
Self-Weighted Quasi-Maximum Likelihood Estimators for a Class of MA-GARCH Model

Abstract
:1. Introduction
2. Self-Weighted QMLE
- A1:
- is an interior point in , and is stationary, ergodic, and identifiable.
- A2:
- is independent and identically distributed with a mean of 0 and a variance of 1.
- A3:
- has a nondegenerate distribution with .
- A4:
- and is a measurable, positive, and bounded function on with , and , .
- ;
- ;
- .
- where
3. Simulation
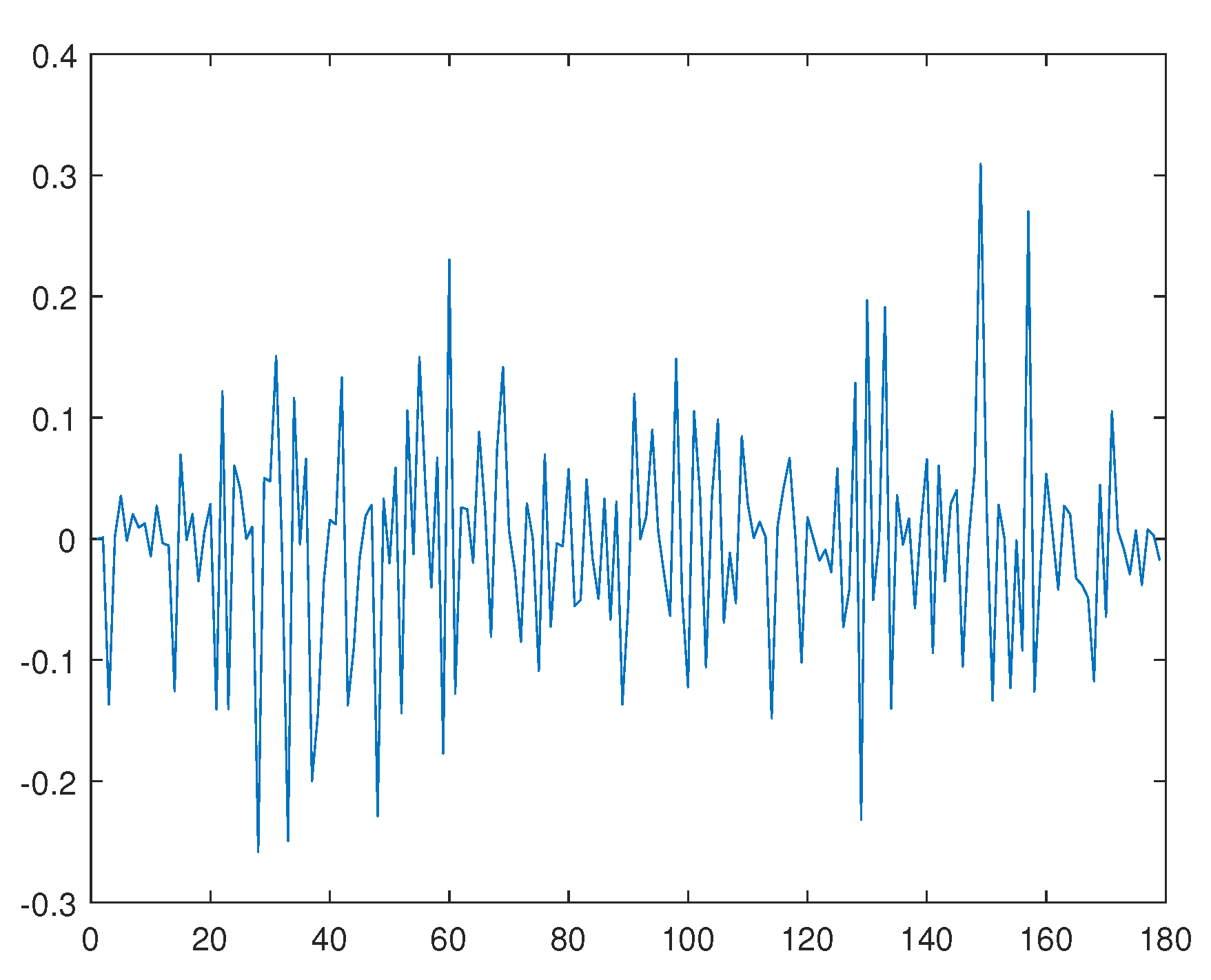
4. A Real Example
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| DOAJ | Directory of open access journals |
| TLA | Three letter acronym |
| LD | Linear dichroism |
Appendix A
Appendix A.1
Appendix A.2
References
- Engle, R.F. Autoregressive conditional heteroscdeasticity with estimates of the variance of united kingdom inflation. Econometrica 1982, 50, 897–1007. [Google Scholar] [CrossRef]
- Bollerslve, T. Generalized autoregressive condition heteroskedasticity. J. Econom. 1986, 31, 307–327. [Google Scholar] [CrossRef]
- Nelson, D.B. Conditional heteroskedasticity in asset returns: A new approach. Econometrica 1991, 59, 347–870. [Google Scholar] [CrossRef]
- Glosten, L.R.; Jagannathan, R.; Runkle, D.E. On the relationship between the expected value and the valatility of the nominal excess return on stocks. J. Financ. 1993, 48, 1779–1801. [Google Scholar] [CrossRef]
- Long, H.V.; Jebreen, H.B.; Dassios, I.; Baleanu, D. On the Statistical GARCH Model for Managing the Risk by Employing a Fat-Tailed Distribution in Finance. Symmetry 2020, 12, 1698. [Google Scholar] [CrossRef]
- Li, X.; Zhang, X.; Li, Y. High-Dimensional Conditional Covariance Matrices Estimation Using a Factor-GARCH Model. Symmetry 2022, 14, 158. [Google Scholar] [CrossRef]
- Baillie, R.T. Long memory processes and fractional integration in econometrics. J. Econom. 1996, 73, 5–59. [Google Scholar] [CrossRef]
- Ling, S. Estimation and testing stationarity for double autoregressive models. J. R. Stat. Soc. 2004, 66, 63–78. [Google Scholar] [CrossRef]
- Ling, S. Self-weighted and local quasi-maximum likelihood estimators for ARMA-GARCH/IGARCH model. J. Econom. 2007, 140, 849–873. [Google Scholar] [CrossRef]
- Zhu, K.; Ling, S. Global self-weighted and local quasi-maximum exponential likelihood estimators forARMA-GARCH/IGARCH models. Ann. Stat. 2011, 39, 2131–2163. [Google Scholar] [CrossRef]
- Pan, B.; Chen, M.; Wang, Y.; Xia, W. Weighted least absolute deviations estimation for ARFIMA time with finite or infinite variance. J. Korean Stat. Soc. 2015, 44, 1–11. [Google Scholar] [CrossRef]
- Ramírez-Parietti, I.; Contreras-Reyes, J.E.; Idrovo-Aguirre, B.J. Cross-sample entropy estimation for time series analysis: A nonparametric approach. Nonlinear Dyn. 2021, 105, 2485–2508. [Google Scholar] [CrossRef]
- Ling, S. A double AR(p) model: Structure and estimation. Stat. Sin. 2007, 17, 161–175. [Google Scholar]
- Zhu, H.; Zhang, X.; Liang, X.; Li, Y. Moving Average Model with an Alternative GARCH-type Error. J. Syst. Sci. Inf. 2018, 6, 165–177. [Google Scholar] [CrossRef]
- Zhu, K.; Ling, S. Quasi-maximum exponential likelihood for a double AR(p) model. Stat. Sin. 2013, 23, 251–270. [Google Scholar]
- Yoshida, N. Quasi-likelihood analysis and its applications. Stat. Inference Stoch. Process. 2022, 25, 43–60. [Google Scholar] [CrossRef]
- Ling, S. Self-weighted least absolute deviation estimation for infinite variance autoragressive models. R. Stat. Soc. 2005, 67, 381–389. [Google Scholar] [CrossRef]
- Huber, P.J. Robust Statistical Procedures; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1997. [Google Scholar]
- Ling, S.; McAleer, M. Asymptotic theory for a new vector ARMA-GARCH model. Econom. Theory 2003, 19, 280–310. [Google Scholar] [CrossRef]
- Amemiya, T. Advanced Econometrics; Harvard University Press: Cambridge, MA, USA, 1985. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n = 400 | QMLE(Bias) | −0.0008 | 0.0053 | −0.0024 | −0.0167 |
| SQMLE(Bias) | 0.0001 | 0.0051 | 0.0048 | −0.0196 | |
| QMLE(SD) | 0.0470 | 0.0263 | 0.0860 | 0.1030 | |
| SQMLE(SD) | 0.0456 | 0.0260 | 0.0929 | 0.1037 | |
| QMLE(AD) | 0.0416 | 0.0224 | 0.0848 | 0.0694 | |
| SQMLE(AD) | 0.0423 | 0.0222 | 0.0938 | 0.0691 | |
| n = 800 | QMLE(Bias) | −0.0014 | 0.0028 | 0.0008 | −0.0099 |
| SQMLE(Bias) | −0.0012 | 0.0028 | 0.0033 | −0.0111 | |
| QMLE(SD) | 0.0330 | 0.0177 | 0.0529 | 0.0707 | |
| SQMLE(SD) | 0.0334 | 0.0177 | 0.0635 | 0.0718 | |
| QMLE(AD) | 0.0324 | 0.0219 | 0.0603 | 0.0722 | |
| SQMLE(AD) | 0.0329 | 0.0227 | 0.0653 | 0.0757 | |
| n = 1200 | QMLE(Bias) | −0.0011 | 0.0013 | 0.0000 | −0.0054 |
| SQMLE(Bias) | −0.0006 | 0.0012 | 0.0010 | −0.0052 | |
| QMLE(SD) | 0.0272 | 0.0139 | 0.0487 | 0.0564 | |
| SQMLE(SD) | 0.0276 | 0.0140 | 0.0539 | 0.0578 | |
| QMLE(AD) | 0.0241 | 0.0140 | 0.0441 | 0.0592 | |
| SQMLE(AD) | 0.0244 | 0.0145 | 0.0492 | 0.0612 | |
| n = 400 | QMLE(Bias) | −0.0003 | 0.0080 | −0.0002 | −0.0304 |
| SQMLE(Bias) | 0.0024 | 0.0060 | 0.0254 | −0.0334 | |
| QMLE(SD) | 0.0506 | 0.0403 | 0.1709 | 0.1809 | |
| SQMLE(SD) | 0.0529 | 0.0405 | 0.2018 | 0.1876 | |
| QMLE(AD) | 0.0576 | 0.0614 | 0.1345 | 0.2946 | |
| SQMLE(AD) | 0.0702 | 0.0561 | 0.2902 | 0.2805 | |
| n = 800 | QMLE(Bias) | −0.0005 | 0.0057 | 0.0026 | −0.0219 |
| SQMLE(Bias) | −0.0008 | 0.0041 | 0.0184 | −0.0221 | |
| QMLE(SD) | 0.0368 | 0.0323 | 0.1299 | 0.1447 | |
| SQMLE(SD) | 0.0383 | 0.0323 | 0.1617 | 0.1519 | |
| QMLE(AD) | 0.0333 | 0.0156 | 0.0908 | 0.0812 | |
| SQMLE(AD) | 0.0362 | 0.0170 | 0.1083 | 0.0952 | |
| n = 1200 | QMLE(Bias) | −0.0001 | 0.0032 | 0.0003 | -0.0119 |
| SQMLE(Bias) | −0.0006 | 0.0021 | 0.0065 | −0.0100 | |
| QMLE(SD) | 0.0297 | 0.0249 | 0.1042 | 0.1174 | |
| SQMLE(SD) | 0.0307 | 0.0257 | 0.1305 | 0.1260 | |
| QMLE(AD) | 0.0289 | 0.0204 | 0.0966 | 0.0880 | |
| SQMLE(AD) | 0.0308 | 0.0200 | 0.1218 | 0.0895 | |
| n = 400 | QMLE(Bias) | −0.0014 | 0.0072 | −0.0160 | −0.0485 |
| SQMLE(Bias) | 0.0003 | 0.0060 | 0.0293 | −0.0490 | |
| QMLE(SD) | 0.0536 | 0.0426 | 0.2223 | 0.1944 | |
| SQMLE(SD) | 0.0555 | 0.0430 | 0.2463 | 0.2016 | |
| QMLE(AD) | 0.0581 | 0.0166 | 0.1437 | 0.1026 | |
| SQMLE(AD) | 0.0638 | 0.0159 | 0.1993 | 0.2042 | |
| n = 800 | QMLE(Bias) | −0.0010 | −0.0046 | −0.0034 | -0.0265 |
| SQMLE(Bias) | −0.0010 | 0.0042 | 0.0191 | −0.0303 | |
| QMLE(SD) | 0.0408 | 0.0357 | 0.1921 | 0.1769 | |
| SQMLE(SD) | 0.0436 | 0.0361 | 0.2191 | 0.1846 | |
| QMLE(AD) | 0.0371 | 0.0244 | 0.1128 | 0.1032 | |
| SQMLE(AD) | 0.0393 | 0.0228 | 0.1304 | 0.0967 | |
| n = 1200 | QMLE(Bias) | −0.0009 | 0.0039 | 0.0059 | −0.0243 |
| SQMLE(Bias) | −0.0010 | 0.0037 | 0.0188 | −0.0279 | |
| QMLE(SD) | 0.0322 | 0.0328 | 0.1767 | 0.1600 | |
| SQMLE(SD) | 0.0334 | 0.0324 | 0.2017 | 0.1603 | |
| QMLE(AD) | 0.0304 | 0.0217 | 0.1243 | 0.0885 | |
| SQMLE(AD) | 0.0316 | 0.0229 | 0.1406 | 0.0941 | |
| Models | RMSE | Log-Likelihood Value |
|---|---|---|
| (8) and (9) | 0.0361 | 2315.2 |
| (10) and (11) | 0.0360 | 2316.4 |
| Models | RMSE | Log-Likelihood Value |
|---|---|---|
| (12) and (13) | 0.0818 | 340.91 |
| (14) and (15) | 0.0818 | 340.91 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, D.; Liang, X.; Liang, R. Self-Weighted Quasi-Maximum Likelihood Estimators for a Class of MA-GARCH Model. Symmetry 2022, 14, 1723. https://doi.org/10.3390/sym14081723
Xie D, Liang X, Liang R. Self-Weighted Quasi-Maximum Likelihood Estimators for a Class of MA-GARCH Model. Symmetry. 2022; 14(8):1723. https://doi.org/10.3390/sym14081723
Chicago/Turabian StyleXie, Danni, Xin Liang, and Ruilin Liang. 2022. "Self-Weighted Quasi-Maximum Likelihood Estimators for a Class of MA-GARCH Model" Symmetry 14, no. 8: 1723. https://doi.org/10.3390/sym14081723
APA StyleXie, D., Liang, X., & Liang, R. (2022). Self-Weighted Quasi-Maximum Likelihood Estimators for a Class of MA-GARCH Model. Symmetry, 14(8), 1723. https://doi.org/10.3390/sym14081723