Abstract
In this paper, we consider skew-normal distributions for constructing new a distribution which allows us to model proportions and rates with zero/one inflation as an alternative to the inflated beta distributions. The new distribution is a mixture between a Bernoulli distribution for explaining the zero/one excess and a censored skew-normal distribution for the continuous variable. The maximum likelihood method is used for parameter estimation. Observed and expected Fisher information matrices are derived to conduct likelihood-based inference in this new type skew-normal distribution. Given the flexibility of the new distributions, we are able to show, in real data scenarios, the good performance of our proposal.
1. Introduction
The recent statistical literature has experienced an intense research activity on skew distributions. It is due to the fact that many data sets are not fitted well with the normal distribution because of asymmetry and/or kurtosis excess [1]. A natural extension of the normal distribution is the skew-normal (SN) distribution, which has been studied in [2,3,4,5,6,7,8], among other works. Note that the Fisher information matrix of the SN distribution is singular [1].
In order to model random variables that take values with bounded support, the beta distribution has been frequently used [9,10,11,12,13,14,15,16,17]. This type of variables have interesting applications when the bounded support is between zero and one. Additionaly, versions with support between zero and one of other distributions, such as the Birnbaum–Saunders and Weibull distributions [18,19,20], have been proposed. Variables with support between zero and one are studied particularly when modeling proportions and rates (for example, in the study of the proportion of deaths caused by a certain virus in a country, the rate of income spent on taxes, and the proportion of family income spent on food).
Note that some random variables cannot be observed below a certain value (lower detection limit (LDL)) and/or above a certain value (upper detection limit (UDL)), with LDL and UDL being often fixed values. When LDL and/or UDL are present, we say that the random variable is single/doubly-censored distributed [21,22]. Data associated with this type of variables can be described by censored normal distributions [23,24,25,26].
If LDL and UDL , extensions of the beta distribution may be considered to model excess of zeros and/or ones. These extensions used to describe variables into the intervals [0,1], [0,1) or (0,1] have been reported in [27,28,29], which are named zero/one inflated beta (ZOIB) distributions. In order to model inflation at zero and/or one, mixtures distributions have been derived [30,31]. Bernoulli-beta mixture distributions for modeling inflated data at zero/one have been studied in [28]. However, in many situations, the distribution of random variables that take values between zero and one present positive or negative asymmetry and/or kurtosis degrees different from the normal or beta distributions. Subsequently, other distributions than the beta and Bernoulli-beta mixture models are needed.
In order to solve the problem of asymmetry in the data, a transformation can be considered. Nevertheless, such a transformation brings with it problems in the interpretability of the distribution parameters and loss of power in the inference. As an alternative to not transform the data in the case of random variables with positive support, asymmetry to the right, and presence of LDL/UDL, the Birnbaum-Saunders, log-normal (LN), and log-SN (LSN) distributions can be used [30,32,33,34,35,36]. However, these distributions only cover positive asymmetry. Then, the doubly-censored SN (DCSN) distribution may be proposed as an extension of the doubly-censored normal distribution covering negative and positive asymmetry. To the best of our knowledge, no extensions of the SN distribution to describe variables that take values with bounded support and high censoring, as in the case of the intervals [0,1], [0,1) or (0,1], have been reported to date.
The objective of this paper is to propose an alternative approach to deal with data sets in the [0,1] interval. Our approach is a mixture distribution between the Bernoulli and DCSN distributions, which we name the BDCSN distribution in short. Given that the information matrix of the DCSN distribution is singular, such as in the case of the SN distribution, to circumvent this singularity, we define a centered DCSN (CDCSN) distribution [37]. Therefore, our proposal solves the mentioned problems of the existing distributions and its maximum likelihood estimators are well behaved, with regularity conditions being satisfied, since the Fisher information matrix is non-singular in the vicinity of symmetry.
The paper is organized as follows. In Section 2, we present the DCSN distribution and the main results on inference for this distribution. Given that the information matrix of the DCSN distribution is singular, to solve this problem, in Section 3, we define the CDCSN distribution. In this section, the doubly censored log-SN (DCLSN) is also introduced. In Section 4, the DCSN and DCLSN distributions are considered for modeling zero and/or one inflation by using the BDCSN distribution. Parameter estimation is dealt with the maximum likelihood method. The corresponding observed and expected Fisher information matrices are derived and shown to be non-singular. Section 5 evaluates the performance of the maximum likelihood estimators with simulations based on the Monte Carlo method and introduces an algorithm to generate random numbers from the BDCSN distribution. Two real data analyses are considered on Section 6 and Section 7 from where we conclude that the distributions presented in this paper are a good alternative to the ZOIB distributions. The conclusions of this research are provided in Section 8. Mathematical derivations of this work are detailed in the Appendix A. All the numerical calculations were performed by using the R software [38].
2. Doubly-Censored SN Distribution
In this section, we define the DCSN distribution and estimate its parameter with the maximum likelihood method.
A general structure for a skew-symmetric probability density function (PDF) was proposed in [1], which can be written as
where f is a symmetric PDF around zero, F is an absolutely continuous cumulative distribution function (CDF) which is symmetric around zero, and is a shape parameter controlling the asymmetry of the distribution. In (1), if and , that is, the PDF and CDF of the standard normal distribution, respectively, the so called SN distribution is obtained with PDF given by
in which case the notation is used. Observe that the hazard and inverse-hazard functions of the SN distribution are, respectively, stated as
where is the SN CDF, with T being the Owen function defined as and is established in (2).
Let . Then, a location-scale extension of Z is obtained considering the transformation , where is a location parameter and is a scale parameter. Therefore, from (2), the PDF of X is expressed as
where . We denote this extension by . Next, based on the extension defined in (4), we introduce the DCSN distribution.
Definition 1.
Let be a random sample of size n, where and that only values of between the constants and are observed, with and being LDL and UDL, respectively. For values of , only the value is reported, while for values of only the value is considered. Then, the observed data set can be written as
for . The resulting sample from (5) is said to be drawn from a DCSN population. For and , we have that
and
where
For the continuous part of , we consider that . In this case, we use the notation , with and being fixed. Note that, for , the DCSN distribution reduces to the doubly censored normal distribution [23]. Figure 1 provides graphs of PDFs of the DCSN distribution, denoted by in this figure.
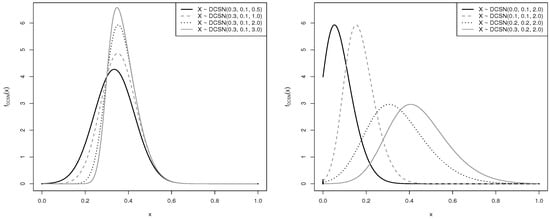
Figure 1.
PDF plots of the DCSN distribution for (left) different values of the parameters and ; and (right) different values of the parameter ; with and .
From Figure 1 (left), note that, as the shape parameter increases, keeping the other parameters fixed, different shapes of the PDF are obtained. From Figure 1 (right), by keeping fixed, it is evident that the parameter modifies the location and modifies the scale of the distribution.
Parameter estimation of the DCSN distribution can be performed using the maximum likelihood method. Thus, denoting by , and the sums corresponding to , and , respectively, the log-likelihood function of for the sample is given by
where are defined in (6) and . Hence, the score vector defined as the derivative of the log-likelihood function stated in (7) with respect to the distribution parameters has elements , , and , which are detailed in the Appendix A. The first order conditions or estimating equations for the maximum likelihood method are obtained equating to zero the elements , , and of the score vector. The solution of these equations leads to the maximum likelihood estimates of . Notice that these estimating equations must be solved numerically by a nonlinear optimization method, as for example, a quasi-Newton algorithm of Broyden–Fletcher–Goldfarb–Shanno (BFGS) type [39], which is available by the optim function of the R software.
The elements of the observed Fisher information matrix corresponding to the DCSN distribution depend on the second derivatives of the likelihood function with respect to the distribution parameters. These elements are provided in the Appendix A. The expected Fisher information matrix corresponding to the DCSN distribution follows then by taking expectations of the elements of the observed information matrix and multiplying by . Subsequently, after intensive algebraic manipulations, the elements of the expected information matrix are obtained and also given in the Appendix A, with
where is defined here due to this is used in Section 4. As mentioned, the Fisher information matrix of the SN distribution is singular [1]. It occurs when , since the score of the parameter is times the score of the parameter , producing linear dependence between the corresponding columns of this matrix. Such a singularity is inherited by the Fisher information matrix corresponding to the DCSN distribution, when . For this case of , a convergence problem exists in the asymptotic inference and the unicity of the corresponding maximum likelihood estimators is not guaranteed.
3. Doubly-Censored Log-SN and Centered SN Distributions
As mentioned, the censored LSN distribution arises as an alternative to not transform the data in the case of random variables with positive support and asymmetry to the right. In this section, we define the DCLSN and centered SN distributions estimating their parameters with the maximum likelihood method.
Recalling that , the PDF of a random variable X with LSN distribution is given by
where is a location parameter and is a scale parameter. Notice that if , then the LN distribution is obtained. We denote this extension of the LN distribution as . The LSN distribution is required to model data with asymmetry different from that of , or equivalently, of . Hence, extending the definition of the DCSN distribution to the LSN case, we obtain the DCLSN distribution with parameters , and , which is denoted by , with and , and replacing x by in the DCSN PDF to avoid that the DCLSN PDF is not defined at zero. In this particular case, from the PDF given in (9), the log-likelihood function of is stated as
where is the log-likelihood function defined in (7) for the DCSN distribution, with being replaced by , by , and by . The score vector and Fisher information matrix associated with the log-likelihood function defined in (10) can be obtained using the score vector and information matrix of the DCSN distribution replacing in the expressions of the Appendix A: (i) by , and (ii) by , where and are the hazard and inverse hazard functions of the SN distribution, respectively, defined in (3). As mentioned, the Fisher information matrix of the DCSN distribution is singular, inherited from the singularity of the SN distribution. Note that this singularity is also presented in the case of the DCLSN distribution. As also mentioned, a centered parametrization is considered to circumvent such a singularity. Observe that the SN PDF with centered parametrization (CSN in short) is given by
where , , , , and . The centrality parameters , and represent, as usual, the mean, standard deviation (SD) and coefficient of skewness of X, respectively. In this case, we use the notation .
Note that the distribution regarding the PDF defined in (11) can be a location-scale distribution denoted by considering
By using the relations stated in (12), we parametrize the DCSN distribution to obtain the CDCSN distribution, denoted by .
Based on the relations established in (12), the observed and expected Fisher information matrices may be obtained for the parameter vector of the CDCSN distribution using , where is a matrix containing the derivatives of the vector of parameters with respect to , and is the observed Fisher information matrix of the non-centered location-scale SN distribution. Upon regularity conditions [40], is a consistent estimator of . In addition, as ,
where , with being the expected Fisher information matrix, and denotes convergence in distribution to. In summary, is consistent and, from (13), it is asymptotically normal distributed with asymptotic covariance matrix expressed as . Note that is a consistent estimator of the asymptotic variance-covariance matrix of .
Figure 2 shows some graphical plots of the PDF of the CDCSN distribution with different values for its parameters. The PDF of the CDCSN distribution is denoted by in this figure. In Figure 2 (left), it is evident that the parameter modifies the symmetry of the PDFs, while in Figure 2 (right) the parameters and modifies the mean and dispersion of the PDFs, respectively.
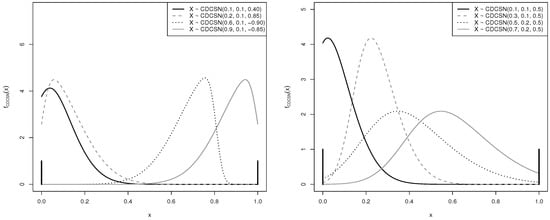
Figure 2.
PDF plots of the CDCSN distribution for (left) different values of the parameters and ; and (right) different values of the parameters and ; with and .
4. The Bernoulli/Doubly-Censored SN Mixture Distribution
As mentioned, when the data set presents detection limits, mixture distributions are often used. In this section, we construct the BDCSN distribution considering the Bernoulli distribution for the discrete mixture variable and the DCSN distribution for the continuous mixture variable.
For the case of proportions, that is, with and , we can construct the mixture of Bernoulli and SN (BSN) distributions. On the one hand, we consider that the zero/one observations are well explained by a Bernoulli distributed variable with parameter , which we denote by . On the other hand, the remaining observations can be modeled by an SN distribution (or LSN for positive data) with parameters , and . The BSN PDF for is given by
where are defined in (6), , , , and , with denoting the SN PDF and being the respective CDF. Observe that and . In this case, we use the notation . After some algebraic manipulations, the CDF of is stated as
where , for , is defined as in (7).
Let be a random sample of size n from , with and where is an indicator function of . Then, from (14) and (15), the log-likelihood function for based on the data set is established as
The elements of the score vector obtained from (16) are detailed in the Appendix A. Maximum likelihood estimates of the parameters p, , , and are the solution to the system which follows by equating the scores to zero. From the first two equations, we obtain an unbiased estimator for p, namely , while an estimator for is given by , corresponding to the proportion of zeros and ones in the sample, as well as the proportions of ones in the subsample of zeros and ones, respectively. The solution to the remaining three parameters can obtained from the last three equations using iterative methods.
The expected Fisher information matrix corresponding to the BSN distribution is derived next. Considering the quantities defined similarly as in (8), with , for and , with , , , and , we have that the elements of the expected Fisher information matrix, denoted by , for , are defined as , , , , , , , , , and detailed in the Appendix A. Thus, the expected Fisher information matrix for is given by
Notice from (17) that the set of parameters for the discrete components and the continuous components are mutually orthogonal. Therefore, the expected Fisher information matrix can be written as where that is, we have block orthogonality. One of the advantages of this orthogonality is that the corresponding parameters may be estimated separately. Estimation methods were discussed in [36] when there is orthogonality in relation to a partition of interest. Moreover, maximum likelihood estimators are independent asymptotically.
Note that the parameterization and in the BSN distribution leads to the BDCSN distribution, for , with PDF being defined as
where and . This is denoted by .
Figure 3 shows graphical plots of the PDF of the BDCSN distribution with different values for its parameters. In Figure 3 (left), we note that, as the shape parameter increases, keeping the other parameters fixed, the shapes of the PDF change. In Figure 3 (right), by keeping fixed, observe that the parameter modifies the location and modifies the scale of the BDCSN distribution. Subsequently, observe that in both figures different values for and are used.
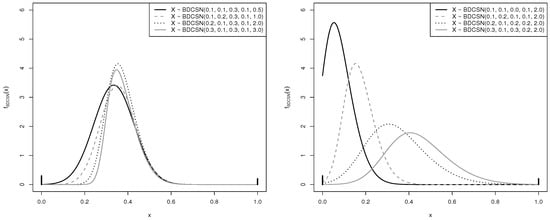
Figure 3.
PDF plots of the BDCSN distribution for (left) different values of parameters , and ; and (right) different values of the parameters , , and .
From the PDF given in (18), the log-likelihood function of based on the data set can be written as
Therefore, from (19), the elements of the score vector for and are and . For , and given by the non-reparametrized distribution, the solution follows using the BFGS algorithm [39]. In addition, is the proportion of zeros in the sample, and is the proportion of ones in the sample. For this distribution, its Fisher information matrix can be written as where the elements of are given by , , and Furthermore, the elements of are the corresponding elements of . Given the orthogonality for the two sets of parameters, their estimates are computed separately.
Next, we present the inflated zero, inflated one and zero/one inflated cases of the BDCSN distribution. For the case of zero inflation with , its PDF is given by
where . Then, from the PDF stated in (20), the log-likelihood function of based on the data set can be written as
Hence, from (21), the score for is defined as . By equating it to zero, we obtain the estimate , that is, the proportion of zeros in the sample. The remaining parameters are estimated similarly as above.
For the case of one inflation with , its PDF is stated as
where . Thus, from the PDF expressed in (22), the log-likelihood function of considering the data is established as
From (23), we reach the score for as By equating it to zero, we obtain the estimate , that is, the proportion of ones in the sample. The remaining parameters are estimated as in the previous case.
Now, by considering the PDF given in (18), the BDCSN distribution is obtained, which can be used for fitting positive data with high kurtosis and asymmetry. Then, from the PDF expressed in (18), the log-likelihood function of considering the data is given by
where and is the log-likelihood function defined in (16) for the BSN distribution, with
and
The score vector and information matrices are easily obtained from (24)–(26), and the previous results.
We denote the mixture between the Bernoulli and CDCSN distributions by . Note that the Fisher information matrix for the continuous part of the BCDCSN distribution is obtained similarly as for the CDCSN distribution, that is, , and .
5. Monte Carlo Simulation Study
In this section, we evaluate the performance of the maximum likelihood estimators with simulations based on the Monte Carlo method. For this simulation study, we consider the BDCSN distribution.
In this Monte Carlo simulation, the true values assumed for the parameters are , and = 0.3, whereas that and . The sample sizes considered are and the number of Monte Carlo replicates is 5000. In each of these replications, we generate random numbers according to Algorithm 1.
| Algorithm 1 Generation of random numbers from the BDCSN distribution. |
| 1: Fix values for , , , , and . |
| 2: Generate values for u from . |
| 3: Compute values for x from
|
| 4: Repeat steps 2–3 until the required numbers of data (n) is completed. |
For each parameter and sample size, we report the empirical mean, variance, bias and root of the mean squared error (RMSE) of the maximum likelihood estimators in Table 1. From this table, in general, note that, as the sample size increases, both the bias and RMSE decrease, as expected. These results empirically shows the good performance of the maximum likelihood estimators for the BDCSN distribution parameters.

Table 1.
Empirical mean, variance, bias and RMSE for the indicated estimator and n with simulated data.
6. Real Data Application 1
In this section, we illustrate the usefulness of the CDCSN and BDCSN distributions considering a first application to a real data set. We name this data set as “death”, which corresponds to the proportions of unexplained infant deaths in 5561 Brazilian counties. The data set is available for downloading at https://datasus.saude.gov.br and contains 3367 zeros (explained deaths) and 174 ones (unexplained deaths).
Table 2 provides descriptive statistics for the death data (uncensored), including central tendency statistics, SD, coefficients of variation (CV), skewness (CS) and kurtosis (CK). From this table, note the presence of skewness and kurtosis in the distribution of the data; see also Figure 4 (left), which depicts the histogram with boxplot revealing the distributional behavior.
Table 2.
Descriptive statistics of the death data.
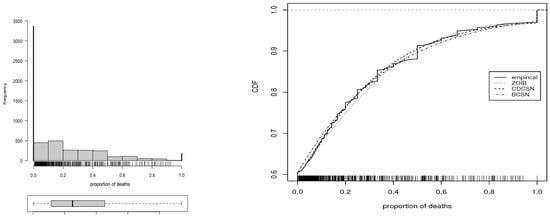
Figure 4.
(left) Histogram of the proportion of deaths and (right) empirical CDF (solid line in stairs), and estimated CDF of the CDCSN (dashed and doted line), BDCSN (dashed line), and ZOIB (doted line) distributions, with death data.
In order to compare our distributions with a standard competitor, the ZOIB distribution [28] is considered and denoted by ZOIB . To estimate the ZOIB distribution parameters, the GAMLSS package of the R software is used. Then, we fit the CDCSN, BDCSN and ZOIB distributions by using the maximum likelihood method to estimate their parameters based on the sn package [41] and its selm and dp2cp functions. The optim function of the R software and the BFGS algorithm are used for this estimation. As starting values to initiate the algorithm, we use the moment estimates proposed in [5]. Table 3 provides the maximum likelihood estimates for the considered distributions. In addition, for the CDCSN distribution, using the corresponding estimated CDF, the estimated proportions of censored observations are 0.6039 (zeros) and 0.0272 (ones), respectively, whereas the corresponding empirical percentages are 0.6055 and 0.0313, revealing the model fits the data well. Figure 4 shows the estimated CDF of the ZOIB, CDCSN and BDCSN distributions indicating their good fit to the data.
Table 3.
Maximum likelihood estimates for ZOIB, CDCSN and BDCSN parameters (with approximate standard errors in parentheses) and information criteria and log-likelihood values, with death data.
We can numerically compare the distributions studied in this application while using the Akaike information criterion (AIC), the Schwarz Bayesian information criterion (BIC), and corrected Akaike information criterion (CAIC) [42]. The AIC, BIC, and CAIC are given, respectively, by
where is the log-likelihood function for , associated with the underlying distribution, evaluated at , d is the dimension of the parameter space, and n is the size of the data set. All of these criteria are based on the log-likelihood function and penalize the distribution with more parameters. A distribution whose information criterion has a smaller value is better [43]. The log-likelihood, AIC, BIC and CAIC values computed according to expressions given in (27), for the distributions studied in this application, are presented in Table 3. From this table, observe that the BDCSN distribution has a better agreement with the death data. Additionally, in order to compare the CDCSN and BDCSN distributions against the ZOIB distribution, we use the Voung test [44], with its statistic being a distance between two distributions measured in terms of the Kullback–Liebler criterion [45]. Then, when comparing the BDCSN and ZOIB distributions, the p-value of the Voung value is <0.001, providing a highly significant evidence in favor that the BDCSN distribution fits the death data better than the ZOIB distribution. Similarly, the Voung p-value is <0.001 when comparing the BDCSN and DCSN distributions in favor of the BDCSN distribution, but the ZOIB distribution fits the data better than the CDCSN distribution. These results demonstrate the fact that the BDCSN distribution is a viable option to the ZOIB distribution to model the death data.
7. Real Data Application 2
In this section, in order to provide evidence that the distributions proposed in this paper fit different types of data, we analyze a second data set corresponding to the cable TV penetration in USA. These data were collected by the Federal Communications Commission (FCC) by means of questionnaires applied to cable community units, which are individual franchise areas. These questionnaires supplied data on prices, costs and cable operator background; see details of the questionnaire in Appendix E of [46]. We name this data set as “FCC” and corresponds to 282 individual areas franchising cable TV; see [12] for an analysis of these data. For FCC data, we study the proportion of subscribers going for additional canals.
The FCC data set contains 62 zeros, with the clump-at-zero in the histogram representing 21.98% of the data; see bold line in the histogram of Figure 5 (left). Therefore, we note that this variable has excess of zeros. Table 4 provides descriptive statistics for the data set in study (uncensored), including median, mean, SD, CV, CS and CK. From this table, note the presence of skewness and kurtosis in the distribution of the data; see also Figure 5 (left), which depicts the histogram with boxplot revealing the behavior of the data.
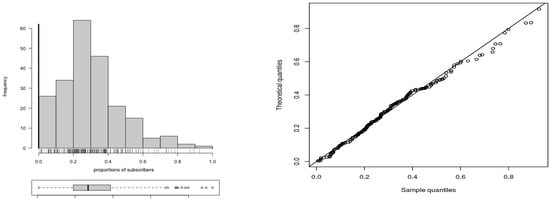
Figure 5.
(left) Histogram for the proportion of subscribers and (right) QQ plot for the BDCSN distribution with FCC data.
Table 4.
Descriptive statistics of the FCC data.
We adjust four distributions to the FCC data: (i) the CSN distribution censored at , (ii) the BDCSN distribution, (iii) the ZOIB distribution (with no ones), and (iv) the normal distribution censored at . The maximum likelihood estimates for the parameters of these four distributions, with approximate standard errors in parentheses, are reported in Table 5. The log-likelihood, AIC, BIC and CAIC values computed according to expressions given in (27), for the distributions studied in this second application, are also presented in Table 5. From this table, observe that the BDCSN distribution has a better agreement with the FCC data. Additionally, when comparing the BDCSN and ZOIB distributions with the Vuong test, the corresponding p-value is 0.2124 indicating a statistically non-significant difference and demonstrating that both distributions are good alternatives to model these data. When comparing the BDCSN and censored normal distributions, the Voung p-value is <0.001 favoring the BDCSN distribution, which also occurs if we compare the CSN and BDCSN distributions. In summary, the BDCSN distribution seems to be a good alternative of modeling for the FCC data, which can be visually corroborated by Figure 5 (right), where the empirical quantile versus theoretical quantile (QQ) plot for the BDCSN distribution is depicted.
Table 5.
Maximum likelihood estimates for ZOIB, censored normal, CSN and BDCSN distributions (with approximate standard errors in parentheses) and information criteria and log-likelihood values, with FCC data.
8. Conclusions and Future Research
This paper reported the following findings:
- (i)
- By using skew-normal distributions, we have proposed a new family of distributions which are an alternative to the beta distribution when an excess zeros and/or one inflation is present.
- (ii)
- The parameters of the distributions were estimated by the maximum likelihood method.
- (iii)
- The expected and observed Fisher information matrices associated with the new family of distributions were derived, and an parameterization was proposed to circumvent a singularity problem in these matrices, which is inherited from the classical skew-normal distribution.
- (iv)
- The Fisher information matrix related to the new mixture distribution obtained in this study resulted to be block ortogonal, facilitating the estimation of parameters and doing it separately in two groups with respect to the discrete and continuous parts of this mixture, respectively.
- (v)
- An algorithm to generate random numbers from the new family of distributions derived in this study was proposed and implemented.
- (vi)
- Monte Carlo simulations based on the new family of distributions proposed in this research were provided to detect performance of the maximum likelihood estimators of their parameters.
- (vii)
- Examples with two real data sets were performed to illustrate the potential applications with the new family of distributions based on the skew-normal distribution proposed in the paper. In addition, we compare the new distributions to their natural competitors, corresponding to the beta and normal distributions, showing their convenience.
In summary, we have proposed new distributions based on the skew-normal distribution, which allows us to model proportions and rates with zero/one inflation as an alternative to the inflated beta distributions. We used the maximum likelihood method for parameter estimation and the observed and expected Fisher information matrices were derived to conduct likelihood-based inference. Numerical studies with simulated and real data were performed to show the good empirical behavior of the estimators and to illustrate potential applications. Therefore, this investigation may be a knowledge addition to the tool-kit of diverse practitioners, including biometrists, engineers, statisticians, and data scientists.
Some open problems that arose from the present investigation are the following:
- (i)
- Parameter estimates of censored distributions are more efficient than when censorship is not considered. Indeed, if censored cases are present and a non-censored distribution is used, evidently it is not possible to estimate the variance of the censored part. However, if censored distributions are utilized in this case, such a variance may be estimated from the data. For more details, see page 199 in [47]. Subsequently, the study of asymptotic efficiency bounds in the new family of distributions proposed in the present investigation is an issue of interest; see details in [48]. In addition, asymptotic behavior and performance of maximum likelihood estimators in more complex statistical models can be studied in [49,50].
- (ii)
- The use of covariates when modeling a doubly-censored response with support in [0, 1] following the new family of distributions is of interest. In this case, type Tobit models can be considered as benchmark to compare the new regression models. Specifically, when studying a doubly-censored response in [0, 1] through a linear predictor which includes covariates, the number of observations below and/or above can be modeled by a Bernoulli distribution with a logit link function and polychotomous response. Given the possible orthogonality in the information matrix, the parameters of this model of two parts can be estimated separately. Refs. [30,36] discussed estimation methods for the regression parameters in a similar context under a mixture structure.
- (iii)
- An extension of the present study to the multivariate case is also of practical relevance [50,51,52].
- (iv)
- Incorporation of temporal, spatial, functional, and quantile regression structures in the modeling, as well as errors-in-variables, and PLS regression, are also of interest [53,54,55,56,57,58,59,60,61].
- (v)
- The derivation of diagnostic techniques to detect potential influential cases are needed, which are an important tool to be used in all statistical modeling [7,58,62].
- (vi)
- Robust estimation methods when outliers are present into the data set can be used [63].
- (vii)
- Applications of the new methodology derived here can be of interest in diverse areas [64].
Therefore, the proposed results in this study promote new challenges and offer an open door to explore other theoretical and numerical issues. Research on these and other issues are in progress and their findings will be reported in future articles.
Author Contributions
Data curation, G.M.-F. and C.M.; formal analysis, G.M.-F., V.L. and C.M.; investigation, G.M.-F., V.L., E.G.-D. and C.M.; methodology, G.M.-F., V.L., E.G.-D. and C.M.; writing—original draft, G.M.-F., V.L. and E.G.-D.; writing—review and editing, V.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported partially by project grant “FCB-03-18” entitled “Distribuciones de probabilidad asimétrica bimodal con soporte positivo”, from the Universidad de Córdoba, Colombia, (G. Martínez-Flórez); and by project grants “Fondecyt 1200525” (V. Leiva) and “Fondecyt 11190636” (C. Marchant)’ from the National Agency for Research and Development (ANID) of the Chilean government.
Acknowledgments
The authors would also like to thank the Editor and Reviewers for their constructive comments which led to improve the presentation of the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Appendix A.1. Doubly-Censored SN Distribution
The elements of the score vector for the DCSN distribution are expressed as
with being defined in (7), being stated in (3), and .
The elements of the observed information matrix corresponding to the DCSN distribution can be written as
The expected Fisher information matrix corresponding to the DCSN distribution has elements
Appendix A.2. The Bernoulli/Doubly-Censored SN Mixture Distribution
The elements of the score vector are given by
where , with , , and .
The elements of the Fisher information matrix are stated as
where and defined in (8).
References
- Azzalini, A. A class of distributions which includes the normal ones. Scand. J. Stat. 1985, 12, 171–178. [Google Scholar]
- Azzalini, A. Further results on a class of distributions which includes the normal ones. Statistica 1986, 46, 199–208. [Google Scholar]
- Henze, N. A probabilistic representation of the skew-normal distribution. Scand. J. Stat. 1986, 13, 271–275. [Google Scholar]
- Chiogna, M. Notes on Estimation Problems with Scalar Skew-Normal Distributions; Technical Report 11997.15; Department of Statistical Science: Padova, Italy, 1997. [Google Scholar]
- Pewsey, A. Problems of inference for Azzalini’s skew-normal distribution. J. Appl. Stat. 2000, 27, 859–870. [Google Scholar] [CrossRef]
- Gómez, H.W.; Venegas, O.; Bolfarine, H. Skew-symmetric distributions generated by the distribution function of the normal distribution. Environmetrics 2007, 18, 395–407. [Google Scholar] [CrossRef]
- Liu, Y.; Mao, G.; Leiva, V.; Liu, S.; Tapia, A. Diagnostic analytics for an autoregressive model under the skew-normal distribution. Mathematics 2020, 8, 693. [Google Scholar] [CrossRef]
- Seijas-Macias, A.; Oliveira, A.; Oliveira, T.; Leiva, V. Approximating the distribution of the product of two normally distributed random variables. Symmetry 2020, 12, 1201. [Google Scholar] [CrossRef]
- Kotz, S.; Van Dorp, J.R. Beyond Beta: Other Continuous Families of Distributions with Bounded Support and Applications; World Scientific: New York, NY, USA, 2004. [Google Scholar]
- Paolino, P. Maximum likelihood estimation of models with beta-distributed dependent variables. Polit. Anal. 2001, 9, 325–346. [Google Scholar] [CrossRef]
- Cribari-Neto, F.; Vasconcellos, K.L.P. Nearly unbiased maximum likelihood estimation for the beta distribution. J. Stat. Comput. Simul. 2002, 72, 107–118. [Google Scholar] [CrossRef]
- Kieschnick, R.; McCullough, B.D. Regression analysis of variates observed on (0, 1): Percentages, proportions and fractions. Stat. Model. 2003, 3, 193–213. [Google Scholar] [CrossRef]
- Ferrari, S.; Cribari-Neto, F. Beta regression for modeling rates and proportions. J. Appl. Stat. 2004, 31, 799–815. [Google Scholar] [CrossRef]
- Gómez–Déniz, E.; Sordo, M.A.; Calderín-Ojeda, E. The log-Lindley distribution as an alternative to the beta regression model with applications consurance. Insur. Math. Econ. 2013, 54, 49–57. [Google Scholar] [CrossRef]
- Vasconcellos, K.L.P.; Cribari-Neto, F. Improved maximum likelihood estimation in a new class of beta regression models. Braz. J. Probab. Stat. 2005, 19, 13–31. [Google Scholar]
- Brascum, A.D.; Johnson, W.O.; Thurmond, M.C. Bayesian beta regression: Applications to household expenditure data and genetic distance between foot-and-mouth disease viruses. Aust. N. Z. J. Stat. 2007, 49, 287–301. [Google Scholar] [CrossRef]
- Bayes, C.; Bazán, J.; García, C. A new robust regression model for proportions. Bayesian Anal. 2012, 7, 841–866. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.B.; Dey, S. The unit-Birnbaum-Saunders distribution with applications. Chilean J. Stat. 2018, 9, 47–57. [Google Scholar]
- Mazucheli, J.; Menezes, A.F.B.; Ghitany, M.E. The unit-Weibull distribution and associated inference. J. Appl. Probab. Stat. 2018, 13, 1–22. [Google Scholar]
- Dasilva, A.; Dias, R.; Leiva, V.; Marchant, C.; Saulo, H. Birnbaum-Saunders regression models: A comparative evaluation of three approaches. J. Stat. Comput. Simul. 2020. [Google Scholar] [CrossRef]
- Cohen, A.C. Truncated and Censored Samples: Theory and Applications; Marcel Dekker: New York, NY, USA, 1991. [Google Scholar]
- Klein, J.P.; Moeschberger, M.L. Survival Analysis: Techniques for Censored and Truncated Data; Springer: New York, NY, USA, 1997. [Google Scholar]
- Schneider, H. Truncated and Censored Samples from Normal Populations; Marcel Dekker: New York, NY, USA, 1986. [Google Scholar]
- Barros, M.; Galea, M.; Gonzalez, M.; Leiva, V. Influence diagnostics in the Tobit censored response model. Stat. Methods Appl. 2010, 19, 379–397. [Google Scholar] [CrossRef]
- Barros, M.; Galea, M.; Leiva, V.; Santos-Neto, M. Generalized Tobit models: Diagnostics and application in econometrics. J. Appl. Stat. 2018, 45, 145–167. [Google Scholar] [CrossRef]
- Desousa, M.; Saulo, H.; Leiva, V.; Scalco, P. On a Tobit-Birnbaum-Saunders model with an application to medical data. J. Appl. Stat. 2018, 45, 932–955. [Google Scholar] [CrossRef]
- Papke, L.E.; Wooldridge, J.M. Econometric methods for fractional response variables with an application to 401(k) plan participation rates. J. Appl. Econ. 1996, 11, 619–632. [Google Scholar] [CrossRef]
- Ospina, R.; Ferrari, S. Inflated beta distributions. Stat. Pap. 2010, 51, 111–126. [Google Scholar] [CrossRef]
- Ospina, R.; Ferrari, S. A general class of zero-or-one inflated beta regression models. Comput. Stat. Data Anal. 2012, 56, 1609–1620. [Google Scholar] [CrossRef]
- Desousa, M.; Saulo, H.; Leiva, V.; Santos-Neto, M. On a new mixture-based regression model: Simulation and application to data with high censoring. J. Stat. Comput. Simul. 2020. [Google Scholar] [CrossRef]
- Leiva, V.; Santos-Neto, M.; Cysneiros, F.J.A.; Barros, M. A methodology for stochastic inventory models based on a zero-adjusted Birnbaum-Saunders distribution. Appl. Stoch. Model. Bus. Ind. 2016, 32, 74–89. [Google Scholar] [CrossRef]
- Moulton, L.; Halsey, N.A. A mixture model with detection limits for regression analyses of antibody response to vaccine. Biometrics 1995, 51, 1570–1578. [Google Scholar] [CrossRef]
- Chai, H.; Bailey, K. Use of log-skew normal distribution in analysis of continuous data with a discrete component at zero. Stat. Med. 2008, 27, 3643–3655. [Google Scholar] [CrossRef]
- Lin, G.D.; Stoyanov, J. The logarithmic skew-normal distribution are moment-indeterminate. J. Appl. Probab. 2009, 46, 909–916. [Google Scholar] [CrossRef]
- Mateu-Figueras, G.; Pawlowsky-Glahn, V.; Barceló-Vidal, C. The natural law in geochemistry: Log-normal or log-skew-normal? In Proceedings of the 32th International Geological Congress, Firenze, Italy, 20–28 August 2004; Volume 2, pp. 233–236. [Google Scholar]
- Farias, R.; Moreno-Arenas, G.; Patriota, A. Reduction of models in the presence of nuisance parameters. Rev. Colomb. Estadíst. 2009, 32, 99–121. [Google Scholar]
- Arellano-Valle, R.B.; Azzalini, A. The centered parametrization for the multivariate skew-normal distribution. J. Multivar. Anal. 2008, 99, 1362–1382. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Lange, K. Numerical Analysis for Statisticians; Springer: New York, NY, USA, 2010. [Google Scholar]
- Cox, D.R.; Hinkley, D.V. Theoretical Statistics; Chapman and Hall: London, UK, 1974. [Google Scholar]
- Azzalini, A. Package ‘sn’. 2017. Available online: http://azzalini.stat.unipd.it/SN/sn-manual.pdf (accessed on 21 July 2020).
- Ventura, M.; Saulo, H.; Leiva, V.; Monsueto, S. Log-symmetric regression models: Information criteria, application to movie business and industry data with economic implications. Appl. Stoch. Model. Bus. Ind. 2019, 34, 963–977. [Google Scholar] [CrossRef]
- Ferreira, M.; Gomes, M.I.; Leiva, V. On an extreme value version of the Birnbaum-Saunders distribution. Revstat 2012, 10, 181–210. [Google Scholar]
- Vuong, Q. Likelihood ratio tests for model selection and non-tested hypotheses. Econometrica 1989, 57, 307–333. [Google Scholar] [CrossRef]
- Kullback, S.; Leiber, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Federal Communication Commission. FCC 93-177, Report and Order and Further Notice of Proposed Rulemaking; Government Printing Office: Washington, DC, USA, 1994.
- Scott, J.L. Regression Models of Categorical and Limited Dependent Variables; Sage: Thousand Oaks, CA, USA, 1997. [Google Scholar]
- Inkmann, J. Asymptotic Efficiency Bounds. In Conditional Moment Estimation of Nonlinear Equation Systems; Springer: Berlin/Heidelberg, Germany, 2001; pp. 36–54. [Google Scholar]
- Genton, M.G.; Zhang, H. Identifiability problems in some non-Gaussian spatial random fields. Chilean J. Stat. 2012, 3, 171–179. [Google Scholar]
- Sánchez, L.; Leiva, V.; Galea, M.; Saulo, H. Birnbaum-Saunders quantile regression models with application to spatial data. Mathematics 2020, 8, 1000. [Google Scholar] [CrossRef]
- Aykroyd, R.G.; Leiva, V.; Marchant, C. Multivariate Birnbaum-Saunders distributions: Modelling and applications. Risks 2018, 6, 21. [Google Scholar] [CrossRef]
- Marchant, C.; Leiva, V.; Christakos, G.; Cavieres, M.F. Monitoring urban environmental pollution by bivariate control charts: New methodology and case study in Santiago, Chile. Environmetrics 2019, 30, e2551. [Google Scholar] [CrossRef]
- Leiva, V.; Sánchez, L.; Galea, M.; Saulo, H. Global and local diagnostic analytics for a geostatistical model based on a new approach to quantile regression. Stoch. Environ. Res. Risk Assess. 2020. [Google Scholar] [CrossRef]
- Leiva, V.; Saulo, H.; Souza, R.; Aykroyd, R.G.; Vila, R. A new BISARMA time series model for forecasting mortality using weather and particulate matter data. J. Forecast. 2020. [Google Scholar] [CrossRef]
- Huerta, M.; Leiva, V.; Rodriguez, M.; Villegas, D. On a partial least squares regression model for asymmetric data with a chemical application in mining. Chem. Intell. Lab. Syst. 2019, 190, 55–68. [Google Scholar] [CrossRef]
- Garcia-Papani, F.; Uribe-Opazo, M.A.; Leiva, V.; Aykroyd, R.G. Birnbaum-Saunders spatial modelling and diagnostics applied to agricultural engineering data. Stoch. Environ. Res. Risk Assess. 2017, 31, 105–124. [Google Scholar] [CrossRef]
- Saulo, H.; Leão, J.; Leiva, V.; Aykroyd, R.G. Birnbaum-Saunders autoregressive conditional duration models applied to high-frequency financial data. Stat. Pap. 2019, 60, 1605–1629. [Google Scholar] [CrossRef]
- Carrasco, J.M.F.; Figueroa-Zuniga, J.I.; Leiva, V.; Riquelme, M.; Aykroyd, R.G. An errors-in-variables model based on the Birnbaum-Saunders and its diagnostics with an application to earthquake data. Stoch. Environ. Res. Risk Assess. 2020, 34, 369–380. [Google Scholar] [CrossRef]
- Sánchez, L.; Leiva, V.; Galea, M.; Saulo, H. Birnbaum-Saunders quantile regression and its diagnostics with application to economic data. Appl. Stoch. Model. Bus. Ind. 2020. [Google Scholar] [CrossRef]
- Martinez, S.; Giraldo, R.; Leiva, V. Birnbaum-Saunders functional regression models for spatial data. Stoch. Environ. Res. Risk Assess. 2019, 33, 1765–1780. [Google Scholar] [CrossRef]
- Giraldo, R.; Herrera, L.; Leiva, V. Cokriging prediction using as secondary variable a functional random field with application in environmental pollution. Mathematics 2020, 8, 1305. [Google Scholar] [CrossRef]
- Garcia-Papani, F.; Leiva, V.; Uribe-Opazo, M.A.; Aykroyd, R.G. Birnbaum-Saunders spatial regression models: Diagnostics and application to chemical data. Chem. Intell. Lab. Syst. 2018, 177, 114–128. [Google Scholar] [CrossRef]
- Velasco, H.; Laniado, H.; Toro, M.; Leiva, V.; Lio, Y. Robust three-step regression based on comedian and its performance in cell-wise and case-wise outliers. Mathematics 2020, 8, 1259. [Google Scholar] [CrossRef]
- Kotz, S.; Leiva, V.; Sanhueza, A. Two new mixture models related to the inverse Gaussian distribution. Methodol. Comput. Appl. Probab. 2010, 12, 199–212. [Google Scholar] [CrossRef]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).