Abstract
In this paper, the estimation of the stress–strength reliability is taken into account when the stress and strength variables have unit Gompertz distributions with a similar scale parameter. The consideration of the unit Gompertz distribution in this context is because of its intriguing symmetric and asymmetric properties that can accommodate various histogram proportional-type data shapes. As the main contribution, the reliability estimate is determined via seven frequentist techniques using the ranked set sampling (RSS) and simple random sampling (SRS). The proposed methods are the maximum likelihood, least squares, weighted least squares, maximum product spacing, Cramér–von Mises, Anderson–Darling, and right tail Anderson–Darling methods. We perform a simulation work to evaluate the effectiveness of the recommended RSS-based estimates by using accuracy metrics. We draw the conclusion that the reliability estimates in the maximum product spacing approach have the lowest value compared to other approaches. In addition, we note that the RSS-based estimates are superior to those obtained by a comparable SRS approach. Additional results are obtained using two genuine data sets that reflect the survival periods of head and neck cancer patients.
1. Introduction
In many practical contexts, we have to deal with the uncertainty of bounded problems. In particular, we commonly encounter quantitative variables that fall within the range of , such as proportions or percentages. For addressing bounded data sets in various disciplines, several probability distributions have been developed. Recent popular ones include the unit Birnbaum–Saunders distribution (see ref. [1]), the unit Weibull distribution (see ref. [2]), the unit Gompertz distribution (UGD) (see ref. [3]), the unit-inverse Gaussian distribution (see ref. [4]), the unit Burr XII distribution (see ref. [5]), the unit Gamma/Gompertz distribution (see ref. [6]), the unit generalized log Burr XII distribution (see ref. [7]), the unit exponentiated half logistic distribution (see ref. [8]), the unit generalized inverse Weibull distribution (see ref. [9]), the another unit Burr XII distribution (see ref. [10]), the unit xgamma distribution (see ref. [11]), the extreme left-skewed unit distribution (see ref. [12]), the unit-power Burr X distribution (see ref. [13]), the unit inverse exponentiated Weibull distribution (see ref. [14]), and the unit log–log distribution (see ref. [15]).
For the purposes of this paper, a retrospective on the UGD is necessary. To begin, its probability density function (PDF) is indicated as:
for , and for , where is the shape parameter and is the scale parameter. Hence, a random variable W with this distribution can be written as UGD. The followings are the related cumulative distribution function (CDF) and hazard function (HF):
for , for , and for , and
for , and for , respectively. In order to understand the modeling capabilities of the UGD, plots of the PDF and HF are represented in Figure 1 for some choices of parameters.
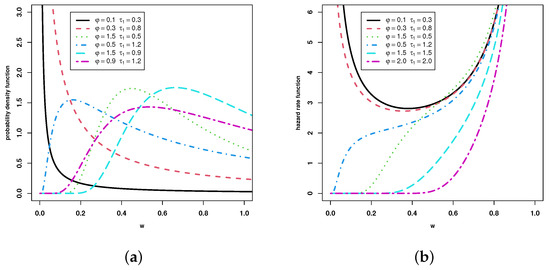
Figure 1.
Various plots of the PDF (subfigure (a)) and HF (subfigure (b)) of the UGD.
In this figure, we observe diverse symmetric and asymmetric shapes. In particular, the PDF can be decreasing or unimodal, and the HF can be J-shaped, growing, or in the form of an upside-down. These impressive panels of shapes demonstrate a functional versatility that is attractive in the fit of proportional-type data. The UGD stands out from most of its direct competitors in this aspect. A number of its features (moments, quantiles, etc.) were examined by ref. [3]. The UGD has comparable behavior to certain well-known probability distributions, such as the beta and Kumaraswamy distributions, in terms of real-data application (see ref. [3]). The authors mentioned that the UGD may be applied to the study of skewed data and may be useful in the fields of industrial reliability, environmental sciences, and survival analysis. In addition, the UGD is involved in current reliability estimation problems. For instance, based on it, the issue of assessing multicomponent stress–strength reliability under progressive type II censoring was explored by ref. [16]. According to ref. [17], the reliability estimation in a multicomponent stress–strength based on the UGD was taken into consideration. In their discussion, ref. [18] used record values and inter-record periods for the inference of the UGD, along with a concrete application. Reference [19] addressed the applicability of actual data for the UGD under dual generalized order statistics. There is, however, a lot to do with the UGD from a statistical perspective. In this spirit and with the motivation to describe our main findings, the ranked set sampling (RSS) needs to be presented.
For a first description, the RSS is acknowledged as a valuable sampling strategy (i) to achieve observational economy and (ii) to enhance the accuracy and efficiency of the estimation in situations where the variable under evaluation is expensive to measure or challenging to obtain yet cheap and simple to rank. The notion of the RSS was initially put forth in ref. [20], and ref. [21] reinforced it with mathematical theory. Even with a ranking error, RSS is more effective than simple random sampling (SRS), according to the study in ref. [22]. To give more details, the RSS of the n units to be measured is produced using the following process: First, units are chosen at random from the population and divided into n groups of n units. The lowest-ranking unit from the first sample is used for measurement, while the other units are not. From a subsequent sample of size n, only the unit ranked second-smallest is selected for measurement. After repeating this procedure, the largest ranking unit of the n-th sample of size n is determined. We call this technique one cycle of a ranked set sample of size n. To create an RSS of size , the cycle is then repeated a number of times. In this context, the terms and denote the set size and cycle count, respectively. The set size n should be mentioned as a significant component of the RSS process. According to ref. [23], set sizes larger than five would likely not considerably boost the RSS’s effectiveness since they would undoubtedly result in too many ranking mistakes. In order to properly rank sets of n units, the set size n is often fixed between two and five (see ref. [23]).
Applications of the RSS in different fields have been considered by several authors. In an east Texas pine-hardwood forest, ref. [24] used the RSS to estimate the weights of browsing and herbage. The use of the RSS to determine the volume of trees in a forest was covered by ref. [25]. Reference [26] used the RSS to estimate the mean of forest, grassland, and other vegetation resources. The application of the RSS in environmental chemistry was investigated in ref. [27]. Reference [28] investigated how well the RSS estimated milk output using data from 402 sheep. Reference [29] estimated the average olive yields in a field in the west of Jordan using the multistage RSS. Using agricultural production information from the United States Department of Agriculture, ref. [30] studied the application of the RSS in determining the mean and median of a population. The RSS approach was considered by ref. [31] in market and consumer surveys. Using actual data on body measurement, ref. [32] employed the RSS approach to obtain the population means and ratio. The authors utilized information on the height and weight of 507 people. The RSS was applied in a study on fisheries by ref. [33].
On the other hand, in the literature, there has been much discussion on the issue of drawing conclusions regarding the stress–strength (S-S) model Here, Q stands for the stress, W for the strength, and is a measure of system reliability. When the stress exceeds the system’s capacity, it is clear that the system will malfunction; otherwise, it will continue to function. In several fields, including engineering, statistics, and biostatistics, the S-S model is widely used. The following are some real-world examples: structures, the aging of concrete pressure vessels, the degeneration of rocket motors, and fatigue failure of aircraft structures (see ref. [34]). Historically, ref. [35] was the one who initially considered the S-S model. Many academics have looked at the estimation of the S-S reliability for varied independent distributions; see, for example, refs. [36,37,38,39].
Current discussions on the RSS and its modification techniques have included statistical inferences about the S-S reliability. In Refs. [40,41], the estimation of the S-S reliability via the RSS for independent random samples from the exponential and Weibull distributions, respectively, was the main topic. Using an independent Lindley distribution, an estimate of has been provided in ref. [42]. The inferences for the S-S reliability of Burr type X distributions based on the RSS were discussed in ref. [43]. For more recent studies, the reader can refer to refs. [44,45,46,47,48,49,50,51].
In this paper, despite the fact that alternative frequentist methods can sometimes yield estimates that are better than the maximum likelihood (ML) method, little attention has been devoted to using them to estimate the S-S reliability based on the RSS. This is why, in addition to the ML method, we seek to apply frequentist estimation methods in this study. The suggested frequentist estimation methods include the maximum product spacing (MPS), least squares (LS), weighted LS (WLS), Cramér–von-Mises (CV), Anderson–Darling (AD), and right tail AD (RTAD) methods. In this research, we concentrate on seven alternative estimation techniques to estimate , when Q and W are independent random variables that follow the UGD and analyze the behavior of the various estimates for various sample sizes and parameter values via the SRS and RSS. The findings are validated using actual data sets.
The structure of the work is as follows: in Section 2, we provide the ML estimate (MLE) of the S-S reliability. The reliability estimate based on the LS and WLS techniques is provided in Section 3. We derive the estimate in Section 4 by employing the MPS technique. In Section 5, the S-S reliability estimate is generated utilizing the AD, RTAD, and CV approaches. Both simulation research and its application to actual scenarios are discussed in Section 6 and Section 7, with comparisons between the RSS estimates and their SRS counterparts. Section 8 concludes the argument in the paper.
2. Maximum Likelihood Estimate of
In this section, we look at the estimation of , when both stress Q and strength W are modeled by random variables with UGDs defined with a common known scale parameter. The SRS and RSS are considered.
Hence, let UGD and UGD be independent random variables, with W of PDF and Q of CDF . Then, the expression of is
In light of this, the S-S reliability is a function of and . In accordance with the MLE’s invariance property, an efficient estimate of is constructed by inserting the MLEs of and in (3).
2.1. MLE Based on the RSS
Let be the order statistics (OS) of the -th sample, , in the -th cycle () from the UGD. Let be the OS of the -th sample, , in the -th cycle () from the the UGD Here, , and are the sample sizes of , and , respectively, where and are the set sizes and , are the cycle numbers.
For the purpose of convenience, we refer to and , respectively, as and throughout the remainder of the work. The PDFs of and are precisely the PDFs of the -th and -th OS assuming that the ordering of the observations is perfect. The PDF of , for , is provided by:
with . It should be noted that a similar process is used to produce the PDF of For the sake of brevity, we will not copy it here. The likelihood function (LF) of the stress Q and the strength W based on the RSS with the perfect ranking assumption is expressed as follows:
The log-LF of (4) based on the RSS, is then provided by:
The MLEs of and , denoted by and , respectively, are obtained by maximizing this function (with respect to and ). To achieve this aim, a differentiable approach is also possible.
Thus, we consider
and
By equating the equations in (5) and (6) to zero and solving the obtained system, it is possible to derive and . Consequently, the MLE of based on the RSS is given by:
Hence, the MLE depends only on and .
2.2. MLE Based on the SRS
Here, the MLE of is obtained under the SRS. Let , and , be a two independent SRS from the UGD and UGD, respectively. The LF of the two observed samples is given by:
The log-LF of (7) based on the SRS is then provided by:
The MLEs for and , say and , respectively, are obtained by maximizing this function. To this end, a differentiable approach is also possible. Thus, we consider
The MLEs are given as the solution of the non-linear equations in (8) after equating them with zero using the numerical technique. As a result, the MLE of based on the SRS is obtained by inserting and in (3), according to the invariance property as below:
3. LS and WLS Estimates of
For estimating the unknown parameters, the LS and WLS procedures are well known (see ref. [52]). Here, the two methods for determining the estimate of are given.
Let be an OS forming a RSS of size from the UGD Also, let be an OS forming a RSS of size from the UGD Here, and are the set sizes and and are the cycle numbers. The LS estimate (LSE) of is obtained by minimizing , that is
Hence, is the solution of the following equation:
Similarly, the LSE of is obtained by solving the following equation:
Hence, the LSE of based on the RSS is obtained by putting produced and from (9) and (10) in (3). Furthermore, the WLS estimate (WLSE) of is obtained by minimizing
Hence, is the solution of the following equation:
Similarly, the WLSE of is obtained by solving the following equation:
Hence, the WLSE of based on the RSS is obtained by putting the determined estimates from (11) and (12) in (3).
Additionally, using the above similar procedure, the LSEs and of and , respectively, based on the SRS and of sizes and , respectively, are obtained by solving numerically the following nonlinear equations:
and
In order to determine the LSE of based on the SRS, we insert and that generated from (13) and (14) in (3). In a similar way, the WLSEs and of and , respectively, based on the SRS and of sizes and , respectively, are obtained by solving numerically the following nonlinear equations:
and
4. Maximum Product Spacing Estimate of
Reference [53] proposed the MPS method for the parameter estimation as an alternative to the ML method. Separately, ref. [54] first suggested it as a reasonable approximation for the Kullback-Leibler information measure. In this section, the MPS estimate (MPSE) of is discussed using the RSS and SRS.
Let be an OS forming an RSS of size from the UGD Here, the spacing of a random sample of size is defined as , , The desired estimate of is computed by maximizing the geometric mean of spacings Alternatively, we maximize and compute the desired estimate of from the following equation:
Next, let be an OS forming a RSS of size from the UGD Let us define , , The desired estimate of is obtained from the following equation:
Thus, it is possible to determine the MPSE of after inserting and produced from (17) and (18) in (3).
Secondly, the MPSE is then provided based on the SRS. Using the above similar procedure, the MPEs and of and , respectively, from the SRS and of sizes and , respectively, are obtained. The uniform spacing is defined by with , for the strength W. In addition, for the stress Q, the uniform spacing is with . Hence, the MPSEs and are obtained by maximizing and , respectively. As a result, the desired estimates of and are obtained by solving the following equations:
and
5. Other Estimation Methods
The minimizing of the test statistics between the empirical CDF and theoretical CDF may be used to support the proposal of a number of estimating methods. Here, we take into account the AD, RTAD, and CV methods to obtain the estimate of .
5.1. Estimates of Based on the RSS
Suppose that is an OS forming a RSS of size from the UGD Also, let be an OS forming a RSS of size from the UGD
and
After inserting the results of and from (21) and (22) in (3), the estimate based on the CV technique is consequently provided.
The AD estimates (ADEs) and of and , respectively, are produced after minimizing the following functions:
and
The reliability estimate based on the AD method is provided after putting the produced and in (3).
The RTAD estimates (RTADEs) and of and , respectively, are produced after minimizing the following functions:
and
The reliability estimate based on the RTAD method is provided after putting and in (3).
5.2. Estimates of Based on the SRS
Here, the CVE, ADE, and RTADE of are obtained under the SRS. Let , be a SRS from the UGD, and suppose that , is a SRS from the UGD, respectively, all independent. With the minimization of the following functions, the CVEs and of and , respectively, are generated:
and
Consequently, the reliability estimate based on the CV method is obtained after putting and in (3). The ADEs and of and , respectively, are produced after minimizing the following functions:
and
The reliability estimate based on the AD method is provided after putting and in (3).
The RTADEs and of and , respectively, are produced after minimizing the following functions:
and
The reliability estimate based on the RTAD method is provided after putting and in (3).
6. Numerical Evaluation
Through the use of MathCAD software, version 14.0 we conduct a simulation study in this section to assess how well the suggested methods for estimating under the RSS and SRS perform. We obtain the absolute bias (AB) and mean squared error (MSE) criteria for different estimates. Additionally, the estimates’ relative efficiencies (REs) are provided, which are defined as follows:
- The parameter values are chosen as , and the true value of is determined as 0.2857, 0.6000, 0.7143, and 0.9375, respectively.
- The observed RSS from the strength and , , from the stress having the set sizes: (2,2), (2,3), (3,3), (3,4), (4,4), (4,5), (5,5), with the cycle numbers . The sample sizes are (20,20), (20,30), (30,40), (40.40),(40,50), (50,50).
- In view of the SRS, the observed SRS , , are drawn from strength and stress with sample sizes (20,20), (20,30), (30,40), (40.40), (40,50), (50,50).
- Using the inverse transformation method, 1000 random samples are created from the strength UGD, and stress UGD.
- Different estimation techniques, along with the selected sample scheme, were used to determine the MLE, MPSE, LSE, WLSE, CVE, ADE, and RTADE, namely, , , based on the RSS, and , , , , , , based on the SRS.
- The AB, MSE, and RE of the different estimates are summarized in Table 1, Table 2 and Table 3 and described graphically in Figure 2, Figure 3, Figure 4, Figure 5, Figure 6, Figure 7, Figure 8 and Figure 9.
 Table 1. Measures of different estimates for the UGD under the RSS.
Table 2. Measures of different estimates for the UGD under the SRS.
Table 3. RE of different estimates of the UGD.
Table 1. Measures of different estimates for the UGD under the RSS.
Table 2. Measures of different estimates for the UGD under the SRS.
Table 3. RE of different estimates of the UGD.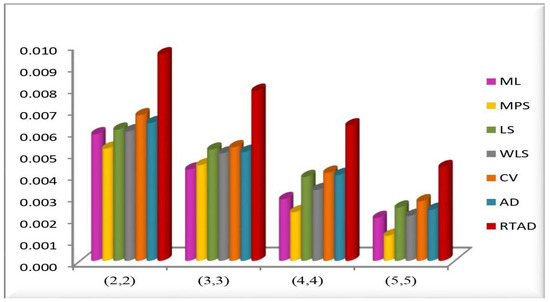 Figure 2. MSE of the estimates for all the methods at in the RSS.
Figure 2. MSE of the estimates for all the methods at in the RSS.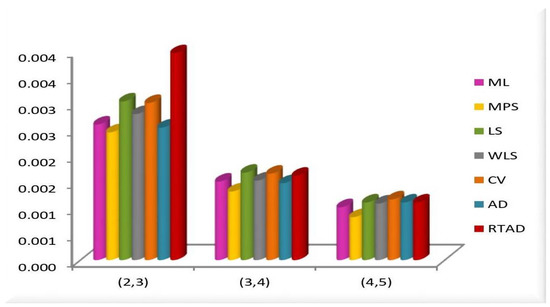 Figure 3. MSE of the estimates for all the methods at in the RSS.
Figure 3. MSE of the estimates for all the methods at in the RSS.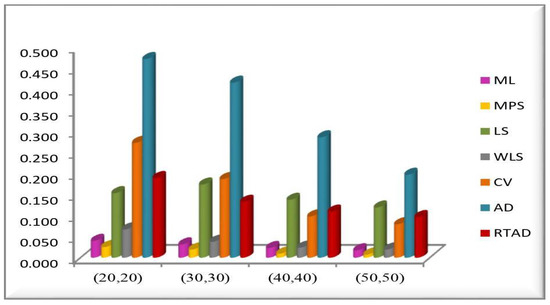 Figure 4. MSE of the estimates for all the methods at in the SRS.
Figure 4. MSE of the estimates for all the methods at in the SRS.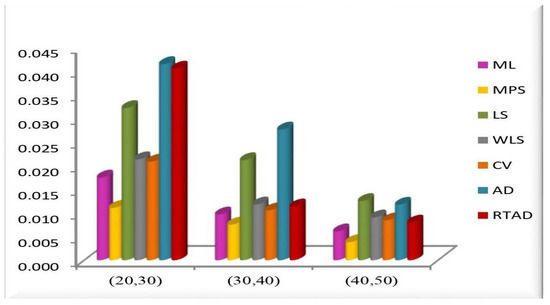 Figure 5. MSE of the estimates for all the methods at in the SRS.
Figure 5. MSE of the estimates for all the methods at in the SRS.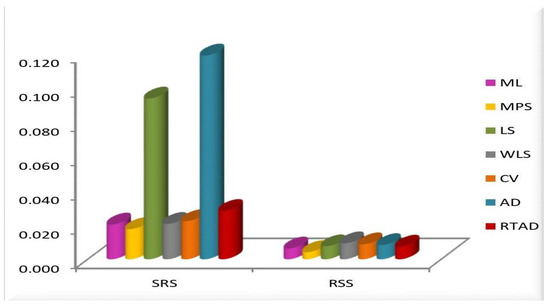 Figure 6. MSE of the estimates for all the methods at and .
Figure 6. MSE of the estimates for all the methods at and .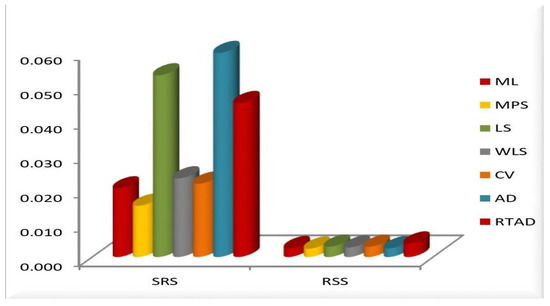 Figure 7. MSE of the estimates for all the methods at and .
Figure 7. MSE of the estimates for all the methods at and .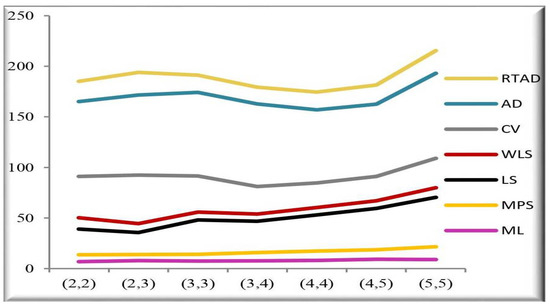 Figure 8. RE of the estimates at for different at .
Figure 8. RE of the estimates at for different at .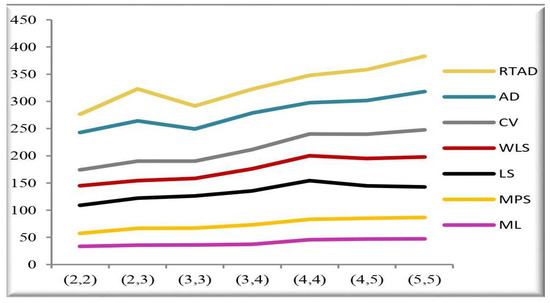 Figure 9. RE of the estimates at for different at = 10.
Figure 9. RE of the estimates at for different at = 10.
We note the following based on the measurement values in these tables and figures.
- In the majority of the cases, as seen in Figure 2, the MSEs of the estimates decrease as and increase.
- For both sampling methods, the MSEs of the estimates for the MPS method have the lowest values. While the MSEs of the estimates for the AD method take the highest values in the SRS, the highest values are given to the MSEs of the estimates for the RTAD method in the RSS scheme.
- The MSE always decreases as and increase, indicating that the estimates are all consistent.
- The estimates become more accurate as and increase, indicating that they are asymptotically unbiased.
- The MSE always decreases as the true value of increases, indicating that the estimates are all consistent.
7. Real Data Applications
Two data sets that ref. [55] proposed were considered in this section. The data collection includes two groups of head and neck cancer patients. The survival times of 58 head and neck cancer patients treated with radiation are shown in the data set for the first group, whereas the survival times of 44 patients treated with radiotherapy plus chemotherapy are shown in the data set for the second group. The information is as follows:
Data set I (): 523, 583, 594, 14.48, 16.1, 22.7, 34, 41.55, 42, 45.28, 49.4, 84, 91, 160, 160, 165, 108, 112, 129, 133, 133, 139, 140, 140, 146, 149, 154, 157, 146, 149, 154, 157, 160, 160, 165, 173, 176, 218, 6.53, 7, 10.42, 225, 241, 248, 273, 277, 297, 405, 417, 53.62, 63, 64, 83, 420, 440, 1101, 1146, 1417.
Data set II (): 25.87, 31.98, 37, 41.35, 47.38, 55.46, 58.36, 63.47, 319, 339, 432, 469, 68.46, 78.26, 173, 179, 194, 195, 74.47, 81.43, 84, 92, 519, 633, 725, 94, 110, 112, 119, 127, 130, 133, 140, 146, 12.2, 23.56, 23.74, 155, 159, 209, 249, 281, 817, 1776.
We divide the data by 2000 to have values between 0 and 1. The Kolmogorov-Smirnov (K-S) goodness-of-fit test is used to fit each of the two data sets individually using the UGD. The UGD fits the data sets, according to the K-S test (K-ST) and the accompanying p-value. It is noted that for Data sets I and II, the K-ST of the UGD has values of 0.16913 and 0.070689, respectively, with p-values of 0.07245 and 0.9694.
The initial PDF shapes are reported utilizing the non-parametric kernel density estimation approach in Figure 10 and Figure 11 for both data sets. From Figure 10 and Figure 11, we can see that the shape of the PDF is asymmetric for both data sets. The normality condition is checked via the QQ plot; see Figure 10 and Figure 11. The outliers can also be spotted using the box plot; see Figure 10 and Figure 11. Henceforth, we can say that there are outliers in both data sets. Figure 12 and Figure 13 display the estimated CDF (ECDF), estimated PDF (EPDF), PP—plots, and estimated survival function (ESF) for the UGD. Thanks to its asymmetric properties, the UGD is an appropriate model for fitting these data.
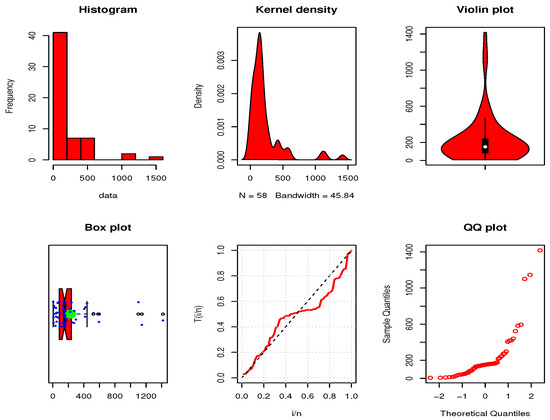
Figure 10.
Some basic non-parametric plots for Data set I.
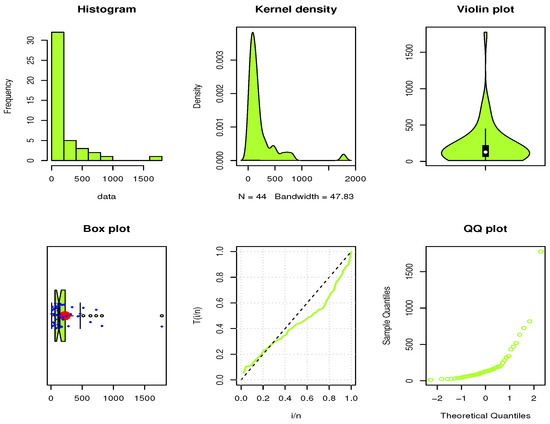
Figure 11.
Some basic non-parametric plots for Data set II.
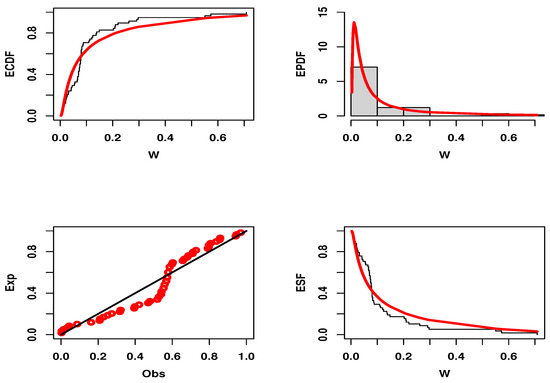
Figure 12.
ECDF, EPDF, PP plots and ESF of the UGD for Data set I.
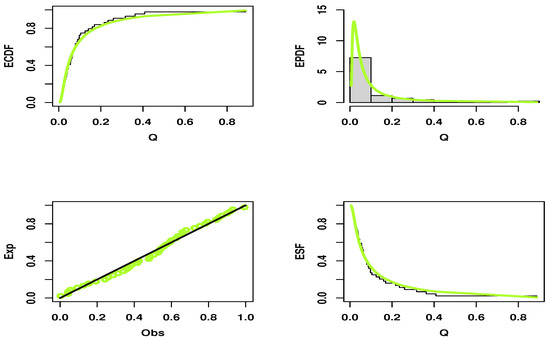
Figure 13.
ECDF, EPDF, PP plots and ESF of the UGD for Data set II.
In the earlier sections, it was assumed that stress and strength random variables followed the UGD with the same scale parameter and that the estimates of were then examined. Consequently, in order to estimate it using actual data, we also need to see if the specifications of their second scale are the same.
First, it is assumed that and . We perform the following tests of the hypothesis: .
The associated likelihood function, based on the SRS, is given by:
The MLEs of and are as follows: and , and the log-likelihood value is
Second, suppose that and also, as the same steps in the above, the corresponding LF is given by:
The MLEs of and are as follows: and and the log-likelihood value is
Then the likelihood ratio statistic is constructed as follows:
that is, As a result, the null hypothesis cannot be rejected. Therefore, in this case, the assumption of is justified. Thus, both tests accept the null hypothesis that each data set is drawn from the UGD with the same scale parameter.
Then, using the suggested estimating methods for real data sets, we acquire various estimates of . We observe that the MPS method cannot be used to estimate the parameters and reliability of Data set I because they have equal values , , based on the strength W, are equal to zero at most observation in both RSS and SRS. A similar observation is found for the second data set. Thus, different methods of estimation under different criteria are used to determine the estimated parameters, CV test (CVT), AD test (ADT), K-ST, and p-values for the proposed model. They are presented in Table 4 and Table 5 for the two real data sets, respectively. Therefore, the only estimates in Table 4 and Table 5 are the ML, LS, WLS, CV, AD, and RTAD estimates.
Table 4.
Different estimates of and for Data sets I and II under the RSS and SRS.
Table 5.
Goodness of fit measures by different estimation methods for Data sets I and II under the RSS and SRS.
From these data, we suppose a SRS of size , whereas for the RSS, a small set size of is considered with cycles count being . It is interesting to observe that the RSS and SRS are contrasted using the same quantity of measurement units. We determine the estimates of the parameters and reliability in each design using the preceding techniques with a perfect ranking. We use the previous criteria measures, i.e., CVT, ADT, K-ST, and p-value, to compare the different estimates from the two data sets.
8. Summary and Conclusions
In this paper, various estimation techniques for estimating the S-S reliability when both stress and strength random variables have the unit Gompertz distribution based on the RSS and SRS are covered. The methods that have been suggested include the maximum likelihood, least squares, weighted least squares, maximum product spacing, Cramér–von Mises, Anderson–Darling, and right tail Anderson–Darling methods. To assess the effectiveness of the proposed estimates based on both sampling designs, a simulation research is conducted. According to the results, for all the estimating techniques taken into consideration, the RSS estimates outperform the SRS estimates in terms of MSE, absolute bias, and efficiency values. The estimates based on the MPS have the smallest MSE for both sampling techniques. The reliability estimates based on the AD and RTAD methods have the largest MSE based on the SRS and RSS, respectively. Two real data sets that indicate the survival times of head and neck cancer patients have been used to provide further findings. Future research might look at the inference in a multicomponent S-S model based on the different RSS modifications.
Author Contributions
Conceptualization, N.A., A.S.H., M.E., C.C. and R.E.M.; methodology, N.A., A.S.H., M.E., C.C. and R.E.M.; software, N.A., A.S.H., M.E., C.C. and R.E.M.; validation, N.A., A.S.H., M.E., C.C. and R.E.M.; formal analysis, N.A., A.S.H., M.E., C.C. and R.E.M.; investigation, N.A., A.S.H., M.E., C.C. and R.E.M.; writing—original draft preparation, N.A., A.S.H., M.E., C.C. and R.E.M.; writing—review and editing, N.A., A.S.H., M.E., C.C. and R.E.M.; visualization, N.A., A.S.H., M.E., C.C. and R.E.M.; funding acquisition, N.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by King Saud University, grant number RSPD2023R548.
Data Availability Statement
Not applicable.
Acknowledgments
Researchers Supporting Project number (RSPD2023R548), King Saud University, Riyadh, Saudi Arabia.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mazucheli, J.; Menezes, A.F.B.; Dey, S. The unit-Birnbaum–Saunders distribution with applications. Chil. J. Stat. 2018, 9, 47–57. [Google Scholar]
- Mazucheli, J.; Menezes, A.F.B.; Fernandes, L.B.; de Oliveira, R.P.; Ghitany, M.E. The unit-Weibull distribution as an alternative to the Kumaraswamy distribution for the modeling of quantiles conditional on covariates. J. Appl. Stat. 2020, 47, 954–974. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.B.; Dey, S. Unit-Gompertz distribution with applications. Stat. J. Appl. Stat. 2019, 79, 25–43. [Google Scholar]
- Ghitany, M.E.; Mazucheli, J.; Menezes, A.F.B.; Alqallaf, F. The unit-inverse Gaussian distribution: A new alternative to two-parameter distributions on the unit interval. Commun. Stat. Theory Methods 2019, 48, 3423–3438. [Google Scholar] [CrossRef]
- Korkmaz, M.C.; Chesneau, C. On the unit Burr-XII distribution with the quantile regression modeling and applications. Comput. Appl. Math. 2021, 40, 29. [Google Scholar] [CrossRef]
- Bantan, R.A.R.; Jamal, F.; Chesneau, C.; Elgarhy, M. Theory and applications of the unit Gamma/Gompertz distribution. Mathematics 2021, 9, 1850. [Google Scholar] [CrossRef]
- Bhatti, F.A.; Ali, A.; Hamedani, G.G.; Korkmaz, M.; Ahmad, M. The unit generalized log Burr XII distribution: Properties and application. AIMS Math. 2021, 6, 10222–10252. [Google Scholar] [CrossRef]
- Hassan, A.S.; Fayomi, A.; Algarni, A.; Almetwally, E.M. Bayesian and non-Bayesian inference for unit-exponentiated half-logistic distribution with data analysis. Appl. Sci. 2022, 12, 11253. [Google Scholar] [CrossRef]
- Khaoula, A.; Dey, S.; Kumar, D.; Seddik-Ameur, N. Different classical methods of estimation and chi-squared goodness-of-fit test for unit generalized inverse Weibull distribution. Austrian J. Stat. 2021, 50, 77–100. [Google Scholar] [CrossRef]
- Ribeiro, T.F.; Peña-Ramírez, F.A.; Guerra, R.R.; Cordeiro, G.M. Another unit Burr XII quantile regression model based on the different reparameterization applied to dropout in Brazilian undergraduate courses. PLoS ONE 2022, 17, e0276695. [Google Scholar] [CrossRef] [PubMed]
- Hashmi, S.; ul-Haq, M.A.; Zafar, J.; and Khaleel, M.A. Unit Xgamma Distribution: Its Properties, Estimation and Application. Proc. Pak. Acad. Sci. 2022, 59, 49–59. [Google Scholar] [CrossRef]
- Chesneau, C. A note on an extreme left skewed unit distribution: Theory, modelling and data fitting. Open Stat. 2021, 2, 1–23. [Google Scholar] [CrossRef]
- Fayomi, A.; Hassan, A.S.; Baaqeel, H.M.; Almetwally, E.M. Bayesian inference and data analysis of the unit-power Burr X distribution. Axioms 2023, 12, 297. [Google Scholar] [CrossRef]
- Hassan, A.S.; Alharbi, R.S. Different estimation methods for the unit inverse exponentiated Weibull distribution. Commun. Stat. Appl. Meth. 2023, 30, 191–213. [Google Scholar] [CrossRef]
- Korkmaz, M.Ç.; Korkmaz, Z.S. The unit log–log distribution: A new unit distribution with alternative quantile regression modeling and educational measurements applications. J. Appl. Stat. 2023, 50, 889–908. [Google Scholar] [CrossRef] [PubMed]
- Jha, M.K.; Dey, S.; Alotaibi, R.M.; Alomani, G.; Tripathi, Y.M. Reliability estimation of a multicomponent stress-strength model for unit Gompertz distribution under progressive Type II censoring. Qual. Reliab. Eng. Inter. 2020, 36, 965–987. [Google Scholar] [CrossRef]
- Jha, M.K.; Dey, S.; Tripathi, Y. Reliability estimation in a multicomponent stress-strength based on unit-Gompertz distribution. Inter. J. Qual. Reliab. Manag. 2019, 37, 428–450. [Google Scholar] [CrossRef]
- Kumar, D.; Dey, S.; Ormoz, E.; MirMostafaee, S.M.T.K. Inference for the unit-Gompertz model based on record values and inter-record times with an application. Rend. Circ. Mat. Palermo Ser. 2 2020, 69, 1295–1319. [Google Scholar] [CrossRef]
- Arshada, M.; Azhadc, Q.J.; Gupta, N.; Pathake, A.K. Bayesian inference of Unit Gompertz distribution based on dual generalized order statistics. Commun. Stat. Simul. Comput. 2021, 1–19. [Google Scholar] [CrossRef]
- McIntyre, G.A. A method for unbiased selective sampling, using ranked sets. Aust. J. Agric. Res. 1952, 3, 385–390. [Google Scholar] [CrossRef]
- Takahasi, K.W. On unbiased estimates of the population mean based on the sample stratified by means of ordering. Ann. Inst. Stat. Math. 1968, 21, 249–255. [Google Scholar] [CrossRef]
- Dell, D.R.; Clutter, J.L. Ranked set sampling theory with order statistics background. Biometrics 1972, 28, 545–555. [Google Scholar] [CrossRef]
- Wolfe, D.A. Ranked Set Sampling: Its Relevance and Impact on Statistical Inference. Int. Sch. Res. Not. Probab. Stat. 2012, 1–32. [Google Scholar] [CrossRef]
- Halls, L.K.; Dell, T.R. Trial of ranked-set sampling for forage yields. For. Sci. 1966, 12, 22–26. [Google Scholar]
- Stokes, S.L.; Sager, T.W. Characterization of a ranked-set sample with application to estimating distribution functions. J. Am. Stat. Assoc. 1988, 83, 374–381. [Google Scholar] [CrossRef]
- Johnson, G.D.; Paul, G.P.; Sinha, A.K. Ranked set sampling for vegetation research. Abstr. Bot. 1993, 17, 87–102. [Google Scholar]
- Gore, S.D.; Patil, G.P.; Sinha, A.K. Environmental Chemistry, Statistical Modeling, and Observational Economy. In Environmental Statistics, Assessment, and Forecasting; Cothern, C.R., Ross, N.P., Eds.; Lewis Publishing/CRC Press: Boca Raton, FL, USA, 1994; pp. 57–97. [Google Scholar]
- Al-Saleh, M.F.; Al-Shrafat, K. Estimation of milk yield using ranked set sampling. Envirometrics 2001, 12, 395–399. [Google Scholar] [CrossRef]
- Al-Saleh, M.F.; Al-Omari, A.I. Multistage ranked set sampling. J. Stat. Plann. Inference 2002, 102, 273–286. [Google Scholar] [CrossRef]
- Husby, C.E.; Stansy, E.A.; Wolfe, D.A. An application of ranked set sampling for mean and median estimation using USDA crop production data. J. Agric. Biolog. Environ. Stat. 2005, 10, 354–373. [Google Scholar] [CrossRef]
- Kowalczyk, B. Alternative sampling designs some applications of qualitative data in survey sampling. Stat. Trans. 2005, 7, 427–443. [Google Scholar]
- Ganeslingam, S.; Ganesh, S. Ranked set sampling versus simple random sampling in the estimation of the mean and the ratio. J. Stat. Manag. Syst. 2006, 2, 459–472. [Google Scholar] [CrossRef]
- Wang, Y.G.; Ye, Y.; Milton, D.A. Efficient designs for sampling and subsampling in fisheries research based on ranked sets. J. Marine Sci. 2009, 66, 928–934. [Google Scholar] [CrossRef]
- Kotz, S.; Lumelskii, Y.; Pensky, M. The Stress-Strength Model and Its Generalizations: Theory and Applications; World Scientific: Singapore, 2003. [Google Scholar]
- Birnbaum, Z.W. On a use if Mann-Whitney statistics. Proc. Third Berkeley Symp. Math. Stat. Probab. 1956, 1, 1317. [Google Scholar]
- Kundu, D.; Gupta, R.D. Estimation of P(Y < X) for Weibull distribution. IEEE Trans. Reliab. 2006, 55, 270–280. [Google Scholar]
- Raqab, M.Z.; Madi, M.D.; Kundu, D. Estimation of P(Y < X) for the 3-parameter generalized exponential distribution. Commun. Stat. Theory Meth. 2008, 37, 2854–2864. [Google Scholar]
- Asgharzadeh, A.; Valiollahi, R.; Raqab, M.Z. Estimation of Pr(Y < X) for the two-parameter generalized exponential records. Commun. Stat. Simul. Comput. 2017, 46, 371–394. [Google Scholar]
- Nadeb, H.; Torabi, H.; Zhao, Y. Stress-strength reliability of exponentiated Fréchet distributions based on Type-II censored data. J. Stat. Comput. Simul. 2019, 89, 1863–1876. [Google Scholar] [CrossRef]
- Muttlak, H.A.; Abu-Dayyeh, W.A.; Saleh, M.F.; Al-Sawi, E. Estimating P(Y < X) using ranked set sampling in case of the exponential distribution. Commun. Stat. Theory Methods 2010, 39, 1855–1868. [Google Scholar]
- Akgül, F.G.; Şenoğlu, B. Estimation of P (X < Y) using ranked set sampling for the Weibull distribution. Qual. Technol. Quant. Manag. 2017, 14, 296–309. [Google Scholar]
- Akgül, F.G.; Acıtaş, Ş.; Şenoğlu, B. Inferences on stress-strength reliability based on ranked set sampling data in case of Lindley distribution. J. Stat. Comput. Simul. 2018, 88, 3018–3032. [Google Scholar] [CrossRef]
- Akgül, F.G.; Acıtaş, Ş.; Şenoğlu, B. Inferences for stress-strength reliability of Burr Type X distributions based on ranked set sampling. Commun. Stat. Simul. Comput. 2022, 51, 3324–3340. [Google Scholar] [CrossRef]
- Esemen, M.; Gurler, S.; Sevinc, B. Estimation of stress-strength reliability based on ranked set sampling for generalized exponential distribution. Int. J. Reliab. Qual. Saf. Eng. 2021, 28, 2150011. [Google Scholar] [CrossRef]
- Hassan, A.S.; Al-Omari, A.I.; Nagy, H.F. Stress-Strength reliability for the generalized inverted exponential distribution using MRSS. Iran. J. Sci. Technol. Trans. A Sci. 2021, 45, 641–659. [Google Scholar] [CrossRef]
- Al-Omari, A.I.; Hassan, A.S.; Alotaibi, N.; Shrahili, M.; Nagy, H.F. Reliability estimation of inverse Lomax distribution using extreme ranked set sampling. Adv. Math. Phys. 2021, 2021, 4599872. [Google Scholar] [CrossRef]
- Yousef, M.M.; Hassan, A.S.; Al-Nefaie, A.H.; Almetwally, E.M.; Almongy, H.M. Bayesian estimation using MCMC method of system reliability for inverted Topp-Leone distribution based on ranked set sampling. Mathematics 2022, 10, 3122. [Google Scholar] [CrossRef]
- Hassan, A.S.; Elshaarawy, R.S.; Onyango, R.; Nagy, H.F. Estimating system reliability using neoteric and median RSS data for generalized exponential distribution. Int. J. Math. Math. Sci. 2022, 2022, 2608656. [Google Scholar] [CrossRef]
- Yahya, M.; Shaaban, M. Estimation of stress-strength reliability from exponentiated inverse Rayleigh Rayleigh distribution based on neoteric ranked set sampling approach. Pak. J. Stat. 2022, 38, 491–511. [Google Scholar]
- Hassan, A.S.; Almanjahie, I.M.; Al-Omari, A.I.; Alzoubi, L.; Nagy, H.F. Stress- strength modeling using median-ranked set sampling: Estimation, simulation, and application. Mathematics 2023, 11, 318. [Google Scholar] [CrossRef]
- Hassan, A.S.; Alsadat, N.; Elgarhy, M.; Chesneau, C.; Nagy, H.F. Analysis of R = P[Y < X < Z] using ranked set sampling for a generalized inverse exponential model. Axioms 2023, 12, 302. [Google Scholar]
- Swain, J.; Venkatraman, S.; Wilson, J. Least squares estimation of distribution function in Johnson’s translation system. J. Stat. Comput. Simul. 1988, 29, 271–297. [Google Scholar] [CrossRef]
- Cheng, R.C.H.; Amin, N.A.K. Estimating parameters in continuous univariate distributions with a shifted origin. J. R. Stat. Soc. 1983, 45, 394–403. [Google Scholar] [CrossRef]
- Ranneby, B. The maximum spacing method: An estimation method related to the maximum likelihood method. Scand. J. Stat. 1984, 11, 93–112. [Google Scholar]
- Efron, B. Logistic regression, survival analysis, and the Kaplan-Meier curve. J. Am. Stat. Assoc. 1988, 83, 414–425. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).