
PCCDiff: Point Cloud Completion with Conditional Denoising Diffusion Probabilistic Models

Abstract
1. Introduction
2. Related Work
2.1. Point Cloud Completion
2.2. Diffusion Models for Point Clouds
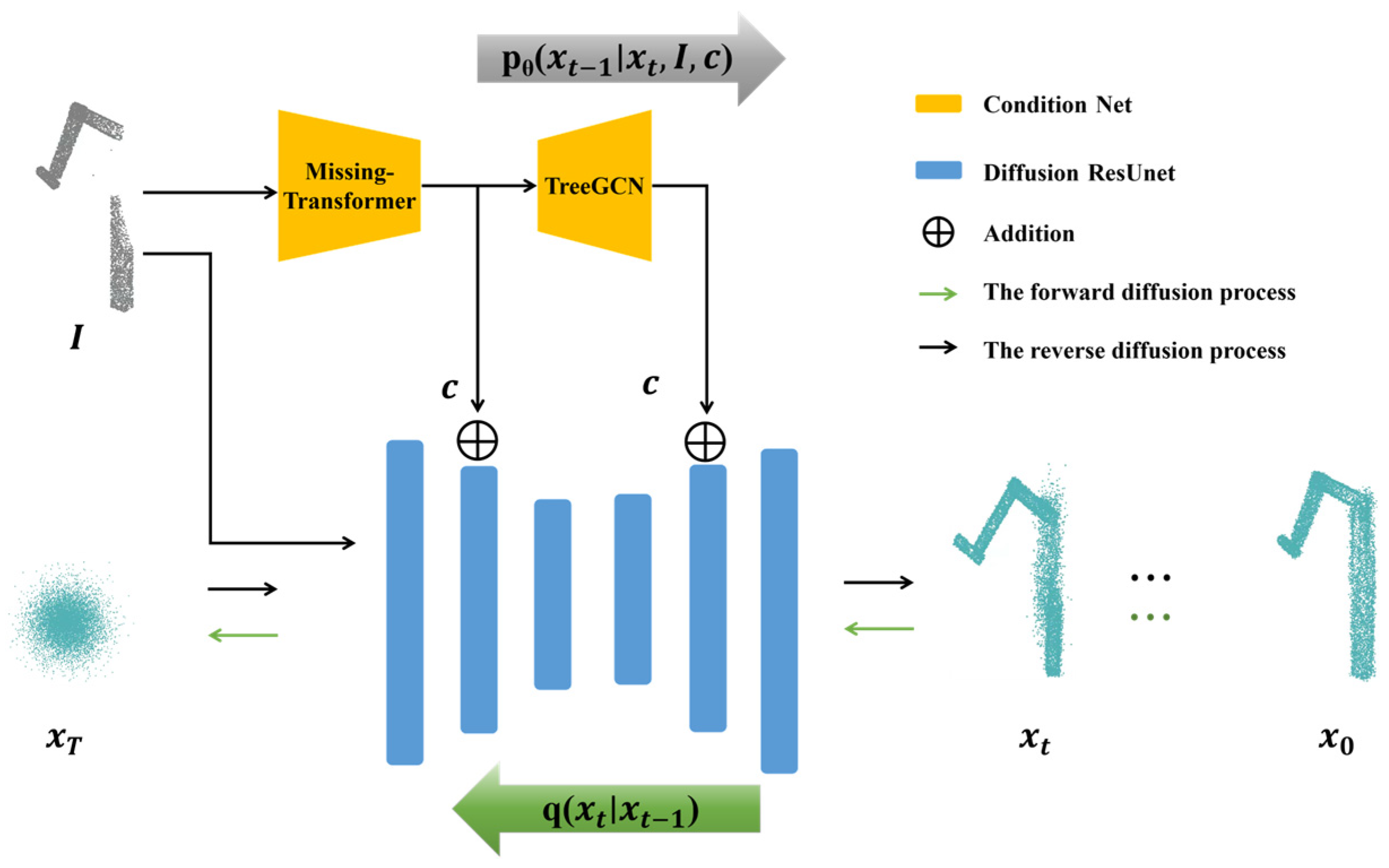
3. Methods
3.1. Point Cloud Completion Conditional Diffusion Models
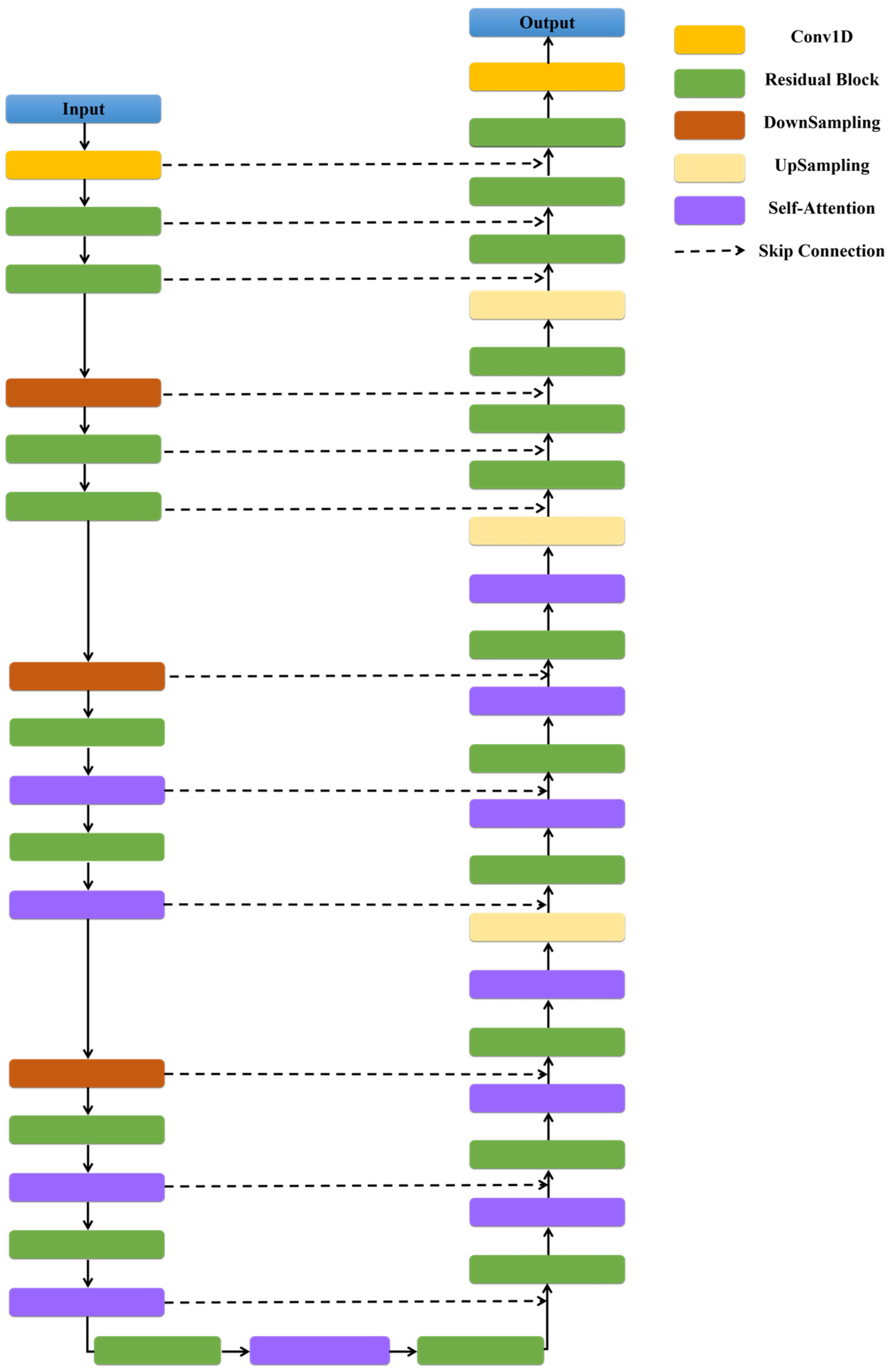
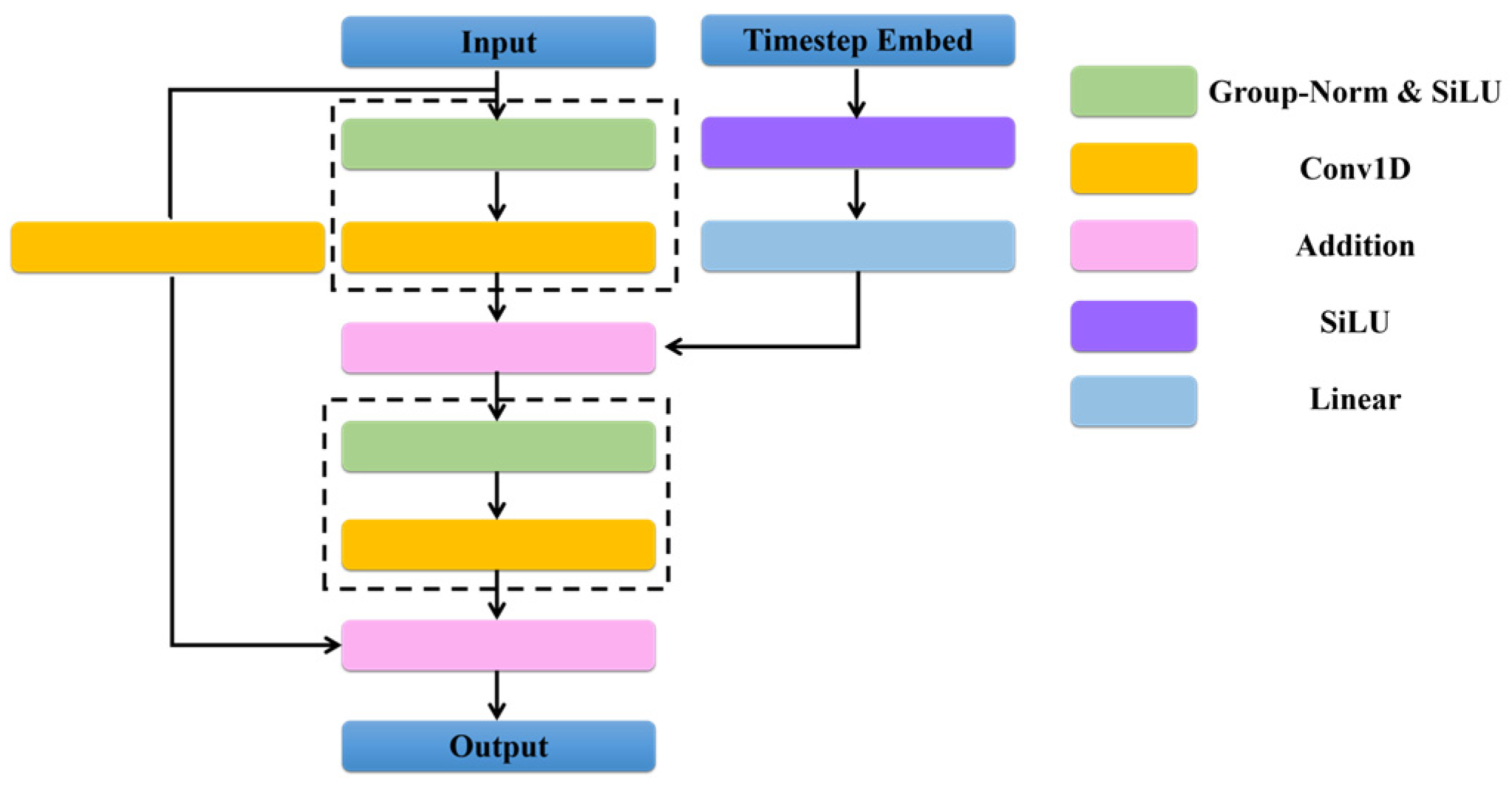
3.2. Diffusion Models
3.3. Conditional Point Cloud Completion Network
3.4. Training Loss
4. Experiments and Results
4.1. Completion Results on ModelNet40
4.2. Completion Results on ShapeNet-34/21
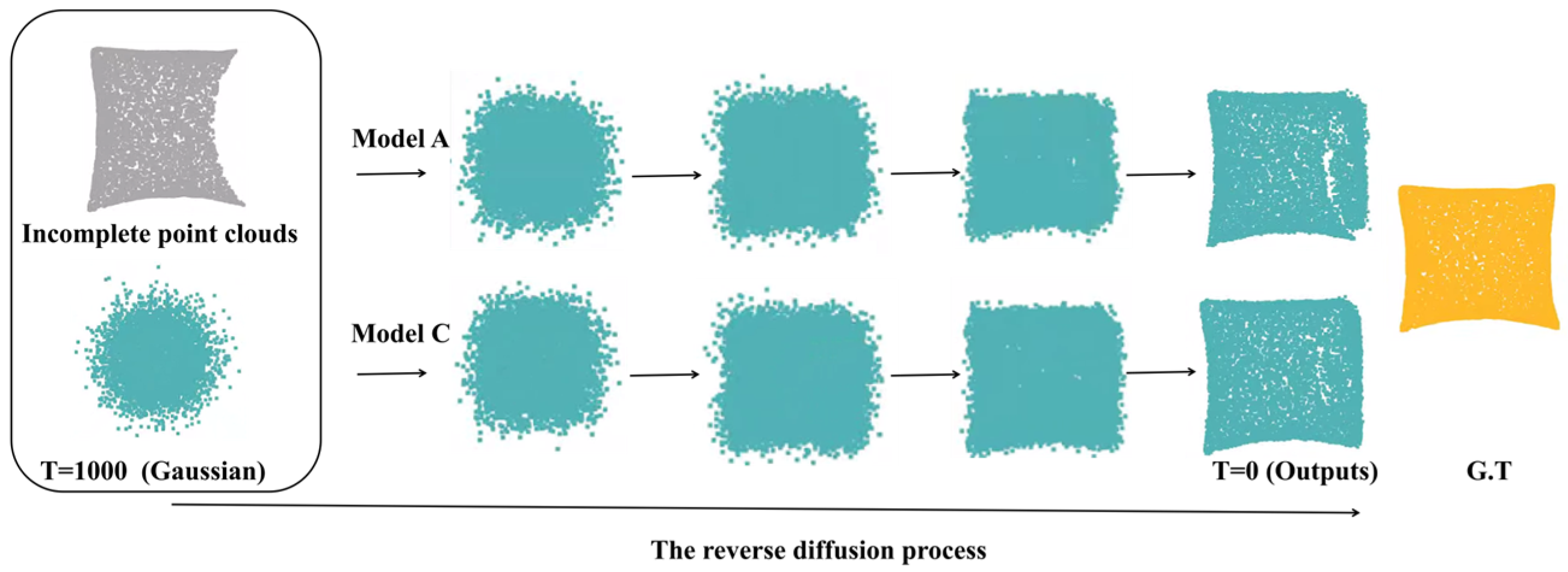
4.3. Ablation Study
4.4. Noise Variance Schedule
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fei, B.; Yang, W.; Chen, W.M.; Li, Z.; Li, Y.; Ma, T.; Ma, L. Comprehensive Review of Deep Learning-Based 3D Point Cloud Completion Processing and Analysis. IEEE Trans. Intell. Transp. Syst. 2022, 23, 22862–22883. [Google Scholar] [CrossRef]
- Zhuang, Z.; Zhi, Z.; Han, T.; Chen, Y.; Chen, J.; Wang, C.; Ma, L. A Survey of Point Cloud Completion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 5691–5711. [Google Scholar] [CrossRef]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. arXiv 2020, arXiv:2006.11239. [Google Scholar]
- Luo, S.; Hu, W. Diffusion Probabilistic Models for 3D Point Cloud Generation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2836–2844. [Google Scholar]
- Xu, X.; Song, D.; Geng, G.; Zhou, M.; Liu, J.; Li, K.; Cao, X. CPDC-MFNet: Conditional point diffusion completion network with Muti-scale Feedback Refine for 3D Terracotta Warriors. Sci. Rep. 2024, 14, 8307. [Google Scholar] [CrossRef] [PubMed]
- Kipf, T.; Welling, M. Variational Graph Auto-Encoders. arXiv 2016, arXiv:1611.07308. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial networks. Commun. ACM 2014, 63, 139–144. [Google Scholar] [CrossRef]
- Niu, A.; Zhang, K.; Pham, T.X.; Sun, J.; Zhu, Y.; Kweon, I.S.; Zhang, Y. CDPMSR: Conditional Diffusion Probabilistic Models for Single Image Super-Resolution. In Proceedings of the 2023 IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Malaysia, 8–11 October 2023; pp. 615–619. [Google Scholar]
- Ren, M.; Delbracio, M.; Talebi, H.; Gerig, G.; Milanfar, P. Multiscale Structure Guided Diffusion for Image Deblurring. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2022; pp. 10687–10699. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2017. [Google Scholar]
- Yuan, W.; Khot, T.; Held, D.; Mertz, C.; Hebert, M. PCN: Point Completion Network. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 728–737. [Google Scholar]
- Yang, Y.; Feng, C.; Shen, Y.; Tian, D. FoldingNet: Interpretable Unsupervised Learning on 3D Point Clouds. arXiv 2017, arXiv:1712.07262. [Google Scholar]
- Xie, H.; Yao, H.; Zhou, S.; Mao, J.; Zhang, S.; Sun, W. GRNet: Gridding Residual Network for Dense Point Cloud Completion. arXiv 2020, arXiv:2006.03761. [Google Scholar]
- Yu, X.; Rao, Y.; Wang, Z.; Liu, Z.; Lu, J.; Zhou, J. PoinTr: Diverse Point Cloud Completion with Geometry-Aware Transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 12478–12487. [Google Scholar]
- Yu, X.; Rao, Y.; Wang, Z.; Lu, J.; Zhou, J. AdaPoinTr: Diverse Point Cloud Completion with Adaptive Geometry-Aware Transformers. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 14114–14130. [Google Scholar] [CrossRef]
- Nichol, A.; Jun, H.; Dhariwal, P.; Mishkin, P.; Chen, M. Point-E: A System for Generating 3D Point Clouds from Complex Prompts. arXiv 2022, arXiv:2212.08751. [Google Scholar]
- Melas-Kyriazi, L.; Rupprecht, C.; Vedaldi, A. PC2: Projection-Conditioned Point Cloud Diffusion for Single-Image 3D Reconstruction. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 12923–12932. [Google Scholar]
- Lyu, Z.; Kong, Z.; Xu, X.; Pan, L.; Lin, D. A Conditional Point Diffusion-Refinement Paradigm for 3D Point Cloud Completion. arXiv 2021, arXiv:2112.03530. [Google Scholar]
- Sohl-Dickstein, J.N.; Weiss, E.A.; Maheswaranathan, N.; Ganguli, S. Deep Unsupervised Learning using Nonequilibrium Thermodynamics. arXiv 2015, arXiv:1503.03585. [Google Scholar]
- Wu, Y.; He, K. Group Normalization. Int. J. Comput. Vis. 2018, 128, 742–755. [Google Scholar] [CrossRef]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-Weighted Linear Units for Neural Network Function Approximation in Reinforcement Learning. Neural Netw. Off. J. Int. Neural Netw. Soc. 2017, 107, 3–11. [Google Scholar] [CrossRef] [PubMed]
- Qi, C.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. Adv. Neural Inf. Process. Syst. 2017, 30, 5105–5114. [Google Scholar]
- Almeida, L.B. Multilayer perceptrons. In Handbook of Neural Computation; CRC Press: Boca Raton, FL, USA, 2020; pp. C1.2:1–C1.2:30. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Trans. Graph. (TOG) 2018, 38, 1–12. [Google Scholar] [CrossRef]
- Singh, P.; Sadekar, K.; Raman, S. TreeGCN-ED: Encoding point cloud using a tree-structured graph network. arXiv 2021, arXiv:2110.03170. [Google Scholar]
- Fan, H.; Su, H.; Guibas, L.J. A point set generation network for 3d object reconstruction from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Loshchilov, I.; Hutter, F. Fixing Weight Decay Regularization in Adam. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Tchapmi, L.P.; Kosaraju, V.; Rezatofighi, H.; Reid, I.D.; Savarese, S. TopNet: Structural Point Cloud Decoder. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 383–392. [Google Scholar]
- Wen, X.; Xiang, P.; Han, Z.; Cao, Y.P.; Wan, P.; Zheng, W.; Liu, Y.S. PMP-Net: Point Cloud Completion by Learning Multi-step Point Moving Paths. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2020; pp. 7439–7448. [Google Scholar]
- Wen, X.; Xiang, P.; Cao, Y.; Wan, P.; Zheng, W.; Liu, Y.-S. PMP-Net++: Point Cloud Completion by Transformer-Enhanced Multi-Step Point Moving Paths. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 852–867. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Desk | Bench | Radio | Chair | Tent | Door | Person | Bathtub | Average |
|---|---|---|---|---|---|---|---|---|---|
| FoldingNet | 3.442 | 1.947 | 2.165 | 2.500 | 2.772 | 0.965 | 2.825 | 2.241 | 2.474 |
| PCN | 3.146 | 1.916 | 1.794 | 1.895 | 2.806 | 0.715 | 3.228 | 1.947 | 2.543 |
| TopNet | 2.626 | 1.640 | 2.141 | 1.714 | 2.435 | 0.825 | 2.362 | 1.876 | 2.112 |
| PMP-Net | 0.792 | 0.514 | 0.942 | 0.517 | 0.903 | 0.376 | 0.623 | 0.808 | 0.762 |
| PMP-Net++ | 0.699 | 0.536 | 0.684 | 0.500 | 0.819 | 0.373 | 1.193 | 0.731 | 0.726 |
| Ours | 0.658 | 0.494 | 0.608 | 0.483 | 0.799 | 0.342 | 0.900 | 0.811 | 0.709 |
| Methods | 34 Seen Categories | 21 Unseen Categories | ||||||
|---|---|---|---|---|---|---|---|---|
| Trash Bin | Bed | Cabinet | Average | Printer | Helmet | Washer | Average | |
| FoldingNet | 1.527 | 2.220 | 1.088 | 1.259 | 2.441 | 3.429 | 1.664 | 1.985 |
| PCN | 1.561 | 2.473 | 1.025 | 1.217 | 2.487 | 4.527 | 1.625 | 2.203 |
| TopNet | 1.413 | 1.879 | 1.020 | 1.089 | 2.141 | 3.317 | 1.494 | 1.774 |
| PMP-Net | 0.782 | 0.735 | 0.553 | 0.520 | 0.900 | 1.361 | 0.854 | 0.964 |
| PMP-Net++ | 0.993 | 0.811 | 0.651 | 0.567 | 0.945 | 1.481 | 0.987 | 0.877 |
| Ours | 0.476 | 0.560 | 0.360 | 0.483 | 0.527 | 0.782 | 0.470 | 0.522 |
| Model | 34 Seen Categories | 21 Unseen Categories | |||||
|---|---|---|---|---|---|---|---|
| Trash Bin | Bed | Average | Helmet | Washer | Average | ||
| A | Without condition network (without Missing-Transformer) | 0.598 | 0.819 | 0.534 | 0.757 | 0.549 | 0.579 |
| B | With condition network (without Missing-Transformer) | 0.572 | 0.607 | 0.514 | 0.772 | 0.525 | 0.547 |
| C (ours) | With condition network (with Missing-Transformer) | 0.476 | 0.560 | 0.483 | 0.782 | 0.470 | 0.522 |
| 34 Seen Categories | 21 Unseen Categories | |
|---|---|---|
| 0.483 | 0.522 | |
| 0.508 | 0.557 | |
| 0.554 | 0.618 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Peng, F.; Dou, F.; Xiao, Y.; Li, Y. PCCDiff: Point Cloud Completion with Conditional Denoising Diffusion Probabilistic Models. Symmetry 2024, 16, 1680. https://doi.org/10.3390/sym16121680
Li Y, Peng F, Dou F, Xiao Y, Li Y. PCCDiff: Point Cloud Completion with Conditional Denoising Diffusion Probabilistic Models. Symmetry. 2024; 16(12):1680. https://doi.org/10.3390/sym16121680
Chicago/Turabian StyleLi, Yang, Fanchen Peng, Feng Dou, Yao Xiao, and Yi Li. 2024. "PCCDiff: Point Cloud Completion with Conditional Denoising Diffusion Probabilistic Models" Symmetry 16, no. 12: 1680. https://doi.org/10.3390/sym16121680
APA StyleLi, Y., Peng, F., Dou, F., Xiao, Y., & Li, Y. (2024). PCCDiff: Point Cloud Completion with Conditional Denoising Diffusion Probabilistic Models. Symmetry, 16(12), 1680. https://doi.org/10.3390/sym16121680