
Concordance of Lateralization Index for Brain Asymmetry Applied to Identify a Reliable Language Task

 ,
,
Abstract
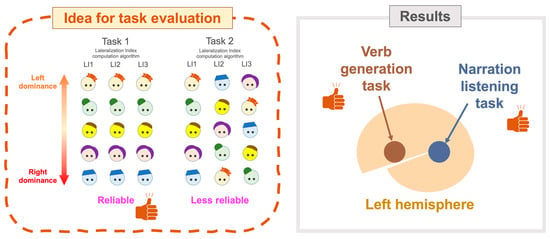
1. Introduction
2. Rationale
2.1. Efficacies and Drawbacks of Direct Clinical Examinations
2.2. Reproducibility/Concordance as a Basis for Evaluation
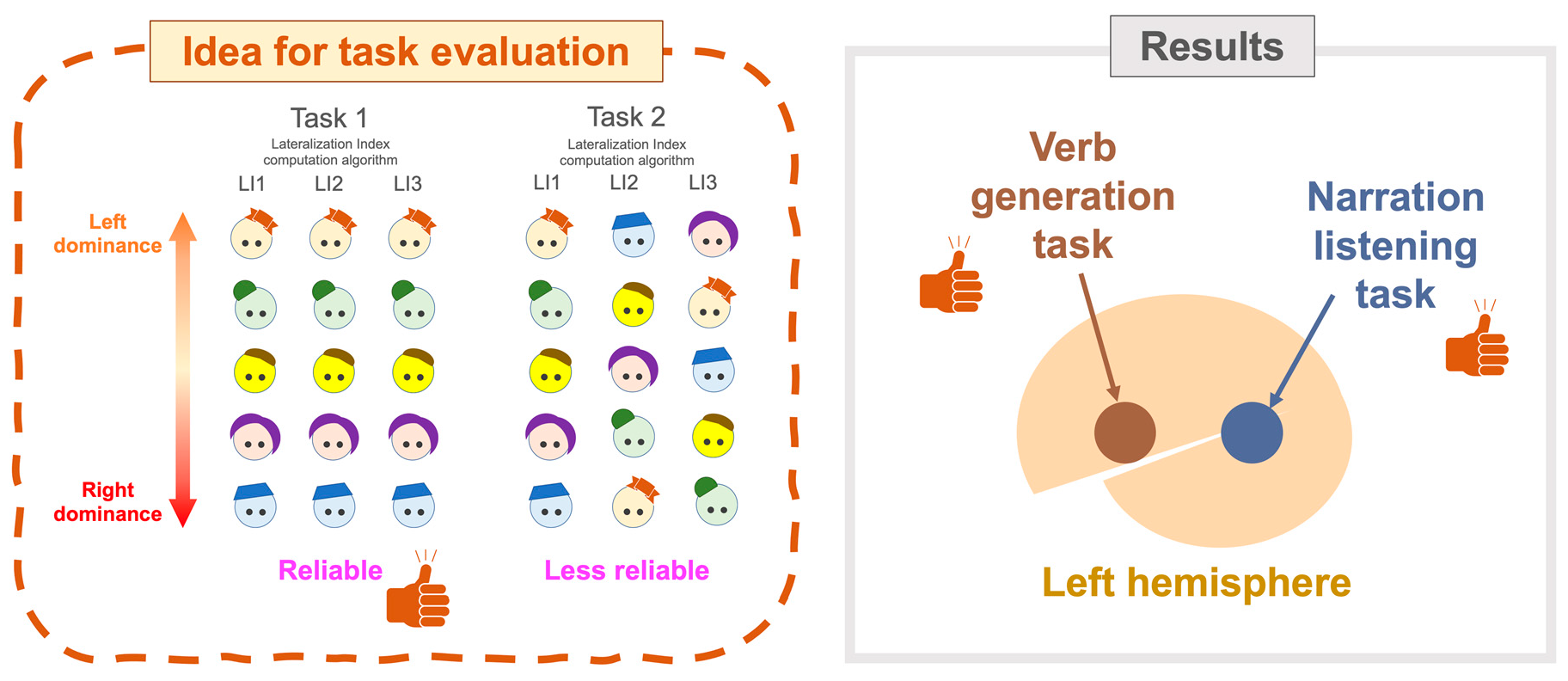
2.3. Evaluating LI Computation Algorithms
2.4. Evaluating Language Tasks
3. Materials and Methods
3.1. Participants
3.2. Magnetic Resonance Imaging (MRI) Parameters
3.3. Language Tasks
3.4. Image Processing
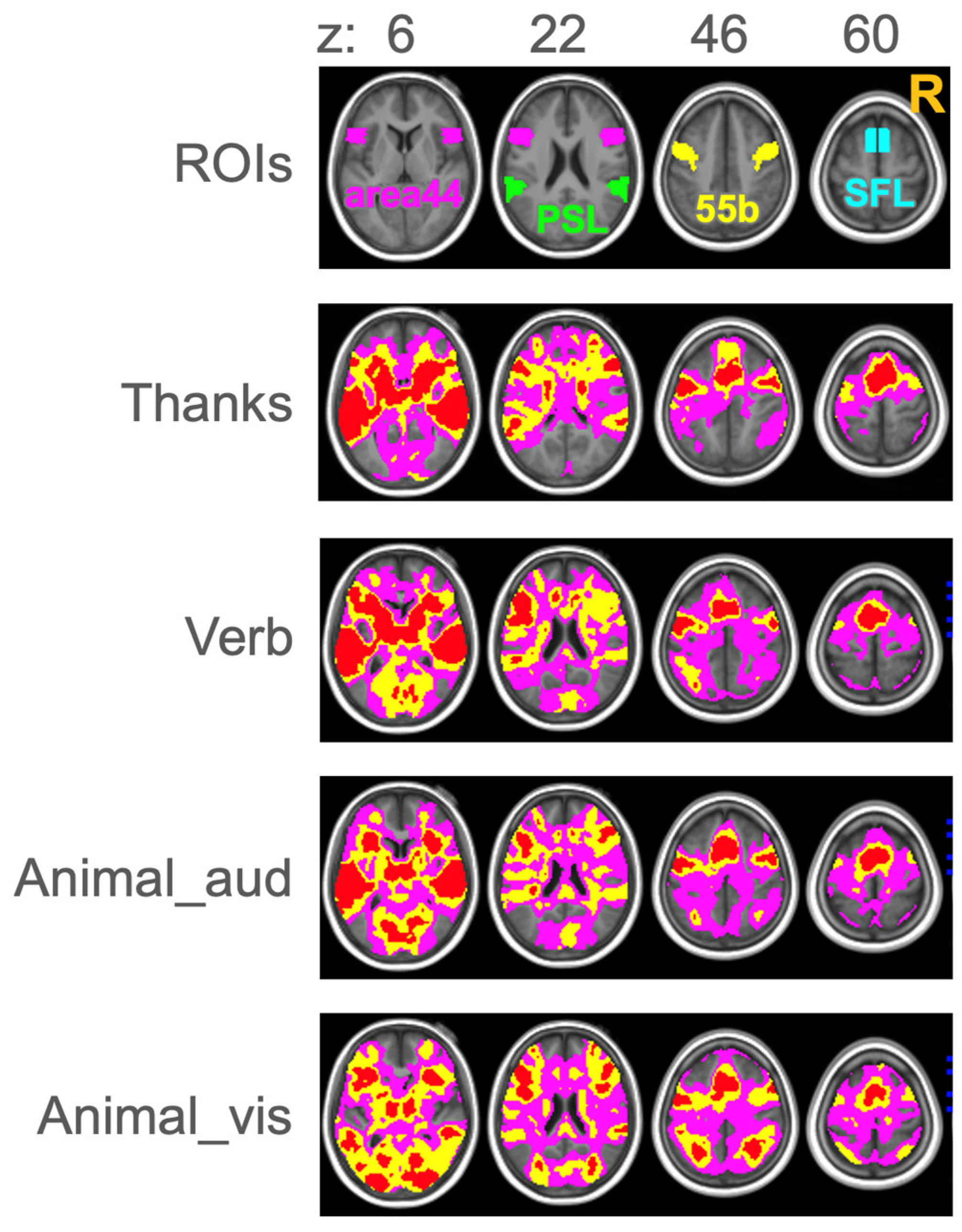
3.5. ROIs
3.6. LIs
3.7. Analysis of Lateralization
3.8. Analysis of Concordance
4. Results
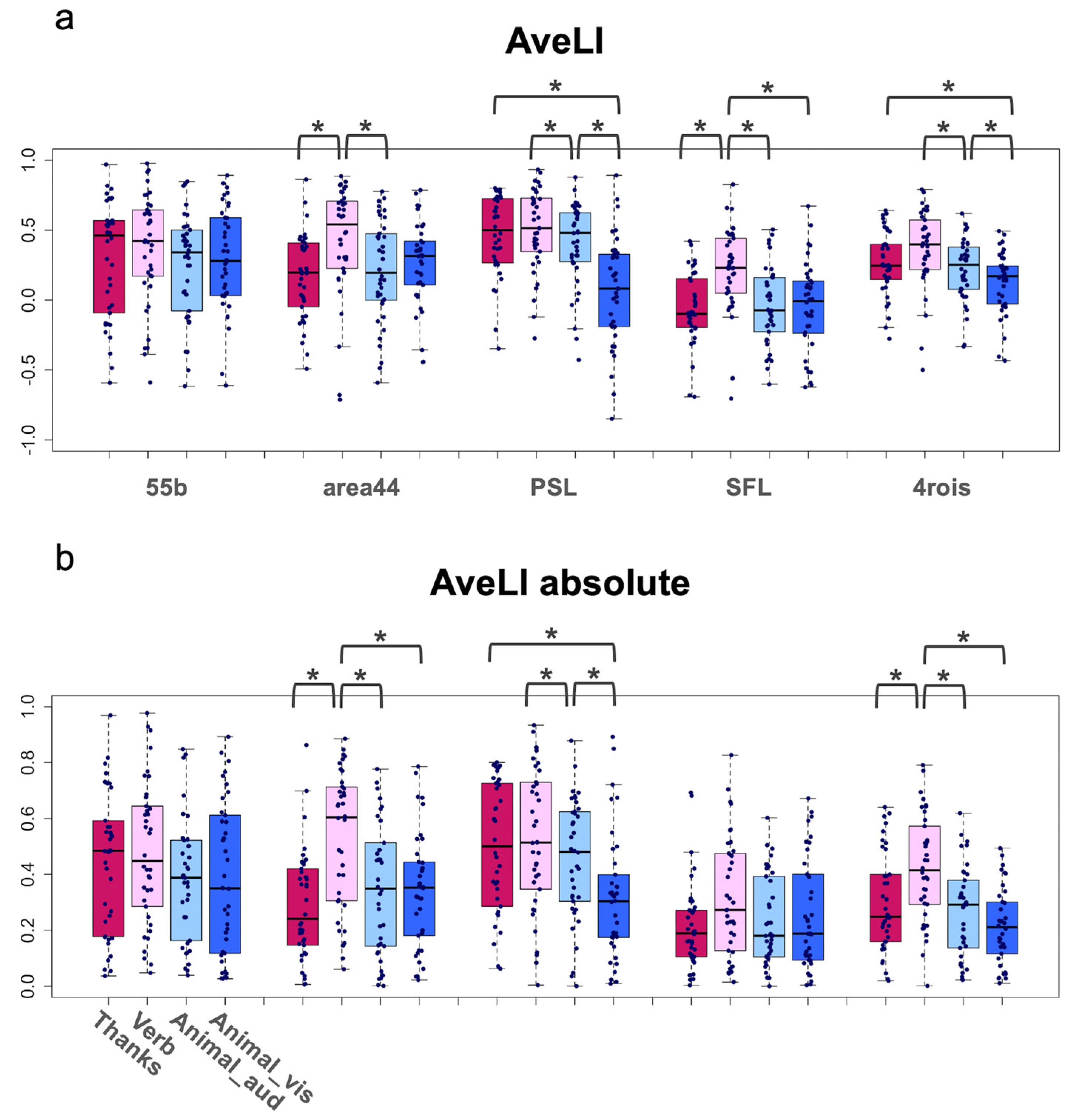
4.1. Lateralization
4.2. Concordance
5. Discussion
5.1. Verb Task Showing Superiority in Both Lateralization and Concordance
5.2. Thanks Task Showing Superiority in PSL
5.3. The Implication of LI Ranking Concordance
5.4. Limitations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Matsuo, K.; Chen, S.H.; Tseng, W.Y. AveLI: A robust lateralization index in functional magnetic resonance imaging using unbiased threshold-free computation. J. Neurosci. Methods 2012, 205, 119–129. [Google Scholar] [CrossRef] [PubMed]
- Matsuo, K.; Kono, K.; Shimoda, K.; Kaji, Y.; Akiyama, K. Reproducibility of the lateralization index in functional magnetic resonance imaging across language tasks. J. Neurolinguistics 2021, 57, 100943. [Google Scholar] [CrossRef]
- Matsuo, K.; Kono, K.; Yasui-Furukori, N.; Shimoda, K.; Kaji, Y.; Akiyama, K. HomotopicLI: Rationale, characteristics, and implications of a new threshold-free lateralization index of functional magnetic resonance imaging. Laterality 2022, 1–31. [Google Scholar] [CrossRef] [PubMed]
- Baxendale, S. The Wada test. Curr. Opin. Neurol. 2009, 22, 185–189. [Google Scholar] [CrossRef] [PubMed]
- Massot-Tarrús, A.; Mousavi, S.R.; Mirsattari, S.M. Comparing the Intracarotid Amobarbital Test and Functional MRI for the Presurgical Evaluation of Language in Epilepsy. Curr. Neurol. Neurosci. Rep. 2017, 17, 54. [Google Scholar] [CrossRef] [PubMed]
- Abou-Khalil, B. An update on determination of language dominance in screening for epilepsy surgery: The Wada test and newer noninvasive alternatives. Epilepsia 2007, 48, 442–455. [Google Scholar] [CrossRef]
- Drane, D.L.; Roraback-Carson, J.; Hebb, A.O.; Hersonskey, T.; Lucas, T.; Ojemann, G.A.; Lettich, E.; Silbergeld, D.L.; Miller, J.W.; Ojemann, J.G. Cortical stimulation mapping and Wada results demonstrate a normal variant of right hemisphere language organization. Epilepsia 2012, 53, 1790–1798. [Google Scholar] [CrossRef]
- Austermuehle, A.; Cocjin, J.; Reynolds, R.; Agrawal, S.; Sepeta, L.; Gaillard, W.D.; Zaghloul, K.A.; Inati, S.; Theodore, W.H. Language functional MRI and direct cortical stimulation in epilepsy preoperative planning. Ann. Neurol. 2017, 81, 526–537. [Google Scholar] [CrossRef]
- Ille, S.; Sollmann, N.; Hauck, T.; Maurer, S.; Tanigawa, N.; Obermueller, T.; Negwer, C.; Droese, D.; Boeckh-Behrens, T.; Meyer, B.; et al. Impairment of preoperative language mapping by lesion location: A functional magnetic resonance imaging, navigated transcranial magnetic stimulation, and direct cortical stimulation study. J. Neurosurg. 2015, 123, 314–324. [Google Scholar] [CrossRef]
- Giussani, C.; Roux, F.E.; Ojemann, J.; Sganzerla, E.P.; Pirillo, D.; Papagno, C. Is preoperative functional magnetic resonance imaging reliable for language areas mapping in brain tumor surgery? Review of language functional magnetic resonance imaging and direct cortical stimulation correlation studies. Neurosurgery 2010, 66, 113–120. [Google Scholar] [CrossRef]
- Vakharia, V.N.; Duncan, J.S.; Witt, J.A.; Elger, C.E.; Staba, R.; Engel, J. Getting the best outcomes from epilepsy surgery. Ann. Neurol. 2018, 83, 676–690. [Google Scholar] [CrossRef] [PubMed]
- Duncan, J.S.; Winston, G.P.; Koepp, M.J.; Ourselin, S. Brain imaging in the assessment for epilepsy surgery. Lancet Neurol. 2016, 15, 420–433. [Google Scholar] [CrossRef] [PubMed]
- Bowyer, S.M.; Zillgitt, A.; Greenwald, M.; Lajiness-O’Neill, R. Language Mapping with Magnetoencephalography: An Update on the Current State of Clinical Research and Practice with Considerations for Clinical Practice Guidelines. J. Clin. Neurophysiol. 2020, 37, 554–563. [Google Scholar] [CrossRef]
- Knake, S.; Haag, A.; Hamer, H.M.; Dittmer, C.; Bien, S.; Oertel, W.H.; Rosenow, F. Language lateralization in patients with temporal lobe epilepsy: A comparison of functional transcranial Doppler sonography and the Wada test. NeuroImage 2003, 19, 1228–1232. [Google Scholar] [CrossRef] [PubMed]
- Massot-Tarrús, A.; Mirsattari, S.M. Roles of fMRI and Wada tests in the presurgical evaluation of language functions in temporal lobe epilepsy. Front. Neurol. 2022, 13, 884730. [Google Scholar] [CrossRef]
- Wada, J.A. A fateful encounter: Sixty years later--reflections on the Wada test. Epilepsia 2008, 49, 726–727. [Google Scholar] [CrossRef] [PubMed]
- Ritaccio, A.L.; Brunner, P.; Schalk, G. Electrical Stimulation Mapping of the Brain: Basic Principles and Emerging Alternatives. J. Clin. Neurophysiol. 2018, 35, 86–97. [Google Scholar] [CrossRef]
- Szelényi, A.; Bello, L.; Duffau, H.; Fava, E.; Feigl, G.C.; Galanda, M.; Neuloh, G.; Signorelli, F.; Sala, F. Intraoperative electrical stimulation in awake craniotomy: Methodological aspects of current practice. Neurosurg. Focus 2010, 28, E7. [Google Scholar] [CrossRef]
- Sanai, N.; Mirzadeh, Z.; Berger, M.S. Functional outcome after language mapping for glioma resection. N. Engl. J. Med. 2008, 358, 18–27. [Google Scholar] [CrossRef]
- Berker, E.A.; Berker, A.H.; Smith, A. Translation of Broca’s 1865 report. Localization of speech in the third left frontal convolution. Arch. Neurol. 1986, 43, 1065–1072. [Google Scholar] [CrossRef]
- Janecek, J.K.; Swanson, S.J.; Sabsevitz, D.S.; Hammeke, T.A.; Raghavan, M.; Rozman, M.R.; Binder, J.R. Language lateralization by fMRI and Wada testing in 229 patients with epilepsy: Rates and predictors of discordance. Epilepsia 2013, 54, 314–322. [Google Scholar] [CrossRef]
- Lee, D.; Swanson, S.J.; Sabsevitz, D.S.; Hammeke, T.A.; Scott Winstanley, F.; Possing, E.T.; Binder, J.R. Functional MRI and Wada studies in patients with interhemispheric dissociation of language functions. Epilepsy Behav. 2008, 13, 350–356. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Rutten, G.J.; Ramsey, N.F.; van Rijen, P.C.; Alpherts, W.C.; van Veelen, C.W. FMRI-determined language lateralization in patients with unilateral or mixed language dominance according to the Wada test. NeuroImage 2002, 17, 447–460. [Google Scholar] [CrossRef]
- Brennan, N.P.; Peck, K.K.; Holodny, A. Language Mapping Using fMRI and Direct Cortical Stimulation for Brain Tumor Surgery: The Good, the Bad, and the Questionable. Top. Magn. Reson. Imaging 2016, 25, 1–10. [Google Scholar] [CrossRef]
- Black, D.F.; Vachha, B.; Mian, A.; Faro, S.H.; Maheshwari, M.; Sair, H.I.; Petrella, J.R.; Pillai, J.J.; Welker, K. American Society of Functional Neuroradiology-Recommended fMRI Paradigm Algorithms for Presurgical Language Assessment. AJNR Am. J. Neuroradiol. 2017, 38, E65–E73. [Google Scholar] [CrossRef]
- Bargalló, N.; Cano-López, I.; Rosazza, C.; Vernooij, M.W.; Smits, M.; Vitali, P.; Alvarez-Linera, J.; Urbach, H.; Mancini, L.; Ramos, A.; et al. Clinical practice of language fMRI in epilepsy centers: A European survey and conclusions by the ESNR Epilepsy Working Group. Neuroradiology 2020, 62, 549–562. [Google Scholar] [CrossRef]
- Trimmel, K.; van Graan, L.A.; Gonzálvez, G.G.; Haag, A.; Caciagli, L.; Vos, S.B.; Bonelli, S.; Sidhu, M.; Thompson, P.J.; Koepp, M.J.; et al. Naming fMRI predicts the effect of temporal lobe resection on language decline. Ann. Clin. Transl. Neurol. 2019, 6, 2186–2196. [Google Scholar] [CrossRef]
- Rosazza, C.; Ghielmetti, F.; Minati, L.; Vitali, P.; Giovagnoli, A.R.; Deleo, F.; Didato, G.; Parente, A.; Marras, C.; Bruzzone, M.G.; et al. Preoperative language lateralization in temporal lobe epilepsy (TLE) predicts peri-ictal, pre- and post-operative language performance: An fMRI study. NeuroImage Clin. 2013, 3, 73–83. [Google Scholar] [CrossRef]
- Polczynska, M.M.; Benjamin, C.F.A.; Moseley, B.D.; Walshaw, P.; Eliashiv, D.; Vigil, C.; Jones, M.; Bookheimer, S.Y. Role of the Wada test and functional magnetic resonance imaging in preoperative mapping of language and memory: Two atypical cases. Neurocase 2015, 21, 707–720. [Google Scholar] [CrossRef]
- Liegeois, F.; Connelly, A.; Salmond, C.H.; Gadian, D.G.; Vargha-Khadem, F.; Baldeweg, T. A direct test for lateralization of language activation using fMRI: Comparison with invasive assessments in children with epilepsy. NeuroImage 2002, 17, 1861–1867. [Google Scholar] [CrossRef]
- Dym, R.J.; Burns, J.; Freeman, K.; Lipton, M.L. Is functional MR imaging assessment of hemispheric language dominance as good as the Wada test? A meta-analysis. Radiology 2011, 261, 446–455. [Google Scholar] [CrossRef] [PubMed]
- Omisade, A.; O’Grady, C.; Sadler, R.M. Divergence between functional magnetic resonance imaging and clinical indicators of language dominance in preoperative language mapping. Hum. Brain Mapp. 2020, 41, 3867–3877. [Google Scholar] [CrossRef] [PubMed]
- Benke, T.; Köylü, B.; Visani, P.; Karner, E.; Brenneis, C.; Bartha, L.; Trinka, E.; Trieb, T.; Felber, S.; Bauer, G.; et al. Language lateralization in temporal lobe epilepsy: A comparison between fMRI and the Wada Test. Epilepsia 2006, 47, 1308–1319. [Google Scholar] [CrossRef]
- Hamberger, M.J.; Cole, J. Language organization and reorganization in epilepsy. Neuropsychol. Rev. 2011, 21, 240–251. [Google Scholar] [CrossRef]
- Dijkstra, K.K.; Ferrier, C.H. Patterns and predictors of atypical language representation in epilepsy. J. Neurol. Neurosurg. Psychiatry 2013, 84, 379–385. [Google Scholar] [CrossRef]
- Thuy, D.H.; Matsuo, K.; Nakamura, K.; Toma, K.; Oga, T.; Nakai, T.; Shibasaki, H.; Fukuyama, H. Implicit and explicit processing of kanji and kana words and non-words studied with fMRI. NeuroImage 2004, 23, 878–889. [Google Scholar] [CrossRef] [PubMed]
- Binder, J.R.; Tong, J.Q.; Pillay, S.B.; Conant, L.L.; Humphries, C.J.; Raghavan, M.; Mueller, W.M.; Busch, R.M.; Allen, L.; Gross, W.L.; et al. Temporal lobe regions essential for preserved picture naming after left temporal epilepsy surgery. Epilepsia 2020, 61, 1939–1948. [Google Scholar] [CrossRef]
- You, X.; Zachery, A.N.; Fanto, E.J.; Norato, G.; Germeyan, S.C.; Emery, E.J.; Sepeta, L.N.; Berl, M.M.; Black, C.L.; Wiggs, E.; et al. fMRI prediction of naming change after adult temporal lobe epilepsy surgery: Activation matters. Epilepsia 2019, 60, 527–538. [Google Scholar] [CrossRef]
- Bonelli, S.B.; Thompson, P.J.; Yogarajah, M.; Vollmar, C.; Powell, R.H.W.; Symms, M.R.; McEvoy, A.W.; Micallef, C.; Koepp, M.J.; Duncan, J.S. Imaging language networks before and after anterior temporal lobe resection: Results of a longitudinal fMRI study. Epilepsia 2012, 53, 639–650. [Google Scholar] [CrossRef]
- Bradshaw, A.R.; Bishop, D.V.M.; Woodhead, Z.V.J. Methodological considerations in assessment of language lateralisation with fMRI: A systematic review. PeerJ 2017, 5, e3557. [Google Scholar] [CrossRef]
- Güntürkün, O.; Ströckens, F.; Ocklenburg, S. Brain Lateralization: A Comparative Perspective. Physiol. Rev. 2020, 100, 1019–1063. [Google Scholar] [CrossRef] [PubMed]
- Bless, J.J.; Westerhausen, R.; Torkildsen, J.v.K.; Gudmundsen, M.; Kompus, K.; Hugdahl, K. Laterality across languages: Results from a global dichotic listening study using a smartphone application. Laterality 2015, 20, 434–452. [Google Scholar] [CrossRef] [PubMed]
- Oldfield, R.C. The assessment and analysis of handedness: The Edinburgh inventory. Neuropsychologia 1971, 9, 97–113. [Google Scholar] [CrossRef]
- Mazoyer, B.; Zago, L.; Jobard, G.; Crivello, F.; Joliot, M.; Perchey, G.; Mellet, E.; Petit, L.; Tzourio-Mazoyer, N. Gaussian mixture modeling of hemispheric lateralization for language in a large sample of healthy individuals balanced for handedness. PLoS ONE 2014, 9, e101165. [Google Scholar] [CrossRef] [PubMed]
- Knecht, S.; Drager, B.; Deppe, M.; Bobe, L.; Lohmann, H.; Floel, A.; Ringelstein, E.B.; Henningsen, H. Handedness and hemispheric language dominance in healthy humans. Brain 2000, 123, 2512–2518. [Google Scholar] [CrossRef] [PubMed]
- Szaflarski, J.P.; Binder, J.R.; Possing, E.T.; McKiernan, K.A.; Ward, B.D.; Hammeke, T.A. Language lateralization in left-handed and ambidextrous people: FMRI data. Neurology 2002, 59, 238–244. [Google Scholar] [CrossRef] [PubMed]
- Isaacs, K.L.; Barr, W.B.; Nelson, P.K.; Devinsky, O. Degree of handedness and cerebral dominance. Neurology 2006, 66, 1855–1858. [Google Scholar] [CrossRef]
- Wong, S.W.; Jong, L.; Bandur, D.; Bihari, F.; Yen, Y.F.; Takahashi, A.M.; Lee, D.H.; Steven, D.A.; Parrent, A.G.; Pigott, S.E.; et al. Cortical reorganization following anterior temporal lobectomy in patients with temporal lobe epilepsy. Neurology 2009, 73, 518–525. [Google Scholar] [CrossRef]
- Lukic, S.; Licata, A.E.; Weis, E.; Bogley, R.; Ratnasiri, B.; Welch, A.E.; Hinkley, L.B.N.; Miller, Z.; Garcia, A.M.; Houde, J.F.; et al. Auditory Verb Generation Performance Patterns Dissociate Variants of Primary Progressive Aphasia. Front. Psychol. 2022, 13, 887591. [Google Scholar] [CrossRef]
- Wager, T.D.; Nichols, T.E. Optimization of experimental design in fMRI: A general framework using a genetic algorithm. NeuroImage 2003, 18, 293–309. [Google Scholar] [CrossRef]
- Moore-Parks, E.N.; Burns, E.L.; Bazzill, R.; Levy, S.; Posada, V.; Müller, R.A. An fMRI study of sentence-embedded lexical-semantic decision in children and adults. Brain Lang. 2010, 114, 90–100. [Google Scholar] [CrossRef] [PubMed]
- Backes, W.; Vuurman, E.; Wennekes, R.; Spronk, P.; Wuisman, M.; van Engelshoven, J.; Jolles, J. Atypical brain activation of reading processes in children with developmental dyslexia. J. Child Neurol. 2002, 17, 867–871. [Google Scholar] [CrossRef] [PubMed]
- Liebig, J.; Froehlich, E.; Morawetz, C.; Braun, M.; Jacobs, A.M.; Heekeren, H.R.; Ziegler, J.C. Neurofunctionally dissecting the reading system in children. Dev. Cogn. Neurosci. 2017, 27, 45–57. [Google Scholar] [CrossRef] [PubMed]
- Glasser, M.F.; Coalson, T.S.; Robinson, E.C.; Hacker, C.D.; Harwell, J.; Yacoub, E.; Ugurbil, K.; Andersson, J.; Beckmann, C.F.; Jenkinson, M.; et al. A multi-modal parcellation of human cerebral cortex. Nature 2016, 536, 171–178. [Google Scholar] [CrossRef]
- Tzourio-Mazoyer, N.; Landeau, B.; Papathanassiou, D.; Crivello, F.; Etard, O.; Delcroix, N.; Mazoyer, B.; Joliot, M. Automated anatomical labeling of activations in SPM using a macroscopic anatomical parcellation of the MNI MRI single-subject brain. NeuroImage 2002, 15, 273–289. [Google Scholar] [CrossRef]
- Maldjian, J.A.; Laurienti, P.J.; Kraft, R.A.; Burdette, J.H. An automated method for neuroanatomic and cytoarchitectonic atlas-based interrogation of fMRI data sets. NeuroImage 2003, 19, 1233–1239. [Google Scholar] [CrossRef]
- Ahmadi, Z.Z.; DiBacco, M.L.; Pearl, P.L. Speech Motor Function and Auditory Perception in Succinic Semialdehyde Dehydrogenase Deficiency: Toward Pre-Supplementary Motor Area (SMA) and SMA-Proper Dysfunctions. J. Child Neurol. 2021, 36, 1210–1217. [Google Scholar] [CrossRef]
- Bradshaw, A.R.; Thompson, P.A.; Wilson, A.C.; Bishop, D.V.M.; Woodhead, Z.V.J. Measuring language lateralisation with different language tasks: A systematic review. PeerJ 2017, 5, e3929. [Google Scholar] [CrossRef]
- Nagata, S.I.; Uchimura, K.; Hirakawa, W.; Kuratsu, J.I. Method for quantitatively evaluating the lateralization of linguistic function using functional MR imaging. AJNR Am. J. Neuroradiol. 2001, 22, 985–991. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Summary of AveLI Values | |||||
| ROI | Task | Mean | SD | Min | Max |
| 55b | Thanks | 0.293 | 0.420 | −0.592 | 0.969 |
| Verb | 0.370 | 0.400 | −0.590 | 0.977 | |
| Animal_aud | 0.246 | 0.371 | −0.616 | 0.848 | |
| Animal_vis | 0.294 | 0.369 | −0.612 | 0.892 | |
| area44 | Thanks | 0.172 | 0.306 | −0.492 | 0.863 |
| Verb | 0.430 | 0.393 | −0.713 | 0.885 | |
| Animal_aud | 0.207 | 0.366 | −0.592 | 0.777 | |
| Animal_vis | 0.261 | 0.303 | −0.444 | 0.786 | |
| PSL | Thanks | 0.467 | 0.287 | −0.348 | 0.801 |
| Verb | 0.505 | 0.295 | −0.274 | 0.934 | |
| Animal_aud | 0.405 | 0.302 | −0.429 | 0.878 | |
| Animal_vis | 0.064 | 0.384 | −0.849 | 0.892 | |
| SFL | Thanks | −0.064 | 0.259 | −0.692 | 0.421 |
| Verb | 0.203 | 0.325 | −0.704 | 0.827 | |
| Animal_aud | −0.039 | 0.283 | −0.602 | 0.505 | |
| Animal_vis | −0.048 | 0.320 | −0.623 | 0.672 | |
| 4rois | Thanks | 0.263 | 0.228 | −0.277 | 0.640 |
| Verb | 0.372 | 0.279 | −0.500 | 0.791 | |
| Animal_aud | 0.216 | 0.224 | −0.332 | 0.619 | |
| Animal_vis | 0.129 | 0.219 | −0.433 | 0.494 | |
| Grand | 0.237 | 0.357 | −0.849 | 0.977 | |
| ANOVA for AveLI Values | |||||
| Source | F-Value | df | p-Value | G.O.^2 | Post hoc test |
| Main effects | |||||
| Task | 15.197 | 3, 111 | 0 *** | 0.055 | T2 > T1 = T3 = T4 |
| ROI | 15.295 | 4, 148 | 0 *** | 0.107 | R3 = R1 = R5 = R2 > R4 |
| Interaction effects | |||||
| Task × ROI *1 | 11.317 | 12, 444 | 0 *** | 0.044 | R2: T2 > T3 = T1 |
| R3: T2 > T3 > T4, T1 > T4 | |||||
| R4: T2 > T4 = T3 = T1 | |||||
| R5: T2 > T3 > T4, T1 > T4 | |||||
| ANOVA for Absolute AveLI Values | |||||
| Source | F-Value | df | p-Value | G.O.^2 | Post hoc test |
| Main effects | |||||
| Task | 15.282 | 3, 111 | 0 *** | 0.060 | T2 > T1 = T3 = T4 |
| ROI | 13.188 | 4, 148 | 0 *** | 0.092 | R3 = R1 > R5 = R4, R2 > R4 |
| Interaction effects | |||||
| Task × ROI *1 | 3.834 | 12, 444 | 0 *** | 0.022 | R2: T2 > T4 = T3 = T1 |
| R3: T2 > T3 > T4, T1 > T4 | |||||
| R5: T2 > T1 = T3 = T4 | |||||
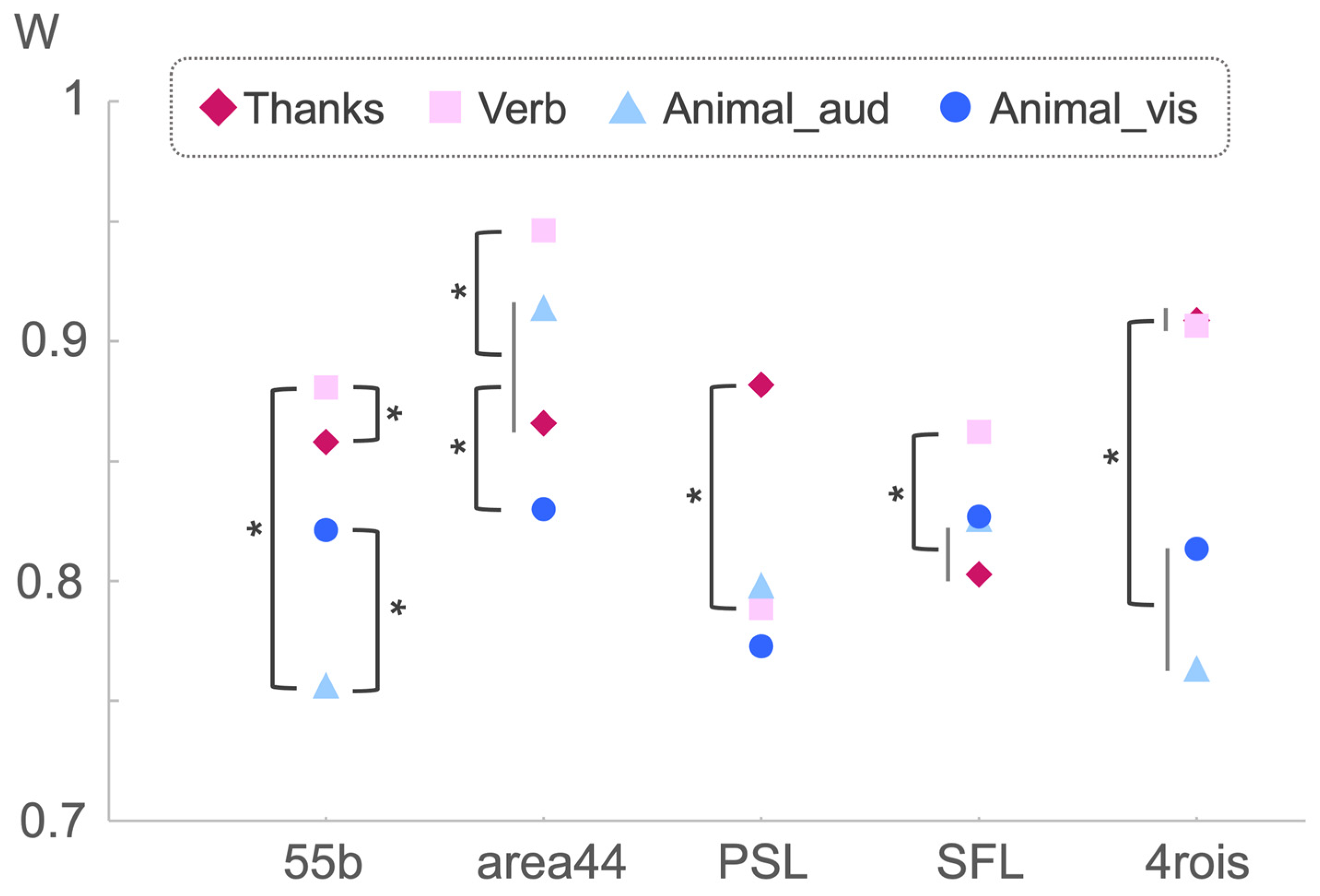
| ANOVA Results of Kendal’s W | |||||
|---|---|---|---|---|---|
| Source | F-Value | df | p-Value | G.O.^2 | |
| Tasks | 2.910 | 3, 12 | 0.078 + | 0.187 | |
| ANOVA results of correlation coefficients between tasks | |||||
| ROI types | F-Value | df | p-Value | G.O.^2 | Post hoc test |
| 55b | 9.694 | 3, 60 | 0.000 *** | 0.044 | T2 > T1 = T3, T4 > T3 |
| area44 | 37.152 | 3, 60 | 0.000 *** | 0.084 | T2 > T3 = T1 > T4 |
| PSL | 2.937 | 3, 60 | 0.040 * | 0.017 | T1 > T2 |
| SFL | 10.532 | 3, 60 | 0.000 *** | 0.033 | T2 > T3 = T1 |
| 4rois | 14.824 | 3, 60 | 0.000 *** | 0.062 | T2 = T1 > T4 = T3 |
| ROI | Recommend | AveLI | Abs. AveLI | W |
|---|---|---|---|---|
| 55b | Verb | n.s. | n.s. | Top |
| area44 | Verb | Top | Top | Top |
| PSL | Thanks | Top (Verb = Thanks) | Top (Verb = Thanks) | Top |
| SFL | Verb | Top | n.s. | Top |
| 4rois | Verb | Top (Verb = Thanks) | Top | Top (Verb = Thanks) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Matsuo, K.; Yasui-Furukori, N.; Shimoda, K.; Kaji, Y.; Akiyama, K. Concordance of Lateralization Index for Brain Asymmetry Applied to Identify a Reliable Language Task. Symmetry 2023, 15, 193. https://doi.org/10.3390/sym15010193
Matsuo K, Yasui-Furukori N, Shimoda K, Kaji Y, Akiyama K. Concordance of Lateralization Index for Brain Asymmetry Applied to Identify a Reliable Language Task. Symmetry. 2023; 15(1):193. https://doi.org/10.3390/sym15010193
Chicago/Turabian StyleMatsuo, Kayako, Norio Yasui-Furukori, Kazutaka Shimoda, Yasushi Kaji, and Kazufumi Akiyama. 2023. "Concordance of Lateralization Index for Brain Asymmetry Applied to Identify a Reliable Language Task" Symmetry 15, no. 1: 193. https://doi.org/10.3390/sym15010193
APA StyleMatsuo, K., Yasui-Furukori, N., Shimoda, K., Kaji, Y., & Akiyama, K. (2023). Concordance of Lateralization Index for Brain Asymmetry Applied to Identify a Reliable Language Task. Symmetry, 15(1), 193. https://doi.org/10.3390/sym15010193