Abstract
Estimation of a conditional covariance matrix is an interesting and important research topic in statistics and econometrics. However, modelling ultra-high dimensional dynamic (conditional) covariance structures is known to suffer from the curse of dimensionality or the problem of singularity. To partially solve this problem, this paper establishes a model by combining the ideas of a factor model and a symmetric GARCH model to describe the dynamics of a high-dimensional conditional covariance matrix. Quasi maximum likelihood estimation (QMLE) and least square estimation (LSE) methods are used to estimate the parameters in the model, and the plug-in method is introduced to obtain the estimation of conditional covariance matrix. Asymptotic properties are established for the proposed method, and simulation studies are given to demonstrate its performance. A financial application is presented to support the methodology.
JEL Classification:
G32; C53
1. Introduction
Estimation of a conditional covariance matrix is an important and popular topic in statistics and econometrics with wide applications in many disciplines, such as engineering, environmentology, psychology, economics and finance. A traditional approach to estimating conditional covariance matrices is based on multivariate GARCH models, e.g., the vectorized multivariate GARCH (VEC-GARCH) model of [1], the Baba, Engle, Kraft and Krone GARCH (BEKK-GARCH) model of [2], the constant conditional correlation GARCH (CCC-GARCH) model of [3] and the dynamic conditional correlation GARCH (DCC-GARCH) model of [4].
These GARCH models can be called symmetric GARCH models, which assume that the response of conditional covariance (volatility) to a shock is a function of the shock strength only without any correlation with the sign of the shock. To capture the leverage effects, some multivariate GARCH models take into account negative shocks with a larger impact on their conditional covariance compared with positive shocks of the same absolute value.
That is to say, the new impact curve, which traces the relation between conditional covariance and the previous shock, is asymmetric. These asymmetric multivariate GARCH models include the asymmetric dynamic covariance GARCH (ADC-GARCH) model of [5], the generalized diagonal VEC-GARCH model of [6] and related models of [7,8].
However, common multivariate GARCH models cannot be directly applied to ultra-high dimensional data, which is often the case when constructing a portfolio allocation in finance. This is because there are too many parameters to be estimated when the dimension is large, see, e.g., [9]. To overcome the problems caused by high dimensions, various methods have been developed to reduce the dimension of data and the number of parameters.
One of effective methods for dimension reduction is the factor analysis for time series, see [10,11,12,13,14] focusing on the conditional mean and [15,16,17] focusing on the conditional covariance. In addition, there are some variants of the factor model that introduce the GARCH structure to describe the conditional covariance, e.g., the full-factor multivariate GARCH (FF-GARCH) model introduced by [18], the orthogonal GARCH (O-GARCH) model proposed by [19] and the generalized O-GARCH (GO-GARCH) model of [20].
Ref. [21] investigated the asymptotic theory for the general factor GARCH model that nested the above three models. But the model proposed by [21] can’t reduce the dimension if loading matrix is a square matrix. O-GARCH model as a special case of [21] is a successful multivariate GARCH model with a parsimonious form. This not only captures the dynamics of conditional covariance but can also reduce the dimensions effectively if the model is identified fairly.
However, the O-GARCH model treats all principal components as conditionally uncorrelated random variables, which may lead to a miss-specification and non-negligible errors in the fitting (see [22]). Moreover, when the number of factors is smaller than the dimension, the conditional covariance matrix obtained by the factor GARCH model is only non-negative definite but not positive-definite.
Recently, Ref. [23] proposed a dynamic structure and developed an estimation procedure for high-dimensional conditional covariance matrices. Their work is insightful but not applicable for the cases when the dimension p is equal to or larger than the sample size T. However, in practical applications, there are many cases facing when modelling the conditional covariance matrices. Hence, it makes sense to study the issue under ultra-high dimensional cases.
Motivated by the above literature, we propose an alternative model for estimating high-dimension conditional covariance matrix. The basic idea is to use a factor model to reduce the dimensions first, then fit the low-dimensional CCC-GARCH model to the common factor and use the univariate GARCH model to fit the idiosyncratic components.
The rest of the article is organised as follows. We begin in Section 2 with the proposed model, estimation methodology and the modelling procedure. In Section 3, asymptotic properties of the proposed estimators, including the necessary assumptions, are given. Section 4 constructs a portfolio allocation based on the formula for Markowitz’s optimal portfolio using the proposed model as a conditional covariance matrix. To assess the performance of the proposed method, we illustrate simulation and a real example in Section 5. Section 6 provides our conclusions. All proofs of theoretical results are put in the Appendix A.
Throughout the paper, we use , and to denote the transpose and the minimum and maximum eigenvalues of a matrix A. Let be the column-stacking vector of a matrix A. The notations , and represent the Frobenius norm, spectral norm (operator norm) and element-wise norm of a matrix A, defined respectively by , and .
When A is a vector, both and are equal to the Euclidean norm. For a random sequence , for some sequence means that , where is defined in Assumption 1(iii).
2. The Model and Methodology
2.1. Setting
In the proposed model, the symmetric GARCH model is used. Let be an observed p-dimensional time series and assume . Then, admits the following structure:
where , for is the unobservable factor loading vectors; is an observable K-dimensional vector of common factors, and K is fixed. is an unknown p-dimensional vector of idiosyncratic errors, which is independent of . We assume satisfies that
where , and with
, and is a symmetric matrix with , for , that is
We further assume that each component of follows a univariate GARCH model,
where
The true parameters in the CCC-GARCH model of the common factor and univariate GARCH of the idiosyncratic components are denoted by and respectively, where , and , for . The number of parameters is .
We focus our attention on the conditional covariance matrix of , which is based on the assumption that :
Compared to the existent factor GARCH models, there are two improved points for our model. One is that we assume the conditional covariance matrix consists of a non-negative positive matrix and a diagonal matrix, which is helpful to flexibly describe the dynamics and guarantee the positive-definiteness of the matrix even though the number of factor K is quite smaller than dimension p. Another is that our factor loading matrix B is only assumed as a full rank matrix and not necessarily to be orthogonal.
2.2. Estimation Procedure
In this study, we assume that is observable. Similar to [24], we first use the least squares method to estimate the factor loading matrix B and obtain
where , , and . Then, let
Following [23], let in (3) be replaced by , and a synthetic GARCH model can be acquired as follows,
for each , assume . Note that the parameters estimating of (5) are based on the residuals rather than the observed data; hence, we call (5) a synthetic GARCH model. The QML approach is used to estimate , and the negative quasi log-likelihood function of is defined as follows
where can be recursively computed by (5) with initial values
Note that [25] demonstrated that the choice of the initial values is unimportant for the asymptotic properties of the QMLE. Hence, we minimise (6) corresponding to on a compact set defined in Assumption 1 and obtain the QMLE of as follows,
Once s are estimated, substitute them into (5) and set the initial values for and , e.g., in (7), an estimator of can be acquired, namely an estimator of is obtained.
In order to estimate , for simplicity, it is assumed that K in (1) is known in this study. We first estimate by QMLE based on the observable factors . Then, obtain the estimator of by substituting it into (2). The process is as the following two steps:
Step 1. We assume
where . We construct the likelihood function
with initial values
Maximize (9), we obtain the QMLE of as follows
Step 2. By substituting the initial values (10) and the estimator into (8), an estimator of , and then the estimator of are acquired.
Similar to [24], by using the plug-in method, we substitute all corresponding estimators into (4) and obtain the estimator of conditional covariance matrix of as follows
3. Theoretical Properties
In this section, we present the asymptotic properties of the proposed estimators. First, the strong mixing conditions are imposed to conduct asymptotic analysis of the LSE. Denote and as the -algebras generated by and , respectively. The mixing coefficient is defined as
Assumption 1.
- (i).
- For each , let be a strictly stationary process with GARCH structure, for and . and are assumed independent of each other.
- (ii).
- Assume , for each t and ℓ. Then, for each , and , where , with a small constant ϵ.
- (iii).
- For each , the true value belongs to the interior of Λ, where Λ is a compact set, and for a constant .
- (iv).
- Assume and , for . If , and have no common roots, , and .
Assumption 1 is a standard regularity assumption in the literature. The second part of condition (i) is standard in factor model literature (see [24,26]), allowing to be weakly dependent with respect to time t. Other conditions are common assumptions of univariate GARCH models (see, e.g., [23]).
Assumption 2.
- (1).
- There is a constant L, such that
- (2).
- There is a constant , for each i and j, such that .
- (3).
- There exist constants and , for all and , such that
Conditions (1) and (2) require that and are bounded. Condition (3) allows us to apply the Bernstein-type inequality for the weakly dependent data. This assumption is standard in the factor model as in [24].
Assumption 3.
for some symmetric positive definite matrix Ω such that is bounded away from zero.
Assumption 3 requires that the factors should be pervasive, that is, impact every individual time series (e.g., [24,26]).
Assumption 4.
Let and . Following convention, , if , and if .
- (a).
- The parameter space Θ is a compact subspace of Euclidean space, such that is an interior point in Θ.
- (b).
- is a strictly stationary and ergodic process.
- (c).
- The components of are independent and their squares have non-degenerate distributions. In addition, there exist constants with and , such that, for all and
- (d).
- If , then and are left coprime and has full rank K, where .
- (e).
- Γ is a positive correlation matrix for all .
- (f).
- .
The above assumption is standard in CCC-GARCH models as in [25]. Conditions (a) and (b) are common conditions for GARCH model. Condition (c) allows us to apply the Bernstein-type inequality for the weakly dependent data. Condition (d) makes sure that and have no common roots. is positive definite under Condition (e). Under Condition (f), has finite d-order comments.
Remark 1.
Under Assumptions 1 and 4, and are strictly stationary and ergodic, and α-mixing with geometric rate (see [27]).
Lemma 1.
Suppose and . Under Assumption 4, there exists a constant , such that
Remark 2.
The result of Lemma 1 can be proved in a similar fashion to Theorem 1 in [28].
Theorem 1.
Under Assumptions 1–3, there exist a constant and a small constant ϵ defined in Lemma 1, such that
When p diverges, the Forbenius norm and operator norm can not fully employ the factor structure (see [29]). Hence, other norms are sought to help us understand the factor structure, and the entropy loss norm introduced by [30] is a good choice. Its formula is
Next, we are going to give the asymptotic properties of the estimator for in the following theorem, where , , and are defined in Assumptions 2 and 4, and Lemma A2.
Theorem 2.
Suppose . Then, under Assumptions 1–4, there exist constants and a small constant ϵ defined in Lemma 1, such that
(i)
(ii)
4. Portfolio Allocation
In this section, a brief introduction on the procedures of constructing the estimated portfolio allocation using our model is given. First, denote as the conditional expectation of , and take conditional expectation of (1), then we can acquire
Hence,
is utilized as the estimate of , where is estimated by applying a VAR(1) model (see [31]) as follows
Based on the mean-variance optimal portfolio proposed by [32,33], we construct the estimated optimal portfolio allocation similar to [23]: let w denote the allocation vector of p risky assets, to be held between times and t, solve the following minimization problem, and assume the solution as the estimate of w,
with as the target return imposed on the portfolio, and is a p-dimensional column vector of 1. Existent result gives the explicit estimator of w as follows
where
5. Numerical Properties
The purpose of this section is to assess the finite-sample performance of the proposed model by using simulation and empirical studies.
5.1. Simulation Studies
In this section, we use a simulated example to illustrate the asymptotic properties, and show how well the proposed model works. In order to display the rates of convergence when p gradually increases, we use the following settings for with replication time : , , , , , and , , , , , . Let
In model , for , we assume
In the conditional covariance matrix of , we set
and , with
In order to define B, we generate its entries independently from a uniform distribution on , and use these same values throughout all simulations.
Now, for each fixed p, the following steps give detailed simulation procedures:
- (1)
- Generate each component of independently from and let ;
- (2)
- Generate from , and let , for each and ;
- (3)
- Generate from , where is the K-dimensional identity matrix, and let , for ;
- (4)
- Calculate , for .
Remark 3.
We generate samples but use only the first T data points to estimate . The additional point helps us to get the 1-period simple return
of a portfolio allocation , where is estimated at time T based on , .
The main purpose of the proposed simulation is to describe the convergence rate of to based on our model and O-GARCH model. We first calculate the means and standard deviations of under the entropy norm and the element-wise norm . We also obtain the means and standard deviations of based on the proposed model. The conditional covariance matrix of O-GARCH model is singular when , and hence we omit the corresponding estimate of based on O-GARCH here. The results are displayed in Table 1, Table 2, Table 3 and Table 4.

Table 1.
The mean and SD of the estimate errors, .
Table 2.
The mean and SD of the estimate errors, .
Table 3.
The mean and SD of the estimate errors, .
Table 4.
The mean and SD of the estimate errors, .
We also use the Sharpe ratio
to assess how well performs, where the standard deviation of is denoted as . For convenience, let the risk-free rate to be zero. To depict the performance of the proposed portfolio allocation when p is large or even larger than T, we calculate the return presented in (13) with a target return . Furthermore, we compare our model with [29], in terms of portfolio allocations based on Markowitz’s formula. The results are presented in Table 5, with replication . In this table, we denote our portfolio allocations by , and the portfolio allocations of [29] by .
Table 5.
The means, standard deviations, Sharpe ratios, and risks.
Based on Table 1, Table 2, Table 3, Table 4 and Table 5, we can make the following observations and conclusions:
- (1).
- Based on the proposed model, both the means and standard deviations are small and their values decrease as the sample size increases. The means of and slightly increase as p increases, and the means of increase a little faster, which is determined by the definitions of norms. Such similar results are also obtained in [29] and [24]. All the standard deviations are stable and significantly small when compared to their corresponding means, especially based on the entropy norm.
- (2).
- Based on the O-GARCH model, the means and standard deviations of are not sensitive to p and T, and the standard deviations are significantly smaller than the means.
- (3).
- The results in Table 5 show that the Sharpe ratio of the proposed portfolio allocation is larger than those of the portfolio allocation based on [29]. The risks of the proposed allocation are smaller than the corresponding risks based on [29].
In conclusion. First, comparing the results between the proposed model and O-GARCH model in terms of the means and deviations of and , we find that the proposed model performs fairly better than the O-GARCH model. Although O-GARCH model also describes the dynamic feature of the conditional covariance matrix, this discards the idiosyncratic components, leading to the poor simulation performance.
Secondly, Table 5 suggests that the proposed allocation outperforms those evaluated by the method of [29], where only unconditional covariance is adopted without taking into account the dynamics of the covariance matrix. Lastly, all results are in good agreement with the theoretical properties in Section 3. In addition, the proposed estimated conditional covariance matrix is invertible no matter how large p is, which is quite important in finance and econometrics. Hence, it is seen that the proposed model works quite well in this simulation.
5.2. Real Data Analysis
In this section, we demonstrate the application of the proposed model to a real data set. We employ the data of daily returns of 49 Industrial Portfolios minus the risk-free rate as the response variable , and take Rm − Rf, SMB and HML as the observable common factors. The data was downloaded from http://mba.tuck.dartmouth.edu/pages/faculty/ken.french/data_library.html (accessed on 3 August 2021). The data series span from 2 January 2001 to 31 December 2010 with a total of 2515 observations. Figure 1 and Figure 2 depict the time plots of the three factors and the first three components of (Agriculture, Food Products and Candy&Soda), respectively. It is clearly seen in the plots that the peaks is displayed evidently during the periods of the 2008–2009 financial crisis.
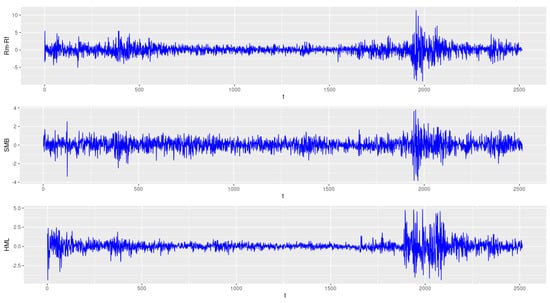
Figure 1.
Time series plots of the three factors (Rm − Rf, SMB and HML).
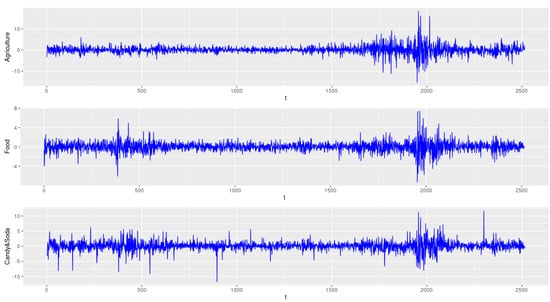
Figure 2.
Time series plots of , and .
In this example, we denote our portfolio allocation by FG, and compare it with the allocation proposed by [29] (denoted by Fan2008) in the terms of annualized Sharpe ratios. The calculation of annualized Sharpe ratio follows the trading strategy similar to [23]. Every year’s trading days are approximately . All possible portfolio allocations are assumed attainable, short selling is admitted, and there is no transaction cost.
In the trading strategy, we form a portfolio allocation at the end of each trading day, and hold it until the end of the next trading day. Between day and t, we calculate the realized return as follows
with calculated based on , for , and . Hence, the annualized Sharpe ratio is evaluated by
where
with as the risk-free rate of day t. We calculate the annualized Sharpe ratios at the end of the final trading day of each year, and repeat this by using sample size and .
Figure 3 shows the plots of the proposed annualized Sharpe ratios based on 100 and 500 respectively. It is seen that the performance of the proposed annualized Sharpe ratio becomes better as sample size n increases.
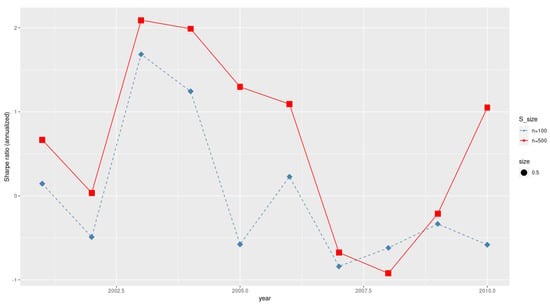
Figure 3.
Annualized Sharpe ratios.
Furthermore, the performances of the two allocations in terms of Sharpe ratio are depicted in Figure 4. It is found that FG outperforms Fan2008 in the majority of the observations. This results can be attributed to the fact that there exists GARCH effect for the considered data. Consequently, the dynamic conditional covariance (FG) is expected to show certain superiority compared to the unconditional covariance (Fan2008).
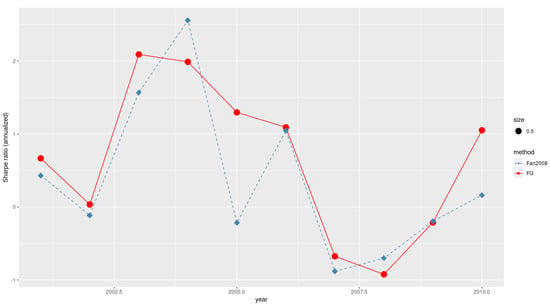
Figure 4.
Annualized Sharpe ratios for .
6. Conclusions
In this article, we proposed a factor-GARCH model for ultra-high dimensional conditional covariance. One advantage of the proposed model is that, when and both diverge, it can capture the dynamics of the conditional covariance matrix well and also guarantees that the estimated matrix is invertible. This plays an important role in practical applications. First, we use the popular factor model constructed by [34] to reduce the dimensions. Then, CCC-GARCH is imposed to fit the common factor vector.
Last, we use the univariate GARCH model to estimate the idiosyncratic errors of . The loading factor matrix is estimated by the least square method, and QMLE is proposed to estimate the parameters in GARCH models. Then, we give the estimate of by using the plug-in method. Asymptotic properties are derived for the estimation, and simulation studies are given to demonstrate its performance. A given financial application shows that the proposed model is of certain superiority compared to the existent models.
On the basis of this paper, several questions are worthy of further study. In the article, we investigated the case where the common factors are observable and K is known, and we assumed that idiosyncratic errors have univariate GARCH structure. However, in some occasions, the common factors may not be observable, the number of factors could be unknown, and the idiosyncratic errors might follow a more complicated structure. Hence, it makes sense to extend the proposed model to more general cases, and these are left for future studies.
Author Contributions
Methology, X.Z.; Simulation, X.L.; Empirical Analysis, X.L.; Supervision, Y.L. All authors have read and agreed to the published version of the manuscript.
Funding
The work was partially supported by National Natural Science Foundation of China (11731015, 11701116), Innovative Team Project of Ordinary Universities in Guangdong Province (2020WCXTD018) (Y.L. and X.Z.) and Guangzhou University Research Fund (YG2020029, YH202108) ( X.Z.).
Data Availability Statement
The data was downloaded at http://mba.tuck.dartmouth.edu/pages/faculty/ken.french/data_library.html (accessed on 3 August 2021).
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proofs
Lemma A1.
Suppose . Under Assumptions 1–3, there exist a constant and a small constant ϵ defined in Lemma 1, such that
Proof.
By using Lemma 3.1(i) in [29], we have
It is easy to derive that
By Assumption 2(1), this lemma follows. □
Lemma A2.
Under Assumptions 1 and 4, there exists constants and c, such that for all
Proof.
Under Assumption 4, are strictly stationary and -mixing with geometric rate (see [27]). By Assumption 1, and are independent, and are -mixing with geometric rate; therefore, there exist positive constant and c, such that for all
□
Proof of Theorem 1.
Let the negative quasi-likelihood function
where is recursively defined, for , by
Let the true value of denoted by for simplicity. First, we demonstrate that is consistent. The negative observed quasi log-likelihood function can be defined as its counterpart
where is defined in Section 2. Following the proof of Theorem 7.1 of [25], we only need to prove
Denote
Then, we have
The condition of Assumption 1(ii) and the compactness of imply that , where is the spectral radius of B. Iterating (A1), we thus obtain
Acquire its counterpart by replacing by in , and by in respectively, with as the initial values, and obtain
Let . Then, if , there exists a constant , such that
Hence, for some constants and , we have
for , there exists . It follows that, for , . Then, for some constants , , , , and , we obtain
where . By Lemma A.1(i), , and imply that . Then, . Hence, by the proof of Theorem 7.1 of [25], we obtain
Following the proof of Theorem 1(IV) in [23], we acquire the convergence rate of . Hence Theorem 1 is proved. □
Lemma A3.
Under Assumptions 1–4, There exist a constant and a small constant ϵ defined in Lemma 1, such that
Proof.
Denote as the th element of the matrix B and as the ith entry of a vector c. The expression of the conditional covariance is given as
To replace by in , we acquire the matrix . and can be defined in the same way. The expression of true conditional variance can be given in the similar way as the counterpart
Hence,
(a) First, we take into account the term and observe that
under Assumption 1(i) and Theorem 1, there exists a constant , such that
is bounded and , hence for a constant , we acquire
As a result, there is a large constant , such that
(b) For , let . Following the definition of and , we have
for small value . with the inequation for and . We acquire
As a result, by selecting a suitable but small , and following Theorem 1, there is a large positive constant , such that
(c) Similar to (a) and (b), it is not hard to prove that and are bounded. Hence, Lemma A3 follows. □
Proof of Theorem 2.
(i) First, by Lemma A3, we have
So
Define
It is easy to obtain
Similar to the proof of Lemma B.3 in [24], we have
and
By Lemma A3, Theorem 2 (i) follows.
(ii) By Lemma A3, we have
then
In addition, we have
Similar to the proof of part (i) of Theorem 2 in [28], we obtain Theorem 2 (ii). □
References
- Bollerslev, T.; Engle, R.F.; Wooldridge, J.M. A Capital Asset Pricing Model With Time-varying Covariances. J. Politic. Econ. 1988, 96, 116–131. [Google Scholar] [CrossRef]
- Engle, R.; Kroner, K.F. Multivariate Simultaneous Generalized ARCH. Econom. Theor. 1995, 11, 122–150. [Google Scholar] [CrossRef]
- Bollerslev, T. Modelling the Coherence in Short-Run Nominal Exchange Rates: A Multivariate Generalized ARCH Model. Rev. Econ. Statist. 1990, 72, 498–505. [Google Scholar] [CrossRef]
- Engle, R. Dynamic Conditional Correlation: A Simple Class of Multivariate Generalized Autoregressive Conditional Heteroskedasticity Models. J. Bus. Econ. Statist. 2002, 20, 339–350. [Google Scholar] [CrossRef]
- Kroner, F.K.; Ng, V.K. Modelling asymmetric comovements of asset returns. Rev. Financ. Stud. 1998, 11, 817–844. [Google Scholar] [CrossRef]
- Hansson, B.; Hordahl, P. Testing the conditional CAPM using multivariate GARCH-M. Appl. Financ. Econm. 1998, 8, 377–388. [Google Scholar] [CrossRef]
- Bauwens, I.; Laurent, S.; Rombouts, J.V.K. Multivariate GARCH model: A survey. J. Appl. Econ. 2006, 21, 79–109. [Google Scholar] [CrossRef] [Green Version]
- Hafner, C.; Herwartz, H. Time-varying market price of risk in the CAPM. Approaches, empirical evidence and implications. Finance 1998, 9, 93–112. [Google Scholar]
- Francq, C.; Zakoïan, J.-M. Estimating multivariate GARCH models equation by equation. J. R. Stat. Soc.-Ser. B 2016, 78, 613–635. [Google Scholar] [CrossRef]
- Gao, Z.; Tsay, R. A structural-factor approach to modeling high-dimensional time series and space-time data. J. Time Ser. Anal. 2019, 40, 343–362. [Google Scholar] [CrossRef] [Green Version]
- Gao, Z.; Tsay, R. Modeling high-dimensional time series: A factor model with dynamically dependent factors and diverging eigenvalues. J. Am. Statist. Assoc. 2020, 1–44. [Google Scholar] [CrossRef]
- Lam, C.; Yao, Q.; Bathia, N. Estimation for latent factor models for high-dimensional time series. Biometrika 2011, 98, 901–918. [Google Scholar] [CrossRef]
- Lam, C.; Yao, Q. Factor modeling for high-dimensional time series: Inference for the number of factors. Ann. Statist. 2012, 40, 694–726. [Google Scholar] [CrossRef] [Green Version]
- Pan, J.; Yao, Q. Modelling multiple time series via common factors. Biometrika 2008, 95, 356–379. [Google Scholar] [CrossRef] [Green Version]
- Engle, R.; Ng, V.; Rothschild, M. Asset pricing with a factor-ARCH covariance structure: Empirical estimates for treasury bill. J. Econmetr. 1990, 45, 213–238. [Google Scholar] [CrossRef] [Green Version]
- Bollerslev, T.; Engle, R. Common persistence in conditional variances. Econometrica 1993, 61, 167–186. [Google Scholar] [CrossRef]
- Lin, W. Alternative estimators for factor GARCH model—A Monte Carlo comparison. J. Appl. Econ. 1992, 7, 259–279. [Google Scholar] [CrossRef]
- Vrontos, I.; Dellaportas, P.; Politis, D. A full-factor multivariate GARCH model. Econmetr. J. 2003, 6, 311–333. [Google Scholar] [CrossRef]
- Alexander, C. Orthogonal GARCH. In Mastering Risk; Financial Times-Prentice-Hall: London, UK, 2001; Volume 2, pp. 21–38. [Google Scholar]
- Van der Weide, R. GO-GARCH: A multivariate generalized orthogonal GARCH model. J. Appl. Econ. 2002, 17, 549–564. [Google Scholar] [CrossRef]
- Hafner, C.; Preminger, A. Asymptotic theory for a factor GARCH model. Econom. Theory 2009, 25, 336–363. [Google Scholar] [CrossRef]
- Fan, J.; Wang, M.; Yao, Q. Modelling multivariate volatilites via conditionally uncorrelated components. J. R. Statist. Soc. B 2008, 70, 679–702. [Google Scholar] [CrossRef] [Green Version]
- Guo, S.; Box, J.L.; Zhang, W. A Dynamic Structure for High-Dimensional Covariance Matrices and Its Application in Portfolio Allocation. J. Am. Statist. Assoc. 2017, 112, 235–253. [Google Scholar] [CrossRef]
- Fan, J.; Mincheva, L.M. High-dimensional covariance matrix estimation in approximate factor models. Ann. Statist. 2011, 39, 3320–3356. [Google Scholar] [CrossRef] [PubMed]
- Francq, C.; Zakoïan, J.-M. GARCH Modes: Structure, Statistical Inference and Financial Applications; John Wiley & Sons: Hoboken, NJ, USA, 2019. [Google Scholar]
- Fan, J.; Liao, Y.; Mincheva, M. Large covariance estimation by thresholding principal orthogonal complements. J. R. Stat. Soc.-Ser. B 2013, 75, 603–680. [Google Scholar] [CrossRef] [Green Version]
- Lindner, A.M. Stationarity, mixing, distributional properties and moments of GARCH(p, q) processes. In Handbook of Financial Time Series; Springer: Berlin/Heidelberg, Germany, 2009; pp. 43–69. [Google Scholar]
- Li, X.; Li, Y.; Pan, J.; Zhang, X. A Factor-GARCH Model for High Dimensional Volatilities. Guangzhou University, Guangzhou, China. Unpublished manuscript.
- Fan, J.; Fan, Y.; Lv, J. High dimensional covariance matrix estimation using a factor model. J. Econmetr. 2008, 147, 186–197. [Google Scholar] [CrossRef] [Green Version]
- James, W.; Stein, C. Estimation with quadratic loss. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics; University of California Press: Berkeley, CA, USA, 1961; pp. 361–379. [Google Scholar]
- Tsay, R.S. Multivariate Time Series Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Markowitz, H.M. Portfolio selection. J. Financ. 1952, 7, 77–91. [Google Scholar]
- Markowitz, H.M. Portfolio Selection: Efficient Diversification of Investments; John Wiley & Sons: Hoboken, NJ, USA, 1959. [Google Scholar]
- Fama, E.; French, K. The cross-section of expected stock returns. J. Financ. 1992, 47, 427–465. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).