


Estimation of the Modified Weibull Additive Hazards Regression Model under Competing Risks



Abstract
:1. Introduction
2. The Proposed Model
3. Maximum Likelihood Estimation
4. Bayesian Estimation
4.1. Gamma Prior
4.2. Weibull Prior
4.3. Log-Normal Prior
4.4. Posterior Analysis
4.5. Loss Function
5. Interval Estimation
5.1. Asymptotic Confidence Interval
5.2. Bayes Credible Interval
6. Simulation Study
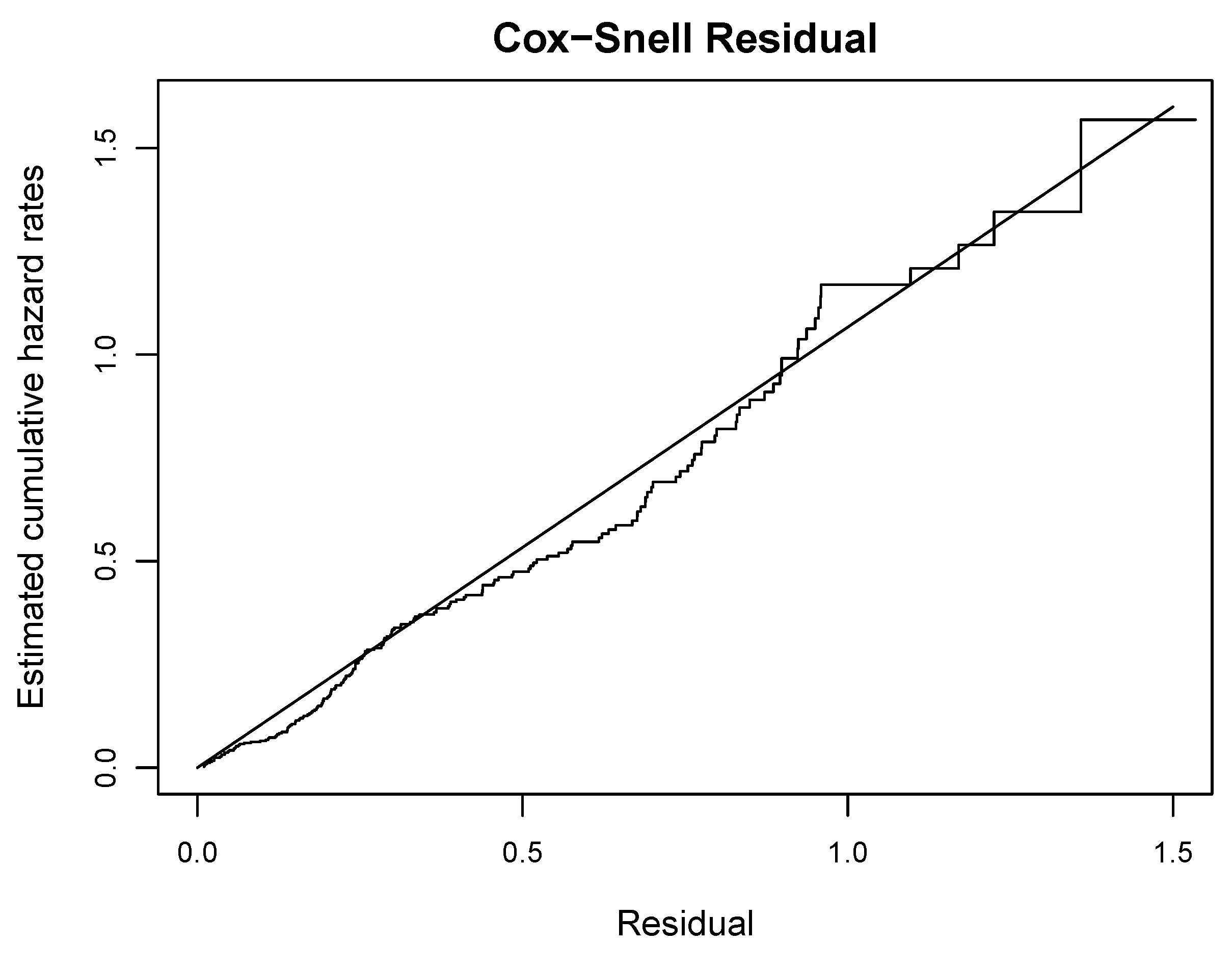
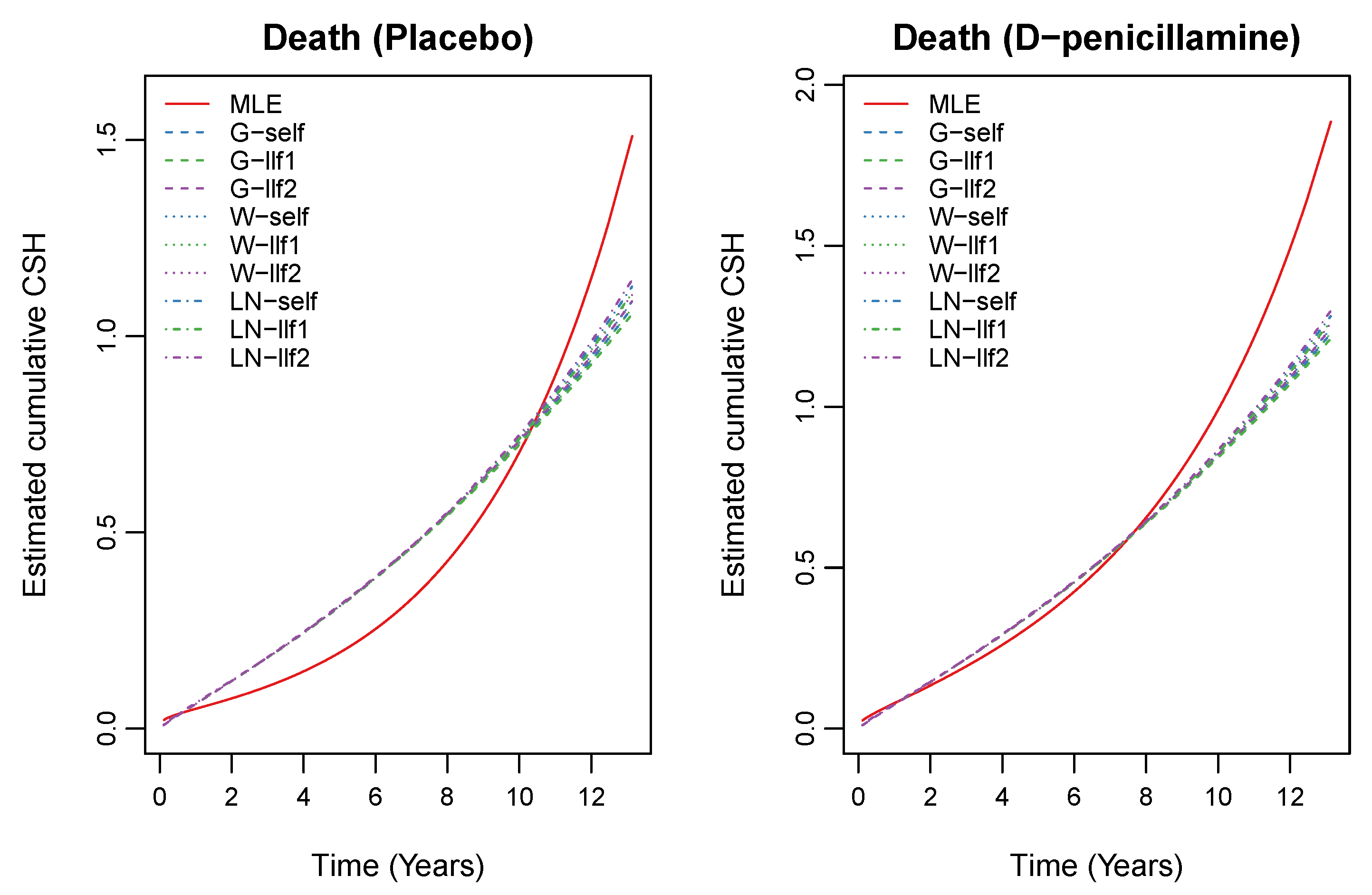
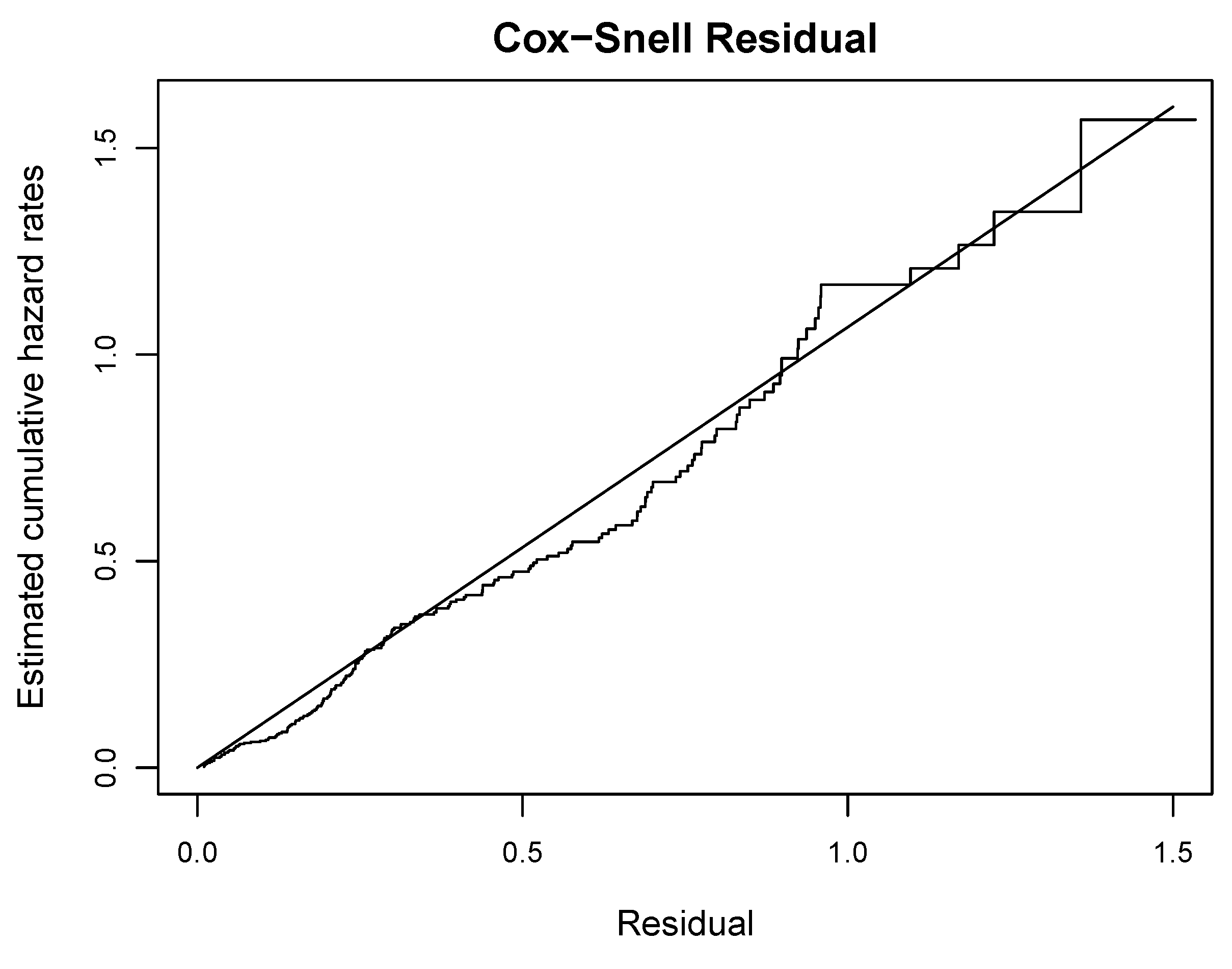
7. Illustrative Application
8. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cox, D.R. Regression models and life-tables. J. R. Stat. Soc. Ser. Methodol. 1972, 34, 187–220. [Google Scholar] [CrossRef]
- Cox, D.R.; Oakes, D. Analysis of Survival Data; Chapman and Hall/CRC: London, UK, 1984. [Google Scholar]
- Breslow, N.E.; Day, N.E. Statistical Methods in Cancer Research; International Agency for Research on Cancer: Lyon, France, 1987; Volume 2. [Google Scholar]
- Aalen, O.O. A linear regression model for the analysis of life times. Stat. Med. 1989, 8, 907–925. [Google Scholar] [CrossRef]
- Lin, D.; Ying, Z. Semiparametric analysis of the additive risk model. Biometrika 1994, 81, 61–71. [Google Scholar] [CrossRef]
- Lin, D.; Ying, Z. Semiparametric analysis of general additive-multiplicative hazard models for counting processes. Ann. Stat. 1995, 23, 1712–1734. [Google Scholar] [CrossRef]
- Kalbfleisch, J.D.; Prentice, R.L. The Statistical Analysis of Failure Time Data; John Wiley & Sons: Hoboken, NJ, USA, 2002; Volume 360. [Google Scholar]
- Haller, B.; Schmidt, G.; Ulm, K. Applying competing risks regression models: An overview. Lifetime Data Anal. 2013, 19, 33–58. [Google Scholar] [CrossRef]
- Lawless, J.F. Statistical Models and Methods for Lifetime Data; John Wiley & Sons: Hoboken, NJ, USA, 2003; Volume 362. [Google Scholar]
- Pintilie, M. Competing Risks: A Practical Perspective; John Wiley & Sons: Chichester, UK, 2006; Volume 58. [Google Scholar]
- Emura, T.; Shih, J.H.; Ha, I.D.; Wilke, R.A. Comparison of the marginal hazard model and the sub-distribution hazard model for competing risks under an assumed copula. Stat. Methods Med. Res. 2020, 29, 2307–2327. [Google Scholar] [CrossRef]
- Meng, C.; Esserman, D.; Li, F.; Zhao, Y.; Blaha, O.; Lu, W.; Wang, Y.; Peduzzi, P.; Greene, E.J. Simulating time-to-event data subject to competing risks and clustering: A review and synthesis. Stat. Methods Med. Res. 2023, 32, 305–333. [Google Scholar] [CrossRef] [PubMed]
- Zuo, Z.; Wang, L.; Lio, Y. Reliability estimation for dependent left-truncated and right-censored competing risks data with illustrations. Energies 2023, 16, 62. [Google Scholar] [CrossRef]
- Jeong, J.H.; Fine, J.P. Parametric regression on cumulative incidence function. Biostatistics 2007, 8, 184–196. [Google Scholar] [CrossRef]
- Anjana, S.; Sankaran, P. Parametric analysis of lifetime data with multiple causes of failure using cause specific reversed hazard rates. Calcutta Stat. Assoc. Bull. 2015, 67, 129–142. [Google Scholar] [CrossRef]
- Lee, M. Parametric inference for quantile event times with adjustment for covariates on competing risks data. J. Appl. Stat. 2019, 46, 2128–2144. [Google Scholar] [CrossRef]
- Lipowski, C.; Lo, S.; Shi, S.; Wilke, R.A. Competing risks regression with dependent multiple spells: Monte Carlo evidence and an application to maternity leave. Jpn. J. Stat. Data Sci. 2021, 4, 953–981. [Google Scholar] [CrossRef]
- Rehman, H.; Chandra, N. Inferences on cumulative incidence function for middle censored survival data with Weibull regression. Jpn. J. Stat. Data Sci. 2022, 5, 65–86. [Google Scholar] [CrossRef]
- Shen, Y.; Cheng, S. Confidence bands for cumulative incidence curves under the additive risk model. Biometrics 1999, 55, 1093–1100. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Sun, L.; Flournoy, N. Additive hazards model for competing risks analysis of the case-cohort design. Commun. Stat. Theory Methods 2004, 33, 351–366. [Google Scholar] [CrossRef]
- Zhang, X.; Akcin, H.; Lim, H.J. Regression analysis of competing risks data via semi-parametric additive hazard model. Stat. Methods Appl. 2011, 20, 357–381. [Google Scholar] [CrossRef]
- Li, W.; Xue, X.; Long, Y. An additive subdistribution hazard model for competing risks data. Commun. Stat. Theory Methods 2017, 46, 11667–11687. [Google Scholar] [CrossRef]
- Sankaran, P.; Prasad, S. Additive risks regression model for middle censored exponentiated-exponential lifetime data. Commun. Stat. Simul. Comput. 2018, 47, 1963–1974. [Google Scholar] [CrossRef]
- Lai, C.; Xie, M.; Murthy, D. A modified Weibull distribution. IEEE Trans. Reliab. 2003, 52, 33–37. [Google Scholar] [CrossRef]
- Byrnes, J.M.; Lin, Y.J.; Tsai, T.R.; Lio, Y. Bayesian inference of δ= P (X< Y) for Burr type XII distribution based on progressively first failure-censored samples. Mathematics 2019, 7, 794. [Google Scholar]
- Martz, H.F.; Waller, R. Bayesian Reliability Analysis; John Wiley & Sons: New York, NY, USA, 1982. [Google Scholar]
- Ranjan, R.; Sen, R.; Upadhyay, S.K. Bayes analysis of some important lifetime models using MCMC based approaches when the observations are left truncated and right censored. Reliab. Eng. Syst. Saf. 2021, 214, 107747. [Google Scholar] [CrossRef]
- Ng, H.K.T. Parameter estimation for a modified Weibull distribution, for progressively type-II censored samples. IEEE Trans. Reliab. 2005, 54, 374–380. [Google Scholar] [CrossRef]
- Jiang, H.; Xie, M.; Tang, L. Markov chain Monte Carlo methods for parameter estimation of the modified Weibull distribution. J. Appl. Stat. 2008, 35, 647–658. [Google Scholar] [CrossRef]
- Upadhyay, S.; Gupta, A. A Bayes analysis of modified Weibull distribution via Markov chain Monte Carlo simulation. J. Stat. Comput. Simul. 2010, 80, 241–254. [Google Scholar] [CrossRef]
- Nelder, J.A.; Mead, R. A simplex method for function minimization. Comput. J. 1965, 7, 308–313. [Google Scholar] [CrossRef]
- Robert, C.P.; Casella, G.; Casella, G. Introducing Monte Carlo Methods with R; Springer Science & Business Media: New York, NY, USA, 2010; Volume 18. [Google Scholar]
- Geman, S.; Geman, D. Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images. IEEE Trans. Pattern Anal. Mach. Intell. 1984, PAMI-6, 721–741. [Google Scholar] [CrossRef] [PubMed]
- Hastings, W.K. Monte Carlo sampling methods using Markov chains and their applications. Biometrika 1970, 57, 97–109. [Google Scholar] [CrossRef]
- Guure, C.B.; Ibrahim, N.A. Bayesian analysis of the survival function and failure rate of Weibull distribution with censored data. Math. Probl. Eng. 2012, 2012. [Google Scholar] [CrossRef]
- Beyersmann, J.; Allignol, A.; Schumacher, M. Competing Risks and Multistate Models with R; Springer Science & Business Media: New York, NY, USA, 2012. [Google Scholar]
- Knight, K. Mathematical Statistics; CRC Press: Boca Raton, FL, USA, 1999. [Google Scholar]
- Dörre, A.; Huang, C.Y.; Tseng, Y.K.; Emura, T. Likelihood-based analysis of doubly-truncated data under the location-scale and AFT model. Comput. Stat. 2021, 36, 375–408. [Google Scholar] [CrossRef]
- Lunn, D.; Jackson, C.; Best, N.; Spiegelhalter, D.; Thomas, A. The BUGS Book: A Practical Introduction to Bayesian Analysis; Chapman and Hall/CRC: Boca Raton, FL, USA, 2012. [Google Scholar]
- Therneau, T.M.; Grambsch, P.M. Modeling Survival Data: Extending the Cox Model; Springer Science & Business Media: New York, NY, USA, 2000. [Google Scholar]
- Lai, X.; Yau, K.K.; Liu, L. Competing risk model with bivariate random effects for clustered survival data. Comput. Stat. Data Anal. 2017, 112, 215–223. [Google Scholar] [CrossRef]
- Klein, J.P.; Moeschberger, M.L. Survival Analysis: Techniques for Censored and Truncated Data; Springer: New York, NY, USA, 2003. [Google Scholar]
- Fan, T.H.; Wang, Y.F.; Ju, S.K. A competing risks model with multiply censored reliability data under multivariate Weibull distributions. IEEE Trans. Reliab. 2019, 68, 462–475. [Google Scholar] [CrossRef]
- Li, Y.; Ye, J. Analysis for partially accelerated dependent competing risks model with masked data based on copula function. Commun. Stat. Simul. Comput. 2022, 1–17. [Google Scholar] [CrossRef]
- Sinha, S. Bayesian Estimation; New Age International (P) Limited Publisher: New Delhi, India, 1998. [Google Scholar]
- Jeffreys, H. Theory of Probability; Oxford University Press: London, UK, 1961. [Google Scholar]
- Gelman, A. Prior distributions for variance parameters in hierarchical models (comment on article by Browne and Draper). Bayesian Anal. 2006, 1, 515–534. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Priors | Hyper-Parameters |
|---|---|
| Gamma | |
| Weibull | |
| Log-normal | , |
| Cause 1 | Cause 2 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| n | Method | |||||||||
| True value | 0.5 | 0.6 | 0.6 | 0.8012 | 0.7 | 0.5 | 0.8 | 1.1187 | ||
| 100 | MLE | AVE | 0.5350 | 0.6494 | 0.6175 | 0.8388 | 0.7567 | 0.5450 | 0.7582 | 1.1492 |
| MSE | 0.0234 | 0.0231 | 0.1642 | 0.0315 | 0.0373 | 0.0075 | 0.2376 | 0.0492 | ||
| ACI | AVL | 0.5672 | 0.4880 | 1.5375 | 0.7412 | 0.6583 | 0.3303 | 1.7849 | 1.0228 | |
| CP | 0.9520 | 0.9500 | 0.9480 | 0.9560 | 0.9340 | 0.9760 | 0.9300 | 0.9620 | ||
| G-self | AVE | 0.5180 | 0.6381 | 0.7453 | 0.8847 | 0.7464 | 0.5848 | 0.8935 | 1.1967 | |
| MSE | 0.0050 | 0.0053 | 0.1063 | 0.0281 | 0.0231 | 0.0108 | 0.1135 | 0.0404 | ||
| G-llf1 | AVE | 0.5107 | 0.6326 | 0.6621 | 0.8650 | 0.7304 | 0.5804 | 0.7883 | 1.1711 | |
| MSE | 0.0047 | 0.0048 | 0.0758 | 0.0239 | 0.0206 | 0.0100 | 0.0934 | 0.0354 | ||
| G-llf2 | AVE | 0.5256 | 0.6438 | 0.8381 | 0.9055 | 0.7633 | 0.5892 | 1.0044 | 1.2233 | |
| MSE | 0.0056 | 0.0059 | 0.1532 | 0.0333 | 0.0264 | 0.0117 | 0.1515 | 0.0469 | ||
| G-BCI | AVL | 0.3864 | 0.3366 | 1.2934 | 0.6311 | 0.5713 | 0.2978 | 1.4296 | 0.7206 | |
| CP | 0.9980 | 0.9880 | 0.9660 | 0.9580 | 0.9360 | 0.8800 | 0.9680 | 0.9360 | ||
| W-self | AVE | 0.5281 | 0.6465 | 0.7368 | 0.8899 | 0.7495 | 0.5824 | 0.8896 | 1.1982 | |
| MSE | 0.0057 | 0.0057 | 0.1038 | 0.0291 | 0.0237 | 0.0115 | 0.1114 | 0.0404 | ||
| W-llf1 | AVE | 0.5206 | 0.6412 | 0.6534 | 0.8703 | 0.7332 | 0.5775 | 0.7843 | 1.1727 | |
| MSE | 0.0053 | 0.0052 | 0.0745 | 0.0247 | 0.0212 | 0.0106 | 0.0921 | 0.0354 | ||
| W-llf2 | AVE | 0.5357 | 0.6518 | 0.8304 | 0.9107 | 0.7667 | 0.5875 | 1.0008 | 1.2248 | |
| MSE | 0.0063 | 0.0063 | 0.1499 | 0.0346 | 0.0271 | 0.0125 | 0.1488 | 0.0470 | ||
| W-BCI | AVL | 0.3901 | 0.3277 | 1.2960 | 0.6309 | 0.5757 | 0.3174 | 1.4310 | 0.7211 | |
| CP | 0.9900 | 0.9840 | 0.9640 | 0.9520 | 0.9380 | 0.8900 | 0.9780 | 0.9380 | ||
| LN-self | AVE | 0.5137 | 0.6360 | 0.7476 | 0.8817 | 0.7346 | 0.5841 | 0.9036 | 1.1896 | |
| MSE | 0.0044 | 0.0053 | 0.1064 | 0.0274 | 0.0218 | 0.0103 | 0.1150 | 0.0389 | ||
| LN-llf1 | AVE | 0.5068 | 0.6303 | 0.6650 | 0.8622 | 0.7189 | 0.5800 | 0.7981 | 1.1643 | |
| MSE | 0.0043 | 0.0047 | 0.0760 | 0.0234 | 0.0197 | 0.0095 | 0.0932 | 0.0343 | ||
| LN-llf2 | AVE | 0.5210 | 0.6418 | 0.8397 | 0.9023 | 0.7513 | 0.5883 | 1.0141 | 1.2160 | |
| MSE | 0.0049 | 0.0060 | 0.1532 | 0.0324 | 0.0247 | 0.0111 | 0.1547 | 0.0450 | ||
| LN-BCI | AVL | 0.3764 | 0.3384 | 1.2921 | 0.6272 | 0.5664 | 0.2888 | 1.4281 | 0.7169 | |
| CP | 0.9940 | 0.9920 | 0.9640 | 0.9580 | 0.9480 | 0.8800 | 0.9700 | 0.9400 | ||
| 200 | MLE | AVE | 0.5198 | 0.6268 | 0.5800 | 0.8084 | 0.7327 | 0.5363 | 0.7980 | 1.1454 |
| MSE | 0.0112 | 0.0070 | 0.0922 | 0.0166 | 0.0151 | 0.0042 | 0.1146 | 0.0238 | ||
| ACI | AVL | 0.3883 | 0.3256 | 1.0495 | 0.4873 | 0.4477 | 0.2291 | 1.2418 | 0.6946 | |
| CP | 0.9400 | 0.9740 | 0.9160 | 0.9260 | 0.9460 | 0.9520 | 0.9240 | 0.9680 | ||
| G-self | AVE | 0.5131 | 0.6300 | 0.6498 | 0.8348 | 0.7317 | 0.5595 | 0.8780 | 1.1786 | |
| MSE | 0.0049 | 0.0036 | 0.0659 | 0.0150 | 0.0120 | 0.0058 | 0.0937 | 0.0240 | ||
| G-llf1 | AVE | 0.5084 | 0.6265 | 0.6034 | 0.8246 | 0.7231 | 0.5571 | 0.8110 | 1.1646 | |
| MSE | 0.0046 | 0.0033 | 0.0576 | 0.0139 | 0.0112 | 0.0055 | 0.0820 | 0.0218 | ||
| G-llf2 | AVE | 0.5180 | 0.6337 | 0.7002 | 0.8454 | 0.7406 | 0.5618 | 0.9481 | 1.1931 | |
| MSE | 0.0051 | 0.0039 | 0.0796 | 0.0164 | 0.0130 | 0.0061 | 0.1136 | 0.0266 | ||
| G-BCI | AVL | 0.3106 | 0.2690 | 0.9754 | 0.4557 | 0.4197 | 0.2172 | 1.1653 | 0.5353 | |
| CP | 0.9760 | 0.9820 | 0.9520 | 0.9420 | 0.9440 | 0.8580 | 0.9440 | 0.9180 | ||
| W-self | AVE | 0.5231 | 0.6394 | 0.6409 | 0.8396 | 0.7325 | 0.5566 | 0.8763 | 1.1790 | |
| MSE | 0.0056 | 0.0043 | 0.0651 | 0.0153 | 0.0123 | 0.0059 | 0.0939 | 0.0241 | ||
| W-llf1 | AVE | 0.5182 | 0.6358 | 0.5943 | 0.8293 | 0.7239 | 0.5540 | 0.8091 | 1.1649 | |
| MSE | 0.0053 | 0.0040 | 0.0575 | 0.0141 | 0.0114 | 0.0056 | 0.0824 | 0.0219 | ||
| W-llf2 | AVE | 0.5281 | 0.6429 | 0.6917 | 0.8502 | 0.7415 | 0.5591 | 0.9466 | 1.1935 | |
| MSE | 0.0059 | 0.0046 | 0.0780 | 0.0168 | 0.0133 | 0.0062 | 0.1137 | 0.0268 | ||
| W-BCI | AVL | 0.3163 | 0.2687 | 0.9771 | 0.4566 | 0.4214 | 0.2266 | 1.1667 | 0.5357 | |
| CP | 0.9640 | 0.9660 | 0.9500 | 0.9340 | 0.9400 | 0.8720 | 0.9420 | 0.9220 | ||
| LN-self | AVE | 0.5093 | 0.6271 | 0.6535 | 0.8330 | 0.7249 | 0.5595 | 0.8857 | 1.1753 | |
| MSE | 0.0044 | 0.0034 | 0.0657 | 0.0150 | 0.0115 | 0.0056 | 0.0949 | 0.0235 | ||
| LN-llf1 | AVE | 0.5047 | 0.6236 | 0.6072 | 0.8228 | 0.7164 | 0.5572 | 0.8187 | 1.1612 | |
| MSE | 0.0042 | 0.0032 | 0.0571 | 0.0139 | 0.0108 | 0.0053 | 0.0823 | 0.0214 | ||
| LN-llf2 | AVE | 0.5140 | 0.6307 | 0.7039 | 0.8437 | 0.7336 | 0.5617 | 0.9558 | 1.1897 | |
| MSE | 0.0046 | 0.0037 | 0.0796 | 0.0164 | 0.0124 | 0.0059 | 0.1158 | 0.0260 | ||
| LN-BCI | AVL | 0.3048 | 0.2682 | 0.9753 | 0.4568 | 0.4164 | 0.2130 | 1.1664 | 0.5352 | |
| CP | 0.9800 | 0.9840 | 0.9520 | 0.9420 | 0.9520 | 0.8600 | 0.9380 | 0.9220 | ||
| 400 | MLE | AVE | 0.5179 | 0.6215 | 0.5873 | 0.8106 | 0.7327 | 0.5364 | 0.7751 | 1.1346 |
| MSE | 0.0071 | 0.0036 | 0.0436 | 0.0074 | 0.0090 | 0.0028 | 0.0705 | 0.0126 | ||
| ACI | AVL | 0.2738 | 0.2262 | 0.7423 | 0.3420 | 0.3166 | 0.1615 | 0.8729 | 0.4866 | |
| CP | 0.9180 | 0.9640 | 0.9260 | 0.9480 | 0.9320 | 0.8880 | 0.8920 | 0.9640 | ||
| G-self | AVE | 0.5146 | 0.6243 | 0.6265 | 0.8258 | 0.7300 | 0.5470 | 0.8309 | 1.1567 | |
| MSE | 0.0037 | 0.0025 | 0.0329 | 0.0071 | 0.0072 | 0.0034 | 0.0589 | 0.0123 | ||
| G-llf1 | AVE | 0.5117 | 0.6222 | 0.6009 | 0.8205 | 0.7254 | 0.5458 | 0.7942 | 1.1493 | |
| MSE | 0.0035 | 0.0024 | 0.0309 | 0.0067 | 0.0068 | 0.0032 | 0.0556 | 0.0115 | ||
| G-llf2 | AVE | 0.5176 | 0.6263 | 0.6532 | 0.8312 | 0.7347 | 0.5482 | 0.8689 | 1.1641 | |
| MSE | 0.0038 | 0.0026 | 0.0365 | 0.0075 | 0.0076 | 0.0035 | 0.0651 | 0.0132 | ||
| G-BCI | AVL | 0.2434 | 0.2044 | 0.7277 | 0.3286 | 0.3057 | 0.1568 | 0.8685 | 0.3875 | |
| CP | 0.9620 | 0.9760 | 0.9520 | 0.9540 | 0.9340 | 0.8280 | 0.9180 | 0.9400 | ||
| W-self | AVE | 0.5229 | 0.6322 | 0.6184 | 0.8294 | 0.7305 | 0.5452 | 0.8291 | 1.1565 | |
| MSE | 0.0041 | 0.0030 | 0.0328 | 0.0073 | 0.0074 | 0.0033 | 0.0587 | 0.0122 | ||
| W-llf1 | AVE | 0.5199 | 0.6301 | 0.5925 | 0.8241 | 0.7259 | 0.5440 | 0.7921 | 1.1491 | |
| MSE | 0.0040 | 0.0029 | 0.0311 | 0.0069 | 0.0070 | 0.0032 | 0.0556 | 0.0115 | ||
| W-llf2 | AVE | 0.5260 | 0.6343 | 0.6454 | 0.8349 | 0.7352 | 0.5465 | 0.8673 | 1.1640 | |
| MSE | 0.0043 | 0.0032 | 0.0361 | 0.0078 | 0.0078 | 0.0034 | 0.0648 | 0.0131 | ||
| W-BCI | AVL | 0.2471 | 0.2068 | 0.7316 | 0.3304 | 0.3069 | 0.1603 | 0.8729 | 0.3884 | |
| CP | 0.9500 | 0.9600 | 0.9580 | 0.9580 | 0.9300 | 0.8380 | 0.9260 | 0.9380 | ||
| LN-self | AVE | 0.5116 | 0.6223 | 0.6296 | 0.8244 | 0.7264 | 0.5471 | 0.8354 | 1.1551 | |
| MSE | 0.0034 | 0.0024 | 0.0327 | 0.0070 | 0.0070 | 0.0033 | 0.0591 | 0.0122 | ||
| LN-llf1 | AVE | 0.5087 | 0.6203 | 0.6040 | 0.8191 | 0.7219 | 0.5459 | 0.7984 | 1.1477 | |
| MSE | 0.0033 | 0.0023 | 0.0305 | 0.0066 | 0.0066 | 0.0032 | 0.0553 | 0.0115 | ||
| LN-llf2 | AVE | 0.5145 | 0.6244 | 0.6562 | 0.8298 | 0.7310 | 0.5483 | 0.8736 | 1.1626 | |
| MSE | 0.0036 | 0.0025 | 0.0364 | 0.0074 | 0.0074 | 0.0034 | 0.0657 | 0.0131 | ||
| LN-BCI | AVL | 0.2407 | 0.2038 | 0.7275 | 0.3293 | 0.3045 | 0.1549 | 0.8732 | 0.3876 | |
| CP | 0.9700 | 0.9780 | 0.9560 | 0.9560 | 0.9340 | 0.8340 | 0.9280 | 0.9420 | ||
| Model | MLE | Log-Likelihood | AIC | BIC |
|---|---|---|---|---|
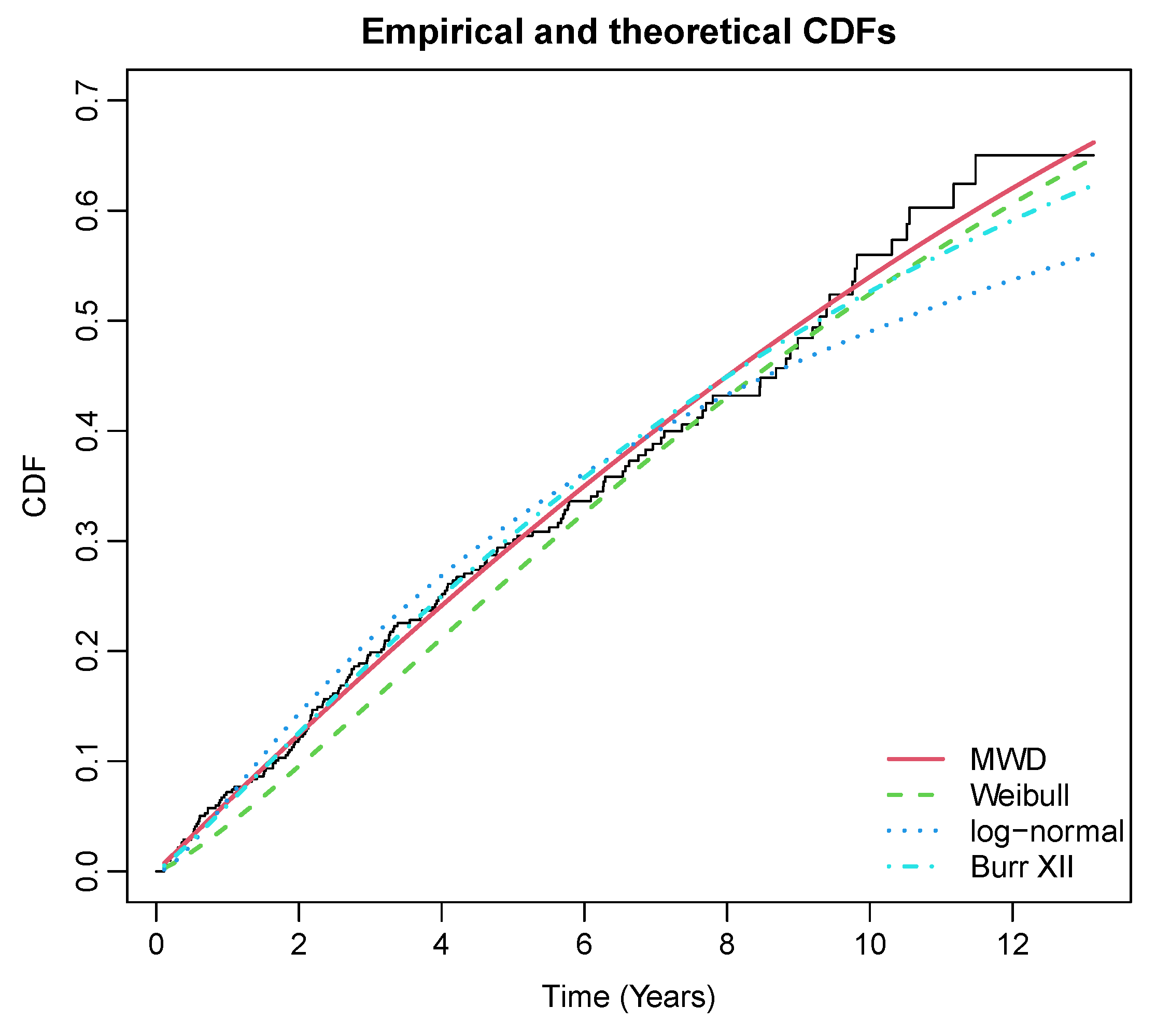
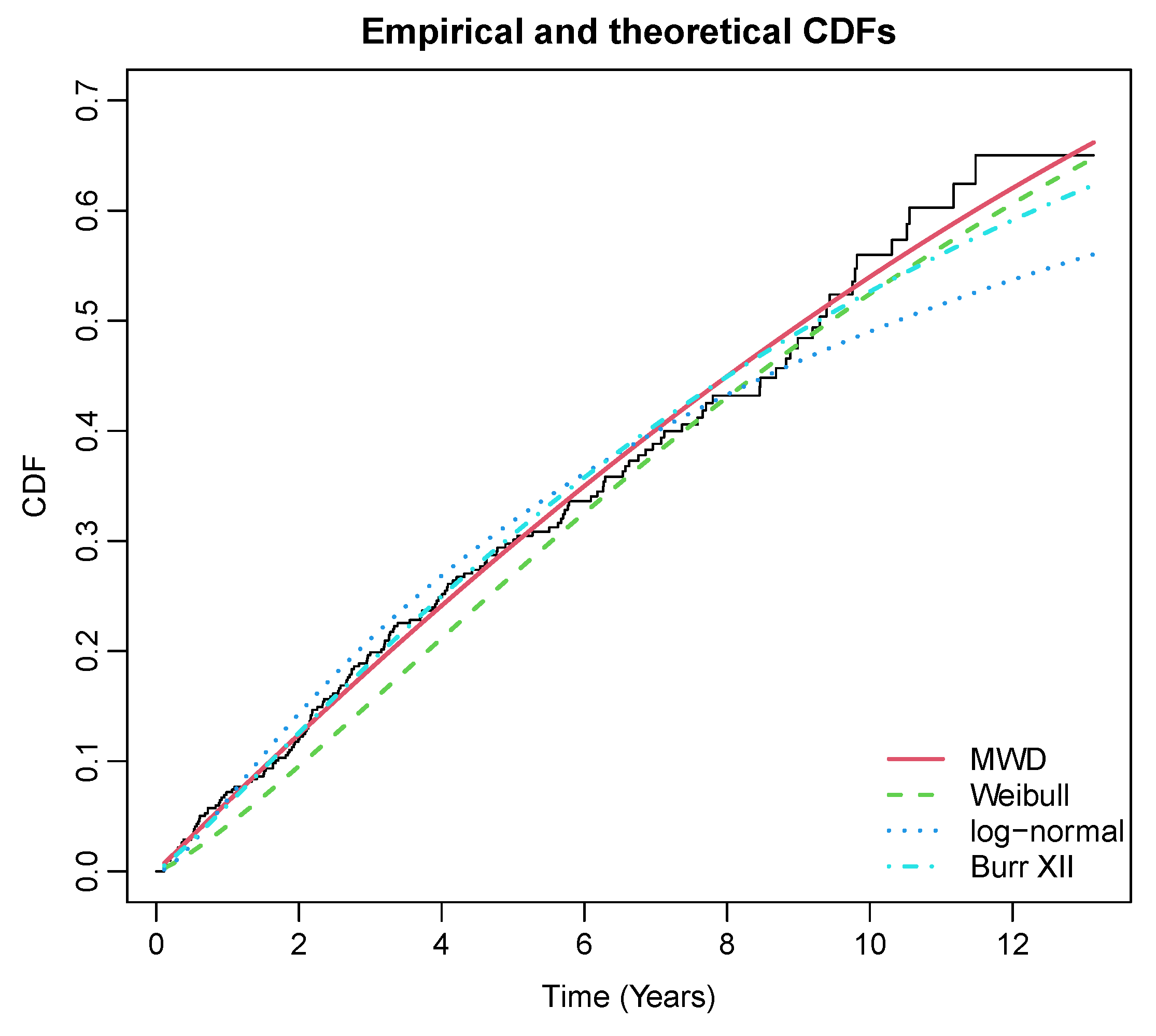
| MWD | , , | −580.870 | 1167.74 | 1179.85 |
| Weibull | Shape = 1.24, Scale = 12.67, | −584.0561 | 1172.11 | 1180.18 |
| Log-normal | Meanlog = 2.341, Sdlog = 1.546 | −585.9771 | 1175.95 | 1184.03 |
| Burr XII | a = 28.53 , | −581.64 | 1169.28 | 1181.39 |
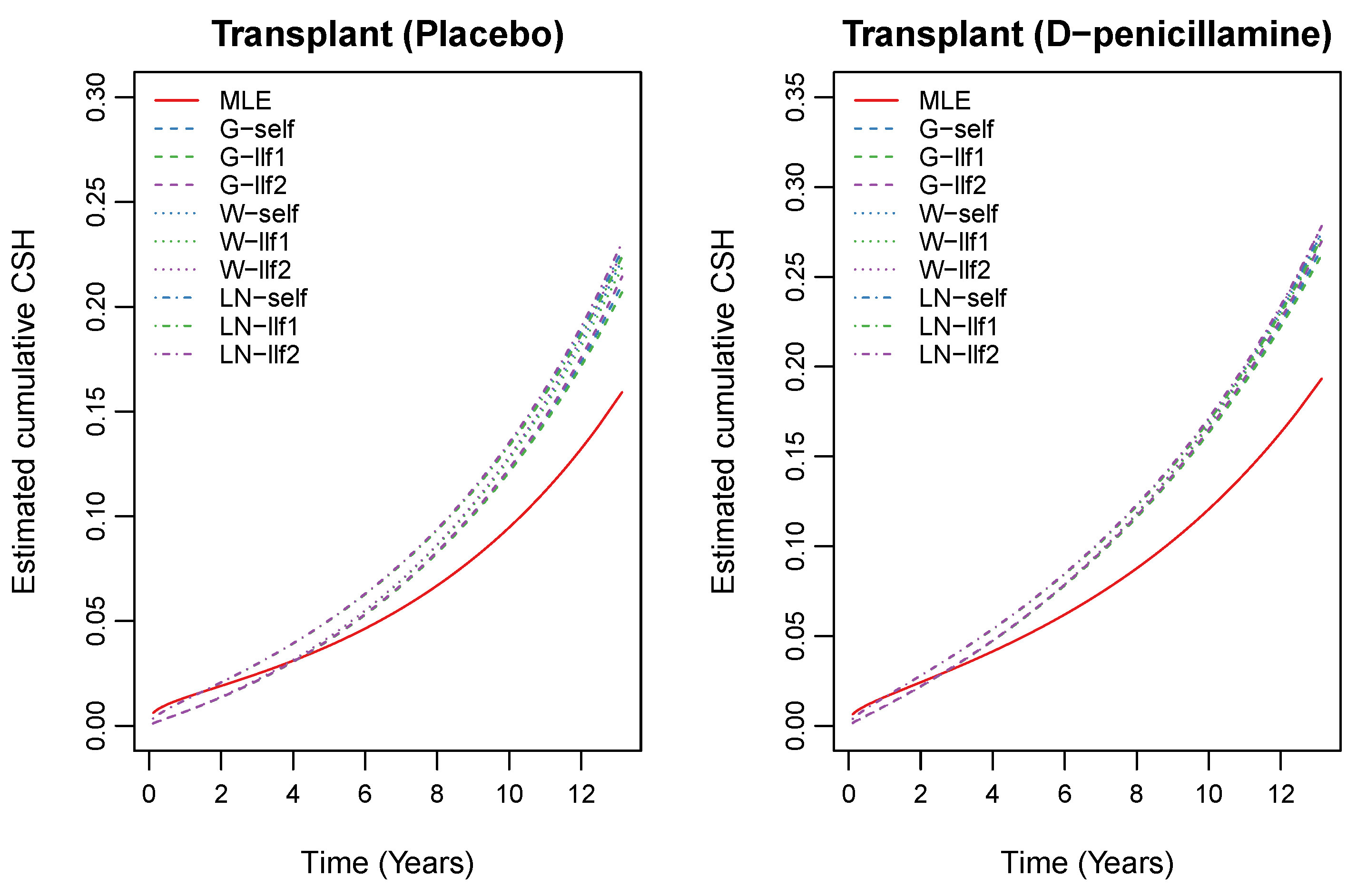
| Transplant | Death | |||||||
|---|---|---|---|---|---|---|---|---|
| Method | ||||||||
| MLE | 0.0117 | 0.3038 | 0.1394 | 0.0026 | 0.0407 | 0.2946 | 0.2174 | 0.0286 |
| MLE.SE | 0.0054 | 0.9331 | 0.1965 | 0.0077 | 0.0101 | 0.0947 | 0.0353 | 0.0096 |
| G-self | 0.0062 | 0.9640 | 0.0852 | 0.0042 | 0.0600 | 0.8965 | 0.0443 | 0.0118 |
| G-llf1 | 0.0062 | 0.8806 | 0.0827 | 0.0042 | 0.0599 | 0.8867 | 0.0439 | 0.0117 |
| G-llf2 | 0.0062 | 1.0445 | 0.0878 | 0.0042 | 0.0601 | 0.9061 | 0.0447 | 0.0118 |
| G.SE | 0.0031 | 0.3312 | 0.0581 | 0.0030 | 0.0109 | 0.1136 | 0.0234 | 0.0079 |
| W-self | 0.0062 | 0.9681 | 0.0878 | 0.0040 | 0.0597 | 0.8828 | 0.0485 | 0.0118 |
| W-llf1 | 0.0062 | 0.9057 | 0.0859 | 0.0040 | 0.0597 | 0.8737 | 0.0481 | 0.0117 |
| W-llf2 | 0.0062 | 1.0295 | 0.0898 | 0.0040 | 0.0598 | 0.8919 | 0.0488 | 0.0118 |
| W.SE | 0.0030 | 0.2876 | 0.0510 | 0.0029 | 0.0109 | 0.1100 | 0.0219 | 0.0080 |
| LN-self | 0.0110 | 0.6324 | 0.1081 | 0.0036 | 0.0617 | 0.8262 | 0.0597 | 0.0118 |
| LN-llf1 | 0.0110 | 0.5906 | 0.1066 | 0.0036 | 0.0616 | 0.8184 | 0.0594 | 0.0117 |
| LN-llf2 | 0.0110 | 0.6756 | 0.1096 | 0.0036 | 0.0618 | 0.8339 | 0.0600 | 0.0118 |
| LN.SE | 0.0041 | 0.2384 | 0.0449 | 0.0027 | 0.0108 | 0.1018 | 0.0205 | 0.0080 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rehman, H.; Chandra, N.; Emura, T.; Pandey, M. Estimation of the Modified Weibull Additive Hazards Regression Model under Competing Risks. Symmetry 2023, 15, 485. https://doi.org/10.3390/sym15020485
Rehman H, Chandra N, Emura T, Pandey M. Estimation of the Modified Weibull Additive Hazards Regression Model under Competing Risks. Symmetry. 2023; 15(2):485. https://doi.org/10.3390/sym15020485
Chicago/Turabian StyleRehman, Habbiburr, Navin Chandra, Takeshi Emura, and Manju Pandey. 2023. "Estimation of the Modified Weibull Additive Hazards Regression Model under Competing Risks" Symmetry 15, no. 2: 485. https://doi.org/10.3390/sym15020485
APA StyleRehman, H., Chandra, N., Emura, T., & Pandey, M. (2023). Estimation of the Modified Weibull Additive Hazards Regression Model under Competing Risks. Symmetry, 15(2), 485. https://doi.org/10.3390/sym15020485