Abstract
Symmetric regression deals with a reversible functional relationship involving a set of variables, where all of them are measured with error and it is not meaningful to consider one as the response and the remaining ones as explanatory. Therefore, it is unsuitable to study any functional (linear) relationship between them by fixing one direction of the regression rather than the other. The scope of the symmetric regression can be expanded by considering a partial symmetric linear regression where the functional relationship is controlled for other variables, which are not assumed to be error-prone. Actually, the word partial in this context, means that we are not interested in a fully symmetric relationship between all the variables but in a symmetric and reversible relationship that holds for some variables of interest, whose functional relationship is of primary concern, for any given value of the control variables. Therefore, a partial symmetric regression modeling strategy is developed within a very general framework that includes different symmetric regression strategies. The finite sample behaviors of the proposed estimators are investigated through numerical studies and illustrated with an application to rheumatology data to find a reversible conversion formula between the Stanford Health Assessment Questionnaire (HAQ) score and the Multi-Dimensional HAQ (MDHAQ) score.
MSC:
62J05; 62F40
1. Introduction
Symmetric regression concerns the study of a functional relationship among a set of variables through a regression model specification without distinguishing between the response and the explanatory variables [,,]. In other words, symmetric regression deals with a reversible functional relationship, regardless of the direction of regression, involving variables that are all supposed to be measured with error []. For simplicity and without loss of generality, let us start off with the bivariate case. For example, the variables may refer to measurements of the same quantity using two (or more) different devices or assays, or may be intrinsically related measures from a clinical or physical point of view, for which we cannot make a clear distinction between response and predictors. In this situation, inference using the symmetric regression model allows us to assess the statistical equivalence or evaluate the bias of measurements conducted by using different tools or methodologies, and to assess their statistical equivalence and practical interchangeability in providing the same results notwithstanding the measurement errors. The study of reversible functional relationships is of interest in many fields, such as physics, economics, social sciences, psychology, biostatistics, astronomy, chemistry, geodesy, allometry, and in general for all those situations where it is meaningful to consider regression in any direction.
In classical simple linear regression, it is possible to consider two different models depending on which variable is assumed to be the response. Let be the conditional expectation of Y for a given x and be the conditional expectation of X for a given y. The simple linear regression of Y on X corresponds to , and the simple linear regression of X on Y is given by . The requirement of symmetry is that the two regression equations are reversible, that is, they are the inverse of each other, with and . Unfortunately, although not fully recognized, the ordinary least squares (OLS) fit is not symmetric since predictions depend on which variable is selected as the response and which variable is selected as the (fixed) explanatory variable; that is, , where denotes the regression of X on Y expressed in y-units unless a perfect correlation exists among the variables. In contrast, within a symmetric linear regression framework, one is interested in establishing a reversible conversion formula between the pair of measurements; that is, it is expected to predict X from Y and Y from X in a reversible fashion, meaning that the two predictions can be obtained one from another, removing the lack of reversibility of OLS regression and providing us with a reversible conversion formula between the predicted values of Y and X. In other words, we are interested in estimating a true functional relationship between variables rather than predicting one variable based on known values of the other variable. Moreover, in the presence of measurement errors, OLS gives rise to biased estimates of the regression coefficients and leads to inconsistent conclusions when the roles of the variables are interchanged, a phenomenon called the regression paradox [].
Several modifications of OLS are available that extend it to the case of simultaneous regression in all directions. The first version of symmetric regression is orthogonal regression (OR), as introduced in [] and also based on the work in [,]. A second version is geometric mean regression (GMR) [,,], also known as reduced major axis, diagonal, or impartial regression. The main improvement over OR is that GMR is scale independent. Additional versions include Pythagorean regression (PR) [] and Deming regression (DR) [,,]. While OR, GMR, and PR are meant to deal with equal measurement errors’ variances and the homoschedastic setting, DR is a general approach to symmetric regression that allows us to take into account different measurement errors in the variables Y and X and across observations. All the symmetric regression methods discussed above can be extended to the multiple linear regression setting, where the goal is to model a functional linear relationship between Y and a set of variables , with .
In this work, we focus on modeling the symmetric linear regression relationship between Y and while adjusting for the effect of additional control covariates, denoted by , with . Specifically, we do not aim to identify a fully reversible dependence structure among all the variables but rather a symmetric relationship between Y and that is conditional on given values of such that
where, with a slight abuse of notation, denotes the prediction from the regression of on expressed in y-units, , and . The proposed methodology is very general and designed to be applicable to every symmetric regression version listed above.
The remainder of the paper is structured as follows: some necessary background on symmetric regression is provided in Section 2; the partial symmetric linear regression approach is introduced in Section 3, and the model fitting is developed as well; numerical studies and an empirical application from rheumatology are covered in Section 4; finally, a discussion concludes the paper in Section 5.
2. Background
Assume that the interest lies in comparing pairs of measurements taken on n units by two alternative methods, . The symmetric linear regression model for states that
with ; that is, the true (but unobservable) values are linked by a linear regression with slope and intercept . The error terms and are realizations of independent random variables with null expectations and constant equal variances; that is, . The model in (1) is also referred to as the Errors-In-Variables model [,]. Under the assumptions of model (1), we have
where and are the conditional expectations of Y and X, respectively. The model specification clearly requires that . Here, denotes the vector of marginal expectations. We note that the same set of regression coefficients determines the regression lines in both directions.
To estimate the parameter of the symmetric regression, one should take into account both y- and x-errors. Obviously, it is not sufficient to minimize the sum of squared errors only in one direction, as for OLS. Rather, it is necessary to define a suitable objective function to be minimized that is based on a summary of both squared vertical and horizontal distances. From (2), we note that . In the following, we review some of the most popular versions of symmetric regression as listed in Section 1 (see [] for a review).
The OLS fit of the regression of Y on X minimizes the sum of squared vertical errors (the segment BP in Figure 1) ; the OLS fit of the regression of X on Y minimizes the sum of squared horizontal errors (the segment AP in Figure 1) . The GMR is defined considering the minimization of the sum of the geometric mean of the squared vertical and horizontal distances; that is,
for . This is equivalent to the minimization of the sum of the areas of the ABP triangles in Figure 1 generated from the projections of the points on the line. We further note that GMR can also be obtained as the maximum agreement linear predictor maximizing the Lin’s concordance correlation coefficient [] between Y and its predicted value . The PR is obtained from the minimization of the sum of the arithmetic mean of the squared distances, so the criterion is
for . This is equivalent to finding the best line minimizing the sum of the squared hypotenuses AB in Figure 1 of the triangles formed by the data points and the line. The OR is obtained from the minimization of the sum of the harmonic mean of the squared vertical and horizontal distances, which leads to the same result as minimizing the sum of the squared orthogonal distances (PH in Figure 1). The squared orthogonal distance from the regression line can be expressed as
and then the criterion becomes
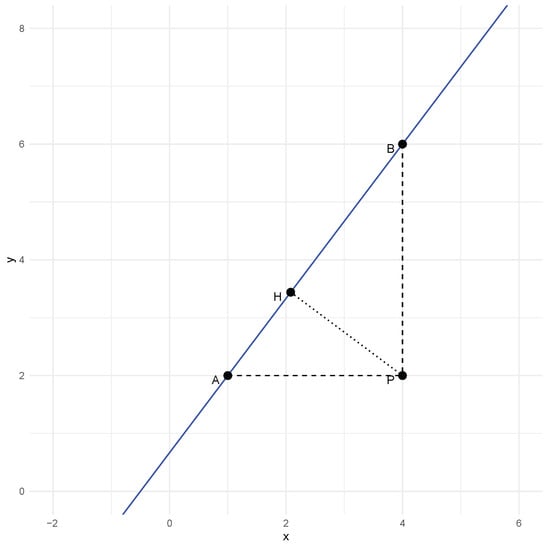
Figure 1.
Geometry of symmetric regression.
It is worth noting that the OR solution also corresponds to maximum likelihood estimation of the Errors-In-Variables model (1).
The DR [] provides a more general solution to the problem of maximum likelihood estimation of the EIV model in (1). Actually, under no restrictions on the error variances, the objective function for the (weighted) DR becomes
with . The variances can be estimated from replicated measurements. Under the hypothesis of proportional variances , then
In practice, when k is not known in advance based on available knowledge, it is estimated using multiple measurements for each subject. We note that OR is recovered for . The reader is referred to [] for a discussion about the effect of the variance ratio k on the bias of the estimators for for the different methods described above. In summary, all the methods lead to (asymptotically) unbiased estimates when the error terms have the same variance, but OR, GMR, and PR exhibit some bias when the variance ratio moves away from unity. In contrast, DR is (asymptotically) unbiased regardless of the variance ratio. Additional details on the effect of the variance ratio on inference can be found in [].
We note that, in all cases, the objective function can be written as , with , hence enabling unified treatment of all considered symmetric regressions. The estimating equation for the slope parameter takes the general form
where denotes the first derivative of and and are the sample variance of Y, the sample variance of X, and their covariance, respectively. The estimate for the intercept term is always given by , where and are the sample means and is the fitted slope obtained from (3). All the symmetric regression lines pass through the point of coordinates as the OLS regression lines. For the cases of OR, GMR, and DR, the estimating equation for the slope is quadratic in . The estimate of corresponds to the solution with the same sign as the correlation between . For GMR, the fitted slope is . The solutions for DR are
The estimating equation for the slope of the PR is quartic []; the estimate is one of two real solutions sharing the same sign as .
Even though, for simplicity, we have focused on the special case of a pair of measurement methods for the same underlying quantity, the symmetric regression methods described above can be generalized to situations where the interest is in modeling a reversible linear relationship among a set of , variables, which we prefer to denote as []. Now, the - and -distances, , from the hyperplane are
and . Then, GMR, PR, and OR correspond to the geometric, arithmetic, and harmonic means of , respectively. Let . In the case of GMR,
with ; for PR, the arithmetic mean leads to
with ; for OR, using the harmonic mean, we have
Standard errors can be obtained using first-order approximations based on the Delta method [], the general theory of M-estimators [], the influence function approach [], the method of moments [], the leave-one-out jackknife [,], and the pair (or nested) bootstrap [,].
3. Material and Methods
In this section, we first introduce the partial symmetric regression model, and then we focus on estimating the corresponding reversible conversion equations. In addition to the error-prone measurements , assume that we also collect data on some control variables , . The control variables are not measured with error, and they describe features that may affect the functional relationship involving , such as sex, age, disease status, etc. For ease of illustration, let us consider the case of a simple partial linear functional relationship for given , that is, when is bivariate. Given the data , , the partial symmetric regression model states that
with and . In terms of conditional expectations, under the assumptions already made for model (1), the reversible regression equations between Y and X, while controlling for , can be written as
for . Let us assume that has finite second-order moments with the mean vector and variance–covariance matrix given by and
Actually, according to (5) and provided that is positive definite (in order to be invertible), the best linear predictor of given is the conditional expectation
where and , implying that the model in (5) can be written as
where and are the slope coefficients of the regressions of Y on and X on , respectively. Then, the model in (6) provides a direct and useful interpretation of the coefficient vector: after replacing and some simple algebra, one finds that
These findings apply straightforwardly to the case when the dimension of is larger than one.
3.1. Model Fitting
Let us consider the model in (4), extended to the case of a reversible conversion formula between more than two variables, that is, between the variables . To fit a partial symmetric linear regression model for , one can build upon the background methodology described in Section 2. Let , with . Here, it is proposed to minimize a combined measure of both squared y- and -distances from the regression hyperplane, but not of squared -distances, assuming that , . The squared y- and -distances from the regression hyperplane are
where is the coefficient vector without the j-th element, and corresponds to removing the j-th variable. After combining these distances using a suitable summary measure, we obtain an objective function of the general form
where the positive real-valued function depends on the selected version of symmetric regression, and with is the vector of sample means. The minimization of through the use of partial derivatives leads to the set of estimating functions
where is the derivative of with respect to . We note that the estimating function in (11) corresponding to the control regression coefficient vector resembles the classical one from OLS regression. In particular, the estimate of for a given is obtained from the OLS regression of on ; the constrained estimate of for a fixed is
consistent with (7). The constrained estimate in (12) depends on the fitted coefficients of the OLS regression of Y on Z and X on Z, respectively. By substituting in (10), and also considering that from (9), we obtain a profile estimating function for whose components are .
In the special case of a bivariate , for GMR, OR, and DR, the profile estimating equation is again quadratic in , whereas, for PR, it is still quartic. Let denote the sample variances of Y and X and denote the sample covariance; is the variance–covariance matrix for ; and are the sample covariance matrices between and , respectively. We find that
and
Then, in the case of GMR, the profile estimating function is
whereas, for DR, we find that
with
The case coresponds to OR.
3.2. Interaction Terms
The model in (5) can be extended further to include interactions terms. Let us restrict our attention to the case with three univariate variables . Now, we consider the functional linear relationship
where the interaction term between X and Z is now included, and to guarantee existence. In this setting, the objective function to be minimized becomes
In the special case of partial GMR, we have that
for PR
and for OR
The estimating functions for and change according to the different form of the function and its partial derivatives. In particular, we have
where denotes the first derivative with respect to , and the first derivative with respect to is .
In particular, when the control variable Z is categorical with ℓ levels, fitting the model specified in (13) corresponds to fitting a separate symmetric regression model within each level of Z, thereby allowing the relationship between Y and X to vary across the strata defined by the levels of the control variable not only with regard to the intercept but also with regard to the slope. In this situation, is the vector of observations from the set of binary variables corresponding to the levels of Z and .
3.3. Uncertainty Evaluation
The proposed estimator belongs to the general class of M-estimators since the estimating function defined through (9)–(11) can be written as the sum of n individual contributions; that is, , with denoting the individual contribution to the estimating function from the observation. Then, the asymptotic distribution of is
with , where is the regression measure of scale, , and . Here, is the matrix of second partial derivatives with elements
An estimate of the asymptotic variance of can be obtained using the empirical counterparts of M and
For ease of illustration, under the model in (5) with univariate X and Z, has elements
The parameter can be estimated by . By analogy with OLS theory, the denominator may be adjusted for the number of fitted coefficients. Alternatively, the variance–covariance matrix can be estimated by using the leave-one-out jackknife or the bootstrap, as in the case of symmetric regression without control variables.
4. Results
4.1. Numerical Studies
To evaluate the performance of the different versions of partial symmetric linear regression (namely GMR, PR, and OR), in this section, several numerical studies are considered. The data have been generated according to model (4). We set , , , and , for sample sizes . We compare the performance of each method using the empirical distributions of the estimators for and , the root mean squared error (RMSE) for the vector of regression coefficients , and the coverage accuracy of Wald-type confidence intervals for and confidence regions for based on jackknife and the normal approximation to the distribution of the estimators. The numerical studies are based on 1000 Monte Carlo trials. Figure 2 and Figure 3 display the empirical distributions of the estimates for and , respectively, under the different scenarios: the distributions are always centered at the true values, and the differences in variability between the three (partial) symmetric regression techniques are negligible. Their satisfactory and very similar behavior can also be noted from the inspection of Figure 4, which shows the distributions of the MSE for the full coefficient vector. Figure 5 shows normal QQ-plots for the distributions of the estimates of , , and , respectively, from left to right, obtained from partial GMR, both when and . The shaded areas correspond to confidence intervals. Having the points covered by the shaded area indicates that the sample quantiles do not differ significantly from the theoretical quantiles, providing support for the asymptotic normality of the estimators under study. Furthermore, Figure 6 shows paired joint distributions, with bivariate normal contour levels overimposed, for , both when and . The visual inspection of the plots provides further support for the (joint) normality of the distribution of the estimators under consideration. The entries in Table 1, Table 2 and Table 3 provide empirical coverage of Wald-type confidence intervals or regions based on leave-one-out jackknife estimation of the variance–covariance matrix and the normal approximation to the distribution of the estimators. In all the considered cases, the coverage accuracy is satisfactory as the discrepancies between empirical and nominal levels are negligible, demonstrating the expected asymptotic behavior as the sample size increases.
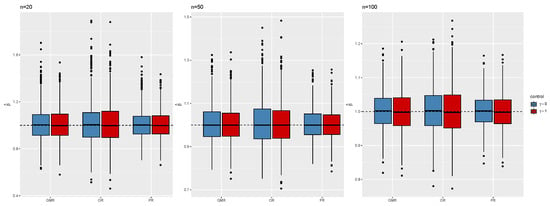
Figure 2.
Distribution of the estimated from GMR, OR, and PR, , , , and .
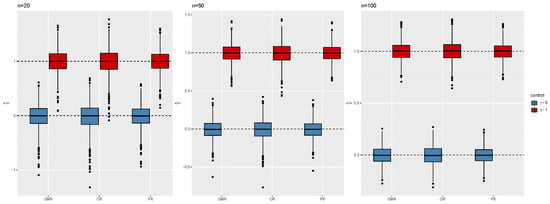
Figure 3.
Distribution of the estimated from GMR, OR, and PR, , , , and .
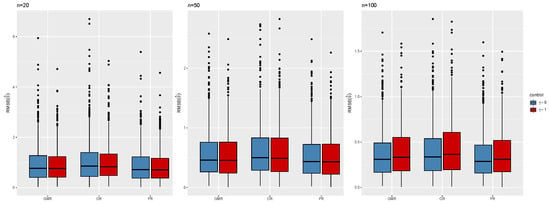
Figure 4.
Distribution of the root mean squared error for the vector from GMR, OR, and PR, , , , and .
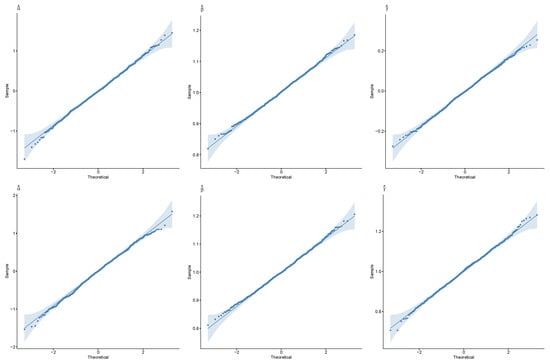
Figure 5.
Normal QQ-plots from GMR, , , (top), and (bottom). The shaded area indicates 0.95-level confidence intervals.
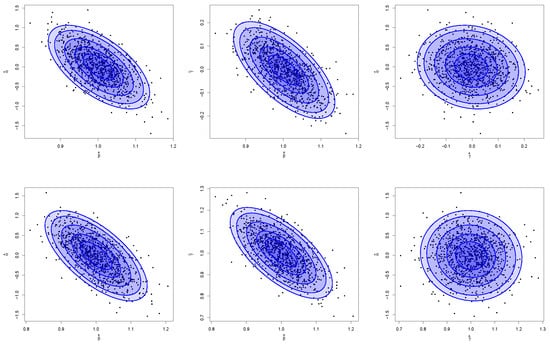
Figure 6.
Paired joint distributions from GMR, , , (top), and (bottom). Gaussian contours overimposed for levels 0.25, 0.50, 0.75, 0.90, and 0.95.

Table 1.
Empirical coverage of jackknife-based Wald-type confidence intervals for , , and nominal levels 0.90 and 0.95.
Table 2.
Empirical coverage of jackknife-based Wald-type confidence regions for , , and nominal levels 0.90 and 0.95.
Table 3.
Empirical coverage of jackknife-based Wald-type confidence regions for , , and nominal levels 0.90 and 0.95.
A second numerical experiment concerns data from the model in (13): the control variable is a dummy variable, based on which the sample is divided into equal sub-groups. The error structure is the same as above. We set . Figure 7 shows the negligible bias of the estimates for the intercept and slopes in the two groups, provided, respectively, by and for all the considered symmetric regressions and sample sizes. Furthermore, we do not observe important differences between the methods in terms of RMSE, as displayed in Figure 8, meaning that GMR, PR, and OR still perform similarly, as expected under the simulation design involving constant and equal error variances. Table 4 provides empirical coverage of asymptotic Wald-type confidence intervals for the two slopes and and confidence regions for the pairs and based on leave-one-out jackknife and the normal approximation. The results are quite satisfactory, with OR providing better results for inference on , in particular as the sample size grows.
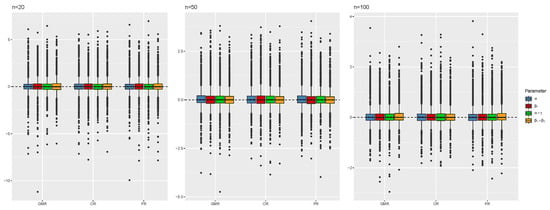
Figure 7.
Distribution of the estimated intercept and slope for the first level of the covariate and the second level of the covariate from GMR, PR, OR, , , , , and . Estimates are centered on the true values.
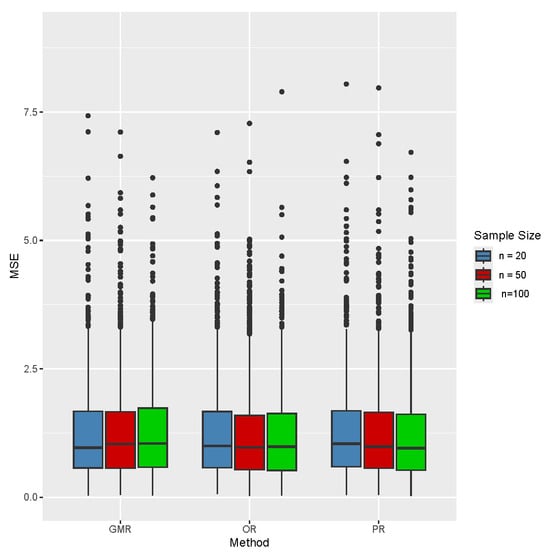
Figure 8.
Distribution of the root mean squared error for the vector from GMR, PR, and OR, , , , , and , in the presence of one binary covariate and the interaction term.
Table 4.
Empirical coverage of jackknife-based Wald-type confidence regions for , , , and with , and nominal levels 0.90 and 0.95 in the presence of one binary covariate and the interaction term.
In summary, the key findings of the numerical studies are the satisfactory accuracy and precision of the proposed estimators under the different scenarios, and the fair reliability of associated inferences. We did not observe any remarkable differences between the symmetric regression methods under investigation.
4.2. Example: Reversible Conversion Formula for the HAQ and MDHAQ Scores
In rheumatology studies, the functional status of patients with inflammatory joint disease is typically measured using the Stanford Health Assessment Questionnaire (HAQ) disability score index []. The HAQ is composed of twenty items regarding eight domains of ability to perform activities of daily living: dressing and grooming, arising, eating, walking, hygiene, reach, grip, and activities. The overall score is obtained from averaging the domain scores and ranges from 0 to 3. However, it has been documented that filling out the HAQ can be time-consuming. To address this concern, a second score, the Multi-Dimensional HAQ (MDHAQ), has been suggested. The MDHAQ only includes eight of the original items from the HAQ, with the addition of two more items addressing some demanding activities that are considered to be more relevant. It also ranges from 0 to 3.
Based on these considerations, there is a practical need to establish a conversion formula between the two scores. The development of a conversion algorithm between the two scores has been pursued recently in [] using data from the DANBIO, a Danish nationwide registry that includes all rheumatologic patients receiving biological drugs: demographic data, markers of disease activity, current treatment, adverse events, and reasons for discontinuation are registered at each visit. Since their methodology was based on OLS, we believe that a partial symmetric regression approach may be more suitable if the goal is to obtain a reversible conversion formula instead of two different formulas, as provided by classic linear regression. Like [], we will use linear regression models despite the intrinsically discrete and bounded nature of HAQ and MDHAQ scores. Transformations that map the [0,3] interval to the real line may be considered to address the bounded nature of the data.
Our analysis is based on a sample of n = 43,522 patients from the DANBIO. We note that our sample size is much larger than the sample size of n = 13,391 from the study in []. The dataset contains the HAQ, MDHAQ, and age of the patient at the first visit where both HAQ and MDHAQ are available regardless of gender and diagnosis. Age is considered as a control variable when developing the conversion formula for the HAQ and MDHAQ scores. Summary statistics for the three variables are provided in Table 5. Their distributions are displayed in Figure 9: the relationship between the pair of measurements HAQ and MDHAQ is also illustrated in the bottom-right panel. We observe that the HAQ scores are larger on average than the MDHAQ scores. Looking at the quantiles, we notice that the distribution of the HAQ scores is shifted towards larger values compared to the distribution of the MDHAQ scores. There are not noticeable differences in variability. The bottom-right panel provides evidence supporting a linear relationship.
Table 5.
Summary statistics for age, MDHAQ, and HAQ.
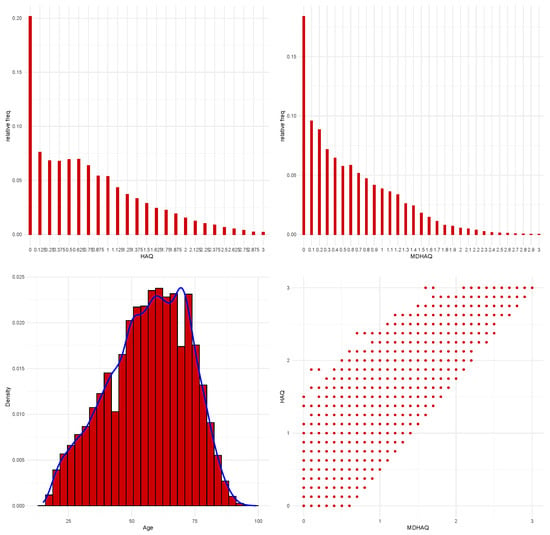
Figure 9.
Distributions of HAQ, MDHAQ, age, and scatter-plot of the pairs of measurements regarding HAQ and MDHAQ.
In order to investigate the effect of age on the linear functional relationship of interest, let us consider the scatter-plot in Figure 10 describing the relationship between age and the difference between the HAQ and MDHAQ values. We observe that the differences in the scores tend to be larger as age increases. Then, it looks reasonable to obtain a conversion formula that also takes age into account.
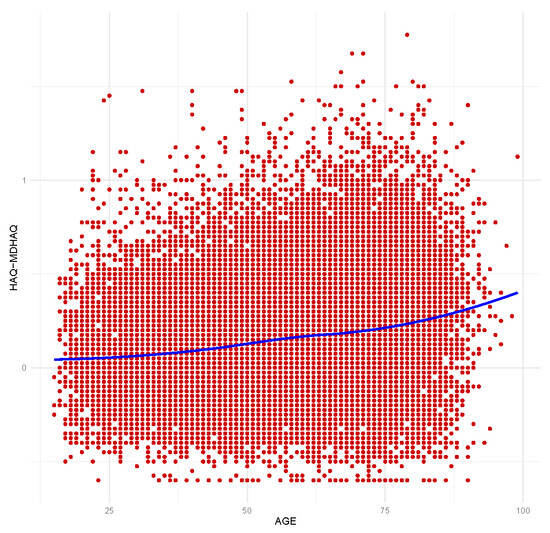
Figure 10.
Scatter-plot of the differences in HAQ–MDHAQ measurements with age. Non-parametric trend line overimposed.
Since HAQ and MDHAQ scores have similar scale, we can use partial GMR. The fitted (reversible) conversion formula from MDHAQ to HAQ is
The estimates of the regression coefficients together with their standard errors (S.E.) are provided in Table 6. The other two methods, OR and PR, yielded almost identical results. The corresponding results from the OLS regression of HAQ on MDHAQ are also provided; estimates are biased because of measurement errors, and the corresponding conversion formula is not reversible. The reversible conversion formula from HAQ to MDHAQ is
The estimate of the slope coefficient corresponding to MDHAQ in (14) is larger than one, as expected since on average the HAQ values are larger than the MDHAQ values. We also note that the estimate for the coefficient corresponding to the control variable age is positive, as expected as well, based on the findings from Figure 10.
Table 6.
Estimated coefficients and standard errors from the partial GMR and OLS regression.
5. Discussion
In this work, we introduced a partial symmetric linear regression model aimed at describing a reliable conversion formula between error-prone measurements in the presence of control variables, which are assumed to be known without error. The extension to partial settings with control variables fills a notable gap in the literature. This approach can be tested in applied domains where parallel measurement tools coexist, such as psychology, health economics, or epidemiology. More generally, symmetric regression could prove to be highly relevant in interdisciplinary fields that rely heavily on measurement harmonization, including environmental science and social research.
The proposed model enables studying the effect of control variables on the functional relationship between a set of variables in terms of their statistical equivalence and practical interchangeability to take into account confounding influences. Compared to classical regression approaches, the proposed methodology offers important advancements by producing reversible mappings and appropriately accounting for measurement error. Partial symmetric regression provides a flexible and powerful tool for enhancing the comparability of measurements across diverse scientific fields. Attention was focused on very popular strategies for symmetric regression, such as OR, GMR, and PR. Model fitting was achieved through the minimization of a suitable objective function that is derived by generalizing the methodology used for symmetric regression to the case when control variables are considered. The key element is that the objective function is based on a suitable summary measure of the squared errors concerning the variables, whose reversible conversion formula is of primary interest, but not the control variables . In detail, GMR is based on the geometric mean of squared errors, PR on the arithmetic mean, and OR on the harmonic mean.
The proposed methodology performed well both in the numerical studies and the empirical application taken from rheumatology. The numerical investigations, described in Section 4.1, provide evidence supporting the reliability of the proposed partial symmetric regression methodology and the accuracy of the related statistical inference. Across a range of simulated scenarios, the estimators displayed negligible bias and satisfactory efficiency. In particular, the empirical coverage of Wald-type confidence intervals and regions consistently matched the nominal level, especially as the sample size increased. These results support the asymptotic theory underlying the estimators and reinforce the practical utility of the new methodology. The observed similarity between the results from the geometric mean regression, orthogonal regression, and Pythagorean regression further suggests that the methodology is not unduly sensitive to the choice of the symmetric regression variant, at least for the settings considered in our study.
The application to rheumatology data, discussed in Section 4.2, illustrates the potential of the new methodology to deliver practically meaningful results. The construction of a reversible conversion formula between the HAQ and MDHAQ scores represents more than a theoretical result: it addresses a substantive clinical need as reversible and statistically consistent mappings between patient-reported outcomes are indispensable for harmonizing research evidence and facilitating longitudinal monitoring across studies and registries. The inclusion of age as a control variable not only improved the fidelity of the conversion but also highlighted the role of demographic heterogeneity when dealing with patient-reported outcomes.
From a methodological perspective, our findings resonate with calls [] to prioritize models that respect measurement error structures and yield interpretable invertible relationships between paired measurements or instruments. As such, this study opens promising avenues for both theoretical developments and practical applications. At the same time, some limitations should be acknowledged. First, while the numerical studies were comprehensive in their scope, they necessarily relied on simplified data-generating mechanisms. Second, while partial symmetric regression provides reversibility, its reliance on linear functional forms may prove to be restrictive when the true relationships between variables are nonlinear. Looking ahead, it would be valuable to extend the present framework to accommodate nonlinear symmetric regression structures [] as a possible direction for future research. A Bayesian extension may also enhance uncertainty quantification and facilitate the inclusion of prior information [].
Author Contributions
Conceptualization, G.L.; Methodology, L.G.; Data curation, L.G. and G.L.; Writing—original draft, L.G.; Writing—review & editing, G.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the PRIN funding scheme of the Italian Ministry of University and Research (Grant no. 2022LANNKC CUP E53D23005810006).
Data Availability Statement
Restrictions apply to the availability of these data. Data were obtained from DANBIO and are available from databasen@danbio-online.dk with the permission of DANBIO. [DANBIO] [https://danbio.dk/] (accessed on 27 March 2024).
Acknowledgments
The authors want to thank Lykke Midtbøll Ørnbjerg, Merete Hetland, and Niels Steen Krogh for providing the DANBIO data used to illustrate the use of partial symmetric linear regression models to construct reversible conversion formulas.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Taagepera, R. Making Social Sciences More Scientific: The Need for Predictive Models; Oxford University Press: Oxford, UK, 2008. [Google Scholar]
- Carr, J.R. Orthogonal regression: A teaching perspective. Int. J. Math. Educ. Sci. Technol. 2012, 43, 134–143. [Google Scholar] [CrossRef]
- Francq, B.G.; Govaerts, B.B. Measurement methods comparison with errors-in-variables regressions. From horizontal to vertical OLS regression, review and new perspectives. Chemom. Intell. Lab. Syst. 2014, 134, 123–139. [Google Scholar] [CrossRef]
- Greco, L.; Luta, G.; Krzywinski, M.; Altman, N. Symmetric alternatives to the ordinary least squares regression. Nat. Methods 2025, 22, 1610–1612. [Google Scholar] [CrossRef] [PubMed]
- Chen, A.; Bengtsson, T.; Ho, T.K. A Regression Paradox for Linear Models: Sufficient Conditions and Relation to Simpson’s Paradox. Am. Stat. 2009, 63, 218–225. [Google Scholar] [CrossRef]
- Pearson, K. On lines and planes of closest fit to systems of points in space. London, Edinburgh, Dublin Philos. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar] [CrossRef]
- Adcock, R.J. A problem in least squares. Analyst 1878, 5, 53–54. [Google Scholar] [CrossRef]
- Adcock, R. Extension of the method of least squares to any number of variables. Analyst 1880, 7, 22–23. [Google Scholar] [CrossRef]
- Stromberg, G. Accidental and Systematic Errors in Spectroscopic Absolute Magnitudes for Dwarf G0-K2 Stars. Astrophys. J. 1940, 92, 156. [Google Scholar] [CrossRef]
- Kermack, K.; Haldane, J.B. Organic correlation and allometry. Biometrika 1950, 37, 30–41. [Google Scholar] [CrossRef]
- Xu, S. A property of geometric mean regression. Am. Stat. 2014, 68, 277–281. [Google Scholar] [CrossRef]
- Greene, N. Generalized Least Squares Regression I: Efficient derivations. In Proceedings of the 1st International Conference on Computational Science and Engineering, Valencia, Spain, 6–8 August 2013. [Google Scholar]
- Deming, W.E. Statistical Adjustments of Data; Dover Publications: New York, NY, USA, 1943. [Google Scholar]
- Ripley, B.D.; Thompson, M. Regression techniques for the detection of analytical bias. Analyst 1987, 112, 377–383. [Google Scholar] [CrossRef]
- Linnet, K. Estimation of the linear relationship between the measurements of two methods with proportional errors. Stat. Med. 1990, 9, 1463–1473. [Google Scholar] [CrossRef] [PubMed]
- Carroll, R.J.; Ruppert, D.; Stefanski, L.A.; Crainiceanu, C.M. Measurement Error in Nonlinear Models: A Modern Perspective; Taylor & Francis Group: Abingdon, UK, 2006. [Google Scholar]
- Fuller, W.A. Measurement Error Models; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Kim, T.; Luta, G.; Bottai, M.; Chausse, P.; Doros, G.; Pena, E.A. Maximum Agreement Linear Prediction via the Concordance Correlation Coefficient. arXiv 2023, arXiv:2304.04221. [Google Scholar]
- Tan, C.Y.; Iglewicz, B. Measurement-methods comparisons and linear statistical relationship. Technometrics 1999, 41, 192–201. [Google Scholar] [CrossRef]
- Greene, N. Generalized Least-Squares Regressions V: Multiple Variables. In New Developments in Pure and Applied Mathematics, Proceedings of the International Conference on Mathematical Methods, Mathematical Models and Simulation in Science and Engineering (MMSSE 2015), Vienna, Austria, 15–17 March 2015; INASE: London, UK, 2015. [Google Scholar]
- Isobe, T.; Feigelson, E.D.; Akritas, M.G.; Babu, G.J. Linear regression in astronomy. Astrophys. J. 1990, 364, 104–113. [Google Scholar] [CrossRef]
- Stefanski, L.A.; Boos, D.D. The calculus of M-estimation. Am. Stat. 2002, 56, 29–38. [Google Scholar] [CrossRef]
- Kelly, G. The influence function in the errors in variables problem. Ann. Stat. 1984, 12, 87–100. [Google Scholar] [CrossRef]
- Gillard, J.; Iles, T. Variance Covariance Matrices for Linear Regression with Errors in Both Variables; Cardiff University School of Mathematics Technical Report; Cardiff University: Cardiff, UK, 2006. [Google Scholar]
- Therneau, T. deming: Deming, Theil-Sen, Passing-Bablock and Total Least Squares Regression, R package version 1.4; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Francq, B.G. Bootstrap in Errors-in-Variables Regressions Applied to Methods Comparison Studies. Inform. Medica Slov. 2014, 19, 1. [Google Scholar]
- Potapov, S.; Model, F.; Schuetzenmeister, A.; Manuilova, E.; Dufey, F.; Raymaekers, J. mcr: Method Comparison Regression, R package version 1.3.3.1; R Foundation for Statistical Computing: Vienna, Austria, 2024. [Google Scholar]
- Fries, J.F. The dimension of health outcomes: The Health Assessment Questionnaire. J. Rheumatol. 1982, 9, 789–793. [Google Scholar]
- Ørnbjerg, L.M.; Svensson, E.; Løngaard, K.; Meincke, R.H.; Pedersen, J.K.; Dreyer, L.; Krogh, N.S.; Jensen, D.V.; Hetland, M.L. Conversion of the MDHAQ to the HAQ score: A simple algorithm developed and validated in a cohort of 13 391 real-world patients. Rheumatology 2022, 61, 3919–3929. [Google Scholar] [CrossRef]
- Li, M.; Ma, Y. An update on measurement error modeling. Annu. Rev. Stat. Its Appl. 2024, 11, 279–296. [Google Scholar] [CrossRef]
- Barry, T.; Roeder, K.; Katsevich, E. Exponential family measurement error models for single-cell CRISPR screens. Biostatistics 2024, 25, 1254–1272. [Google Scholar] [CrossRef]
- Ma, Z.; Chen, M.H. A Bayesian model-based reduced major axis regression. Biom. J. 2024, 66, 2300279. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).