterings that lack fairness considerations as input. The optimization is performed iteratively, and the final clustering results are represented directly by a label matrix obtained efficiently using a coordinate descent approach. By integrating fairness into the clustering process, the method avoids the need for post-processing to achieve fair results. Comprehensive experiments on both real-world and synthetic datasets validate the effectiveness and practicality of the proposed method.
1. Introduction
Clustering is an unsupervised learning technique in which a set of unlabeled data points is partitioned into clusters to reveal intrinsic structures and patterns within the data [1]. It is widely applied in fields such as image segmentation [2], speech recognition [3], and text mining [4], and can be categorized into various types, including hierarchical clustering, partition-based clustering, density-based clustering, model-based clustering, grid-based clustering, graph-based clustering, and fuzzy clustering.
However, the results of a single clustering method may vary due to differences in algorithms and initialization strategies or the risk of falling into local optima. To address this, ensemble clustering was proposed [5,6]. The core idea of ensemble clustering is to combine multiple clustering results, exploiting their diversity and complementarity to produce more stable, accurate, and robust final clustering outcomes. Early studies employed simple voting methods to aggregate cluster labels for each data point [7,8]. The effectiveness of these approaches was limited by their inadequate consideration of base classifier fusion strategies, which included a lack of evaluation and weighting of base cluster quality. Furthermore, these methods failed to capture the intrinsic local structures of the data.
A popular recent approach is the co-association matrix method, which constructs a symmetric co-association matrix from the frequencies with which data points appear in the same cluster across base clustering results, as co-occurrence is a symmetric relation. A clustering algorithm is then applied to the co-association matrix to generate the final partitioning [9,10,11,12,13,14]. The symmetry of this matrix arises naturally from the reciprocal nature of co-occurrence relationships: if sample i is clustered with sample j, then j is also clustered with i. Since the co-association matrix reflects pairwise similarities between samples, it can serve as a similarity or adjacency matrix.
Clustering methods based on similarity matrices are then applied to the co-association matrix, yielding ensemble clustering results through graph partitioning [15]. Clustering methods based on graph partitioning have been extensively studied [16,17,18,19]. To further enhance the expressive power of the co-association (CA) matrix and improve the stability of clustering results, Bian et al. proposed a fuzzy-neighbor-based CA matrix learning method called EC–CA–FN [20]. This method simultaneously considers both intra-cluster and inter-cluster relationships among samples and introduces a fuzzy index to control the degree of fuzziness, thereby significantly improving the robustness and stability of clustering performance. In addition, Bai et al. addressed the limitation of traditional k-means in identifying nonlinearly separable structures by proposing a multiple k-means ensemble algorithm [21]. By extracting locally credible labels and constructing a cluster relationship graph, their approach enables linear clusterers to simulate nonlinear partitioning, expanding the applicability of ensemble clustering to more complex data structures. For large-scale data, Zhang et al. introduced a fast spectral ensemble clustering algorithm called FSEC, which is based on anchor graphs [22]. By performing spectral embedding only once and leveraging anchor-based graph construction along with singular value decomposition (SVD) for dimensionality reduction, the algorithm significantly reduces computational cost while maintaining high clustering efficiency on large datasets. Deep ensemble clustering methods have also gradually gained popularity. For example, Hao et al. [18] proposed ECAR, an ensemble clustering method that incorporates attention mechanisms and joint optimization strategies, demonstrating the potential of combining deep learning and ensemble clustering. In multi-view data contexts, Huang et al. [23] introduced FastMICE, which focuses on scalability and efficiency for large-scale data.
Although ensemble clustering has shown promise in improving clustering quality, its results can exhibit implicit unfairness, a problem that has been largely overlooked. In recent years, machine learning technologies have played an important role in data-driven decision-making. However, traditional algorithms may introduce biases when handling data involving sensitive attributes (e.g., gender, race, or age), leading to systemic neglect or unfair treatment of certain groups. This undermines the trustworthiness of algorithms in real-world applications and risks exacerbating societal inequalities [24,25]. Designing fair clustering algorithms has thus become an important research area.
The practical urgency of fair clustering is evident in applications like resume screening or credit scoring, where algorithmic grouping may reinforce societal biases if sensitive attributes are ignored. Ensuring fairness in such unsupervised learning stages is therefore critical for developing trustworthy and equitable machine learning systems. There are two main concepts of fairness in clustering: group and individual fairness. In this study, we focus on group fairness, in which the goal is to ensure proportional representation of sensitive groups while maintaining clustering quality. This prevents systemic neglect of any group [26]. For instance, Chierichetti et al. proposed the fairlet decomposition method, which partitions data into small, fair “fairlets” for clustering to meet group fairness constraints. However, this method has a high computational complexity. Building on this, Backurs et al. [27] developed a near-linear-time fair clustering algorithm that significantly improves efficiency for large-scale datasets. Bera et al. [28] extended k-means clustering by incorporating upper- and lower-bound constraints into the optimization objective, enabling flexible control over group proportions. In spectral clustering, Kleindessner et al. [29] enforced group fairness by adding linear constraints to a Laplacian matrix optimization objective, ensuring that the group proportions in clustering results closely match their overall distribution while maintaining low RatioCut or NCut values, which indicate a high clustering quality. Ghadiri et al. [30] proposed a cost-balance-based fairness concept that minimizes clustering cost disparities across groups.
Individual fairness, in contrast, emphasizes that similar individuals should be treated similarly in clustering results, such as by imposing constraints on pairwise distances between samples [31]. Although some fairness studies have focused on single clustering algorithms, their methods are often specific to a given algorithm and difficult to generalize. Ensemble clustering offers a more flexible framework by synthesizing results from distinct base clustering models without accessing raw data features. However, fairness in ensemble clustering has been underexplored.
Unlike prior fair clustering methods that enforce fairness within a single clustering model, our approach embeds fairness directly into an ensemble consensus process, where multiple base clusterings are aggregated under fairness constraints. The only existing study on fair ensemble clustering, by Zhou et al. [32], introduced fairness regularization into the consensus objective to balance fairness with clustering quality, assuming equal capacity for each cluster.
To address scenarios where cluster sizes may naturally vary, we build upon the parameter-free ensemble framework of Nie et al. [6] and incorporate the proportional fairness notion from Chierichetti et al. [26]. Our method ensures that the distribution of sensitive attributes within each cluster aligns with the global distribution, without imposing equal cluster capacity. A key feature of our formulation is the consistent use of a symmetric similarity matrix, which directly encodes pairwise sample relationships. This symmetric representation better preserves the relational structure within the data and promotes stable, efficient convergence during the consensus optimization. The key innovation lies in the joint optimization framework that simultaneously learns this fair similarity matrix A and a label matrix Y, embedding fairness directly into the consensus process and avoiding post-processing. This enables dynamic, fairness-aware clustering that adapts to both data structure and group proportions.
The main contributions of this study are as follows:
- We address fairness in ensemble clustering, making it applicable to diverse clustering scenarios and improving the robustness and accuracy of clustering results.
- We propose a fast iterative optimization framework based on coordinate descent to solve the optimization problem.
- We present experimental results demonstrating that our method effectively balances clustering quality and fairness, validating its effectiveness.
2. Related Work
2.1. Notation
Here, we define some notation used throughout this paper. The transpose of a matrix X is denoted by , and represents the weighted adjacency matrix or similarity matrix. The Laplacian matrix is given by , and is the clustering indicator matrix with elements, where if the i-th sample belongs to the j-th cluster, otherwise, . The binary indicator matrices for each base clustering (BCs) are denoted as ,with the number of partitions for each BC represented by . For the l-th BC, the dimension of is , and the true number of clusters in the dataset X is c. The balance matrix for each partition is denoted as , which is a diagonal matrix containing the elements , where .
2.2. Ensemble Clustering
Ensemble clustering, also known as consensus clustering, aims to enhance clustering robustness by integrating multiple BCs. Traditional clustering methods, such as k-means and spectral clustering, often suffer from sensitivity to initialization and parameter settings. By aggregating the outputs of diverse BCs, ensemble clustering mitigates the biases of individual models and improves overall performance.
A common approach is to construct a co-association matrix that records how often data points are clustered together across different BCs. However, this method assumes equal contributions from all BCs, ignoring differences in their quality and reliability. To address this limitation, weighted ensemble clustering frameworks assign varying importance to BCs and clusters. However, many existing methods use fixed weights determined by predefined metrics, limiting their adaptability.
A more advanced approach is to introduce a parameter-free dynamic weighting mechanism that learns a structured similarity matrix A directly from multiple BCs [6]. Unlike traditional methods that rely on a co-association matrix, this framework dynamically adjusts the weights of BCs and clusters to reflect their quality. The weight of a given BC is computed on the basis of its consistency with the learned matrix A, while the cluster-level weights address cluster imbalances within each BC. From Theorem 1 in [6], to ensure that A has exactly c connected components, thereby allowing the samples to be partitioned into c classes, it can be shown that the rank of should be equal to . Therefore, a rank constraint is imposed on the learned similarity matrix A.
The objective function is formulated as:
Here, represents the label matrix of the l-th BC, and is defined as:
To optimize the objective, we perform iterative updates. The rank constraint on is non-convex and difficult to solve directly. Therefore, we transform this constraint during the optimization process. Since is a positive semi-definite matrix, its eigenvalues are non-negative. The rank constraint can be converted into the condition that the c smallest eigenvalues of are zero. When optimizing A while fixing other variables, the problem can be written as:
Here, the regularization parameter should be sufficiently large. According to Ky Fan’s theorem [33], we have the following equality:
where F is an orthogonal matrix. This transformation allows us to replace the non-convex rank constraint with a trace minimization over an orthogonal matrix, which can be efficiently optimized. Therefore, the problem can be rewritten as:
The alternating optimization for updating A and F is carried out next. A more detailed exposition of this algorithm and optimization process has been presented by Xie et al. [6]. By iteratively updating A, , and , the framework adapts to the diversity and quality of the BCs. This parameter-free ensemble clustering approach dynamically balances the contributions of BCs and clusters, achieving superior performance across diverse datasets and establishing itself as a robust and efficient clustering solution. A more detailed exposition of this algorithm and optimization process has been presented by Xie et al. [6].
2.3. Fairness
In this work, we focus exclusively on group fairness, which ensures that each cluster’s sensitive group distribution aligns with the global distribution. Individual fairness, which would require similar treatment for similar individuals, is not enforced here, as our objective is to prevent systemic bias against protected groups at the cluster level. This aligns with real-world applications such as demographic-balanced resource allocation.
Group fairness refers to the principle that groups with different sensitive attribute values should receive similar treatment in model decisions. Following the fairness definition proposed by Chierichetti et al. [26], we formalize fairness as follows. Assume a dataset X is divided into w protected groups , where each group corresponds to a specific sensitive attribute value. Furthermore, the data are clustered into c partitions . The proportion of group in the overall dataset is given by:
The proportion of group within the v-th cluster is:
The fairness of cluster can then be expressed as:
Here, represents the allowable deviation, which defines the acceptable range of fairness. To achieve fairness, it is required that the distribution of the protected group within each cluster aligns closely with its global distribution.
Unlike single-model fair clustering methods, our approach enforces fairness at the ensemble level. Moreover, instead of imposing equal cluster sizes, we require each cluster’s sensitive attribute distribution to match the global proportion. This proportional fairness is integrated directly into the joint optimization of the similarity matrix and cluster labels, ensuring fairness is intrinsic to the consensus process.
3. Proposed Algorithm
In Section 2.2, the ensemble clustering algorithm of Nie et al. [6] was discussed, with Equation (1) describing the learning of a similarity matrix A from multiple BCs. In our proposed algorithm, a fairness objective function is added so that the similarity matrix and the clustering result are fair.
3.1. Fair Ensemble Clustering
We assume that the dataset V consists of w groups, i.e., . Following the fairness concept introduced in Section 2.3, we ensure that the distribution of different groups within each cluster matches the global distribution. Consider the vector space which represents the group matrix. This binary matrix is defined as:
We then construct the following formulation to enforce fairness:
where represents the label matrix of the final clustering result. This fairness term penalizes deviations from the global group distribution in each cluster, acting as a soft proportional constraint.
Assume , where . The element in matrix B represents the number of points with the i-th sensitive attribute in the j-th cluster. Multiplying B by the inverse of the matrix yields a result that indicates the proportional distribution. The matrix is constructed to reflect the global distribution of different groups; each column of U is the same vector u, and represents the proportion of the i-th group in the entire dataset. By adjusting Y, we ensure that the distribution of different groups in each cluster matches the global distribution represented by U, thereby achieving fairness in the clustering results.
The proposed fairness constraint is formulated using the label matrix Y to ensure that the proportions of different sensitive attributes in each cluster are accurately represented, thereby making the difference with the global distribution matrix more reflective of fairness. Additionally, using the label matrix , we ensure the data are divided into c clusters without needing to further constrain the rank of the Laplacian matrix in Equation (1).
From Equation (1), we only learn the similarity matrix A; the label matrix is derived from A in a post-processing step. However, we need to learn the 0–1 label matrix Y directly. To achieve this, inspired by NCUT [34], we add the term to learn the label matrix Y from the similarity matrix A.
Based on this idea and the existing ensemble clustering framework introduced in Section 2.2, we propose the following objective function:
Here, are Lagrange multipliers that control the trade-off between clustering quality and fairness. A larger places greater emphasis on satisfying the proportional fairness constraint, which corresponds to enforcing a smaller allowable deviation in Equation (8).
3.2. Optimization
We sequentially update A, Y, , and , keeping the other variables fixed when updating each one. We initialize and . The variables Y and , are randomly initialized.
3.2.1. Updating A
The subproblem can be formulated as:
Referring to the integrated algorithm for updating A mentioned in Section 2.3, the above problem can be rewritten as:
where , , and is the i-th column of G. It can be observed that the problems for different values of i are independent. Thus, for a specific i, the problem can be written as:
where , and and are the i-th columns of A and , respectively.
Let ; then the above problem can be transformed into:
To solve this problem, we use the Lagrange multiplier method proposed by Nie et al. [6], and the final solution is:
where and . Here, is a Lagrange multiplier and . The solution for is , where is the root of the following equation solved using the Newton’s method:
where and .
3.2.2. Updating Y
The subproblem for updating Y can be formulated as follows:
Here, Y represents the clustering label matrix, where each data point belongs to exactly one cluster. Consequently, each row of Y has only a single element equal to 1, with all other elements 0. Using this property, we employ the coordinate descent method to update Y, treating each row as an independent variable. When updating the i-th row, all other rows remain unchanged. The update involves iterating over all possible cluster assignments, setting one column to 1 while others are set to 0, and selecting the assignment that minimizes the objective function.
3.2.3. Updating
The augmented Lagrangian multiplier method is used to update , as detailed by Nie et al. [6]. The updated value of is the solution to the following augmented Lagrangian function:
where , , and is the penalty coefficient. The update step for is given by:
The optimization problem for is:
The solution process follows a similar approach to the previous problems, as detailed in Algorithm 1.
| Algorithm 1 Augmented Lagrangian Multiplier (ALM) Method for Optimizing |
|
3.2.4. Updating
The update step for follows the formula in Equation (2). The detailed algorithmic process is summarized in Algorithm 2.
| Algorithm 2 The Algorithm of Solving Problem (12) |
|
3.3. Refining
Using coordinate descent to update Y directly results in a computational complexity of . To address this inefficiency, Nie et al. [35] proposed a faster coordinate descent approach for solving the NCUT problem. We augment their method with an improved update strategy for Y to reduce its computational complexity. The terms in Equation (1) can be rewritten as follows:
Thus, the subproblem for updating Y can be reformulated as:
The update for the r-th row, denoted as , can be represented as:
When updating the r-th row while keeping the other rows fixed, there are c possible update strategies, denoted as , where is a one-hot vector with the k-th element set to 1. The r-th row is updated to , and the other rows are fixed as . When updating the r-th row, computations related to the other rows become redundant, so the expression can be simplified to:
To further optimize the computational efficiency, we can precompute the terms , , , and . Assuming the original label of the r-th point is p, we now consider the following two scenarios:
- (1)
- When , we have and . Therefore,Thus, the objective function becomes:Since the terms on the right-hand side of Equation (28) have already been precomputed, the time complexity of calculating this expression is .
- (2)
- When , we have and . Then,and
Thus, the objective function can be written as:
Similarly, the time complexity of computing Equation (31) is .
After updating the r-th row, it is necessary to update the stored values of , , , and . If the label of the r-th point remains unchanged, the stored values are not changed. However, if the label changes, let , where . In this case, the corresponding values need to be updated as follows. We can derive that and . Consequently, the expressions involving are computed as follows:
These two terms have already been computed when evaluating the objective function and do not introduce additional computational complexity. For the term involving , we have
This computation has a complexity of . Similarly, for the term involving P:
This operation has a complexity of . Since , the total computational complexity for these four operations is .
For the expressions involving , the computational complexity follows the same pattern as those involving :
These updates maintain the same computational complexity, ensuring efficient evaluation of the required terms. The redefined method is summarized in Algorithm 3.
| Algorithm 3 The Algorithm for Quickly Solving Problem (12) |
|
3.4. Time Complexity Analysis
The time complexity of the proposed method can be determined as follows. The computation required to initialize and is negligible. When updating A, the time complexity of computing T is , whereas for U, it is . Thus, the overall complexity of computing A is . To update Y, the fast coordinate descent method is used. The initialization involves computing , , , and , whose respective complexities are , , , and . At each point operations are required to evaluate the objective function for each potential solution. When a better solution is found, the corresponding label update involves computing and , each with a complexity of . Let be the number of outer iterations, and let denote the number of improved solutions. Then, the time complexity of updating Y is given by . Under the conditions and , this complexity simplifies to . The time complexity of updating and are and , respectively. Thus, the overall time complexity of our method is , where t represents the number of iterations.
3.5. Convergence Analysis
The proposed method employs an alternating optimization approach in which, at each step, a subproblem involving the current variable is minimized. Let the value of the objective function after the t-th update be . It follows that
which implies that the objective function does not increase during any optimization step; thus, its value is monotonically decreasing.
The objective function can be divided into three terms. The first term, , and the third term, , both represent the squared Frobenius norm, and hence are non-negative. The second term, , is also non-negative.
Proof.
Let denote the Laplacian matrix, which is defined as , where D is the degree matrix. The Laplacian matrix is a positive semi-definite matrix, meaning all its eigenvalues are non-negative. Therefore, for any non-zero vector , we have
Since Y is the clustering label matrix, for any vector , we observe that
Thus, is also a positive semi-definite matrix. Additionally, is a diagonal matrix whose diagonal elements correspond to the sum of degrees in each cluster. Since D is a positive definite diagonal matrix, is also positive definite; therefore, its inverse square root, , is positive definite as well.
Given these properties, the matrix
is positive semi-definite, as its eigenvalues are non-negative. Consequently, the trace of Z is also non-negative:
where are the eigenvalues of Z.
Thus, the objective function has a lower bound:
As a result, the objective function cannot decrease indefinitely, and each variable update process is convergent. Therefore, we can conclude that the algorithm converges. □
4. Experiments
4.1. Datasets
To evaluate the effectiveness of the proposed method, it was tested on multiple synthetic and real-world datasets, as detailed in Table 1. The four synthetic datasets DS-577, 2d-4c-no0, 2d-4c-no1, and 2d-4c-no4 are extensively employed in clustering research. In the absence of explicit sensitive attributes, their ground-truth labels are treated as implicit sensitive attributes. As shown in Figure 1, the shape of each point in these synthetic two-dimensional datasets indicates its group membership. The shape of each point represents the group to which it belongs. For real-world datasets, we selected several widely used benchmarks. The HAR dataset [36] is used for human activity recognition and consists of data collected from sensors in smartphones, including accelerometers and gyroscopes. It categorizes six common activities such as walking and running, forming protected groups based on activity types. The MNIST-USPS dataset [37] combines the classical MNIST and USPS handwritten digit datasets, which contain 28 × 28 and 16 × 16 grayscale images, respectively, and forms protected groups based on the dataset origin. Reverse MNIST [37] is a variant of MNIST in which the colors are inverted, making the background black and the digits white, used to test the robustness of models to data transformations, with the protected attribute being whether the image has been inverted. The JAFFE dataset [38] consists of facial expression images from 10 Japanese women, with seven basic emotions such as happiness and sadness, used for emotion analysis and facial expression recognition. The protected attribute used for these images is the expression category. These datasets provide a diverse experimental foundation to assess the algorithm’s performance across different scenarios.

Table 1.
Datasets.
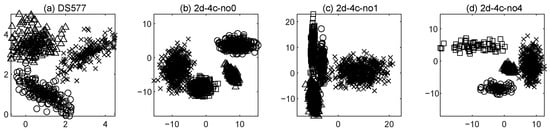
Figure 1.
Four synthetic datasets. The shape of a point in the graph represents its sensitive attribute. (a) DS-577; (b) 2d-4c-no0; (c) 2d-4c-no1; (d) 2d-4c-no4.
4.2. Experimental Setup
To comprehensively evaluate the proposed method, we conducted experiments on both two-dimensional synthetic datasets and real-world datasets. We compared our approach against several baseline methods, including K-means, ensemble clustering methods (PFEC, LEGP [39], LEWA [39], ECPCS_MC [40], ECPCS_HC [40]), mainstream fair clustering algorithms (fair unnormalized spectral clustering (FSCUN) [29], fair normalized spectral clustering (FSCN) [29], fair algorithms for clustering (FAC) [28]), and the fair ensemble clustering method (FCE) proposed by Zhou et al. For our method, we constructed a pool of 100 base clusterings, generated by varying the initialization centroids of K-means and the number of clusters. The random seed for cluster center initialization was fixed at 2025. The number of clusters was sampled from the interval . In each trial, we randomly selected 20 base clusterings to execute our method, and repeated this process 10 times without parameter adjustments to compute the mean and variance. The optimal settings for the hyperparameters and were determined through a grid search. Comparative methods were configured according to their original recommended settings, with FCE utilizing K-means generated base clusterings. The details of our method and the comparative methods are summarized in Table 2.
Table 2.
Comparison of clustering methods in terms of fairness consideration, fairness type, ensemble framework, and complexity.
We employed four evaluation metrics: two external metrics (ACC and NMI) to measure the similarity between clustering results and ground truth labels, thus assessing clustering quality; one internal metric (SSE) to evaluate intra-cluster tightness; and two fairness metrics (BAL and MNCE) to quantify the balance of sensitive attribute distributions across clusters.
For each dataset, the ideal fair state is defined such that the proportion of each sensitive group within every cluster matches its global proportion in the entire dataset, i.e.,
The BAL metric measures the balance between different sensitive groups within clusters, with higher values indicating more equitable distributions. Specifically, BAL is defined as the minimum ratio between the sizes of the smallest and largest sensitive groups in any cluster:
where and represent the number of instances in the smallest and largest sensitive groups in cluster , respectively. Values closer to 1 indicate fairer clustering results.
MNCE evaluates distributional imbalance by comparing the entropy of sensitive group distributions within clusters against the global entropy of sensitive group distributions:
where denotes the number of instances from the i-th sensitive group in cluster , represents the total instances in cluster , indicates the total instances in the i-th sensitive group, and n is the overall sample size. Higher MNCE values indicate better fairness by minimizing the unevenness of sensitive attribute distributions.
The convergence condition is set as: the relative change in the objective function value between two consecutive iterations is less than , or the maximum number of iterations is reached.
4.3. Experimental Results and Comparison
As shown in Figure 2, the proposed method introduces a fairness mechanism, which distinguishes it from the original ensemble clustering algorithm PFEC as well as several existing fair clustering algorithms. This mechanism ensures that the distribution of sensitive attributes within each cluster remains consistent with the global distribution. However, incorporating such fairness constraints inevitably affects clustering quality to some degree, a trade-off that becomes especially pronounced when the data distribution is highly correlated with sensitive attributes. For example, on several synthetic datasets, to obtain fairer outcomes, it was necessary to assign some geographically proximate points to different clusters so that the proportion of points possessing each sensitive attribute within every cluster matches the overall distribution. Our objective is to achieve relatively high clustering quality while maintaining strong fairness, keeping points within clusters more compactly grouped rather than sacrificing clustering performance entirely in pursuit of fairness. Empirical evidence from Table 3, Table 4, Table 5, Table 6 and Table 7 indicates that several fair clustering methods underperform on the two-dimensional datasets depicted in Figure 2 with respect to conventional clustering quality metrics. Notwithstanding this, they achieve superior performance in fairness metrics. Compared to the FCE algorithm, our method attains excellent fairness values on the DS577 dataset while simultaneously demonstrating advantages in terms of Accuracy (ACC), Normalized Mutual Information (NMI), and Sum of Squared Errors (SSE). Visual inspection of the results reveals that our method yields more compact and coherent clusters. On the 2d-4c-no0 and 2d-4c-no1 datasets, a marginal deficiency is observed in the fairness metrics of our method relative to FCE. It is noteworthy, however, that this minor discrepancy is attributable to only one or two outlier data points, thereby exerting a negligible impact on the overall results. Furthermore, our method maintains superior performance on standard clustering metrics. On the 2d-4c-no4 dataset, our approach comprehensively surpasses FCE across all evaluated metrics.
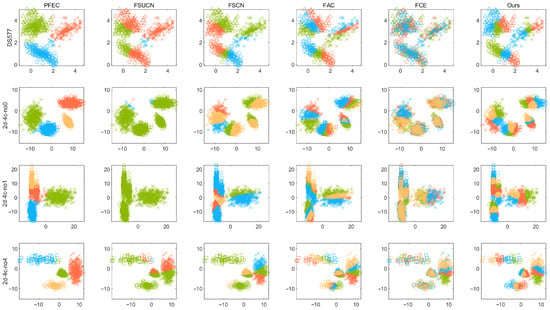
Figure 2.
Clustering results on the synthetic datasets. Clusters are represented by different colors, and sensitive attributes are indicated by shapes.
Table 3.
The ACC(%) values of our algorithm and the comparative algorithms (optimal values in bold, suboptimal values underlined).
Table 4.
The NMI(%) values of our algorithm and the comparative algorithms (optimal values in bold, suboptimal values underlined).
Table 5.
The SSE values of our algorithm and the comparative algorithms (optimal values in bold, suboptimal values underlined).
Table 6.
The BAL values of our algorithm and the comparative algorithms (optimal values in bold, suboptimal values underlined).
Table 7.
The MNCE values of our algorithm and the comparative algorithms (optimal values in bold, suboptimal values underlined).
The distribution of data points with sensitive attributes in real-world datasets often diverges significantly from the characteristics of synthetic datasets. As the results demonstrate, traditional algorithms such as K-means and ensemble methods including PFEC, LEGP, LEWA, ECPCS_MC, and ECPCS_HC yield comparatively poor results in terms of ACC and NMI on these real datasets. Additionally, the MNCE values on the HAR and JAFFE datasets are not uniformly zero, which contrasts with their performance on the two-dimensional datasets. This discrepancy suggests that the underlying data structures of these real-world datasets deviate from the property observed in two-dimensional data, where spatially proximate points typically share identical sensitive attributes. On these real-world datasets, our method not only achieves outstanding results in fairness metrics but also attains the best performance in external validation indices, namely ACC and NMI, outperforming all baseline algorithms. Although its performance on the SSE internal metric is inferior to that of standard clustering algorithms. It remains competitive when compared to other fair clustering approaches such as FSCUN, FSCN, FAC, and FCE. In summary, our method exhibits consistent improvements over FCE in both clustering quality and fairness enforcement. Table 8 presents the runtime of the proposed method on various datasets, demonstrating its computational efficiency under different data scales and complexities.
Table 8.
Runtime of the Proposed Method on Various Datasets (Unit: seconds).
4.4. Sensitivity Analysis
To investigate the sensitivity of the model to key hyperparameters, we conducted a systematic sensitivity analysis on the regularization parameters and . The experiment was carried out on several synthetic datasets and the real-world facial dataset JAFFE. By varying the values of and , we observed their effects on the model’s classification accuracy (ACC) and balance (BAL). The experimental results are shown in Figure 3.
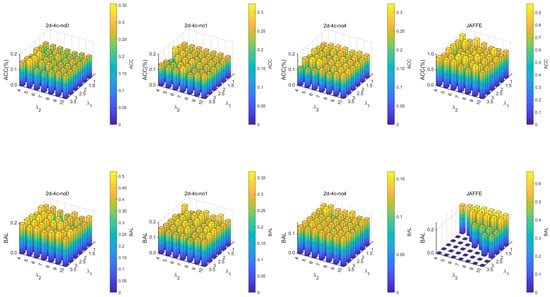
Figure 3.
Sensitivity Analysis.
As can be seen from the figure, the model exhibits good robustness to changes in and on the synthetic datasets. Both ACC and BAL remain relatively stable under different parameter settings. This indicates that the synthetic data distributions are relatively uniform and the model is less dependent on fairness constraints.
However, on the real-world dataset JAFFE, the model’s performance shows a notably different trend. The results reveal that the BAL metric improves significantly only when is set to a relatively large value, which corresponds to imposing a stronger fairness constraint, while ACC remains at a high level. This suggests that when dealing with real-world data bias, strengthening the fairness constraint is crucial for improving the fairness of model decisions. Therefore, in subsequent experiments on real-world datasets, we set to a larger value to better balance model performance and fairness.
In summary, the sensitivity analysis not only verifies the stability of the model on synthetic data but also highlights the necessity of adjusting fairness constraints in real-world scenarios, providing an experimental basis for hyperparameter selection.
4.5. Ablation Study
To verify the practical effect of the fairness constraint in ensemble clustering, we conduct an ablation study to investigate its impact in real-world scenarios. HAR and MNIST-USPS are selected for the experiment, representing sensor-based activity recognition and cross-domain handwritten digit classification tasks, respectively. Both datasets possess clear sensitive attributes and inherent structural complexity, making them closer to actual application environments. In the objective function, the second constraint controlled by the parameter plays a structural role and cannot be omitted; therefore, is maintained in all experiments. This study mainly compares the full method (Ours) with a version that removes the fairness constraint. The results are summarized in Table 9. From the experimental outcomes, it can be observed that after introducing the fairness constraint, the fairness metrics BAL and MNCE on both datasets are significantly improved, indicating that the model can effectively promote a balanced distribution of each sensitive group in the clustering. Meanwhile, the clustering quality metrics ACC and NMI also show improvement on HAR and MNIST-USPS, suggesting that the fairness constraint does not harm the overall consistency of the clustering structure and may even bring some structural optimization due to the re-balancing of group distributions in real data. Notably, on the MNIST-USPS dataset, the SSE value increases after adding the fairness constraint, implying a slight decrease in intra-cluster compactness. This may stem from the inconsistency between the distribution of the sensitive attribute and the clustering structure in this dataset; the fairness constraint causes a slight perturbation to the original geometric structure when adjusting group proportions. Overall, the ablation study demonstrates that the introduced fairness constraint can notably enhance group fairness in clustering results and, in most cases, does not significantly degrade clustering quality. It may even lead to improved overall performance in real-world scenarios, indicating that the method achieves a good balance between fairness and clustering effectiveness, and possesses potential for practical applications.
Table 9.
Ablation study of objective fuction.
5. Conclusions
In this paper, we have presented a fair ensemble clustering method that extends the framework of Nie et al. [6] by incorporating proportional fairness constraints. Our key contribution is the integration methodology, which embeds fairness directly into the ensemble objective and optimizes it jointly with clustering quality. By introducing a regularization term, it ensures that the distribution of protected groups within each cluster closely aligns with their overall distribution in the dataset while also balancing cluster sizes to prevent extreme imbalances. Unlike conventional post-processing techniques, this method embeds fairness constraints directly into the objective function and employs an iterative optimization strategy to achieve both group fairness and a high clustering quality. Experimental results demonstrate that the proposed approach consistently delivers robust and fair clustering outcomes across datasets of varying sizes, establishing a solid foundation for its application in fairness-sensitive domains. In future work, we will explore how fairness-related information is embedded within the similarity matrix. Specifically, we will investigate the underlying mechanisms that govern the presence and representation of fairness information in the matrix, with the goal of enhancing the interpretability and effectiveness of fairness-aware clustering methods. Nevertheless, our method primarily focuses on group fairness and may face challenges with extremely high-dimensional or large-scale data due to the iterative optimization of the label matrix. Future work could extend this framework to individual fairness notions or integrate fairness constraints into other ensemble mechanisms, such as graph-based or deep ensemble clustering frameworks.
Author Contributions
Conceptualization, Y.L., R.F. and C.Z.; Methodology, Y.L., R.F. and C.Z.; Software, Y.L.; Formal analysis, Y.L.; Investigation, Y.L.; Writing—original draft, Y.L. and R.F.; Writing—review & editing, Y.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (Grant No. 62172242), the Ningbo Science and Technology Fund (Grant Nos. 2023Z228, 2023 Z213, 2024Z126, 2024Z202, and 2024Z119), and the Ningbo Key Laboratory of Intelligent Home Appliances, College of Science and Technology, Ningbo University.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data clustering: A review. ACM Comput. Surv. (CSUR) 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Wang, L.; Pan, C. Robust level set image segmentation via a local correntropy-based K-means clustering. Pattern Recognit. 2014, 47, 1917–1925. [Google Scholar] [CrossRef]
- Chen, D.; Lv, J.; Yi, Z. Graph Regularized Restricted Boltzmann Machine. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2651–2659. [Google Scholar] [CrossRef]
- Tunali, V.; Bilgin, T.; Camurcu, A. An improved clustering algorithm for text mining: Multi-cluster spherical K-Means. Int. Arab. J. Inf. Technol. (IAJIT) 2016, 13, 12–19. [Google Scholar]
- Zhang, M. Weighted clustering ensemble: A review. Pattern Recognit. 2022, 124, 108428. [Google Scholar] [CrossRef]
- Xie, F.; Nie, F.; Yu, W.; Li, X. Parameter-free ensemble clustering with dynamic weighting mechanism. Pattern Recognit. 2024, 151, 110389. [Google Scholar] [CrossRef]
- Fred, A.; Jain, A. Data clustering using evidence accumulation. In Proceedings of the International Conference on Pattern Recognition, Quebec City, QC, Canada, 11–15 August 2002; Volume 4, pp. 276–280. [Google Scholar] [CrossRef]
- Ayad, H.G.; Kamel, M.S. On voting-based consensus of cluster ensembles. Pattern Recognit. 2010, 43, 1943–1953. [Google Scholar] [CrossRef]
- Fred, A.L.; Jain, A.K. Combining multiple clusterings using evidence accumulation. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 835–850. [Google Scholar] [CrossRef]
- Huang, D.; Wang, C.D.; Wu, J.S.; Lai, J.H.; Kwoh, C.K. Ultra-Scalable Spectral Clustering and Ensemble Clustering. IEEE Trans. Knowl. Data Eng. 2020, 32, 1212–1226. [Google Scholar] [CrossRef]
- Jia, Y.; Liu, H.; Hou, J.; Zhang, Q. Clustering ensemble meets low-rank tensor approximation. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 7970–7978. [Google Scholar]
- Wang, T. CA-Tree: A hierarchical structure for efficient and scalable coassociation-based cluster ensembles. IEEE Trans. Syst. Man, Cybern. Part B (Cybern.) 2010, 41, 686–698. [Google Scholar] [CrossRef]
- Cai, Y.; Mahmud, M.S.; Xu, J.; Sun, X.; Huang, J.Z. Spectral ensemble clustering with doubly stochastic co-association matrix. Inf. Sci. 2025, 686, 121314. [Google Scholar] [CrossRef]
- Wu, Y.; Wu, R.; Liu, J.; Tang, X. Metawce: Learning to weight for weighted cluster ensemble. Inf. Sci. 2023, 629, 39–61. [Google Scholar] [CrossRef]
- Jia, Y.; Tao, S.; Wang, R.; Wang, Y. Ensemble Clustering via Co-Association Matrix Self-Enhancement. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 11168–11179. [Google Scholar] [CrossRef] [PubMed]
- Zhou, P.; Du, L.; Shen, Y.D.; Li, X. Tri-level robust clustering ensemble with multiple graph learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 11125–11133. [Google Scholar]
- Chen, M.S.; Lin, J.Q.; Wang, C.D.; Xi, W.D.; Huang, D. On regularizing multiple clusterings for ensemble clustering by graph tensor learning. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 3069–3077. [Google Scholar]
- Zhou, P.; Du, L.; Li, X. Self-paced consensus clustering with bipartite graph. In Proceedings of the 29th International Conference on International Joint Conferences on Artificial Intelligence, Macao, China, 19–25 August 2021; pp. 2133–2139. [Google Scholar]
- Yang, X.; Zhao, W.; Wang, J.; Peng, S.; Nie, F. Auto-weighted Graph Reconstruction for efficient ensemble clustering. Inf. Sci. 2025, 689, 121486. [Google Scholar] [CrossRef]
- Bian, Z.; Yu, L.; Qu, J.; Deng, Z.; Wang, S. An Ensemble Clustering Method via Learning the CA Matrix with Fuzzy Neighbors. Inf. Fusion 2025, 120, 103105. [Google Scholar] [CrossRef]
- Bai, L.; Liang, J.; Cao, F. A multiple k-means clustering ensemble algorithm to find nonlinearly separable clusters. Inf. Fusion 2020, 61, 36–47. [Google Scholar] [CrossRef]
- Zhang, R.; Hang, S.; Sun, Z.; Nie, F.; Wang, R.; Li, X. Anchor-based fast spectral ensemble clustering. Inf. Fusion 2025, 113, 102587. [Google Scholar] [CrossRef]
- Huang, D.; Wang, C.D.; Lai, J.H. Fast multi-view clustering via ensembles: Towards scalability, superiority, and simplicity. IEEE Trans. Knowl. Data Eng. 2023, 35, 11388–11402. [Google Scholar] [CrossRef]
- Mehrabi, N.; Morstatter, F.; Saxena, N.; Lerman, K.; Galstyan, A. A survey on bias and fairness in machine learning. ACM Comput. Surv. (CSUR) 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Caton, S.; Haas, C. Fairness in machine learning: A survey. ACM Comput. Surv. 2024, 56, 1–38. [Google Scholar] [CrossRef]
- Chierichetti, F.; Kumar, R.; Lattanzi, S.; Vassilvitskii, S. Fair clustering through fairlets. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Backurs, A.; Indyk, P.; Onak, K.; Schieber, B.; Vakilian, A.; Wagner, T. Scalable fair clustering. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 405–413. [Google Scholar]
- Bera, S.; Chakrabarty, D.; Flores, N.; Negahbani, M. Fair algorithms for clustering. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Kleindessner, M.; Samadi, S.; Awasthi, P.; Morgenstern, J. Guarantees for spectral clustering with fairness constraints. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 3458–3467. [Google Scholar]
- Ghadiri, M.; Samadi, S.; Vempala, S. Socially fair k-means clustering. In Proceedings of the ACM Conference on Fairness, Accountability, and Transparency, Online, 3–10 March 2021; pp. 438–448. [Google Scholar]
- Kleindessner, M.; Awasthi, P.; Morgenstern, J. Fair k-center clustering for data summarization. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 3448–3457. [Google Scholar]
- Zhou, P.; Li, R.; Ling, Z.; Du, L.; Liu, X. Fair Clustering Ensemble With Equal Cluster Capacity. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 47, 1729–1746. [Google Scholar] [CrossRef] [PubMed]
- Fan, K. On a theorem of Weyl concerning eigenvalues of linear transformations I. Proc. Natl. Acad. Sci. USA 1949, 35, 652–655. [Google Scholar] [CrossRef] [PubMed]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar] [CrossRef]
- Nie, F.; Lu, J.; Wu, D.; Wang, R.; Li, X. A novel normalized-cut solver with nearest neighbor hierarchical initialization. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 659–666. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A public domain dataset for human activity recognition using smartphones. In Proceedings of the European Symposium on Artificial Neural Networks (ESANN), Bruges, Belgium, 24–26 April 2013; Volume 3, pp. 3–4. [Google Scholar]
- Li, P.; Zhao, H.; Liu, H. Deep fair clustering for visual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9070–9079. [Google Scholar]
- Lyons, M.J.; Akamatsu, S.; Kamachi, M.; Gyoba, J.; Budynek, J. The Japanese female facial expression (JAFFE) database. In Proceedings of the 3rd International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; pp. 14–16. [Google Scholar]
- Huang, D.; Wang, C.D.; Lai, J.H. Locally weighted ensemble clustering. IEEE Trans. Cybern. 2017, 48, 1460–1473. [Google Scholar] [CrossRef]
- Huang, D.; Wang, C.D.; Peng, H.; Lai, J.; Kwoh, C.K. Enhanced ensemble clustering via fast propagation of cluster-wise similarities. IEEE Trans. Syst. Man Cybern. Syst. 2018, 51, 508–520. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).