1. Introduction
Modern computer graphics applications require an extensive range of 3D models and textures to populate virtual environments. First of all, we see an increasing demand for realistic virtual content in the growing game and movie industries. The popularity of virtual and augmented reality also enforces this demand. Manual creation of all models requires much time and resources. A significant part of virtual content is created from real-life objects via 3D reconstruction, which remains one of the most important tasks at the intersection of computer vision and graphics. In recent years, we have also seen increased interest in procedural model generation and representation. Sophisticated procedural generation tools are being implemented in game engines. The procedural approach also has other advantages:
Procedural models are editable, semantically meaningful, and often can be animated;
A mesh obtained from such models has high-quality triangulation;
Procedural models are memory-saving compared to other 3D representations.
Despite the known advantages of procedural models, their creation remains a predominantly manual process. Reconstruction of objects using procedural models can speed up their creation, simplify subsequent modification of models, and bring other advantages of the procedural approach to the field of 3D reconstruction. This is why a 3D reconstruction method that creates procedural geometry is badly needed. However, the intersection of these two groups of methods (3D reconstruction and procedural generation) remains relatively unexplored.
Typically, a combination of different approaches is employed, when generated or reconstructed models are further refined by artists. This is especially common in video games, as each model in the game is not only a 3D mesh with a set of textures, but also a more complex object with various levels of detail, animation, physics, etc. 3D reconstruction is a fundamental task in computer vision and numerous methodologies have been proposed over the past decades. To achieve high-quality 3D geometric reconstruction, scanners or LIDARs are the most optimal solution, provided the necessary equipment is available. Image-based approaches are much easier to use and will be the topic of this paper. In recent years, deep learning methods, such as NeRF [
1], have made remarkable progress in solving the new problem of view synthesis. Although NeRF and its successors are good at capturing details, they require a significant amount of time and many input images. Other deep learning methods, such as [
2,
3], focus on 3D reconstruction from a single image, but their results are unlikely to be applicable due to low quality. Additionally, it should be noted that deep learning methods rely on an implicit representation of the model in neural network weights, and extracting the actual mesh and textures from it becomes a challenging task [
4,
5].
Differentiable rendering is a promising and rapidly developing approach to 3D reconstruction [
6]. It enables gradient-based optimization of scene parameters, such as vertex positions and textures, to achieve a better match with the input images. One application of differentiable rendering is the reconstruction of complex materials’ Bidirectional Reflectance Distribution Functions (BRDFs). Although differentiable rendering can be used with implicit representations such as signed distance functions (SDF) [
7], most approaches use a classical mesh-textures representation, which is more user-friendly than deep learning methods.
Despite the progress made in the field of image-based 3D reconstruction in recent years, there are still significant obstacles preventing the wider adoption of these methods in practical applications. First, performing high-quality reconstruction requires a significant number of images ([
6] uses 100 images to achieve high quality). Single-view reconstruction methods are barely applicable, while others often require dozens of images of different views. Second, even the best approaches struggle to reconstruct complex objects with many thin parts, such as trees and other vegetation. The key point is that an exact reconstruction of every small branch and leaf is not necessary; rather, the model should be sufficiently detailed and visually similar to the given reference. The third and, perhaps, the most significant problem of reconstruction is the difficulty of editing the resulting models. Typically, these methods create one large triangular mesh that lacks information about the structure of the object, such as which branch a particular triangle belongs to in the tree model. Artifacts in the resulting model are also a serious problem, often requiring regularization or post-processing techniques to reduce them.
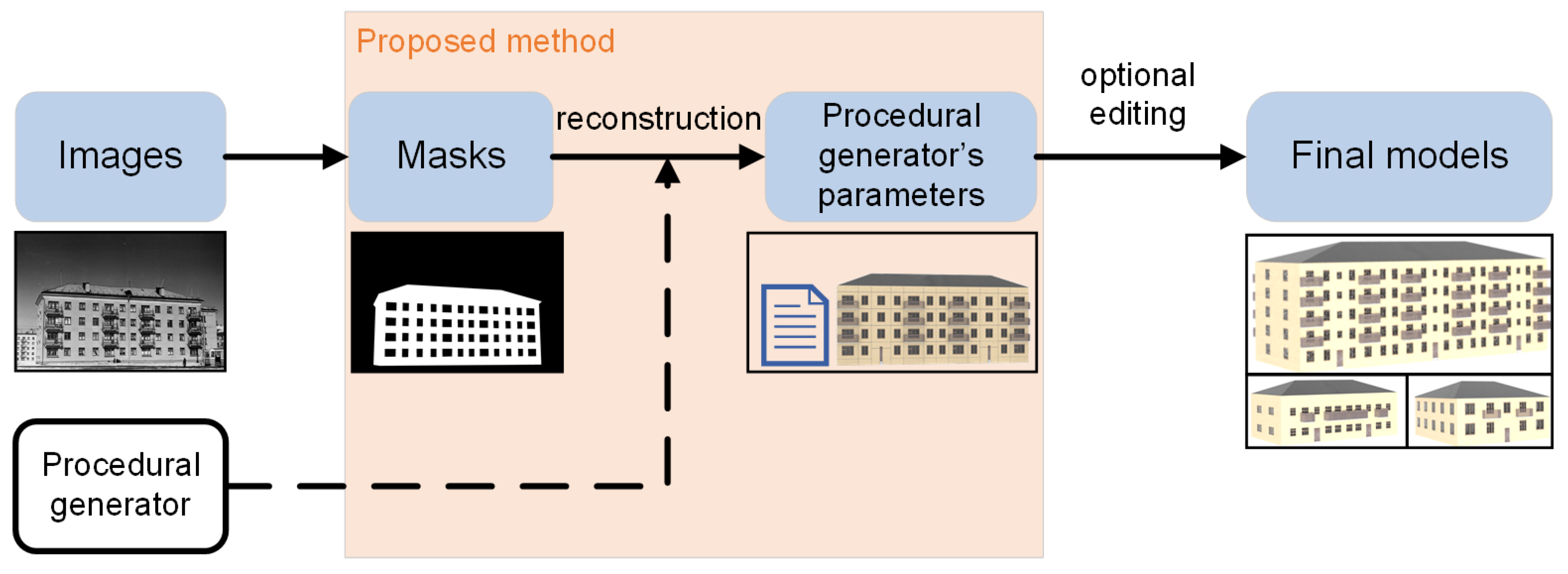
Most image-based reconstruction methods do not take into account an important aspect of applications and human perception: the structure of an object. Modification is often required to use the reconstructed model, and lack of structural information makes any modifications much more difficult. Procedural generation is an alternative method for obtaining 3D models, consisting of rules that establish a correlation between input parameters and 3D objects of a certain class. In this paper, we propose a novel approach that utilizes procedural generation for single-view and multi-view reconstruction of triangular meshes. Instead of directly estimating the position of mesh vertices, we estimate the input parameters of the procedural generator through a silhouette loss function between the reference and rendered images, using differentiable rendering and creating partially differentiable procedural generators for gradient-based optimization. Our approach also allows us to conveniently modify/edit the model by changing the estimated input parameters, such as creating new levels of detail, altering the geometry and textures of individual mesh parts, and more. In summary, the contributions of this work are outlined as follows:
An algorithm for single-view 3D reconstruction using procedural modeling is proposed. Unlike many other methods, it produces an editable 3D procedural model that can be easily converted in high-quality mesh grids and arbitrary levels of details.
To obtain an editable 3D procedural model as a reconstruction result, two procedural modeling approaches were studied: non-differentiable and differentiable. The first approach is easier to implement for a wider range of tasks, while the second can be used to obtain more precise reconstruction.
Our model outperforms modern single-view reconstruction methods and shows results comparable to state-of-the-art approaches for multi-view reconstruction (it demonstrates IoU metrics more than 0.9 for most models with the exception of extremely complex ones).
It should be noted that symmetry is a key property that allows one to reduce the dimension of phase space. Thanks to this property, high-quality optimization of an object is possible using just one image. For real-life objects that do not have symmetry our method also works, but it performs only an approximate reconstruction. However, even in this case the resulting 3D object does not have artifacts typical of most other reconstruction methods.
This work generalizes and extends the results presented at the conferences [
8,
9]. The novelty of this work is that we propose a general approach for both differentiable and non-differentiable procedural generators as well as an intermediate case when only several parameters of procedural generator are differentiable (for example, the case of buildings). In addition to the conference papers, we performed an extensive comparison and showed the benefits of the proposed approach on different types of procedural generators and 3D models. Finally, we showed that for inverse procedural modeling, it is enough to apply differentiable rendering to a silhouette image only. This, in algorithmic terms, significantly reduces computational complexity and allows us to use simpler and lighter-weight approaches to differentiable rendering (
Section 4.4).
The remainder of this paper is organized as follows.
Section 2 describes other reconstruction methods and related studies, including inverse procedural modeling, which we consider to be closest to the topic of this research. The proposed method is introduced in
Section 3.
Section 4 discusses the implementation and demonstrates the results of the proposed approach. Finally,
Section 5 outlines the discussions and conclusions.
4. Results
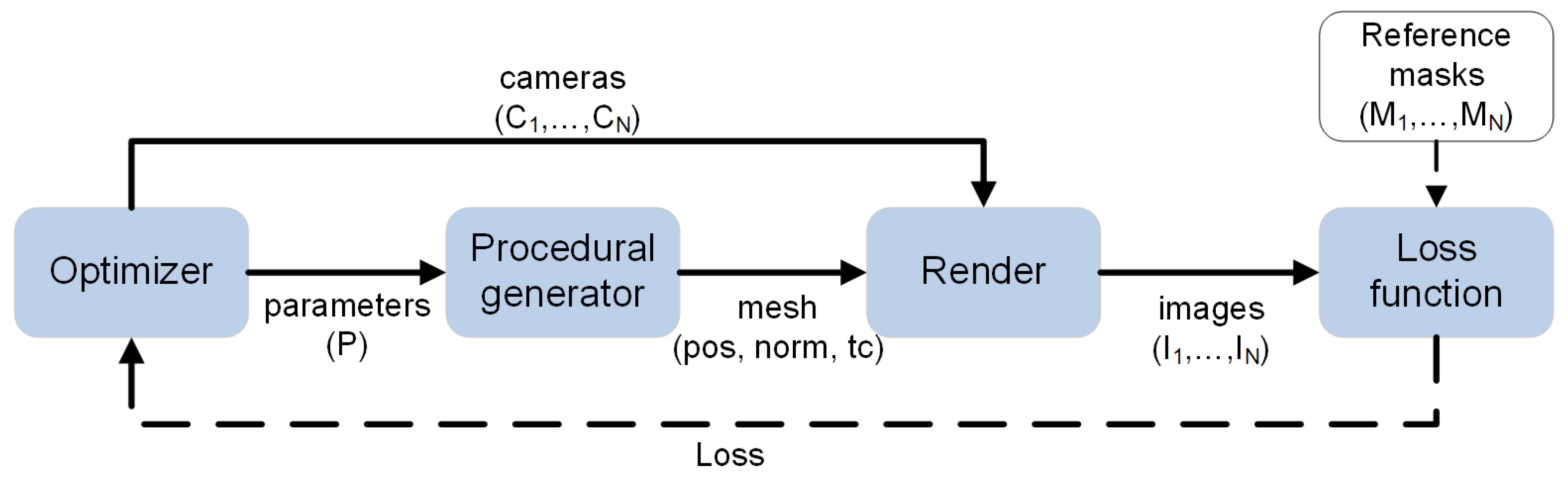
We implemented our method as a standalone program written mostly in C++. Differentiable procedural generators were written from scratch and the CppAD library [
61] was used for automatic differentiation inside the generators. We also implemented a differentiable renderer for fast rendering of silhouettes during optimization. We used our own differentiable renderer to reconstruct the models shown here, and Mitsuba 3 [
60] was only used for forward rendering of final images.
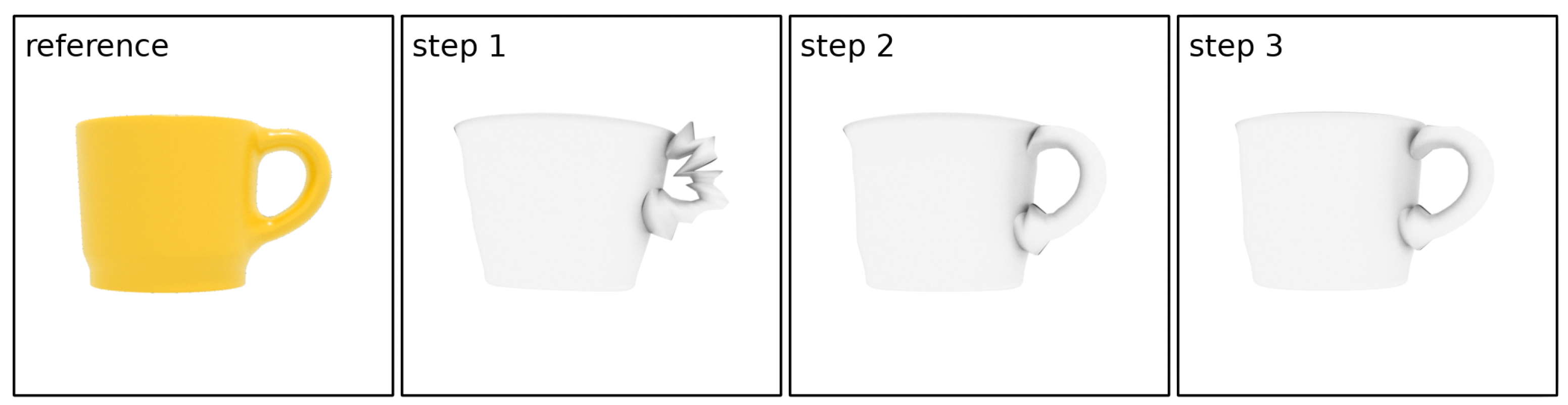
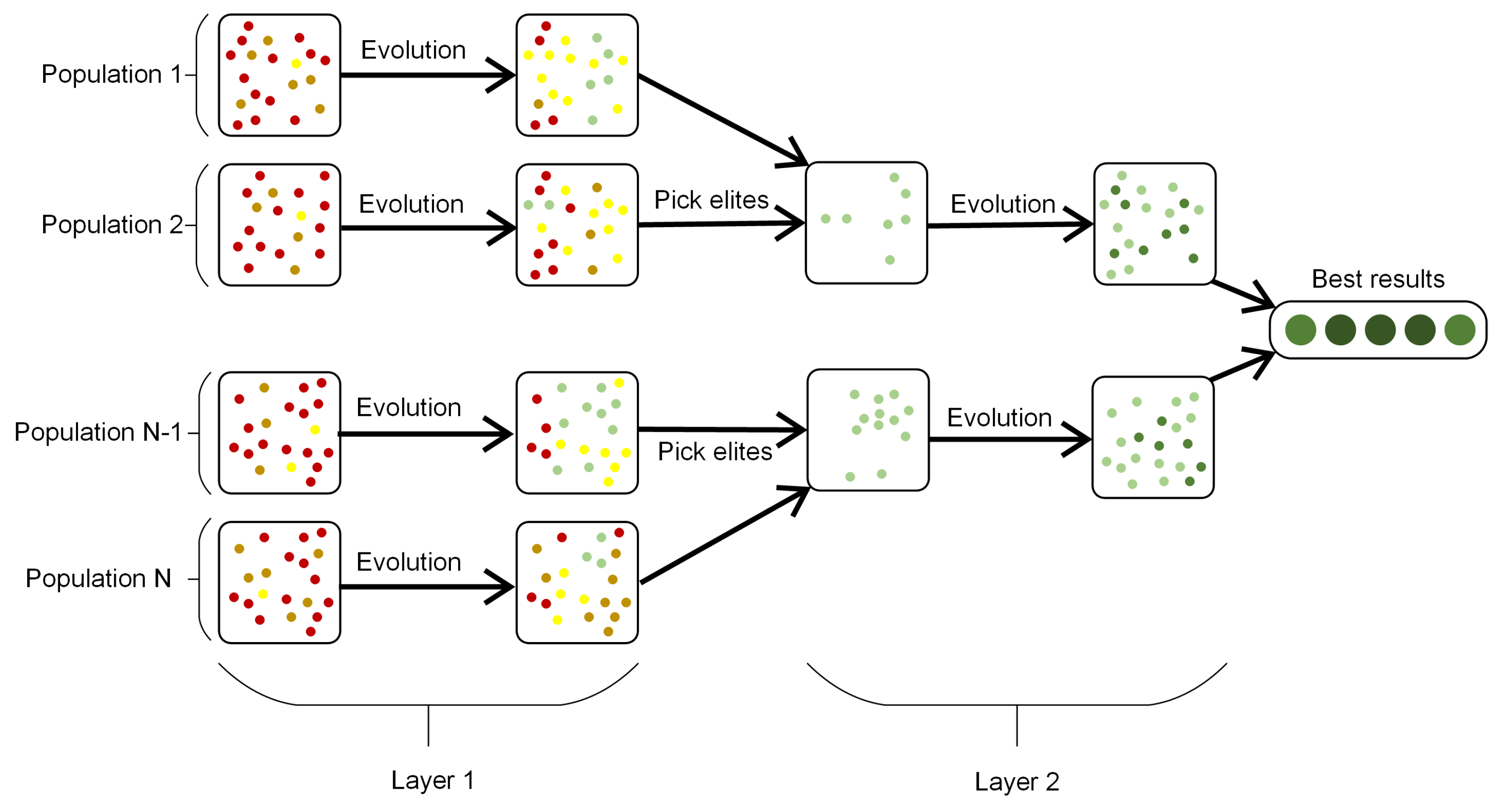
Our method requires defining a set of hyperparameters, such as the number of rendering stages, the size of rendering image, the number of iterations for each stage, and the parameters of genetic or memetic algorithm. We used basically the same set of hyperparameters for all of our results. For reconstruction with differentiable generators, we set the number of optimization stages to 3 or 4 with a rendering resolution 128 × 128 for the first stage and doubled it in each subsequent stage. The memetic algorithm is used only in the first stage with a limit of 5000 iterations; in subsequent stages the Adam optimizer is used with 200–300 iterations per stage. For reconstruction with non-differentiable tree generators, we used only one stage with a rendering resolution of 256 × 256 and a limit of 50 thousand iterations for the genetic algorithm. The whole optimization process takes about 10–20 min with the differentiable procedural generator and up to 30 min with the non-differentiable one. These timings were measured on a PC with AMD Ryzen 7 3700X and NVIDIA RTX 3070 GPU. In general, the implemented algorithm does not place high demands on used hardware. In the experiments described in this section, the program took up no more than 2 gigabytes of RAM and several hundred megabytes of video memory. Our implementation of the algorithm can work on any relatively modern PC or laptop with a GPU.
4.1. Single-View Reconstruction Results
Figure 9 shows the results of single-view reconstruction for different types of objects using the corresponding procedural generators. For building reconstruction, we provided window masks that were created manually, while all other masks were generated automatically. As expected, all presented models are free of usual reconstruction artifacts, are detailed, and have adequate texture coordinates, allowing textures to be applied to them. Reconstruction of the cups and building with differentiable generators results in models very close to the reference ones. The main quality limitation here is the generator itself. The quality of reconstruction with the non-differentiable tree generator is lower because the genetic algorithm struggles to precisely find the local minimum. However, the overall shape of the tree is preserved and the model itself is quite good.
Table 1 shows the time required for reconstruction of different models.
4.2. Comparison with Other Approaches
We compared the results of our work with various state-of-the-art image-based 3D reconstruction approaches to demonstrate that our method avoids the problems common to all these algorithms. Four algorithms were used for comparison: InstantNGP, DiffSDF, Pixel2Mesh, and Triplane Gaussian Splatting (TGS). InstantNGP [
38] is a modern approach to multi-view reconstruction from NVidia based on the idea of neural radiance fields. It provides the same reconstruction quality as the original NeRF [
1], but is an order of magnitude faster. However, it still requires dozens of input images and provides models with various visual artifacts, mainly arising from the transformation of the radiance field into a mesh. DiffSDF [
30] is a method that represents a scene as a signed distance field (SDF) and utilizes differentiable rendering to optimize it. It requires fewer input images than NeRF-based approaches and achieves better results for opaque models due to better surface representation. In [
30], SDF values are stored in a spatial grid with relatively small resolution. This limits the method’s ability to reconstruct fine details. Pixel2Mesh [
12] is a deep neural network capable of creating a 3D mesh from a single image, that does not require training a separate model for every class of objects. TGS [
22] is today’s most advanced and powerful approach to single-view 3D reconstruction that highly relies on generative models, such as transformers. It achieves better quality and works faster than previous methods. However, it represents the reconstructed model as a set of 3D Gaussians that cannot be used directly in most applications.
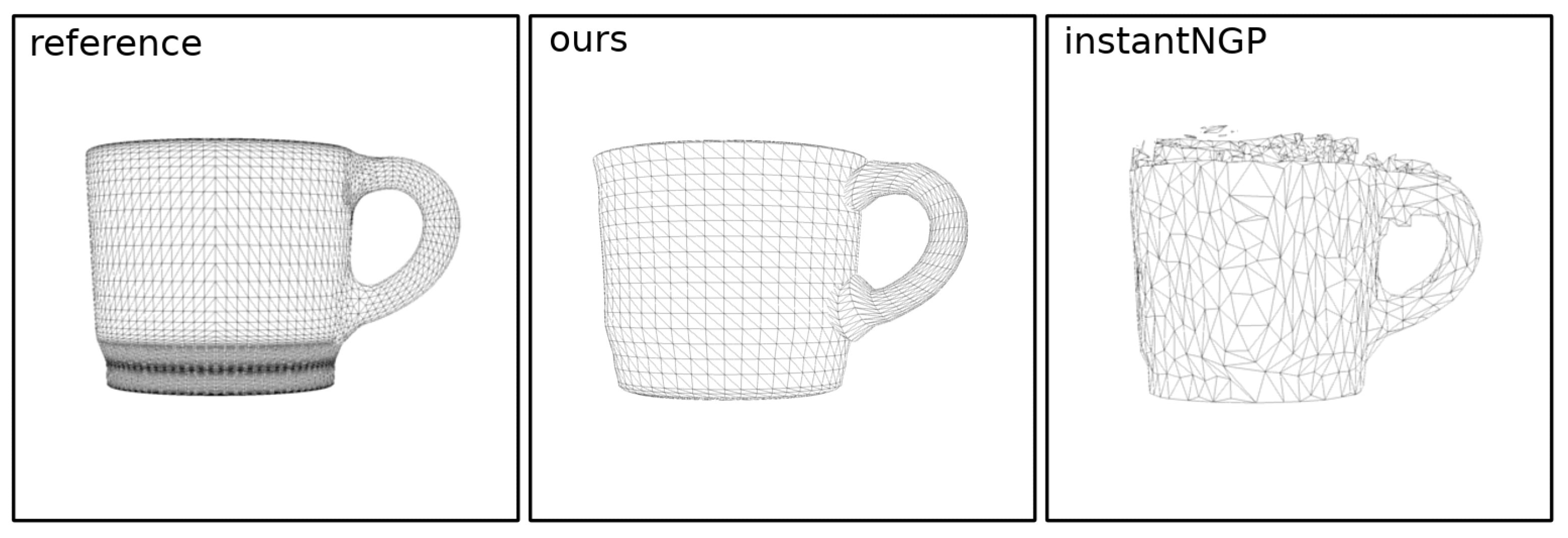
Figure 10 demonstrates the results of different algorithms on a relatively simple cup model. It shows that Pixel2Mesh failed to reconstruct the shape of the model from a single image, while methods that use multiple images achieved results comparable to ours. However, they both struggled to represent the concave shape of the model and produced meshes with significant artifacts. In
Figure 11, some of the reconstructed meshes are visualized in wireframe mode. The diffSDF algorithm achieved a slightly better IoU value but took significantly more time. It also created a model with a rough surface, which will require refinement before use. The result of TGS is the closest to ours in terms of both IoU and required input data. However, the result of this method is a set of Gaussians, not a 3D mesh. The authors did not consider the problem of converting them into a mesh in [
22] but, by analogy with NeRF-based methods, it can be assumed that such a conversion will reduce the quality of the result. The Gaussian representation makes it much more difficult to use or modify the resulting model because it is not supported by 3D modeling tools and rendering engines.
For more complex objects, such as trees and buildings, the ability to reconstruct the object’s structure becomes even more important. For most applications, such as, for example, video games, the reconstructed meshes need to be modified and augmented with some specific data. This becomes much easier if the initial mesh contains some structural information. In this particular case, it is necessary to distinguish between triangles related to different parts of a building or to leaves/branches of a tree in order to be able to meaningfully modify these models.
Figure 12 shows the results of reconstruction of buildings and trees using different approaches.
We also tested our approach on more models from the given classes and compared it with differentiable SDF reconstruction [
30], InstantNGP [
38], Pixel2Mesh [
12], and TGS [
22] algorithms. The diffSDF was tested with 2, 6, and 12 input images, and InstantNGP with 16 and 64 input images. The results of the comparison on the studied models are presented in
Table 2. Although our method performs worse on average than the multi-view reconstruction algorithms diffSDF and InstantNGP in terms of the IoU metric, it is able to produce better models even if it fails to achieve high similarity to the reference images. This can be demonstrated using the tree models; the last two columns of the table and the bottom row in
Figure 12 correspond to them. The IoU values for our approach are less than those for the diffSDF algorithm, and diffSDF produced a tree model that was closer in overall shape to the original, but failed to reconstruct the expected structure of the tree. So, our model is more suitable for many applications, especially considering that procedural models are easier to refine. Moreover, diffSDF does not create a triangle mesh but rather a 3D grid with values of reconstructed signed distance function. This representation of the scene imposes serious limitations, for example, it cannot be used with 2D texture maps.
4.3. Multi-View Reconstruction
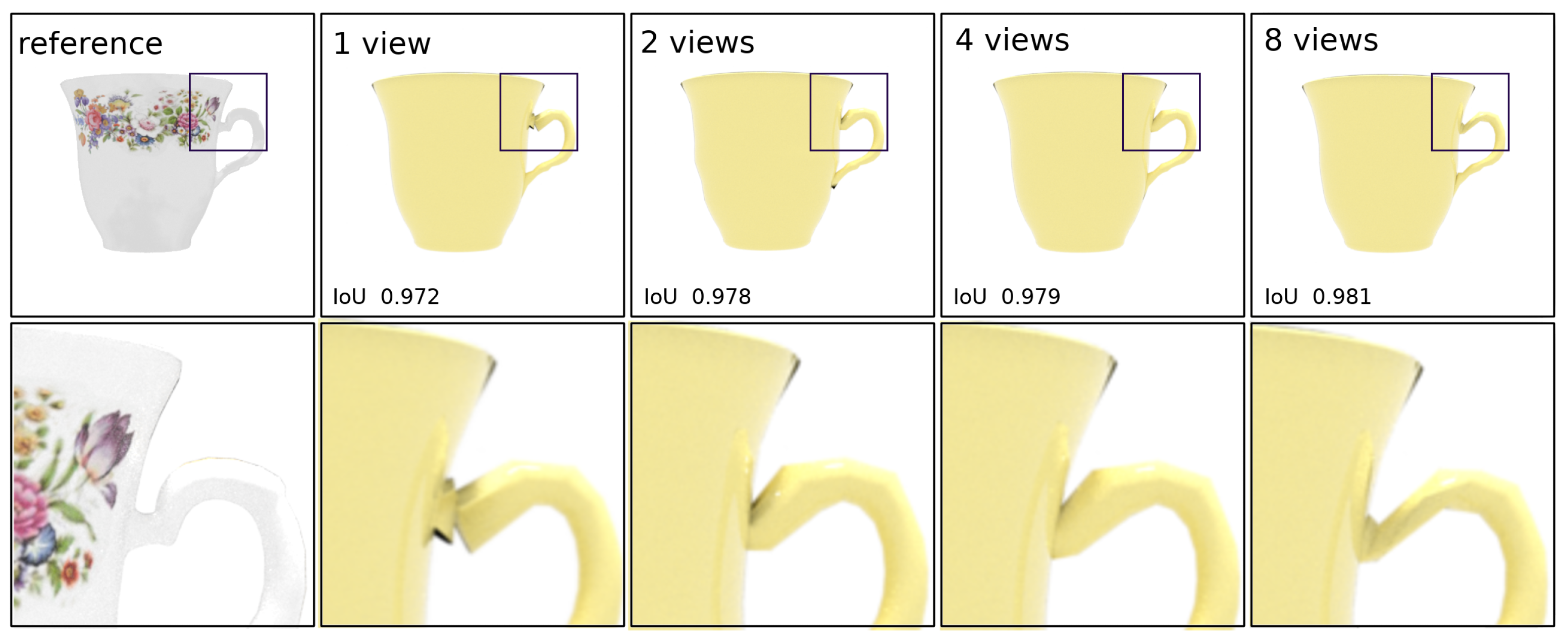
We mainly focused on single-view reconstruction in this work but our approach also supports multi-view reconstruction. However, although we have found that adding a new view does not usually result in a significant increase in quality, it can be useful for more complex objects or texture reconstruction.
Figure 13 shows how increasing the number of views used for reconstruction affects the result for the relatively simple cap model. Although increasing the number of input images has almost no effect on quality, it significantly increases the running time of the algorithm, as shown in the
Table 3.
4.4. Differentiable Renderer
During the reconstruction process, most of the time is spent on differentiable rendering. The rendering is performed in silhouette mode, which means that we only obtain vertex position gradients from edge of the silhouette. This can be performed by Mitsuba 3 [
60], but there is no need to use such a powerful tool for this simple task. Instead, we created our own implementation of a differentiable renderer that uses edge sampling [
68] to calculate the required derivatives.
Figure 14 shows that its use does not reduce the quality of reconstruction, but almost doubles its speed.
Table 4 shows the difference in rendering speed for our renderer and Mitsuba 3.
4.5. Discussion
Our work provides a bridge between two groups of methods: (1) inverse procedural modeling [
44,
45,
46,
47] and (2) approaches based on differential rendering [
6,
23,
24,
25,
26]. Methods of the first group take 3D models as input, while methods of the second group calculate gradients from an input image for some conventional representation of a 3D model (mesh, SDF, etc.). Our approach allows us to directly obtain procedural generator parameters from the image. Unlike conventional meshes and SDF, procedural models are easy to edit and animate because a procedural model by its construction has separate parts with a specific semantic meaning. This allows our method to reconstruct 3D models that can later be modified and used by professional artists in existing software. This also opens up great opportunities for AI-driven 3D modeling tools such as text-to-3D or image-to-3D.
5. Conclusions
In this work, we present a novel approach to 3D reconstruction that estimates the input parameters of a procedural generator to reconstruct the model. In other words, we propose an image-driven approach for procedural modeling. We optimize the parameters of the procedural generator so that the rendering of the resulting 3D model is similar to the reference image or images. We have implemented several differentiable procedural generators and demonstrated that high-quality results can be achieved using them.
We also proposed an alternative version of the same approach that does not rely on the differentiability of the generator and allows it to achieve decent quality using already existing non-differentiable procedural generators. We have implemented an efficient strategy to find the optimal parameter sets for both versions of the proposed approach. For a small number of input images, our methods perform better than existing approaches and produce meshes with fewer artifacts.
Our approach works well with the certain class of objects that the underlying procedural generator can reproduce. The differentiable procedural generators used in this work are created from scratch and are limited in their capabilities. We consider that the main limitation of our method is that it is currently not capable of reconstructing arbitrary models. We also foresee challenges in scaling our approach to more complex procedural models with hundreds or thousands of parameters. Thus, the following topics for future work can be proposed:
Development of a universal procedural generator with more flexible models, capable of representing a wide class of objects;
Creation of a method for automated generation of the procedural generator itself, for example Large Language Models;
Optimization or reconstruction of more complex models through increasing the number of parameters for optimization by an order of magnitude (this is a problem with genetic algorithms).
Overall, in future research we plan to extend our approach to a wider class of objects.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}