1. Introduction
Reducing energy is a key design goal for all computing domains including low-power embedded devices and high performance computing centers. To reduce energy, hardware resources, such as the number of cores and the core’s configuration, must closely match, or be specialized to, the applications’ hardware requirements such that both dynamic and idle energy are minimized. If hardware resources are excessive or very large (redundant core(s), a large cache memory, high clock frequency, etc.) idle energy of the unused resource is wasted. Alternatively, if the hardware resources are too small or scarce, applications require longer periods of time to execute and expend excessive dynamic energy.
Heterogeneous systems and configurable systems provide coarse- and fine-grained hardware specialization, respectively, that meet the applications’ hardware requirements. Heterogeneous multicore systems such as the ARM big.LITTLE [
1] or OMAP3530 [
2] provide coarse-grained hardware specialization via disparate, fixed hardware parameter values, such as voltage, clock frequency, cache size/associativity, etc. The specific configuration of these parameters’ values that most closely adheres to the application’s requirements while achieving design goals (e.g., lowest energy consumption, highest performance, or a trade-off) constitutes the application’s best core. Even though the specialized cores are heterogeneous, offering different configurations for different application requirements, these configurations are fixed, thus the total number of different configurations (e.g., the design space) is very small, which limits potential adherence to design goals [
3] (e.g., energy savings in our work). Alternatively, configurable systems have cores with runtime configurable parameters, which increase the design space and thus potential adherence to design goals based on varying, unknown application requirements. However, to exploit adherence to the design goal, heterogeneous multicore systems and configurable systems impose profiling and tuning challenges, respectively.
Application profiling can be done statically during design time or dynamically during runtime. Static profiling requires a priori knowledge of the applications, but can be leveraged to determine the best core configurations based on these requirements, thus offering greater energy savings potential at the expense of an inflexible, static system. However, due to this application-specific specialization, this method is only suitable for static, known applications. Dynamic profiling increases system flexibility, which is necessary for general purpose systems, by profiling unknown applications during runtime to determine the application’s best configuration. However, dynamic profiling introduces three challenges: (1) runtime profiling incurs profiling overhead (e.g., performance/dynamic energy) while profiling the applications and expend idle energy by the other cores; (2) this overhead is tightly coupled to the degree of heterogeneity (i.e., higher heterogeneity typically requires more profiling/sampling); and (3) since the applications are not known a priori, the cores’ configurations must be generally suitable for any application, and thus may not closely adhere to each application’s specific requirements, which decreases the energy savings potential. Alternative to profiling, tuning is adjusting the hardware resources parameters to obtain a best configuration that most closely adheres to the application’s hardware requirements. However, configurable systems impose large tuning overhead when executing/evaluating applications in inappropriate, non-best configurations [
4], especially for highly configurable cores with many parameters and parameter values (e.g.,
NM where
N is the number of cores and
M is the number of core configurations).
Dynamic profiling and tuning overhead can be alleviated if the system comprises a small degree of heterogeneous cores with a small set of tunable configurations, respectively. The key challenges are then determining a set of cores and the cores’ constituent configurations. If the cores’ heterogeneity is of a small degree, such that one application profiling is required to determine the best core with the configuration(s) that most closely adhere(s) to the application’s hardware requirements, then the profiling overhead can be alleviated. Furthermore, if the number of configurations evaluated during tuning is narrowed to the most promising best or near-best configuration, then tuning overhead is alleviated. Since applications with similar execution requirements belonged to similar application domains, and have similar, but not necessarily the same, best configurations [
5], the design space can be subsetted to a small fraction of the complete design space, while still offering best, or near-best configurations for each application. If these subsets are offered in a multicore system, such as each core is offering a distinct subset, then the multicore system offers adherence to disparate domains of applications, with a small degree of heterogeneity. To determine the application domain, and hence the core, only a single profiling execution of the application is required to determine the application’s domain, and hence the application’s best core. Furthermore, once the core is determined, tuning evaluates only the configurations of the subsets of that domain/core, and tuning overhead is alleviated.
In addition to alleviating dynamic profiling and tuning overhead, a key challenge is to reduce the idle energy expended by idle cores. If the best core for a domain remains idle due to the lack of applications of that domain, the cores could expend precious energy—a growing concern in recent technology [
6]. One method to reduce idle energy is to power-gate idle cores (e.g., [
7]). However, to avoid unpredictable performance behavior, power-gating an entire core requires a priori knowledge of applications’ schedule, or a hardware-based oracle to monitor application memory access patterns to predict the performance of power-gating the core. Alternatively, idle energy can be saved if the cores are kept busy executing applications of other domains, when available.
Based on these observations, we propose, to the best of our knowledge, the first heterogeneous, configurable multicore system architecture with domain-specific core configuration subsets and an associated scheduling and tuning (SaT) algorithm. Each core offers a distinct subset of configuration (heterogeneous), and can be tuned/specialized to a configuration of this subset (configurable).
Whereas this fundamental architecture and approach is applicable to any configurable parameters such as issue window (e.g., [
8]) and reorder buffer (e.g., [
9]), we focused on configurable caches due to the cache’s large contribution to system energy consumption [
10] and configurable caches’ energy savings potential [
8,
9,
10,
11]. The key contribution of our architecture is providing close adherence to application’s hardware requirements with low profiling and tuning overhead.
To exploit the system’s ability to adhere to design goals, we propose an associated scheduling and tuning (SaT) algorithm. SaT dynamically profiles the applications to determine the applications’ domains, and schedules the applications to the best core that provides the most suitable configuration. Once the application is scheduled to a core, SaT tunes that core’s parameter to the best configuration that adheres to the application’s hardware requirement. SaT’s key contribution is the ability to save energy with no designer effort in a highly configurable system without any a priori knowledge of the applications. Furthermore, SaT balances dynamic and idle energy by determining whether or not to halt or execute the application on an idle, non-best core. If executing an application on a non-best, idle core expends less dynamic energy than idle energy expended by leaving the core idle, SaT schedules the application to that non-best idle core.
We compared our system to a base system, prior work, and performance-centric system, all of which had a priori knowledge of the applications. Our results revealed our system can save up to 31.6% and 22.6% energy, as compared to the base system and prior work, respectively. Furthermore, our performance analysis revealed that SaT can outperform prior work and performance-centric systems in 50% of the cases, and that our system provided energy-delay product (EDP) within 10.9% of a performance-centric system.
The remaining of the paper is organized as follows:
Section 2 discusses heterogeneous and configurable systems as hardware specialization approaches, and scheduling and tuning algorithms used with these systems, respectively. We describe our heterogeneous and configurable system design approach in
Section 3, and our associated scheduling and tuning (SaT) algorithm in
Section 4.
Section 5 and
Section 6 provide our experiment setup and evaluation methodology, respectively. We discuss the results and analysis in
Section 7 and conclude our work in
Section 8.
3. Heterogeneous, Configurable Multicore System Architecture
3.1. Overview
To design a multicore system that provides coarse- and fine- grained adherences, the cores of the system must comprise coarse- and fine-grained configurations. However, to limit redundant configurations and reduce core hardware area, we map configurations to the cores based on the hardware area requirements. This section details our configuration selection and mapping methodology using an illustrative example of a quad-core system.
3.2. Selecting Coarse- and Fine-Grained Configurations
Since our approach focuses on configurable caches, we define coarse-grained configurations as configurations that have the highest impact on performance, and fine-grained configurations as configurations with lower impact on performance, as compared to disparate configurations. Prior work [
10] demonstrated that cache size has the highest impact on performance, followed by line size and associativity. Given the energy-performance trade-off (higher performance requires higher energy), performance-impact ordering is highly probably applicable to energy as well; cache size has the highest impact on energy. Therefore, our coarse-grained configurations are those of distinct cache sizes, and fine-grained configurations are configurations with similar cache size but different line size and associativity.
Table 1 depicts the complete cache configuration design space, which corresponds to our sample architecture and the requirements of our embedded system’s experimental applications (
Section 5). Columns represent the line sizes in bytes (B) and rows represent the sizes in Kbytes (K) and associativity (W). Each column–row intersection denotes a unique configuration
cn. We select subsets of the complete design space using our subset selection methodology.
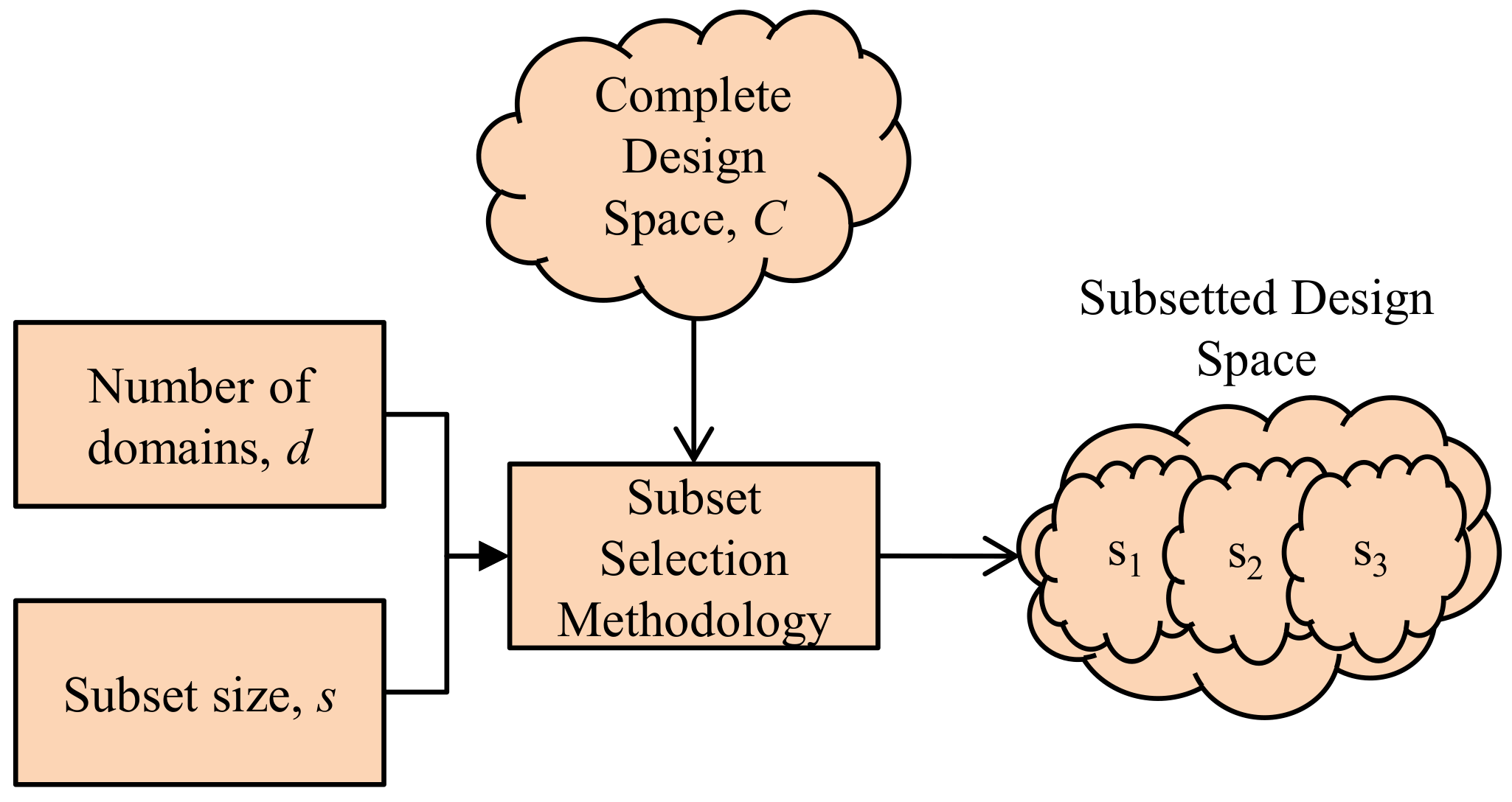
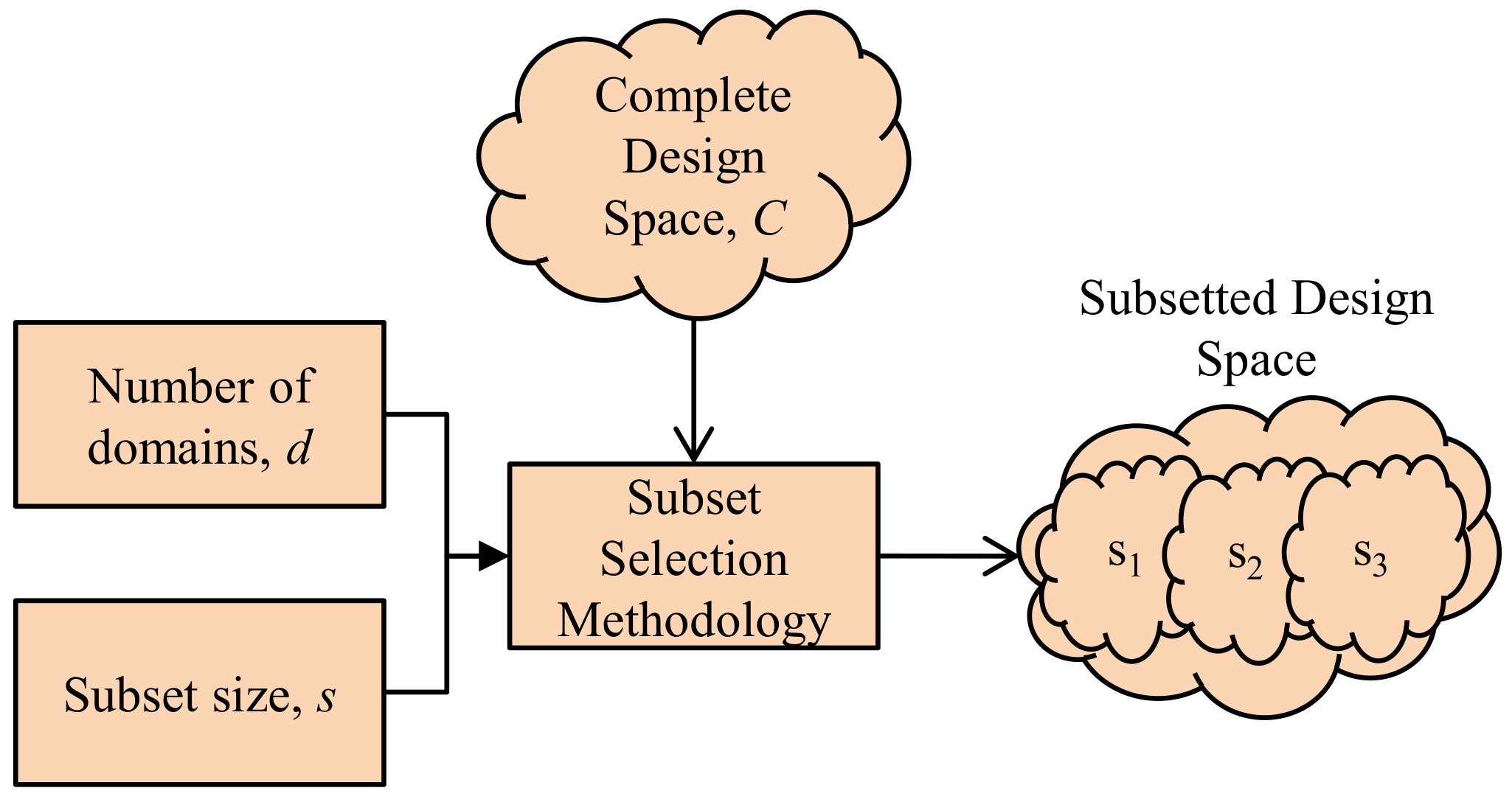
Figure 1 depicts the design space subsetting for multi-domain subsets. The subset selection methodology takes in as inputs the number of domains,
d, subset size,
s, and the complete design space,
C, and produces subsetted design space comprised of
n subsets
S (note that n = d). For each
d, the methodology selects the best subset
S, comprised of
s configurations out of
C using a design space exploration methodology adapted from [
11].
Based on application profiling and our prior evaluations, we determined that small domain-specific configuration subsets attained nearly the same energy savings as the complete design space. Since these evaluations showed that three domain-specific subsets were sufficient to meet disparate application requirements, we consider three domain-specific subsets. Each domain subset meets a given range of application profiling information (e.g., cache miss rate ranges), and during runtime, SaT (
Section 4) profiles the applications and uses the profiling information to determine the applications’ domains. Since the cores’ subsets are specialized to meet application domain-specific requirements, the domain dictates the applications’ best subset and, hence, best cores.
Subsequently, we set the number of domains
d to three, which corresponds to domains of applications with low, mid-range, and large cache hardware requirements; we use
Table 1 as our complete design space, (
C = 18); and we set the subset size,
s, to four since a four-configuration subset is large enough to represent the complete design space of size 18 [
5,
11].
The subset selection methodology creates all of the configuration subsets, evaluate these subsets using application kernels and select the highest quality subset for each domain. First, the subset selection methodology creates all combinations of possible subsets out of the complete design space (3040, given
C = 18 and
s = 4). Once created, the methodology evaluates the quality of each subset using
d sets of applications. These applications are kernels that represent common tasks in the anticipated applications—34 in our case (
Section 5). To create
d sets of kernel applications, the methodology classifies these applications hierarchically, using Euclidian distance of the applications’ cache miss-rate
c18. The output of the classification is
d classes of applications, grouped based on the similarity of the applications cache miss-rate—three classes in our case.
Finally, to select the highest quality subset for each domain, the methodology exhaustively evaluates all of the subsets with the applications of that domain, and select the subset that most closely adhere to the design constraint, as shown in Algorithm 1. The algorithm takes in as its inputs n configuration subsets, d, and kernel application-set per domain kd, and returns the best subset per domain. For each domain, the algorithm executes all of the kernel application-set of that domain with each subset and calculates the average energy consumption of this execution. Once all of the subsets are evaluated with for this domain, the algorithm selects the subset that resulted in the lowest average energy consumption as the best subset for that domain.
We note that for much larger design spaces the design space subsetting for multi-domain subsets process could be prohibitively lengthy, and a design space exploration heuristic could be employed to speed up the process (e.g., [
34]). For example, a design space that considers 18 cache memory sizes/line sizes/associativity, 24 pipeline depths (PD), 16 issue window (IW) sizes, and 10 voltage-frequency (VF) values will have 69,120 configurations, and 9.50 × 10
17 subsets. The configurations could be subsetted independently (e.g., PD) or jointly (e.g., PD × VF) before they are used in our subset selection methodology.
| Algorithm 1. Subset evaluation and selection. |
Input: n configuration subsets: Sn;
Number of domains: d
Kernel application-set per domain: kd
Output: Best subset per domain: S1-Sd
For all d
For all n
Execute each application in kd on each configuration in Sn
Calculate average energy consumption
End for
Select subset with lowest energy
End for
Return (S1-Sd)
End |
Once the methodology selects the constituent configurations of subsets
S1,
S2, and
S3, we map these subsets to a quad-core system, such that the cores’ subsets contain configurations from
Table 1, and the union of the cores’ subsets’ configurations is specialized to meet different domain-specific application requirements. For our setup, the algorithm selected subsets
S1,
S2, and
S3, with the configuration sets {
c1,
c2,
c7,
c13}, {
c3,
c9,
c14,
c15}, and {
c5,
c11,
c12,
c18}, respectively.
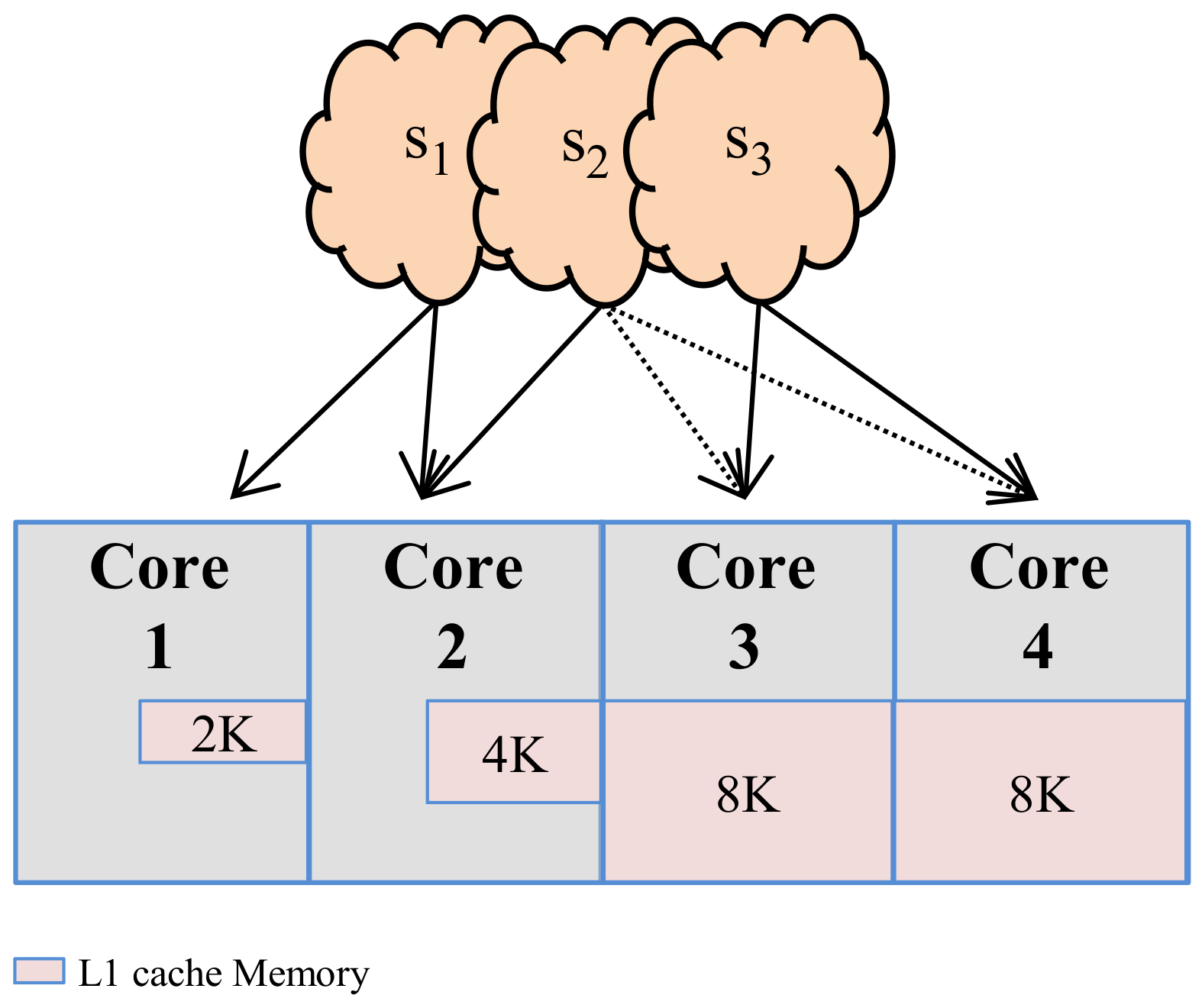
3.3. Mapping Subsets to Cores
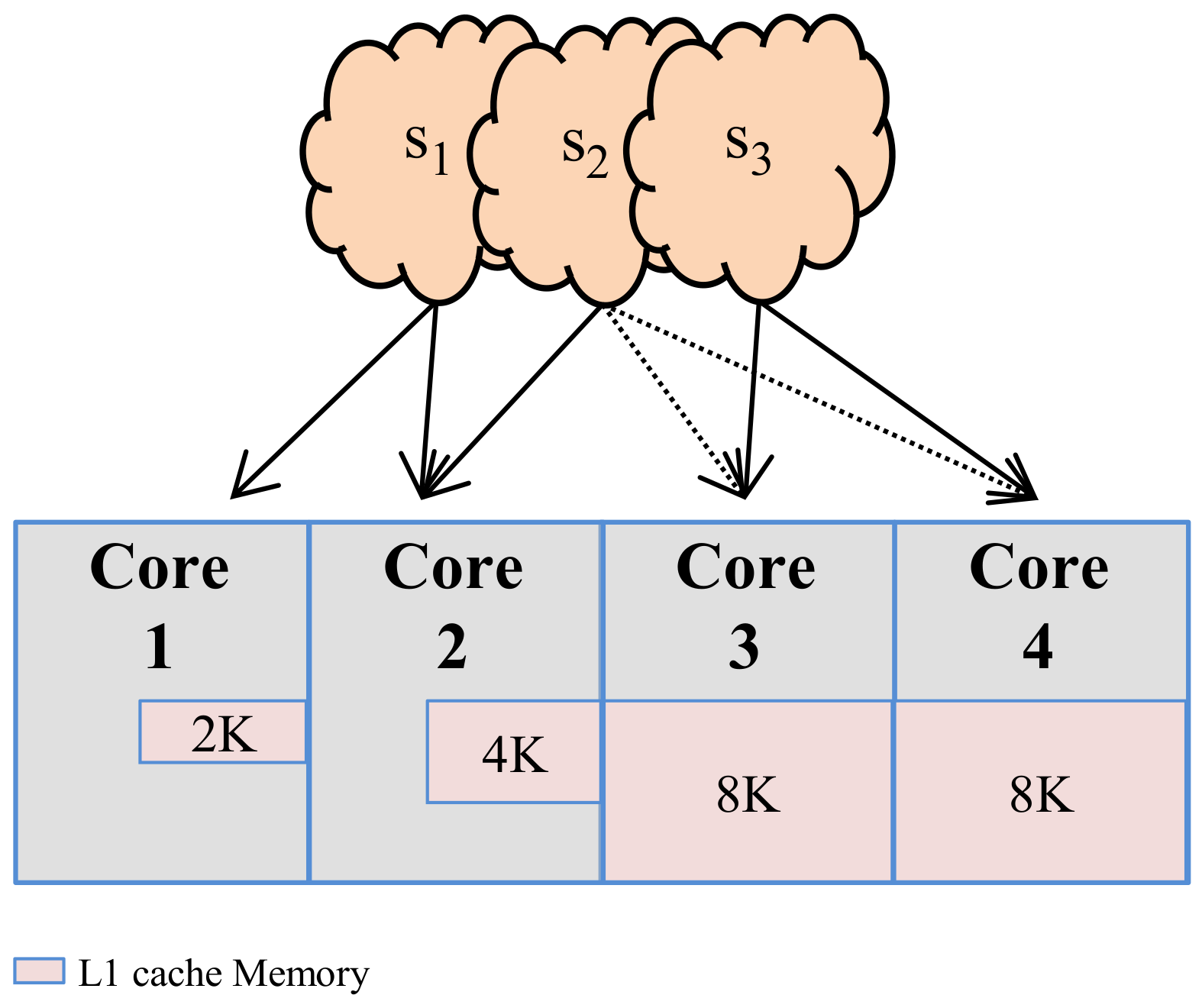
To avoid hardware overhead, redundant configurations must not be mapped multiples times; however, best configurations must be distributed amongst the cores to alleviate possible performance bottleneck(s). Given n subsets of size s, mapping each subset to a core will require r cores, where r ϵ [1, n]. If r = 1, then all subsets are mapped into one core and that core becomes a performance bottleneck. Alternatively, if r = n, then each subset is mapped to a dedicated core and the potential bottleneck is alleviated. However, dedicating each subset to an individual core can result in redundant configurations and wasted hardware area, since the subsets could comprise similar configurations. For instance, if c14 ϵ S1 and S2, and S3, then only one instance of c14 is mapped to the core with the cache size of c14.
Furthermore, to reduce area overhead, the logical grouping of configurations (subsetting) must be disjoined from the physical implementation of these subsets on actual hardware. If distinct subsets contain configurations of similar coarse-granularity (e.g., same cache size), then these subsets will duplicate the hardware area requirements (e.g., three cores with the same cache size). To reduce this redundancy, configurations of similar coarse-granularity (e.g., cache size) are mapped to the core of the same cache size.
Figure 2 depicts our three subsets mapped to a quad core system. Given the union of these domain-specific configuration subsets, we grouped the configurations based on the configurations’ cache sizes (i.e., three given
Table 1), and mapped each group to the corresponding core with the same cache size. Thus, the core’s mapped configurations comprise that core’s subset, which restricts the core’s configuration design space. Any core with
c18 can be used as a profiling core (
c18 is the best-performance cache on average over all of our experimental applications, and thus minimizes the profiling overhead); however, if
c18 is not part of any domain-specific subset,
c18 can be easily included in at least one of the subsets.
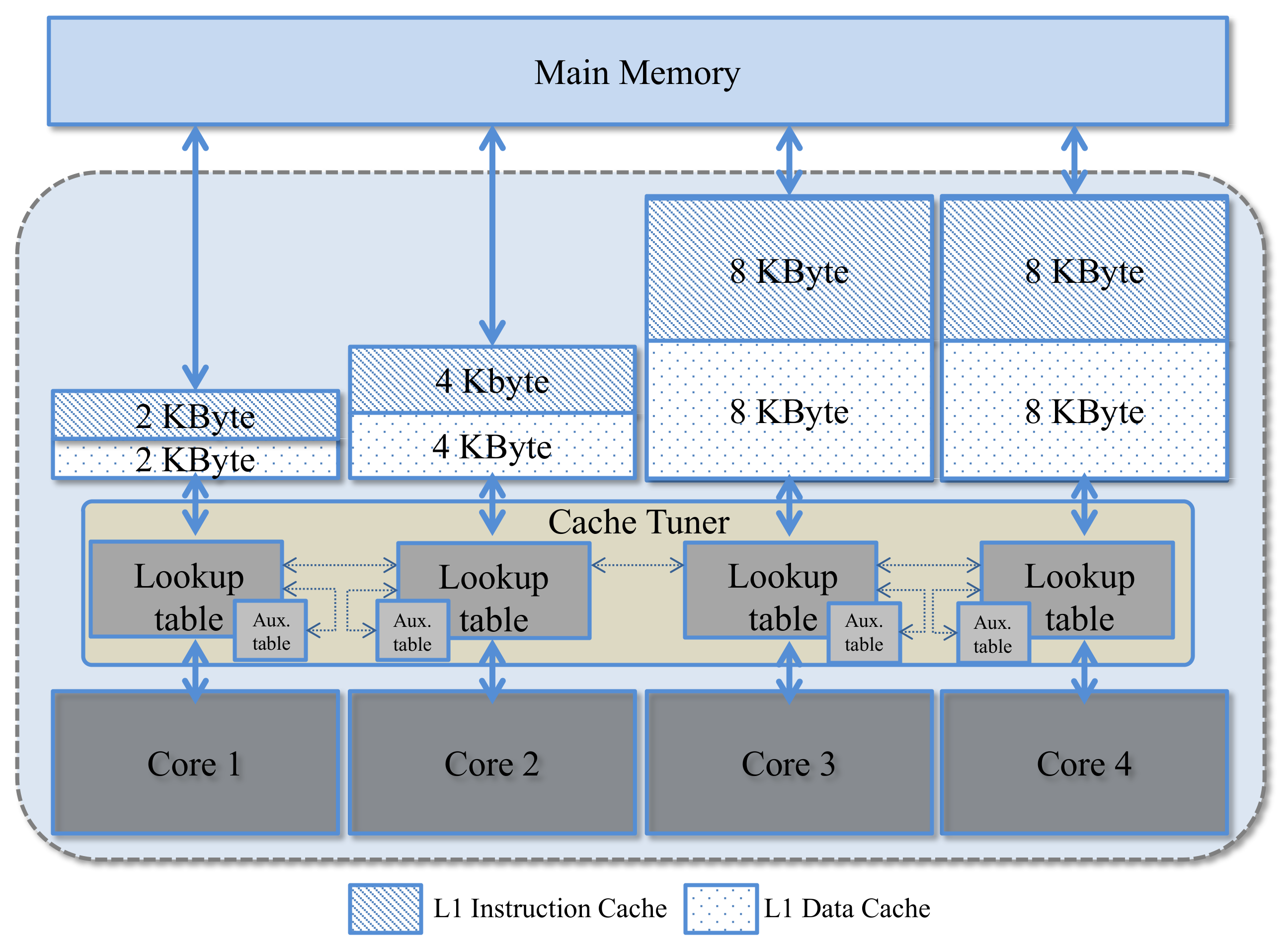
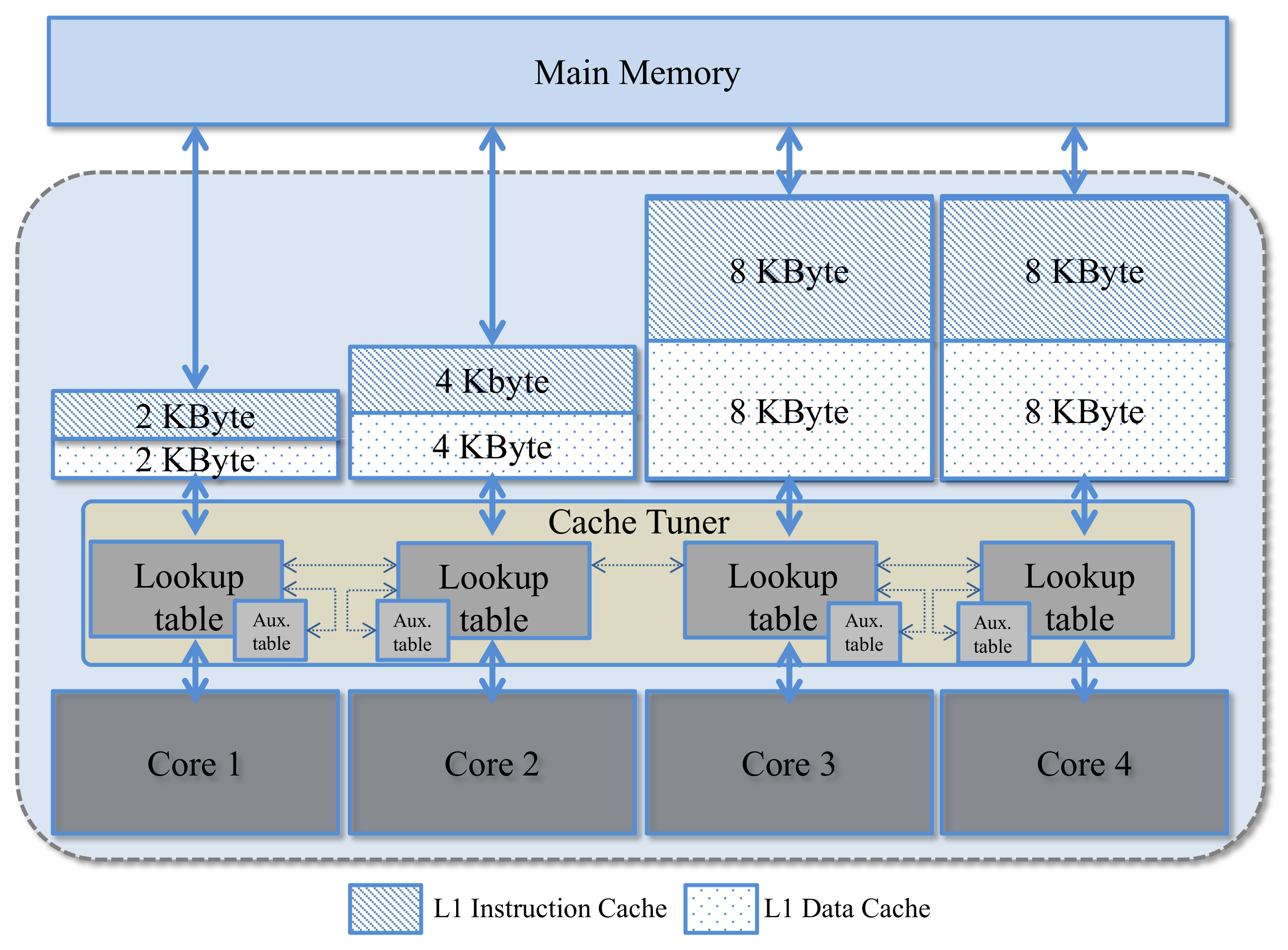
Figure 3 depicts our sample quad-core heterogeneous, configurable multicore architecture based on our subset selection and mapping process. Each core has private, dedicated L1 data and instruction caches. Since cache size has the largest impact on energy consumption [
31], and to limit the cores’ design spaces, the cores’ caches have disparate, fixed cache sizes and the caches’ line sizes and associativities are configurable. To alleviate the hardware requirement for the cache tuner, we use a global hardware tuner (
Section 3.4).
Our experiments show that since domain-specific subsets typically contain at least one configuration with a cache size of 8 K, the overhead to include c18 in any subset without c18 requires only a few additional control bits. Since this mapping only requires three of the four cores, the fourth core’s subset replicates the core with the largest cache size (i.e., 8 Kbyte). Even though the fourth core could replicate any of the other cores’ subsets, replicating the largest cache size is pessimistic with respect to energy savings, and provides a second profiling core.
Even though our work evaluates this specific system architecture and configuration design space, and three application domains, our fundamental methodologies are generally applicable to any arbitrary number of cores, configurations, and application domains, and increasing any of these parameters would increase the potential energy savings. For instance, given a system comprising cores with configurable cache memory, PD, IW, and VF, mapping of the configuration could be based on single or joint configuration types. Furthermore, since cores with higher VF could benefit from larger cache memory, (e.g., ARM big.LITTLE [
1]), the cache memory size-VF pairing (e.g., larger cache size paired with higher VF range) provides the system’s heterogeneity; however, the cache line-size and associativity provides the system’s configurability.
3.4. Hardware Support Requirements
To alleviate the hardware requirement for the cache tuner, we use a global hardware tuner that requires only the control logic bits, which are negligible as compared to the size of the caches (Equations (1) and (2)). The tuner reads in the application’s tuning information stored in the tuner’s lookup table and adjusts the caches’ line size and associativity based on our SaT algorithm (
Section 4). To enable portability to any operating system scheduling, we integrate SaT’s finite state machine (FSM) into the global hardware tuner, which is triggered by the operating system’s scheduling invocation.
The tuner stores the application profiling information in lookup tables, along with the application’s identification number (ID), execution status (i.e., ready, executing, terminating, etc.), arrival time, etc. The application profiling information contains the application’s cache statistics, such as the L1 cache miss rate, which is obtained from the core’s hardware counters [
1], and is used to calculate the application’s energy and performance (
Section 4.2), and to determine the application’s best core. The profiling information also stores the application’s best core and best configuration after these have been determined. Since, during scheduling, the application’s best core may not be available (
Section 4.2), to facilitate scheduling to the best alternative core, the profiling information also stores a history of the energy consumption and performance for all of the prior cores/configurations that the application has been executed on.
The storage requirement for each application profile is:
bits, where
a,
r, and
c represent the number of anticipated applications that will execute on the system, the number of cores, and total number of configurations across all cores, respectively, and
e and
t represent the energy and performance in number of cycles, respectively, for each application execution per core/configuration. Since most embedded systems typically run a fixed set of persistent applications,
m requires limited number of bits, which can be stored in main memory and requires no additional hardware storage unit.
To limit area overhead, this complete tuning information is only stored for an application during scheduling and tuning. After the best configuration is determined, only that configuration is retained in a smaller auxiliary lookup table. To enable scalability to an arbitrary number of applications, we utilize a least recently used replacement policy to govern the auxiliary table’s information. Thus, given
a applications, the total tuning information storage requirement
M in bits is:
which imposes only 4.7% area overhead in embedded processors such as the MIPS M4k [
35].
4. Application Scheduling and Tuning (SaT) Algorithm
4.1. Overview
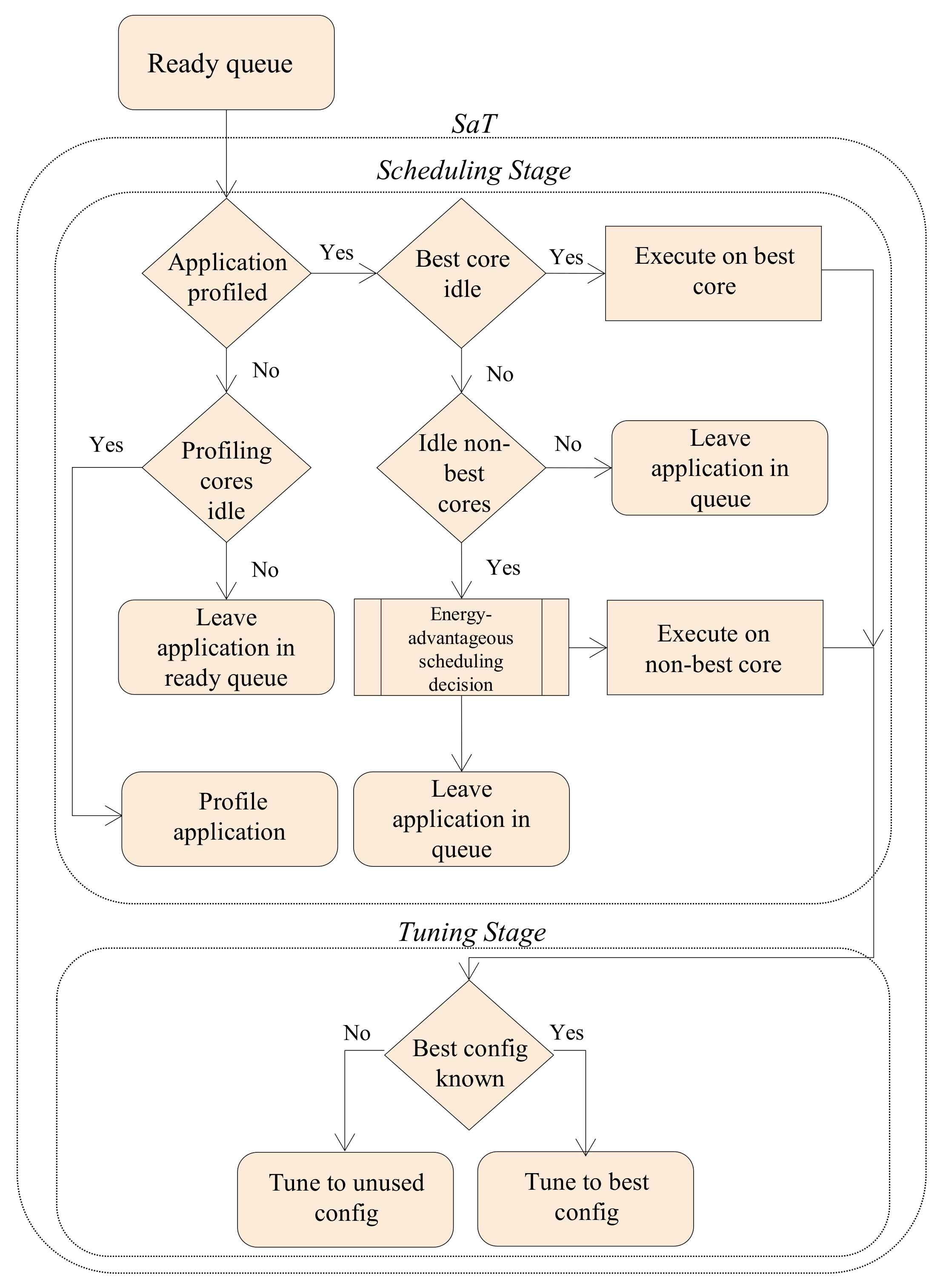
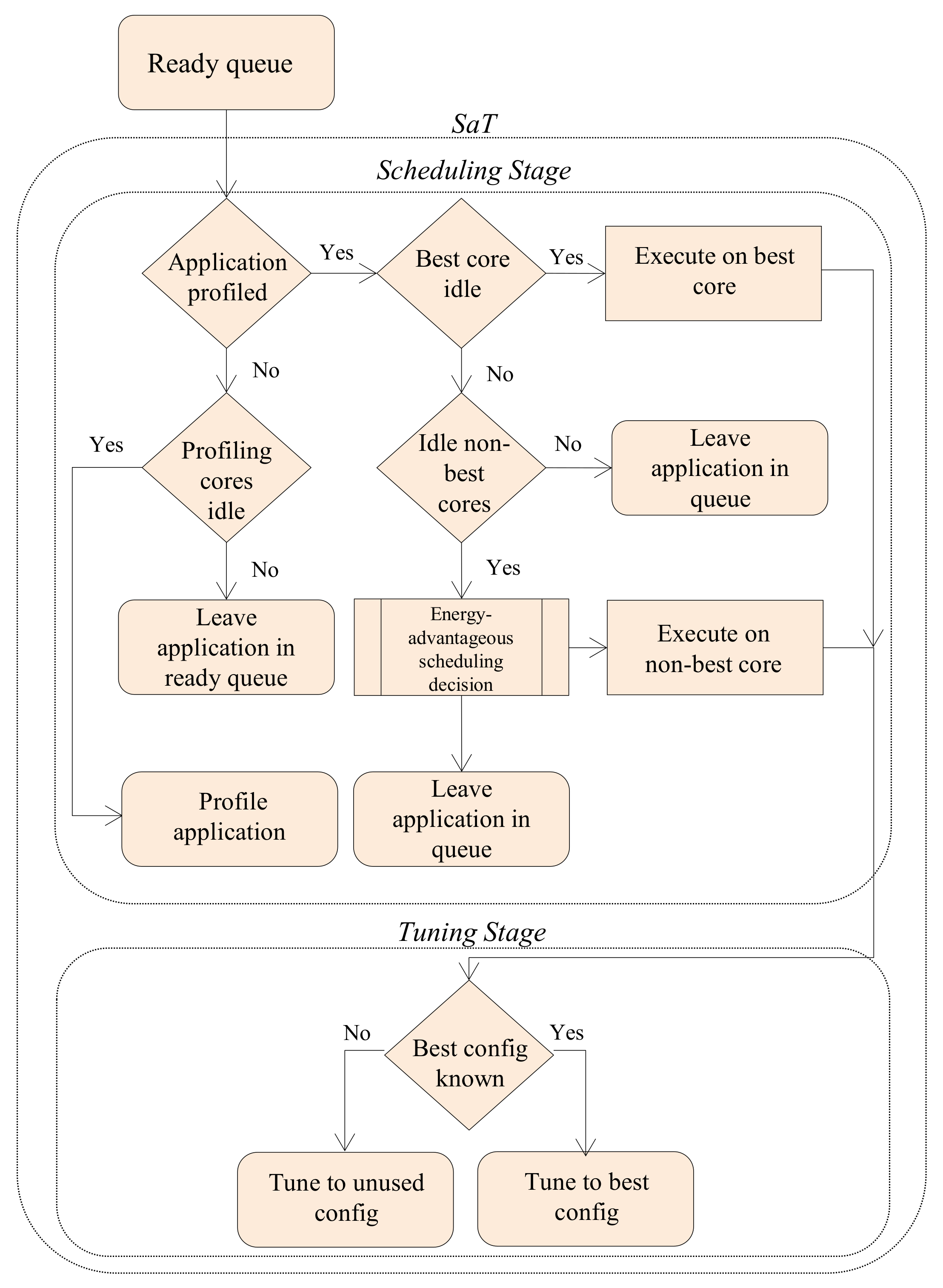
Figure 4 depicts SaT’s operational flow, which has two stages:
scheduling, which determines the application’s best core, effectively determining the application’s best cache size, and
tuning, which configures the core to the application’s best cache line size and associativity. To save dynamic energy, SaT schedules the application to the best core, and, to reduce idle energy, SaT schedules the application to an idle non-best core, if the best core is busy.
SaT is invoked when an application is placed in the ready queue by the operating system. On each invocation, SaT processes applications in the ready queue in first come first served (FCFS) order, and attempts to schedule the application such that the total energy is minimized. Since dynamic energy is the primary energy contributor, SaT first attempts to schedule the application to the application’s best core/configuration. If the best core is busy and there are idle, non-best cores, to reduce wasted idle energy, SaT evaluates the energy advantage for scheduling the application to a non-best core as compared to leaving the application in the ready queue to wait for the application’s best core, thus wasting idle energy as idle cores are unused.
If SaT is unable to schedule an application (e.g., all cores are busy) or determines that it is energy advantageous for an application to wait for the application’s best core, the application remains in the ready queue and SaT attempts to schedule the next application in the ready queue. If SaT successfully schedules an application, the application’s profiling information is updated when the application terminates.
We note that, to avoid starvation, we can employ a preemption mechanism into SaT that ensures fair resource sharing amongst applications. However, since our study does not aim for hard real-time systems, we plan to incorporate such techniques in future work.
4.2. Scheduling Stage
In the scheduling stage, SaT checks the application’s profiling information. If there is no profiling information, the application is executing for the first time and SaT schedules the application to any arbitrary idle profiling core (i.e., cores 3 or 4 in our sample architecture (
Section 3.3)), removes the application from the queue, profiles the application, and updates the application’s profiling information in the lookup table. If no profiling core is idle, SaT leaves the application in the ready queue, since attempting to schedule the application without any profiling information may force the application to execute with an extreme configuration. Extreme configurations are configurations that are so ill-suited to the application’s requirements that the configuration causes a significant increase in the energy consumption [
4], and thus should be avoided.
If there is profiling information for the application, the best core is known. If the best core is idle, SaT schedules the application to this core and removes the application from the ready queue.
If the application’s best core is not idle, but other non-best cores are idle, SaT evaluates an idle-to-dynamic energy-advantageous scheduling decision using the application’s profiling information. This evaluation determines if it is energy-advantageous to schedule the application to a non-best core or leave the application in the ready queue to wait for the best core to be idle. Essentially, the non-best core executes the application with more dynamic energy; however, waiting for the best core to become available expends idle energy by the idle, non-best core. SaT evaluates if the worse-than-best dynamic energy is more advantageous than expending idle energy.
The energy-advantageous scheduling decision is a Boolean value
Th calculated by:
where
a1 is the application being scheduled,
a2 is the application executing on
a1’s best core
c1,
c2 is an idle, non-best core,
Edyn(
ax,
cx) is the dynamic energy expended by executing
ax on
cx, and
Eidl(
a2,
c2) is the idle energy expended by idle
c2 while waiting for
c1 to finish executing
a2. Essentially, if the dynamic energy
Edyn(
a1,
c2) to execute the application being scheduled
a1 on an idle, non-best core
c2 is less than the idle energy expended
Eidl(
a2,
c2) by the idle, non-best core
c2 plus the dynamic energy
Edyn(
a2,
c1) of the busy, best core
c1 to both complete execution of
a2 and execute
a1,
a1 is scheduled to the idle, non-best core
c2. Otherwise, SaT leaves
a1 in the ready queue.
Th can only be calculated if both applications
a1 and
a2 have previously executed in all configurations on cores
c1 and
c2 (i.e., the applications’ best configurations’ are known). If any core configuration energy consumption is unknown, SaT optimistically assumes
Th is true and schedules
a1 to execute on
c2, and removes the application from the ready queue, which promotes throughput since the application may have to wait for a long period of time, and models prior scheduling algorithms [
24]. Additionally, this scheduling enables SaT to populate the energy consumption and performance history for additional core configurations, which enhances future scheduling decisions.
4.3. Tuning Stage
Once an application is scheduled to execute on a core, either best or non-best, SaT enters the tuning stage. If the application’s profiling information contains energy consumptions for all of the core’s configurations, SaT directly tunes the core to the application’s best (i.e., lowest energy) configuration for that core.
If there is any core configuration with unknown energy consumption, then the application’s best configuration on that core is not yet known and SaT must execute the application with one of the unknown configurations. Since all configurations must be executed, SaT arbitrarily chooses an unknown configuration from the core’s subset, and tunes the core to that configuration, and updates the application’s profiling information with this configuration’s energy consumption. We note that, since the core subsets are small (four configurations in our experiments), this exhaustive exploration is feasible; however, for advanced systems with larger subsetted design spaces per core, search heuristics can also be used [
5,
34].
5. Experimental Setup
We evaluated SaT using our proposed architecture (
Figure 3) with 34 embedded applications: sixteen (complete suite) from the EEMBC automotive application suite [
36], six from Mediabench [
37], and twelve from Motorola’s Powerstone applications [
29], which represent a diversity of application requirements [
3,
10,
11].
Since embedded system applications are typically persistent, we replicated the applications in the ready queue. Each application is identified with an ID from one to 34, and we generated a series of 1000 IDs using a discrete uniform distribution. We modeled the application arrival times using a normal distribution centered at the mean and within one standard deviation of the average execution time of all applications using the base configuration. To model common operating system schedulers [
38,
39], we invoked SaT every 2000 cycles, which represents less than 1% of the average execution time of the applications using the base configuration.
Since many embedded systems do not have level two caches [
3], and SaT’s efficacy can be evaluated with L1 caches, our experimental architecture’s (
Figure 3) private, separate L1 data and instruction caches can be tuned independently and simultaneously. We used SimpleScalar to obtain cache accesses/hits/misses, and obtained off-chip access energy from a standard low-power Samsung memory. We estimated that a fetch from main memory took forty times longer than an L1 cache fetch, and the memory bandwidth was 50% of the miss penalty [
32].
In order to directly compare to previous research [
11],
Figure 5 depicts our cache hierarchy energy model (similar to [
19]) and we determined the dynamic energy using CACTI [
40] for 0.18 um technology. Even though 0.18 um technology is a large technology, many embedded systems do not require cutting edge technologies. Furthermore, since SaT reduces the idle energy and the idle energy constitutes a larger percentage of the total energy as the technology size decreases (over 30% of the total energy in smaller technologies (e.g., 0.032 um) [
22]), this technology gives pessimistic energy savings for SaT: larger technology present lower idle-energy advantages of SaT. We estimated the idle and static energies each as 10% of the dynamic energy [
32] and the CPU stall energy as 20% of the active energy [
11].
6. Evaluation Methodology
We compared SaT with prior configurable cache research [
5,
11] and scheduling algorithms [
38,
39] using three systems, denoted as system-1, system-2, and system-3. All systems had the same configurable heterogeneous multicore architecture (
Figure 3), and provided the same per-core configurations mapping (
Figure 2), but used different scheduling algorithms. We compared the systems’ energy consumptions by normalizing the energy consumption to a base system with all four cores configured to
c18 that scheduled applications using first-available-core policy [
38,
39].
System-1 was modeled similarly to [
11] and provided insights on the significance of wasted idle energy, and served as a near-optimal system for comparison purposes. System-1 assumed a priori knowledge of the applications’ domains (i.e., no profiling overhead) and best configurations (i.e., no tuning overhead). System-1 only scheduled an application to the application’s best core using the best configuration, and left the application in the ready queue if the application’s best core was not idle, even if other, non-best cores were idle and wasting idle energy.
Alternatively, instead of requiring an application to wait for the application’s best core to be available, the application can be scheduled to a non-best core, if available, which trades off saved idle energy for increased dynamic energy. System-2 modeled this performance-centric system, which maximizes throughput and core utilization. Similarly to system-1, system-2 had a priori knowledge of the applications’ domains and best configurations. However, the overall energy implications of this performance-centric system are unclear. If there is an idle, non-best core, and the idle core’s wasted energy while the application awaits in the ready queue for the application’s best core to be available is greater than the dynamic energy for executing the application on a non-best core, then system-2 consumes less energy than system-1. However, prior works have shown that non-best configurations, and thus non-best cores, can significantly increase the energy consumption [
11], thus, if the dynamic energy for executing the application with a non-best core is greater than the wasted idle energy expended while the application waits in the ready queue, then system-1 consumes less energy than system-2. Since this evaluation is highly dependent on the actual applications’ best cores/configurations and the applications’ arrival orders, our experiments consider myriad applications and the results were averaged over 1000 application arrivals to capture an average case.
Finally, system-3 evaluated SaT’s ability to achieve energy savings without any designer effort or a priori knowledge of the applications’ domains or best core/configuration, and to give insights on idle and dynamic energy trade-offs for different scheduling decisions. System-3 also provided insights on the significance of profiling and tuning overhead, which determines the feasibility of using SaT in general purpose and/or constrained embedded systems. SaT imposes profiling overhead while profiling the applications using the base configuration, which is not necessarily the best configuration and may incur large dynamic energy overhead, and since not all cores offer the base configuration, profiling can force applications to wait in the ready queue for a profiling core to be idle, and thus incurs idle energy overhead. Additionally, SaT imposes tuning overhead when exhaustively executing the applications on all core configurations, which forces applications to execute using non-best configurations, and thus incurs dynamic energy overhead. Designer effort and a priori knowledge of the applications’ best configurations enables SaT to directly execute the applications with the applications’ best configurations, thereby eliminating profiling and tuning overhead. We evaluated SaT’s profiling and tuning overhead by computing the energy difference between executing system-3 with and without a priori knowledge the of applications’ domains and best configurations, and normalized this energy difference to the base system.
Since the energy savings trades off performance [
1], we measured the performance of system-1, -2, and -3, and to obtain insight on the performance traded for the energy savings potential, and calculated the energy-delay product (EDP) for these systems. Since system-1 and system-2 represent energy-conservative and performance-centric systems, respectively, we compared SaT’s performance and energy-delay product to these systems.
To measure the performance of the system, we measured the execution time required for the system to process the applications queue in our experiment (
Section 5). The shorter the execution time, the better the performance. Since the cores executed different applications at the same time, the cores’ execution times differed, and we designated the longest execution time as the system’s execution time. We used the total energy (idle + dynamic), and the longest execution time for the energy and performance in the EDP calculations.
7. Results and Analysis
Given the extensive analysis of our work, this section presents the energy, performance, and energy-delay product (EDP) results and analysis based on our experiment setup and evaluation methodology.
7.1. Energy Analysis
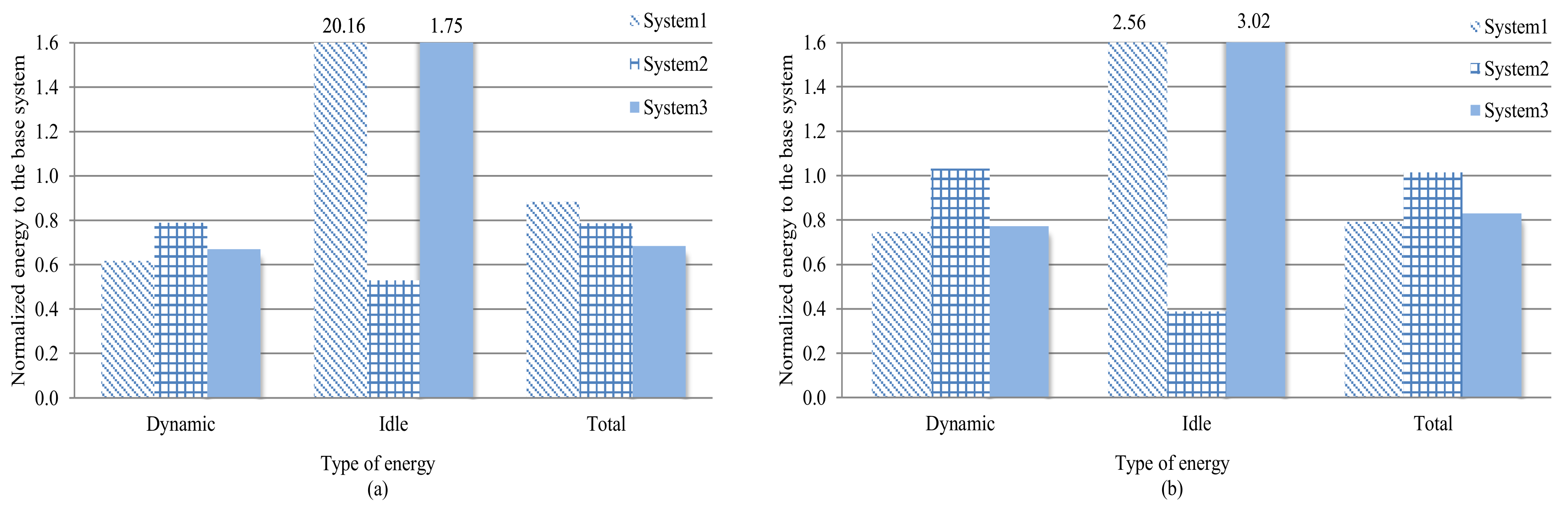
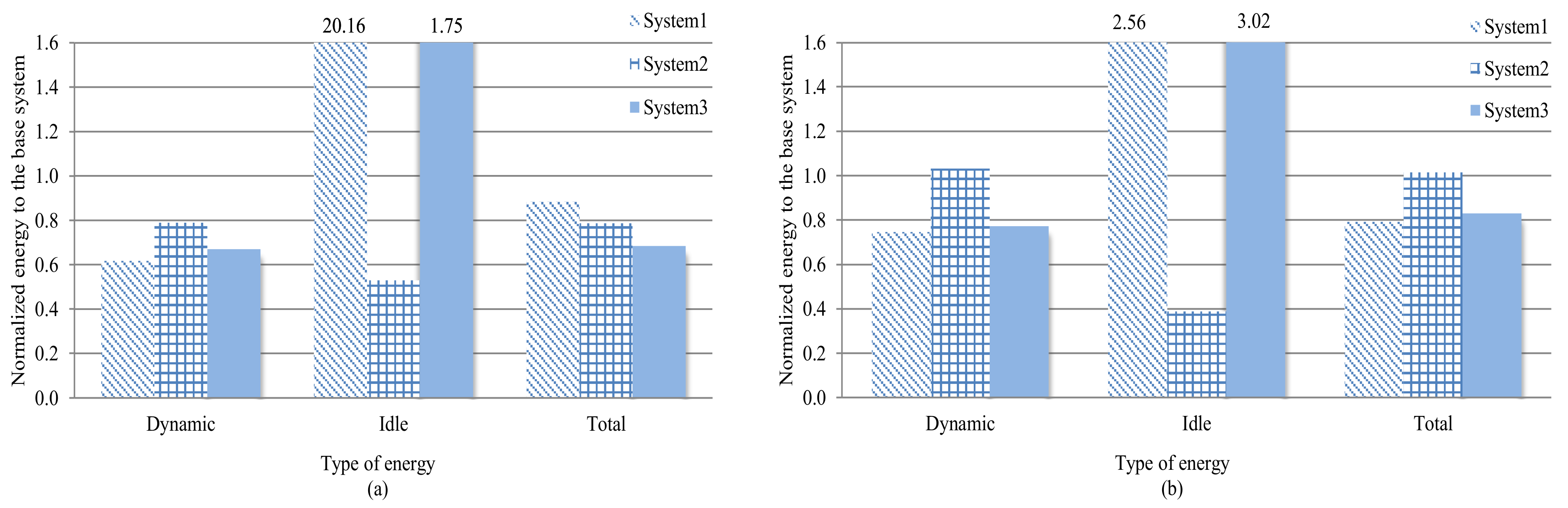
Figure 6a,b depict the dynamic, idle, and total energy consumptions for system-1, -2, and -3 (system-3 results include profiling and tuning overhead) normalized to the energy consumption of the base system for the data and instruction caches, respectively. Values below/above 1 correspond to less/more energy consumption than the base system.
Compared to the base system for the data and instruction caches respectively, system-1 (prior work) reduced the dynamic energy consumption by 38.2% and 25.4%, but increased the idle energy consumption by 1916.4% and 155.6%, resulting in total energy savings of 11.6% and 20.8%. The idle energy increase suggests that the applications’ best cores were not equally distributed across the cores’ subsets, which caused core bottlenecks while applications waited indefinitely for the applications’ best cores to be available. Alleviating this bottleneck is difficult since a balanced distribution of the applications’ best configurations across the cores is highly dependent on the actual applications that are executing. An alternate solution is to increase the number of cores; however, this solution could increase the system’s total energy consumption, and still does not eliminate the potential for bottlenecks (i.e., depending on the applications). As a result, systems with an increased number of cores are more likely to waste more idle energy than to save dynamic energy.
Since system-2 was performance-centric and scheduled applications to any available core, best or non-best, system-2’s cores were less likely to be idle and thus consumed less idle energy. System-2 reduced the idle energy compared to the base system and system-1 by 47.0% and 97.4%, respectively, for the data cache, and by 61.1% and 84.8% for the instruction cache, respectively. Compared to system-1, system-2 increased the dynamic energy by 27.9% and 38.3% for the data and instruction caches, respectively, which is expected since system-2 did not guarantee that applications executed on/with the applications’ best cores/configurations. Compared to the base system, system-2 decreased the dynamic energy for the data cache by 21.0%, but increased the dynamic energy for the instruction cache by 3.19%. For the data and instruction caches respectively, system-2 decreased the total energy by 21.4% and increased the total energy by 1.5% as compared to the base system, and decreased the total energy by 11.2% and increased the total energy by 28.2% as compared to system-1.
The increases in dynamic and total energies for the instruction cache, as compared to the decreases in dynamic and total energies for the data cache, are attributed to the fact that system-2 ran more applications with extreme instruction cache configurations. Since our analysis showed that instruction caches tended to exhibit less miss rate and cache requirement variation as compared to data caches across different applications (prior work also showed that instruction cache subsets can be smaller than data cache subsets [
5]), executing in a non-best instruction cache configuration causes a larger energy consumption increase due to the likelihood that a non-best instruction cache configuration is an extreme configuration. The increase in the instruction cache’s total energy consumption with respect to system-1 suggests that the idle energy savings is not large enough to compensate for the increased dynamic energy consumption. Avoiding extreme configurations can reduce the dynamic energy increase, and thus the idle energy savings would reduce the total energy. We conjecture that process migration and process preemption can alleviate this increased dynamic energy for extreme configurations by migrating the process to a core with a different configuration subset, or by returning the application to the ready queue until the application’s best core is available. However, both process migration and preemption incur performance overhead due to saving the process’s context and requires hardware support to store and restore the process’s context, which is beyond the scope of this paper and is part of our future work.
As compared to the base system, for data and instruction caches respectively, system-3 (SaT) reduced the dynamic energy by 33.0% and 22.7%, and the total energy by 31.6% and17.0%. However, SaT increased the idle energy for the instruction and data caches, respectively, by 74.9% and 202.4%, as compared to the base system. SaT was able to save dynamic energy by scheduling applications to the best cores, at the expense of more idle energy. However, since SaT performed scheduling decisions using Equation (3), the total energy of SaT was still less than the base system’s. This result suggests that SaT saves energy in a system if the savings in dynamic energy makes up for the expended idle energy.
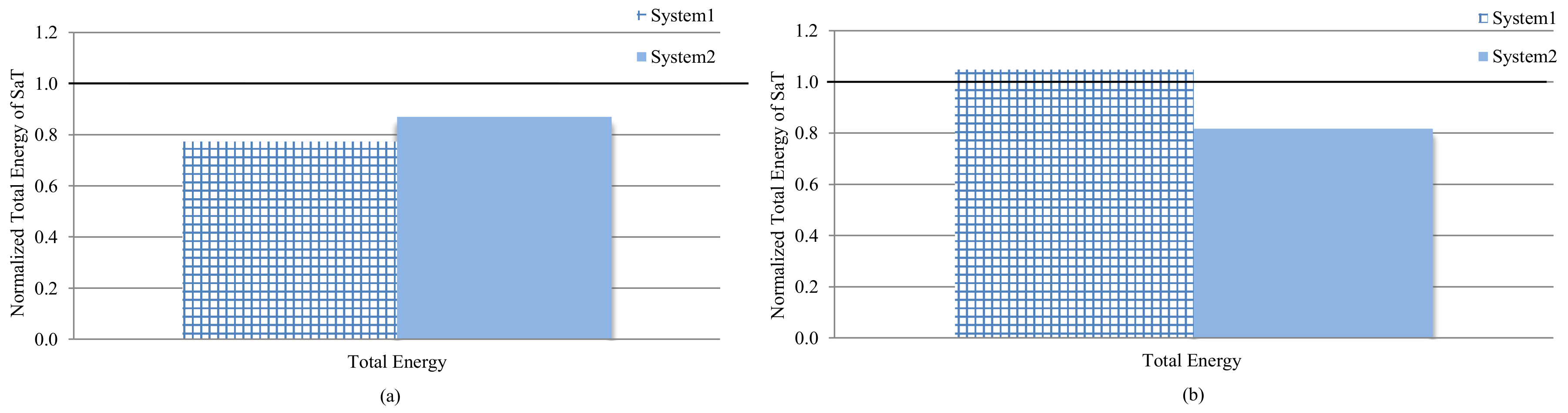
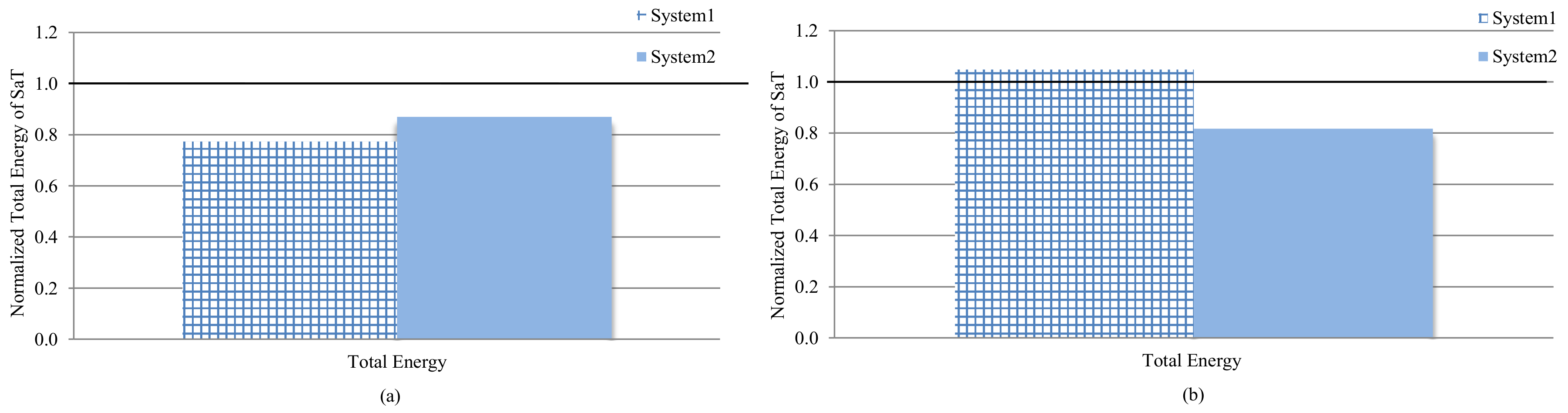
To obtain further insight on the benefits of trading off dynamic or idle energy expenditure, we compared SaT to system-1 (prior work) and system-2 (performance centric), since these systems attempted to reduce dynamic energy and idle energy, respectively. We normalized the total energy of SaT to the total energy of system-1 and system-2.
Figure 7a,b depicts the total energy of system-3 (SaT) normalized to the total energy of system-1 and system-2, for data and instruction caches, respectively. SaT saved 22.6% and 13.0% more energy, as compared to system-1 and system-2, respectively for data caches. SaT saved 18.2% more energy as compared to system-2 for instruction caches; however, it increased the total energy by only 4.8%, as compared to system-1. These results provide the following insights: (1) SaT outperformed prior work and performance-centric in energy savings for data cache without requiring a priori knowledge of applications; (2) the energy savings superseded the profiling and tuning overhead of SaT for data caches, and SaT can save energy for systems with disparate data access patterns; (3) SaT increased the total energy for the instruction caches, as compared to prior work due to the instruction cache’s higher requirement variations; and (4) a priori knowledge of the applications’ domains and best configurations only provided minor energy improvements (4.8%) in prior work, compared to SaT. Unlike prior work, SaT dynamically profiled the applications and tuned the hardware, which broadens SaT’s applicability and usability to any general purpose system.
Although SaT increased the instruction cache energy as compared to system-1 (prior work), SaT outperformed system-1 with respect to the data cache energy savings, and SaT outperformed the base system, system-1, and system-2 with respect to both the instruction and data cache energy savings. Since system-3 outperformed system-1, which prioritized energy savings, and system-1, which was performance-centric, in 75% of the cases, system-3 can save energy in performance-centric systems and systems with low energy constraints.
7.2. Performance Analysis
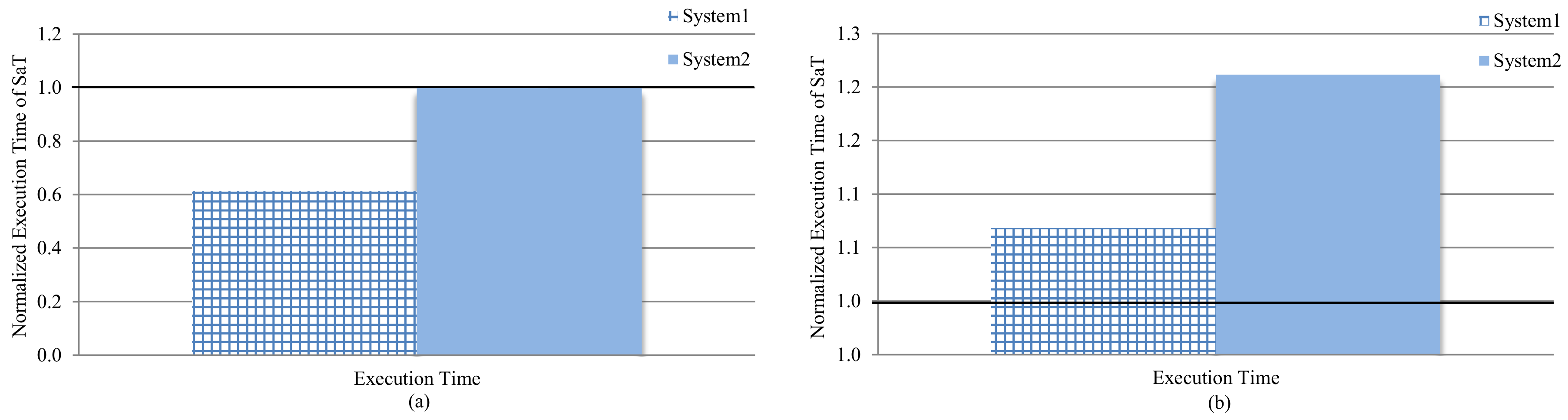
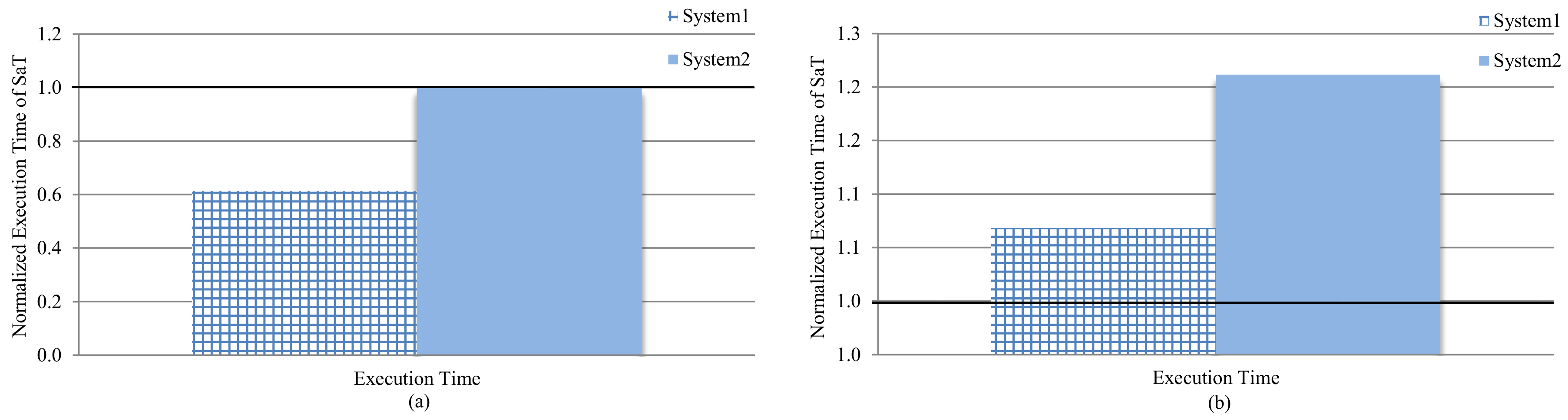
Figure 8a,b depict the performance for system-3 (SaT), normalized to the performance of system-1 (prior work) and system-2 (performance-centric) for the data and instruction caches, respectively. Values below/above 1 correspond to enhanced/degraded performance as compared to the base system.
SaT executed the applications 38.7% faster and 6.8% slower, as compared to system-1, for the data and instruction caches, respectively. Similarly, SaT executed the applications as fast as system-2 for the data cache and 21.2% slower than system-2 for the instruction cache. Since SaT prioritized energy to core utilization (performance), SaT exhibited closer behavior to system-1 than to system-2.
System-1 always scheduled applications to the best core, and applications must be halted until the best core was idle. Furthermore, since applications that belonged to the same domain contended for the same best core, the execution time was exacerbated based on the number of applications halted until the best core was idle: a queue that comprises applications of mostly a single domain will result in more performance degradation, as compared to a queue that comprises applications that belong to multiple domains.
Alternatively, system-2 was performance centric and aimed to maximize throughput and core utilization. In addition, system-2 alleviated the best-core bottleneck by scheduling applications to idle, non-best cores, using first available core policy, and, hence, outperformed SaT. This outcome was expected since SaT prioritized energy savings to performance and/or core utilization; SaT’s decision to schedule applications to idle, non-busy core(s) was based on the energy saving advantage using Equation (3). Since Equation (3) used energy-advantage calculation to make scheduling decisions, to make SaT’s performance comparable to a performance-centric system (e.g., system-2), a key modification is to allow the scheduling decisions based not only on energy, but also performance. A quality-of-service policy (e.g., [
41]) can be incorporated into the decision-making process to guarantee adherence to performance constraints within a prefixed threshold.
Furthermore, the variation between data and instruction caches performance of SaT, compared to system-2 (i.e., only instruction cache performance was lower) can be explained by the fact that unknown configurations can affect instruction cache more than data caches [
42]. Since SaT profiled the applications during runtime, SaT executed the applications on different cache configurations with unknown performance expectations, and the unknown configurations could degrade performance for the instruction cache more than data cache. One method to alleviate unknown performance impact while tuning is to use phase-based tuning [
43], and/or incorporating quality-of-service threshold policy [
40] into the decision-making of SaT, in order to make SaT suitable for performance centric systems. We plan to investigate these possibilities in future work.
7.3. Energy-Delay Product Analysis
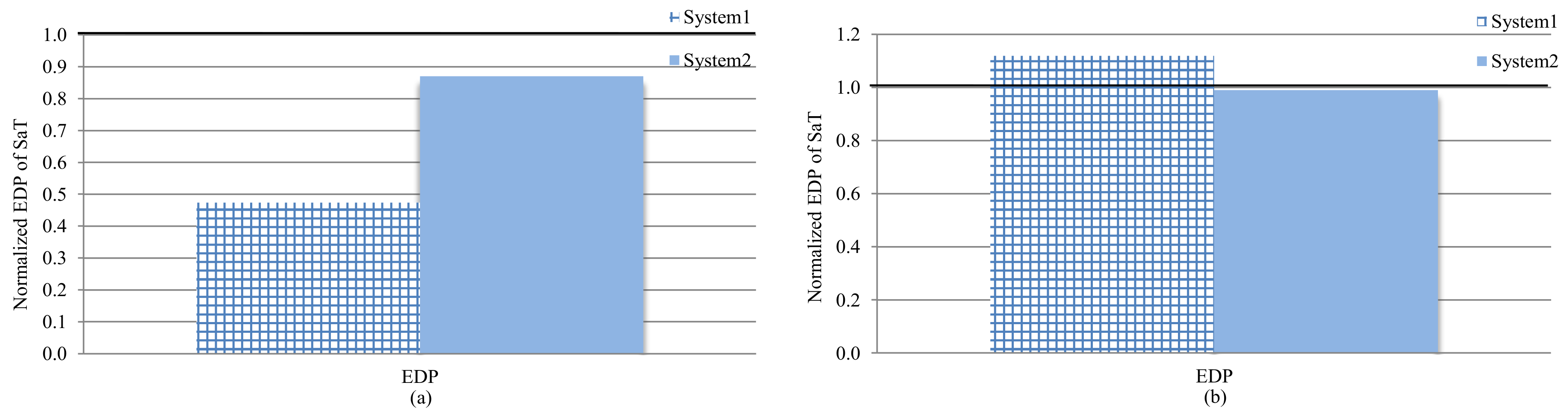
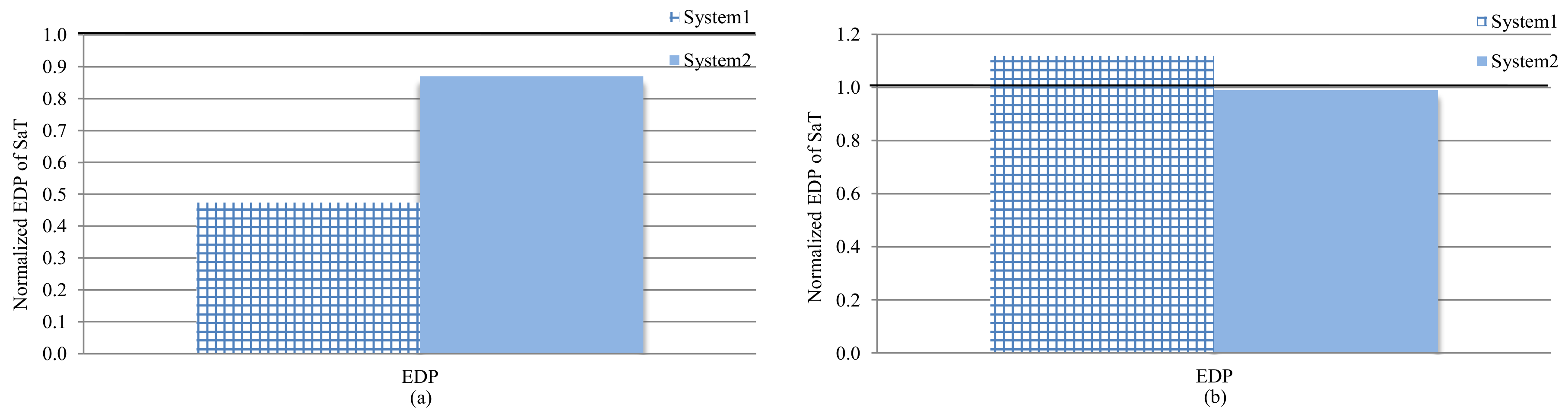
Figure 9 depicts the energy-delay product (EDP) for system-3 (SaT), normalized to the EDP of system-1 (prior work) and system-2 (performance-centric) for (a) data and (b) instruction caches. Values below/above 1 correspond to reduced/increased EDP as compared to the base system. The results revealed that, for the data cache, SaT outperformed system-1 and system-2 by 52.5% and 12.9%, respectively, and thus SaT met or outperformed system-1 and system-2 in terms of total energy saved (
Section 7.1), performance (
Section 7.2), and EDP. As for instruction cache, SaT under- and outperformed as compared to system-1 and system-2, respectively. SaT outperformed system-2 by 1%, which suggests that the energy savings compensated for the performance degradation, as compared to system-2. However, SaT underperformed system-1 by 10.9%. Even though SaT saved 18.2% energy, as compared to system-2, this energy saving was not enough to offset the 21.2% performance degradation.
This result suggests that SaT is amenable to the majority of design goals such as low-energy, high-performance, or commercial-off-the-shelf systems. However, for systems with hard real-time constraints, SaT must utilize a policy that prioritizes performance as well as energy. We reiterate that, in general, SaT achieved substantial energy savings as compared to the base configuration and prior work, and, for future work, we intend to explore techniques for improving SaT’s performance such as phase-based tuning [
43], and/or incorporating quality-of-service monitoring policy [
41] into the decision-making of SaT, in order to make SaT suitable for performance centric systems.
8. Conclusions
Heterogeneous and configurable multicore systems provide hardware specialization to meet disparate application hardware requirements. Multicore systems with a high degree of heterogeneity or highly configurable parameters provide a fine-grained hardware specialization at the expense of higher profiling, tuning overhead, and/or designer effort. To minimize profiling and tuning overhead and alleviate designer efforts, while providing fine-grained hardware specializations, we propose, to the best of our knowledge, the first heterogeneous and configurable multicore system with application-domain specific configuration subsets and an associated scheduling and tuning (SaT) algorithm.
To evaluate our system, we used a base, energy-conservative (representing prior work), and performance-centric systems, all of which had a priori knowledge of the applications. Our results revealed that our system saved up to 31.6% of energy, as compared to the base systems. Additionally, as much as 22.6% of energy compared to prior work, and with only 4.8% of profiling and tuning overhead. Furthermore, our results also revealed that our system outperformed prior work and performance-centric systems in 50% of the cases, and that our system provided EDP within 10.9% of a performance-centric system, which had a priori knowledge of the applications and the application’s best core/configuration.
Future work includes integrating additional energy savings techniques into SaT, such as dynamic core shutdown and dynamic voltage and frequency scaling. To extend SaT capabilities to hard real-time systems, we plan to incorporate performance-and-energy based scheduling policies into SaT’s decision-making. Finally, we also intend to study different subset-to-core mapping methodologies with an increased number of cores to gain insight into the best per-core subset distributions and potential bottlenecks.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}