Abstract
The paper discusses the estimation and prediction problems for the Nadarajah-Haghighi distribution using progressive type-II censored samples. For the unknown parameters, we first calculate the maximum likelihood estimates through the Expectation–Maximization algorithm. In order to choose the best Bayesian estimator, a loss function must be specified. When the loss is essentially symmetric, it is reasonable to use the square error loss function. However, for some estimation problems, the actual loss is often asymmetric. Therefore, we also need to choose an asymmetric loss function. Under the balanced squared error and symmetric squared error loss functions, the Tierney and Kadane method is used for calculating different kinds of approximate Bayesian estimates. The Metropolis-Hasting algorithm is also provided here. In addition, we construct a variety of interval estimations of the unknown parameters including asymptotic intervals, bootstrap intervals, and highest posterior density intervals using the sample derived from the Metropolis-Hasting algorithm. Furthermore, we compute the point predictions and predictive intervals for a future sample when facing the one-sample and two-sample situations. At last, we compare and appraise the performance of the provided techniques by carrying out a simulation study and analyzing a real rainfall data set.
1. Introduction
Nowadays, censoring has aroused great concern in the aspects of various reliability studies and life tests. There are already certain kinds of censoring schemes introduced in many references, among which type-I and type-II censoring are likely to be the two most famous types. Plenty of literature has discussed them, such as [1,2]. A life test in type-I censoring ends at a prespecified time, so the number of observations is random. By contrast, a life test in type-II censoring is not finished until a prefixed number of failures occur.
However, there are some constraints in type-I and type-II censoring. The units cannot be withdrawn when an experiment is in progress, for example. In this case, a kind of more flexible and more general censoring scheme named progressive type-II censoring scheme was put forward in order to improve this disadvantage. That is, it allows the removal of units in between. This scheme is introduced as follows. We assume that the number of n units are put in a life test. of the surviving units are withdrawn at random from the experiment as the first failure takes place. Likewise, after the second failure, out of the remaining surviving units are randomly removed again. This experiment continues until m failures happen. The remaining units of size are withdrawn from the test at this moment, where . Then, is named the progressive type-II censoring scheme, which should be prefixed before the experiment. Many statistical inferences and studies have been done involved with progressive censoring by several researchers like [3,4,5,6].
An extension of the exponential distribution was suggested by [7] by introducing a shape parameter. Its corresponding probability density function (PDF) is defined by
and cumulative distribution function (CDF) is expressed as
where the shape and scale parameters are respectively and . Both of them are positive. We denote this distribution by NH(). In addition, the NH distribution in some other literature is also named the extended exponential distribution, such as [8,9].
Ref. [7] made a discovery that even though some data sets contained the value zero, an NH distribution still could provide suitable fits to them. In addition, the trend of hazard rate function is dependent on in this distribution. For instance, the hazard rate function tends to increase (decrease) when , respectively. However, the hazard rate function turns into a constant as is given the value of 1. At this time, (1) becomes the one-parameter exponential distribution as well.
Some literature can be found with regard to the statistical inferences for the NH distribution. As for the estimation of the unknown parameters, based on progressive type-II censored samples with binomial removals, Ref. [10] has discussed the maximum likelihood and Bayes estimations. Then, Ref. [11] researched progressive type-II censored data. They calculated the maximum likelihood estimates (MLEs) through the method of Newton–Raphson, and Bayes estimates through the Markov Chain Monte Carlo method. Interval estimations were made like asymptotic confidence intervals (CIs) and the highest posterior density (HPD) intervals as well. Several references also laid emphasis on the problems of order statistics of an NH distribution, such as [8,9]. They both worked on recurrence formulas of the moments for order statistics. However, the former dealt with the situation in progressive type-II right censoring while the latter focused on the complete samples. Additionally, for the unknown parameters, Ref. [12] discussed MLEs, and Bayesian estimates by the Lindley approximation. The point and interval predictions for future records were also made by making use of non-Bayesian and Bayesian predictions. In addition, based on the progressively first-failure censored NH distribution, Ref. [13] studied the MLEs and Bayes estimates for the two unknown parameters and lifetime parameters of survival and hazard rate functions. They also suggested an optimal censoring scheme through different optimality criteria.
In the article, using progressive type-II censored samples, we discuss the estimation and prediction problems for the NH distribution by diverse kinds of methods. In addition, we compare their performance through the simulation study and a real rainfall data set.
In Section 2, for the unknown parameters, we utilize the Expectation–Maximization (EM) algorithm for calculating the MLEs. Then, on the basis of the Fisher information matrix, we set up the asymptotic intervals. Furthermore, here bootstrap intervals are introduced as well. In Section 3, under two types of loss functions, Bayesian estimators of unknown parameters are calculated through both the Metropolis-Hasting (MH) method and Tierney and Kadane (TK) algorithm. Then, using the sample generated by the MH algorithm, we get the HPD credible intervals as well. In Section 4, Bayesian predictive intervals and the point prediction of a future sample are discussed. Additionally, we compare and appraise the performance of the provided techniques by carrying out a simulation study and analyzing a real data set in Section 5.
2. Maximum Likelihood Estimation
We assume that the number of n units are placed in a life test. They are independent and identically follow the NH distribution defined in (1). Under a progressive type-II censoring scheme , let us denote a set of censored samples of size m by from the NH distribution. In light of [3], the likelihood function related to and is written as
where , and stands for the corresponding observed value of X. Ignoring the constant, we compute the log-likelihood function by
As usual, to acquire the MLEs of and , we are supposed to solve the corresponding likelihood equations as
However, it is infeasible to solve the above equations analytically in closed form. Therefore, some numerical techniques like the EM algorithm are suggested for calculating the desired MLEs. As a solution to lost or partial data situations, Ref. [14] introduced the EM algorithm at first.
We are aware that the progressive type-II censored data are not complete, so they can be treated as a set of incomplete data. Now we assume that represents censored data and represents observed data. It is worth noting that for , every is a set of vectors of . Consequently, observed data X combine censored data Z to form the complete data set as . We disregard the additive constant and then obtain the corresponding log-likelihood function for V as
where denotes a censored value of for and .
The EM algorithm is composed of two parts named E-step and M-step. To begin with, the E-step is involved with calculation related to the corresponding pseudo-log-likelihood function as
where
As for the M-step, the maximum value of (8) depends on the values of and . We assume that the estimate of is referred to as in the jth iteration. Thus, we can figure out through maximizing the function
As the values of and are known, at first, is calculated through solving the equation
Once is obtained, we can also solve by the following equation
Then, in the next iteration, we treat as the updated numeric value for . Like this, we proceed with the above two steps repeatedly before and finally converge to their MLEs. According to [15], the log-likelihood function is ensured to increase with each iteration. As a result, the EM algorithm almost always manages to make the likelihood function attain its local maximum value despite beginning with a random value of the parameter domain. When, in Section 5, using the EM algorithm for MLEs under progressive type-II censoring, we take the MLEs derived from complete samples as initial values.
2.1. Fisher Information Matrix
Let denote the unknown parameter . We assume that V represents the complete data and X represents the observed data. Then, let us denote the observed, missing, and complete information by , , and , respectively. Based on the idea of [16], we can obtain
where
and
We note that these are two matrices. Moreover, stands for the Fisher information matrix of one single observation which is censored as the jth failure occurs. Subsequently, we first calculate the elements of as follows.
From (16), we also have
Then, we can calculate the total missing information matrix by the following expression
Based on the two matrices above, we easily compute the observed information matrix from (14) and its inverse matrix as well. The MLE has asymptotic normality, so we can write it as . As a consequence, the asymptotic CIs are derived by
where and is a numerical number of the upper th percentile of the standard normal variate. Here, two elements of the main diagonal of are and .
2.2. Bootstrap Confidence Intervals
As is known to us, the asymptotic CIs perform poorly in a sample with a small size. The bootstrap methods are more likely to provide more approximate confidence intervals. As a result, we introduce two CIs using the bootstrap methods. One is the percentile bootstrap (Boot-p) method which was put forward by [17]. According to [18], another is called the bootstrap-t (Boot-t) method. The Boot-p method and the Boot-t method are presented in Algorithms 1 and 2, respectively.
| Algorithm 1 Boot-p method |
| Require: The number of simulation times N; the censoring scheme R; the confidence level ; the progressive type-II censored sample X |
| Ensure: The boot-p CI for , , where can be and ; |
| 1: Compute the MLE from X; |
| 2: for to N do |
| 3: Derive a bootstrap sample from the NH distribution by using under R; |
| 4: Calculate the MLE based on the bootstrap sample; |
| 5: end for |
| 6: Sort ascendingly as ; |
| 7: Compute and , where is the largest integer that does not exceed . |
| 8: return ; |
| Algorithm 2 Boot-t method |
| Require: The number of simulation times N; the censoring scheme R; the confidence level ; the progressive type-II censored sample X |
| Ensure: The boot-t CI for , , where can be and ; |
| 1: Compute the MLE from X; |
| 2: for to N do |
| 3: Derive a bootstrap sample from the NH distribution by using under R; |
| 4: Calculate the MLE based on the bootstrap sample; |
| 5: Compute the statistic ; |
| 6: end for |
| 7: Sort ascendingly as ; |
| 8: Pick , , and their corresponding MLEs , ; |
| 9: Compute and ; |
| 10: return ; |
3. Bayesian Estimation
In order to choose the best Bayesian estimator, a loss function must be specified and used to represent the penalty associated with each possible estimator. Researchers usually use the symmetric squared error loss function. There is no doubt that it is reasonable to use the squared error loss function when the loss is essentially symmetric. However, for some estimation problems, the actual loss is often asymmetric. Therefore, we also need to choose an asymmetric loss function.
We consider Bayesian estimators under symmetric and asymmetric loss functions. We suppose that is a Bayesian estimate for . Firstly, the symmetric squared error loss (SEL) function is written as
Hence, under , the Bayesian estimate for is expressed by
In light of [19], the balanced squared error loss (BSEL) function has the following form:
where , and is a known estimate of . It is worth noting that when is given as the value of 0, the BESL function turns into the SEL function. Based on the BSEL function , the Bayes estimator is calculated by
Let us denote a set of progressive type-II censored samples by from the NH distribution. Suppose that two independent parameters and follow the gamma prior distributions as
Here, the prior information is shown by selecting the numerical numbers for four hyperparameters and d. Hence, the joint prior density is expressed by
Consequently, the joint posterior density is then obtained by
where denotes a normalizing constant.
As we can see, it is impractical to deal with the joint posterior distribution analytically. The Bayesian estimators of some functions involved with and also include the rates between two integrals. Therefore, as we calculate Bayesian estimators based on these two kinds of loss functions, two approximate methods are proposed to cope with the corresponding ratio of integrals in the next two subsections, respectively.
3.1. Tierney and Kadane Method
Based on the idea of [20], we take advantage of the TK method and then calculate approximate Bayes estimates. The posterior expectation for can be expressed as
where , and represents the log-likelihood function (4). Moreover, and are defined as
Suppose that and respectively maximize the functions and . Through the TK method, is approximated as
Here, the determinants of negative inverse Hessian for and are and , respectively. Note that and in (27) do not depend on the function while the other two expressions do rely on . We observe that
Then, are solved by the system of equations:
The relevant second partial derivatives can be also computed by
and
Next, we obtain as
As for , we first obtain from the following expressions:
Then, the corresponding second-order derivatives are obtained as
Next, we obtain as
For the reason that and in (27) depend on the function , we respectively take and when proceeding with the above computation steps. Therefore, the Bayes estimates through the TK method can be calculated as
In the same way, the corresponding Bayesian estimates are also calculated based on the BSEL function. Here, we do not go into details for the sake of brevity.
3.2. Metropolis-Hastings Algorithm
As we can see from the previous subsection, for the unknown parameters, the TK method is not able to make interval estimates. Thus, we introduce another method called the MH algorithm to obtain some approximate Bayesian point and interval estimations. The MH algorithm is a very general type of Markov Chain Monte Carlo technique. For the first time, Ref. [21] suggested this technique. Then, it was expanded based on the idea of [22]. From their studies, we are aware that no matter how complex the known target distribution is, the MH algorithm can still derive random samples from it.
A bivariate normal distribution is treated as the proposal distribution for and . Using the posterior density, for unknown parameters, we can derive samples from it so as to calculate Bayesian point estimators and HPD interval estimations. We present the main steps of the MH algorithm in Algorithm 3.
For the sake of ensuring the convergence and reducing some effects brought by , we abandon the initial number and then compute estimates from the rest of the samples. Therefore, using the SEL function, we can calculate the Bayesian estimates by
where can be and .
Likewise, we also calculate the corresponding Bayes estimates based on the BSEL function. In addition, the HPD credible intervals are set up as well according to [23]. We sort the rest of samples in ascending order to be . Then, we can compute the Bayes interval estimate of as
The shortest interval among (39) is taken as the HPD interval of .
| Algorithm 3 MH algorithm |
| Require: The joint posterior distribution ; the initial values ; the number of simulation times N; the variance–covariance matrix . |
| Ensure: The N number of samples ; |
| 1: for to N do |
| 2: Generate from the bivariate normal ; |
| 3: Calculate ; |
| 4: Derive a figure that follows a Uniform distribution; |
| 5: if then |
| 6: ←; |
| 7: else |
| 8: ←; |
| 9: end if |
| 10: end for |
| 11: return ; |
4. Bayesian Prediction
We consider estimates of future samples in terms of known information and compute corresponding predictive intervals as well. Using the predictive distribution, the Bayesian approach on the prediction of future samples is treated as a significant topic in statistics. Subsequently, in the light of [24], we make discussions about Bayesian prediction facing the one-sample and two-sample situations indicated.
4.1. One-Sample Prediction
Let us denote a set of m progressive type-II censored data by . It is obtained from n samples which follow the NH distribution described in (1) based on a censoring scheme . Suppose that stands for the ordered statistic of removed units as the ith failure is observed. Using the observed samples , we focus on predicting the value of . As a consequence, we can get the conditional density of z as
According to the conditional density, the survival function can be expressed by
Therefore, based on a prior , the associated posterior predictive density is given by
and posterior survival function is also given by
Consequently, the two-sided symmetric predictive interval of z is the solution to the following equations:
As for the point prediction of the kth future sample z of the surviving units, on the basis of the SEL function, it is predicted by
where
In our model, we then obtain that
We note that we cannot evaluate the above expressions analytically. Thus, we adopt the MH algorithm to tackle this problem and then compute the point predictions. Assume that denote the samples which are derived from the posterior distribution. Therefore, we can compute the point prediction for z as
4.2. Two-Sample Prediction
We generally consider the prediction in a two-sample situation as an extension of that in a one-sample situation. There are two samples in the two-sample prediction problem. One is named the informative sample, and another is referred to as the future sample. Suppose that of size M stands for the ordered statistic of future observations, and it is independent of the informative sample . Thus, we focus on making predictions of observation of the jth failure of a future sample W generated identically from the target distribution. Therefore, we can calculate the predictive density of by
where denotes the value of . Then, the survival function can be computed as
Consequently, the posterior survival function is written by
where . The two-sided symmetric predictive interval of is the solution to the following expressions:
The posterior density is also obtained as
Then, we can compute the point prediction of jth order lifetime as
where
Using the MH algorithm as in the previous subsection, we can calculate the point prediction of a future sample as
5. Data Analysis and Simulation Study
For the purpose of demonstrating practical applications of provided techniques on estimation and prediction problems, in the next two subsections, we compare and appraise their performance by carrying out a simulation study and analyzing real data, respectively.
5.1. Data Analysis
We consider a set of real data on the total annual rainfall (unit: inches) during January from 1880 to 1916 researched by [12]. It is listed in Table 1 below.

Table 1.
A set of real data recorded by [12].
With an aim to analyze real data, at first, we calculate the MLEs through the EM algorithm and then figure out the Akaike information criterion (AIC), Bayesian information criterion (BIC), and Kolmogorov–Smirnov (K–S) statistics for goodness-of-fit tests. For comparison, some other life distributions are also put on goodness-of-fit tests, such as Generalized Exponential, Chen, and Inverse Weibull distributions. Their PDFs are given as below, respectively.
- (1)
- The PDF of the Generalized Exponential distribution is
- (2)
- The PDF of the Chen distribution is
- (3)
- The PDF of the Inverse Weibull distribution is
Table 2 presents all the test results of these distributions. As we all know, the smaller the numerical values of K–S, AIC, and BIC are, the bigger the log-likelihood function value is, and the better the model performs. Therefore, it can be seen from the table that the NH distribution provides a more suitable fit to this set of real data. For more fitting illustration, two plots made through the MLEs are provided in Figure 1. The first plot contains the fitted CDFs of the Nadarajah-Haghighi, Generalized Exponential, Chen, and Inverse Weibull distributions for the real data set. The second plot consists of the histogram of the real data and the fitted PDFs of these four distributions.
Table 2.
Goodness-of-fit test inferences on real data by the proposed distributions.
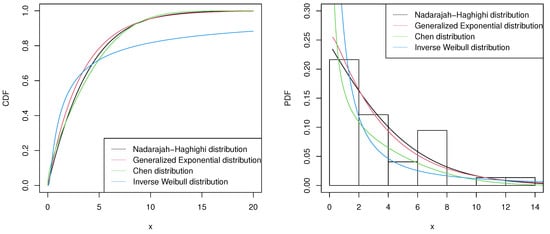
Figure 1.
Fitted CDFs and PDFs of different distributions for the real data set.
Next, we get two sets of censored data under two dissimilar progressive type-II censored schemes. They are and , respectively, where short notation denotes . The two corresponding sets of observed data are presented in Table 3 and Table 4.
Table 3.
The first censored data set under .
Table 4.
The second censored data set under .
Then, we obtain some statistical inferences for the two sets of data. For the unknown parameters, we calculate TK and MH estimations accompanied by their MLEs under different loss functions in Table 5. Then we tabulate some interval estimations of and in Table 6 which include asymptotic CIs, bootstrap CIs, and HPD interval. Additionally, in Table 7, in the one-sample situation, we tabulate point predictions and the predictive intervals for the kth experimental unit which is censored at the ith failure. Furthermore, Table 8 includes the point prediction and also the 95% predictive intervals for the top five items of future observations of size 25 and 30 under the two-sample framework, respectively.
Table 5.
Average estimators of and for real data.
Table 6.
Interval estimations of and for real data.
Table 7.
One-sample point predictions and predictive intervals for real data.
Table 8.
Two-sample point predictions and predictive intervals for real data.
5.2. Simulation Study
We implement a simulation study for comparison of numerical results and then evaluate the proposed methods. Using different censoring schemes, we first derive progressive type-II censored samples that follow an NH distribution, where and are true values we choose. Next, the EM algorithm can be applied so as to compute the MLEs. Afterwards, we give hyperparameters the values as . The Bayesian estimators under two different types of loss functions are calculated by the TK and MH methods. We take the mean-squared error (MSE) values into account for comparing these Bayes estimates with different methods. The MSEs of and have the following forms
where and denote the estimates of and at qth simulation time from different methods.
Different values of in the BSEL functions are considered as a kind of measure of its influence on Bayes estimates. In addition, all the and censored schemes are shown in the tables, where m denotes the quantity of observed samples and n denotes the quantity of complete samples.
In Table 9, we tabulate average estimators and also the values of MSEs for and under diverse censoring schemes. For each with each censoring scheme, the first and the second rows show the average estimators of and their MSEs. In addition, the average estimators of and their MSEs are shown in the third and fourth rows. This table demonstrates that the estimators computed through the MH algorithm have better performance than those obtained by the TK method. Additionally, Bayes estimates almost always play a more prominent role than the corresponding MLEs.
Table 9.
Average estimators and MSE values under diverse censoring schemes.
In Table 10, under pre-specified sample sizes and censoring schemes, we construct varieties of interval estimations for the unknown parameters along with their coverage probabilities (CPs) and average length (AL). In each with each censoring scheme, the first and second rows respectively show the statistical inferences of and . For more illustration, we also provide four plots in Figure 2 and Figure 3, where the numbers 1 to 12 on the x-axis denote all the schemes from top to bottom in the table. Figure 2 includes the AL for different intervals of and under different schemes, respectively. In addition, under different schemes, the CPs for different intervals of and are provided in Figure 3.
Table 10.
Interval estimations for and .
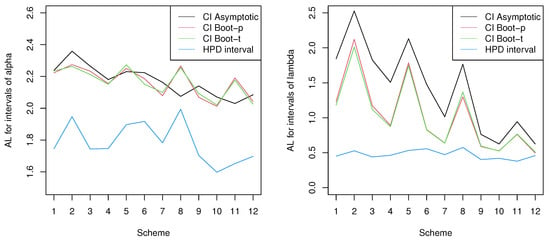
Figure 2.
The AL for different intervals of and under different schemes.
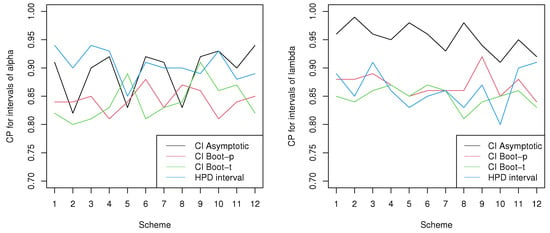
Figure 3.
The CPs for different intervals of and under different schemes.
As we can see, the AL of the HPD intervals are the shortest, followed by the bootstrap intervals, and the asymptotic intervals are the longest. However, as for the CPs, the asymptotic intervals hold the highest, followed by the HPD intervals, while the CPs of bootstrap often lie below the nominal level. Therefore, considering both AL and CPs, we believe that the asymptotic and bootstrap intervals are inferior to the HPD intervals.
In Table 11, we compute point prediction and 95% predictive intervals for different censored observations using the MH algorithm. We can see from the predicted intervals that when we censor more than one unit at a time, the AL of the prediction intervals of the unit censored at the early stage is shorter than that at the late stage. However, when we censor just one unit many times, we find that the later the stage is, the smaller the AL of the interval prediction is. The AL of prediction intervals is inclined to shorten as the observed sample grows in number.
Table 11.
One-sample point prediction estimates and predictive intervals for future observations.
In Table 12, under the two-sample prediction frame, we tabulate the point predictions and predictive intervals of the first, the third, and the fifth future observations of total size 5. It is worth noting that the lengths for these interval predictions are prone to become longer with the increasing value of j. As a consequence, is taken into consideration when the real data are under analysis.
Table 12.
Two-sample point prediction estimates and predictive intervals for future observations.
6. Conclusions
This article provides the classical and Bayesian estimations for Nadarajah-Haghighi distribution using progressive type-II censored samples. As for the unknown parameters, we compute maximum likelihood estimates through an Expectation–Maximization algorithm. Under two different kinds of loss functions including the balanced squared error and squared error loss functions, we calculate varieties of approximate Bayes estimates using both the Metropolis-Hasting algorithm and the Tierney and Kadane method. In addition, we get estimation results of confidence intervals, which include the asymptotic intervals, and bootstrap intervals. Then, using the sample derived from the Metropolis-Hasting algorithm, we also obtain the highest posterior density intervals. Furthermore, the point and interval prediction for a future sample is considered in the one-sample and two-sample situations. In the end, we compare and appraise the performance of the provided techniques through a simulation study. For further explanation, one set of real rainfall data is also analyzed.
Overall, we can learn from the numerical studies that the proposed methods can work well. For instance, compared with maximum likelihood estimates and the Bayes estimates using the Tierney and Kadane method, the Bayes estimates using the Metropolis-Hasting algorithm are quite closer to the true values of unknown parameters. The MSEs are mostly less than . In addition, in Table 7, we can see that the true values of censored samples are completely in the predictive intervals.
Additionally, the methods provided in this article can be extended to other life distributions.
Author Contributions
Investigation, M.W.; Supervision, W.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by Project 202110004106 supported by Beijing Training Program of Innovation and Entrepreneurship for Undergraduates.
Data Availability Statement
The data presented in this study are openly available in reference [12].
Conflicts of Interest
The authors declare no conflict of interest.
References
- Balakrishnan, N.; Cohen, A.C. Order Statistics and Inference: Estimation Methods; Academic Press: Boston, MA, USA, 1991. [Google Scholar]
- Lawless, J.F. Statistical Models and Methods for Lifetime Data; Wiley: New York, NY, USA, 1982. [Google Scholar]
- Balakrishnan, N.; Aggarwala, R. Progressive Censoring: Theory, Methods, and Applications; Birkhäuser: Boston, MA, USA, 2000. [Google Scholar]
- Cohen, A.C. Truncated and Censored Samples: Theory and Applications; Marcel Dekker: New York, NY, USA, 1991. [Google Scholar]
- Rastogi, M.K.; Tripathi, Y.M.; Wu, S.-J. Estimating the parameters of a bathtub-shaped distribution under progressive type-II censoring. J. Appl. Stat. 2012, 39, 2389–2411. [Google Scholar] [CrossRef]
- Ren, J.; Gui, W. Inference and optimal censoring scheme for progressively type-ii censored competing risks model for generalized rayleigh distribution. Comput. Stat. 2020, 36, 479–513. [Google Scholar] [CrossRef]
- Nadarajah, S.; Haghighi, F. An extension of the exponential distribution. Statistics 2011, 45, 543–558. [Google Scholar] [CrossRef]
- Kumar, D.; Dey, S.; Nadarajah, S. Extended exponential distribution based on order statistics. Commun. Stat. Theory Methods 2017, 46, 9166–9184. [Google Scholar] [CrossRef]
- Kumar, D.; Malik, M.R.; Dey, S.; Shahbaz, M.Q. Recurrence relations for moments and estimation of parameters of extended exponential distribution based on progressive type-II right-censored order statistics. J. Stat. Theory Appl. 2019, 18, 171–181. [Google Scholar] [CrossRef]
- Singh, S.; Singh, U.; Kumar, M.; Vishwakarma, P. Classical and Bayesian inference for an extension of the exponential distribution under progressive type-II censored data with binomial removals. J. Stat. Appl. Probab. Lett. 2014, 1, 75–86. [Google Scholar] [CrossRef]
- Singh, U.; Singh, S.K.; Yadav, A.S. Bayesian estimation for extension of exponential distribution under progressive type-II censored data using Markov Chain Monte Carlo method. J. Stat. Appl. Probab. 2015, 4, 275–283. [Google Scholar]
- Selim, M.A. Estimation and prediction for Nadarajah-Haghighi distribution based on record values. Pak. J. Stat. 2018, 34, 77–90. [Google Scholar] [CrossRef]
- Ashour, S.K.; El-Sheikh, A.A.; Elshahhat, A. Inferences and optimal censoring schemes for progressively first-failure censored Nadarajah-Haghighi distribution. Sankhya A 2020, 1–39. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. (Methodol.) 1977, 39, 1–38. [Google Scholar]
- Ruud, P.A. Extensions of estimation methods using the EM algorithm. J. Econom. 1991, 49, 305–341. [Google Scholar] [CrossRef]
- Louis, T.A. Finding the observed information matrix when using the EM algorithm. J. R. Stat. Soc. Ser. (Methodol.) 1982, 44, 226–233. [Google Scholar]
- Efron, B. The Jackknife, the Bootstrap and Other Resampling Plans; SIAM: Philadelphia, PA, USA, 1982. [Google Scholar]
- Hall, P. Theoretical comparison of Bootstrap confidence intervals. Ann. Stat. 1988, 16, 927–953. [Google Scholar] [CrossRef]
- Ahmed, E.A. Bayesian estimation based on progressive type-II censoring from two-parameter bathtub-shaped lifetime model: An Markov Chain Monte Carlo approach. J. Appl. Stat. 2014, 41, 752–768. [Google Scholar] [CrossRef]
- Tierney, L.; Kadane, J.B. Accurate approximations for posterior moments and marginal densities. J. Am. Stat. Assoc. 1986, 81, 82–86. [Google Scholar] [CrossRef]
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H.; Teller, E. Equation of state calculations by fast computing machines. J. Chem. Phys. 1953, 21, 1087–1092. [Google Scholar] [CrossRef]
- Hastings, W.K. Monte Carlo sampling methods using Markov chains and their applications. Biometrika 1970, 57, 97–109. [Google Scholar] [CrossRef]
- Chen, M.-H.; Shao, Q.-M. Monte Carlo estimation of Bayesian credible and HPD intervals. J. Comput. Graph. Stat. 1999, 8, 69–92. [Google Scholar]
- Al-Hussaini, E.K. Predicting observables from a general class of distributions. J. Stat. Plan. Inference 1999, 79, 79–91. [Google Scholar] [CrossRef]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).