Abstract
This work proposes a new distribution defined on the unit interval. It is obtained by a novel transformation of a normal random variable involving the hyperbolic secant function and its inverse. The use of such a function in distribution theory has not received much attention in the literature, and may be of interest for theoretical and practical purposes. Basic statistical properties of the newly defined distribution are derived, including moments, skewness, kurtosis and order statistics. For the related model, the parametric estimation is examined through different methods. We assess the performance of the obtained estimates by two complementary simulation studies. Also, the quantile regression model based on the proposed distribution is introduced. Applications to three real datasets show that the proposed models are quite competitive in comparison to well-established models.
1. Introduction
Over the past twenty years, many statisticians and researchers have focused on proposing new extended or generalized distributions by adding additional parameters to the basic probability distributions. The common point of these studies is to obtain better inferences than those of the baseline probability distributions. In this context, especially, the modeling approaches on the unit interval have recently multiplied since they are related to specific issues such as the recovery rate, mortality rate, daily patient rate, etc. The beta distribution is the best-known distribution defined over the unit interval for modeling the above measures. It has great flexibility in the shapes of the probability density function (pdf) and hazard rate function (hrf). Although it has very flexible forms for data modeling, sometimes it is not sufficient for modeling and explaining unit datasets. For this reason, new alternative unit models have been proposed in the statistical distribution literature, including the Johnson [1], Topp-Leone [2], Kumaraswamy [3], standart two-sided power [4], log-Lindley [5], log-xgamma [6], unit Birnbaum-Saunders [7], unit Weibull [8], unit Lindley [9], unit inverse Gaussian [10], unit Gompertz [11], second degree unit Lindley [12], log-weighted exponential [13], logit slash [14], unit generalized half normal [15], unit Johnson [16], trapezoidal beta [17] and unit Rayleigh [18] distributions. Many of the above distributions were obtained by transforming the baseline distribution, and they performed better than the beta distribution in terms of data modeling. For instance, the Johnson distribution was created via logistic transformation of the ordinary normal distribution. In this way, a very flexible unit normal distribution was obtained over the unit interval. The other mentioned unit distributions introduced over the last decade can also be seen as alternatives to the well-known beta, Johnson , Topp-Leone and Kumaraswamy distributions.
On the other hand, the ordinary regression models explain the response variable for given certain values of the covariates based on the conditional mean. However, the mean may be affected by a skewed distribution or outliers in the measurements. Possible solutions are provided by the quantile regression models proposed by [19], particularly popular for being less sensitive to outliers than the ordinary regression models.
In line with above, the aim of this study is to introduce a new alternative unit probability distribution based on the normal distribution. More precisely, we use a new transformation of the normal distribution based on the hyperbolic secant function. As a matter of fact, the use of the hyperbolic function has not received enough attention in the published literature on distribution theory, despite the great interest among students and practitioners of the few distributions based on it. Examples include the famous hyperbolic secant distribution and its generalizations as presented in [20]. In a sense, we show that the proposed methodology allows us to transport the applicability and working capacity of the normal distribution to the unit interval. In particular, we develop a new quantile regression modeling via the re-parameterizing of the new probability distribution in terms of any quantile. All these aspects are developed in the article through mathematical, graphical and numerical approaches.
The paper has been set as follows. We define the proposed distribution in Section 2. Its basic distributional properties are described in Section 3. Section 4 is devoted to the procedures of the different parametric estimation methods. Two different simulation studies are given to see the performance of the different estimates of the model parameters in Section 5. The new quantile regression model based on the proposed distribution and its residual analysis are introduced by Section 6. Three real data illustrations, one of which relates to quantile modeling and others to univariate data modeling, are illustrated in Section 7. Finally, the paper is ended with conclusions in Section 8.
2. The New Unit Distribution and Its Properties
The new unit distribution is defined as follows: Let Y be a random variable such that where and , and X be the random variable defined by
where is the hyperbolic secant function for , also known as the inverse of the hyperbolic cosine function. Then the distribution of X is called “arcsech” normal distribution and it is denoted by or when and are required. To our knowledge, it constitutes a new unit distribution; It is unlisted in the literature. Before stating the motivations for the distribution, the corresponding cumulative distribution function (cdf) and pdf are presented in the following proposition.
Proposition 1.
The cdf and pdf of the distribution are given as
and
respectively, for , where is the hyperbolic arcsecant function (or inverse hyperbolic secant function) for , and are the cdf and pdf of the distribution, respectively. For , standard completions on these functions are performed.
For the sake of presentation, the proof of this result and those of the results to come are given in Appendix A.
Based on Proposition 1, as a first property, note that, for and , the cdf and pdf are reduced to the quite manageable functions:
and
In full generality, for , an alternative formulation for the pdf is
where is the hyperbolic cosine function for . Eventually, we can express the cosh term in Equation (5) as
Let us now focus on the behavior of at the boundaries.
- When x tends to 0, since and it appears in power 2 the exponential term, we have .
- When x tends to 1, since , we haveIf is large and , or is large, the point appears as a “special singularity” in the following sense: The function can decrease to 0 in the neighborhood of , then suddenly explodes at . This phenomenon is only punctual; this is not a particular disadvantage for statistical modeling purposes.
Also, from Equation (2), it can seen that
This means that the pdf shapes of the distribution coincide with those of the distribution. Another remark is that the distribution can have one mode into , and it corresponds to the x satisfying the following equation:
This equation is complex and needs a numerical treatment to determine the value of the mode, if it exists.
The hrf of the distribution is given by
Some plots of and are shown in Figure 1.
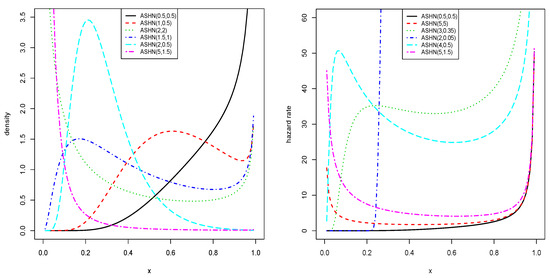
Figure 1.
The possible pdf and hrf shapes of the distribution.
From Figure 1, the flexibility of the obtained curves is flagrant; J, reversed J, U and bell shapes are observed for the pdf, whereas U, N and reversed J shapes are observed for the hrf. This panel of shapes is a plus for the distribution, motivating its use for statistical modeling.
3. Distributional Properties
This section is devoted to some mathematical properties satisfied by the distribution.
3.1. A Likelihood Ratio Order Result
The proposition below shows that the distribution satisfies a strong intrinsic stochastic order result.
Proposition 2.
Let and with and . Then X is smaller than Y in likelihood ratio order.
In the general case where , there is no actual proof of such stochastic ordering properties. Further, let us mention that the likelihood order is a strong property, implying various stochastic orders such that the usual stochastic, hazard rate, reversed mean inactivity time, mean residual life and harmonic mean residual life orders, among others. We may refer the reader to [21] for all the theory and details about the concept of stochastic ordering.
3.2. Quantile Function
The theoretical definition of the quantile function (qf) of the distribution is the inverse function of Equation (1), that is
In full generality, due to the complexity of , it is not possible to have a closed-form expression of this qf. However, in the case , we arrive at
where denotes the inverse function of , which also corresponds to the qf of the distribution. In this case, the first quartile is obtained as , the median is given by , and the third quartile is defined by . Further, from , one can generate values from the distribution through basic simulation methods.
3.3. Moments
Let . As prime definition, for any integer r, by denoting as E the expectation operator, the rth ordinary moment of X is defined by
For the special case , one can express it via the qf as
Clearly, there is no simple expression for . When the parameters are fixed, it can be calculated numerically through standard numerical integration techniques. As the main analytical approach, one can consider a series expansion for as stated in the result below.
Proposition 3.
The rth moment of has the following expansion:
where with , and , and denotes the indicator function.
The function introduced in Proposition 3 can be viewed as the upper incomplete version of the moment generating function of the distribution. Naturally, it can be bounded from above as for and . By applying the Markov inequality, a lower is obtained as for and .
Proposition 3 gives an analytical approach for mathematical manipulations or computations of . Further, the following finite sum approximation is an immediate consequence:
where K denotes a reasonably large integer.
From the moments, we can derive other measures of interest for X. For instance, the mean of X is just , the variance of X can be determined through the Koenig-Huyghens formula involving and , that is , the rth central moment defined by can be expressed via by using the binomial formula, the skewness coefficient of X is defined by and the kurtosis coefficient of X is given by . These coefficients evaluate the “peakedness” and “tailedness” of the distribution, respectively. Figure 2 represents these coefficients while varying the values for and .
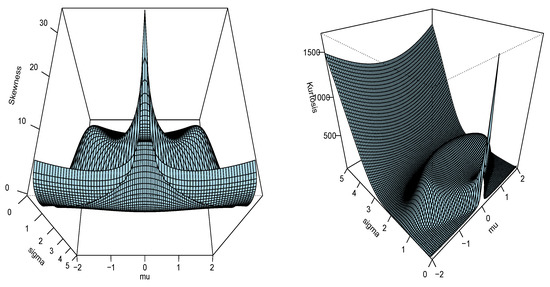
Figure 2.
The skewness and kurtosis plots of the distribution.
From Figure 2, we see that the skewness coefficient can be negative and positive, and the kurtosis coefficient can be either very small or very large. Both have a complex non-monotonic structure. These facts attest to the ability of the distribution to adapt to various situations from heterogeneous unit data.
3.4. Order Statistics
The order statistics are important since they are involved in many statistical modeling and methods. Here, the basics of them in the context of the distribution are described. Let be a random sample from , and be the corresponding order statistics, that is . Then, the pdf of has the following general expression:
The pdf of the extreme statistics and are derived by substituting and in the above equation, respectively. Other important results are that
The order statistics, as well as their mean and variance, will be useful in the next section.
4. Different Methods of the Parameter Estimation
In this section, we point out some different estimators to estimate the parameters of the model. More precisely, the maximum likelihood, maximum product spacings, least squares, weighted least squares, Anderson-Darling and Cramér-von Mises estimates are derived.
4.1. Maximum Likelihood Estimation
Let be a random sample from the distribution with observed values and be the vector of the model parameters. Then, the log-likelihood function is given by
Based on , the maximum likelihood estimations (MLEs) of and , say and , respectively, are obtained as
Mathematically, this is equivalent to solve the following equations with respect to the parameters:
and
From Equation (10), we have
Substituting the right hand side of Equation (12) in Equation (11), the following equation is obtained for the desired solution for :
Then, substituting Equation (13) in Equation (9), we obtain the profile log-likelihood according to as
Following the normal routine of the parameter estimation based on the profile log-likelihood function, we have
Hence, the numerical methods are needed to obtain . Once is obtained, the MLE is obtained by taking the square root of as governed by Equation (13).
The well-known theory of the maximum likelihood method states that, under mild regularity conditions, one can use the bivariate normal distribution with mean and covariance matrix , where
to construct confidence intervals or likelihood ratio test on the parameters. The components of I can be derived through standard derivatives formula. Then, approximate confidence intervals for and can be determined by and , respectively, where is the upper th percentile of the standard normal distribution, is the first diagonal element of and is its second diagonal element. Thus defined, they are the (asymptotic) standard errors (SEs) of and , respectively.
4.2. Maximum Product Spacing Estimation
Cheng and Aming [22] have proposed the maximum product spacing (MPS) method as an alternative to the maximum likelihood method. It is based on the idea that differences (spacings) between the values of the cdf at consecutive data points should be identically distributed. Now, let be the order statistics from the distribution with sample size n, and be the ordered observed values. Then, the MPS estimates (MPSEs) of and , say and , respectively, are given as
where
They are also given as the simultaneous solutions of the following equations:
and
where
and
4.3. Least Squares Estimation
The least square estimates (LSEs) of and , say and , respectively, are obtained as
where
where, by Equation (8), for . Then, and are solutions of the following equations:
and
where and are mentioned before.
4.4. Weighted Least Squares Estimation
Similarly to LSEs, the weighted least square estimates (WLSEs) of and , say and , respectively, are given as
where
where, by Equation (8), and for . Then, and are solutions of the following equations:
and
4.5. Anderson-Darling Estimation
The Anderson-Darling minimum distance estimates (ADEs) of and , say and , respectively, are determined as
where
Therefore, and can be obtained as the solutions of the following system of equations:
and
4.6. The Cramér-von Mises Estimation
The Cramér-von Mises minimum distance estimates (CVMEs) of and , say and , respectively, are specified as
where
Therefore, the estimates and can be obtained as the solutions of the following system of equations:
and
All the presented equations contain complex non-linear functions; it is not possible to obtain explicit forms of all estimates. Therefore, they need to be solved through numerical methods such as the Newton-Raphson and quasi-Newton algorithms. In addition, Equations (9) and (14)–(18) can be also optimized directly by using the software such as R (constrOptim and optim), S-Plus and Matlab to numerically optimize , , , , and functions.
5. Empirical Simulations
In this section, we perform two graphical simulation studies to see the performance of the above estimates with varying sample size n. We generate samples of size from the distribution based on the following parameter values: (, ) and (, ) for the first and second simulation studies, respectively. The random numbers generation is obtained by the qf of the model. All the estimates based on the estimation methods are obtained by using the constrOptim function in the R program. Further, we calculate the empirical mean, bias and mean square error (MSE) of the estimates for comparisons between the methods. For or , the bias and MSE associated to are calculated by
respectively, where i is related to the ith sample. We expect that the empirical means are close to true values when the MSEs and biases are near zero. The results of this simulation study are shown in Figure 3 and Figure 4.
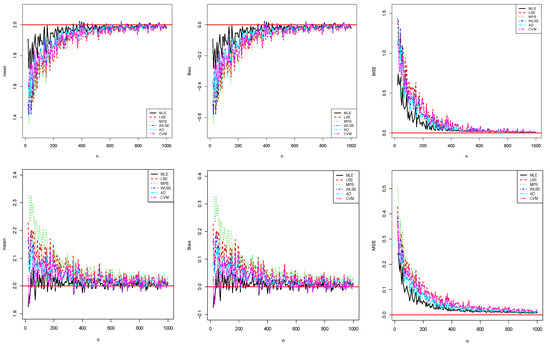
Figure 3.
The results related to (top) and (bottom) for the first simulation study.
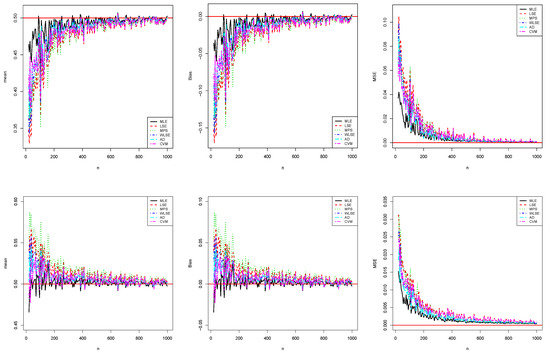
Figure 4.
The results related to (top) and (bottom) for the second simulation study.
Figure 3 and Figure 4 show that all estimates are consistent since the MSE and biasedness decrease to zero with increasing sample size as expected. One can state that all estimates are asymptotic unbiased. According to these two simulation studies, the amount of the biases and MSEs of the MLE method are smaller than those of the other methods for both parameters. Therefore, the ;MLE method can be chosen as more reliable than other methods of the newly defined model. Generally, the performances of all estimates are close when sample size increases. The similar results can be seen for different parameter values.
Moreover, we also give simulation study of the MLEs based on their 95% confidence intervals. In this regard, we use the coverage probability (CP) criteria defined by
where is the SE of the MLE . Figure 5 displays the obtained simulation results. From Figure 5, as expected, for each parameter, the CPs converge to the nominal value, that is 0.95, when sample size increases. The simulation results verify the consistency property of the MLEs.
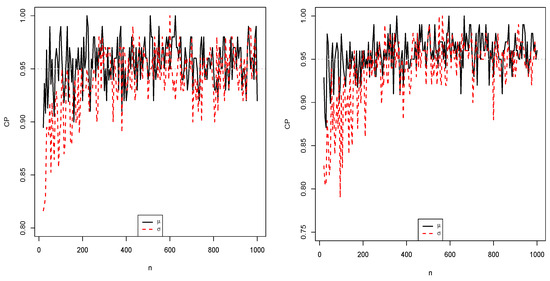
Figure 5.
Estimated CPs for the first (left) and second (right) simulation studies.
6. A New Quantile Regression Model Based on the Special Distribution
6.1. Motivation
The quantile regression has been developed in the seminal work of [19] as a way to model the conditional quantiles of an outcome variable as a function of covariates (regressors). Since this analysis aims to model the conditional quantiles of the response variable, it is a good robust alternative model to the ordinary LSE model, which estimates the conditional mean of the response variable. This is because the mean is affected by a skewed distribution or outliers in the measurements. Hence, the quantile response regression model will be less sensitive to outliers than the mean response regression model.
On the other hand, if the support of the response variable is defined on the unit interval, one can use an unit regression model based on an unit distribution for modeling the conditional mean or quantiles of the response variable via covariates. The beta regression [23] model first comes to mind to relate to continuous unit mean response variables in the unit interval with covariates. One may also see [12,13,24,25,26] for alternative unit mean response regression models to beta regression models. If the conditional dependent variable is skewed or has outliers, the quantile response modeling may be more appropriate when compared with the mean response modeling. The model is also motivated by the natural idea of replacing mean by median as a central tendency measure when the response data is severely asymmetric [27].
On the other hand, with the re-parameterizing the probability distribution as a function of the quantile approach, the Kumaraswamy [28,29] and unit Weibull [30] quantile regression models have been proposed for modeling the conditional quantiles of the unit response. One may also refer to [27,31,32,33,34] for alternative quantile response regression models. On the basis of these references, we want to propose an alternative quantile regression model considering a parameterization of the distribution in terms of its any quantile. More precisely, the re-parameterizing process is applied via a scale parameter as being a quantile of the of the distribution.
6.2. Proposed Quantile Regression Model
Now, we can focus on introducing an alternative quantile regression model based on a special distribution. Since the distribution has not an explicit qf, we propose another distribution based on a special distribution. We call it exponentiated () distribution. Its cdf and pdf are given by
and
respectively, where and . For , standard completions on these functions are performed. The cdf in Equation (19) is obtained as the exponentiated distribution, that is . We can call this model as Lehmann type I model.
The qf of the distribution is given by
where . We are also motivated with the quantile regression modeling thanks to its manageable qf. Then, the pdf of the distribution can be re-parameterized in terms of its uth quantile as . Let . Then, the cdf and pdf of the re-parameterized distribution are given by
and
respectively, where is the shape parameter. The parameter represents the quantile parameter and it is assumed that u is known. A random variable Y having the pdf in Equation (21) is denoted by . Some possible shapes of the re-parameterized model are shown in Figure 6. We see that the possible pdf shapes of the distribution are the skewed shapes as well as U-shapes, N-shapes and increasing shapes.
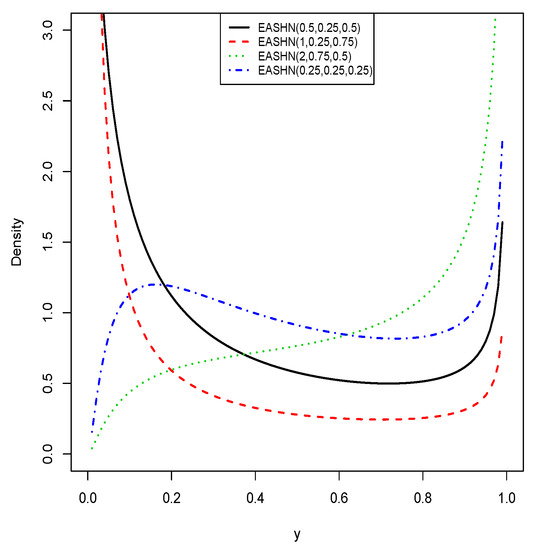
Figure 6.
The pdf shapes of the re-parameterized distribution.
We present the quantile regression model based on the distribution with pdf in Equation (21). Let be n random observations from the re-parameterized distribution such that, for , is a realization of , with unknown parameters and , recalling that the parameter u is known. Then the quantile regression model is defined as
where and are the unknown regression parameter vector and known ith vector of the covariates. Thus defined, is the link function which is used to link the covariates to conditional quantile of the response variable. For instance, when , the covariates are linked to conditional median of the response variable. The choice of the appropriate link function should be done considering the domain of the distribution.
6.3. Parameter Estimation
The unknown parameters of the quantile regression model are obtained by means of the MLE method. Since the distribution is defined on the unit interval, we use the logit-link function, that is
implying that
By putting Equation (22) into Equation (21), the log-likelihood function of the quantile regression model is
where denotes the unknown parameter vector. Since Equation (23) includes nonlinear function according to model parameters, it can be maximized directly by software such as R, S-Plus, and Mathematica. Note that, when , this is equivalent to modeling the conditional median. Under mild conditions of regularity, the asymptotic distribution of is multivariate normal , where variance-covariance matrix is defined by the inverse of the expected information matrix. For practical aims, we can use the observed information matrix instead of J. The elements of this observed information matrix are evaluated numerically by the software. We use the maxLik function implemented in the R software to maximize Equation (23) (see [35]). This function also gives asymptotic SEs numerically, which are obtained by the observed information matrix.
6.4. Residual Analysis
Residual analysis may be necessary to verify if the regression model is suitable. To see this, we work with the randomized quantile residuals [36] and the Cox-Snell residuals [37].
For , the ith randomized quantile residual is defined by
where is the cdf of the re-parameterized distribution specified by Equation (20) and is defined by Equation (22) with replacing . If the fitted model successfully processes the dataset, the distribution of the randomized quantile residuals will distribute the standard normal distribution.
Alternatively, for , the ith Cox and Snell residual is given by
If the model fits to data accordingly, the distribution of the Cox and Snell residuals will distribute a standard exponential distribution, that is with scale parameter 1.
7. Data Analysis
To emphasize the importance of the modeling ability of the normal distribution, this section is devoted to three real data applications for both univariate data and quantile modelings.
7.1. Univariate Real Data Modeling
Here, we provide applications to two real datasets to prove empirically the potentiality of the model. The proposed model is compared with some well-known two-parameter unit distributions in the literature, namely:
- Beta distribution.The two-parameter beta pdf is given bywhere and are shape parameters, and is the classical beta function.
- Kumaraswamy (Kw) distribution (see [3]).The two-parameter Kw pdf is expressed aswhere and are shape parameters.
- Johnson distribution (see [1]).The two-parameter Johnson pdf is given bywhere and are shape parameters, and is the pdf of the standard normal distribution. For each model, we estimate the unknown parameters using the maximum likelihood approach.
Two datasets are considered. For them, in order to determine the optimum model, we compute the estimated log-likelihood values , Akaike Information Criteria (AIC), Bayesian Information Criteria (BIC), Kolmogorov-Smirnov (KS), Anderson-Darling () and Cramér-von Mises () goodness-of-fit statistics for all models. In general, it can be chosen as the best model the one with the smaller values of the AIC, BIC, KS, and statistics and the larger values of . The p-value of the KS test is also considered; more it is close to 1, better is the model. All computations are performed by using the maxLik [35] and goftest routines in the R software.
7.1.1. Data Analysis I
First, we consider an application to real dataset to show the modeling ability of the proposed distribution. The dataset introduces failure times of the 20 mechanical components given in [38]. The data are: 0.067, 0.068, 0.076, 0.081, 0.084, 0.085, 0.085, 0.086, 0.089, 0.098, 0.098, 0.114, 0.114, 0.115, 0.121, 0.125, 0.131, 0.149, 0.160, 0.485. Recently, these data was analyzed via different approaches by [15,39,40].
Table 1 lists the MLEs of the parameters and their SEs from the above fitted models and the values of the statistics: , AIC, BIC, , and KS goodness-of-fit statistics. As it can be seen, the results indicate that the model has the smallest values of these statistics among the fitted models, and therefore it could be considered as the best model. The p-value of the KS test confirms this claim.

Table 1.
MLEs, SEs of the estimates (in parentheses), and goodness-of-fits statistics for the first dataset (p-value is given in ).
The plots of the fitted pdfs and cdfs are displayed in Figure 7. These plots show that the model provides the correct fit to these data compared to other models. Further, it captures data skewness and kurtosis better than other models.
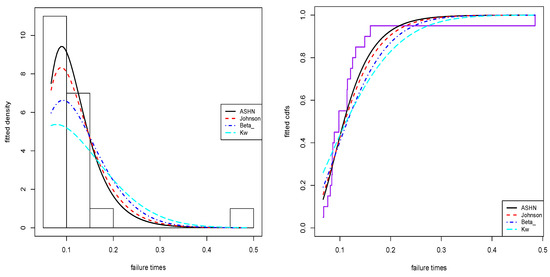
Figure 7.
The fitted plots for the first dataset.
Figure 8 shows plots of the profile log-likelihood (PLL) functions for the parameters and based on the first dataset. We observe that the likelihood equations have unique solutions for the MLEs.
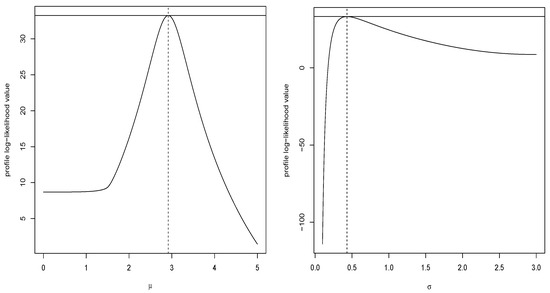
Figure 8.
The plots of the PLL functions for the first dataset.
7.1.2. Data Analysis II
Here, the Better Life Index (BLI) dataset is used to illustrate the usefulness of the distribution. The dataset can be found via link https://stats.oecd.org/index.aspx?DataSetCode=BLI2015. The BLI dataset is used to classify the OECD (Organisation for Economic Co-operation and Development) countries with 11 indicators and 24 variables as well as non-OECD economies such as Brazil and Russia. Here, we use an indicator that is entitled Job security as the dataset. This indicator presents the probability to become unemployed. Recently, these data was analyzed by [14]. We give the summary statistics of the dataset in Table 2. The data are right-skewed and have a consequent kurtosis.
Table 2.
Some summary statistics of the second dataset.
Table 3 lists the MLEs, their SEs, and goodness-of-fits statistics from the fitted models for this dataset. Table 3 shows that the proposed model could be chosen as the best model among the fitted models since it has the lowest values of the AIC, BIC, , and KS statistics and have the biggest value. It also has the biggest p-value of the KS test.
Table 3.
MLEs, SEs of the estimates (in parentheses), and goodness-of-fits statistics for the second dataset (p-value is given in ).
The plots of the fitted pdfs and cdfs are displayed in Figure 9. These plots show that the model provides the good fit to these data compared to the other models.
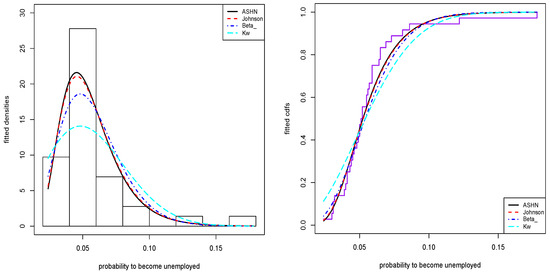
Figure 9.
The fitted plots for the second dataset.
Figure 10 shows plots of PLL functions for the parameters and based on the second dataset. From this figure, we see that the likelihood equations have unique solutions for the MLEs.
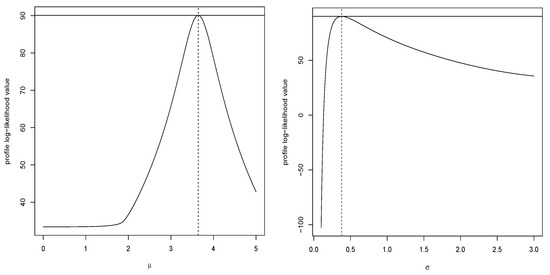
Figure 10.
The plots of the PLL functions for the second dataset.
7.2. The Quantile Modeling Application of the Reading Accuracy with the Dyslexia and Intelligence Quotient
Here, a real data application is given in order to see the applicability of the newly defined regression model. We compare its results with the unit Weibull quantile regression model [30]. The quantile parameter u has been taken as 0.5 to model the median for regression models. The pdf of the unit Weibull quantile distribution is given by
where is the median and is the shape parameter. The dataset consists of the reading accuracy for nondyslexic and dyslexic Australian children and contains 44 observations on 3 variables. The variable of interest is accuracy providing the scores on a test of reading accuracy taken by 44 children, which is predicted by the two regressors: dyslexia and nonverbal intelligence quotient (IQ). The dataset has been collected by [41], and analyzed by [42,43] via the beta regression modeling based on the data mean modeling. It is noticed that the original reading accuracy score has been transformed by [43] so that accuracy is in the open unit interval. Further, this dataset can be found easily via betareg function [42] in the R software.
The aim is to associate the reading accuracy values with covariates. The response variable and covariates are:
- y: reading score;
- : Is the child dyslexic? (0 for no, 1 for yes);
- : nonverbal intelligence quotient (IQ, converted to z scores).
The regression model based on is given by
where denotes the median for the unit Weibull and models.
The results of the and unit Weibull regression models with model selection criteria are given in Table 4. As seen from the values of AIC and BIC statistics, the proposed regression model has lower values than those of the unit Weibull regression model. So, one can say that the regression model exhibits better modeling ability than the unit Weibull regression model. Additionally, according to the estimated parameters of the regression model, the parameters and have been seen statistically significant at any usual level. Hence, it is concluded that, when IQ increases, the reading accuracy increases also. However, the reading accuracy of the children with no dyslexia is higher than those of the children with dyslexia as expected.
Table 4.
The results of the and unit Weibull regression models with model selection criteria.
Figure 11 and Figure 12 display the QQ plots of the randomized quantile residuals and PP plot of the Cox-Snell residuals for both regression models, respectively. These figures indicate that the fit of the regression model is better than the one of the unit Weibull model.
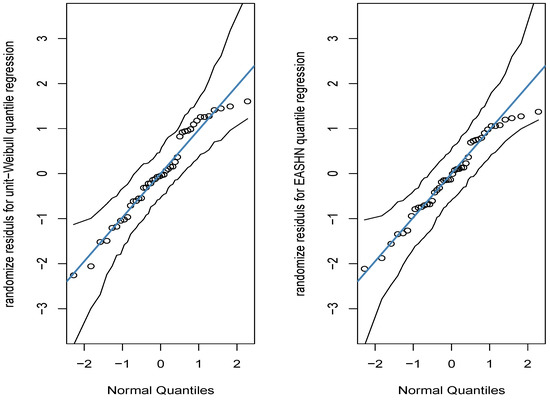
Figure 11.
The QQ plot of the randomized quantile residuals.
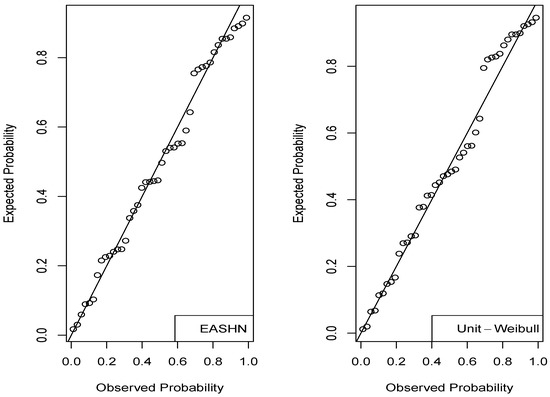
Figure 12.
The PP plots of the Cox-Snell residuals based on the regression application.
Since the randomized quantile residuals have standard normal distributions, one may see whether they fit this corresponding distribution. The KS, and results are given in Table 5. It is clear that the results based on the quantile regression model of the randomized quantile residuals are more suitable than those of the unit Weibull regression model.
Table 5.
The goodness-of-fit results of the randomized quantile residuals for the regression models.
8. Conclusions
We define a new unit model, called “arcsech” normal distribution, in order to model percentage, proportion and rate measurements. The idea is to take advantage of the hyperbolic arcsecant function to transpose the modeling capacities of the normal distribution for the processing of data defined on the unit interval. We investigate general structural properties of the new distribution. The model parameters are estimated by six different methods. The simulation studies are performed to see the performances of these estimates. The empirical findings indicate that the proposed model provides better fits than the well-known unit probability distributions in the literature for both its univariate data modeling and its regression modeling. It is hoped that the new distribution will attract attention in the other disciplines.
Author Contributions
M.Ç.K., C.C. and Z.S.K. have contributed equally to this work. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Acknowledgments
The authors are grateful to the two anonymous referees helpful comments that improved the paper.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
The proofs of our main results are contained in this appendix.
Proof of Proposition 1.
Firstly, it is noticed that the hyperbolic secant function is the symmetrical on the interval as well as it is the increasing function on the interval and it is the decreasing function on the interval. Based on the representation , where , the cdf of X can be determined as
We get the declared definition of . By differentiation of with respect to x, since , the pdf follows, ending the proof. □
Proof of Proposition 2.
In the case , owing to Equation (4), some simplifications give
Since is a positive decreasing function, if , the above ratio function is decreasing with respect to x as composition of an increasing exponential function and a decreasing function. This proves the desired result. □
Proof of Proposition 3.
We propose to exploit the following characterization of the distribution: We can express X as with . Then, through the use of the generalized version of the binomial formula, we obtain
Therefore, since , we get
In the distribution sense, one can write with , implying that
and
The stated result follows by combining the equations above together. □
References
- Johnson, N.L. Systems of frequency curves generated by methods of translation. Biometrika 1949, 36, 149–176. [Google Scholar] [CrossRef]
- Topp, C.W.; Leone, F.C. A family of J-shaped frequency functions. J. Am. Stat. Assoc. 1955, 50, 209–219. [Google Scholar] [CrossRef]
- Kumaraswamy, P. A generalized probability density function for double-bounded random processes. J. Hydrol. 1980, 46, 79–88. [Google Scholar] [CrossRef]
- Van Dorp, J.R.; Kotz, S. The standard two-sided power distribution and its properties: With applications in financial engineering. Am. Stat. 2002, 56, 90–99. [Google Scholar] [CrossRef]
- Gómez-Déniz, E.; Sordo, M.A.; Calderín-Ojeda, E. The log–Lindley distribution as an alternative to the beta regression model with applications in insurance. Insur. Math. Econ. 2014, 54, 49–57. [Google Scholar] [CrossRef]
- Altun, E.; Hamedani, G.G. The log-xgamma distribution with inference and application. J. Soc. Fr. Stat. 2018, 159, 40–55. [Google Scholar]
- Mazucheli, J.; Menezes, A.F.; Dey, S. The unit-Birnbaum-Saunders distribution with applications. Chil. J. Stat. 2018, 9, 47–57. [Google Scholar]
- Mazucheli, J.; Menezes, A.F.B.; Ghitany, M.E. The unit-Weibull distribution and associated inference. J. Appl. Probab. Stat. 2018, 13, 1–22. [Google Scholar]
- Mazucheli, J.; Menezes, A.F.B.; Chakraborty, S. On the one parameter unit-Lindley distribution and its associated regression model for proportion data. J. Appl. Stat. 2019, 46, 700–714. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Mazucheli, J.; Menezes, A.F.B.; Alqallaf, F. The unit-inverse Gaussian distribution: A new alternative to two-parameter distributions on the unit interval. Commun. Stat. Theory Methods 2019, 48, 3423–3438. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.; Dey, S. Unit-Gompertz distribution with applications. Statistica 2019, 79, 25–43. [Google Scholar]
- Altun, E. The log-weighted exponential regression model: Alternative to the beta regression model. Commun. Stat. Theory Methods 2021. [Google Scholar] [CrossRef]
- Altun, E.; Cordeiro, G.M. The unit-improved second-degree Lindley distribution: Inference and regression modeling. Comput. Stat. 2020, 35, 259–279. [Google Scholar] [CrossRef]
- Korkmaz, M.Ç. A new heavy-tailed distribution defined on the bounded interval: The logit slash distribution and its application. J. Appl. Stat. 2020, 47, 2097–2119. [Google Scholar] [CrossRef]
- Korkmaz, M.Ç. The unit generalized half normal distribution: A new bounded distribution with inference and application. Univ. Politeh. Buchar. Sci. Bull. Ser. Appl. Math. Phys. 2020, 82, 133–140. [Google Scholar]
- Gündüz, S.; Korkmaz, M.Ç. A New Unit Distribution Based On The Unbounded Johnson Distribution Rule: The Unit Johnson SU Distribution. Pak. J. Stat. Oper. Res. 2020, 16, 471–490. [Google Scholar] [CrossRef]
- Figueroa-Zu, J.I.; Niklitschek-Soto, S.A.; Leiva, V.; Liu, S. Modeling heavy-tailed bounded data by the trapezoidal beta distribution with applications. Revstat 2021. Available online: https://www.ine.pt/revstat/pdf/ModelingBoundedDataWithHeavyTails.pdf (accessed on 10 January 2021).
- Bantan, R.A.R.; Chesneau, C.; Jamal, F.; Elgarhy, M.; Tahir, M.H.; Aqib, A.; Zubair, M.; Anam, S. Some new facts about the unit-Rayleigh distribution with applications. Mathematics 2020, 8, 1954. [Google Scholar] [CrossRef]
- Koenker, R.; Bassett, G., Jr. Regression quantiles. Econom. J. Econom. Soc. 1978, 46, 33–50. [Google Scholar] [CrossRef]
- Fischer, M.J. Generalized Hyperbolic Secant Distributions: With Applications to Finance; Springer-Verlag Berlin and Heidelberg GmbH & Co. KG: Berlin, Germany, 2013. [Google Scholar]
- Shaked, M.; Shanthikumar, J.G. Stochastic Orders; Wiley: New York, NY, USA, 2007. [Google Scholar]
- Cheng, R.C.H.; Amin, N.A.K. Maximum Product of Spacings Estimation with Application to the Lognormal Distribution; Math Report; University of Wales Institute of Science and Technology: Cardiff, Wales, 1979; p. 79-1. [Google Scholar]
- Ferrari, S.; Cribari-Neto, F. Beta regression for modelling rates and proportions. J. Appl. Stat. 2004, 31, 799–815. [Google Scholar] [CrossRef]
- Bayes, C.L.; Bazán, J.L.; García, C. A new robust regression model for proportions. Bayesian Anal. 2012, 7, 841–866. [Google Scholar] [CrossRef]
- Kieschnick, R.; McCullough, B.D. Regression analysis of variates observed on (0, 1): Percentages, proportions and fractions. Stat. Model. 2003, 3, 193–213. [Google Scholar] [CrossRef]
- Migliorati, S.; Di Brisco, A.M.; Ongaro, A. A new regression model for bounded responses. Bayesian Anal. 2018, 13, 845–872. [Google Scholar] [CrossRef]
- Galarza, C.E.; Zhang, P.; Lachos, V.H. Logistic quantile regression for bounded outcomes using a family of heavy-tailed distributions. Sankhya B 2020, 1–25. [Google Scholar] [CrossRef]
- Bayes, C.L.; Bazán, J.L.; De Castro, M. A quantile parametric mixed regression model for bounded response variables. Stat. Its Interface 2017, 10, 483–493. [Google Scholar] [CrossRef]
- Mitnik, P.A.; Baek, S. The Kumaraswamy distribution: Median-dispersion re-parameterizations for regression modeling and simulation-based estimation. Stat. Pap. 2013, 54, 177–192. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.B.; Fernandes, L.B.; de Oliveira, R.P.; Ghitany, M.E. The unit-Weibull distribution as an alternative to the Kumaraswamy distribution for the modeling of quantiles conditional on covariates. J. Appl. Stat. 2020, 47, 954–974. [Google Scholar] [CrossRef]
- Gallardo, D.I.; Gómez-Déniz, E.; Gómez, H.W. Discrete generalized half-normal distribution and its applications in quantile regression. Sort-Stat. Oper. Res. Trans. 2020, 265–284. [Google Scholar] [CrossRef]
- Jodra, P.; Jiménez-Gamero, M.D. A quantile regression model for bounded responses based on the exponential-geometric distribution. Revstat-Stat. J. 2020, 18, 415–436. [Google Scholar]
- Korkmaz, M.Ç.; Chesneau, C.; Korkmaz, Z.S. Transmuted unit Rayleigh quantile regression model: Alternative to beta and Kumaraswamy quantile regression models. Univ. Politeh. Buchar. Sci. Bull. Ser. Appl. Math. Phys. 2021. to appear. [Google Scholar]
- Sánchez, L.; Leiva, V.; Galea, M.; Saulo, H. Birnbaum-Saunders quantile regression models with application to spatial data. Mathematics 2020, 8, 1000. [Google Scholar] [CrossRef]
- Henningsen, A.; Toomet, O. maxLik: A package for maximum likelihood estimation in R. Comput. Stat. 2011, 26, 443–458. [Google Scholar] [CrossRef]
- Dunn, P.K.; Smyth, G.K. Randomized quantile residuals. J. Comput. Graph. Stat. 1996, 5, 236–244. [Google Scholar]
- Cox, D.R.; Snell, E.J. A general definition of residuals. J. R. Stat. Soc. Ser. (Methodol.) 1968, 30, 248–265. [Google Scholar] [CrossRef]
- Murthy, D.P.; Xie, M.; Jiang, R. Weibull Models; John Wiley & Sons: Hoboken, NJ, USA, 2004; Volume 505. [Google Scholar]
- Silva, R.B.; Bourguignon, M.; Dias, C.R.; Cordeiro, G.M. The compound class of extended Weibull power series distributions. Comput. Stat. Data Anal. 2013, 58, 352–367. [Google Scholar] [CrossRef]
- Genç, A.A.; Korkmaz, M.Ç.; Kus, C. The Beta Moyal-Slash Distribution. J. Selçuk Univ. Nat. Appl. Sci. 2014, 3, 88–104. [Google Scholar]
- Pammer, K.; Kevan, A. The Contribution of Visual Sensitivity, Phonological Processing and Non-Verbal IQ to Children’s Reading; The Australian National University: Canberra, Australia, 2004; Unpublished manuscript. [Google Scholar]
- Cribari-Neto, F.; Zeileis, A. Beta regression in R. J. Stat. Softw. 2010, 34, 1–24. [Google Scholar] [CrossRef]
- Smithson, M.; Verkuilen, J. A better lemon squeezer? Maximum-likelihood regression with beta-distributed dependent variables. Psychol. Methods 2006, 11, 54. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).