Abstract
In this paper, we address the estimation of the parameters for a two-parameter Kumaraswamy distribution by using the maximum likelihood and Bayesian methods based on simple random sampling, ranked set sampling, and maximum ranked set sampling with unequal samples. The Bayes loss functions used are symmetric and asymmetric. The Metropolis-Hastings-within-Gibbs algorithm was employed to calculate the Bayes point estimates and credible intervals. We illustrate a simulation experiment to compare the implications of the proposed point estimators in sense of bias, estimated risk, and relative efficiency as well as evaluate the interval estimators in terms of average confidence interval length and coverage percentage. Finally, a real-life example and remarks are presented.
1. Introduction
The Kumaraswamy distribution was proposed for double-bounded random processes by [1]. The cumulative distribution function (CDF) and the corresponding probability density function (PDF) can be expressed as
and:
respectively.
For simplicity, we denote Kumaraswamy distribution with two positive parameters and as . Based on varying values of and , there are similar shape properties between Kumaraswamy distribution and Beta distribution. However, the former is superior to the latter in some respects: there are not any special functions involved in and its quantile function; the generation of random variables is simple, as L-moments and moments of order statistics for have simple formulars (see [2]). For the PDF of , as shown on the left of Figure 1, when and , it is unimodal; when and , it is increasing; when and , it is decreasing; when and , it is uniantimodal; when , it is constant. The CDF of (the plot is presented on the right of Figure 1) has an explicit expression, while the CDF of the Beta distribution appears in an integral form. Therefore, Kumaraswamy distribution is considered as a substitutive model for Beta distribution in practical terms. For instance, Kumaraswamy distribution has an outstanding fitting effect on daily rainfall, individual heights, unemployment numbers, and ball bearing revolutions (see [3,4,5,6]).
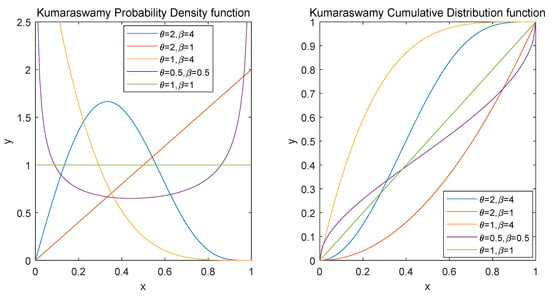
Figure 1.
PDF and CDF of .
Recently, Kumaraswamy distribution has drawn much academic attention and concern. The authors in Ref. [7] obtained the estimators of parameters for Kumaraswamy distribution based on the progressive type-II censoring data using Bayesian and non-Bayesian methods; the authors in Ref. [8] studied the estimations of parameters for this distribution under hybrid censoring; the authors in Ref. [9] ulteriorly discussed the estimations of the stress–strength parameters based on an incorporation of progressive type II and hybrid censoring schemes. Then, the authors in Ref. [10] continued to focus on this distribution under hybrid progressive type I censored samples. The authors in Ref. [11] discussed the estimations of parameters in Kumaraswamy distribution under the generalized progressive hybrid censored samples. On the basis of the Kumaraswamy distribution, a range of new distributions were proposed, such as the Kumaraswamy Birnbaum–Saunders distribution due to [12]), generalized inverted Kumaraswamy distribution due to [13], and transmuted Kumaraswamy distribution due to [14].
Ranked set sampling (RSS), first introduced by [15], is considered to be a more effective method than simple random sampling (SRS) in estimating the mean values of a distribution (see [16]). It is appropriate to employ RSS in many fields where sampling schemes cost a lot of human strength and money. It has a widespread application in the domains of the environment, biology, engineering applications, and agriculture (see [17,18,19,20]). Recently, the authors in Ref. [21] proposed a new sampling design known as the maximum ranked set sampling procedure with unequal samples (MRSSU).
The difficulties overcome in this paper are that (a) it is difficult to obtain the solutions of the equations of maximum likelihood estimation to tackle Big Data problems [22]. Hence, we adopted the Newton–Raphson iterative algorithm to derive the approximate and numerical roots; (b) since it is difficult to express the integrals for Bayes estimates in closed forms [23], we chose the Metropolis-Hastings-within-Gibbs algorithm to obtain the estimates [24,25,26,27,28].
The organization of this paper is summarized as follows. In Section 2, Section 3 and Section 4, we consider point and interval estimates for Kumaraswamy distribution based on three sampling schemes, namely SRS, RSS, and MRSSU, and two estimation methods of maximum likelihood estimation and Bayes estimation. Section 5 compares the performance of proposed estimators and Section 6 presents an illustrative example. This paper concludes with some comments in Section 7.
2. Estimations of the Parameters Using SRS
2.1. Maximum Likelihood Estimations Based on SRS
Considering that is an SRS scheme of size s from and the likelihood function is given by
where is the observed sample of X. The corresponding log-likelihood function is:
Calculate the first derivatives of (3) about , and equate them to zero. The maximum likelihood estimates (MLEs) of and can be earned by solving follow equations:
We obtain the MLE of and denote it as
According to the formula in (6), exists and is unique for fixed . Substituting the (6) into (3), the profile log-likelihood function of can be expressed as
is defined to the MLE of , which can be obtained by maximizing (7). Since it is difficult to determine the explicit solutions of and , the Newton–Raphson iterative algorithm is adopted to obtain MLEs.
Theorem 1.
exists and is unique.
Proof of Theorem 1.
We then consider the confidence intervals (CIs) under the SRS scheme based on maximum likelihood estimation. The second derivatives of (3) can be expressed as
Denote , and the expected Fisher information matrix is given by
Here:
Let be the MLEs of based on SRS. The inverse matrix of is the approximate variance–covariance matrix of MLEs with:
The asymptotic distribution of is . Thus, we derive the two-sided approximate confidence intervals (ACIs) for and .
Theorem 2.
The two-sided ACIs for θ, β based on SRS are:
and:
respectively.
Here, is the th quantile of , the standard normal distribution. Since the lower bound for the CI will possibly be less than zero and , are greater than zero, we set the lower bound to be the larger value of the computed lower bound and zero.
2.2. Bayes Estimations Based on SRS
In this section, we focus on Bayesian inference of and based on SRS, and obtain Bayesian estimates (BEs) and credible intervals (CrIs). Let us consider the following independent gamma priors:
The joint posterior distribution of can be expressed as
where:
The conditional posterior densities of and are written as
and:
Generally, Bayes point estimators are acquired by minimizing the loss function. Here, we consider two typical loss functions. The first one is symmetric, which is the square error (SE) loss function. Let be the estimator of d, and the definition of SE loss function and Bayes estimators are given by
and:
Symmetric functions assign equal weight to both overestimation and underestimation, so there emerge many asymmetric functions. The second is the general entropy (GE) loss function, which is an asymmetric function proposed by [29] defined as
The corresponding Bayes estimator is:
Here, the positive errors make more mistakes than the negative errors when , and vice versa when .
Based on SE and GE loss functions, Bayes point estimators of can be gained as
and:
provided that the expectations exist, while the Bayes estimator of is able to be obtained in a similar way. It is easily observed that while using the above integrals, it is difficult to gain the explicit solutions. Therefore, we employed the MHG algorithm to generate samples from the posterior density distribution (13) and computed the approximated BEs and the symmetric CrIs. More information about this algorithm can be found in [30].
The logarithmic calculations in the 5th and 11th steps of Algorithm 1 are for the purpose of narrowing down the value to facilitate the calculation and preventing the generation of infinity in the process of program operation.
We can obtain the approximated Bayes point estimates of and under the SE and GE loss functions as
and:
where H is a burn-in period (which refers to the iteration times required before the stationary distribution is reached). and can be acquired by a similar way.
Order and as and . Then, the symmetric Bayes CrIs of and are acquired by
and:
respectively.
| Algorithm 1 The Metropolis-Hastings-within-Gibbs algorithm |
Input:M: total number of iterations. Output:, and . Initial , and . while do Generate and from and , two normal distributions, where and are diagonal elements of the variance–covariance matrix. Generate from the Uniform distribution . if then . Here, is the probability density of . else Generate from the Uniform distribution . if then . Here, is the probability density of . else |
3. Estimations of the Parameters Using RSS
3.1. Maximum Likelihood Estimations Based on RSS
The RSS scheme aims to sample and observe the data by using the ranking mechanism. First, we draw m random sample sets of size m from and sort each dataset from the smallest to the largest, meaning that:
Here, means p-th ranked units, j-th set, and i-th cycle (). Then, the j-th ordered unit from the j-th set () is chosen for practical quantification. After n cycle of above process, we end up with a complete RSS scheme of size expressed as
where m is the set size and n is the number of cycles.
To simplify the notations, we use to denote . Let . The likelihood function is given by
where is the observed sample of , and the log-likelihood function is:
Calculate the first derivatives of (14) about , and equate them to zero. The MLEs of , can be earned by solving the follow system of equations:
The second derivatives of (14) are expressed as
We can derive the expected Fisher information matrix , where:
Because the integral form of matrix is difficult to calculate, the observed Fisher information matrix is used to replace matrix , where:
Let be the MLEs of . The inverse matrix of is the approximate variance–covariance matrix of MLEs with:
Theorem 3.
The two-sided ACIs for θ and β based on RSS are given by
and:
respectively.
3.2. Bayes Estimations Based on RSS
The conditional posterior densities of , are given by
and:
The Algorithm 1 mentioned in Section 2 was employed to generate a large number of samples from the posterior distribution (18). Then, Bayes point estimators of under SE and GE loss functions are given by
and:
Order the sample as . Then, symmetric Bayes CrIs of is given by
Similarly, we can derive the Bayes point estimators and symmetric Bayes CrI for .
4. Estimations of the Parameters Using MRSSU
4.1. Maximum Likelihood Estimations Based on MRSSU
First, we select m random sample sets from the population, where the j-th sample set possesses j units and sort the units in each dataset from smallest to largest, meaning that:
Here, means p-th ranked units, the j-th set which contains j units and i-th cycle (). In each circle, the total number of units of samples we draw is .
Then, the maximum element in each sample set () is chosen for practical quantification. After n iterations of the above process, we end up with a complete MRSSU of size expressed as
where m is the set size and n is the number of cycles.
To simplify the notations, we used to denote . Let . The corresponding likelihood function is:
where is the observation of Y, and the log-likelihood function is:
Calculate the first derivatives of (19) about , and equate them to zero. By solving the follow equations:
the MLEs of , can be earned. The second derivatives of (19) are expressed as
Thus, we derive expected Fisher information matrix , where:
We adopt the observed Fisher information matrix to replace matrix , where:
Let be the MLEs of . The inverse matrix of is the approximate variance–covariance matrix of MLEs with:
Theorem 4.
The two-sided ACIs for θ, β based MRSSU are given by
respectively.
4.2. Bayes Estimations Based on MRSSU
We use the same independent gamma priors (11) and (12). The joint posterior distribution of is:
where:
The conditional posterior densities of , are denoted by
and:
The Algorithm 1 is used to generate a large number of samples from the posterior distribution (23). Then, Bayes point estimators of under SE and GE loss functions, are expressed as
and:
Order the sample as . Symmetric Bayes CrI of is given by
Similarly, we can derive the Bayes point estimators and symmetric Bayes CrI for .
5. Simulation Result
In this section, we intend to carry out comparisons of the SRS, RSS, and MRSSU schemes under different hyperparameter values and sample sizes, by comparing the numerical performance of point estimates and interval estimates. We evaluate bias and estimated risks (ERs) based on SE and GE loss functions by the following formulas:
Here, N denotes the iteration number of the simulation while means the estimate obtained in the t-th iteration. As for the three sampling methods, namely RSR, RSS and MRSSU, we can draw the samples, respectively, from through Algorithms 2–4:
| Algorithm 2 The random number generator for based on SRS |
Input:, and s. Output:. initial . while do Generate . |
| Algorithm 3 The random number generator for based on RSS |
Input:, , n and m. Output:. initial and . while do while do Use Algorithm 2 (input ) to generate . Rank from smallest to largest to get . . . . |
| Algorithm 4 The random number generator for based on MRSSU |
Input:, , n and m. Output:. initial and . while do while do Use Algorithm 2 (input ) to generate . Rank from smallest to largest to get . . . . |
In addition, based on different sampling schemes, we evaluate the relative efficiency (RE) values based on SE and GE loss functions which are given by
Here, are the corresponding estimates of based on different sample methods. Obviously, if , then we know the estimate of in the numerator outperforms the estimate of in the denominator. Equally, the bias, ERs and RE values of can be calculated by similar formulas.
In the simulation, all calculations are performed by R language while true values are denoted to . We design three sampling schemes and two prior sets, namely the informative prior distribution and non-informative prior distribution. Each sampling scheme contains three sampling methods: SRS, RSS, and MRSSU. All information related to schemes and priors is given as follows:
- Scheme I (Sch I):
- Scheme II (Sch II):
- Scheme III (Sch II):
- Prior 1:
- Prior 2:
Consider the iteration number as and take , in the MHG algorithm of Bayesian estimation. The ERs and biases of and based on SRS, RSS and MRSSU using maximum likelihood and Bayesian methods are shown in Table 1, Table 2 and Table 3. The RE values for MLEs of and are presented on Table 4, and for BEs of and based on SE loss function and GE loss function are presented on Table 5, Table 6 and Table 7, respectively.

Table 1.
The ER of the estimates of .
Table 2.
The ER of the estimates of .
Table 3.
The biases of estimates of and .
Table 4.
The and for maximum likelihood estimations of and .
Table 5.
The and for Bayes estimations of and based on SE loss function.
Table 6.
The and for Bayes estimations of and based on GE loss function .
Table 7.
The and for Bayes estimations of and based on GE loss function .
We also calculate the average CIs lengths (ACLs) and coverage percentages (CPs) to compare the performance of the interval estimators. For each case, we generate CIs and verify whether fall into the corresponding CIs with 2500 iterations. The results are presented in Table 8.
Table 8.
The CPs and ACLs of interval estimations of and .
In Table 1 and Table 2, it can be seen that the ERs of estimates become small when the number of samples increases. Furthermore, the Bayesian methods outperform the maximum likelihood methods, while the estimators of are better than the estimators of . For maximum likelihood estimations, the ERs of the estimators of are larger when the sample sets are smaller. For example, the ER of under the scheme I is 2.37421, while the ER of under schemes II and III is 1.26192 and 0.81074, respectively. For Bayesian estimation, information prior is superior to non-information prior and the SE loss function is best followed by GE loss function and GE loss function .
Table 3 shows that the Bayesian estimates of have a tendency to underestimate because they have the negative biases. Observing Table 4, we know that, based on maximum-likelihood estimation, the RSS schemes are more suitable for the estimation of and than MRSSU and RSS schemes. Furthermore, the SRS schemes exceed the MRSSU schemes on the estimation of while they perform similarly on the estimation of (except for scheme I). As it can be seen in Table 6 and Table 7, there is a regularity of RSS schemes being superior to MRSSU and SRS schemes, in Bayesian estimation as well.
As shown in Table 8, with the reduction in the sample size, the ACLs of interval estimates increase and the CPs also ascend. Figure 2 and Figure 3 visually show the change of ACLs of and . Whereas the CPs of ACIs are always less than 1, and the CPs of CrIs remain unchanged (are equal to 1) and Figure 4 clearly illustrates the trend. This indicates that Bayesian estimation has better performance than the maximum likelihood estimation in the sense of interval estimation. The optimal interval estimations are the Bayes CrIs based on MRSSU schemes except for (i) for scheme I and (ii) for scheme II under prior 2.
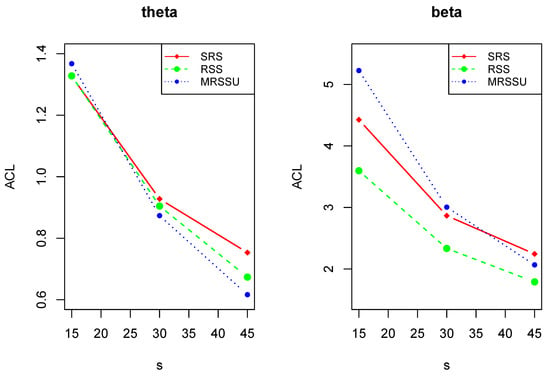
Figure 2.
The plots of the ACLs of maximum likelihood interval estimations of and .
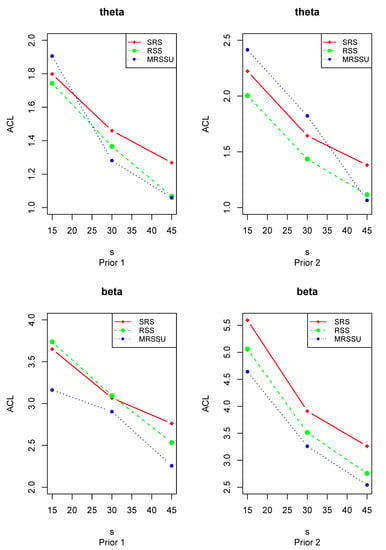
Figure 3.
The plots of the ACLs of Bayes interval estimations of and .
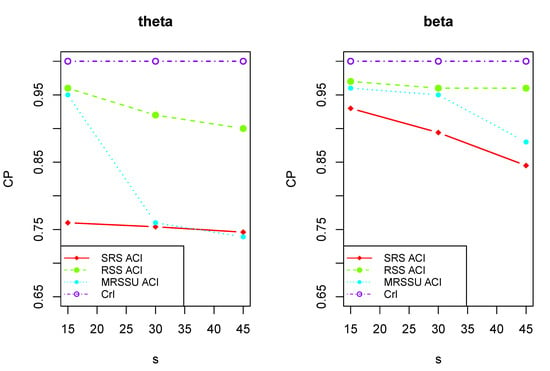
Figure 4.
The plots of the CPs of and .
6. Data Analysis
Here, an open access dataset from the California Data Exchange Center is illustrated, which can be found in [31]. It is related to the monthly water capacity from the Shasta Reservoir in California, USA, between August and December from 1975 to 2016. The set of data, previously used by some authors such as [11,32], contains a total of 42 observations, which is given in Table 9.
Table 9.
The real dataset.
For evaluating the proposed point estimators and interval estimators based on SRS, RSS and MRSSU, we designed and . Use different sampling methods and draw a random sample of size 12. In the case of SRS, a random sample of size 12 is directly drawn. In the case of RSS and MRSSU, three sample sets of size 3 are drawn primarily and some components are selected with iterations according to the specific procedure described in Section 3 and Section 4.
We consider the CIs and a non-information prior, i.e., . Then, maximum likelihood point and interval estimation, Bayesian point and interval estimation are given with the results are summarized in Table 10 and Table 11.
Table 10.
The point estimates of and .
Table 11.
The interval estimates of and .
7. Conclusions
In this paper, based on Kumaraswamy distribution, point estimations and corresponding interval estimations of unknown parameters grounded on SRS, RSS and MRSSU were investigated by the use of the maximum likelihood approach and Bayes approach. From the perspective of Bayes estimation, we consider squared error and general entropy loss functions. Furthermore, a simulation experiment was illustrated for the purpose of comparing the proposed point estimator (in terms of biases, estimated risks, relative efficiency) and the interval estimator (in the sense of average lengths and coverage percentages).
From numerical outcomes, our first suggestion is to adopt the ranked set sampling scheme, and the second is the simple random sampling scheme, generally. In addition, the Bayes estimators under the squared error loss function outperform the maximum likelihood estimators and Bayes estimators which are under the general entropy loss function. We also focus on a set of real-life data.
In the future, some other problems concerning the Kumaraswamy distribution and the ranked set sample can be further studied, such as the estimations for Kumaraswamy distribution based on the ranked set sample under type I and type II censoring or progressive hybrid censoring.
Author Contributions
Investigation, H.J.; Supervision, W.G. Both authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data presented in this study are openly available in website [31].
Conflicts of Interest
The authors declare no conflict of interest.
References
- Kumaraswamy, P. A generalized probability density function for double-bounded random processes. J. Hydrol. 2008, 46, 79–88. [Google Scholar] [CrossRef]
- Jones, M.C. Kumaraswamy’s distribution: A beta-type distribution with some tractability advantages. Stat. Methodol. 2009, 6, 70–81. [Google Scholar] [CrossRef]
- Ponnambalam, K.; Seifi, A.; Vlach, J. Probabilistic design of systems with general distributions of parameters. J. Abbr. 2001, 29, 527–536. [Google Scholar] [CrossRef]
- Dey, S.; Mazucheli, J.; Nadarajah, S. Kumaraswamy distribution: Different methods of estimation. Comput. Appl. Math. 2018, 37, 2094–2111. [Google Scholar] [CrossRef]
- Sindhu, T.N.; Feroze, N.; Aslam, M. Bayesian analysis of the Kumaraswamy distribution under failure censoring sampling scheme. Int. J. Adv. Sci. Technol. 2013, 51, 39–58. [Google Scholar]
- Abd El-Monsef, M.M.E.; Hassanein, W.A.A.E.L. Assessing the lifetime performance index for Kumaraswamy distribution under first-failure progressive censoring scheme for ball bearing revolutions. Qual. Reliab. Eng. Int. 2020, 36, 1086–1097. [Google Scholar] [CrossRef]
- Gholizadeh, R.; Khalilpor, M.; Hadian, M. Bayesian estimations in the Kumaraswamy distribution under progressively type II censoring data. Int. J. Eng. Sci. Technol. 2011, 3, 47–65. [Google Scholar] [CrossRef] [Green Version]
- Sultana, F.; Tripathi, Y.M.; Rastogi, M.K.; Wu, S.J. Parameter estimation for the Kumaraswamy distribution based on hybrid censoring. Am. J. Math. Manag. Sci. 2018, 37, 243–261. [Google Scholar] [CrossRef]
- Kohansal, A.; Nadarajah, S. Stress–strength parameter estimation based on type-II hybrid progressive censored samples for a Kumaraswamy distribution. IEEE Trans. Reliab. 2019, 68, 1296–1310. [Google Scholar] [CrossRef]
- Sultana, F.; Tripathi, Y.M.; Wu, S.J.; Sen, T. Inference for Kumaraswamy Distribution Based on Type I Progressive Hybrid Censoring. Ann. Data Sci. 2020, 1–25. [Google Scholar] [CrossRef]
- Tu, J.; Gui, W. Bayesian Inference for the Kumaraswamy Distribution under Generalized Progressive Hybrid Censoring. Entropy 2020, 22, 1032. [Google Scholar] [CrossRef]
- Saulo, H.; Leão, J.; Bourguignon, M. The kumaraswamy birnbaum-saunders distribution. J. Stat. Theory Pract. 2012, 6, 745–759. [Google Scholar] [CrossRef]
- Iqbal, Z.; Tahir, M.M.; Riaz, N.; Ali, S.A.; Ahmad, M. Generalized Inverted Kumaraswamy Distribution: Properties and Application. Open J. Stat. 2017, 7, 645. [Google Scholar] [CrossRef] [Green Version]
- Khan, M.S.; King, R.; Hudson, I.L. Transmuted kumaraswamy distribution. Stat. Transit. New Ser. 2016, 17, 183–210. [Google Scholar] [CrossRef]
- McIntyre, G.A. A method for unbiased selective sampling, using ranked sets. Aust. J. Agric. Res. 1952, 3, 385–390. [Google Scholar] [CrossRef]
- McIntyre, G.A. Ranked set sampling: Ranking error models and estimation of visual judgment error variance. Biom. J. J. Math. Methods Biosci. 2004, 46, 255–263. [Google Scholar]
- Al-Saleh, M.F.; Al-Hadrami, S.A. Parametric estimation for the location parameter for symmetric distributions using moving extremes ranked set sampling with application to trees data. Environmetrics Off. J. Int. Environmetrics Soc. 2003, 14, 651–664. [Google Scholar] [CrossRef]
- Mahmood, T. On developing linear profile methodologies: A ranked set approach with engineering application. J. Eng. Res. 2020, 8, 203–225. [Google Scholar]
- Sevil, Y.C.; Yildiz, T.Ö. Performances of the Distribution Function Estimators Based on Ranked Set Sampling Using Body Fat Data. Türkiye Klin. Biyoistatistik 2020, 12, 218–228. [Google Scholar] [CrossRef]
- Bocci, C.; Petrucci, A.; Rocco, E. Ranked set sampling allocation models for multiple skewed variables: An application to agricultural data. Environ. Ecol. Stat. 2010, 17, 333–345. [Google Scholar] [CrossRef]
- Biradar, B.S.; Santosha, C.D. Estimation of the mean of the exponential distribution using maximum ranked set sampling with unequal samples. Open J. Stat. 2014, 4, 641. [Google Scholar] [CrossRef] [Green Version]
- Provost, F.; Fawcett, T. Data science and its relationship to Big Data and data-driven decision making. Big Data 2013, 1, 51–59. [Google Scholar] [CrossRef]
- Liang, F.; Paulo, R.; Molina, G.; Clyde, M.A.; Berger, J.O. Mixtures of g priors for Bayesian variable selection. J. Am. Stat. Assoc. 2008, 103, 410–423. [Google Scholar] [CrossRef]
- Caraka, R.E.; Yusra, Y.; Toharudin, T.; Chen, R.C.; Basyuni, M.; Juned, V.; Gio, P.U.; Pardamean, B. Did Noise Pollution Really Improve during COVID-19? Evidence from Taiwan. Sustainability 2021, 13, 5946. [Google Scholar] [CrossRef]
- Salimans, T.; Kingma, D.; Welling, M. Markov chain monte carlo and variational inference: Bridging the gap. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 1218–1226. [Google Scholar]
- Dellaportas, P.; Forster, J.J.; Ntzoufras, I. On Bayesian model and variable selection using MCMC. Stat. Comput. 2002, 12, 27–36. [Google Scholar] [CrossRef]
- Caraka, R.E.; Nugroho, N.T.; Tai, S.K.; Chen, R.C.; Toharudin, T.; Pardamean, B. Feature importance of the aortic anatomy on endovascular aneurysm repair (EVAR) using Boruta and Bayesian MCMC. Commun. Math. Biol. Neurosci. 2020. [Google Scholar] [CrossRef]
- Rabinovich, M.; Angelino, E.; Jordan, M.I. Variational consensus monte carlo. arXiv 2015, arXiv:1506.03074. [Google Scholar]
- Biradar, B.S.; Santosha, C.D. Point estimation under asymmetric loss functions for left-truncated exponential samples. Commun. Stat. Theory Methods 1996, 25, 585–600. [Google Scholar]
- Brooks, S.; Gelman, A.; Jones, G.; Meng, X.L. (Eds.) Handbook of Markov Chain Monte Carlo; Chapman & Hall/CRC: Boca Raton, FL, USA, 2011. [Google Scholar]
- Query Monthly CDEC Senser Values. Available online: http://cdec.water.ca.gov/dynamicapp/QueryMonthly?SHA (accessed on 19 June 2021).
- Kohansal, A. On estimation of reliability in a multicomponent stress-strength model for a Kumaraswamy distribution based on progressively censored sample. Stat. Pap. 2019, 60, 2185–2224. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).