

Optimised DNN-Based Agricultural Land Mapping Using Sentinel-2 and Landsat-8 with Google Earth Engine




Abstract
1. Introduction
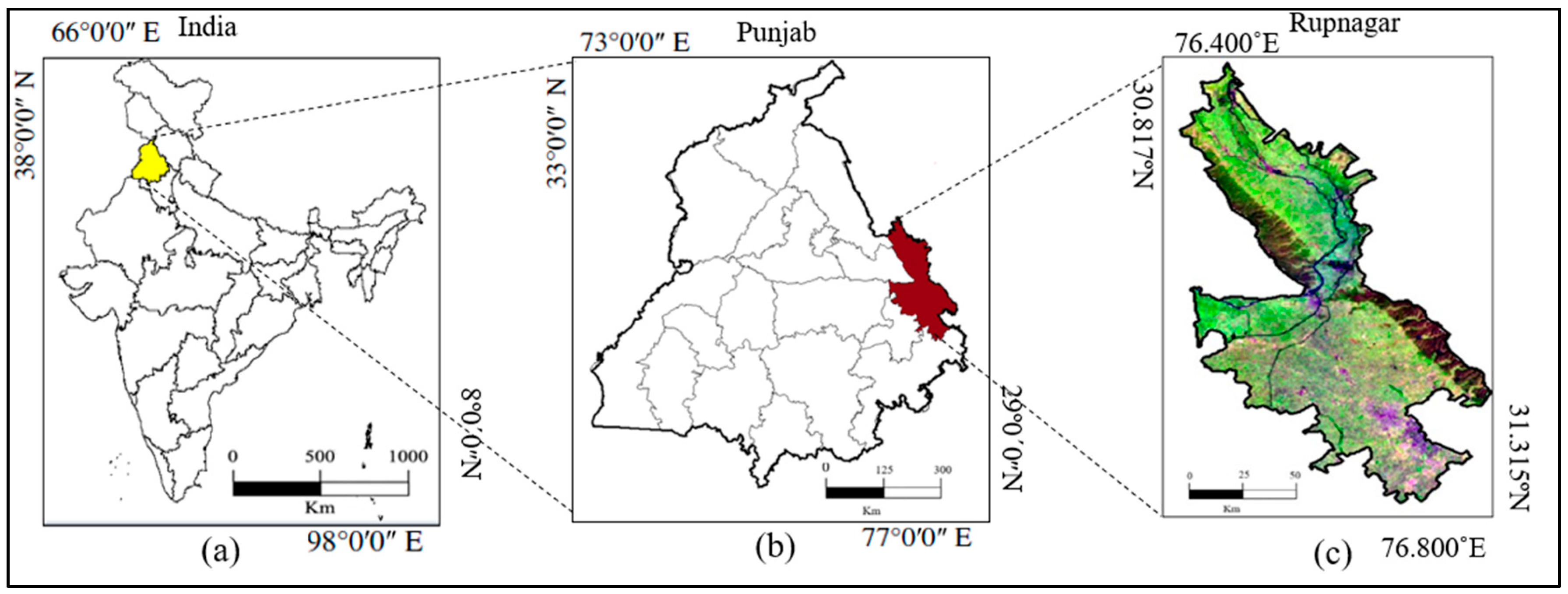
2. Study Site and Satellite Dataset
Satellite Dataset
3. Materials and Methods
3.1. Pre-Processing
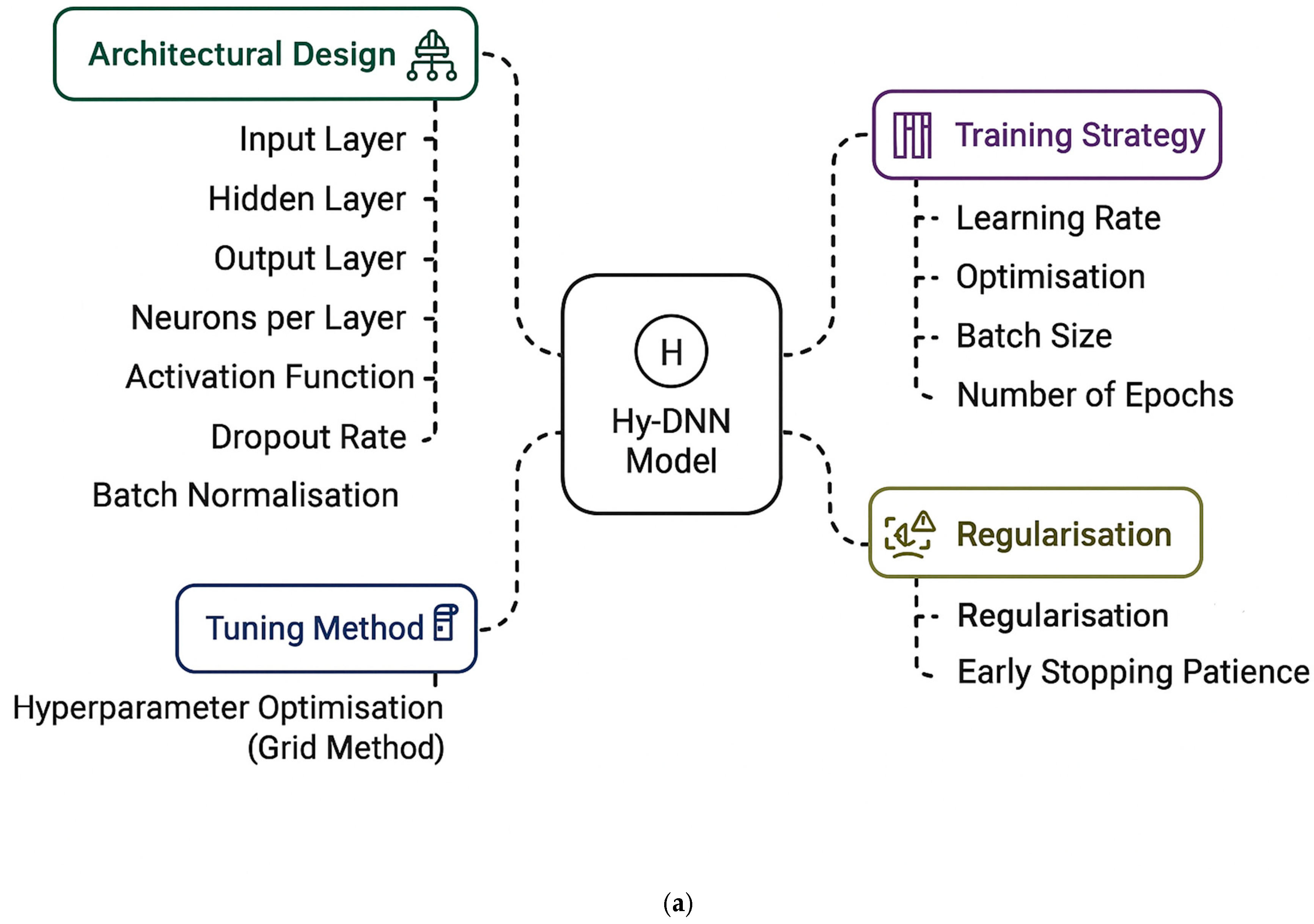
3.2. Hyper-Tuned Deep Neural Network (Hy-DNN)
3.3. Cross-Referencing with Other Machine Learning Classification Algorithms
3.3.1. Random Forest (RF)
3.3.2. CART
3.3.3. Minimum Distance Classifier
3.3.4. Naive Bayes
3.3.5. Convolution Neural Network
3.4. Accuracy Assessment
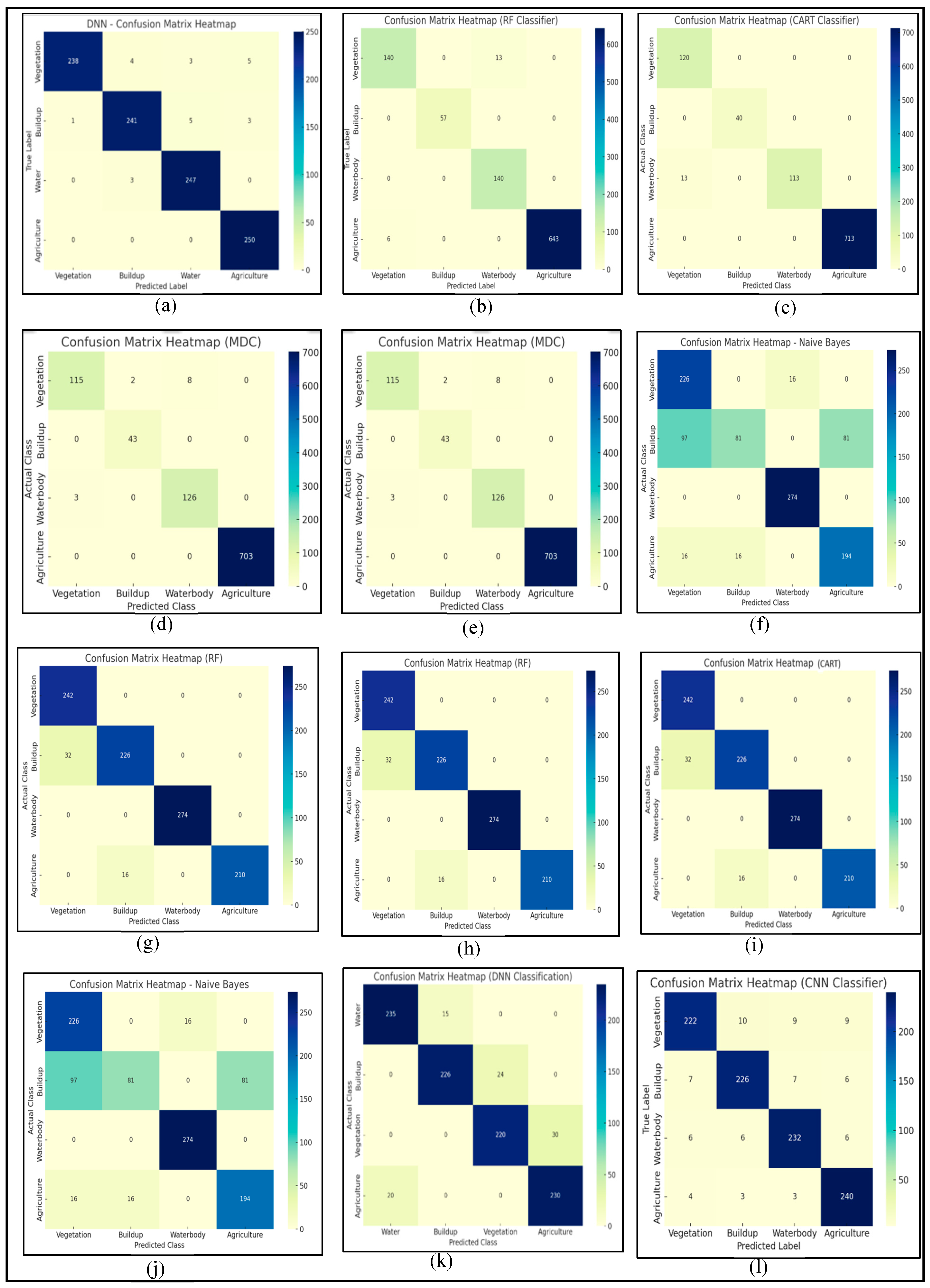
4. Results Analysis
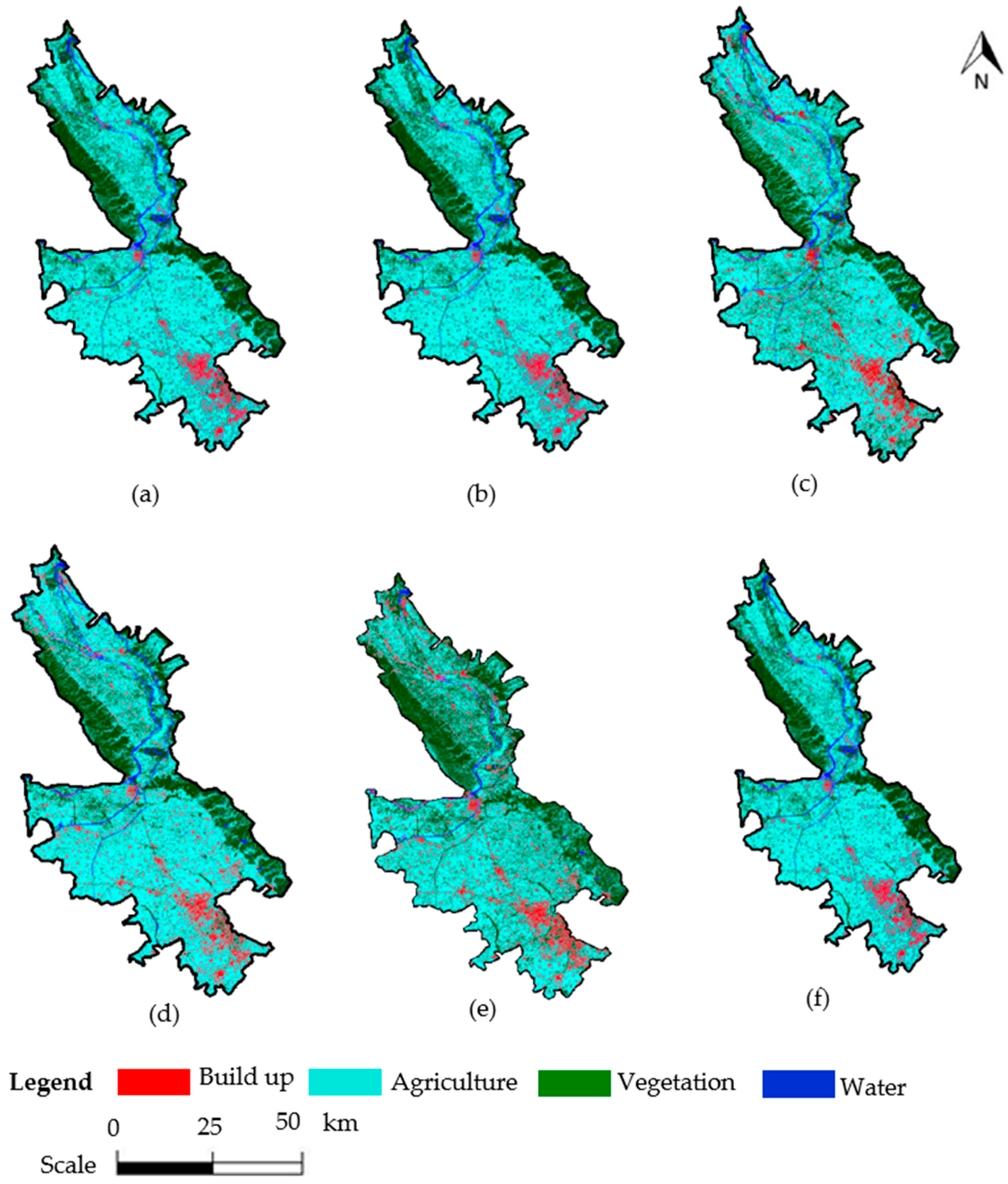
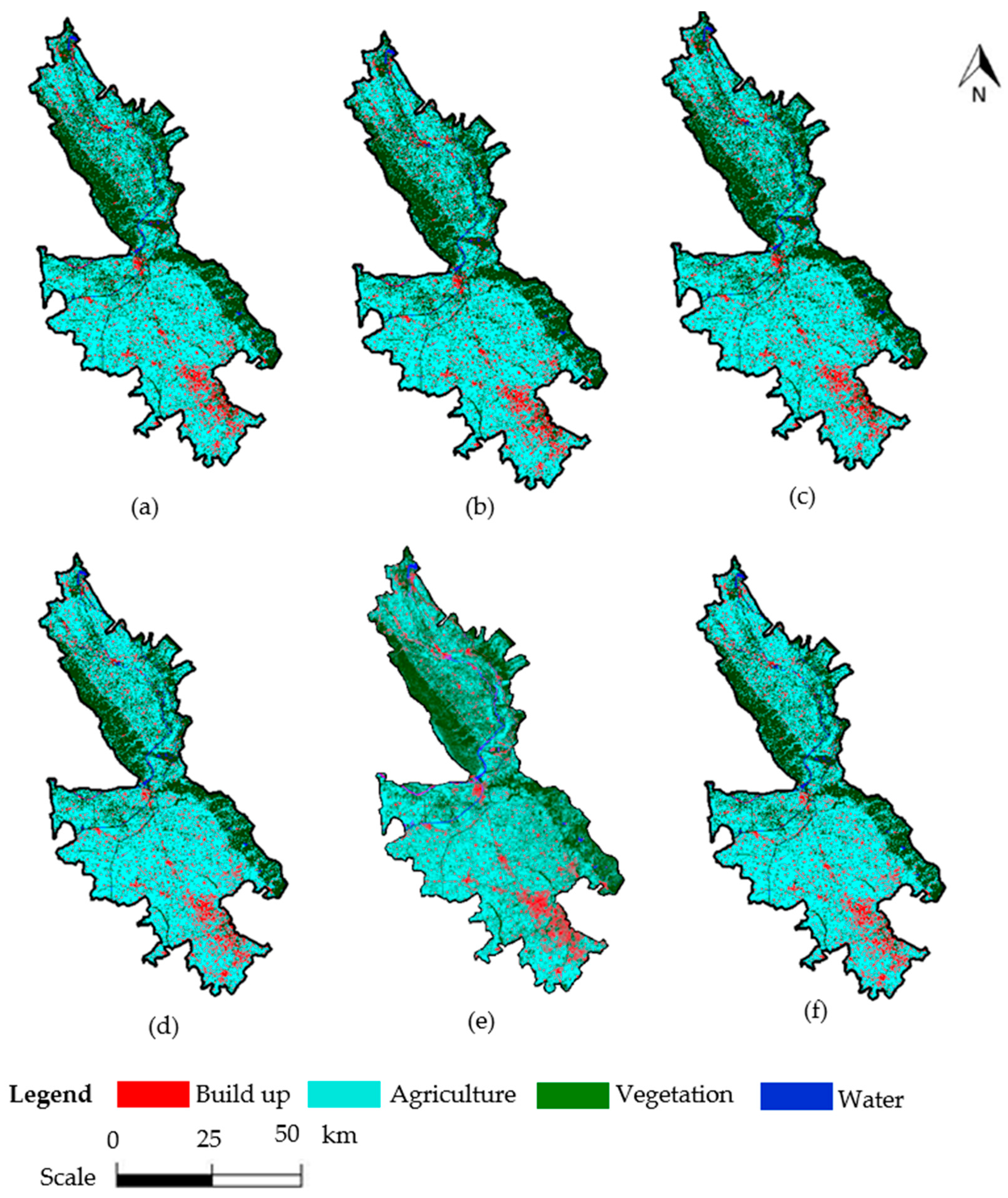
4.1. Visual Analysis of Classified Maps
4.2. Statistical Analysis of Classified Maps
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sharma, I.; Kaur, K. Datasets for Satellite Remote Sensing in Agriculture: An Overview and Analysis. In Proceedings of the 2024 3rd Edition of IEEE Delhi Section Flagship Conference (DELCON), New Delhi, India, 21–23 November 2024; pp. 1–7. [Google Scholar] [CrossRef]
- Colliander, A.; Fisher, J.B.; Halverson, G.; Merlin, O.; Misra, S.; Bindlish, R.; Jackson, T.J.; Yueh, S. Spatial Downscaling of SMAP Soil Moisture Using MODIS Land Surface Temperature and NDVI during SMAPVEX15. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2107–2111. [Google Scholar] [CrossRef]
- Boonman, C.C.F.; Heuts, T.S.; Vroom, R.J.E.; Geurts, J.J.M.; Fritz, C. Wetland Plant Development Overrides Nitrogen Effects on Initial Methane Emissions after Peat Rewetting. Aquat. Bot. 2023, 184, 103598. [Google Scholar] [CrossRef]
- Sharma, N.; Chawla, S. Digital Change Detection Analysis Criteria and Techniques Used for Land Use and Land Cover Classification in Agriculture. In Proceedings of the 2023 3rd International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Greater Noida, India, 12 May 2023; pp. 331–335. [Google Scholar] [CrossRef]
- Saini, R.; Singh, S. Land Use Land Cover Classification Using Machine Learning and Remote Sensing Data: A Case Study of Karnaprayag, Uttarakhand, India. In Proceedings of the 2024 First International Conference on Electronics, Communication and Signal Processing (ICECSP), New Delhi, India, 8–10 August 2024; pp. 1–6. [Google Scholar]
- Zhao, Q.; Yu, L.; Li, X.; Peng, D.; Zhang, Y.; Gong, P. Progress and Trends in the Application of Google Earth and Google Earth Engine. Remote Sens. 2021, 13, 3778. [Google Scholar] [CrossRef]
- Chowdhury, A.; Dwarakish, G.S. Selection of Algorithm for Land Use Land Cover Classification and Change Detection. IJARSCT 2022, 2, 15–24. [Google Scholar] [CrossRef]
- Mahdi, A.S. The Land Use and Land Cover Classification on the Urban Area. Iraqi J. Sci. 2022, 66, 4609–4619. [Google Scholar] [CrossRef]
- Thaiki, M.; Bounoua, L.; Cherkaoui Dekkaki, H. Using Satellite Data to Characterize Land Surface Processes in Morocco. Remote Sens. 2023, 15, 5389. [Google Scholar] [CrossRef]
- Santos, M.P.; Prado, L.A.D.S.; Cogo, A.J.D.; Lopes, A.V.S.; Caldeira, C.F.; Cavalcante, A.B.; Martins, R.L.; de Assis Esteves, F.; Duarte, H.M.; Zandonadi, D.B. High Irradiance Impairs Isoëtes Cangae Growth. Aquat. Bot. 2023, 184. [Google Scholar] [CrossRef]
- Jasim, B.S.; Jasim, O.Z.; AL-Hameedawi, A.N. Evaluating Land Use Land Cover Classification Based on Machine Learning Algorithms. Eng. Technol. J. 2024, 42. [Google Scholar] [CrossRef]
- Chomani, K.; Pshdari, S. Evaluation of Different Classification Algorithms for Land Use Land Cover Mapping. Kurdistan J. Appl. Res. 2024, 9, 13–22. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep Learning Classification of Land Cover and Crop Types Using Remote Sensing Data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Srivastav, A.L.; Dhyani, R.; Ranjan, M.; Madhav, S.; Sillanpää, M. Climate-Resilient Strategies for Sustainable Management of Water Resources and Agriculture. Environ. Sci. Pollut. Res. 2021, 28, 41576–41595. [Google Scholar] [CrossRef] [PubMed]
- Manandhar, R.; Odehi, I.O.A.; Ancevt, T. Improving the Accuracy of Land Use and Land Cover Classification of Landsat Data Using Post-Classification Enhancement. Remote Sens. 2009, 1, 330. [Google Scholar] [CrossRef]
- Mhanna, S.; Halloran, L.J.S.; Zwahlen, F.; Asaad, A.H.; Brunner, P. Using Machine Learning and Remote Sensing to Track Land Use/Land Cover Changes Due to Armed Conflict. Sci. Total Environ. 2023, 898, 165600. [Google Scholar] [CrossRef]
- Celebrezze, J.V.; Alegbeleye, O.M.; Glavich, D.A.; Shipley, L.A.; Meddens, A.J.H. Classifying Rocky Land Cover Using Random Forest Modeling: Lessons Learned and Potential Applications in Washington, USA. Remote Sens. 2025, 17, 915. [Google Scholar] [CrossRef]
- Aberle, R.; Enderlin, E.; O’Neel, S.; Florentine, C.; Sass, L.; Dickson, A.; Marshall, H.-P.; Flores, A. Automated Snow Cover Detection on Mountain Glaciers Using Spaceborne Imagery and Machine Learning. Cryosphere 2025, 19, 1675–1693. [Google Scholar] [CrossRef]
- Zeferino, L.B.; de Souza, L.F.T.; Amaral, C.H.D.; Filho, E.I.F.; de Oliveira, T.S. Does Environmental Data Increase the Accuracy of Land Use and Land Cover Classification? Int. J. Appl. Earth Obs. Geoinf. 2020, 91, 102128. [Google Scholar] [CrossRef]
- Ayushi; Buttar, P.K. Satellite Imagery Analysis for Crop Type Segmentation Using U-Net Architecture. Procedia Comput. Sci. 2024, 235, 3418–3427. [Google Scholar] [CrossRef]
- Luo, K.; Lu, L.; Xie, Y.; Chen, F.; Yin, F.; Li, Q. Crop Type Mapping in the Central Part of the North China Plain Using Sentinel-2 Time Series and Machine Learning. Comput. Electron. Agric. 2023, 205, 107577. [Google Scholar] [CrossRef]
- Latif, B.A.; Lecerf, R.; Mercier, G.; Hubert-Moy, L. Preprocessing of Low-Resolution Time Series Contaminated by Clouds and Shadows. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2083–2096. [Google Scholar] [CrossRef]
- Kluger, D.M.; Wang, S.; Lobell, D.B. Two Shifts for Crop Mapping: Leveraging Aggregate Crop Statistics to Improve Satellite-Based Maps in New Regions. Remote Sens. Environ. 2021, 262, 112488. [Google Scholar] [CrossRef]
- Marujo, R.F.B.; Fronza, J.G.; Soares, A.R.; Queiroz, G.R.; Ferreira, K.R. Evaluating the Impact of Lasrc and Sen2cor Atmospheric Correction Algorithms on Landsat-8/Oli and Sentinel-2/Msi Data Over Aeronet Stations in Brazilian Territory. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2021, 3, 271–277. [Google Scholar] [CrossRef]
- Mandal, D.; Kumar, V.; Bhattacharya, A.; Rao, Y.S.; Siqueira, P.; Bera, S. Sen4Rice: A Processing Chain for Differentiating Early and Late Transplanted Rice Using Time-Series Sentinel-1 SAR Data with Google Earth Engine. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1947–1951. [Google Scholar] [CrossRef]
- Jamal, S.; Ahmad, W.S. Assessing Land Use Land Cover Dynamics of Wetland Ecosystems Using Landsat Satellite Data. SN Appl. Sci. 2020, 2, 1–24. [Google Scholar] [CrossRef]
- Vyas, N.; Singh, S.; Sethi, G.K. A Novel Image Fusion-Based Post Classification Framework for Agricultural Variations Detection Using Sentinel-1 and Sentinel-2 Data. Earth Sci. Inform. 2025, 18. [Google Scholar] [CrossRef]
- Singh, G.; Dahiya, N.; Sood, V.; Singh, S.; Sharma, A. ENVINet5 Deep Learning Change Detection Framework for the Estimation of Agriculture Variations during 2012–2023 with Landsat Series Data. Environ. Monit. Assess. 2024, 196, 233–245. [Google Scholar] [CrossRef]
- Talukdar, S.; Singha, P.; Mahato, S.; Shahfahad; Pal, S.; Liou, Y.A.; Rahman, A. Land-Use Land-Cover Classification by Machine Learning Classifiers for Satellite Observations-A Review. Remote Sens. 2020, 12, 1135. [Google Scholar] [CrossRef]
- Li, Y.; Liu, C.; Zhang, J.; Zhang, P.; Xue, Y. Monitoring Spatial and Temporal Patterns of Rubber Plantation Dynamics Using Time-Series Landsat Images and Google Earth Engine. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9450–9461. [Google Scholar] [CrossRef]
- Setiawan, M.D.; Setiawan, E.B. Machine Learning Method for Carbon Stock Classification with Drone and GEE Data. In Proceedings of the 2025 International Conference on Advancement in Data Science, E-learning and Information System (ICADEIS), Bandung, Indonesia, 3–4 February 2025; pp. 1–7. [Google Scholar]
- Ravirathinam, P.; Ghosh, R.; Khandelwal, A.; Jia, X.; Mulla, D.; Kumar, V. Combining Satellite and Weather Data for Crop Type Mapping: An Inverse Modelling Approach. In Proceedings of the 2024 SIAM International Conference on Data Mining (SDM), Houston, TX, USA, 18–20 April 2024; pp. 445–453. [Google Scholar] [CrossRef]
- Kafle, S.; Sandeep, K.C.; Poudyal, B.; Devkota, S. Machine Learning Approach to Detect Land Use Land Cover (LULC) Change in Chure Region of Sarlahi District, Nepal. Arch. Agric. Environ. Sci. 2023, 8, 168–174. [Google Scholar] [CrossRef]
- De Oliveira, J.P.; Costa, M.G.F.; Costa Filho, C.F.F. Methodology of Data Fusion Using Deep Learning for Semantic Segmentation of Land Types in the Amazon. IEEE Access 2020, 8, 187864–187875. [Google Scholar] [CrossRef]
- Xie, G.; Niculescu, S. Mapping and Monitoring of Land Cover/Land Use (LCLU) Changes in the Crozon Peninsula (Brittany, France) from 2007 to 2018 by Machine Learning Algorithms (Support Vector Machine, Random Forest, and Convolutional Neural Network) and by Post-Classification Comparison (PCC). Remote Sens. 2021, 13, 3899. [Google Scholar] [CrossRef]
- Jamali, A. Evaluation and Comparison of Eight Machine Learning Models in Land Use/Land Cover Mapping Using Landsat 8 OLI: A Case Study of the Northern Region of Iran. SN Appl. Sci. 2019, 1, 1448. [Google Scholar] [CrossRef]
- Singh, S.; Tiwari, R.K.; Gusain, H.S.; Sood, V. Potential Applications of SCATSAT-1 Satellite Sensor: A Systematic Review. IEEE Sens. J. 2020, 20, 12459–12471. [Google Scholar] [CrossRef]
- Basheer, S.; Wang, X.; Farooque, A.A.; Nawaz, R.A.; Liu, K.; Adekanmbi, T.; Liu, S. Comparison of Land Use Land Cover Classifiers Using Different Satellite Imagery and Machine Learning Techniques. Remote Sens. 2022, 14, 4978. [Google Scholar] [CrossRef]
- Srivastava, A.; Bharadwaj, S.; Dubey, R.; Sharma, V.B.; Biswas, S. Mapping Vegetation and Measuring the Performance of Machine Learning Algorithm in Lulc Classification in the Large Area Using Sentinel-2 and Landsat-8 Datasets of Dehradun as a Test Case. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, 43, 529–535. [Google Scholar] [CrossRef]
- Gøttcke, J.M.N.; Zimek, A.; Campello, R.J.G.B. Bayesian Label Distribution Propagation: A Semi-Supervised Probabilistic k Nearest Neighbor Classifier. Inf. Syst. 2025, 129, 102507. [Google Scholar] [CrossRef]
- Jackins, V.; Vimal, S.; Kaliappan, M.; Lee, M.Y. AI-Based Smart Prediction of Clinical Disease Using Random Forest Classifier and Naive Bayes. J. Supercomput. 2021, 77, 5198–5219. [Google Scholar] [CrossRef]
- He, Y.; Ou, G.; Fournier-Viger, P.; Huang, J.Z. Attribute Grouping-Based Naive Bayesian Classifier. Sci. China Inf. Sci. 2025, 68, 132106. [Google Scholar] [CrossRef]
- Liu, T.; Yang, L.; Lunga, D. Change Detection Using Deep Learning Approach with Object-Based Image Analysis. Remote Sens. Environ. 2021, 256, 112308. [Google Scholar] [CrossRef]
- Dahiya, N.; Singh, S.; Gupta, S. Comparative Analysis and Implication of Hyperion Hyperspectral and Landsat-8 Multispectral Dataset in Land Classification. J. Indian Soc. Remote Sens. 2023, 51, 2201–2213. [Google Scholar] [CrossRef]
- Waghela, H.; Patel, S.; Sudesan, P.; Raorane, S.; Borgalli, R. Land Use Land Cover Classification Using Machine Learning. In Proceedings of the 2022 International Conference on Automation, Computing and Renewable Systems (ICACRS), Pudukkottai, India, 13–15 December 2022; pp. 708–711. [Google Scholar]
- Fan, C.-L. Evaluation Model for Crack Detection with Deep Learning: Improved Confusion Matrix Based on Linear Features. J. Constr. Eng. Manag. 2025, 151, 4024210. [Google Scholar] [CrossRef]
- Jiang, Y.; Liu, Z.; Kabirzadeh, P.; Wu, Y.; Li, Y.; Miljkovic, N.; Wang, P. Multi-Fidelity Physics-Informed Convolutional Neural Network for Heat Map Prediction of Battery Packs. Reliab. Eng. Syst. Saf. 2025, 256, 110752. [Google Scholar] [CrossRef]
- Amani, M.; Ghorbanian, A.; Ahmadi, S.A.; Kakooei, M.; Moghimi, A.; Mirmazloumi, S.M.; Moghaddam, S.H.A.; Mahdavi, S.; Ghahremanloo, M.; Parsian, S.; et al. Google Earth Engine Cloud Computing Platform for Remote Sensing Big Data Applications: A Comprehensive Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5326–5350. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factors | Landsat-8 | Sentinel-2 |
|---|---|---|
| Sensor Types | OLI-2 (Operational Land Imager-2, TIRS-I (Thermal Infrared Sensor) | Multispectral imager (MSI) |
| Spectral Bands | It works on 11 spectral bands: OLI-2 works on multispectral bands 1–9 (0.43–1.38 µm), TIRS works on panchromatic band 10 (10.6 + 0–11–19 µm), and Band 11 (11.5–12.51 µm). | It uses 13 Spectral bands from visible to the infrared (VIS/NIR) |
| Spatial Resolution | Bands 1–7 and 9: 30 m, Band 8: 15 m, Band 10–11: 100 m | 10 m (VIS/NIR bands), 20 m (red-edge and SWIR bands, and 60 m (atmospheric correction bands) |
| Temporal Resolution | 16 days | 5 days |
| Swath Width | 185 km | 290 km |
| Orbit | Sun-synchronous, near-polar orbit | Sun-synchronous, near-polar orbit |
| Data Format | GeoTIFF | JPEG 2000, XML with metadata |
| Operational | 11 February 2013 | 23 January 2015 |
| Accuracy Parameters | |||||
|---|---|---|---|---|---|
| Classifier | Classified Data | PA | CA | Kc | OA |
| NB | Agriculture | 0.82 | 0.85 | 83.00% | 85.00% |
| Vegetation | 0.53 | 0.96 | |||
| Built-up | 0.86 | 0.83 | |||
| Waterbody | 0.8 | 0.8 | |||
| MDC | Agriculture | 0.92 | 0.97 | 85.00% | 87.00% |
| Vegetation | 0.84 | 0.96 | |||
| Built-up | 0.97 | 0.93 | |||
| Waterbody | 0.82 | 0.83 | |||
| CART | Agriculture | 0.9 | 0.9 | 89.00% | 90.00% |
| Vegetation | 0.93 | 0.92 | |||
| Built-up | 0.89 | 0.85 | |||
| Waterbody | 0.86 | 0.87 | |||
| RF | Agriculture | 0.84 | 0.92 | 91.00% | 92.00% |
| Vegetation | 0.89 | 0.91 | |||
| Built-up | 0.94 | 0.93 | |||
| Waterbody | 0.93 | 0.94 | |||
| Hyper-tuned DNN | Agriculture | 0.96 | 1 | 96.80% | 97.60% |
| Vegetation | 0.99 | 0.95 | |||
| Built-up | 0.97 | 0.96 | |||
| Waterbody | 0.96 | 0.98 | |||
| CNN | Agriculture | 0.91 | 0.96 | 94.00% | 95.23% |
| Vegetation | 0.97 | 0.89 | |||
| Built-up | 0.92 | 0.92 | |||
| Waterbody | 0.91 | 0.93 | |||
| Accuracy Parameters | |||||
|---|---|---|---|---|---|
| Classifier | Classified Classes | PA | CA | Kc | OA |
| NB | Agriculture | 0.93 | 0.66 | 69.00% | 77.00% |
| Vegetation | 0.31 | 0.83 | |||
| Built-up | 0.82 | 0.94 | |||
| Waterbody | 0.94 | 0.7 | |||
| MDC | Agriculture | 0.93 | 0.82 | 76.39% | 82.25% |
| Vegetation | 0.43 | 0.87 | |||
| Built-up | 1 | 0.94 | |||
| Waterbody | 0.92 | 0.68 | |||
| CART | Agriculture | 1 | 0.88 | 85.00% | 87.00% |
| Vegetation | 0.87 | 0.93 | |||
| Built-up | 0.83 | 0.91 | |||
| Waterbody | 0.92 | 1 | |||
| RF | Agriculture | 1 | 0.88 | 87.00% | 88.00% |
| Vegetation | 0.87 | 0.93 | |||
| Built-up | 0.81 | 0.83 | |||
| Waterbody | 0.92 | 0.82 | |||
| Hyper-tuned DNN | Agriculture | 0.88 | 0.92 | 88.10% | 91.10% |
| Vegetation | 0.9 | 0.88 | |||
| Built-up | 0.93 | 0.9 | |||
| Waterbody | 0.92 | 0.94 | |||
| CNN | Agriculture | 0.87 | 0.9 | 87.23% | 88.13% |
| Vegetation | 0.88 | 0.85 | |||
| Built-up | 0.92 | 0.89 | |||
| Waterbody | 0.9 | 0.93 | |||
| Classifier | Sentinel-2 (Kc/OA) | Landsat-8 (Kc/OA) | Scalability | Usability in QGIS/ArcGIS |
|---|---|---|---|---|
| NB | Kc = 83% OA = 85% | Kc = 69% OA = 77% | Very High (lightweight, fast) | Fully integrated in QGIS (SCP) and ArcGIS; easy to use |
| MDC | Kc = 85% OA = 87% | Kc = 76% OA = 82% | High (low memory, but sensitive to stats) | Available in QGIS/ArcGIS via classification toolsets |
| CART | Kc = 89% OA = 90% | Kc = 85% OA = 87% | High (interpretable and fast training) | Built in GEE, QGIS (SCP), and ArcGIS Model Builder |
| RF | Kc = 91% OA = 92% | Kc = 87% OA = 88% | Very High (robust, scalable with ensemble) | Fully supported in QGIS (SCP) and ArcGIS (Classifier tool) |
| CNN | Kc = 88% OA = 91% | Kc = 94% OA = 95% | High (requires GPU, scalable for moderate datasets) | Limited native support; requires integration via Python (3.9.11) or deep learning plugins in GEE or custom QGIS tools |
| Hyper-tuned DNN | Kc = 96% OA = 97% | Kc = 88% OA = 91% | Very High (best for large, complex datasets; requires tuning and training resources) | Not natively supported in QGIS/ArcGIS; requires GEE, Python, TensorFlow |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharma, N.; Singh, S.; Kaur, K. Optimised DNN-Based Agricultural Land Mapping Using Sentinel-2 and Landsat-8 with Google Earth Engine. Land 2025, 14, 1578. https://doi.org/10.3390/land14081578
Sharma N, Singh S, Kaur K. Optimised DNN-Based Agricultural Land Mapping Using Sentinel-2 and Landsat-8 with Google Earth Engine. Land. 2025; 14(8):1578. https://doi.org/10.3390/land14081578
Chicago/Turabian StyleSharma, Nisha, Sartajvir Singh, and Kawaljit Kaur. 2025. "Optimised DNN-Based Agricultural Land Mapping Using Sentinel-2 and Landsat-8 with Google Earth Engine" Land 14, no. 8: 1578. https://doi.org/10.3390/land14081578
APA StyleSharma, N., Singh, S., & Kaur, K. (2025). Optimised DNN-Based Agricultural Land Mapping Using Sentinel-2 and Landsat-8 with Google Earth Engine. Land, 14(8), 1578. https://doi.org/10.3390/land14081578