Abstract
The Bayesian approach offers a flexible, interpretable and powerful framework for statistical analysis, making it a valuable tool to help in making optimal decisions under uncertainty. It incorporates prior knowledge or beliefs about the parameters, which can lead to more accurate and informative results. Also, it offers credible intervals as a measure of uncertainty, which are often more interpretable than confidence intervals. Hence, the Bayesian approach is utilized to estimate the parameters, reliability function, hazard rate function and reversed hazard rate function of a new competing risks model. A squared error loss function as a symmetric loss function and a linear exponential loss function as an asymmetric loss function are employed to derive the Bayesian estimators. Credible intervals of the parameters, reliability function, hazard rate function and reversed hazard rate function are obtained. Predicting future observations is important in many fields, from finance and weather forecasting to healthcare and engineering. Thus, two-sample prediction (as a special case of the multi-sample prediction) for future observation is considered. An adaptive Metropolis algorithm is applied to conduct a simulation study to evaluate the performance of the Bayes estimates and predictors. Moreover, two applications of medical and engineering data sets are used to test and validate the theoretical results, ensuring that they are accurate, applicable to real-world scenarios and contribute to the understanding of the world and inform decision-making.
1. Introduction
Competing risks often occur in reliability studies and demographic, medical, biological sciences and engineering applications, where there is more than one cause or mode of failure. These failure modes in some sense compete to cause the failure of the experimental item. So, in statistical literature this is known as competing risks. Also, competing risks happened in series systems, in which their components are arranged in series. The lifetime of each component has a certain distribution with certain parameters. By assuming that the lifetimes of the components of the series system are statistically independent of each other, the lifetime of the series system can be obtained as the minimum of its components lifetimes. Additionally, the competing risks model is also known as a series model, additive model and multi-risk model.
Based on the concept of competing risks, a wide range of lifetime distributions have been introduced in the statistical literature, each contributing to the understanding and modeling of time-to-event data. Key contributions in this area include foundational work by [1] and subsequent developments by [2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20]. More recently, [21] proposed the additive xgamma-Burr XII distribution, introducing further flexibility to the modeling framework by accommodating complex hazard behaviors.
Incorporating competing risks into structural reliability assessments has been further refined by recent methodologies, such as power transformation approaches that improve access to reliability indexes under structural uncertainties (see [22]). Similarly, in seismic fragility analysis, particularly for nuclear power plants, structural parameter uncertainty introduces additional competing risk factors that influence fragility estimation (see [23]).
The additive xgamma-BurrXII (Xg-BXII) distribution was introduced by [21] by considering a series system with two components functioning independently in series. The lifetime of the first component, , has the xgamma (Xg) distribution with parameters , and the lifetime of the second component, , has Burr XII (BXII) distribution with parameters and . Therefore, the lifetime of the system has the Xg-BXII distribution with a vector of parameters . The probability density function (pdf), cumulative distribution function (cdf), reliability function (rf), hazard rate function (hrf) and reversed hazard rate function (rhrf) of the Xg-BXII distribution are expressed, respectively, as follows:
and
where
The importance of this distribution seems to be from its pdf and hrf, which display high flexibility and diversity in shape (see, e.g., [24]). The Xg-BXII distribution hrf has two main shapes, bathtub and modified bathtub, which are very important in reliability analyses. These shapes increase the applicability of this distribution for lifetime data modeling. Moreover, the Xg-BXII distribution has some new additive models as special cases, some of which are well-known models. Ref. [21] derived some main properties of the Xg-BXII distribution and estimated the model parameters, the rf, hrf and rhrf, using the maximum likelihood method. Also, they obtained the asymptotic confidence intervals of the parameters rf, hrf and rhrf. Moreover, they demonstrated the applicability and flexibility of the Xg-BXII distribution over some existing distributions through four applications.
This article focuses on Bayesian estimation of the parameters of the Xg-BXII distribution and its rf, hrf and rhrf due to its advantages. Among these advantages is that it considers the prior information about the unknown parameters represented in the joint prior distribution and the sample information represented in the likelihood function (LF) and combines them in the posterior distribution (see, e.g., [25]). Another advantage of the Bayesian estimation is that it is widely appropriate in the cases of small sample sizes and censored data. On the other hand, the most popular loss functions in Bayesian estimation problems are the squared error (SE) loss function as a symmetric loss function and the linear exponential (LINEX) loss function, which was introduced by [26] and popularized by [27] as an asymmetric loss function. The SE and LINEX loss functions are defined, respectively, as
and
where is an unknown parameter and is its Bayes estimator, is a constant, is a constant that determines the shape of the loss function and .
The prediction of future observations is an important problem in many practical applications, such as agricultural, industrial, demographic, medical, biological and engineering experiments. Therefore, in this article, the problem of predicting a future observation from the Xg-BXII distribution based on one-sample and two-sample prediction approaches is considered.
Many researchers have considered predictions for future observation from different lifetime distributions. Ref. [28] applied Bayesian one-sample and two-sample prediction to predict a future observation using a Type II censored sample from a general class of distributions. Ref. [29] studied one-sample and two-sample Bayesian prediction for future observation from Type II censored samples from the flexible Weibull extension distribution. Ref. [30] discussed the Bayesian prediction for the Nadarajah–Haghighi distribution under progressive Type II censored samples for one-sample and two-sample prediction schemes. Ref. [31] studied the one-sample and two-sample prediction schemes for a future observation from Burr X distribution based on a unified hybrid censoring scheme using likelihood and Bayesian prediction methods. Recently, ref. [32] derived Bayesian prediction intervals for future observations based on unified hybrid censored data from the three-parameter BXII distribution using both one-sample and two-sample prediction techniques. More recently, ref. [33] presented one-sample and two-sample non-Bayesian and Bayesian prediction of future observations from the additive flexible Weibull extension–Lomax distribution based on Type II censored samples. Ref. [34] discussed one-sample and two-sample prediction problems based on observed Type II progressive censored samples and predictive intervals under a Bayesian framework.
The rest of this paper is organized as follows: in Section 2, Bayesian estimation for the unknown parameters rf, hrf and rhrf of the Xg-BXII distribution are derived under the SE and LINEX loss functions. Also, credible intervals (CIs) are obtained. A Bayesian two-sample prediction of future observation from the Xg-BXII distribution is discussed in Section 3. Additionally, in Section 4, a simulation study is presented to illustrate the theoretical results derived for Bayesian estimation and prediction by applying the adaptive Metropolis (AM) algorithm. Moreover, applications are given in Section 5 to show the applicability of the derived estimators and predictors. Finally, a general conclusion is given in Section 6.
2. Bayesian Estimation
In this section, Bayes estimators of the parameters rf, hrf and rhrf of the Xg-BXII distribution under the SE and LINEX loss functions are given. Also, CIs are obtained.
Suppose that is a random sample of size from the Xg-BXII distribution with parameter vector . Then, the LF is given by
where
and
Treating the parameters of the Xg-BXII distribution as unknown random variables, each one is assigned an independent gamma prior distribution, which is defined by the pdf:
where and are the hyperparameters of the parameters for .
Therefore, the joint prior distribution of is given by
where and are the hyperparameters of the joint prior distribution for .
Hence, the joint posterior distribution of can be obtained using and as follows:
Then,
where is the normalized constant defined by
where
The marginal posterior distribution of the parameter can be obtained as
Gamma priors were selected due to their flexibility and their compatibility with the parameters under consideration, which are positive and therefore align well with the support of the gamma distribution. The gamma prior also allows to incorporate prior knowledge about the scale of the parameters in a straightforward manner, using the shape and rate parameters to encode beliefs about their likely values. The gamma distribution enables us to control the degree of informativeness of the prior by adjusting these parameters.
2.1. Point Estimation
This subsection is devoted to derive point Bayes estimators of the parameters rf, hrf and rhrf of the Xg-BXII distribution under two loss functions: the SE and the LINEX loss functions.
- I.
- Bayesian estimation under the squared error loss function
Under the SE loss function, the Bayes estimator of a parameter , denoted by , is an estimator that minimizes the expected loss function, which is known as the posterior risk (PR) and is defined as
(For more details see [35,36]).
The Bayes estimator of that minimizes Equation is given by
Therefore, Bayes estimators of the parameters are the means of their marginal posterior distributions. Hence, based on the marginal posterior distribution in , the Bayes estimators can be obtained as follows:
where , , , and are defined earlier in this section, as is defined in , is the normalized constant defined in , and are given, respectively, in and and and are given in .
Also, the Bayes estimators of the rf, hrf and rhrf can be obtained using and as follows:
where
and
and
where , , , and are defined earlier in this section, as is defined in , is the normalized constant defined in , and are given, respectively, in and , and are given in and and and are given in .
To obtain the Bayes estimates of the parameters, the rf and hrf based on the SE loss function, (20), (21), (24) and (25) can be solved numerically using the AM algorithm with the Markov chain Monte Carlo (MCMC) method of simulation (see [37]).
- II.
- Bayesian estimation under the linear exponential loss function
Under the LINEX loss function, the PR of the Bayes estimator of the parameter , denoted by , is defined as
(For more details, see [26,27,38]).
The Bayes estimator under the LINEX loss function that minimizes (26) is
Therefore, the Bayes estimators of the parameters can be derived using (27) as follows:
where
where , A, , and are defined earlier in this section, as is defined in (6), A is the normalized constant defined in (15), and are given, respectively, in (10) and (11) and and are given in (16).
Furthermore, the Bayes estimators of the rf, hrf and rhrf can be obtained using , (17) and (27) as follows:
where
where
and
where
where , A, , and , and are defined earlier in this section, as is defined in (6), A is the normalized constant defined in (15), and are given, respectively, in (10) and (11), and are given in (22) and (23) and and are given in (16).
The Bayes estimates of the parameters, rf and hrf using the LINEX loss function under Type II censoring can be obtained by solving (28)–(35) and numerically applying the AM algorithm of the MCMC method of simulation through the R programming language.
2.2. Credible Intervals
In this subsection, the CIs of the parameters of the Xg-BXII distribution are derived.
In general, a two-sided, , CIs of are given by
where and are the lower limit (LL) and the upper limit (UL), and is the credible coefficient.
Since the marginal posterior distributions of the parameters are given by Equation (17), then a two-sided CIs of can be given by
and
To obtain the two-sided CIs of , Equations (37) and (38) can be solved numerically by means of the R programming language.
3. Bayesian Prediction
This section is dedicated to obtaining the two-sample Bayes predictor of future observation from the Xg-BXII distribution under the SE and LINEX loss functions.
Suppose that is the observed ordered lifetimes of a sample of size (the informative sample) from the Xg-BXII distribution and is the order statistics of a future sample of size from the Xg-BXII distribution. Assuming that the two samples are independent. This section aims to derive different predictors for the future order statistic , for . The pdf of the order statistic from the future sample is defined by
where
Since
using the binomial expansion of . Hence,
Then, (39) can be rewritten as follows:
where
Substituting (3) and (4) into (40), then the pdf of the order statistic from the future sample is given by
where is defined in (41) and
The Bayes predictors (BPs) of can be derived from the Bayesian predictive density (BPD) of . Using the pdf of , and the joint posterior distribution of , , the BPD of given is defined by
Substituting (14) and (42) into (44), the BPD can be obtained as follows:
where , , and are defined earlier in this section, as is defined in (6), is the normalized constant defined in (15), and are given, respectively, in and , and are given in , is defined in and is given .
3.1. Point Prediction
The BP of under the SE loss function, denoted by , can be derived as follows:
Using the BPD in and substituting it into as given below
The BP of under the LINEX loss function can be derived as follows:
where
Substituting into , the BP under the LINEX loss function can be obtained.
3.2. Interval Prediction
The Bayesian predictive bounds (BPBs), of the future order statistic, , can be obtained using the following probabilities:
and
Substituting the BPD given by into and and solving numerically to obtain the BPBs.
Remarks
- If , the BP under the SE and LINEX loss functions, and , of the first observation in the future sample can be obtained.
- If (when the future sample size is odd), the BP under the SE and LINEX loss functions, and , of the median of the future sample can be obtained.
- If , the BP under the SE and LINEX loss functions, and , of the last observation in the future sample can be obtained.
4. Simulation Study
In this section, a simulation study is conducted to evaluate the performance of Bayes estimates of the parameters rf, hrf and rhrf of the Xg-BXII distribution by applying the AM algorithm introduced by [37] using the R programming language.
The AM algorithm consists of the following steps:
- Step 1:
- Select a vector of starting values for the parameter vector .
- Step 2:
- For each iteration , where , draw a candidate from the proposal distribution . The proposal distribution employed in this algorithm is Gaussian distribution with the mean at the current point and covariance .
For more details see [37].
The covariance may be viewed as a function of variables from having values in uniformly positive definite matrices.
This is solved by setting after an initial period, where is a parameter that depends only on dimension and is a constant that we may choose that is very small compared to the size of . Here, denotes the -dimensional identity matrix. To start, an arbitrary initial covariance is selected , which is strictly positive definite, according to our best prior knowledge (which may be quite poor). An index is selected for the length of an initial period.
The definition of the empirical covariance matrix is determined by points
where and the elements are considered as column vectors. So, one obtains that in definition , for , the covariance satisfies the recursion formula.
This allows one to calculate without too much computational cost since the mean also satisfies an obvious recursion formula.
- Step 3:
- Compute the acceptance rate (AR):
- Step 4:
- Accept as with probability . If is not accepted, then . This can be performed by generating a value from the uniform distribution. If , then ; otherwise, .
- Step 5:
- Repeat Steps 2–4 times, and should be large enough.
- Step 6:
- Use a burn-in period to reduce the effect of initial values; of the generated values are discarded.
Under the AM algorithm, the Bayes estimates and their corresponding PRs of , , under the SE and LINEX loss functions can be obtained, respectively, as
and
where , are generated from the posterior density and is the burn-in period.
The simulation study is conducted by applying the following steps:
- To generate a random sample from the Xg-BXII distribution the following steps are used:
- Specifying the sample size and parameter values
- I.
- ,
- II.
- .
- Using the function of (uniroot) in R programming to get a numerical solution of the quantile function of the Xg-BXII distribution given by:
a random sample with size is obtained. - Bayes estimates are computed by considering independent gamma priors, the mean and variance of the prior distributions displayed in Table 1. Prior I and II are selected in such a manner that the prior means are the same with different variations. Furthermore, Priors III and IV are selected in the same manner.
- Using and . At each time, are generated from the joint posterior distribution given in .
- Calculate Bayes estimates of the parameters based on SE loss function and LINEX loss function for using the AM algorithm discussed above along with their PRs.
- Calculate Bayes estimates of the rf, hrf and rhrf based on SE loss function and LINEX loss function for and at time points using the AM algorithm along with their PRs.
- The 95% CI limits of the parameters , rf, hrf and rhrf under the SE and the LINEX loss functions are computed along with their lengths under SE and LINEX loss functions.
- For the two-sample prediction, the pdf of the order statistic for given values of and the future sample size , where , is used for evaluating the BPD of a future observation, , from the Xg-BXII distribution.
- The BPs are calculated based on the SE and LINEX loss functions given .

Table 1.
Prior mean and variance (in the brackets) of the hyperparameters of the parameters of the Xg-BXII distribution.
Table 1.
Prior mean and variance (in the brackets) of the hyperparameters of the parameters of the Xg-BXII distribution.
| Prior I | Prior II | Prior III | Prior IV | |||||
|---|---|---|---|---|---|---|---|---|
| Mean | Variance | Mean | Variance | Mean | Variance | Mean | Variance | |
| 2 | 0.05 | 2 | 0.03 | 0.5 | 0.05 | 0.5 | 0.03 | |
| 0.5 | 0.05 | 0.5 | 0.03 | 3 | 0.05 | 3 | 0.03 | |
| 0.3 | 0.05 | 0.3 | 0.03 | 1.5 | 0.05 | 1.5 | 0.03 | |
Also, the BPBs along with their lengths are evaluated.
Table 2 and Table 3 display the Bayes estimates and PRs under the SE and LINEX loss functions for of the parameters of the Xg-BXII distribution and the 95% CI limits of the parameters with the lengths based on Prior I, II, III and IV. Table 4, Table 5, Table 6, Table 7, Table 8 and Table 9 show the Bayes estimates and PRs under the SE and LINEX loss functions for of the rf, hrf and rhrf of the Xg-BXII distribution and the 95% CI limits with the lengths and time points based on Prior I, II, III and IV.
Table 2.
Bayes estimates and their PRs under the SE and LINEX loss functions for of the parameters of the Xg-BXII distribution and the 95% credible intervals of the parameters along with their lengths based on Priors I and II.
Table 3.
Bayes estimates and their PRs under the SE and LINEX loss functions for of the parameters of the Xg-BXII distribution and the 95% credible intervals of the parameters along with their lengths based on Priors III and IV.
Table 4.
Bayes estimates and their PRs under the SE and LINEX loss functions for of the rf, hrf and rhrf of the Xg-BXII distribution and the 95% credible intervals along with their lengths based on Priors I and II at .
Table 5.
Bayes estimates and their PRs under the SE and LINEX loss functions for of the rf, hrf and rhrf of the Xg-BXII distribution and the 95% credible intervals along with their lengths based on Priors III and IV at .
Table 6.
Bayes estimates and their PRs under the SE and LINEX loss functions for of the rf, hrf and rhrf of the Xg-BXII distribution and the 95% credible intervals along with their lengths based on Priors I and II at .
Table 7.
Bayes estimates and their PRs under the SE and LINEX loss functions for of the rf, hrf and rhrf of the Xg-BXII distribution and the 95% credible intervals along with their lengths based on Priors III and IV at
Table 8.
Bayes estimates and their PRs under the SE and LINEX loss functions for of the rf, hrf and rhrf of the Xg-BXII distribution and the 95% credible intervals along with their lengths based on Priors I and II at .
Table 9.
Bayes estimates and their PRs under the SE and LINEX loss functions for of the rf, hrf and rhrf of the Xg-BXII distribution and the 95% credible intervals along with their lengths based on Priors III and IV at
The convergence of one of the generated chains that is arbitrarily chosen is presented in Figure 1, Figure 2 and Figure 3, where these figures are the trace plots, autocorrelation plots and the histogram of the simulated parameters and the posterior density of each parameter. The trace plots show the sampling path of the chains over iterations, helping to verify that a stable region has been reached. The autocorrelation plots illustrate the independence between successive samples, indicating how quickly the chain mixes. The histograms and posterior density plots summarize the distribution of each parameter, providing additional evidence of convergence by showing consistent shapes across samples. Together, these visualizations confirm that the chains are well mixed and have converged to the target posterior distribution.
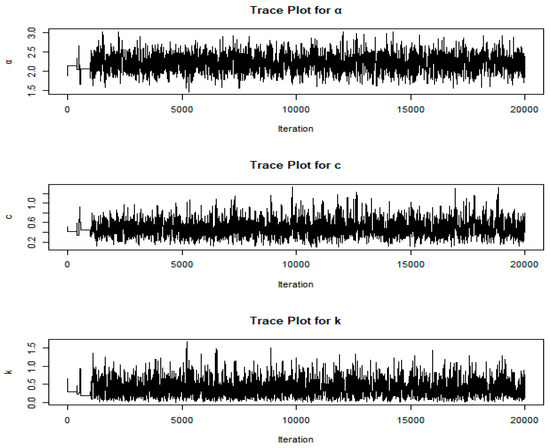
Figure 1.
Trace plots of and
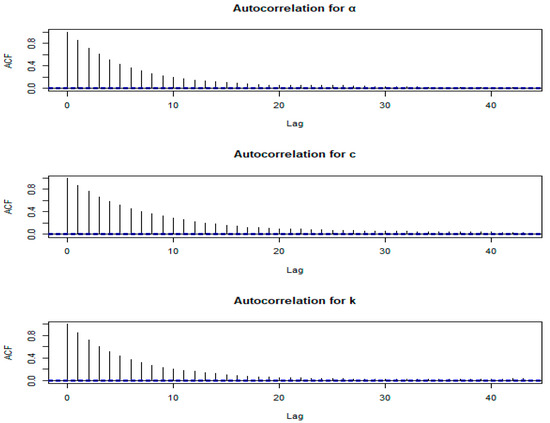
Figure 2.
Autocorrelation plots of and
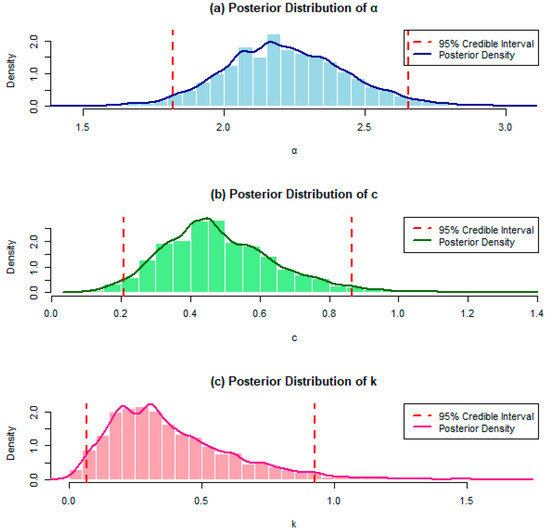
Figure 3.
Histogram, posterior density and the lower and upper limits of the 95% credible intervals of and
Table 10, Table 11, Table 12 and Table 13 present the BPs and BPBs of future observations from the Xg-BXII distribution along with their lengths based on the two-sample prediction scheme and the four priors given in Table 1.
Table 10.
Two-sample Bayes predictor and 95% Bayesian prediction bounds of future observations from the Xg-BXII distribution with their lengths under SE and LINEX loss functions for sample sizes based on prior I.
Table 11.
Two-sample Bayes predictor and 95% Bayesian prediction bounds of future observations from the Xg-BXII distribution with their lengths under SE and LINEX loss functions for sample sizes based on Prior II.
Table 12.
Two-sample Bayes predictor and 95% Bayesian prediction bounds of future observations from the Xg-BXII distribution with their lengths under SE and LINEX loss functions for sample sizes based on Prior III.
Table 13.
Two-sample Bayes predictor and 95% Bayesian prediction bounds of future observations from the Xg-BXII distribution with their lengths under SE and LINEX loss functions for sample sizes n = 30, m = 15 based on Prior IV.
Concluding remarks
- As the sample size n increases, the PRs of the Bayes estimates of the Xg-BXII distribution parameters decrease, supporting the objective of obtaining reliable parameter estimates for the Xg-BXII distribution, where higher sample sizes allow for better parameter stability.
- For all results, the Bayes estimates under LINEX loss function perform better than the Bayes estimates under the SE loss function. Also, the results under the LINEX loss function with is better than their corresponding values when using in terms of having minimum PRs and 95% CI lengths. Moreover, the Bayes estimates under the LINEX loss function with are quite close to their corresponding estimates under the SE loss function; that is, as , Bayes estimates under LINEX loss function are close to the Bayes estimates under the SE loss function. This suggests that the LINEX loss function may be more suitable for applications where asymmetry in risk is critical, such as engineering risk assessments and survival analysis in medical studies.
- For all results, the Bayes estimates based on Prior II and IV (priors have small variances) perform much better than the Bayes estimates based on Prior I and III (with large variances). This aligns with our objective to provide robust Bayes estimates by selecting informative priors that lead to improved estimation precision, a key consideration in medical and engineering applications, where prior knowledge can significantly influence model performance.
- As the sample size increases, the length of the CIs of the parameters of the Xg-BXII distribution decreases and the CIs turn out to be narrower, reflecting greater confidence in the estimated parameter values. Narrower intervals suggest that the estimates are more precise, meaning there is less variability or that they are spread around the estimated values as the data quantity increases. This behavior is desirable, as it shows the model’s estimates become more stable and dependable with larger data sets.
- As increases, the BPs under the SE and LINEX loss functions increase.
- For all prediction intervals, the lower and upper bounds and their lengths increase as increases; that is, the lower and upper bounds and their length of the first order statistic are less than the lower and upper bounds and their length of the last order statistic.
- The BPs under the SE and LINEX loss functions are included between the lower and upper bounds of all prediction intervals.
- In all cases, the lengths of the BPBs under the LINEX loss function are less than the lengths of the BPBs under the SE loss function.
- The BPs under LINEX loss with are quite close to the BPs under the SE loss function. Additionally, the BPs under the LINEX loss function with have the minimum lengths of the BPBs compared to the other BPs.
- The BPs based on Prior II and IV have the minimum lengths of the BPBs compared to the BPs based on Prior I and III.
The results can be summarized as follows:
- The results in Table 10, Table 11, Table 12 and Table 13 show how the BPs change with the order statistic. As increases, the bounds and lengths of the prediction intervals grow, which is particularly relevant for predicting extreme values, such as the time to last failure in engineering or the longest survival time in a medical context. Notably, the BPs under LINEX loss (with ) closely align with those under the SE loss, while offering narrower prediction bounds overall. This result supports the utility of the LINEX loss function for applications that prioritize reduced prediction uncertainty.
- Across all cases, the LINEX loss function outperforms the SE loss function in terms of narrower BPs and CIs, indicating that the LINEX loss function provides more precise prediction. This is especially beneficial in risk-averse applications in engineering and healthcare, where asymmetrical loss can be critical for decision-making.
- The decrease in CIs lengths and narrower CIs as the sample size increases further supports the model’s applicability for large-sample contexts, such as medical and engineering data sets. This finding contributes to our objective of developing a model that can adapt to various sample sizes and produce reliable predictions across different data contexts.
5. Some Applications
This section is devoted to assess the performance of Bayes estimates and predictions through three real-life data sets from engineering and medical applications that have been used by [21] to illustrate the theoretical results in Bayesian inference.
Bayesian estimation and prediction for the Xg-BXII distribution can indeed be applied to both engineering and medical contexts without significant changes to the core functions or estimation approach. However, there may be context-specific differences in the interpretation of parameters and model assumptions: (1) Engineering data often involves precise failure time measurements with potentially lower variability, whereas medical data may have more censoring or variability due to biological factors and patient heterogeneity. (2) The functional form of the hazard rate may vary between contexts based on domain-specific risk factors. For instance, in engineering, hazards often increase over time (e.g., wear-out failures), whereas in medical applications, hazards may be more complex due to age or disease progression. The model can accommodate these differences by selecting context-appropriate baseline hazard functions. (3) When using a Bayesian framework, prior distributions could be adjusted to reflect domain-specific knowledge. For instance, prior information in engineering might be based on historical failure data for specific components, while in medical applications, priors might incorporate clinical or epidemiological data.
5.1. Application 1
This application is given by [2] and represents the time-to-failure data of 18 electronic devices. The data are tabulated in Table 14.
Table 14.
Failure times of Wang’s data.
The applicability of the Xg-BXII distribution to this data set has been assessed using the Kolmogorov–Smirnov () test statistic and its corresponding p-value, which were and p-value = 0.9883. Based on these results, one can say that the Xg-BXII distribution can be used for modeling this data set.
Bayes estimates and their PRs of the parameters rf, hrf and rhrf of the Xg-BXII distribution for the failure times of Wang’s data are tabulated in Table 15 under SE and LINEX loss functions, where the LINEX loss is used at and time points are considered. For Bayesian calculation, these combinations of means and variances and was used in calculating the hyperparameters of the joint prior.
Table 15.
Bayes estimates and their relevant PRs and 95% credible intervals of the parameters rf, hrf, rhrf of the Xg-BXII distribution along with their lengths under SE and LINEX loss functions for and time points for Wang’s data.
Additionally, Figure 4, Figure 5 and Figure 6 exhibit trace, autocorrelation plots and the histogram of the simulated parameters and the posterior density of each parameter for Wang’s data. These figures include a more detailed description of the trace plots to show convergence, the autocorrelation plots to examine parameter independence, and the histograms and posterior density plots to provide insights into the distribution and behavior of the simulated parameters for Wang’s data.
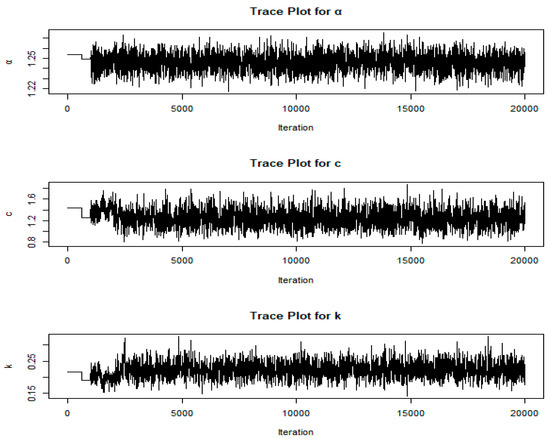
Figure 4.
Trace plots of α, c and k for Wang’s data.
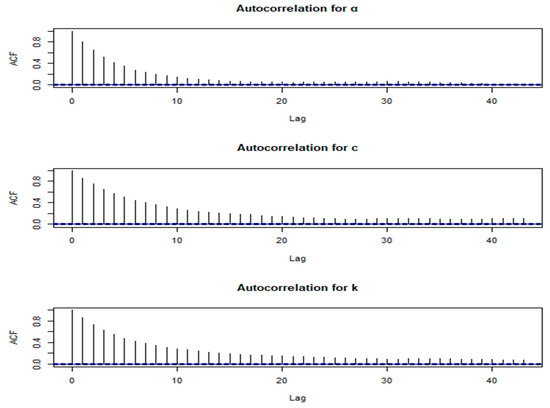
Figure 5.
Autocorrelation plots of α, c and k for Wang’s data.
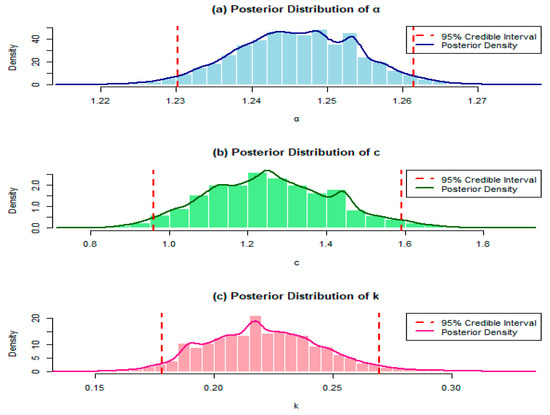
Figure 6.
Histogram, posterior density and the lower and upper limits of the 95% credible intervals of the parameters of the Xg-BXII distribution for Wang’s data.
The trace plots display the sampled values of each parameter across iterations in the MCMC simulation. They help assess convergence by showing if the parameter values stabilize over iterations. A well-mixed, stationary trace plot (one without upward or downward trends) suggests that the simulation has likely reached its stationary distribution, indicating reliable parameter estimates.
The autocorrelation plots show the correlation of each parameter with its values from previous iterations (lags). These plots assess the independence of samples. Low autocorrelation at various lags indicates that the samples are relatively independent, improving the efficiency of the MCMC simulation and the quality of the posterior estimates. A high autocorrelation might suggest the need for a longer chain or adjustments to the MCMC algorithm.
The histograms illustrate the distribution of each simulated parameter across all iterations. They provide an empirical view of the parameter distribution, showing the spread and central tendency of the posterior samples. This visual helps assess the variability and potential skewness of each parameter, indicating the range within which the true parameter values likely fall.
The posterior density plots show the estimated posterior density of each parameter. They offer a smoothed view of the parameter’s posterior distribution, giving more precise insight into the probable values of each parameter based on the data. Peaks in the density indicate high-probability values, while the spread reflects parameter uncertainty.
Together, these plots provide a comprehensive view of the parameter behavior, model convergence, and the quality of the posterior estimates for Wang’s data, giving confidence in the robustness and interpretability of the Bayesian model’s results.
Table 16 and Table 17 display the sample size of the first (observed) sample, , and represents the sample size of the second (future) sample for which the prediction is considered. It denotes the number of new observations that we want to predict based on the information from the first sample. Also, Table 16 and Table 17 show the two-sample Bayesian prediction of , where , and a future observation, , from a future sample with size of the time to failure of electronic devices under the SE and LINEX loss functions based on . Also, the BPBs and their lengths are presented.
Table 16.
Two-sample Bayesian prediction and 95% Bayesian prediction bounds of future observations from the Xg-BXII distribution with their lengths under SE loss function for the failure times of Wang’s data.
Table 17.
Two-sample Bayesian prediction and 95% Bayesian prediction bounds of future observations from the Xg-BXII distribution with their lengths under LINEX loss function for the failure times of Wang’s data.
5.2. Application 2
This application is given by [39]. The data represent COVID-19 data belonging to the United Kingdom, capturing 76 days, from 15 April to 30 June 2020. The data consist of drought mortality rates. The data are tabulated in Table 18.
Table 18.
Drought mortality rates of United Kingdom’s data.
Based on the value of the and its corresponding p-value = 0.9242, one can say that the Xg-BXII distribution provides a good fitting to this real data set.
The Bayes estimates and their PRs of the parameters rf, hrf and rhrf of the Xg-BXII distribution for COVID-19 data from the United Kingdom are tabulated in Table 19 under SE and LINEX loss functions, where the LINEX loss is used at and time points are considered. For Bayesian calculation, these combinations of means and variances and was used to calculate the hyperparameters of the joint prior.
Table 19.
Bayes estimates and their relevant standard errors and 95% credible intervals of the parameters of the Xg-BXII distribution along with their lengths under SE loss function for COVID-19 data from the United Kingdom.
Figure 7, Figure 8 and Figure 9 exhibit trace, autocorrelation plots and the histogram of the simulated parameters and the posterior density of each parameter for COVID-19 data from the United Kingdom. The trace plots demonstrate the convergence of the parameters, the autocorrelation plots to assess parameter independence, and the histograms to illustrate the posterior distribution of each parameter for the COVID-19 data. These figures are essential for verifying the stability and reliability of the parameter estimates, which directly support the accuracy and validity of our model as applied to COVID-19 data.
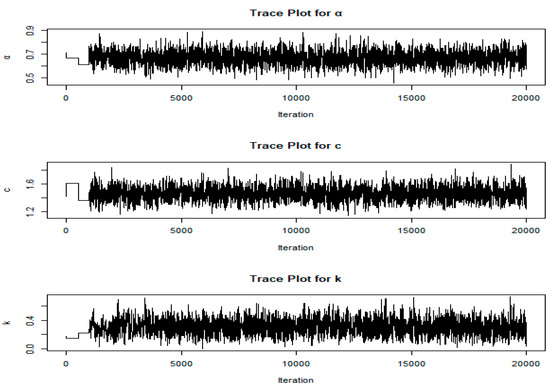
Figure 7.
Trace plots of the parameters α, c and k for COVID-19 data from the United Kingdom.
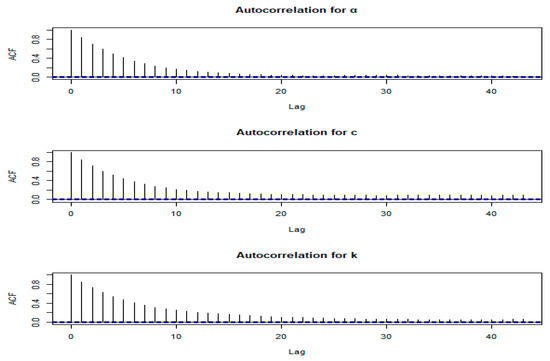
Figure 8.
Autocorrelation plots of the parameters α, c and k for COVID-19 data from the United Kingdom.
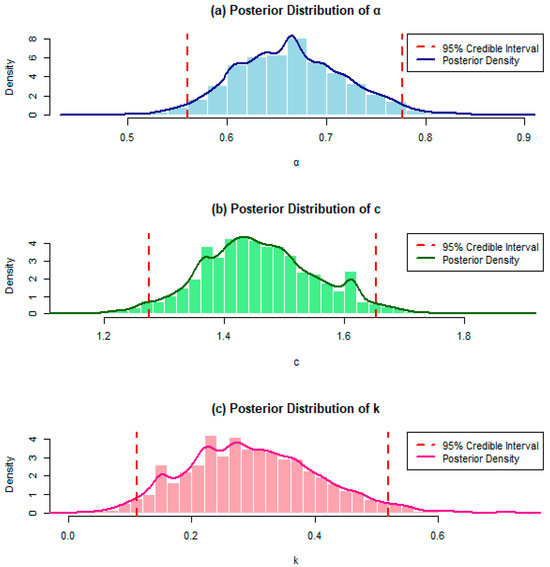
Figure 9.
Histogram, posterior density and the lower and upper limits of the 95% credible intervals of the parameters of the Xg-BXII distribution for COVID-19 data from the United Kingdom.
Table 20 and Table 21 display the two-sample Bayesian prediction of , where , and a future observation, , from a future sample with a size of drought mortality rates of COVID-19 in the United Kingdom under the SE and LINEX loss functions based on . Also, the BPBs and their lengths are presented.
Table 20.
Two-sample Bayesian prediction and 95% Bayesian prediction bounds of future observations from the Xg-BXII distribution with their lengths under SE loss function for COVID-19 data from the United Kingdom.
Table 21.
Two-sample Bayesian prediction and 95% Bayesian prediction bounds of future observations from the Xg-BXII distribution with their lengths under LINEX loss function for COVID-19 data from the United Kingdom.
5.3. Concluding Remarks
- The Bayes estimates of the parameters of the Xg-BXII distribution have smaller PRs and lengths under the LINEX loss function compared to the corresponding results under the SE loss function. This implies that the estimates are closer to the true parameter values on average, making the LINEX loss function a more suitable loss function in situations where asymmetry or skew in errors is important.
- Also, the results under the LINEX loss function when is greater than when using . This suggests that a lower value makes the LINEX loss function more sensitive to estimation deviations, potentially leading to larger posterior risk and interval lengths. Also, the results of are close to the results under the SE loss function; this indicates that the LINEX loss function with behaves more symmetrically, approaching the properties of the SE loss function, which is symmetrical by nature.
- As increases, the BPs under the SE and LINEX loss functions increase. The increase in the Bayes predictors with higher order statistics suggests a positive association between the size of the order statistic and the predicted values, reflecting the model’s sensitivity to larger future observations. Moreover, the rate of increase might differ depending on the asymmetry in LINEX, illustrating the effect of different loss function choices on prediction levels.
- For all prediction intervals, the lower and upper bounds and their lengths increase as increases. This reflects increased variability or a spread in the distribution at higher order statistics, necessitating wider intervals to represent the range of potential outcomes accurately. The lower and upper bounds and their lengths of the first order statistic are less than the lower and upper bounds and their lengths of the last order statistic; this could be due to the model’s natural behavior or the characteristics of the data set, where extreme values (like the last order statistic) naturally have wider variability.
- The BPs under the SE and LINEX loss functions are included between the lower and upper bounds of all prediction intervals, which suggests that the intervals accurately represent the range of potential outcomes, thereby supporting the reliability of the model’s prediction. Also, it indicates robustness in the model prediction, regardless of the loss function used, including the symmetry (SE) or asymmetry (LINEX) loss functions.
- In all cases, the lengths of the BPBs under the LINEX loss function are shorter than the lengths of the BPBs under the SE loss function. This implies that (1) the shorter lengths of BPBs suggest that the LINEX loss function provides more precise prediction, which can be particularly valuable in decision-making situations where the costs of overestimating or underestimating differ. (2) The narrower predictive bounds under LINEX loss indicate reduced uncertainty in the parameter estimates, which leads to more reliable prediction, making the model more useful for practical applications. (3) It focuses on the importance of selecting a suitable loss function based on the characteristics of the data and the consequences of prediction errors. (4) The choice of the loss function can significantly impact the performance of Bayesian estimation.
- The BPs under LINEX loss with are quite close to the BPs under the SE loss function; this result highlights that the LINEX loss function behaves similarly to the traditional squared error loss. This indicates that the choice of (which controls the asymmetry of the LINEX loss) can lead to outcomes that are not significantly different from what would be obtained with SE loss function, thereby providing flexibility in loss function selection depending on the problem context.
- Additionally, BPs under the LINEX loss function with have the minimum lengths of the BPBs compared to the other BPs. This can be explained as a more effective balance between the underestimation and overestimation of parameters, leading to narrower predictive intervals and thus greater confidence in prediction. This result may suggest that when dealing with problems where the cost of underestimating is higher, setting to 1.5 can yield better outcomes. The results underline the importance of carefully selecting not only the loss function but also its parameters. Narrower predictive bounds (especially those under ) can lead to improved decision-making in practice, as they reflect greater certainty in the estimated parameters. This can be particularly relevant in fields such as finance, healthcare or engineering, where precise prediction is critical.
6. Conclusions
In this paper, point and interval Bayesian estimation of the parameters of the Xg-BXII distribution are considered under the SE and the LINEX loss functions. Informative independent gamma priors are assumed for the parameters of the Xg-BXII distribution. Moreover, point and interval two-sample Bayesian prediction is presented for future observations from the Xg-BXII distribution. A comprehensive simulation study using the AM algorithm is conducted to evaluate the performance of the Bayes estimates and Bayesian prediction. Based on the simulation results, one can conclude generally that as the sample size increases, the efficiency of the Xg-BXII distribution increases. Also, the Bayes results under the LINEX loss function with a shape parameter near zero are quite close to the Bayes results under the SE loss function. In addition, the Bayes results when assuming priors with small variances are more efficient than priors with large variances. The results are applied to two different applications.
All the results highlight the advantage of using the LINEX loss function in producing more accurate and concise parameter estimates, which may be particularly beneficial for applications sensitive to asymmetrical errors. Also, these findings highlight how tuning the asymmetry parameter affects the balance between sensitivity and precision in the estimates, with lower values yielding results closer to those from the SE loss function. The results demonstrate that higher order statistics in future samples lead to increased Bayes predictions, which can be crucial for applications where large future observations are expected or important to consider. Additionally, these results highlight a positive relationship between and the prediction interval width, indicating a broader range of potential values as predictions move from early to later order statistics. These results highlight that the prediction intervals effectively include the Bayes predictors, validating the reliability and robustness of the model’s predictive capability across different loss functions. Moreover, the results illustrate the importance of loss function selection in Bayesian predictive modeling and suggest that the LINEX loss function may lead to better predictive performance in specific applications. The results emphasize the effectiveness of the LINEX loss function with appropriate parameter choices in generating more reliable predictive bounds, contributing to the understanding of Bayesian modeling’s flexibility and applicability in various contexts.
In cases where the sample size is small, the performance of our model may be impacted, potentially leading to wider credible intervals and less precise parameter estimates. Small sample sizes can reduce the informativeness of the data, making the prior assumptions more influential on the posterior results.
Future research could explore the extension of the proposed model to multivariate settings, allowing for the analysis of multiple competing risks simultaneously across various medical and engineering applications. Also, as a future potential work, we may consider the ML, Bayesian estimation and prediction from the Xg-BXII distribution based on record values. Additionally, we may study the ML, Bayesian estimation and prediction for the Xg-BXII distribution based on different types of censoring under different loss functions. Finally, investigating the integration of Bayesian competing risks models with machine learning techniques could lead to more powerful predictive tools, combining the strengths of both approaches.
Author Contributions
Conceptualization, H.H.M. and F.S.A.; methodology, H.H.M., F.S.A., H.N.S. and A.A.E.-H.; software, A.A.E.-H. and H.N.S.; validation, H.N.S. and A.A.E.-H.; formal analysis, H.N.S. and A.A.E.-H.; investigation, H.H.M., F.S.A., H.N.S. and A.A.E.-H.; resources, H.H.M.; data curation, A.A.E.-H. and H.N.S.; writing—original draft preparation, H.H.M. and F.S.A.; writing—review and editing, A.A.E.-H. and H.N.S.; visualization, H.H.M., F.S.A., H.N.S. and A.A.E.-H.; supervision, A.A.E.-H.; project administration, H.H.M. and F.S.A.; funding acquisition, H.H.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research project was funded by the Deanship of Scientific Research, Princess Nourah bint Abdulrahman University, through the Program of Research Project Funding After Publication, grant No (44-PRFA-P-142), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Data Availability Statement
All data generated or analyzed through the paper are associated with its references and sources.
Acknowledgments
This research project was funded by the Deanship of Scientific Research, Princess Nourah bint Abdulrahman University, through the Program of Research Project Funding After Publication, grant No (44-PRFA-P-142), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia
Conflicts of Interest
The authors state no conflicts of interest.
References
- Xie, M.; Lai, C.D. Reliability analysis using an additive Weibull model with bathtub-shaped failure rate function. Reliab. Eng. Syst. Saf. 1996, 52, 87–93. [Google Scholar] [CrossRef]
- Wang, F.K. A new model with bathtub-shaped failure rate using an additive Burr XII distribution. Reliab. Eng. Syst. Saf. 2000, 70, 305–312. [Google Scholar] [CrossRef]
- Almalki, S.J.; Yuan, J. A new modified Weibull distribution. Reliab. Eng. Syst. Saf. 2013, 111, 164–170. [Google Scholar] [CrossRef]
- He, B.; Cui, W.; Du, X. An additive modified Weibull distribution. Reliab. Eng. Syst. Saf. 2016, 145, 28–37. [Google Scholar] [CrossRef]
- Oluyede, B.O.; Foya, S.; Warahena-Liyanage, G.; Huang, S. The log-logistic Weibull distribution with applications to lifetime data. Austrian J. Stat. 2016, 45, 43–69. [Google Scholar] [CrossRef]
- Singh, B. An additive Perks-Weibull model with bathtub-shaped hazard rate function. Commun. Math. Stat. 2016, 4, 473–493. [Google Scholar] [CrossRef]
- Mdlongwa, P.; Oluyede, B.O.; Amey, A.; Huang, S. The Burr XII modified Weibull distribution: Model, Properties and Applications. Electron. J. Appl. Stat. Anal. 2017, 10, 118–145. [Google Scholar]
- Tarvirdizade, B.; Ahmedpour, M. A new extension of Chen distribution with applications to lifetime data. Math. Stat. 2019, 9, 23–38. [Google Scholar] [CrossRef]
- Shakhatreh, M.K.; Lemonte, A.J.; Moreno-Arenas, G. The log-normal modified Weibull distribution and its reliability implications. Reliab. Eng. Syst. Saf. 2019, 188, 6–22. [Google Scholar] [CrossRef]
- Osagie, S.A.; Osemwenkhae, J.E. Lomax-Weibull distribution with properties and applications in lifetime analysis. Int. J. Math. Anal. Optim. Theory Appl. 2020, 2020, 718–732. [Google Scholar]
- Kamal, R.M.; Ismail, M.A. The flexible Weibull extension-Burr XII distribution: Model, properties and applications. Pak. J. Stat. Oper. Res. 2020, 16, 447–460. [Google Scholar] [CrossRef]
- Thach, T.T.; Bris, R. An additive Chen-Weibull distribution and its applications in reliability modeling. Qual. Reliab. Eng. Int. 2020, 37, 352–373. [Google Scholar] [CrossRef]
- Makubate, B.; Oluyede, B.; Gabanakgosi, M. A new Lindley-Burr XII distribution: Model, Properties and Applications. Int. J. Stat. Probab. 2021, 10, 33–51. [Google Scholar] [CrossRef]
- Abba, B.; Wang, H.; Bakouch, H.S. A reliability and survival model for one and two failure modes system with applications to complete and censored datasets. Reliab. Eng. Syst. Saf. 2022, 223, 108460. [Google Scholar] [CrossRef]
- Xavier, T.; Jose, J.K.; Nadarajah, S. An additive power-transformed half-logistic model and its applications in reliability. Qual. Reliab. Eng. Int. 2022, 38, 3179–3196. [Google Scholar] [CrossRef]
- Thach, T.T. A Three-Component Additive Weibull Distribution and Its Reliability Implications. Symmetry 2022, 14, 1455. [Google Scholar] [CrossRef]
- Salem, H.N.; AL-Dayian, G.R.; EL-Helbawy, A.A.; Abd EL-Kader, R.E. The additive flexible Weibull extension-Lomax distribution: Properties and estimation with applications to COVID-19 data. Acad. Period. Ref. J. AL-Azhar Univ. 2022, 28, 1–44. [Google Scholar] [CrossRef]
- Méndez-González, L.C.; Rodríguez-Picón, L.A.; Pérez Olguínm, I.J.C.; García, V.; Luviano-Cruz, D. The additive Perks distribution and its applications in reliability analysis. Qual. Technol. Quant. Manag. 2022, 20, 784–808. [Google Scholar] [CrossRef]
- Méndez-González, L.C.; Rodríguez-Picón, L.A.; Pérez-Olguín, I.J.C.; Vidal Portilla, L.R. An additive Chen distribution with applications to lifetime data. Axioms 2023, 12, 118. [Google Scholar] [CrossRef]
- Méndez-González, L.C.; Rodríguez-Picón, L.A.; Rodríguez Borbón, M.I.; Sohn, H. The Chen–Perks distribution: Properties and Reliability Applications. Mathematics 2023, 11, 3001. [Google Scholar] [CrossRef]
- Mohammad, H.H.; Alamri, F.S.; Salem, H.N.; EL-Helbawy, A.A. The Additive Xgamma-Burr XII Distribution: Properties, Estimation and Applications. Symmetry 2024, 16, 659. [Google Scholar] [CrossRef]
- Zhao, Y.-G.; Qin, M.-J.; Lu, Z.-H.; Zhang, L.-W. Seismic fragility analysis of nuclear power plants considering structural parameter uncertainty. Reliab. Eng. Syst. Saf. 2021, 216, 107970. [Google Scholar] [CrossRef]
- Zhang, L.-W.; Dang, C.; Zhao, Y.-G. An efficient method for accessing structural reliability indexes via power transformation family. Reliab. Eng. Syst. Saf. 2023, 233, 109097. [Google Scholar] [CrossRef]
- Lawless, J.F. Statistical Models and Methods for Lifetime Data, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2003. [Google Scholar]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Dunson, D.B.; Vehtari, A.; Rubin, D.B. Bayesian Data Analysis, 3rd ed.; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Varian, H.R. A Bayesian approach to real estate assessment. In Studies in Bayesian Econometrics and Statistics in Honor of Leonard J. Savage; Savage, L.J., Feinberg, S.E., Zellner, A., Eds.; North-Holland Pub. Co.: Amsterdam, The Netherlands, 1975; pp. 195–208. [Google Scholar]
- Zellner, A. Bayesian estimation and prediction using asymmetric loss function. J. Am. Stat. Assoc. 1986, 81, 446–451. [Google Scholar] [CrossRef]
- AL-Hussaini, E.K. Predicting observables from a general class of distributions. J. Stat. Plan. Inference 1999, 79, 79–91. [Google Scholar] [CrossRef]
- Singh, S.K.; Singh, U.; Sharma, V.K. Bayesian estimation and prediction for flexible Weibull model under Type-II censoring scheme. J. Probab. Stat. 2013, 2013, 1–16. [Google Scholar] [CrossRef]
- Wu, M.; Gui, W. Estimation and prediction for Nadarajah-Haghighi distribution under progressive Type-II censoring. Symmetry 2021, 13, 999. [Google Scholar] [CrossRef]
- Ateya, S.F.; Alghamdi, A.S.; Mousa, A.A.A. Future failure time prediction based on a unified hybrid censoring scheme for the Burr-X model with engineering applications. Mathematics 2022, 10, 1450. [Google Scholar] [CrossRef]
- Hasaballah, M.M.; Al-Babtain, A.A.; Hossain, M.M.; Bakr, M.E. Theoretical aspects for Bayesian predictions based on three-parameter Burr-XII distribution and Its applications in climatic data. Symmetry 2023, 15, 1552. [Google Scholar] [CrossRef]
- EL-Helbawy, A.A.; AL-Dayian, G.R.; Salem, H.N.; Abd EL-Kader, R.E. Non-Bayesian and Bayesian prediction for additive flexible Weibull extension-Lomax distribution. J. Econom. Stat. 2024, 4, 79–104. [Google Scholar] [CrossRef]
- Dey, S.; Al-Mosawi, R. Classical and Bayesian Inference of Unit Gompertz Distribution Based on Progressively Type II Censored Data. Am. J. Math. Manag. Sci. 2024, 43, 61–89. [Google Scholar] [CrossRef]
- Berger, J.O. Statistical Decision Theory and Bayesian Analysis; Springer Series in Statistics; Springer: New York, NY, USA, 1985. [Google Scholar]
- Press, S.J. Bayesian Statistics: Principles, Models and Applications; John Wiley and Sons, Inc.: New York, NY, USA, 1989. [Google Scholar]
- Haario, H.; Saksman, E.; Tamminen, J. An adaptive Metropolis algorithm. Bernoulli 2001, 7, 223–242. [Google Scholar] [CrossRef]
- Jaheen, Z.F. Empirical Bayes analysis of record statistics based on LINEX and quadratic loss functions. Comput. Math. Appl. 2004, 47, 947–954. [Google Scholar] [CrossRef]
- Mubarak, A.E.; Almetwally, E.M. A new extension exponential distribution with applications of COVID-19 data. J. Financ. Bus. Res. 2021, 22, 444–460. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).