Abstract
This manuscript focuses on the statistical inference of the Kavya–Manoharan generalized exponential distribution under the generalized type-I progressive hybrid censoring sample (GTI-PHCS). Different classical approaches of estimation, such as maximum likelihood, the maximum product of spacing, least squares (LS), weighted LS, and percentiles under GTI-PHCS, are investigated. Based on the squared error and linear exponential loss functions, the Bayes estimates for the unknown parameters utilizing separate gamma priors under GTI-PHCS have been derived. Point and interval estimates of unknown parameters are developed. We carry out a simulation using the Monte Carlo algorithm to show the performance of the inferential procedures. Finally, real-world data collection is examined for illustration purposes.
1. Introduction
Censoring schemes (CSs) play a significant role in lifespan and reliability studies. According to the estimated experiment time and accompanying cost, many practical experiments that rely on the lifespan of objects may be completed before failing all of the items. In these situations, just a subset of an item’s failure information is recorded, and the data collected is known as censored data.
The most popular censoring methods used in life tests are type-I and type-II CSs. Ref. [1] proposed a hybrid CS, which is a combination of type-I and type-II CSs. In many cases, it is prepared in advance to remove items prior to failure at several stages of the experiment; however, the above CS lack the flexibility to allow for items to be removed from the experiment at stages other than the trial’s endpoint. To address this issue, Ref. [2] proposed a type-II progressive CS (T-IIPCS) as a generalization for the censoring systems described previously.
The following can be used to establish T-IIPCS: Assume that a life-test experiment is conducted on a random sampling of n items and that the trial’s starting point is the number of reported failures , which was previously progressive CS (). During the time of the smallest failure, , operating items are picked at random and left out of the experiment. At the second lowest failure time , operational items are randomly chosen and eliminated from the experiment. The procedure is continued until the final failure time takes place, at which point all remaining operational items are removed from the experiment. The experiment is then terminated at .
T-IIPCS has one big drawback in that if the items being studied are reliable and of excellent quality, the experiment time may be very long. This restriction was addressed in Ref. [3] with an improved system known as a type-I progressive hybrid CS (TI-PHCS), in which and (), as well as the experimental duration , is determined beforehand. In this case, the experiment is completed at time min. Except for the last time point, this scheme is identical to T-IIPCS.
One of T-IIPHCS’s most significant shortcomings is that the effective sample size is random and might be relatively small. As a result, statistical inference techniques may be unreliable or less efficient. A novel variation of progressive censoring called the generalized TI-PHCS (GTI-PHCS) was introduced in Ref. [4] to eliminate the problems that emerged in TI-PHCS, in which a smaller number of failures is predetermined. Using this filtering method would save time and money throughout a lifetime test trial. Additionally, the experiment having more failures improves estimates of statistical efficacy. The CS aids in ensuring that at least a constant number of observed items are satisfied to attain the efficiency necessary for statistical evaluation. It also controls the experiment’s overall duration to be close to that time if the number of observed failures appears to be very low up until . In this case, the experiment is completed at the moment and any remaining operational items are removed from the experiment.
Numerous researchers have reported different techniques of estimation using the GTI-PHCS. In accordance with maximum product spacing (MPS), Ref. [5] introduced progressive type-II hybrid CS. For an exponential (E) model and a Weibull model, respectively Refs. [4,6] provided an accurate likelihood inference and entropy estimation methodology. Salem et al. [7] discussed a joint Type-II generalized progressive hybrid censoring scheme based on exponential distribution. By combining the generalized E (GE) and the basic step-stress accelerated life test with the competing risks model Ref. [8] investigated the statistical prediction problem of unobserved failure durations. In Refs [9,10], Bayesian and maximum likelihood (ML) estimation strategies for the E and Weibull under competing risks models were examined. When applying partially accelerated life tests to units whose lives are exponentially distributed under normal stress circumstances, [11] explored several point and interval estimates for the parameters involved, as well as the ideal stress change time. Ref. [12] examined the competing risk models under GTI-PHCS based on Chen distribution. Ref. [13] used GTI-PHCS to estimate the Weibull distribution’s unknown parameters, reliability, and hazard functions with application to real data. Ref. [14] provided the ML and Bayesian estimators of the distribution’s parameters, together with the reliability and hazard functions, based on GTI-PHCS data, from a GE distribution with application to numbers of million revolutions data before failure for each of the 23 ball bearings in the life test.
The GE model has been shown to be beneficial in a wide range of applications involving life testing, survival analysis, and reliability. Ref. [15] investigated this model, which is a special instance of the exponentiated Weibull model [16,17]. The followings are the cumulative distribution function (CDF) and probability density function (PDF) of the GE model, with scale parameter and shape parameter , for :
Several authors used the PDF (2) and CDF (1) to generate new extensions of the GE model, such as beta GE model [18], Marshall–Olkin GE [19], half-Cauchy GE [20], odd Lomax GE [21], and modified slashed GE [22]. Recently, [23] introduced the Kavya–Manoharan GE (KMGE) model as the special case of the Kavya–Manoharan exponentiated Weibull model. The KMGE distribution is a new extension where it does not require any additional parameters to the baseline distribution which absolutely is an advantage with no more parameters. The CDF, PDF, and hazard rate function (HRF) of the KMGE model are
and
The plots of these PDF and HRF are displayed in Figure 1. It can be noticed from this figure that the PDF can be uni-modal, decreasing, and right-skewed, but the HRF can be increasing, decreasing, and constant. These curves indicate that the KMGE model is very flexible in modeling different types of data.
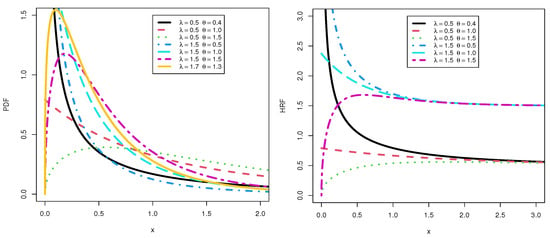
Figure 1.
Plots of the PDF and HRF of the KMGE model.
As far as we are aware, there has not been any research that uses MPS, LS, and weighted LS (WLS) estimation techniques to estimate model parameters of probability distribution in the presence of the GTI-PHC data. Then according to the novelty of the KMGE distribution, we provide three important estimation methods besides the ML, percentiles (PE), and Bayesian methods. After that, a medical and engineering data application is supplied in accordance with the flexibility of the KMGE distribution (see Figure 1). In this regard, we summarized our study’s objectives as follows:
- Discuss the point and interval statistical inference of the two unknown parameters and for the KMGE distribution using five classical estimation approaches such as ML, MPS, LS, WLS, and PE based on GTI-PHCS.
- Estimate the model’s parameters of the KMGE distribution in view of the Bayesian estimation strategy using symmetric and asymmetric loss functions.
- Using specific metrics of accuracy, a simulation study is run to look at how different estimates behave.
- A potential application based on GTI-PHCS has been explored for data from engineering and medical sciences.
The rest of this paper is structured as follows: the model formulation of GTI-PHCS is proposed in the Section 2. Five classical estimation approaches such as ML, MPS, LS, WLS, and PE are investigated in the Section 3. Bayesian estimation with credible intervals is discussed in the Section 4. In Section 5, we evaluate the quality points and interval estimators using a Monte Carlo approach. In Section 6, we employ the theoretical study findings to real-world data. Finally, the discussion and conclusion are presented in Section 7.
2. Generalized Type-I Progressive Hybrid Censoring
The implementation steps of the GTI-PHCS are described below:
- Assume that a random sample of n units undergoes a lifetime testing trial.
- Assume that before starting the experiment, the integers , the experimental time and () are assigned, so that , .
- The operational units are chosen at random and eliminated from the experiment at , the first failure time. At the subsequent failure time , operating units are randomly selected and eliminated from the experiment, and the procedure is repeated. Eventually, the experiment is completed when , and any remaining operational units are omitted from the experiment. Table 1 contains the values of the final censoring number .
 Table 1. Values of , , , and , for three cases.
Table 1. Values of , , , and , for three cases. - Assume that represents the number of units that fail prior to . The experiment’s end time is, therefore, provided byAny one of the subsequent six cases could be observed for the results:
- Case I: If the observed time happens to occur before the wth failure time and failures occur up to time , . Afterward, we won’t remove any operating units from the experiment until the failure times, after which we will remove all of the remaining operating units from the experiment at the wth failure time, thereby stopping the experiment at , where , see Figure 2. In this case, we allow the experiment to continue after experimental time is reached to guarantee that at least the wth failure time happens. The following remarks, in this case, will be made:
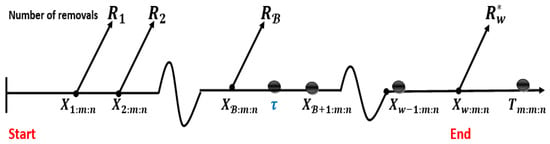 Figure 2. Case 1. The sampling process under GTI-PHCS, when .
Figure 2. Case 1. The sampling process under GTI-PHCS, when . - Case II: When wth failure time happens before the , , and failures occur up to the time. The experiment is terminated at by removing all of the remaining operational units , as shown in Figure 3. The following observations will be made in this situation: .
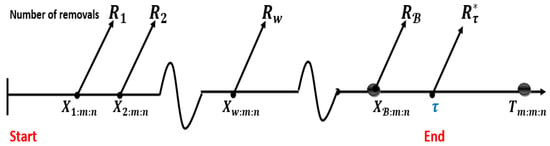 Figure 3. Case 2. The sampling process under GTI-PHCS, when .
Figure 3. Case 2. The sampling process under GTI-PHCS, when . - Case III: When the mth failure time happens before the time , , then all the remaining operational units are deleted from the experiment, terminating it at , as shown in Figure 4. The following observations will be made in this situation:
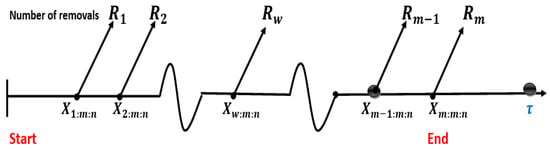 Figure 4. Case 3. The sampling process under GTI-PHCS, when .
Figure 4. Case 3. The sampling process under GTI-PHCS, when .
3. Different Classical Approaches of Estimation
This section discusses five classical methods for calculating ML, MPS, LS, WLS, and PE of the underlying parameters and using data gathered via GTI-PHCS.
3.1. Approach of ML Estimation
The likelihood function based on GTI-PHCS is provided via
where = , , final censored number , and , , be experiment end time values based on three cases are reported in Table 1. It is interesting to note that, in Case I, several values of , may be different throughout the test than those set before the test even starts.
Note that, we write instead of for the simplified form. According to Equation (6), of , can be computed as below: The ML estimates (MLEs) of and may be determined by taking the first partial derivatives of (6) with regard to and and equating them to zero as
The MLEs and of and may be computed by solving the score equations, and , with regards to and and solving these equations concurrently to produce the MLEs. Because analytical solutions cannot get the roots, these equations can indeed be investigated numerically utilizing iterative procedures employing statistical software via the “maxLik” package installed through the R 4.3.0 programming language.
According to the usual asymptotic normality theory of MLEs, we may assume that and can be approximated by
where and are the variance of and which may be founded by computing the inverse of the Fisher information matrix, i.e.,
where the caret denotes that the derivative is evaluated at . It is simple to obtain the second partial derivatives of the probability function’s natural logarithm for and .
Suppose that and , then, a normal approximation confidence interval (NACI) of , for , may be easily computed as below:
where is the upper percentile of distribution, and is the MLE of .
In the lower bound of NACI, as ∞, the positive parameter can occasionally have a negative value. Ref. [24], as ∞, recommended using a log transformation confidence interval (LTCI) in this situation. Based on the log-transformed MLE’s usual estimate, , where , as a standard normal distribution can be approximated.
where . Accordingly, a LTCI for is characterized
3.2. Approach of Maximum Product of Spacing Estimation
Ref. [25] proposed an alternate technique to the ML method for estimating unknown parameters in continuous distributions. Refs. [26,27] utilized progressive type-II censoring to estimate the parameters involved in the Weibull and Kavya–Manoharan inverse length biased exponential distributions. The MPS estimates (MPSEs) are yielded by maximizing the next product of spacing for and .
where and , and the expression about GTI-PHCS model has been discussed in Table 1. Utilizing (3) and by maximizing the product of spacing for and , then the MPSEs and of and are provided
where .
To obtain the MPSEs, the nonlinear equations can also be solved simultaneously. Since an exact solution cannot obtain the roots, these equations are analytically resolved using iterative strategies and statistical software:
where
the same forms are provided for , or .
3.3. Approaches of LS and WLS
Ref. [28] established the LS and WLS techniques for estimating the parameters of the beta distribution. Refs. [29,30] employed progressive type-II censoring to estimate the parameters contained in the doubly Poisson-exponential and exponential-doubly Poisson distributions. To estimate the parameters in the Poisson-logarithmic half-logistic distribution under a progressive-stress accelerated life test, Ref. [31] proposed adaptive type-II progressive hybrid censoring.
Let () be the ordered GTI-PHCS sample from the KMGE model of size . The LS estimates (LSEs) of are derived by minimizing the below formula
in which E denotes the empirical CDF expectation, as supplied in [32]
As a result, the LSEs and of and are yielded by minimizing the following formula
These estimates can also be achieved by simultaneously solving the nonlinear equations to generate the LSEs. These equations can be resolved analytically using iterative methods and statistical tools since precise solutions cannot get the roots.
where and are provided in (10) and (11), respectively.
The WLS estimates (WLSEs) of and may be generated by minimizing the below formula
where is the weight factor and is the variance of the empirical CDF, see [32], which is provided via
where
Minimizing the next quantity, we get the WLSEs and of and .
3.4. Approach of Percentiles Estimation
Ref. [33] suggested a percentile approach for estimating distribution. If data from a closed-form CDF were gathered, it would only make sense to estimate the unknown parameter by adjusting a straight line between the theoretical points generated by the CDF and the percentile points of the sample. In this method, the empirical CDF looks like this:
where is defined as in Table 1 and
Based on GTI-PHCS, the PEs of the considered parameters can be obtained as follows: It is feasible to acquire the PEs and of and by reducing the following quantity with regards to and .
where
These estimates can also be achieved by concurrently solving the nonlinear equations and obtaining the PEs. Because an exact solution cannot yield the roots, these equations can be investigated numerically by employing iterative procedures employing statistical software:
4. Bayesian Estimation
Here, the squared error loss (SEL) function and linear exponential loss (LINEXL) function are used to generate the Bayes estimators of and . To accomplish this, we supposed that the KMGE model parameters, and , each have independent gamma priors of the forms and . Gamma priors should be considered for a variety of reasons, including the fact that they are (a) adjustable, (b) offer diverse shapes based on parameter values, and (c) are fairly simple and brief and might not produce a solution with a challenging estimation problem. The KMGE parameters and joint prior density is given by
where the hyper-parameters , and are the ones that hold the previous data. Many academic authors created Bayesian estimates for their parameter models utilizing instructive gamma priors, including Refs. [34,35], and Ref. [36]. The informative priors will be used to elicit the hyper-parameters. The mean and variance using the maximum likelihood estimates of the KMGE distribution are determined. The priors (gamma priors) of the and mean and variance will be identical to and . We may find the means and variances of and by equating them with the mean and variance of the gamma priors, as below
After resolving the two equations above, the estimated hyper-parameters can now be expressed as
The likelihood function (5) and the joint prior (14) may be combined to obtain the posterior distribution, say , which is defined as
the joint posterior density can be denoted in the final form:
The SEL function should be taken into account in a Bayesian analysis for several reasons: In addition to being a typical symmetric loss and being straightforward, obvious, and easy to understand, it also assumes that overestimation and underestimation are treated equally and directly builds the Bayes estimator by using the posterior mean. However, when considering the SEL function, the posterior expectation of (16), which is expressed as
The most widely used asymmetric loss function is the LINEXL function. In many ways, the asymmetric loss function is thought to be more complete, according to Varian [37]. The Bayes estimate (BEs) of any function under the LINEXL function can be determined as
It is clear from (16), that it is impossible to express the marginal posterior densities of and explicitly. We propose utilizing Bayesian Markov chain Monte Carlo (MCMC) methods to generate samples from (16). The conditional posterior density functions of and are, thus, obtained, respectively, from (16), as
and
The posterior density functions of and , respectively, cannot be analytically reduced to any known distribution, as shown in (19) and (20). As a result, it is believed that the Metropolis–Hastings (M–H) method is the best approach to resolving this problem; for further information, see Refs. [38,39,40]. The following describes the sampling method for the M–H algorithm based on the normal proposal distribution:
- Set the starting values and .
- Set i = 1.
- Create and from and , respectively.
- Find , .
- Utilizing the uniform distribution, generate samples and .
- If both and are less than and , respectively, then set and , respectively. Otherwise, set and , respectively.
- Set i = i + 1.
- Redo steps 3–7 H times to get and for .
5. Results of Simulation
Because assessing the efficiency of estimating methods is conceptually challenging, a Monte Carlo simulation is employed to address this obstacle. Here, we evaluate the performance and efficacy of the estimating approaches presented in earlier parts using Monte Carlo simulation. The procedure is as follows:
- Specify the sample size n and parameter values. Moreover, specify , , and values.
- Create n observations from the Uniform (0, 1) distribution .
- The observations may be obtained via CDF (3).
- As described in Section 2, employ GTI-PHCS to the random sample produced in Step 3.
- Compute the MLEs, MPSEs, LSEs, WLSEs, PEs, NACIs, and LTCIs of as mentioned in Section 3.
- Repeat the preceding steps = 1000 times.
- Determine the average of estimates, mean squared error (MSEr), and relative bias (RB) of across samples as described in the following:where is an estimate of .
- Determine the mean of the different estimates with their MSErs and RBs utilizing Step 9.
- Compute the average of the RBs (ARB) and MSErs (AMSEr) as below:
- Calculate the average lengths (ALs) and coverage probabilities (COVPs) of the parameters , then their 95% NACIs and LTCIs. Calculate also the average of the ALs (AAL) as below:
The sample generation uses the following CSs:
- CS.1:
- CS.2:
- CS.3:
- CS.4:
The calculations were performed using the true parameter values and . Moreover, the values n = 40, 80, (of the sample size) (), , (of the sample size), and are used in the simulation analysis via R 4.3.0 programming software by installing the “maxLik” package to estimate MLE, along with their “coda” package in R 4.3.0 programming software, to obtain the Bayes point estimates.
The following points may be detected based on the computation results contained in Table 2, Table 3, Table 4, Table 5, Table 6, Table 7, Table 8, Table 9, Table 10 and Table 11:
Table 2.
Simulation results of MLEs and MPSEs of and with their MSErs, RBs, AMSEr, and ARB at true value and .
Table 3.
Simulation results of MLEs and MPSEs of and with their MSErs, RBs, AMSEr, and ARB at the true values of and .
Table 4.
Simulation results of LSEs and WLSEs of and with their MSErs, RBs, AMSEr, and ARB at the exact values of and .
Table 5.
Simulation results of LSEs and WLSEs of and with their MSErs, RBs, AMSEr, and ARB at the exact values of and .
Table 6.
Simulation results of PEs of and with their MSErs, RBs, AMSEr, and ARB at the true values of and .
Table 7.
Simulation results of PEs of and with their MSErs, RBs, AMSEr, and ARB, at the exact values of and .
Table 8.
Simulation results of ALs and COVPs (in %) of 95% CIs of and at the true values of and .
Table 9.
Simulation results of ALs and COVPs (in %) of 95% CIs of and at the true values of and .
Table 10.
Simulation results of the Bayesian and with their MSErs, RBs, AMSEr, and ARB at the true values of and .
Table 11.
Simulation results of the Bayesian and with their MSErs, RBs, AMSEr, and ARB at the true values of and .
- The MPSEs are the best estimates through the AMSErs and ARBs.
- The MLEs are comparable to the LSEs, WLSEs, and PEs through the ARBs and AMSErs.
- The WLSEs are comparable to the LSEs and PEs through the ARBs and AMSErs.
- The LSEs are comparable to the PEs through the ARBs and AMSErs.
- The NACIs are comparable to the LTCIs through the AALs.
- For similar values of m and , and as n rises, the RBs, MSErs, ARBs, AMSErs, AL, and AAL decrease.
- For the same values of n, and , and as m increases, the RBs, MSErs, ARBs, AMSErs, AL, and AAL decrease.
- For similar values of n and m, by rising , the RBs, MSErs, ARBs, and AMSErs decrease for the MPSEs, MLEs, LSEs, and WLSEs, while the RBs, MSErs, ARBs, and AMSErs increase for the PEs.
- As increases, for the same values of n and m, the AL, and AAL decrease for CS.1 and CS.2, while the AL, and AAL increase for CS.3 and CS.4.
- As increases, for fixed values of n and m, the increases for CS.1 and CS.2, while the equals m for CS.3 and CS.4, where is the average number of observed failures when the experiment stops.
- The COVPs are close to 95%, as n, m, or increases.
6. Applications
The significance and applicability of the suggested KMGE model are illustrated using two real data sets from engineering and medical science. We use the “maxLik” program in the R package to compute likelihood estimates using the Newton–Raphson (NR) algorithms; for further information, see [41].
The first data set contains the minutes that 100 bank customers had to wait before receiving the service. It was first employed by [42]. “18.4, 18.9, 19, 27, 21.3, 21.4, 21.9, 23.0, 2.1, 2.6, 2.7, 2.9, 3.1, 3.2, 3.3, 3.5, 7.1, 7.1, 7.4, 3.6, 4.0, 0.8, 0.8, 19.9, 20.6, 4.1, 1.9, 4.8, 4.9, 4.9, 5, 4.2, 4.2, 4.3, 4.3, 4.4, 4.4, 4.6, 6.3, 6.7, 6.9, 7.1, 7.1, 7.6, 7.7, 8, 8.2, 8.6, 13.3, 13.6, 13.7, 8.6, 8.6, 8.8, 8.8, 8.9, 8.9, 9.5, 9.6, 9.7, 9.8, 10.7, 10.9, 11, 11, 11.1, 11.2, 4.7, 4.7, 1.3, 1.5, 1.8, 1.9, 5.3, 5.5, 5.7, 5.7, 6.1, 6.2, 6.2, 6.2, 11.2, 11.5, 11.9, 12.4, 12.5, 12.9, 13, 13.1, 13.9, 14.1, 15.4, 15.4, 17.3, 17.3, 18.1, 18.2, 31.6, 33.1, 38.5”.
The second dataset from [43] includes the number of hours (in thousands) between failures of secondary reactor pumps: “0.954, 0.491, 6.560, 4.992, 0.347, 0.070, 0.062, 0.150, 0.358, 0.101, 1.359, 3.465, 1.060, 0.614, 2.160, 0.746, 0.402, 1.921, 4.082, 0.199, 0.605, 0.273, 5.320”.
For data I: From Table 12, the MLEs (with their standard errors (SE)) of and , meanwhile the Kolmogorov–Smirnov test (KS) (p-value) was 0.0366 (0.9993). Figure 5 illustrates data I: the estimated and empirical CDF of KMGE in the left, the estimated and histogram of KMGE density in the center, and the generate and quantile (Q-Q) of the KMGE in the right for the waiting time before receiving the banking service data using a graphic visualization. In the results in Table 12, we can confirm that the data I have fitted the KMGE distribution.
Table 12.
MLE of complete sample for parameters of KMGE distribution.
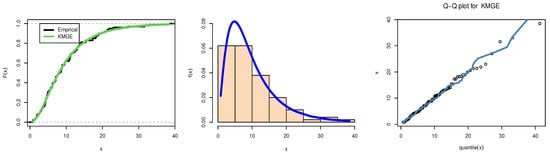
Figure 5.
Estimated PDF and CDF with lines plots and Q-Q plot: data I.
For data II: From Table 12, the MLEs (with their SE) of and , meanwhile the KS (p-value) was 0.1198 (0.8579). It means that the KMGE lifetime model fits the number of hours (in thousands) between failures of secondary reactor pumps data well. Figure 6 illustrates the estimated and empirical CDF of KMGE on the left, the estimated and histogram of KMGE density in the center, and the Q-Q of KMGE on the right for the number of hours (in thousands) between the failures of the secondary reactor pump data using a graphic visualization. From the results in Table 12, we can confirm that data II fitted the KMGE distribution.
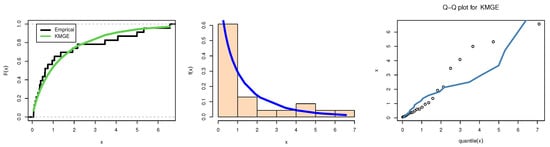
Figure 6.
Estimated PDF and CDF with lines plots and Q-Q plot: data II.
For the GTI-PHCS of data I: Different GTI-PHCS samples (where m = 80, = 70, and = 12) based on various CS selections were obtained from the waiting period before getting the banking service data and are shown in Table 13 to evaluate our acquired estimators. Also, MLE and Bayesian estimates based on GTI-PHCS for data I have been obtained in Table 14.
Table 13.
Sample observation based on GTI-PHCS: data I.
Table 14.
MLE and Bayesian Estimate based on GTI-PHCS: data I.
For the GTI-PHCS of data II: Different GTI-PHCS samples (where m = 20, = 15, and = 2) based on various CS as
CS.1: , and the where .
CS.2: , and the where .
CS.3: , and the where .
CS.4: , and the where .
selections were obtained from the number of hours (in thousands) between failures of secondary reactor pumps data and are shown in Table 15 to evaluate our acquired estimators.
Table 15.
Sample observation based on GTI-PHCS: data II.
Figure 7 and Figure 8 discussed the contour of the log-likelihood function in relation to different and values. It confirmed the results of the KS test and demonstrated the existence, uniqueness, and originality of the MLE. The Bayes estimates (along with their SE) were assessed using gamma priors which are also supplied in Table 14 and Table 16 because there was no prior knowledge about the unknown KMGE parameters and from the available data set. Figure 9 and Figure 10 show the trace plots of each generated sample to show how the MCMC iterations have converged. Figure 11 and Figure 12 discussed MCMC posterior density and scatter plot for parameters based on CS.4 for data I, data II, respectively.
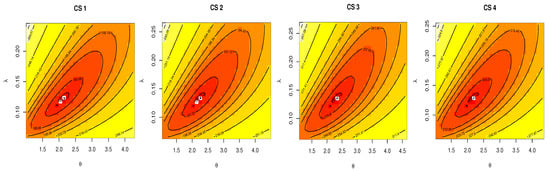
Figure 7.
Contour plots: data I.
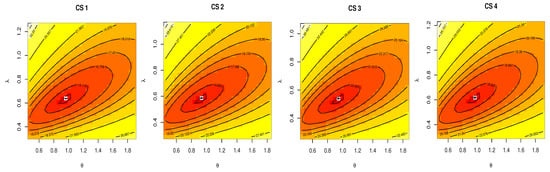
Figure 8.
Contour plots: data II.
Table 16.
MLE and Bayesian Estimate based on GTI-PHCS: data II.
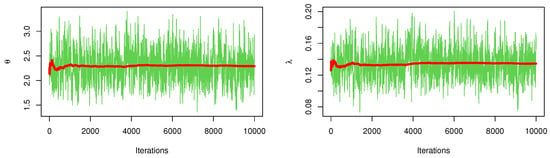
Figure 9.
MCMC trace plot with convergence line: data I, CS.4.
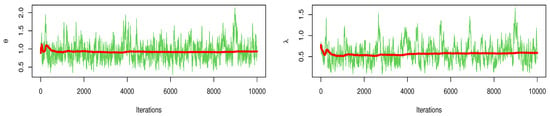
Figure 10.
MCMC trace with convergence line: data II, CS.4.
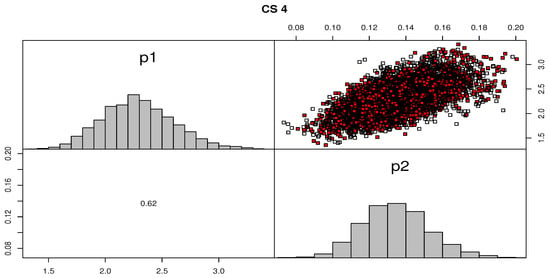
Figure 11.
MCMC posterior density and scatter plot: data I, CS.4.
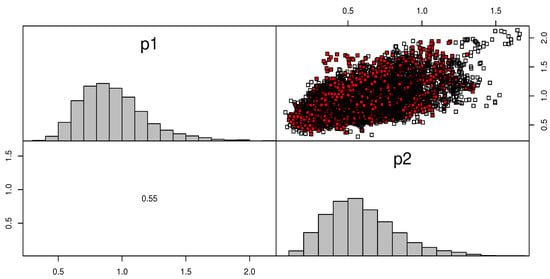
Figure 12.
MCMC posterior density and scatter plot: data II, CS.4.
7. Concluding Remarks
In this paper, we considered the problems of parameter estimation of the KMGE distribution under the generalized progressively hybrid censored samples. For point estimation, five classical approaches of estimation such as ML, MPS, LS, WLS, and PE are discussed. Moreover, the Bayesian approach is studied. For interval estimation, we use the ML method of estimation by using the normal approximation confidence interval and the normal approximation of log-transformed MLE. The considered five classical estimation methods were then compared in terms of RB, MSEr, ARB, AMSEr, and AL of CI via Monte Carlo simulations. The MPS method shows better performance than the other four classical estimation methods for most of the considered cases. Bayesian estimation of the unknown parameters is presented under informative prior using two different loss functions. The results in the illustrative example show that the proposed ML and Bayesian work well again. In summary, the improved estimation methods of the ML, MPS, LS, WLS, PE, and Bayesian approaches contribute to more accurate parameter estimation for the KMGE distribution. These methods have practical utility in industries such as finance, insurance, engineering, healthcare, environmental modeling, social sciences, and more. By utilizing these estimation methods, practitioners can obtain reliable parameter estimates, leading to improved decision-making and predictive modeling in real-world applications. Future studies will take into account the estimation problem based on a broad framework called unified hybrid censoring.
Author Contributions
Conceptualization, M.M.A.; Methodology, M.M.A., A.B.G., A.S.H., M.E., E.M.A. and A.F.H.; Software, E.M.A. and A.F.H.; Formal analysis, E.M.A. and A.F.H.; Data curation, M.M.A., A.B.G., A.S.H. and M.E.; Writing—original draft, M.M.A., A.B.G., A.S.H., M.E., E.M.A. and A.F.H.; Supervision, M.M.A., A.B.G., A.S.H., M.E., E.M.A. and A.F.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Data sets are available in the Section 6.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Epstein, B. Truncated life-tests in the exponential case. Ann. Math. Statist. 1954, 25, 555–564. [Google Scholar] [CrossRef]
- Cohen, A.C. Progressively censored samples in life testing. Technometrics 1963, 5, 327–329. [Google Scholar] [CrossRef]
- Kundu, D.; Joarder, A. Analysis of type-II progressively hybrid censored data. Comput. Statist. Data Anal. 2006, 50, 2509–2528. [Google Scholar] [CrossRef]
- Cho, Y.; Sun, H.; Lee, K. Exact likelihood inference for an exponential parameter under generalized progressive hybrid CS. Statist. Method. 2015, 23, 18–34. [Google Scholar] [CrossRef]
- El-Sherpieny, E.S.A.; Almetwally, E.M.; Muhammed, H.Z. Progressive Type-II hybrid censored schemes based on maximum product spacing with application to Power Lomax distribution. Phys. A Stat. Mech. Its Appl. 2020, 553, 124251. [Google Scholar] [CrossRef]
- Cho, Y.; Sun, H.; Lee, K. Estimating the entropy of a Weibull distribution under generalized progressive hybrid censoring. Entropy 2015, 17, 102–122. [Google Scholar] [CrossRef]
- Salem, S.; Abo-Kasem, O.E.; Hussien, A. On Joint Type-II Generalized Progressive Hybrid Censoring Scheme. Comput. J. Math. Stat. Sci. 2023, 2, 123–158. [Google Scholar] [CrossRef]
- Zhang, C.; Shi, Y. Statistical prediction of failure times under generalized progressive hybrid censoring in a simple step-stress accelerated competing risks model. J. Syst. Eng. Elect. 2017, 28, 282–291. [Google Scholar]
- Wang, L.; Tripathi, Y.M.; Lodhi, C. Inference for Weibull competing risks model with partially observed failure causes under generalized progressive hybrid censoring. J. Comput. Appl. Math. 2020, 368, 112537. [Google Scholar] [CrossRef]
- Koley, A.; Kundu, D. On generalized progressive hybrid censoring in presence of competing risks. Metrika 2017, 80, 401–426. [Google Scholar] [CrossRef]
- Abdel-Hamid, A.H.; Hashem, A.F. Inference for the Exponential Distribution under Generalized Progressively Hybrid Censored Data from Partially Accelerated Life Tests with a Time Transformation Function. Mathematics 2021, 9, 1510. [Google Scholar] [CrossRef]
- Sayed-Ahmed, N.; Jawa, T.M.; Aloafi, T.A.; Bayones, F.S.; Elhag, A.A.; Bouslimi, J.; Abd-Elmougod, G.A. Generalized Type-I hybrid censoring scheme in estimation competing risks Chen lifetime populations. Math. Probl. Eng. 2021, 2021, 6693243. [Google Scholar] [CrossRef]
- Nagy, M.; Alrasheedi, A.F. The lifetime analysis of the Weibull model based on Generalized Type-I progressive hybrid censoring schemes. Math. Biosci. Eng. 2022, 19, 2330–2354. [Google Scholar] [CrossRef] [PubMed]
- Nagy, M.; Alrasheedi, A.F. Estimations of generalized exponential distribution parameters based on Type I generalized progressive hybrid censored data. Comput. Math. Methods Med. 2022, 2022, 8058473. [Google Scholar] [CrossRef] [PubMed]
- Gupta, R.C.; Gupta, P.L.; Gupta, R.D. Modeling failure time data by Lehman alternatives. Commun. Stat.-Theory Methods 1998, 27, 887–904. [Google Scholar] [CrossRef]
- Mudholkar, G.S.; Srivastava, D.K. Exponentiated Weibull family for analyzing bathtub failure-rate data. IEEE Trans. Reliab. 1993, 42, 299–302. [Google Scholar] [CrossRef]
- Mudholkar, G.S.; Srivastava, D.K.; Freimer, M. The exponentiated Weibull family: A reanalysis of the bus-motor-failure data. Technometrics 1995, 37, 436–445. [Google Scholar] [CrossRef]
- Barreto-Souza, W.; Santos, A.H.; Cordeiro, G.M. The beta generalized exponential distribution. J. Stat. Comput. Simul. 2010, 80, 159–172. [Google Scholar] [CrossRef]
- Ristic, M.M.; Kundu, D. Marshall-Olkin generalized exponential distribution. Metron 2015, 73, 317–333. [Google Scholar] [CrossRef]
- Chaudhary, A.K.; Sapkota, L.P.; Kumar, V. Half-Cauchy Generalized Exponential Distribution: Theory and Application. J. Nepal Math. Soc. (JNMS) 2022, 5, 1–10. [Google Scholar] [CrossRef]
- Sapkota, L.P.; Kumar, V. Odd Lomax Generalized Exponential Distribution: Application to Engineering and COVID-19 data. Pak. J. Stat. Oper. Res. 2022, 18, 883–900. [Google Scholar] [CrossRef]
- Astorga, J.M.; Iriarte, Y.A.; Gómez, H.W.; Bolfarine, H. Modified slashed generalized exponential distribution. Commun. Stat.-Theory Methods 2019, 49, 4603–4617. [Google Scholar] [CrossRef]
- Alotaibi, N.; Elbatal, I.; Almetwally, E.M.; Alyami, S.A.; Al-Moisheer, A.S.; Elgarhy, M. Bivariate Step-Stress Accelerated Life Tests for the Kavya-Manoharan Exponentiated Weibull Model under Progressive Censoring with Applications. Symmetry 2022, 14, 1791. [Google Scholar] [CrossRef]
- Meeker, W.Q.; Escobar, L.A. Statistical Method for Reliability Data; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Cheng, R.C.H.; Amin, N.A.K. Estimating parameters in continuous univariate distributions with a shifted origin. J. R. Stat. Soc. B 1983, 45, 394–403. [Google Scholar] [CrossRef]
- Ng, H.K.T.; Luo, L.; Hu, Y.; Duan, F. Parameter estimation of three-parameter Weibull distribution based on progressively type-II censored samples. J. Stat. Comput. Simul. 2012, 82, 1661–1678. [Google Scholar] [CrossRef]
- Alotaibi, N.; Hashem, A.F.; Elbatal, I.; Alyami, S.A.; Al-Moisheer, A.S.; Elgarhy, M. Inference for a Kavya–Manoharan Inverse Length Biased Exponential Distribution under Progressive-Stress Model Based on Progressive Type-II Censoring. Entropy 2022, 24, 1033. [Google Scholar] [CrossRef] [PubMed]
- Swain, J.J.; Venkatraman, S.; Wilson, J.R. Least-squares estimation of distribution function in Johnson’s translation system. J. Statist. Comput. Simul. 1988, 29, 271–297. [Google Scholar] [CrossRef]
- Abdel-Hamid, A.H.; Hashem, A.F. A new lifetime distribution for a series-parallel system: Properties, applications and estimations under progressive type-II censoring. J. Statist. Comput. Simul. 2017, 87, 993–1024. [Google Scholar] [CrossRef]
- Hashem, A.F.; Alyami, S.A. Inference on a New Lifetime Distribution under Progressive Type-II Censoring for a Parallel-Series structure. Complexity 2021, 2021, 6684918. [Google Scholar] [CrossRef]
- Hashem, A.F.; Kuş, C.; Pekgör, A.; Abdel-Hamid, A.H. Poisson-logarithmic half-logistic distribution with inference under a progressive-stress model based on adaptive type-II progressive hybrid censoring. J. Egypt Math. Soc. 2022, 30, 15. [Google Scholar] [CrossRef]
- Aggarwala, R.; Balakrishnan, N. Some properties of progressive censored order statistics from arbitrary and uniform distributions with applications to inference and simulation. J. Stat. Plann. Inf. 1998, 70, 35–49. [Google Scholar] [CrossRef]
- Kao, J.H.K. A graphical estimation of mixed Weibull parameters in life testing electron tube. Technometrics 1959, 1, 389–407. [Google Scholar] [CrossRef]
- Dey, S.; Ali, S.; Park, C. Weighted exponential distribution: Properties and different methods of estimation. J. Stat. Comput. Simul. 2015, 85, 3641–3661. [Google Scholar] [CrossRef]
- Dey, S.; Singh, S.; Tripathi, Y.M.; Asgharzadeh, A. Estimation and prediction for a progressively censored generalized inverted exponential distribution. Stat. Methodol. 2016, 32, 185–202. [Google Scholar] [CrossRef]
- Hamdy, A.; Almetwally, E.M. Bayesian and Non-Bayesian Inference for The Generalized Power Akshaya Distribution with Application in Medical. Comput. J. Math. Stat. Sci. 2023, 2, 31–51. [Google Scholar] [CrossRef]
- Varian, H.R. Bayesian approach to real estate assessment. In Studies in Bayesian Econometrics and Statistics; Savage, L.J., Feinderg, S.E., Zellner, A., Eds.; North-Holland: Amsterdam, The Netherlands, 1975; pp. 195–208. [Google Scholar]
- Bantan, R.; Hassan, A.S.; Almetwally, E.; Elgarhy, M.; Jamal, F.; Chesneau, C.; Elsehetry, M. Bayesian analysis in partially accelerated life tests for weighted lomax distribution. Comput. Mater. Contin 2021, 68, 2859–2875. [Google Scholar] [CrossRef]
- Almongy, H.M.; Almetwally, E.M.; Alharbi, R.; Alnagar, D.; Hafez, E.H.; Mohie El-Din, M.M. The Weibull generalized exponential distribution with censored sample: Estimation and application on real data. Complexity 2021, 2021, 6653534. [Google Scholar] [CrossRef]
- Alotaibi, R.; Alamri, F.S.; Almetwally, E.M.; Wang, M.; Rezk, H. Classical and Bayesian Inference of a Progressive-Stress Model for the Nadarajah–Haghighi Distribution with Type II Progressive Censoring and Different Loss Functions. Mathematics 2022, 10, 1602. [Google Scholar] [CrossRef]
- Henningsen, A.; Toomet, O. maxLik: A package for maximum likelihood estimation in R. Comput. Stat. 2011, 26, 443–458. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Atieh, B.; Nadarajah, S. Lindley distribution and its application. Math. Comput. Simul. 2008, 78, 493–506. [Google Scholar] [CrossRef]
- Suprawhardana, M.S.; Prayoto, S. Total time on test plot analysis for mechanical components of the RSG-GAS reactor. At. Indones 1999, 25, 81–90. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).