Abstract
The canonical skewness vector is an analytically simple function of the third-order, standardized moments of a random vector. Statistical applications of this skewness measure include semiparametric modeling, independent component analysis, model-based clustering, and multivariate normality testing. This paper investigates some properties of the canonical skewness vector with respect to representations, transformations, and norm. In particular, the paper shows its connections with tensor contraction, scalar measures of multivariate kurtosis and Mardia’s skewness, the best-known scalar measure of multivariate skewness. A simulation study empirically compares the powers of tests for multivariate normality based on the squared norm of the canonical skewness vector and on Mardia’s skewness. An example with financial data illustrates the statistical applications of the canonical skewness vector.
1. Introduction
Let be a p-dimensional random vector with mean , nonsingular covariance matrix and finite third-order moments. Ref. [1] introduced the vector-valued measure of multivariate skewness as follows:
where is the standardization of and is the positive definite symmetric square root of the concentration matrix , that is, the inverse of :
The i-th element of is as follows:
where is the k-th component of . We shall refer to as the canonical skewness vector to distinguish it from less known vector-valued measures of multivariate skewness [2,3]. In the following, all vectors are regarded as column vectors.
The intuition behind might be better appreciated by considering some special but relevant cases. In the univariate case, that is, when the only component of is the random variable X, the skewness vector coincides with the skewness of X, that is, its third standardized moment, as follows:
where and are the expected value and the standard deviation, respectively, of X. The canonical skewness vector is a null vector when is centrally symmetric, that is, if and if are identically distributed [4]. In the bivariate case, the skewness vector admits the simpler representation as follows:
The canonical skewness vector appears in several areas of multivariate statistical analysis. In model-based clustering, the projection of the standardized data onto the direction of the sample counterpart of is used to estimate the best discriminant projection [5]. In independent component analysis (ICA), is the product of an orthogonal matrix and the vector whose i-th element is the skewness of the i-th independent component ([6]). In the semiparametric model posed by [7], is instrumental in identifying the parameter of the model. Within an invariant coordinate selection (ICS) approach, the vector might be regarded as the standardized difference between two appropriately chosen random vectors ([8]).
Unfortunately, the canonical skewness vector might be a null vector, even if the underlying distribution is skewed with finite third moments and a positive definite covariance matrix. For example, let the density function of the random vector be , where is the standard normal probability density function, is the standard normal cumulative distribution function, and is a non-null real value. Then, is a standard random vector, and its only non-null third moment is . The canonical skewness vector is then the three-dimensional null vector.
The partial skewness of is just the squared norm of its canonical skewness vector:
It was independently proposed by several authors (see, for example, refs. [1,8,9]) as a scalar measure of multivariate skewness; its name reminds that it does not depend on the cross-product moment when i, j, and k differ from each other [6]. Partial skewness is nonnegative, equals zero if is centrally symmetric, and is invariant with respect to affine, nonsingular transformations. Its statistical applications include multivariate normality testing [10] and multivariate analysis of variance [9].
Ref. [11] proposed to measure the skewness of by the following expectation:
where and are identically distributed and mutually independent. In the following, we shall refer to as the total skewness since it depends on all third-order standardized moments of . Just like partial skewness, total skewness is nonnegative, equals zero if the underlying distribution is centrally symmetric, and is invariant with respect to nonsingular affine transformations. Moreover, just like partial skewness, total skewness is used in multivariate normality testing [11] and in multivariate analysis of variance [9]. However, is by far more popular than , to the point of being a default measure of multivariate skewness, as remarked by [3].
The total skewness is always positive when some third-order cumulants of the underlying distribution are non-null and the covariance matrix is positive definite. This feature constitutes a major advantage of total skewness over partial skewness. For example, the total skewness and the partial skewness of the random vector with probability density function are and . As remarked before, the sample counterparts of both skewness measures were used to test normality, but they are suited for testing symmetry since there are many multivariate distributions which are centrally symmetric without being normal, such as the multivariate Student t distribution.
There are many more measures of multivariate skewness (see, for example, ref. [12]). Similarly, there are other notions of multivariate symmetry other than central symmetry, such as weak symmetry, sign symmetry and elliptical symmetry. A detailed investigation of notions of multivariate symmetry and measures of multivariate skewness falls outside the scope of the present paper. We defer the interested reader to [4], where the previous literature on both topics is thoroughly reviewed.
This paper contributes to the literature on the canonical skewness vector both with empirical and theoretical results. The theorems in Section 2 provide some alternative representations for , and , together with some skewness–kurtosis inequalities and some insights into the behavior of these skewness measures under some well-known transformations. The simulation studies in Section 3 compare the performance of partial skewness and total skewness for testing multivariate symmetry. Section 4 uses financial data to illustrate the statistical applications of the canonical skewness vector and partial skewness. Section 5 contains some concluding remarks and hints for future research. The proofs of the theorems are relegated to Appendix A.
2. Theory
This section contains several theoretical results related to the canonical skewness vector. Theorems 1 and 2 represent the canonical skewness vector by means of the star product of matrices and the vectorization operator. Theorems 3 and 4 investigate the behavior of the canonical skewness vector under linear transformations and convolution. Theorems 5 and 6 focus on partial skewness and total skewness by providing alternative representations and by establishing skewness–kurtosis inequalities.
The third moment matrix of a p-dimensional random vector with finite third-order moments is as follows:
The matrix denotes the Kronecker product of the matrices and , that is, the block matrix whose -th block is the matrix The third cumulant of , that is, the third moment of , is the following:
The third standardized moment of , which coincides with its third standardized cumulant, is the third moment (cumulant) of , given as follows:
The matrices , and are the matricized versions of the third moment tensor, as follows:
the third cumulant tensor, as follows:
and the third standardized moment tensor, as follows:
that is, the third-order arrays containing all the third moments of , , and . Third-order tensors provide a natural tool for representing the skewness of a random vector [1]. In particular, the canonical skewness vector is just the tensor contraction of and . Its i-th component is as follows:
Some tensor contractions might be represented by means of the star product of matrices as defined by [13]. The star product of the matrix and the block matrix is the matrix as follows:
that is, the linear combination of the blocks of where the coefficients are the elements of . The following theorem shows that the canonical skewness vector is the star product of an identity matrix and the third standardized moment.
Theorem 1.
Let be the standardization of a -dimensional random vector with a positive definite covariance matrix and finite third-order moments. Then, the canonical skewness vector of is the star product of the identity matrix and the third standardized cumulant matrix :
We illustrate the above theorem with the bivariate random vector , whose standardization is . The star product of the identity matrix and the third standardized moment of is as follows:
which coincides with the canonical skewness vector of , as defined in the Introduction.
A location vector and a scatter matrix of a p-dimensional random vector are a p-dimensional vector and a symmetric, positive definite matrix, satisfying the following:
for any matrix of full rank and for any p-dimensional real vector (see, for example, ref. [14]). The mean and
are examples of location vectors [8]. The covariance and
are examples of scatter matrices [8]. Let , and be two location vectors and a scatter matrix of a p-dimensional random vector . Ref. [14] suggests using the following:
as a scalar measure of multivariate skewness, where is the inverse of . It measures the skewness in the direction of the vector-valued measure of multivariate skewness:
where is the positive definite symmetric square root of . The following theorem represents the canonical skewness vector and the partial skewness as and , where the following holds:
The theorem also represents the canonical skewness vector by means of simple matrix functions acting on the third cumulant and on the covariance matrix.
Theorem 2.
Let be a p-dimensional random vector with a positive, definite covariance matrix and finite third-order moments. Additionally, let , , and be the mean vector, the concentration matrix and the third cumulant of . Then, the canonical skewness vector of is as follows:
where is the positive definite symmetric square root of .
The canonical skewness vector is location invariant: for any p-dimensional real vector . On the other hand, the canonical skewness vector is neither invariant nor equivariant with respect to linear transformations: may differ from both and , where is a nonsingular real matrix. Ref. [5] conjectures that for some orthogonal matrix . The following theorem makes this statement more precise.
Theorem 3.
Let be the canonical skewness vector of the p-dimensional random vector . Additionally, let be the canonical skewness vector of , where is a nonsingular matrix and is a p-dimensional real vector. Finally, let , where and are the positive definite symmetric square roots of the concentration matrix of and of the covariance matrix of . Then, is orthogonal, coincides with when itself is orthogonal and .
Let , ..., be independent and identically distributed random variables whose third standardized cumulant is . It is well-known that the third cumulant of the sum is . The following theorem generalizes this statement to multivariate random vectors.
Theorem 4.
Let , ..., be independent and identically distributed -dimensional random vectors with positive definite covariance matrices and finite third-order moments. Additionally, let , and be the canonical skewness vector, the partial skewness and the total skewness of , for , ..., . Finally, let , and be the canonical skewness vector, the partial skewness and the total skewness of . Then, the following identities hold true:
The total skewness and the partial skewness are the squared norms of the third standardized moment matrix and the canonical skewness vector. Therefore, both skewness measures are functions of the third standardized moments. The following theorem shows that they can also be represented as functions of the second and third central moments, by means of simple matrix operations acting on the covariance and on the third cumulant. Thus, the following theorem provides an alternative representation for the partial and total skewness measures.
Theorem 5.
Let be a p-dimensional random vector with finite third-order moments and positive definite covariance matrix. Additionally, let and be the third cumulant and the concentration matrix of . Then, the total skewness and the partial skewness of are as follows:
The fourth-order standardized moment of a p-dimensional random vector with finite fourth-order moments and positive definite covariance is as follows:
where is the standardization of . Refs. [11,15] defined the partial kurtosis (also known as Mardia’s kurtosis) and the total kurtosis (also known as Koziol’s kurtosis) as the trace and the squared norm of the following: :
Ref. [1] as well as [16] provided some skewness–kurtosis inequalities involving partial skewness. The following theorem contributes to the literature on inequalities between multivariate measures of skewness and kurtosis.
Theorem 6.
Let be a -dimensional random vector with a positive definite covariance matrix and finite fourth-order moments. Additionally, let , , , and be the total skewness, the partial skewness, the total kurtosis and the partial kurtosis of . Then, the following inequalities hold true:
As a corollary, the inequality holds true for a random variable X whose third and fourth standardized moments are and .
3. Simulations
In this section, we use simulations for comparing the powers of symmetry tests based on partial and total skewness. To this end, we simulated from the two-component normal mixture with proportional covariances and the multivariate skew-normal distribution. For both models, testing symmetry is a crucial issue, where ordinary likelihood-based methods are somewhat problematic. For each choice of the parameters, variables and units, we computed the percentage of samples rejected at the level by the testing procedure proposed by [1,11]. We refer to the former and the latter testing procedures as “Mori” and “Mardia”, respectively. The results given by the simulations clearly hint that “Mori” is a strong competitor for “Mardia”.
We first simulated 10,000 samples of 100 observations from the mixture for , , , , , 10, 15, 20 and , 1, 2. The symbols , and denote the dimensional vector of zeros, the dimensional vector of ones and the dimensional identity matrix, respectively. The two-component normal mixture with proportional covariances describes the worst case from a multivariate outlier detection perspective and leads to an unbounded likelihood function (see, for example, ref. [5]). The scatter plot in Figure 1 depicts 10,000 outcomes from and exemplifies the skewness of normal mixtures.
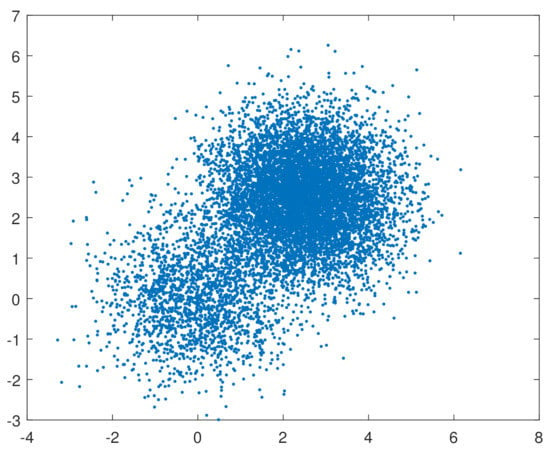
Figure 1.
Scatterplot of 10,000 outcomes from .
The results of this simulation study are reported in Table 1 and may be summarized as follows. When less weight is placed on the more dispersed component, “Mori” always outperforms “Mardia”, although both tests show a very high power. When the components are equally dispersed, “Mardia” always outperforms “Mori”, although only slightly. Both tests show a very low power, which tends to decrease with the absolute difference between the components’ weights. When more weight is placed on the more dispersed component, “Mori” always outperforms “Mardia”, except when the weight of the less dispersed component is . The powers of “Mardia” and “Mori” increase as increases, that is, as the absolute difference between the mixture weights and increases.

Table 1.
For samples generated from normal mixture distributions, the columns contain the percentages of samples rejected by the test based on Mardia’s skewness (header: Mardia) and by the test based on partial skewness (header: Mori) at the level for , and .
We also simulated 10,000 samples of sizes , 200, 500 from the multivariate skew–normal density function , where , 2, 3, 4 and is the probability density function of a p-dimensional standard normal distribution, with , 10, 15, and 20. The information matrix of the multivariate skew–normal distribution is singular when , thus preventing the use of standard likelihood-based methods when testing symmetry. Table 2 reports the results given in this simulation study, which somewhat differ from those in the previous one. Firstly, “Mardia” nearly always outperforms “Mori”, although only slightly. Secondly, the performance of both “Mardia” and “Mori” improves with the number of units and the parameter , but deteriorate with the number of variables. Thirdly, the difference between the performance of “Mardia” and “Mori” tends to decrease as the number of units increases. The scatter plot in Figure 2 depicts 10,000 outcomes from and exemplifies the skewness of skew–normal distributions.
Table 2.
For samples generated from skew–normal distributions, the columns contain the percentages of samples rejected by the test based on Mardia’s skewness (header: Mardia) and by the test based on partial skewness (header: Mori) at the level for , and .
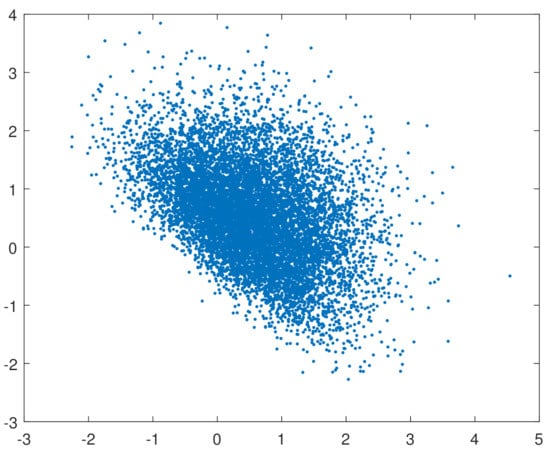
Figure 2.
Scatterplot of 10,000 outcomes from .
4. Example
This section uses the financial data in [17] to illustrate a statistical application of the canonical skewness vector and the partial skewness. The dataset, which we shall refer to as ALL, includes the percentage logarithmic daily returns recorded in the French, Dutch and Spanish financial markets from 25 June 2003 to 23 June 2008. Let GOOD be the subset of ALL, which includes the returns in ALL following a positive return of the U.S. financial market, that is, good news from the leading world financial market. Similarly, let BAD be the subset of ALL, which includes all the returns in ALL following a negative return of the U.S. financial market, that is, bad news from the leading world financial market. The three datasets are instrumental in investigating the behavior of financial markets in the presence of either good or bad news [18,19].
Let be the i-th univariate observation in a sample of size n. The sample mean, the sample variance and the sample skewness are as follows:
The sample skewnesses of the French, Danish and Spanish data in ALL are negative: , and .The sample skewnesses of the French, Danish and Spanish data in BAD are negative as well: , and . On the other hand, the sample skewnesses of the French, Danish and Spanish data in GOOD are positive: , and . The absolute skewnesses of the three markets in ALL are smaller than the corresponding absolute skewnesses in GOOD, which in turn are smaller than the corresponding absolute skewnesses in BAD. All these features are well-known stylized facts of financial markets and are modeled by the SGARCH model in [18].
Let the vector be the i-th multivariate observation in a sample of size n. The sample mean, the sample variance, the sample canonical skewness vector and the sample partial skewness are as follows:
In the ALL, GOOD and BAD datasets, is the trivariate vector whose elements are the returns of the French, Dutch and Spanish financial markets recorded during the i-th day. The canonical skewness vectors of ALL, GOOD and BAD are negative, positive and negative:
Their squared norms, that is, the partial skewnesses of ALL, GOOD and BAD are as follows:
The partial skewness of ALL is smaller than the partial skewness of GOOD, which in turn is smaller than the partial skewness of BAD. Therefore, for the data at hand, the canonical skewness vector and the partial skewness nicely generalize to the multivariate case and the univariate features of financial returns.
5. Conclusions
This paper investigated some theoretical and empirical properties of the canonical skewness vector. The theoretical contribution is threefold. Theorems 1 and 2 pertain to the representation of the canonical skewness vector, either with the star product or with some location vectors. Theorems 3 and 4 deal with transformations, which may be either linear transformations or convolutions. Theorems 5 and 6 highlight some connections between the partial skewness and the total skewness, with respect to representations and inequalities. The empirical contribution is twofold. Firstly, the results of the simulation studies hint that partial skewness might outperform total skewness as a test statistic for symmetry. Secondly, the canonical skewness vector, when applied to the financial data in Section 4, generalizes to multivariate financial returns—a well-known feature of univariate financial returns.
Regrettably, the literature on the analytical forms and properties of the canonical skewness vector under well-known parametric assumptions is quite sparse. For example, to the best of our knowledge, there does not exist any theoretical result regarding the canonical skewness vector of skew–elliptical distributions [20], which are very useful in modeling linear functions of order statistics (see, for example, ref. [21]). We believe that the problem might be conveniently addressed within the smaller class of scale mixtures of skew–normal distributions by jointly using the results on their moments [22,23,24] and those in this paper (see, for example, Theorem 5). Additionally, the projection of a random vector onto the direction of its canonical skewness vector has a simple parametric interpretation when the underlying distribution is a location mixture of two normal distributions with proportional covariance matrices [5]. It would be interesting to know whether this result might be somewhat extended to scale mixtures of skew–normal distributions.
For the dataset in Section 4, the canonical skewness vector and the partial skewness generalize to the multivariate case the tendency of univariate financial returns to be more skewed in the presence of bad news. This empirical result encourages addressing the following research questions. Firstly, do the results for the dataset in Section 4 hold for other financial markets and for other time periods? Secondly, could the canonical skewness vector be meaningfully used to measure the effect of news about the COVID-19 pandemic on financial markets? Thirdly, does the canonical skewness vector or the partial skewness have a simple analytical form under the multivariate SGARCH model? Fourthly, is the partial skewness of several small, capitalized financial markets smaller than the partial skewness of the same number of larger financial markets? We hope to address these interesting research questions in future works.
Funding
This research received no external funding.
Data Availability Statement
The dataset used in this paper is available from Morgan Stanley Capital International (https://www.msci.com/, accessed on 1 September 2021).
Acknowledgments
The author would like to thank three anonymous reviewers whose insightful comments greatly helped to improve the quality of this paper.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Proof of Theorem 1.
By definition, the third standardized cumulant of is as follows:
which might be represented as follows:
by applying the following identities:
where and are any two vectors ([25], page 199). As a direct consequence, the third standardized cumulant might be represented as a block column vector:
Let be the j-th column of the matrix :
By definition, the star product of the identity matrix and the third standardized cumulant is the sum of the vectors multiplied by the elements of with the same indices, that is, the following:
where is the element of belonging to its i-th row and to its j-th column, given as follows:
The definitions of and , together with linear properties of the expectation, yield the following:
The last expectation coincides with the definition of the canonical skewness vector. The proof is then complete. □
Proof of Theorem 2.
By definition, the vectorial skewness of is as follows:
The replacement of with in the definition of yields the following:
Applying the linear properties of the expectation yields the following:
where the last equality follows by taking into account that is a random vector having a zero mean vector and a covariance matrix equal to the identity matrix .
We now use two properties of the vectorization and Kronecker operators: (1) (2) , where , and . Applying these properties, we obtain the following:
and , from which we obtain the following:
from which the following holds true:
as we aimed to prove. □
Proof of Theorem 3.
Let , and be the covariance matrix of , the concentration matrix of and the positive definite symmetric square root of . Additionally, let , and be the covariance matrix of , the concentration matrix of and the positive definite symmetric square root of . Let us also denote by the transpose of the matrix .
We first prove that is orthogonal as follows:
The definitions of and imply the following identities:
so that the product of and its transpose is an identity matrix as follows:
Therefore is an orthogonal matrix; this concludes the first part of the proof.
We assume without loss of generality that is centered at the origin and that is a null vector: . The following identities hold true when is an orthogonal matrix:
The canonical skewness vector of is then the following:
Applying now the linear properties of the expected value completes the second part of the proof:
By definition, the canonical skewness vectors of and are as follows:
By the ordinary properties of matrix inverses and the definition of , we have the following:
The canonical skewness vector of is then the following:
Apply now the linear properties of the expected value and recall the definition of to obtain the following identity:
□
Proof of Theorem 4.
The canonical skewness vector, the partial skewness, and the total skewness are location invariant. Therefore, we can assume without loss of generality that the means of , ..., and of their sum coincide with the p-dimensional null vector as follows:
Let , and be the covariance matrix of , the concentration matrix of and the positive definite symmetric square root of . Then, the covariance matrix of , the concentration matrix of and its positive definite symmetric square root are as follows:
By definition, the canonical skewness vectors of and are as follows:
The definitions of and the linear properties of the expectation yield the following identities:
By assumption, the random vectors , ..., are mutually independent and centered. Therefore, the mean of is the p-dimensional null vector if at least one of the three indices differs from the other two:
The above identity and linear properties of the expectation yield the following:
The random vectors , ..., are identically distributed, and their canonical skewness vector is . Therefore, we can complete the first part of the proof:
By definition, the partial skewness of a random vector is just the squared norm of its canonical skewness vector, so we can complete the second part of the proof:
Let , ..., be n random vectors independent of each other and independent of , ...,. Additionally, let and be identically distributed, for , ..., n. Finally, let the following hold:
Then, the total skewness of is as follows:
By recalling the definitions of , and , we obtain the following:
By assumption, the random vectors , ...,, , ..., are mutually independent and centered, so the mean of is zero whenever at least one index differs from the others:
The total skewness of is then as follows:
By assumption, the random vectors and are identically distributed, for , ..., n:
We conclude the proof by recalling the definition of the total skewness of :
□
Proof of Theorem 5.
Let be the standardization of , where is the mean of and is the symmetric, positive definite square root of :
By definition, the third standardized cumulant of is the third cumulant of , that is, the following:
The total skewness of might be represented as the squared Euclidean norm of [26]:
The third standardized cumulant of might be represented by means of and :
The two identities above imply the following one:
The trace of the product of two symmetric matrices with the same number of rows does not depend on the order of the matrices themselves:
By the distributive property of the Kronecker product and the ordinary matrix product, if matrices , , and are of appropriate size, then the following holds:
(see, for example, ref. [25], page 194). By applying this property to the above identity, we obtain the following:
By definition, the product of by itself coincides with the concentration matrix so that the following holds:
and the first part of the proof is complete.
We now prove the second part of the theorem. As a straightforward implication of Theorem 2, we have the following:-4.6cm0cm
as we aimed to prove. □
Proof of Theorem 6.
Without loss of generality, we can assume that is a standard random vector:
Let be a random vector independent of and with its same distribution. The first and second moments of are as follows:
The variance of the random variable is nonnegative, thus implying the following inequality:
By expanding the square and using linear properties of the expected value, we obtain the following:
The second, third and fourth moments of are p, and :
We now prove the second part of the theorem. The expectation of is as follows:
The random vectors and are independent and identically distributed by the assumption so that the expectation of is as follows:
The variance of the random variable is nonnegative, thus implying the following inequality:
Expansion of the square and linear properties of the expected value yields the following:
The partial skewness and the partial kurtosis of may be represented as follows (Ref. [27], page 82; ref. [26]):
thus leading to the following inequality:
□
References
- Mòri, T.; Rohatgi, V.; Székely, G. On multivariate skewness and kurtosis. Theory Probab. Its Appl. 1993, 38, 547–551. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Brito, M.; Quiroz, A. A Vectorial Notion of Skewness and Its Use in Testing for Multivariate Symmetry. Commun. Stat.-Theory Methods 2007, 36, 1757–1767. [Google Scholar] [CrossRef]
- Kollo, T. Multivariate skewness and kurtosis measures with an application in ICA. J. Multivar. Anal. 2008, 99, 2328–2338. [Google Scholar] [CrossRef]
- Serfling, R.J. Multivariate symmetry and asymmetry. In Encyclopedia of Statistical Sciences, 2nd ed.; Kotz, S., Read, C.B., Balakrishnan, N., Vidakovic, B., Eds.; Wiley: New York, NY, USA, 2006. [Google Scholar]
- Loperfido, N. Vector-Valued Skewness for Model-Based Clustering. Stat. Probab. Lett. 2015, 99, 230–237. [Google Scholar] [CrossRef]
- Loperfido, N. Singular Value Decomposition of the Third Multivariate Moment. Linear Algebra Its Appl. 2015, 473, 202–216. [Google Scholar] [CrossRef]
- Nordhausen, K.; Oja, H.; Ollila, E. Multivariate models and the first four moments. In Nonparametric Statistics and Mixture Models—A Festschrift for Thomas P. Hettmansperger; Hunter, D., Richards, D., Rosenberger, J.L., Eds.; World Scientific Publishing Co Pte Ltd.: Singapore, 2011. [Google Scholar]
- Ilmonen, P.; Oja, H.; Serfling, R. On Invariant Coordinate System (ICS) Functionals. Int. Stat. Rev. 2012, 80, 93–110. [Google Scholar] [CrossRef]
- Davis, A. On the Effects of Moderate Multivariate Nonnormality on Wilks’s Likelihood Ratio Criterion. Biometrika 1980, 67, 419–427. [Google Scholar] [CrossRef]
- Henze, N. Limit laws for multivariate skewness in the sense of Mòri, Rohatgi and Székely. Stat. Probab. Lett. 1997, 33, 299–307. [Google Scholar] [CrossRef]
- Mardia, K. Measures of multivariate skewness and kurtosis with applications. Biometrika 1970, 57, 519–530. [Google Scholar] [CrossRef]
- Malkovich, J.; Afifi, A. On Tests for Multivariate Normality. J. Am. Stat. Assoc. 1973, 68, 176–179. [Google Scholar] [CrossRef]
- MacRae, E. Matrix derivatives with an application to an adaptive linear decision problem. Ann. Stat. 1974, 2, 337–346. [Google Scholar] [CrossRef]
- Kankainen, A.; Taskinen, S.; Oja, H. Tests of multinormality based on location vectors and scatter matrices. Stat. Methods Appl. 2007, 16, 357–379. [Google Scholar] [CrossRef]
- Koziol, J. A note on measures of multivariate kurtosis. Biom. J. 1989, 31, 619–624. [Google Scholar] [CrossRef]
- Ogasawara, H. Extensions of Pearson’s inequality between skewness and kurtosis to multivariate cases. Stat. Probab. Lett. 2017, 30, 12–16. [Google Scholar] [CrossRef]
- De Luca, G.; Loperfido, N. Modelling Multivariate Skewness in Financial Returns: A SGARCH Approach. Eur. J. Financ. 2015, 21, 1113–1131. [Google Scholar] [CrossRef]
- De Luca, G.; Loperfido, N. A Skew-in-Mean GARCH Model for Financial Returns. In Skew-Elliptical Distributions and Their Applications: A Journey Beyond Normality; Genton, M.G., Ed.; Chapman & Hall, CRC: Boca Raton, FL, USA, 2004; pp. 205–222. [Google Scholar]
- De Luca, G.; Genton, M.; Loperfido, N. A Multivariate Skew-Garch Model. In Advances in Econometrics: Econometric Analysis of Economic and Financial Time Series, Part A (Special Volume in Honor of Robert Engle and Clive Granger, the 2003 Winners of the Nobel Prize in Economics); Terrell, D., Ed.; Elsevier: Oxford, UK, 2006; Volume 20, pp. 33–56. [Google Scholar]
- Branco, M.; Dey, D. A general class of skew-elliptical distributions. J. Multivar. Anal. 2001, 79, 99–113. [Google Scholar] [CrossRef]
- Loperfido, N. A Note on Skew-Elliptical Distributions and Linear Functions of Order Statistics. Stat. Probab. Lett. 2008, 78, 3184–3186. [Google Scholar] [CrossRef]
- Kim, H.M. Moments of variogram estimator for a generalized skew t distribution. J. Korean Stat. Soc. 2005, 34, 109–123. [Google Scholar]
- Kim, H.M. A note on scale mixtures of skew-normal distributions. Stat. Probab. Lett. 2008, 78, 1694–1701. [Google Scholar] [CrossRef]
- Kim, H.M. Corrigendum to “A note on scale mixtures of skew normal distribution” [Statist. Probab. Lett. 78 (2008) 1694–1701]. Stat. Probab. Lett. 2013, 83, 1937. [Google Scholar] [CrossRef]
- Rao, C.; Rao, M. Matrix Algebra and Its Applications to Statistics and Econometrics; World Scientific Co. Pte. Ltd.: Singapore, 1998. [Google Scholar]
- Kollo, T.; Srivastava, M. Estimation and testing of parameters in multivariate Laplace distribution. Commun. Stat.-Theory Methods 2005, 33, 2363–2687. [Google Scholar] [CrossRef]
- Kotz, S.; Balakrishnan, N.; Johnson, N. Continuous Multivariate Distributions, Volume 1: Models and Applications, 2nd ed.; Wiley: New York, NY, USA, 2000. [Google Scholar]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).