Abstract
Recently, the style-based generative adversarial network StyleGAN2 yields state-of-art performance on unconditional high-quality image synthesis. However, from the perspective of steganography, the image security is not guaranteed during the image synthesis. Relying on the optimal properties of StyleGAN2, this paper proposes a noise-optimization stacked StyleGAN2 named NOStyle to generate the secure and high-quality cover (image used for data hiding). In our proposed scheme, we decompose the image synthesis into two stages with symmetrical mode. In stage-I, StyleGAN2 is preserved to generate a high-quality benchmark image. In the stage-II generator, based on the progressive mechanism and shortcut connection, we design a noise secure optimization network by which the different-scale stochastic variation (noise map) is automatically adjusted according to the results of the stage-II discriminator. After injecting the stochastic variation into different resolutions of the synthesis network, the stage-II generator obtains an intermediate image. For the symmetrical stage-II discriminator, we combine the image secure loss and fidelity loss to construct the noise loss which is used to evaluate the difference between two images generated by the stage-I generator and stage-II generator. Taking the outputs of stage-II discriminator as inputs, by iteration, the stage-II generator finally creates the optimal image. Extensive experiments show that the generated image is not only secure but high quality. Moreover, we make a conclusion that the security of the generated image is inverse proportion to the fidelity.
1. Introduction
Steganography is a technology to embed additional data into digital media by slight alteration to achieve covert communication without drawing suspicion [1]. Generally, the original digital media (cover) is the spatial/JPEG images which can be chosen from the standard image sets or be downloaded from the Internet [2]. For all the steganographic algorithms, the effect of data embedding can be viewed as adding a string of independent pseudo noise to the cover and the modified image is called a stego image [3]. Therefore, after data embedding, the steganographic changes are concealed by the cover content. In order to measure the distortion caused by embedding operation, each element (pixels for an uncompressed image or non-zero AC coefficient for a JPEG image) is assigned a distortion value computed by the predefined distortion function and total embedding distortion of all cover elements can be theoretically minimized with the aid of Syndrome-Trellis codes (STC) which nearly reaches the payload-distortion bound [4,5,6]. To achieve high security, a group of novel content-adaptive embedding algorithms are developed, such as wavelet obtained weights (WOW) [7], spatial universal wavelet relative distortion (S-UNIWARD) [8], high-pass low-pass and low-pass (HILL) [9,10], minimizing the power of optimal detector (MiPOD) [11], JPEG universal wavelet relative distortion (J-UNIWARD), uniform embedding distortion (UED), and uniform embedding revisited distortion (UERD) [10]. The underlying designing principle of these steganographic algorithms is that the complex region used for loading message is difficult to be modelled with simple and single statistical model [12,13].
To detect whether the suspicious image is a cover or a stego one, the effective and typical method is steganalysis containing two separated parts denoted as feature extraction and ensemble classifier (EC) training [14]. Generally, the feature extraction is to handle the cover/stego objects by a set of diverse linear and non-linear high-pass filters to suppress the image content and expose the minor steganographic changes. Then, the computed residual samples are represented with one-dimensional or two-dimensional statistical feature. The existed excellent features are spatial rich model (SRM) [15], JPEG rich model (JRM) [16], and DCT residuals (DCTR) [17]. After training EC with extracted feature, we can obtain an optimal classifier owning outstanding detection performance.
From the aspect of content-adaptive steganography [18], even with STC, if the cover is not secure, therefore, the corresponding stego image is easily detected by the trained classifier. Moreover, if the cover is downloaded from the Internet, the risk of repetitive compression of the chosen JPEG image is so high [19]. Although there are some existing steganographic works focusing on the transport channel, the multiple upload and download operations may arouse the third part vigilance [20,21]. Therefore, to obtain directly optimal cover, the synthesis of secure cover is desirable and has practical significance.
In the past few years, the photo-realistic image synthesis has become a hot topic. However, due to the complex and high dimensionality of natural image, the generation of high-quality images become a tough task. The modern and effective approach to conquer this problem is the generative adversarial network (GAN) which aims to build a good generative model of natural images by the competition of a generator and a discriminator [22]. Based on GAN, numerous novel schemes have been proposed. Zhang et al. proposed stacked GAN (StackGAN) including two stages of generator training to generate vivid image containing low- and high-resolution object parts. Combing the Laplacian pyramid framework, Emily Denton et al. described a Laplacian pyramid GAN (LapGAN) architecture to achieve a coarse-to-fine mode of image generation [23]. However, when the resolution of generation is high, the architecture of StackGAN or LapGAN is deep and the training processing is rather slow. In order to deal with the mentioned problems, Karras et al. proposed PGGAN [24]. The key idea of PGGAN is to progressively train the generator and discriminator from the low resolution () to the high resolution () with lower training time complexity. Following the progressive growing mechanism, Karras et al. proposed StyleGAN and StyleGAN2 which can control the synthesis of high-quality images by the disentanglement and style mixing [25]. Moreover, by injecting the noise into different layers of the synthesis network, StyleGAN and StyleGAN2 achieve the stochastic realizations of generated image at various scales, especially for the high-level attributes [26]. However, from the perspective of steganography, the generated image may be unsuited to be used as a cover to accomplish the secure communication.
Since the effect of stochastic variation adjustment relies on the injected noise at each layer of synthesis network, due to the similar adding operation, we hypothesize that this noise-adding operation can be seen as another type of data embedding (steganography). Therefore, if the injecting noise is optimized, along with the image synthesis, we could obtain the proper images which own higher security. Motivated by the abovementioned works, this article proposes a noise-optimization stacked StyleGAN2 named NOStyle for secure steganographic cover generation. The proposed scheme aims to enhance the security and, meanwhile, keep the fidelity of generated image. As shown in Figure 1, the whole architecture of NOStyle is segmented into two stages with symmetrical mode. The structure of the first stage is the same as StyleGAN2 composed by a set of stage-I generator (SI-G) and stage-I discriminator (SI-D). The second stage also includes a pair of new stage-II generator (SII-G) and discriminator (SII-D). In Figure 1, we show the detailed framework.
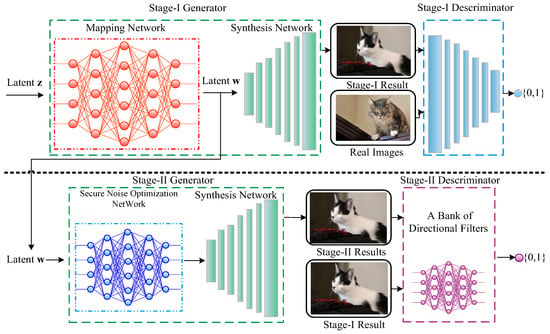
Figure 1.
Sketch of the proposed architecture.
MN firstly uses a latent code z as the input and outputs an intermediate latent code w. Then, with w and the progressive growing, SI-G generates an image. Meanwhile, compared with a real image, SI-D makes judgement whether the quality of generated image is vivid. After iteration and parameter optimization, SI-G creates the high-quality benchmark image. At the second stage, based on the basic architectural of StyleGAN2, we design a new generator SII-G composed by a secure noise optimization network (SNON) and a synthesis network (SyN).
Consider the disentanglement and progressive growing, SNON aims to achieve the controlling of image details by adjusting the noise and injecting the optimized noise into finer layer ( and ) of SyN. In SII-D, we design a noise loss, including the image secure loss and fidelity loss, and compute the difference between the outputs of SI-G and SII-G. By minimizing the noise loss, SNON outputs multiple-scale optimized noise maps which are injected into the corresponding scales of SyN and we finally obtain the secure and high-quality image (cover). Therefore, after image synthesis, the proposed architecture generates the vivid image, while the security of generated image is enhanced.
Summarily, the whole training can be separated into two stages. In the first phase, with given dataset, we obtain a typical StyleGAN2 which accomplishes image generation task and outputs a benchmark high-quality image. Then, applying SNON and the noise loss, we achieve the noise optimization and image evaluation. Finally, the proposed architecture generates a vivid image. The contributions of this article are listed as follows:
- We hope to make a tightly connection between the image generation and the steganography. Consider the image synthesis, we hypothesis the noise injection is seen as another type of steganography. Hence, by optimizing the injecting noise map, the security of generated image can be enhanced and guaranteed.
- The proposed architecture NOStyle which is to balance between the security and quality of generated image. To achieve this goal, combing the image secure loss and fidelity loss, we design the noise loss that can evaluate the complexity and fidelity of generated image.
- We try to make a conclusion between the security and fidelity of image. To give a clearer explanation, we calculate the Fréchet inception distance (FID) and give various secure testing on multiple steganographic algorithms. According to the experimental results, it is clearly that, for the style-based image synthesis, the security of the generated image is inverse proportion to the fidelity.
The rest of this article is organized as follows. In Section 2, we show the basic notation, the basic theory of GAN, concept of secure steganography, and a typical steganographic distortion. The detailed architecture and the training processing of our proposed scheme are described in Section 3. In Section 4, we give extensive experiments and detailed analysis on the security and quality of generated image. Finally, Section 5 concludes the whole paper and provides further discussion.
2. Preliminaries
2.1. Notation
Throughout the whole paper, the capital letters are used for random variables and the boldface symbols stands for matrices and vectors. The symbol represents the cover image (spatial/JPEG) and is the corresponding stego image. According to the image format, the dynamic range of each element of cover or stego image is or . Meanwhile, M represents the embedding data. If the range of embedding change is set to 2 or 3, the embedding operation is called binary or ternary embedding.
2.2. Generative Adversarial Networks
Generative adversarial networks (GAN) are used to alternatively train the generator G and the discriminator D by competitive mechanism. The optimized G aims to create the true data distribution represented by the fake images which are hard for the optimized D to differentiate from real images. The terminal point of competition mechanism is to achieve the Nash equilibrium [22] with value function . Overall, the procedure is defined as a min-max game between G and D. The optimized procedure is defined as follows,
where pdata is the true data distribution which is used to generate a real data x. To the opposite, z is a noise vector sampled from distribution pz. Meanwhile, E is the expectation to evaluate the difference between pdata and pz. Generally, pz is uniform or Gaussian distribution.
2.3. Concept of Secure Steganography
Content secure steganography is achieved by the combination of STC and distortion function. Generally, the distortion function is designed to measure the distortion caused by embedding changes. Assume the given cover and stego , the differences between and are measured by assigning embedding cost matrix on each image elements, where , . Suppose the target payload capacity of embedding message M is and the embedding operation is independent, after data embedding, the overall distortion can be represented as the sum of each individual distortion value,
where is defined as the probability to modify .
Here, is a positive parameter which must be used to satisfy the Equation (4),
Using the deduction, the payload-limited steganography is obtained by solving a constrained optimization problem defined as
where is the stego distribution and it means that sender embeds a fixed average payload of bits while minimizing the average distortion with STC.
2.4. Distortion Function in WOW
There are many classical spatial/JPEG distortion functions and the typical distortion functions are WOW, S-UNIWARD, and J-UNIWARD. These distortion functions always use a set of directional filter banks to evaluate the smoothness of an image along horizontal, vertical, and diagonal directions. Given three linear shift-invariant wavelet filters , we obtain three directional residuals:
where is a mirror-padded convolution operation and .
Assume a pair of cover and stego images is and , applying the convolution operation, we compute and , , and . Then, the distortion is defined as the weighted absolute values of the filtered residual differences between and (only one difference at position ) and the distortion value is computed as
where is a constant stabilizing the numerical calculations. When the directional residual is larger, the distortion is smaller. To minimize the embedding distortion, the data are always embedded into the complex and non-modellable regions in which the computed residuals are larger.
3. Proposed NOStyle Architecture
3.1. Basic Idea
In the proposed work, based on StyleGAN2, we design a secure cover generation architecture. Specifically, the mapping network takes a latent code z as the input to generate an intermediate latent code w. Then, using z and w, the generator outputs a high-quality image from low-resolution to high-resolution with progressive growing and stochastic variation (noise map).
Consider the distinguishing characteristics of typical architecture StyleGAN2 and the demanding of security, the main goal of our proposed architecture is to enhance the security of generated image by optimizing the stochastic variation, while the fidelity of created image is kept as vivid as possible [27,28,29]. Unlike the previous works StyleGAN and StyleGAN2, the stochastic variation represented as noise map is not random and, based on the progressive growing and short connection [30,31,32], we design a secure noise optimization network (SNON) which aims to optimize the noise map. After optimization, we can obtain proper noise map which will be involved in the synthesis of the high-resolution and secure image. Apart from the network structure, the convergence of SNON relies on the output of SII-D in which we combine the predefined steganographic distortion function and learned perceptual image patch similarity (LPIPS) to construct the noise loss which is employed to evaluate the differences between the two results of SI-G and SII-G. Here, we hypothesis that, for image generation, the security and fidelity are two contradictory topics. Therefore, our proposed scheme is a strategy which tries to makes a tradeoff between the security and fidelity.
3.2. Proposed Architecture Overview
According to the methodology described above, we now give a detailed description of the architecture of NOStyle which is shown in Figure 2 and the details are described as follows.
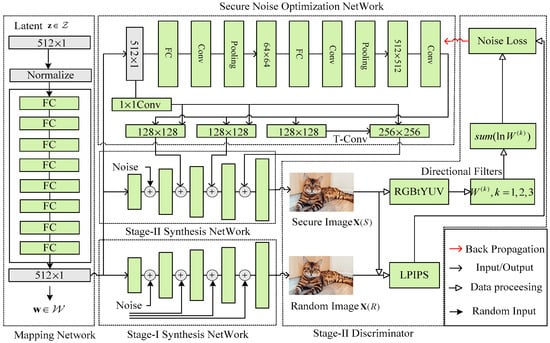
Figure 2.
Details of the proposed architecture.
It is obvious that our proposed architecture mainly owns five dependent parts which are MN, SNON, stage-I SyN, stage-II SyN, and SII-D. The stage-I NOStyle generator is inherited from original StyleGAN2 including MN and stage-I SyN. In the first stage, we apply the StyleGAN2 to generate a high-quality image which is used as a benchmark image and is injected into SII-G. Taking SI-G results as input, the second stage-II NOStyle optimizes the injecting noise and generates a high-quality/secure image. The architecture of the stage-II NOStyle is composed of SNON, stage-II SyN, and SII-D. The designing principle of SNON is motivated by the progressive growing and short connection by which different-scale noise map is optimized and injected into finer layers of the stage-II SyN. Employing the optimized noise map, the random noise z, and an intermediate latent code w, stage-II SyN finally outputs the high-quality and secure image. Here, the architectures of stage-I SyN and stage-II SyN are the same and the differences focus on the inputs of network.
Generally, the per-pixel added noise map is sample from the Gaussian distribution . Suppose the added noise map is , combining , the synthesis networks Stage-I SyN can output a random image . With the same latent code , Stage-II SyN generates a secure image . Then, and are entered into SII-D. Using the wavelet filter banks and LPIPS, SII-D constructs the noise loss (NL) to evaluate the complexity and fidelity of the generated image. By minimizing NL, we can adjust the injecting noise map. The details are illustrated in Section 3.3.
3.3. Structural Design
As discussed above, the proposed architecture mainly consists of MN, SNON, SyN, and SII-D. The individual parts are described as follows.
- Mapping network (MN) accepts a non-linear latent code as the input, where is the corresponding density in the training data. The original is represented as the combination of many factors of variations. According to theory of disentanglement, the optimal latent code should be the combination of linear subspaces, each of which controls one factor of variation. Then, after normalization and eight full connected layers (FC), is disentangled and we obtain a more linear intermediate latent code .
- Synthesis network (SyN) takes a latent code to generate a vivid image with the progressive growing and noise. During the training of network, this architecture aims to firstly create low resolution images and then, step by step, output higher resolution images. Therefore, the different resolution features are not affected by each other. Meanwhile, without affecting the overall features, the injected noise adjusts the local changes to make the image more vivid.
- Generator network contains two networks which are stage-II SyN and SNON. The first network (Figure 3, right) is the synthesis network and another (Figure 3, left and middle) is the noise optimization network. Consider the optimal characters of the disentangled latent code , these two networks also use as the input.
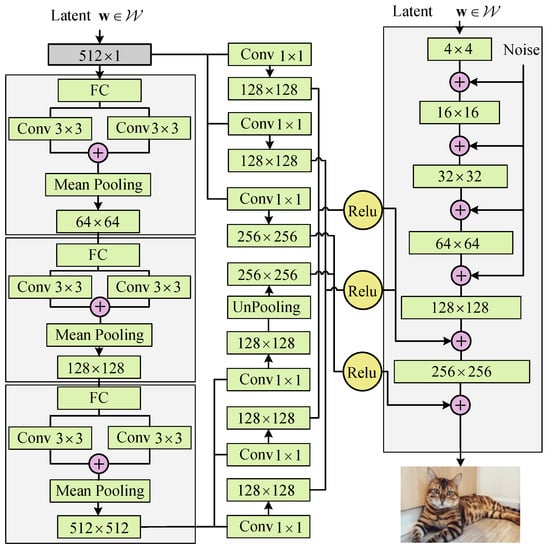 Figure 3. Detailed description of the generator architecture.
Figure 3. Detailed description of the generator architecture.
Our noise optimization network is mainly inspired by PGGAN and ResNet [33,34,35]. Two simple designing rules are given to optimize the injecting noise: First, we introduce the progressive mechanism to generate the noise with the same size as the different resolution image. Second, the disentangled latent code is indirectly utilized to form the secure noise by shortcut connection. The progressive model is formed by three blocks in which there are a full connected layer, two convolution layers, and an average pooling layer with stride of 1. Each block aims to shift the low resolution to the high resolution. Therefore, after three times promoting, the latent code is changed into a feature map. Here, we want to adjust the injecting noise at two resolutions ( and ). Hence, we narrow the number of feature map into resolution with three convolution kernels and obtain three corresponding feature maps denoted as Rn1, Rn2, and Rn3, respectively.
We deduce that the disentangled latent code is useful to construct the secure noise. To fully utilize , we introduce an underlying mapping to represent as . Motivated by the previous works, we decide to adopt three convolution kernels to achieve the mapping and output three feature maps Rw1, Rw2, and Rw3 sized by , , and , respectively. Therefore, we totally obtain six feature maps which are Rn1, Rn2, Rn3, Rw1, Rw2, and Rw3.
We deem that the merged operation can enhance the effectiveness of feature maps. Therefore, we merge four different feature maps into two groups which are denoted as and . After applying the activation function (leaky ReLU) to and , two noise maps are created and injected into layers of the synthesis network. Moreover, by up-sampling, we double the size of feature map Rw3 into . Combing Rw3 and the same activation function leaky ReLU, the third group is turned into the third noise map which will be injected into layer of the synthesis network. For other layers of stage-II SyN, the injected noise maps are kept unchanged.
3.4. Loss Function
The SII-D and SII-G will be trained according to the noise loss which is the combination of the image secure loss and fidelity loss . Image secure loss is used to measure the complexity of image [36]. As discussed in Section 2.4, with the filter banks , three directional residuals are obtained, where . Suppose we directly use as the image secure loss, the quality of generated image will be dominated by the image secure loss . Therefore, the created image could lack fidelity. In our scheme, we use “ln” operation to turn the larger residual into the smaller one. Combining three converted residuals, is written as
Fidelity loss is to make the synthetic image more vivid. Inspired by optimal characteristics of LPIPS, we adopt LPIPS matrix as our feature-level loss to evaluate the quality of generated image. LPIPS matrix is the average of normalized and extracted feature of total stacks. Assume the reference and distorted patches are and sized by , given a network owning L layers, we compute the normalized and scaled embedding parameters , of layer l. Collecting all parameters of total layers, distance between and is computed as follows
where is the scale parameter which is equivalent to the cosine distance. is defined as
We hypothesize that the security and the fidelity are contradictory topics. It means that if is higher, the generated image may be more secure and less vivid. However, when is lower, the quality of the created image could be higher. Therefore, the final distortion should make a tradeoff between and . Following the described hypothesis, the noise loss is defined as the sum of the secure loss and fidelity loss:
where and are the tunable parameters.
To give a clear explanation, the processing of the proposed scheme is described in Algorithm 1.
| Algorithm 1 Secure Image (Cover) Generation |
| Input: a pre-trained StyleGAN2 generator SI-G; a latent code w; SNON; stage-II SyN; a discriminator SII-D; a random noise map N ∈ ; the noise loss . Output: secure synthesis image (cover) X(S).
|
4. Experimental Results and Discussion
In this section, we show the extensive experimental results for the performance evaluation and image quality analysis.
4.1. Settings
4.1.1. Image Sets
In our scheme, there are totally three image sets which are used in our experiments. The first one is the LSUN containing around one million labeled images for each of ten scene categories and twenty object categories. We decide to choose the LSUN Cat as training set which is used in the two stages of NOStyle. Here, due to the high demanding of GPU and energy consumption, we adopt the pre-trained model as the choice of the first stage of our architecture. The second image set named GSI (generated secure images) contains 80,000 gray images created by StyleGAN2, NOStyle-SLA, NOStyle-SLB, and NOStyle. NOStyle-SLA and NOStyle-SLB are the monolayer version of NOStyle. The third image set includes 10,000 images which are the down-sampled version of BOSSbase ver.1.01 by the “imresize” Matlab function [37].
4.1.2. Steganographic Methods
Totally, four steganographic methods are used as the testing algorithms, including spatial method S-UNIWARD, two JPEG methods J-UNIWARD and UED, and a deep learning steganographic method SGAN. S-UNIWARD and J-UNIWARD are based on the directional high-pass filter groups which have been discussed in Section 2.4. For these methods, the steganographic distortions are relied on the directional residuals which are computed from the spatial/decompressed JPEG image. Based on the intra/inter-block neighborhood coefficients, another typical steganographic method UED aims to minimize the whole statistical changes of DCT coefficients by modifying the non-zero quantized DCT coefficients with equal probability. Apart from the classical methods, there exists many GAN-based and CNN-based schemes. Among these methods, SGAN utilizes the GAN-based architecture to achieve better security.
Generally, the amount of embedded data is measured by the payload which is represented as the ratio of the capacity of embedding data and the available elements (pixels or non-zero JPEG coefficients). According to the format of cover, the payload is measured as the bits per pixel (bpp) or bits per non-zero AC coefficient (bpnzAC). For example, assume the capacity of the embedding data is C and the number of available pixels is N, the relative payload is . Applying STC, the message is embedded into a cover with the minimized distortion to achieve undetectability.
4.1.3. Steganalyzers
Three novel steganalyzers DCTR, JRM, and SRMQ1 are employed to evaluate the security performance of the generated images. Depending on the mutual position of two adjacent/nonadjacent coefficients, SRMQ1 and JRM use co-occurrence to show the correlation of coefficients and statistical dependency. DCTR is the first-order statistics of quantized noise residuals which are calculated from the decompressed JPEG image using 64 kernels of the discrete cosine transform.
4.1.4. Security Evaluation
The security evaluation is carried on two databases GSI and BOSSbase ver.1.01. Meanwhile, the chosen classifier is called an ensemble classifier in which, based on subspace of original feature space, a series of sub-classifier is constructed, and the final decision is made by mixing the individual decision of each sub-classifier denoted as Fisher linear discriminator (FLD).
The whole experimental process is divided into two stages denoted as training and testing. At the training stage, using the designated steganography algorithm and cover dataset, we can construct the corresponding stego images. Then, for the cover and stego set, we randomly choose one half of these two image sets with equal number and create the training set. Finally, based on the statistical difference between the selected cover and stego images, we obtain a trained ensemble classifier which can be employed to judge whether an image is a cover or stego one.
Combing the remaining cover and stego images, we construct the testing set and the performance is evaluated on the testing set. In the testing stage, there are two kinds of testing errors. The first one is that a cover is judged as a stego and the second case is that a stego is seen as a cover. These two errors, respectively, stand for the false alarm and missed detection which are abbreviated to PFA and PMD. Finally, the classification error is defined by the minimal average error under equal probability of these two errors,
The security of the generated cover is evaluated by PE and higher PE means cover owns better security.
4.2. Key Elements of Proposed Architecture
4.2.1. Image Secure Loss
As discussed in Section 3.4, the image secure loss aims to guarantee the security of generated image. According to Equation (8), we use the directional residuals to design the image secure loss. Let us suppose the directional residuals are large, if we directly use them to build the image secure loss , the final noise loss could be dominated by and the affection of may be ignored. In this case, the fidelity of the generated image cannot be guaranteed. To give a clear explanation, we give a comparison on the generated normal image and abnormal image which is created without using the “ln” operation. According to the results shown in Figure 4, compared with normal image (left image), it is clearly that the generated image (right image) looks like a random noise. Therefore, it is necessary to use the “ln” operation to turn the larger directional residuals to be the smaller one.

Figure 4.
Two generated images. (a) Generated by StyleGAN2. (b) Generated by NOStyle without using “ln” operation.
4.2.2. Fidelity Loss
As analysis in Section 3.3, fidelity is another key part to construct the noise loss. Inspired by the optimal charateristics of LPIPS, we use LPIPS to measures the fidelity of the generated image. We find that only using the image secure loss may make the image less vivid. Even when the operation “ln” is used, the fidelity of image cannot be guaranteed. To reveal the affections of fidelity loss, we represent a group of comparison images shown in Figure 5. The left image is generated by StyleGAN2 and the right one is created by NOStyle without using LPIPS. Compared with StyleGAN2, the generated image is blurry. Hence, according to the comparative results of Figure 4 and Figure 5, the final noise loss should be the optimal combination of the image secure loss and fidelity loss.

Figure 5.
Two generated images. (a) Generated by StyleGAN2. (b) Generated by NOStyle without using LPIPS.
4.2.3. Hyperparameters
Based on the conclusions on analysis above, and are both important keys to generate the secure and high-quality image. Consider the value of residuals and LPIPS, two tunable parameters were set to and . Meanwhile, we use leaky ReLU with slope and the equalized learning rate for all layers. To enhance the quality of image, we follow the some valuable conclusions and use the truncation trick to capture the area of high density. Here, the truncated parameter is set to 0.5. Meanwhile, an Adam optimizer with learning rate 0.1 is used to train our network.
4.3. Ablation Experiment
According to the discussion in Section 3.2, by iteration, the proposed architecture aims to generate and adjust the injecting three noise map groups , , and to enhance the security of generated image. Here, each size of three noise map groups is , , and . To evaluate the affection of each noise map group, we individually inject and into synthesis network to create image and the generative methods are named NOStyle-SLA and NOStyle-SLB.
To testify the security of above two methods, we choose two image datasets BOSSbase and GSI as the cover sets. Firstly, all spatial images are compressed into JPEG version with quality factor 75 and 95. Then, we employ steganographic methods J-UNIWARD and UED to create stego images. After extracting the DCTR feature and applying the ensemble classifier, the results are given in Table 1, Table 2, Table 3 and Table 4 which are listed as follows.

Table 1.
Detection error comparison of BOSSbass, StyleGAN2, NOStyle-SLA, and NOStyle-SLB for detecting J-UNIWARD with DCTR for JPEG quality factors 75.
Table 2.
Detection error comparison of BOSSbass, StyleGAN2, NOStyle-SLA, and NOStyle-SLB for detecting J-UNIWARD with DCTR for JPEG quality factors 95.
Table 3.
Detection error comparison of BOSSbass, StyleGAN2, NOStyle-SLA, and NOStyle-SLB for detecting UED with DCTR for JPEG quality factors 75.
Table 4.
Detection error comparison of BOSSbass, StyleGAN2, NOStyle-SLA, and NOStyle-SLB for detecting UED with DCTR for JPEG quality factors 95.
We observe that the security of images generated by NOStyle-SLA and NOStyle-SLB outperform the standard image set BOSSbase and another image set created by StyleGAN2. Across six relative embedding rates, the average improvements of NOStyle-SLA and NOStyle-SLB over StyleGAN2 are about 0.44% and 1.21%. Moreover, the results show that, at most relative payloads, NOStyle-SLB is more secure than NOStyle-SLA. Therefore, we make a conclusion that, compared with , the noise map group can effectively enhance the security of generated images. Since and also show the ability of raising the security of generated image, in our final scheme, and are both employed to create the secure image (cover).
4.4. Quality of Generated Images
4.4.1. Comparison of Macroscopic Architecture
Based on LSUN CAT and the optimal parameters, we own three image synthesis methods which are NOStyle-SLA, NOStyle-SLB, and NOStyle. Combining the novel method StyleGAN2, we totally obtain four methods. Using different image generation methods, with the same non-linear latent code z, we can create similar image with the same scene. In Figure 6, we give a set of comparison examples. Each comparison image includes two sub-images which are generated by StyleGAN2 (left sub-image) and NOStyle (right sub-image). The results show that the overall structure of each image is almost the same and the stochastic details of generated image are precisely represented. Therefore, we can see that the quality of the images generated by NOStyle is rather high. However, if we carefully observe the image, we find that there are some tiny differences distributed in the detailed region. The corresponding analysis of comparison results will be given in next subsection.

Figure 6.
Macroscopic comparison of two methods. Four sub-figures (a–d) are generated by StyleGAN2 and NOStyle. Each sub-figure contains two images. The left one is an image generated by StyleGAN2 and the right image is created by NOStyle.
Except the visual characteristic, we hope to discuss the feature representation of generated image. As discussed in [25], Fréchet inception distance (FID) is an excellent value to measure the quality of image. Lower FID score is an indicator of high-quality images, and vice versa. FID is defined as
Suppose p(·) and pw(·) represent the distribution of generated images and real images, m and C are the mean and variance of p(·). mw and Cw are the mean and variance of pw(·). Here, for 80,000 generated images, we also calculate FID to measure the quality of image. The corresponding FIDs are listed in Table 5.
Table 5.
Fréchet inception distance (FIDs) for four synthesis models.
The results of Table 5 show that FID of NOStyle is highest and, to the opposite, the corresponding value of StyleGAN2 is lowest. According to the related conclusion, lower FID means the quality of generated images is higher. Therefore, we conclude that the quality of the image generated by model NOStyle is lower than the other three generative networks. However, the gap between the four FID values is quite small and we can infer that, for the given four image generative methods, the difference in image quality is rather small. Meanwhile, compared with FIDs of NOStyle-SLA and NOStyle-SLB, we see that the FID value of NOStyle-SLB is a little higher than the FID of NOStyle-SLA. Hence, the generated image of model NOStyle-SLA is higher than the corresponding result of NOStyle-SLB. Combing the detection results and FID, for the unconditional high-quality image synthesis, we conclude that higher FID value means higher image security. Here, we suppose that there is tight connection between the FID and image security. To give more explanations, the corresponding analysis will be discussed in Section 4.6.
4.4.2. Detail Comparison of Various Methods
According to the experimental results in [24] and analysis above, StyleGAN2 displays excellent performance to generate high-quality image. Compared with StyleGAN2, NOStyle keeps some key architectures including MN and SyN. The big differences between these two style-based generative networks focus on SNON and stage-II discriminator. Therefore, compared with multiple images generated by different generative models, we assert that the styles corresponding to coarse and middle spatial resolutions are the same, while the details distributed into the complex regions have minor differences.
To show the local difference of various generated images, we focus on the same complex region of four images created by StyleGAN2, NOStyle-SLA, NOStyle-SLB, and NOStyle. Then, we give comparison results in Figure 7. It is clear, for the given four methods, the chosen regions look almost the same. However, if we carefully observe four comparison results, we know that there are some tiny differences distributed in the complex region. The reason is that we just adjust the high-resolution noise maps. In fact, these spatial differences bring about changes in security and fidelity. Figure 8 gives the examples of the generated covers, the corresponding stego images, and the modification maps. The stego images are generated by J-UNIWARD on 0.2 bpnzAC for JPEG quality factors 85. Although four stego images look like almost the same, the modification maps show that the embedding changes in DCT domain are quite different. From the view of steganography, the embedding differences cause the difference of security and we conclude that there is a strong connection between the image synthesis and security.

Figure 7.
Details comparison of four generative models. For four sub-figures (a–d), each sub-figure contains five sub-images which are generated by StyleGAN2, NOStyle-SLA, NOStyle-SLB, and NOStyle, respectively. For each sub-figure, the largest sub-image is a benchmark image generated by StyleGAN2. For other four smaller sub-images, under the same scene, the top left sub-image and top right sub-image are generated by StyleGAN2 and NOStyle-SLA. The bottom left sub-image and low right sub-image are created by NOStyle-SLB and NOStyle, respectively.

Figure 8.
Illustrations of four cover images, stego images, and corresponding modification maps of J-UNIWARD at 0.2 bpnzAC for StyleGAN2, NOStyle-SLA, NOStyle-SLB, and NOStyle. (a–d) are cover images are generated by above mentioned four generative methods. (e–h) are corresponding stego images. (i–l) are the modification maps in JPEG domain.
4.5. Security Performance
In this part, we compare the security performance of original image set BOSSbase and different image sets generated by other generative models, including StyleGAN2, NOStyle-SLA, NOStyle-SLB, and NOStyle. The experiments are carried out on the spatial and JPEG domain. In order to construct JPEG image set, the original gray images set GSI are compressed into JPGE images with quality factors 75, 85, and 95. After the compression operation, we totally obtain 40,000 spatial images and 120,000 JPEG images. Finally, the experiments are executed on the 160,000 images and the payloads for each image set are 0.05, 0.1, 0.2, 0,3, 0.4, and 0.5.
For spatial cover set, we choose three novel steganographic schemes, including S-UNIWARD, HILL, and SGAN, to generate stego images. Meanwhile, for JPEG cover set, two novel JPEG steganographic schemes J-UNIWARD and UED are used as the choices to create stego images. Later, the original image set and the corresponding stego image sets are divided into two parts with equal size. Finally, with FLD, we obtain the corresponding detection results which are shown in Table 6, Table 7 and Table 8 and Figure 9, Figure 10, Figure 11 and Figure 12.
Table 6.
Detection error comparison of BOSSbass, StyleGAN2, and NOStyle for detecting S-UNIWARD with SRMQ1.
Table 7.
Detection error comparison of BOSSbass, StyleGAN2, and NOStyle for detecting HILL with SRMQ1.
Table 8.
Detection error comparison of BOSSbass, StyleGAN2, and NOStyle for detecting SGAN with SRMQ1.
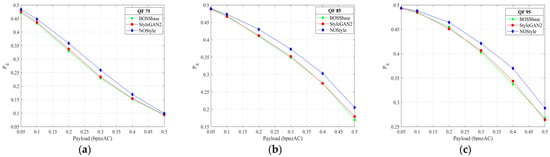
Figure 9.
Detection performance comparison of BOSSbass, StyleGAN2, NOStyle-SLA, and NOStyle-SLB for detection J-UNIWARD with DCTR for JPEG quality factors 75, 85, and 95. (a) Detection error for J-UNIWARD for 75. (b) Detection error for J-UNIWARD for 85. (c) Detection error for J-UNIWARD for 95.

Figure 10.
Detection performance comparison of BOSSbass, StyleGAN2, NOStyle-SLA, and NOStyle-SLB for detection UED with DCTR for JPEG quality factors 75, 85, and 95. (a) Detection error for UED for 75. (b) Detection error for UED for 85. (c) Detection error for UED for 95.
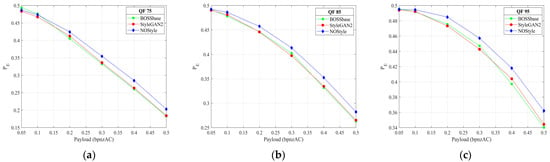
Figure 11.
Detection performance comparison of BOSSbass, StyleGAN2, NOStyle-SLA, and NOStyle-SLB for detection J-UNIWARD with JRM for JPEG quality factors 75, 85, and 95. (a) Detection comparison for J-UNIWARD for 75. (b) Detection comparison for J-UNIWARD for 85. (c) Detection comparison for J-UNIWARD for 95.
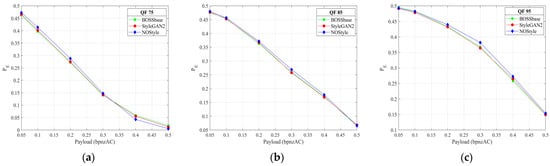
Figure 12.
Detection performance comparison of BOSSbass, StyleGAN2, NOStyle-SLA, and NOStyle-SLB for detection UED with JRM for JPEG quality factors 75, 85, and 95. (a) Detection comparison for UED for 75. (b) Detection comparison for UED for 85. (c) Detection comparison for UED for 95.
According to the above testing results, we can see that, compared with other four image sets BOSSbase, StyleGAN2, NOStyle-SLA, and NOStyle-SLB, NOStyle achieves best secure performance at almost every payload against SRMQ1, regardless of the typical spatial and GAN-based steganographic schemes. On the other hand, for two JPEG steganographic methods UED and J-UNIWARD, NOStyle is more secure than StyleGAN2 against JRM and DCTR. On average, across six payloads, the improvements of NOStyle are 1.19%, 0.94%, 1.32%, 1.02%, 1.28%, and 0.71% over StyleGAN2, respectively. The experiments indicate that, compared with the typical image generation scheme StyleGAN2, NOStyle can optimize the injected noise map and enhance the security performance of generated image. Compared with spatial and JPEG detection results, we observe that NOStyle gains bigger improvement on JPEG steganographic schemes.
4.6. Connection between Security and Fidelity
In this section, we hope to construct the connection between the security and quality. To achieve this goal, we firstly select 8000 images from 4 image sets created by StyleGAN2, NOStyle, NOStyle-SLA, and NOStyle-SLB with equal size. For the sake of convenience, we refer to four schemes as SG2, NS, NSA, and NSB. The experiments are carried out on all given images and three experimental relative payloads for each image set are 0.2, 0,3, and 0.4. Meanwhile, we use two JPEG steganographic methods (J-UNIWARD and UED) to generate stego images. Finally, the security testing is carried on the extracted novels features DCTR and JRM. For two steganographic methods, three relative payloads, and two quality factors, we can obtain many combination schemes. For example, if we use DCTR to test J-UNIWARD at embedding rate 0.2 for JPEG quality factor 75, this category is abbreviated to “D-J-75-2”.
Suppose we fix a testing combination and, for four methods, we obtain four detection errors. Here, we define a value PSF which is computed as the division of any PE and the maximum of detection errors of four generative models. Therefore, the ratio value PSF is defined as follows
Additionally, we use the same operation to deal with the corresponding FID values in Table 5. Across all the parameter combinations and FID, we totally obtain 13 ratios which are listed in Table 9.
Table 9.
Detection error ratios PSF of four image generative methods.
According to the results shown in Table 9, in nearly all cases, PSF of NOStyle is 1. It means that the detection error of NOStyle is the highest and the security of corresponding generated image is the highest. Moreover, we see that the tendency of PSF of various combinations and FID is consistent. Therefore, we assert that the security of the generated image is inverse proportion to the fidelity of the created image. It implies that, under the generative mechanism, the fidelity is lower and the corresponding image security is less, and vice versa for the case of a higher fidelity.
We aim to describe the relationship between the security of the generated image and the fidelity. As previous discussions, in the classical framework of image generation, the key task is to maintain the fidelity of generated image by the disentanglement and style mixing mechanism. Generally, the stochastic controlling of image detail is achieved by the injecting of stochastic noise located at different layers of the synthesis network which is trained based on the noise loss. From the aspect of steganography, combining the security loss and fidelity loss, we redesign the network loss, retrain the synthesis network, and obtain the stochastic map. However, for image generation, the given stochastic map is not optimal and, during the processing of image synthesis, the fidelity of generated image is diminished. Indeed, according to the results of Table 5, FID of NOstyle is a little higher than the FID of StyleGAN2. It means that the fidelity of image generated by NOstyle is a little worse than the corresponding image created by StyleGAN2. Therefore, the above analysis testifies that the security of generated image is inverse proportion to the fidelity. However, we see that the difference of fidelity between two methods is tiny. Experiments show, compared with StyleGAN2, NOstyle makes a bigger progress in image security.
Based on the experimental results and analysis, we see that, by redefining the secure noise optimization network and an optimal noise loss, we achieve the optimization of the injected noise which can be used to generate the secure and high-quality image. Finally, the proposed scheme can make a tradeoff between the security and fidelity.
4.7. Computational Complexity
For model-base image synthesis, the computational complexity is the key point to make the proposed approach applicable. We execute a set of experiments to testify the computational complexity of three methods. To train our model, we choose the subset of LSUN Cat dataset as training set to train our proposed image synthesis network NOstyle. Based on the previous discussion, our network architecture mainly owns two stages denoted as stage-I and stage-II. The stage-I NOStyle generator is inherited from the pretrained StyleGAN2 and the stage-II NOStyle is used to optimize the injecting noise and generate a high-quality/secure image. Therefore, the computational complexity of the proposed scheme mainly depends on the computational complexity of stage-II. The experiments are tested on a server with 2.2 GHz CPU, 16 GB memory, and a 2080 Ti GPU. The computational complexity represented as training time (h) is listed in Figure 13 in which NS, NSA, and NSB, respectively, stand for three comparative methods.
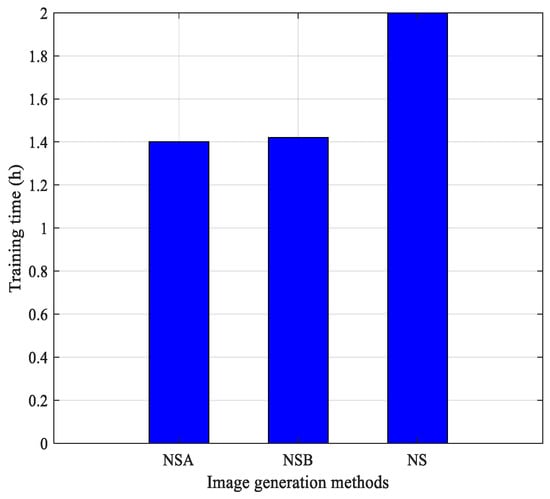
Figure 13.
Computational complexity comparison between NS, NSA, and NSB.
According to given results in Figure 13, the computational complexity of NS is higher than the corresponding values of NSA and NSB. Meanwhile, due to the similar mechanism of NSA and NSB, the training time of two generative methods are almost the same. However, the differences between NS and other two methods are small. On average, the difference of training time is about half an hour. As previous discussion, consider the high demanding of GPU and energy consumption, we directly use the pre-train model of StyleGAN2 and, therefore, the training time of StyleGAN2 is not represented in Figure 13. Obviously, we firmly believe that the computational complexity of StyleGAN2 is higher than other three methods NS, NSA, and NSB. With the lower computational complexity, the practicality of the proposed approach is rather high.
4.8. Stochastic Variation
Let us consider how the style-based methods implement the stochastic variation. Given the designed network, the stochastic realizations (noise map) are achieved by adding per-pixel noise after each convolution of network. According to the comparative results in Figure 6 and Figure 7 and the related discussion in [25], the noise only affects the stochastic aspects of generated image, such as hairs, fur, or freckles. Meanwhile, we can see the overall composition of different generated images remains unchanged. For our proposed architecture NOStyle, on the one hand, the injected noise is not totally random and the noise is adjusted to maintain the image fidelity and security. Therefore, the pseudo-random noise indeed affects the security of the generated image. However, our proposed architecture optimizes the given noise and makes an ideal tradeoff between image security and fidelity.
5. Conclusions and Future Work
Traditional steganography usually uses the given image to achieve secure communication and undetectability. In this article, we propose a noise-optimization stacked StyleGAN2 called NOStyle to generate the secure and vivid image which can be used as an optimal cover. The proposed image synthesis is decomposed into two stages. The architecture of the stage-I is the same as the original StyleGAN2 which is used to generate a high-quality benchmark image. Consider the optimal characters of StyleGAN2, for the stage-II generator, the mapping network and synthesis network are kept. The highlight is that, based on the progressive growing and shortcut connection, we design a secure noise optimization network to output the optimal noise maps which is used as the stochastic variation of synthesis network. Relying on the disentanglement, in the image synthesis phase, the optimized noise maps are injected into the finer layers to achieve the detail controlling of generated image. To train our proposed network, combining the steganographic distortion and LPIPS matrix, we design a noise loss which is used to evaluating the difference between the benchmark image and the results of SII-G. Taking the result of SII-D and optimized noise, SII-G finally outputs the secure and high-quality image. Across multiple steganographic methods and steganalyzers, extensive results indicate that the security of image set generated by NOStyle outperforms the standard image set BOSSbase and the generative model StyleGAN2. Meanwhile, NOStyle also owns excellent ability to generate the high-quality image. Moreover, comparing FID and the detection error, our proposed method makes a conclusion that the security of the generated image is inverse proportion to the fidelity. In the future, we hope the secure noise adjustment can be spread into other layers of synthesis network and we could use other spatial/JPEG distortion functions to construct the discriminator to measure the quality of generated image.
Author Contributions
Writing—original draft, J.Y.; software, X.Z. (Xiaoyi Zhou); validation, W.S.; funding acquisition, F.L.; supervision, C.L.; supervision, X.Z. (Xinpeng Zhang). All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Natural Science Foundation of Shanghai under Grants 20ZR1421600, in part by Research Fund of Guangxi Key Lab of Multi-source Information Mining & Security under Grant MIMS21-M-02.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ker, A.D.; Bas, P.; Böhme, R.; Cogranne, R.; Craver, S.; Filler, T.; Fridrich, J.; Pevný, T. Moving steganography and steganalysis from the laboratory into the real world. In Proceedings of the ACM Information Hiding and Multimedia Security Workshop, Montpellier, France, 17–19 June 2013; pp. 45–58. [Google Scholar]
- Zhang, X. Behavior steganography in social network. In Advances in Intelligent Information Hiding and Multimedia Signal Processing, Proceedings of the Twelfth International Conference on Intelligent Information Hiding and Multimedia Signal Processing, 21–23 November 2016, Kaohsiung, Taiwan; Springer: Berlin/Heidelberg, Germany, 2012; pp. 4206–4210. [Google Scholar] [CrossRef]
- Böhme, R. Advanced Statistical Steganalysis; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Wang, Z.; Qian, Z.; Zhang, X.; Yang, M.; Ye, D. On improving distortion functions for JPEG steganography. IEEE Access 2018, 6, 74917–74930. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, X.; Yin, Z. Joint cover-selection and payload-allocation by steganographic distortion optimization. IEEE Signal Process. Lett. 2018, 25, 1530–1534. [Google Scholar] [CrossRef]
- Pevny, T.; Bas, P.; Fridrich, J. Steganalysis by subtractive pixel adjacency matrix. IEEE Trans. Inf. Forensics Secur. 2010, 5, 215–224. [Google Scholar] [CrossRef]
- Holub, V.; Fridrich, J.; Denemark, T. Universal distortion function for steganography in an arbitrary domain. EURASIP J. Inf. Secur. 2014, 2014, 1–3. [Google Scholar] [CrossRef]
- Filler, T.; Judas, J.; Fridrich, J. Minimizing additive distortion in steganography using syndrome-trellis codes. IEEE Trans. Inf. Forensics Secur. 2011, 6, 920–935. [Google Scholar] [CrossRef]
- Holub, V.; Fridrich, J. Designing steganographic distortion using directional filters. In Proceedings of the 2012 IEEE International Workshop on Information Forensics and Security (WIFS), Costa Adeje, Spain, 2–5 December 2012; pp. 234–239. [Google Scholar] [CrossRef]
- Li, B.; Wang, M.; Huang, J.; Li, X. A new cost function for spatial image steganography. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 4206–4210. [Google Scholar] [CrossRef]
- Sedighi, V.; Cogranne, R.; Fridrich, J. Content-adaptive steganography by minimizing statistical detectability. IEEE Trans. Inf. Forensics Secur. 2015, 11, 221–234. [Google Scholar] [CrossRef]
- Fridrich, J.; Kodovsky, J. Rich models for steganalysis of digital images. IEEE Trans. Inf. Forensics Secur. 2012, 7, 868–882. [Google Scholar] [CrossRef]
- Guo, L.; Ni, J.; Su, W.; Tang, C.; Shi, Y.-Q. Using statistical image model for JPEG steganography: Uniform embedding revisited. IEEE Trans. Inf. Forensics Secur. 2015, 10, 2669–2680. [Google Scholar] [CrossRef]
- Kodovsky, J.; Fridrich, J.; Holub, V. Holub, Ensemble classifiers for steganalysis of digital media. IEEE Trans. Inf. Forensics Secur. 2012, 7, 432–444. [Google Scholar] [CrossRef]
- Holub, V.; Fridrich, J. Low-Complexity Features for JPEG Steganalysis Using Undecimated DCT. IEEE Trans. Inf. Forensics Secur. 2015, 10, 219–228. [Google Scholar] [CrossRef]
- Shi, Y.Q.; Sutthiwan, P.; Chen, L. Textural features for steganalysis. In Proceedings of the 14th International Conference, IH 2012, Berkeley, CA, USA, 15–18 May 2012; pp. 63–77. [Google Scholar] [CrossRef]
- Li, F.; Zhang, X.; Cheng, H.; Yu, J. Digital image steganalysis based on local texture feature and double dimensionality reduction. Secur. Commun. Netw. 2016, 9, 729–736. [Google Scholar] [CrossRef]
- Li, B.; Tan, S.; Wang, M.; Huang, J. Investigation on cost assignment in spatial image steganography. IEEE Trans. Inf. Forensics Secur. 2014, 9, 1264–1277. [Google Scholar] [CrossRef]
- Li, F.; Wu, K.; Qin, C.; Lei, J. Anti-compression JPEG steganography over repetitive compression networks. Signal Process. 2020, 170, 107454. [Google Scholar] [CrossRef]
- Zhao, Z.; Guan, Q.; Zhang, H.; Zhao, X. Improving the robustness of adaptive steganographic algorithms based on transport channel matching. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1843–1856. [Google Scholar] [CrossRef]
- Tao, J.; Li, S.; Zhang, X.; Wang, Z. Towards robust image steganography. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 594–600. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.C.; Bengio, Y. Generative adversarial nets. In Proceedings of the Annual Conference on Neural Information Processing Systems, Montreal, ON, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Emily, D.; Soumith, C.; Szlam, A.; Rob, F. Deep generative image models using a Laplacian pyramid of adversarial networks. In Proceedings of the Annual Conference on Neural Information Processing Systems (NIPS 2015), Montreal, ON, Canada, 7–12 December 2015; pp. 1486–1494. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4396–4405. [Google Scholar] [CrossRef]
- Huang, X.; Li, Y.; Poursaeed, O.; Hopcroft, J.; Belongie, S. Belongie, Stacked generative adversarial networks. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1866–1875. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Wei, T.; Chen, D.; Zhou, W.; Liao, J.; Zhang, W.; Yuan, L.; Hua, G.; Yu, N. E2Style: Improve the Efficiency and Effectiveness of StyleGAN Inversion. IEEE Trans. Image Process. 2022, 31, 3267–3280. [Google Scholar] [CrossRef]
- Yu, F.; Seff, A.; Zhang, Y.; Song, S.; Funkhouser, T.; Xiao, J. LSUN: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv 2015, arXiv:1506.03365. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as perceptual metric. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of StyleGAN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020; pp. 8107–8116. [Google Scholar] [CrossRef]
- Volkhonskiy, D.; Nazarov, I.; Burnaev, E. Steganographic generative adversarial networks. arXiv 2017, arXiv:1703.05502. [Google Scholar]
- Rehman, A.U.; Rahim, R.; Nadeem, S.; Hussain, S.U. End-to-end trained cnn encoder-decoder networks for image steganography. arXiv 2017, arXiv:1711.07201. [Google Scholar]
- Zhang, R.; Dong, S.; Liu, J. Invisible steganography via generative adversarial network. Multimed. Tools Appl. 2018, 78, 8559–8575. [Google Scholar] [CrossRef]
- Chen, J.; Lu, W.; Fang, Y.; Liu, X.; Yeung, Y.; Xue, Y. Binary image steganalysis based on local texture pattern. J. Vis. Commun. Image Represent. 2018, 55, 149–156. [Google Scholar] [CrossRef]
- DDE Download. 2022. Available online: http://dde.binghamton.edu/download/ (accessed on 5 September 2022).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).