Switching Competitors Reduces Win-Stay but Not Lose-Shift Behaviour: The Role of Outcome-Action Association Strength on Reinforcement Learning


{kind=link}
Abstract
1. Introduction
2. Method
2.1. Participants
2.2. Stimuli and Apparatus
2.3. Design
2.4. Procedure
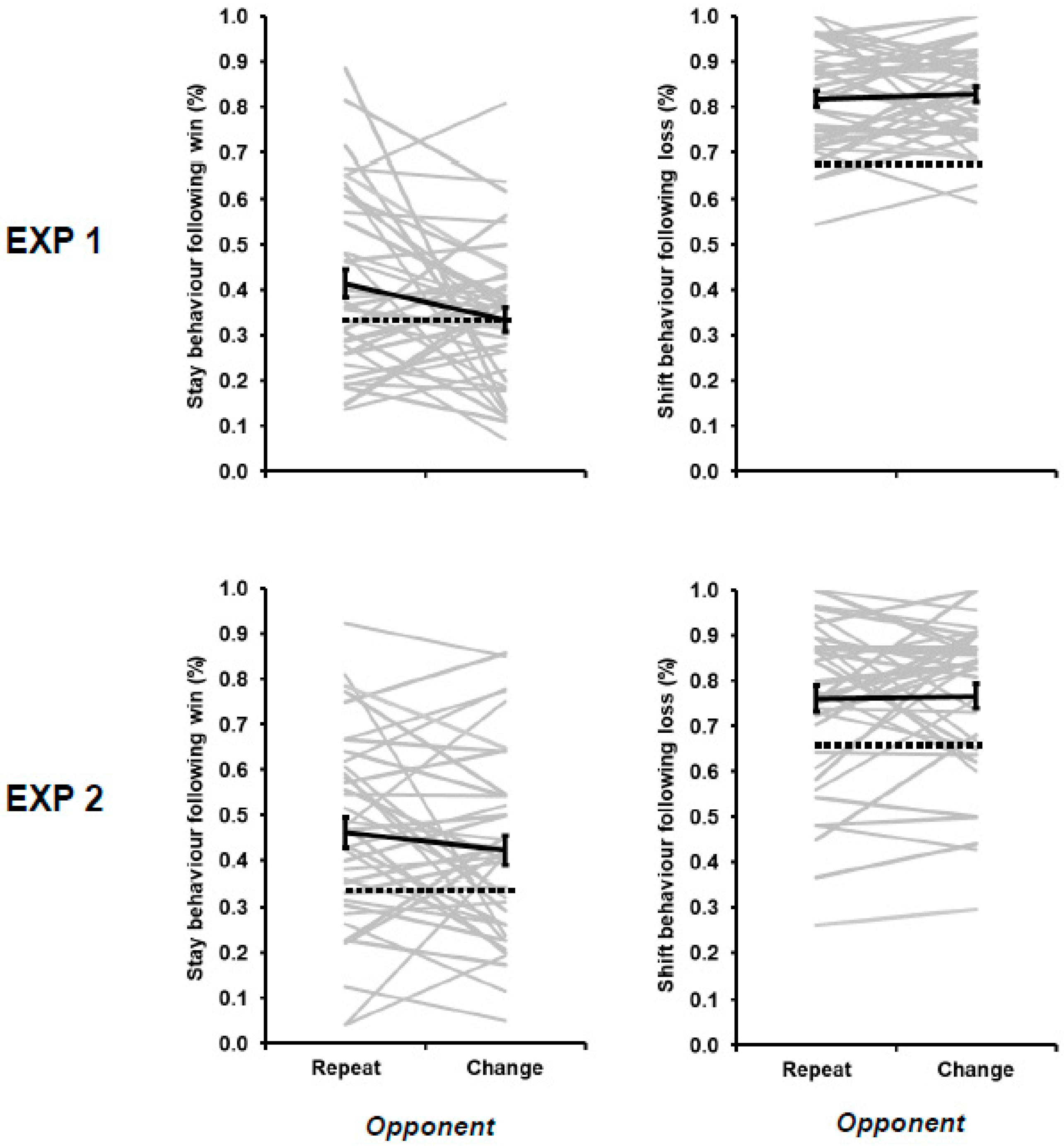
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Miltner, W.H.R.; Brown, C.H.; Coles, M.G.H. Event related brain potentials following incorrect feedback in a time estimation task: Evidence for a generic neural system for error detection. J. Cogn. Neurosci. 1997, 9, 787–796. [Google Scholar] [CrossRef] [PubMed]
- Abe, H.; Lee, D. Distributed coding of actual and hypothetical outcomes in the orbital and dorsolateral prefrontal cortex. Neuron 2011, 70, 731–741. [Google Scholar] [CrossRef]
- Baek, K.; Kim, Y.-T.; Kim, M.; Choi, Y.; Lee, M.; Lee, K.; Hahn, S.; Jeong, J. Response randomization of one- and two-person Rock-Paper-Scissors games in individuals with schizophrenia. Psychiatry Res. 2013, 207, 158–163. [Google Scholar] [CrossRef]
- Bi, Z.; Zhou, H.-J. Optimal cooperation-trap strategies for the iterated rock-paper-scissors game. PLoS ONE 2014, 9, e111278. [Google Scholar] [CrossRef]
- Loertscher, S. Rock-Scissors-Paper and evolutionarily stable strategies. Econ. Lett. 2013, 118, 473–474. [Google Scholar] [CrossRef]
- Griessinger, T.; Coricelli, G. The neuroeconomics of strategic interaction. Curr. Opin. Behav. Sci. 2015, 3, 73–79. [Google Scholar] [CrossRef]
- Scheibehenne, B.; Wilke, A.; Todd, P.M. Expectations of clumpy resources influence predictions of sequential events. Evol. Hum. Behav. 2011, 32, 326–333. [Google Scholar] [CrossRef]
- Dyson, B.J. Behavioural isomorphism, cognitive economy and recursive thought in non-transitive game strategy. Games 2019, 10, 32. [Google Scholar] [CrossRef]
- Thorndike, E.L. Animal Intelligence; Macmillan Company: New York, NY, USA, 1911. [Google Scholar]
- Kahneman, D.; Tversky, A. Prospect theory: An analysis of decision under risk. Econometrica 1979, 47, 263–291. [Google Scholar] [CrossRef]
- Bolles, R.C. Species-specific defense reactions and avoidance learning. Psychol. Rev. 1970, 77, 32–48. [Google Scholar] [CrossRef]
- West, R.L.; Lebiere, C.; Bothell, D.J. Cognitive architectures, game playing and human evolution. In Cognition and Multi-Agent Interaction: From Cognitive Modeling to Social Smulation; Sun, R., Ed.; Cambridge University Press: Cambridge, UK, 2006; pp. 102–123. [Google Scholar]
- Gruber, A.J.; Thapa, R. The memory trace supporting lose-shift responding decays rapidly after reward omission and is distinct from other learning mechanisms in rats. ENeuro 2016, 3, 6. [Google Scholar] [CrossRef]
- Kubanek, J.; Snyder, L.H.; Abrams, R.A. Reward and punishment act as distinct factors in guiding behavior. Cognition 2015, 139, 154–167. [Google Scholar] [CrossRef] [PubMed]
- Andrade, E.B.; Ariely, D. The enduring impact of transient emotions on decision making. Organ. Behav. Hum. Decis. Process. 2009, 109, 1–8. [Google Scholar] [CrossRef]
- Lerner, J.S.; Li, Y.; Veldesolo, P.; Kassam, K.S. Emotion and decision making. Annu. Rev. Psychol. 2015, 66, 799–823. [Google Scholar] [CrossRef] [PubMed]
- Pham, M.T. Emotion and rationality: A critical review and interpretation of empirical evidence. Rev. Gen. Psychol. 2007, 11, 155–178. [Google Scholar] [CrossRef]
- Sanfey, A.G.; Rilling, J.K.; Aronson, J.A.; Nystrom, L.E.; Cohen, J.D. The neural basis of economic decision-making in the ultimatum game. Science 2003, 300, 1755–1758. [Google Scholar] [CrossRef]
- Dixon, M.J.; MacLaren, V.; Jarick, M.; Fugelsang, J.A.; Harrigan, K.A. The frustrating effects of just missing the jackpot: Slot machine near-misses trigger large skin conductance responses, but no post-reinforcement pauses. J. Gambl. Stud. 2013, 29, 661–674. [Google Scholar] [CrossRef]
- Dixon, M.R.; Schreiber, J.E. Near-miss effects on response latencies and win estimations of slot machine players. Psychol. Rec. 2004, 54, 335–348. [Google Scholar] [CrossRef]
- Dyson, B.J.; Sundvall, J.; Forder, L.; Douglas, S. Failure generates impulsivity only when outcomes cannot be controlled. J. Exp. Psychol. Hum. Percept. Perform. 2018, 44, 1483–1487. [Google Scholar] [CrossRef]
- Verbruggen, F.; Chambers, C.D.; Lawrence, N.S.; McLaren, I.P.L. Winning and losing: Effects on impulsive action. J. Exp. Psychol. Hum. Percept. Perform 2017, 43, 147–168. [Google Scholar] [CrossRef]
- Williams, P.; Heathcote, A.; Nesbitt, K.; Eidels, A. Post-error recklessness and the hot hand. Judgm. Decis. Mak. 2016, 11, 174–184. [Google Scholar]
- Zheng, Y.; Li, Q.; Zhang, Y.; Li, Q.; Shen, H.; Gao, Q.; Zhou, S. Reward processing in gain versus loss context: An ERP study. Psychophys 2017, 54, 1040–1053. [Google Scholar] [CrossRef]
- Dyson, B.J.; Steward, B.A.; Meneghetti, T.; Forder, L. Behavioural and neural limits in competitive decision making: The roles of outcome, opponency and observation. Biol. Psychol. 2020, 149, 107778. [Google Scholar] [CrossRef] [PubMed]
- Dyson, B.J.; Wilbiks, J.M.P.; Sandhu, R.; Papanicolaou, G.; Lintag, J. Negative outcomes evoke cyclic irrational decisions in Rock, Paper, Scissors. Sci. Rep. 2016, 6, 20479. [Google Scholar] [CrossRef] [PubMed]
- Dyson, B.J.; Musgrave, C.; Rowe, C.; Sandhur, R. Behavioural and neural interactions between objective and subjective performance in a Matching Pennies game. Int. J. Psychophysiol. 2020, 147, 128–136. [Google Scholar] [CrossRef] [PubMed]
- Nevo, I.; Erev, I. On surprise, change, and the effects of recent outcomes. Front. Psychol. 2012, 3, 24. [Google Scholar] [CrossRef] [PubMed]
- Forder, L.; Dyson, B.J. Behavioural and neural modulation of win-stay but not lose-shift strategies as a function of outcome value in Rock, Paper, Scissors. Sci. Rep. 2016, 6, 33809. [Google Scholar] [CrossRef]
- Cohen, M.X.; Elger, C.E.; Ranganath, C. Reward expectation modulates feedback-related negativity and EEG spectra. NeuroImage 2007, 35, 968–978. [Google Scholar] [CrossRef] [PubMed]
- Hajcak, G.; Moser, J.S.; Holroyd, C.B.; Simons, R.F. The feedback-related negativity reflects the binary evaluation of good versus bad outcomes. Biol. Psychol. 2006, 71, 148–154. [Google Scholar] [CrossRef] [PubMed]
- Engelstein, G. Achievement Relocked: Loss Aversion and Game Design; MIT Press: London, UK, 2020. [Google Scholar]
- Laakasuo, M.; Palomäki, J.; Salmela, J.M. Emotional and social factors influence poker decision making accuracy. J. Gambl. Stud. 2015, 31, 933–947. [Google Scholar] [CrossRef]
- Mitzenmacher, M.; Upfal, E. Probability and Computing: Randomized Algorithms and Probabilistic Analysis; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Barreda-Tarrazona, I.; Jaramillo-Gutierrez, A.; Pavan, M.; Sabater-Grande, G. Individual Characteristics vs. Experience: An Experimental Study on Cooperation in Prisoner’s Dilemma. Front. Psychol. 2017, 8, 596. [Google Scholar] [CrossRef] [PubMed]
- D’Addario, M.; Pancani, L.; Cappelletti, E.R.; Greco, A.; Monzani, D.; Steca, P. The hidden side of the Ultimatum Game: The role of motivations and mind-reading in a two-level one-shot Ultimatum Game. J. Cogn. Psychol. 2015, 27, 898–907. [Google Scholar] [CrossRef]
- Coleman, A.M. Cooperation, psychological game theory, and limitation of rationality in social interaction. Behav. Brain Sci. 2003, 26, 139–153. [Google Scholar] [CrossRef] [PubMed]
- Brown, J.N.; Rosenthal, R.W. Testing the minimax hypothesis: A re-examination of O’Neill’s game experiment. Econometrica 1990, 58, 1065–1081. [Google Scholar] [CrossRef]
- Garnefski, N.; Kraaij, V. Cognitive emotion regulation questionnaire–development of a short 18-item version (CERQ-short). Personal. Individ. Differ. 2006, 41, 1045–1053. [Google Scholar] [CrossRef]
- O’Neill, B. Nonmetric test of the minimax theory of two-person zerosum games. Proc. Natl. Acad. Sci. USA 1987, 84, 2106–2109. [Google Scholar] [CrossRef]
- O’Neill, B. Comments on Brown and Rosenthal’s re-examination. Econometric 1991, 59, 503–507. [Google Scholar] [CrossRef]
- Kahneman, D. Thinking, Fast and Slow; Farrar, Straus and Giroux: New York, NY, USA, 2011. [Google Scholar]
- Sloman, S.A. The empirical case for two systems of reasoning. Psychol. Bull. 1996, 119, 3–22. [Google Scholar] [CrossRef]
- Weibel, D.; Wissmath, B.; Habegger, S.; Steiner, Y.; Groner, R. Playing online games against computer- vs. human-controlled opponents: Effects on presence, flow, and enjoyment. Comput. Hum. Behav. 2008, 24, 2274–2291. [Google Scholar] [CrossRef]
- West, R.L.; Lebiere, C. Simple games as dynamic, coupled systems: Randomness and other emergent properties. J. Cogn. Syst. Res. 2001, 1, 221–239. [Google Scholar] [CrossRef]
- Sundvall, J.; Dyson, B.J. Breaking the bonds of reinforcement: Effects of trial outcome, rule consistency and rule complexity against exploitable and unexploitable opponents. submitted.
- Lee, D.; McGreevy, B.P.; Barraclough, D.J. Learning decision making in monkeys during a rock-paper-scissors game. Cogn. Brain Res. 2005, 25, 416–430. [Google Scholar] [CrossRef] [PubMed]
- Budescu, D.V.; Rapoport, A. Subjective randomization in one- and two-person games. J. Behav. Decis. Mak. 1992, 7, 261–278. [Google Scholar] [CrossRef]
- Pulford, B.D.; Colman, A.M.; Loomes, G. Incentive magnitude effects in experimental games: Bigger is not necessarily better. Games 2018, 9, 4. [Google Scholar] [CrossRef]
- Yechiam, E.; Hochman, G. Losses as modulators of attention: Review and analysis of the unique effects of losses over gains. Psychol. Bull. 2013, 139, 497–518. [Google Scholar] [CrossRef] [PubMed]
- Ma, Q.; Jin, J.; Meng, L.; Shen, Q. The dark side of monetary incentive: How does extrinsic reward crowd out intrinsic motivation. Neuroreport 2014, 25, 194–198. [Google Scholar] [CrossRef]
- Rapoport, A.; Budescu, D.V. Generation of random series in two-person strictly competitive games. J. Exp. Psychol. Gen. 1992, 121, 352–363. [Google Scholar] [CrossRef]
- Carver, C.S.; White, T.L. Behavioral inhibition, behavioral activation, and affective responses to impending reward and punishment: The BIS/BAS scales. J. Personal. Soc. Psychol. 1994, 67, 319–333. [Google Scholar] [CrossRef]
- Anderson, J.R. The Adaptive Character of Thought; Erlbaum: Hillsdale, NJ, USA, 1990. [Google Scholar]
- Hillstrom, A. Repetition effects in visual search. Percept. Psychophys. 2000, 62, 800–817. [Google Scholar] [CrossRef]
- Holroyd, C.B.; Hajcak, G.; Larsen, J.T. The good, the bad and the neutral: Electrophysiological responses to feedback stimuli. Brain Res. 2006, 1105, 93–101. [Google Scholar] [CrossRef] [PubMed]
- Muller, S.V.; Moller, J.; Rodriguez-Fornells, A.; Munte, T.F. Brain potentials related to self-generated and external information used for performance monitoring. Clin. Neurophysiol. 2005, 116, 63–74. [Google Scholar] [CrossRef] [PubMed]
- Ivan, V.E.; Banks, P.J.; Goodfellow, K.; Gruber, A.J. Lose-shift responding in humans is promoted by increased cognitive load. Front. Integr. Neurosci. 2018, 12, 9. [Google Scholar] [CrossRef] [PubMed]
| 1 | Such predictions also appear in [38], p. 1081 in their suggestion that with opponent ‘rotation,’ participants “ought to feel freer to condition on their own past choices as an aid in achieving any desired move frequencies.” |
| 2 | For one participant, only 287 trials were recorded resulting in 143 pairs (286 trials) being used. For a second participant, only 285 trials were recorded resulting in 142 pairs (284 trials) being used. |
| 3 | The decrease in win–stay behavior during opponent change relative to opponent repeat trials was replicated when the 2 opponents playing with an item bias were removed from the overall averages for Experiment 1 (43.55% versus 38.15%; F[1,78] = 5.693, MSE = 0.020, p = 0.019, ƞp2 = 0.068) |
| 4 | These differences in win–stay and lose–shift flexibility cannot be attributed to the variable experience of positive and negative outcomes in the current study. At a group level, the proportion of wins (33.51%) was equivalent to the proportion of losses (33.12%; t[79] = 0.814, p = 0.418). At an individual level, the degree of win–stay behavior was not correlated with individually experienced (r = 0.106, p = 0.350), nor was lose–shift behavior correlated with individually experienced lose rates (r = −0.131, p = 0.247). |
| 5 | It is interesting to note that when comparing unexploitable with exploitable computer opponents, participants report an increased sense of co-presence for an automated program that played randomly [46]. |
| 6 | More broadly, the mental representation of zero-sum games only with respect to the relationship between items can lead to identical behavior with more traditional representations that preserve both items and outcomes. For example, reference [8] discusses the behavioral isomorphism between zero-sum game strategy rules expressed in terms of the opponent’s previous response only versus the participant’s previous response and outcome. |

© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Srihaput, V.; Craplewe, K.; Dyson, B.J. Switching Competitors Reduces Win-Stay but Not Lose-Shift Behaviour: The Role of Outcome-Action Association Strength on Reinforcement Learning. Games 2020, 11, 25. https://doi.org/10.3390/g11030025
Srihaput V, Craplewe K, Dyson BJ. Switching Competitors Reduces Win-Stay but Not Lose-Shift Behaviour: The Role of Outcome-Action Association Strength on Reinforcement Learning. Games. 2020; 11(3):25. https://doi.org/10.3390/g11030025
Chicago/Turabian StyleSrihaput, Vincent, Kaylee Craplewe, and Benjamin James Dyson. 2020. "Switching Competitors Reduces Win-Stay but Not Lose-Shift Behaviour: The Role of Outcome-Action Association Strength on Reinforcement Learning" Games 11, no. 3: 25. https://doi.org/10.3390/g11030025
APA StyleSrihaput, V., Craplewe, K., & Dyson, B. J. (2020). Switching Competitors Reduces Win-Stay but Not Lose-Shift Behaviour: The Role of Outcome-Action Association Strength on Reinforcement Learning. Games, 11(3), 25. https://doi.org/10.3390/g11030025