1. Introduction
The gamma zero-truncated Poisson (GZTP) and complementary gamma zero-truncated Poisson (CGZTP) distributions hold significant importance in statistical modeling, particularly for lifetime data exhibiting nonmonotonic hazard functions. The GZTP distribution provides a flexible model for phenomena where an event is guaranteed to occur, effectively handling datasets where zero counts are inapplicable. This makes it ideal for reliability analyses where the time to first failure is of interest. The CGZTP further extends this utility by modeling the bathtub-shaped hazard function, which is characterized by an initial decrease, followed by a constant rate, and then an increase. Such a capability to fit a bathtub hazard function makes the CGZTP a robust tool for complex survival data, overcoming the limitations of traditional models such as the gamma distribution.
The GZTP distribution, introduced by Niyomdecha et al. [
1], is derived from compounding the gamma and zero-truncated Poisson distributions using the minimum function. Consider a collection of
N independent and identically distributed random variables
, each following a gamma distribution with a probability density function
defined as
, where
is a shape parameter and
is a rate parameter. The variable
N follows a zero-truncated Poisson distribution, given by:
, and
. Assuming
X and
N are independent,
Z is defined as the minimum of
. The probability density function (pdf) of the GZTP distribution is denoted as
where
is the upper incomplete gamma function. The CGZTP distribution utilizes the same compounding principle as the GZTP but employs the maximum function instead [
2]. Consider Y to be the maximum of
. The pdf for the CGZTP distribution is then given as follows:
These distributions exhibit flexible shapes of distribution functions, as shown in
Figure 1. Previous studies have covered inferential procedures for the parameters of the GZTP and CGZTP distributions. Niyomdecha et al. [
1] employed maximum likelihood estimation (MLE) to estimate GZTP parameters and then examine their asymptotic properties, while the MLEs and asymptotic confidence intervals for CGZTP parameters were discussed by Niyomdecha and Srisuradetchai [
2]. The MLEs exhibited accurate estimations, and the confidence interval achieved the nominal coverage probability in the case of a large sample size. Several studies have been conducted on compound distributions using Bayesian methods. Xu et al. [
3] investigated Bayesian estimators of Exponential-Poisson (EP) parameters by employing general noninformation prior distributions under symmetric and asymmetric loss functions. Yan et al. [
4] determined the Bayesian estimators of the parameters in the EP distribution under general entropy, LINEX, and a scaled squared loss function based on type-II censoring. In a study conducted by Pathak et al. [
5], the Bayesian estimators of Weibull–Poisson (WP) parameters were obtained by assuming that these parameters follow independently distributed prior distributions.
The loss function is instrumental in measuring how much an estimated parameter value deviates from its true value. The squared error loss function, a symmetric loss function, is commonly used in practice, especially when overestimation and underestimation are equally problematic [
6,
7]. Elbatal et al. [
8] addressed parameter estimation for the Nadarajah–Haghighi distribution with progressive Type-1 censoring, employing the squared error loss function to produce Bayes estimates and credible intervals for maximum posterior density. Eliwa et al. [
9] utilized balanced linear exponential and general entropy loss functions to estimate parameters for the new Weibull-Pareto distribution. Similarly, Abdel-Aty et al. [
10] applied squared error, LINEX, and general entropy loss functions for future failure times in a joint type-II censored sample from multiple exponential populations.
In many studies, the posterior distributions often become complicated and cannot be simplified into any closed form. The samples were obtained from the posteriors using a Markov Chain Monte Carlo (MCMC) method, such as the Gibbs sampler (see [
11]) and the Metropolis–Hastings algorithm (see [
12]). Additionally, a summary of the predicted posteriors is provided based on a sample-based approach. The MCMC based on Metropolis–Hastings algorithms was used in [
13] to estimate the unknown parameters of the alpha-power Weibull distribution under Type II hybrid censoring. In [
14], the parameters of the unit-log-logistic distribution were estimated using a Bayesian approach. Noninformative priors were used, and samples from the joint posterior distribution were obtained using the random walk Metropolis algorithm. El-Sagheer et al. [
15] employed Gibbs sampling to estimate the parameters for an asymmetric distribution and various lifetime indices, including reliability and hazard rate functions.
It is widely regarded that the conjugate prior for the Poisson parameter and the gamma rate parameter follow a gamma distribution. However, there is no proper conjugate prior for the gamma shape parameter [
16,
17]. Several papers explore Bayesian inference for estimating the parameters of the gamma distribution. Naji and Rasheed [
18] derived Bayes estimators for the shape and scale parameters of the gamma distribution using the precautionary loss function. They assumed gamma and exponential priors for the shape and scale parameters, respectively, to represent prior information. Moala et al. [
19] studied various noninformative priors, including Jeffreys prior, reference prior, maximal data information prior, Tibshirani prior, and a novel prior based on the copula method. Additionally, Pradhan and Kundu [
20] assumed that the scale parameter follows a gamma distribution prior, while the shape parameter follows a log-concave distribution prior.
The existing literature has not addressed Bayesian inference on parameters of the GZTP and CGZTP) distributions. While Niyomdecha et al. [
1] and Niyomdecha and Srisuradetchai [
2] have conducted MLE and Wald’s interval analyses, their findings suggest that the mean square errors of MLEs remain high and that Wald’s interval coverage probabilities are below the nominal level for small sample sizes. This study, therefore, seeks to explore Bayesian inference for the GZTP and CGZTP distributions.
This paper is structured as follows:
Section 2 delves into maximum likelihood estimation along with the corresponding interval estimation, which will be compared with the Bayesian credible interval.
Section 3 elaborates on the prior and posterior distributions, estimation procedures based on the squared error loss function, and the application of the random walk Metropolis algorithm for simulating posterior samples. Simulation studies, which are conducted for scenarios involving one and two unknown parameters within both GZTP and CGZTP distributions, are presented in
Section 4.
Section 5 demonstrates two example applications using real data. Finally, the paper concludes with a discussion in
Section 6.
2. Maximum Likelihood Estimation
Let
be random samples from a GZTP distribution and
be random samples from a CGZTP distribution. The likelihood functions based on the observed random sample of size
will be as follows:
The corresponding log-likelihood function of the GZTP distribution is
and the log-likelihood function of the CGZTP distribution is
The maximum likelihood estimators of , and for the GZTP and CGZTP distributions are obtained by maximizing (5) and (6). This process is accomplished by solving the first derivatives with respect to each parameter of the log-likelihood function. These first derivatives are difficult and complex to solve, making it impossible to find the MLE of , and analytically. Consequently, numerical techniques such as the simulated annealing method are employed to estimate , and that maximize the likelihood function.
The MLEs are asymptotically normally distributed with a multivariate normal (MVN) distribution given by
where
is the Fisher information matrix with element
and
[
21]. The asymptotic variances of MLEs can be obtained from the inverse Fisher information matrix. Then, the corresponding
Wald confidence intervals for
are given by
, where
is the
ii-th element of the inverse of
, i.e.,
and
is the
-th quantile of the standard normal [
22].
4. Simulation Study
The simulation study encompasses various sample sizes and hyperparameter values. Specifically, sample sizes
and
are examined.
Table 1 presents the hyperparameter values for informative prior distributions. The means of the prior distributions, which have small and large variances, are equal to the true values of the unknown parameters,
and
. For example, for the case of
and
, with the hyperparameters of Prior 1 (
,
), the variance of
equals 4, and with the hyperparameters of Prior 2 (
,
), the variance of
equals 2. Thus, the variance of Prior 1 is considered “High” compared to that of Prior 2. Both prior distributions of
have the same mean, 2, which equals to the true value.
Values of
and
are selected to create a variety of distribution shapes, as shown in
Figure 1. Additionally,
Table 2 details the prior distributions of the parameter
. The shapes of gamma prior distributions with different hyperparameters, as presented in
Table 1 and
Table 2 are illustrated in
Figure 2.
The RWM algorithm, as described in
Section 3.3, is executed for 10,000 iterations with a burn-in period of 1000. In both panels of
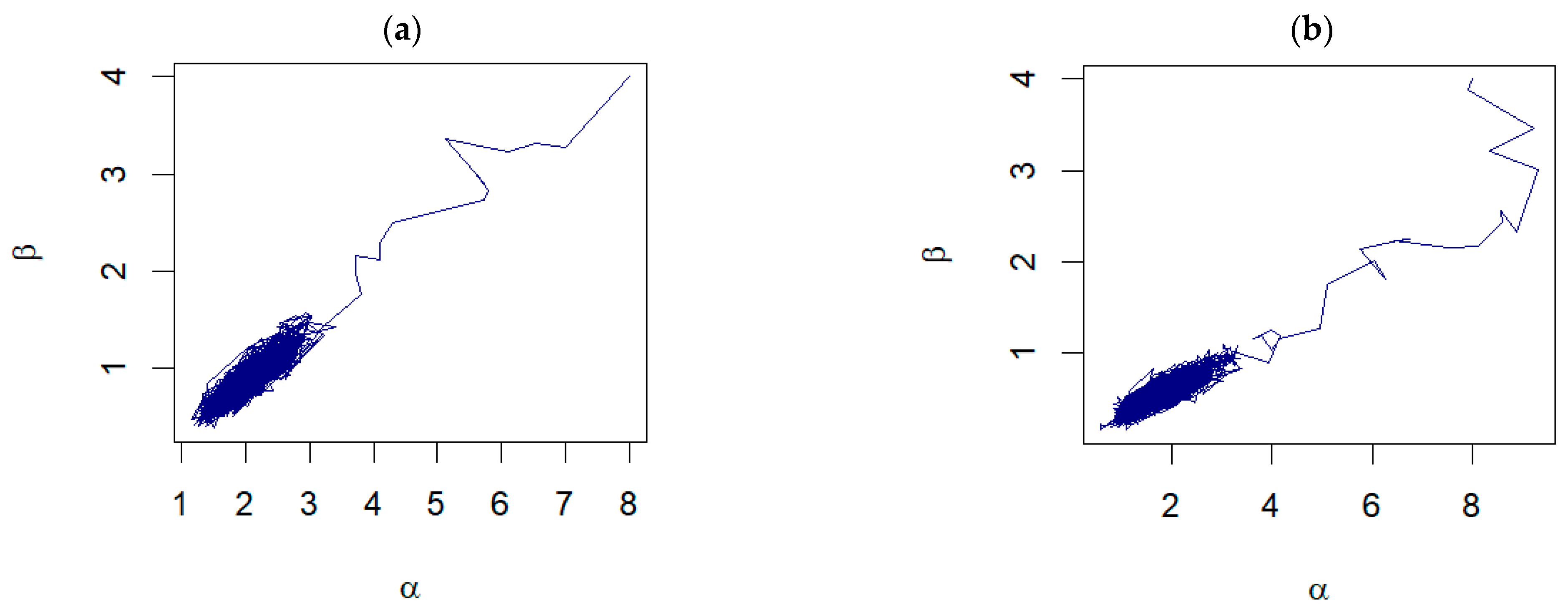
Figure 3, the examples of the trace plots for α and β suggest that the Markov chains have reached a stationary distribution, evidenced by the dense and fuzzy appearance of the plots, which indicates good mixing of the chains. The variability observed within each plot is consistent with the stochastic nature expected from RWM sampling, and there are no discernible trends or drifts to suggest nonconvergence.
Further examination of the pair plots shown in
Figure 4 reveals that, despite the initial starting points being far from the true values, the pairs of samples drawn from the RWM algorithm progress toward a densely clustered area. This dense cluster signifies the region of high probability density within the posterior distribution, illustrating the algorithm’s ability to converge to the region of interest. For unknown
, the examples of the trace plots are shown in
Figure 5.
Monte Carlo simulations are performed to compare the performances of the Bayes estimators with those of the classical estimators. Point estimates for parameters are averaged over 1000 iterations. Subsequently, the mean squared errors (MSEs) of the parameter estimates are calculated. The coverage probabilities (CPs) of 95% Wald confidence intervals and credible intervals and their average lengths (ALs) are determined.
Table 3 presents the detailed MLEs and MSEs obtained from simulated data sets from GZTP where the values of
and
are unknown. As sample sizes increase, estimates become more accurate and the MSE values decrease. For example, for the parameter set (0.5, 2, 0.5), the MLE of
α decreases from 2.3637 with an MSE of 0.8896 at sample size 15 to 2.0644 with an MSE of 0.0760 at sample size 100. It is also noticed that the MSEs of
and Bayes estimate
increase as
increases given that
is fixed. For example, in a case where
,
β = 1, and the sample size is 15, when
α is 1, the MSE for Prior 2 is 0.0566; whereas when α increases to 2, the MSE for the same prior and sample size is 0.2314. Similarly, when
is fixed, the MSEs of
and Bayes estimate
increase as
increases. When the sample size is small, MLEs tend to have higher MSE compared to Bayesian estimates. However, between the two priors, Prior 2 has the lowest MSE. For instance, for the parameter set (0.5, 2, 0.5) and a sample size of 25, Prior 2 produces an estimate for
α with an MSE of 0.1854, which is lower than the MSE of 0.2777 for Prior 1, indicating that the more informative Prior 2 generally results in a lower MSE.
Form
Table 4, the 95% credible intervals and Wald confidence intervals for
and
are presented. As the sample size increases, the CPs tend to approach the nominal coverage probability of 0.95, while the ALs decrease. Typically, CPs are generally above 0.95, despite the small sample size of 15. Moreover, the Prior 2 tends to have the smallest ALs with the same sample size.
Figure 6 graphically summarizes the average of estimates, MSEs, CPs, and ALs for a selected case of GZTP. In the first row, which shows estimates of
α and
β, there are two line graphs, one for each parameter. These results display the average estimates obtained through MLE and two Bayesian methods with different priors (Prior 1 and Prior 2). Prior 2 yields the most accuracy, followed by Prior 1 and MLE. However, as the sample size increases, the estimates from all methods converge, suggesting that larger sample sizes lead to more accurate estimations. From the second row, the bar charts show that the precision of the estimation methods improves with larger samples. Bayesian estimates, particularly those with Prior 2, tend to have lower MSEs than MLEs. In the third row, the CPs from Prior 2 tend to be higher than the others, especially in the small sample size. As the sample size increases, all the methods tend to produce about the same CP. From the last row, the ALs generally decrease as the sample size increases, showing that the intervals become narrower and, thus, more precise with larger samples. The Bayesian estimates with Prior 2 consistently show the shortest ALs across all sample sizes for both parameters.
From simulated CGZTP datasets where the values of
and
are unknown, the conclusions are consistent with those from GZTP. The detailed results are summarized in
Appendix A,
Table A1 and
Table A2 which provide the average Bayesian estimates, MSEs, CPs, and ALs of parameters. As sample sizes increase, estimates become more accurate, and the MSE values decrease. It is observed that, while holding
constant, the MSEs of
and
increase as
increases. Likewise, as
increases, the MSEs of
and Bayes estimate
increase when
remains constant. Applying Prior 2 results in the lowest MSE values for
and
.
Figure 7 graphically summarizes the averages of estimates, MSEs, CPs, and ALs for
and
of the two-parameter CGZTP distribution with
, and
of CGZTP.
For parameter λ of the GZTP distribution, the MSE values decrease as sample sizes increase, as shown in
Figure 8. Both the MLE and the Jeffreys prior estimates result in poor estimations with large MSEs. As expected, the performance of these methods improves as the sample size increases. However, Prior 2 yields the lowest MSE, even with a sample size as small as 15. In all situations, the CPs either approach the desired coverage probability or exceed 0.95, and the ALs decrease as sample sizes increase. For additional scenarios,
Table A3 and
Table A4 in
Appendix A provide a summary of all estimates, MSEs, CPs, and ALs. Similarly, the findings for
λ of the CGZTP distribution are in line with those for the GZTP distribution. The MSEs of Bayesian estimates under informative priors are lower than those for the MLE and the Jeffreys prior. The CPs of credible intervals from informative priors tend to be higher than those from Wald intervals and the credible interval from the Jeffreys prior.
Figure 9 presents estimates, MSEs, CPs, and ALs for three methods in a specific case, while results for other scenarios are compiled in
Table A5 and
Table A6.
.
6. Conclusions and Discussion
Both point and interval estimation have been studied within Bayesian frameworks. For point estimation, informative gamma priors with both low and high variance, as well as Jeffreys prior, are employed, and the results are compared with those obtained from MLE in terms of MSEs. Since the posterior distributions for GZTP and CGZTP do not have closed forms, the RWM algorithm is utilized to generate posterior samples. Furthermore, the Bayesian credible intervals are compared to Wald’s intervals in terms of coverage probability and average length.
Bayesian estimates using informative priors are obviously superior to the MLE and Bayesian estimates with Jeffreys priors in terms of MSEs. Among the informative priors having the mean equal to the true parameter, the one with a low variance yields a slightly lower MSE compared to that with high variance. In detail, when is fixed, the MSEs of and Bayes estimate increase as increases. Similarly, the MSEs of and Bayesian estimate increase as increases given that is fixed. In the case of an unknown λ, where the Jeffreys prior can be mathematically derived, the corresponding Bayesian estimates are slightly better than the MLE. However, as the sample size increases, the discrepancy among the MSEs obtained from all methods tends to decrease.
For interval estimation, the Bayesian credible intervals tend to be more conservative, with coverage probabilities exceeding the nominal level of 0.95, particularly for small sample sizes. The ALs of the credible intervals are notably shorter than those of the Wald confidence intervals. It is worth noting that credible intervals can achieve greater coverage with shorter interval lengths because Priors 1 and 2 were deliberately chosen so that the expected value of the prior equals the true parameter value. These informative priors have a substantial impact, often outweighing the data in their influence on the posterior. As the sample size increases, the influence of the data begins to outweigh that of the prior. In such cases, the lengths of the credible intervals tend to converge towards those of the frequentist confidence intervals, such as Wald’s intervals, and the high coverage probabilities adjust closer to the expected levels under the true confidence level.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}