Abstract
Epidemiologists often study the associations between a set of exposures and multiple biologically relevant outcomes. However, the frequently used scale-and-context-dependent regression coefficients may not offer meaningful comparisons and could further complicate the interpretation if these outcomes do not have similar units. Additionally, when scaling up a hypothesis-driven study based on preliminary data, knowing how large to make the sample size is a major uncertainty for epidemiologists. Conventional p-value-based sample size calculations emphasize precision and might lead to a large sample size for small- to moderate-effect sizes. This asymmetry between precision and utility is costly and might lead to the detection of irrelevant effects. Here, we introduce the “-score” concept, by modifying Cohen’s . -score is scale independent and circumvents the challenges of regression coefficients. Further, under a new hypothesis testing framework, it quantifies the maximum Cohen’s with certain optimal properties. We also introduced “Sufficient sample size”, which is the minimum sample size required to attain a -score. Finally, we used data on adults from a 2017–2018 U.S. National Health and Nutrition Examination Survey to demonstrate how the -score and sufficient sample size reduced the asymmetry between precision and utility by finding associations between mixtures of per-and polyfluoroalkyl substances and metals with serum high-density and low-density lipoprotein cholesterol.
1. Introduction
Estimating an effect size with high precision is the essence of epidemiological research, so when given a hypothesis with specific aims, preliminary data is collected. But this can be costly, as can processing biological samples; therefore, this stage protects against the waste of resources should the study does not progress as planned. Next depending on the effect estimate and resource constraints, a larger study is planned. For example, consider a scenario where an epidemiologist wants to study the association between perfluoroalkyl and polyfluoroalkyl substances (PFAS) and liver enzyme alanine aminotransferase (ALT) and cytokeratin-18 (CK-18), a marker of liver-cell death in school-age children.
PFAS belong to a diverse class of environmental pollutants of “emerging concern” because they interfere with multiple metabolic and hormonal systems in humans [1]. ALT and CK-18 may or may not be measured in similar units, and they quantify different aspects of liver injury. Although animal studies have shown a biologically plausible cause-effect relationship between PFAS exposure and increased ALT/CK-18 levels, their associations in humans are not well studied ([2,3]).
Now, let us assume that the regression estimate for both the associations is a two-unit increase for every unit increase in PFAS. If the units of ALT and CK-18 are different, comparing these estimates is difficult. Even a conversion to scale-free outcomes makes the interpretation non-intuitive. Further, if ALT and CK-18 are measured in same scale, a two-unit increase in one would have very different clinical and practical implications to a similar increase in the other, because one has a higher potential for public health intervention. Moreover, it was assumed that none of these associations is statistically significant at the current sample size. Based on this hypothesis, the epidemiologist decided to scale up the study and apply for a grant based on the preliminary data. A p-value based sample-size calculation yielded large and comparable sample sizes with corresponding statistically significant effect sizes. This situation led to some quandaries. First, the increased precision due to a larger sample size may not indicate a meaningful effect size, but it would guarantee that any irrelevant or tiny effect sizes would be detectable ([4,5]). Second, for a meaningful and statistically significant effect size, this high precision may not be needed if the effect size does not change considerably with sample size increases. Moreover, measuring PFAS/ALT/CK-18 in child serum is time consuming and costly; therefore, if the effect estimate allows for a contextual, biological or clinical implication, even for a small-to-moderate sample size, there would be no need to increase the sample size without a strong justification for higher precision. Therefore a p-value based association analysis further deepens the asymmetry between precision and utility.
A long established index for reporting the strength of an explanatory association is Cohen’s [6], which evaluates the impact of additional variables over baseline covariates. Over the past three decades, Cohen’s has been used extensively in the behavioral, psychological, and social sciences because of its immense practical utility and ease of interpretation [7]. A similar treatment for scale-free effect-size methodologies can be found in [8,9]. Analogous ideas like genome-wide complex trait analysis are widely used in genome-wide association studies to estimate heritability ([10,11]). In environmental epidemiology, ref. [12] recently introduced the idea of total explained variation (TEV) approach to estimate an overall effect for highly correlated mixtures of exposures using a p-value-based inference. In this paper, we propose a -score by modifying Cohen’s to evaluate the strength of the explanatory association in a more fundamental and scale-independent way. Similar to Cohen’s , the -score moves the contextual reference to baseline covariates and evaluates the effect size contributed solely by a set of exposures or exposure-mixtures on top of those baseline covariates. Further, under a special hypothesis-testing framework, we show that the -score quantifies the maximum Cohen’s and admits some useful optimal properties. The idea was naturally extended to a new concept, “Sufficient sample size", which is an estimate of the minimum sample size required to attain a -score.
Through illustrative examples and application in 2017–2018 U.S. National Health and Nutrition Examination Survey (NHANES) data, we quantified -scores and sufficient sample sizes for associations between mixtures of PFAS and metals on lipoprotein-cholesterols and demonstrated that sufficient sample sizes are usually smaller than the p-value-based sample-size estimates.
2. Methods
A common problem of testing occurs when a set of exposures in a regression model is associated with the outcome after adjusting for covariates and confounders. For example, consider the linear model, : we want to find out the strength of the association of after adjusting for and to compare hypothesis ) with hypothesis ), where is a positive and pre-defined meaningful quantity. In the sections below, we briefly discuss Cohen’s in linear regression and then move on to formulate an error-calibrated hypothesis-testing framework. Lastly, we introduce the idea of the -score and sufficient sample size under that framework.
2.1. Cohen’s in Linear Regression
Consider the linear regression model noted above and assume , where is an identity matrix of dimension . Let be the non-centrality parameter, then equals 0 when y is generated under . When y is generated under the alternative, has the form of , where is the projection matrix onto the linear space spanned by the column vectors of ([13,14]) (see Section S1 of the Supplementary Materials). For the typical regression design in which the predictor vector of each subject is drawn from a common population, grows linearly on n. Note that does not depend on y but rather on the design matrix X and underlying parameters and . A long-established index of quantifying additional impact in linear regression is Cohen’s ,
where and are the squared multiple correlations for under and under , respectively. quantifies the proportion of variation in y accounted for by on top of the variation accounted for by , a concept most researchers can relate to intuitively [15]. In linear regression, Cohen’s and non-centrality parameter can be connected through Lemma 1.
Lemma 1.
where the notation denotes convergence in probability. See the proof in Section S2 of the Supplementary Materials. Further discussion on Cohen’s in generalized linear models is presented in Section S3 of the Supplementary Materials.2.2. Formulation of Error Calibrated Cutoff in a New Hypothesis Testing Framework
Following the hypothesis in (1) and for a meaningful value of , we specify our main hypothesis:
Let be the maximum likelihood estimate (MLE) for a model with only design matrix , and let and be the MLEs for the model with design matrices and . The standard test to compare a null and alternative is through F statistic, , where is the sum of the squared errors under , and is the sum of the squared errors under . Then , where and are degrees of freedom and is the non-centrality parameter. When the data is generated under the null or the alternative hypothesis, and, as while remain fixed, this F distribution can be approximated by the chi-squared distribution . On the other hand, suppose that the likelihood ratio test statistic for testing this hypothesis is, . As the sample size , the likelihood ratio statistic follows a central chi-squared distribution with degrees of freedom when y is generated under the model in . follows a non-central chi-squared distribution with degrees of freedom and non-centrality parameter when y is generated under .
Let the test statistic for a linear regression and for other generalized linear models. These specifications are motivated by the fact that asymptotically follows a chi-squared distribution. Let, T be a cutoff value which depends on sample size n and unknown parameters and effect size . Then, given a cutoff value T and based on hypothesis (1), the type 1 error can be expressed as , and the type 2 error can be expressed as . Such specification of type 1 and type 2 errors is inspired by model selection procedures, Akaike’s information criterion [16] and the Bayesian information criterion [17], which are often used in place of hypothesis testing for choosing between competing models [18]. As a consequence, given the error calibrated cutoff value of T, we have
Our central idea was to choose T so that the type 1 error and the type 2 error satisfied the relationship, , with , and is pre-specified. Using the chi-square approximation to , we solved for the calibrated cutoff value T by equation
When T is fixed, the left side of Equation (2) remains constant as , while the right side diminishes to 0 rapidly under the non-centrality parameter . Therefore, Equation (2) implies as . In Theorem 1 stated below, we elaborate more on T. The results in this theorem depend on the normality approximation of the non-central chi-square distribution; that is, for large n, Equation (2) was rewritten as
where, denotes the cumulative density function of a standardized normal random variable. For ease of interpretation and theoretical derivations, we considered in the following sections when both the type 1 and type 2 errors decay at the same rate. The cases with can be developed similarly.
Theorem 1.
Consider the hypothesis of interest where denotes Cohen’s . Assume response vector y is generated under the alternative. Then following the constraint , as in (2) and for large n, the error calibrated cutoff value T has the expression
Further, the type 1 or type 2 error rates can be expressed as
where and is a constant of integration.
The proof is presented in Section S4 of the Supplementary Materials, and in Section S4.2 the explicit expressions of and are derived. Theorem 1 sheds light on the behavior of the cutoff value T and the rates of the corresponding type 1 or type 2 errors when the sample size n is large. Since both errors tended to 0 as , this procedure for testing the hypothesis was consistent and kept error rates equal. It should be noted that both errors decayed at an exponential rate even at moderate sample sizes. To gauge the accuracy of Theorem 1, we presented the type 1 and type 2 error rates and the rate of change of T with respect to n using the results from Theorem 1 and the corresponding numerical results from Equation (3). As seen in Table 1, irrespective of Cohen’s , as n increased, the rate of change of T, log (type 1) and log (type 2) converged to the corresponding theoretical rates specified in Theorem 1. We also conducted a Monte Carlo simulation to estimate the calibrated type 1 and type 2 errors for different values of n, and (see Section S5 and Table S1 of the Supplementary Materials). Moreover, a detailed discussion of the properties of the error calibrated cutoff T and the type 2 error is presented in Section S6 of the Supplementary Materials.

Table 1.
Rates of cutoff value T, log (type 1) or log (type 2) with respect to sample size n based on Equation (3) and Theorem 1.
2.3. Notion of -Score
We can borrow the convention for [6] and call , and as representing small, moderate, and large effect sizes, respectively. This can serve as a guide to understating the effect size obtained from the data. Further, given the data, one can use this hypothesis by sequentially choosing and testing increasing values of as long as the null is rejected and stops when the it can no longer be rejected. Finally, this brings us to the question of whether, given any data, there exists any maximum such that the null will always be rejected. Let the likelihood ratio test statistic be . We reject the null if and only if . Hence, attains a maximum at the upper bound . Denote this value at which attains the maximum value as , and consider the reformulated hypothesis (1) as below, with as the final choice of :
We note some interesting properties of through the following corollary,
Corollary 1.
Under the hypothesis in (6), let be the unique solution to the equation . Therefore, admits the following properties:
- is the maximum value of Cohen’s such that the null is still rejected.
- For any , the asymptotic type 1 error, is a monotonically decreasing function of h, whereas the asymptotic type 2 error,is a monotonically increasing function of h.
See the proof in Section S8 of Supplementary Materials. Further, for large n, undertakes asymptotic convergence (Lemma 3.1 of [19]), and we define “-score” as noted below:
Under the hypothesis-testing framework in (1), -score captures the asymptotic and maximum Cohen’s , which was contributed solely by the larger exposure model on top of the baseline covariate-only model. Unlike usual null hypothesis significance testing based on sequential testing [20], this framework does not inflate the type 1 error and circumvents the issue through its use of the error calibrated cutoff value and keeps the error rates in balance. Instead of simply estimating Cohen’s , this procedure introduces hypothesis testing for error-balanced decision making.
One might use hypothesis (1) solely for testing, since, under the error calibrated framework it induces an expanded null hypothesis which nicely connects to the interval null hypothesis in the literature ([21,22,23,24]). This expanded null hypothesis guards against near-certain rejection of the null when the sample size is large enough and the null is true (see Section S6 of Supplementary Materials). Although the -score can be interpreted through the lens of this hypothesis, it should be primarily used only for estimations and comparisons. The reason is that, for a set of exposures and their corresponding outcome, the -score signifies the maximum Cohen’s that can be attained within the possible zone of rejection. Therefore, the -score concept is firmly rooted in the rejection interval no matter the effect size; however, since Cohen’s cannot be larger than the -score within this region, the -score facilitates comparisons among multiple outcomes.
2.4. Notion of Sufficient Sample Size
The -score can be estimated by bootstrapping a large sample size N (say or ) with replacement from the original sample of size n, with . Moreover, because of its convergence, one can find a much smaller bootstrapped sample size and corresponding estimated -score such that it will be in the “practically close neighborhood” of the converged -score based on a considerably large bootstrap size. We defined the smaller bootstrapped size as a “Sufficient sample size”.
Consider the equivalence tests for the ratio of two means with prespecified equivalence bounds ([25,26]). Let and be the underlying random variables for two separate -scores to be estimated under sample sizes N and , respectively. To formulate the test of non-equivalence between these two estimated -scores, consider this hypothesis:
where, and are the lower and upper equivalence bounds with and . The null hypothesis will be rejected to favour the alternative if a two-sided CI is completely included within and . We will assume and following typical practice [27], but less strict values can be chosen for practical purposes. and are approximated by using Taylor series expansions (detailed in Section S2 of the Supplementary Materials). The mean and variance after logarithmic transformation are found using direct application of the delta theorem on . Finally, we declared an alternative hypothesis if the level CI on were within the equivalence limits:
where is the percentile in a standard t-distribution. As long as the hypothesis of non-equivalence in (7) is rejected in favour of the alternative, can be regarded as a “sufficient sample size” at equivalence bounds of with a corresponding -score of . Ratio type estimators such as discussed above can be further improved by involving either first or third quartile of the corresponding auxiliary variable (see [28] for further details).
3. Illustration with a Simulated Example
Consider a normally distributed outcome and one single exposure with five baseline covariates with a sample size of 300. Further assume that the for the baseline covariate-only model is , and the true and unknown -score due to the exposure is . Therefore, the for the larger model with a single exposure and five covariates is (the mean correlation between the covariates is set at , and the error variance is assumed to be 5). See Section S7 of the Supplementary Materials for the data generating process.
Assume a researcher collected these data and intends to find the association between the outcome and exposure after controlling for the five baseline covariates. As a first step, the -score is estimated by bootstrapping a sample of size from an original sample size of . The estimated -score is , which is very close to the true -score of ). Similarly, the -scores are estimated at bootstrapped sample sizes , and 2500 to illustrate the gradual convergence as the bootstrap size increases (Figure 1A). Further note that even when precision increased with bootstrap size, the mean of regression coefficients remained stable (Figure 1B) while the p-values from linear regression keep getting smaller (Figure 1C). Moreover, the power based on the likelihood ratio test and corresponding calibrated cutoff value of kept increasing rapidly (Figure 1D).
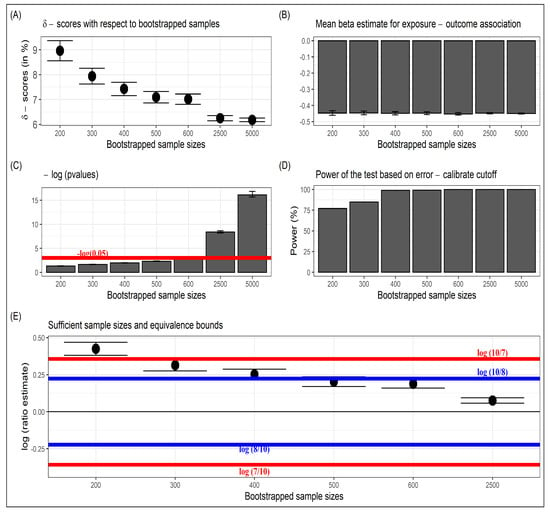
Figure 1.
Results from simulated example. (A) Illustration of -scores for different bootstrapped sample sizes and their eventual convergence, (B) Mean estimates and standard errors of the exposure–outcome association, (C) Negative log (base = e) p-values as bootstrapped sample sizes increased, (D) Power of the likelihood ratio test based on the calibrated cutoff value , and (E) Sufficient sample sizes concerning the choices of equivalence bounds.
For the original sample size of , the corresponding p-value of the regression estimate was not significant. The researcher, therefore, might have wanted to scale up the study to collect more data and increase the original sample size based on statistical power calculation and sample size determination, which estimated that a sample size of around 1000 was required assuming power of the test and the type 1 error was fixed at . Sufficient sample-size estimation using -score struck a balance between precision and utility. We estimated based on 2000 iterations and used the non-equivalence hypothesis in (7) to compare the -scores at , and 2500 with respect to the estimated -score at (Figure 1E). At , and its CI lie within the bounds of and , whereas at and 300, it breached the upper bound of but stayed within the bounds of and . Accordingly, the researcher can choose a sufficient sample size of or at equivalence bounds of or , respectively, with corresponding -scores of and . These -scores were within a close neighborhood of the converged -scores of (based on the bootstrapped size of ).
4. Application in Exposure–Mixture Association of PFAS and Metals with Serum Lipids among US Adults
PFAS are exclusively artificial endocrine disrupting chemicals (EDCs) and environmentally persistent chemicals that are used to manufacture a wide variety of consumer and industrial products: non-stick, stain, and water resistant coatings; fire suppression foam; and cleaning products ([29,30]). Both PFAS and metals have been associated with an increase in cardiovascular disease (CVD) or death as evidenced by many cross-sectional and longitudinal observational studies and experimental animal models [31]. Hypercholesterolemia is one of the significant risk factors for CVD characterized by high levels of serum cholesterol. High levels of low-density lipoprotein (LDL), total serum cholesterol, and low levels of high-density lipoprotein (HDL) are some of the factors implicated in the pathogenesis of this disorder [32]. Using the theory discussed in the sections above, we quantified the -scores of PFAS and metal mixtures on serum lipoprotein cholesterols and estimated corresponding sufficient sample sizes.
4.1. Study Population
Using cross-sectional data from the 2017–2018 U.S. NHANES [33], this study used data on 683 adults. Data on baseline covariates–––age, sex, ethnicity, body mass index (BMI) (in kg/m), smoking status, and ratio of family income to poverty—were downloaded and matched to the IDs of the NHANES participants. See Table 2 for details on participant characteristics. A weight variable was added in the regression models to adjust for oversampling of non-Hispanic black, non-Hispanic Asian, and Hispanic in this NHANES data. A list of individual PFAS, metals, and their lower detection limits can be found in Section S9 in the Supplementary Materials.
Table 2.
Study characteristics of the population under investigation. (Data from National Health and Nutrition Examination Survey 2017–2018.)
4.2. Methods
We used weighted quantile sum regression [34], but other exposure mixture models such as Bayesian kernel machine regression [35], Bayesian weighted quantile sum regression [36], and Quantile g-computation [37] can also be used, as long as the likelihood ratio test statistic can be estimated (see [11,38] for a detailed discussion on exposure–mixture methods in environmental epidemiology). All the PFAS and metals were converted to decile. As an additional analysis, both serum cholesterols were dichotomized using their 90th percentile, to demonstrate the effectiveness of -scores on binary outcomes. -scores were estimated using bootstrapped sizes of 5000 from the original sample size of 683, and the process was iterated 100 times.
4.3. Results
For metals and PFAS, the -scores of continuous HDL-C were CI: and CI: , respectively, whereas for continuous LDL-C, the scores were CI: and CI: , respectively. Both mixtures had relatively higher -scores on LDL-C than HDL-C. Furthermore, for both cholesterols, the metal mixture had a slightly higher -score than the PFAS mixture (Figure 2A,B). PFAS and Metal mixtures have higher -scores for LDL-C than HDL-C. Further, after dichotomizing the cholesterols at their 90th percentile, the -scores for the metal mixture remained similar to the continuous cholesterol outcome (HDL-C: CI: and LDL-C: CI: ), but decreased slightly for the PFAS mixture (HDL-C: CI: and LDL-C: CI: ). The decrease might have been due to some loss of information during dichotomizing the outcomes (Figure 2C,D).
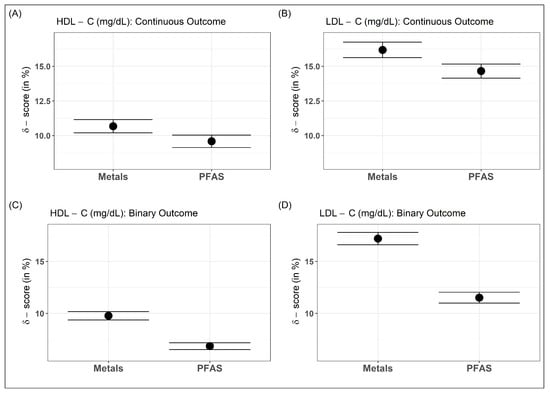
Figure 2.
-scores of EDC exposure–mixture of metals and PFAS for continuous (A,B) and dichotomized (C,D) serum lipoprotein–cholesterols.
Sufficient sample sizes were also estimated for this dataset at the equivalence bounds of , . For both metal and PFAS mixtures, the and their corresponding CIs for bootstrap size 683, lay well within the equivalence bounds. Further, even at a decreased sample size of 483, the and their CIs, remained within the equivalence bounds. Therefore, is a sufficient sample size at equivalence bounds , for both metal and PFAS mixtures (Figure 3), but a further decrease in the bootstrap size, would not be sufficient at this pre-fixed equivalence bounds. One can further modify the bootstrap size to obtain a precise estimate of sufficient sample size.
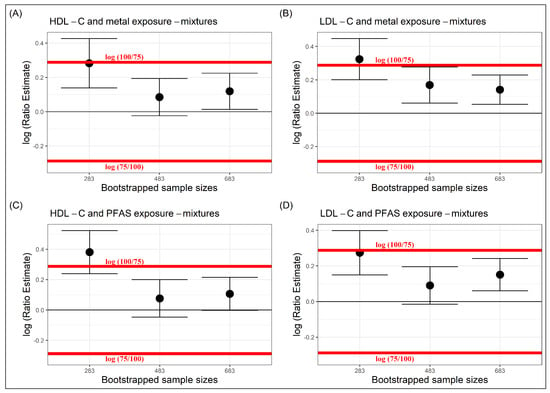
Figure 3.
Sufficient sample sizes to estimate the -scores in serum lipoprotein-cholesterols at equivalence bounds of with respect to EDC metal mixtures (A,B) and EDC PFAS mixtures (C,D).
5. Concluding Remarks
This paper introduced the idea of the -score and sufficient sample size for the exposure–outcome association. -score is easily interpretable, scale independent, and because of its connection to Cohen’s , it allows for direct comparisons between outcomes measured on different scales, separate studies or in meta-analyses. The -score could be used to compare and choose between multiple outcomes with varying units and scales. Furthermore, sample-size determination based on preliminary data might use a sufficient sample size in designing more cost-efficient human studies. We recommend the simultaneous use of the score and regression coefficient-based measures in designing studies to balance precision and utility.
This framework has limitations. The bootstrapped estimation of the -score assumed that the original sample was well representative of the true target population. Any estimate of the -score, therefore, carried this implicit assumption, but such an assumption is at the core of many statistical analyses, and a well-designed study can ideally resolve such issues or be corrected to be well represented. Oversampling with replacement might cause over-fitting of the data, but splitting the data repeatedly in training and testing under various random seeds can overcome this issue [39]. In addition, this theory is based on the likelihood ratio test of nested models, but future work can extend this framework to strictly non-nested or overlapping models [19]. Although the -score was initially developed for nested linear models, its theoretical framework can be extended to non-linear regressions, as well as to non-Gaussian error distributions. For example, ref. [40] studied growth variability in harvested fish populations using a nonlinear mixed effects (NLME) model, developed under a Bayesian approach with non-Gaussian distributions. The score can be used for such a model since it basically requires an estimate of the likelihood ratio test statistics under the null and the alternative hypothesis (see the definition of in generalized linear models). The likelihood ratio statistics for this Bayesian formulation of NLME has often been used in the literature and is readily available through various R functions [41]. Further, in cases of non-Gaussian error distribution, the focus should shift to improving the error variance estimate.
Progress can also be made to estimate the -score in a high-dimensional setting, for example, in metabolomic studies ([11,42]). Although concepts rooted in “proportion of the variation” are extensively used in genome-wide association studies, such measures are rarely used in environmental epidemiology or population health studies. This highlights new opportunities for theoretical development and practical implementation in exposomic studies, especially in multi-scale geospatial environmental data, where the integration of multi-source high-dimensional data is not straightforward [43]. In conclusion, quantifying the impact of the exposure–mixture on health using the score could have direct implications for policy decisions and, when used with regression estimates, might prove to be very informative.
Supplementary Materials
The Supplementary information can be downloaded at: https://www.mdpi.com/article/10.3390/sym14101962/s1, Figure S1: Null and alternative neighborhoods induced through neutral effect size and corresponding type 2 error function for sample sizes n = 250 and n = 1000; Table S1: Type 1 and type 2 error rates for error calibrated cutoff; Supplementary Methods: (1) Derivation of non-centrality parameter in linear regression using Information Method, (2) Proof of Lemma 1, (3) Cohen’s in Generalized Linear Models, (4) Proof of Lemma 1, (5) Calibrated type 1 and type 2 errors remain approximately same under T, (6) Type 2 error function, (7) Proof of Corollary 1, (8) Data generating process for simulation, (9) List of PFAS and metal exposures and Serum lipoprotein-cholesterols outcomes.
Author Contributions
Conceptualization, V.M., J.L. and C.G.; Data curation, V.M.; Formal analysis, V.M.; Funding acquisition, R.O.W. and D.V.; Investigation, V.M., J.L. and C.G.; Methodology, V.M. and C.G.; Software, V.M.; Supervision, J.L., C.G., E.C., S.L.T. and D.V.; Validation, V.M.; Visualization, V.M.; Writing—original draft, V.M.; Writing—review & editing, V.M., J.L., C.G., E.C., S.L.T., R.O.W. and D.V. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Institute of Environmental Health Sciences (NIEHS) grant number P30ES023515. The APC was funded by Damaskini Valvi.
Data Availability Statement
Data for this analysis are freely available for download from US NHANES (2017–2018) (https://wwwn.cdc.gov/nchs/nhanes/continuousnhanes/default.aspx?BeginYear=2017 (accessed on 1 September 2022)). All codes are written in R and available at github (https://github.com/vishalmidya/Quantification-of-variation-in-environmental-mixtures (accessed on 1 September 2022)).
Acknowledgments
The authors are very grateful to the five anonymous reviewers and editors for their thorough review and expert guidance in the revision of this paper.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| EDC | Endocrine Disrupting Chemical |
| PFAS | Perfluoroalkyl and Polyfluoroalkyl Substances |
| ALT | Alanine aminotransferase |
| CK-18 | Cytokeratin-18 |
| NHANES | National Health and Nutrition Examination Survey |
| BMI | Body Mass Index |
| LDL-C | Low-Density Lipoprotein Cholesterol |
| HDL-C | High-Density Lipoprotein Cholesterol |
| WQS | Weighted Quantile Sum |
References
- Futran Fuhrman, V.; Tal, A.; Arnon, S. Why endocrine disrupting chemicals (edcs) challenge traditional risk assessment and how to respond. J. Hazard. Mater. 2015, 286, 589–611. [Google Scholar] [CrossRef] [PubMed]
- Cano, R.; Pérez, J.L.; Dávila, L.A.; Ortega, A.; Gómez, Y.; Valero-Cedeño, N.J.; Parra, H.; Manzano, A.; Véliz Castro, T.I.; Albornoz, M.P.D.; et al. Role of endocrine-disrupting chemicals in the pathogenesis of non-alcoholic fatty liver disease: A comprehensive review. Int. J. Mol. Sci. 2021, 22, 4807. [Google Scholar] [CrossRef] [PubMed]
- Midya, V.; Colicino, E.; Conti, D.V.; Berhane, K.; Garcia, E.; Stratakis, N.; Andrusaityte, S.; Basagaña, X.; Casas, M.; Fossati, S.; et al. Association of prenatal exposure to endocrine-disrupting chemicals with liver injury in children. JAMA Netw. Open 2022, 5, e2220176. [Google Scholar] [CrossRef] [PubMed]
- Ioannidis, J.P.A.; Greenland, S.; Hlatky, M.A.; Khoury, M.J.; Macleod, M.R.; Moher, D.; Schulz, K.F.; Tibshirani, R. Increasing value and reducing waste in research design, conduct, and analysis. Lancet 2014, 383, 166–175. [Google Scholar] [CrossRef]
- Wasserstein, R.L.; Lazar, N.A. The asa statement on p-values: Context, process, and purpose. Am. Stat. 2016, 70, 129–133. [Google Scholar] [CrossRef]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences; Lawrence Erlbaum Associates: New York, NY, USA, 1976; pp. 273–403. [Google Scholar]
- Schäfer, T.; Schwarz, M.A. The meaningfulness of effect sizes in psychological research: Differences between sub-disciplines and the impact of potential biases. Front. Psychol. 2019, 10, 813. [Google Scholar] [CrossRef]
- Smithson, M. Confidence Intervals; Number No. 140 in Confidence Intervals; SAGE Publications: Thousand Oaks, CA, USA, 2003. [Google Scholar]
- Grissom, R.; Kim, J. Effect Sizes for Research: A Broad Practical Approach; Lawrence Erlbaum Associates: Mahwah, NJ, USA, 2005. [Google Scholar]
- Yang, J.; Benyamin, B.; McEvoy, B.P.; Gordon, S.; Henders, A.K.; Nyholt, D.R.; Madden, P.A.; Heath, A.C.; Martin, N.G.; Montgomery, G.W.; et al. Common snps explain a large proportion of the heritability for human height. Nat. Genet. 2010, 42, 565–569. [Google Scholar] [CrossRef]
- Joubert, B.R.; Kioumourtzoglou, M.A.; Chamberlain, T.; Chen, H.Y.; Gennings, C.; Turyk, M.E.; Miranda, M.L.; Webster, T.F.; Ensor, K.B.; Dunson, D.B.; et al. Powering research through innovative methods for mixtures in epidemiology (prime) program: Novel and expanded statistical methods. Int. J. Environ. Res. Public Health 2022, 19, 1378. [Google Scholar] [CrossRef]
- Chen, H.Y.; Li, H.; Argos, M.; Persky, V.W.; Turyk, M.E. Statistical methods for assessing the explained variation of a health outcome by a mixture of exposures. Int. J. Environ. Res. Public Health 2022, 19, 2693. [Google Scholar] [CrossRef]
- Wilks, S.S. The large-sample distribution of the likelihood ratio for testing composite hypotheses. Ann. Math. Stat. 1938, 9, 60–62. [Google Scholar] [CrossRef]
- Brown, B.W.; Lovato, J.; Russell, K. Asymptotic power calculations: Description, examples, computer code. Stat. Med. 1999, 18, 3137–3151. [Google Scholar] [CrossRef]
- Selya, A.; Rose, J.; Dierker, L.; Hedeker, D.; Mermelstein, R. A practical guide to calculating cohen’s f2, a measure of local effect size, from proc mixed. Front. Psychol. 2012, 3, 111. [Google Scholar] [CrossRef] [PubMed]
- Akaike, H. Information theory and an extension of the maximum likelihood principle. In Selected Papers of Hirotugu Akaike; Parzen, E., Tanabe, K., Kitagawa, G., Eds.; Springer: New York, NY, USA, 1998; pp. 199–213. [Google Scholar]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Dziak, J.J.; Coffman, D.L.; Lanza, S.T.; Li, R.; Jermiin, L.S. Sensitivity and specificity of information criteria. Brief. Bioinform. 2019, 21, 553–565. [Google Scholar] [CrossRef]
- Vuong, Q.H. Likelihood ratio tests for model selection and non-nested hypotheses. Econometrica 1989, 57, 307–333. [Google Scholar] [CrossRef]
- Schönbrodt, F.D.; Wagenmakers, E.J.; Zehetleitner, M.; Perugini, M. Sequential hypothesis testing with bayes factors: Efficiently testing mean differences. Psychol. Methods 2017, 22, 322–339. [Google Scholar] [CrossRef]
- Morey, R.D.; Rouder, J.N. Bayes factor approaches for testing interval null hypotheses. Psychol. Methods 2011, 16, 406. [Google Scholar] [CrossRef]
- Kruschke, J.K. Bayesian estimation supersedes the t test. J. Exp. Psychol. Gen. 2013, 142, 573. [Google Scholar] [CrossRef]
- Liao, J.G.; Midya, V.; Berg, A. Connecting and contrasting the bayes factor and a modified rope procedure for testing interval null hypotheses. Am. Stat. 2020, 75, 256–264. [Google Scholar] [CrossRef]
- Midya, V.; Liao, J. Systematic deviation in mean of log bayes factor: Implication and application. Commun. Stat.-Theory Methods 2021, 1–10. [Google Scholar] [CrossRef]
- Schuirmann, D.J. A comparison of the two one-sided tests procedure and the power approach for assessing the equivalence of average bioavailability. J. Pharmacokinet. Biopharm. 1987, 15, 657–680. [Google Scholar] [CrossRef] [PubMed]
- Phillips, K.F. Power of the two one-sided tests procedure in bioequivalence. J. Pharmacokinet. Biopharm. 1990, 18, 137–144. [Google Scholar] [CrossRef] [PubMed]
- Phillips, K.F. Power for testing multiple instances of the two one-sided tests procedure. Int. J. Biostat. 2009, 5, 1–14. [Google Scholar] [CrossRef]
- Long, C.; Chen, W.; Yang, R.; Yao, D. Ratio estimation of the population mean using auxiliary information under the optimal sampling design. Probab. Eng. Inf. Sci. 2022, 36, 449–460. [Google Scholar] [CrossRef]
- Liu, H.S.; Wen, L.L.; Chu, P.L.; Lin, C.Y. Association among total serum isomers of perfluorinated chemicals, glucose homeostasis, lipid profiles, serum protein and metabolic syndrome in adults: Nhanes, 2013–2014. Environ. Pollut. 2018, 232, 73–79. [Google Scholar] [CrossRef]
- Jain, R.B.; Ducatman, A. Associations between lipid/lipoprotein levels and perfluoroalkyl substances among us children aged 6–11 years. Environ. Pollut. 2018, 243, 1–8. [Google Scholar] [CrossRef]
- Meneguzzi, A.; Fava, C.; Castelli, M.; Minuz, P. Exposure to perfluoroalkyl chemicals and cardiovascular disease: Experimental and epidemiological evidence. Front. Endocrinol. 2021, 12, 850. [Google Scholar] [CrossRef]
- Buhari, O.; Dayyab, F.; Igbinoba, O.; Atanda, A.; Medhane, F.; Faillace, R. The association between heavy metal and serum cholesterol levels in the us population: National health and nutrition examination survey 2009–2012. Hum. Exp. Toxicol. 2020, 39, 355–364. [Google Scholar] [CrossRef]
- CDC; NCHS. US National Health and Nutrition Examination Survey Data, 2017–2018. Available online: https://wwwn.cdc.gov/nchs/nhanes/search/datapage.aspx?Component=Laboratory&Cycle=2017-2018 (accessed on 1 September 2022).
- Carrico, C.; Gennings, C.; Wheeler, D.C.; Factor-Litvak, P. Characterization of weighted quantile sum regression for highly correlated data in a risk analysis setting. J. Agric. Biol. Environ. Stat. 2015, 20, 100–120. [Google Scholar] [CrossRef]
- Bobb, J.F.; Valeri, L.; Claus Henn, B.; Christiani, D.C.; Wright, R.O.; Mazumdar, M.; Godleski, J.J.; Coull, B.A. Bayesian kernel machine regression for estimating the health effects of multi-pollutant mixtures. Biostatistics 2014, 16, 493–508. [Google Scholar] [CrossRef]
- Colicino, E.; Pedretti, N.F.; Busgang, S.A.; Gennings, C. Per- and poly-fluoroalkyl substances and bone mineral density. Environ. Epidemiol. 2020, 4, e092. [Google Scholar] [CrossRef] [PubMed]
- Keil, A.P.; Buckley, J.P.; O’Brien, K.M.; Ferguson, K.K.; Zhao, S.; White, A.J. A quantile-based g-computation approach to addressing the effects of exposure mixtures. Environ. Health Perspect. 2020, 128, 047004. [Google Scholar] [CrossRef]
- Gibson, E.A.; Nunez, Y.; Abuawad, A.; Zota, A.R.; Renzetti, S.; Devick, K.L.; Gennings, C.; Goldsmith, J.; Coull, B.A.; Kioumourtzoglou, M.A. An overview of methods to address distinct research questions on environmental mixtures: An application to persistent organic pollutants and leukocyte telomere length. Environ. Health 2019, 18, 76. [Google Scholar] [CrossRef]
- Nunez, Y.; Gibson, E.A.; Tanner, E.M.; Gennings, C.; Coull, B.A.; Goldsmith, J.; Kioumourtzoglou, M.A. Reflection on modern methods: Good practices for applied statistical learning in epidemiology. Int. J. Epidemiol. 2021, 50, 685–693. [Google Scholar] [CrossRef] [PubMed]
- Contreras-Reyes, J.E.; López Quintero, F.O.; Wiff, R. Bayesian modeling of individual growth variability using back-calculation: Application to pink cusk-eel (genypterus blacodes) off chile. Ecol. Model. 2018, 385, 145–153. [Google Scholar] [CrossRef]
- Vincenzi, S.; Mangel, M.; Crivelli, A.J.; Munch, S.; Skaug, H.J. Determining individual variation in growth and its implication for life-history and population processes using the empirical bayes method. PLoS Comput. Biol. 2014, 10, e1003828. [Google Scholar] [CrossRef] [PubMed]
- Maitre, L.; Guimbaud, J.B.; Warembourg, C.; Güil-Oumrait, N.; Marcela Petrone, P.; Chadeau-Hyam, M.; Vrijheid, M.; Gonzalez, J.R.; Basagaña, X. State-of-the-art methods for exposure-health studies: Results from the exposome data challenge event. Environ. Int. 2022, 168, 107422. [Google Scholar] [CrossRef]
- Cui, Y.; Eccles, K.M.; Kwok, R.K.; Joubert, B.R.; Messier, K.P.; Balshaw, D.M. Integrating multiscale geospatial environmental data into large population health studies: Challenges and opportunities. Toxics 2022, 10, 403. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).